Weka - Phân nhóm
Một thuật toán phân cụm tìm các nhóm các trường hợp giống nhau trong toàn bộ tập dữ liệu. WEKA hỗ trợ một số thuật toán phân cụm như EM, FilteredClusterer, HierarchicalClusterer, SimpleKMeans, v.v. Bạn nên hiểu hoàn toàn các thuật toán này để khai thác hết khả năng của WEKA.
Như trong trường hợp phân loại, WEKA cho phép bạn hình dung các cụm được phát hiện bằng đồ thị. Để chứng minh sự phân cụm, chúng tôi sẽ sử dụng cơ sở dữ liệu mống mắt được cung cấp. Tập dữ liệu chứa ba lớp gồm 50 cá thể mỗi lớp. Mỗi lớp đề cập đến một loại cây diên vĩ.
Đang tải dữ liệu
Trong trình khám phá WEKA, hãy chọn Preprocesschuyển hướng. Bấm vàoOpen file ... tùy chọn và chọn iris.arfftệp trong hộp thoại chọn tệp. Khi bạn tải dữ liệu, màn hình sẽ giống như hình dưới đây -
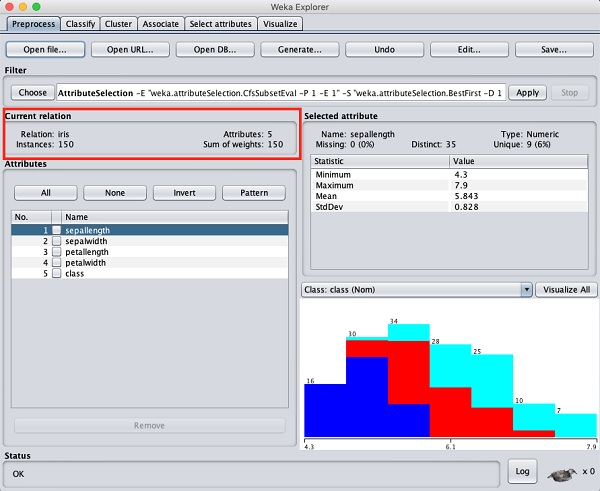
Bạn có thể quan sát thấy rằng có 150 trường hợp và 5 thuộc tính. Tên của các thuộc tính được liệt kê dưới dạngsepallength, sepalwidth, petallength, petalwidth và class. Bốn thuộc tính đầu tiên thuộc kiểu số trong khi lớp là kiểu danh nghĩa với 3 giá trị riêng biệt. Kiểm tra từng thuộc tính để hiểu các tính năng của cơ sở dữ liệu. Chúng tôi sẽ không xử lý trước dữ liệu này và ngay lập tức tiến hành xây dựng mô hình.
Phân cụm
Bấm vào ClusterTAB để áp dụng các thuật toán phân cụm cho dữ liệu đã tải của chúng tôi. Bấm vàoChoosecái nút. Bạn sẽ thấy màn hình sau:

Bây giờ, hãy chọn EMnhư là thuật toán phân cụm. bên trongCluster mode cửa sổ phụ, chọn Classes to clusters evaluation như được hiển thị trong ảnh chụp màn hình bên dưới -

Bấm vào Startđể xử lý dữ liệu. Sau một thời gian, kết quả sẽ được hiển thị trên màn hình.
Tiếp theo, chúng ta hãy nghiên cứu kết quả.
Kiểm tra đầu ra
Đầu ra của quá trình xử lý dữ liệu được hiển thị trong màn hình bên dưới:
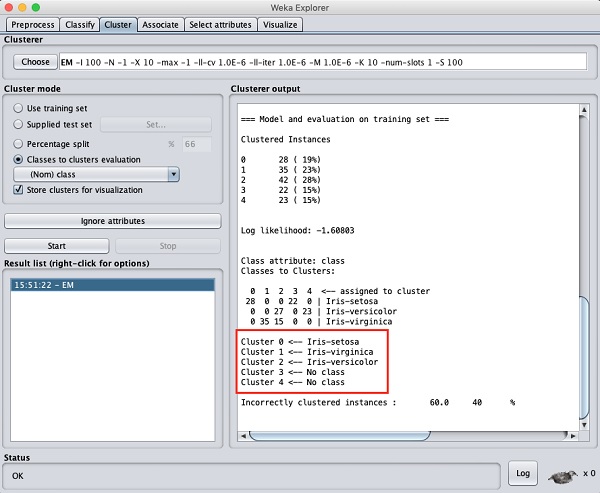
Từ màn hình đầu ra, bạn có thể quan sát thấy -
Có 5 trường hợp nhóm được phát hiện trong cơ sở dữ liệu.
Các Cluster 0 đại diện cho setosa, Cluster 1 đại diện cho virginica, Cluster 2 đại diện cho màu sắc, trong khi hai cụm cuối cùng không có bất kỳ lớp nào liên kết với chúng.
Nếu bạn cuộn cửa sổ đầu ra lên, bạn cũng sẽ thấy một số thống kê cung cấp giá trị trung bình và độ lệch chuẩn cho từng thuộc tính trong các cụm được phát hiện khác nhau. Điều này được hiển thị trong ảnh chụp màn hình dưới đây -
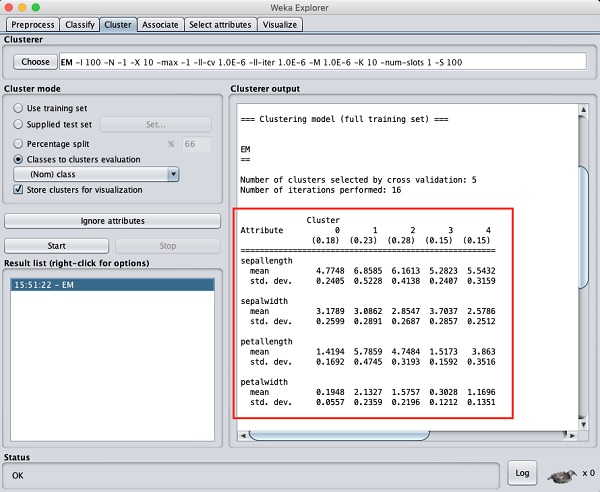
Tiếp theo, chúng ta sẽ xem xét biểu diễn trực quan của các cụm.
Hình dung các cụm
Để hình dung các cụm, hãy nhấp chuột phải vào EM kết quả là Result list. Bạn sẽ thấy các tùy chọn sau:
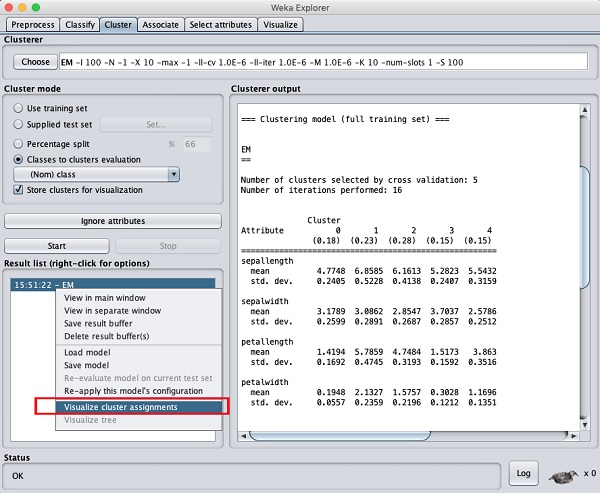
Lựa chọn Visualize cluster assignments. Bạn sẽ thấy kết quả sau:
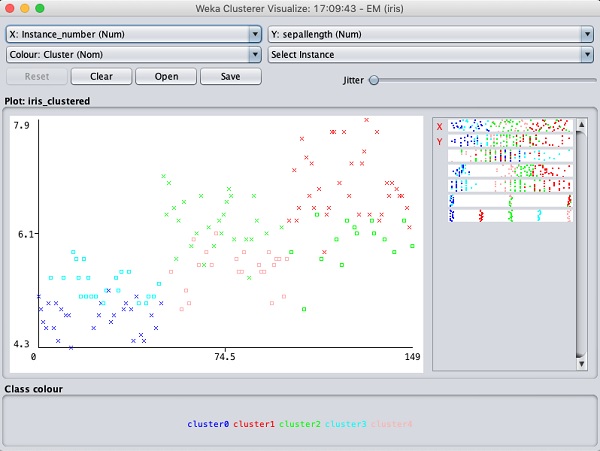
Như trong trường hợp phân loại, bạn sẽ nhận thấy sự phân biệt giữa các trường hợp được xác định đúng và sai. Bạn có thể chơi xung quanh bằng cách thay đổi trục X và Y để phân tích kết quả. Bạn có thể sử dụng jittering như trong trường hợp phân loại để tìm ra nồng độ của các trường hợp được xác định chính xác. Các thao tác trong biểu đồ trực quan tương tự như thao tác bạn đã nghiên cứu trong trường hợp phân loại.
Áp dụng Phân cụm phân cấp
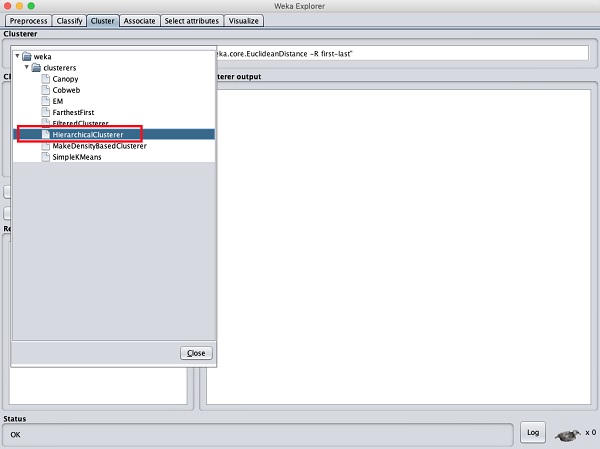
Để chứng minh sức mạnh của WEKA, bây giờ chúng ta hãy xem xét một ứng dụng của một thuật toán phân cụm khác. Trong trình khám phá WEKA, hãy chọnHierarchicalClusterer như thuật toán ML của bạn như được hiển thị trong ảnh chụp màn hình bên dưới -
Chọn Cluster mode lựa chọn Classes to cluster evaluationvà nhấp vào Startcái nút. Bạn sẽ thấy kết quả sau:
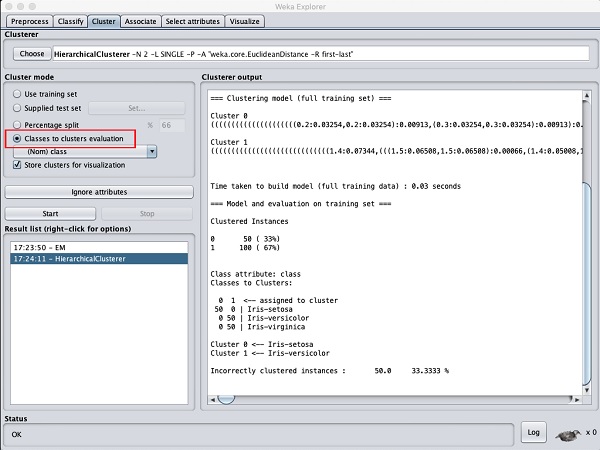
Lưu ý rằng trong Result list, có hai kết quả được liệt kê: kết quả đầu tiên là kết quả EM và kết quả thứ hai là Phân cấp hiện tại. Tương tự như vậy, bạn có thể áp dụng nhiều thuật toán ML cho cùng một tập dữ liệu và nhanh chóng so sánh kết quả của chúng.
Nếu bạn kiểm tra cây được tạo ra bởi thuật toán này, bạn sẽ thấy kết quả sau:
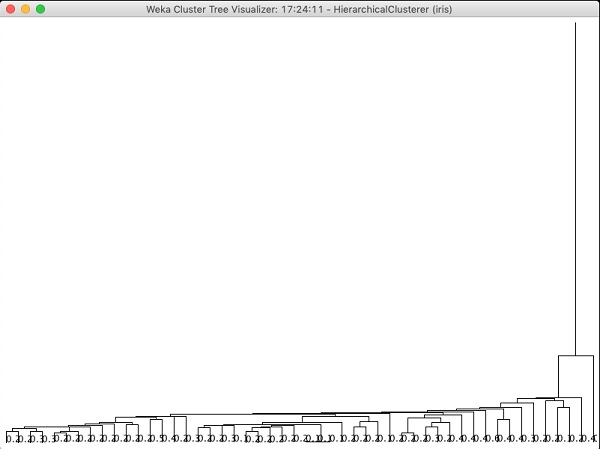
Trong chương tiếp theo, bạn sẽ nghiên cứu Associate loại thuật toán ML.