Weka - Lựa chọn tính năng
Khi một cơ sở dữ liệu chứa một số lượng lớn các thuộc tính, sẽ có một số thuộc tính không trở nên quan trọng trong phân tích mà bạn hiện đang tìm kiếm. Do đó, việc loại bỏ các thuộc tính không mong muốn khỏi tập dữ liệu trở thành một nhiệm vụ quan trọng trong việc phát triển một mô hình học máy tốt.
Bạn có thể kiểm tra toàn bộ tập dữ liệu một cách trực quan và quyết định các thuộc tính không liên quan. Đây có thể là một nhiệm vụ lớn đối với cơ sở dữ liệu chứa một số lượng lớn các thuộc tính như trường hợp siêu thị mà bạn đã thấy trong một bài học trước. May mắn thay, WEKA cung cấp một công cụ tự động để lựa chọn tính năng.
Chương này trình bày tính năng này trên cơ sở dữ liệu có chứa một số lượng lớn các thuộc tính.
Đang tải dữ liệu
bên trong Preprocess của trình thám hiểm WEKA, hãy chọn labor.arfftệp để tải vào hệ thống. Khi bạn tải dữ liệu, bạn sẽ thấy màn hình sau:
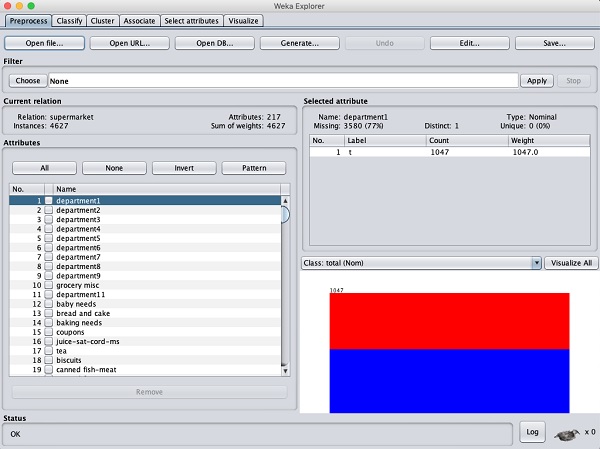
Chú ý rằng có 17 thuộc tính. Nhiệm vụ của chúng tôi là tạo một tập dữ liệu giảm thiểu bằng cách loại bỏ một số thuộc tính không liên quan đến phân tích của chúng tôi.
Tính năng chiết xuất
Bấm vào Select attributesTAB.Bạn sẽ thấy màn hình sau:
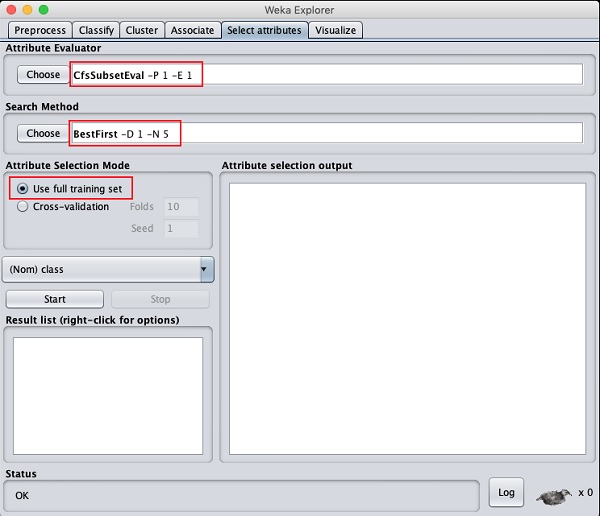
Phía dưới cái Attribute Evaluator và Search Method, bạn sẽ tìm thấy một số tùy chọn. Chúng tôi sẽ chỉ sử dụng các giá trị mặc định ở đây. bên trongAttribute Selection Mode, sử dụng tùy chọn tập hợp đào tạo đầy đủ.
Nhấp vào nút Bắt đầu để xử lý tập dữ liệu. Bạn sẽ thấy kết quả sau:

Ở cuối cửa sổ kết quả, bạn sẽ nhận được danh sách Selectedthuộc tính. Để có được hình ảnh đại diện, hãy nhấp chuột phải vào kết quả trongResult danh sách.
Kết quả được hiển thị trong ảnh chụp màn hình sau:
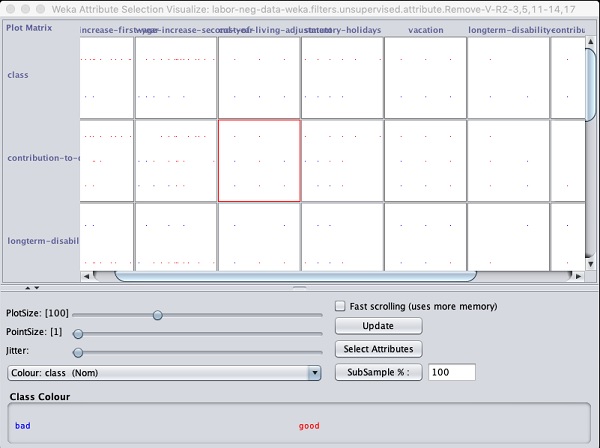
Nhấp vào bất kỳ ô vuông nào sẽ cung cấp cho bạn biểu đồ dữ liệu để bạn phân tích thêm. Biểu đồ dữ liệu điển hình được hiển thị bên dưới:
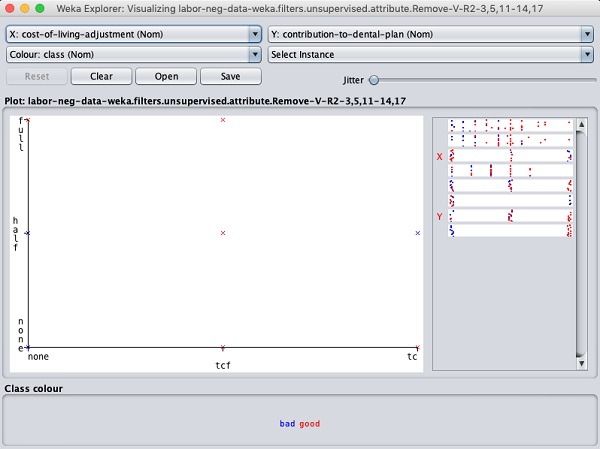
Điều này tương tự như những gì chúng ta đã thấy trong các chương trước. Chơi xung quanh với các tùy chọn khác nhau có sẵn để phân tích kết quả.
Cái gì tiếp theo?
Cho đến nay, bạn đã thấy sức mạnh của WEKA trong việc phát triển nhanh chóng các mô hình học máy. Những gì chúng tôi đã sử dụng là một công cụ đồ họa có tênExplorerđể phát triển các mô hình này. WEKA cũng cung cấp giao diện dòng lệnh cung cấp cho bạn nhiều sức mạnh hơn được cung cấp trong trình thám hiểm.
Nhấp vào Simple CLI nút GUI Chooser ứng dụng khởi động giao diện dòng lệnh này được hiển thị trong ảnh chụp màn hình bên dưới -
Nhập lệnh của bạn vào hộp nhập ở dưới cùng. Bạn sẽ có thể làm tất cả những gì bạn đã làm cho đến nay trong trình thám hiểm và nhiều hơn thế nữa. Tham khảo tài liệu WEKA (https://www.cs.waikato.ac.nz/ml/weka/documentation.html) để biết thêm chi tiết.
Cuối cùng, WEKA được phát triển bằng Java và cung cấp giao diện cho API của nó. Vì vậy, nếu bạn là một nhà phát triển Java và muốn đưa các triển khai WEKA ML vào các dự án Java của riêng mình, bạn có thể làm như vậy dễ dàng.
Phần kết luận
WEKA là một công cụ mạnh mẽ để phát triển các mô hình học máy. Nó cung cấp triển khai một số thuật toán ML được sử dụng rộng rãi nhất. Trước khi các thuật toán này được áp dụng cho tập dữ liệu của bạn, nó cũng cho phép bạn xử lý trước dữ liệu. Các loại thuật toán được hỗ trợ được phân loại theo các thuộc tính Classify, Cluster, Associate và Select. Kết quả ở các giai đoạn xử lý khác nhau có thể được hình dung bằng một hình ảnh trực quan đẹp và mạnh mẽ. Điều này giúp Nhà khoa học dữ liệu dễ dàng áp dụng nhanh các kỹ thuật học máy khác nhau trên tập dữ liệu của mình, so sánh kết quả và tạo mô hình tốt nhất cho lần sử dụng cuối cùng.