Weka - Hướng dẫn nhanh
Nền tảng của bất kỳ ứng dụng Học máy nào là dữ liệu - không chỉ là một ít dữ liệu mà là một dữ liệu khổng lồ được gọi là Big Data theo thuật ngữ hiện hành.
Để huấn luyện máy phân tích dữ liệu lớn, bạn cần phải xem xét một số dữ liệu -
- Dữ liệu phải sạch.
- Nó không được chứa các giá trị rỗng.
Bên cạnh đó, không phải tất cả các cột trong bảng dữ liệu đều hữu ích cho loại phân tích mà bạn đang cố gắng đạt được. Các cột dữ liệu hoặc 'tính năng' không liên quan như được gọi trong thuật ngữ Học máy, phải được xóa trước khi dữ liệu được đưa vào thuật toán học máy.
Tóm lại, dữ liệu lớn của bạn cần nhiều tiền xử lý trước khi có thể sử dụng cho Học máy. Khi dữ liệu đã sẵn sàng, bạn sẽ áp dụng các thuật toán Học máy khác nhau như phân loại, hồi quy, phân cụm, v.v. để giải quyết vấn đề cuối cùng của bạn.
Loại thuật toán mà bạn áp dụng phần lớn dựa trên kiến thức miền của bạn. Ngay cả trong cùng một loại, ví dụ phân loại, có một số thuật toán có sẵn. Bạn có thể muốn thử nghiệm các thuật toán khác nhau trong cùng một lớp để xây dựng mô hình học máy hiệu quả. Trong khi làm như vậy, bạn muốn trực quan hóa dữ liệu đã xử lý hơn và do đó bạn cũng yêu cầu các công cụ trực quan hóa.
Trong các chương sắp tới, bạn sẽ tìm hiểu về Weka, một phần mềm hoàn thành tất cả những điều trên một cách dễ dàng và cho phép bạn làm việc với dữ liệu lớn một cách thoải mái.
WEKA - một phần mềm mã nguồn mở cung cấp các công cụ để xử lý trước dữ liệu, triển khai một số thuật toán Máy học và công cụ trực quan hóa để bạn có thể phát triển các kỹ thuật máy học và áp dụng chúng vào các vấn đề khai thác dữ liệu trong thế giới thực. Những gì WEKA cung cấp được tóm tắt trong sơ đồ sau:
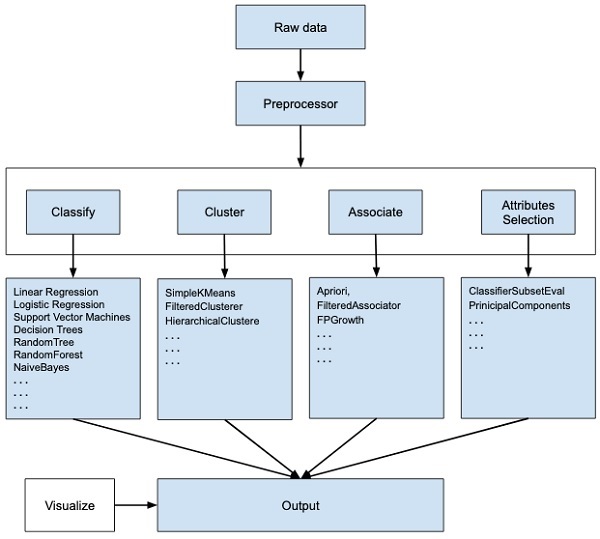
Nếu bạn quan sát phần đầu của luồng hình ảnh, bạn sẽ hiểu rằng có nhiều giai đoạn trong việc xử lý Dữ liệu lớn để làm cho nó phù hợp với máy học -
Đầu tiên, bạn sẽ bắt đầu với dữ liệu thô được thu thập từ thực địa. Dữ liệu này có thể chứa một số giá trị rỗng và các trường không liên quan. Bạn sử dụng các công cụ xử lý trước dữ liệu được cung cấp trong WEKA để xóa dữ liệu.
Sau đó, bạn sẽ lưu dữ liệu đã xử lý trước vào bộ nhớ cục bộ của mình để áp dụng các thuật toán ML.
Tiếp theo, tùy thuộc vào loại mô hình ML mà bạn đang cố gắng phát triển, bạn sẽ chọn một trong các tùy chọn như Classify, Cluster, hoặc là Associate. CácAttributes Selection cho phép lựa chọn tự động các tính năng để tạo tập dữ liệu giảm.
Lưu ý rằng trong mỗi danh mục, WEKA cung cấp việc triển khai một số thuật toán. Bạn sẽ chọn một thuật toán mà bạn lựa chọn, đặt các tham số mong muốn và chạy nó trên tập dữ liệu.
Sau đó, WEKA sẽ cung cấp cho bạn kết quả thống kê của quá trình xử lý mô hình. Nó cung cấp cho bạn một công cụ trực quan để kiểm tra dữ liệu.
Các mô hình khác nhau có thể được áp dụng trên cùng một tập dữ liệu. Sau đó, bạn có thể so sánh kết quả đầu ra của các mô hình khác nhau và chọn loại tốt nhất đáp ứng mục đích của bạn.
Do đó, việc sử dụng WEKA dẫn đến sự phát triển nhanh hơn của các mô hình học máy nói chung.
Bây giờ chúng ta đã biết WEKA là gì và nó có chức năng gì, trong chương tiếp theo chúng ta hãy tìm hiểu cách cài đặt WEKA trên máy tính cục bộ của bạn.
Để cài đặt WEKA trên máy của bạn, hãy truy cập trang web chính thức của WEKA và tải xuống tệp cài đặt. WEKA hỗ trợ cài đặt trên Windows, Mac OS X và Linux. Bạn chỉ cần làm theo hướng dẫn trên trang này để cài đặt WEKA cho hệ điều hành của mình.
Các bước cài đặt trên Mac như sau:
- Tải xuống tệp cài đặt Mac.
- Nhấp đúp vào phần đã tải xuống weka-3-8-3-corretto-jvm.dmg file.
Bạn sẽ thấy màn hình sau khi cài đặt thành công.
- Bấm vào weak-3-8-3-corretto-jvm biểu tượng để bắt đầu Weka.
- Theo tùy chọn, bạn có thể bắt đầu nó từ dòng lệnh -
java -jar weka.jarỨng dụng WEKA GUI Chooser sẽ khởi động và bạn sẽ thấy màn hình sau:
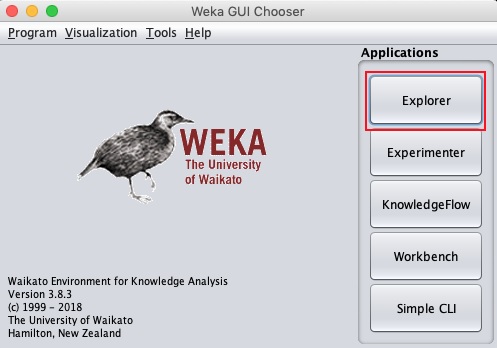
Ứng dụng GUI Chooser cho phép bạn chạy năm loại ứng dụng khác nhau như được liệt kê ở đây -
- Explorer
- Experimenter
- KnowledgeFlow
- Workbench
- CLI đơn giản
Chúng tôi sẽ sử dụng Explorer trong hướng dẫn này.
Trong chương này, chúng ta hãy xem xét các chức năng khác nhau mà trình thám hiểm cung cấp để làm việc với dữ liệu lớn.
Khi bạn nhấp vào Explorer nút trong Applications bộ chọn, nó sẽ mở ra màn hình sau -
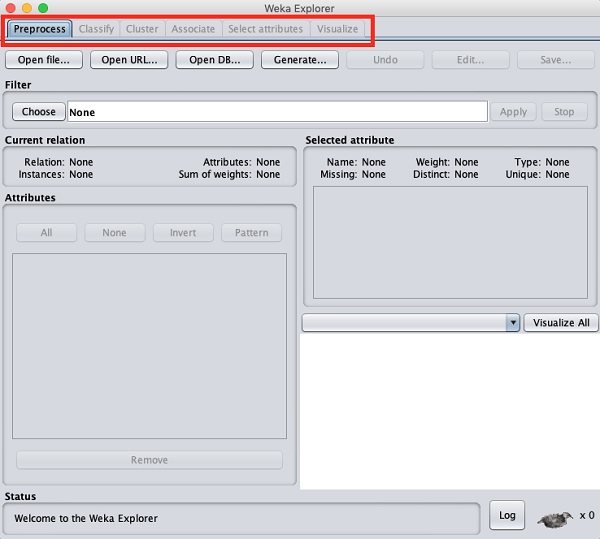
Ở trên cùng, bạn sẽ thấy một số tab như được liệt kê ở đây -
- Preprocess
- Classify
- Cluster
- Associate
- Chọn thuộc tính
- Visualize
Dưới các tab này, có một số thuật toán học máy được triển khai trước. Bây giờ chúng ta hãy xem xét từng chi tiết.
Tab tiền xử lý
Ban đầu khi bạn mở trình khám phá, chỉ Preprocesstab được bật. Bước đầu tiên trong học máy là xử lý trước dữ liệu. Do đó, trongPreprocess tùy chọn, bạn sẽ chọn tệp dữ liệu, xử lý và làm cho tệp phù hợp để áp dụng các thuật toán học máy khác nhau.
Phân loại Tab
Các Classifytab cung cấp cho bạn một số thuật toán máy học để phân loại dữ liệu của bạn. Để liệt kê một số, bạn có thể áp dụng các thuật toán như Hồi quy tuyến tính, Hồi quy logistic, Máy vectơ hỗ trợ, Cây quyết định, RandomTree, RandomForest, NaiveBayes, v.v. Danh sách này rất đầy đủ và cung cấp cả thuật toán học máy có giám sát và không giám sát.
Tab cụm
Phía dưới cái Cluster , có một số thuật toán phân cụm được cung cấp - chẳng hạn như SimpleKMeans, FilteredClusterer, HierarchicalClusterer, v.v.
Tab liên kết
Phía dưới cái Associate , bạn sẽ tìm thấy Apriori, FilteredAssociator và FPGrowth.
Chọn tab thuộc tính
Select Attributes cho phép bạn làm nổi bật các lựa chọn dựa trên một số thuật toán như ClassifierSubsetEval, PrinicipalComponents, v.v.
Hình ảnh hóa tab
Cuối cùng, Visualize tùy chọn cho phép bạn trực quan hóa dữ liệu đã xử lý của mình để phân tích.
Như bạn đã nhận thấy, WEKA cung cấp một số thuật toán sẵn sàng sử dụng để thử nghiệm và xây dựng các ứng dụng học máy của bạn. Để sử dụng WEKA một cách hiệu quả, bạn phải có kiến thức vững chắc về các thuật toán này, cách chúng hoạt động, nên chọn thuật toán nào trong hoàn cảnh nào, tìm kiếm điều gì trong đầu ra đã xử lý của chúng, v.v. Tóm lại, bạn phải có nền tảng vững chắc về học máy để sử dụng WEKA hiệu quả trong việc xây dựng ứng dụng của mình.
Trong các chương sắp tới, bạn sẽ nghiên cứu sâu từng tab trong trình khám phá.
Trong chương này, chúng ta bắt đầu với tab đầu tiên mà bạn sử dụng để xử lý trước dữ liệu. Điều này là chung cho tất cả các thuật toán mà bạn sẽ áp dụng cho dữ liệu của mình để xây dựng mô hình và là bước chung cho tất cả các hoạt động tiếp theo trong WEKA.
Để thuật toán máy học cung cấp độ chính xác có thể chấp nhận được, điều quan trọng là bạn phải làm sạch dữ liệu của mình trước. Điều này là do dữ liệu thô được thu thập từ trường có thể chứa các giá trị rỗng, các cột không liên quan, v.v.
Trong chương này, bạn sẽ học cách xử lý trước dữ liệu thô và tạo một tập dữ liệu sạch, có ý nghĩa để sử dụng tiếp.
Đầu tiên, bạn sẽ học cách tải tệp dữ liệu vào trình khám phá WEKA. Dữ liệu có thể được tải từ các nguồn sau:
- Hệ thống tệp cục bộ
- Web
- Database
Trong chương này, chúng ta sẽ xem chi tiết cả ba tùy chọn tải dữ liệu.
Tải dữ liệu từ hệ thống tệp cục bộ
Ngay dưới các tab Học máy mà bạn đã nghiên cứu trong bài học trước, bạn sẽ tìm thấy ba nút sau:
- Mở tệp…
- Mở URL…
- Mở DB…
Bấm vào Open file... cái nút. Cửa sổ điều hướng thư mục mở ra như được hiển thị trong màn hình sau:
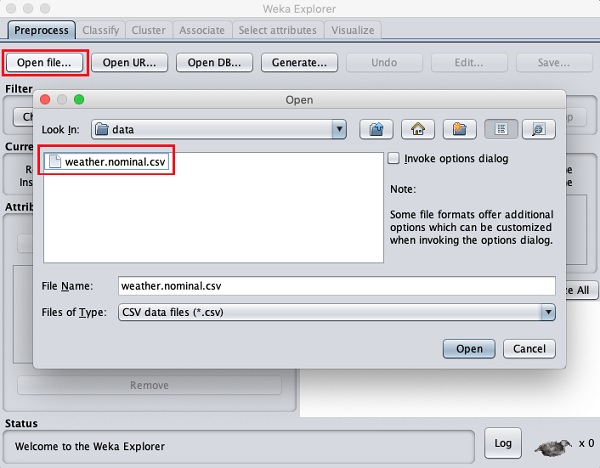
Bây giờ, điều hướng đến thư mục lưu trữ các tệp dữ liệu của bạn. Cài đặt WEKA đưa ra nhiều cơ sở dữ liệu mẫu để bạn thử nghiệm. Chúng có sẵn trongdata thư mục cài đặt WEKA.
Đối với mục đích học tập, hãy chọn bất kỳ tệp dữ liệu nào từ thư mục này. Nội dung của tệp sẽ được tải trong môi trường WEKA. Chúng tôi sẽ sớm tìm hiểu cách kiểm tra và xử lý dữ liệu đã tải này. Trước đó, chúng ta hãy xem cách tải tệp dữ liệu từ Web.
Tải dữ liệu từ Web
Khi bạn nhấp vào Open URL … , bạn có thể thấy một cửa sổ như sau:
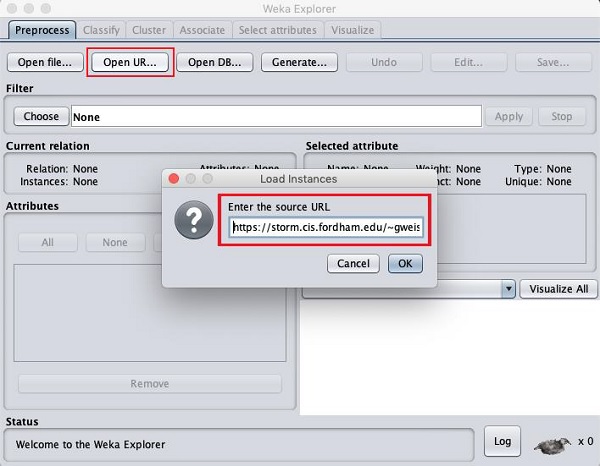
Chúng tôi sẽ mở tệp từ một URL công khai Nhập URL sau vào hộp bật lên -
https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
Bạn có thể chỉ định bất kỳ URL nào khác nơi dữ liệu của bạn được lưu trữ. CácExplorer sẽ tải dữ liệu từ trang web từ xa vào môi trường của nó.
Đang tải dữ liệu từ DB
Khi bạn nhấp vào Open DB ..., bạn có thể thấy một cửa sổ như sau:
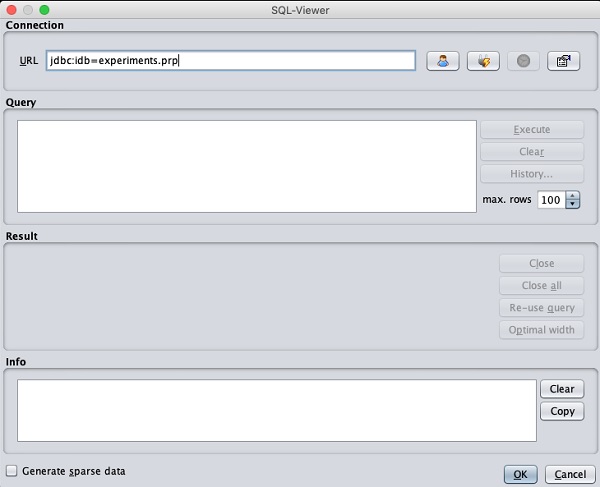
Đặt chuỗi kết nối vào cơ sở dữ liệu của bạn, thiết lập truy vấn lựa chọn dữ liệu, xử lý truy vấn và tải các bản ghi đã chọn trong WEKA.
WEKA hỗ trợ một số lượng lớn các định dạng tệp cho dữ liệu. Đây là danh sách đầy đủ -
- arff
- arff.gz
- bsi
- csv
- dat
- data
- json
- json.gz
- libsvm
- m
- names
- xrff
- xrff.gz
Các loại tệp mà nó hỗ trợ được liệt kê trong hộp danh sách thả xuống ở cuối màn hình. Điều này được hiển thị trong ảnh chụp màn hình dưới đây.
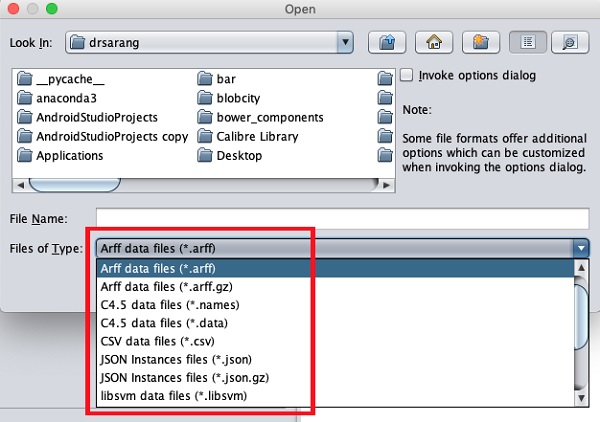
Như bạn sẽ thấy, nó hỗ trợ một số định dạng bao gồm CSV và JSON. Loại tệp mặc định là Arff.
Định dạng Arff
An Arff tệp chứa hai phần - tiêu đề và dữ liệu.
- Tiêu đề mô tả các loại thuộc tính.
- Phần dữ liệu chứa danh sách dữ liệu được phân tách bằng dấu phẩy.
Ví dụ cho định dạng Arff, Weather tệp dữ liệu được tải từ cơ sở dữ liệu mẫu WEKA được hiển thị bên dưới:

Từ ảnh chụp màn hình, bạn có thể suy ra các điểm sau:
Thẻ @relation xác định tên của cơ sở dữ liệu.
Thẻ @attribute xác định các thuộc tính.
Thẻ @data bắt đầu danh sách các hàng dữ liệu, mỗi hàng chứa các trường được phân tách bằng dấu phẩy.
Các thuộc tính có thể nhận giá trị danh nghĩa như trong trường hợp triển vọng được hiển thị ở đây -
@attribute outlook (sunny, overcast, rainy)Các thuộc tính có thể nhận giá trị thực như trong trường hợp này -
@attribute temperature realBạn cũng có thể đặt một biến Target hoặc Class được gọi là play như được hiển thị ở đây -
@attribute play (yes, no)Mục tiêu giả định hai giá trị danh nghĩa có hoặc không.
Các định dạng khác
Explorer có thể tải dữ liệu ở bất kỳ định dạng nào đã đề cập trước đó. Vì arff là định dạng ưa thích trong WEKA, bạn có thể tải dữ liệu từ bất kỳ định dạng nào và lưu nó thành định dạng arff để sử dụng sau này. Sau khi xử lý trước dữ liệu, chỉ cần lưu nó ở định dạng arff để phân tích thêm.
Bây giờ bạn đã học cách tải dữ liệu vào WEKA, trong chương tiếp theo, bạn sẽ học cách xử lý trước dữ liệu.
Dữ liệu được thu thập từ hiện trường có nhiều điều không mong muốn dẫn đến phân tích sai. Ví dụ: dữ liệu có thể chứa các trường rỗng, nó có thể chứa các cột không liên quan đến phân tích hiện tại, v.v. Do đó, dữ liệu phải được xử lý trước để đáp ứng các yêu cầu của loại phân tích bạn đang tìm kiếm. Điều này được thực hiện trong mô-đun tiền xử lý.
Để chứng minh các tính năng có sẵn trong tiền xử lý, chúng tôi sẽ sử dụng Weather cơ sở dữ liệu được cung cấp trong cài đặt.
Sử dụng Open file ... tùy chọn trong Preprocess thẻ chọn weather-nominal.arff tập tin.
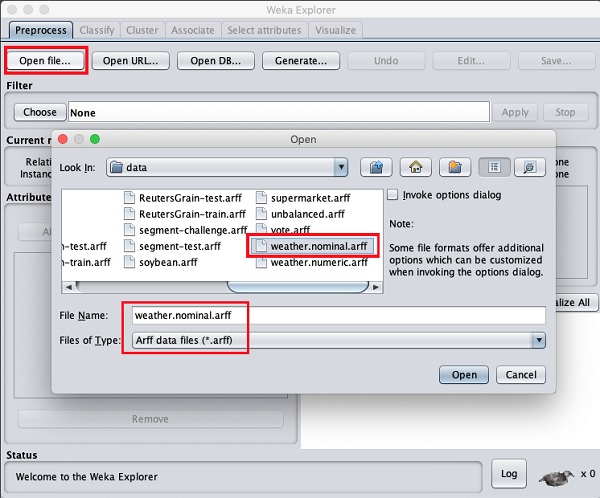
Khi bạn mở tệp, màn hình của bạn trông giống như được hiển thị ở đây -
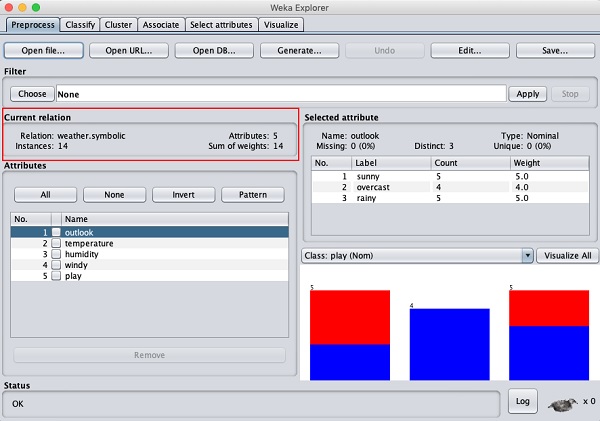
Màn hình này cho chúng ta biết một số điều về dữ liệu đã tải, sẽ được thảo luận thêm trong chương này.
Hiểu dữ liệu
Đầu tiên chúng ta hãy xem xét các Current relationcửa sổ phụ. Nó hiển thị tên của cơ sở dữ liệu hiện đang được tải. Bạn có thể suy ra hai điểm từ cửa sổ phụ này -
Có 14 trường hợp - số hàng trong bảng.
Bảng chứa 5 thuộc tính - các trường, sẽ được thảo luận trong các phần sắp tới.
Ở phía bên trái, lưu ý Attributes cửa sổ phụ hiển thị các trường khác nhau trong cơ sở dữ liệu.
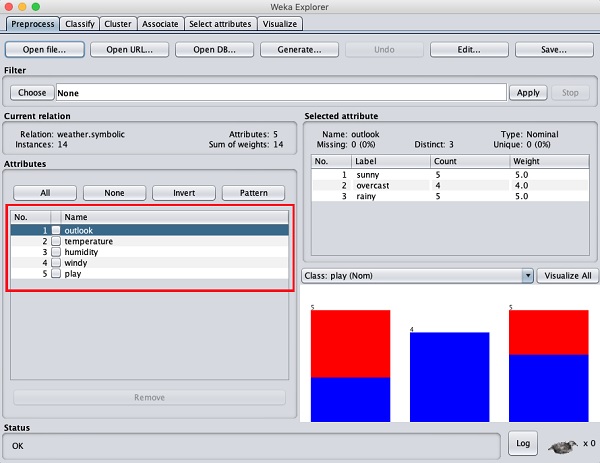
Các weathercơ sở dữ liệu chứa năm trường - triển vọng, nhiệt độ, độ ẩm, gió và chơi. Khi bạn chọn một thuộc tính từ danh sách này bằng cách nhấp vào nó, các chi tiết khác về bản thân thuộc tính đó được hiển thị ở phía bên tay phải.
Hãy để chúng tôi chọn thuộc tính nhiệt độ trước. Khi bạn nhấp vào nó, bạn sẽ thấy màn hình sau:
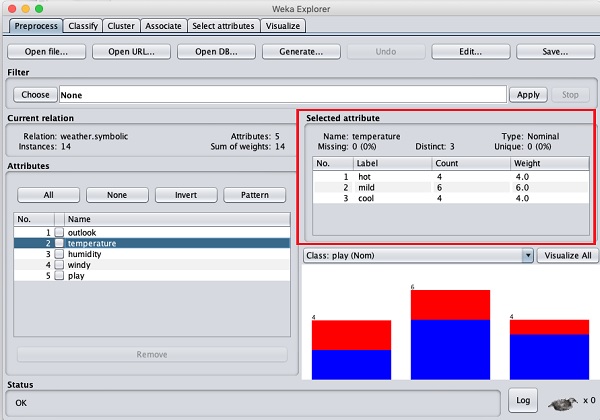
bên trong Selected Attribute subwindow, bạn có thể quan sát những điều sau:
Tên và loại thuộc tính được hiển thị.
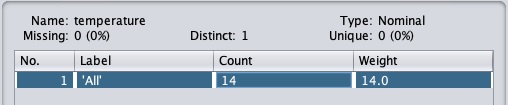
Loại cho temperature thuộc tính là Nominal.
Số lượng Missing giá trị bằng không.
Có ba giá trị khác biệt không có giá trị duy nhất.
Bảng bên dưới thông tin này hiển thị các giá trị danh nghĩa cho trường này là nóng, nhẹ và lạnh.
Nó cũng hiển thị số lượng và trọng lượng theo tỷ lệ phần trăm cho mỗi giá trị danh nghĩa.
Ở cuối cửa sổ, bạn sẽ thấy phần trình bày trực quan của class các giá trị.
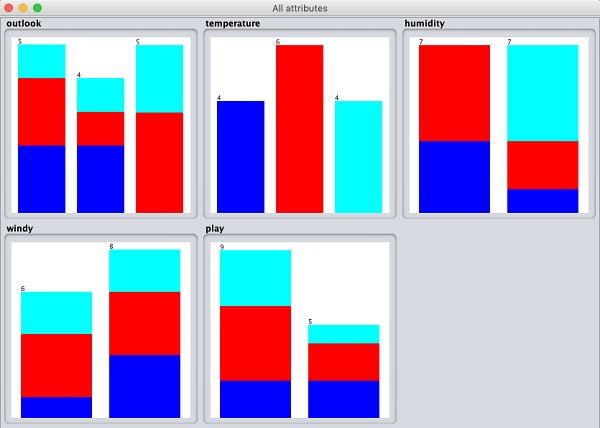
Nếu bạn nhấp vào Visualize All , bạn sẽ có thể xem tất cả các tính năng trong một cửa sổ duy nhất như được hiển thị ở đây -
Xóa các thuộc tính
Đôi khi, dữ liệu mà bạn muốn sử dụng để xây dựng mô hình có nhiều trường không liên quan. Ví dụ: cơ sở dữ liệu khách hàng có thể chứa số điện thoại di động của anh ta có liên quan trong việc phân tích xếp hạng tín dụng của anh ta.
Để loại bỏ Thuộc tính / s, hãy chọn chúng và nhấp vào Remove ở dưới cùng.
Các thuộc tính đã chọn sẽ bị xóa khỏi cơ sở dữ liệu. Sau khi xử lý trước đầy đủ dữ liệu, bạn có thể lưu dữ liệu đó để xây dựng mô hình.
Tiếp theo, bạn sẽ học cách xử lý trước dữ liệu bằng cách áp dụng các bộ lọc trên dữ liệu này.
Áp dụng bộ lọc
Một số kỹ thuật học máy như khai thác quy tắc kết hợp yêu cầu dữ liệu phân loại. Để minh họa việc sử dụng các bộ lọc, chúng tôi sẽ sử dụngweather-numeric.arff cơ sở dữ liệu chứa hai numeric thuộc tính - temperature và humidity.
Chúng tôi sẽ chuyển đổi chúng thành nominalbằng cách áp dụng bộ lọc trên dữ liệu thô của chúng tôi. Bấm vàoChoose nút trong Filter subwindow và chọn bộ lọc sau -
weka→filters→supervised→attribute→Discretize

Bấm vào Apply nút và kiểm tra temperature và / hoặc humiditythuộc tính. Bạn sẽ nhận thấy rằng chúng đã thay đổi từ kiểu số sang kiểu danh nghĩa.
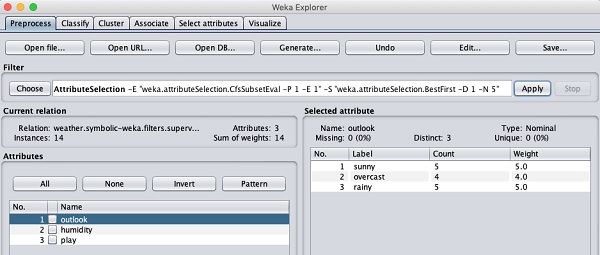
Bây giờ chúng ta hãy xem xét một bộ lọc khác. Giả sử bạn muốn chọn các thuộc tính tốt nhất để quyết địnhplay. Chọn và áp dụng bộ lọc sau -
weka→filters→supervised→attribute→AttributeSelection
Bạn sẽ nhận thấy rằng nó loại bỏ các thuộc tính nhiệt độ và độ ẩm khỏi cơ sở dữ liệu.
Sau khi bạn hài lòng với việc xử lý trước dữ liệu của mình, hãy lưu dữ liệu bằng cách nhấp vào Save... cái nút. Bạn sẽ sử dụng tệp đã lưu này để xây dựng mô hình.
Trong chương tiếp theo, chúng ta sẽ khám phá việc xây dựng mô hình bằng cách sử dụng một số thuật toán ML được xác định trước.
Nhiều ứng dụng học máy có liên quan đến phân loại. Ví dụ, bạn có thể muốn phân loại khối u là ác tính hoặc lành tính. Bạn có thể quyết định chơi một trò chơi bên ngoài tùy thuộc vào điều kiện thời tiết. Nói chung, quyết định này phụ thuộc vào một số đặc điểm / điều kiện của thời tiết. Vì vậy, bạn có thể thích sử dụng bộ phân loại cây để đưa ra quyết định có nên chơi hay không.
Trong chương này, chúng ta sẽ học cách xây dựng một bộ phân loại cây như vậy trên dữ liệu thời tiết để quyết định các điều kiện chơi.
Đặt dữ liệu kiểm tra
Chúng ta sẽ sử dụng tệp dữ liệu thời tiết đã được xử lý trước từ bài trước. Mở tệp đã lưu bằng cách sử dụngOpen file ... tùy chọn trong Preprocess , nhấp vào Classify và bạn sẽ thấy màn hình sau:
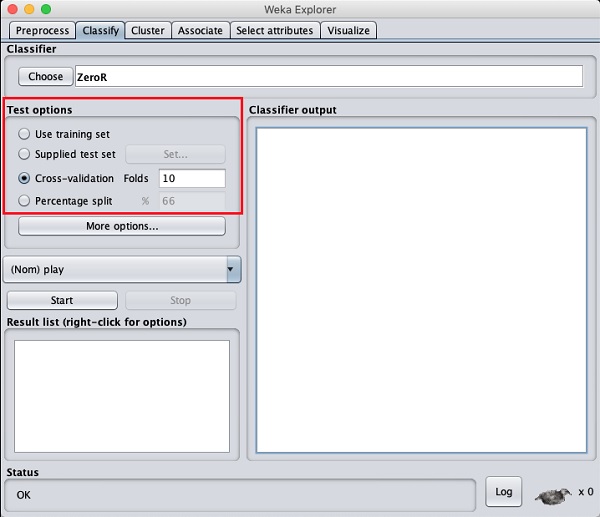
Trước khi bạn tìm hiểu về các bộ phân loại có sẵn, hãy để chúng tôi kiểm tra các tùy chọn Kiểm tra. Bạn sẽ nhận thấy bốn tùy chọn thử nghiệm như được liệt kê bên dưới -
- Tập huấn luyện
- Bộ thử nghiệm được cung cấp
- Cross-validation
- Phần trăm phân chia
Trừ khi bạn có bộ đào tạo của riêng mình hoặc bộ kiểm tra do khách hàng cung cấp, bạn sẽ sử dụng các tùy chọn xác thực chéo hoặc phân chia theo tỷ lệ phần trăm. Trong xác nhận chéo, bạn có thể đặt số lần gấp mà toàn bộ dữ liệu sẽ được chia nhỏ và sử dụng trong mỗi lần lặp lại đào tạo. Trong phần tách phần trăm, bạn sẽ chia dữ liệu giữa đào tạo và thử nghiệm bằng cách sử dụng phần trăm phân chia đã đặt.
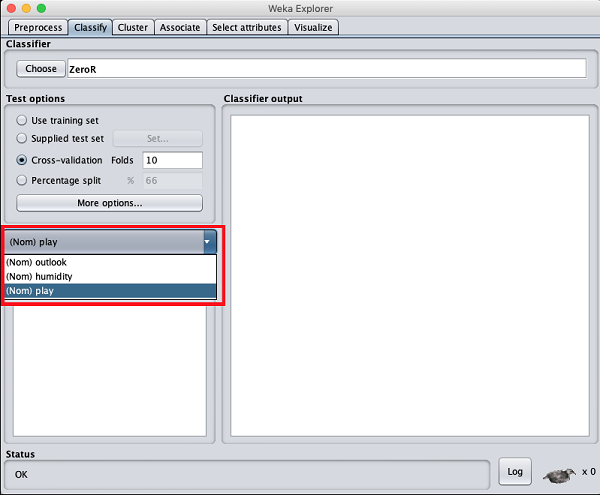
Bây giờ, hãy giữ nguyên giá trị mặc định play tùy chọn cho lớp đầu ra -
Tiếp theo, bạn sẽ chọn bộ phân loại.
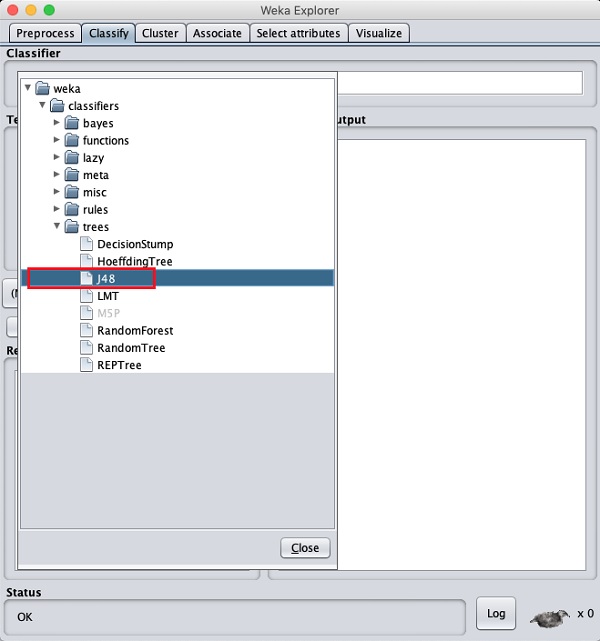
Chọn bộ phân loại
Nhấp vào nút Chọn và chọn bộ phân loại sau:
weka→classifiers>trees>J48
Điều này được hiển thị trong ảnh chụp màn hình bên dưới -
Bấm vào Startđể bắt đầu quá trình phân loại. Sau một thời gian, kết quả phân loại sẽ được hiển thị trên màn hình của bạn như được hiển thị ở đây -
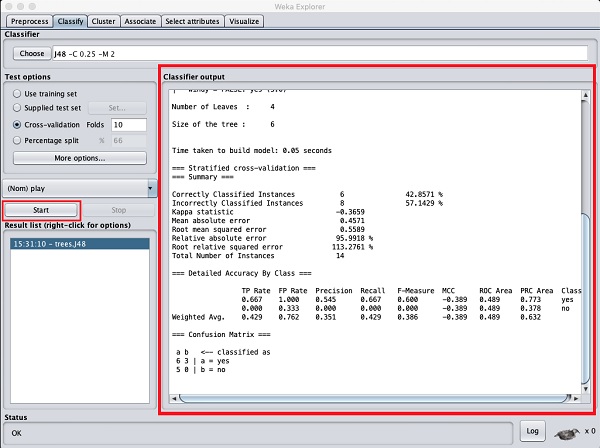
Hãy để chúng tôi kiểm tra đầu ra được hiển thị ở phía bên phải của màn hình.
Nó cho biết kích thước của cây là 6. Bạn sẽ rất nhanh chóng nhìn thấy hình ảnh đại diện của cái cây. Trong Tóm tắt, nó nói rằng các trường hợp được phân loại chính xác là 2 và các trường hợp được phân loại không chính xác là 3, Nó cũng nói rằng sai số tuyệt đối tương đối là 110%. Nó cũng cho thấy Ma trận nhầm lẫn. Đi vào phân tích các kết quả này nằm ngoài phạm vi của hướng dẫn này. Tuy nhiên, từ những kết quả này, bạn có thể dễ dàng nhận ra rằng việc phân loại không được chấp nhận và bạn sẽ cần thêm dữ liệu để phân tích, để tinh chỉnh lựa chọn tính năng, xây dựng lại mô hình, v.v. cho đến khi bạn hài lòng với độ chính xác của mô hình. Dù sao, đó là tất cả những gì WEKA hướng đến. Nó cho phép bạn kiểm tra ý tưởng của mình một cách nhanh chóng.
Hình dung kết quả
Để xem biểu diễn trực quan của kết quả, hãy nhấp chuột phải vào kết quả trong Result listcái hộp. Một số tùy chọn sẽ bật lên trên màn hình như được hiển thị ở đây -
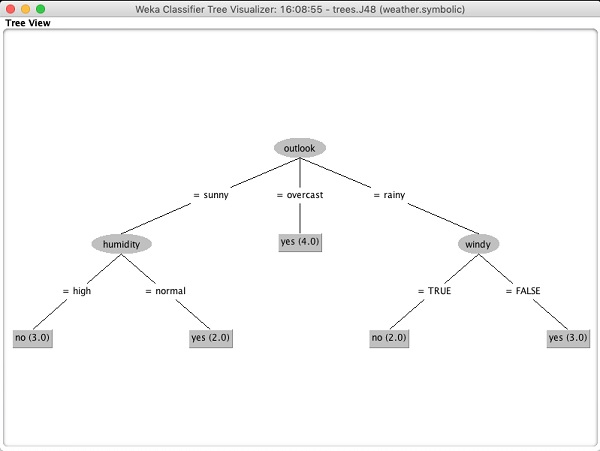
Lựa chọn Visualize tree để có được hình ảnh đại diện trực quan của cây truyền tải như trong ảnh chụp màn hình bên dưới -
Lựa chọn Visualize classifier errors sẽ vẽ biểu đồ kết quả phân loại như được hiển thị ở đây -
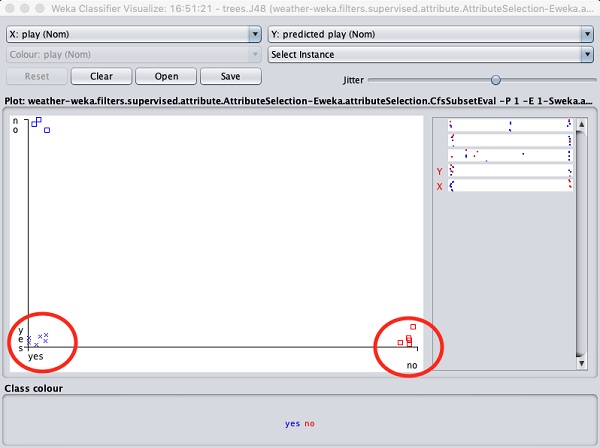
A cross đại diện cho một phiên bản được phân loại chính xác trong khi squaresđại diện cho các trường hợp được phân loại không chính xác. Ở góc dưới bên trái của mảnh đất, bạn thấycross điều đó chỉ ra nếu outlook sau đó nắng playtro choi. Vì vậy, đây là một trường hợp được phân loại chính xác. Để xác định vị trí các phiên bản, bạn có thể giới thiệu một số jitter trong đó bằng cách trượtjitter thanh trượt.
Cốt truyện hiện tại là outlook đấu với play. Chúng được biểu thị bằng hai hộp danh sách thả xuống ở đầu màn hình.
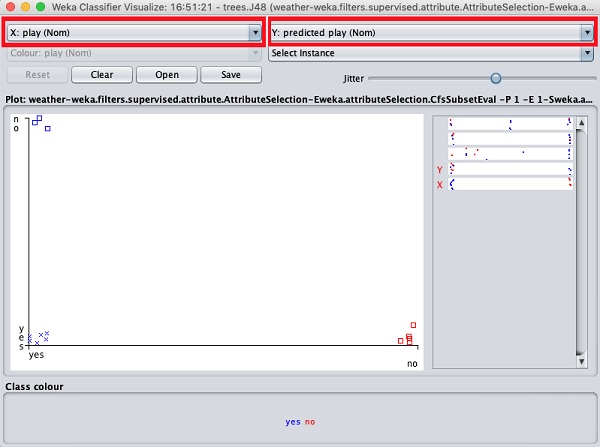
Bây giờ, hãy thử một lựa chọn khác nhau trong mỗi hộp này và chú ý cách trục X & Y thay đổi. Điều tương tự cũng có thể đạt được bằng cách sử dụng các dải ngang ở phía bên tay phải của mảnh đất. Mỗi dải đại diện cho một thuộc tính. Nhấp chuột trái vào dải đặt thuộc tính đã chọn trên trục X trong khi nhấp chuột phải sẽ đặt thuộc tính trên trục Y.
Có một số âm mưu khác được cung cấp để bạn phân tích sâu hơn. Sử dụng chúng một cách thận trọng để tinh chỉnh mô hình của bạn. Một trong những âm mưu củaCost/Benefit analysis được hiển thị bên dưới để bạn tham khảo nhanh.
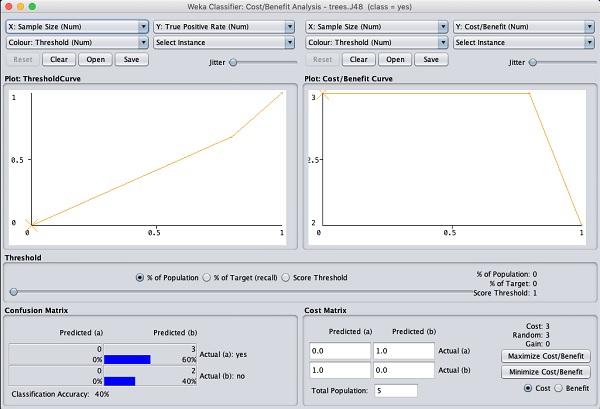
Giải thích phân tích trong các biểu đồ này nằm ngoài phạm vi của hướng dẫn này. Người đọc được khuyến khích nâng cao kiến thức về phân tích các thuật toán học máy.
Trong chương tiếp theo, chúng ta sẽ tìm hiểu bộ thuật toán học máy tiếp theo, đó là phân cụm.
Một thuật toán phân cụm tìm các nhóm các trường hợp giống nhau trong toàn bộ tập dữ liệu. WEKA hỗ trợ một số thuật toán phân cụm như EM, FilteredClusterer, HierarchicalClusterer, SimpleKMeans, v.v. Bạn nên hiểu hoàn toàn các thuật toán này để khai thác hết khả năng của WEKA.
Như trong trường hợp phân loại, WEKA cho phép bạn hình dung các cụm được phát hiện bằng đồ thị. Để chứng minh sự phân cụm, chúng tôi sẽ sử dụng cơ sở dữ liệu mống mắt được cung cấp. Tập dữ liệu chứa ba lớp gồm 50 cá thể mỗi lớp. Mỗi lớp đề cập đến một loại cây diên vĩ.
Đang tải dữ liệu
Trong trình khám phá WEKA, hãy chọn Preprocesschuyển hướng. Bấm vàoOpen file ... tùy chọn và chọn iris.arfftệp trong hộp thoại chọn tệp. Khi bạn tải dữ liệu, màn hình sẽ giống như hình dưới đây -
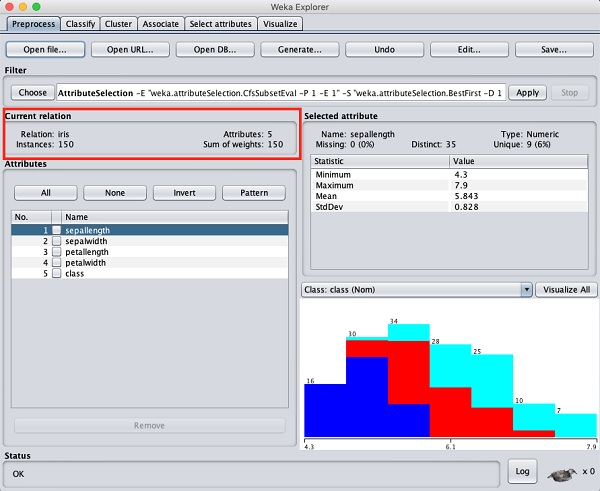
Bạn có thể quan sát thấy rằng có 150 trường hợp và 5 thuộc tính. Tên của các thuộc tính được liệt kê dưới dạngsepallength, sepalwidth, petallength, petalwidth và class. Bốn thuộc tính đầu tiên thuộc kiểu số trong khi lớp là kiểu danh nghĩa với 3 giá trị riêng biệt. Kiểm tra từng thuộc tính để hiểu các tính năng của cơ sở dữ liệu. Chúng tôi sẽ không xử lý trước dữ liệu này và ngay lập tức tiến hành xây dựng mô hình.
Phân cụm
Bấm vào ClusterTAB để áp dụng các thuật toán phân cụm cho dữ liệu đã tải của chúng tôi. Bấm vàoChoosecái nút. Bạn sẽ thấy màn hình sau:

Bây giờ, hãy chọn EMnhư là thuật toán phân cụm. bên trongCluster mode cửa sổ phụ, chọn Classes to clusters evaluation như được hiển thị trong ảnh chụp màn hình bên dưới -

Bấm vào Startđể xử lý dữ liệu. Sau một thời gian, kết quả sẽ được hiển thị trên màn hình.
Tiếp theo, chúng ta hãy nghiên cứu kết quả.
Kiểm tra đầu ra
Đầu ra của quá trình xử lý dữ liệu được hiển thị trong màn hình bên dưới:
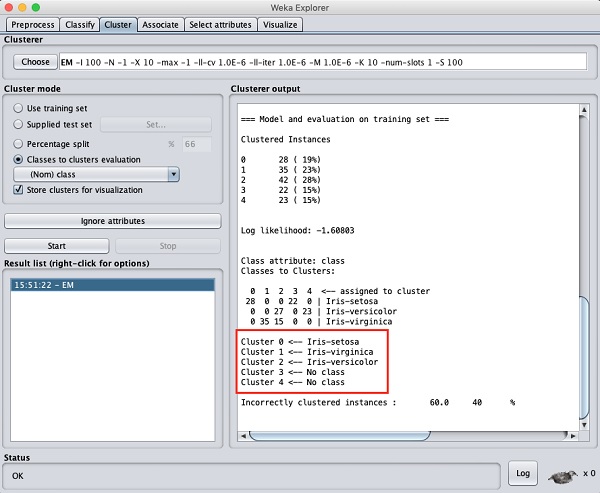
Từ màn hình đầu ra, bạn có thể quan sát thấy -
Có 5 trường hợp nhóm được phát hiện trong cơ sở dữ liệu.
Các Cluster 0 đại diện cho setosa, Cluster 1 đại diện cho virginica, Cluster 2 đại diện cho màu sắc, trong khi hai cụm cuối cùng không có bất kỳ lớp nào liên kết với chúng.
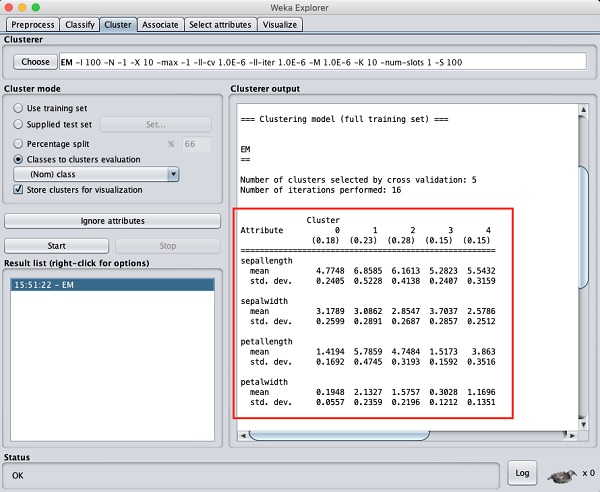
Nếu bạn cuộn cửa sổ đầu ra lên, bạn cũng sẽ thấy một số thống kê cung cấp giá trị trung bình và độ lệch chuẩn cho từng thuộc tính trong các cụm được phát hiện khác nhau. Điều này được hiển thị trong ảnh chụp màn hình dưới đây -
Tiếp theo, chúng ta sẽ xem xét biểu diễn trực quan của các cụm.
Hình dung các cụm
Để hình dung các cụm, hãy nhấp chuột phải vào EM kết quả là Result list. Bạn sẽ thấy các tùy chọn sau:
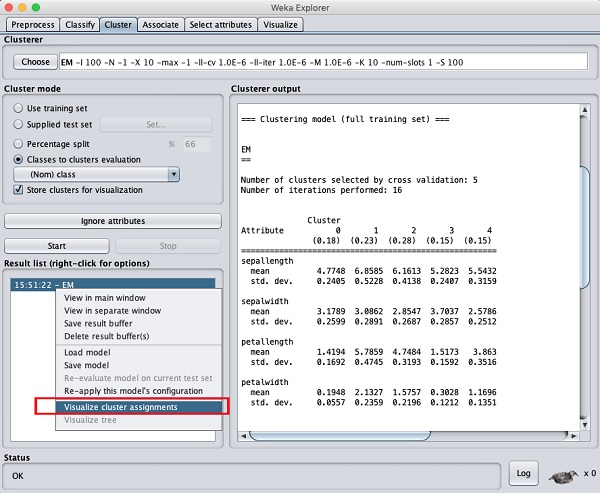
Lựa chọn Visualize cluster assignments. Bạn sẽ thấy kết quả sau:
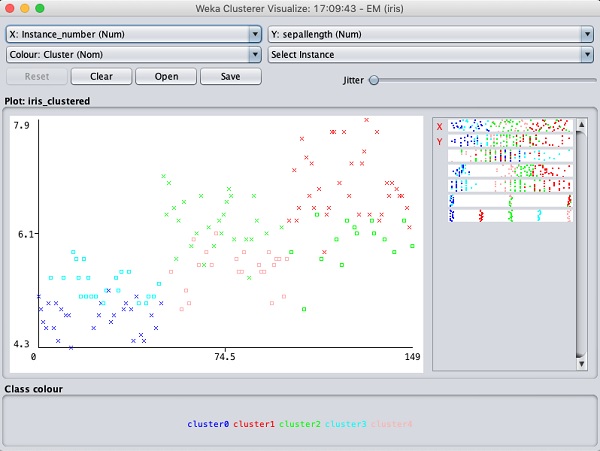
Như trong trường hợp phân loại, bạn sẽ nhận thấy sự phân biệt giữa các trường hợp được xác định đúng và sai. Bạn có thể chơi xung quanh bằng cách thay đổi trục X và Y để phân tích kết quả. Bạn có thể sử dụng jittering như trong trường hợp phân loại để tìm ra nồng độ của các trường hợp được xác định chính xác. Các thao tác trong biểu đồ trực quan tương tự như thao tác bạn đã nghiên cứu trong trường hợp phân loại.
Áp dụng Phân cụm phân cấp
Để chứng minh sức mạnh của WEKA, bây giờ chúng ta hãy xem xét một ứng dụng của một thuật toán phân cụm khác. Trong trình khám phá WEKA, hãy chọnHierarchicalClusterer như thuật toán ML của bạn như được hiển thị trong ảnh chụp màn hình bên dưới -
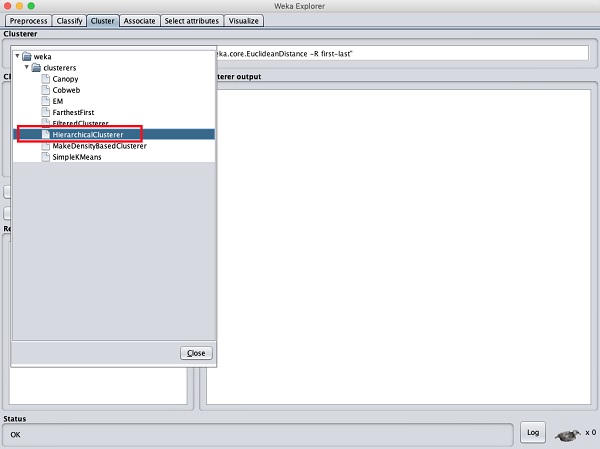
Chọn Cluster mode lựa chọn Classes to cluster evaluationvà nhấp vào Startcái nút. Bạn sẽ thấy kết quả sau:
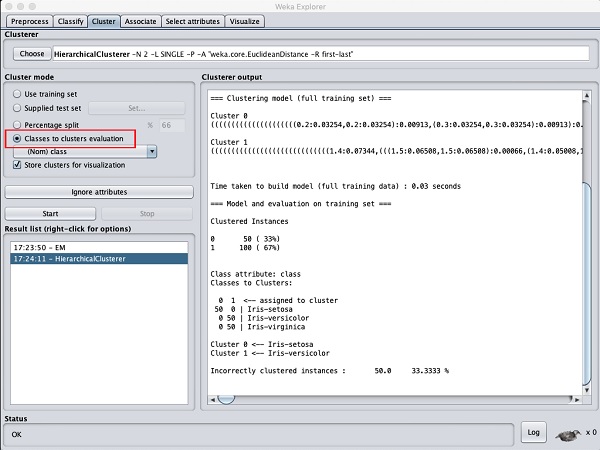
Lưu ý rằng trong Result list, có hai kết quả được liệt kê: kết quả đầu tiên là kết quả EM và kết quả thứ hai là Phân cấp hiện tại. Tương tự như vậy, bạn có thể áp dụng nhiều thuật toán ML cho cùng một tập dữ liệu và nhanh chóng so sánh kết quả của chúng.
Nếu bạn kiểm tra cây được tạo ra bởi thuật toán này, bạn sẽ thấy kết quả sau:
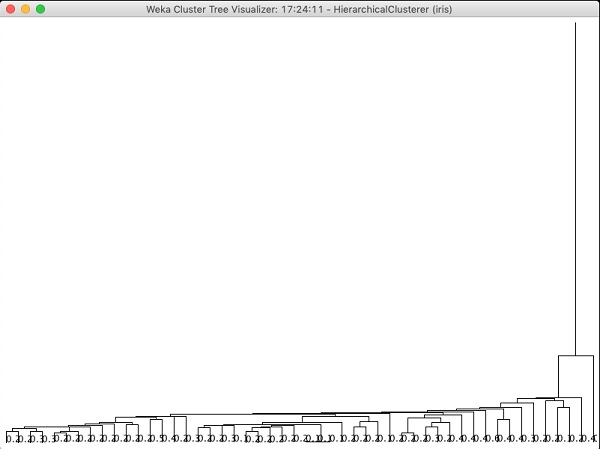
Trong chương tiếp theo, bạn sẽ nghiên cứu Associate loại thuật toán ML.
Người ta quan sát thấy rằng những người mua bia cũng mua tã lót cùng một lúc. Đó là có một hiệp hội trong việc mua bia và tã với nhau. Mặc dù điều này có vẻ không thuyết phục lắm, nhưng quy tắc liên kết này đã được khai thác từ cơ sở dữ liệu khổng lồ của các siêu thị. Tương tự, có thể tìm thấy mối liên hệ giữa bơ đậu phộng và bánh mì.
Việc tìm kiếm những liên kết như vậy trở nên quan trọng đối với các siêu thị vì họ sẽ dự trữ tã lót bên cạnh bia để khách hàng có thể tìm thấy cả hai mặt hàng một cách dễ dàng, dẫn đến tăng doanh số bán hàng cho siêu thị.
Các Apriorithuật toán là một trong những thuật toán như vậy trong ML tìm ra các liên kết có thể xảy ra và tạo ra các quy tắc kết hợp. WEKA cung cấp việc triển khai thuật toán Apriori. Bạn có thể xác định mức hỗ trợ tối thiểu và mức độ tin cậy có thể chấp nhận được trong khi tính toán các quy tắc này. Bạn sẽ áp dụngApriori thuật toán cho supermarket dữ liệu được cung cấp trong cài đặt WEKA.
Đang tải dữ liệu
Trong trình khám phá WEKA, hãy mở Preprocess , nhấp vào Open file ... và chọn supermarket.arffcơ sở dữ liệu từ thư mục cài đặt. Sau khi dữ liệu được tải, bạn sẽ thấy màn hình sau:
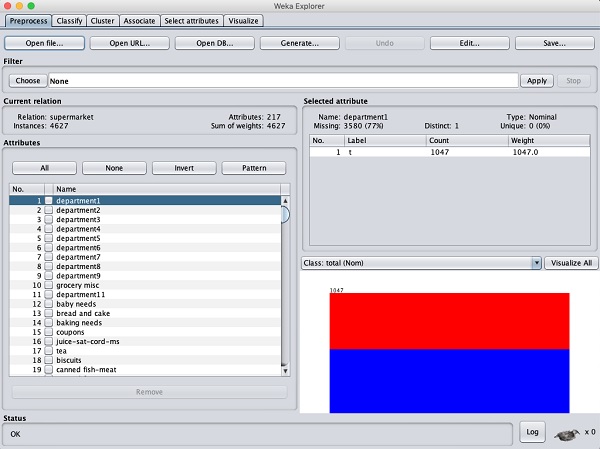
Cơ sở dữ liệu chứa 4627 phiên bản và 217 thuộc tính. Bạn có thể dễ dàng hiểu rằng sẽ khó khăn như thế nào để phát hiện mối liên hệ giữa một số lượng lớn các thuộc tính như vậy. May mắn thay, nhiệm vụ này được tự động hóa với sự trợ giúp của thuật toán Apriori.
Người liên kết
Bấm vào Associate TAB và nhấp vào Choosecái nút. ChọnApriori liên kết như được hiển thị trong ảnh chụp màn hình -
Để thiết lập các tham số cho thuật toán Apriori, bạn bấm vào tên của nó, một cửa sổ hiện ra như hình bên dưới cho phép bạn thiết lập các tham số -
Sau khi bạn đặt các thông số, hãy nhấp vào Startcái nút. Sau một thời gian, bạn sẽ thấy kết quả như trong ảnh chụp màn hình bên dưới -
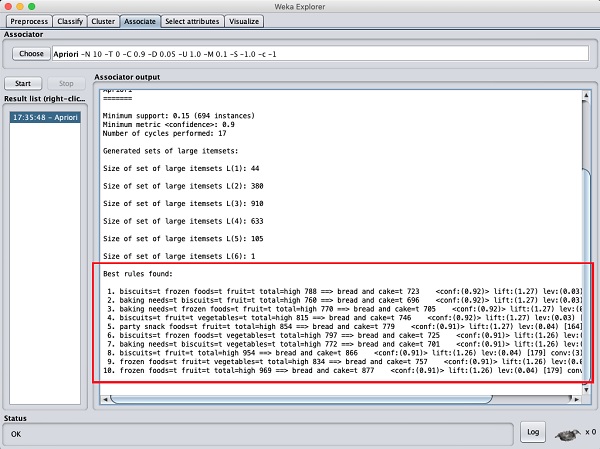
Ở phía dưới, bạn sẽ tìm thấy các quy tắc liên kết tốt nhất được phát hiện. Điều này sẽ giúp siêu thị dự trữ sản phẩm của họ trong các kệ thích hợp.
Khi một cơ sở dữ liệu chứa một số lượng lớn các thuộc tính, sẽ có một số thuộc tính không trở nên quan trọng trong phân tích mà bạn hiện đang tìm kiếm. Do đó, việc loại bỏ các thuộc tính không mong muốn khỏi tập dữ liệu trở thành một nhiệm vụ quan trọng trong việc phát triển một mô hình học máy tốt.
Bạn có thể kiểm tra toàn bộ tập dữ liệu một cách trực quan và quyết định các thuộc tính không liên quan. Đây có thể là một nhiệm vụ lớn đối với cơ sở dữ liệu chứa một số lượng lớn các thuộc tính như trường hợp siêu thị mà bạn đã thấy trong bài học trước. May mắn thay, WEKA cung cấp một công cụ tự động để lựa chọn tính năng.
Chương này trình bày tính năng này trên cơ sở dữ liệu có chứa một số lượng lớn các thuộc tính.
Đang tải dữ liệu
bên trong Preprocess của trình thám hiểm WEKA, hãy chọn labor.arfftệp để tải vào hệ thống. Khi bạn tải dữ liệu, bạn sẽ thấy màn hình sau:
Chú ý rằng có 17 thuộc tính. Nhiệm vụ của chúng tôi là tạo một tập dữ liệu giảm thiểu bằng cách loại bỏ một số thuộc tính không liên quan đến phân tích của chúng tôi.
Tính năng chiết xuất
Bấm vào Select attributesTAB.Bạn sẽ thấy màn hình sau:
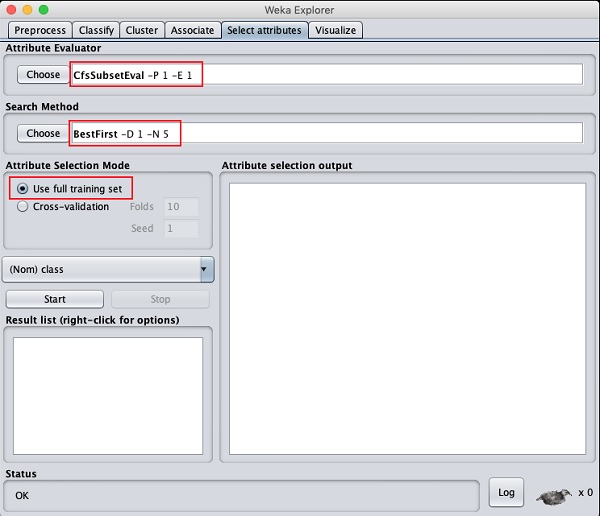
Phía dưới cái Attribute Evaluator và Search Method, bạn sẽ tìm thấy một số tùy chọn. Chúng tôi sẽ chỉ sử dụng các giá trị mặc định ở đây. bên trongAttribute Selection Mode, sử dụng tùy chọn tập hợp đào tạo đầy đủ.
Nhấp vào nút Bắt đầu để xử lý tập dữ liệu. Bạn sẽ thấy kết quả sau:

Ở cuối cửa sổ kết quả, bạn sẽ nhận được danh sách Selectedthuộc tính. Để có được hình ảnh đại diện, hãy nhấp chuột phải vào kết quả trongResult danh sách.
Kết quả được hiển thị trong ảnh chụp màn hình sau:
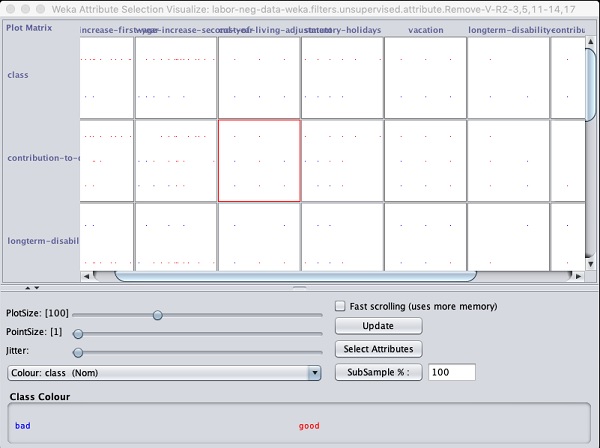
Nhấp vào bất kỳ ô vuông nào sẽ cung cấp cho bạn biểu đồ dữ liệu để bạn phân tích thêm. Biểu đồ dữ liệu điển hình được hiển thị bên dưới:
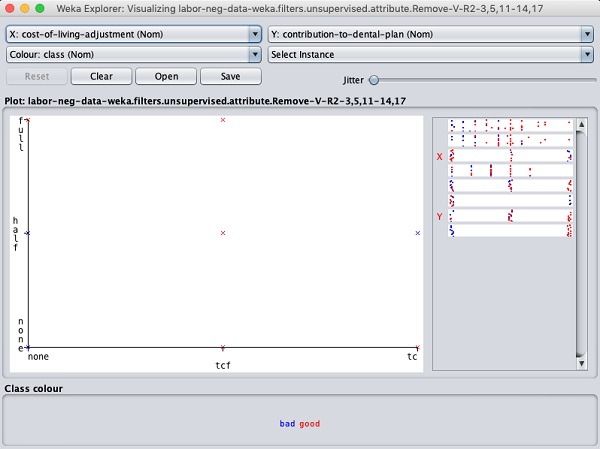
Điều này tương tự như những gì chúng ta đã thấy trong các chương trước. Chơi với các tùy chọn khác nhau có sẵn để phân tích kết quả.
Cái gì tiếp theo?
Cho đến nay, bạn đã thấy sức mạnh của WEKA trong việc phát triển nhanh chóng các mô hình học máy. Những gì chúng tôi đã sử dụng là một công cụ đồ họa có tên làExplorerđể phát triển các mô hình này. WEKA cũng cung cấp giao diện dòng lệnh cung cấp cho bạn nhiều sức mạnh hơn được cung cấp trong trình thám hiểm.
Nhấp vào Simple CLI nút GUI Chooser ứng dụng khởi động giao diện dòng lệnh này được hiển thị trong ảnh chụp màn hình bên dưới -
Nhập lệnh của bạn vào hộp nhập ở dưới cùng. Bạn sẽ có thể làm tất cả những gì bạn đã làm cho đến nay trong trình thám hiểm và nhiều hơn thế nữa. Tham khảo tài liệu WEKA (https://www.cs.waikato.ac.nz/ml/weka/documentation.html) để biết thêm chi tiết.
Cuối cùng, WEKA được phát triển bằng Java và cung cấp giao diện cho API của nó. Vì vậy, nếu bạn là một nhà phát triển Java và muốn đưa các triển khai WEKA ML vào các dự án Java của riêng mình, bạn có thể làm như vậy dễ dàng.
Phần kết luận
WEKA là một công cụ mạnh mẽ để phát triển các mô hình học máy. Nó cung cấp triển khai một số thuật toán ML được sử dụng rộng rãi nhất. Trước khi các thuật toán này được áp dụng cho tập dữ liệu của bạn, nó cũng cho phép bạn xử lý trước dữ liệu. Các loại thuật toán được hỗ trợ được phân loại theo các thuộc tính Classify, Cluster, Associate và Select. Kết quả ở các giai đoạn xử lý khác nhau có thể được hình dung bằng một hình ảnh trực quan đẹp và mạnh mẽ. Điều này giúp Nhà khoa học dữ liệu dễ dàng áp dụng nhanh các kỹ thuật máy học khác nhau trên tập dữ liệu của mình, so sánh kết quả và tạo mô hình tốt nhất cho lần sử dụng cuối cùng.