KI mit Python - NLTK-Paket
In diesem Kapitel erfahren Sie, wie Sie mit dem Natural Language Toolkit-Paket beginnen.
Voraussetzung
Wenn wir Anwendungen mit der Verarbeitung natürlicher Sprache erstellen möchten, ist die Änderung des Kontexts am schwierigsten. Der Kontextfaktor beeinflusst, wie die Maschine einen bestimmten Satz versteht. Daher müssen wir Anwendungen in natürlicher Sprache mithilfe von Ansätzen des maschinellen Lernens entwickeln, damit die Maschine auch verstehen kann, wie ein Mensch den Kontext verstehen kann.
Um solche Anwendungen zu erstellen, verwenden wir das Python-Paket NLTK (Natural Language Toolkit Package).
NLTK importieren
Wir müssen NLTK installieren, bevor wir es verwenden können. Es kann mit Hilfe des folgenden Befehls installiert werden:
pip install nltkVerwenden Sie den folgenden Befehl, um ein Conda-Paket für NLTK zu erstellen:
conda install -c anaconda nltkNachdem Sie das NLTK-Paket installiert haben, müssen Sie es über die Python-Eingabeaufforderung importieren. Wir können es importieren, indem wir den folgenden Befehl an die Python-Eingabeaufforderung schreiben:
>>> import nltkHerunterladen der NLTK-Daten
Nach dem Import von NLTK müssen wir nun die erforderlichen Daten herunterladen. Dies kann mit Hilfe des folgenden Befehls an der Python-Eingabeaufforderung erfolgen:
>>> nltk.download()Installieren anderer erforderlicher Pakete
Für die Erstellung von Anwendungen zur Verarbeitung natürlicher Sprache mithilfe von NLTK müssen die erforderlichen Pakete installiert werden. Die Pakete sind wie folgt -
gensim
Es ist eine robuste semantische Modellierungsbibliothek, die für viele Anwendungen nützlich ist. Wir können es installieren, indem wir den folgenden Befehl ausführen:
pip install gensimMuster
Es wird verwendet, um zu machen gensimPaket funktioniert richtig. Wir können es installieren, indem wir den folgenden Befehl ausführen
pip install patternKonzept der Tokenisierung, Stemming und Lemmatisierung
In diesem Abschnitt werden wir verstehen, was Tokenisierung, Stemming und Lemmatisierung sind.
Tokenisierung
Es kann als der Prozess des Aufbrechens des gegebenen Textes definiert werden, dh der Zeichenfolge in kleinere Einheiten, die als Token bezeichnet werden. Die Token können Wörter, Zahlen oder Satzzeichen sein. Es wird auch Wortsegmentierung genannt. Das Folgende ist ein einfaches Beispiel für die Tokenisierung -
Input - Mango, Banane, Ananas und Apfel sind Früchte.
Output - -

Das Aufbrechen des angegebenen Textes kann mithilfe der Wortgrenzen erfolgen. Das Ende eines Wortes und der Anfang eines neuen Wortes werden Wortgrenzen genannt. Das Schriftsystem und die typografische Struktur der Wörter beeinflussen die Grenzen.
Im Python NLTK-Modul gibt es verschiedene Pakete zur Tokenisierung, mit denen wir den Text gemäß unseren Anforderungen in Token unterteilen können. Einige der Pakete sind wie folgt:
Paket sent_tokenize
Wie der Name schon sagt, teilt dieses Paket den eingegebenen Text in Sätze. Wir können dieses Paket mit Hilfe des folgenden Python-Codes importieren:
from nltk.tokenize import sent_tokenizeword_tokenize-Paket
Dieses Paket unterteilt den eingegebenen Text in Wörter. Wir können dieses Paket mit Hilfe des folgenden Python-Codes importieren:
from nltk.tokenize import word_tokenizeWordPunctTokenizer-Paket
Dieses Paket unterteilt den eingegebenen Text in Wörter sowie die Satzzeichen. Wir können dieses Paket mit Hilfe des folgenden Python-Codes importieren:
from nltk.tokenize import WordPuncttokenizerStemming
Bei der Arbeit mit Wörtern stoßen wir aus grammatikalischen Gründen auf viele Variationen. Das Konzept der Variationen bedeutet hier, dass wir uns mit verschiedenen Formen der gleichen Wörter wie beschäftigen müssendemocracy, democratic, und democratization. Maschinen müssen unbedingt verstehen, dass diese verschiedenen Wörter dieselbe Grundform haben. Auf diese Weise wäre es nützlich, die Grundformen der Wörter zu extrahieren, während wir den Text analysieren.
Wir können dies erreichen, indem wir eindämmen. Auf diese Weise können wir sagen, dass Stemming der heuristische Prozess ist, bei dem die Grundformen der Wörter durch Abhacken der Wortenden extrahiert werden.
Im Python NLTK-Modul gibt es verschiedene Pakete zum Thema Stemming. Diese Pakete können verwendet werden, um die Grundformen von Wörtern zu erhalten. Diese Pakete verwenden Algorithmen. Einige der Pakete sind wie folgt:
PorterStemmer-Paket
Dieses Python-Paket verwendet den Porter-Algorithmus, um das Basisformular zu extrahieren. Wir können dieses Paket mit Hilfe des folgenden Python-Codes importieren:
from nltk.stem.porter import PorterStemmerZum Beispiel, wenn wir das Wort geben ‘writing’ Als Eingabe für diesen Stemmer werden wir das Wort bekommen ‘write’ nach dem Stemming.
LancasterStemmer-Paket
Dieses Python-Paket verwendet den Lancaster-Algorithmus, um das Basisformular zu extrahieren. Wir können dieses Paket mit Hilfe des folgenden Python-Codes importieren:
from nltk.stem.lancaster import LancasterStemmerZum Beispiel, wenn wir das Wort geben ‘writing’ Als Eingabe für diesen Stemmer werden wir das Wort bekommen ‘write’ nach dem Stemming.
SnowballStemmer-Paket
Dieses Python-Paket verwendet den Schneeball-Algorithmus, um das Basisformular zu extrahieren. Wir können dieses Paket mit Hilfe des folgenden Python-Codes importieren:
from nltk.stem.snowball import SnowballStemmerZum Beispiel, wenn wir das Wort geben ‘writing’ Als Eingabe für diesen Stemmer werden wir das Wort bekommen ‘write’ nach dem Stemming.
Alle diese Algorithmen haben unterschiedliche Strenge. Wenn wir diese drei Stemmers vergleichen, sind die Porter-Stemmers am wenigsten streng und Lancaster am strengsten. Schneeball-Stemmer ist sowohl in Bezug auf Geschwindigkeit als auch in Bezug auf Strenge gut zu verwenden.
Lemmatisierung
Wir können die Grundform von Wörtern auch durch Lemmatisierung extrahieren. Grundsätzlich wird diese Aufgabe unter Verwendung eines Vokabulars und einer morphologischen Analyse von Wörtern ausgeführt, wobei normalerweise nur die Beugung von Beugungsenden angestrebt wird. Diese Art der Grundform eines Wortes wird Lemma genannt.
Der Hauptunterschied zwischen Stemming und Lemmatisierung besteht in der Verwendung des Wortschatzes und der morphologischen Analyse der Wörter. Ein weiterer Unterschied besteht darin, dass das Stemming am häufigsten derivativ verwandte Wörter zusammenbricht, während die Lemmatisierung gewöhnlich nur die verschiedenen Flexionsformen eines Lemmas zusammenbricht. Wenn wir beispielsweise das Wort saw als Eingabewort angeben, gibt das Stemming möglicherweise das Wort 's' zurück, aber die Lemmatisierung würde versuchen, das Wort see oder saw zurückzugeben, je nachdem, ob die Verwendung des Tokens ein Verb oder ein Substantiv war.
Im Python NLTK-Modul haben wir das folgende Paket zum Lemmatisierungsprozess, mit dem wir die Grundformen von Wörtern erhalten können -
WordNetLemmatizer-Paket
Dieses Python-Paket extrahiert die Grundform des Wortes, je nachdem, ob es als Substantiv oder als Verb verwendet wird. Wir können dieses Paket mit Hilfe des folgenden Python-Codes importieren:
from nltk.stem import WordNetLemmatizerChunking: Aufteilen von Daten in Chunks
Es ist einer der wichtigsten Prozesse in der Verarbeitung natürlicher Sprache. Die Hauptaufgabe des Chunking besteht darin, die Wortarten und kurzen Phrasen wie Nominalphrasen zu identifizieren. Wir haben bereits den Prozess der Tokenisierung, die Erstellung von Token, untersucht. Chunking ist im Grunde die Kennzeichnung dieser Token. Mit anderen Worten, Chunking zeigt uns die Struktur des Satzes.
Im folgenden Abschnitt lernen wir die verschiedenen Arten von Chunking kennen.
Arten von Chunking
Es gibt zwei Arten von Chunking. Die Typen sind wie folgt:
Chunking up
In diesem Prozess des Zerhackens werden das Objekt, die Dinge usw. allgemeiner und die Sprache wird abstrakter. Es gibt mehr Chancen auf Einigung. In diesem Prozess verkleinern wir. Wenn wir zum Beispiel die Frage aufwerfen, „für welchen Zweck Autos sind“? Wir können die Antwort "Transport" bekommen.
Chunking down
In diesem Prozess des Zerhackens werden das Objekt, die Dinge usw. spezifischer und die Sprache wird durchdringender. Die tiefere Struktur würde beim Zerlegen untersucht. In diesem Prozess zoomen wir hinein. Wenn wir beispielsweise die Frage „Erzählen Sie speziell von einem Auto“ aufteilen? Wir werden kleinere Informationen über das Auto erhalten.
Example
In diesem Beispiel führen wir das Nunk-Phrase-Chunking durch, eine Chunking-Kategorie, bei der die Nomen-Phrasen-Chunks im Satz mithilfe des NLTK-Moduls in Python gefunden werden.
Follow these steps in python for implementing noun phrase chunking −
Step 1- In diesem Schritt müssen wir die Grammatik für das Chunking definieren. Es würde aus den Regeln bestehen, denen wir folgen müssen.
Step 2- In diesem Schritt müssen wir einen Chunk-Parser erstellen. Es würde die Grammatik analysieren und die Ausgabe geben.
Step 3 - In diesem letzten Schritt wird die Ausgabe in einem Baumformat erzeugt.
Importieren wir das erforderliche NLTK-Paket wie folgt:
import nltkJetzt müssen wir den Satz definieren. Hier bedeutet DT die Determinante, VBP das Verb, JJ das Adjektiv, IN die Präposition und NN das Substantiv.
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Jetzt müssen wir die Grammatik geben. Hier geben wir die Grammatik in Form eines regulären Ausdrucks an.
grammar = "NP:{<DT>?<JJ>*<NN>}"Wir müssen einen Parser definieren, der die Grammatik analysiert.
parser_chunking = nltk.RegexpParser(grammar)Der Parser analysiert den Satz wie folgt:
parser_chunking.parse(sentence)Als nächstes müssen wir die Ausgabe erhalten. Die Ausgabe wird in der einfachen Variablen namens generiertoutput_chunk.
Output_chunk = parser_chunking.parse(sentence)Nach Ausführung des folgenden Codes können wir unsere Ausgabe in Form eines Baums zeichnen.
output.draw()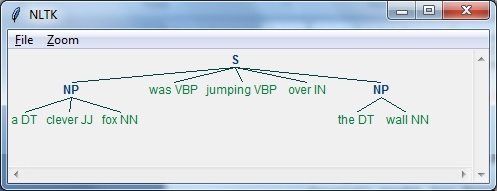
Bag of Word (BoW) Modell
Bag of Word (BoW), ein Modell in der Verarbeitung natürlicher Sprache, wird im Wesentlichen verwendet, um die Merkmale aus Text zu extrahieren, damit der Text bei der Modellierung verwendet werden kann, beispielsweise bei Algorithmen für maschinelles Lernen.
Nun stellt sich die Frage, warum wir die Features aus dem Text extrahieren müssen. Dies liegt daran, dass die Algorithmen für maschinelles Lernen nicht mit Rohdaten arbeiten können und numerische Daten benötigen, damit sie aussagekräftige Informationen daraus extrahieren können. Die Umwandlung von Textdaten in numerische Daten wird als Merkmalsextraktion oder Merkmalskodierung bezeichnet.
Wie es funktioniert
Dies ist ein sehr einfacher Ansatz zum Extrahieren der Features aus Text. Angenommen, wir haben ein Textdokument und möchten es in numerische Daten konvertieren oder sagen, wir möchten die Features daraus extrahieren. Dann extrahiert dieses Modell zunächst ein Vokabular aus allen Wörtern im Dokument. Mithilfe einer Dokumenttermmatrix wird dann ein Modell erstellt. Auf diese Weise stellt BoW das Dokument nur als Wortsack dar. Alle Informationen über die Reihenfolge oder Struktur der Wörter im Dokument werden verworfen.
Konzept der Dokumenttermmatrix
Der BoW-Algorithmus erstellt ein Modell unter Verwendung der Dokumenttermmatrix. Wie der Name schon sagt, ist die Dokumenttermmatrix die Matrix verschiedener Wortzahlen, die im Dokument vorkommen. Mit Hilfe dieser Matrix kann das Textdokument als gewichtete Kombination verschiedener Wörter dargestellt werden. Durch Festlegen des Schwellenwerts und Auswählen der aussagekräftigeren Wörter können wir ein Histogramm aller Wörter in den Dokumenten erstellen, die als Merkmalsvektor verwendet werden können. Das Folgende ist ein Beispiel, um das Konzept der Dokumenttermmatrix zu verstehen -
Example
Angenommen, wir haben die folgenden zwei Sätze -
Sentence 1 - Wir verwenden das Bag of Words-Modell.
Sentence 2 - Das Bag of Words-Modell wird zum Extrahieren der Features verwendet.
Wenn wir nun diese beiden Sätze betrachten, haben wir die folgenden 13 verschiedenen Wörter -
- we
- are
- using
- the
- bag
- of
- words
- model
- is
- used
- for
- extracting
- features
Jetzt müssen wir für jeden Satz ein Histogramm erstellen, indem wir die Wortzahl in jedem Satz verwenden -
Sentence 1 - [1,1,1,1,1,1,1,1,0,0,0,0,0]
Sentence 2 - [0,0,0,1,1,1,1,1,1,1,1,1,1]
Auf diese Weise haben wir die Merkmalsvektoren, die extrahiert wurden. Jeder Merkmalsvektor ist 13-dimensional, da wir 13 verschiedene Wörter haben.
Konzept der Statistik
Das Konzept der Statistik heißt TermFrequency-Inverse Document Frequency (tf-idf). Jedes Wort ist im Dokument wichtig. Die Statistiken helfen uns, die Wichtigkeit jedes Wortes zu verstehen.
Laufzeit (tf)
Dies ist das Maß dafür, wie häufig jedes Wort in einem Dokument vorkommt. Dies kann erreicht werden, indem die Anzahl jedes Wortes durch die Gesamtzahl der Wörter in einem bestimmten Dokument geteilt wird.
Inverse Dokumentfrequenz (idf)
Dies ist das Maß dafür, wie eindeutig ein Wort für dieses Dokument in den angegebenen Dokumenten ist. Um idf zu berechnen und einen charakteristischen Merkmalsvektor zu formulieren, müssen wir die Gewichtung häufig vorkommender Wörter wie das reduzieren und die seltenen Wörter abwägen.
Erstellen eines Bag of Words-Modells in NLTK
In diesem Abschnitt definieren wir eine Sammlung von Zeichenfolgen, indem wir mit CountVectorizer Vektoren aus diesen Sätzen erstellen.
Lassen Sie uns das notwendige Paket importieren -
from sklearn.feature_extraction.text import CountVectorizerDefinieren Sie nun die Menge der Sätze.
Sentences = ['We are using the Bag of Word model', 'Bag of Word model is
used for extracting the features.']
vectorizer_count = CountVectorizer()
features_text = vectorizer.fit_transform(Sentences).todense()
print(vectorizer.vocabulary_)Das obige Programm erzeugt die Ausgabe wie unten gezeigt. Es zeigt, dass wir in den beiden obigen Sätzen 13 verschiedene Wörter haben -
{'we': 11, 'are': 0, 'using': 10, 'the': 8, 'bag': 1, 'of': 7,
'word': 12, 'model': 6, 'is': 5, 'used': 9, 'for': 4, 'extracting': 2, 'features': 3}Dies sind die Merkmalsvektoren (Text in numerische Form), die für maschinelles Lernen verwendet werden können.
Probleme lösen
In diesem Abschnitt werden wir einige verwandte Probleme lösen.
Kategorie Vorhersage
In einer Reihe von Dokumenten sind nicht nur die Wörter, sondern auch die Kategorie der Wörter wichtig. In welche Textkategorie fällt ein bestimmtes Wort? Zum Beispiel möchten wir vorhersagen, ob ein bestimmter Satz zur Kategorie E-Mail, Nachrichten, Sport, Computer usw. gehört. Im folgenden Beispiel werden wir tf-idf verwenden, um einen Merkmalsvektor zu formulieren, um die Kategorie von Dokumenten zu finden. Wir werden die Daten aus 20 Newsgroup-Datensätzen von sklearn verwenden.
Wir müssen die notwendigen Pakete importieren -
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizerDefinieren Sie die Kategorieübersicht. Wir verwenden fünf verschiedene Kategorien mit den Namen Religion, Autos, Sport, Elektronik und Weltraum.
category_map = {'talk.religion.misc':'Religion','rec.autos''Autos',
'rec.sport.hockey':'Hockey','sci.electronics':'Electronics', 'sci.space': 'Space'}Erstellen Sie das Trainingsset -
training_data = fetch_20newsgroups(subset = 'train',
categories = category_map.keys(), shuffle = True, random_state = 5)Erstellen Sie einen Count-Vektorisierer und extrahieren Sie die Termzählungen -
vectorizer_count = CountVectorizer()
train_tc = vectorizer_count.fit_transform(training_data.data)
print("\nDimensions of training data:", train_tc.shape)Der tf-idf-Transformator wird wie folgt erstellt:
tfidf = TfidfTransformer()
train_tfidf = tfidf.fit_transform(train_tc)Definieren Sie nun die Testdaten -
input_data = [
'Discovery was a space shuttle',
'Hindu, Christian, Sikh all are religions',
'We must have to drive safely',
'Puck is a disk made of rubber',
'Television, Microwave, Refrigrated all uses electricity'
]Die obigen Daten helfen uns, einen multinomialen Naive Bayes-Klassifikator zu trainieren -
classifier = MultinomialNB().fit(train_tfidf, training_data.target)Transformieren Sie die Eingabedaten mit dem Count Vectorizer -
input_tc = vectorizer_count.transform(input_data)Jetzt werden wir die vektorisierten Daten mit dem tfidf-Transformator transformieren -
input_tfidf = tfidf.transform(input_tc)Wir werden die Ausgabekategorien vorhersagen -
predictions = classifier.predict(input_tfidf)Die Ausgabe wird wie folgt generiert:
for sent, category in zip(input_data, predictions):
print('\nInput Data:', sent, '\n Category:', \
category_map[training_data.target_names[category]])Der Kategorie-Prädiktor generiert die folgende Ausgabe:
Dimensions of training data: (2755, 39297)
Input Data: Discovery was a space shuttle
Category: Space
Input Data: Hindu, Christian, Sikh all are religions
Category: Religion
Input Data: We must have to drive safely
Category: Autos
Input Data: Puck is a disk made of rubber
Category: Hockey
Input Data: Television, Microwave, Refrigrated all uses electricity
Category: ElectronicsGender Finder
In dieser Problemstellung würde ein Klassifikator geschult, um das Geschlecht (männlich oder weiblich) durch Angabe der Namen zu finden. Wir müssen eine Heuristik verwenden, um einen Merkmalsvektor zu konstruieren und den Klassifikator zu trainieren. Wir werden die gekennzeichneten Daten aus dem scikit-learn-Paket verwenden. Es folgt der Python-Code zum Erstellen eines Gender Finders -
Lassen Sie uns die notwendigen Pakete importieren -
import random
from nltk import NaiveBayesClassifier
from nltk.classify import accuracy as nltk_accuracy
from nltk.corpus import namesJetzt müssen wir die letzten N Buchstaben aus dem eingegebenen Wort extrahieren. Diese Buchstaben dienen als Merkmale -
def extract_features(word, N = 2):
last_n_letters = word[-N:]
return {'feature': last_n_letters.lower()}
if __name__=='__main__':Erstellen Sie die Trainingsdaten mit beschrifteten Namen (männlich wie weiblich), die in NLTK verfügbar sind -
male_list = [(name, 'male') for name in names.words('male.txt')]
female_list = [(name, 'female') for name in names.words('female.txt')]
data = (male_list + female_list)
random.seed(5)
random.shuffle(data)Jetzt werden Testdaten wie folgt erstellt:
namesInput = ['Rajesh', 'Gaurav', 'Swati', 'Shubha']Definieren Sie die Anzahl der für Zug und Test verwendeten Proben mit dem folgenden Code
train_sample = int(0.8 * len(data))Jetzt müssen wir verschiedene Längen durchlaufen, damit die Genauigkeit verglichen werden kann -
for i in range(1, 6):
print('\nNumber of end letters:', i)
features = [(extract_features(n, i), gender) for (n, gender) in data]
train_data, test_data = features[:train_sample],
features[train_sample:]
classifier = NaiveBayesClassifier.train(train_data)Die Genauigkeit des Klassifikators kann wie folgt berechnet werden:
accuracy_classifier = round(100 * nltk_accuracy(classifier, test_data), 2)
print('Accuracy = ' + str(accuracy_classifier) + '%')Jetzt können wir die Ausgabe vorhersagen -
for name in namesInput:
print(name, '==>', classifier.classify(extract_features(name, i)))Das obige Programm erzeugt die folgende Ausgabe -
Number of end letters: 1
Accuracy = 74.7%
Rajesh -> female
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 2
Accuracy = 78.79%
Rajesh -> male
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 3
Accuracy = 77.22%
Rajesh -> male
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 4
Accuracy = 69.98%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 5
Accuracy = 64.63%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> femaleIn der obigen Ausgabe können wir sehen, dass die Genauigkeit der maximalen Anzahl von Endbuchstaben zwei beträgt und mit zunehmender Anzahl von Endbuchstaben abnimmt.
Themenmodellierung: Identifizieren von Mustern in Textdaten
Wir wissen, dass Dokumente im Allgemeinen in Themen gruppiert sind. Manchmal müssen wir die Muster in einem Text identifizieren, die einem bestimmten Thema entsprechen. Die Technik dazu wird als Themenmodellierung bezeichnet. Mit anderen Worten, wir können sagen, dass die Themenmodellierung eine Technik ist, um abstrakte Themen oder verborgene Strukturen in den angegebenen Dokumenten aufzudecken.
Wir können die Themenmodellierungstechnik in den folgenden Szenarien verwenden:
Textklassifizierung
Mithilfe der Themenmodellierung kann die Klassifizierung verbessert werden, da ähnliche Wörter zusammengefasst werden, anstatt jedes Wort einzeln als Feature zu verwenden.
Empfehlungssysteme
Mithilfe der Themenmodellierung können wir die Empfehlungssysteme mithilfe von Ähnlichkeitsmaßen erstellen.
Algorithmen zur Themenmodellierung
Die Themenmodellierung kann mithilfe von Algorithmen implementiert werden. Die Algorithmen sind wie folgt:
Latent Dirichlet Allocation (LDA)
Dieser Algorithmus ist der beliebteste für die Themenmodellierung. Es verwendet die probabilistischen grafischen Modelle zur Implementierung der Themenmodellierung. Wir müssen das Gensim-Paket in Python importieren, um den LDA-Algorithmus verwenden zu können.
Latent Semantic Analysis (LDA) oder Latent Semantic Indexing (LSI)
Dieser Algorithmus basiert auf der linearen Algebra. Grundsätzlich wird das Konzept der SVD (Singular Value Decomposition) in der Dokumenttermmatrix verwendet.
Nicht negative Matrixfaktorisierung (NMF)
Es basiert auch auf der linearen Algebra.
Alle oben genannten Algorithmen zur Themenmodellierung hätten die number of topics als Parameter, Document-Word Matrix als Eingabe und WTM (Word Topic Matrix) & TDM (Topic Document Matrix) als Ausgabe.