KI mit Python - Spracherkennung
In diesem Kapitel lernen wir die Spracherkennung mit AI mit Python kennen.
Sprache ist das grundlegendste Mittel der menschlichen Kommunikation zwischen Erwachsenen. Das grundlegende Ziel der Sprachverarbeitung besteht darin, eine Interaktion zwischen Mensch und Maschine bereitzustellen.
Das Sprachverarbeitungssystem hat hauptsächlich drei Aufgaben -
First, Spracherkennung, mit der die Maschine die Wörter, Phrasen und Sätze erfassen kann, die wir sprechen
SecondVerarbeitung natürlicher Sprache, damit die Maschine verstehen kann, was wir sprechen, und
ThirdSprachsynthese, damit die Maschine sprechen kann.
Dieses Kapitel konzentriert sich auf speech recognition, der Prozess des Verstehens der Wörter, die von Menschen gesprochen werden. Denken Sie daran, dass die Sprachsignale mit Hilfe eines Mikrofons erfasst werden und dann vom System verstanden werden müssen.
Erstellen eines Spracherkenners
Spracherkennung oder automatische Spracherkennung (ASR) stehen im Mittelpunkt von KI-Projekten wie der Robotik. Ohne ASR ist es nicht möglich, sich einen kognitiven Roboter vorzustellen, der mit einem Menschen interagiert. Es ist jedoch nicht ganz einfach, einen Spracherkenner zu erstellen.
Schwierigkeiten bei der Entwicklung eines Spracherkennungssystems
Die Entwicklung eines hochwertigen Spracherkennungssystems ist wirklich ein schwieriges Problem. Die Schwierigkeit der Spracherkennungstechnologie kann in einer Reihe von Dimensionen allgemein charakterisiert werden, wie nachstehend erörtert wird -
Size of the vocabulary- Die Größe des Wortschatzes wirkt sich auf die einfache Entwicklung eines ASR aus. Berücksichtigen Sie zum besseren Verständnis die folgenden Wortschatzgrößen.
Ein kleines Vokabular besteht beispielsweise aus 2 bis 100 Wörtern, wie in einem Sprachmenüsystem
Ein mittelgroßes Vokabular besteht aus mehreren 100 bis 1000 Wörtern, beispielsweise wie bei einer Datenbankabrufaufgabe
Ein großes Vokabular besteht wie bei einer allgemeinen Diktataufgabe aus mehreren 10.000 Wörtern.
Channel characteristics- Die Kanalqualität ist ebenfalls eine wichtige Dimension. Beispielsweise enthält menschliche Sprache eine hohe Bandbreite mit vollem Frequenzbereich, während eine Telefonsprache aus einer niedrigen Bandbreite mit begrenztem Frequenzbereich besteht. Beachten Sie, dass es in letzterem schwieriger ist.
Speaking mode- Die einfache Entwicklung eines ASR hängt auch vom Sprechmodus ab, dh davon, ob sich die Sprache im isolierten Wortmodus oder im Modus für verbundene Wörter oder im kontinuierlichen Sprachmodus befindet. Beachten Sie, dass eine fortlaufende Sprache schwerer zu erkennen ist.
Speaking style- Eine Lesesprache kann formell oder spontan und gesprächig mit lässigem Stil sein. Letzteres ist schwerer zu erkennen.
Speaker dependency- Die Sprache kann sprecherabhängig, sprecheradaptiv oder sprecherunabhängig sein. Ein unabhängiger Sprecher ist am schwierigsten zu bauen.
Type of noise- Lärm ist ein weiterer Faktor, der bei der Entwicklung eines ASR berücksichtigt werden muss. Das Signal-Rausch-Verhältnis kann in verschiedenen Bereichen liegen, abhängig von der akustischen Umgebung, in der weniger als mehr Hintergrundgeräusche beobachtet werden.
Wenn das Signal-Rausch-Verhältnis größer als 30 dB ist, wird dies als hoher Bereich angesehen
Wenn das Signal-Rausch-Verhältnis zwischen 30 dB und 10 dB liegt, wird es als mittleres SNR betrachtet
Wenn das Signal-Rausch-Verhältnis kleiner als 10 dB ist, wird dies als niedriger Bereich angesehen
Microphone characteristics- Die Qualität des Mikrofons kann gut, durchschnittlich oder unterdurchschnittlich sein. Auch der Abstand zwischen Mund und Mikrofon kann variieren. Diese Faktoren sollten auch für Erkennungssysteme berücksichtigt werden.
Beachten Sie, dass es umso schwieriger ist, eine Erkennung durchzuführen, je größer der Wortschatz ist.
Beispielsweise trägt die Art des Hintergrundgeräuschs wie stationäres, nicht menschliches Geräusch, Hintergrundsprache und Übersprechen durch andere Sprecher ebenfalls zur Schwierigkeit des Problems bei.
Trotz dieser Schwierigkeiten arbeiteten die Forscher viel an verschiedenen Aspekten der Sprache, wie dem Verstehen des Sprachsignals, des Sprechers und dem Erkennen der Akzente.
Sie müssen die folgenden Schritte ausführen, um eine Spracherkennung zu erstellen -
Audiosignale visualisieren - Aus einer Datei lesen und daran arbeiten
Dies ist der erste Schritt beim Aufbau eines Spracherkennungssystems, da es ein Verständnis für die Struktur eines Audiosignals vermittelt. Einige allgemeine Schritte, die zum Arbeiten mit Audiosignalen ausgeführt werden können, sind folgende:
Aufzeichnung
Wenn Sie das Audiosignal aus einer Datei lesen müssen, nehmen Sie es zunächst mit einem Mikrofon auf.
Probenahme
Bei der Aufnahme mit Mikrofon werden die Signale digitalisiert gespeichert. Aber um daran zu arbeiten, braucht die Maschine sie in der diskreten numerischen Form. Daher sollten wir eine Abtastung mit einer bestimmten Frequenz durchführen und das Signal in die diskrete numerische Form umwandeln. Die Wahl der Hochfrequenz für die Abtastung bedeutet, dass Menschen, die das Signal hören, es als kontinuierliches Audiosignal empfinden.
Beispiel
Das folgende Beispiel zeigt einen schrittweisen Ansatz zum Analysieren eines Audiosignals mit Python, das in einer Datei gespeichert ist. Die Frequenz dieses Audiosignals beträgt 44.100 Hz.
Importieren Sie die erforderlichen Pakete wie hier gezeigt -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfileLesen Sie nun die gespeicherte Audiodatei. Es werden zwei Werte zurückgegeben: die Abtastfrequenz und das Audiosignal. Geben Sie den Pfad der Audiodatei an, in der sie gespeichert ist, wie hier gezeigt -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Zeigen Sie die Parameter wie die Abtastfrequenz des Audiosignals, den Datentyp des Signals und seine Dauer mit den angezeigten Befehlen an -
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')Dieser Schritt beinhaltet das Normalisieren des Signals wie unten gezeigt -
audio_signal = audio_signal / np.power(2, 15)In diesem Schritt extrahieren wir die ersten 100 Werte aus diesem Signal, um sie zu visualisieren. Verwenden Sie dazu die folgenden Befehle:
audio_signal = audio_signal [:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(frequency_sampling)Visualisieren Sie nun das Signal mit den folgenden Befehlen:
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()Sie können ein Ausgabediagramm und Daten sehen, die für das obige Audiosignal extrahiert wurden, wie in der Abbildung hier gezeigt

Signal shape: (132300,)
Signal Datatype: int16
Signal duration: 3.0 secondsCharakterisierung des Audiosignals: Transformation in den Frequenzbereich
Das Charakterisieren eines Audiosignals umfasst das Umwandeln des Zeitbereichssignals in einen Frequenzbereich und das Verstehen seiner Frequenzkomponenten durch. Dies ist ein wichtiger Schritt, da er viele Informationen über das Signal liefert. Sie können ein mathematisches Werkzeug wie die Fourier-Transformation verwenden, um diese Transformation durchzuführen.
Beispiel
Das folgende Beispiel zeigt Schritt für Schritt, wie Sie das Signal mit Python charakterisieren, das in einer Datei gespeichert ist. Beachten Sie, dass wir hier das mathematische Fourier-Transformationswerkzeug verwenden, um es in den Frequenzbereich umzuwandeln.
Importieren Sie die erforderlichen Pakete wie hier gezeigt -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfileLesen Sie nun die gespeicherte Audiodatei. Es werden zwei Werte zurückgegeben: die Abtastfrequenz und das Audiosignal. Geben Sie den Pfad der Audiodatei an, in der sie gespeichert ist, wie im Befehl hier gezeigt -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/sample.wav")In diesem Schritt zeigen wir die Parameter wie die Abtastfrequenz des Audiosignals, den Datentyp des Signals und seine Dauer mit den folgenden Befehlen an:
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')In diesem Schritt müssen wir das Signal normalisieren, wie im folgenden Befehl gezeigt -
audio_signal = audio_signal / np.power(2, 15)Dieser Schritt beinhaltet das Extrahieren der Länge und der halben Länge des Signals. Verwenden Sie dazu die folgenden Befehle:
length_signal = len(audio_signal)
half_length = np.ceil((length_signal + 1) / 2.0).astype(np.int)Jetzt müssen wir mathematische Werkzeuge zur Transformation in den Frequenzbereich anwenden. Hier verwenden wir die Fourier-Transformation.
signal_frequency = np.fft.fft(audio_signal)Führen Sie nun die Normalisierung des Frequenzbereichssignals durch und quadrieren Sie es -
signal_frequency = abs(signal_frequency[0:half_length]) / length_signal
signal_frequency **= 2Als nächstes extrahieren Sie die Länge und die halbe Länge des frequenztransformierten Signals -
len_fts = len(signal_frequency)Beachten Sie, dass das Fourier-transformierte Signal sowohl für den geraden als auch für den ungeraden Fall angepasst werden muss.
if length_signal % 2:
signal_frequency[1:len_fts] *= 2
else:
signal_frequency[1:len_fts-1] *= 2Extrahieren Sie nun die Leistung in Dezibel (dB) -
signal_power = 10 * np.log10(signal_frequency)Stellen Sie die Frequenz in kHz für die X-Achse ein -
x_axis = np.arange(0, len_half, 1) * (frequency_sampling / length_signal) / 1000.0Visualisieren Sie nun die Charakterisierung des Signals wie folgt:
plt.figure()
plt.plot(x_axis, signal_power, color='black')
plt.xlabel('Frequency (kHz)')
plt.ylabel('Signal power (dB)')
plt.show()Sie können das Ausgabediagramm des obigen Codes beobachten, wie in der Abbildung unten gezeigt -

Monotones Audiosignal erzeugen
Die beiden Schritte, die Sie bisher gesehen haben, sind wichtig, um mehr über Signale zu erfahren. Dieser Schritt ist jetzt nützlich, wenn Sie das Audiosignal mit einigen vordefinierten Parametern erzeugen möchten. Beachten Sie, dass dieser Schritt das Audiosignal in einer Ausgabedatei speichert.
Beispiel
Im folgenden Beispiel generieren wir mit Python ein monotones Signal, das in einer Datei gespeichert wird. Dazu müssen Sie folgende Schritte ausführen:
Importieren Sie die erforderlichen Pakete wie gezeigt -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import writeGeben Sie die Datei an, in der die Ausgabedatei gespeichert werden soll
output_file = 'audio_signal_generated.wav'Geben Sie nun die Parameter Ihrer Wahl wie gezeigt an -
duration = 4 # in seconds
frequency_sampling = 44100 # in Hz
frequency_tone = 784
min_val = -4 * np.pi
max_val = 4 * np.piIn diesem Schritt können wir das Audiosignal wie gezeigt erzeugen -
t = np.linspace(min_val, max_val, duration * frequency_sampling)
audio_signal = np.sin(2 * np.pi * tone_freq * t)Speichern Sie nun die Audiodatei in der Ausgabedatei -
write(output_file, frequency_sampling, signal_scaled)Extrahieren Sie die ersten 100 Werte für unser Diagramm wie gezeigt -
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(sampling_freq)Visualisieren Sie nun das erzeugte Audiosignal wie folgt:
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time in milliseconds')
plt.ylabel('Amplitude')
plt.title('Generated audio signal')
plt.show()Sie können die Darstellung wie in der hier gezeigten Abbildung sehen -
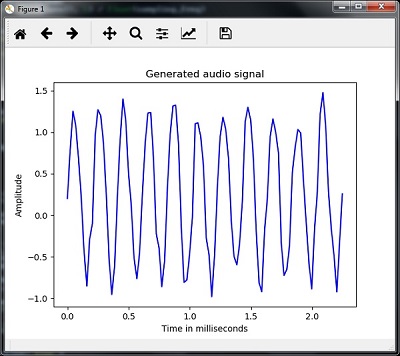
Merkmalsextraktion aus der Sprache
Dies ist der wichtigste Schritt beim Aufbau eines Spracherkenners, da das Sprachsignal nach der Umwandlung in den Frequenzbereich in die verwendbare Form eines Merkmalsvektors umgewandelt werden muss. Zu diesem Zweck können wir verschiedene Merkmalsextraktionstechniken wie MFCC, PLP, PLP-RASTA usw. verwenden.
Beispiel
Im folgenden Beispiel werden die Funktionen mithilfe von Python mithilfe der MFCC-Technik Schritt für Schritt aus dem Signal extrahiert.
Importieren Sie die erforderlichen Pakete wie hier gezeigt -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from python_speech_features import mfcc, logfbankLesen Sie nun die gespeicherte Audiodatei. Es werden zwei Werte zurückgegeben - die Abtastfrequenz und das Audiosignal. Geben Sie den Pfad der Audiodatei an, in der sie gespeichert ist.
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Beachten Sie, dass wir hier die ersten 15000 Proben zur Analyse entnehmen.
audio_signal = audio_signal[:15000]Verwenden Sie die MFCC-Techniken und führen Sie den folgenden Befehl aus, um die MFCC-Funktionen zu extrahieren:
features_mfcc = mfcc(audio_signal, frequency_sampling)Drucken Sie nun die MFCC-Parameter wie gezeigt aus -
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0])
print('Length of each feature =', features_mfcc.shape[1])Zeichnen und visualisieren Sie nun die MFCC-Funktionen mit den folgenden Befehlen:
features_mfcc = features_mfcc.T
plt.matshow(features_mfcc)
plt.title('MFCC')In diesem Schritt arbeiten wir mit den Funktionen der Filterbank wie folgt:
Extrahieren Sie die Filterbankfunktionen -
filterbank_features = logfbank(audio_signal, frequency_sampling)Drucken Sie nun die Filterbankparameter.
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0])
print('Length of each feature =', filterbank_features.shape[1])Zeichnen und visualisieren Sie nun die Filterbankfunktionen.
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()Als Ergebnis der obigen Schritte können Sie die folgenden Ausgaben beobachten: Abbildung 1 für MFCC und Abbildung 2 für Filter Bank

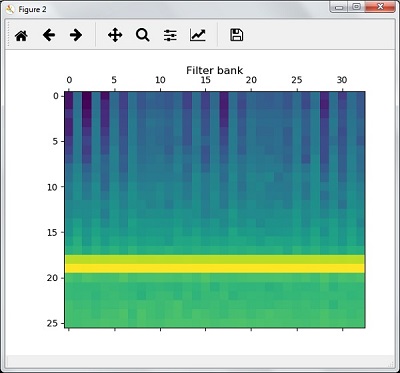
Erkennung gesprochener Wörter
Spracherkennung bedeutet, dass eine Maschine es versteht, wenn Menschen sprechen. Hier verwenden wir die Google Speech API in Python, um dies zu ermöglichen. Wir müssen die folgenden Pakete dafür installieren -
Pyaudio - Es kann mit installiert werden pip install Pyaudio Befehl.
SpeechRecognition - Dieses Paket kann mit installiert werden pip install SpeechRecognition.
Google-Speech-API - Es kann mit dem Befehl installiert werden pip install google-api-python-client.
Beispiel
Beachten Sie das folgende Beispiel, um die Erkennung gesprochener Wörter zu verstehen:
Importieren Sie die erforderlichen Pakete wie gezeigt -
import speech_recognition as srErstellen Sie ein Objekt wie unten gezeigt -
recording = sr.Recognizer()Jetzt die Microphone() Modul nimmt die Stimme als Eingabe -
with sr.Microphone() as source: recording.adjust_for_ambient_noise(source)
print("Please Say something:")
audio = recording.listen(source)Jetzt würde Google API die Stimme erkennen und die Ausgabe geben.
try:
print("You said: \n" + recording.recognize_google(audio))
except Exception as e:
print(e)Sie können die folgende Ausgabe sehen -
Please Say Something:
You said:Zum Beispiel, wenn Sie sagten tutorialspoint.com, dann erkennt das System es korrekt wie folgt:
tutorialspoint.com