Datenstrukturen und Algorithmen - Kurzanleitung
Die Datenstruktur ist eine systematische Methode zum Organisieren von Daten, um sie effizient zu nutzen. Die folgenden Begriffe sind die Grundbegriffe einer Datenstruktur.
Interface- Jede Datenstruktur hat eine Schnittstelle. Die Schnittstelle repräsentiert die Menge von Operationen, die eine Datenstruktur unterstützt. Eine Schnittstelle enthält nur die Liste der unterstützten Operationen, den Typ der Parameter, die sie akzeptieren können, und den Typ dieser Operationen.
Implementation- Die Implementierung bietet die interne Darstellung einer Datenstruktur. Die Implementierung liefert auch die Definition der Algorithmen, die in den Operationen der Datenstruktur verwendet werden.
Eigenschaften einer Datenstruktur
Correctness - Die Implementierung der Datenstruktur sollte die Schnittstelle korrekt implementieren.
Time Complexity - Die Laufzeit oder die Ausführungszeit von Operationen der Datenstruktur muss so klein wie möglich sein.
Space Complexity - Die Speichernutzung einer Datenstrukturoperation sollte so gering wie möglich sein.
Bedarf an Datenstruktur
Da Anwendungen immer komplexer und datenreicher werden, gibt es drei häufige Probleme, mit denen Anwendungen heutzutage konfrontiert sind.
Data Search- Betrachten Sie einen Bestand von 1 Million (10 6 ) Artikeln eines Geschäfts. Wenn die Anwendung einen Artikel durchsuchen soll, muss sie jedes Mal, wenn die Suche verlangsamt wird, einen Artikel in 1 Million (10 6 ) Artikeln suchen. Wenn die Daten wachsen, wird die Suche langsamer.
Processor speed - Die Prozessorgeschwindigkeit ist zwar sehr hoch, wird jedoch begrenzt, wenn die Daten auf Milliarden Datensätze anwachsen.
Multiple requests - Da Tausende von Benutzern gleichzeitig auf einem Webserver nach Daten suchen können, fällt selbst der schnelle Server beim Durchsuchen der Daten aus.
Um die oben genannten Probleme zu lösen, werden Datenstrukturen gerettet. Daten können in einer Datenstruktur so organisiert werden, dass möglicherweise nicht alle Elemente durchsucht werden müssen und die erforderlichen Daten fast sofort durchsucht werden können.
Ausführungszeitfälle
Es gibt drei Fälle, die normalerweise verwendet werden, um die Ausführungszeit verschiedener Datenstrukturen relativ zu vergleichen.
Worst Case- Dies ist das Szenario, in dem eine bestimmte Datenstrukturoperation maximal so lange dauert. Wenn die Worst-Case-Zeit einer Operation ƒ (n) ist, dauert diese Operation nicht länger als ƒ (n), wobei ƒ (n) die Funktion von n darstellt.
Average Case- Dies ist das Szenario, das die durchschnittliche Ausführungszeit einer Operation einer Datenstruktur darstellt. Wenn eine Operation bei der Ausführung ƒ (n) Zeit benötigt, benötigen m Operationen mƒ (n) Zeit.
Best Case- Dies ist das Szenario, das die geringstmögliche Ausführungszeit einer Operation einer Datenstruktur darstellt. Wenn eine Operation bei der Ausführung ƒ (n) Zeit benötigt, kann die tatsächliche Operation Zeit als Zufallszahl benötigen, die maximal ƒ (n) betragen würde.
Grundbegriffe
Data - Daten sind Werte oder Wertesätze.
Data Item - Datenelement bezieht sich auf eine einzelne Werteinheit.
Group Items - Datenelemente, die in Unterelemente unterteilt sind, werden als Gruppenelemente bezeichnet.
Elementary Items - Datenelemente, die nicht geteilt werden können, werden als Elementarelemente bezeichnet.
Attribute and Entity - Eine Entität ist eine Entität, die bestimmte Attribute oder Eigenschaften enthält, denen Werte zugewiesen werden können.
Entity Set - Entitäten mit ähnlichen Attributen bilden einen Entitätssatz.
Field - Feld ist eine einzelne elementare Informationseinheit, die ein Attribut einer Entität darstellt.
Record - Datensatz ist eine Sammlung von Feldwerten einer bestimmten Entität.
File - Datei ist eine Sammlung von Datensätzen der Entitäten in einem bestimmten Entitätssatz.
Probieren Sie es Option Online
Sie müssen wirklich keine eigene Umgebung einrichten, um mit dem Erlernen der Programmiersprache C zu beginnen. Der Grund ist sehr einfach: Wir haben die C-Programmierumgebung bereits online eingerichtet, sodass Sie alle verfügbaren Beispiele gleichzeitig online kompilieren und ausführen können, wenn Sie Ihre theoretische Arbeit erledigen. Dies gibt Ihnen Vertrauen in das, was Sie lesen, und um das Ergebnis mit verschiedenen Optionen zu überprüfen. Sie können jedes Beispiel ändern und online ausführen.
Versuchen Sie das folgende Beispiel mit dem Try it Option in der oberen rechten Ecke des Beispielcodefelds verfügbar -
#include <stdio.h>
int main(){
/* My first program in C */
printf("Hello, World! \n");
return 0;
}Für die meisten Beispiele in diesem Tutorial finden Sie die Option "Probieren Sie es aus". Nutzen Sie sie also einfach und genießen Sie das Lernen.
Einrichtung der lokalen Umgebung
Wenn Sie weiterhin bereit sind, Ihre Umgebung für die Programmiersprache C einzurichten, benötigen Sie die folgenden zwei auf Ihrem Computer verfügbaren Tools: (a) Texteditor und (b) C-Compiler.
Texteditor
Dies wird verwendet, um Ihr Programm einzugeben. Beispiele für wenige Editoren sind Windows Notepad, OS Edit-Befehl, Brief, Epsilon, EMACS und vim oder vi.
Der Name und die Version des Texteditors können auf verschiedenen Betriebssystemen variieren. Beispielsweise wird Notepad unter Windows verwendet, und vim oder vi können sowohl unter Windows als auch unter Linux oder UNIX verwendet werden.
Die Dateien, die Sie mit Ihrem Editor erstellen, werden als Quelldateien bezeichnet und enthalten Programmquellcode. Die Quelldateien für C-Programme werden normalerweise mit der Erweiterung ".c".
Stellen Sie vor Beginn der Programmierung sicher, dass Sie über einen Texteditor verfügen und über genügend Erfahrung verfügen, um ein Computerprogramm zu schreiben, in einer Datei zu speichern, zu kompilieren und schließlich auszuführen.
Der C-Compiler
Der in die Quelldatei geschriebene Quellcode ist die vom Menschen lesbare Quelle für Ihr Programm. Es muss "kompiliert" werden, damit es in die Maschinensprache übergeht, damit Ihre CPU das Programm gemäß den angegebenen Anweisungen tatsächlich ausführen kann.
Dieser C-Programmiersprachen-Compiler wird verwendet, um Ihren Quellcode in ein endgültiges ausführbares Programm zu kompilieren. Wir gehen davon aus, dass Sie über die Grundkenntnisse eines Programmiersprachen-Compilers verfügen.
Der am häufigsten verwendete und frei verfügbare Compiler ist der GNU C / C ++ - Compiler. Andernfalls können Sie Compiler von HP oder Solaris verwenden, wenn Sie über entsprechende Betriebssysteme verfügen.
Im folgenden Abschnitt erfahren Sie, wie Sie den GNU C / C ++ - Compiler unter verschiedenen Betriebssystemen installieren. Wir erwähnen C / C ++ zusammen, weil der GNU GCC-Compiler sowohl für C- als auch für C ++ - Programmiersprachen funktioniert.
Installation unter UNIX / Linux
Wenn Sie verwenden Linux or UNIXÜberprüfen Sie anschließend, ob GCC auf Ihrem System installiert ist, indem Sie den folgenden Befehl über die Befehlszeile eingeben:
$ gcc -vWenn Sie einen GNU-Compiler auf Ihrem Computer installiert haben, sollte er eine Meldung wie die folgende drucken:
Using built-in specs.
Target: i386-redhat-linux
Configured with: ../configure --prefix = /usr .......
Thread model: posix
gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)Wenn GCC nicht installiert ist, müssen Sie es selbst installieren, indem Sie die detaillierten Anweisungen unter verwenden https://gcc.gnu.org/install/
Dieses Tutorial wurde basierend auf Linux geschrieben und alle angegebenen Beispiele wurden auf Cent OS-Version des Linux-Systems kompiliert.
Installation unter Mac OS
Wenn Sie Mac OS X verwenden, können Sie GCC am einfachsten herunterladen, indem Sie die Xcode-Entwicklungsumgebung von der Apple-Website herunterladen und die einfachen Installationsanweisungen befolgen. Sobald Sie Xcode eingerichtet haben, können Sie den GNU-Compiler für C / C ++ verwenden.
Xcode ist derzeit unter developer.apple.com/technologies/tools/ verfügbar.
Installation unter Windows
Um GCC unter Windows zu installieren, müssen Sie MinGW installieren. Um MinGW zu installieren, rufen Sie die MinGW-Homepage unter www.mingw.org auf und folgen Sie dem Link zur MinGW-Downloadseite. Laden Sie die neueste Version des MinGW-Installationsprogramms herunter, die den Namen MinGW- <Version> .exe tragen sollte.
Während der Installation von MinWG müssen Sie mindestens gcc-core, gcc-g ++, binutils und die MinGW-Laufzeit installieren. Möglicherweise möchten Sie jedoch mehr installieren.
Fügen Sie das Unterverzeichnis bin Ihrer MinGW-Installation zu Ihrem hinzu PATH Umgebungsvariable, damit Sie diese Tools in der Befehlszeile anhand ihrer einfachen Namen angeben können.
Nach Abschluss der Installation können Sie gcc, g ++, ar, ranlib, dlltool und mehrere andere GNU-Tools über die Windows-Befehlszeile ausführen.
Der Algorithmus ist eine schrittweise Prozedur, die eine Reihe von Anweisungen definiert, die in einer bestimmten Reihenfolge ausgeführt werden müssen, um die gewünschte Ausgabe zu erhalten. Algorithmen werden im Allgemeinen unabhängig von den zugrunde liegenden Sprachen erstellt, dh ein Algorithmus kann in mehr als einer Programmiersprache implementiert werden.
Aus Sicht der Datenstruktur sind im Folgenden einige wichtige Kategorien von Algorithmen aufgeführt:
Search - Algorithmus zum Suchen eines Elements in einer Datenstruktur.
Sort - Algorithmus zum Sortieren von Elementen in einer bestimmten Reihenfolge.
Insert - Algorithmus zum Einfügen eines Elements in eine Datenstruktur.
Update - Algorithmus zum Aktualisieren eines vorhandenen Elements in einer Datenstruktur.
Delete - Algorithmus zum Löschen eines vorhandenen Elements aus einer Datenstruktur.
Eigenschaften eines Algorithmus
Nicht alle Prozeduren können als Algorithmus bezeichnet werden. Ein Algorithmus sollte die folgenden Eigenschaften haben:
Unambiguous- Der Algorithmus sollte klar und eindeutig sein. Jeder seiner Schritte (oder Phasen) und seine Ein- / Ausgänge sollten klar sein und dürfen nur zu einer Bedeutung führen.
Input - Ein Algorithmus sollte 0 oder mehr genau definierte Eingaben haben.
Output - Ein Algorithmus sollte 1 oder mehr genau definierte Ausgaben haben und mit der gewünschten Ausgabe übereinstimmen.
Finiteness - Algorithmen müssen nach einer endlichen Anzahl von Schritten beendet werden.
Feasibility - Sollte mit den verfügbaren Ressourcen machbar sein.
Independent - Ein Algorithmus sollte schrittweise Anweisungen haben, die unabhängig von Programmcode sein sollten.
Wie schreibe ich einen Algorithmus?
Es gibt keine genau definierten Standards für das Schreiben von Algorithmen. Es ist vielmehr problem- und ressourcenabhängig. Algorithmen werden niemals geschrieben, um einen bestimmten Programmiercode zu unterstützen.
Da wir wissen, dass alle Programmiersprachen grundlegende Codekonstrukte wie Schleifen (do, for, while), Flusskontrolle (if-else) usw. gemeinsam haben, können diese allgemeinen Konstrukte zum Schreiben eines Algorithmus verwendet werden.
Wir schreiben Algorithmen Schritt für Schritt, aber das ist nicht immer der Fall. Das Schreiben von Algorithmen ist ein Prozess und wird ausgeführt, nachdem die Problemdomäne genau definiert wurde. Das heißt, wir sollten die Problemdomäne kennen, für die wir eine Lösung entwerfen.
Beispiel
Versuchen wir anhand eines Beispiels, das Schreiben von Algorithmen zu lernen.
Problem - Entwerfen Sie einen Algorithmus, um zwei Zahlen hinzuzufügen und das Ergebnis anzuzeigen.
Step 1 − START
Step 2 − declare three integers a, b & c
Step 3 − define values of a & b
Step 4 − add values of a & b
Step 5 − store output of step 4 to c
Step 6 − print c
Step 7 − STOPAlgorithmen sagen den Programmierern, wie sie das Programm codieren sollen. Alternativ kann der Algorithmus wie folgt geschrieben werden:
Step 1 − START ADD
Step 2 − get values of a & b
Step 3 − c ← a + b
Step 4 − display c
Step 5 − STOPBeim Entwurf und der Analyse von Algorithmen wird normalerweise die zweite Methode verwendet, um einen Algorithmus zu beschreiben. Dies erleichtert dem Analysten die Analyse des Algorithmus, wobei alle unerwünschten Definitionen ignoriert werden. Er kann beobachten, welche Operationen verwendet werden und wie der Prozess abläuft.
Schreiben step numbers, es ist optional.
Wir entwerfen einen Algorithmus, um eine Lösung für ein bestimmtes Problem zu erhalten. Ein Problem kann auf mehrere Arten gelöst werden.
Daher können viele Lösungsalgorithmen für ein gegebenes Problem abgeleitet werden. Der nächste Schritt besteht darin, diese vorgeschlagenen Lösungsalgorithmen zu analysieren und die am besten geeignete Lösung zu implementieren.
Algorithmusanalyse
Die Effizienz eines Algorithmus kann in zwei verschiedenen Phasen vor und nach der Implementierung analysiert werden. Sie sind die folgenden -
A Priori Analysis- Dies ist eine theoretische Analyse eines Algorithmus. Die Effizienz eines Algorithmus wird gemessen, indem angenommen wird, dass alle anderen Faktoren, beispielsweise die Prozessorgeschwindigkeit, konstant sind und keinen Einfluss auf die Implementierung haben.
A Posterior Analysis- Dies ist eine empirische Analyse eines Algorithmus. Der ausgewählte Algorithmus wird mit der Programmiersprache implementiert. Dies wird dann auf dem Zielcomputer ausgeführt. In dieser Analyse werden aktuelle Statistiken wie Laufzeit und Platzbedarf gesammelt.
Wir werden etwas über eine A-priori- Algorithmus-Analyse lernen . Die Algorithmusanalyse befasst sich mit der Ausführung oder Laufzeit verschiedener beteiligter Operationen. Die Laufzeit einer Operation kann als die Anzahl der pro Operation ausgeführten Computeranweisungen definiert werden.
Komplexität des Algorithmus
Annehmen X ist ein Algorithmus und n ist die Größe der Eingabedaten, die vom Algorithmus X verwendete Zeit und der Raum sind die beiden Hauptfaktoren, die die Effizienz von X bestimmen.
Time Factor - Die Zeit wird gemessen, indem die Anzahl der Schlüsseloperationen wie Vergleiche im Sortieralgorithmus gezählt wird.
Space Factor - Der Speicherplatz wird gemessen, indem der vom Algorithmus maximal benötigte Speicherplatz gezählt wird.
Die Komplexität eines Algorithmus f(n) gibt die Laufzeit und / oder den vom Algorithmus benötigten Speicherplatz in Bezug auf an n als Größe der Eingabedaten.
Raumkomplexität
Die Raumkomplexität eines Algorithmus repräsentiert die Menge an Speicherplatz, die der Algorithmus in seinem Lebenszyklus benötigt. Der von einem Algorithmus benötigte Platz entspricht der Summe der folgenden beiden Komponenten:
Ein fester Teil, der zum Speichern bestimmter Daten und Variablen erforderlich ist, die unabhängig von der Größe des Problems sind. Zum Beispiel verwendete einfache Variablen und Konstanten, Programmgröße usw.
Ein variabler Teil ist ein Platz, der von Variablen benötigt wird, deren Größe von der Größe des Problems abhängt. Zum Beispiel dynamische Speicherzuweisung, Rekursionsstapelspeicher usw.
Die Raumkomplexität S (P) eines beliebigen Algorithmus P ist S (P) = C + SP (I), wobei C der feste Teil und S (I) der variable Teil des Algorithmus ist, der von der Instanzcharakteristik I abhängt ist ein einfaches Beispiel, das versucht, das Konzept zu erklären -
Algorithm: SUM(A, B)
Step 1 - START
Step 2 - C ← A + B + 10
Step 3 - StopHier haben wir drei Variablen A, B und C und eine Konstante. Daher ist S (P) = 1 + 3. Nun hängt der Raum von Datentypen gegebener Variablen und konstanter Typen ab und wird entsprechend multipliziert.
Zeitliche Komplexität
Die zeitliche Komplexität eines Algorithmus gibt die Zeit an, die der Algorithmus benötigt, um vollständig ausgeführt zu werden. Zeitanforderungen können als numerische Funktion T (n) definiert werden, wobei T (n) als Anzahl von Schritten gemessen werden kann, vorausgesetzt, jeder Schritt verbraucht konstante Zeit.
Zum Beispiel dauert das Hinzufügen von zwei n-Bit-Ganzzahlen nSchritte. Folglich ist die Gesamtberechnungszeit T (n) = c ≤ n, wobei c die Zeit ist, die für die Addition von zwei Bits benötigt wird. Hier beobachten wir, dass T (n) mit zunehmender Eingangsgröße linear wächst.
Die asymptotische Analyse eines Algorithmus bezieht sich auf die Definition der mathematischen Grenze / des Rahmens seiner Laufzeitleistung. Mit Hilfe der asymptotischen Analyse können wir sehr gut den besten Fall, den durchschnittlichen Fall und das schlechteste Szenario eines Algorithmus schließen.
Die asymptotische Analyse ist eingabegebunden, dh wenn keine Eingabe in den Algorithmus erfolgt, wird davon ausgegangen, dass sie in einer konstanten Zeit funktioniert. Mit Ausnahme der "Eingabe" werden alle anderen Faktoren als konstant betrachtet.
Die asymptotische Analyse bezieht sich auf die Berechnung der Laufzeit einer Operation in mathematischen Recheneinheiten. Beispielsweise wird die Laufzeit einer Operation als f (n) berechnet und kann für eine andere Operation als g (n 2 ) berechnet werden . Dies bedeutet, dass die Laufzeit des ersten Vorgangs linear mit der Zunahme von zunimmtn und die Laufzeit der zweiten Operation wird exponentiell ansteigen, wenn nerhöht sich. In ähnlicher Weise ist die Laufzeit beider Operationen nahezu gleich, wennn ist deutlich klein.
Normalerweise fällt die von einem Algorithmus benötigte Zeit unter drei Typen:
Best Case - Mindestzeit für die Programmausführung.
Average Case - Durchschnittliche Zeit für die Programmausführung.
Worst Case - Maximale Zeit für die Programmausführung.
Asymptotische Notationen
Im Folgenden sind die häufig verwendeten asymptotischen Notationen aufgeführt, um die Laufzeitkomplexität eines Algorithmus zu berechnen.
- Ο Notation
- Ω Notation
- θ Notation
Big Oh Notation, Ο
Die Notation Ο (n) ist der formale Weg, um die Obergrenze der Laufzeit eines Algorithmus auszudrücken. Es misst die Zeitkomplexität im ungünstigsten Fall oder die längste Zeit, die ein Algorithmus möglicherweise in Anspruch nehmen kann.
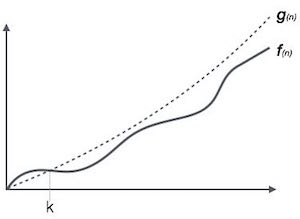
Zum Beispiel für eine Funktion f(n)
Ο(f(n)) = { g(n) : there exists c > 0 and n0 such that f(n) ≤ c.g(n) for all n > n0. }Omega-Notation, Ω
Die Notation Ω (n) ist der formale Weg, um die Untergrenze der Laufzeit eines Algorithmus auszudrücken. Es misst die beste Zeitkomplexität oder die beste Zeit, die ein Algorithmus möglicherweise für die Fertigstellung benötigt.
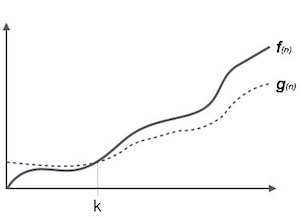
Zum Beispiel für eine Funktion f(n)
Ω(f(n)) ≥ { g(n) : there exists c > 0 and n0 such that g(n) ≤ c.f(n) for all n > n0. }Theta-Notation, θ
Die Notation θ (n) ist der formale Weg, um sowohl die Untergrenze als auch die Obergrenze der Laufzeit eines Algorithmus auszudrücken. Es wird wie folgt dargestellt:
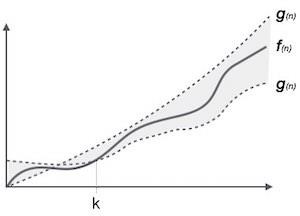
θ(f(n)) = { g(n) if and only if g(n) = Ο(f(n)) and g(n) = Ω(f(n)) for all n > n0. }Allgemeine asymptotische Notationen
Es folgt eine Liste einiger gebräuchlicher asymptotischer Notationen -
| Konstante | - - | Ο (1) |
| logarithmisch | - - | Ο (log n) |
| linear | - - | Ο (n) |
| n log n | - - | Ο (n log n) |
| quadratisch | - - | Ο (n 2 ) |
| kubisch | - - | Ο (n 3 ) |
| Polynom | - - | n Ο (1) |
| exponentiell | - - | 2 Ο (n) |
Ein Algorithmus wurde entwickelt, um eine optimale Lösung für ein bestimmtes Problem zu erreichen. Beim gierigen Algorithmus werden Entscheidungen aus der gegebenen Lösungsdomäne getroffen. Als gierig wird die nächstgelegene Lösung gewählt, die eine optimale Lösung zu bieten scheint.
Gierige Algorithmen versuchen, eine lokalisierte optimale Lösung zu finden, die schließlich zu global optimierten Lösungen führen kann. Im Allgemeinen bieten gierige Algorithmen jedoch keine global optimierten Lösungen.
Münzen zählen
Dieses Problem besteht darin, durch Auswahl der kleinstmöglichen Münzen bis zu einem gewünschten Wert zu zählen, und der gierige Ansatz zwingt den Algorithmus, die größtmögliche Münze auszuwählen. Wenn uns Münzen im Wert von 1, 2, 5 und 10 Pfund Sterling zur Verfügung gestellt werden und wir aufgefordert werden, 18 Pfund Sterling zu zählen, ist das gierige Verfahren -
1 - Wählen Sie eine 10-Pfund-Münze aus, die verbleibende Anzahl beträgt 8
2 - Wählen Sie dann eine 5-Pfund-Münze aus, die verbleibende Anzahl beträgt 3
3 - Wählen Sie dann eine 2-Pfund-Münze aus, die verbleibende Anzahl beträgt 1
4 - Und schließlich löst die Auswahl von 1-Pfund-Münzen das Problem
Obwohl es gut zu funktionieren scheint, müssen wir für diese Zählung nur 4 Münzen auswählen. Wenn wir das Problem jedoch geringfügig ändern, kann derselbe Ansatz möglicherweise nicht das gleiche optimale Ergebnis erzielen.
Für das Währungssystem, in dem wir Münzen mit einem Wert von 1, 7, 10 haben, ist das Zählen von Münzen für den Wert 18 absolut optimal, aber für das Zählen wie 15 werden möglicherweise mehr Münzen als erforderlich verwendet. Zum Beispiel verwendet der gierige Ansatz 10 + 1 + 1 + 1 + 1 + 1, insgesamt 6 Münzen. Während das gleiche Problem mit nur 3 Münzen (7 + 7 + 1) gelöst werden könnte
Wir können daher den Schluss ziehen, dass der gierige Ansatz eine sofort optimierte Lösung auswählt und fehlschlägt, wenn die globale Optimierung ein Hauptanliegen ist.
Beispiele
Die meisten Netzwerkalgorithmen verwenden den gierigen Ansatz. Hier ist eine Liste von wenigen -
- Problem mit dem reisenden Verkäufer
- Prims Minimal Spanning Tree-Algorithmus
- Kruskals Minimal Spanning Tree-Algorithmus
- Dijkstras Minimal Spanning Tree-Algorithmus
- Grafik - Kartenfärbung
- Grafik - Scheitelpunktabdeckung
- Rucksackproblem
- Job Scheduling Problem
Es gibt viele ähnliche Probleme, bei denen der gierige Ansatz verwendet wird, um eine optimale Lösung zu finden.
Beim Teilen und Erobern wird das vorliegende Problem in kleinere Unterprobleme unterteilt, und dann wird jedes Problem unabhängig gelöst. Wenn wir die Teilprobleme weiter in noch kleinere Teilprobleme aufteilen, erreichen wir möglicherweise ein Stadium, in dem keine weitere Aufteilung möglich ist. Diese "atomaren" kleinstmöglichen Unterprobleme (Brüche) werden gelöst. Die Lösung aller Unterprobleme wird schließlich zusammengeführt, um die Lösung eines ursprünglichen Problems zu erhalten.
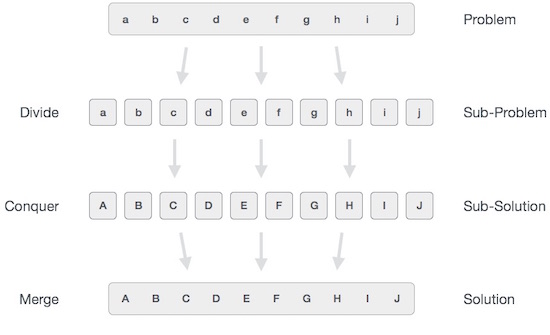
Im Großen und Ganzen können wir verstehen divide-and-conquer Ansatz in einem dreistufigen Prozess.
Teilen / Brechen
Dieser Schritt beinhaltet das Aufteilen des Problems in kleinere Unterprobleme. Unterprobleme sollten einen Teil des ursprünglichen Problems darstellen. Dieser Schritt verwendet im Allgemeinen einen rekursiven Ansatz, um das Problem zu teilen, bis kein Unterproblem mehr teilbar ist. In diesem Stadium werden Unterprobleme atomarer Natur, stellen jedoch immer noch einen Teil des eigentlichen Problems dar.
Erobern / Lösen
Dieser Schritt erhält viele kleinere Teilprobleme, die gelöst werden müssen. Auf dieser Ebene werden die Probleme im Allgemeinen als eigenständig „gelöst“ betrachtet.
Zusammenführen / kombinieren
Wenn die kleineren Teilprobleme gelöst sind, werden sie in dieser Phase rekursiv kombiniert, bis sie eine Lösung des ursprünglichen Problems formulieren. Dieser algorithmische Ansatz funktioniert rekursiv und Conquer & Merge-Schritte arbeiten so nahe, dass sie als eins angezeigt werden.
Beispiele
Die folgenden Computeralgorithmen basieren auf divide-and-conquer Programmieransatz -
- Zusammenführen, sortieren
- Schnelle Sorte
- Binäre Suche
- Strassens Matrixmultiplikation
- Nächstes Paar (Punkte)
Es gibt verschiedene Möglichkeiten, um jedes Computerproblem zu lösen, aber die genannten sind ein gutes Beispiel für den Divide and Conquer-Ansatz.
Der dynamische Programmieransatz ähnelt dem Teilen und Erobern, indem das Problem in immer kleinere Unterprobleme unterteilt wird. Im Gegensatz zu Teilen und Erobern werden diese Unterprobleme jedoch nicht unabhängig voneinander gelöst. Vielmehr werden die Ergebnisse dieser kleineren Unterprobleme gespeichert und für ähnliche oder überlappende Unterprobleme verwendet.
Dynamische Programmierung wird verwendet, wenn wir Probleme haben, die in ähnliche Unterprobleme unterteilt werden können, damit deren Ergebnisse wiederverwendet werden können. Meist werden diese Algorithmen zur Optimierung verwendet. Vor dem Lösen des vorliegenden Unterproblems versucht der dynamische Algorithmus, die Ergebnisse der zuvor gelösten Unterprobleme zu untersuchen. Die Lösungen von Teilproblemen werden kombiniert, um die beste Lösung zu erzielen.
Also können wir das sagen -
Das Problem sollte in kleinere überlappende Unterprobleme unterteilt werden können.
Eine optimale Lösung kann erreicht werden, indem eine optimale Lösung kleinerer Teilprobleme verwendet wird.
Dynamische Algorithmen verwenden Memoization.
Vergleich
Im Gegensatz zu gierigen Algorithmen, bei denen die lokale Optimierung angesprochen wird, sind dynamische Algorithmen für eine Gesamtoptimierung des Problems motiviert.
Im Gegensatz zu Divide- und Conquer-Algorithmen, bei denen Lösungen kombiniert werden, um eine Gesamtlösung zu erhalten, verwenden dynamische Algorithmen die Ausgabe eines kleineren Teilproblems und versuchen dann, ein größeres Teilproblem zu optimieren. Dynamische Algorithmen verwenden Memoization, um sich an die Ausgabe bereits gelöster Unterprobleme zu erinnern.
Beispiel
Die folgenden Computerprobleme können mithilfe eines dynamischen Programmieransatzes gelöst werden:
- Fibonacci-Zahlenreihe
- Rucksackproblem
- Turm von Hanoi
- Alle Paare kürzester Weg von Floyd-Warshall
- Kürzester Weg von Dijkstra
- Projektplanung
Die dynamische Programmierung kann sowohl von oben nach unten als auch von unten nach oben erfolgen. In den meisten Fällen ist es natürlich billiger, sich auf die vorherige Lösungsausgabe zu beziehen, als die CPU-Zyklen neu zu berechnen.
In diesem Kapitel werden die grundlegenden Begriffe zur Datenstruktur erläutert.
Datendefinition
Datendefinition definiert bestimmte Daten mit den folgenden Merkmalen.
Atomic - Die Definition sollte ein einziges Konzept definieren.
Traceable - Die Definition sollte einem Datenelement zugeordnet werden können.
Accurate - Die Definition sollte eindeutig sein.
Clear and Concise - Definition sollte verständlich sein.
Datenobjekt
Datenobjekt repräsentiert ein Objekt mit Daten.
Datentyp
Der Datentyp ist eine Möglichkeit, verschiedene Datentypen wie Ganzzahlen, Zeichenfolgen usw. zu klassifizieren, die die Werte bestimmen, die mit dem entsprechenden Datentyp verwendet werden können, die Art der Operationen, die für den entsprechenden Datentyp ausgeführt werden können. Es gibt zwei Datentypen -
- Eingebauter Datentyp
- Abgeleiteter Datentyp
Eingebauter Datentyp
Die Datentypen, für die eine Sprache eine integrierte Unterstützung bietet, werden als integrierte Datentypen bezeichnet. Beispielsweise bieten die meisten Sprachen die folgenden integrierten Datentypen.
- Integers
- Boolescher Wert (wahr, falsch)
- Floating (Dezimalzahlen)
- Charakter und Streicher
Abgeleiteter Datentyp
Diejenigen Datentypen, die implementierungsunabhängig sind, da sie auf die eine oder andere Weise implementiert werden können, werden als abgeleitete Datentypen bezeichnet. Diese Datentypen werden normalerweise durch die Kombination von primären oder integrierten Datentypen und zugehörigen Operationen erstellt. Zum Beispiel -
- List
- Array
- Stack
- Queue
Grundoperationen
Die Daten in den Datenstrukturen werden von bestimmten Operationen verarbeitet. Die bestimmte gewählte Datenstruktur hängt weitgehend von der Häufigkeit der Operation ab, die an der Datenstruktur ausgeführt werden muss.
- Traversing
- Searching
- Insertion
- Deletion
- Sorting
- Merging
Array ist ein Container, der eine feste Anzahl von Elementen enthalten kann. Diese Elemente sollten vom gleichen Typ sein. Die meisten Datenstrukturen verwenden Arrays, um ihre Algorithmen zu implementieren. Im Folgenden finden Sie wichtige Begriffe zum Verständnis des Array-Konzepts.
Element - Jedes in einem Array gespeicherte Element wird als Element bezeichnet.
Index - Jede Position eines Elements in einem Array verfügt über einen numerischen Index, mit dem das Element identifiziert wird.
Array-Darstellung
Arrays können auf verschiedene Arten in verschiedenen Sprachen deklariert werden. Nehmen wir zur Veranschaulichung die C-Array-Deklaration.

Arrays können auf verschiedene Arten in verschiedenen Sprachen deklariert werden. Nehmen wir zur Veranschaulichung die C-Array-Deklaration.
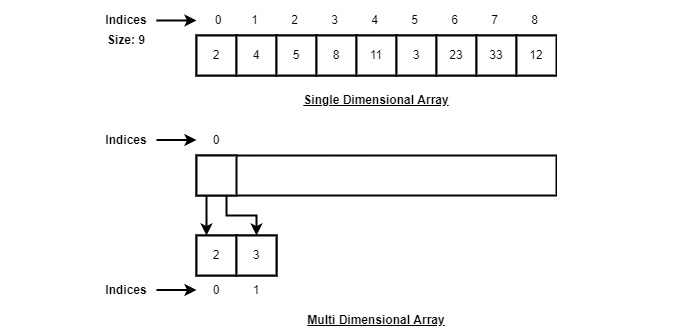
Gemäß der obigen Abbildung sind die folgenden wichtigen Punkte zu berücksichtigen.
Der Index beginnt mit 0.
Die Array-Länge beträgt 10, was bedeutet, dass 10 Elemente gespeichert werden können.
Auf jedes Element kann über seinen Index zugegriffen werden. Zum Beispiel können wir ein Element am Index 6 als 9 abrufen.
Grundoperationen
Im Folgenden sind die grundlegenden Operationen aufgeführt, die von einem Array unterstützt werden.
Traverse - Drucken Sie alle Array-Elemente einzeln aus.
Insertion - Fügt ein Element am angegebenen Index hinzu.
Deletion - Löscht ein Element am angegebenen Index.
Search - Sucht ein Element anhand des angegebenen Index oder anhand des Werts.
Update - Aktualisiert ein Element am angegebenen Index.
Wenn in C ein Array mit der Größe initialisiert wird, weist es seinen Elementen Standardwerte in der folgenden Reihenfolge zu.
| Datentyp | Standardwert |
|---|---|
| Bool | falsch |
| verkohlen | 0 |
| int | 0 |
| schweben | 0.0 |
| doppelt | 0.0f |
| Leere | |
| wchar_t | 0 |
Verfahrbetrieb
Diese Operation dient zum Durchlaufen der Elemente eines Arrays.
Beispiel
Das folgende Programm durchläuft und druckt die Elemente eines Arrays:
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int item = 10, k = 3, n = 5;
int i = 0, j = n;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}Wenn wir das obige Programm kompilieren und ausführen, ergibt es das folgende Ergebnis:
Ausgabe
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8Einfügevorgang
Die Einfügeoperation besteht darin, ein oder mehrere Datenelemente in ein Array einzufügen. Abhängig von der Anforderung kann ein neues Element am Anfang, am Ende oder an einem beliebigen Array-Index hinzugefügt werden.
Hier sehen wir eine praktische Implementierung der Einfügeoperation, bei der wir Daten am Ende des Arrays hinzufügen -
Beispiel
Es folgt die Implementierung des obigen Algorithmus -
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int item = 10, k = 3, n = 5;
int i = 0, j = n;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
n = n + 1;
while( j >= k) {
LA[j+1] = LA[j];
j = j - 1;
}
LA[k] = item;
printf("The array elements after insertion :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}Wenn wir das obige Programm kompilieren und ausführen, ergibt es das folgende Ergebnis:
Ausgabe
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after insertion :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 10
LA[4] = 7
LA[5] = 8Für andere Variationen der Array-Einfügeoperation klicken Sie hier
Löschvorgang
Löschen bezieht sich auf das Entfernen eines vorhandenen Elements aus dem Array und das Neuorganisieren aller Elemente eines Arrays.
Algorithmus
Erwägen LA ist ein lineares Array mit N Elemente und K ist eine positive ganze Zahl, so dass K<=N. Es folgt der Algorithmus zum Löschen eines Elements, das an der k- ten Position von LA verfügbar ist .
1. Start
2. Set J = K
3. Repeat steps 4 and 5 while J < N
4. Set LA[J] = LA[J + 1]
5. Set J = J+1
6. Set N = N-1
7. StopBeispiel
Es folgt die Implementierung des obigen Algorithmus -
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int k = 3, n = 5;
int i, j;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
j = k;
while( j < n) {
LA[j-1] = LA[j];
j = j + 1;
}
n = n -1;
printf("The array elements after deletion :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}Wenn wir das obige Programm kompilieren und ausführen, ergibt es das folgende Ergebnis:
Ausgabe
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after deletion :
LA[0] = 1
LA[1] = 3
LA[2] = 7
LA[3] = 8Suchvorgang
Sie können eine Suche nach einem Array-Element basierend auf seinem Wert oder seinem Index durchführen.
Algorithmus
Erwägen LA ist ein lineares Array mit N Elemente und K ist eine positive ganze Zahl, so dass K<=N. Es folgt der Algorithmus zum Suchen eines Elements mit dem Wert ITEM mithilfe der sequentiellen Suche.
1. Start
2. Set J = 0
3. Repeat steps 4 and 5 while J < N
4. IF LA[J] is equal ITEM THEN GOTO STEP 6
5. Set J = J +1
6. PRINT J, ITEM
7. StopBeispiel
Es folgt die Implementierung des obigen Algorithmus -
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int item = 5, n = 5;
int i = 0, j = 0;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
while( j < n){
if( LA[j] == item ) {
break;
}
j = j + 1;
}
printf("Found element %d at position %d\n", item, j+1);
}Wenn wir das obige Programm kompilieren und ausführen, ergibt es das folgende Ergebnis:
Ausgabe
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
Found element 5 at position 3Vorgang aktualisieren
Der Aktualisierungsvorgang bezieht sich auf das Aktualisieren eines vorhandenen Elements aus dem Array an einem bestimmten Index.
Algorithmus
Erwägen LA ist ein lineares Array mit N Elemente und K ist eine positive ganze Zahl, so dass K<=N. Es folgt der Algorithmus zum Aktualisieren eines Elements, das an der k- ten Position von LA verfügbar ist .
1. Start
2. Set LA[K-1] = ITEM
3. StopBeispiel
Es folgt die Implementierung des obigen Algorithmus -
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int k = 3, n = 5, item = 10;
int i, j;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
LA[k-1] = item;
printf("The array elements after updation :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}Wenn wir das obige Programm kompilieren und ausführen, ergibt es das folgende Ergebnis:
Ausgabe
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after updation :
LA[0] = 1
LA[1] = 3
LA[2] = 10
LA[3] = 7
LA[4] = 8Eine verknüpfte Liste ist eine Folge von Datenstrukturen, die über Verknüpfungen miteinander verbunden sind.
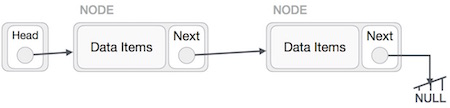
Verknüpfte Liste ist eine Folge von Links, die Elemente enthalten. Jeder Link enthält eine Verbindung zu einem anderen Link. Die verknüpfte Liste ist nach dem Array die am zweithäufigsten verwendete Datenstruktur. Im Folgenden finden Sie wichtige Begriffe zum Verständnis des Konzepts der verknüpften Liste.
Link - Jeder Link einer verknüpften Liste kann Daten speichern, die als Element bezeichnet werden.
Next - Jeder Link einer verknüpften Liste enthält einen Link zum nächsten Link namens Weiter.
LinkedList - Eine verknüpfte Liste enthält den Verbindungslink zum ersten Link namens First.
Darstellung der verknüpften Liste
Die verknüpfte Liste kann als eine Kette von Knoten dargestellt werden, wobei jeder Knoten auf den nächsten Knoten zeigt.

Gemäß der obigen Abbildung sind die folgenden wichtigen Punkte zu berücksichtigen.
Verknüpfte Liste enthält ein Verknüpfungselement, das zuerst aufgerufen wird.
Jede Verbindung enthält ein Datenfeld und ein Verbindungsfeld, das als nächstes aufgerufen wird.
Jeder Link wird über seinen nächsten Link mit seinem nächsten Link verknüpft.
Der letzte Link enthält einen Link als null, um das Ende der Liste zu markieren.
Arten von verknüpften Listen
Im Folgenden sind die verschiedenen Arten von verknüpften Listen aufgeführt.
Simple Linked List - Die Objektnavigation ist nur vorwärts.
Doubly Linked List - Elemente können vorwärts und rückwärts navigiert werden.
Circular Linked List - Das letzte Element enthält einen Link des ersten Elements als nächstes und das erste Element enthält einen Link zum letzten Element wie zuvor.
Grundoperationen
Im Folgenden sind die grundlegenden Vorgänge aufgeführt, die von einer Liste unterstützt werden.
Insertion - Fügt am Anfang der Liste ein Element hinzu.
Deletion - Löscht ein Element am Anfang der Liste.
Display - Zeigt die vollständige Liste an.
Search - Sucht ein Element mit dem angegebenen Schlüssel.
Delete - Löscht ein Element mit dem angegebenen Schlüssel.
Einfügevorgang
Das Hinzufügen eines neuen Knotens zur verknüpften Liste ist eine mehr als einstufige Aktivität. Wir werden dies hier anhand von Diagrammen lernen. Erstellen Sie zunächst einen Knoten mit derselben Struktur und suchen Sie den Ort, an dem er eingefügt werden muss.

Stellen Sie sich vor, wir fügen einen Knoten ein B (NewNode), zwischen A (LeftNode) und C(RightNode). Dann zeigen Sie B. neben C -
NewNode.next −> RightNode;Es sollte so aussehen -

Jetzt sollte der nächste Knoten links auf den neuen Knoten zeigen.
LeftNode.next −> NewNode;
Dadurch wird der neue Knoten in die Mitte der beiden gesetzt. Die neue Liste sollte so aussehen -

Ähnliche Schritte sollten unternommen werden, wenn der Knoten am Anfang der Liste eingefügt wird. Beim Einfügen am Ende sollte der vorletzte Knoten der Liste auf den neuen Knoten und der neue Knoten auf NULL zeigen.
Löschvorgang
Das Löschen ist auch ein mehr als einstufiger Prozess. Wir werden mit bildlicher Darstellung lernen. Suchen Sie zunächst den zu entfernenden Zielknoten mithilfe von Suchalgorithmen.

Der linke (vorherige) Knoten des Zielknotens sollte jetzt auf den nächsten Knoten des Zielknotens zeigen -
LeftNode.next −> TargetNode.next;
Dadurch wird der Link entfernt, der auf den Zielknoten zeigte. Mit dem folgenden Code entfernen wir nun, auf was der Zielknoten zeigt.
TargetNode.next −> NULL;
Wir müssen den gelöschten Knoten verwenden. Wir können das im Speicher behalten, andernfalls können wir einfach den Speicher freigeben und den Zielknoten vollständig löschen.

Rückwärtsbetrieb
Diese Operation ist gründlich. Wir müssen den letzten Knoten machen, auf den der Kopfknoten zeigt, und die gesamte verknüpfte Liste umkehren.
Zuerst gehen wir zum Ende der Liste. Es sollte auf NULL zeigen. Jetzt werden wir es auf seinen vorherigen Knoten verweisen lassen -
Wir müssen sicherstellen, dass der letzte Knoten nicht der letzte Knoten ist. Wir haben also einen temporären Knoten, der aussieht wie der Kopfknoten, der auf den letzten Knoten zeigt. Jetzt lassen wir alle Knoten auf der linken Seite nacheinander auf ihre vorherigen Knoten zeigen.
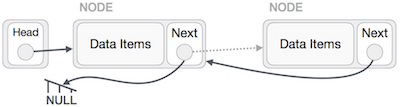
Mit Ausnahme des Knotens (erster Knoten), auf den der Hauptknoten zeigt, sollten alle Knoten auf ihren Vorgänger zeigen und sie zu ihrem neuen Nachfolger machen. Der erste Knoten zeigt auf NULL.

Wir werden den Kopfknoten mithilfe des temporären Knotens auf den neuen ersten Knoten zeigen lassen.
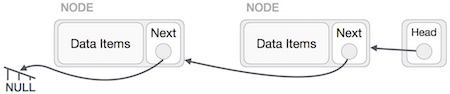
Die verknüpfte Liste ist jetzt umgekehrt. Klicken Sie hier , um die Implementierung der verknüpften Liste in der Programmiersprache C anzuzeigen .
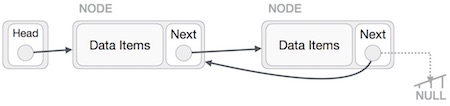
Doppelt verknüpfte Liste ist eine Variante der verknüpften Liste, bei der die Navigation auf beide Arten möglich ist, entweder vorwärts oder rückwärts im Vergleich zur einzelnen verknüpften Liste. Im Folgenden sind die wichtigen Begriffe aufgeführt, um das Konzept der doppelt verknüpften Liste zu verstehen.
Link - Jeder Link einer verknüpften Liste kann Daten speichern, die als Element bezeichnet werden.
Next - Jeder Link einer verknüpften Liste enthält einen Link zum nächsten Link namens Weiter.
Prev - Jeder Link einer verknüpften Liste enthält einen Link zum vorherigen Link namens Prev.
LinkedList - Eine verknüpfte Liste enthält den Verbindungslink zum ersten Link namens First und zum letzten Link Last.
Doppelt verknüpfte Listendarstellung

Gemäß der obigen Abbildung sind die folgenden wichtigen Punkte zu berücksichtigen.
Die doppelt verknüpfte Liste enthält ein Verknüpfungselement mit den Namen first und last.
Jede Verbindung enthält ein Datenfeld und zwei Verbindungsfelder, die als next und prev bezeichnet werden.
Jeder Link wird über seinen nächsten Link mit seinem nächsten Link verknüpft.
Jeder Link ist über seinen vorherigen Link mit seinem vorherigen Link verknüpft.
Der letzte Link enthält einen Link als null, um das Ende der Liste zu markieren.
Grundoperationen
Im Folgenden sind die grundlegenden Vorgänge aufgeführt, die von einer Liste unterstützt werden.
Insertion - Fügt am Anfang der Liste ein Element hinzu.
Deletion - Löscht ein Element am Anfang der Liste.
Insert Last - Fügt am Ende der Liste ein Element hinzu.
Delete Last - Löscht ein Element am Ende der Liste.
Insert After - Fügt ein Element nach einem Element der Liste hinzu.
Delete - Löscht mit dem Schlüssel ein Element aus der Liste.
Display forward - Zeigt die vollständige Liste vorwärts an.
Display backward - Zeigt die vollständige Liste rückwärts an.
Einfügevorgang
Der folgende Code demonstriert den Einfügevorgang am Anfang einer doppelt verknüpften Liste.
Beispiel
//insert link at the first location
void insertFirst(int key, int data) {
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()) {
//make it the last link
last = link;
} else {
//update first prev link
head->prev = link;
}
//point it to old first link
link->next = head;
//point first to new first link
head = link;
}Löschvorgang
Der folgende Code demonstriert den Löschvorgang am Anfang einer doppelt verknüpften Liste.
Beispiel
//delete first item
struct node* deleteFirst() {
//save reference to first link
struct node *tempLink = head;
//if only one link
if(head->next == NULL) {
last = NULL;
} else {
head->next->prev = NULL;
}
head = head->next;
//return the deleted link
return tempLink;
}Einfügen am Ende einer Operation
Der folgende Code demonstriert den Einfügevorgang an der letzten Position einer doppelt verknüpften Liste.
Beispiel
//insert link at the last location
void insertLast(int key, int data) {
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()) {
//make it the last link
last = link;
} else {
//make link a new last link
last->next = link;
//mark old last node as prev of new link
link->prev = last;
}
//point last to new last node
last = link;
}Um die Implementierung in der Programmiersprache C zu sehen, klicken Sie bitte hier .
Circular Linked List ist eine Variation der Linked List, bei der das erste Element auf das letzte Element und das letzte Element auf das erste Element zeigt. Sowohl die einfach verknüpfte Liste als auch die doppelt verknüpfte Liste können zu einer zirkulären verknüpften Liste erstellt werden.
Einfach verknüpfte Liste als Rundschreiben
In einer einfach verknüpften Liste zeigt der nächste Zeiger des letzten Knotens auf den ersten Knoten.

Doppelt verknüpfte Liste als Rundschreiben
In einer doppelt verknüpften Liste zeigt der nächste Zeiger des letzten Knotens auf den ersten Knoten und der vorherige Zeiger des ersten Knotens auf den letzten Knoten, wodurch das Kreis in beide Richtungen verläuft.

Gemäß der obigen Abbildung sind die folgenden wichtigen Punkte zu berücksichtigen.
Der nächste Link verweist auf den ersten Link der Liste, sowohl bei einfach als auch bei doppelt verknüpfter Liste.
Der vorherige Link des ersten Links zeigt bei doppelt verknüpfter Liste auf den letzten der Liste.
Grundoperationen
Im Folgenden sind die wichtigen Vorgänge aufgeführt, die von einer Rundschreibenliste unterstützt werden.
insert - Fügt am Anfang der Liste ein Element ein.
delete - Löscht ein Element vom Anfang der Liste.
display - Zeigt die Liste an.
Einfügevorgang
Der folgende Code demonstriert den Einfügevorgang in eine zirkuläre verknüpfte Liste basierend auf einer einzelnen verknüpften Liste.
Beispiel
//insert link at the first location
void insertFirst(int key, int data) {
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data= data;
if (isEmpty()) {
head = link;
head->next = head;
} else {
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
}Löschvorgang
Der folgende Code demonstriert den Löschvorgang in einer zirkulären verknüpften Liste basierend auf einer einzelnen verknüpften Liste.
//delete first item
struct node * deleteFirst() {
//save reference to first link
struct node *tempLink = head;
if(head->next == head) {
head = NULL;
return tempLink;
}
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}Listenbetrieb anzeigen
Der folgende Code demonstriert die Anzeigelistenoperation in einer zirkular verknüpften Liste.
//display the list
void printList() {
struct node *ptr = head;
printf("\n[ ");
//start from the beginning
if(head != NULL) {
while(ptr->next != ptr) {
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
}
printf(" ]");
}Um mehr über die Implementierung in der Programmiersprache C zu erfahren, klicken Sie bitte hier .
Ein Stapel ist ein abstrakter Datentyp (ADT), der in den meisten Programmiersprachen häufig verwendet wird. Es wird Stapel genannt, da es sich beispielsweise wie ein realer Stapel verhält - ein Kartenspiel oder ein Stapel Teller usw.

Ein realer Stapel ermöglicht Operationen nur an einem Ende. Zum Beispiel können wir eine Karte oder einen Teller nur von der Oberseite des Stapels platzieren oder entfernen. Ebenso erlaubt Stack ADT alle Datenoperationen nur an einem Ende. Zu jedem Zeitpunkt können wir nur auf das oberste Element eines Stapels zugreifen.
Diese Funktion macht es LIFO-Datenstruktur. LIFO steht für Last-in-first-out. Hier wird zuerst auf das Element zugegriffen, das zuletzt platziert (eingefügt oder hinzugefügt) wurde. In der Stapelterminologie wird die Einfügeoperation aufgerufenPUSH Operation und Entfernung Operation wird aufgerufen POP Betrieb.
Stapelrepräsentation
Das folgende Diagramm zeigt einen Stapel und seine Operationen -

Ein Stapel kann mithilfe von Array, Struktur, Zeiger und verknüpfter Liste implementiert werden. Der Stapel kann entweder eine feste Größe haben oder eine dynamische Größenänderung aufweisen. Hier werden wir Stack mithilfe von Arrays implementieren, was es zu einer Stack-Implementierung mit fester Größe macht.
Grundoperationen
Bei Stapeloperationen kann der Stapel initialisiert, verwendet und anschließend de-initialisiert werden. Abgesehen von diesen grundlegenden Dingen wird ein Stapel für die folgenden zwei Hauptoperationen verwendet -
push() - Schieben (Speichern) eines Elements auf dem Stapel.
pop() - Entfernen (Zugreifen) eines Elements vom Stapel.
Wenn Daten auf den Stapel gedrückt werden.
Um einen Stapel effizient zu nutzen, müssen wir auch den Status des Stapels überprüfen. Aus dem gleichen Grund wird den Stapeln die folgende Funktionalität hinzugefügt:
peek() - Holen Sie sich das oberste Datenelement des Stapels, ohne es zu entfernen.
isFull() - Überprüfen Sie, ob der Stapel voll ist.
isEmpty() - Überprüfen Sie, ob der Stapel leer ist.
Wir behalten jederzeit einen Zeiger auf die letzten PUSHed-Daten auf dem Stapel bei. Da dieser Zeiger immer die Spitze des Stapels darstellt, daher benannttop. Dastop Der Zeiger liefert den höchsten Wert des Stapels, ohne ihn tatsächlich zu entfernen.
Zuerst sollten wir uns mit Verfahren zur Unterstützung von Stapelfunktionen vertraut machen -
spähen()
Algorithmus der Funktion peek () -
begin procedure peek
return stack[top]
end procedureImplementierung der Funktion peek () in der Programmiersprache C -
Example
int peek() {
return stack[top];
}ist voll()
Algorithmus der isfull () Funktion -
begin procedure isfull
if top equals to MAXSIZE
return true
else
return false
endif
end procedureImplementierung der Funktion isfull () in der Programmiersprache C -
Example
bool isfull() {
if(top == MAXSIZE)
return true;
else
return false;
}ist leer()
Algorithmus der Funktion isempty () -
begin procedure isempty
if top less than 1
return true
else
return false
endif
end procedureDie Implementierung der Funktion isempty () in der Programmiersprache C unterscheidet sich geringfügig. Wir initialisieren top bei -1, da der Index im Array bei 0 beginnt. Wir prüfen also, ob der top unter Null oder -1 liegt, um festzustellen, ob der Stapel leer ist. Hier ist der Code -
Example
bool isempty() {
if(top == -1)
return true;
else
return false;
}Push-Betrieb
Das Einfügen eines neuen Datenelements in einen Stapel wird als Push-Operation bezeichnet. Der Push-Betrieb umfasst eine Reihe von Schritten -
Step 1 - Überprüft, ob der Stapel voll ist.
Step 2 - Wenn der Stapel voll ist, wird ein Fehler ausgegeben und beendet.
Step 3 - Wenn der Stapel nicht voll ist, werden die Schritte erhöht top um auf den nächsten leeren Raum zu zeigen.
Step 4 - Fügt dem Stapelspeicherort ein Datenelement hinzu, auf das oben zeigt.
Step 5 - Gibt den Erfolg zurück.
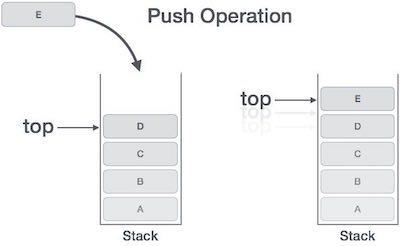
Wenn die verknüpfte Liste zum Implementieren des Stapels verwendet wird, müssen wir in Schritt 3 Speicherplatz dynamisch zuweisen.
Algorithmus für den PUSH-Betrieb
Ein einfacher Algorithmus für die Push-Operation kann wie folgt abgeleitet werden:
begin procedure push: stack, data
if stack is full
return null
endif
top ← top + 1
stack[top] ← data
end procedureDie Implementierung dieses Algorithmus in C ist sehr einfach. Siehe folgenden Code -
Example
void push(int data) {
if(!isFull()) {
top = top + 1;
stack[top] = data;
} else {
printf("Could not insert data, Stack is full.\n");
}
}Pop-Betrieb
Der Zugriff auf den Inhalt beim Entfernen vom Stapel wird als Pop-Operation bezeichnet. In einer Array-Implementierung der pop () -Operation wird das Datenelement stattdessen nicht entfernttopwird auf eine niedrigere Position im Stapel dekrementiert, um auf den nächsten Wert zu zeigen. Bei der Implementierung von verknüpften Listen entfernt pop () jedoch tatsächlich Datenelemente und gibt Speicherplatz frei.
Eine Pop-Operation kann die folgenden Schritte umfassen:
Step 1 - Überprüft, ob der Stapel leer ist.
Step 2 - Wenn der Stapel leer ist, wird ein Fehler ausgegeben und beendet.
Step 3 - Wenn der Stapel nicht leer ist, wird auf das Datenelement zugegriffen, an dem top zeigt.
Step 4 - Verringert den Wert von top um 1.
Step 5 - Gibt den Erfolg zurück.

Algorithmus für die Pop-Operation
Ein einfacher Algorithmus für die Pop-Operation kann wie folgt abgeleitet werden:
begin procedure pop: stack
if stack is empty
return null
endif
data ← stack[top]
top ← top - 1
return data
end procedureDie Implementierung dieses Algorithmus in C ist wie folgt:
Example
int pop(int data) {
if(!isempty()) {
data = stack[top];
top = top - 1;
return data;
} else {
printf("Could not retrieve data, Stack is empty.\n");
}
}Für ein vollständiges Stack-Programm in der Programmiersprache C klicken Sie bitte hier .
Die Art und Weise, einen arithmetischen Ausdruck zu schreiben, ist als a bekannt notation. Ein arithmetischer Ausdruck kann in drei verschiedenen, aber äquivalenten Notationen geschrieben werden, dh ohne das Wesen oder die Ausgabe eines Ausdrucks zu ändern. Diese Notationen sind -
- Infix-Notation
- Präfix (polnisch) Notation
- Postfix (Reverse-Polish) Notation
Diese Notationen werden so benannt, wie sie den Operator im Ausdruck verwenden. Das werden wir hier in diesem Kapitel lernen.
Infix-Notation
Wir schreiben Ausdruck in infix Notation, zB a - b + c, wo Operatoren verwendet werden in-zwischen Operanden. Es ist für uns Menschen leicht, in Infix-Notation zu lesen, zu schreiben und zu sprechen, aber das gleiche gilt nicht für Computergeräte. Ein Algorithmus zur Verarbeitung der Infixnotation kann hinsichtlich Zeit- und Raumverbrauch schwierig und kostspielig sein.
Präfixnotation
In dieser Notation ist der Operator prefixIn Operanden geschrieben, dh der Operator wird vor die Operanden geschrieben. Zum Beispiel,+ab. Dies entspricht der Infix-Notationa + b. Die Präfixnotation wird auch als bezeichnetPolish Notation.
Postfix-Notation
Dieser Notationsstil ist bekannt als Reversed Polish Notation. In diesem Notationsstil ist der Operatorpostfixzu den Operanden, dh der Operator wird nach den Operanden geschrieben. Zum Beispiel,ab+. Dies entspricht der Infix-Notationa + b.
Die folgende Tabelle versucht kurz, den Unterschied in allen drei Notationen zu zeigen -
| Sr.Nr. | Infix-Notation | Präfixnotation | Postfix-Notation |
|---|---|---|---|
| 1 | a + b | + ab | ab + |
| 2 | (a + b) ∗ c | ∗ + abc | ab + c ∗ |
| 3 | a ∗ (b + c) | ∗ a + bc | abc + ∗ |
| 4 | a / b + c / d | + / ab / cd | ab / cd / + |
| 5 | (a + b) ∗ (c + d) | ∗ + ab + cd | ab + cd + ∗ |
| 6 | ((a + b) ∗ c) - d | - ∗ + abcd | ab + c ∗ d - |
Analysieren von Ausdrücken
Wie wir bereits besprochen haben, ist es keine sehr effiziente Möglichkeit, einen Algorithmus oder ein Programm zum Parsen von Infix-Notationen zu entwerfen. Stattdessen werden diese Infixnotationen zuerst in Postfix- oder Präfixnotationen konvertiert und dann berechnet.
Um einen arithmetischen Ausdruck zu analysieren, müssen wir uns auch um die Priorität und Assoziativität des Operators kümmern.
Vorrang
Wenn sich ein Operand zwischen zwei verschiedenen Operatoren befindet, entscheidet der Vorrang eines Operators vor anderen, welcher Operator zuerst den Operanden übernimmt. Zum Beispiel -

Da die Multiplikationsoperation Vorrang vor der Addition hat, wird zuerst b * c ausgewertet. Eine Tabelle mit der Priorität des Operators wird später bereitgestellt.
Assoziativität
Assoziativität beschreibt die Regel, nach der Operatoren mit derselben Priorität in einem Ausdruck erscheinen. Beispielsweise haben im Ausdruck a + b - c sowohl + als auch - die gleiche Priorität. Welcher Teil des Ausdrucks zuerst ausgewertet wird, wird durch die Assoziativität dieser Operatoren bestimmt. Hier bleiben sowohl + als auch - assoziativ, sodass der Ausdruck als ausgewertet wird(a + b) − c.
Vorrang und Assoziativität bestimmen die Reihenfolge der Bewertung eines Ausdrucks. Es folgt eine Operator-Prioritäts- und Assoziativitätstabelle (höchste bis niedrigste) -
| Sr.Nr. | Operator | Vorrang | Assoziativität |
|---|---|---|---|
| 1 | Potenzierung ^ | Höchste | Richtig assoziativ |
| 2 | Multiplikation (∗) & Division (/) | Zweithöchster | Linker Assoziativer |
| 3 | Addition (+) & Subtraktion (-) | Am niedrigsten | Linker Assoziativer |
Die obige Tabelle zeigt das Standardverhalten von Operatoren. Zu jedem Zeitpunkt der Ausdrucksbewertung kann die Reihenfolge mithilfe von Klammern geändert werden. Zum Beispiel -
Im a + b*c, der Ausdrucksteil b* *cwird zuerst bewertet, wobei die Multiplikation Vorrang vor der Addition hat. Wir verwenden hier Klammern füra + b zuerst ausgewertet werden, wie (a + b)*c.
Postfix-Bewertungsalgorithmus
Wir werden uns nun den Algorithmus zur Bewertung der Postfix-Notation ansehen -
Step 1 − scan the expression from left to right
Step 2 − if it is an operand push it to stack
Step 3 − if it is an operator pull operand from stack and perform operation
Step 4 − store the output of step 3, back to stack
Step 5 − scan the expression until all operands are consumed
Step 6 − pop the stack and perform operationUm die Implementierung in der Programmiersprache C zu sehen, klicken Sie bitte hier .
Queue ist eine abstrakte Datenstruktur, die Stacks ähnelt. Im Gegensatz zu Stapeln ist eine Warteschlange an beiden Enden offen. Ein Ende wird immer zum Einfügen von Daten (Enqueue) und das andere zum Entfernen von Daten (Dequeue) verwendet. Die Warteschlange folgt der First-In-First-Out-Methode, dh auf das zuerst gespeicherte Datenelement wird zuerst zugegriffen.

Ein reales Beispiel für eine Warteschlange kann eine einspurige Einbahnstraße sein, bei der das Fahrzeug zuerst ein- und zuerst ausfährt. Weitere Beispiele aus der Praxis können als Warteschlangen an den Fahrkartenschaltern und Bushaltestellen angesehen werden.
Warteschlangendarstellung
Da wir jetzt verstehen, dass wir in der Warteschlange aus unterschiedlichen Gründen auf beide Enden zugreifen. Das folgende Diagramm versucht, die Darstellung der Warteschlange als Datenstruktur zu erklären.

Wie in Stapeln kann eine Warteschlange auch mithilfe von Arrays, verknüpften Listen, Zeigern und Strukturen implementiert werden. Der Einfachheit halber werden wir Warteschlangen unter Verwendung eines eindimensionalen Arrays implementieren.
Grundoperationen
Bei Warteschlangenoperationen kann die Warteschlange initialisiert oder definiert, verwendet und dann vollständig aus dem Speicher gelöscht werden. Hier werden wir versuchen, die grundlegenden Operationen zu verstehen, die mit Warteschlangen verbunden sind -
enqueue() - Hinzufügen (Speichern) eines Elements zur Warteschlange.
dequeue() - Entfernen (Zugreifen) eines Elements aus der Warteschlange.
Es sind nur wenige weitere Funktionen erforderlich, um den oben genannten Warteschlangenbetrieb effizient zu gestalten. Dies sind -
peek() - Ruft das Element an der Vorderseite der Warteschlange ab, ohne es zu entfernen.
isfull() - Überprüft, ob die Warteschlange voll ist.
isempty() - Überprüft, ob die Warteschlange leer ist.
In der Warteschlange werden Daten, auf die verwiesen wird, immer aus der Warteschlange entfernt (oder auf Daten zugegriffen) front Zeiger und beim Einreihen (oder Speichern) von Daten in die Warteschlange helfen wir rear Zeiger.
Lassen Sie uns zunächst die unterstützenden Funktionen einer Warteschlange kennenlernen -
spähen()
Diese Funktion hilft, die Daten am zu sehen frontder Warteschlange. Der Algorithmus der Funktion peek () lautet wie folgt:
Algorithm
begin procedure peek
return queue[front]
end procedureImplementierung der Funktion peek () in der Programmiersprache C -
Example
int peek() {
return queue[front];
}ist voll()
Da wir zum Implementieren der Warteschlange ein eindimensionales Array verwenden, prüfen wir nur, ob der hintere Zeiger bei MAXSIZE erreicht ist, um festzustellen, ob die Warteschlange voll ist. Wenn wir die Warteschlange in einer zirkulären verknüpften Liste verwalten, unterscheidet sich der Algorithmus. Algorithmus der isfull () Funktion -
Algorithm
begin procedure isfull
if rear equals to MAXSIZE
return true
else
return false
endif
end procedureImplementierung der Funktion isfull () in der Programmiersprache C -
Example
bool isfull() {
if(rear == MAXSIZE - 1)
return true;
else
return false;
}ist leer()
Algorithmus der Funktion isempty () -
Algorithm
begin procedure isempty
if front is less than MIN OR front is greater than rear
return true
else
return false
endif
end procedureWenn der Wert von front kleiner als MIN oder 0 ist, bedeutet dies, dass die Warteschlange noch nicht initialisiert und daher leer ist.
Hier ist der C-Programmcode -
Example
bool isempty() {
if(front < 0 || front > rear)
return true;
else
return false;
}Warteschlangenbetrieb
Warteschlangen verwalten zwei Datenzeiger. front und rear. Daher sind seine Operationen vergleichsweise schwierig zu implementieren als die von Stapeln.
Die folgenden Schritte sollten ausgeführt werden, um Daten in eine Warteschlange zu stellen (einzufügen):
Step 1 - Überprüfen Sie, ob die Warteschlange voll ist.
Step 2 - Wenn die Warteschlange voll ist, erzeugen Sie einen Überlauffehler und beenden Sie den Vorgang.
Step 3 - Wenn die Warteschlange nicht voll ist, erhöhen Sie sie rear Zeiger auf den nächsten leeren Raum.
Step 4 - Fügen Sie ein Datenelement zur Warteschlangenposition hinzu, auf die die Rückseite zeigt.
Step 5 - Erfolg zurückgeben.

Manchmal prüfen wir auch, ob eine Warteschlange initialisiert ist oder nicht, um unvorhergesehene Situationen zu bewältigen.
Algorithmus für den Enqueue-Betrieb
procedure enqueue(data)
if queue is full
return overflow
endif
rear ← rear + 1
queue[rear] ← data
return true
end procedureImplementierung von enqueue () in der Programmiersprache C -
Example
int enqueue(int data)
if(isfull())
return 0;
rear = rear + 1;
queue[rear] = data;
return 1;
end procedureWarteschlangenbetrieb
Der Zugriff auf Daten aus der Warteschlange besteht aus zwei Aufgaben: Zugriff auf die Daten wo frontzeigt und entfernt die Daten nach dem Zugriff. Die folgenden Schritte werden ausgeführtdequeue Betrieb -
Step 1 - Überprüfen Sie, ob die Warteschlange leer ist.
Step 2 - Wenn die Warteschlange leer ist, erzeugen Sie einen Unterlauffehler und beenden Sie den Vorgang.
Step 3 - Wenn die Warteschlange nicht leer ist, greifen Sie auf die Daten zu, bei denen front zeigt.
Step 4 - Inkrementieren front Zeiger auf das nächste verfügbare Datenelement.
Step 5 - Erfolg zurückgeben.
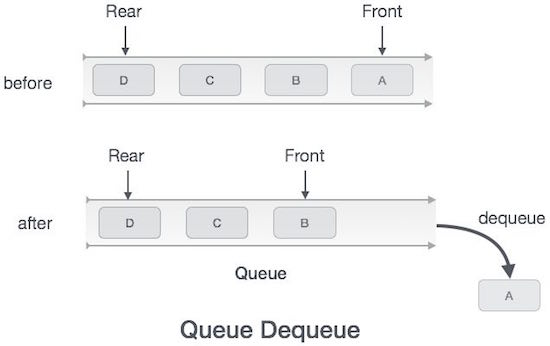
Algorithmus für den Dequeue-Betrieb
procedure dequeue
if queue is empty
return underflow
end if
data = queue[front]
front ← front + 1
return true
end procedureImplementierung von dequeue () in der Programmiersprache C -
Example
int dequeue() {
if(isempty())
return 0;
int data = queue[front];
front = front + 1;
return data;
}Für ein vollständiges Warteschlangenprogramm in der Programmiersprache C klicken Sie bitte hier .
Die lineare Suche ist ein sehr einfacher Suchalgorithmus. Bei dieser Art der Suche wird nacheinander eine Suche nach allen Elementen durchgeführt. Jedes Element wird überprüft, und wenn eine Übereinstimmung gefunden wird, wird dieses bestimmte Element zurückgegeben, andernfalls wird die Suche bis zum Ende der Datenerfassung fortgesetzt.

Algorithmus
Linear Search ( Array A, Value x)
Step 1: Set i to 1
Step 2: if i > n then go to step 7
Step 3: if A[i] = x then go to step 6
Step 4: Set i to i + 1
Step 5: Go to Step 2
Step 6: Print Element x Found at index i and go to step 8
Step 7: Print element not found
Step 8: ExitPseudocode
procedure linear_search (list, value)
for each item in the list
if match item == value
return the item's location
end if
end for
end procedureUm mehr über die Implementierung der linearen Suche in der Programmiersprache C zu erfahren, klicken Sie bitte hier .
Die binäre Suche ist ein schneller Suchalgorithmus mit einer Laufzeitkomplexität von Ο (log n). Dieser Suchalgorithmus arbeitet nach dem Prinzip des Teilens und Eroberens. Damit dieser Algorithmus ordnungsgemäß funktioniert, sollte die Datenerfassung in sortierter Form erfolgen.
Bei der binären Suche wird nach einem bestimmten Element gesucht, indem das mittlere Element der Sammlung verglichen wird. Wenn eine Übereinstimmung auftritt, wird der Index des Elements zurückgegeben. Wenn das mittlere Element größer als das Element ist, wird das Element im Unterarray links vom mittleren Element gesucht. Andernfalls wird das Element im Unterarray rechts neben dem mittleren Element gesucht. Dieser Prozess wird auch auf dem Subarray fortgesetzt, bis die Größe des Subarrays auf Null reduziert ist.
Wie funktioniert die binäre Suche?
Damit eine binäre Suche funktioniert, muss das Zielarray sortiert werden. Wir werden den Prozess der binären Suche anhand eines Bildbeispiels lernen. Das Folgende ist unser sortiertes Array und wir nehmen an, dass wir die Position des Werts 31 mithilfe der binären Suche suchen müssen.

Zuerst werden wir die Hälfte des Arrays mit dieser Formel bestimmen -
mid = low + (high - low) / 2Hier ist es 0 + (9 - 0) / 2 = 4 (ganzzahliger Wert von 4,5). 4 ist also die Mitte des Arrays.

Jetzt vergleichen wir den an Position 4 gespeicherten Wert mit dem gesuchten Wert, dh 31. Wir stellen fest, dass der Wert an Position 4 27 ist, was nicht übereinstimmt. Da der Wert größer als 27 ist und wir ein sortiertes Array haben, wissen wir auch, dass der Zielwert im oberen Teil des Arrays liegen muss.

Wir ändern unser Tief auf Mittel + 1 und finden den neuen Mittelwert wieder.
low = mid + 1
mid = low + (high - low) / 2Unsere neue Mitte ist jetzt 7. Wir vergleichen den an Position 7 gespeicherten Wert mit unserem Zielwert 31.

Der an Position 7 gespeicherte Wert stimmt nicht überein, sondern ist mehr als das, wonach wir suchen. Der Wert muss sich also im unteren Teil von dieser Stelle befinden.

Daher berechnen wir die Mitte erneut. Diesmal ist es 5.

Wir vergleichen den an Position 5 gespeicherten Wert mit unserem Zielwert. Wir finden, dass es ein Match ist.

Wir schließen daraus, dass der Zielwert 31 an Position 5 gespeichert ist.
Die binäre Suche halbiert die durchsuchbaren Elemente und reduziert so die Anzahl der durchzuführenden Vergleiche auf sehr wenige Zahlen.
Pseudocode
Der Pseudocode von binären Suchalgorithmen sollte folgendermaßen aussehen:
Procedure binary_search
A ← sorted array
n ← size of array
x ← value to be searched
Set lowerBound = 1
Set upperBound = n
while x not found
if upperBound < lowerBound
EXIT: x does not exists.
set midPoint = lowerBound + ( upperBound - lowerBound ) / 2
if A[midPoint] < x
set lowerBound = midPoint + 1
if A[midPoint] > x
set upperBound = midPoint - 1
if A[midPoint] = x
EXIT: x found at location midPoint
end while
end procedureKlicken Sie hier , um Informationen zur Implementierung der binären Suche mit einem Array in der Programmiersprache C zu erhalten .
Die Interpolationssuche ist eine verbesserte Variante der binären Suche. Dieser Suchalgorithmus arbeitet an der Prüfposition des erforderlichen Werts. Damit dieser Algorithmus ordnungsgemäß funktioniert, sollte die Datenerfassung sortiert und gleichmäßig verteilt sein.
Die binäre Suche hat einen großen Vorteil der Zeitkomplexität gegenüber der linearen Suche. Die lineare Suche hat die Worst-Case-Komplexität von Ο (n), während die binäre Suche Ο (log n) hat.
Es gibt Fälle, in denen der Ort der Zieldaten im Voraus bekannt sein kann. Zum Beispiel im Fall eines Telefonverzeichnisses, wenn wir die Telefonnummer von Morphius suchen möchten. Hier scheint die lineare Suche und sogar die binäre Suche langsam zu sein, da wir direkt in den Speicherbereich springen können, in dem die Namen ab 'M' gespeichert sind.
Positionierung in der binären Suche
Wenn bei der binären Suche die gewünschten Daten nicht gefunden werden, wird der Rest der Liste in zwei Teile unterteilt, niedriger und höher. Die Suche wird in einem von beiden durchgeführt.




Selbst wenn die Daten sortiert sind, nutzt die binäre Suche nicht den Vorteil, die Position der gewünschten Daten zu prüfen.
Positionsabtastung in der Interpolationssuche
Die Interpolationssuche findet ein bestimmtes Element durch Berechnen der Sondenposition. Zu Beginn ist die Sondenposition die Position des mittelsten Elements der Sammlung.


Wenn eine Übereinstimmung auftritt, wird der Index des Elements zurückgegeben. Um die Liste in zwei Teile zu teilen, verwenden wir die folgende Methode:
mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo])
where −
A = list
Lo = Lowest index of the list
Hi = Highest index of the list
A[n] = Value stored at index n in the listWenn das mittlere Element größer als das Element ist, wird die Sondenposition erneut im Unterarray rechts vom mittleren Element berechnet. Andernfalls wird das Element im Subarray links vom mittleren Element gesucht. Dieser Prozess wird auch auf dem Subarray fortgesetzt, bis die Größe des Subarrays auf Null reduziert ist.
Die Laufzeitkomplexität des Interpolationssuchalgorithmus ist Ο(log (log n)) verglichen mit Ο(log n) von BST in günstigen Situationen.
Algorithmus
Da es sich um eine Improvisation des vorhandenen BST-Algorithmus handelt, erwähnen wir die Schritte zum Durchsuchen des 'Ziel'-Datenwertindex mithilfe der Positionsprüfung -
Step 1 − Start searching data from middle of the list.
Step 2 − If it is a match, return the index of the item, and exit.
Step 3 − If it is not a match, probe position.
Step 4 − Divide the list using probing formula and find the new midle.
Step 5 − If data is greater than middle, search in higher sub-list.
Step 6 − If data is smaller than middle, search in lower sub-list.
Step 7 − Repeat until match.Pseudocode
A → Array list
N → Size of A
X → Target Value
Procedure Interpolation_Search()
Set Lo → 0
Set Mid → -1
Set Hi → N-1
While X does not match
if Lo equals to Hi OR A[Lo] equals to A[Hi]
EXIT: Failure, Target not found
end if
Set Mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo])
if A[Mid] = X
EXIT: Success, Target found at Mid
else
if A[Mid] < X
Set Lo to Mid+1
else if A[Mid] > X
Set Hi to Mid-1
end if
end if
End While
End ProcedureKlicken Sie hier , um mehr über die Implementierung der Interpolationssuche in der Programmiersprache C zu erfahren .
Hash Table ist eine Datenstruktur, in der Daten auf assoziative Weise gespeichert werden. In einer Hash-Tabelle werden Daten in einem Array-Format gespeichert, wobei jeder Datenwert seinen eigenen eindeutigen Indexwert hat. Der Zugriff auf Daten wird sehr schnell, wenn wir den Index der gewünschten Daten kennen.
Somit wird es zu einer Datenstruktur, in der Einfüge- und Suchvorgänge unabhängig von der Größe der Daten sehr schnell sind. Die Hash-Tabelle verwendet ein Array als Speichermedium und generiert mithilfe der Hash-Technik einen Index, in den ein Element eingefügt werden soll oder von dem aus es gefunden werden soll.
Hashing
Hashing ist eine Technik zum Konvertieren eines Bereichs von Schlüsselwerten in einen Bereich von Indizes eines Arrays. Wir werden den Modulo-Operator verwenden, um eine Reihe von Schlüsselwerten zu erhalten. Betrachten Sie ein Beispiel für eine Hash-Tabelle der Größe 20, und die folgenden Elemente müssen gespeichert werden. Artikel sind im Format (Schlüssel, Wert).

- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.Nr. | Schlüssel | Hash | Array-Index |
|---|---|---|---|
| 1 | 1 | 1% 20 = 1 | 1 |
| 2 | 2 | 2% 20 = 2 | 2 |
| 3 | 42 | 42% 20 = 2 | 2 |
| 4 | 4 | 4% 20 = 4 | 4 |
| 5 | 12 | 12% 20 = 12 | 12 |
| 6 | 14 | 14% 20 = 14 | 14 |
| 7 | 17 | 17% 20 = 17 | 17 |
| 8 | 13 | 13% 20 = 13 | 13 |
| 9 | 37 | 37% 20 = 17 | 17 |
Lineare Abtastung
Wie wir sehen können, kann es vorkommen, dass die Hashing-Technik verwendet wird, um einen bereits verwendeten Index des Arrays zu erstellen. In einem solchen Fall können wir die nächste leere Stelle im Array durchsuchen, indem wir in die nächste Zelle schauen, bis wir eine leere Zelle finden. Diese Technik wird als lineare Abtastung bezeichnet.
| Sr.Nr. | Schlüssel | Hash | Array-Index | Nach der linearen Prüfung Array-Index |
|---|---|---|---|---|
| 1 | 1 | 1% 20 = 1 | 1 | 1 |
| 2 | 2 | 2% 20 = 2 | 2 | 2 |
| 3 | 42 | 42% 20 = 2 | 2 | 3 |
| 4 | 4 | 4% 20 = 4 | 4 | 4 |
| 5 | 12 | 12% 20 = 12 | 12 | 12 |
| 6 | 14 | 14% 20 = 14 | 14 | 14 |
| 7 | 17 | 17% 20 = 17 | 17 | 17 |
| 8 | 13 | 13% 20 = 13 | 13 | 13 |
| 9 | 37 | 37% 20 = 17 | 17 | 18 |
Grundoperationen
Im Folgenden sind die grundlegenden primären Operationen einer Hash-Tabelle aufgeführt.
Search - Sucht ein Element in einer Hash-Tabelle.
Insert - fügt ein Element in eine Hash-Tabelle ein.
delete - Löscht ein Element aus einer Hash-Tabelle.
DataItem
Definieren Sie ein Datenelement mit einigen Daten und Schlüsseln, anhand dessen die Suche in einer Hash-Tabelle durchgeführt werden soll.
struct DataItem {
int data;
int key;
};Hash-Methode
Definieren Sie eine Hashing-Methode, um den Hash-Code des Schlüssels des Datenelements zu berechnen.
int hashCode(int key){
return key % SIZE;
}Suchvorgang
Wenn ein Element durchsucht werden soll, berechnen Sie den Hash-Code des übergebenen Schlüssels und suchen Sie das Element anhand dieses Hash-Codes als Index im Array. Verwenden Sie die lineare Prüfung, um das Element voranzubringen, wenn das Element im berechneten Hash-Code nicht gefunden wird.
Beispiel
struct DataItem *search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}Operation einfügen
Wenn ein Element eingefügt werden soll, berechnen Sie den Hash-Code des übergebenen Schlüssels und suchen Sie den Index unter Verwendung dieses Hash-Codes als Index im Array. Verwenden Sie die lineare Prüfung für die leere Position, wenn im berechneten Hashcode ein Element gefunden wird.
Beispiel
void insert(int key,int data) {
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}Vorgang löschen
Wenn ein Element gelöscht werden soll, berechnen Sie den Hash-Code des übergebenen Schlüssels und suchen Sie den Index anhand dieses Hash-Codes als Index im Array. Verwenden Sie die lineare Prüfung, um das Element voranzubringen, wenn im berechneten Hash-Code kein Element gefunden wird. Wenn gefunden, speichern Sie dort ein Dummy-Element, um die Leistung der Hash-Tabelle aufrechtzuerhalten.
Beispiel
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}Um mehr über die Hash-Implementierung in der Programmiersprache C zu erfahren, klicken Sie bitte hier .
Sortieren bezieht sich auf das Anordnen von Daten in einem bestimmten Format. Der Sortieralgorithmus gibt an, wie Daten in einer bestimmten Reihenfolge angeordnet werden sollen. Die meisten gängigen Ordnungen erfolgen in numerischer oder lexikografischer Reihenfolge.
Die Bedeutung der Sortierung liegt in der Tatsache, dass die Datensuche auf einem sehr hohen Niveau optimiert werden kann, wenn Daten sortiert gespeichert werden. Die Sortierung wird auch verwendet, um Daten in besser lesbaren Formaten darzustellen. Im Folgenden finden Sie einige Beispiele für das Sortieren in realen Szenarien:
Telephone Directory - Das Telefonverzeichnis speichert die Telefonnummern von Personen, sortiert nach ihren Namen, so dass die Namen leicht gesucht werden können.
Dictionary - Das Wörterbuch speichert Wörter in alphabetischer Reihenfolge, so dass die Suche nach Wörtern einfach wird.
In-Place-Sortierung und Nicht-In-Place-Sortierung
Sortieralgorithmen erfordern möglicherweise zusätzlichen Platz zum Vergleichen und temporären Speichern weniger Datenelemente. Diese Algorithmen benötigen keinen zusätzlichen Speicherplatz und die Sortierung soll direkt oder beispielsweise innerhalb des Arrays selbst erfolgen. Das nennt manin-place sorting. Die Blasensortierung ist ein Beispiel für die In-Place-Sortierung.
Bei einigen Sortieralgorithmen benötigt das Programm jedoch Platz, der größer oder gleich den zu sortierenden Elementen ist. Eine Sortierung, die gleich viel oder mehr Platz benötigt, wird aufgerufennot-in-place sorting. Die Zusammenführungssortierung ist ein Beispiel für eine nicht vorhandene Sortierung.
Stabile und nicht stabile Sortierung
Wenn ein Sortieralgorithmus nach dem Sortieren des Inhalts die Reihenfolge ähnlicher Inhalte, in denen sie angezeigt werden, nicht ändert, wird er aufgerufen stable sorting.

Wenn ein Sortieralgorithmus nach dem Sortieren des Inhalts die Reihenfolge ähnlicher Inhalte ändert, in denen sie angezeigt werden, wird er aufgerufen unstable sorting.

Die Stabilität eines Algorithmus ist wichtig, wenn wir die Reihenfolge der ursprünglichen Elemente beibehalten möchten, wie beispielsweise in einem Tupel.
Adaptiver und nicht adaptiver Sortieralgorithmus
Ein Sortieralgorithmus wird als adaptiv bezeichnet, wenn er bereits 'sortierte' Elemente in der Liste nutzt, die sortiert werden sollen. Das heißt, während beim Sortieren, wenn in der Quellliste bereits ein Element sortiert ist, berücksichtigen adaptive Algorithmen dies und versuchen, diese nicht neu zu ordnen.
Ein nicht adaptiver Algorithmus ist ein Algorithmus, der die bereits sortierten Elemente nicht berücksichtigt. Sie versuchen, jedes einzelne Element neu zu ordnen, um ihre Sortierung zu bestätigen.
Wichtige Begriffe
Einige Begriffe werden im Allgemeinen bei der Erörterung von Sortiertechniken geprägt. Hier finden Sie eine kurze Einführung in diese Begriffe.
Zunehmende Ordnung
Eine Folge von Werten soll in sein increasing order, wenn das aufeinanderfolgende Element größer als das vorherige ist. Zum Beispiel sind 1, 3, 4, 6, 8, 9 in aufsteigender Reihenfolge, da jedes nächste Element größer als das vorherige Element ist.
In absteigender Folge
Eine Folge von Werten soll in sein decreasing order, wenn das aufeinanderfolgende Element kleiner als das aktuelle ist. Zum Beispiel sind 9, 8, 6, 4, 3, 1 in absteigender Reihenfolge, da jedes nächste Element kleiner als das vorherige Element ist.
Nicht zunehmende Reihenfolge
Eine Folge von Werten soll in sein non-increasing order, wenn das aufeinanderfolgende Element kleiner oder gleich seinem vorherigen Element in der Sequenz ist. Diese Reihenfolge tritt auf, wenn die Sequenz doppelte Werte enthält. Zum Beispiel sind 9, 8, 6, 3, 3, 1 in nicht aufsteigender Reihenfolge, da jedes nächste Element kleiner oder gleich (im Fall von 3), aber nicht größer als jedes vorherige Element ist.
Nicht abnehmende Reihenfolge
Eine Folge von Werten soll in sein non-decreasing order, wenn das aufeinanderfolgende Element größer oder gleich seinem vorherigen Element in der Sequenz ist. Diese Reihenfolge tritt auf, wenn die Sequenz doppelte Werte enthält. Zum Beispiel sind 1, 3, 3, 6, 8, 9 in nicht abnehmender Reihenfolge, da jedes nächste Element größer oder gleich (im Fall von 3), aber nicht kleiner als das vorherige ist.
Die Blasensortierung ist ein einfacher Sortieralgorithmus. Dieser Sortieralgorithmus ist ein vergleichsbasierter Algorithmus, bei dem jedes Paar benachbarter Elemente verglichen wird und die Elemente ausgetauscht werden, wenn sie nicht in Ordnung sind. Dieser Algorithmus ist nicht für große Datenmengen geeignet, da seine durchschnittliche und Worst-Case-Komplexität Ο (n 2 ) beträgt, wobein ist die Anzahl der Elemente.
Wie funktioniert die Blasensortierung?
Wir nehmen ein unsortiertes Array für unser Beispiel. Die Blasensortierung dauert Ο (n 2 ), daher halten wir sie kurz und präzise.

Die Blasensortierung beginnt mit den ersten beiden Elementen und vergleicht sie, um zu überprüfen, welches größer ist.

In diesem Fall ist der Wert 33 größer als 14, sodass er sich bereits an sortierten Stellen befindet. Als nächstes vergleichen wir 33 mit 27.

Wir stellen fest, dass 27 kleiner als 33 ist und diese beiden Werte ausgetauscht werden müssen.

Das neue Array sollte so aussehen -

Als nächstes vergleichen wir 33 und 35. Wir stellen fest, dass sich beide in bereits sortierten Positionen befinden.

Dann gehen wir zu den nächsten beiden Werten, 35 und 10.

Wir wissen dann, dass 10 kleiner ist 35. Daher sind sie nicht sortiert.

Wir tauschen diese Werte aus. Wir stellen fest, dass wir das Ende des Arrays erreicht haben. Nach einer Iteration sollte das Array folgendermaßen aussehen:

Um genau zu sein, zeigen wir jetzt, wie ein Array nach jeder Iteration aussehen sollte. Nach der zweiten Iteration sollte es so aussehen -

Beachten Sie, dass sich nach jeder Iteration am Ende mindestens ein Wert bewegt.

Und wenn kein Tausch erforderlich ist, erfährt die Blasensortierung, dass ein Array vollständig sortiert ist.

Nun sollten wir uns einige praktische Aspekte der Blasensortierung ansehen.
Algorithmus
Wir nehmen an list ist ein Array von nElemente. Wir gehen weiter davon ausswap Funktion tauscht die Werte der angegebenen Array-Elemente aus.
begin BubbleSort(list)
for all elements of list
if list[i] > list[i+1]
swap(list[i], list[i+1])
end if
end for
return list
end BubbleSortPseudocode
Wir beobachten im Algorithmus, dass Bubble Sort jedes Paar von Array-Elementen vergleicht, es sei denn, das gesamte Array ist vollständig in aufsteigender Reihenfolge sortiert. Dies kann zu einigen Komplexitätsproblemen führen, z. B. wenn das Array nicht mehr ausgetauscht werden muss, da alle Elemente bereits aufsteigend sind.
Um das Problem zu beheben, verwenden wir eine Flag-Variable swappedDies hilft uns zu sehen, ob ein Tausch stattgefunden hat oder nicht. Wenn kein Swap stattgefunden hat, dh das Array keine weitere Verarbeitung zum Sortieren erfordert, wird es aus der Schleife herauskommen.
Der Pseudocode des BubbleSort-Algorithmus kann wie folgt geschrieben werden:
procedure bubbleSort( list : array of items )
loop = list.count;
for i = 0 to loop-1 do:
swapped = false
for j = 0 to loop-1 do:
/* compare the adjacent elements */
if list[j] > list[j+1] then
/* swap them */
swap( list[j], list[j+1] )
swapped = true
end if
end for
/*if no number was swapped that means
array is sorted now, break the loop.*/
if(not swapped) then
break
end if
end for
end procedure return listImplementierung
Ein weiteres Problem, das wir in unserem ursprünglichen Algorithmus und seinem improvisierten Pseudocode nicht angesprochen haben, ist, dass sich nach jeder Iteration die höchsten Werte am Ende des Arrays einstellen. Daher muss die nächste Iteration keine bereits sortierten Elemente enthalten. Zu diesem Zweck beschränken wir in unserer Implementierung die innere Schleife, um bereits sortierte Werte zu vermeiden.
Klicken Sie hier , um mehr über die Implementierung der Blasensortierung in der Programmiersprache C zu erfahren .
Dies ist ein Vergleichs-basierter Sortieralgorithmus an Ort und Stelle. Hier wird eine Unterliste gepflegt, die immer sortiert ist. Beispielsweise wird der untere Teil eines Arrays zum Sortieren beibehalten. Ein Element, das in diese sortierte Unterliste 'eingefügt' werden soll, muss seinen geeigneten Platz finden und dann dort eingefügt werden. Daher der Name,insertion sort.
Das Array wird nacheinander durchsucht und unsortierte Elemente werden verschoben und in die sortierte Unterliste (im selben Array) eingefügt. Dieser Algorithmus ist nicht für große Datenmengen geeignet, da seine durchschnittliche und Worst-Case-Komplexität Ο (n 2 ) beträgt , wobein ist die Anzahl der Elemente.
Wie funktioniert die Einfügungssortierung?
Wir nehmen ein unsortiertes Array für unser Beispiel.

Die Einfügesortierung vergleicht die ersten beiden Elemente.

Es zeigt sich, dass sowohl 14 als auch 33 bereits in aufsteigender Reihenfolge sind. Derzeit befindet sich 14 in einer sortierten Unterliste.

Die Einfügesortierung wird fortgesetzt und vergleicht 33 mit 27.

Und stellt fest, dass 33 nicht in der richtigen Position ist.

Es tauscht 33 gegen 27. Es prüft auch alle Elemente der sortierten Unterliste. Hier sehen wir, dass die sortierte Unterliste nur ein Element 14 hat und 27 größer als 14 ist. Daher bleibt die sortierte Unterliste nach dem Austausch sortiert.

Inzwischen haben wir 14 und 27 in der sortierten Unterliste. Als nächstes vergleicht es 33 mit 10.

Diese Werte sind nicht in einer sortierten Reihenfolge.

Also tauschen wir sie aus.

Durch das Austauschen werden jedoch 27 und 10 unsortiert.

Daher tauschen wir sie auch aus.

Wieder finden wir 14 und 10 in einer unsortierten Reihenfolge.

Wir tauschen sie wieder. Am Ende der dritten Iteration haben wir eine sortierte Unterliste von 4 Elementen.

Dieser Vorgang wird fortgesetzt, bis alle unsortierten Werte in einer sortierten Unterliste behandelt sind. Nun werden wir einige Programmieraspekte der Einfügesortierung sehen.
Algorithmus
Jetzt haben wir ein umfassenderes Bild davon, wie diese Sortiertechnik funktioniert, sodass wir einfache Schritte ableiten können, mit denen wir eine Einfügesortierung erreichen können.
Step 1 − If it is the first element, it is already sorted. return 1;
Step 2 − Pick next element
Step 3 − Compare with all elements in the sorted sub-list
Step 4 − Shift all the elements in the sorted sub-list that is greater than the
value to be sorted
Step 5 − Insert the value
Step 6 − Repeat until list is sortedPseudocode
procedure insertionSort( A : array of items )
int holePosition
int valueToInsert
for i = 1 to length(A) inclusive do:
/* select value to be inserted */
valueToInsert = A[i]
holePosition = i
/*locate hole position for the element to be inserted */
while holePosition > 0 and A[holePosition-1] > valueToInsert do:
A[holePosition] = A[holePosition-1]
holePosition = holePosition -1
end while
/* insert the number at hole position */
A[holePosition] = valueToInsert
end for
end procedureKlicken Sie hier , um Informationen zur Implementierung der Einfügesortierung in der Programmiersprache C zu erhalten .
Die Auswahlsortierung ist ein einfacher Sortieralgorithmus. Dieser Sortieralgorithmus ist ein Vergleichsalgorithmus, bei dem die Liste in zwei Teile unterteilt ist, den sortierten Teil am linken Ende und den unsortierten Teil am rechten Ende. Anfangs ist der sortierte Teil leer und der unsortierte Teil ist die gesamte Liste.
Das kleinste Element wird aus dem unsortierten Array ausgewählt und gegen das Element ganz links ausgetauscht, und dieses Element wird Teil des sortierten Arrays. Bei diesem Vorgang wird die unsortierte Array-Grenze um ein Element nach rechts verschoben.
Dieser Algorithmus ist nicht für große Datenmengen geeignet, da seine durchschnittliche und Worst-Case-Komplexität Ο (n 2 ) beträgt , wobein ist die Anzahl der Elemente.
Wie funktioniert die Auswahlsortierung?
Betrachten Sie das folgende abgebildete Array als Beispiel.
Für die erste Position in der sortierten Liste wird die gesamte Liste nacheinander gescannt. An der ersten Stelle, an der derzeit 14 gespeichert ist, durchsuchen wir die gesamte Liste und stellen fest, dass 10 der niedrigste Wert ist.

Also ersetzen wir 14 durch 10. Nach einer Iteration erscheint 10, was zufällig der Mindestwert in der Liste ist, an der ersten Position der sortierten Liste.

Für die zweite Position, an der sich 33 befindet, scannen wir den Rest der Liste linear.

Wir finden, dass 14 der zweitniedrigste Wert in der Liste ist und an zweiter Stelle erscheinen sollte. Wir tauschen diese Werte aus.

Nach zwei Iterationen werden zwei kleinste Werte sortiert am Anfang positioniert.

Der gleiche Vorgang wird auf die übrigen Elemente im Array angewendet.
Es folgt eine bildliche Darstellung des gesamten Sortiervorgangs -

Lassen Sie uns nun einige Programmieraspekte der Auswahlsortierung lernen.
Algorithmus
Step 1 − Set MIN to location 0
Step 2 − Search the minimum element in the list
Step 3 − Swap with value at location MIN
Step 4 − Increment MIN to point to next element
Step 5 − Repeat until list is sortedPseudocode
procedure selection sort
list : array of items
n : size of list
for i = 1 to n - 1
/* set current element as minimum*/
min = i
/* check the element to be minimum */
for j = i+1 to n
if list[j] < list[min] then
min = j;
end if
end for
/* swap the minimum element with the current element*/
if indexMin != i then
swap list[min] and list[i]
end if
end for
end procedureKlicken Sie hier , um Informationen zur Implementierung der Auswahlsortierung in der Programmiersprache C zu erhalten .
Die Zusammenführungssortierung ist eine Sortiertechnik, die auf der Teilungs- und Eroberungstechnik basiert. Mit der Zeitkomplexität im schlimmsten Fall von Ο (n log n) ist dies einer der angesehensten Algorithmen.
Die Zusammenführungssortierung teilt das Array zunächst in gleiche Hälften und kombiniert sie dann sortiert.
Wie funktioniert die Sortierung zusammenführen?
Um die Zusammenführungssortierung zu verstehen, nehmen wir ein unsortiertes Array wie folgt:
Wir wissen, dass die Zusammenführungssortierung zuerst das gesamte Array iterativ in gleiche Hälften teilt, sofern die Atomwerte nicht erreicht werden. Wir sehen hier, dass ein Array von 8 Elementen in zwei Arrays der Größe 4 unterteilt ist.

Dies ändert nichts an der Reihenfolge des Erscheinungsbilds von Elementen im Original. Nun teilen wir diese beiden Arrays in zwei Hälften.

Wir teilen diese Arrays weiter und erreichen einen Atomwert, der nicht mehr geteilt werden kann.

Jetzt kombinieren wir sie genauso, wie sie zerlegt wurden. Bitte beachten Sie die Farbcodes in diesen Listen.
Wir vergleichen zuerst das Element für jede Liste und kombinieren sie dann sortiert zu einer anderen Liste. Wir sehen, dass 14 und 33 in sortierten Positionen sind. Wir vergleichen 27 und 10 und setzen in der Zielliste von 2 Werten zuerst 10, gefolgt von 27. Wir ändern die Reihenfolge von 19 und 35, während 42 und 44 nacheinander platziert werden.

In der nächsten Iteration der Kombinationsphase vergleichen wir Listen mit zwei Datenwerten und führen sie zu einer Liste gefundener Datenwerte zusammen, die alle in einer sortierten Reihenfolge angeordnet sind.

Nach dem endgültigen Zusammenführen sollte die Liste folgendermaßen aussehen:

Jetzt sollten wir einige Programmieraspekte der Zusammenführungssortierung lernen.
Algorithmus
Die Zusammenführungssortierung teilt die Liste so lange in gleiche Hälften, bis sie nicht mehr geteilt werden kann. Wenn es sich per Definition nur um ein Element in der Liste handelt, wird es sortiert. Beim Zusammenführen der Sortierung werden dann die kleineren sortierten Listen kombiniert, wobei auch die neue Liste sortiert bleibt.
Step 1 − if it is only one element in the list it is already sorted, return.
Step 2 − divide the list recursively into two halves until it can no more be divided.
Step 3 − merge the smaller lists into new list in sorted order.Pseudocode
Wir werden nun die Pseudocodes für Sortierfunktionen zum Zusammenführen sehen. Wie unsere Algorithmen zeigen, sind zwei Hauptfunktionen - Teilen und Zusammenführen.
Die Zusammenführungssortierung funktioniert mit Rekursion, und wir werden unsere Implementierung auf die gleiche Weise sehen.
procedure mergesort( var a as array )
if ( n == 1 ) return a
var l1 as array = a[0] ... a[n/2]
var l2 as array = a[n/2+1] ... a[n]
l1 = mergesort( l1 )
l2 = mergesort( l2 )
return merge( l1, l2 )
end procedure
procedure merge( var a as array, var b as array )
var c as array
while ( a and b have elements )
if ( a[0] > b[0] )
add b[0] to the end of c
remove b[0] from b
else
add a[0] to the end of c
remove a[0] from a
end if
end while
while ( a has elements )
add a[0] to the end of c
remove a[0] from a
end while
while ( b has elements )
add b[0] to the end of c
remove b[0] from b
end while
return c
end procedureKlicken Sie hier , um Informationen zur Implementierung der Zusammenführungssortierung in der Programmiersprache C zu erhalten .
Die Shell-Sortierung ist ein hocheffizienter Sortieralgorithmus und basiert auf dem Einfügungssortieralgorithmus. Dieser Algorithmus vermeidet große Verschiebungen wie bei der Einfügesortierung, wenn der kleinere Wert ganz rechts liegt und ganz links verschoben werden muss.
Dieser Algorithmus verwendet die Einfügesortierung für weit verbreitete Elemente, um sie zuerst zu sortieren und dann die weniger weit auseinander liegenden Elemente zu sortieren. Dieser Abstand wird als bezeichnetinterval. Dieses Intervall wird basierend auf Knuths Formel als - berechnet
Knuths Formel
h = h * 3 + 1
where −
h is interval with initial value 1Dieser Algorithmus ist für mittelgroße Datensätze sehr effizient, da seine durchschnittliche und Worst-Case-Komplexität Ο (n) beträgt, wobei n ist die Anzahl der Elemente.
Wie funktioniert Shell Sort?
Betrachten wir das folgende Beispiel, um eine Vorstellung davon zu bekommen, wie die Shell-Sortierung funktioniert. Wir verwenden dasselbe Array, das wir in unseren vorherigen Beispielen verwendet haben. Für unser Beispiel und zum besseren Verständnis nehmen wir das Intervall 4 an. Erstellen Sie eine virtuelle Unterliste aller Werte, die sich im Intervall von 4 Positionen befinden. Hier sind diese Werte {35, 14}, {33, 19}, {42, 27} und {10, 44}.

Wir vergleichen die Werte in jeder Unterliste und tauschen sie (falls erforderlich) im ursprünglichen Array aus. Nach diesem Schritt sollte das neue Array folgendermaßen aussehen:

Dann nehmen wir ein Intervall von 2 und diese Lücke erzeugt zwei Unterlisten - {14, 27, 35, 42}, {19, 10, 33, 44}

Wir vergleichen und tauschen die Werte bei Bedarf im ursprünglichen Array aus. Nach diesem Schritt sollte das Array folgendermaßen aussehen:

Schließlich sortieren wir den Rest des Arrays nach dem Intervall von Wert 1. Die Shell-Sortierung verwendet die Einfügesortierung, um das Array zu sortieren.
Es folgt die schrittweise Darstellung -

Wir sehen, dass nur vier Swaps erforderlich waren, um den Rest des Arrays zu sortieren.
Algorithmus
Es folgt der Algorithmus für die Shell-Sortierung.
Step 1 − Initialize the value of h
Step 2 − Divide the list into smaller sub-list of equal interval h
Step 3 − Sort these sub-lists using insertion sort
Step 3 − Repeat until complete list is sortedPseudocode
Es folgt der Pseudocode für die Shell-Sortierung.
procedure shellSort()
A : array of items
/* calculate interval*/
while interval < A.length /3 do:
interval = interval * 3 + 1
end while
while interval > 0 do:
for outer = interval; outer < A.length; outer ++ do:
/* select value to be inserted */
valueToInsert = A[outer]
inner = outer;
/*shift element towards right*/
while inner > interval -1 && A[inner - interval] >= valueToInsert do:
A[inner] = A[inner - interval]
inner = inner - interval
end while
/* insert the number at hole position */
A[inner] = valueToInsert
end for
/* calculate interval*/
interval = (interval -1) /3;
end while
end procedureKlicken Sie hier , um mehr über die Implementierung der Shell-Sortierung in der Programmiersprache C zu erfahren .
Die Shell-Sortierung ist ein hocheffizienter Sortieralgorithmus und basiert auf dem Einfügungssortieralgorithmus. Dieser Algorithmus vermeidet große Verschiebungen wie bei der Einfügesortierung, wenn der kleinere Wert ganz rechts liegt und ganz links verschoben werden muss.
Dieser Algorithmus verwendet die Einfügesortierung für weit verbreitete Elemente, um sie zuerst zu sortieren und dann die weniger weit auseinander liegenden Elemente zu sortieren. Dieser Abstand wird als bezeichnetinterval. Dieses Intervall wird basierend auf Knuths Formel als - berechnet
Knuths Formel
h = h * 3 + 1
where −
h is interval with initial value 1Dieser Algorithmus ist für mittelgroße Datensätze sehr effizient, da seine durchschnittliche und Worst-Case-Komplexität dieses Algorithmus von der Lückenfolge abhängt, von der die bekannteste Ο (n) ist, wobei n die Anzahl der Elemente ist. Und die Worst-Case-Raumkomplexität ist O (n).
Wie funktioniert Shell Sort?
Betrachten wir das folgende Beispiel, um eine Vorstellung davon zu bekommen, wie die Shell-Sortierung funktioniert. Wir verwenden dasselbe Array, das wir in unseren vorherigen Beispielen verwendet haben. Für unser Beispiel und zum besseren Verständnis nehmen wir das Intervall 4 an. Erstellen Sie eine virtuelle Unterliste aller Werte, die sich im Intervall von 4 Positionen befinden. Hier sind diese Werte {35, 14}, {33, 19}, {42, 27} und {10, 44}.
Wir vergleichen die Werte in jeder Unterliste und tauschen sie (falls erforderlich) im ursprünglichen Array aus. Nach diesem Schritt sollte das neue Array folgendermaßen aussehen:
Dann nehmen wir das Intervall 1 und diese Lücke erzeugt zwei Unterlisten - {14, 27, 35, 42}, {19, 10, 33, 44}
Wir vergleichen und tauschen die Werte bei Bedarf im ursprünglichen Array aus. Nach diesem Schritt sollte das Array folgendermaßen aussehen:
Schließlich sortieren wir den Rest des Arrays nach dem Intervall von Wert 1. Die Shell-Sortierung verwendet die Einfügesortierung, um das Array zu sortieren.
Es folgt die schrittweise Darstellung -
Wir sehen, dass nur vier Swaps erforderlich waren, um den Rest des Arrays zu sortieren.
Algorithmus
Es folgt der Algorithmus für die Shell-Sortierung.
Step 1 − Initialize the value of h
Step 2 − Divide the list into smaller sub-list of equal interval h
Step 3 − Sort these sub-lists using insertion sort
Step 3 − Repeat until complete list is sortedPseudocode
Es folgt der Pseudocode für die Shell-Sortierung.
procedure shellSort()
A : array of items
/* calculate interval*/
while interval < A.length /3 do:
interval = interval * 3 + 1
end while
while interval > 0 do:
for outer = interval; outer < A.length; outer ++ do:
/* select value to be inserted */
valueToInsert = A[outer]
inner = outer;
/*shift element towards right*/
while inner > interval -1 && A[inner - interval] >= valueToInsert do:
A[inner] = A[inner - interval]
inner = inner - interval
end while
/* insert the number at hole position */
A[inner] = valueToInsert
end for
/* calculate interval*/
interval = (interval -1) /3;
end while
end procedureKlicken Sie hier , um mehr über die Implementierung der Shell-Sortierung in der Programmiersprache C zu erfahren .
Die schnelle Sortierung ist ein hocheffizienter Sortieralgorithmus und basiert auf der Partitionierung von Datenarrays in kleinere Arrays. Ein großes Array wird in zwei Arrays aufgeteilt, von denen eines Werte enthält, die kleiner als der angegebene Wert sind, z. B. Pivot, basierend auf dem die Partition erstellt wird, und ein anderes Array Werte enthält, die größer als der Pivot-Wert sind.
Quicksort partitioniert ein Array und ruft sich dann zweimal rekursiv auf, um die beiden resultierenden Subarrays zu sortieren. Dieser Algorithmus ist für große Datenmengen sehr effizient, da seine durchschnittliche und Worst-Case-Komplexität O (nLogn) bzw. image.png (n 2 ) beträgt .
Partition in Quick Sort
Die folgende animierte Darstellung erklärt, wie Sie den Pivot-Wert in einem Array finden.

Der Pivot-Wert teilt die Liste in zwei Teile. Und rekursiv finden wir den Drehpunkt für jede Unterliste, bis alle Listen nur noch ein Element enthalten.
Schneller Sortier-Pivot-Algorithmus
Basierend auf unserem Verständnis der Partitionierung in schneller Sortierung werden wir nun versuchen, einen Algorithmus dafür zu schreiben, der wie folgt lautet.
Step 1 − Choose the highest index value has pivot
Step 2 − Take two variables to point left and right of the list excluding pivot
Step 3 − left points to the low index
Step 4 − right points to the high
Step 5 − while value at left is less than pivot move right
Step 6 − while value at right is greater than pivot move left
Step 7 − if both step 5 and step 6 does not match swap left and right
Step 8 − if left ≥ right, the point where they met is new pivotSchneller Sortier-Pivot-Pseudocode
Der Pseudocode für den obigen Algorithmus kann abgeleitet werden als -
function partitionFunc(left, right, pivot)
leftPointer = left
rightPointer = right - 1
while True do
while A[++leftPointer] < pivot do
//do-nothing
end while
while rightPointer > 0 && A[--rightPointer] > pivot do
//do-nothing
end while
if leftPointer >= rightPointer
break
else
swap leftPointer,rightPointer
end if
end while
swap leftPointer,right
return leftPointer
end functionSchneller Sortieralgorithmus
Wenn wir den Pivot-Algorithmus rekursiv verwenden, erhalten wir kleinere mögliche Partitionen. Jede Partition wird dann zur schnellen Sortierung verarbeitet. Wir definieren den rekursiven Algorithmus für Quicksort wie folgt:
Step 1 − Make the right-most index value pivot
Step 2 − partition the array using pivot value
Step 3 − quicksort left partition recursively
Step 4 − quicksort right partition recursivelyPseudocode schnell sortieren
Weitere Informationen finden Sie im Pseudocode für den schnellen Sortieralgorithmus.
procedure quickSort(left, right)
if right-left <= 0
return
else
pivot = A[right]
partition = partitionFunc(left, right, pivot)
quickSort(left,partition-1)
quickSort(partition+1,right)
end if
end procedureKlicken Sie hier , um Informationen zur schnellen Implementierung der Sortierung in der Programmiersprache C zu erhalten .
Ein Diagramm ist eine bildliche Darstellung einer Gruppe von Objekten, bei denen einige Objektpaare durch Verknüpfungen verbunden sind. Die miteinander verbundenen Objekte werden durch Punkte dargestellt, die als bezeichnet werdenverticesund die Verknüpfungen, die die Eckpunkte verbinden, werden aufgerufen edges.
Formal ist ein Graph ein Paar von Mengen (V, E), wo V ist die Menge der Eckpunkte und Eist die Menge der Kanten, die die Eckpunktpaare verbinden. Schauen Sie sich die folgende Grafik an -
In der obigen Grafik
V = {a, b, c, d, e}
E = {ab, ac, bd, cd, de}
Diagrammdatenstruktur
Mathematische Graphen können in Datenstruktur dargestellt werden. Wir können einen Graphen mit einem Array von Eckpunkten und einem zweidimensionalen Array von Kanten darstellen. Bevor wir fortfahren, machen wir uns mit einigen wichtigen Begriffen vertraut -
Vertex- Jeder Knoten des Diagramms wird als Scheitelpunkt dargestellt. Im folgenden Beispiel repräsentiert der beschriftete Kreis Scheitelpunkte. Somit sind A bis G Eckpunkte. Wir können sie mit einem Array darstellen, wie im folgenden Bild gezeigt. Hier kann A durch Index 0 identifiziert werden. B kann unter Verwendung von Index 1 usw. identifiziert werden.
Edge- Kante repräsentiert einen Pfad zwischen zwei Eckpunkten oder eine Linie zwischen zwei Eckpunkten. Im folgenden Beispiel repräsentieren die Linien von A nach B, B nach C usw. Kanten. Wir können ein zweidimensionales Array verwenden, um ein Array darzustellen, wie im folgenden Bild gezeigt. Hier kann AB als 1 in Zeile 0, Spalte 1, BC als 1 in Zeile 1, Spalte 2 usw. dargestellt werden, wobei andere Kombinationen als 0 beibehalten werden.
Adjacency- Zwei Knoten oder Eckpunkte sind benachbart, wenn sie über eine Kante miteinander verbunden sind. Im folgenden Beispiel ist B neben A, C ist neben B und so weiter.
Path- Der Pfad repräsentiert eine Folge von Kanten zwischen den beiden Eckpunkten. Im folgenden Beispiel repräsentiert ABCD einen Pfad von A nach D.
Grundoperationen
Es folgen grundlegende primäre Operationen eines Graphen -
Add Vertex - Fügt dem Diagramm einen Scheitelpunkt hinzu.
Add Edge - Fügt eine Kante zwischen den beiden Eckpunkten des Diagramms hinzu.
Display Vertex - Zeigt einen Scheitelpunkt des Diagramms an.
Um mehr über Graph zu erfahren, lesen Sie bitte das Graph Theory Tutorial . In den kommenden Kapiteln erfahren Sie, wie Sie ein Diagramm durchlaufen.
Der DFS-Algorithmus (Depth First Search) durchläuft einen Graphen in einer Tiefenbewegung und verwendet einen Stapel, um sich daran zu erinnern, den nächsten Scheitelpunkt zum Starten einer Suche zu erhalten, wenn in einer Iteration eine Sackgasse auftritt.

Wie im obigen Beispiel durchläuft der DFS-Algorithmus zuerst von S nach A nach D nach G nach E nach B, dann nach F und zuletzt nach C. Er verwendet die folgenden Regeln.
Rule 1- Besuchen Sie den angrenzenden nicht besuchten Scheitelpunkt. Markieren Sie es als besucht. Zeigen Sie es an. Schieben Sie es in einen Stapel.
Rule 2- Wenn kein benachbarter Scheitelpunkt gefunden wird, öffnen Sie einen Scheitelpunkt aus dem Stapel. (Es werden alle Scheitelpunkte aus dem Stapel angezeigt, die keine benachbarten Scheitelpunkte haben.)
Rule 3 - Wiederholen Sie Regel 1 und Regel 2, bis der Stapel leer ist.
| Schritt | Durchquerung | Beschreibung |
|---|---|---|
| 1 |

|
Initialisieren Sie den Stapel. |
| 2 |

|
Kennzeichen Swie besucht und auf den Stapel legen. Erkunden Sie alle nicht besuchten benachbarten Knoten vonS. Wir haben drei Knoten und können jeden von ihnen auswählen. In diesem Beispiel nehmen wir den Knoten in alphabetischer Reihenfolge. |
| 3 |

|
Kennzeichen Awie besucht und auf den Stapel legen. Untersuchen Sie alle nicht besuchten benachbarten Knoten von A. BeideS und D sind neben A Wir sind jedoch nur für nicht besuchte Knoten besorgt. |
| 4 |

|
Besuch Dund als besucht markieren und auf den Stapel legen. Hier haben wirB und C Knoten, die benachbart sind Dund beide sind nicht besucht. Wir werden jedoch wieder in alphabetischer Reihenfolge wählen. |
| 5 |

|
Wir wählen B, als besucht markieren und auf den Stapel legen. HierBhat keinen nicht besuchten Nachbarknoten. Also knallen wirB vom Stapel. |
| 6 |

|
Wir überprüfen die Stapeloberseite auf Rückkehr zum vorherigen Knoten und prüfen, ob nicht besuchte Knoten vorhanden sind. Hier finden wirD oben auf dem Stapel sein. |
| 7 |

|
Nur nicht besuchte benachbarte Knoten sind von D ist Cjetzt. Also besuchen wirC, markieren Sie es als besucht und legen Sie es auf den Stapel. |
Wie Chat keinen nicht besuchten Nachbarknoten, daher knallen wir den Stapel weiter, bis wir einen Knoten finden, der einen nicht besuchten Nachbarknoten hat. In diesem Fall gibt es keine und wir knallen weiter, bis der Stapel leer ist.
Klicken Sie hier , um mehr über die Implementierung dieses Algorithmus in der Programmiersprache C zu erfahren .
Der BFS-Algorithmus (Breadth First Search) durchläuft ein Diagramm in einer Bewegung in der Breite und verwendet eine Warteschlange, um sich daran zu erinnern, den nächsten Scheitelpunkt zum Starten einer Suche zu erhalten, wenn in einer Iteration eine Sackgasse auftritt.

Wie im obigen Beispiel wechselt der BFS-Algorithmus zuerst von A nach B nach E nach F, dann nach C und zuletzt nach D. Er verwendet die folgenden Regeln.
Rule 1- Besuchen Sie den angrenzenden nicht besuchten Scheitelpunkt. Markieren Sie es als besucht. Zeigen Sie es an. Fügen Sie es in eine Warteschlange ein.
Rule 2 - Wenn kein benachbarter Scheitelpunkt gefunden wird, entfernen Sie den ersten Scheitelpunkt aus der Warteschlange.
Rule 3 - Wiederholen Sie Regel 1 und Regel 2, bis die Warteschlange leer ist.
| Schritt | Durchquerung | Beschreibung |
|---|---|---|
| 1 |

|
Initialisieren Sie die Warteschlange. |
| 2 |
|
Wir beginnen mit einem Besuch S (Startknoten) und markieren Sie ihn als besucht. |
| 3 |

|
Wir sehen dann einen nicht besuchten Nachbarknoten von S. In diesem Beispiel haben wir drei Knoten, aber wir wählen alphabetischA, markieren Sie es als besucht und stellen Sie es in die Warteschlange. |
| 4 |

|
Als nächstes wird der nicht besuchte Nachbarknoten von S ist B. Wir markieren es als besucht und stellen es in die Warteschlange. |
| 5 |

|
Als nächstes wird der nicht besuchte Nachbarknoten von S ist C. Wir markieren es als besucht und stellen es in die Warteschlange. |
| 6 |

|
Jetzt, Sbleibt ohne nicht besuchte benachbarte Knoten. Also stellen wir uns in die Warteschlange und findenA. |
| 7 |

|
Von A wir haben Dals nicht besuchter Nachbarknoten. Wir markieren es als besucht und stellen es in die Warteschlange. |
Zu diesem Zeitpunkt haben wir keine nicht markierten (nicht besuchten) Knoten mehr. Gemäß dem Algorithmus werden wir jedoch weiterhin aus der Warteschlange entfernt, um alle nicht besuchten Knoten zu erhalten. Wenn die Warteschlange geleert wird, ist das Programm beendet.
Die Implementierung dieses Algorithmus in der Programmiersprache C ist hier zu sehen .
Baum repräsentiert die Knoten, die durch Kanten verbunden sind. Wir werden speziell auf den Binärbaum oder den Binärsuchbaum eingehen.
Binary Tree ist eine spezielle Datenstruktur, die zur Datenspeicherung verwendet wird. Ein Binärbaum hat eine spezielle Bedingung, dass jeder Knoten maximal zwei untergeordnete Knoten haben kann. Ein Binärbaum bietet die Vorteile eines geordneten Arrays und einer verknüpften Liste, da die Suche so schnell ist wie in einem sortierten Array und der Einfüge- oder Löschvorgang so schnell ist wie in einer verknüpften Liste.

Wichtige Begriffe
Es folgen die wichtigen Begriffe in Bezug auf den Baum.
Path - Pfad bezieht sich auf die Folge von Knoten entlang der Kanten eines Baums.
Root- Der Knoten oben im Baum heißt root. Es gibt nur eine Wurzel pro Baum und einen Pfad vom Wurzelknoten zu einem Knoten.
Parent - Jeder Knoten außer dem Wurzelknoten hat eine Kante nach oben zu einem Knoten namens Parent.
Child - Der Knoten unter einem bestimmten Knoten, der durch seine Kante nach unten verbunden ist, wird als untergeordneter Knoten bezeichnet.
Leaf - Der Knoten, der keinen untergeordneten Knoten hat, wird als Blattknoten bezeichnet.
Subtree - Teilbaum repräsentiert die Nachkommen eines Knotens.
Visiting - Besuch bezieht sich auf die Überprüfung des Werts eines Knotens, wenn sich die Steuerung auf dem Knoten befindet.
Traversing - Durchqueren bedeutet, Knoten in einer bestimmten Reihenfolge zu durchlaufen.
Levels- Die Ebene eines Knotens repräsentiert die Erzeugung eines Knotens. Befindet sich der Wurzelknoten auf Ebene 0, befindet sich sein nächster untergeordneter Knoten auf Ebene 1, sein Enkel auf Ebene 2 usw.
keys - Schlüssel stellt einen Wert eines Knotens dar, auf dessen Grundlage eine Suchoperation für einen Knoten ausgeführt werden soll.
Darstellung des binären Suchbaums
Der binäre Suchbaum weist ein besonderes Verhalten auf. Das linke Kind eines Knotens muss einen Wert haben, der kleiner als der Wert seines Elternteils ist, und das rechte Kind des Knotens muss einen Wert haben, der größer als sein übergeordneter Wert ist.

Wir werden den Baum mithilfe eines Knotenobjekts implementieren und durch Referenzen verbinden.
Baumknoten
Der Code zum Schreiben eines Baumknotens ähnelt dem unten angegebenen. Es hat einen Datenteil und verweist auf seinen linken und rechten untergeordneten Knoten.
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};In einem Baum haben alle Knoten ein gemeinsames Konstrukt.
BST-Grundoperationen
Die grundlegenden Operationen, die an einer binären Suchbaumdatenstruktur ausgeführt werden können, sind die folgenden:
Insert - Fügt ein Element in einen Baum ein / erstellt einen Baum.
Search - Sucht ein Element in einem Baum.
Preorder Traversal - Durchquert einen Baum vorbestellt.
Inorder Traversal - Durchquert einen Baum in der richtigen Reihenfolge.
Postorder Traversal - Durchquert einen Baum nachträglich.
In diesem Kapitel lernen wir, eine Baumstruktur zu erstellen (einzufügen) und ein Datenelement in einem Baum zu suchen. Wir werden im nächsten Kapitel etwas über Baumüberquerungsmethoden lernen.
Operation einfügen
Die allererste Einfügung erstellt den Baum. Wenn danach ein Element eingefügt werden soll, suchen Sie zuerst die richtige Position. Starten Sie die Suche vom Stammknoten aus. Wenn die Daten kleiner als der Schlüsselwert sind, suchen Sie nach der leeren Position im linken Teilbaum und fügen Sie die Daten ein. Suchen Sie andernfalls nach der leeren Stelle im rechten Teilbaum und fügen Sie die Daten ein.
Algorithmus
If root is NULL
then create root node
return
If root exists then
compare the data with node.data
while until insertion position is located
If data is greater than node.data
goto right subtree
else
goto left subtree
endwhile
insert data
end IfImplementierung
Die Implementierung der Einfügefunktion sollte folgendermaßen aussehen:
void insert(int data) {
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty, create root node
if(root == NULL) {
root = tempNode;
} else {
current = root;
parent = NULL;
while(1) {
parent = current;
//go to left of the tree
if(data < parent->data) {
current = current->leftChild;
//insert to the left
if(current == NULL) {
parent->leftChild = tempNode;
return;
}
}
//go to right of the tree
else {
current = current->rightChild;
//insert to the right
if(current == NULL) {
parent->rightChild = tempNode;
return;
}
}
}
}
}Suchvorgang
Wenn ein Element durchsucht werden soll, starten Sie die Suche vom Stammknoten aus. Wenn die Daten kleiner als der Schlüsselwert sind, suchen Sie im linken Teilbaum nach dem Element. Suchen Sie andernfalls nach dem Element im rechten Teilbaum. Befolgen Sie für jeden Knoten den gleichen Algorithmus.
Algorithmus
If root.data is equal to search.data
return root
else
while data not found
If data is greater than node.data
goto right subtree
else
goto left subtree
If data found
return node
endwhile
return data not found
end ifDie Implementierung dieses Algorithmus sollte so aussehen.
struct node* search(int data) {
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data) {
if(current != NULL)
printf("%d ",current->data);
//go to left tree
if(current->data > data) {
current = current->leftChild;
}
//else go to right tree
else {
current = current->rightChild;
}
//not found
if(current == NULL) {
return NULL;
}
return current;
}
}Um mehr über die Implementierung der binären Suchbaumdatenstruktur zu erfahren, klicken Sie bitte hier .
Beim Durchlaufen werden alle Knoten eines Baums besucht und möglicherweise auch deren Werte gedruckt. Da alle Knoten über Kanten (Links) verbunden sind, beginnen wir immer am Wurzelknoten (Kopfknoten). Das heißt, wir können nicht zufällig auf einen Knoten in einem Baum zugreifen. Es gibt drei Möglichkeiten, wie wir einen Baum durchqueren können:
- In-Order-Traversal
- Traversal vorbestellen
- Nachbestellungsdurchquerung
Im Allgemeinen durchlaufen wir einen Baum, um ein bestimmtes Element oder einen bestimmten Schlüssel im Baum zu suchen oder zu finden oder um alle darin enthaltenen Werte zu drucken.
In-Order-Traversal
Bei dieser Traversal-Methode wird zuerst der linke Teilbaum, dann die Wurzel und später der rechte Teilbaum besucht. Wir sollten uns immer daran erinnern, dass jeder Knoten selbst einen Teilbaum darstellen kann.
Wenn ein Binärbaum durchlaufen wird in-orderDie Ausgabe erzeugt sortierte Schlüsselwerte in aufsteigender Reihenfolge.

Wir fangen an von Aund nach dem Durchlaufen der Reihenfolge bewegen wir uns zu seinem linken Teilbaum B. Bwird auch in der richtigen Reihenfolge durchlaufen. Der Vorgang wird fortgesetzt, bis alle Knoten besucht sind. Die Ausgabe der Inorder Traversal dieses Baums ist -
D → B → E → A → F → C → G
Algorithmus
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Visit root node.
Step 3 − Recursively traverse right subtree.Traversal vorbestellen
Bei dieser Traversal-Methode wird zuerst der Wurzelknoten besucht, dann der linke Teilbaum und schließlich der rechte Teilbaum.

Wir fangen an von Aund nach dem Durchlaufen der Vorbestellung besuchen wir zuerst A selbst und dann zu seinem linken Teilbaum bewegen B. Bwird auch vorbestellt durchlaufen. Der Vorgang wird fortgesetzt, bis alle Knoten besucht sind. Die Ausgabe der Vorbestellungsdurchquerung dieses Baums ist -
A → B → D → E → C → F → G
Algorithmus
Until all nodes are traversed −
Step 1 − Visit root node.
Step 2 − Recursively traverse left subtree.
Step 3 − Recursively traverse right subtree.Nachbestellungsdurchquerung
Bei dieser Traversal-Methode wird der Stammknoten zuletzt besucht, daher der Name. Zuerst durchlaufen wir den linken Teilbaum, dann den rechten Teilbaum und schließlich den Wurzelknoten.

Wir fangen an von ANach dem Durchlauf nach der Bestellung besuchen wir zuerst den linken Teilbaum B. Bwird auch nachbestellt. Der Vorgang wird fortgesetzt, bis alle Knoten besucht sind. Die Ausgabe der Nachbestellungsdurchquerung dieses Baums ist -
D → E → B → F → G → C → A
Algorithmus
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Recursively traverse right subtree.
Step 3 − Visit root node.Klicken Sie hier, um die C-Implementierung von Tree Traversing zu überprüfen .
Ein binärer Suchbaum (BST) ist ein Baum, in dem alle Knoten den unten genannten Eigenschaften folgen.
Der Wert des Schlüssels des linken Unterbaums ist kleiner als der Wert des Schlüssels des übergeordneten (Stamm-) Knotens.
Der Wert des Schlüssels des rechten Teilbaums ist größer oder gleich dem Wert des Schlüssels des übergeordneten (Stamm-) Knotens.
Somit teilt BST alle seine Unterbäume in zwei Segmente ein; der linke Unterbaum und der rechte Unterbaum und können definiert werden als -
left_subtree (keys) < node (key) ≤ right_subtree (keys)Darstellung
BST ist eine Sammlung von Knoten, die so angeordnet sind, dass sie die BST-Eigenschaften beibehalten. Jeder Knoten hat einen Schlüssel und einen zugehörigen Wert. Während der Suche wird der gewünschte Schlüssel mit den Schlüsseln in BST verglichen, und wenn er gefunden wird, wird der zugehörige Wert abgerufen.
Es folgt eine bildliche Darstellung von BST -
Wir beobachten, dass der Wurzelknotenschlüssel (27) alle weniger wertvollen Schlüssel im linken Teilbaum und die höherwertigen Schlüssel im rechten Teilbaum hat.
Grundoperationen
Es folgen die grundlegenden Operationen eines Baums -
Search - Sucht ein Element in einem Baum.
Insert - Fügt ein Element in einen Baum ein.
Pre-order Traversal - Durchquert einen Baum vorbestellt.
In-order Traversal - Durchquert einen Baum in der richtigen Reihenfolge.
Post-order Traversal - Durchquert einen Baum nachträglich.
Knoten
Definieren Sie einen Knoten mit einigen Daten und Verweisen auf seinen linken und rechten untergeordneten Knoten.
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};Suchvorgang
Wenn ein Element durchsucht werden soll, starten Sie die Suche vom Stammknoten aus. Wenn die Daten kleiner als der Schlüsselwert sind, suchen Sie im linken Teilbaum nach dem Element. Suchen Sie andernfalls nach dem Element im rechten Teilbaum. Befolgen Sie für jeden Knoten den gleichen Algorithmus.
Algorithmus
struct node* search(int data){
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data){
if(current != NULL) {
printf("%d ",current->data);
//go to left tree
if(current->data > data){
current = current->leftChild;
} //else go to right tree
else {
current = current->rightChild;
}
//not found
if(current == NULL){
return NULL;
}
}
}
return current;
}Operation einfügen
Wenn ein Element eingefügt werden soll, suchen Sie zuerst die richtige Position. Starten Sie die Suche vom Stammknoten aus. Wenn die Daten kleiner als der Schlüsselwert sind, suchen Sie nach der leeren Position im linken Teilbaum und fügen Sie die Daten ein. Suchen Sie andernfalls nach der leeren Stelle im rechten Teilbaum und fügen Sie die Daten ein.
Algorithmus
void insert(int data) {
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty
if(root == NULL) {
root = tempNode;
} else {
current = root;
parent = NULL;
while(1) {
parent = current;
//go to left of the tree
if(data < parent->data) {
current = current->leftChild;
//insert to the left
if(current == NULL) {
parent->leftChild = tempNode;
return;
}
} //go to right of the tree
else {
current = current->rightChild;
//insert to the right
if(current == NULL) {
parent->rightChild = tempNode;
return;
}
}
}
}
}Was ist, wenn die Eingabe in den binären Suchbaum sortiert (aufsteigend oder absteigend) erfolgt? Es wird dann so aussehen -

Es wird beobachtet, dass die Worst-Case-Leistung von BST den linearen Suchalgorithmen am nächsten kommt, dh Ο (n). In Echtzeitdaten können wir das Datenmuster und ihre Häufigkeit nicht vorhersagen. Es besteht also die Notwendigkeit, die bestehende BST auszugleichen.
Benannt nach ihrem Erfinder Adelson, Velski & Landis, AVL treessind höhenausgleichende binäre Suchbaum. Der AVL-Baum überprüft die Höhe der linken und rechten Unterbäume und stellt sicher, dass der Unterschied nicht mehr als 1 beträgt. Dieser Unterschied wird als bezeichnetBalance Factor.
Hier sehen wir, dass der erste Baum ausgeglichen ist und die nächsten beiden Bäume nicht ausgeglichen sind -
Im zweiten Baum der linke Teilbaum von C hat Höhe 2 und der rechte Teilbaum hat Höhe 0, der Unterschied ist also 2. Im dritten Baum ist der rechte Teilbaum von Ahat Höhe 2 und die linke fehlt, also ist es 0 und die Differenz ist wieder 2. Der AVL-Baum erlaubt, dass die Differenz (Ausgleichsfaktor) nur 1 beträgt.
BalanceFactor = height(left-sutree) − height(right-sutree)Wenn der Höhenunterschied zwischen linken und rechten Teilbäumen mehr als 1 beträgt, wird der Baum mithilfe einiger Rotationstechniken ausgeglichen.
AVL-Rotationen
Um sich selbst auszugleichen, kann ein AVL-Baum die folgenden vier Arten von Rotationen ausführen:
- Linksdrehung
- Rechtsdrehung
- Links-Rechts-Drehung
- Rechts-Links-Drehung
Die ersten beiden Umdrehungen sind Einzelumdrehungen und die nächsten beiden Umdrehungen sind Doppelumdrehungen. Um einen unausgeglichenen Baum zu haben, brauchen wir mindestens einen Baum der Höhe 2. Bei diesem einfachen Baum verstehen wir sie nacheinander.
Linksdrehung
Wenn ein Baum aus dem Gleichgewicht gerät und ein Knoten in den rechten Teilbaum des rechten Teilbaums eingefügt wird, führen wir eine einzelne Linksdrehung durch -

In unserem Beispiel Knoten Aist aus dem Gleichgewicht geraten, als ein Knoten in den rechten Teilbaum des rechten Teilbaums von A eingefügt wird. Wir führen die Linksdrehung durch, indem wir machenA der linke Teilbaum von B.
Rechtsdrehung
Der AVL-Baum kann aus dem Gleichgewicht geraten, wenn ein Knoten in den linken Teilbaum des linken Teilbaums eingefügt wird. Der Baum braucht dann eine Rechtsdrehung.

Wie dargestellt, wird der unausgeglichene Knoten durch Ausführen einer Rechtsdrehung zum rechten Kind seines linken Kindes.
Links-Rechts-Drehung
Doppelrotationen sind eine etwas komplexe Version bereits erklärter Versionen von Rotationen. Um sie besser zu verstehen, sollten wir jede Aktion notieren, die während der Rotation ausgeführt wird. Lassen Sie uns zunächst überprüfen, wie die Links-Rechts-Drehung durchgeführt wird. Eine Links-Rechts-Drehung ist eine Kombination aus Links- und Rechtsdrehung.
| Zustand | Aktion |
|---|---|

|
Ein Knoten wurde in den rechten Teilbaum des linken Teilbaums eingefügt. Das machtCein unausgeglichener Knoten. Diese Szenarien führen dazu, dass der AVL-Baum eine Links-Rechts-Drehung ausführt. |

|
Wir führen zuerst die Linksdrehung im linken Teilbaum von durch C. Das machtA, der linke Teilbaum von B. |

|
Knoten C ist immer noch unausgeglichen, aber jetzt liegt es am linken Teilbaum des linken Teilbaums. |

|
Wir werden jetzt den Baum nach rechts drehen und machen B der neue Wurzelknoten dieses Teilbaums. C Jetzt wird der rechte Teilbaum seines eigenen linken Teilbaums. |

|
Der Baum ist jetzt ausgeglichen. |
Rechts-Links-Drehung
Die zweite Art der Doppelrotation ist die Rechts-Links-Rotation. Es ist eine Kombination aus Rechtsdrehung und Linksdrehung.
| Zustand | Aktion |
|---|---|

|
Ein Knoten wurde in den linken Teilbaum des rechten Teilbaums eingefügt. Das machtAein unsymmetrischer Knoten mit Ausgleichsfaktor 2. |

|
Zuerst führen wir die richtige Drehung durch C Knoten machen C der rechte Teilbaum seines eigenen linken Teilbaums B. Jetzt,B wird der richtige Teilbaum von A. |

|
Knoten A ist aufgrund des rechten Teilbaums seines rechten Teilbaums immer noch unausgeglichen und erfordert eine Linksdrehung. |

|
Eine Linksdrehung wird durch Machen ausgeführt B der neue Wurzelknoten des Teilbaums. A wird der linke Teilbaum seines rechten Teilbaums B. |
|
|
Der Baum ist jetzt ausgeglichen. |
Ein Spanning Tree ist eine Teilmenge von Graph G, bei der alle Eckpunkte mit einer möglichst geringen Anzahl von Kanten abgedeckt sind. Daher hat ein Spanning Tree keine Zyklen und kann nicht getrennt werden.
Durch diese Definition können wir den Schluss ziehen, dass jeder verbundene und ungerichtete Graph G mindestens einen Spannbaum hat. Ein nicht verbundener Graph hat keinen Spanning Tree, da er nicht auf alle seine Eckpunkte gespannt werden kann.

Wir fanden drei überspannende Bäume in einem vollständigen Diagramm. Ein vollständiger ungerichteter Graph kann maximal seinnn-2 Anzahl der überspannenden Bäume, wo nist die Anzahl der Knoten. In dem oben angesprochenen Beispiel istn is 3, daher 33−2 = 3 Spannbäume sind möglich.
Allgemeine Eigenschaften von Spanning Tree
Wir verstehen jetzt, dass ein Graph mehr als einen Spanning Tree haben kann. Im Folgenden sind einige Eigenschaften des Spanning Tree aufgeführt, die mit dem Diagramm G verbunden sind.
Ein verbundener Graph G kann mehr als einen Spannbaum haben.
Alle möglichen Spannbäume des Graphen G haben die gleiche Anzahl von Kanten und Eckpunkten.
Der Spanning Tree hat keinen Zyklus (Schleifen).
Wenn Sie eine Kante aus dem Spanning Tree entfernen, wird das Diagramm getrennt, dh der Spanning Tree ist minimally connected.
Durch Hinzufügen einer Kante zum Spanning Tree wird eine Schaltung oder Schleife erstellt, dh der Spanning Tree ist maximally acyclic.
Mathematische Eigenschaften von Spanning Tree
Spanning Tree hat n-1 Kanten, wo n ist die Anzahl der Knoten (Eckpunkte).
Aus einem vollständigen Diagramm durch Entfernen des Maximums e - n + 1 Kanten können wir einen Spannbaum konstruieren.
Ein vollständiger Graph kann maximal sein nn-2 Anzahl der überspannenden Bäume.
Wir können daher den Schluss ziehen, dass Spanning Tree eine Teilmenge des verbundenen Graphen G ist und getrennte Graphen keinen Spanning Tree haben.
Anwendung von Spanning Tree
Der Spanning Tree wird im Wesentlichen verwendet, um einen Mindestpfad für die Verbindung aller Knoten in einem Diagramm zu finden. Übliche Anwendung von Spannbäumen sind -
Civil Network Planning
Computer Network Routing Protocol
Cluster Analysis
Lassen Sie uns dies anhand eines kleinen Beispiels verstehen. Betrachten Sie das Stadtnetz als ein riesiges Diagramm und planen Sie nun, Telefonleitungen so bereitzustellen, dass wir mit minimalen Leitungen eine Verbindung zu allen Stadtknoten herstellen können. Hier kommt der Spannbaum ins Spiel.
Minimum Spanning Tree (MST)
In einem gewichteten Diagramm ist ein minimaler Spannbaum ein Spannbaum, der ein minimales Gewicht hat als alle anderen Spannbäume desselben Graphen. In realen Situationen kann dieses Gewicht als Entfernung, Überlastung, Verkehrslast oder ein beliebiger Wert gemessen werden, der an den Kanten angegeben wird.
Minimaler Spanning-Tree-Algorithmus
Wir werden hier zwei der wichtigsten Spanning Tree-Algorithmen kennenlernen -
Kruskals Algorithmus
Prims Algorithmus
Beide sind gierige Algorithmen.
Heap ist ein Sonderfall einer ausgeglichenen binären Baumdatenstruktur, bei der der Wurzelknotenschlüssel mit seinen untergeordneten Elementen verglichen und entsprechend angeordnet wird. Wennα hat untergeordneten Knoten β dann -
Schlüssel (α) ≥ Schlüssel (β)
Da der Wert von parent größer als der von child ist, wird diese Eigenschaft generiert Max Heap. Basierend auf diesen Kriterien kann ein Heap von zwei Arten sein -
For Input → 35 33 42 10 14 19 27 44 26 31Min-Heap - Wenn der Wert des Wurzelknotens kleiner oder gleich einem seiner untergeordneten Knoten ist.
Max-Heap - Wenn der Wert des Wurzelknotens größer oder gleich einem seiner untergeordneten Knoten ist.

Beide Bäume werden mit derselben Eingabe und Ankunftsreihenfolge erstellt.
Max Heap Konstruktionsalgorithmus
Wir werden dasselbe Beispiel verwenden, um zu demonstrieren, wie ein Max Heap erstellt wird. Die Vorgehensweise zum Erstellen von Min Heap ist ähnlich, wir verwenden jedoch Min-Werte anstelle von Max-Werten.
Wir werden einen Algorithmus für den maximalen Heap ableiten, indem wir jeweils ein Element einfügen. Zu jedem Zeitpunkt muss der Heap sein Eigentum behalten. Beim Einfügen wird auch davon ausgegangen, dass wir einen Knoten in einen bereits Heapified-Baum einfügen.
Step 1 − Create a new node at the end of heap.
Step 2 − Assign new value to the node.
Step 3 − Compare the value of this child node with its parent.
Step 4 − If value of parent is less than child, then swap them.
Step 5 − Repeat step 3 & 4 until Heap property holds.Note - Beim Min Heap-Konstruktionsalgorithmus erwarten wir, dass der Wert des übergeordneten Knotens kleiner als der des untergeordneten Knotens ist.
Lassen Sie uns die Max-Heap-Konstruktion anhand einer animierten Illustration verstehen. Wir betrachten das gleiche Eingabebeispiel, das wir zuvor verwendet haben.

Max Heap Deletion Algorithmus
Lassen Sie uns einen Algorithmus ableiten, der aus dem maximalen Heap gelöscht werden soll. Das Löschen im maximalen (oder minimalen) Heap erfolgt immer im Stammverzeichnis, um den maximalen (oder minimalen) Wert zu entfernen.
Step 1 − Remove root node.
Step 2 − Move the last element of last level to root.
Step 3 − Compare the value of this child node with its parent.
Step 4 − If value of parent is less than child, then swap them.
Step 5 − Repeat step 3 & 4 until Heap property holds.
In einigen Computerprogrammiersprachen kann sich ein Modul oder eine Funktion selbst aufrufen. Diese Technik wird als Rekursion bezeichnet. In der Rekursion eine Funktionα ruft sich entweder direkt auf oder ruft eine Funktion auf β das wiederum ruft die ursprüngliche Funktion auf α. Die Funktionα heißt rekursive Funktion.
Example - eine Funktion, die sich selbst aufruft.
int function(int value) {
if(value < 1)
return;
function(value - 1);
printf("%d ",value);
}Example - eine Funktion, die eine andere Funktion aufruft, die sie wiederum erneut aufruft.
int function1(int value1) {
if(value1 < 1)
return;
function2(value1 - 1);
printf("%d ",value1);
}
int function2(int value2) {
function1(value2);
}Eigenschaften
Eine rekursive Funktion kann wie eine Schleife unendlich werden. Um eine unendliche Ausführung der rekursiven Funktion zu vermeiden, muss eine rekursive Funktion zwei Eigenschaften haben:
Base criteria - Es muss mindestens ein Basiskriterium oder eine Grundbedingung vorhanden sein, damit die Funktion sich nicht mehr rekursiv aufruft, wenn diese Bedingung erfüllt ist.
Progressive approach - Die rekursiven Aufrufe sollten so fortschreiten, dass sie bei jedem rekursiven Aufruf den Basiskriterien näher kommen.
Implementierung
Viele Programmiersprachen implementieren die Rekursion mittels stacks. Im Allgemeinen, wann immer eine Funktion (caller) ruft eine andere Funktion auf (callee) oder selbst als Angerufene überträgt die Aufruferfunktion die Ausführungskontrolle an den Angerufenen. Dieser Übertragungsprozess kann auch einige Daten beinhalten, die vom Anrufer an den Angerufenen weitergeleitet werden müssen.
Dies bedeutet, dass die Aufruferfunktion ihre Ausführung vorübergehend unterbrechen und später fortsetzen muss, wenn die Ausführungssteuerung von der Angerufenenfunktion zurückkehrt. Hier muss die Aufruferfunktion genau an dem Punkt der Ausführung beginnen, an dem sie sich selbst in die Warteschleife stellt. Es benötigt auch genau die gleichen Datenwerte, an denen es gearbeitet hat. Zu diesem Zweck wird ein Aktivierungsdatensatz (oder Stapelrahmen) für die Aufruferfunktion erstellt.

Dieser Aktivierungsdatensatz enthält die Informationen zu lokalen Variablen, formalen Parametern, der Absenderadresse und allen Informationen, die an die Aufruferfunktion übergeben werden.
Analyse der Rekursion
Man kann argumentieren, warum Rekursion verwendet werden soll, da dieselbe Aufgabe mit Iteration ausgeführt werden kann. Der erste Grund ist, dass die Rekursion ein Programm lesbarer macht und aufgrund der neuesten erweiterten CPU-Systeme die Rekursion effizienter ist als Iterationen.
Zeitliche Komplexität
Bei Iterationen nehmen wir die Anzahl der Iterationen, um die zeitliche Komplexität zu zählen. Ebenso versuchen wir im Falle einer Rekursion unter der Annahme, dass alles konstant ist, herauszufinden, wie oft ein rekursiver Aufruf erfolgt. Ein Aufruf einer Funktion ist Ο (1), daher ergibt die (n) Häufigkeit, mit der ein rekursiver Aufruf erfolgt, die rekursive Funktion Ο (n).
Raumkomplexität
Die Speicherplatzkomplexität wird als die Menge an zusätzlichem Speicherplatz gezählt, die für die Ausführung eines Moduls erforderlich ist. Bei Iterationen benötigt der Compiler kaum zusätzlichen Speicherplatz. Der Compiler aktualisiert ständig die Werte der in den Iterationen verwendeten Variablen. Im Falle einer Rekursion muss das System jedoch bei jedem rekursiven Aufruf einen Aktivierungsdatensatz speichern. Daher wird angenommen, dass die Raumkomplexität der rekursiven Funktion höher sein kann als die einer Funktion mit Iteration.
Der Turm von Hanoi ist ein mathematisches Puzzle, das aus drei Türmen (Heringen) und mehr als einem Ring besteht.

Diese Ringe sind unterschiedlich groß und in aufsteigender Reihenfolge gestapelt, dh der kleinere sitzt über dem größeren. Es gibt andere Varianten des Puzzles, bei denen die Anzahl der Festplatten zunimmt, die Anzahl der Türme jedoch gleich bleibt.
Regeln
Die Mission besteht darin, alle Festplatten in einen anderen Turm zu verschieben, ohne die Reihenfolge der Anordnung zu verletzen. Einige Regeln für den Turm von Hanoi sind:
- Es kann immer nur eine Scheibe zwischen den Türmen bewegt werden.
- Nur die "obere" Festplatte kann entfernt werden.
- Keine große Festplatte kann über einer kleinen Festplatte liegen.
Es folgt eine animierte Darstellung des Lösens eines Tower of Hanoi-Puzzles mit drei Scheiben.

Tower of Hanoi Puzzle mit n Scheiben kann in minimal gelöst werden 2n−1Schritte. Diese Präsentation zeigt, dass ein Puzzle mit 3 Scheiben genommen hat23 - 1 = 7 Schritte.
Algorithmus
Um einen Algorithmus für Tower of Hanoi zu schreiben, müssen wir zunächst lernen, wie dieses Problem mit einer geringeren Anzahl von Festplatten gelöst werden kann, z. B. → 1 oder 2. Wir markieren drei Türme mit dem Namen, source, destination und aux(nur um das Verschieben der Festplatten zu erleichtern). Wenn wir nur eine Festplatte haben, kann diese problemlos vom Quell- zum Zielstift verschoben werden.
Wenn wir 2 Festplatten haben -
- Zuerst verschieben wir die kleinere (obere) Festplatte in den Aux Peg.
- Dann verschieben wir die größere (untere) Festplatte zum Zielstift.
- Und schließlich verschieben wir die kleinere Festplatte vom Aux zum Ziel-Peg.

Jetzt sind wir in der Lage, einen Algorithmus für Tower of Hanoi mit mehr als zwei Festplatten zu entwerfen. Wir teilen den Plattenstapel in zwei Teile. Die größte Festplatte (n- te Festplatte) befindet sich in einem Teil und alle anderen (n-1) Festplatten befinden sich im zweiten Teil.
Unser oberstes Ziel ist es, die Festplatte zu bewegen nvon der Quelle zum Ziel und legen Sie dann alle anderen (n1) Festplatten darauf. Wir können uns vorstellen, dasselbe für alle gegebenen Festplattensätze rekursiv anzuwenden.
Die folgenden Schritte sind:
Step 1 − Move n-1 disks from source to aux
Step 2 − Move nth disk from source to dest
Step 3 − Move n-1 disks from aux to destEin rekursiver Algorithmus für Tower of Hanoi kann wie folgt gesteuert werden:
START
Procedure Hanoi(disk, source, dest, aux)
IF disk == 1, THEN
move disk from source to dest
ELSE
Hanoi(disk - 1, source, aux, dest) // Step 1
move disk from source to dest // Step 2
Hanoi(disk - 1, aux, dest, source) // Step 3
END IF
END Procedure
STOPKlicken Sie hier, um die Implementierung in der C-Programmierung zu überprüfen .
Die Fibonacci-Reihe generiert die nachfolgende Nummer durch Hinzufügen von zwei vorherigen Nummern. Die Fibonacci-Serie beginnt mit zwei Zahlen -F0 & F1. Die Anfangswerte von F 0 und F 1 können 0, 1 oder 1, 1 sein.
Die Fibonacci-Serie erfüllt die folgenden Bedingungen:
Fn = Fn-1 + Fn-2Daher kann eine Fibonacci-Serie so aussehen -
F 8 = 0 1 1 2 3 5 8 13
oder dies -
F 8 = 1 1 2 3 5 8 13 21
Zur Veranschaulichung wird Fibonacci von F 8 als - angezeigt

Iterativer Fibonacci-Algorithmus
Zuerst versuchen wir, den iterativen Algorithmus für die Fibonacci-Reihe zu entwerfen.
Procedure Fibonacci(n)
declare f0, f1, fib, loop
set f0 to 0
set f1 to 1
display f0, f1
for loop ← 1 to n
fib ← f0 + f1
f0 ← f1
f1 ← fib
display fib
end for
end procedureKlicken Sie hier , um mehr über die Implementierung des oben genannten Algorithmus in der Programmiersprache C zu erfahren .
Rekursiver Fibonacci-Algorithmus
Lassen Sie uns lernen, wie man einen rekursiven Algorithmus Fibonacci-Reihen erstellt. Die Grundkriterien der Rekursion.
START
Procedure Fibonacci(n)
declare f0, f1, fib, loop
set f0 to 0
set f1 to 1
display f0, f1
for loop ← 1 to n
fib ← f0 + f1
f0 ← f1
f1 ← fib
display fib
end for
ENDKlicken Sie hier, um die Implementierung des obigen Algorithmus in der Programmiersprache c zu sehen .