Hadoop - Big Data-Lösungen
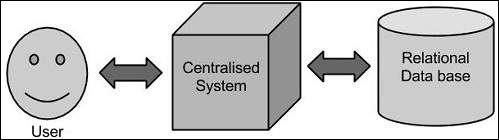
Traditioneller Ansatz
Bei diesem Ansatz verfügt ein Unternehmen über einen Computer zum Speichern und Verarbeiten von Big Data. Zu Speicherzwecken nehmen die Programmierer die Hilfe ihrer Wahl von Datenbankanbietern wie Oracle, IBM usw. in Anspruch. Bei diesem Ansatz interagiert der Benutzer mit der Anwendung, die wiederum den Teil der Datenspeicherung und -analyse übernimmt.
Einschränkung
Dieser Ansatz funktioniert gut mit Anwendungen, die weniger umfangreiche Daten verarbeiten, die von Standard-Datenbankservern aufgenommen werden können, oder bis zur Grenze des Prozessors, der die Daten verarbeitet. Wenn es jedoch um den Umgang mit großen Mengen skalierbarer Daten geht, ist es eine hektische Aufgabe, solche Daten durch einen einzigen Datenbankexpaß zu verarbeiten.
Googles Lösung
Google hat dieses Problem mit einem Algorithmus namens MapReduce gelöst. Dieser Algorithmus unterteilt die Aufgabe in kleine Teile, weist sie vielen Computern zu und sammelt die Ergebnisse daraus, die bei Integration den Ergebnisdatensatz bilden.

Hadoop
Mit der von Google bereitgestellten Lösung Doug Cutting und sein Team entwickelte ein Open Source-Projekt namens HADOOP.
Hadoop führt Anwendungen mit dem MapReduce-Algorithmus aus, bei dem die Daten parallel zu anderen verarbeitet werden. Kurz gesagt, Hadoop wird verwendet, um Anwendungen zu entwickeln, die eine vollständige statistische Analyse großer Datenmengen durchführen können.
