Hadoop - HDFS Übersicht
Das Hadoop-Dateisystem wurde unter Verwendung eines verteilten Dateisystemdesigns entwickelt. Es wird auf Standardhardware ausgeführt. Im Gegensatz zu anderen verteilten Systemen ist HDFS sehr fehlertolerant und wurde mit kostengünstiger Hardware entwickelt.
HDFS enthält sehr große Datenmengen und bietet einen einfacheren Zugriff. Um so große Datenmengen zu speichern, werden die Dateien auf mehreren Computern gespeichert. Diese Dateien werden redundant gespeichert, um das System bei einem Ausfall vor möglichen Datenverlusten zu schützen. HDFS stellt auch Anwendungen für die Parallelverarbeitung zur Verfügung.
Funktionen von HDFS
- Es ist für die verteilte Speicherung und Verarbeitung geeignet.
- Hadoop bietet eine Befehlsschnittstelle für die Interaktion mit HDFS.
- Mit den integrierten Servern von namenode und datanode können Benutzer den Status des Clusters auf einfache Weise überprüfen.
- Streaming-Zugriff auf Dateisystemdaten.
- HDFS bietet Dateiberechtigungen und Authentifizierung.
HDFS-Architektur
Im Folgenden wird die Architektur eines Hadoop-Dateisystems angegeben.
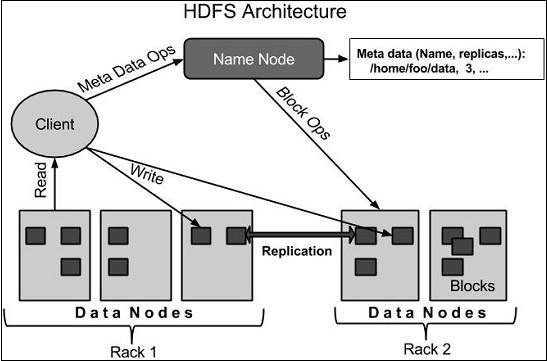
HDFS folgt der Master-Slave-Architektur und weist die folgenden Elemente auf.
Namenode
Der Namensknoten ist die Standardhardware, die das GNU / Linux-Betriebssystem und die Namensknotensoftware enthält. Es ist eine Software, die auf Standardhardware ausgeführt werden kann. Das System mit dem Namensknoten fungiert als Master-Server und führt die folgenden Aufgaben aus:
Verwaltet den Dateisystem-Namespace.
Reguliert den Zugriff des Clients auf Dateien.
Außerdem werden Dateisystemvorgänge wie das Umbenennen, Schließen und Öffnen von Dateien und Verzeichnissen ausgeführt.
Datenknoten
Der Datenknoten ist eine Standardhardware mit dem Betriebssystem GNU / Linux und der Datenknotensoftware. Für jeden Knoten (Commodity-Hardware / System) in einem Cluster gibt es einen Datenknoten. Diese Knoten verwalten die Datenspeicherung ihres Systems.
Datenknoten führen Lese- / Schreibvorgänge auf den Dateisystemen gemäß Clientanforderung aus.
Sie führen auch Vorgänge wie das Erstellen, Löschen und Replizieren von Blöcken gemäß den Anweisungen des Namensknotens aus.
Block
Im Allgemeinen werden die Benutzerdaten in den Dateien von HDFS gespeichert. Die Datei in einem Dateisystem wird in ein oder mehrere Segmente unterteilt und / oder in einzelnen Datenknoten gespeichert. Diese Dateisegmente werden als Blöcke bezeichnet. Mit anderen Worten, die minimale Datenmenge, die HDFS lesen oder schreiben kann, wird als Block bezeichnet. Die Standardblockgröße beträgt 64 MB, kann jedoch je nach Notwendigkeit einer Änderung der HDFS-Konfiguration erhöht werden.
Ziele von HDFS
Fault detection and recovery- Da HDFS eine große Anzahl von Standardhardware enthält, kommt es häufig zu einem Ausfall von Komponenten. Daher sollte HDFS über Mechanismen zur schnellen und automatischen Fehlererkennung und -behebung verfügen.
Huge datasets - HDFS sollte Hunderte von Knoten pro Cluster haben, um die Anwendungen mit großen Datenmengen zu verwalten.
Hardware at data- Eine angeforderte Aufgabe kann effizient ausgeführt werden, wenn die Berechnung in der Nähe der Daten erfolgt. Insbesondere bei großen Datenmengen wird der Netzwerkverkehr reduziert und der Durchsatz erhöht.