Hadoop - Kurzanleitung
"90% der weltweiten Daten wurden in den letzten Jahren generiert."
Aufgrund des Aufkommens neuer Technologien, Geräte und Kommunikationsmittel wie Social-Networking-Sites wächst die von der Menschheit produzierte Datenmenge jedes Jahr rasant. Die von uns von Anfang an bis 2003 erzeugte Datenmenge betrug 5 Milliarden Gigabyte. Wenn Sie die Daten in Form von Datenträgern stapeln, kann dies ein ganzes Fußballfeld füllen. Der gleiche Betrag wurde alle zwei Tage in erstellt2011und alle zehn Minuten in 2013. Diese Rate wächst immer noch enorm. Obwohl all diese Informationen aussagekräftig sind und bei der Verarbeitung nützlich sein können, werden sie vernachlässigt.
Was ist Big Data?
Big dataist eine Sammlung großer Datensätze, die mit herkömmlichen Computertechniken nicht verarbeitet werden können. Es ist keine einzelne Technik oder ein Werkzeug, sondern es ist zu einem vollständigen Thema geworden, das verschiedene Werkzeuge, Techniken und Rahmenbedingungen umfasst.
Was kommt unter Big Data?
Bei Big Data handelt es sich um Daten, die von verschiedenen Geräten und Anwendungen erzeugt werden. Im Folgenden sind einige der Felder aufgeführt, die unter dem Dach von Big Data zusammengefasst sind.
Black Box Data - Es ist eine Komponente von Hubschraubern, Flugzeugen und Jets usw. Es erfasst Stimmen der Flugbesatzung, Aufzeichnungen von Mikrofonen und Kopfhörern sowie die Leistungsinformationen des Flugzeugs.
Social Media Data - Soziale Medien wie Facebook und Twitter enthalten Informationen und Ansichten von Millionen von Menschen auf der ganzen Welt.
Stock Exchange Data - Die Börsendaten enthalten Informationen zu Kauf- und Verkaufsentscheidungen, die von den Kunden für einen Anteil verschiedener Unternehmen getroffen wurden.
Power Grid Data - Die Stromnetzdaten enthalten Informationen, die von einem bestimmten Knoten in Bezug auf eine Basisstation verbraucht werden.
Transport Data - Die Transportdaten umfassen Modell, Kapazität, Entfernung und Verfügbarkeit eines Fahrzeugs.
Search Engine Data - Suchmaschinen rufen viele Daten aus verschiedenen Datenbanken ab.

Somit umfasst Big Data ein großes Volumen, eine hohe Geschwindigkeit und eine erweiterbare Datenvielfalt. Es gibt drei Arten von Daten.
Structured data - Relationale Daten.
Semi Structured data - XML-Daten.
Unstructured data - Word-, PDF-, Text- und Medienprotokolle.
Vorteile von Big Data
Mithilfe der Informationen, die im sozialen Netzwerk wie Facebook gespeichert sind, erfahren die Marketingagenturen Informationen über die Reaktion auf ihre Kampagnen, Werbeaktionen und andere Werbemittel.
Mithilfe der Informationen in den sozialen Medien wie Präferenzen und Produktwahrnehmung ihrer Verbraucher planen Produktunternehmen und Einzelhandelsorganisationen ihre Produktion.
Mit den Daten zur Krankengeschichte der Patienten bieten Krankenhäuser einen besseren und schnelleren Service.
Big Data-Technologien
Big-Data-Technologien sind wichtig für eine genauere Analyse. Dies kann zu konkreteren Entscheidungen führen, die zu einer höheren betrieblichen Effizienz, Kostensenkungen und geringeren Risiken für das Unternehmen führen.
Um die Leistungsfähigkeit von Big Data nutzen zu können, benötigen Sie eine Infrastruktur, die große Mengen strukturierter und unstrukturierter Daten in Echtzeit verwalten und verarbeiten sowie Datenschutz und Sicherheit schützen kann.
Es gibt verschiedene Technologien auf dem Markt von verschiedenen Anbietern, darunter Amazon, IBM, Microsoft usw., um Big Data zu verarbeiten. Bei der Untersuchung der Technologien, die mit Big Data umgehen, untersuchen wir die folgenden zwei Technologieklassen:
Operative Big Data
Dazu gehören Systeme wie MongoDB, die Betriebsfunktionen für interaktive Echtzeit-Workloads bereitstellen, bei denen Daten hauptsächlich erfasst und gespeichert werden.
NoSQL Big Data-Systeme wurden entwickelt, um die Vorteile neuer Cloud-Computing-Architekturen zu nutzen, die im letzten Jahrzehnt entstanden sind, damit massive Berechnungen kostengünstig und effizient ausgeführt werden können. Dies macht betriebliche Big-Data-Workloads viel einfacher zu verwalten, billiger und schneller zu implementieren.
Einige NoSQL-Systeme bieten Einblicke in Muster und Trends basierend auf Echtzeitdaten mit minimaler Codierung und ohne die Notwendigkeit von Datenwissenschaftlern und zusätzlicher Infrastruktur.
Analytische Big Data
Dazu gehören Systeme wie MPP-Datenbanksysteme (Massively Parallel Processing) und MapReduce, die Analysefunktionen für die retrospektive und komplexe Analyse bieten, die die meisten oder alle Daten berühren können.
MapReduce bietet eine neue Methode zur Analyse von Daten, die die von SQL bereitgestellten Funktionen ergänzt, und ein auf MapReduce basierendes System, das von einzelnen Servern auf Tausende von High- und Low-End-Computern skaliert werden kann.
Diese beiden Technologieklassen ergänzen sich und werden häufig zusammen eingesetzt.
Operative vs. analytische Systeme
| Betriebsbereit | Analytisch | |
|---|---|---|
| Latenz | 1 ms - 100 ms | 1 min - 100 min |
| Parallelität | 1000 - 100.000 | 1 - 10 |
| Zugriffsmuster | Schreibt und liest | Liest |
| Abfragen | Selektiv | Nicht selektiv |
| Datenumfang | Betriebsbereit | Rückblick |
| Endbenutzer | Kunde | Datenwissenschaftler |
| Technologie | NoSQL | MapReduce, MPP-Datenbank |
Big Data-Herausforderungen
Die größten Herausforderungen im Zusammenhang mit Big Data sind:
- Daten erfassen
- Curation
- Storage
- Searching
- Sharing
- Transfer
- Analysis
- Presentation
Um die oben genannten Herausforderungen zu bewältigen, verwenden Unternehmen normalerweise die Hilfe von Unternehmensservern.
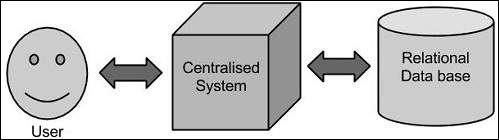
Traditioneller Ansatz
Bei diesem Ansatz verfügt ein Unternehmen über einen Computer zum Speichern und Verarbeiten von Big Data. Zu Speicherzwecken nehmen die Programmierer die Hilfe ihrer Wahl von Datenbankanbietern wie Oracle, IBM usw. in Anspruch. Bei diesem Ansatz interagiert der Benutzer mit der Anwendung, die wiederum den Teil der Datenspeicherung und -analyse übernimmt.
Einschränkung
Dieser Ansatz funktioniert gut mit Anwendungen, die weniger umfangreiche Daten verarbeiten, die von Standarddatenbankservern aufgenommen werden können, oder bis zur Grenze des Prozessors, der die Daten verarbeitet. Wenn es jedoch um den Umgang mit großen Mengen skalierbarer Daten geht, ist es eine hektische Aufgabe, solche Daten durch einen einzigen Datenbankexpaß zu verarbeiten.
Googles Lösung
Google hat dieses Problem mit einem Algorithmus namens MapReduce gelöst. Dieser Algorithmus unterteilt die Aufgabe in kleine Teile, weist sie vielen Computern zu und sammelt die Ergebnisse daraus, die bei Integration den Ergebnisdatensatz bilden.

Hadoop
Mit der von Google bereitgestellten Lösung Doug Cutting und sein Team entwickelte ein Open Source-Projekt namens HADOOP.
Hadoop führt Anwendungen mit dem MapReduce-Algorithmus aus, bei dem die Daten parallel zu anderen verarbeitet werden. Kurz gesagt, Hadoop wird verwendet, um Anwendungen zu entwickeln, die eine vollständige statistische Analyse großer Datenmengen durchführen können.

Hadoop ist ein in Java geschriebenes Open Source-Framework von Apache, das die verteilte Verarbeitung großer Datenmengen über Computercluster mithilfe einfacher Programmiermodelle ermöglicht. Die Hadoop-Framework-Anwendung arbeitet in einer Umgebung, die verteilten Speicher und Berechnungen über mehrere Computercluster hinweg bereitstellt . Hadoop wurde entwickelt, um von einem einzelnen Server auf Tausende von Computern zu skalieren, von denen jeder lokale Berechnungen und Speicher bietet.
Hadoop-Architektur
Im Kern hat Hadoop zwei Hauptschichten, nämlich -
- Verarbeitungs- / Berechnungsschicht (MapReduce) und
- Speicherebene (Hadoop Distributed File System).

Karte verkleinern
MapReduce ist ein paralleles Programmiermodell zum Schreiben verteilter Anwendungen, die bei Google entwickelt wurden, um große Datenmengen (Multi-Terabyte-Datensätze) auf großen Clustern (Tausenden von Knoten) von Standardhardware zuverlässig und fehlertolerant zu verarbeiten. Das MapReduce-Programm läuft auf Hadoop, einem Open-Source-Framework von Apache.
Hadoop Distributed File System
Das verteilte Hadoop-Dateisystem (HDFS) basiert auf dem Google-Dateisystem (GFS) und bietet ein verteiltes Dateisystem, das für die Ausführung auf Standardhardware ausgelegt ist. Es hat viele Ähnlichkeiten mit vorhandenen verteilten Dateisystemen. Die Unterschiede zu anderen verteilten Dateisystemen sind jedoch erheblich. Es ist sehr fehlertolerant und für den Einsatz auf kostengünstiger Hardware ausgelegt. Es bietet Zugriff auf Anwendungsdaten mit hohem Durchsatz und eignet sich für Anwendungen mit großen Datenmengen.
Neben den beiden oben genannten Kernkomponenten enthält das Hadoop-Framework auch die folgenden zwei Module:
Hadoop Common - Dies sind Java-Bibliotheken und Dienstprogramme, die von anderen Hadoop-Modulen benötigt werden.
Hadoop YARN - Dies ist ein Framework für die Jobplanung und die Verwaltung von Clusterressourcen.
Wie funktioniert Hadoop?
Es ist ziemlich teuer, größere Server mit umfangreichen Konfigurationen zu erstellen, die eine Verarbeitung in großem Maßstab ermöglichen. Alternativ können Sie jedoch viele Standardcomputer mit einer einzelnen CPU als ein einziges funktionales verteiltes System zusammenbinden, und praktisch können die Cluster-Computer den Datensatz lesen parallel und bieten einen viel höheren Durchsatz. Darüber hinaus ist es billiger als ein High-End-Server. Dies ist also der erste Motivationsfaktor für die Verwendung von Hadoop, der auf Cluster- und kostengünstigen Computern ausgeführt wird.
Hadoop führt Code auf einem Cluster von Computern aus. Dieser Prozess umfasst die folgenden Kernaufgaben, die Hadoop ausführt:
Die Daten werden zunächst in Verzeichnisse und Dateien unterteilt. Dateien werden in Blöcke mit einheitlicher Größe von 128 MB und 64 MB (vorzugsweise 128 MB) unterteilt.
Diese Dateien werden dann zur weiteren Verarbeitung auf verschiedene Clusterknoten verteilt.
HDFS befindet sich über dem lokalen Dateisystem und überwacht die Verarbeitung.
Blöcke werden zur Behandlung von Hardwarefehlern repliziert.
Überprüfen, ob der Code erfolgreich ausgeführt wurde.
Durchführen der Sortierung zwischen der Karte und Reduzieren von Stufen.
Senden der sortierten Daten an einen bestimmten Computer.
Schreiben der Debugging-Protokolle für jeden Job.
Vorteile von Hadoop
Mit dem Hadoop-Framework kann der Benutzer verteilte Systeme schnell schreiben und testen. Es ist effizient und verteilt automatisch die Daten und die Arbeit auf die Maschinen und nutzt wiederum die zugrunde liegende Parallelität der CPU-Kerne.
Hadoop ist nicht auf Hardware angewiesen, um Fehlertoleranz und Hochverfügbarkeit (FTHA) bereitzustellen. Die Hadoop-Bibliothek selbst wurde entwickelt, um Fehler auf der Anwendungsebene zu erkennen und zu behandeln.
Server können dynamisch zum Cluster hinzugefügt oder daraus entfernt werden, und Hadoop arbeitet ohne Unterbrechung weiter.
Ein weiterer großer Vorteil von Hadoop ist, dass es nicht nur Open Source ist, sondern auch auf allen Plattformen kompatibel ist, da es auf Java basiert.
Hadoop wird von der GNU / Linux-Plattform und ihren Varianten unterstützt. Daher müssen wir ein Linux-Betriebssystem installieren, um die Hadoop-Umgebung einzurichten. Wenn Sie ein anderes Betriebssystem als Linux haben, können Sie eine Virtualbox-Software darin installieren und Linux in der Virtualbox haben.
Setup vor der Installation
Bevor wir Hadoop in der Linux-Umgebung installieren, müssen wir Linux mit einrichten ssh(Sichere Shell). Führen Sie die folgenden Schritte aus, um die Linux-Umgebung einzurichten.
Benutzer erstellen
Zu Beginn wird empfohlen, einen separaten Benutzer für Hadoop zu erstellen, um das Hadoop-Dateisystem vom Unix-Dateisystem zu isolieren. Führen Sie die folgenden Schritte aus, um einen Benutzer zu erstellen.
Öffnen Sie den Stamm mit dem Befehl "su".
Erstellen Sie einen Benutzer aus dem Root-Konto mit dem Befehl "useradd username".
Jetzt können Sie mit dem Befehl "su username" ein bestehendes Benutzerkonto eröffnen.
Öffnen Sie das Linux-Terminal und geben Sie die folgenden Befehle ein, um einen Benutzer zu erstellen.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdSSH-Setup und Schlüsselgenerierung
Das SSH-Setup ist erforderlich, um verschiedene Vorgänge in einem Cluster auszuführen, z. B. Starten, Stoppen und verteilte Daemon-Shell-Vorgänge. Um verschiedene Benutzer von Hadoop zu authentifizieren, muss ein öffentliches / privates Schlüsselpaar für einen Hadoop-Benutzer bereitgestellt und für verschiedene Benutzer freigegeben werden.
Die folgenden Befehle werden zum Generieren eines Schlüsselwertpaars mit SSH verwendet. Kopieren Sie die öffentlichen Schlüssel aus id_rsa.pub in autorisierte Schlüssel und geben Sie dem Eigentümer Lese- und Schreibberechtigungen für die Datei "autorisierte Schlüssel".
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keysJava installieren
Java ist die Hauptvoraussetzung für Hadoop. Zunächst sollten Sie die Existenz von Java in Ihrem System mit dem Befehl "java -version" überprüfen. Die Syntax des Java-Versionsbefehls ist unten angegeben.
$ java -versionWenn alles in Ordnung ist, erhalten Sie die folgende Ausgabe.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Wenn Java nicht auf Ihrem System installiert ist, führen Sie die folgenden Schritte aus, um Java zu installieren.
Schritt 1
Laden Sie Java (JDK <neueste Version> - X64.tar.gz) herunter, indem Sie den folgenden Link besuchen: www.oracle.com
Dann jdk-7u71-linux-x64.tar.gz wird in Ihr System heruntergeladen.
Schritt 2
Im Allgemeinen finden Sie die heruntergeladene Java-Datei im Ordner Downloads. Überprüfen Sie es und extrahieren Sie diejdk-7u71-linux-x64.gz Datei mit den folgenden Befehlen.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzSchritt 3
Um Java allen Benutzern zur Verfügung zu stellen, müssen Sie es an den Speicherort „/ usr / local /“ verschieben. Öffnen Sie root und geben Sie die folgenden Befehle ein.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitSchritt 4
Zum Einrichten PATH und JAVA_HOME Variablen, fügen Sie die folgenden Befehle hinzu ~/.bashrc Datei.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=$PATH:$JAVA_HOME/binÜbernehmen Sie nun alle Änderungen in das aktuell laufende System.
$ source ~/.bashrcSchritt 5
Verwenden Sie die folgenden Befehle, um Java-Alternativen zu konfigurieren:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarÜberprüfen Sie nun den Befehl java -version vom Terminal aus, wie oben erläutert.
Hadoop herunterladen
Laden Sie Hadoop 2.4.1 mit den folgenden Befehlen von Apache Software Foundation herunter und extrahieren Sie es.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitHadoop-Betriebsmodi
Nachdem Sie Hadoop heruntergeladen haben, können Sie Ihren Hadoop-Cluster in einem der drei unterstützten Modi betreiben:
Local/Standalone Mode - Nach dem Herunterladen von Hadoop auf Ihr System wird es standardmäßig in einem eigenständigen Modus konfiguriert und kann als einzelner Java-Prozess ausgeführt werden.
Pseudo Distributed Mode- Es handelt sich um eine verteilte Simulation auf einer einzelnen Maschine. Jeder Hadoop-Daemon wie HDFS, Garn, MapReduce usw. wird als separater Java-Prozess ausgeführt. Dieser Modus ist nützlich für die Entwicklung.
Fully Distributed Mode- Dieser Modus ist vollständig verteilt, wobei mindestens zwei oder mehr Computer als Cluster vorhanden sind. Wir werden in den kommenden Kapiteln ausführlich auf diesen Modus eingehen.
Hadoop im Standalone-Modus installieren
Hier werden wir die Installation von diskutieren Hadoop 2.4.1 im Standalone-Modus.
Es werden keine Daemons ausgeführt und alles wird in einer einzigen JVM ausgeführt. Der Standalone-Modus eignet sich zum Ausführen von MapReduce-Programmen während der Entwicklung, da sie einfach getestet und debuggt werden können.
Hadoop einrichten
Sie können Hadoop-Umgebungsvariablen festlegen, indem Sie die folgenden Befehle an anhängen ~/.bashrc Datei.
export HADOOP_HOME=/usr/local/hadoopBevor Sie fortfahren, müssen Sie sicherstellen, dass Hadoop einwandfrei funktioniert. Geben Sie einfach den folgenden Befehl ein:
$ hadoop versionWenn mit Ihrem Setup alles in Ordnung ist, sollten Sie das folgende Ergebnis sehen:
Hadoop 2.4.1
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Dies bedeutet, dass das Standalone-Modus-Setup Ihres Hadoop einwandfrei funktioniert. Standardmäßig ist Hadoop so konfiguriert, dass es in einem nicht verteilten Modus auf einem einzelnen Computer ausgeführt wird.
Beispiel
Schauen wir uns ein einfaches Beispiel für Hadoop an. Die Hadoop-Installation liefert das folgende Beispiel für eine MapReduce-JAR-Datei, die grundlegende Funktionen von MapReduce bietet und zur Berechnung des Pi-Werts, der Wortanzahl in einer bestimmten Liste von Dateien usw. verwendet werden kann.
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarLassen Sie uns ein Eingabeverzeichnis haben, in dem wir einige Dateien pushen. Unsere Anforderung besteht darin, die Gesamtzahl der Wörter in diesen Dateien zu zählen. Um die Gesamtzahl der Wörter zu berechnen, müssen wir unser MapReduce nicht schreiben, vorausgesetzt, die .jar-Datei enthält die Implementierung für die Wortanzahl. Sie können andere Beispiele mit derselben JAR-Datei ausprobieren. Geben Sie einfach die folgenden Befehle ein, um die unterstützten MapReduce-Funktionsprogramme anhand der Datei hadoop-mapreduce-examples-2.2.0.jar zu überprüfen.
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jarSchritt 1
Erstellen Sie temporäre Inhaltsdateien im Eingabeverzeichnis. Sie können dieses Eingabeverzeichnis überall dort erstellen, wo Sie arbeiten möchten.
$ mkdir input $ cp $HADOOP_HOME/*.txt input $ ls -l inputEs werden die folgenden Dateien in Ihrem Eingabeverzeichnis angezeigt -
total 24
-rw-r--r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt
-rw-r--r-- 1 root root 101 Feb 21 10:14 NOTICE.txt
-rw-r--r-- 1 root root 1366 Feb 21 10:14 README.txtDiese Dateien wurden aus dem Ausgangsverzeichnis der Hadoop-Installation kopiert. Für Ihr Experiment können Sie verschiedene und große Sätze von Dateien haben.
Schritt 2
Starten wir den Hadoop-Prozess, um die Gesamtzahl der Wörter in allen im Eingabeverzeichnis verfügbaren Dateien wie folgt zu zählen:
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar wordcount input outputSchritt 3
Schritt 2 führt die erforderliche Verarbeitung durch und speichert die Ausgabe in der Datei output / part-r00000, die Sie mit - überprüfen können.
$cat output/*Es werden alle Wörter zusammen mit ihrer Gesamtzahl aufgelistet, die in allen im Eingabeverzeichnis verfügbaren Dateien verfügbar sind.
"AS 4
"Contribution" 1
"Contributor" 1
"Derivative 1
"Legal 1
"License" 1
"License"); 1
"Licensor" 1
"NOTICE” 1
"Not 1
"Object" 1
"Source” 1
"Work” 1
"You" 1
"Your") 1
"[]" 1
"control" 1
"printed 1
"submitted" 1
(50%) 1
(BIS), 1
(C) 1
(Don't) 1
(ECCN) 1
(INCLUDING 2
(INCLUDING, 2
.............Installieren von Hadoop im Pseudo Distributed Mode
Führen Sie die folgenden Schritte aus, um Hadoop 2.4.1 im pseudoverteilten Modus zu installieren.
Schritt 1 - Einrichten von Hadoop
Sie können Hadoop-Umgebungsvariablen festlegen, indem Sie die folgenden Befehle an anhängen ~/.bashrc Datei.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOMEÜbernehmen Sie nun alle Änderungen in das aktuell laufende System.
$ source ~/.bashrcSchritt 2 - Hadoop-Konfiguration
Sie finden alle Hadoop-Konfigurationsdateien unter dem Speicherort "$ HADOOP_HOME / etc / hadoop". Es ist erforderlich, Änderungen an diesen Konfigurationsdateien entsprechend Ihrer Hadoop-Infrastruktur vorzunehmen.
$ cd $HADOOP_HOME/etc/hadoopUm Hadoop-Programme in Java zu entwickeln, müssen Sie die Java-Umgebungsvariablen in zurücksetzen hadoop-env.sh Datei durch Ersetzen JAVA_HOME Wert mit dem Speicherort von Java in Ihrem System.
export JAVA_HOME=/usr/local/jdk1.7.0_71Im Folgenden finden Sie eine Liste der Dateien, die Sie bearbeiten müssen, um Hadoop zu konfigurieren.
core-site.xml
Das core-site.xml Die Datei enthält Informationen wie die für die Hadoop-Instanz verwendete Portnummer, den für das Dateisystem zugewiesenen Speicher, das Speicherlimit zum Speichern der Daten und die Größe der Lese- / Schreibpuffer.
Öffnen Sie die Datei core-site.xml und fügen Sie die folgenden Eigenschaften zwischen den Tags <configuration>, </ configuration> hinzu.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
Das hdfs-site.xmlDie Datei enthält Informationen wie den Wert der Replikationsdaten, den Namensknotenpfad und den Datenknotenpfad Ihrer lokalen Dateisysteme. Dies ist der Ort, an dem Sie die Hadoop-Infrastruktur speichern möchten.
Nehmen wir die folgenden Daten an.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeÖffnen Sie diese Datei und fügen Sie die folgenden Eigenschaften zwischen den Tags <configuration> </ configuration> in dieser Datei hinzu.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>Note - In der obigen Datei sind alle Eigenschaftswerte benutzerdefiniert und Sie können Änderungen entsprechend Ihrer Hadoop-Infrastruktur vornehmen.
yarn-site.xml
Diese Datei wird verwendet, um Garn in Hadoop zu konfigurieren. Öffnen Sie die Datei yarn-site.xml und fügen Sie die folgenden Eigenschaften zwischen den Tags <configuration>, </ configuration> in dieser Datei hinzu.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Diese Datei wird verwendet, um anzugeben, welches MapReduce-Framework wir verwenden. Standardmäßig enthält Hadoop eine Vorlage von yarn-site.xml. Zunächst muss die Datei von kopiert werdenmapred-site.xml.template zu mapred-site.xml Datei mit dem folgenden Befehl.
$ cp mapred-site.xml.template mapred-site.xmlÖffnen mapred-site.xml Datei und fügen Sie die folgenden Eigenschaften zwischen den Tags <configuration>, </ configuration> in dieser Datei hinzu.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Überprüfen der Hadoop-Installation
Die folgenden Schritte werden verwendet, um die Hadoop-Installation zu überprüfen.
Schritt 1 - Einrichtung des Namensknotens
Richten Sie den Namensknoten mit dem Befehl "hdfs namenode -format" wie folgt ein.
$ cd ~
$ hdfs namenode -formatDas erwartete Ergebnis ist wie folgt.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Schritt 2 - Überprüfen von Hadoop dfs
Der folgende Befehl wird verwendet, um dfs zu starten. Durch Ausführen dieses Befehls wird Ihr Hadoop-Dateisystem gestartet.
$ start-dfs.shDie erwartete Ausgabe ist wie folgt:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Schritt 3 - Überprüfen des Garnskripts
Der folgende Befehl wird verwendet, um das Garnskript zu starten. Wenn Sie diesen Befehl ausführen, werden Ihre Garn-Dämonen gestartet.
$ start-yarn.shDie erwartete Ausgabe wie folgt -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outSchritt 4 - Zugriff auf Hadoop über den Browser
Die Standardportnummer für den Zugriff auf Hadoop ist 50070. Verwenden Sie die folgende URL, um Hadoop-Dienste im Browser abzurufen.
http://localhost:50070/
Schritt 5 - Überprüfen Sie alle Anwendungen für Cluster
Die Standardportnummer für den Zugriff auf alle Clusteranwendungen lautet 8088. Verwenden Sie die folgende URL, um diesen Dienst aufzurufen.
http://localhost:8088/
Das Hadoop-Dateisystem wurde unter Verwendung eines verteilten Dateisystemdesigns entwickelt. Es wird auf Standardhardware ausgeführt. Im Gegensatz zu anderen verteilten Systemen ist HDFS sehr fehlertolerant und wurde mit kostengünstiger Hardware entwickelt.
HDFS enthält sehr große Datenmengen und bietet einen einfacheren Zugriff. Um so große Datenmengen zu speichern, werden die Dateien auf mehreren Computern gespeichert. Diese Dateien werden redundant gespeichert, um das System im Falle eines Fehlers vor möglichen Datenverlusten zu schützen. HDFS stellt auch Anwendungen für die Parallelverarbeitung zur Verfügung.
Funktionen von HDFS
- Es ist für die verteilte Speicherung und Verarbeitung geeignet.
- Hadoop bietet eine Befehlsschnittstelle für die Interaktion mit HDFS.
- Mit den integrierten Servern von namenode und datanode können Benutzer den Status des Clusters auf einfache Weise überprüfen.
- Streaming-Zugriff auf Dateisystemdaten.
- HDFS bietet Dateiberechtigungen und Authentifizierung.
HDFS-Architektur
Im Folgenden wird die Architektur eines Hadoop-Dateisystems angegeben.
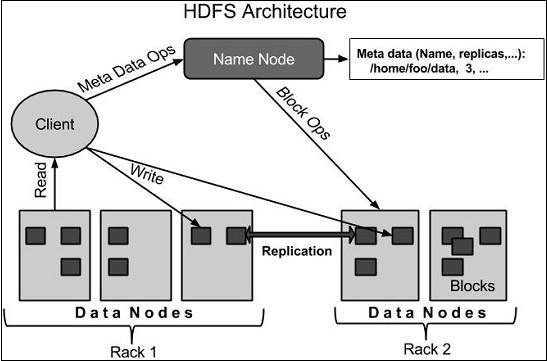
HDFS folgt der Master-Slave-Architektur und weist die folgenden Elemente auf.
Namenode
Der Namensknoten ist die Standardhardware, die das GNU / Linux-Betriebssystem und die Namensknotensoftware enthält. Es ist eine Software, die auf Standardhardware ausgeführt werden kann. Das System mit dem Namensknoten fungiert als Master-Server und führt die folgenden Aufgaben aus:
Verwaltet den Dateisystem-Namespace.
Reguliert den Zugriff des Clients auf Dateien.
Außerdem werden Dateisystemvorgänge wie das Umbenennen, Schließen und Öffnen von Dateien und Verzeichnissen ausgeführt.
Datenknoten
Der Datenknoten ist eine Standardhardware mit dem Betriebssystem GNU / Linux und der Datenknotensoftware. Für jeden Knoten (Commodity-Hardware / System) in einem Cluster gibt es einen Datenknoten. Diese Knoten verwalten die Datenspeicherung ihres Systems.
Datenknoten führen Lese- / Schreibvorgänge auf den Dateisystemen gemäß Clientanforderung aus.
Sie führen auch Vorgänge wie das Erstellen, Löschen und Replizieren von Blöcken gemäß den Anweisungen des Namensknotens aus.
Block
Im Allgemeinen werden die Benutzerdaten in den Dateien von HDFS gespeichert. Die Datei in einem Dateisystem wird in ein oder mehrere Segmente unterteilt und / oder in einzelnen Datenknoten gespeichert. Diese Dateisegmente werden als Blöcke bezeichnet. Mit anderen Worten, die minimale Datenmenge, die HDFS lesen oder schreiben kann, wird als Block bezeichnet. Die Standardblockgröße beträgt 64 MB, kann jedoch je nach Notwendigkeit einer Änderung der HDFS-Konfiguration erhöht werden.
Ziele von HDFS
Fault detection and recovery- Da HDFS eine große Anzahl von Standardhardware enthält, kommt es häufig zu einem Ausfall von Komponenten. Daher sollte HDFS über Mechanismen zur schnellen und automatischen Fehlererkennung und -behebung verfügen.
Huge datasets - HDFS sollte Hunderte von Knoten pro Cluster haben, um die Anwendungen mit großen Datenmengen zu verwalten.
Hardware at data- Eine angeforderte Aufgabe kann effizient ausgeführt werden, wenn die Berechnung in der Nähe der Daten erfolgt. Insbesondere bei großen Datenmengen wird der Netzwerkverkehr reduziert und der Durchsatz erhöht.
Starten von HDFS
Zunächst müssen Sie das konfigurierte HDFS-Dateisystem formatieren, den Namensknoten (HDFS-Server) öffnen und den folgenden Befehl ausführen.
$ hadoop namenode -formatStarten Sie nach dem Formatieren des HDFS das verteilte Dateisystem. Der folgende Befehl startet den Namensknoten sowie die Datenknoten als Cluster.
$ start-dfs.shAuflisten von Dateien in HDFS
Nach dem Laden der Informationen auf den Server können wir die Liste der Dateien in einem Verzeichnis, den Status einer Datei, mithilfe von finden ‘ls’. Unten ist die Syntax von angegebenls dass Sie als Argument an ein Verzeichnis oder einen Dateinamen übergeben können.
$ $HADOOP_HOME/bin/hadoop fs -ls <args>Einfügen von Daten in HDFS
Angenommen, wir haben Daten in der Datei file.txt im lokalen System, die im hdfs-Dateisystem gespeichert werden sollen. Führen Sie die folgenden Schritte aus, um die erforderliche Datei in das Hadoop-Dateisystem einzufügen.
Schritt 1
Sie müssen ein Eingabeverzeichnis erstellen.
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/inputSchritt 2
Übertragen und speichern Sie eine Datendatei mit dem Befehl put von lokalen Systemen in das Hadoop-Dateisystem.
$ $HADOOP_HOME/bin/hadoop fs -put /home/file.txt /user/inputSchritt 3
Sie können die Datei mit dem Befehl ls überprüfen.
$ $HADOOP_HOME/bin/hadoop fs -ls /user/inputDaten aus HDFS abrufen
Angenommen, wir haben eine Datei in HDFS mit dem Namen outfile. Im Folgenden finden Sie eine einfache Demonstration zum Abrufen der erforderlichen Datei aus dem Hadoop-Dateisystem.
Schritt 1
Zeigen Sie zunächst die Daten von HDFS mit an cat Befehl.
$ $HADOOP_HOME/bin/hadoop fs -cat /user/output/outfileSchritt 2
Holen Sie sich die Datei von HDFS in das lokale Dateisystem mit get Befehl.
$ $HADOOP_HOME/bin/hadoop fs -get /user/output/ /home/hadoop_tp/HDFS herunterfahren
Sie können das HDFS mit dem folgenden Befehl herunterfahren.
$ stop-dfs.shEs gibt viel mehr Befehle in "$HADOOP_HOME/bin/hadoop fs"als hier gezeigt, obwohl diese grundlegenden Operationen Ihnen den Einstieg erleichtern. Wenn Sie ./bin/hadoop dfs ohne zusätzliche Argumente ausführen, werden alle Befehle aufgelistet, die mit dem FsShell-System ausgeführt werden können. Außerdem,$HADOOP_HOME/bin/hadoop fs -help commandName zeigt eine kurze Verwendungsübersicht für den betreffenden Vorgang an, wenn Sie nicht weiterkommen.
Eine Tabelle aller Operationen ist unten gezeigt. Die folgenden Konventionen werden für Parameter verwendet -
"<path>" means any file or directory name.
"<path>..." means one or more file or directory names.
"<file>" means any filename.
"<src>" and "<dest>" are path names in a directed operation.
"<localSrc>" and "<localDest>" are paths as above, but on the local file system.Alle anderen Dateien und Pfadnamen beziehen sich auf die Objekte in HDFS.
| Sr.Nr. | Befehl & Beschreibung |
|---|---|
| 1 | -ls <path> Listet den Inhalt des durch den Pfad angegebenen Verzeichnisses auf und zeigt die Namen, Berechtigungen, Eigentümer, Größe und Änderungsdatum für jeden Eintrag an. |
| 2 | -lsr <path> Verhält sich wie -ls, zeigt jedoch rekursiv Einträge in allen Unterverzeichnissen des Pfads an. |
| 3 | -du <path> Zeigt die Festplattennutzung in Byte für alle Dateien an, die dem Pfad entsprechen. Dateinamen werden mit dem vollständigen HDFS-Protokollpräfix gemeldet. |
| 4 | -dus <path> Wie -du, gibt jedoch eine Zusammenfassung der Festplattennutzung aller Dateien / Verzeichnisse im Pfad aus. |
| 5 | -mv <src><dest> Verschiebt die von src angegebene Datei oder das Verzeichnis innerhalb von HDFS nach dest. |
| 6 | -cp <src> <dest> Kopiert die von src angegebene Datei oder das Verzeichnis in dest nach dest in HDFS. |
| 7 | -rm <path> Entfernt die durch den Pfad angegebene Datei oder das leere Verzeichnis. |
| 8 | -rmr <path> Entfernt die durch den Pfad angegebene Datei oder das Verzeichnis. Löscht rekursiv alle untergeordneten Einträge (dh Dateien oder Unterverzeichnisse des Pfads). |
| 9 | -put <localSrc> <dest> Kopiert die Datei oder das Verzeichnis aus dem von localSrc identifizierten lokalen Dateisystem in das Ziel innerhalb der DFS. |
| 10 | -copyFromLocal <localSrc> <dest> Identisch mit -put |
| 11 | -moveFromLocal <localSrc> <dest> Kopiert die Datei oder das Verzeichnis aus dem von localSrc identifizierten lokalen Dateisystem in dest in HDFS und löscht die lokale Kopie bei Erfolg. |
| 12 | -get [-crc] <src> <localDest> Kopiert die von src identifizierte Datei oder das Verzeichnis in HDFS in den von localDest angegebenen lokalen Dateisystempfad. |
| 13 | -getmerge <src> <localDest> Ruft alle Dateien ab, die dem Pfad src in HDFS entsprechen, und kopiert sie in eine einzelne zusammengeführte Datei im lokalen Dateisystem, das von localDest identifiziert wird. |
| 14 | -cat <filen-ame> Zeigt den Inhalt des Dateinamens auf stdout an. |
| 15 | -copyToLocal <src> <localDest> Identisch zu -get |
| 16 | -moveToLocal <src> <localDest> Funktioniert wie -get, löscht jedoch die HDFS-Kopie bei Erfolg. |
| 17 | -mkdir <path> Erstellt ein Verzeichnis mit dem Namen path in HDFS. Erstellt alle übergeordneten Verzeichnisse im Pfad, die fehlen (z. B. mkdir -p unter Linux). |
| 18 | -setrep [-R] [-w] rep <path> Legt den Zielreplikationsfaktor für Dateien fest, die durch den Pfad zu rep identifiziert werden. (Der tatsächliche Replikationsfaktor bewegt sich mit der Zeit auf das Ziel zu.) |
| 19 | -touchz <path> Erstellt eine Datei im Pfad, die die aktuelle Zeit als Zeitstempel enthält. Schlägt fehl, wenn eine Datei bereits im Pfad vorhanden ist, es sei denn, die Datei hat bereits die Größe 0. |
| 20 | -test -[ezd] <path> Gibt 1 zurück, wenn der Pfad vorhanden ist. hat eine Länge von Null; oder ist ein Verzeichnis oder 0 sonst. |
| 21 | -stat [format] <path> Druckt Informationen zum Pfad. Format ist eine Zeichenfolge, die die Dateigröße in Blöcken (% b), den Dateinamen (% n), die Blockgröße (% o), die Replikation (% r) und das Änderungsdatum (% y,% Y) akzeptiert. |
| 22 | -tail [-f] <file2name> Zeigt die letzten 1 KB der Datei auf stdout an. |
| 23 | -chmod [-R] mode,mode,... <path>... Ändert die Dateiberechtigungen, die einem oder mehreren durch den Pfad identifizierten Objekten zugeordnet sind. Führt Änderungen rekursiv mit R. durch. Der Modus ist ein dreistelliger Oktalmodus oder {augo} +/- {rwxX}. Nimmt an, wenn kein Bereich angegeben ist und keine Umask angewendet wird. |
| 24 | -chown [-R] [owner][:[group]] <path>... Legt den besitzenden Benutzer und / oder die Gruppe für Dateien oder Verzeichnisse fest, die durch den Pfad gekennzeichnet sind. Legt den Besitzer rekursiv fest, wenn -R angegeben ist. |
| 25 | -chgrp [-R] group <path>... Legt die Eigentümergruppe für Dateien oder Verzeichnisse fest, die durch den Pfad gekennzeichnet sind. Legt die Gruppe rekursiv fest, wenn -R angegeben ist. |
| 26 | -help <cmd-name> Gibt Nutzungsinformationen für einen der oben aufgeführten Befehle zurück. Sie müssen das führende '-' Zeichen in cmd weglassen. |
MapReduce ist ein Framework, mit dem wir Anwendungen schreiben können, um große Datenmengen parallel auf großen Clustern von Standardhardware zuverlässig zu verarbeiten.
Was ist MapReduce?
MapReduce ist eine Verarbeitungstechnik und ein Programmmodell für verteiltes Computing auf Basis von Java. Der MapReduce-Algorithmus enthält zwei wichtige Aufgaben, nämlich Map und Reduce. Map nimmt einen Datensatz und konvertiert ihn in einen anderen Datensatz, in dem einzelne Elemente in Tupel (Schlüssel / Wert-Paare) zerlegt werden. Zweitens reduzieren Sie die Aufgabe, bei der die Ausgabe einer Karte als Eingabe verwendet und diese Datentupel zu einem kleineren Satz von Tupeln kombiniert werden. Wie die Reihenfolge des Namens MapReduce impliziert, wird die Reduzierungsaufgabe immer nach dem Kartenjob ausgeführt.
Der Hauptvorteil von MapReduce besteht darin, dass die Datenverarbeitung einfach über mehrere Rechenknoten skaliert werden kann. Im MapReduce-Modell werden die Datenverarbeitungsprimitive als Mapper und Reducer bezeichnet. Das Zerlegen einer Datenverarbeitungsanwendung in Mapper und Reduzierer ist manchmal nicht trivial. Sobald wir jedoch eine Anwendung im MapReduce-Formular schreiben, ist die Skalierung der Anwendung auf Hunderte, Tausende oder sogar Zehntausende von Computern in einem Cluster lediglich eine Konfigurationsänderung. Diese einfache Skalierbarkeit hat viele Programmierer dazu bewegt, das MapReduce-Modell zu verwenden.
Der Algorithmus
Im Allgemeinen basiert das MapReduce-Paradigma darauf, den Computer an den Ort zu senden, an dem sich die Daten befinden!
Das MapReduce-Programm wird in drei Phasen ausgeführt, nämlich Map-Phase, Shuffle-Phase und Reduktionsphase.
Map stage- Die Aufgabe der Karte oder des Mappers besteht darin, die Eingabedaten zu verarbeiten. Im Allgemeinen liegen die Eingabedaten in Form einer Datei oder eines Verzeichnisses vor und werden im Hadoop-Dateisystem (HDFS) gespeichert. Die Eingabedatei wird zeilenweise an die Mapper-Funktion übergeben. Der Mapper verarbeitet die Daten und erstellt mehrere kleine Datenblöcke.
Reduce stage - Diese Phase ist die Kombination der Shuffle Bühne und die ReduceBühne. Die Aufgabe des Reduzierers besteht darin, die Daten zu verarbeiten, die vom Mapper stammen. Nach der Verarbeitung wird ein neuer Ausgabesatz erstellt, der im HDFS gespeichert wird.
Während eines MapReduce-Jobs sendet Hadoop die Map- und Reduce-Aufgaben an die entsprechenden Server im Cluster.
Das Framework verwaltet alle Details der Datenübergabe, z. B. das Ausgeben von Aufgaben, das Überprüfen der Aufgabenerfüllung und das Kopieren von Daten im Cluster zwischen den Knoten.
Der größte Teil der Datenverarbeitung findet auf Knoten mit Daten auf lokalen Festplatten statt, wodurch der Netzwerkverkehr reduziert wird.
Nach Abschluss der angegebenen Aufgaben sammelt und reduziert der Cluster die Daten, um ein geeignetes Ergebnis zu erhalten, und sendet sie an den Hadoop-Server zurück.

Ein- und Ausgänge (Java-Perspektive)
Das MapReduce-Framework arbeitet mit <Schlüssel, Wert> -Paaren, dh das Framework betrachtet die Eingabe in den Job als Satz von <Schlüssel, Wert> -Paaren und erzeugt einen Satz von <Schlüssel, Wert> -Paaren als Ausgabe des Jobs denkbar von verschiedenen Arten.
Der Schlüssel und die Werteklassen sollten vom Framework serialisiert werden und müssen daher die beschreibbare Schnittstelle implementieren. Darüber hinaus müssen die Schlüsselklassen die Schnittstelle Writable-Comparable implementieren, um das Sortieren nach Framework zu erleichtern. Eingabe- und Ausgabetypen von aMapReduce job - (Eingabe) <k1, v1> → Karte → <k2, v2> → reduzieren → <k3, v3> (Ausgabe).
| Eingang | Ausgabe | |
|---|---|---|
| Karte | <k1, v1> | Liste (<k2, v2>) |
| Reduzieren | <k2, Liste (v2)> | Liste (<k3, v3>) |
Terminologie
PayLoad - Anwendungen implementieren die Funktionen Map und Reduce und bilden den Kern des Jobs.
Mapper - Mapper ordnet die Eingabeschlüssel / Wert-Paare einem Satz von Zwischenschlüssel / Wert-Paaren zu.
NamedNode - Knoten, der das Hadoop Distributed File System (HDFS) verwaltet.
DataNode - Knoten, auf dem die Daten vor der Verarbeitung im Voraus präsentiert werden.
MasterNode - Knoten, auf dem JobTracker ausgeführt wird und der Jobanforderungen von Clients akzeptiert.
SlaveNode - Knoten, auf dem das Map and Reduce-Programm ausgeführt wird.
JobTracker - Plant Jobs und verfolgt die dem Task-Tracker zugewiesenen Jobs.
Task Tracker - Verfolgt die Aufgabe und meldet den Status an JobTracker.
Job - Ein Programm ist eine Ausführung eines Mapper und Reducer in einem Datensatz.
Task - Eine Ausführung eines Mappers oder eines Reduzierers auf einem Datenabschnitt.
Task Attempt - Eine bestimmte Instanz eines Versuchs, eine Aufgabe auf einem SlaveNode auszuführen.
Beispielszenario
Nachstehend sind die Daten zum Stromverbrauch einer Organisation aufgeführt. Es enthält den monatlichen Stromverbrauch und den Jahresdurchschnitt für verschiedene Jahre.
| Jan. | Feb. | Beschädigen | Apr. | Kann | Jun | Jul | Aug. | Sep. | Okt. | Nov. | Dez. | Durchschn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Wenn die oben genannten Daten als Eingabe angegeben werden, müssen wir Anwendungen schreiben, um sie zu verarbeiten und Ergebnisse zu erzielen, z. B. das Jahr der maximalen Nutzung, das Jahr der minimalen Nutzung usw. Dies ist ein Rundgang für Programmierer mit einer begrenzten Anzahl von Datensätzen. Sie schreiben einfach die Logik, um die erforderliche Ausgabe zu erzeugen, und übergeben die Daten an die geschriebene Anwendung.
Denken Sie jedoch an die Daten, die den Stromverbrauch aller großen Industrien eines bestimmten Staates seit seiner Gründung darstellen.
Wenn wir Anwendungen schreiben, um solche Massendaten zu verarbeiten,
Die Ausführung wird viel Zeit in Anspruch nehmen.
Es wird einen starken Netzwerkverkehr geben, wenn wir Daten von der Quelle auf den Netzwerkserver usw. verschieben.
Um diese Probleme zu lösen, haben wir das MapReduce-Framework.
Eingabedaten
Die obigen Daten werden als gespeichert sample.txtund als Eingabe gegeben. Die Eingabedatei sieht wie folgt aus.
1979 23 23 2 43 24 25 26 26 26 26 25 26 25
1980 26 27 28 28 28 30 31 31 31 30 30 30 29
1981 31 32 32 32 33 34 35 36 36 34 34 34 34
1984 39 38 39 39 39 41 42 43 40 39 38 38 40
1985 38 39 39 39 39 41 41 41 00 40 39 39 45Beispielprogramm
Im Folgenden wird das Programm für die Beispieldaten mit dem MapReduce-Framework angegeben.
package hadoop;
import java.util.*;
import java.io.IOException;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits {
//Mapper class
public static class E_EMapper extends MapReduceBase implements
Mapper<LongWritable ,/*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens()) {
lasttoken = s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends MapReduceBase implements Reducer< Text, IntWritable, Text, IntWritable > {
//Reduce function
public void reduce( Text key, Iterator <IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int maxavg = 30;
int val = Integer.MIN_VALUE;
while (values.hasNext()) {
if((val = values.next().get())>maxavg) {
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception {
JobConf conf = new JobConf(ProcessUnits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}Speichern Sie das obige Programm als ProcessUnits.java. Die Kompilierung und Ausführung des Programms wird nachfolgend erläutert.
Zusammenstellung und Ausführung des Programms für Prozesseinheiten
Nehmen wir an, wir befinden uns im Home-Verzeichnis eines Hadoop-Benutzers (z. B. / home / hadoop).
Führen Sie die folgenden Schritte aus, um das obige Programm zu kompilieren und auszuführen.
Schritt 1
Mit dem folgenden Befehl erstellen Sie ein Verzeichnis zum Speichern der kompilierten Java-Klassen.
$ mkdir unitsSchritt 2
Herunterladen Hadoop-core-1.2.1.jar,Hiermit wird das MapReduce-Programm kompiliert und ausgeführt. Besuchen Sie den folgenden Link mvnrepository.com , um das Glas herunterzuladen. Nehmen wir an, der heruntergeladene Ordner ist/home/hadoop/.
Schritt 3
Die folgenden Befehle werden zum Kompilieren von verwendet ProcessUnits.java Programm und Erstellen eines Glases für das Programm.
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java
$ jar -cvf units.jar -C units/ .Schritt 4
Der folgende Befehl wird verwendet, um ein Eingabeverzeichnis in HDFS zu erstellen.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirSchritt 5
Der folgende Befehl wird verwendet, um die Eingabedatei mit dem Namen zu kopieren sample.txtim Eingabeverzeichnis von HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dirSchritt 6
Der folgende Befehl wird verwendet, um die Dateien im Eingabeverzeichnis zu überprüfen.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Schritt 7
Der folgende Befehl wird verwendet, um die Anwendung Eleunit_max auszuführen, indem die Eingabedateien aus dem Eingabeverzeichnis übernommen werden.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirWarten Sie eine Weile, bis die Datei ausgeführt wird. Nach der Ausführung enthält die Ausgabe, wie unten gezeigt, die Anzahl der Eingabesplits, die Anzahl der Map-Aufgaben, die Anzahl der Reduzierungsaufgaben usw.
INFO mapreduce.Job: Job job_1414748220717_0002
completed successfully
14/10/31 06:02:52
INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read = 61
FILE: Number of bytes written = 279400
FILE: Number of read operations = 0
FILE: Number of large read operations = 0
FILE: Number of write operations = 0
HDFS: Number of bytes read = 546
HDFS: Number of bytes written = 40
HDFS: Number of read operations = 9
HDFS: Number of large read operations = 0
HDFS: Number of write operations = 2 Job Counters
Launched map tasks = 2
Launched reduce tasks = 1
Data-local map tasks = 2
Total time spent by all maps in occupied slots (ms) = 146137
Total time spent by all reduces in occupied slots (ms) = 441
Total time spent by all map tasks (ms) = 14613
Total time spent by all reduce tasks (ms) = 44120
Total vcore-seconds taken by all map tasks = 146137
Total vcore-seconds taken by all reduce tasks = 44120
Total megabyte-seconds taken by all map tasks = 149644288
Total megabyte-seconds taken by all reduce tasks = 45178880
Map-Reduce Framework
Map input records = 5
Map output records = 5
Map output bytes = 45
Map output materialized bytes = 67
Input split bytes = 208
Combine input records = 5
Combine output records = 5
Reduce input groups = 5
Reduce shuffle bytes = 6
Reduce input records = 5
Reduce output records = 5
Spilled Records = 10
Shuffled Maps = 2
Failed Shuffles = 0
Merged Map outputs = 2
GC time elapsed (ms) = 948
CPU time spent (ms) = 5160
Physical memory (bytes) snapshot = 47749120
Virtual memory (bytes) snapshot = 2899349504
Total committed heap usage (bytes) = 277684224
File Output Format Counters
Bytes Written = 40Schritt 8
Der folgende Befehl wird verwendet, um die resultierenden Dateien im Ausgabeordner zu überprüfen.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Schritt 9
Der folgende Befehl wird verwendet, um die Ausgabe in anzuzeigen Part-00000 Datei. Diese Datei wird von HDFS generiert.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000Unten sehen Sie die vom MapReduce-Programm generierte Ausgabe.
1981 34
1984 40
1985 45Schritt 10
Der folgende Befehl wird verwendet, um den Ausgabeordner von HDFS zur Analyse in das lokale Dateisystem zu kopieren.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs get output_dir /home/hadoopWichtige Befehle
Alle Hadoop-Befehle werden von der aufgerufen $HADOOP_HOME/bin/hadoopBefehl. Wenn Sie das Hadoop-Skript ohne Argumente ausführen, wird die Beschreibung für alle Befehle gedruckt.
Usage - hadoop [--config confdir] BEFEHL
In der folgenden Tabelle sind die verfügbaren Optionen und ihre Beschreibung aufgeführt.
| Sr.Nr. | Option & Beschreibung |
|---|---|
| 1 | namenode -format Formatiert das DFS-Dateisystem. |
| 2 | secondarynamenode Führt den sekundären DFS-Namensknoten aus. |
| 3 | namenode Führt den DFS-Namensknoten aus. |
| 4 | datanode Führt einen DFS-Datenknoten aus. |
| 5 | dfsadmin Führt einen DFS-Administratorclient aus. |
| 6 | mradmin Führt einen Map-Reduce-Admin-Client aus. |
| 7 | fsck Führt ein Dienstprogramm zur Überprüfung des DFS-Dateisystems aus. |
| 8 | fs Führt einen generischen Dateisystem-Benutzerclient aus. |
| 9 | balancer Führt ein Dienstprogramm zum Clusterausgleich aus. |
| 10 | oiv Wendet den Offline-Fsimage-Viewer auf ein Fsimage an. |
| 11 | fetchdt Ruft ein Delegierungstoken vom NameNode ab. |
| 12 | jobtracker Führt den MapReduce-Job-Tracker-Knoten aus. |
| 13 | pipes Führt einen Pipes-Job aus. |
| 14 | tasktracker Führt einen MapReduce-Task-Tracker-Knoten aus. |
| 15 | historyserver Führt Jobverlaufsserver als eigenständigen Daemon aus. |
| 16 | job Manipuliert die MapReduce-Jobs. |
| 17 | queue Ruft Informationen zu JobQueues ab. |
| 18 | version Druckt die Version. |
| 19 | jar <jar> Führt eine JAR-Datei aus. |
| 20 | distcp <srcurl> <desturl> Kopiert Dateien oder Verzeichnisse rekursiv. |
| 21 | distcp2 <srcurl> <desturl> DistCp Version 2. |
| 22 | archive -archiveName NAME -p <parent path> <src>* <dest> Erstellt ein Hadoop-Archiv. |
| 23 | classpath Druckt den Klassenpfad, der zum Abrufen des Hadoop-Jars und der erforderlichen Bibliotheken erforderlich ist. |
| 24 | daemonlog Abrufen / Festlegen der Protokollstufe für jeden Dämon |
So interagieren Sie mit MapReduce-Jobs
Verwendung - Hadoop-Job [GENERIC_OPTIONS]
Im Folgenden sind die allgemeinen Optionen aufgeführt, die in einem Hadoop-Job verfügbar sind.
| Sr.Nr. | GENERIC_OPTION & Beschreibung |
|---|---|
| 1 | -submit <job-file> Sendet den Job. |
| 2 | -status <job-id> Druckt die Karte und reduziert den Fertigstellungsgrad sowie alle Auftragszähler. |
| 3 | -counter <job-id> <group-name> <countername> Druckt den Zählerwert. |
| 4 | -kill <job-id> Tötet den Job. |
| 5 | -events <job-id> <fromevent-#> <#-of-events> Druckt die vom Jobtracker empfangenen Ereignisdetails für den angegebenen Bereich. |
| 6 | -history [all] <jobOutputDir> - history < jobOutputDir> Druckt Auftragsdetails, fehlgeschlagene und getötete Tippdetails. Weitere Details zum Job, z. B. erfolgreiche Aufgaben und Aufgabenversuche für jede Aufgabe, können durch Angabe der Option [alle] angezeigt werden. |
| 7 | -list[all] Zeigt alle Jobs an. -list zeigt nur Jobs an, die noch abgeschlossen werden müssen. |
| 8 | -kill-task <task-id> Tötet die Aufgabe. Getötete Aufgaben werden NICHT auf fehlgeschlagene Versuche angerechnet. |
| 9 | -fail-task <task-id> Schlägt die Aufgabe fehl. Fehlgeschlagene Aufgaben werden gegen fehlgeschlagene Versuche gezählt. |
| 10 | -set-priority <job-id> <priority> Ändert die Priorität des Jobs. Zulässige Prioritätswerte sind VERY_HIGH, HIGH, NORMAL, LOW, VERY_LOW |
Den Status des Jobs anzeigen
$ $HADOOP_HOME/bin/hadoop job -status <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -status job_201310191043_0004Anzeigen des Verlaufs des Jobausgabeverzeichnisses
$ $HADOOP_HOME/bin/hadoop job -history <DIR-NAME> e.g. $ $HADOOP_HOME/bin/hadoop job -history /user/expert/outputDen Job töten
$ $HADOOP_HOME/bin/hadoop job -kill <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -kill job_201310191043_0004Hadoop-Streaming ist ein Dienstprogramm, das mit der Hadoop-Distribution geliefert wird. Mit diesem Dienstprogramm können Sie Map / Reduce-Jobs mit jeder ausführbaren Datei oder jedem Skript als Mapper und / oder Reduzierer erstellen und ausführen.
Beispiel mit Python
Beim Hadoop-Streaming betrachten wir das Problem der Wortanzahl. Jeder Job in Hadoop muss zwei Phasen haben: Mapper und Reducer. Wir haben Codes für den Mapper und den Reduzierer im Python-Skript geschrieben, um es unter Hadoop auszuführen. Man kann dasselbe auch in Perl und Ruby schreiben.
Mapper-Phasencode
!/usr/bin/python
import sys
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Break the line into words
words = myline.split()
# Iterate the words list
for myword in words:
# Write the results to standard output
print '%s\t%s' % (myword, 1)Stellen Sie sicher, dass diese Datei über die Ausführungsberechtigung verfügt (chmod + x / home / Expert / hadoop-1.2.1 / mapper.py).
Reduzierphasencode
#!/usr/bin/python
from operator import itemgetter
import sys
current_word = ""
current_count = 0
word = ""
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Split the input we got from mapper.py word,
count = myline.split('\t', 1)
# Convert count variable to integer
try:
count = int(count)
except ValueError:
# Count was not a number, so silently ignore this line continue
if current_word == word:
current_count += count
else:
if current_word:
# Write result to standard output print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# Do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)Speichern Sie die Mapper- und Reducer-Codes in mapper.py und reducer.py im Hadoop-Home-Verzeichnis. Stellen Sie sicher, dass diese Dateien über Ausführungsberechtigungen verfügen (chmod + x mapper.py und chmod + x reducer.py). Da Python einrückungsempfindlich ist, kann derselbe Code über den folgenden Link heruntergeladen werden.
Ausführung des WordCount-Programms
$ $HADOOP_HOME/bin/hadoop jar contrib/streaming/hadoop-streaming-1.
2.1.jar \
-input input_dirs \
-output output_dir \
-mapper <path/mapper.py \
-reducer <path/reducer.pyWobei "\" für die Zeilenfortsetzung zur besseren Lesbarkeit verwendet wird.
Zum Beispiel,
./bin/hadoop jar contrib/streaming/hadoop-streaming-1.2.1.jar -input myinput -output myoutput -mapper /home/expert/hadoop-1.2.1/mapper.py -reducer /home/expert/hadoop-1.2.1/reducer.pyWie Streaming funktioniert
Im obigen Beispiel sind sowohl der Mapper als auch der Reduzierer Python-Skripte, die die Eingabe von der Standardeingabe lesen und die Ausgabe an die Standardausgabe ausgeben. Das Dienstprogramm erstellt einen Map / Reduce-Job, sendet den Job an einen geeigneten Cluster und überwacht den Fortschritt des Jobs, bis er abgeschlossen ist.
Wenn ein Skript für Mapper angegeben wird, startet jede Mapper-Task das Skript als separaten Prozess, wenn der Mapper initialisiert wird. Während die Mapper-Task ausgeführt wird, konvertiert sie ihre Eingaben in Zeilen und führt die Zeilen der Standardeingabe (STDIN) des Prozesses zu. In der Zwischenzeit sammelt der Mapper die zeilenorientierten Ausgaben von der Standardausgabe (STDOUT) des Prozesses und konvertiert jede Zeile in ein Schlüssel / Wert-Paar, das als Ausgabe des Mappers gesammelt wird. Standardmäßig ist das Präfix einer Zeile bis zum ersten Tabulatorzeichen der Schlüssel und der Rest der Zeile (ohne das Tabulatorzeichen) ist der Wert. Wenn die Zeile kein Tabulatorzeichen enthält, wird die gesamte Zeile als Schlüssel betrachtet und der Wert ist null. Dies kann jedoch nach Bedarf angepasst werden.
Wenn ein Skript für Reduzierer angegeben ist, startet jede Reduziereraufgabe das Skript als separaten Prozess, und der Reduzierer wird initialisiert. Während die Reduzierungsaufgabe ausgeführt wird, konvertiert sie ihre Eingabe-Schlüssel / Wert-Paare in Zeilen und führt die Zeilen der Standardeingabe (STDIN) des Prozesses zu. In der Zwischenzeit sammelt der Reduzierer die zeilenorientierten Ausgaben von der Standardausgabe (STDOUT) des Prozesses und wandelt jede Zeile in ein Schlüssel / Wert-Paar um, das als Ausgang des Reduzierers gesammelt wird. Standardmäßig ist das Präfix einer Zeile bis zum ersten Tabulatorzeichen der Schlüssel und der Rest der Zeile (ohne das Tabulatorzeichen) der Wert. Dies kann jedoch gemäß den spezifischen Anforderungen angepasst werden.
Wichtige Befehle
| Parameter | Optionen | Beschreibung |
|---|---|---|
| -Eingabeverzeichnis / Dateiname | Erforderlich | Eingabeort für Mapper. |
| -ausgabeverzeichnisname | Erforderlich | Ausgangsort für Reduzierstück. |
| -mapper ausführbare Datei oder Skript oder JavaClassName | Erforderlich | Mapper ausführbare Datei. |
| -reducer ausführbare Datei oder Skript oder JavaClassName | Erforderlich | Reduzierbare ausführbare Datei. |
| -Datei Dateiname | Optional | Stellt die ausführbare Mapper-, Reducer- oder Combiner-Datei lokal auf den Rechenknoten zur Verfügung. |
| -inputformat JavaClassName | Optional | Die von Ihnen angegebene Klasse sollte Schlüssel / Wert-Paare der Textklasse zurückgeben. Wenn nicht angegeben, wird standardmäßig TextInputFormat verwendet. |
| -outputformat JavaClassName | Optional | Die von Ihnen angegebene Klasse sollte Schlüssel / Wert-Paare der Textklasse annehmen. Wenn nicht angegeben, wird standardmäßig TextOutputformat verwendet. |
| -Partitionierer JavaClassName | Optional | Klasse, die bestimmt, an welche Reduzierung ein Schlüssel gesendet wird. |
| -combiner StreamingCommand oder JavaClassName | Optional | Combiner ausführbar für die Kartenausgabe. |
| -cmdenv name = value | Optional | Übergibt die Umgebungsvariable an Streaming-Befehle. |
| -Inputreader | Optional | Aus Gründen der Abwärtskompatibilität: Gibt eine Datensatzleserklasse an (anstelle einer Eingabeformatklasse). |
| -verbose | Optional | Ausführliche Ausgabe. |
| -lazyOutput | Optional | Erzeugt träge Ausgabe. Wenn das Ausgabeformat beispielsweise auf FileOutputFormat basiert, wird die Ausgabedatei nur beim ersten Aufruf von output.collect (oder Context.write) erstellt. |
| -numReduceTasks | Optional | Gibt die Anzahl der Reduzierungen an. |
| -mapdebug | Optional | Skript, das aufgerufen werden soll, wenn die Kartenaufgabe fehlschlägt. |
| -reduzierter Fehler | Optional | Skript zum Aufrufen, wenn die Reduzierungsaufgabe fehlschlägt. |
In diesem Kapitel wird die Einrichtung des Hadoop Multi-Node-Clusters in einer verteilten Umgebung erläutert.
Da nicht der gesamte Cluster demonstriert werden kann, erklären wir die Hadoop-Clusterumgebung anhand von drei Systemen (einem Master und zwei Slaves). unten angegeben sind ihre IP-Adressen.
- Hadoop-Meister: 192.168.1.15 (Hadoop-Meister)
- Hadoop-Sklave: 192.168.1.16 (Hadoop-Sklave-1)
- Hadoop-Sklave: 192.168.1.17 (Hadoop-Sklave-2)
Führen Sie die folgenden Schritte aus, um das Hadoop Multi-Node-Cluster-Setup durchzuführen.
Java installieren
Java ist die Hauptvoraussetzung für Hadoop. Zunächst sollten Sie die Existenz von Java in Ihrem System mithilfe von "Java-Version" überprüfen. Die Syntax des Java-Versionsbefehls ist unten angegeben.
$ java -versionWenn alles gut funktioniert, erhalten Sie die folgende Ausgabe.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Wenn Java nicht in Ihrem System installiert ist, befolgen Sie die angegebenen Schritte zur Installation von Java.
Schritt 1
Laden Sie Java (JDK <neueste Version> - X64.tar.gz) herunter, indem Sie den folgenden Link besuchen: www.oracle.com
Dann jdk-7u71-linux-x64.tar.gz wird in Ihr System heruntergeladen.
Schritt 2
Im Allgemeinen finden Sie die heruntergeladene Java-Datei im Ordner Downloads. Überprüfen Sie es und extrahieren Sie diejdk-7u71-linux-x64.gz Datei mit den folgenden Befehlen.
$ cd Downloads/ $ ls
jdk-7u71-Linux-x64.gz
$ tar zxf jdk-7u71-Linux-x64.gz $ ls
jdk1.7.0_71 jdk-7u71-Linux-x64.gzSchritt 3
Um Java allen Benutzern zur Verfügung zu stellen, müssen Sie es an den Speicherort „/ usr / local /“ verschieben. Öffnen Sie das Stammverzeichnis und geben Sie die folgenden Befehle ein.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitSchritt 4
Zum Einrichten PATH und JAVA_HOME Variablen, fügen Sie die folgenden Befehle hinzu ~/.bashrc Datei.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=PATH:$JAVA_HOME/binÜberprüfen Sie nun die java -versionBefehl vom Terminal wie oben erläutert. Befolgen Sie den obigen Vorgang und installieren Sie Java auf allen Ihren Clusterknoten.
Benutzerkonto erstellen
Erstellen Sie ein Systembenutzerkonto auf Master- und Slave-Systemen, um die Hadoop-Installation zu verwenden.
# useradd hadoop
# passwd hadoopZuordnen der Knoten
Sie müssen bearbeiten hosts Datei in /etc/ Geben Sie auf allen Knoten die IP-Adresse jedes Systems gefolgt von den Hostnamen an.
# vi /etc/hosts
enter the following lines in the /etc/hosts file.
192.168.1.109 hadoop-master
192.168.1.145 hadoop-slave-1
192.168.56.1 hadoop-slave-2Schlüsselbasierte Anmeldung konfigurieren
Richten Sie ssh in jedem Knoten so ein, dass sie ohne Aufforderung zur Eingabe eines Kennworts miteinander kommunizieren können.
# su hadoop
$ ssh-keygen -t rsa $ ssh-copy-id -i ~/.ssh/id_rsa.pub tutorialspoint@hadoop-master
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp1@hadoop-slave-1 $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp2@hadoop-slave-2
$ chmod 0600 ~/.ssh/authorized_keys $ exitHadoop installieren
Laden Sie Hadoop auf dem Master-Server mit den folgenden Befehlen herunter und installieren Sie es.
# mkdir /opt/hadoop
# cd /opt/hadoop/
# wget http://apache.mesi.com.ar/hadoop/common/hadoop-1.2.1/hadoop-1.2.0.tar.gz
# tar -xzf hadoop-1.2.0.tar.gz
# mv hadoop-1.2.0 hadoop
# chown -R hadoop /opt/hadoop
# cd /opt/hadoop/hadoop/Hadoop konfigurieren
Sie müssen den Hadoop-Server konfigurieren, indem Sie die folgenden Änderungen wie unten angegeben vornehmen.
core-site.xml
Öffne das core-site.xml Datei und bearbeiten Sie es wie unten gezeigt.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>hdfs-site.xml
Öffne das hdfs-site.xml Datei und bearbeiten Sie es wie unten gezeigt.
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hadoop/dfs/name/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>mapred-site.xml
Öffne das mapred-site.xml Datei und bearbeiten Sie es wie unten gezeigt.
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master:9001</value>
</property>
</configuration>hadoop-env.sh
Öffne das hadoop-env.sh Datei und bearbeiten Sie JAVA_HOME, HADOOP_CONF_DIR und HADOOP_OPTS wie unten gezeigt.
Note - Stellen Sie JAVA_HOME gemäß Ihrer Systemkonfiguration ein.
export JAVA_HOME=/opt/jdk1.7.0_17
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
export HADOOP_CONF_DIR=/opt/hadoop/hadoop/confInstallieren von Hadoop auf Slave-Servern
Installieren Sie Hadoop auf allen Slave-Servern, indem Sie die angegebenen Befehle befolgen.
# su hadoop
$ cd /opt/hadoop $ scp -r hadoop hadoop-slave-1:/opt/hadoop
$ scp -r hadoop hadoop-slave-2:/opt/hadoopKonfigurieren von Hadoop auf dem Master Server
Öffnen Sie den Master-Server und konfigurieren Sie ihn mit den angegebenen Befehlen.
# su hadoop
$ cd /opt/hadoop/hadoopHauptknoten konfigurieren
$ vi etc/hadoop/masters
hadoop-masterSlave-Knoten konfigurieren
$ vi etc/hadoop/slaves
hadoop-slave-1
hadoop-slave-2Format Name Node auf Hadoop Master
# su hadoop
$ cd /opt/hadoop/hadoop $ bin/hadoop namenode –format
11/10/14 10:58:07 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop-master/192.168.1.109
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.2.0
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1479473;
compiled by 'hortonfo' on Mon May 6 06:59:37 UTC 2013
STARTUP_MSG: java = 1.7.0_71
************************************************************/
11/10/14 10:58:08 INFO util.GSet: Computing capacity for map BlocksMap
editlog=/opt/hadoop/hadoop/dfs/name/current/edits
………………………………………………….
………………………………………………….
………………………………………………….
11/10/14 10:58:08 INFO common.Storage: Storage directory
/opt/hadoop/hadoop/dfs/name has been successfully formatted.
11/10/14 10:58:08 INFO namenode.NameNode:
SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-master/192.168.1.15
************************************************************/Starten von Hadoop Services
Der folgende Befehl dient zum Starten aller Hadoop-Dienste auf dem Hadoop-Master.
$ cd $HADOOP_HOME/sbin
$ start-all.shHinzufügen eines neuen DataNode im Hadoop-Cluster
Im Folgenden sind die Schritte aufgeführt, die zum Hinzufügen neuer Knoten zu einem Hadoop-Cluster ausgeführt werden müssen.
Vernetzung
Fügen Sie einem vorhandenen Hadoop-Cluster neue Knoten mit einer geeigneten Netzwerkkonfiguration hinzu. Nehmen Sie die folgende Netzwerkkonfiguration an.
Für neue Knotenkonfiguration -
IP address : 192.168.1.103
netmask : 255.255.255.0
hostname : slave3.inHinzufügen von Benutzer- und SSH-Zugriff
Fügen Sie einen Benutzer hinzu
Fügen Sie auf einem neuen Knoten den Benutzer "hadoop" hinzu und setzen Sie das Kennwort des Hadoop-Benutzers mit den folgenden Befehlen auf "hadoop123" oder einem beliebigen gewünschten Wert.
useradd hadoop
passwd hadoopSetup Passwortlose Konnektivität vom Master zum neuen Slave.
Führen Sie auf dem Master Folgendes aus
mkdir -p $HOME/.ssh
chmod 700 $HOME/.ssh ssh-keygen -t rsa -P '' -f $HOME/.ssh/id_rsa
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
chmod 644 $HOME/.ssh/authorized_keys Copy the public key to new slave node in hadoop user $HOME directory
scp $HOME/.ssh/id_rsa.pub [email protected]:/home/hadoop/Führen Sie auf den Slaves Folgendes aus
Melden Sie sich bei hadoop an. Wenn nicht, melden Sie sich beim Hadoop-Benutzer an.
su hadoop ssh -X [email protected]Kopieren Sie den Inhalt des öffentlichen Schlüssels in eine Datei "$HOME/.ssh/authorized_keys" und ändern Sie dann die Berechtigung dafür, indem Sie die folgenden Befehle ausführen.
cd $HOME mkdir -p $HOME/.ssh
chmod 700 $HOME/.ssh cat id_rsa.pub >>$HOME/.ssh/authorized_keys
chmod 644 $HOME/.ssh/authorized_keysÜberprüfen Sie die SSH-Anmeldung vom Master-Computer. Überprüfen Sie nun, ob Sie ohne ein Kennwort vom Master zum neuen Knoten ssh können.
ssh [email protected] or hadoop@slave3Legen Sie den Hostnamen des neuen Knotens fest
Sie können den Hostnamen in der Datei festlegen /etc/sysconfig/network
On new slave3 machine
NETWORKING = yes
HOSTNAME = slave3.inUm die Änderungen wirksam zu machen, starten Sie entweder den Computer neu oder führen Sie den Befehl hostname auf einem neuen Computer mit dem entsprechenden Hostnamen aus (Neustart ist eine gute Option).
Auf Slave3-Knotenmaschine -
Hostname Slave3.in
Aktualisieren /etc/hosts auf allen Computern des Clusters mit den folgenden Zeilen -
192.168.1.102 slave3.in slave3Versuchen Sie nun, den Computer mit Hostnamen zu pingen, um zu überprüfen, ob er in IP aufgelöst wird oder nicht.
Auf neuem Knotencomputer -
ping master.inStarten Sie den DataNode auf dem neuen Knoten
Starten Sie den Datenknoten-Daemon manuell mit $HADOOP_HOME/bin/hadoop-daemon.sh script. Es wird automatisch den Master (NameNode) kontaktieren und dem Cluster beitreten. Wir sollten den neuen Knoten auch zur Datei conf / Slaves auf dem Master-Server hinzufügen. Die skriptbasierten Befehle erkennen den neuen Knoten.
Melden Sie sich bei einem neuen Knoten an
su hadoop or ssh -X [email protected]Starten Sie HDFS auf einem neu hinzugefügten Slave-Knoten mit dem folgenden Befehl
./bin/hadoop-daemon.sh start datanodeÜberprüfen Sie die Ausgabe des Befehls jps auf einem neuen Knoten. Es sieht wie folgt aus.
$ jps
7141 DataNode
10312 JpsEntfernen eines DataNode aus dem Hadoop-Cluster
Wir können einen Knoten während der Ausführung ohne Datenverlust aus einem Cluster entfernen. HDFS bietet eine Funktion zur Außerbetriebnahme, mit der sichergestellt wird, dass das Entfernen eines Knotens sicher durchgeführt wird. Befolgen Sie dazu die folgenden Schritte, um es zu verwenden -
Schritt 1 - Melden Sie sich beim Master an
Melden Sie sich beim Master-Computerbenutzer an, auf dem Hadoop installiert ist.
$ su hadoopSchritt 2 - Ändern Sie die Cluster-Konfiguration
Vor dem Starten des Clusters muss eine Ausschlussdatei konfiguriert werden. Fügen Sie einen Schlüssel mit dem Namen dfs.hosts.exclude zu unserem hinzu$HADOOP_HOME/etc/hadoop/hdfs-site.xmlDatei. Der diesem Schlüssel zugeordnete Wert gibt den vollständigen Pfad zu einer Datei im lokalen Dateisystem des NameNode an, die eine Liste der Computer enthält, die keine Verbindung zu HDFS herstellen dürfen.
Fügen Sie diese Zeilen beispielsweise hinzu etc/hadoop/hdfs-site.xml Datei.
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt</value>
<description>DFS exclude</description>
</property>Schritt 3 - Bestimmen Sie die Hosts für die Außerbetriebnahme
Jeder Computer, der außer Betrieb genommen werden soll, sollte der durch hdfs_exclude.txt angegebenen Datei hinzugefügt werden, ein Domänenname pro Zeile. Dadurch wird verhindert, dass sie eine Verbindung zum NameNode herstellen. Inhalt der"/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt" Die Datei wird unten angezeigt, wenn Sie DataNode2 entfernen möchten.
slave2.inSchritt 4 - Neuladen der Konfiguration erzwingen
Führen Sie den Befehl aus "$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes" ohne die Anführungszeichen.
$ $HADOOP_HOME/bin/hadoop dfsadmin -refreshNodesDadurch wird der NameNode gezwungen, seine Konfiguration einschließlich der neu aktualisierten Ausschlussdatei erneut zu lesen. Die Knoten werden über einen bestimmten Zeitraum außer Betrieb genommen, sodass die Blöcke jedes Knotens auf Maschinen repliziert werden können, die aktiv bleiben sollen.
Auf slave2.inÜberprüfen Sie die Ausgabe des Befehls jps. Nach einiger Zeit wird der DataNode-Prozess automatisch heruntergefahren.
Schritt 5 - Knoten herunterfahren
Nach Abschluss des Stilllegungsprozesses kann die stillgelegte Hardware zur Wartung sicher heruntergefahren werden. Führen Sie den Befehl report an dfsadmin aus, um den Status der Außerbetriebnahme zu überprüfen. Der folgende Befehl beschreibt den Status des Außerbetriebnahmeknotens und der mit dem Cluster verbundenen Knoten.
$ $HADOOP_HOME/bin/hadoop dfsadmin -reportSchritt 6 - Bearbeiten schließt Datei erneut aus
Sobald die Maschinen außer Betrieb genommen wurden, können sie aus der Ausschlussdatei entfernt werden. Laufen"$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes"liest die Ausschlussdatei erneut in den NameNode zurück; Ermöglichen, dass die DataNodes nach Abschluss der Wartung wieder dem Cluster beitreten können oder erneut zusätzliche Kapazität im Cluster erforderlich ist usw.
Special Note- Wenn der obige Prozess befolgt wird und der Tasktracker-Prozess noch auf dem Knoten ausgeführt wird, muss er heruntergefahren werden. Eine Möglichkeit besteht darin, die Maschine wie in den obigen Schritten getrennt zu trennen. Der Master erkennt den Prozess automatisch und erklärt ihn für tot. Es ist nicht erforderlich, denselben Vorgang zum Entfernen des Tasktrackers auszuführen, da dieser im Vergleich zum DataNode NICHT sehr wichtig ist. DataNode enthält die Daten, die Sie ohne Datenverlust sicher entfernen möchten.
Der Tasktracker kann jederzeit mit dem folgenden Befehl im laufenden Betrieb ausgeführt / heruntergefahren werden.
$ $HADOOP_HOME/bin/hadoop-daemon.sh stop tasktracker $HADOOP_HOME/bin/hadoop-daemon.sh start tasktracker