IMS DB - DL / I-Verarbeitung
IMS DB speichert Daten auf verschiedenen Ebenen. Daten werden abgerufen und eingefügt, indem DL / I-Aufrufe von einem Anwendungsprogramm ausgegeben werden. Wir werden in den kommenden Kapiteln ausführlich auf DL / I-Anrufe eingehen. Daten können auf zwei Arten verarbeitet werden:
- Sequentielle Verarbeitung
- Zufällige Verarbeitung
Sequentielle Verarbeitung
Wenn Segmente nacheinander aus der Datenbank abgerufen werden, folgt DL / I einem vordefinierten Muster. Lassen Sie uns die sequentielle Verarbeitung von IMS DB verstehen.
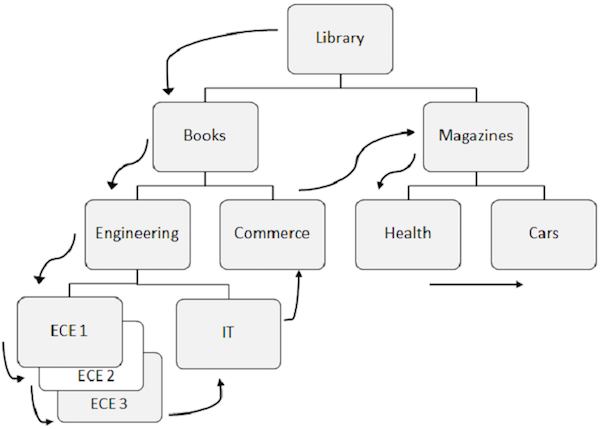
Nachfolgend sind die Punkte aufgeführt, die bei der sequentiellen Verarbeitung zu beachten sind:
Das vordefinierte Muster für den Zugriff auf Daten in DL / I befindet sich zuerst in der Hierarchie und dann von links nach rechts.
Das Wurzelsegment wird zuerst abgerufen, dann bewegt sich DL / I zum ersten linken Kind und es geht bis zur untersten Ebene. Auf der untersten Ebene werden alle Vorkommen von Zwillingssegmenten abgerufen. Dann geht es zum richtigen Segment.
Beachten Sie zum besseren Verständnis die Pfeile in der obigen Abbildung, die den Ablauf für den Zugriff auf die Segmente zeigen. Die Bibliothek ist das Wurzelsegment und der Fluss beginnt von dort bis zu den Autos, um auf einen einzelnen Datensatz zuzugreifen. Der gleiche Vorgang wird für alle Vorkommen wiederholt, um alle Datensätze abzurufen.
Beim Zugriff auf Daten verwendet das Programm die position in der Datenbank, die beim Abrufen und Einfügen von Segmenten hilft.
Zufällige Verarbeitung
Die zufällige Verarbeitung wird auch als direkte Verarbeitung von Daten in der IMS-Datenbank bezeichnet. Nehmen wir ein Beispiel, um die Zufallsverarbeitung in IMS DB zu verstehen -
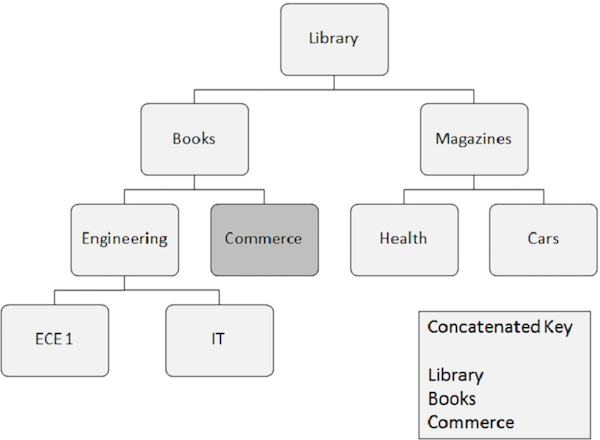
Nachfolgend sind die Punkte aufgeführt, die bei der zufälligen Verarbeitung zu beachten sind -
Das zufällige Auftreten von Segmenten erfordert Schlüsselfelder aller Segmente, von denen es abhängt. Diese Schlüsselfelder werden vom Anwendungsprogramm bereitgestellt.
Ein verketteter Schlüssel identifiziert den Pfad vom Stammsegment zum Segment, das Sie abrufen möchten, vollständig.
Angenommen, Sie möchten ein Vorkommen des Commerce-Segments abrufen, dann müssen Sie die verketteten Schlüsselfeldwerte der Segmente angeben, von denen es abhängt, z. B. Bibliothek, Bücher und Commerce.
Die zufällige Verarbeitung ist schneller als die sequentielle Verarbeitung. Im realen Szenario kombinieren die Anwendungen sowohl sequentielle als auch zufällige Verarbeitungsmethoden, um die besten Ergebnisse zu erzielen.
Schlüsselfeld
Zu beachtende Punkte -
Ein Schlüsselfeld wird auch als Sequenzfeld bezeichnet.
Innerhalb eines Segments ist ein Schlüsselfeld vorhanden, mit dem das Auftreten des Segments abgerufen werden kann.
Ein Schlüsselfeld verwaltet das Segmentvorkommen in aufsteigender Reihenfolge.
In jedem Segment kann nur ein einziges Feld als Schlüsselfeld oder Sequenzfeld verwendet werden.
Suchfeld
Wie bereits erwähnt, kann nur ein einziges Feld als Schlüsselfeld verwendet werden. Wenn Sie nach Inhalten anderer Segmentfelder suchen möchten, die keine Schlüsselfelder sind, wird das Feld zum Abrufen der Daten als Suchfeld bezeichnet.