IMS DB - Kurzanleitung
Ein kurzer Überblick
Die Datenbank ist eine Sammlung korrelierter Datenelemente. Diese Datenelemente sind so organisiert und gespeichert, dass ein schneller und einfacher Zugriff möglich ist. Die IMS-Datenbank ist eine hierarchische Datenbank, in der Daten auf verschiedenen Ebenen gespeichert werden und jede Entität von Entitäten höherer Ebene abhängig ist. Die physischen Elemente auf einem Anwendungssystem, die IMS verwenden, sind in der folgenden Abbildung dargestellt.
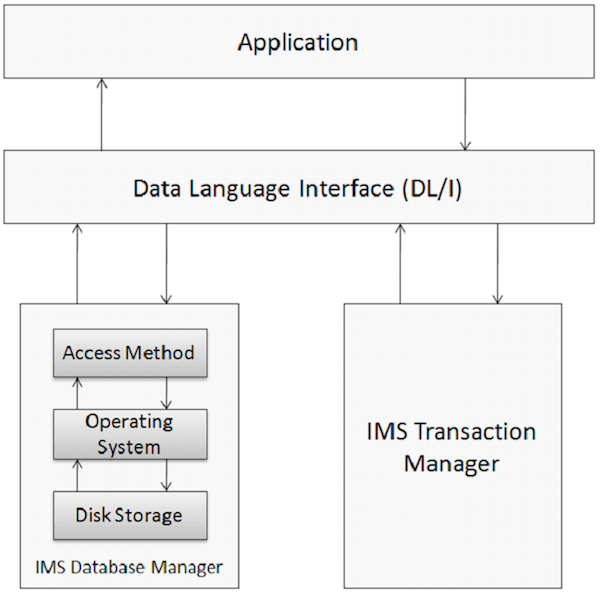
Datenbankmanagement
Ein Datenbankverwaltungssystem ist eine Reihe von Anwendungsprogrammen, die zum Speichern, Zugreifen auf und Verwalten von Daten in der Datenbank verwendet werden. Das IMS-Datenbankverwaltungssystem behält die Integrität bei und ermöglicht eine schnelle Wiederherstellung von Daten, indem es so organisiert wird, dass es leicht abzurufen ist. IMS verwaltet mithilfe seines Datenbankverwaltungssystems eine große Menge von Unternehmensdaten weltweit.
Transaktionsmanager
Die Funktion des Transaktionsmanagers besteht darin, eine Kommunikationsplattform zwischen der Datenbank und den Anwendungsprogrammen bereitzustellen. IMS fungiert als Transaktionsmanager. Ein Transaktionsmanager befasst sich mit dem Endbenutzer, um Daten zu speichern und aus der Datenbank abzurufen. IMS kann IMS DB oder DB2 als Back-End-Datenbank zum Speichern der Daten verwenden.
DL / I - Datensprachenschnittstelle
DL / I besteht aus Anwendungsprogrammen, die Zugriff auf die in der Datenbank gespeicherten Daten gewähren. IMS DB verwendet DL / I, die als Schnittstellensprache dient, mit der Programmierer in einem Anwendungsprogramm auf die Datenbank zugreifen. Wir werden dies in den kommenden Kapiteln genauer besprechen.
Eigenschaften von IMS
Zu beachtende Punkte -
- IMS unterstützt Anwendungen aus verschiedenen Sprachen wie Java und XML.
- Auf IMS-Anwendungen und -Daten kann über jede Plattform zugegriffen werden.
- Die IMS-DB-Verarbeitung ist im Vergleich zu DB2 sehr schnell.
Einschränkungen von IMS
Zu beachtende Punkte -
- Die Implementierung von IMS DB ist sehr komplex.
- Die vordefinierte IMS-Baumstruktur reduziert die Flexibilität.
- IMS DB ist schwer zu verwalten.
Hierarchische Struktur
Eine IMS-Datenbank ist eine Sammlung von Daten, die physische Dateien enthalten. In einer hierarchischen Datenbank enthält die oberste Ebene die allgemeinen Informationen zur Entität. Während wir von der obersten zur untersten Ebene in der Hierarchie übergehen, erhalten wir immer mehr Informationen über die Entität.
Jede Ebene in der Hierarchie enthält Segmente. In Standarddateien ist es schwierig, Hierarchien zu implementieren, aber DL / I unterstützt Hierarchien. Die folgende Abbildung zeigt die Struktur der IMS-Datenbank.
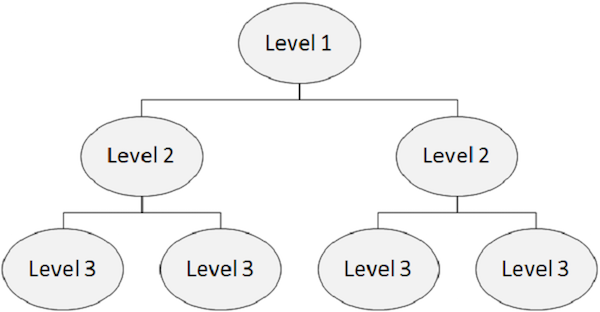
Segment
Zu beachtende Punkte -
Ein Segment wird durch Gruppieren ähnlicher Daten erstellt.
Dies ist die kleinste Informationseinheit, die DL / I während einer Eingabe-Ausgabe-Operation zu und von einem Anwendungsprogramm überträgt.
In einem Segment können ein oder mehrere Datenfelder zusammengefasst sein.
Im folgenden Beispiel verfügt das Segment Student über vier Datenfelder.
| Student | |||
|---|---|---|---|
| Rollennummer | Name | Kurs | Handynummer |
Feld
Zu beachtende Punkte
Ein Feld ist ein einzelnes Datenelement in einem Segment. Beispielsweise sind Rollennummer, Name, Kurs und Handynummer einzelne Felder im Studentensegment.
Ein Segment besteht aus verwandten Feldern, um die Informationen einer Entität zu sammeln.
Felder können als Schlüssel zum Ordnen der Segmente verwendet werden.
Felder können als Qualifikationsmerkmal für die Suche nach Informationen zu einem bestimmten Segment verwendet werden.
Segmenttyp
Zu beachtende Punkte -
Der Segmenttyp ist eine Datenkategorie in einem Segment.
Eine DL / I-Datenbank kann 255 verschiedene Segmenttypen und 15 Hierarchieebenen haben.
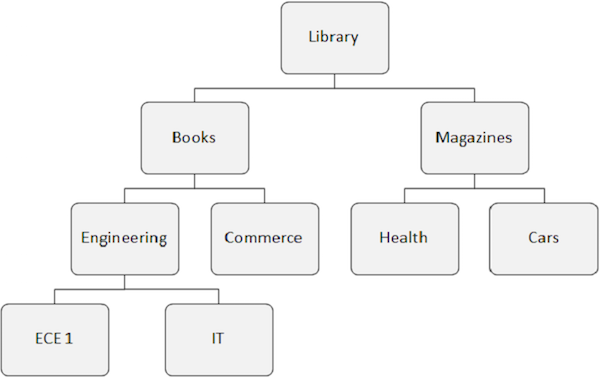
In der folgenden Abbildung gibt es drei Segmente: Bibliothek, Buchinformationen und Schülerinformationen.
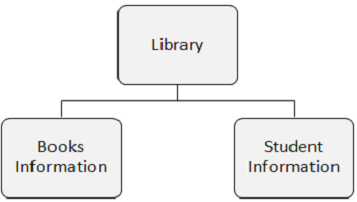
Segmentvorkommen
Zu beachtende Punkte -
Ein Segmentvorkommen ist ein einzelnes Segment eines bestimmten Typs, das Benutzerdaten enthält. Im obigen Beispiel handelt es sich bei Buchinformationen um einen Segmenttyp, und es kann eine beliebige Anzahl von Vorkommen davon geben, da die Informationen zu einer beliebigen Anzahl von Büchern gespeichert werden können.
Innerhalb der IMS-Datenbank gibt es nur ein Vorkommen für jeden Segmenttyp, es kann jedoch eine unbegrenzte Anzahl von Vorkommen für jeden Segmenttyp geben.
Hierarchische Datenbanken bearbeiten die Beziehungen zwischen zwei oder mehr Segmenten. Das folgende Beispiel zeigt, wie Segmente in der IMS-Datenbankstruktur miteinander verknüpft sind.
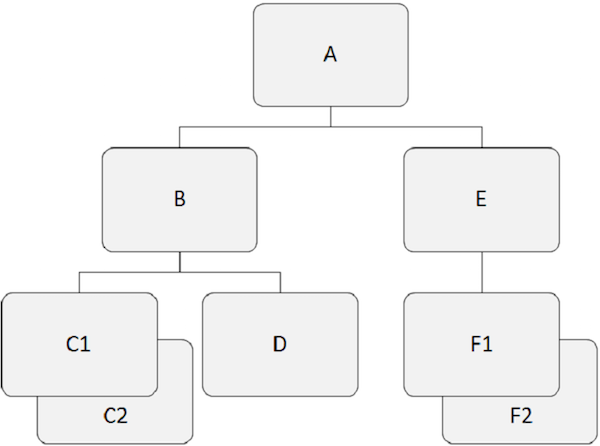
Wurzelsegment
Zu beachtende Punkte -
Das Segment, das oben in der Hierarchie liegt, wird als Stammsegment bezeichnet.
Das Stammsegment ist das einzige Segment, über das auf alle abhängigen Segmente zugegriffen wird.
Das Stammsegment ist das einzige Segment in der Datenbank, das niemals ein untergeordnetes Segment ist.
Es kann nur ein Stammsegment in der IMS-Datenbankstruktur geben.
Zum Beispiel, 'A' ist das Wurzelsegment im obigen Beispiel.
Übergeordnetes Segment
Zu beachtende Punkte -
Ein übergeordnetes Segment hat ein oder mehrere abhängige Segmente direkt darunter.
Zum Beispiel, 'A', 'B', und 'E' sind die übergeordneten Segmente im obigen Beispiel.
Abhängiges Segment
Zu beachtende Punkte -
Alle Segmente außer dem Stammsegment werden als abhängige Segmente bezeichnet.
Abhängige Segmente hängen von einem oder mehreren Segmenten ab, um eine vollständige Bedeutung zu erhalten.
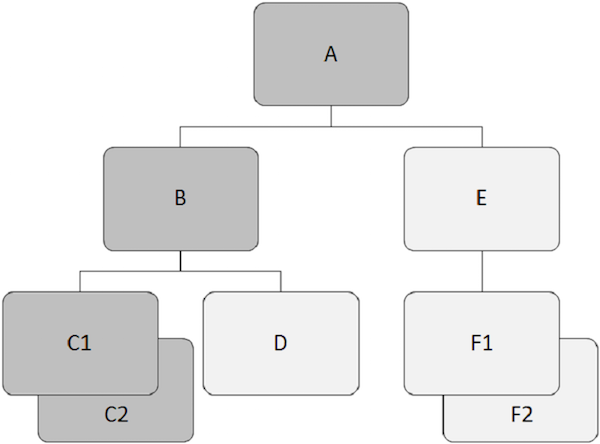
Zum Beispiel, 'B', 'C1', 'C2', 'D', 'E', 'F1' und 'F2' sind abhängige Segmente in unserem Beispiel.
Untergeordnetes Segment
Zu beachtende Punkte -
Jedes Segment mit einem Segment direkt darüber in der Hierarchie wird als untergeordnetes Segment bezeichnet.
Jedes abhängige Segment in der Struktur ist ein untergeordnetes Segment.
Zum Beispiel, 'B', 'C1', 'C2', 'D', 'E', 'F1' und 'F2' sind untergeordnete Segmente.
Zwillingssegmente
Zu beachtende Punkte -
Zwei oder mehr Segmentvorkommen eines bestimmten Segmenttyps unter einem einzelnen übergeordneten Segment werden als Zwillingssegmente bezeichnet.
Zum Beispiel, 'C1' und 'C2' sind Zwillingssegmente, so auch 'F1' und 'F2' sind.
Geschwistersegment
Zu beachtende Punkte -
Geschwistersegmente sind die Segmente verschiedener Typen und des gleichen Elternteils.
Zum Beispiel, 'B' und 'E' sind Geschwistersegmente. Ähnlich,'C1', 'C2', und 'D' sind Geschwistersegmente.
Datenbankeintrag
Zu beachtende Punkte -
Jedes Vorkommen des Stammsegments sowie alle Vorkommen untergeordneter Segmente bilden einen Datenbankeintrag.
Jeder Datenbankdatensatz hat nur ein Stammsegment, kann jedoch eine beliebige Anzahl von Segmentvorkommen aufweisen.
Bei der Standarddateiverarbeitung ist ein Datensatz eine Dateneinheit, die ein Anwendungsprogramm für bestimmte Vorgänge verwendet. In DL / I wird diese Dateneinheit als Segment bezeichnet. Ein einzelner Datenbankdatensatz weist viele Segmentvorkommen auf.
Datenbankpfad
Zu beachtende Punkte -
Ein Pfad ist die Reihe von Segmenten, die vom Stammsegment eines Datenbankeintrags bis zu einem bestimmten Segmentvorkommen beginnt.
Ein Pfad in der Hierarchiestruktur muss nicht bis zur untersten Ebene vollständig sein. Dies hängt davon ab, wie viele Informationen wir über eine Entität benötigen.
Ein Pfad muss durchgehend sein und wir können keine Zwischenebenen in der Struktur überspringen.
In der folgenden Abbildung zeigen die untergeordneten Datensätze in dunkelgrauer Farbe einen Pfad, der beginnt 'A' und geht durch 'C2'.
IMS DB speichert Daten auf verschiedenen Ebenen. Daten werden abgerufen und eingefügt, indem DL / I-Aufrufe von einem Anwendungsprogramm ausgegeben werden. Wir werden in den kommenden Kapiteln ausführlich auf DL / I-Anrufe eingehen. Daten können auf zwei Arten verarbeitet werden:
- Sequentielle Verarbeitung
- Zufällige Verarbeitung
Sequentielle Verarbeitung
Wenn Segmente nacheinander aus der Datenbank abgerufen werden, folgt DL / I einem vordefinierten Muster. Lassen Sie uns die sequentielle Verarbeitung von IMS DB verstehen.
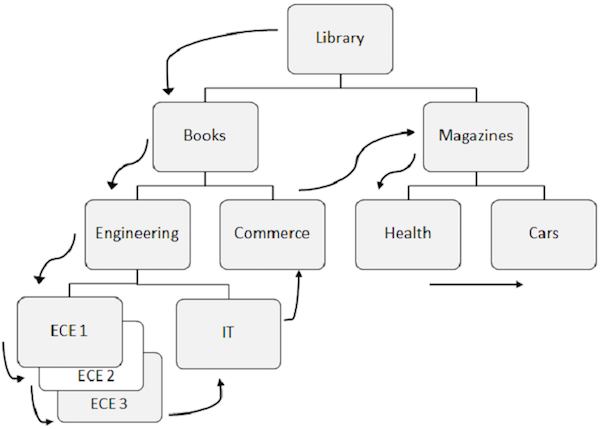
Nachfolgend sind die Punkte aufgeführt, die bei der sequentiellen Verarbeitung zu beachten sind:
Das vordefinierte Muster für den Zugriff auf Daten in DL / I befindet sich zuerst in der Hierarchie und dann von links nach rechts.
Das Wurzelsegment wird zuerst abgerufen, dann bewegt sich DL / I zum ersten linken Kind und es geht bis zur untersten Ebene. Auf der untersten Ebene werden alle Vorkommen von Zwillingssegmenten abgerufen. Dann geht es zum richtigen Segment.
Beachten Sie zum besseren Verständnis die Pfeile in der obigen Abbildung, die den Ablauf für den Zugriff auf die Segmente zeigen. Die Bibliothek ist das Wurzelsegment und der Fluss beginnt von dort bis zu den Autos, um auf einen einzelnen Datensatz zuzugreifen. Der gleiche Vorgang wird für alle Vorkommen wiederholt, um alle Datensätze abzurufen.
Beim Zugriff auf Daten verwendet das Programm die position in der Datenbank, die beim Abrufen und Einfügen von Segmenten hilft.
Zufällige Verarbeitung
Die zufällige Verarbeitung wird auch als direkte Verarbeitung von Daten in der IMS-Datenbank bezeichnet. Nehmen wir ein Beispiel, um die Zufallsverarbeitung in IMS DB zu verstehen -
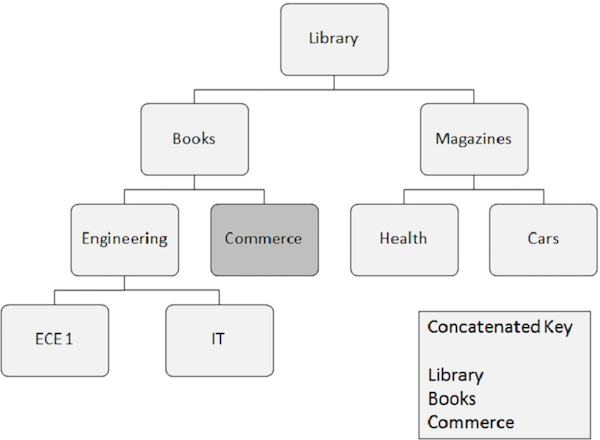
Nachfolgend sind die Punkte aufgeführt, die bei der zufälligen Verarbeitung zu beachten sind -
Das zufällige Auftreten von Segmenten erfordert Schlüsselfelder aller Segmente, von denen es abhängt. Diese Schlüsselfelder werden vom Anwendungsprogramm bereitgestellt.
Ein verketteter Schlüssel identifiziert den Pfad vom Stammsegment zum Segment, das Sie abrufen möchten, vollständig.
Angenommen, Sie möchten ein Vorkommen des Commerce-Segments abrufen, dann müssen Sie die verketteten Schlüsselfeldwerte der Segmente angeben, von denen es abhängt, z. B. Bibliothek, Bücher und Commerce.
Die zufällige Verarbeitung ist schneller als die sequentielle Verarbeitung. Im realen Szenario kombinieren die Anwendungen sowohl sequentielle als auch zufällige Verarbeitungsmethoden, um die besten Ergebnisse zu erzielen.
Schlüsselfeld
Zu beachtende Punkte -
Ein Schlüsselfeld wird auch als Sequenzfeld bezeichnet.
Innerhalb eines Segments ist ein Schlüsselfeld vorhanden, mit dem das Auftreten des Segments abgerufen werden kann.
Ein Schlüsselfeld verwaltet das Segmentvorkommen in aufsteigender Reihenfolge.
In jedem Segment kann nur ein einziges Feld als Schlüsselfeld oder Sequenzfeld verwendet werden.
Suchfeld
Wie bereits erwähnt, kann nur ein einziges Feld als Schlüsselfeld verwendet werden. Wenn Sie nach Inhalten anderer Segmentfelder suchen möchten, die keine Schlüsselfelder sind, wird das Feld zum Abrufen der Daten als Suchfeld bezeichnet.
IMS-Steuerblöcke definieren die Struktur der IMS-Datenbank und den Zugriff eines Programms darauf. Das folgende Diagramm zeigt den Aufbau von IMS-Steuerblöcken.
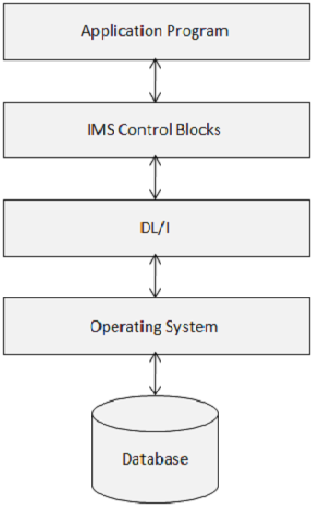
DL / I verwendet die folgenden drei Arten von Steuerblöcken:
- Datenbankdeskriptor (DBD)
- Programmspezifikationsblock (PSB)
- Zugangskontrollblock (ACB)
Datenbankdeskriptor (DBD)
Zu beachtende Punkte -
DBD beschreibt die vollständige physische Struktur der Datenbank, sobald alle Segmente definiert wurden.
Während der Installation einer DL / I-Datenbank muss eine DBD erstellt werden, die für den Zugriff auf die IMS-Datenbank erforderlich ist.
Anwendungen können unterschiedliche Ansichten des DBD verwenden. Sie werden als Anwendungsdatenstrukturen bezeichnet und im Programmspezifikationsblock angegeben.
Der Datenbankadministrator erstellt eine DBD durch Codierung DBDGEN Steueranweisungen.
DBDGEN
DBDGEN ist ein Datenbankdeskriptor-Generator. Das Erstellen von Steuerblöcken liegt in der Verantwortung des Datenbankadministrators. Alle Lademodule werden in der IMS-Bibliothek gespeichert. Assembler-Makroanweisungen werden zum Erstellen von Steuerblöcken verwendet. Im Folgenden finden Sie einen Beispielcode, der zeigt, wie eine DBD mithilfe von DBDGEN-Steueranweisungen erstellt wird.
PRINT NOGEN
DBD NAME=LIBRARY,ACCESS=HIDAM
DATASET DD1=LIB,DEVICE=3380
SEGM NAME=LIBSEG,PARENT=0,BYTES=10
FIELD NAME=(LIBRARY,SEQ,U),BYTES=10,START=1,TYPE=C
SEGM NAME=BOOKSEG,PARENT=LIBSEG,BYTES=5
FIELD NAME=(BOOKS,SEQ,U),BYTES=10,START=1,TYPE=C
SEGM NAME=MAGSEG,PARENT=LIBSEG,BYTES=9
FIELD NAME=(MAGZINES,SEQ),BYTES=8,START=1,TYPE=C
DBDGEN
FINISH
ENDLassen Sie uns die in der obigen DBDGEN verwendeten Begriffe verstehen -
Wenn Sie die obigen Steueranweisungen in ausführen JCLEs wird eine physische Struktur erstellt, in der LIBRARY das Stammsegment und BOOKS und MAGZINES die untergeordneten Segmente sind.
Die erste DBD-Makroanweisung identifiziert die Datenbank. Hier müssen wir den Namen und den Zugriff erwähnen, die von DL / I verwendet werden, um auf diese Datenbank zuzugreifen.
Die zweite DATASET-Makroanweisung identifiziert die Datei, die die Datenbank enthält.
Die Segmenttypen werden mit der Makroanweisung SEGM definiert. Wir müssen die ELTERN dieses Segments angeben. Wenn es sich um ein Root-Segment handelt, erwähnen Sie PARENT = 0.
Die folgende Tabelle zeigt die in der FIELD-Makroanweisung verwendeten Parameter -
| S.No. | Parameter & Beschreibung |
|---|---|
| 1 | Name Name des Feldes, normalerweise 1 bis 8 Zeichen lang |
| 2 | Bytes Länge des Feldes |
| 3 | Start Position des Feldes innerhalb des Segments |
| 4 | Type Datentyp des Feldes |
| 5 | Type C Zeichendatentyp |
| 6 | Type P Gepackter dezimaler Datentyp |
| 7 | Type Z Zonierter Dezimaldatentyp |
| 8 | Type X Hexadezimaler Datentyp |
| 9 | Type H Halbwort-Binärdatentyp |
| 10 | Type F Vollwort-Binärdatentyp |
Programmspezifikationsblock (PSB)
Die Grundlagen von PSB sind wie folgt:
Eine Datenbank hat eine einzelne physische Struktur, die von einer DBD definiert wird, aber die Anwendungsprogramme, die sie verarbeiten, können unterschiedliche Ansichten der Datenbank haben. Diese Ansichten werden als Anwendungsdatenstruktur bezeichnet und im PSB definiert.
Kein Programm kann mehr als ein PSB in einer einzigen Ausführung verwenden.
Anwendungsprogramme haben ein eigenes PSB, und es ist üblich, dass Anwendungsprogramme mit ähnlichen Anforderungen an die Datenbankverarbeitung ein PSB gemeinsam nutzen.
PSB besteht aus einem oder mehreren Steuerblöcken, die als Program Communication Blocks (PCBs) bezeichnet werden. Das PSB enthält eine Leiterplatte für jede DL / I-Datenbank, auf die das Anwendungsprogramm zugreifen wird. Wir werden in den kommenden Modulen mehr über Leiterplatten diskutieren.
PSBGEN muss ausgeführt werden, um ein PSB für das Programm zu erstellen.
PSBGEN
PSBGEN ist als Programmspezifikationsblockgenerator bekannt. Im folgenden Beispiel wird ein PSB mit PSBGEN erstellt.
PRINT NOGEN
PCB TYPE=DB,DBDNAME=LIBRARY,KEYLEN=10,PROCOPT=LS
SENSEG NAME=LIBSEG
SENSEG NAME=BOOKSEG,PARENT=LIBSEG
SENSEG NAME=MAGSEG,PARENT=LIBSEG
PSBGEN PSBNAME=LIBPSB,LANG=COBOL
ENDLassen Sie uns die in der obigen DBDGEN verwendeten Begriffe verstehen -
Die erste Makroanweisung ist der Program Communication Block (PCB), der den Datenbanktyp, den Namen, die Schlüssellänge und die Verarbeitungsoption beschreibt.
Der Parameter DBDNAME im PCB-Makro gibt den Namen der DBD an. KEYLEN gibt die Länge des längsten verketteten Schlüssels an. Das Programm kann in der Datenbank verarbeiten. Der Parameter PROCOPT gibt die Verarbeitungsoptionen des Programms an. Zum Beispiel bedeutet LS nur LOAD Operations.
SENSEG ist als Segment Level Sensitivity bekannt. Es definiert den Zugriff des Programms auf Teile der Datenbank und wird auf Segmentebene identifiziert. Das Programm hat Zugriff auf alle Felder innerhalb der Segmente, für die es empfindlich ist. Ein Programm kann auch eine Empfindlichkeit auf Feldebene haben. In diesem definieren wir einen Segmentnamen und den übergeordneten Namen des Segments.
Die letzte Makroanweisung ist PCBGEN. PSBGEN ist die letzte Anweisung, die besagt, dass keine weiteren Anweisungen zu verarbeiten sind. PSBNAME definiert den Namen des PSB-Ausgangsmoduls. Der Parameter LANG gibt die Sprache an, in der das Anwendungsprogramm geschrieben ist, z. B. COBOL.
Zugangskontrollblock (ACB)
Nachfolgend sind die Punkte aufgeführt, die bei Zugriffssteuerungsblöcken zu beachten sind.
Zugriffssteuerungsblöcke für ein Anwendungsprogramm kombinieren den Datenbankdeskriptor und den Programmspezifikationsblock zu einer ausführbaren Form.
ACBGEN ist als Access Control Blocks Generator bekannt. Es wird verwendet, um ACBs zu generieren.
Für Online-Programme müssen wir ACBs vorab erstellen. Daher wird das Dienstprogramm ACBGEN ausgeführt, bevor das Anwendungsprogramm ausgeführt wird.
Bei Batch-Programmen können ACBs auch zur Ausführungszeit generiert werden.
Ein Anwendungsprogramm, das DL / I-Aufrufe enthält, kann nicht direkt ausgeführt werden. Stattdessen ist eine JCL erforderlich, um das IMS DL / I-Batch-Modul auszulösen. Das Stapelinitialisierungsmodul in IMS ist DFSRRC00. Das Anwendungsprogramm und das DL / I-Modul werden zusammen ausgeführt. Das folgende Diagramm zeigt die Struktur eines Anwendungsprogramms, das DL / I-Aufrufe für den Zugriff auf eine Datenbank enthält.
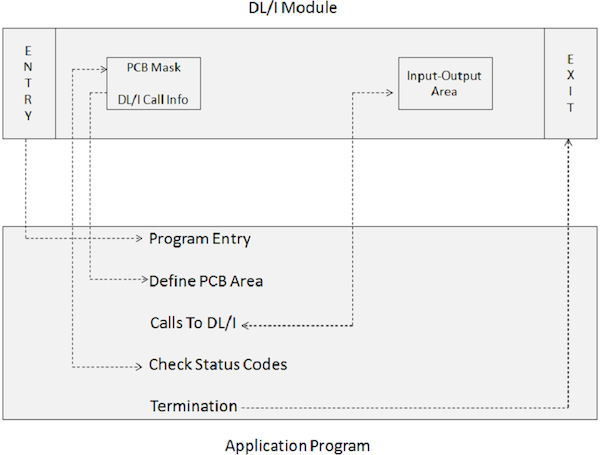
Das Anwendungsprogramm ist über die folgenden Programmelemente mit IMS DL / I-Modulen verbunden:
Eine ENTRY-Anweisung gibt an, dass die Leiterplatten vom Programm verwendet werden.
Eine PCB-Maske bezieht sich auf die Informationen, die in der vorkonstruierten PCB gespeichert sind, die Rückgabeinformationen vom IMS empfängt.
Ein Eingabe-Ausgabe-Bereich wird zum Übergeben von Datensegmenten an und von der IMS-Datenbank verwendet.
Aufrufe von DL / I spezifizieren die Verarbeitungsfunktionen wie Abrufen, Einfügen, Löschen, Ersetzen usw.
Statuscodes prüfen wird verwendet, um den SQL-Rückkehrcode der angegebenen Verarbeitungsoption zu überprüfen und festzustellen, ob der Vorgang erfolgreich war oder nicht.
Eine Terminate-Anweisung wird verwendet, um die Verarbeitung des Anwendungsprogramms zu beenden, das das DL / I enthält.
Segmentlayout
Ab sofort haben wir erfahren, dass das IMS aus Segmenten besteht, die in höheren Programmiersprachen für den Zugriff auf Daten verwendet werden. Betrachten Sie die folgende IMS-Datenbankstruktur einer Bibliothek, die wir zuvor gesehen haben, und hier sehen wir das Layout ihrer Segmente in COBOL -
01 LIBRARY-SEGMENT.
05 BOOK-ID PIC X(5).
05 ISSUE-DATE PIC X(10).
05 RETURN-DATE PIC X(10).
05 STUDENT-ID PIC A(25).
01 BOOK-SEGMENT.
05 BOOK-ID PIC X(5).
05 BOOK-NAME PIC A(30).
05 AUTHOR PIC A(25).
01 STUDENT-SEGMENT.
05 STUDENT-ID PIC X(5).
05 STUDENT-NAME PIC A(25).
05 DIVISION PIC X(10).Anwendungsprogrammübersicht
Die Struktur eines IMS-Anwendungsprogramms unterscheidet sich von der eines Nicht-IMS-Anwendungsprogramms. Ein IMS-Programm kann nicht direkt ausgeführt werden. Vielmehr wird es immer als Unterprogramm aufgerufen. Ein IMS-Anwendungsprogramm besteht aus Programmspezifikationsblöcken, um eine Ansicht der IMS-Datenbank bereitzustellen.
Das Anwendungsprogramm und die mit diesem Programm verknüpften PSBs werden geladen, wenn wir ein Anwendungsprogramm ausführen, das IMS DL / I-Module enthält. Dann werden die von den Anwendungsprogrammen ausgelösten CALL-Anforderungen vom IMS-Modul ausgeführt.
IMS-Dienste
Die folgenden IMS-Dienste werden vom Anwendungsprogramm verwendet:
- Zugriff auf Datenbankeinträge
- Ausgabe von IMS-Befehlen
- IMS-Serviceaufrufe ausgeben
- Checkpoint-Aufrufe
- Anrufe synchronisieren
- Senden oder Empfangen von Nachrichten von Online-Benutzerterminals
Wir fügen DL / I-Aufrufe in das COBOL-Anwendungsprogramm ein, um mit der IMS-Datenbank zu kommunizieren. Wir verwenden die folgenden DL / I-Anweisungen im COBOL-Programm, um auf die Datenbank zuzugreifen:
- Eintragungserklärung
- Goback-Erklärung
- Anruferklärung
Eintragungserklärung
Es wird verwendet, um die Steuerung vom DL / I an das COBOL-Programm zu übergeben. Hier ist die Syntax der entry-Anweisung -
ENTRY 'DLITCBL' USING pcb-name1
[pcb-name2]Die obige Anweisung ist in der Procedure Divisioneines COBOL-Programms. Gehen wir auf die Details der Eintragsanweisung im COBOL-Programm ein -
Das Batch-Initialisierungsmodul löst das Anwendungsprogramm aus und wird unter seiner Kontrolle ausgeführt.
Das DL / I lädt die erforderlichen Steuerblöcke und Module sowie das Anwendungsprogramm, und die Steuerung wird an das Anwendungsprogramm übergeben.
DLITCBL steht für DL/I to COBOL. Die entry-Anweisung wird verwendet, um den Einstiegspunkt im Programm zu definieren.
Wenn wir ein Unterprogramm in COBOL aufrufen, wird auch dessen Adresse angegeben. Wenn der DL / I dem Anwendungsprogramm die Steuerung gibt, gibt er auch die Adresse jeder im PSB des Programms definierten Leiterplatte an.
Alle im Anwendungsprogramm verwendeten Leiterplatten müssen innerhalb der definiert werden Linkage Section des COBOL-Programms, da sich die Leiterplatte außerhalb des Anwendungsprogramms befindet.
Die PCB-Definition im Verknüpfungsabschnitt wird als bezeichnet PCB Mask.
Die Beziehung zwischen Leiterplattenmasken und tatsächlich im Speicher befindlichen Leiterplatten wird durch Auflisten der Leiterplatten in der Eintragsanweisung erstellt. Die Reihenfolge der Auflistung in der Eintragsanweisung sollte mit der im PSBGEN übereinstimmen.
Goback-Erklärung
Es wird verwendet, um die Steuerung an das IMS-Steuerungsprogramm zurückzugeben. Es folgt die Syntax der Goback-Anweisung:
GOBACKNachfolgend sind die grundlegenden Punkte aufgeführt, die bei der Goback-Anweisung zu beachten sind:
GOBACK wird am Ende des Anwendungsprogramms codiert. Es gibt die Steuerung vom Programm an DL / I zurück.
Wir sollten STOP RUN nicht verwenden, da es die Steuerung an das Betriebssystem zurückgibt. Wenn wir STOP RUN verwenden, hat der DL / I nie die Möglichkeit, seine Abschlussfunktionen auszuführen. Aus diesem Grund wird in DL / I-Anwendungsprogrammen die Goback-Anweisung verwendet.
Vor dem Ausgeben einer Goback-Anweisung müssen alle im COBOL-Anwendungsprogramm verwendeten Nicht-DL / I-Datensätze geschlossen werden, da das Programm sonst abnormal beendet wird.
Anruferklärung
Die Aufrufanweisung wird verwendet, um DL / I-Dienste anzufordern, z. B. das Ausführen bestimmter Vorgänge in der IMS-Datenbank. Hier ist die Syntax der call-Anweisung -
CALL 'CBLTDLI' USING DLI Function Code
PCB Mask
Segment I/O Area
[Segment Search Arguments]Die obige Syntax zeigt Parameter, die Sie mit der call-Anweisung verwenden können. Wir werden jeden von ihnen in der folgenden Tabelle diskutieren -
| S.No. | Parameter & Beschreibung |
|---|---|
| 1 | DLI Function Code Identifiziert die auszuführende DL / I-Funktion. Dieses Argument ist der Name der vier Zeichenfelder, die die E / A-Operation beschreiben. |
| 2 | PCB Mask Die PCB-Definition im Verknüpfungsabschnitt wird als PCB-Maske bezeichnet. Sie werden in der entry-Anweisung verwendet. Es sind keine Anweisungen SELECT, ASSIGN, OPEN oder CLOSE erforderlich. |
| 3 | Segment I/O Area Name eines Eingabe- / Ausgabe-Arbeitsbereichs. Dies ist ein Bereich des Anwendungsprogramms, in den der DL / I ein angefordertes Segment einfügt. |
| 4 | Segment Search Arguments Dies sind optionale Parameter, abhängig von der Art des ausgegebenen Anrufs. Sie werden zum Durchsuchen von Datensegmenten in der IMS-Datenbank verwendet. |
Nachstehend sind die Punkte aufgeführt, die bei der Call-Anweisung zu beachten sind.
CBLTDLI steht für COBOL to DL/I. Dies ist der Name eines Schnittstellenmoduls, das mit dem Objektmodul Ihres Programms verknüpft ist.
Nach jedem DL / I-Aufruf speichert das DLI einen Statuscode auf der Platine. Das Programm kann diesen Code verwenden, um festzustellen, ob der Aufruf erfolgreich war oder fehlgeschlagen ist.
Beispiel
Zum besseren Verständnis von COBOL können Sie hier unser COBOL-Tutorial durchgehen . Das folgende Beispiel zeigt die Struktur eines COBOL-Programms, das IMS-Datenbank- und DL / I-Aufrufe verwendet. Wir werden jeden der im Beispiel verwendeten Parameter in den kommenden Kapiteln ausführlich diskutieren.
IDENTIFICATION DIVISION.
PROGRAM-ID. TEST1.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.
01 SEGMENT-I-O-AREA PIC X(150).
LINKAGE SECTION.
01 STUDENT-PCB-MASK.
05 STD-DBD-NAME PIC X(8).
05 STD-SEGMENT-LEVEL PIC XX.
05 STD-STATUS-CODE PIC XX.
05 STD-PROC-OPTIONS PIC X(4).
05 FILLER PIC S9(5) COMP.
05 STD-SEGMENT-NAME PIC X(8).
05 STD-KEY-LENGTH PIC S9(5) COMP.
05 STD-NUMB-SENS-SEGS PIC S9(5) COMP.
05 STD-KEY PIC X(11).
PROCEDURE DIVISION.
ENTRY 'DLITCBL' USING STUDENT-PCB-MASK.
A000-READ-PARA.
110-GET-INVENTORY-SEGMENT.
CALL ‘CBLTDLI’ USING DLI-GN
STUDENT-PCB-MASK
SEGMENT-I-O-AREA.
GOBACK.Die DL / I-Funktion ist der erste Parameter, der in einem DL / I-Aufruf verwendet wird. Diese Funktion gibt an, welche Operation vom IMS DL / I-Aufruf an der IMS-Datenbank ausgeführt werden soll. Die Syntax der DL / I-Funktion lautet wie folgt:
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.Diese Syntax repräsentiert die folgenden Schlüsselpunkte:
Für diesen Parameter können wir einen beliebigen vierstelligen Namen als Speicherfeld zum Speichern des Funktionscodes angeben.
Der DL / I-Funktionsparameter ist im Arbeitsspeicherabschnitt des COBOL-Programms codiert.
Um die DL / I-Funktion anzugeben, muss der Programmierer einen der Datennamen der Ebene 05 wie DLI-GU in einem DL / I-Aufruf codieren, da COBOL das Codieren von Literalen in einer CALL-Anweisung nicht zulässt.
DL / I-Funktionen sind in drei Kategorien unterteilt: Get-, Update- und andere Funktionen. Lassen Sie uns jeden von ihnen im Detail besprechen.
Funktionen abrufen
Get-Funktionen ähneln der Leseoperation, die von jeder Programmiersprache unterstützt wird. Mit der Get-Funktion werden Segmente aus einer IMS DL / I-Datenbank abgerufen. Die folgenden Get-Funktionen werden in IMS DB verwendet:
- Einzigartig werden
- Holen Sie sich als nächstes
- Holen Sie sich Next in Parent
- Holen Sie sich Hold Unique
- Als nächstes halten
- Halten Sie Next in Parent
Betrachten wir die folgende IMS-Datenbankstruktur, um die DL / I-Funktionsaufrufe zu verstehen:
Einzigartig werden
'GU'-Code wird für die Funktion Get Unique verwendet. Es funktioniert ähnlich wie die zufällige Leseanweisung in COBOL. Es wird verwendet, um ein bestimmtes Segmentvorkommen basierend auf den Feldwerten abzurufen. Die Feldwerte können mithilfe von Segment-Suchargumenten bereitgestellt werden. Die Syntax eines GU-Aufrufs lautet wie folgt:
CALL 'CBLTDLI' USING DLI-GU
PCB Mask
Segment I/O Area
[Segment Search Arguments]Wenn Sie die obige Aufrufanweisung ausführen, indem Sie geeignete Werte für alle Parameter im COBOL-Programm angeben, können Sie das Segment im Segment-E / A-Bereich aus der Datenbank abrufen. Wenn Sie im obigen Beispiel die Feldwerte Bibliothek, Zeitschriften und Gesundheit angeben, erhalten Sie das gewünschte Vorkommen des Segments Gesundheit.
Holen Sie sich als nächstes
Der GN-Code wird für die Funktion "Weiter" verwendet. Es funktioniert ähnlich wie die Anweisung read next in COBOL. Es wird verwendet, um Segmentvorkommen in einer Sequenz abzurufen. Das vordefinierte Muster für den Zugriff auf Datensegmentvorkommen befindet sich in der Hierarchie und dann von links nach rechts. Die Syntax eines GN-Aufrufs lautet wie folgt:
CALL 'CBLTDLI' USING DLI-GN
PCB Mask
Segment I/O Area
[Segment Search Arguments]Wenn Sie die obige Aufrufanweisung ausführen, indem Sie geeignete Werte für alle Parameter im COBOL-Programm angeben, können Sie das Segmentvorkommen im Segment-E / A-Bereich in einer sequentiellen Reihenfolge aus der Datenbank abrufen. Im obigen Beispiel beginnt der Zugriff auf das Bibliothekssegment, dann auf das Buchsegment usw. Wir führen den GN-Aufruf immer wieder durch, bis wir das gewünschte Segmentvorkommen erreichen.
Holen Sie sich Next in Parent
Der BSP-Code wird für Get Next in Parent verwendet. Diese Funktion wird verwendet, um Segmentvorkommen in einer Reihenfolge abzurufen, die einem festgelegten übergeordneten Segment untergeordnet ist. Die Syntax eines BSP-Aufrufs lautet wie folgt:
CALL 'CBLTDLI' USING DLI-GNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Holen Sie sich Hold Unique
Der 'GHU'-Code wird für Get Hold Unique verwendet. Die Hold-Funktion gibt an, dass das Segment nach dem Abrufen aktualisiert wird. Die Funktion Get Hold Unique entspricht dem Aufruf Get Unique. Unten ist die Syntax eines GHU-Aufrufs angegeben -
CALL 'CBLTDLI' USING DLI-GHU
PCB Mask
Segment I/O Area
[Segment Search Arguments]Als nächstes halten
Der 'GHN'-Code wird für Get Hold Next verwendet. Die Hold-Funktion gibt an, dass das Segment nach dem Abrufen aktualisiert wird. Die Funktion "Get Hold Next" entspricht dem Aufruf "Get Next". Unten ist die Syntax eines GHN-Aufrufs angegeben -
CALL 'CBLTDLI' USING DLI-GHN
PCB Mask
Segment I/O Area
[Segment Search Arguments]Halten Sie Next in Parent
Der 'GHNP'-Code wird für Get Hold Next in Parent verwendet. Die Hold-Funktion gibt an, dass das Segment nach dem Abrufen aktualisiert wird. Die Funktion Get Next Next in Parent entspricht dem Aufruf Get Next in Parent. Unten ist die Syntax eines GHNP-Aufrufs angegeben -
CALL 'CBLTDLI' USING DLI-GHNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Funktionen aktualisieren
Aktualisierungsfunktionen ähneln dem erneuten Schreiben oder Einfügen von Vorgängen in einer anderen Programmiersprache. Aktualisierungsfunktionen werden zum Aktualisieren von Segmenten in einer IMS DL / I-Datenbank verwendet. Vor Verwendung der Aktualisierungsfunktion muss ein erfolgreicher Aufruf mit der Hold-Klausel für das Auftreten des Segments vorliegen. Die folgenden Aktualisierungsfunktionen werden in IMS DB verwendet:
- Insert
- Delete
- Replace
Einfügen
Der ISRT-Code wird für die Einfügefunktion verwendet. Mit der ISRT-Funktion wird der Datenbank ein neues Segment hinzugefügt. Es wird verwendet, um eine vorhandene Datenbank zu ändern oder eine neue Datenbank zu laden. Unten ist die Syntax eines ISRT-Aufrufs angegeben -
CALL 'CBLTDLI' USING DLI-ISRT
PCB Mask
Segment I/O Area
[Segment Search Arguments]Löschen
Der DLET-Code wird für die Löschfunktion verwendet. Es wird verwendet, um ein Segment aus einer IMS DL / I-Datenbank zu entfernen. Unten ist die Syntax eines DLET-Aufrufs angegeben -
CALL 'CBLTDLI' USING DLI-DLET
PCB Mask
Segment I/O Area
[Segment Search Arguments]Ersetzen
Der 'REPL'-Code wird für Get Hold Next in Parent verwendet. Die Funktion Ersetzen wird verwendet, um ein Segment in der IMS DL / I-Datenbank zu ersetzen. Unten ist die Syntax eines REPL-Aufrufs angegeben -
CALL 'CBLTDLI' USING DLI-REPL
PCB Mask
Segment I/O Area
[Segment Search Arguments]Andere Funktionen
Die folgenden anderen Funktionen werden in IMS DL / I-Aufrufen verwendet:
- Checkpoint
- Restart
- PCB
Kontrollpunkt
Für die Checkpoint-Funktion wird der 'CHKP'-Code verwendet. Es wird in den Wiederherstellungsfunktionen von IMS verwendet. Unten ist die Syntax eines CHKP-Aufrufs angegeben -
CALL 'CBLTDLI' USING DLI-CHKP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Neu starten
Der 'XRST'-Code wird für die Neustartfunktion verwendet. Es wird in den Neustartfunktionen von IMS verwendet. Unten ist die Syntax eines XRST-Aufrufs angegeben -
CALL 'CBLTDLI' USING DLI-XRST
PCB Mask
Segment I/O Area
[Segment Search Arguments]PCB
Die PCB-Funktion wird in CICS-Programmen in der IMS DL / I-Datenbank verwendet. Unten ist die Syntax eines PCB-Aufrufs angegeben -
CALL 'CBLTDLI' USING DLI-PCB
PCB Mask
Segment I/O Area
[Segment Search Arguments]Weitere Details zu diesen Funktionen finden Sie im Kapitel Wiederherstellung.
PCB steht für Program Communication Block. PCB Mask ist der zweite Parameter, der im DL / I-Aufruf verwendet wird. Es wird im Verknüpfungsabschnitt deklariert. Unten ist die Syntax einer PCB-Maske angegeben -
01 PCB-NAME.
05 DBD-NAME PIC X(8).
05 SEG-LEVEL PIC XX.
05 STATUS-CODE PIC XX.
05 PROC-OPTIONS PIC X(4).
05 RESERVED-DLI PIC S9(5).
05 SEG-NAME PIC X(8).
05 LENGTH-FB-KEY PIC S9(5).
05 NUMB-SENS-SEGS PIC S9(5).
05 KEY-FB-AREA PIC X(n).Hier sind die wichtigsten Punkte zu beachten -
Für jede Datenbank verwaltet der DL / I einen Speicherbereich, der als Programmkommunikationsblock bezeichnet wird. Es speichert die Informationen über die Datenbank, auf die in den Anwendungsprogrammen zugegriffen wird.
Die Anweisung ENTRY stellt eine Verbindung zwischen den Leiterplattenmasken im Verknüpfungsabschnitt und den Leiterplatten im PSB des Programms her. Die in einem DL / I-Aufruf verwendeten PCB-Masken geben an, welche Datenbank für den Betrieb verwendet werden soll.
Sie können davon ausgehen, dass dies der Angabe eines Dateinamens in einer COBOL READ-Anweisung oder eines Datensatznamens in einer COBOL-Schreibanweisung ähnelt. Es sind keine Anweisungen SELECT, ASSIGN, OPEN oder CLOSE erforderlich.
Nach jedem DL / I-Aufruf speichert der DL / I einen Statuscode auf der Platine, und das Programm kann anhand dieses Codes feststellen, ob der Aufruf erfolgreich war oder fehlgeschlagen ist.
PCB Name
Zu beachtende Punkte -
PCB Name ist der Name des Bereichs, der sich auf die gesamte Struktur der PCB-Felder bezieht.
PCB Name wird in Programmanweisungen verwendet.
PCB Name ist kein Feld in der PCB.
DBD-Name
Zu beachtende Punkte -
Der DBD-Name enthält die Zeichendaten. Es ist acht Bytes lang.
Das erste Feld auf der Leiterplatte ist der Name der zu verarbeitenden Datenbank und enthält den DBD-Namen aus der Bibliothek der Datenbankbeschreibungen, die einer bestimmten Datenbank zugeordnet sind.
Segmentebene
Zu beachtende Punkte -
Die Segmentebene wird als Segmenthierarchieebenenindikator bezeichnet. Es enthält Zeichendaten und ist zwei Bytes lang.
In einem Feld auf Segmentebene wird die Ebene des verarbeiteten Segments gespeichert. Wenn ein Segment erfolgreich abgerufen wurde, wird hier die Ebenennummer des abgerufenen Segments gespeichert.
Ein Segmentebenenfeld hat niemals einen Wert größer als 15, da dies die maximal zulässige Anzahl von Ebenen in einer DL / I-Datenbank ist.
Statuscode
Zu beachtende Punkte -
Das Statuscodefeld enthält zwei Bytes Zeichendaten.
Der Statuscode enthält den DL / I-Statuscode.
Leerzeichen werden in das Statuscodefeld verschoben, wenn DL / I die Verarbeitung von Anrufen erfolgreich abgeschlossen hat.
Nicht-Leerzeichen geben an, dass der Anruf nicht erfolgreich war.
Der Statuscode GB zeigt das Dateiende an und der Statuscode GE zeigt an, dass das angeforderte Segment nicht gefunden wurde.
Proc-Optionen
Zu beachtende Punkte -
Proc-Optionen werden als Verarbeitungsoptionen bezeichnet, die vierstellige Datenfelder enthalten.
Ein Feld Verarbeitungsoption gibt an, zu welcher Art von Verarbeitung das Programm in der Datenbank berechtigt ist.
Reserviert DL / I.
Zu beachtende Punkte -
Reserviertes DL / I wird als reservierter Bereich des IMS bezeichnet. Es speichert vier Byte Binärdaten.
IMS verwendet diesen Bereich für seine eigene interne Verknüpfung mit einem Anwendungsprogramm.
Segmentname
Zu beachtende Punkte -
Der SEG-Name wird als Segmentnamen-Feedback-Bereich bezeichnet. Es enthält 8 Bytes Zeichendaten.
Der Name des Segments wird nach jedem DL / I-Aufruf in diesem Feld gespeichert.
Länge FB Key
Zu beachtende Punkte -
Die Länge des FB-Schlüssels wird als Länge des Tastenrückmeldungsbereichs bezeichnet. Es speichert vier Bytes Binärdaten.
In diesem Feld wird die Länge des verketteten Schlüssels des Segments der untersten Ebene angegeben, das während des vorherigen Aufrufs verarbeitet wurde.
Es wird mit dem wichtigsten Feedback-Bereich verwendet.
Anzahl der Empfindlichkeitssegmente
Zu beachtende Punkte -
Die Anzahl der Empfindlichkeitssegmente speichert vier Byte Binärdaten.
Es definiert, auf welcher Ebene ein Anwendungsprogramm empfindlich ist. Es repräsentiert die Anzahl der Segmente in der logischen Datenstruktur.
Wichtiger Feedback-Bereich
Zu beachtende Punkte -
Der Längenrückkopplungsbereich variiert von Leiterplatte zu Leiterplatte in der Länge.
Es enthält den längstmöglichen verketteten Schlüssel, der mit der Programmansicht der Datenbank verwendet werden kann.
Nach einer Datenbankoperation gibt DL / I den verketteten Schlüssel des in diesem Feld verarbeiteten Segments der untersten Ebene und die Länge des Schlüssels im Bereich für die Schlüssellängenrückmeldung zurück.
SSA steht für Segment Search Arguments. SSA wird verwendet, um das Segmentvorkommen zu identifizieren, auf das zugegriffen wird. Dies ist ein optionaler Parameter. Wir können je nach Anforderung eine beliebige Anzahl von SSAs einschließen. Es gibt zwei Arten von SSAs:
- Nicht qualifizierte SSA
- Qualifizierte SSA
Nicht qualifizierte SSA
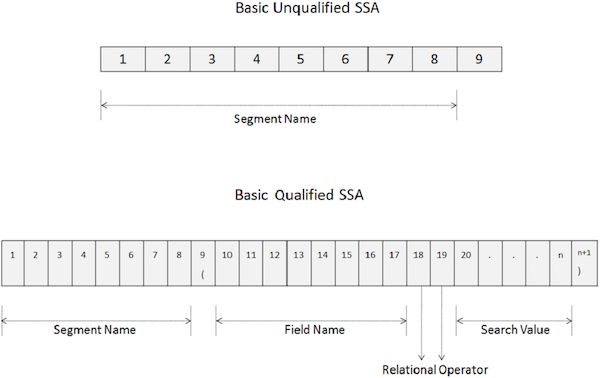
Ein nicht qualifizierter SSA gibt den Namen des Segments an, das innerhalb des Anrufs verwendet wird. Nachstehend ist die Syntax eines nicht qualifizierten SSA angegeben.
01 UNQUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X VALUE SPACE.Die wichtigsten Punkte einer nicht qualifizierten SSA sind:
Ein unqualifizierter Basis-SSA ist 9 Byte lang.
Die ersten 8 Bytes enthalten den Segmentnamen, der für die Verarbeitung verwendet wird.
Das letzte Byte enthält immer Leerzeichen.
DL / I verwendet das letzte Byte, um den SSA-Typ zu bestimmen.
Um auf ein bestimmtes Segment zuzugreifen, verschieben Sie den Namen des Segments in das Feld SEGMENT-NAME.
Die folgenden Bilder zeigen die Strukturen nicht qualifizierter und qualifizierter SSAs -
Qualifizierte SSA
Ein qualifizierter SSA liefert dem Segmenttyp das spezifische Datenbankvorkommen eines Segments. Unten ist die Syntax eines qualifizierten SSA angegeben -
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.Die wichtigsten Punkte einer qualifizierten SSA sind:
Die ersten 8 Bytes eines qualifizierten SSA enthalten den Segmentnamen, der für die Verarbeitung verwendet wird.
Das neunte Byte ist eine linke Klammer '('.
Die nächsten 8 Bytes ab der zehnten Position geben den Feldnamen an, nach dem gesucht werden soll.
Nach dem Feldnamen, in dem 18 - ten und 19 - ten Positionen, geben wir relationalen Operator Code aus zwei Zeichen.
Dann geben wir den Feldwert an und im letzten Byte steht eine rechte Klammer ')'.
Die folgende Tabelle zeigt die in einem qualifizierten SSA verwendeten Vergleichsoperatoren.
| Vergleichsoperator | Symbol | Beschreibung |
|---|---|---|
| EQ | = | Gleich |
| NE | ~ = ˜ | Nicht gleich |
| GT | > | Größer als |
| GE | > = | Größer als oder gleich |
| LT | << | Weniger als |
| LE | <= | Weniger als oder gleich |
Befehlscodes
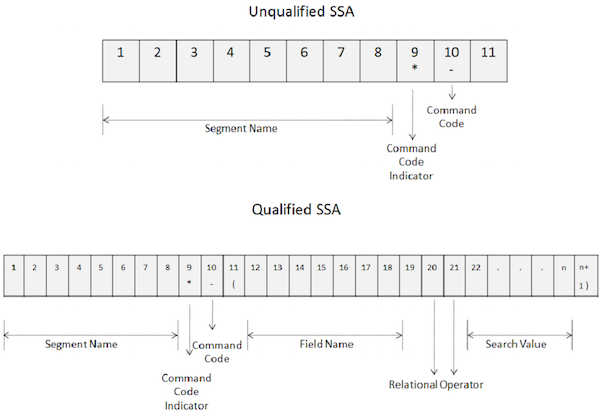
Befehlscodes werden verwendet, um die Funktionalität von DL / I-Aufrufen zu verbessern. Befehlscodes reduzieren die Anzahl der DL / I-Aufrufe, wodurch die Programme einfach werden. Außerdem wird die Leistung verbessert, da die Anzahl der Anrufe verringert wird. Das folgende Bild zeigt, wie Befehlscodes in nicht qualifizierten und qualifizierten SSAs verwendet werden.
Die wichtigsten Punkte von Befehlscodes sind wie folgt:
Um Befehlscodes zu verwenden, gibt ein Sternchen in der 9 - ten Position des SSA wie in der obigen Abbildung dargestellt.
Der Befehlscode ist an der zehnten Stelle codiert.
Vom 10. - ten ab Position hält DL / I alle Zeichen Befehlscodes sein , bis sie einen Platz für einen nicht qualifizierten SSA und eine linke Klammer für eine qualifizierte SSA treffen.
Die folgende Tabelle zeigt die Liste der in SSA verwendeten Befehlscodes -
| Befehlscode | Beschreibung |
|---|---|
| C. | Verketteter Schlüssel |
| D. | Pfadaufruf |
| F. | Erstes Auftreten |
| L. | Letztes Vorkommen |
| N. | Pfadaufruf ignorieren |
| P. | Elternschaft festlegen |
| Q. | Segment in die Warteschlange stellen |
| U. | Position auf dieser Ebene halten |
| V. | Behalten Sie die Position auf dieser und allen oben genannten Ebenen bei |
| - - | Null-Befehlscode |
Mehrere Qualifikationen
Die grundlegenden Punkte mehrerer Qualifikationen sind wie folgt:
Mehrere Qualifikationen sind erforderlich, wenn zwei oder mehr Qualifikationen oder Felder zum Vergleich verwendet werden müssen.
Wir verwenden Boolesche Operatoren wie AND und OR, um zwei oder mehr Qualifikationen zu verbinden.
Mehrere Qualifikationen können verwendet werden, wenn ein Segment basierend auf einem Bereich möglicher Werte für ein einzelnes Feld verarbeitet werden soll.
Unten ist die Syntax von Multiple Qualifications angegeben -
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME1 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE1 PIC X(m).
05 MUL-QUAL PIC X VALUE '&'.
05 FIELD-NAME2 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE2 PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.MUL-QUAL ist eine Kurzform für MULtiple QUALIification, in der wir boolesche Operatoren wie AND oder OR bereitstellen können.
Die verschiedenen Datenabrufmethoden, die in IMS DL / I-Aufrufen verwendet werden, sind wie folgt:
- GU Anruf
- GN Anruf
- Befehlscodes verwenden
- Mehrfachverarbeitung
Betrachten wir die folgende IMS-Datenbankstruktur, um die Aufrufe der Datenabruffunktion zu verstehen:
GU Anruf
Die Grundlagen des GU-Aufrufs sind wie folgt:
Der GU-Aufruf wird als Get Unique Call bezeichnet. Es wird für die zufällige Verarbeitung verwendet.
Wenn eine Anwendung die Datenbank nicht regelmäßig aktualisiert oder wenn die Anzahl der Datenbankaktualisierungen geringer ist, verwenden wir eine zufällige Verarbeitung.
Der GU-Aufruf wird verwendet, um den Zeiger an einer bestimmten Position zum weiteren sequentiellen Abrufen zu platzieren.
GU-Aufrufe sind unabhängig von der Zeigerposition, die durch die vorherigen Aufrufe festgelegt wurde.
Die GU-Anrufverarbeitung basiert auf den eindeutigen Schlüsselfeldern, die in der Aufrufanweisung angegeben sind.
Wenn wir ein Schlüsselfeld angeben, das nicht eindeutig ist, gibt DL / I das erste Segmentvorkommen des Schlüsselfelds zurück.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSADas obige Beispiel zeigt, dass wir einen GU-Aufruf ausgeben, indem wir einen vollständigen Satz qualifizierter SSAs bereitstellen. Es enthält alle Schlüsselfelder von der Stammebene bis zum Segmentvorkommen, das wir abrufen möchten.
Überlegungen zu GU-Anrufen
Wenn wir im Aufruf nicht den vollständigen Satz qualifizierter SSAs bereitstellen, funktioniert DL / I folgendermaßen:
Wenn wir in einem GU-Aufruf einen nicht qualifizierten SSA verwenden, greift DL / I auf das erste Segmentvorkommen in der Datenbank zu, das die von Ihnen angegebenen Kriterien erfüllt.
Wenn wir einen GU-Aufruf ohne SSAs ausgeben, gibt DL / I das erste Vorkommen des Stammsegments in der Datenbank zurück.
Wenn einige SSAs auf mittleren Ebenen im Aufruf nicht erwähnt werden, verwendet DL / I entweder die festgelegte Position oder den Standardwert eines nicht qualifizierten SSA für das Segment.
Statuscodes
Die folgende Tabelle zeigt die relevanten Statuscodes nach einem GU-Aufruf -
| S.No. | Statuscode & Beschreibung |
|---|---|
| 1 | Spaces Erfolgreicher Anruf |
| 2 | GE DL / I konnte kein Segment finden, das die im Aufruf angegebenen Kriterien erfüllt |
GN Anruf
Die Grundlagen des GN-Aufrufs sind wie folgt:
Der GN-Anruf wird als Get Next-Anruf bezeichnet. Es wird für die grundlegende sequentielle Verarbeitung verwendet.
Die Anfangsposition des Zeigers in der Datenbank befindet sich vor dem Stammsegment des ersten Datenbankdatensatzes.
Die Datenbankzeigerposition befindet sich vor dem nächsten Segmentvorkommen in der Sequenz nach einem erfolgreichen GN-Aufruf.
Der GN-Anruf startet über die Datenbank an der Position, die durch den vorherigen Anruf festgelegt wurde.
Wenn ein GN-Aufruf nicht qualifiziert ist, gibt er das nächste Segmentvorkommen in der Datenbank unabhängig von seinem Typ in hierarchischer Reihenfolge zurück.
Wenn ein GN-Aufruf SSAs enthält, ruft DL / I nur Segmente ab, die die Anforderungen aller angegebenen SSAs erfüllen.
CALL 'CBLTDLI' USING DLI-GN
PCB-NAME
IO-AREA
BOOKS-SSADas obige Beispiel zeigt, dass wir einen GN-Aufruf ausgeben, der die Startposition zum sequentiellen Lesen der Datensätze bereitstellt. Es ruft das erste Auftreten des BOOKS-Segments ab.
Statuscodes
Die folgende Tabelle zeigt die relevanten Statuscodes nach einem GN-Anruf -
| S.No. | Statuscode & Beschreibung |
|---|---|
| 1 | Spaces Erfolgreicher Anruf |
| 2 | GE DL / I konnte kein Segment finden, das die im Aufruf angegebenen Kriterien erfüllt. |
| 3 | GA Ein nicht qualifizierter GN-Aufruf wird in der Datenbankhierarchie um eine Ebene nach oben verschoben, um das Segment abzurufen. |
| 4 | GB Das Ende der Datenbank ist erreicht und das Segment wurde nicht gefunden. |
GK Ein nicht qualifizierter GN-Aufruf versucht, ein Segment eines anderen Typs als das gerade abgerufene abzurufen, bleibt jedoch auf derselben Hierarchieebene. |
Befehlscodes
Befehlscodes werden bei Aufrufen verwendet, um ein Segmentvorkommen abzurufen. Die verschiedenen Befehlscodes, die bei Aufrufen verwendet werden, werden unten erläutert.
F Befehlscode
Zu beachtende Punkte -
Wenn in einem Aufruf ein F-Befehlscode angegeben wird, verarbeitet der Aufruf das erste Auftreten des Segments.
F-Befehlscodes können verwendet werden, wenn wir nacheinander verarbeiten möchten, und sie können mit GN-Aufrufen und GNP-Aufrufen verwendet werden.
Wenn wir bei einem GU-Aufruf einen F-Befehlscode angeben, hat dieser keine Bedeutung, da GU-Aufrufe standardmäßig das erste Segmentvorkommen abrufen.
L Befehlscode
Zu beachtende Punkte -
Wenn in einem Aufruf ein L-Befehlscode angegeben wird, verarbeitet der Aufruf das letzte Vorkommen des Segments.
L-Befehlscodes können verwendet werden, wenn sie nacheinander verarbeitet werden sollen, und sie können mit GN-Aufrufen und GNP-Aufrufen verwendet werden.
D Befehlscode
Zu beachtende Punkte -
Der Befehlscode D wird verwendet, um mehr als ein Segmentvorkommen mit nur einem einzigen Aufruf abzurufen.
Normalerweise arbeitet DL / I mit dem Segment der niedrigsten Ebene, das in einem SSA angegeben ist. In vielen Fällen möchten wir jedoch auch Daten von anderen Ebenen. In diesen Fällen können wir den D-Befehlscode verwenden.
Der Befehlscode D erleichtert das Abrufen des gesamten Segmentpfads.
C Befehlscode
Zu beachtende Punkte -
Der C-Befehlscode wird zum Verketten von Schlüsseln verwendet.
Die Verwendung von Vergleichsoperatoren ist etwas komplex, da wir einen Feldnamen, einen Vergleichsoperator und einen Suchwert angeben müssen. Stattdessen können wir einen C-Befehlscode verwenden, um einen verketteten Schlüssel bereitzustellen.
Das folgende Beispiel zeigt die Verwendung des C-Befehlscodes -
01 LOCATION-SSA.
05 FILLER PIC X(11) VALUE ‘INLOCSEG*C(‘.
05 LIBRARY-SSA PIC X(5).
05 BOOKS-SSA PIC X(4).
05 ENGINEERING-SSA PIC X(6).
05 IT-SSA PIC X(3)
05 FILLER PIC X VALUE ‘)’.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LOCATION-SSAP Befehlscode
Zu beachtende Punkte -
Wenn wir einen GU- oder GN-Aufruf ausgeben, stellt der DL / I seine Abstammung auf dem Segment der untersten Ebene her, das abgerufen wird.
Wenn wir einen P-Befehlscode einfügen, legt der DL / I seine Abstammung auf einem übergeordneten Segment im hierarchischen Pfad fest.
U Befehlscode
Zu beachtende Punkte -
Wenn in einem nicht qualifizierten SSA in einem GN-Aufruf ein U-Befehlscode angegeben wird, schränkt der DL / I die Suche nach dem Segment ein.
U-Befehlscode wird ignoriert, wenn er mit einem qualifizierten SSA verwendet wird.
V Befehlscode
Zu beachtende Punkte -
Der V-Befehlscode funktioniert ähnlich wie der U-Befehlscode, beschränkt jedoch die Suche nach einem Segment auf einer bestimmten Ebene und auf allen Ebenen über der Hierarchie.
Der V-Befehlscode wird bei Verwendung mit einem qualifizierten SSA ignoriert.
Q Befehlscode
Zu beachtende Punkte -
Der Q-Befehlscode wird verwendet, um ein Segment für die ausschließliche Verwendung Ihres Anwendungsprogramms in die Warteschlange zu stellen oder zu reservieren.
Der Q-Befehlscode wird in einer interaktiven Umgebung verwendet, in der ein anderes Programm möglicherweise Änderungen an einem Segment vornimmt.
Mehrfachverarbeitung
Ein Programm kann mehrere Positionen in der IMS-Datenbank haben, was als Mehrfachverarbeitung bezeichnet wird. Die Mehrfachverarbeitung kann auf zwei Arten erfolgen:
- Mehrere Leiterplatten
- Mehrfachpositionierung
Mehrere Leiterplatten
Für eine Datenbank können mehrere Leiterplatten definiert werden. Wenn mehrere Leiterplatten vorhanden sind, kann ein Anwendungsprogramm unterschiedliche Ansichten davon haben. Diese Methode zum Implementieren der Mehrfachverarbeitung ist aufgrund des durch die zusätzlichen Leiterplatten verursachten Overheads ineffizient.
Mehrfachpositionierung
Ein Programm kann mit einer einzigen Leiterplatte mehrere Positionen in einer Datenbank verwalten. Dies wird erreicht, indem für jeden hierarchischen Pfad eine eigene Position beibehalten wird. Die Mehrfachpositionierung wird verwendet, um gleichzeitig auf Segmente von zwei oder mehr Typen gleichzeitig zuzugreifen.
Die verschiedenen Datenmanipulationsmethoden, die in IMS DL / I-Aufrufen verwendet werden, sind wie folgt:
- ISRT-Anruf
- Halten Sie Anrufe
- REPL Anruf
- DLET-Aufruf
Betrachten wir die folgende IMS-Datenbankstruktur, um die Aufrufe der Datenmanipulationsfunktion zu verstehen:
ISRT-Anruf
Zu beachtende Punkte -
Der ISRT-Aufruf wird als Insert-Aufruf bezeichnet, mit dem einer Datenbank Segmentvorkommen hinzugefügt werden.
ISRT-Aufrufe werden zum Laden einer neuen Datenbank verwendet.
Wir geben einen ISRT-Aufruf aus, wenn ein Segmentbeschreibungsfeld mit Daten geladen wird.
Im Aufruf muss eine nicht qualifizierte oder qualifizierte SSA angegeben werden, damit der DL / I weiß, wo ein Segmentvorkommen platziert werden soll.
Wir können im Anruf eine Kombination aus nicht qualifiziertem und qualifiziertem SSA verwenden. Für alle oben genannten Ebenen kann eine qualifizierte SSA angegeben werden. Betrachten wir das folgende Beispiel:
CALL 'CBLTDLI' USING DLI-ISRT
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
UNQUALIFIED-ENGINEERING-SSADas obige Beispiel zeigt, dass wir einen ISRT-Aufruf ausgeben, indem wir eine Kombination aus qualifizierten und nicht qualifizierten SSAs bereitstellen.
Wenn ein neues Segment, das wir einfügen, ein eindeutiges Schlüsselfeld hat, wird es an der richtigen Position hinzugefügt. Wenn das Schlüsselfeld nicht eindeutig ist, wird es durch die von einem Datenbankadministrator definierten Regeln hinzugefügt.
Wenn wir einen ISRT-Aufruf ohne Angabe eines Schlüsselfelds ausgeben, gibt die Einfügeregel an, wo die Segmente relativ zu vorhandenen Zwillingssegmenten platziert werden sollen. Unten sind die Einfügeregeln angegeben -
First - Wenn die Regel an erster Stelle steht, wird das neue Segment vor vorhandenen Zwillingen hinzugefügt.
Last - Wenn die Regel die letzte ist, wird das neue Segment nach allen vorhandenen Zwillingen hinzugefügt.
Here - Wenn die Regel hier ist, wird sie an der aktuellen Position relativ zu vorhandenen Zwillingen hinzugefügt, die zuerst, zuletzt oder irgendwo sein können.
Statuscodes
Die folgende Tabelle zeigt die relevanten Statuscodes nach einem ISRT-Aufruf -
| S.No. | Statuscode & Beschreibung |
|---|---|
| 1 | Spaces Erfolgreicher Anruf |
| 2 | GE Es werden mehrere SSAs verwendet, und der DL / I kann den Anruf nicht mit dem angegebenen Pfad erfüllen. |
| 3 | II Versuchen Sie, ein Segmentvorkommen hinzuzufügen, das bereits in der Datenbank vorhanden ist. |
| 4 | LB / LC LD / LE Wir erhalten diese Statuscodes während der Ladeverarbeitung. In den meisten Fällen weisen sie darauf hin, dass Sie die Segmente nicht in einer exakten hierarchischen Reihenfolge einfügen. |
Halten Sie einen Anruf
Zu beachtende Punkte -
Es gibt drei Arten von Get Hold-Anrufen, die wir in einem DL / I-Aufruf angeben:
Get Hold Unique (GHU)
Als nächstes festhalten (GHN)
Als nächstes in Parent (GHNP) festhalten
Die Hold-Funktion gibt an, dass das Segment nach dem Abrufen aktualisiert wird. Vor einem REPL- oder DLET-Aufruf muss daher ein erfolgreicher Hold-Aufruf ausgegeben werden, der dem DL / I die Absicht mitteilt, die Datenbank zu aktualisieren.
REPL Anruf
Zu beachtende Punkte -
Nach einem erfolgreichen Get Hold Hold-Aufruf geben wir einen REPL-Aufruf aus, um ein Segmentvorkommen zu aktualisieren.
Wir können die Länge eines Segments nicht mit einem REPL-Aufruf ändern.
Wir können den Wert eines Schlüsselfelds nicht mit einem REPL-Aufruf ändern.
Wir können keine qualifizierte SSA mit einem REPL-Aufruf verwenden. Wenn wir einen qualifizierten SSA angeben, schlägt der Aufruf fehl.
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
*Move the values which you want to update in IT segment occurrence*
CALL ‘CBLTDLI’ USING DLI-REPL
PCB-NAME
IO-AREA.Das obige Beispiel aktualisiert das Auftreten von IT-Segmenten mithilfe eines REPL-Aufrufs. Zuerst geben wir einen GHU-Aufruf aus, um das Segmentvorkommen abzurufen, das wir aktualisieren möchten. Anschließend geben wir einen REPL-Aufruf aus, um die Werte dieses Segments zu aktualisieren.
DLET-Aufruf
Zu beachtende Punkte -
Der DLET-Aufruf funktioniert ähnlich wie ein REPL-Aufruf.
Nach einem erfolgreichen Get-Hold-Aufruf geben wir einen DLET-Aufruf aus, um ein Segmentvorkommen zu löschen.
Wir können keinen qualifizierten SSA mit einem DLET-Aufruf verwenden. Wenn wir einen qualifizierten SSA angeben, schlägt der Aufruf fehl.
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
CALL ‘CBLTDLI’ USING DLI-DLET
PCB-NAME
IO-AREA.Im obigen Beispiel wird das Auftreten des IT-Segments mithilfe eines DLET-Aufrufs gelöscht. Zuerst geben wir einen GHU-Aufruf aus, um das Segmentvorkommen abzurufen, das wir löschen möchten. Anschließend geben wir einen DLET-Aufruf aus, um die Werte dieses Segments zu aktualisieren.
Statuscodes
Die folgende Tabelle zeigt die relevanten Statuscodes nach einem REPL- oder DLET-Aufruf -
| S.No. | Statuscode & Beschreibung |
|---|---|
| 1 | Spaces Erfolgreicher Anruf |
| 2 | AJ Qualifizierter SSA, der beim REPL- oder DLET-Aufruf verwendet wird. |
| 3 | DJ Das Programm gibt einen Ersetzungsaufruf ohne unmittelbar vorhergehenden Abruf aus. |
| 4 | DA Das Programm ändert das Schlüsselfeld des Segments, bevor der REPL- oder DLET-Aufruf ausgegeben wird |
Die Sekundärindizierung wird verwendet, wenn wir auf eine Datenbank zugreifen möchten, ohne den vollständigen verketteten Schlüssel zu verwenden, oder wenn wir die primären Primärfelder nicht verwenden möchten.
Indexzeigersegment
DL / I speichert den Zeiger auf Segmente der indizierten Datenbank in einer separaten Datenbank. Das Indexzeigersegment ist die einzige Art von Sekundärindex. Es besteht aus zwei Teilen -
- Präfixelement
- Datenelement
Präfixelement
Der Präfixteil des Indexzeigersegments enthält einen Zeiger auf das Indexzielsegment. Das Indexzielsegment ist das Segment, auf das über den Sekundärindex zugegriffen werden kann.
Datenelement
Das Datenelement enthält den Schlüsselwert aus dem Segment in der indizierten Datenbank, über die der Index erstellt wird. Dies wird auch als Indexquellensegment bezeichnet.
Hier sind die wichtigsten Punkte zur Sekundärindizierung:
Das Indexquellsegment und das Zielquellensegment müssen nicht identisch sein.
Wenn wir einen Sekundärindex einrichten, wird dieser automatisch vom DL / I verwaltet.
Der DBA definiert viele Sekundärindizes gemäß den Mehrfachzugriffspfaden. Diese Sekundärindizes werden in einer separaten Indexdatenbank gespeichert.
Wir sollten keine weiteren Sekundärindizes erstellen, da diese dem DL / I zusätzlichen Verarbeitungsaufwand auferlegen.
Sekundärschlüssel
Zu beachtende Punkte -
Das Feld im Indexquellensegment, über das der Sekundärindex erstellt wird, wird als Sekundärschlüssel bezeichnet.
Jedes Feld kann als Sekundärschlüssel verwendet werden. Es muss nicht das Segmentsequenzfeld sein.
Sekundärschlüssel können eine beliebige Kombination einzelner Felder innerhalb des Indexquellensegments sein.
Sekundärschlüsselwerte müssen nicht eindeutig sein.
Sekundäre Datenstrukturen
Zu beachtende Punkte -
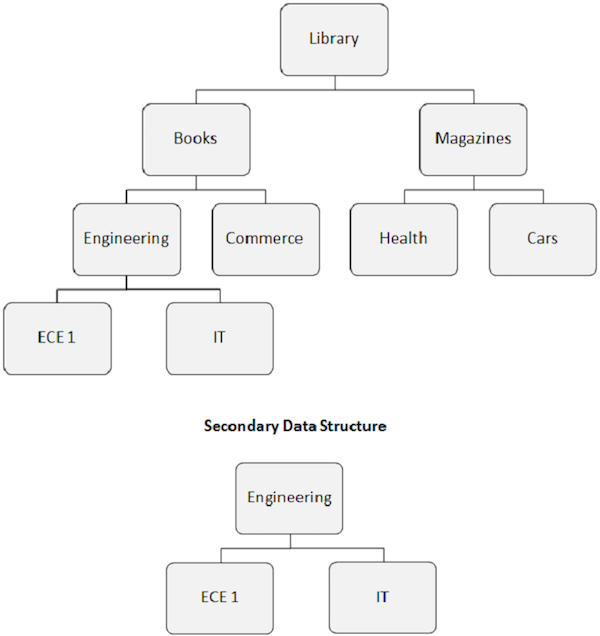
Wenn wir einen Sekundärindex erstellen, wird auch die scheinbare hierarchische Struktur der Datenbank geändert.
Das Indexzielsegment wird zum scheinbaren Wurzelsegment. Wie in der folgenden Abbildung gezeigt, wird das Engineering-Segment zum Stammsegment, auch wenn es kein Stammsegment ist.
Die durch den Sekundärindex verursachte Neuordnung der Datenbankstruktur wird als Sekundärdatenstruktur bezeichnet.
Sekundäre Datenstrukturen nehmen keine Änderungen an der auf der Festplatte vorhandenen physischen Hauptdatenbankstruktur vor. Dies ist nur eine Möglichkeit, die Datenbankstruktur vor dem Anwendungsprogramm zu ändern.
Unabhängiger UND-Betreiber
Zu beachtende Punkte -
Wenn ein AND-Operator (* oder &) mit Sekundärindizes verwendet wird, wird er als abhängiger AND-Operator bezeichnet.
Ein unabhängiges UND (#) ermöglicht es uns, Qualifikationen anzugeben, die mit einem abhängigen UND unmöglich wären.
Dieser Operator kann nur für Sekundärindizes verwendet werden, bei denen das Indexquellsegment vom Indexzielsegment abhängig ist.
Wir können eine SSA mit einem unabhängigen UND codieren, um anzugeben, dass ein Vorkommen des Zielsegments basierend auf den Feldern in zwei oder mehr abhängigen Quellensegmenten verarbeitet wird.
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.Sparsame Sequenzierung
Zu beachtende Punkte -
Sparse Sequencing wird auch als Sparse Indexing bezeichnet. Wir können einige der Indexquellensegmente mithilfe einer spärlichen Sequenzierung mit einer sekundären Indexdatenbank aus dem Index entfernen.
Eine sparsame Sequenzierung wird verwendet, um die Leistung zu verbessern. Wenn einige Vorkommen des Indexquellensegments nicht verwendet werden, können wir dies entfernen.
DL / I verwendet einen Unterdrückungswert oder eine Unterdrückungsroutine oder beides, um zu bestimmen, ob ein Segment indiziert werden soll.
Wenn der Wert eines Sequenzfelds im Indexquellensegment mit einem Unterdrückungswert übereinstimmt, wird keine Indexbeziehung hergestellt.
Die Unterdrückungsroutine ist ein vom Benutzer geschriebenes Programm, das das Segment auswertet und bestimmt, ob es indiziert werden soll oder nicht.
Wenn eine spärliche Indizierung verwendet wird, werden ihre Funktionen vom DL / I übernommen. Wir müssen im Antragsprogramm keine besonderen Vorkehrungen treffen.
DBDGEN-Anforderungen
Wie in früheren Modulen erläutert, wird DBDGEN zum Erstellen einer DBD verwendet. Beim Erstellen von Sekundärindizes sind zwei Datenbanken beteiligt. Ein DBA muss zwei DBDs mit zwei DBDGENs erstellen, um eine Beziehung zwischen einer indizierten Datenbank und einer sekundären indizierten Datenbank herzustellen.
PSBGEN-Anforderungen
Nach dem Erstellen des Sekundärindex für eine Datenbank muss der DBA die PSBs erstellen. PSBGEN für das Programm gibt die richtige Verarbeitungssequenz für die Datenbank im Parameter PROCSEQ des PSB-Makros an. Für den Parameter PROCSEQ codiert der DBA den DBD-Namen für die Sekundärindexdatenbank.
In der IMS-Datenbank gilt die Regel, dass jeder Segmenttyp nur ein übergeordnetes Element haben darf. Dies begrenzt die Komplexität der physischen Datenbank. Viele DL / I-Anwendungen erfordern eine komplexe Struktur, die es einem Segment ermöglicht, zwei übergeordnete Segmenttypen zu haben. Um diese Einschränkung zu überwinden, ermöglicht DL / I dem DBA, logische Beziehungen zu implementieren, in denen ein Segment sowohl physische als auch logische Eltern haben kann. Wir können zusätzliche Beziehungen innerhalb einer physischen Datenbank erstellen. Die neue Datenstruktur nach der Implementierung der logischen Beziehung wird als logische Datenbank bezeichnet.
Logische Beziehung
Eine logische Beziehung hat die folgenden Eigenschaften:
Eine logische Beziehung ist ein Pfad zwischen zwei Segmenten, die logisch und nicht physisch miteinander verbunden sind.
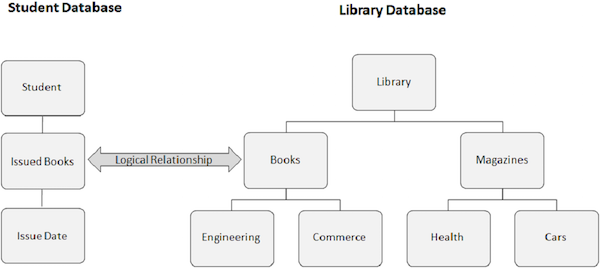
Normalerweise wird eine logische Beziehung zwischen separaten Datenbanken hergestellt. Es ist jedoch möglich, eine Beziehung zwischen den Segmenten einer bestimmten Datenbank herzustellen.
Das folgende Bild zeigt zwei verschiedene Datenbanken. Eine ist eine Studentendatenbank und die andere ist eine Bibliotheksdatenbank. Wir erstellen eine logische Beziehung zwischen dem Segment "Bücher ausgestellt" aus der Studentendatenbank und dem Segment "Bücher" aus der Bibliotheksdatenbank.
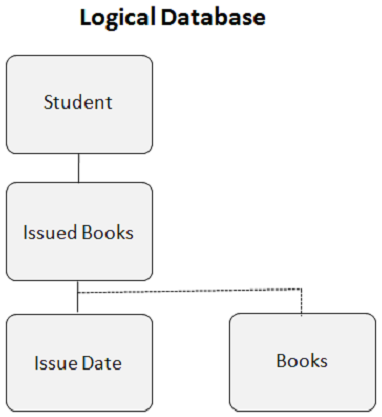
So sieht die logische Datenbank aus, wenn Sie eine logische Beziehung erstellen -
Logisches untergeordnetes Segment
Das logische untergeordnete Segment ist die Grundlage einer logischen Beziehung. Es ist ein physisches Datensegment, aber für DL / I scheint es, als hätte es zwei Eltern. Das Buchsegment im obigen Beispiel hat zwei übergeordnete Segmente. Das Segment "Ausgestellte Bücher" ist das logische übergeordnete Element und das Segment "Bibliothek" das physische übergeordnete Element. Ein logisches untergeordnetes Segmentvorkommen hat nur ein logisches übergeordnetes Segmentvorkommen, und ein logisches übergeordnetes Segmentvorkommen kann viele logische untergeordnete Segmentvorkommen haben.
Logische Zwillinge
Logische Zwillinge sind die Vorkommen eines logischen untergeordneten Segmenttyps, die alle einem einzelnen Vorkommen des logischen übergeordneten Segmenttyps untergeordnet sind. DL / I lässt das logische untergeordnete Segment einem tatsächlichen physischen untergeordneten Segment ähnlich erscheinen. Dies wird auch als virtuelles logisches untergeordnetes Segment bezeichnet.
Arten von logischen Beziehungen
Ein DBA erstellt logische Beziehungen zwischen Segmenten. Um eine logische Beziehung zu implementieren, muss der DBA sie in den DBDGENs für die beteiligten physischen Datenbanken angeben. Es gibt drei Arten von logischen Beziehungen:
- Unidirectional
- Bidirektionale virtuelle
- Bidirektionale physikalische
Unidirektional
Die logische Verbindung geht vom logischen Kind zum logischen Elternteil und kann nicht umgekehrt sein.
Bidirektionale virtuelle
Es ermöglicht den Zugang in beide Richtungen. Das logische Kind in seiner physischen Struktur und das entsprechende virtuelle logische Kind können als gepaarte Segmente angesehen werden.
Bidirektionale physikalische
Das logische Kind ist ein physisch gespeicherter Untergebener sowohl seiner physischen als auch seiner logischen Eltern. Für Anwendungsprogramme sieht es genauso aus wie ein bidirektionales virtuelles logisches Kind.
Programmierüberlegungen
Die Programmierüberlegungen für die Verwendung einer logischen Datenbank lauten wie folgt:
DL / I-Aufrufe für den Zugriff auf die Datenbank bleiben auch bei der logischen Datenbank gleich.
Der Programmspezifikationsblock gibt die Struktur an, die wir in unseren Aufrufen verwenden. In einigen Fällen können wir nicht feststellen, dass wir eine logische Datenbank verwenden.
Logische Beziehungen fügen der Datenbankprogrammierung eine neue Dimension hinzu.
Sie müssen beim Arbeiten mit logischen Datenbanken vorsichtig sein, da zwei Datenbanken zusammen integriert sind. Wenn Sie eine Datenbank ändern, müssen dieselben Änderungen in der anderen Datenbank übernommen werden.
Programmspezifikationen sollten angeben, welche Verarbeitung in einer Datenbank zulässig ist. Wenn eine Verarbeitungsregel verletzt wird, erhalten Sie einen nicht leeren Statuscode.
Verkettetes Segment
Ein logisches untergeordnetes Segment beginnt immer mit dem vollständigen verketteten Schlüssel des übergeordneten Ziels. Dies wird als DPCK (Destination Parent Concatenated Key) bezeichnet. Sie müssen das DPCK immer am Anfang Ihres Segment-E / A-Bereichs für ein logisches Kind codieren. In einer logischen Datenbank stellt das verkettete Segment die Verbindung zwischen Segmenten her, die in verschiedenen physischen Datenbanken definiert sind. Ein verkettetes Segment besteht aus den folgenden zwei Teilen:
- Logisches untergeordnetes Segment
- Übergeordnetes Zielsegment
Ein logisches untergeordnetes Segment besteht aus den folgenden zwei Teilen:
- Verketteter Zielschlüssel (DPCK)
- Logische untergeordnete Benutzerdaten

Wenn wir während der Aktualisierung mit verketteten Segmenten arbeiten, können die Daten möglicherweise sowohl im logischen untergeordneten als auch im übergeordneten Ziel mit einem einzigen Aufruf hinzugefügt oder geändert werden. Dies hängt auch von den Regeln ab, die der DBA für die Datenbank angegeben hat. Stellen Sie für einen Einsatz das DPCK in der richtigen Position bereit. Ändern Sie zum Ersetzen oder Löschen weder das DPCK noch die Sequenzfelddaten in einem Teil des verketteten Segments.
Der Datenbankadministrator muss die Datenbankwiederherstellung bei Systemfehlern planen. Es gibt viele Arten von Fehlern, z. B. Anwendungsabstürze, Hardwarefehler, Stromausfälle usw.
Einfacher Ansatz
Einige einfache Ansätze zur Datenbankwiederherstellung sind wie folgt:
Erstellen Sie regelmäßig Sicherungskopien wichtiger Datensätze, damit alle für die Datensätze gebuchten Transaktionen beibehalten werden.
Wenn ein Dataset aufgrund eines Systemfehlers beschädigt wird, wird dieses Problem durch Wiederherstellen der Sicherungskopie behoben. Anschließend werden die akkumulierten Transaktionen erneut auf die Sicherungskopie gebucht, um sie auf den neuesten Stand zu bringen.
Nachteile des einfachen Ansatzes
Die Nachteile eines einfachen Ansatzes zur Datenbankwiederherstellung sind folgende:
Das erneute Buchen der akkumulierten Transaktionen nimmt viel Zeit in Anspruch.
Alle anderen Anwendungen müssen auf die Ausführung warten, bis die Wiederherstellung abgeschlossen ist.
Die Datenbankwiederherstellung ist länger als die Dateiwiederherstellung, wenn logische und sekundäre Indexbeziehungen beteiligt sind.
Abnormale Beendigungsroutinen
Ein DL / I-Programm stürzt anders ab als ein Standardprogramm, da ein Standardprogramm direkt vom Betriebssystem ausgeführt wird, ein DL / I-Programm jedoch nicht. Durch die Verwendung einer abnormalen Beendigungsroutine stört das System, so dass die Wiederherstellung nach dem ABnormal END (ABEND) erfolgen kann. Die Routine für abnormale Beendigung führt die folgenden Aktionen aus:
- Schließt alle Datensätze
- Bricht alle ausstehenden Jobs in der Warteschlange ab
- Erstellt einen Speicherauszug, um die Grundursache von ABEND herauszufinden
Die Einschränkung dieser Routine besteht darin, dass nicht sichergestellt wird, ob die verwendeten Daten korrekt sind oder nicht.
DL / I-Protokoll
Wenn ein Anwendungsprogramm abbricht, müssen die vom Anwendungsprogramm vorgenommenen Änderungen rückgängig gemacht, der Fehler behoben und das Anwendungsprogramm erneut ausgeführt werden. Dazu ist das DL / I-Protokoll erforderlich. Hier sind die wichtigsten Punkte zur DL / I-Protokollierung:
Ein DL / I zeichnet alle von einem Anwendungsprogramm vorgenommenen Änderungen in einer Datei auf, die als Protokolldatei bezeichnet wird.
Wenn das Anwendungsprogramm ein Segment ändert, werden seine Vorabbilder und Nachbilder vom DL / I erstellt.
Diese Segmentabbilder können zum Wiederherstellen der Segmente verwendet werden, falls das Anwendungsprogramm abstürzt.
DL / I verwendet eine Technik namens Write-Ahead-Protokollierung, um Datenbankänderungen aufzuzeichnen. Bei der Vorausschreibprotokollierung wird eine Datenbankänderung in das Protokolldatensatz geschrieben, bevor sie in das tatsächliche Dataset geschrieben wird.
Da sich das Protokoll immer vor der Datenbank befindet, können die Wiederherstellungsdienstprogramme den Status jeder Datenbankänderung ermitteln.
Wenn das Programm einen Aufruf zum Ändern eines Datenbanksegments ausführt, kümmert sich der DL / I um seinen Protokollierungsteil.
Wiederherstellung - vorwärts und rückwärts
Die beiden Ansätze der Datenbankwiederherstellung sind:
Forward Recovery - DL / I verwendet die Protokolldatei zum Speichern der Änderungsdaten. Die akkumulierten Transaktionen werden mithilfe dieser Protokolldatei erneut gebucht.
Backward Recovery- Die Rückwärtswiederherstellung wird auch als Backout-Wiederherstellung bezeichnet. Die Protokollsätze für das Programm werden rückwärts gelesen und ihre Auswirkungen in der Datenbank umgekehrt. Wenn das Backout abgeschlossen ist, befinden sich die Datenbanken in demselben Zustand wie vor dem Fehler, vorausgesetzt, dass in der Zwischenzeit kein anderes Anwendungsprogramm die Datenbank geändert hat.
Kontrollpunkt
Ein Prüfpunkt ist eine Phase, in der die vom Anwendungsprogramm vorgenommenen Datenbankänderungen als vollständig und genau angesehen werden. Nachfolgend sind die Punkte aufgeführt, die bei einem Checkpoint zu beachten sind.
Datenbankänderungen, die vor dem letzten Prüfpunkt vorgenommen wurden, werden durch die Rückwärtswiederherstellung nicht rückgängig gemacht.
Datenbankänderungen, die nach dem letzten Prüfpunkt protokolliert wurden, werden während der Vorwärtswiederherstellung nicht auf eine Image-Kopie der Datenbank angewendet.
Mit der Checkpoint-Methode wird die Datenbank am letzten Checkpoint nach Abschluss des Wiederherstellungsprozesses in ihren Zustand zurückversetzt.
Die Standardeinstellung für Stapelverarbeitungsprogramme ist, dass der Prüfpunkt der Anfang des Programms ist.
Ein Checkpoint kann mit einem Checkpoint Call (CHKP) eingerichtet werden.
Ein Checkpoint-Aufruf bewirkt, dass ein Checkpoint-Datensatz in das DL / I-Protokoll geschrieben wird.
Unten ist die Syntax eines CHKP-Aufrufs dargestellt -
CALL 'CBLTDLI' USING DLI-CHKP
PCB-NAME
CHECKPOINT-IDEs gibt zwei Checkpoint-Methoden:
Basic Checkpointing - Der Programmierer kann Prüfpunktaufrufe ausgeben, die die DL / I-Wiederherstellungsdienstprogramme während der Wiederherstellungsverarbeitung verwenden.
Symbolic Checkpointing- Es handelt sich um eine erweiterte Form des Checkpointing, die in Kombination mit der erweiterten Neustartfunktion verwendet wird. Durch symbolisches Checkpointing und erweiterten Neustart kann der Anwendungsprogrammierer die Programme so codieren, dass sie die Verarbeitung am Punkt unmittelbar nach dem Checkpoint wieder aufnehmen können.