IMS DB - Sekundärindizierung
Die Sekundärindizierung wird verwendet, wenn auf eine Datenbank zugegriffen werden soll, ohne den vollständigen verketteten Schlüssel zu verwenden, oder wenn die primären Primärfelder nicht verwendet werden sollen.
Indexzeigersegment
DL / I speichert den Zeiger auf Segmente der indizierten Datenbank in einer separaten Datenbank. Das Indexzeigersegment ist die einzige Art von Sekundärindex. Es besteht aus zwei Teilen -
- Präfixelement
- Datenelement
Präfixelement
Der Präfixteil des Indexzeigersegments enthält einen Zeiger auf das Indexzielsegment. Das Indexzielsegment ist das Segment, auf das über den Sekundärindex zugegriffen werden kann.
Datenelement
Das Datenelement enthält den Schlüsselwert aus dem Segment in der indizierten Datenbank, über die der Index erstellt wird. Dies wird auch als Indexquellensegment bezeichnet.
Hier sind die wichtigsten Punkte zur Sekundärindizierung:
Das Indexquellsegment und das Zielquellensegment müssen nicht identisch sein.
Wenn wir einen Sekundärindex einrichten, wird dieser automatisch vom DL / I verwaltet.
Der DBA definiert viele Sekundärindizes gemäß den Mehrfachzugriffspfaden. Diese Sekundärindizes werden in einer separaten Indexdatenbank gespeichert.
Wir sollten keine weiteren Sekundärindizes erstellen, da diese dem DL / I zusätzlichen Verarbeitungsaufwand auferlegen.
Sekundärschlüssel
Zu beachtende Punkte -
Das Feld im Indexquellensegment, über das der Sekundärindex erstellt wird, wird als Sekundärschlüssel bezeichnet.
Jedes Feld kann als Sekundärschlüssel verwendet werden. Es muss nicht das Segmentsequenzfeld sein.
Sekundärschlüssel können eine beliebige Kombination einzelner Felder innerhalb des Indexquellensegments sein.
Sekundärschlüsselwerte müssen nicht eindeutig sein.
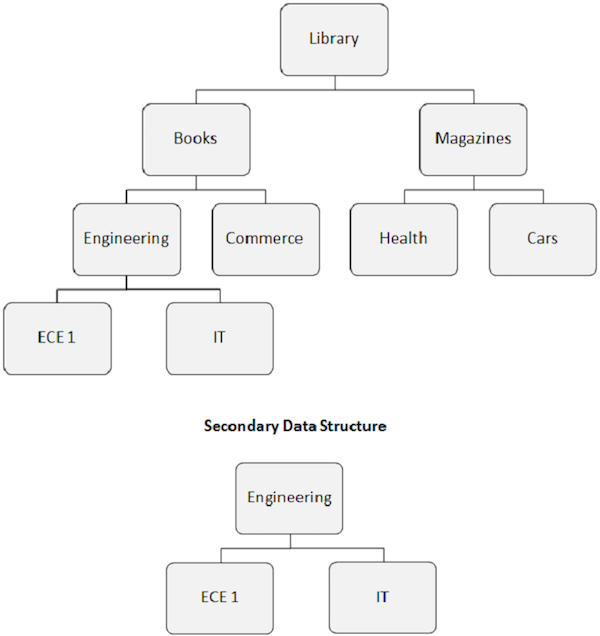
Sekundäre Datenstrukturen
Zu beachtende Punkte -
Wenn wir einen Sekundärindex erstellen, wird auch die scheinbare hierarchische Struktur der Datenbank geändert.
Das Indexzielsegment wird zum scheinbaren Wurzelsegment. Wie in der folgenden Abbildung gezeigt, wird das Engineering-Segment zum Stammsegment, auch wenn es kein Stammsegment ist.
Die durch den Sekundärindex verursachte Neuordnung der Datenbankstruktur wird als Sekundärdatenstruktur bezeichnet.
Sekundäre Datenstrukturen nehmen keine Änderungen an der auf der Festplatte vorhandenen physischen Hauptdatenbankstruktur vor. Dies ist nur eine Möglichkeit, die Datenbankstruktur vor dem Anwendungsprogramm zu ändern.
Unabhängiger UND-Betreiber
Zu beachtende Punkte -
Wenn ein AND-Operator (* oder &) mit Sekundärindizes verwendet wird, wird er als abhängiger AND-Operator bezeichnet.
Ein unabhängiges UND (#) ermöglicht es uns, Qualifikationen anzugeben, die mit einem abhängigen UND unmöglich wären.
Dieser Operator kann nur für Sekundärindizes verwendet werden, bei denen das Indexquellsegment vom Indexzielsegment abhängig ist.
Wir können eine SSA mit einem unabhängigen UND codieren, um anzugeben, dass ein Vorkommen des Zielsegments basierend auf den Feldern in zwei oder mehr abhängigen Quellensegmenten verarbeitet wird.
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.Sparsame Sequenzierung
Zu beachtende Punkte -
Sparse Sequencing wird auch als Sparse Indexing bezeichnet. Wir können einige der Indexquellensegmente aus dem Index entfernen, indem wir eine spärliche Sequenzierung mit einer sekundären Indexdatenbank verwenden.
Eine sparsame Sequenzierung wird verwendet, um die Leistung zu verbessern. Wenn einige Vorkommen des Indexquellensegments nicht verwendet werden, können wir dies entfernen.
DL / I verwendet einen Unterdrückungswert oder eine Unterdrückungsroutine oder beides, um zu bestimmen, ob ein Segment indiziert werden soll.
Wenn der Wert eines Sequenzfelds im Indexquellensegment mit einem Unterdrückungswert übereinstimmt, wird keine Indexbeziehung hergestellt.
Die Unterdrückungsroutine ist ein vom Benutzer geschriebenes Programm, das das Segment auswertet und bestimmt, ob es indiziert werden soll oder nicht.
Wenn eine spärliche Indizierung verwendet wird, werden ihre Funktionen vom DL / I übernommen. Wir müssen im Antragsprogramm keine besonderen Vorkehrungen treffen.
DBDGEN-Anforderungen
Wie in früheren Modulen erläutert, wird DBDGEN zum Erstellen einer DBD verwendet. Beim Erstellen von Sekundärindizes sind zwei Datenbanken beteiligt. Ein DBA muss zwei DBDs mit zwei DBDGENs erstellen, um eine Beziehung zwischen einer indizierten Datenbank und einer sekundären indizierten Datenbank herzustellen.
PSBGEN-Anforderungen
Nach dem Erstellen des Sekundärindex für eine Datenbank muss der DBA die PSBs erstellen. PSBGEN für das Programm gibt die richtige Verarbeitungssequenz für die Datenbank im Parameter PROCSEQ des PSB-Makros an. Für den Parameter PROCSEQ codiert der DBA den DBD-Namen für die Sekundärindexdatenbank.