Seaborn - Kurzanleitung
In der Welt der Analytik ist die Visualisierung der Daten der beste Weg, um Einblicke zu erhalten. Daten können visualisiert werden, indem sie als Diagramme dargestellt werden, die leicht zu verstehen, zu erkunden und zu erfassen sind. Solche Daten helfen dabei, die Aufmerksamkeit der Schlüsselelemente auf sich zu ziehen.
Um einen Datensatz mit Python zu analysieren, verwenden wir Matplotlib, eine weit verbreitete 2D-Plotbibliothek. Ebenso ist Seaborn eine Visualisierungsbibliothek in Python. Es ist auf Matplotlib gebaut.
Seaborn Vs Matplotlib
Zusammenfassend lässt sich sagen, dass Seaborn, wenn Matplotlib „versucht, einfache und schwierige Dinge einfach zu machen“, auch versucht, eine genau definierte Reihe schwieriger Dinge zu vereinfachen.
Seaborn hilft bei der Lösung der beiden Hauptprobleme, mit denen Matplotlib konfrontiert ist. Die Probleme sind -
- Standardparameter von Matplotlib
- Arbeiten mit Datenrahmen
Da Seaborn Matplotlib ergänzt und erweitert, verläuft die Lernkurve recht allmählich. Wenn Sie Matplotlib kennen, sind Sie bereits auf halbem Weg durch Seaborn.
Wichtige Merkmale von Seaborn
Seaborn basiert auf Pythons Kernvisualisierungsbibliothek Matplotlib. Es soll als Ergänzung und nicht als Ersatz dienen. Seaborn verfügt jedoch über einige sehr wichtige Funktionen. Lassen Sie uns hier einige davon sehen. Die Funktionen helfen in -
- Eingebaute Themen für das Styling von Matplotlib-Grafiken
- Visualisierung von univariaten und bivariaten Daten
- Anpassung und Visualisierung linearer Regressionsmodelle
- Zeichnen statistischer Zeitreihendaten
- Seaborn funktioniert gut mit NumPy- und Pandas-Datenstrukturen
- Es enthält integrierte Themen für die Gestaltung von Matplotlib-Grafiken
In den meisten Fällen verwenden Sie Matplotlib weiterhin zum einfachen Plotten. Die Kenntnis von Matplotlib wird empfohlen, um die Standarddiagramme von Seaborn zu optimieren.
In diesem Kapitel werden wir die Umgebungseinstellungen für Seaborn erläutern. Beginnen wir mit der Installation und verstehen, wie wir beginnen, wenn wir weitermachen.
Seaborn installieren und loslegen
In diesem Abschnitt werden die Schritte zur Installation von Seaborn erläutert.
Pip Installer verwenden
Um die neueste Version von Seaborn zu installieren, können Sie pip -
pip install seabornFür Windows, Linux und Mac mit Anaconda
Anaconda (aus https://www.anaconda.com/ist eine kostenlose Python-Distribution für den SciPy-Stack. Es ist auch für Linux und Mac verfügbar.
Es ist auch möglich, die veröffentlichte Version mit conda - zu installieren.
conda install seabornSo installieren Sie die Entwicklungsversion von Seaborn direkt von Github
https://github.com/mwaskom/seaborn"
Abhängigkeiten
Betrachten Sie die folgenden Abhängigkeiten von Seaborn -
- Python 2.7 oder 3.4+
- numpy
- scipy
- pandas
- matplotlib
In diesem Kapitel wird erläutert, wie Datensätze und Bibliotheken importiert werden. Beginnen wir mit dem Verständnis des Importierens von Bibliotheken.
Bibliotheken importieren
Beginnen wir mit dem Import von Pandas, einer großartigen Bibliothek zum Verwalten relationaler Datasets (Tabellenformat). Seaborn ist praktisch, wenn es um DataFrames geht, die am häufigsten verwendete Datenstruktur für die Datenanalyse.
Der folgende Befehl hilft Ihnen beim Importieren von Pandas -
# Pandas for managing datasets
import pandas as pdImportieren wir nun die Matplotlib-Bibliothek, mit deren Hilfe wir unsere Diagramme anpassen können.
# Matplotlib for additional customization
from matplotlib import pyplot as pltWir werden die Seaborn-Bibliothek mit dem folgenden Befehl importieren:
# Seaborn for plotting and styling
import seaborn as sbDatensätze importieren
Wir haben die benötigten Bibliotheken importiert. In diesem Abschnitt erfahren Sie, wie Sie die erforderlichen Datensätze importieren.
Seaborn enthält einige wichtige Datensätze in der Bibliothek. Wenn Seaborn installiert ist, werden die Datensätze automatisch heruntergeladen.
Sie können jeden dieser Datensätze für Ihr Lernen verwenden. Mit Hilfe der folgenden Funktion können Sie den gewünschten Datensatz laden
load_dataset()Daten als Pandas DataFrame importieren
In diesem Abschnitt importieren wir einen Datensatz. Dieser Datensatz wird standardmäßig als Pandas DataFrame geladen. Wenn der Pandas DataFrame eine Funktion enthält, funktioniert diese auf diesem DataFrame.
Die folgende Codezeile hilft Ihnen beim Importieren des Datensatzes:
# Seaborn for plotting and styling
import seaborn as sb
df = sb.load_dataset('tips')
print df.head()Die obige Codezeile generiert die folgende Ausgabe:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4Um alle verfügbaren Datensätze in der Seaborn-Bibliothek anzuzeigen, können Sie den folgenden Befehl mit dem verwenden get_dataset_names() Funktion wie unten gezeigt -
import seaborn as sb
print sb.get_dataset_names()Die obige Codezeile gibt die Liste der verfügbaren Datensätze als folgende Ausgabe zurück
[u'anscombe', u'attention', u'brain_networks', u'car_crashes', u'dots',
u'exercise', u'flights', u'fmri', u'gammas', u'iris', u'planets', u'tips',
u'titanic']DataFramesSpeichern Sie Daten in Form von rechteckigen Gittern, mit denen die Daten leicht angezeigt werden können. Jede Zeile des rechteckigen Gitters enthält Werte einer Instanz, und jede Spalte des Gitters ist ein Vektor, der Daten für eine bestimmte Variable enthält. Dies bedeutet, dass Zeilen eines DataFrames keine Werte desselben Datentyps enthalten müssen. Sie können numerisch, zeichenweise, logisch usw. sein. DataFrames für Python werden mit der Pandas-Bibliothek geliefert und sind als zweidimensional beschriftete Datenstrukturen definiert mit möglicherweise unterschiedlichen Arten von Spalten.
Weitere Informationen zu DataFrames finden Sie in unserem Tutorial zu Pandas.
Die Visualisierung von Daten ist ein Schritt, und die weitere Verbesserung der Visualisierung der visualisierten Daten ist ein weiterer Schritt. Die Visualisierung spielt eine wichtige Rolle bei der Vermittlung quantitativer Erkenntnisse an ein Publikum, um dessen Aufmerksamkeit zu erregen.
Ästhetik bedeutet eine Reihe von Prinzipien, die sich mit der Natur und der Wertschätzung von Schönheit befassen, insbesondere in der Kunst. Visualisierung ist eine Kunst, Daten auf effektive und einfachste Weise darzustellen.
Die Matplotlib-Bibliothek unterstützt die Anpassung in hohem Maße. Wenn Sie jedoch wissen, welche Einstellungen angepasst werden müssen, um ein attraktives und vorweggenommenes Diagramm zu erzielen, sollten Sie sich dessen bewusst sein, um sie nutzen zu können. Im Gegensatz zu Matplotlib bietet Seaborn zahlreiche benutzerdefinierte Themen und eine übergeordnete Benutzeroberfläche zum Anpassen und Steuern des Aussehens von Matplotlib-Figuren.
Beispiel
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
sinplot()
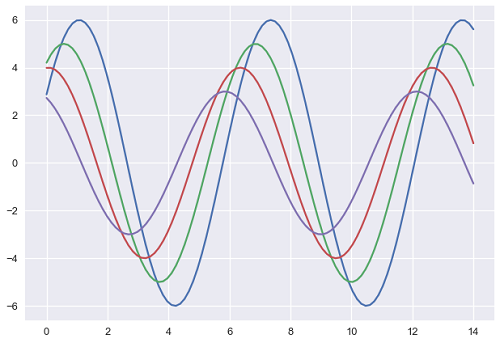
plt.show()So sieht ein Plot mit den Standardeinstellungen Matplotlib aus -

Verwenden Sie die Option, um dasselbe Diagramm in die Standardeinstellungen von Seaborn zu ändern set() Funktion -
Beispiel
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set()
sinplot()
plt.show()Ausgabe
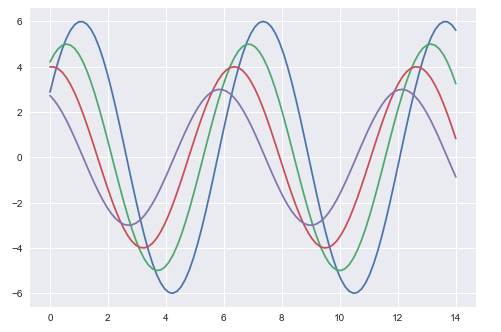
Die obigen beiden Abbildungen zeigen den Unterschied zwischen den Standardplots Matplotlib und Seaborn. Die Darstellung der Daten ist gleich, aber der Darstellungsstil variiert in beiden Fällen.
Grundsätzlich teilt Seaborn die Matplotlib-Parameter in zwei Gruppen auf
- Plotstile
- Handlungsskala
Seaborn Figurenstile
Die Schnittstelle zum Bearbeiten der Stile ist set_style(). Mit dieser Funktion können Sie das Thema des Plots festlegen. Nach der neuesten aktualisierten Version sind unten die fünf verfügbaren Themen aufgeführt.
- Darkgrid
- Whitegrid
- Dark
- White
- Ticks
Versuchen wir, ein Thema aus der oben genannten Liste anzuwenden. Das Standardthema des Plots istdarkgrid was wir im vorherigen Beispiel gesehen haben.
Beispiel
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("whitegrid")
sinplot()
plt.show()Ausgabe
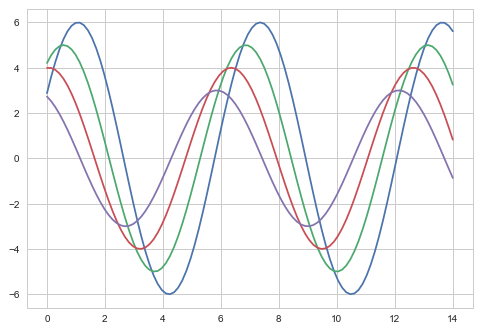
Der Unterschied zwischen den beiden obigen Darstellungen ist die Hintergrundfarbe
Achsen Stacheln entfernen
In den Themen Weiß und Häkchen können wir die Stacheln der oberen und rechten Achse mit dem entfernen despine() Funktion.
Beispiel
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("white")
sinplot()
sb.despine()
plt.show()Ausgabe
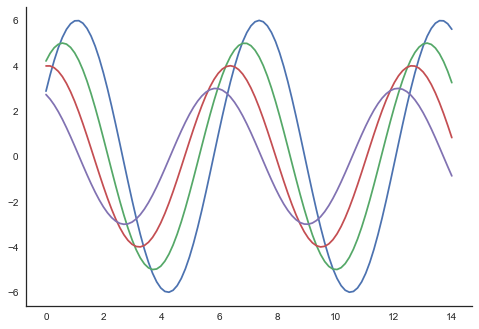
In den regulären Plots verwenden wir nur die linke und die untere Achse. Verwendung derdespine() Funktion können wir die unnötigen Stacheln der rechten und oberen Achse vermeiden, die in Matplotlib nicht unterstützt werden.
Elemente überschreiben
Wenn Sie die Seaborn-Stile anpassen möchten, können Sie ein Wörterbuch mit Parametern an die übergeben set_style() Funktion. Verfügbare Parameter werden mit angezeigtaxes_style() Funktion.
Beispiel
import seaborn as sb
print sb.axes_styleAusgabe
{'axes.axisbelow' : False,
'axes.edgecolor' : 'white',
'axes.facecolor' : '#EAEAF2',
'axes.grid' : True,
'axes.labelcolor' : '.15',
'axes.linewidth' : 0.0,
'figure.facecolor' : 'white',
'font.family' : [u'sans-serif'],
'font.sans-serif' : [u'Arial', u'Liberation
Sans', u'Bitstream Vera Sans', u'sans-serif'],
'grid.color' : 'white',
'grid.linestyle' : u'-',
'image.cmap' : u'Greys',
'legend.frameon' : False,
'legend.numpoints' : 1,
'legend.scatterpoints': 1,
'lines.solid_capstyle': u'round',
'text.color' : '.15',
'xtick.color' : '.15',
'xtick.direction' : u'out',
'xtick.major.size' : 0.0,
'xtick.minor.size' : 0.0,
'ytick.color' : '.15',
'ytick.direction' : u'out',
'ytick.major.size' : 0.0,
'ytick.minor.size' : 0.0}Durch Ändern der Werte eines Parameters wird der Plotstil geändert.
Beispiel
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("darkgrid", {'axes.axisbelow': False})
sinplot()
sb.despine()
plt.show()Ausgabe
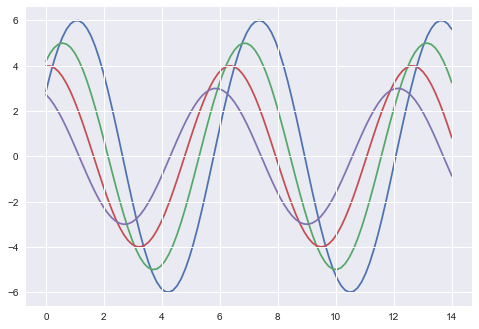
Skalieren von Plotelementen
Wir haben auch die Kontrolle über die Plotelemente und können den Maßstab des Plots mit dem steuern set_context()Funktion. Wir haben vier voreingestellte Vorlagen für Kontexte, basierend auf der relativen Größe. Die Kontexte werden wie folgt benannt
- Paper
- Notebook
- Talk
- Poster
Standardmäßig ist der Kontext auf Notizbuch eingestellt. und wurde in den obigen Darstellungen verwendet.
Beispiel
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("darkgrid", {'axes.axisbelow': False})
sinplot()
sb.despine()
plt.show()Ausgabe
Die Ausgabegröße des tatsächlichen Diagramms ist im Vergleich zu den obigen Diagrammen größer.
Note - Aufgrund der Skalierung von Bildern auf unserer Webseite können Sie den tatsächlichen Unterschied in unseren Beispieldiagrammen übersehen.
Farbe spielt eine wichtige Rolle als jeder andere Aspekt in den Visualisierungen. Bei effektiver Verwendung verleiht Farbe dem Plot mehr Wert. Eine Palette bedeutet eine flache Oberfläche, auf der ein Maler Farben arrangiert und mischt.
Farbpalette erstellen
Seaborn bietet eine Funktion namens color_palette(), die verwendet werden können, um Plots Farben zu verleihen und ihnen mehr ästhetischen Wert zu verleihen.
Verwendung
seaborn.color_palette(palette = None, n_colors = None, desat = None)Parameter
In der folgenden Tabelle sind die Parameter für die Erstellung der Farbpalette aufgeführt.
| Sr.Nr. | Palatte & Beschreibung |
|---|---|
| 1 | n_colors Anzahl der Farben in der Palette. Wenn Keine, hängt die Standardeinstellung davon ab, wie die Palette angegeben wird. Standardmäßig der Wert vonn_colors ist 6 Farben. |
| 2 | desat Anteil, um jede Farbe zu entsättigen. |
Rückkehr
Return bezieht sich auf die Liste der RGB-Tupel. Im Folgenden finden Sie die leicht verfügbaren Seaborn-Paletten -
- Deep
- Muted
- Bright
- Pastel
- Dark
- Colorblind
Daneben kann man auch eine neue Palette generieren
Es ist schwer zu entscheiden, welche Palette für einen bestimmten Datensatz verwendet werden soll, ohne die Eigenschaften der Daten zu kennen. Da wir uns dessen bewusst sind, werden wir die verschiedenen Verwendungsmöglichkeiten klassifizierencolor_palette() Typen -
- qualitative
- sequential
- diverging
Wir haben eine andere Funktion seaborn.palplot()welches sich mit Farbpaletten befasst. Diese Funktion zeichnet die Farbpalette als horizontales Array. Wir werden mehr darüber wissenseaborn.palplot() in den kommenden Beispielen.
Qualitative Farbpaletten
Qualitative oder kategoriale Paletten eignen sich am besten zum Zeichnen der kategorialen Daten.
Beispiel
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(current_palette)
plt.show()Ausgabe

Wir haben keine Parameter übergeben color_palette();Standardmäßig sehen wir 6 Farben. Sie können die gewünschte Anzahl von Farben anzeigen, indem Sie einen Wert an die übergebenn_colorsParameter. Hier daspalplot() wird verwendet, um das Farbfeld horizontal zu zeichnen.
Sequentielle Farbpaletten
Sequentielle Diagramme sind geeignet, um die Verteilung von Daten auszudrücken, die von relativ niedrigeren Werten bis zu höheren Werten innerhalb eines Bereichs reichen.
Wenn Sie der Farbe, die an den Farbparameter übergeben wird, ein zusätzliches Zeichen hinzufügen, wird das sequentielle Diagramm gezeichnet.
Beispiel
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(sb.color_palette("Greens"))
plt.show()
Note −Wir müssen 's' an den Parameter wie 'Greens' im obigen Beispiel anhängen.
Abweichende Farbpalette
Unterschiedliche Paletten verwenden zwei verschiedene Farben. Jede Farbe repräsentiert eine Variation des Wertes, die von einem gemeinsamen Punkt in beide Richtungen reicht.
Angenommen, Sie zeichnen die Daten im Bereich von -1 bis 1 auf. Die Werte von -1 bis 0 haben eine Farbe und 0 bis +1 eine andere Farbe.
Standardmäßig werden die Werte von Null zentriert. Sie können es mit parameter center steuern, indem Sie einen Wert übergeben.
Beispiel
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(sb.color_palette("BrBG", 7))
plt.show()Ausgabe

Festlegen der Standardfarbpalette
Die Funktionen color_palette() hat einen Begleiter namens set_palette()Die Beziehung zwischen ihnen ähnelt den im Kapitel Ästhetik behandelten Paaren. Die Argumente sind für beide gleichset_palette() und color_palette(), Die Standardparameter von Matplotlib werden jedoch so geändert, dass die Palette für alle Diagramme verwendet wird.
Beispiel
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("white")
sb.set_palette("husl")
sinplot()
plt.show()Ausgabe

Univariate Verteilung zeichnen
Die Verteilung von Daten ist das Wichtigste, was wir bei der Analyse der Daten verstehen müssen. Hier werden wir sehen, wie Seaborn uns hilft, die univariate Verteilung der Daten zu verstehen.
Funktion distplot()bietet die bequemste Möglichkeit, einen kurzen Blick auf die univariate Verteilung zu werfen. Diese Funktion zeichnet ein Histogramm, das zur Schätzung der Kerneldichte der Daten passt.
Verwendung
seaborn.distplot()Parameter
In der folgenden Tabelle sind die Parameter und ihre Beschreibung aufgeführt.
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | data Serie, 1d Array oder eine Liste |
| 2 | bins Spezifikation der Histbins |
| 3 | hist Bool |
| 4 | kde Bool |
Dies sind grundlegende und wichtige Parameter, die untersucht werden müssen.
Histogramme stellen die Datenverteilung dar, indem sie Bins entlang des Datenbereichs bilden und dann Balken zeichnen, um die Anzahl der Beobachtungen anzuzeigen, die in jeden Bin fallen.
Seaborn wird mit einigen Datensätzen geliefert, und wir haben in unseren vorherigen Kapiteln nur wenige Datensätze verwendet. Wir haben gelernt, wie Sie den Datensatz laden und die Liste der verfügbaren Datensätze nachschlagen.
Seaborn wird mit einigen Datensätzen geliefert, und wir haben in unseren vorherigen Kapiteln nur wenige Datensätze verwendet. Wir haben gelernt, wie Sie den Datensatz laden und die Liste der verfügbaren Datensätze nachschlagen.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],kde = False)
plt.show()Ausgabe
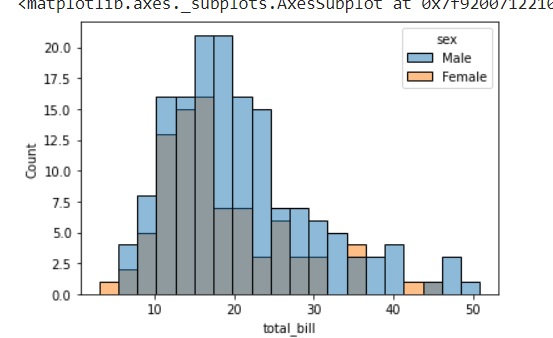
Hier, kdeFlag ist auf False gesetzt. Infolgedessen wird die Darstellung des Kernel-Schätzungsdiagramms entfernt und nur das Histogramm wird aufgezeichnet.
Die Kernel Density Estimation (KDE) ist eine Methode zur Schätzung der Wahrscheinlichkeitsdichtefunktion einer kontinuierlichen Zufallsvariablen. Es wird für nichtparametrische Analysen verwendet.
Einstellen der hist Flagge auf Falsch in distplot ergibt das Kernel-Dichteschätzungsdiagramm.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],hist=False)
plt.show()Ausgabe
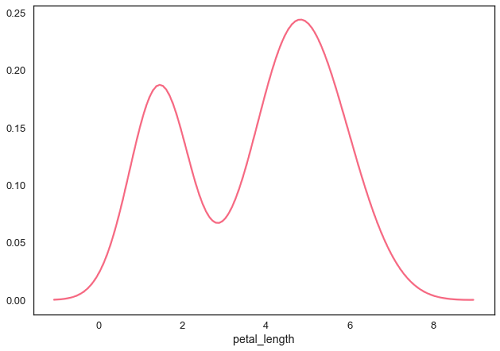
Anpassen der parametrischen Verteilung
distplot() wird verwendet, um die parametrische Verteilung eines Datensatzes zu visualisieren.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'])
plt.show()Ausgabe
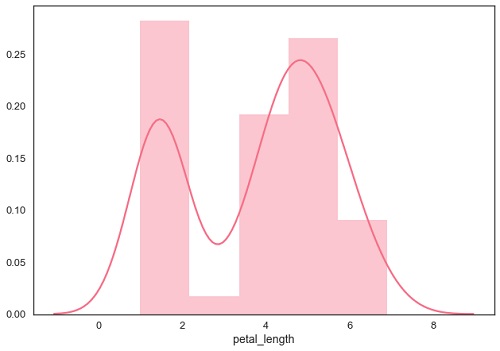
Bivariate Verteilung zeichnen
Die bivariate Verteilung wird verwendet, um die Beziehung zwischen zwei Variablen zu bestimmen. Dies betrifft hauptsächlich die Beziehung zwischen zwei Variablen und das Verhalten einer Variablen in Bezug auf die andere.
Der beste Weg, um die bivariate Verteilung bei Seegeborenen zu analysieren, ist die Verwendung von jointplot() Funktion.
Jointplot erstellt eine Multi-Panel-Figur, die die bivariate Beziehung zwischen zwei Variablen sowie die univariate Verteilung jeder Variablen auf separaten Achsen projiziert.
Streudiagramm
Das Streudiagramm ist der bequemste Weg, um die Verteilung zu visualisieren, bei der jede Beobachtung in einem zweidimensionalen Diagramm über die x- und y-Achse dargestellt wird.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df)
plt.show()Ausgabe
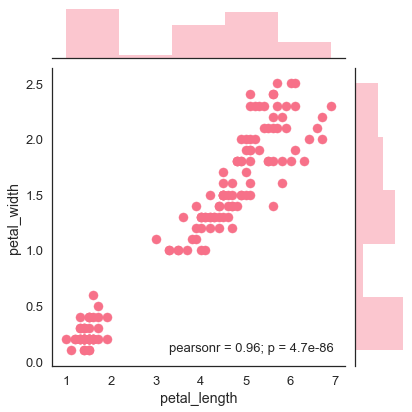
Die obige Abbildung zeigt die Beziehung zwischen dem petal_length und petal_widthin den Iris-Daten. Ein Trend in der Darstellung besagt, dass eine positive Korrelation zwischen den untersuchten Variablen besteht.
Hexbin Plot
Hexagonales Binning wird bei der bivariaten Datenanalyse verwendet, wenn die Daten eine geringe Dichte aufweisen, dh wenn die Daten sehr gestreut und durch Streudiagramme schwer zu analysieren sind.
Ein Additionsparameter namens 'kind' und value 'hex' zeichnet das Hexbin-Diagramm.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()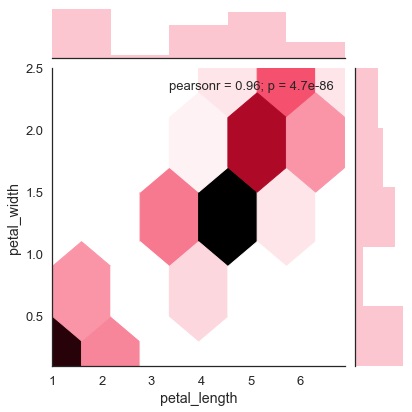
Kernel Density Estimation
Die Kernel-Dichteschätzung ist eine nicht parametrische Methode zur Schätzung der Verteilung einer Variablen. In Seaborn können wir eine KDE mit zeichnenjointplot().
Übergeben Sie den Wert 'kde' an die Parameterart, um den Kernel-Plot zu zeichnen.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()Ausgabe
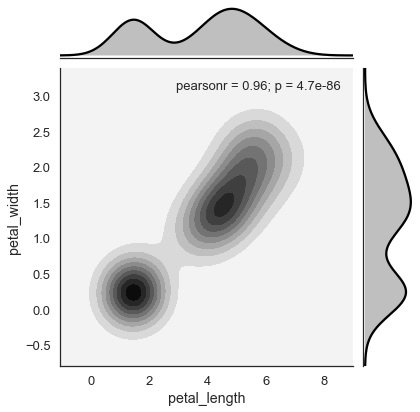
In Echtzeit untersuchte Datensätze enthalten viele Variablen. In solchen Fällen sollte die Beziehung zwischen jeder Variablen analysiert werden. Das Zeichnen der bivariaten Verteilung für (n, 2) Kombinationen ist ein sehr komplexer und zeitaufwändiger Prozess.
Um mehrere paarweise bivariate Verteilungen in einem Datensatz zu zeichnen, können Sie die verwenden pairplot()Funktion. Dies zeigt die Beziehung für die (n, 2) Kombination von Variablen in einem DataFrame als Matrix von Plots, und die diagonalen Plots sind die univariaten Plots.
Achsen
In diesem Abschnitt erfahren Sie, was Achsen, ihre Verwendung, Parameter usw. sind.
Verwendung
seaborn.pairplot(data,…)Parameter
In der folgenden Tabelle sind die Parameter für Achsen aufgeführt -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | data Datenrahmen |
| 2 | hue Variable Daten, um Plotaspekte verschiedenen Farben zuzuordnen. |
| 3 | palette Farbsatz zum Zuordnen der Farbtonvariablen |
| 4 | kind Art der Handlung für die Nichtidentitätsbeziehungen. {'Scatter', 'reg'} |
| 5 | diag_kind Art der Darstellung für die diagonalen Unterzeichnungen. {'hist', 'kde'} |
Mit Ausnahme der Daten sind alle anderen Parameter optional. Es gibt nur wenige andere Parameter, diepairplotkann akzeptieren. Die oben genannten werden häufig als Parameter verwendet.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.set_style("ticks")
sb.pairplot(df,hue = 'species',diag_kind = "kde",kind = "scatter",palette = "husl")
plt.show()Ausgabe
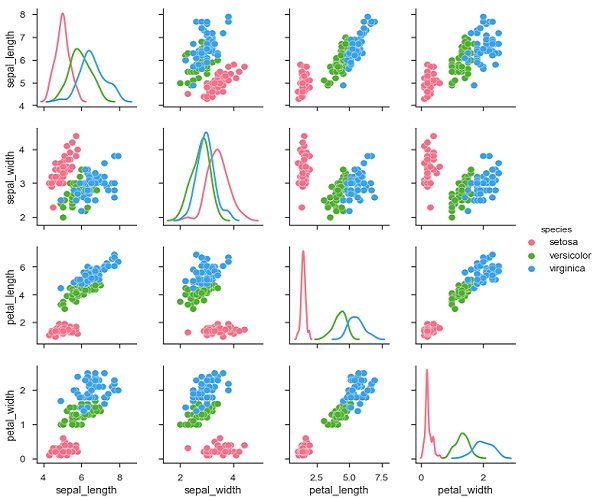
Wir können die Variationen in jeder Handlung beobachten. Die Diagramme sind im Matrixformat, wobei der Zeilenname die x-Achse und der Spaltenname die y-Achse darstellt.
Die diagonalen Diagramme sind Kerneldichtediagramme, wobei die anderen Diagramme wie erwähnt Streudiagramme sind.
In unseren vorherigen Kapiteln haben wir Streudiagramme, Hexbin-Diagramme und kde-Diagramme kennengelernt, die zur Analyse der untersuchten kontinuierlichen Variablen verwendet werden. Diese Diagramme sind nicht geeignet, wenn die untersuchte Variable kategorisch ist.
Wenn eine oder beide der untersuchten Variablen kategorisch sind, verwenden wir Diagramme wie striplot (), swarmplot () usw. Seaborn bietet hierfür eine Schnittstelle.
Kategoriale Streudiagramme
In diesem Abschnitt lernen wir kategoriale Streudiagramme kennen.
stripplot ()
stripplot () wird verwendet, wenn eine der untersuchten Variablen kategorisch ist. Es repräsentiert die Daten in sortierter Reihenfolge entlang einer beliebigen Achse.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df)
plt.show()Ausgabe
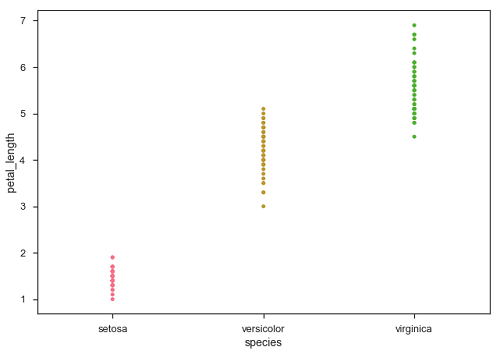
In der obigen Darstellung können wir den Unterschied von deutlich sehen petal_lengthin jeder Art. Das Hauptproblem bei dem obigen Streudiagramm besteht jedoch darin, dass sich die Punkte auf dem Streudiagramm überlappen. Wir verwenden den Parameter 'Jitter', um diese Art von Szenario zu behandeln.
Jitter fügt den Daten zufälliges Rauschen hinzu. Dieser Parameter passt die Positionen entlang der kategorialen Achse an.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df, jitter = Ture)
plt.show()Ausgabe
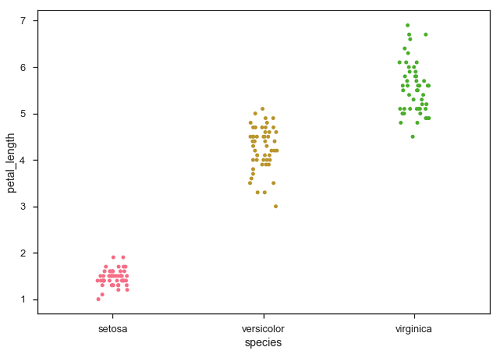
Jetzt kann die Verteilung der Punkte leicht gesehen werden.
Schwarmplot ()
Eine andere Option, die als Alternative zu 'Jitter' verwendet werden kann, ist die Funktion swarmplot(). Diese Funktion positioniert jeden Punkt des Streudiagramms auf der kategorialen Achse und vermeidet dadurch überlappende Punkte -
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.swarmplot(x = "species", y = "petal_length", data = df)
plt.show()Ausgabe
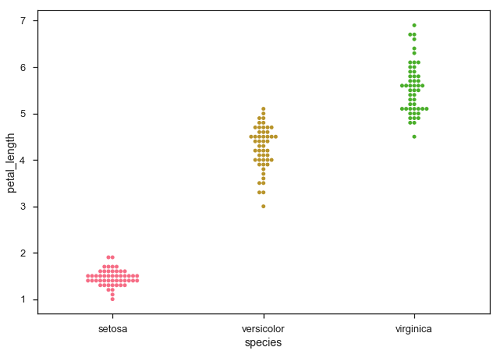
In kategorialen Streudiagrammen, die wir im vorherigen Kapitel behandelt haben, wird der Ansatz in den Informationen eingeschränkt, die er über die Verteilung von Werten innerhalb jeder Kategorie liefern kann. Lassen Sie uns nun weiter gehen und sehen, was uns den Vergleich mit Kategorien erleichtern kann.
Box Plots
Boxplot ist eine bequeme Möglichkeit, die Verteilung von Daten über ihre Quartile zu visualisieren.
Box-Plots haben normalerweise vertikale Linien, die sich von den Boxen erstrecken, die als Whisker bezeichnet werden. Diese Whisker zeigen Variabilität außerhalb des oberen und unteren Quartils an, daher werden Box-Plots auch als bezeichnetbox-and-whisker Handlung und box-and-whisker Diagramm. Alle Ausreißer in den Daten werden als einzelne Punkte dargestellt.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.swarmplot(x = "species", y = "petal_length", data = df)
plt.show()Ausgabe
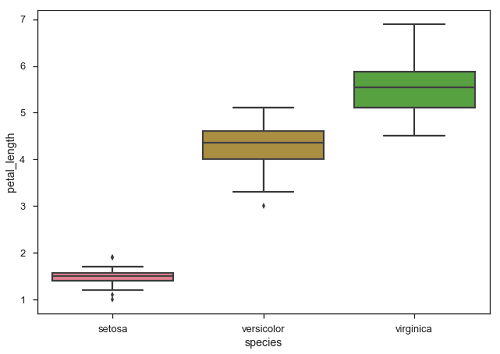
Die Punkte auf dem Plot zeigen den Ausreißer an.
Geigengrundstücke
Violinplots sind eine Kombination des Boxplots mit den Kernel-Dichteschätzungen. Diese Diagramme sind daher einfacher zu analysieren und die Verteilung der Daten zu verstehen.
Verwenden wir den aufgerufenen Tipp-Datensatz, um mehr über Geigenpläne zu erfahren. Dieser Datensatz enthält Informationen zu den Tipps der Kunden in einem Restaurant.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y = "total_bill", data=df)
plt.show()Ausgabe
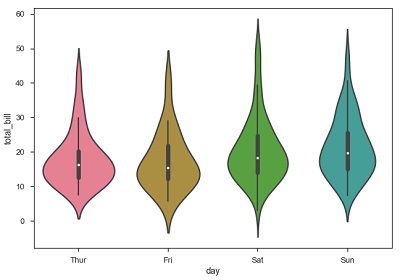
Die Quartil- und Whiskerwerte aus dem Boxplot werden in der Geige angezeigt. Da das Geigenplot KDE verwendet, zeigt der breitere Teil der Geige die höhere Dichte an und der schmale Bereich repräsentiert eine relativ niedrigere Dichte. Der Interquartilbereich im Boxplot und der Anteil mit höherer Dichte in kde fallen in den gleichen Bereich jeder Kategorie des Geigenplots.
Das obige Diagramm zeigt die Verteilung von total_bill an vier Wochentagen. Wenn wir jedoch darüber hinaus sehen möchten, wie sich die Verteilung in Bezug auf das Geschlecht verhält, wollen wir dies im folgenden Beispiel untersuchen.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y = "total_bill",hue = 'sex', data = df)
plt.show()Ausgabe

Jetzt können wir das Ausgabeverhalten zwischen Mann und Frau deutlich sehen. Wir können leicht sagen, dass Männer mehr Geld verdienen als Frauen, wenn sie sich die Handlung ansehen.
Und wenn die Farbtonvariable nur zwei Klassen hat, können wir die Handlung verschönern, indem wir jede Geige an einem bestimmten Tag in zwei statt in zwei Geigen aufteilen. Beide Teile der Geige beziehen sich auf jede Klasse in der Farbtonvariablen.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y="total_bill",hue = 'sex', data = df)
plt.show()Ausgabe

In den meisten Situationen befassen wir uns mit Schätzungen der gesamten Verteilung der Daten. Wenn es jedoch um die zentrale Tendenzschätzung geht, brauchen wir einen bestimmten Weg, um die Verteilung zusammenzufassen. Mittelwert und Median sind die sehr häufig verwendeten Techniken, um die zentrale Tendenz der Verteilung abzuschätzen.
In allen Plots, die wir im obigen Abschnitt gelernt haben, haben wir die gesamte Verteilung visualisiert. Lassen Sie uns nun die Diagramme diskutieren, mit denen wir die zentrale Tendenz der Verteilung abschätzen können.
Bar Plot
Das barplot()zeigt die Beziehung zwischen einer kategorialen Variablen und einer kontinuierlichen Variablen. Die Daten werden in rechteckigen Balken dargestellt, wobei die Länge des Balkens den Anteil der Daten in dieser Kategorie darstellt.
Das Balkendiagramm repräsentiert die Schätzung der zentralen Tendenz. Verwenden wir den 'Titanic'-Datensatz, um Balkendiagramme zu lernen.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.barplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()Ausgabe
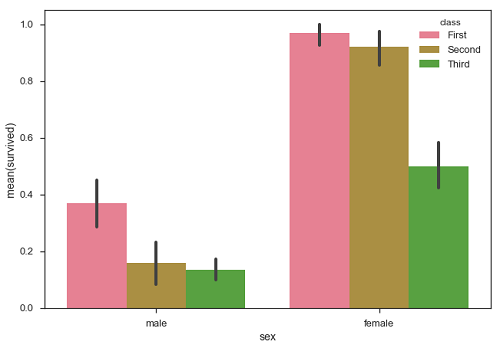
Im obigen Beispiel können wir sehen, dass die durchschnittliche Anzahl der Überlebenden von Männern und Frauen in jeder Klasse. Aus der Handlung können wir verstehen, dass mehr Frauen überlebten als Männer. Sowohl bei Männern als auch bei Frauen sind mehr Überlebende aus der ersten Klasse.
Ein Sonderfall im Barplot besteht darin, die Anzahl der Beobachtungen in jeder Kategorie anzuzeigen, anstatt eine Statistik für eine zweite Variable zu berechnen. Dafür verwenden wircountplot().
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.countplot(x = " class ", data = df, palette = "Blues");
plt.show()Ausgabe
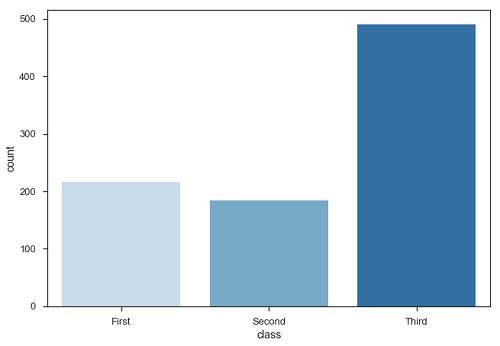
Laut Plot ist die Anzahl der Passagiere in der dritten Klasse höher als in der ersten und zweiten Klasse.
Punktdiagramme
Punktdiagramme dienen als Balkendiagramme, jedoch in einem anderen Stil. Anstelle des vollen Balkens wird der Wert der Schätzung durch den Punkt auf einer bestimmten Höhe auf der anderen Achse dargestellt.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.pointplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()Ausgabe

Es ist immer vorzuziehen, "Long-From" - oder "Ordentlich" -Datensätze zu verwenden. In Zeiten, in denen wir keine andere Wahl haben, als ein 'Wide-Form'-Dataset zu verwenden, können dieselben Funktionen auch auf' Wide-Form'-Daten in einer Vielzahl von Formaten angewendet werden, einschließlich Pandas-Datenrahmen oder zweidimensionalem NumPy Arrays. Diese Objekte sollten direkt an den Datenparameter übergeben werden. Die Variablen x und y müssen als Zeichenfolgen angegeben werden
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.boxplot(data = df, orient = "h")
plt.show()Ausgabe
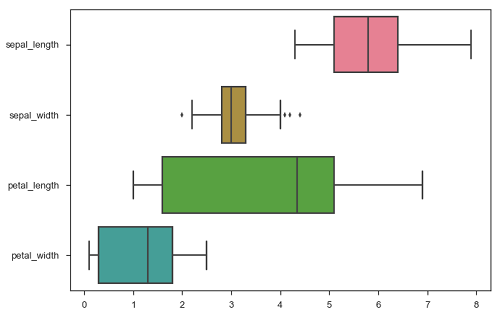
Darüber hinaus akzeptieren diese Funktionen Vektoren von Pandas- oder NumPy-Objekten anstelle von Variablen in einem DataFrame.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.boxplot(data = df, orient = "h")
plt.show()Ausgabe
Der Hauptvorteil der Verwendung von Seaborn für viele Entwickler in der Python-Welt besteht darin, dass das Pandas-DataFrame-Objekt als Parameter verwendet werden kann.
Kategoriale Daten können wir anhand von zwei Plots visualisieren. Sie können entweder die Funktionen verwenden pointplot()oder die übergeordnete Funktion factorplot().
Factorplot
Factorplot zeichnet ein kategoriales Diagramm auf einem FacetGrid. Mit dem Parameter 'kind' können wir das Diagramm wie Boxplot, Violinplot, Barplot und Stripplot auswählen. FacetGrid verwendet standardmäßig Pointplot.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = pulse", hue = "kind",data = df);
plt.show()Ausgabe
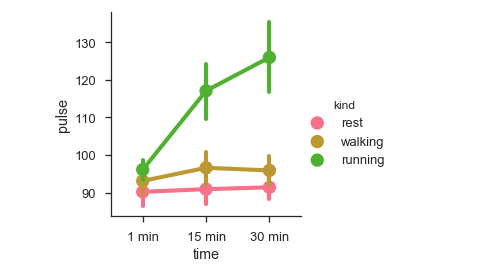
Wir können verschiedene Diagramme verwenden, um dieselben Daten mit dem zu visualisieren kind Parameter.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = "pulse", hue = "kind", kind = 'violin',data = df);
plt.show()Ausgabe
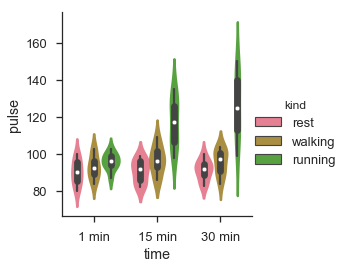
Im Faktorplot werden die Daten in einem Facettenraster dargestellt.
Was ist Facettengitter?
Facet grid bildet durch Teilen der Variablen eine Matrix aus Feldern, die durch Zeilen und Spalten definiert sind. Aufgrund von Panels sieht ein einzelnes Diagramm wie mehrere Diagramme aus. Es ist sehr hilfreich, alle Kombinationen in zwei diskreten Variablen zu analysieren.
Lassen Sie uns die obige Definition anhand eines Beispiels visualisieren
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = "pulse", hue = "kind", kind = 'violin', col = "diet", data = df);
plt.show()Ausgabe
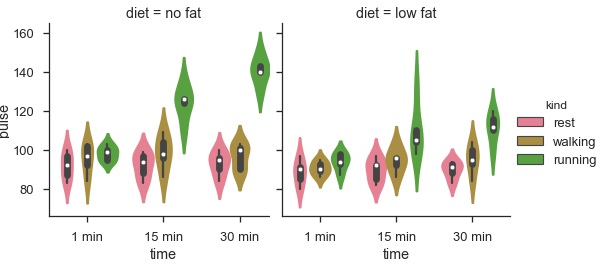
Der Vorteil der Verwendung von Facet besteht darin, dass wir eine weitere Variable in das Diagramm eingeben können. Das obige Diagramm ist in zwei Diagramme unterteilt, basierend auf einer dritten Variablen namens "Diät" unter Verwendung des Parameters "col".
Wir können viele Spaltenfacetten erstellen und sie an den Zeilen des Rasters ausrichten -
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
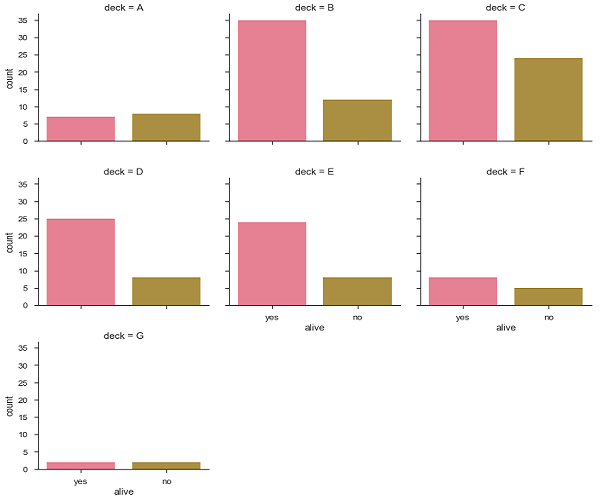
sb.factorplot("alive", col = "deck", col_wrap = 3,data = df[df.deck.notnull()],kind = "count")
plt.show()Ausgabe
In den meisten Fällen verwenden wir Datensätze, die mehrere quantitative Variablen enthalten, und das Ziel einer Analyse besteht häufig darin, diese Variablen miteinander in Beziehung zu setzen. Dies kann über die Regressionslinien erfolgen.
Beim Erstellen der Regressionsmodelle prüfen wir häufig, ob multicollinearity,wo wir die Korrelation zwischen allen Kombinationen kontinuierlicher Variablen sehen mussten und die notwendigen Maßnahmen ergreifen werden, um Multikollinearität zu entfernen, falls vorhanden. In solchen Fällen helfen die folgenden Techniken.
Funktionen zum Zeichnen linearer Regressionsmodelle
In Seaborn gibt es zwei Hauptfunktionen, um eine durch Regression bestimmte lineare Beziehung zu visualisieren. Diese Funktionen sindregplot() und lmplot().
regplot vs lmplot
| neu planen | lmplot |
|---|---|
| Akzeptiert die x- und y-Variablen in einer Vielzahl von Formaten, einschließlich einfacher Numpy-Arrays, Pandas Series-Objekte oder als Verweise auf Variablen in einem Pandas DataFrame | hat Daten als erforderlichen Parameter und die Variablen x und y müssen als Zeichenfolgen angegeben werden. Dieses Datenformat wird als "Langform" -Daten bezeichnet |
Lassen Sie uns nun die Handlungen zeichnen.
Beispiel
Zeichnen Sie den Regplot und dann den lmplot mit denselben Daten in diesem Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.regplot(x = "total_bill", y = "tip", data = df)
sb.lmplot(x = "total_bill", y = "tip", data = df)
plt.show()Ausgabe
Sie können den Unterschied in der Größe zwischen zwei Plots sehen.
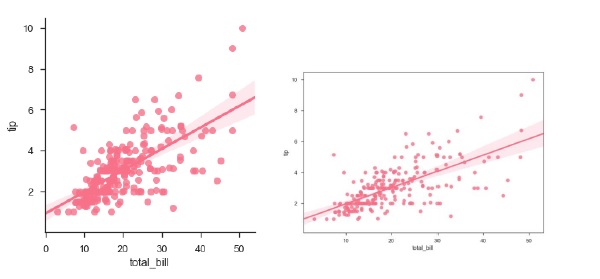
Wir können auch eine lineare Regression anpassen, wenn eine der Variablen diskrete Werte annimmt
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.lmplot(x = "size", y = "tip", data = df)
plt.show()Ausgabe
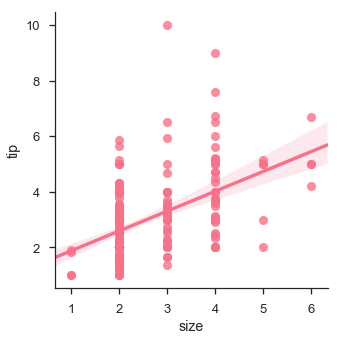
Anpassen verschiedener Arten von Modellen
Das oben verwendete einfache lineare Regressionsmodell ist sehr einfach anzupassen, aber in den meisten Fällen sind die Daten nicht linear und die obigen Methoden können die Regressionslinie nicht verallgemeinern.
Verwenden wir den Datensatz von Anscombe mit den Regressionsdiagrammen -
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x="x", y="y", data=df.query("dataset == 'I'"))
plt.show()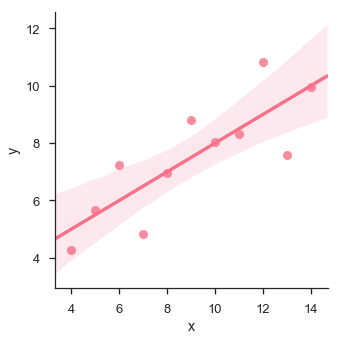
In diesem Fall passen die Daten gut für ein lineares Regressionsmodell mit geringerer Varianz.
Lassen Sie uns ein anderes Beispiel sehen, bei dem die Daten eine hohe Abweichung aufweisen, was zeigt, dass die Linie der besten Anpassung nicht gut ist.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"))
plt.show()Ausgabe
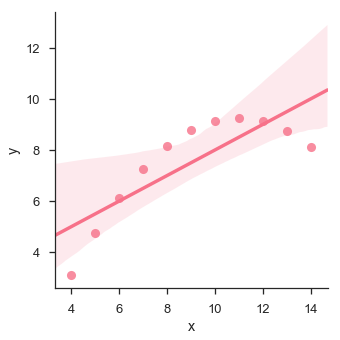
Das Diagramm zeigt die hohe Abweichung der Datenpunkte von der Regressionslinie. Eine solche nichtlineare höhere Ordnung kann mit dem visualisiert werdenlmplot() und regplot()Dies kann in ein Polynom-Regressionsmodell passen, um einfache Arten nichtlinearer Trends im Datensatz zu untersuchen.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"),order = 2)
plt.show()Ausgabe
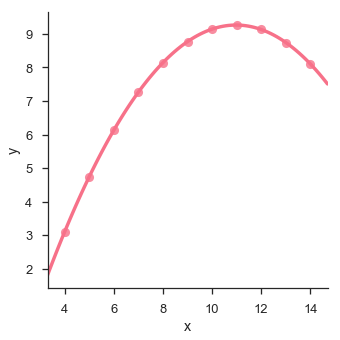
Ein nützlicher Ansatz zur Untersuchung mitteldimensionaler Daten besteht darin, mehrere Instanzen desselben Diagramms in verschiedenen Teilmengen Ihres Datensatzes zu zeichnen.
Diese Technik wird allgemein als "Gitter" - oder "Gitter" -Diagramm bezeichnet und steht im Zusammenhang mit der Idee "kleiner Vielfacher".
Um diese Funktionen nutzen zu können, müssen sich Ihre Daten in einem Pandas DataFrame befinden.
Zeichnen kleiner Vielfacher von Datenuntermengen
Im vorherigen Kapitel haben wir das FacetGrid-Beispiel gesehen, in dem die FacetGrid-Klasse bei der Visualisierung der Verteilung einer Variablen sowie der Beziehung zwischen mehreren Variablen innerhalb von Teilmengen Ihres Datasets mithilfe mehrerer Bedienfelder hilft.
Ein FacetGrid kann mit bis zu drei Dimensionen gezeichnet werden - Zeile, Spalte und Farbton. Die ersten beiden haben eine offensichtliche Übereinstimmung mit der resultierenden Anordnung von Achsen; Stellen Sie sich die Farbtonvariable als dritte Dimension entlang einer Tiefenachse vor, in der verschiedene Ebenen mit unterschiedlichen Farben dargestellt werden.
FacetGrid Das Objekt verwendet einen Datenrahmen als Eingabe und die Namen der Variablen, die die Zeilen-, Spalten- oder Farbtonabmessungen des Rasters bilden.
Die Variablen sollten kategorisch sein und die Daten auf jeder Ebene der Variablen werden für eine Facette entlang dieser Achse verwendet.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "time")
plt.show()Ausgabe
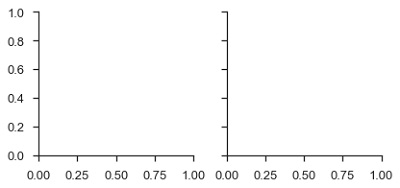
Im obigen Beispiel haben wir gerade das initialisiert facetgrid Objekt, das nichts auf sie zeichnet.
Der Hauptansatz für die Visualisierung von Daten in diesem Raster ist der mit FacetGrid.map()Methode. Betrachten wir die Verteilung der Tipps in jeder dieser Untergruppen anhand eines Histogramms.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "time")
g.map(plt.hist, "tip")
plt.show()Ausgabe
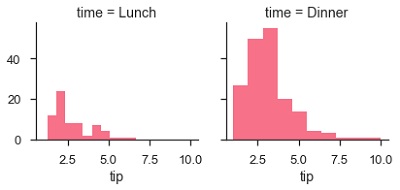
Die Anzahl der Diagramme ist aufgrund des Parameters col mehr als eins. Wir haben in unseren vorherigen Kapiteln über col-Parameter gesprochen.
Übergeben Sie die mehreren Variablennamen, um ein relationales Diagramm zu erstellen.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "sex", hue = "smoker")
g.map(plt.scatter, "total_bill", "tip")
plt.show()Ausgabe
Mit PairGrid können wir ein Raster von Unterplots mit demselben Plottyp zeichnen, um Daten zu visualisieren.
Im Gegensatz zu FacetGrid werden für jedes Unterdiagramm unterschiedliche Variablenpaare verwendet. Es bildet eine Matrix von Untergrundstücken. Es wird manchmal auch als "Streudiagramm-Matrix" bezeichnet.
Die Verwendung von pairgrid ähnelt facetgrid. Initialisieren Sie zuerst das Raster und übergeben Sie dann die Plotfunktion.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
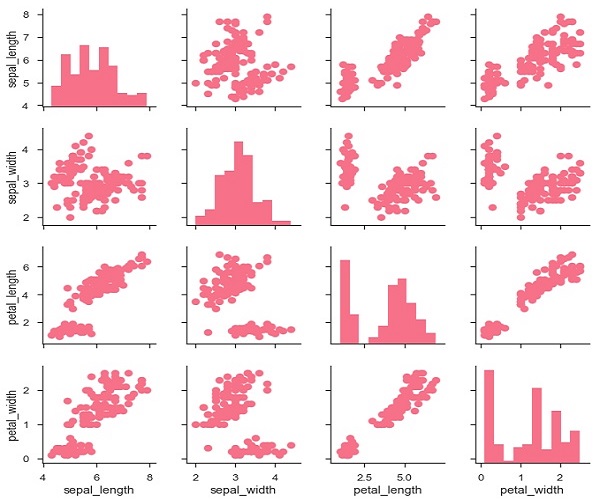
g = sb.PairGrid(df)
g.map(plt.scatter);
plt.show()
Es ist auch möglich, eine andere Funktion auf der Diagonale zu zeichnen, um die univariate Verteilung der Variablen in jeder Spalte anzuzeigen.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter);
plt.show()Ausgabe
Wir können die Farbe dieser Diagramme mithilfe einer anderen kategorialen Variablen anpassen. Der Iris-Datensatz enthält beispielsweise vier Messungen für jede der drei verschiedenen Arten von Irisblüten, sodass Sie sehen können, wie sie sich unterscheiden.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter);
plt.show()Ausgabe
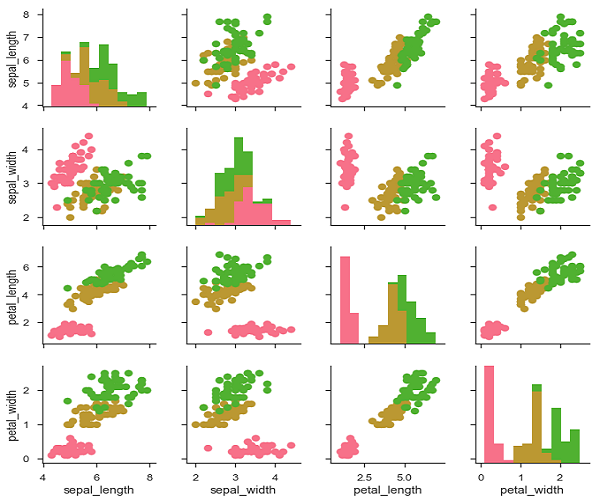
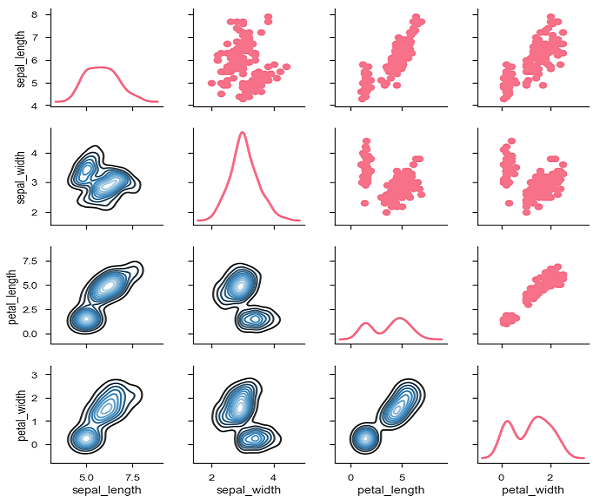
Wir können eine andere Funktion im oberen und unteren Dreieck verwenden, um verschiedene Aspekte der Beziehung zu sehen.
Beispiel
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_upper(plt.scatter)
g.map_lower(sb.kdeplot, cmap = "Blues_d")
g.map_diag(sb.kdeplot, lw = 3, legend = False);
plt.show()Ausgabe