Verteilte Architektur
In einer verteilten Architektur werden Komponenten auf verschiedenen Plattformen dargestellt, und mehrere Komponenten können über ein Kommunikationsnetzwerk zusammenarbeiten, um ein bestimmtes Ziel zu erreichen.
In dieser Architektur ist die Informationsverarbeitung nicht auf eine einzelne Maschine beschränkt, sondern auf mehrere unabhängige Computer verteilt.
Ein verteiltes System kann durch die Client-Server-Architektur demonstriert werden, die die Basis für mehrschichtige Architekturen bildet. Alternativen sind die Broker-Architektur wie CORBA und die Service-Oriented Architecture (SOA).
Es gibt verschiedene Technologie-Frameworks zur Unterstützung verteilter Architekturen, darunter .NET-, J2EE-, CORBA-, .NET-Webdienste, AXIS Java-Webdienste und Globus Grid-Dienste.
Middleware ist eine Infrastruktur, die die Entwicklung und Ausführung verteilter Anwendungen angemessen unterstützt. Es bietet einen Puffer zwischen den Anwendungen und dem Netzwerk.
Es befindet sich in der Mitte des Systems und verwaltet oder unterstützt die verschiedenen Komponenten eines verteilten Systems. Beispiele sind Transaktionsverarbeitungsmonitore, Datenkonverter und Kommunikationscontroller usw.
Middleware als Infrastruktur für verteilte Systeme

Die Basis einer verteilten Architektur ist ihre Transparenz, Zuverlässigkeit und Verfügbarkeit.
In der folgenden Tabelle sind die verschiedenen Formen der Transparenz in einem verteilten System aufgeführt:
| Sr.Nr. | Transparenz & Beschreibung |
|---|---|
| 1 | Access Versteckt die Art und Weise, wie auf Ressourcen zugegriffen wird, und die Unterschiede in der Datenplattform. |
| 2 | Location Versteckt, wo sich Ressourcen befinden. |
| 3 | Technology Versteckt verschiedene Technologien wie Programmiersprache und Betriebssystem vor dem Benutzer. |
| 4 | Migration / Relocation Verstecken Sie Ressourcen, die möglicherweise an einen anderen Speicherort verschoben werden, der gerade verwendet wird. |
| 5 | Replication Verstecken Sie Ressourcen, die an mehreren Stellen kopiert werden können. |
| 6 | Concurrency Verstecken Sie Ressourcen, die möglicherweise für andere Benutzer freigegeben sind. |
| 7 | Failure Blendet Fehler und Wiederherstellung von Ressourcen vor dem Benutzer aus. |
| 8 | Persistence Blendet aus, ob sich eine Ressource (Software) im Speicher oder auf der Festplatte befindet. |
Vorteile
Resource sharing - gemeinsame Nutzung von Hardware- und Softwareressourcen.
Openness - Flexibilität bei der Verwendung von Hardware und Software verschiedener Anbieter.
Concurrency - Gleichzeitige Verarbeitung zur Leistungssteigerung.
Scalability - Erhöhter Durchsatz durch Hinzufügen neuer Ressourcen.
Fault tolerance - Die Fähigkeit, den Betrieb fortzusetzen, nachdem ein Fehler aufgetreten ist.
Nachteile
Complexity - Sie sind komplexer als zentralisierte Systeme.
Security - Anfälliger für externe Angriffe.
Manageability - Mehr Aufwand für die Systemverwaltung.
Unpredictability - Unvorhersehbare Antworten je nach Systemorganisation und Netzwerklast.
Zentrales System vs. verteiltes System
| Kriterien | Zentrales System | Verteiltes System |
|---|---|---|
| Wirtschaft | Niedrig | Hoch |
| Verfügbarkeit | Niedrig | Hoch |
| Komplexität | Niedrig | Hoch |
| Konsistenz | Einfach | Hoch |
| Skalierbarkeit | Arm | Gut |
| Technologie | Homogen | Heterogen |
| Sicherheit | Hoch | Niedrig |
Client-Server-Architektur
Die Client-Server-Architektur ist die am häufigsten verwendete verteilte Systemarchitektur, die das System in zwei wichtige Subsysteme oder logische Prozesse zerlegt.
Client - Dies ist der erste Prozess, der eine Anforderung an den zweiten Prozess, dh den Server, ausgibt.
Server - Dies ist der zweite Prozess, der die Anforderung empfängt, ausführt und eine Antwort an den Client sendet.
In dieser Architektur wird die Anwendung als eine Reihe von Diensten modelliert, die von Servern bereitgestellt werden, und als eine Reihe von Clients, die diese Dienste verwenden. Die Server müssen nichts über Clients wissen, aber die Clients müssen die Identität der Server kennen, und die Zuordnung von Prozessoren zu Prozessen erfolgt nicht unbedingt 1: 1

Die Client-Server-Architektur kann basierend auf der Funktionalität des Clients in zwei Modelle unterteilt werden:
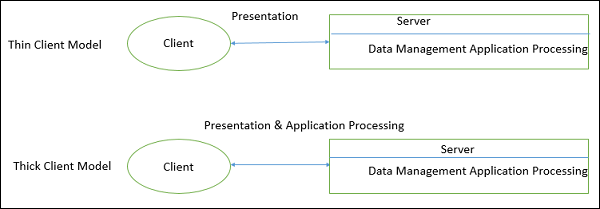
Thin-Client-Modell
Im Thin-Client-Modell wird die gesamte Anwendungsverarbeitung und Datenverwaltung vom Server ausgeführt. Der Kunde ist lediglich für die Ausführung der Präsentationssoftware verantwortlich.
Wird verwendet, wenn Legacy-Systeme auf Client-Server-Architekturen migriert werden, bei denen Legacy-Systeme als eigenständiger Server mit einer auf einem Client implementierten grafischen Oberfläche fungieren
Ein Hauptnachteil besteht darin, dass sowohl der Server als auch das Netzwerk stark belastet werden.
Dick / Fett-Client-Modell
Im Thick-Client-Modell ist der Server nur für die Datenverwaltung verantwortlich. Die Software auf dem Client implementiert die Anwendungslogik und die Interaktionen mit dem Systembenutzer.
Am besten geeignet für neue C / S-Systeme, bei denen die Funktionen des Client-Systems im Voraus bekannt sind
Komplexer als ein Thin Client-Modell, insbesondere für das Management. Neue Versionen der Anwendung müssen auf allen Clients installiert werden.
Vorteile
Aufgabentrennung wie Präsentation der Benutzeroberfläche und Verarbeitung der Geschäftslogik.
Wiederverwendbarkeit von Serverkomponenten und Potenzial für Parallelität
Vereinfacht das Design und die Entwicklung verteilter Anwendungen
Es erleichtert die Migration oder Integration vorhandener Anwendungen in eine verteilte Umgebung.
Außerdem werden Ressourcen effektiv genutzt, wenn eine große Anzahl von Clients auf einen Hochleistungsserver zugreift.
Nachteile
Mangel an heterogener Infrastruktur zur Bewältigung der Anforderungsänderungen.
Sicherheitskomplikationen.
Begrenzte Serververfügbarkeit und Zuverlässigkeit.
Eingeschränkte Testbarkeit und Skalierbarkeit.
Fette Kunden mit Präsentation und Geschäftslogik zusammen.
Mehrschichtige Architektur (n-Tier-Architektur)
Die mehrschichtige Architektur ist eine Client-Server-Architektur, bei der die Funktionen wie Präsentation, Anwendungsverarbeitung und Datenverwaltung physisch getrennt sind. Durch die Aufteilung einer Anwendung in Ebenen erhalten Entwickler die Möglichkeit, eine bestimmte Ebene zu ändern oder hinzuzufügen, anstatt die gesamte Anwendung zu überarbeiten. Es bietet ein Modell, mit dem Entwickler flexible und wiederverwendbare Anwendungen erstellen können.

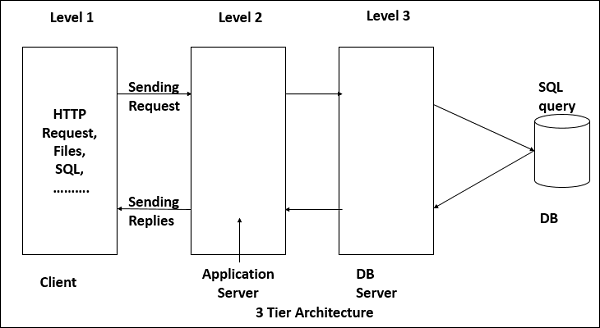
Die allgemeinste Verwendung der mehrschichtigen Architektur ist die dreistufige Architektur. Eine dreistufige Architektur besteht normalerweise aus einer Präsentationsebene, einer Anwendungsebene und einer Datenspeicherebene und kann auf einem separaten Prozessor ausgeführt werden.
Präsentationsstufe
Die Präsentationsschicht ist die oberste Ebene der Anwendung, über die Benutzer direkt auf eine Webseite oder die Benutzeroberfläche des Betriebssystems (grafische Benutzeroberfläche) zugreifen können. Die Hauptfunktion dieser Ebene besteht darin, die Aufgaben und Ergebnisse in etwas zu übersetzen, das der Benutzer verstehen kann. Es kommuniziert mit anderen Ebenen, sodass die Ergebnisse der Browser- / Client-Ebene und allen anderen Ebenen im Netzwerk zugewiesen werden.
Anwendungsebene (Geschäftslogik, Logikschicht oder mittlere Schicht)
Die Anwendungsebene koordiniert die Anwendung, verarbeitet die Befehle, trifft logische Entscheidungen, bewertet sie und führt Berechnungen durch. Es steuert die Funktionalität einer Anwendung durch detaillierte Verarbeitung. Außerdem werden Daten zwischen den beiden umgebenden Ebenen verschoben und verarbeitet.
Datenebene
In dieser Schicht werden Informationen gespeichert und aus der Datenbank oder dem Dateisystem abgerufen. Die Informationen werden dann zur Verarbeitung und dann an den Benutzer zurückgegeben. Es enthält die Datenpersistenzmechanismen (Datenbankserver, Dateifreigaben usw.) und stellt der Anwendungsebene eine API (Application Programming Interface) zur Verfügung, die Methoden zum Verwalten der gespeicherten Daten bereitstellt.
Advantages
Bessere Leistung als ein Thin-Client-Ansatz und einfacher zu verwalten als ein Thick-Client-Ansatz.
Verbessert die Wiederverwendbarkeit und Skalierbarkeit - bei steigenden Anforderungen können zusätzliche Server hinzugefügt werden.
Bietet Multithreading-Unterstützung und reduziert den Netzwerkverkehr.
Bietet Wartbarkeit und Flexibilität
Disadvantages
Unbefriedigende Testbarkeit aufgrund fehlender Testwerkzeuge.
Kritischere Serverzuverlässigkeit und -verfügbarkeit.
Broker Architekturstil
Broker Architectural Style ist eine Middleware-Architektur, die im verteilten Computing verwendet wird, um die Kommunikation zwischen registrierten Servern und Clients zu koordinieren und zu ermöglichen. Hier erfolgt die Objektkommunikation über ein Middleware-System, das als Object Request Broker (Software Bus) bezeichnet wird.
Client und Server interagieren nicht direkt miteinander. Client und Server haben eine direkte Verbindung zu ihrem Proxy, der mit dem Mediator-Broker kommuniziert.
Ein Server stellt Dienste bereit, indem er seine Schnittstellen beim Broker registriert und veröffentlicht, und Clients können die Dienste vom Broker statisch oder dynamisch durch Nachschlagen anfordern.
CORBA (Common Object Request Broker Architecture) ist ein gutes Implementierungsbeispiel für die Brokerarchitektur.
Komponenten des Broker-Architekturstils
Die Komponenten des Broker-Architekturstils werden in den folgenden Abschnitten erläutert:
Broker
Der Broker ist für die Koordination der Kommunikation verantwortlich, z. B. für die Weiterleitung und den Versand der Ergebnisse und Ausnahmen. Dies kann entweder ein aufruforientierter Dienst, ein Dokument oder ein nachrichtenorientierter Broker sein, an den Clients eine Nachricht senden.
Es ist dafür verantwortlich, die Serviceanfragen zu vermitteln, einen geeigneten Server zu finden, Anfragen zu senden und Antworten an Clients zurückzusenden.
Die Registrierungsinformationen der Server, einschließlich ihrer Funktionen und Dienste sowie Standortinformationen, werden beibehalten.
Es bietet APIs für Clients zum Anfordern, Server zum Antworten, Registrieren oder Aufheben der Registrierung von Serverkomponenten, Übertragen von Nachrichten und Auffinden von Servern.
Stub
Stubs werden zur statischen Kompilierungszeit generiert und dann auf der Clientseite bereitgestellt, die als Proxy für den Client verwendet wird. Der clientseitige Proxy fungiert als Vermittler zwischen dem Kunden und dem Broker und bietet zusätzliche Transparenz zwischen ihm und dem Kunden. Ein entferntes Objekt erscheint wie ein lokales.
Der Proxy verbirgt den IPC (Inter-Process Communication) auf Protokollebene und führt das Marshalling von Parameterwerten und das Un-Marshalling von Ergebnissen vom Server durch.
Skeleton
Das Skelett wird durch die Kompilierung der Serviceschnittstelle generiert und dann auf der Serverseite bereitgestellt, die als Proxy für den Server verwendet wird. Der serverseitige Proxy kapselt systemspezifische Netzwerkfunktionen auf niedriger Ebene und bietet APIs auf hoher Ebene, um zwischen dem Server und dem Broker zu vermitteln.
Es empfängt die Anforderungen, entpackt die Anforderungen, entschlüsselt die Methodenargumente, ruft den geeigneten Dienst auf und stellt das Ergebnis zusammen, bevor es an den Client zurückgesendet wird.
Bridge
Eine Bridge kann zwei verschiedene Netzwerke basierend auf verschiedenen Kommunikationsprotokollen verbinden. Es vermittelt verschiedene Broker, einschließlich DCOM-, .NET Remote- und Java CORBA-Broker.
Bridges sind optionale Komponenten, die die Implementierungsdetails verbergen, wenn zwei Broker zusammenarbeiten und Anforderungen und Parameter in einem Format annehmen und in ein anderes Format übersetzen.

Broker implementation in CORBA
CORBA ist ein internationaler Standard für einen Object Request Broker - eine Middleware zur Verwaltung der Kommunikation zwischen verteilten Objekten, die von OMG (Object Management Group) definiert wurden.

Serviceorientierte Architektur (SOA)
Ein Service ist eine Komponente der Geschäftsfunktionalität, die genau definiert, in sich geschlossen, unabhängig, veröffentlicht und über eine Standardprogrammierschnittstelle verwendet werden kann. Die Verbindungen zwischen Diensten werden über gemeinsame und universelle nachrichtenorientierte Protokolle wie das SOAP-Webdienstprotokoll hergestellt, das Anforderungen und Antworten zwischen Diensten lose übermitteln kann.
Serviceorientierte Architektur ist ein Client / Server-Design, das einen geschäftsorientierten IT-Ansatz unterstützt, bei dem eine Anwendung aus Softwarediensten und Softwaredienstkonsumenten (auch als Clients oder Serviceanforderer bezeichnet) besteht.
Merkmale von SOA
Eine serviceorientierte Architektur bietet die folgenden Funktionen:
Distributed Deployment - Stellen Sie Unternehmensdaten und Geschäftslogik als lose, gekoppelte, auffindbare, strukturierte, standardbasierte, grobkörnige, zustandslose Funktionseinheiten dar, die als Dienste bezeichnet werden.
Composability - Stellen Sie neue Prozesse aus vorhandenen Diensten zusammen, die über gut definierte, veröffentlichte und standardmäßige Schnittstellen für Beschwerden in einer gewünschten Granularität verfügbar gemacht werden.
Interoperability - Gemeinsame Funktionen und Wiederverwendung gemeinsam genutzter Dienste in einem Netzwerk, unabhängig von den zugrunde liegenden Protokollen oder der Implementierungstechnologie.
Reusability - Wählen Sie einen Dienstanbieter und greifen Sie auf vorhandene Ressourcen zu, die als Dienste verfügbar gemacht werden.
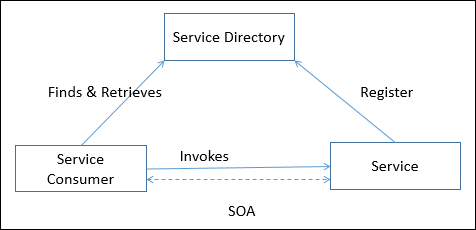
SOA-Betrieb
Die folgende Abbildung zeigt, wie SOA funktioniert -

Advantages
Die lose Kopplung von Service-Orientierung bietet Unternehmen eine große Flexibilität, um alle verfügbaren Service-Ressourcen unabhängig von Plattform- und Technologieeinschränkungen zu nutzen.
Jede Dienstkomponente ist aufgrund der zustandslosen Dienstfunktion unabhängig von anderen Diensten.
Die Implementierung eines Dienstes wirkt sich nicht auf die Anwendung des Dienstes aus, solange die exponierte Schnittstelle nicht geändert wird.
Ein Client oder ein Dienst kann unabhängig von seiner Plattform, Technologie, seinen Anbietern oder Sprachimplementierungen auf andere Dienste zugreifen.
Wiederverwendbarkeit von Assets und Services, da Kunden eines Service nur die öffentlichen Schnittstellen und die Servicezusammensetzung kennen müssen.
Die Entwicklung von SOA-basierten Geschäftsanwendungen ist zeit- und kostenintensiver.
Verbessert die Skalierbarkeit und bietet eine Standardverbindung zwischen Systemen.
Effiziente und effektive Nutzung von 'Business Services'.
Die Integration wird viel einfacher und die intrinsische Interoperabilität verbessert.
Abstrakte Komplexität für Entwickler und Anregung von Geschäftsprozessen näher am Endbenutzer.