Kurzanleitung
Die Architektur eines Systems beschreibt seine Hauptkomponenten, ihre Beziehungen (Strukturen) und wie sie miteinander interagieren. Die Softwarearchitektur und das Design umfassen verschiedene Faktoren wie Geschäftsstrategie, Qualitätsmerkmale, menschliche Dynamik, Design und IT-Umgebung.

Wir können Software-Architektur und -Design in zwei verschiedene Phasen unterteilen: Software-Architektur und Software-Design. ImArchitectureNicht funktionierende Entscheidungen werden durch die funktionalen Anforderungen getroffen und getrennt. Im Design werden funktionale Anforderungen erfüllt.
Softwarearchitektur
Architektur dient als blueprint for a system. Es bietet eine Abstraktion zur Verwaltung der Systemkomplexität und zur Einrichtung eines Kommunikations- und Koordinierungsmechanismus zwischen Komponenten.
Es definiert a structured solution um alle technischen und betrieblichen Anforderungen zu erfüllen und gleichzeitig die gemeinsamen Qualitätsmerkmale wie Leistung und Sicherheit zu optimieren.
Darüber hinaus beinhaltet es eine Reihe wichtiger Entscheidungen über die Organisation im Zusammenhang mit der Softwareentwicklung, und jede dieser Entscheidungen kann erhebliche Auswirkungen auf Qualität, Wartbarkeit, Leistung und den Gesamterfolg des Endprodukts haben. Diese Entscheidungen umfassen:
Auswahl der Strukturelemente und ihrer Schnittstellen, aus denen das System besteht.
Verhalten wie in der Zusammenarbeit zwischen diesen Elementen angegeben.
Zusammensetzung dieser Struktur- und Verhaltenselemente zu einem großen Teilsystem.
Architekturentscheidungen richten sich nach den Geschäftszielen.
Architekturstile leiten die Organisation.
Software-Design
Software-Design bietet eine design plandas beschreibt die Elemente eines Systems, wie sie passen und zusammenarbeiten, um die Anforderungen des Systems zu erfüllen. Die Ziele eines Entwurfsplans sind wie folgt:
Aushandlung der Systemanforderungen und Festlegung von Erwartungen mit Kunden, Marketing- und Managementpersonal.
Als Blaupause während des Entwicklungsprozesses fungieren.
Führen Sie die Implementierungsaufgaben, einschließlich detailliertes Design, Codierung, Integration und Testen.
Es erfolgt vor dem detaillierten Entwurf, der Codierung, der Integration und dem Testen sowie nach der Domänenanalyse, Anforderungsanalyse und Risikoanalyse.
Ziele der Architektur
Das Hauptziel der Architektur besteht darin, Anforderungen zu identifizieren, die sich auf die Struktur der Anwendung auswirken. Eine übersichtliche Architektur reduziert die mit dem Aufbau einer technischen Lösung verbundenen Geschäftsrisiken und schlägt eine Brücke zwischen geschäftlichen und technischen Anforderungen.
Einige der anderen Ziele sind wie folgt:
Legen Sie die Struktur des Systems offen, verbergen Sie jedoch die Implementierungsdetails.
Realisieren Sie alle Anwendungsfälle und Szenarien.
Versuchen Sie, auf die Anforderungen verschiedener Stakeholder einzugehen.
Behandeln Sie sowohl funktionale als auch Qualitätsanforderungen.
Reduzieren Sie das Ziel der Eigenverantwortung und verbessern Sie die Marktposition des Unternehmens.
Verbessern Sie die Qualität und Funktionalität des Systems.
Verbessern Sie das externe Vertrauen in die Organisation oder das System.
Einschränkungen
Die Softwarearchitektur ist immer noch eine aufstrebende Disziplin in der Softwareentwicklung. Es hat die folgenden Einschränkungen -
Mangel an Werkzeugen und standardisierten Darstellungsweisen für Architektur.
Fehlende Analysemethoden, um vorherzusagen, ob die Architektur zu einer Implementierung führt, die den Anforderungen entspricht.
Mangelndes Bewusstsein für die Bedeutung des Architekturdesigns für die Softwareentwicklung.
Mangelndes Verständnis für die Rolle des Softwarearchitekten und schlechte Kommunikation zwischen den Stakeholdern.
Mangel an Verständnis für den Entwurfsprozess, Entwurfserfahrung und Bewertung des Entwurfs.
Rolle des Software-Architekten
Ein Software-Architekt bietet eine Lösung, die das technische Team für die gesamte Anwendung erstellen und entwerfen kann. Ein Softwarearchitekt sollte über Fachwissen in den folgenden Bereichen verfügen:
Design-Expertise
Experte für Software-Design, einschließlich verschiedener Methoden und Ansätze wie objektorientiertes Design, ereignisgesteuertes Design usw.
Führen Sie das Entwicklungsteam und koordinieren Sie die Entwicklungsbemühungen für die Integrität des Designs.
Sollte in der Lage sein, Designvorschläge und Kompromisse untereinander zu überprüfen.
Domain-Know-how
Experte für das zu entwickelnde System und Plan für die Softwareentwicklung.
Unterstützung beim Anforderungsuntersuchungsprozess, um Vollständigkeit und Konsistenz sicherzustellen.
Koordinieren Sie die Definition des Domänenmodells für das zu entwickelnde System.
Technologiekompetenz
Experte für verfügbare Technologien, die bei der Implementierung des Systems helfen.
Koordinieren Sie die Auswahl der Programmiersprache, des Frameworks, der Plattformen, Datenbanken usw.
Methodische Expertise
Experte für Softwareentwicklungsmethoden, die während des SDLC (Software Development Life Cycle) angewendet werden können.
Wählen Sie die geeigneten Entwicklungsansätze, die dem gesamten Team helfen.
Versteckte Rolle des Software-Architekten
Erleichtert die technische Arbeit unter den Teammitgliedern und stärkt die Vertrauensbeziehung im Team.
Informationsspezialist, der Wissen teilt und über umfangreiche Erfahrungen verfügt.
Schützen Sie die Teammitglieder vor externen Kräften, die sie ablenken und weniger Wert für das Projekt bringen würden.
Leistungen des Architekten
Eine klare, vollständige, konsistente und erreichbare Reihe von funktionalen Zielen
Eine Funktionsbeschreibung des Systems mit mindestens zwei Zersetzungsschichten
Ein Konzept für das System
Ein Entwurf in Form des Systems mit mindestens zwei Zersetzungsschichten
Eine Vorstellung des Timings, der Bedienerattribute sowie der Implementierungs- und Betriebspläne
Ein Dokument oder Prozess, der die funktionale Zerlegung sicherstellt, wird befolgt und die Form der Schnittstellen wird gesteuert
Qualitätsmerkmale
Qualität ist ein Maß für Exzellenz oder der Zustand, frei von Mängeln oder Mängeln zu sein. Qualitätsattribute sind die Systemeigenschaften, die von der Funktionalität des Systems getrennt sind.
Die Implementierung von Qualitätsattributen erleichtert die Unterscheidung eines guten von einem schlechten System. Attribute sind allgemeine Faktoren, die das Laufzeitverhalten, das Systemdesign und die Benutzererfahrung beeinflussen.
Sie können klassifiziert werden als -
Statische Qualitätsattribute
Reflektieren Sie die Struktur eines Systems und einer Organisation, die in direktem Zusammenhang mit Architektur, Design und Quellcode stehen. Sie sind für den Endbenutzer unsichtbar, wirken sich jedoch auf die Entwicklungs- und Wartungskosten aus, z. B. Modularität, Testbarkeit, Wartbarkeit usw.
Dynamische Qualitätsattribute
Reflektieren Sie das Verhalten des Systems während seiner Ausführung. Sie stehen in direktem Zusammenhang mit der Architektur, dem Design, dem Quellcode, der Konfiguration, den Bereitstellungsparametern, der Umgebung und der Plattform des Systems.
Sie sind für den Endbenutzer sichtbar und zur Laufzeit vorhanden, z. B. Durchsatz, Robustheit, Skalierbarkeit usw.
Qualitätsszenarien
Qualitätsszenarien legen fest, wie verhindert werden kann, dass ein Fehler zum Fehler wird. Sie können basierend auf ihren Attributspezifikationen in sechs Teile unterteilt werden -
Source - Eine interne oder externe Einheit wie Personen, Hardware, Software oder physische Infrastruktur, die den Anreiz erzeugt.
Stimulus - Eine Bedingung, die berücksichtigt werden muss, wenn sie auf einem System eintrifft.
Environment - Der Reiz tritt unter bestimmten Bedingungen auf.
Artifact - Ein ganzes System oder ein Teil davon wie Prozessoren, Kommunikationskanäle, persistente Speicher, Prozesse usw.
Response - Eine Aktivität, die nach dem Eintreffen eines Stimulus ausgeführt wird, z. B. Fehler erkennen, Fehler beheben, Ereignisquelle deaktivieren usw.
Response measure - Sollte die aufgetretenen Antworten messen, damit die Anforderungen getestet werden können.
Gemeinsame Qualitätsmerkmale
In der folgenden Tabelle sind die allgemeinen Qualitätsmerkmale aufgeführt, die eine Softwarearchitektur aufweisen muss:
| Kategorie | Qualitätsattribut | Beschreibung |
|---|---|---|
| Designqualitäten | Konzeptionelle Integrität | Definiert die Konsistenz und Kohärenz des Gesamtdesigns. Dies schließt die Art und Weise ein, wie Komponenten oder Module entworfen werden. |
| Wartbarkeit | Fähigkeit des Systems, Änderungen mit einem gewissen Grad vorzunehmen. | |
| Wiederverwendbarkeit | Definiert die Fähigkeit von Komponenten und Subsystemen, für die Verwendung in anderen Anwendungen geeignet zu sein. | |
| Laufzeitqualitäten | Interoperabilität | Fähigkeit eines Systems oder verschiedener Systeme, erfolgreich zu arbeiten, indem Informationen mit anderen externen Systemen kommuniziert und ausgetauscht werden, die von externen Parteien geschrieben und betrieben werden. |
| Verwaltbarkeit | Definiert, wie einfach es für Systemadministratoren ist, die Anwendung zu verwalten. | |
| Verlässlichkeit | Fähigkeit eines Systems, über einen längeren Zeitraum betriebsbereit zu bleiben. | |
| Skalierbarkeit | Fähigkeit eines Systems, entweder die Lastzunahme zu bewältigen, ohne die Leistung des Systems zu beeinträchtigen, oder die Fähigkeit, leicht vergrößert zu werden. | |
| Sicherheit | Fähigkeit eines Systems, böswillige oder versehentliche Handlungen außerhalb der vorgesehenen Verwendungszwecke zu verhindern. | |
| Performance | Angabe der Reaktionsfähigkeit eines Systems zur Ausführung einer Aktion innerhalb eines bestimmten Zeitintervalls. | |
| Verfügbarkeit | Definiert den Zeitanteil, in dem das System funktionsfähig ist und funktioniert. Sie kann als Prozentsatz der gesamten Systemausfallzeit über einen vordefinierten Zeitraum gemessen werden. | |
| Systemqualitäten | Unterstützbarkeit | Fähigkeit des Systems, Informationen bereitzustellen, die hilfreich sind, um Probleme zu identifizieren und zu lösen, wenn es nicht richtig funktioniert. |
| Testbarkeit | Messen Sie, wie einfach es ist, Testkriterien für das System und seine Komponenten zu erstellen. | |
| Benutzerqualitäten | Benutzerfreundlichkeit | Definiert, wie gut die Anwendung die Anforderungen von Benutzer und Verbraucher erfüllt, indem sie intuitiv ist. |
| Architekturqualität | Richtigkeit | Verantwortlichkeit für die Erfüllung aller Anforderungen des Systems. |
| Nicht-Laufzeitqualität | Portabilität | Fähigkeit des Systems, unter verschiedenen Computerumgebungen zu laufen. |
| Integrität | Fähigkeit, separat entwickelte Komponenten des Systems korrekt zusammenarbeiten zu lassen. | |
| Modifizierbarkeit | Leichtigkeit, mit der jedes Softwaresystem Änderungen an seiner Software vornehmen kann. | |
| Geschäftsqualitätsattribute | Kosten und Zeitplan | Kosten des Systems in Bezug auf Time-to-Market, erwartete Projektlebensdauer und Nutzung des Erbes. |
| Marktfähigkeit | Verwendung des Systems im Hinblick auf den Marktwettbewerb. |
Die Softwarearchitektur wird als Organisation eines Systems beschrieben, bei dem das System eine Reihe von Komponenten darstellt, die die definierten Funktionen ausführen.
Architektonischer Stil
Das architectural style, auch genannt als architectural patternist eine Reihe von Prinzipien, die eine Anwendung formen. Es definiert einen abstrakten Rahmen für eine Systemfamilie in Bezug auf das Muster der strukturellen Organisation.
Der architektonische Stil ist verantwortlich für -
Stellen Sie ein Lexikon von Komponenten und Konnektoren mit Regeln zur Verfügung, wie sie kombiniert werden können.
Verbessern Sie die Partitionierung und ermöglichen Sie die Wiederverwendung von Design, indem Sie Lösungen für häufig auftretende Probleme bereitstellen.
Beschreiben einer bestimmten Methode zum Konfigurieren einer Sammlung von Komponenten (ein Modul mit genau definierten Schnittstellen, wiederverwendbar und austauschbar) und Konnektoren (Kommunikationsverbindung zwischen Modulen).
Die Software, die für computergestützte Systeme entwickelt wurde, weist einen von vielen Architekturstilen auf. Jeder Stil beschreibt eine Systemkategorie, die Folgendes umfasst:
Eine Reihe von Komponententypen, die eine vom System erforderliche Funktion ausführen.
Eine Reihe von Konnektoren (Unterprogrammaufruf, Remoteprozeduraufruf, Datenstrom und Socket), die die Kommunikation, Koordination und Zusammenarbeit zwischen verschiedenen Komponenten ermöglichen.
Semantische Einschränkungen, die definieren, wie Komponenten zur Bildung des Systems integriert werden können.
Ein topologisches Layout der Komponenten, das ihre Laufzeitbeziehungen angibt.
Gemeinsame architektonische Gestaltung
In der folgenden Tabelle sind Architekturstile aufgeführt, die nach ihrem Hauptfokusbereich organisiert werden können:
| Kategorie | Architekturdesign | Beschreibung |
|---|---|---|
| Kommunikation | Nachrichtenbus | Verschreibt die Verwendung eines Softwaresystems, das Nachrichten über einen oder mehrere Kommunikationskanäle empfangen und senden kann. |
| Serviceorientierte Architektur (SOA) | Definiert die Anwendungen, die Funktionen als Service mithilfe von Verträgen und Nachrichten verfügbar machen und nutzen. | |
| Einsatz | Kundenserver | Teilen Sie das System in zwei Anwendungen auf, in denen der Client Anforderungen an den Server stellt. |
| 3-Tier oder N-Tier | Trennt die Funktionalität in separate Segmente, wobei jedes Segment eine Schicht ist, die sich auf einem physisch separaten Computer befindet. | |
| Domain | Domain Driven Design | Konzentrierte sich auf die Modellierung einer Geschäftsdomäne und die Definition von Geschäftsobjekten basierend auf Entitäten innerhalb der Geschäftsdomäne. |
| Struktur | Komponentenbasiert | Teilen Sie das Anwendungsdesign in wiederverwendbare funktionale oder logische Komponenten auf, die genau definierte Kommunikationsschnittstellen verfügbar machen. |
| Geschichtet | Teilen Sie die Anliegen der Anwendung in gestapelte Gruppen (Ebenen). | |
| Objektorientierter | Basierend auf der Aufteilung der Verantwortlichkeiten einer Anwendung oder eines Systems in Objekte, die jeweils die Daten und das für das Objekt relevante Verhalten enthalten. |
Arten von Architektur
Aus Sicht eines Unternehmens gibt es vier Arten von Architekturen, und zusammen werden diese Architekturen als bezeichnet enterprise architecture.
Business architecture - Definiert die Strategie von Geschäft, Governance, Organisation und wichtigen Geschäftsprozessen innerhalb eines Unternehmens und konzentriert sich auf die Analyse und Gestaltung von Geschäftsprozessen.
Application (software) architecture - Dient als Vorlage für einzelne Anwendungssysteme, ihre Interaktionen und ihre Beziehungen zu den Geschäftsprozessen der Organisation.
Information architecture - Definiert die logischen und physischen Datenbestände und Datenverwaltungsressourcen.
Information technology (IT) architecture - Definiert die Hardware- und Software-Bausteine, aus denen das gesamte Informationssystem der Organisation besteht.
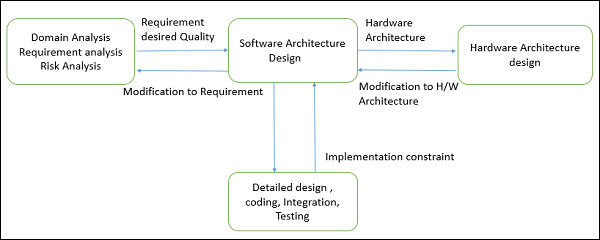
Architektur-Design-Prozess
Der Architekturentwurfsprozess konzentriert sich auf die Zerlegung eines Systems in verschiedene Komponenten und deren Wechselwirkungen, um funktionale und nicht funktionale Anforderungen zu erfüllen. Die wichtigsten Eingaben für das Design der Softwarearchitektur sind:
Die Anforderungen der Analyseaufgaben.
Die Hardwarearchitektur (der Softwarearchitekt stellt wiederum Anforderungen an den Systemarchitekten, der die Hardwarearchitektur konfiguriert).
Das Ergebnis oder die Ausgabe des Architekturentwurfsprozesses ist ein architectural description. Der grundlegende Architekturentwurfsprozess besteht aus den folgenden Schritten:
Verstehe das Problem
Dies ist der wichtigste Schritt, da er die Qualität des folgenden Designs beeinflusst.
Ohne ein klares Verständnis des Problems ist es nicht möglich, eine effektive Lösung zu finden.
Viele Softwareprojekte und -produkte gelten als Fehler, da sie ein gültiges Geschäftsproblem nicht gelöst haben oder keinen erkennbaren Return on Investment (ROI) aufweisen.
Identifizieren Sie Designelemente und ihre Beziehungen
Erstellen Sie in dieser Phase eine Basislinie zum Definieren der Grenzen und des Kontexts des Systems.
Zerlegung des Systems in seine Hauptkomponenten basierend auf funktionalen Anforderungen. Die Zerlegung kann mithilfe einer Entwurfsstrukturmatrix (DSM) modelliert werden, die die Abhängigkeiten zwischen Entwurfselementen anzeigt, ohne die Granularität der Elemente anzugeben.
In diesem Schritt erfolgt die erste Validierung der Architektur durch Beschreibung einer Reihe von Systeminstanzen. Dieser Schritt wird als funktionsbasiertes Architekturdesign bezeichnet.
Bewerten Sie das Architekturdesign
Jedes Qualitätsmerkmal erhält eine Schätzung. Um qualitative Maße oder quantitative Daten zu erfassen, wird das Design bewertet.
Dabei wird die Architektur auf Übereinstimmung mit den Anforderungen an architektonische Qualitätsattribute bewertet.
Wenn alle geschätzten Qualitätsmerkmale dem erforderlichen Standard entsprechen, ist der architektonische Entwurfsprozess abgeschlossen.
Wenn nicht, wird die dritte Phase des Entwurfs der Softwarearchitektur eingeleitet: die Architekturtransformation. Wenn das beobachtete Qualitätsmerkmal nicht den Anforderungen entspricht, muss ein neues Design erstellt werden.
Transformieren Sie das Architekturdesign
Dieser Schritt wird nach einer Bewertung des architektonischen Entwurfs durchgeführt. Das architektonische Design muss geändert werden, bis die Anforderungen an die Qualitätsmerkmale vollständig erfüllt sind.
Es geht darum, Entwurfslösungen auszuwählen, um die Qualitätsattribute zu verbessern und gleichzeitig die Domänenfunktionalität zu erhalten.
Ein Design wird durch Anwenden von Designoperatoren, -stilen oder -mustern transformiert. Nehmen Sie für die Transformation das vorhandene Design und wenden Sie den Designoperator an, z. B. Zerlegung, Replikation, Komprimierung, Abstraktion und gemeinsame Nutzung von Ressourcen.
Das Design wird erneut bewertet und derselbe Vorgang wird bei Bedarf mehrmals wiederholt und sogar rekursiv ausgeführt.
Die Transformationen (dh Lösungen zur Optimierung von Qualitätsattributen) verbessern im Allgemeinen ein oder einige Qualitätsattribute, während sie andere negativ beeinflussen
Wichtige Architekturprinzipien
Im Folgenden sind die wichtigsten Prinzipien aufgeführt, die beim Entwerfen einer Architektur berücksichtigt werden müssen:
Bauen, um zu ändern, anstatt zu bauen, um zu halten
Überlegen Sie, wie sich die Anwendung im Laufe der Zeit möglicherweise ändern muss, um neuen Anforderungen und Herausforderungen gerecht zu werden, und bauen Sie die Flexibilität ein, um dies zu unterstützen.
Reduzieren Sie das zu analysierende Risiko und Modell
Verwenden Sie Entwurfswerkzeuge, Visualisierungen und Modellierungssysteme wie UML, um Anforderungen und Entwurfsentscheidungen zu erfassen. Die Auswirkungen können auch analysiert werden. Formalisieren Sie das Modell nicht in dem Maße, in dem es die Fähigkeit unterdrückt, das Design leicht zu iterieren und anzupassen.
Verwenden Sie Modelle und Visualisierungen als Kommunikations- und Kollaborationswerkzeug
Eine effiziente Kommunikation des Designs, der Entscheidungen und laufenden Änderungen am Design ist für eine gute Architektur von entscheidender Bedeutung. Verwenden Sie Modelle, Ansichten und andere Visualisierungen der Architektur, um das Design effizient zu kommunizieren und mit allen Beteiligten zu teilen. Dies ermöglicht eine schnelle Kommunikation von Änderungen am Design.
Identifizieren und verstehen Sie wichtige technische Entscheidungen und Bereiche, in denen Fehler am häufigsten gemacht werden. Investieren Sie beim ersten Mal in die richtigen Entscheidungen, um das Design flexibler zu gestalten und weniger wahrscheinlich durch Änderungen beschädigt zu werden.
Verwenden Sie einen inkrementellen und iterativen Ansatz
Beginnen Sie mit der Basisarchitektur und entwickeln Sie dann Kandidatenarchitekturen durch iterative Tests, um die Architektur zu verbessern. Fügen Sie dem Design über mehrere Durchgänge iterativ Details hinzu, um das große oder richtige Bild zu erhalten, und konzentrieren Sie sich dann auf die Details.
Wichtige Gestaltungsprinzipien
Im Folgenden sind die Entwurfsprinzipien aufgeführt, die zur Minimierung von Kosten, Wartungsanforderungen und Maximierung der Erweiterbarkeit und Benutzerfreundlichkeit der Architektur zu berücksichtigen sind.
Trennung von Bedenken
Teilen Sie die Komponenten des Systems in bestimmte Merkmale ein, damit sich die Funktionen der Komponenten nicht überschneiden. Dies sorgt für eine hohe Kohäsion und eine geringe Kopplung. Dieser Ansatz vermeidet die gegenseitige Abhängigkeit zwischen Systemkomponenten, was zur einfachen Wartung des Systems beiträgt.
Prinzip der Einzelverantwortung
Jedes Modul eines Systems sollte eine bestimmte Verantwortung haben, die dem Benutzer hilft, das System klar zu verstehen. Es sollte auch bei der Integration der Komponente in andere Komponenten helfen.
Prinzip des geringsten Wissens
Komponenten oder Objekte sollten nicht über die internen Details anderer Komponenten informiert sein. Dieser Ansatz vermeidet gegenseitige Abhängigkeiten und trägt zur Wartbarkeit bei.
Minimieren Sie großes Design im Voraus
Minimieren Sie große Designs im Voraus, wenn die Anforderungen einer Anwendung unklar sind. Wenn die Möglichkeit besteht, Anforderungen zu ändern, vermeiden Sie es, ein großes Design für das gesamte System zu erstellen.
Wiederholen Sie die Funktionalität nicht
Funktion nicht wiederholen gibt an, dass die Funktionalität von Komponenten nicht wiederholt werden soll und daher ein Code nur in einer Komponente implementiert werden soll. Das Duplizieren von Funktionen innerhalb einer Anwendung kann es schwierig machen, Änderungen zu implementieren, die Klarheit zu verringern und potenzielle Inkonsistenzen einzuführen.
Ziehen Sie die Komposition der Vererbung vor, während Sie die Funktionalität wiederverwenden
Vererbung schafft Abhängigkeit zwischen untergeordneten und übergeordneten Klassen und blockiert daher die freie Verwendung der untergeordneten Klassen. Im Gegensatz dazu bietet die Komposition ein hohes Maß an Freiheit und reduziert die Vererbungshierarchien.
Identifizieren Sie Komponenten und gruppieren Sie sie in logischen Ebenen
Identitätskomponenten und der Problembereich, der im System benötigt wird, um die Anforderungen zu erfüllen. Gruppieren Sie dann diese verwandten Komponenten in einer logischen Schicht, um dem Benutzer zu helfen, die Struktur des Systems auf hoher Ebene zu verstehen. Vermeiden Sie es, Komponenten unterschiedlicher Art von Bedenken in derselben Schicht zu mischen.
Definieren Sie das Kommunikationsprotokoll zwischen Ebenen
Verstehen Sie, wie Komponenten miteinander kommunizieren, was umfassende Kenntnisse der Bereitstellungsszenarien und der Produktionsumgebung erfordert.
Definieren Sie das Datenformat für eine Ebene
Verschiedene Komponenten interagieren über das Datenformat miteinander. Mischen Sie die Datenformate nicht, damit Anwendungen einfach implementiert, erweitert und gewartet werden können. Versuchen Sie, das Datenformat für eine Ebene gleich zu halten, damit verschiedene Komponenten die Daten während der Kommunikation nicht codieren / decodieren müssen. Dies reduziert den Verarbeitungsaufwand.
Systemdienstkomponenten sollten abstrakt sein
Code in Bezug auf Sicherheit, Kommunikation oder Systemdienste wie Protokollierung, Profilerstellung und Konfiguration sollte in den separaten Komponenten abstrahiert werden. Mischen Sie diesen Code nicht mit der Geschäftslogik, da es einfach ist, das Design zu erweitern und zu warten.
Entwurfsausnahmen und Ausnahmebehandlungsmechanismus
Das Definieren von Ausnahmen im Voraus hilft den Komponenten, Fehler oder unerwünschte Situationen auf elegante Weise zu verwalten. Die Ausnahmeverwaltung ist im gesamten System gleich.
Regeln der Namensgebung
Namenskonventionen sollten im Voraus definiert werden. Sie bieten ein konsistentes Modell, das den Benutzern hilft, das System leicht zu verstehen. Es ist für Teammitglieder einfacher, von anderen geschriebenen Code zu validieren, und erhöht somit die Wartbarkeit.
Die Softwarearchitektur umfasst die Struktur der Abstraktion von Softwaresystemen auf hoher Ebene unter Verwendung von Zerlegung und Komposition mit Architekturstil und Qualitätsattributen. Ein Software-Architektur-Design muss den wichtigsten Funktions- und Leistungsanforderungen des Systems entsprechen und die nicht funktionalen Anforderungen wie Zuverlässigkeit, Skalierbarkeit, Portabilität und Verfügbarkeit erfüllen.
Eine Softwarearchitektur muss ihre Komponentengruppe, ihre Verbindungen, Interaktionen zwischen ihnen und die Bereitstellungskonfiguration aller Komponenten beschreiben.
Eine Softwarearchitektur kann auf viele Arten definiert werden -
UML (Unified Modeling Language) - UML ist eine objektorientierte Lösung für die Modellierung und das Design von Software.
Architecture View Model (4+1 view model) - Das Architekturansichtsmodell repräsentiert die funktionalen und nicht funktionalen Anforderungen der Softwareanwendung.
ADL (Architecture Description Language) - ADL definiert die Softwarearchitektur formal und semantisch.
UML
UML steht für Unified Modeling Language. Es ist eine Bildsprache, mit der Software-Blaupausen erstellt werden. UML wurde von der Object Management Group (OMG) erstellt. Der Entwurf der UML 1.0-Spezifikation wurde der OMG im Januar 1997 vorgeschlagen. Er dient als Standard für die Analyse von Softwareanforderungen und Entwurfsdokumente, die die Grundlage für die Entwicklung einer Software bilden.
UML kann als universelle visuelle Modellierungssprache zum Visualisieren, Spezifizieren, Erstellen und Dokumentieren eines Softwaresystems beschrieben werden. Obwohl UML im Allgemeinen zur Modellierung von Softwaresystemen verwendet wird, ist es innerhalb dieser Grenze nicht beschränkt. Es wird auch verwendet, um Nicht-Software-Systeme wie Prozessabläufe in einer Fertigungseinheit zu modellieren.
Die Elemente sind wie Komponenten, die auf unterschiedliche Weise verknüpft werden können, um ein vollständiges UML-Bild zu erstellen, das als a bezeichnet wird diagram. Daher ist es sehr wichtig, die verschiedenen Diagramme zu verstehen, um das Wissen in realen Systemen zu implementieren. Wir haben zwei große Kategorien von Diagrammen, die weiter in Unterkategorien unterteilt sind, d. H.Structural Diagrams und Behavioral Diagrams.
Strukturdiagramme
Strukturdiagramme repräsentieren die statischen Aspekte eines Systems. Diese statischen Aspekte stellen diejenigen Teile eines Diagramms dar, die die Hauptstruktur bilden und daher stabil sind.
Diese statischen Teile werden durch Klassen, Schnittstellen, Objekte, Komponenten und Knoten dargestellt. Strukturdiagramme können wie folgt unterteilt werden:
- Klassen Diagramm
- Objektdiagramm
- Komponentendiagramm
- Bereitstellungsdiagramm
- Paketdiagramm
- Verbundstruktur
Die folgende Tabelle enthält eine kurze Beschreibung dieser Diagramme.
| Sr.Nr. | Diagramm & Beschreibung |
|---|---|
| 1 | Class Repräsentiert die Objektorientierung eines Systems. Zeigt, wie Klassen statisch zusammenhängen. |
| 2 | Object Stellt eine Reihe von Objekten und deren Beziehungen zur Laufzeit dar und stellt auch die statische Ansicht des Systems dar. |
| 3 | Component Beschreibt alle Komponenten, ihre Wechselbeziehungen, Interaktionen und Schnittstellen des Systems. |
| 4 | Composite structure Beschreibt die innere Struktur der Komponente einschließlich aller Klassen, Schnittstellen der Komponente usw. |
| 5 | Package Beschreibt die Paketstruktur und -organisation. Deckt Klassen im Paket und Pakete in einem anderen Paket ab. |
| 6 | Deployment Bereitstellungsdiagramme sind eine Reihe von Knoten und ihre Beziehungen. Diese Knoten sind physische Einheiten, in denen die Komponenten bereitgestellt werden. |
Verhaltensdiagramme
Verhaltensdiagramme erfassen grundsätzlich den dynamischen Aspekt eines Systems. Dynamische Aspekte sind im Grunde die sich ändernden / bewegenden Teile eines Systems. UML verfügt über die folgenden Arten von Verhaltensdiagrammen:
- Anwendungsfalldiagramm
- Sequenzdiagramm
- Kommunikationsdiagramm
- Zustandsdiagramm
- Aktivitätsdiagramm
- Interaktionsübersicht
- Zeitablaufdiagramm
Die folgende Tabelle enthält eine kurze Beschreibung dieses Diagramms -
| Sr.Nr. | Diagramm & Beschreibung |
|---|---|
| 1 | Use case Beschreibt die Beziehungen zwischen den Funktionen und ihren internen / externen Controllern. Diese Controller werden als Akteure bezeichnet. |
| 2 | Activity Beschreibt den Kontrollfluss in einem System. Es besteht aus Aktivitäten und Links. Der Fluss kann sequentiell, gleichzeitig oder verzweigt sein. |
| 3 | State Machine/state chart Repräsentiert die ereignisgesteuerte Statusänderung eines Systems. Es beschreibt im Wesentlichen die Zustandsänderung einer Klasse, einer Schnittstelle usw. Wird verwendet, um die Reaktion eines Systems durch interne / externe Faktoren zu visualisieren. |
| 4 | Sequence Visualisiert die Reihenfolge der Aufrufe in einem System, um eine bestimmte Funktionalität auszuführen. |
| 5 | Interaction Overview Kombiniert Aktivitäts- und Sequenzdiagramme, um einen Kontrollflussüberblick über System- und Geschäftsprozesse bereitzustellen. |
| 6 | Communication Entspricht dem Sequenzdiagramm, außer dass es sich auf die Rolle des Objekts konzentriert. Jede Kommunikation ist mit einer Sequenzreihenfolge, einer Nummer und den vergangenen Nachrichten verknüpft. |
| 7 | Time Sequenced Beschreibt die Änderungen durch Meldungen in Status, Zustand und Ereignissen. |
Architekturansichtsmodell
Ein Modell ist eine vollständige, grundlegende und vereinfachte Beschreibung der Softwarearchitektur, die aus mehreren Ansichten aus einer bestimmten Perspektive oder Sichtweise besteht.
Eine Ansicht ist eine Darstellung eines gesamten Systems aus der Perspektive einer Reihe verwandter Anliegen. Es wird verwendet, um das System aus der Sicht verschiedener Interessengruppen wie Endbenutzer, Entwickler, Projektmanager und Tester zu beschreiben.
4 + 1 Modell anzeigen
Das 4 + 1-Ansichtsmodell wurde von Philippe Kruchten entworfen, um die Architektur eines softwareintensiven Systems zu beschreiben, das auf der Verwendung mehrerer und gleichzeitiger Ansichten basiert. Es ist einmultiple viewModell, das verschiedene Funktionen und Anliegen des Systems berücksichtigt. Es standardisiert die Software-Designdokumente und macht das Design für alle Beteiligten leicht verständlich.
Es ist eine Architekturüberprüfungsmethode zum Studieren und Dokumentieren des Entwurfs von Softwarearchitekturen und deckt alle Aspekte der Softwarearchitektur für alle Beteiligten ab. Es bietet vier wesentliche Ansichten -
The logical view or conceptual view - Es beschreibt das Objektmodell des Entwurfs.
The process view - Es beschreibt die Aktivitäten des Systems, erfasst die Parallelitäts- und Synchronisationsaspekte des Entwurfs.
The physical view - Es beschreibt die Zuordnung von Software zu Hardware und spiegelt deren verteilten Aspekt wider.
The development view - Es beschreibt die statische Organisation oder Struktur der Software bei der Entwicklung der Umgebung.
Dieses Ansichtsmodell kann durch Hinzufügen einer weiteren aufgerufenen Ansicht erweitert werden scenario view oder use case viewfür Endbenutzer oder Kunden von Softwaresystemen. Es stimmt mit den anderen vier Ansichten überein und wird verwendet, um die Architektur zu veranschaulichen, die als "plus eins" -Ansicht (4 + 1) -Ansichtsmodell dient. Die folgende Abbildung beschreibt die Softwarearchitektur anhand eines Modells mit fünf gleichzeitigen Ansichten (4 + 1).

Warum heißt es 4 + 1 statt 5?
Das use case viewhat eine besondere Bedeutung, da es die hohen Anforderungen eines Systems detailliert beschreibt, während andere Ansichten detailliert beschreiben - wie diese Anforderungen realisiert werden. Wenn alle anderen vier Ansichten abgeschlossen sind, ist sie effektiv redundant. Alle anderen Ansichten wären jedoch ohne sie nicht möglich. Das folgende Bild und die folgende Tabelle zeigen die 4 + 1-Ansicht im Detail -
| Logisch | Prozess | Entwicklung | Körperlich | Szenario | |
|---|---|---|---|---|---|
| Beschreibung | Zeigt die Komponente (Objekt) des Systems sowie deren Interaktion an | Zeigt die Prozesse / Workflow-Regeln des Systems und wie diese Prozesse kommunizieren, konzentriert sich auf die dynamische Ansicht des Systems | Gibt Bausteinansichten des Systems und beschreibt die statische Organisation der Systemmodule | Zeigt die Installation, Konfiguration und Bereitstellung der Softwareanwendung an | Zeigt an, dass das Design vollständig ist, indem Validierung und Illustration durchgeführt werden |
| Viewer / Stakeholder | Endbenutzer, Analysten und Designer | Integratoren & Entwickler | Programmierer und Software-Projektmanager | Systemingenieur, Bediener, Systemadministratoren und Systeminstallateure | Alle Ansichten ihrer Ansichten und Bewerter |
| Erwägen | Funktionale Anforderungen | Nicht-funktionale Anforderungen | Organisation des Softwaremoduls (Wiederverwendung des Softwaremanagements, Einschränkung der Tools) | Nicht funktionierende Anforderung bezüglich der zugrunde liegenden Hardware | Systemkonsistenz und Gültigkeit |
| UML - Diagramm | Klasse, Zustand, Objekt, Sequenz, Kommunikationsdiagramm | Aktivitätsdiagramm | Komponente, Paketdiagramm | Bereitstellungsdiagramm | Anwendungsfalldiagramm |
Architekturbeschreibungssprachen (ADLs)
Eine ADL ist eine Sprache, die Syntax und Semantik zum Definieren einer Softwarearchitektur bereitstellt. Es handelt sich um eine Notationsspezifikation, die Funktionen zum Modellieren der konzeptionellen Architektur eines Softwaresystems bietet, die sich von der Implementierung des Systems unterscheiden.
ADLs müssen die Architekturkomponenten, ihre Verbindungen, Schnittstellen und Konfigurationen unterstützen, die den Baustein der Architekturbeschreibung bilden. Es ist eine Ausdrucksform zur Verwendung in Architekturbeschreibungen und bietet die Möglichkeit, Komponenten zu zerlegen, die Komponenten zu kombinieren und die Schnittstellen von Komponenten zu definieren.
Eine Architekturbeschreibungssprache ist eine formale Spezifikationssprache, die die Softwarefunktionen wie Prozesse, Threads, Daten und Unterprogramme sowie Hardwarekomponenten wie Prozessoren, Geräte, Busse und Speicher beschreibt.
Es ist schwierig, eine ADL und eine Programmiersprache oder eine Modellierungssprache zu klassifizieren oder zu unterscheiden. Es gibt jedoch folgende Anforderungen für die Einstufung einer Sprache als ADL:
Es sollte angemessen sein, die Architektur allen Beteiligten mitzuteilen.
Es sollte für Aufgaben der Architekturerstellung, -verfeinerung und -validierung geeignet sein.
Es sollte eine Grundlage für die weitere Implementierung bieten, daher muss es in der Lage sein, Informationen zur ADL-Spezifikation hinzuzufügen, damit die endgültige Systemspezifikation von der ADL abgeleitet werden kann.
Es sollte die Fähigkeit haben, die meisten gängigen Architekturstile darzustellen.
Es sollte Analysefunktionen unterstützen oder schnell generierbare Prototypimplementierungen bereitstellen.
Das objektorientierte (OO) Paradigma nahm seine Form aus dem ursprünglichen Konzept eines neuen Programmieransatzes an, während das Interesse an Entwurfs- und Analysemethoden viel später kam. Das OO-Analyse- und Design-Paradigma ist das logische Ergebnis der breiten Akzeptanz von OO-Programmiersprachen.
Die erste objektorientierte Sprache war Simula (Simulation realer Systeme), die 1960 von Forschern des norwegischen Rechenzentrums entwickelt wurde.
Im Jahr 1970 Alan Kay und seine Forschungsgruppe bei Xerox PARC erstellte einen Personal Computer mit dem Namen Dynabook und die erste reine objektorientierte Programmiersprache (OOPL) - Smalltalk zum Programmieren des Dynabooks.
In den 1980er Jahren, Grady Boochveröffentlichte ein Papier mit dem Titel Object Oriented Design, das hauptsächlich ein Design für die Programmiersprache Ada vorstellte. In den folgenden Ausgaben erweiterte er seine Ideen auf eine vollständige objektorientierte Entwurfsmethode.
In den 1990ern, Coad Verhaltensideen in objektorientierte Methoden integriert.
Die anderen bedeutenden Innovationen waren Object Modeling Techniques (OMT) von James Rum Baugh und objektorientiertes Software Engineering (OOSE) von Ivar Jacobson.
Einführung in das OO-Paradigma
Das OO-Paradigma ist eine wichtige Methode für die Entwicklung jeder Software. Die meisten Architekturstile oder -muster wie Pipe und Filter, Datenrepository und komponentenbasiert können mithilfe dieses Paradigmas implementiert werden.
Grundlegende Konzepte und Terminologien objektorientierter Systeme -
Objekt
Ein Objekt ist ein reales Element in einer objektorientierten Umgebung, die eine physische oder konzeptionelle Existenz haben kann. Jedes Objekt hat -
Identität, die es von anderen Objekten im System unterscheidet.
Status, der die charakteristischen Eigenschaften eines Objekts sowie die Werte der Eigenschaften bestimmt, die das Objekt enthält.
Verhalten, das von außen sichtbare Aktivitäten eines Objekts in Bezug auf Änderungen seines Zustands darstellt.
Objekte können entsprechend den Anforderungen der Anwendung modelliert werden. Ein Objekt kann eine physische Existenz haben, wie ein Kunde, ein Auto usw.; oder eine immaterielle konzeptuelle Existenz, wie ein Projekt, ein Prozess usw.
Klasse
Eine Klasse repräsentiert eine Sammlung von Objekten mit denselben charakteristischen Eigenschaften, die ein gemeinsames Verhalten aufweisen. Es gibt den Entwurf oder die Beschreibung der Objekte, die daraus erstellt werden können. Das Erstellen eines Objekts als Mitglied einer Klasse wird als Instanziierung bezeichnet. Ein Objekt ist also eininstance einer Klasse.
Die Bestandteile einer Klasse sind -
Eine Reihe von Attributen für die Objekte, die aus der Klasse instanziiert werden sollen. Im Allgemeinen unterscheiden sich verschiedene Objekte einer Klasse in den Werten der Attribute. Attribute werden häufig als Klassendaten bezeichnet.
Eine Reihe von Operationen, die das Verhalten der Objekte der Klasse darstellen. Operationen werden auch als Funktionen oder Methoden bezeichnet.
Example
Betrachten wir eine einfache Klasse, Kreis, die den geometrischen Figurenkreis in einem zweidimensionalen Raum darstellt. Die Attribute dieser Klasse können wie folgt identifiziert werden:
- x-Koordinate, um die x-Koordinate des Zentrums zu bezeichnen
- y-Koordinate, um die y-Koordinate des Zentrums zu bezeichnen
- a, um den Radius des Kreises zu bezeichnen
Einige seiner Operationen können wie folgt definiert werden:
- findArea (), eine Methode zur Berechnung der Fläche
- findCircumference (), eine Methode zur Berechnung des Umfangs
- scale (), eine Methode zum Vergrößern oder Verkleinern des Radius
Verkapselung
Bei der Kapselung werden sowohl Attribute als auch Methoden innerhalb einer Klasse miteinander verbunden. Durch die Kapselung können die internen Details einer Klasse von außen ausgeblendet werden. Es ermöglicht den Zugriff auf die Elemente der Klasse von außen nur über die von der Klasse bereitgestellte Schnittstelle.
Polymorphismus
Polymorphismus ist ursprünglich ein griechisches Wort, das die Fähigkeit bedeutet, mehrere Formen anzunehmen. In einem objektorientierten Paradigma impliziert Polymorphismus die Verwendung von Operationen auf unterschiedliche Weise, abhängig von den Instanzen, mit denen sie arbeiten. Durch Polymorphismus können Objekte mit unterschiedlichen internen Strukturen eine gemeinsame externe Schnittstelle haben. Polymorphismus ist besonders effektiv bei der Implementierung der Vererbung.
Example
Betrachten wir zwei Klassen, Kreis und Quadrat, jede mit einer Methode findArea (). Obwohl der Name und der Zweck der Methoden in den Klassen identisch sind, ist die interne Implementierung, dh das Verfahren zum Berechnen einer Fläche, für jede Klasse unterschiedlich. Wenn ein Objekt der Klasse Circle seine findArea () -Methode aufruft, findet die Operation den Bereich des Kreises ohne Konflikt mit der findArea () -Methode der Square-Klasse.
Relationships
Um ein System zu beschreiben, müssen sowohl dynamische (Verhaltens-) als auch statische (logische) Spezifikationen eines Systems angegeben werden. Die dynamische Spezifikation beschreibt die Beziehungen zwischen Objekten, z. B. Nachrichtenübermittlung. Die statische Spezifikation beschreibt die Beziehungen zwischen Klassen, z. B. Aggregation, Zuordnung und Vererbung.
Nachrichtenübermittlung
Jede Anwendung erfordert eine Reihe von Objekten, die auf harmonische Weise interagieren. Objekte in einem System können mithilfe der Nachrichtenübermittlung miteinander kommunizieren. Angenommen, ein System hat zwei Objekte - obj1 und obj2. Das Objekt obj1 sendet eine Nachricht an das Objekt obj2, wenn obj1 möchte, dass obj2 eine seiner Methoden ausführt.
Zusammensetzung oder Aggregation
Aggregation oder Zusammensetzung ist eine Beziehung zwischen Klassen, durch die eine Klasse aus einer beliebigen Kombination von Objekten anderer Klassen bestehen kann. Damit können Objekte direkt im Körper anderer Klassen platziert werden. Aggregation wird als "Teil-von" - oder "hat-eine" -Beziehung bezeichnet, mit der Fähigkeit, vom Ganzen zu seinen Teilen zu navigieren. Ein Aggregatobjekt ist ein Objekt, das aus einem oder mehreren anderen Objekten besteht.
Verband
Assoziation ist eine Gruppe von Verbindungen mit gemeinsamer Struktur und gemeinsamem Verhalten. Die Zuordnung zeigt die Beziehung zwischen Objekten einer oder mehrerer Klassen. Ein Link kann als Instanz einer Zuordnung definiert werden. Der Grad einer Assoziation gibt die Anzahl der an einer Verbindung beteiligten Klassen an. Der Abschluss kann unär, binär oder ternär sein.
- Eine unäre Beziehung verbindet Objekte derselben Klasse.
- Eine binäre Beziehung verbindet Objekte zweier Klassen.
- Eine ternäre Beziehung verbindet Objekte von drei oder mehr Klassen.
Erbe
Es ist ein Mechanismus, mit dem neue Klassen aus vorhandenen Klassen erstellt werden können, indem seine Funktionen erweitert und verfeinert werden. Die vorhandenen Klassen werden als Basisklassen / Elternklassen / Superklassen bezeichnet, und die neuen Klassen werden als abgeleitete Klassen / Kindklassen / Unterklassen bezeichnet.
Die Unterklasse kann die Attribute und Methoden der Oberklasse (n) erben oder ableiten, sofern die Oberklasse dies zulässt. Außerdem kann die Unterklasse ihre eigenen Attribute und Methoden hinzufügen und jede der Superklassenmethoden modifizieren. Vererbung definiert eine "ist - eine" Beziehung.
Example
Aus einer Klasse Säugetier können eine Reihe von Klassen abgeleitet werden, wie Mensch, Katze, Hund, Kuh usw. Menschen, Katzen, Hunde und Kühe haben alle die unterschiedlichen Eigenschaften von Säugetieren. Darüber hinaus hat jedes seine eigenen Besonderheiten. Man kann sagen, dass eine Kuh ein Säugetier ist.
OO-Analyse
In der objektorientierten Analysephase der Softwareentwicklung werden die Systemanforderungen ermittelt, die Klassen identifiziert und die Beziehungen zwischen Klassen anerkannt. Ziel der OO-Analyse ist es, die Anwendungsdomäne und die spezifischen Anforderungen des Systems zu verstehen. Das Ergebnis dieser Phase ist die Anforderungsspezifikation und die erste Analyse der logischen Struktur und Machbarkeit eines Systems.
Die drei Analysetechniken, die für die objektorientierte Analyse zusammen verwendet werden, sind Objektmodellierung, dynamische Modellierung und Funktionsmodellierung.
Objektmodellierung
Die Objektmodellierung entwickelt die statische Struktur des Softwaresystems in Bezug auf Objekte. Es identifiziert die Objekte, die Klassen, in die die Objekte gruppiert werden können, und die Beziehungen zwischen den Objekten. Außerdem werden die Hauptattribute und -operationen identifiziert, die jede Klasse charakterisieren.
Der Prozess der Objektmodellierung kann in den folgenden Schritten visualisiert werden:
- Identifizieren Sie Objekte und gruppieren Sie sie in Klassen
- Identifizieren Sie die Beziehungen zwischen Klassen
- Erstellen Sie ein Benutzerobjektmodelldiagramm
- Definieren Sie Benutzerobjektattribute
- Definieren Sie die Operationen, die für die Klassen ausgeführt werden sollen
Dynamische Modellierung
Nachdem das statische Verhalten des Systems analysiert wurde, muss sein Verhalten in Bezug auf Zeit und externe Änderungen untersucht werden. Dies ist der Zweck der dynamischen Modellierung.
Dynamische Modellierung kann definiert werden als „eine Art zu beschreiben, wie ein einzelnes Objekt auf Ereignisse reagiert, entweder interne Ereignisse, die von anderen Objekten ausgelöst werden, oder externe Ereignisse, die von der Außenwelt ausgelöst werden.“
Der Prozess der dynamischen Modellierung kann in den folgenden Schritten visualisiert werden:
- Identifizieren Sie die Zustände jedes Objekts
- Identifizieren Sie Ereignisse und analysieren Sie die Anwendbarkeit von Aktionen
- Erstellen Sie ein dynamisches Modelldiagramm, das aus Zustandsübergangsdiagrammen besteht
- Drücken Sie jeden Status in Form von Objektattributen aus
- Validieren Sie die gezeichneten Zustandsübergangsdiagramme
Funktionsmodellierung
Die funktionale Modellierung ist die letzte Komponente der objektorientierten Analyse. Das Funktionsmodell zeigt die Prozesse, die innerhalb eines Objekts ausgeführt werden, und wie sich die Daten ändern, wenn sie sich zwischen Methoden bewegen. Es gibt die Bedeutung der Operationen einer Objektmodellierung und der Aktionen einer dynamischen Modellierung an. Das Funktionsmodell entspricht dem Datenflussdiagramm der traditionellen strukturierten Analyse.
Der Prozess der Funktionsmodellierung kann in den folgenden Schritten visualisiert werden:
- Identifizieren Sie alle Ein- und Ausgänge
- Erstellen Sie Datenflussdiagramme mit funktionalen Abhängigkeiten
- Geben Sie den Zweck jeder Funktion an
- Identifizieren Sie die Einschränkungen
- Optimierungskriterien angeben
Objektorientiertes Design
Nach der Analysephase wird das konzeptionelle Modell mithilfe des objektorientierten Designs (OOD) zu einem objektorientierten Modell weiterentwickelt. In OOD werden die technologieunabhängigen Konzepte im Analysemodell auf implementierende Klassen abgebildet, Einschränkungen identifiziert und Schnittstellen entworfen, was zu einem Modell für die Lösungsdomäne führt. Das Hauptziel des OO-Designs ist die Entwicklung der strukturellen Architektur eines Systems.
Die Stufen für objektorientiertes Design können identifiziert werden als -
- Den Kontext des Systems definieren
- Entwerfen der Systemarchitektur
- Identifikation der Objekte im System
- Konstruktion von Designmodellen
- Spezifikation von Objektschnittstellen
OO Design kann in zwei Phasen unterteilt werden - Konzeption und Detailplanung.
Conceptual design
In dieser Phase werden alle Klassen identifiziert, die zum Erstellen des Systems benötigt werden. Darüber hinaus sind jeder Klasse bestimmte Verantwortlichkeiten zugeordnet. Das Klassendiagramm wird verwendet, um die Beziehungen zwischen Klassen zu verdeutlichen, und das Interaktionsdiagramm wird verwendet, um den Ablauf von Ereignissen darzustellen. Es ist auch bekannt alshigh-level design.
Detailed design
In dieser Phase werden jeder Klasse Attribute und Operationen basierend auf ihrem Interaktionsdiagramm zugewiesen. Zustandsmaschinendiagramme werden entwickelt, um die weiteren Details des Entwurfs zu beschreiben. Es ist auch bekannt alslow-level design.
Design-Prinzipien
Im Folgenden sind die wichtigsten Gestaltungsprinzipien aufgeführt:
Principle of Decoupling
Es ist schwierig, ein System mit einer Reihe stark voneinander abhängiger Klassen zu warten, da Änderungen in einer Klasse zu kaskadierenden Aktualisierungen anderer Klassen führen können. In einem OO-Design kann eine enge Kopplung durch Einführung neuer Klassen oder Vererbung beseitigt werden.
Ensuring Cohesion
Eine zusammenhängende Klasse führt eine Reihe eng verwandter Funktionen aus. Mangelnder Zusammenhalt bedeutet, dass eine Klasse nicht verwandte Funktionen ausführt, obwohl dies den Betrieb des gesamten Systems nicht beeinträchtigt. Dadurch ist es schwierig, die gesamte Softwarestruktur zu verwalten, zu erweitern, zu warten und zu ändern.
Open-closed Principle
Nach diesem Prinzip sollte ein System erweitert werden können, um die neuen Anforderungen zu erfüllen. Die vorhandene Implementierung und der Code des Systems sollten infolge einer Systemerweiterung nicht geändert werden. Darüber hinaus müssen die folgenden Richtlinien im Open-Closed-Prinzip befolgt werden:
Für jede konkrete Klasse müssen separate Schnittstellen und Implementierungen gepflegt werden.
Halten Sie in einer Multithread-Umgebung die Attribute privat.
Minimieren Sie die Verwendung globaler Variablen und Klassenvariablen.
In der Datenflussarchitektur wird das gesamte Softwaresystem als eine Reihe von Transformationen auf aufeinanderfolgenden Teilen oder Eingabedatensätzen betrachtet, bei denen Daten und Operationen unabhängig voneinander sind. Bei diesem Ansatz werden die Daten in das System eingegeben und fließen dann einzeln durch die Module, bis sie einem endgültigen Ziel (Ausgabe oder Datenspeicher) zugewiesen werden.
Die Verbindungen zwischen den Komponenten oder Modulen können als E / A-Stream, E / A-Puffer, Rohrleitungen oder andere Arten von Verbindungen implementiert werden. Die Daten können in der Graphentopologie mit Zyklen, in einer linearen Struktur ohne Zyklen oder in einer Baumstruktur geflogen werden.
Das Hauptziel dieses Ansatzes besteht darin, die Eigenschaften der Wiederverwendung und Modifizierbarkeit zu erreichen. Es eignet sich für Anwendungen, die eine genau definierte Reihe unabhängiger Datentransformationen oder Berechnungen für ordnungsgemäß definierte Ein- und Ausgaben umfassen, z. B. Compiler und Geschäftsdatenverarbeitungsanwendungen. Es gibt drei Arten von Ausführungssequenzen zwischen Modulen
- Batch sequentiell
- Rohr- und Filter- oder nicht sequentieller Pipeline-Modus
- Prozesssteuerung
Batch Sequential
Batch Sequential ist ein klassisches Datenverarbeitungsmodell, bei dem ein Datentransformations-Subsystem seinen Prozess erst initiieren kann, nachdem sein vorheriges Subsystem vollständig durchlaufen hat -
Der Datenfluss überträgt einen Datenstapel als Ganzes von einem Subsystem zum anderen.
Die Kommunikation zwischen den Modulen erfolgt über temporäre Zwischendateien, die von aufeinanderfolgenden Subsystemen entfernt werden können.
Dies gilt für Anwendungen, bei denen Daten gestapelt werden und jedes Subsystem verwandte Eingabedateien liest und Ausgabedateien schreibt.
Eine typische Anwendung dieser Architektur umfasst die Verarbeitung von Geschäftsdaten wie Bankgeschäfte und Abrechnungen von Versorgungsunternehmen.

Vorteile
Bietet einfachere Unterteilungen in Subsysteme.
Jedes Subsystem kann ein unabhängiges Programm sein, das an Eingabedaten arbeitet und Ausgabedaten erzeugt.
Nachteile
Bietet hohe Latenz und geringen Durchsatz.
Bietet keine Parallelität und interaktive Schnittstelle.
Für die Implementierung ist eine externe Steuerung erforderlich.
Rohr- und Filterarchitektur
Dieser Ansatz legt den Schwerpunkt auf die inkrementelle Transformation von Daten nach aufeinanderfolgenden Komponenten. Bei diesem Ansatz wird der Datenfluss von Daten gesteuert und das gesamte System wird in Komponenten von Datenquellen, Filtern, Pipes und Datensenken zerlegt.
Die Verbindungen zwischen Modulen sind Datenströme, bei denen es sich um First-In / First-Out-Puffer handelt, die aus Bytes, Zeichen oder einem anderen Typ dieser Art bestehen können. Das Hauptmerkmal dieser Architektur ist die gleichzeitige und inkrementelle Ausführung.
Filter
Ein Filter ist ein unabhängiger Datenstromtransformator oder Stromwandler. Es transformiert die Daten des Eingabedatenstroms, verarbeitet sie und schreibt den transformierten Datenstrom über eine Pipe, damit der nächste Filter verarbeitet werden kann. Es arbeitet in einem inkrementellen Modus, in dem es zu arbeiten beginnt, sobald Daten über die angeschlossene Pipe eingehen. Es gibt zwei Arten von Filtern -active filter und passive filter.
Active filter
Mit dem aktiven Filter können verbundene Pipes Daten in die transformierten Daten hinein- und herausschieben. Es arbeitet mit einem passiven Rohr, das Lese- / Schreibmechanismen zum Ziehen und Drücken bietet. Dieser Modus wird im UNIX-Pipe- und Filtermechanismus verwendet.
Passive filter
Mit dem passiven Filter können angeschlossene Rohre Daten ein- und ausziehen. Es arbeitet mit einer aktiven Pipe, die Daten aus einem Filter zieht und Daten in den nächsten Filter überträgt. Es muss einen Lese- / Schreibmechanismus bieten.

Vorteile
Bietet Parallelität und hohen Durchsatz für übermäßige Datenverarbeitung.
Bietet Wiederverwendbarkeit und vereinfacht die Systemwartung.
Bietet Modifizierbarkeit und geringe Kopplung zwischen Filtern.
Bietet Einfachheit, indem klare Trennlinien zwischen zwei durch Rohr verbundenen Filtern angeboten werden.
Bietet Flexibilität durch Unterstützung sowohl der sequentiellen als auch der parallelen Ausführung.
Nachteile
Nicht für dynamische Interaktionen geeignet.
Für die Übertragung von Daten in ASCII-Formaten wird ein kleiner gemeinsamer Nenner benötigt.
Overhead der Datentransformation zwischen Filtern.
Bietet keine Möglichkeit für Filter, kooperativ zu interagieren, um ein Problem zu lösen.
Es ist schwierig, diese Architektur dynamisch zu konfigurieren.
Rohr
Pipes sind zustandslos und tragen Binär- oder Zeichenströme, die zwischen zwei Filtern existieren. Es kann einen Datenstrom von einem Filter zu einem anderen verschieben. Pipes verwenden ein wenig Kontextinformationen und behalten zwischen den Instanziierungen keine Statusinformationen bei.
Prozesssteuerungsarchitektur
Es handelt sich um eine Art Datenflussarchitektur, bei der Daten weder sequentiell als auch per Pipeline übertragen werden. Der Datenfluss stammt aus einer Reihe von Variablen, die die Ausführung des Prozesses steuern. Es zerlegt das gesamte System in Subsysteme oder Module und verbindet diese.
Arten von Subsystemen
Eine Prozesssteuerungsarchitektur hätte eine processing unit zum Ändern der Prozesssteuervariablen und a controller unit zur Berechnung der Anzahl der Änderungen.
Eine Steuereinheit muss die folgenden Elemente aufweisen:
Controlled Variable- Die gesteuerte Variable liefert Werte für das zugrunde liegende System und sollte von Sensoren gemessen werden. Zum Beispiel Geschwindigkeit im Tempomatsystem.
Input Variable- Misst eine Eingabe in den Prozess. Zum Beispiel die Temperatur der Rückluft im Temperaturregelsystem
Manipulated Variable - Der Wert der Stellgröße wird von der Steuerung angepasst oder geändert.
Process Definition - Es enthält Mechanismen zur Manipulation einiger Prozessvariablen.
Sensor - Ermittelt Werte von Prozessvariablen, die für die Steuerung relevant sind, und kann als Rückkopplungsreferenz zur Neuberechnung manipulierter Variablen verwendet werden.
Set Point - Dies ist der gewünschte Wert für eine Regelgröße.
Control Algorithm - Hiermit wird entschieden, wie Prozessvariablen bearbeitet werden sollen.
Anwendungsbereiche
Die Prozesssteuerungsarchitektur eignet sich für die folgenden Bereiche:
Entwurf einer eingebetteten Systemsoftware, bei der das System durch Prozesssteuerungsvariablendaten manipuliert wird.
Anwendungen, deren Ziel es ist, bestimmte Eigenschaften der Prozessausgaben bei vorgegebenen Referenzwerten zu halten.
Anwendbar für Auto-Tempomat- und Gebäudetemperaturregelungssysteme.
Echtzeit-Systemsoftware zur Steuerung von Antiblockiersystemen, Kernkraftwerken usw.
In einer datenzentrierten Architektur werden die Daten zentralisiert und häufig von anderen Komponenten abgerufen, die Daten ändern. Der Hauptzweck dieses Stils besteht darin, die Integrität von Daten zu erreichen. Die datenzentrierte Architektur besteht aus verschiedenen Komponenten, die über gemeinsam genutzte Datenrepositorys kommunizieren. Die Komponenten greifen auf eine gemeinsam genutzte Datenstruktur zu und sind relativ unabhängig, da sie nur über den Datenspeicher interagieren.
Das bekannteste Beispiel für die datenzentrierte Architektur ist eine Datenbankarchitektur, bei der das gemeinsame Datenbankschema mit dem Datendefinitionsprotokoll erstellt wird - beispielsweise eine Reihe zusammengehöriger Tabellen mit Feldern und Datentypen in einem RDBMS.
Ein weiteres Beispiel für datenzentrierte Architekturen ist die Webarchitektur, die ein gemeinsames Datenschema (dh eine Metastruktur des Webs) aufweist und dem Hypermedia-Datenmodell folgt und Prozesse kommuniziert, die über gemeinsam genutzte webbasierte Datendienste kommunizieren.

Arten von Komponenten
Es gibt zwei Arten von Komponenten -
EIN central dataStruktur oder Datenspeicher oder Datenrepository, das für die Bereitstellung eines permanenten Datenspeichers verantwortlich ist. Es repräsentiert den aktuellen Status.
EIN data accessor oder eine Sammlung unabhängiger Komponenten, die im zentralen Datenspeicher arbeiten, Berechnungen durchführen und die Ergebnisse möglicherweise zurücksetzen.
Interaktionen oder Kommunikation zwischen den Datenzugriffsanbietern erfolgt nur über den Datenspeicher. Die Daten sind das einzige Kommunikationsmittel zwischen Kunden. Der Kontrollfluss unterscheidet die Architektur in zwei Kategorien -
- Repository-Architekturstil
- Tafel-Architektur-Stil
Repository-Architekturstil
In Repository Architecture Style ist der Datenspeicher passiv und die Clients (Softwarekomponenten oder Agenten) des Datenspeichers sind aktiv, die den Logikfluss steuern. Die beteiligten Komponenten überprüfen den Datenspeicher auf Änderungen.
Der Client sendet eine Anforderung an das System, um Aktionen auszuführen (z. B. Daten einfügen).
Die Rechenprozesse sind unabhängig und werden durch eingehende Anfragen ausgelöst.
Wenn die Transaktionstypen in einem Eingabestrom von Transaktionen die Auswahl der auszuführenden Prozesse auslösen, handelt es sich um eine traditionelle Datenbank- oder Repository-Architektur oder ein passives Repository.
Dieser Ansatz wird häufig in DBMS, Bibliotheksinformationssystemen, dem Schnittstellen-Repository in CORBA, Compilern und CASE-Umgebungen (Computer Aided Software Engineering) verwendet.

Vorteile
Bietet Funktionen für Datenintegrität, Sicherung und Wiederherstellung.
Bietet Skalierbarkeit und Wiederverwendbarkeit von Agenten, da diese nicht direkt miteinander kommunizieren.
Reduziert den Overhead vorübergehender Daten zwischen Softwarekomponenten.
Nachteile
Es ist anfälliger für Fehler und Datenreplikation oder -duplizierung ist möglich.
Hohe Abhängigkeit zwischen der Datenstruktur des Datenspeichers und seinen Agenten.
Änderungen in der Datenstruktur wirken sich stark auf die Clients aus.
Die Entwicklung von Daten ist schwierig und teuer.
Kosten für das Verschieben von Daten im Netzwerk für verteilte Daten.
Tafel-Architektur-Stil
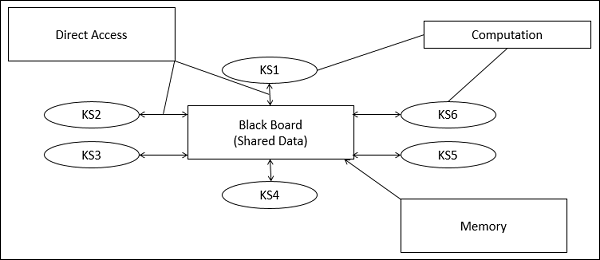
In Blackboard Architecture Style ist der Datenspeicher aktiv und seine Clients sind passiv. Daher wird der logische Ablauf durch den aktuellen Datenstatus im Datenspeicher bestimmt. Es verfügt über eine Blackboard-Komponente, die als zentrales Datenrepository fungiert, und eine interne Darstellung wird von verschiedenen Rechenelementen erstellt und verarbeitet.
Eine Reihe von Komponenten, die unabhängig von der gemeinsamen Datenstruktur wirken, werden in der Tafel gespeichert.
In diesem Stil interagieren die Komponenten nur über die Tafel. Der Datenspeicher warnt die Clients bei jeder Änderung des Datenspeichers.
Der aktuelle Status der Lösung wird in der Tafel gespeichert und die Verarbeitung wird durch den Status der Tafel ausgelöst.
Das System sendet Benachrichtigungen, die als bekannt sind trigger und Daten an die Clients, wenn Änderungen an den Daten auftreten.
Dieser Ansatz findet sich in bestimmten KI-Anwendungen und komplexen Anwendungen wie Spracherkennung, Bilderkennung, Sicherheitssystem und Business Resource Management-Systemen usw.
Wenn der aktuelle Status der zentralen Datenstruktur der Hauptauslöser für die Auswahl der auszuführenden Prozesse ist, kann das Repository eine Tafel sein und diese gemeinsam genutzte Datenquelle ist ein aktiver Agent.
Ein Hauptunterschied zu herkömmlichen Datenbanksystemen besteht darin, dass der Aufruf von Rechenelementen in einer Blackboard-Architektur durch den aktuellen Status der Blackboard und nicht durch externe Eingaben ausgelöst wird.
Teile des Blackboard-Modells
Das Tafelmodell besteht normalerweise aus drei Hauptteilen:
Knowledge Sources (KS)
Wissensquellen, auch bekannt als Listeners oder Subscriberssind unterschiedliche und unabhängige Einheiten. Sie lösen Teile eines Problems und aggregieren Teilergebnisse. Die Interaktion zwischen Wissensquellen erfolgt eindeutig über die Tafel.
Blackboard Data Structure
Die Zustandsdaten zur Problemlösung sind in einer anwendungsabhängigen Hierarchie organisiert. Wissensquellen nehmen Änderungen an der Tafel vor, die schrittweise zu einer Lösung des Problems führen.
Control
Die Steuerung verwaltet Aufgaben und überprüft den Arbeitsstatus.
Vorteile
Bietet Skalierbarkeit, die das Hinzufügen oder Aktualisieren von Wissensquellen erleichtert.
Bietet Parallelität, mit der alle Wissensquellen parallel arbeiten können, da sie unabhängig voneinander sind.
Unterstützt das Experimentieren für Hypothesen.
Unterstützt die Wiederverwendbarkeit von Agenten für Wissensquellen.
Nachteile
Die Strukturänderung von Blackboard kann erhebliche Auswirkungen auf alle Agenten haben, da eine enge Abhängigkeit zwischen Blackboard und Wissensquelle besteht.
Es kann schwierig sein, zu entscheiden, wann die Argumentation beendet werden soll, da nur eine ungefähre Lösung erwartet wird.
Probleme bei der Synchronisation mehrerer Agenten.
Große Herausforderungen beim Entwurf und Testen von Systemen.
Die hierarchische Architektur betrachtet das gesamte System als eine Hierarchiestruktur, in der das Softwaresystem auf verschiedenen Hierarchieebenen in logische Module oder Subsysteme zerlegt wird. Dieser Ansatz wird normalerweise beim Entwerfen von Systemsoftware wie Netzwerkprotokollen und Betriebssystemen verwendet.
Beim Entwurf von Systemsoftware-Hierarchien stellt ein Subsystem auf niedriger Ebene Dienste für seine benachbarten Subsysteme auf höherer Ebene bereit, die die Methoden auf der unteren Ebene aufrufen. Die untere Schicht bietet spezifischere Funktionen wie E / A-Dienste, Transaktionen, Zeitplanung, Sicherheitsdienste usw. Die mittlere Schicht bietet domänenabhängigere Funktionen wie Geschäftslogik und Kernverarbeitungsdienste. Die obere Schicht bietet abstraktere Funktionen in Form von Benutzeroberflächen wie GUIs, Shell-Programmierfunktionen usw.
Es wird auch bei der Organisation von Klassenbibliotheken wie der .NET-Klassenbibliothek in der Namespace-Hierarchie verwendet. Alle Designtypen können diese hierarchische Architektur implementieren und häufig mit anderen Architekturstilen kombinieren.
Hierarchische Architekturstile sind unterteilt in -
- Main-subroutine
- Master-slave
- Virtuelle Maschine
Hauptunterprogramm
Ziel dieses Stils ist es, die Module wiederzuverwenden und einzelne Module oder Unterprogramme frei zu entwickeln. In diesem Stil wird ein Softwaresystem durch Verwendung einer Top-Down-Verfeinerung entsprechend der gewünschten Funktionalität des Systems in Unterprogramme unterteilt.
Diese Verfeinerungen führen vertikal, bis die zerlegten Module einfach genug sind, um ihre ausschließliche unabhängige Verantwortung zu übernehmen. Die Funktionalität kann von mehreren Anrufern in den oberen Schichten wiederverwendet und gemeinsam genutzt werden.
Es gibt zwei Möglichkeiten, wie Daten als Parameter an Unterprogramme übergeben werden, nämlich:
Pass by Value - Unterprogramme verwenden nur die vergangenen Daten, können diese jedoch nicht ändern.
Pass by Reference - Unterprogramme verwenden und ändern den Wert der Daten, auf die der Parameter verweist.

Vorteile
Das System lässt sich leicht anhand der Verfeinerung der Hierarchie zerlegen.
Kann in einem Subsystem für objektorientiertes Design verwendet werden.
Nachteile
Anfällig, da es global freigegebene Daten enthält.
Eine enge Kopplung kann zu stärkeren Welligkeitseffekten von Änderungen führen.
Master-Slave
Dieser Ansatz wendet das Prinzip „Teilen und Erobern“ an und unterstützt die Fehlerberechnung und Rechengenauigkeit. Es ist eine Modifikation der Haupt-Subroutinen-Architektur, die Zuverlässigkeit des Systems und Fehlertoleranz bietet.
In dieser Architektur stellen Slaves dem Master doppelte Dienste zur Verfügung, und der Master wählt durch eine bestimmte Auswahlstrategie ein bestimmtes Ergebnis unter den Slaves aus. Die Slaves können dieselbe Funktionsaufgabe durch unterschiedliche Algorithmen und Methoden oder durch völlig unterschiedliche Funktionen ausführen. Es enthält paralleles Rechnen, bei dem alle Slaves parallel ausgeführt werden können.

Die Implementierung des Master-Slave-Musters erfolgt in fünf Schritten:
Geben Sie an, wie die Berechnung der Aufgabe in eine Reihe gleicher Unteraufgaben unterteilt werden kann, und identifizieren Sie die Unterdienste, die zur Verarbeitung einer Unteraufgabe erforderlich sind.
Geben Sie an, wie das Endergebnis des gesamten Dienstes mithilfe der Ergebnisse aus der Verarbeitung einzelner Unteraufgaben berechnet werden kann.
Definieren Sie eine Schnittstelle für den in Schritt 1 identifizierten Unterdienst. Sie wird vom Slave implementiert und vom Master verwendet, um die Verarbeitung einzelner Unteraufgaben zu delegieren.
Implementieren Sie die Slave-Komponenten gemäß den im vorherigen Schritt entwickelten Spezifikationen.
Implementieren Sie den Master gemäß den in den Schritten 1 bis 3 entwickelten Spezifikationen.
Anwendungen
Geeignet für Anwendungen, bei denen die Zuverlässigkeit von Software von entscheidender Bedeutung ist.
Weit verbreitet in den Bereichen paralleles und verteiltes Rechnen.
Vorteile
Schnellere Berechnung und einfache Skalierbarkeit.
Bietet Robustheit, da Slaves dupliziert werden können.
Slave kann unterschiedlich implementiert werden, um semantische Fehler zu minimieren.
Nachteile
Kommunikationsaufwand.
Nicht alle Probleme können geteilt werden.
Schwer zu implementieren und Portabilitätsproblem.
Architektur der virtuellen Maschine
Die Architektur der virtuellen Maschine gibt einige Funktionen vor, die nicht der Hardware und / oder Software eigen sind, auf der sie implementiert ist. Eine virtuelle Maschine baut auf einem vorhandenen System auf und bietet eine virtuelle Abstraktion, eine Reihe von Attributen und Operationen.
In der Architektur virtueller Maschinen verwendet der Master den gleichen Unterdienst vom Slave und führt Funktionen wie Split-Arbeit, Aufruf von Slaves und Kombinieren von Ergebnissen aus. Entwickler können damit noch nicht erstellte Plattformen simulieren und testen sowie "Katastrophen" -Modi simulieren, die zu komplex, kostspielig oder gefährlich wären, um sie mit dem realen System zu testen.
In den meisten Fällen trennt eine virtuelle Maschine eine Programmiersprache oder Anwendungsumgebung von einer Ausführungsplattform. Das Hauptziel ist die Bereitstellungportability. Die Interpretation eines bestimmten Moduls über eine virtuelle Maschine kann wie folgt wahrgenommen werden:
Die Interpretationsmaschine wählt eine Anweisung aus dem zu interpretierenden Modul aus.
Basierend auf der Anweisung aktualisiert die Engine den internen Status der virtuellen Maschine und der obige Vorgang wird wiederholt.
Die folgende Abbildung zeigt die Architektur einer Standard-VM-Infrastruktur auf einer einzelnen physischen Maschine.

Das hypervisor, auch die genannt virtual machine monitor, läuft auf dem Host-Betriebssystem und weist jedem Gast-Betriebssystem übereinstimmende Ressourcen zu. Wenn der Gast einen Systemaufruf tätigt, fängt der Hypervisor ihn ab und übersetzt ihn in den entsprechenden Systemaufruf, der vom Host-Betriebssystem unterstützt wird. Der Hypervisor steuert den Zugriff jeder virtuellen Maschine auf die CPU, den Speicher, den dauerhaften Speicher, die E / A-Geräte und das Netzwerk.
Anwendungen
Die Architektur der virtuellen Maschine eignet sich für die folgenden Bereiche:
Geeignet zur Lösung eines Problems durch Simulation oder Übersetzung, wenn es keine direkte Lösung gibt.
Beispielanwendungen umfassen Interpreter für Mikroprogrammierung, XML-Verarbeitung, Ausführung von Skriptbefehlssprachen, regelbasierte Systemausführung, Programmiersprache vom Typ Smalltalk und Java Interpreter.
Häufige Beispiele für virtuelle Maschinen sind Interpreter, regelbasierte Systeme, syntaktische Shells und Befehlssprachenprozessoren.
Vorteile
Portabilität und Unabhängigkeit der Maschinenplattform.
Einfachheit der Softwareentwicklung.
Bietet Flexibilität durch die Möglichkeit, das Programm zu unterbrechen und abzufragen.
Simulation für ein Katastrophenarbeitsmodell.
Führen Sie zur Laufzeit Änderungen ein.
Nachteile
Langsame Ausführung des Dolmetschers aufgrund der Dolmetschernatur.
Aufgrund der zusätzlichen Berechnung, die mit der Ausführung verbunden ist, entstehen Leistungskosten.
Überlagerter Stil
Bei diesem Ansatz wird das System in einer Reihe von höheren und niedrigeren Schichten in einer Hierarchie zerlegt, und jede Schicht hat ihre eigene alleinige Verantwortung im System.
Jede Schicht besteht aus einer Gruppe verwandter Klassen, die in einem Paket, in einer bereitgestellten Komponente oder als Gruppe von Unterroutinen im Format einer Methodenbibliothek oder einer Headerdatei gekapselt sind.
Jede Schicht stellt einen Dienst für die darüber liegende Schicht bereit und dient als Client für die darunter liegende Schicht, dh die Anforderung an die Schicht i + 1 ruft die von der Schicht i über die Schnittstelle der Schicht i bereitgestellten Dienste auf. Die Antwort kann auf die Ebene i + 1 zurückgehen, wenn die Aufgabe abgeschlossen ist. Andernfalls ruft Schicht I kontinuierlich Dienste von Schicht I -1 unten auf.
Anwendungen
Layered Style eignet sich in folgenden Bereichen -
Anwendungen mit unterschiedlichen Dienstklassen, die hierarchisch organisiert werden können.
Jede Anwendung, die in anwendungsspezifische und plattformspezifische Teile zerlegt werden kann.
Anwendungen, die eine klare Trennung zwischen Kerndiensten, kritischen Diensten und Benutzeroberflächendiensten usw. aufweisen.
Vorteile
Design basierend auf inkrementellen Abstraktionsebenen.
Bietet Verbesserungsunabhängigkeit, da Änderungen an der Funktion einer Ebene höchstens zwei andere Ebenen betreffen.
Trennung der Standardschnittstelle und deren Implementierung.
Implementiert durch die Verwendung komponentenbasierter Technologie, die das Plug-and-Play neuer Komponenten im System erheblich vereinfacht.
Jede Schicht kann eine abstrakte Maschine sein, die unabhängig bereitgestellt wird und die Portabilität unterstützt.
Das System lässt sich anhand der Definition der Aufgaben von oben nach unten leicht zerlegen
Verschiedene Implementierungen (mit identischen Schnittstellen) derselben Schicht können austauschbar verwendet werden
Nachteile
Viele Anwendungen oder Systeme lassen sich nicht einfach mehrschichtig strukturieren.
Geringere Laufzeitleistung, da die Anforderung eines Clients oder eine Antwort an den Client möglicherweise mehrere Ebenen durchlaufen muss.
Es gibt auch Leistungsprobleme hinsichtlich des Overheads beim Daten-Marshalling und -Puffern durch jede Schicht.
Das Öffnen der Zwischenschichtkommunikation kann zu Deadlocks führen, und das „Überbrücken“ kann zu einer engen Kopplung führen.
Ausnahmen und Fehlerbehandlung sind ein Problem in der Schichtarchitektur, da sich Fehler in einer Schicht auf alle aufrufenden Schichten nach oben ausbreiten müssen
Das Hauptziel einer interaktionsorientierten Architektur besteht darin, die Interaktion des Benutzers von der Datenabstraktion und der Geschäftsdatenverarbeitung zu trennen. Die interaktionsorientierte Softwarearchitektur zerlegt das System in drei Hauptpartitionen:
Data module - Das Datenmodul liefert die Datenabstraktion und die gesamte Geschäftslogik.
Control module - Das Steuermodul identifiziert den Ablauf der Steuerungs- und Systemkonfigurationsaktionen.
View presentation module - Das Präsentationsmodul anzeigen ist für die visuelle oder akustische Präsentation der Datenausgabe verantwortlich und bietet auch eine Schnittstelle für Benutzereingaben.
Interaktionsorientierte Architektur hat zwei Hauptstile - Model-View-Controller (MVC) und Presentation-Abstraction-Control(PAC). Sowohl MVC als auch PAC schlagen eine Zerlegung von drei Komponenten vor und werden für interaktive Anwendungen wie Webanwendungen mit mehreren Gesprächen und Benutzerinteraktionen verwendet. Sie unterscheiden sich in ihrem Kontroll- und Organisationsfluss. PAC ist eine agentenbasierte hierarchische Architektur, MVC hat jedoch keine klare hierarchische Struktur.
Model-View-Controller (MVC)
MVC zerlegt eine bestimmte Softwareanwendung in drei miteinander verbundene Teile, die dazu beitragen, die internen Darstellungen von Informationen von den Informationen zu trennen, die dem Benutzer präsentiert oder von ihm akzeptiert werden.
| Modul | Funktion |
|---|---|
| Modell | Kapselung der zugrunde liegenden Daten und Geschäftslogik |
| Regler | Reagieren Sie auf Benutzeraktionen und leiten Sie den Anwendungsfluss |
| Aussicht | Formatiert und präsentiert die Daten vom Modell zum Benutzer. |
Modell
Das Modell ist eine zentrale Komponente von MVC, die die Daten, die Logik und die Einschränkungen einer Anwendung direkt verwaltet. Es besteht aus Datenkomponenten, die die Rohdaten der Anwendung und die Anwendungslogik für die Schnittstelle verwalten.
Es ist eine unabhängige Benutzeroberfläche und erfasst das Verhalten der Anwendungsproblemdomäne.
Es ist die domänenspezifische Software-Simulation oder Implementierung der zentralen Struktur der Anwendung.
Wenn sich der Status geändert hat, benachrichtigt es die zugehörige Ansicht, um eine aktualisierte Ausgabe zu erstellen, und die Steuerung, um den verfügbaren Befehlssatz zu ändern.
Aussicht
Die Ansicht kann verwendet werden, um jede Ausgabe von Informationen in grafischer Form wie Diagramm oder Diagramm darzustellen. Es besteht aus Präsentationskomponenten, die die visuelle Darstellung von Daten ermöglichen
Ansichten fordern Informationen von ihrem Modell an und generieren eine Ausgabedarstellung für den Benutzer.
Es sind mehrere Ansichten derselben Informationen möglich, z. B. ein Balkendiagramm für die Verwaltung und eine tabellarische Ansicht für Buchhalter.
Regler
Ein Controller akzeptiert eine Eingabe und konvertiert sie in Befehle für das Modell oder die Ansicht. Es besteht aus Eingabeverarbeitungskomponenten, die Eingaben des Benutzers durch Ändern des Modells verarbeiten.
Es fungiert als Schnittstelle zwischen den zugehörigen Modellen und Ansichten und den Eingabegeräten.
Es kann Befehle an das Modell senden, um den Status des Modells zu aktualisieren, und an die zugehörige Ansicht, um die Darstellung des Modells in der Ansicht zu ändern.

MVC - ich
Es ist eine einfache Version der MVC-Architektur, bei der das System in zwei Subsysteme unterteilt ist:
The Controller-View - Die Controller-Ansicht fungiert als Eingabe- / Ausgabeschnittstelle und die Verarbeitung erfolgt.
The Model - Das Modell bietet alle Daten- und Domänendienste.
MVC-I Architecture
Das Modellmodul benachrichtigt das Controller-View-Modul über Datenänderungen, sodass die Grafikdatenanzeige entsprechend geändert wird. Die Steuerung ergreift auch geeignete Maßnahmen bei den Änderungen.

Die Verbindung zwischen Controller-Ansicht und Modell kann in einem Muster (wie im obigen Bild gezeigt) von Subscribe-Notify entworfen werden, wobei die Controller-Ansicht das Modell abonniert und Model die Controller-Ansicht über Änderungen benachrichtigt.
MVC - II
MVC-II ist eine Erweiterung der MVC-I-Architektur, bei der das Ansichtsmodul und das Controller-Modul getrennt sind. Das Modellmodul spielt eine aktive Rolle wie in MVC-I, indem es alle Kernfunktionen und Daten bereitstellt, die von der Datenbank unterstützt werden.
Das Ansichtsmodul präsentiert Daten, während das Steuerungsmodul Eingabeanforderungen akzeptiert, Eingabedaten validiert, das Modell, die Ansicht und ihre Verbindung initiiert und auch die Aufgabe versendet.
MVC-II Architecture

MVC-Anwendungen
MVC-Anwendungen sind effektiv für interaktive Anwendungen, bei denen mehrere Ansichten für ein einzelnes Datenmodell erforderlich sind, und lassen sich einfach in eine neue Ansicht oder eine geänderte Schnittstellenansicht einfügen.
MVC-Anwendungen eignen sich für Anwendungen, bei denen eine klare Trennung zwischen den Modulen besteht, sodass verschiedene Fachkräfte zugewiesen werden können, um gleichzeitig an verschiedenen Aspekten solcher Anwendungen zu arbeiten.
Advantages
Es sind viele MVC Vendor Framework-Toolkits verfügbar.
Mehrere Ansichten mit demselben Datenmodell synchronisiert.
Einfaches Einstecken neuer oder Ersetzen von Schnittstellenansichten.
Wird für die Anwendungsentwicklung verwendet, bei der Grafikfachleute, Programmierer und Datenbankentwickler in einem entworfenen Projektteam arbeiten.
Disadvantages
Nicht geeignet für agentenorientierte Anwendungen wie interaktive Mobil- und Robotikanwendungen.
Mehrere Paare von Controllern und Ansichten, die auf demselben Datenmodell basieren, verteuern jede Änderung des Datenmodells.
Die Trennung zwischen der Ansicht und dem Controller ist in einigen Fällen nicht klar.
Presentation-Abstraction-Control (PAC)
In PAC ist das System in einer Hierarchie vieler kooperierender Agenten (Triaden) angeordnet. Es wurde von MVC entwickelt, um die Anwendungsanforderungen mehrerer Agenten zusätzlich zu interaktiven Anforderungen zu unterstützen.
Jeder Agent besteht aus drei Komponenten:
The presentation component - Formatiert die visuelle und akustische Darstellung von Daten.
The abstraction component - Ruft die Daten ab und verarbeitet sie.
The control component - Erledigt die Aufgabe wie den Kontroll- und Kommunikationsfluss zwischen den beiden anderen Komponenten.
Die PAC-Architektur ähnelt MVC in dem Sinne, dass das Präsentationsmodul dem Ansichtsmodul von MVC ähnelt. Das Abstraktionsmodul sieht aus wie das Modellmodul von MVC und das Steuermodul ist wie das Steuerungsmodul von MVC, unterscheidet sich jedoch in ihrem Steuerungs- und Organisationsfluss.
In jedem Agenten gibt es keine direkten Verbindungen zwischen Abstraktionskomponente und Präsentationskomponente. Die Steuerkomponente in jedem Agenten ist für die Kommunikation mit anderen Agenten verantwortlich.
Die folgende Abbildung zeigt ein Blockdiagramm für einen einzelnen Agenten im PAC-Design.

PAC mit mehreren Agenten
In PACs, die aus mehreren Agenten bestehen, stellt der Agent der obersten Ebene Kerndaten und Geschäftslogiken bereit. Die Agenten der untersten Ebene definieren detaillierte spezifische Daten und Präsentationen. Der Agent der mittleren oder mittleren Ebene fungiert als Koordinator der Agenten der unteren Ebene.
Jeder Agent hat seinen eigenen zugewiesenen Job.
Für einige Agenten der mittleren Ebene sind die interaktiven Präsentationen nicht erforderlich, sodass sie keine Präsentationskomponente haben.
Die Steuerungskomponente wird für alle Agenten benötigt, über die alle Agenten miteinander kommunizieren.
Die folgende Abbildung zeigt die mehreren Agenten, die an PAC teilnehmen.

Applications
Wirksam für ein interaktives System, bei dem das System hierarchisch in viele kooperierende Agenten zerlegt werden kann.
Wirksam, wenn erwartet wird, dass die Kopplung zwischen den Agenten locker ist, so dass Änderungen an einem Agenten andere nicht beeinflussen.
Wirksam für verteilte Systeme, bei denen alle Agenten entfernt verteilt sind und jeder seine eigenen Funktionen mit Daten und interaktiver Schnittstelle hat.
Geeignet für Anwendungen mit umfangreichen GUI-Komponenten, bei denen jede ihre eigenen aktuellen Daten und ihre interaktive Schnittstelle behält und mit anderen Komponenten kommunizieren muss.
Vorteile
Unterstützung für Multitasking und Multi-Viewing
Unterstützung für Wiederverwendbarkeit und Erweiterbarkeit von Agenten
Einfach, einen neuen Agenten anzuschließen oder einen vorhandenen zu ändern
Unterstützung für Parallelität, wenn mehrere Agenten gleichzeitig in verschiedenen Threads oder auf verschiedenen Geräten oder Computern ausgeführt werden
Nachteile
Overhead aufgrund der Kontrollbrücke zwischen Präsentation und Abstraktion und der Kommunikation von Kontrollen zwischen Agenten.
Aufgrund der losen Kopplung und der hohen Unabhängigkeit zwischen den Agenten ist es schwierig, die richtige Anzahl von Agenten zu bestimmen.
Die vollständige Trennung von Präsentation und Abstraktion durch Kontrolle in jedem Agenten führt zu Entwicklungskomplexität, da die Kommunikation zwischen Agenten nur zwischen den Kontrollen der Agenten stattfindet
In einer verteilten Architektur werden Komponenten auf verschiedenen Plattformen dargestellt, und mehrere Komponenten können über ein Kommunikationsnetzwerk zusammenarbeiten, um ein bestimmtes Ziel zu erreichen.
In dieser Architektur ist die Informationsverarbeitung nicht auf eine einzelne Maschine beschränkt, sondern auf mehrere unabhängige Computer verteilt.
Ein verteiltes System kann durch die Client-Server-Architektur demonstriert werden, die die Basis für mehrschichtige Architekturen bildet. Alternativen sind die Broker-Architektur wie CORBA und die Service-Oriented Architecture (SOA).
Es gibt verschiedene Technologie-Frameworks zur Unterstützung verteilter Architekturen, darunter .NET-, J2EE-, CORBA-, .NET-Webdienste, AXIS Java-Webdienste und Globus Grid-Dienste.
Middleware ist eine Infrastruktur, die die Entwicklung und Ausführung verteilter Anwendungen angemessen unterstützt. Es bietet einen Puffer zwischen den Anwendungen und dem Netzwerk.
Es befindet sich in der Mitte des Systems und verwaltet oder unterstützt die verschiedenen Komponenten eines verteilten Systems. Beispiele sind Transaktionsverarbeitungsmonitore, Datenkonverter und Kommunikationscontroller usw.
Middleware als Infrastruktur für verteilte Systeme

Die Basis einer verteilten Architektur ist ihre Transparenz, Zuverlässigkeit und Verfügbarkeit.
In der folgenden Tabelle sind die verschiedenen Formen der Transparenz in einem verteilten System aufgeführt:
| Sr.Nr. | Transparenz & Beschreibung |
|---|---|
| 1 | Access Versteckt die Art und Weise, wie auf Ressourcen zugegriffen wird, und die Unterschiede in der Datenplattform. |
| 2 | Location Versteckt, wo sich Ressourcen befinden. |
| 3 | Technology Versteckt verschiedene Technologien wie Programmiersprache und Betriebssystem vor dem Benutzer. |
| 4 | Migration / Relocation Verstecken Sie Ressourcen, die möglicherweise an einen anderen Speicherort verschoben werden, der gerade verwendet wird. |
| 5 | Replication Verstecken Sie Ressourcen, die an mehreren Stellen kopiert werden können. |
| 6 | Concurrency Verstecken Sie Ressourcen, die möglicherweise für andere Benutzer freigegeben sind. |
| 7 | Failure Blendet Fehler und Wiederherstellung von Ressourcen vor dem Benutzer aus. |
| 8 | Persistence Blendet aus, ob sich eine Ressource (Software) im Speicher oder auf der Festplatte befindet. |
Vorteile
Resource sharing - gemeinsame Nutzung von Hardware- und Softwareressourcen.
Openness - Flexibilität bei der Verwendung von Hardware und Software verschiedener Anbieter.
Concurrency - Gleichzeitige Verarbeitung zur Leistungssteigerung.
Scalability - Erhöhter Durchsatz durch Hinzufügen neuer Ressourcen.
Fault tolerance - Die Fähigkeit, den Betrieb fortzusetzen, nachdem ein Fehler aufgetreten ist.
Nachteile
Complexity - Sie sind komplexer als zentralisierte Systeme.
Security - Anfälliger für externe Angriffe.
Manageability - Mehr Aufwand für die Systemverwaltung.
Unpredictability - Unvorhersehbare Antworten je nach Systemorganisation und Netzwerklast.
Zentrales System vs. verteiltes System
| Kriterien | Zentrales System | Verteiltes System |
|---|---|---|
| Wirtschaft | Niedrig | Hoch |
| Verfügbarkeit | Niedrig | Hoch |
| Komplexität | Niedrig | Hoch |
| Konsistenz | Einfach | Hoch |
| Skalierbarkeit | Arm | Gut |
| Technologie | Homogen | Heterogen |
| Sicherheit | Hoch | Niedrig |
Client-Server-Architektur
Die Client-Server-Architektur ist die am häufigsten verwendete verteilte Systemarchitektur, die das System in zwei wichtige Subsysteme oder logische Prozesse zerlegt.
Client - Dies ist der erste Prozess, der eine Anforderung an den zweiten Prozess, dh den Server, ausgibt.
Server - Dies ist der zweite Prozess, der die Anforderung empfängt, ausführt und eine Antwort an den Client sendet.
In dieser Architektur wird die Anwendung als eine Reihe von Diensten modelliert, die von Servern bereitgestellt werden, und als eine Reihe von Clients, die diese Dienste verwenden. Die Server müssen nichts über Clients wissen, aber die Clients müssen die Identität der Server kennen, und die Zuordnung von Prozessoren zu Prozessen muss nicht unbedingt 1: 1 sein

Die Client-Server-Architektur kann basierend auf der Funktionalität des Clients in zwei Modelle unterteilt werden:
Thin-Client-Modell
Im Thin-Client-Modell wird die gesamte Anwendungsverarbeitung und Datenverwaltung vom Server ausgeführt. Der Kunde ist lediglich für die Ausführung der Präsentationssoftware verantwortlich.
Wird verwendet, wenn Legacy-Systeme auf Client-Server-Architekturen migriert werden, bei denen Legacy-Systeme als eigenständiger Server mit einer auf einem Client implementierten grafischen Oberfläche fungieren
Ein Hauptnachteil besteht darin, dass sowohl der Server als auch das Netzwerk stark belastet werden.
Dick / Fett-Client-Modell
Im Thick-Client-Modell ist der Server nur für die Datenverwaltung verantwortlich. Die Software auf dem Client implementiert die Anwendungslogik und die Interaktionen mit dem Systembenutzer.
Am besten geeignet für neue C / S-Systeme, bei denen die Funktionen des Client-Systems im Voraus bekannt sind
Komplexer als ein Thin Client-Modell, insbesondere für das Management. Neue Versionen der Anwendung müssen auf allen Clients installiert werden.
Vorteile
Aufgabentrennung wie Präsentation der Benutzeroberfläche und Verarbeitung der Geschäftslogik.
Wiederverwendbarkeit von Serverkomponenten und Potenzial für Parallelität
Vereinfacht das Design und die Entwicklung verteilter Anwendungen
Es erleichtert die Migration oder Integration vorhandener Anwendungen in eine verteilte Umgebung.
Außerdem werden Ressourcen effektiv genutzt, wenn eine große Anzahl von Clients auf einen Hochleistungsserver zugreift.
Nachteile
Mangel an heterogener Infrastruktur zur Bewältigung der Anforderungsänderungen.
Sicherheitskomplikationen.
Begrenzte Serververfügbarkeit und Zuverlässigkeit.
Eingeschränkte Testbarkeit und Skalierbarkeit.
Fette Kunden mit Präsentation und Geschäftslogik zusammen.
Mehrschichtige Architektur (n-Tier-Architektur)
Die mehrschichtige Architektur ist eine Client-Server-Architektur, bei der die Funktionen wie Präsentation, Anwendungsverarbeitung und Datenverwaltung physisch getrennt sind. Durch die Aufteilung einer Anwendung in Ebenen erhalten Entwickler die Möglichkeit, eine bestimmte Ebene zu ändern oder hinzuzufügen, anstatt die gesamte Anwendung zu überarbeiten. Es bietet ein Modell, mit dem Entwickler flexible und wiederverwendbare Anwendungen erstellen können.

Die allgemeinste Verwendung der mehrschichtigen Architektur ist die dreistufige Architektur. Eine dreistufige Architektur besteht normalerweise aus einer Präsentationsebene, einer Anwendungsebene und einer Datenspeicherebene und kann auf einem separaten Prozessor ausgeführt werden.
Präsentationsstufe
Die Präsentationsschicht ist die oberste Ebene der Anwendung, über die Benutzer direkt auf eine Webseite oder die Benutzeroberfläche des Betriebssystems (grafische Benutzeroberfläche) zugreifen können. Die Hauptfunktion dieser Ebene besteht darin, die Aufgaben und Ergebnisse in etwas zu übersetzen, das der Benutzer verstehen kann. Es kommuniziert mit anderen Ebenen, sodass die Ergebnisse der Browser- / Client-Ebene und allen anderen Ebenen im Netzwerk zugewiesen werden.
Anwendungsebene (Geschäftslogik, Logikschicht oder mittlere Schicht)
Die Anwendungsebene koordiniert die Anwendung, verarbeitet die Befehle, trifft logische Entscheidungen, bewertet sie und führt Berechnungen durch. Es steuert die Funktionalität einer Anwendung durch detaillierte Verarbeitung. Außerdem werden Daten zwischen den beiden umgebenden Ebenen verschoben und verarbeitet.
Datenebene
In dieser Schicht werden Informationen gespeichert und aus der Datenbank oder dem Dateisystem abgerufen. Die Informationen werden dann zur Verarbeitung und dann an den Benutzer zurückgegeben. Es enthält die Datenpersistenzmechanismen (Datenbankserver, Dateifreigaben usw.) und stellt der Anwendungsebene eine API (Application Programming Interface) zur Verfügung, die Methoden zum Verwalten der gespeicherten Daten bereitstellt.
Advantages
Bessere Leistung als ein Thin-Client-Ansatz und einfacher zu verwalten als ein Thick-Client-Ansatz.
Verbessert die Wiederverwendbarkeit und Skalierbarkeit - bei steigenden Anforderungen können zusätzliche Server hinzugefügt werden.
Bietet Multithreading-Unterstützung und reduziert den Netzwerkverkehr.
Bietet Wartbarkeit und Flexibilität
Disadvantages
Unbefriedigende Testbarkeit aufgrund fehlender Testwerkzeuge.
Kritischere Serverzuverlässigkeit und -verfügbarkeit.
Broker Architekturstil
Broker Architectural Style ist eine Middleware-Architektur, die im verteilten Computing verwendet wird, um die Kommunikation zwischen registrierten Servern und Clients zu koordinieren und zu ermöglichen. Hier erfolgt die Objektkommunikation über ein Middleware-System, das als Object Request Broker (Software Bus) bezeichnet wird.
Client und Server interagieren nicht direkt miteinander. Client und Server haben eine direkte Verbindung zu ihrem Proxy, der mit dem Mediator-Broker kommuniziert.
Ein Server stellt Dienste bereit, indem er seine Schnittstellen beim Broker registriert und veröffentlicht, und Clients können die Dienste vom Broker statisch oder dynamisch durch Nachschlagen anfordern.
CORBA (Common Object Request Broker Architecture) ist ein gutes Implementierungsbeispiel für die Brokerarchitektur.
Komponenten des Broker-Architekturstils
Die Komponenten des Broker-Architekturstils werden in den folgenden Abschnitten erläutert:
Broker
Der Broker ist für die Koordination der Kommunikation verantwortlich, z. B. für die Weiterleitung und den Versand der Ergebnisse und Ausnahmen. Dies kann entweder ein aufruforientierter Dienst, ein Dokument oder ein nachrichtenorientierter Broker sein, an den Clients eine Nachricht senden.
Es ist dafür verantwortlich, die Serviceanfragen zu vermitteln, einen geeigneten Server zu finden, Anfragen zu senden und Antworten an Clients zurückzusenden.
Die Registrierungsinformationen der Server, einschließlich ihrer Funktionen und Dienste sowie Standortinformationen, werden beibehalten.
Es bietet APIs für Clients zum Anfordern, Server zum Antworten, Registrieren oder Aufheben der Registrierung von Serverkomponenten, Übertragen von Nachrichten und Auffinden von Servern.
Stub
Stubs werden zur statischen Kompilierungszeit generiert und dann auf der Clientseite bereitgestellt, die als Proxy für den Client verwendet wird. Der clientseitige Proxy fungiert als Vermittler zwischen dem Kunden und dem Broker und bietet zusätzliche Transparenz zwischen ihm und dem Kunden. Ein entferntes Objekt erscheint wie ein lokales.
Der Proxy verbirgt den IPC (Inter-Process Communication) auf Protokollebene und führt das Marshalling von Parameterwerten und das Un-Marshalling von Ergebnissen vom Server durch.
Skeleton
Das Skelett wird durch die Kompilierung der Serviceschnittstelle generiert und dann auf der Serverseite bereitgestellt, die als Proxy für den Server verwendet wird. Der serverseitige Proxy kapselt systemspezifische Netzwerkfunktionen auf niedriger Ebene und bietet APIs auf hoher Ebene, um zwischen dem Server und dem Broker zu vermitteln.
Es empfängt die Anforderungen, entpackt die Anforderungen, entschlüsselt die Methodenargumente, ruft den geeigneten Dienst auf und stellt das Ergebnis zusammen, bevor es an den Client zurückgesendet wird.
Bridge
Eine Bridge kann zwei verschiedene Netzwerke basierend auf verschiedenen Kommunikationsprotokollen verbinden. Es vermittelt verschiedene Broker, einschließlich DCOM-, .NET Remote- und Java CORBA-Broker.
Bridges sind optionale Komponenten, die die Implementierungsdetails verbergen, wenn zwei Broker zusammenarbeiten und Anforderungen und Parameter in einem Format annehmen und in ein anderes Format übersetzen.

Broker implementation in CORBA
CORBA ist ein internationaler Standard für einen Object Request Broker - eine Middleware zur Verwaltung der Kommunikation zwischen verteilten Objekten, die von OMG (Object Management Group) definiert wurden.

Serviceorientierte Architektur (SOA)
Ein Service ist eine Komponente der Geschäftsfunktionalität, die genau definiert, in sich geschlossen, unabhängig, veröffentlicht und über eine Standardprogrammierschnittstelle verwendet werden kann. Die Verbindungen zwischen Diensten werden von gemeinsamen und universellen nachrichtenorientierten Protokollen wie dem SOAP-Webdienstprotokoll hergestellt, das Anforderungen und Antworten zwischen Diensten lose übermitteln kann.
Serviceorientierte Architektur ist ein Client / Server-Design, das einen geschäftsorientierten IT-Ansatz unterstützt, bei dem eine Anwendung aus Softwarediensten und Softwaredienstkonsumenten (auch als Clients oder Serviceanforderer bezeichnet) besteht.
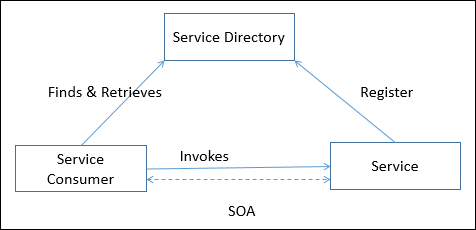
Merkmale von SOA
Eine serviceorientierte Architektur bietet die folgenden Funktionen:
Distributed Deployment - Stellen Sie Unternehmensdaten und Geschäftslogik als lose, gekoppelte, auffindbare, strukturierte, standardbasierte, grobkörnige, zustandslose Funktionseinheiten dar, die als Dienste bezeichnet werden.
Composability - Stellen Sie neue Prozesse aus vorhandenen Diensten zusammen, die über genau definierte, veröffentlichte und standardmäßige Beschwerdeschnittstellen in der gewünschten Granularität verfügbar gemacht werden.
Interoperability - Gemeinsame Funktionen und Wiederverwendung gemeinsam genutzter Dienste in einem Netzwerk, unabhängig von den zugrunde liegenden Protokollen oder der Implementierungstechnologie.
Reusability - Wählen Sie einen Dienstanbieter und greifen Sie auf vorhandene Ressourcen zu, die als Dienste verfügbar gemacht werden.
SOA-Betrieb
Die folgende Abbildung zeigt, wie SOA funktioniert -

Advantages
Die lose Kopplung von Service-Orientierung bietet Unternehmen eine große Flexibilität, um alle verfügbaren Service-Ressourcen unabhängig von Plattform- und Technologieeinschränkungen zu nutzen.
Jede Dienstkomponente ist aufgrund der zustandslosen Dienstfunktion unabhängig von anderen Diensten.
Die Implementierung eines Dienstes wirkt sich nicht auf die Anwendung des Dienstes aus, solange die exponierte Schnittstelle nicht geändert wird.
Ein Client oder ein Dienst kann unabhängig von seiner Plattform, Technologie, seinen Anbietern oder Sprachimplementierungen auf andere Dienste zugreifen.
Wiederverwendbarkeit von Assets und Services, da Kunden eines Service nur die öffentlichen Schnittstellen und die Servicezusammensetzung kennen müssen.
Die Entwicklung von SOA-basierten Geschäftsanwendungen ist zeit- und kostenintensiver.
Verbessert die Skalierbarkeit und bietet eine Standardverbindung zwischen Systemen.
Effiziente und effektive Nutzung von 'Business Services'.
Die Integration wird viel einfacher und die intrinsische Interoperabilität verbessert.
Abstrakte Komplexität für Entwickler und Anregung von Geschäftsprozessen näher am Endbenutzer.
Die komponentenbasierte Architektur konzentriert sich auf die Zerlegung des Entwurfs in einzelne funktionale oder logische Komponenten, die genau definierte Kommunikationsschnittstellen darstellen, die Methoden, Ereignisse und Eigenschaften enthalten. Es bietet eine höhere Abstraktionsebene und unterteilt das Problem in Unterprobleme, die jeweils Komponentenpartitionen zugeordnet sind.
Das Hauptziel der komponentenbasierten Architektur ist die Sicherstellung component reusability. Eine Komponente kapselt die Funktionalität und das Verhalten eines Softwareelements in einer wiederverwendbaren und selbst bereitstellbaren Binäreinheit. Es gibt viele Standardkomponenten-Frameworks wie COM / DCOM, JavaBean, EJB, CORBA, .NET, Webdienste und Grid-Dienste. Diese Technologien werden häufig im Design lokaler Desktop-GUI-Anwendungen verwendet, z. B. grafische JavaBean-Komponenten, MS ActiveX-Komponenten und COM-Komponenten, die durch einfaches Ziehen und Ablegen wiederverwendet werden können.
Komponentenorientiertes Software-Design bietet viele Vorteile gegenüber herkömmlichen objektorientierten Ansätzen wie -
Reduzierte Zeit auf dem Markt und Entwicklungskosten durch Wiederverwendung vorhandener Komponenten.
Erhöhte Zuverlässigkeit durch Wiederverwendung der vorhandenen Komponenten.
Was ist eine Komponente?
Eine Komponente ist ein modularer, portabler, austauschbarer und wiederverwendbarer Satz klar definierter Funktionen, die ihre Implementierung kapseln und als übergeordnete Schnittstelle exportieren.
Eine Komponente ist ein Softwareobjekt, das mit anderen Komponenten interagieren und bestimmte Funktionen oder eine Reihe von Funktionen einschließen soll. Es hat eine offensichtlich definierte Schnittstelle und entspricht einem empfohlenen Verhalten, das allen Komponenten innerhalb einer Architektur gemeinsam ist.
Eine Softwarekomponente kann als Kompositionseinheit mit einer vertraglich festgelegten Schnittstelle und nur expliziten Kontextabhängigkeiten definiert werden. Das heißt, eine Softwarekomponente kann unabhängig bereitgestellt werden und unterliegt der Zusammensetzung durch Dritte.
Ansichten einer Komponente
Eine Komponente kann drei verschiedene Ansichten haben - objektorientierte Ansicht, konventionelle Ansicht und prozessbezogene Ansicht.
Object-oriented view
Eine Komponente wird als eine Gruppe von einer oder mehreren kooperierenden Klassen angesehen. Jede Problemdomänenklasse (Analyse) und Infrastrukturklasse (Design) wird erläutert, um alle Attribute und Operationen zu identifizieren, die für ihre Implementierung gelten. Dazu gehört auch die Definition der Schnittstellen, über die Klassen kommunizieren und zusammenarbeiten können.
Conventional view
Es wird als Funktionselement oder Modul eines Programms angesehen, das die Verarbeitungslogik, die zur Implementierung der Verarbeitungslogik erforderlichen internen Datenstrukturen und eine Schnittstelle integriert, über die die Komponente aufgerufen und Daten an sie übergeben werden können.
Process-related view
In dieser Ansicht erstellt das System nicht jede Komponente von Grund auf neu, sondern baut auf vorhandenen Komponenten auf, die in einer Bibliothek verwaltet werden. Bei der Formulierung der Softwarearchitektur werden Komponenten aus der Bibliothek ausgewählt und zum Auffüllen der Architektur verwendet.
Eine Benutzeroberflächenkomponente enthält Raster, Schaltflächen, die als Steuerelemente bezeichnet werden, und Dienstprogrammkomponenten stellen eine bestimmte Teilmenge von Funktionen bereit, die in anderen Komponenten verwendet werden.
Andere gängige Arten von Komponenten sind ressourcenintensiv, auf die nicht häufig zugegriffen wird und die mithilfe des Just-in-Time-Ansatzes (JIT) aktiviert werden müssen.
Viele Komponenten sind unsichtbar und werden in Unternehmensanwendungen und Internet-Webanwendungen wie Enterprise JavaBean (EJB), .NET-Komponenten und CORBA-Komponenten verteilt.
Eigenschaften von Bauteilen
Reusability- Komponenten sind normalerweise so konzipiert, dass sie in verschiedenen Situationen in verschiedenen Anwendungen wiederverwendet werden können. Einige Komponenten können jedoch für eine bestimmte Aufgabe ausgelegt sein.
Replaceable - Komponenten können frei durch andere ähnliche Komponenten ersetzt werden.
Not context specific - Komponenten sind für den Betrieb in verschiedenen Umgebungen und Kontexten ausgelegt.
Extensible - Eine Komponente kann von vorhandenen Komponenten erweitert werden, um neues Verhalten bereitzustellen.
Encapsulated - Die AA-Komponente zeigt die Schnittstellen, über die der Aufrufer seine Funktionalität nutzen kann, und legt keine Details der internen Prozesse oder interne Variablen oder Zustände offen.
Independent - Komponenten sind so konzipiert, dass sie nur minimale Abhängigkeiten von anderen Komponenten aufweisen.
Prinzipien des komponentenbasierten Designs
Ein Entwurf auf Komponentenebene kann mithilfe einer Zwischendarstellung (z. B. grafisch, tabellarisch oder textbasiert) dargestellt werden, die in Quellcode übersetzt werden kann. Das Design von Datenstrukturen, Schnittstellen und Algorithmen sollte den etablierten Richtlinien entsprechen, um die Einführung von Fehlern zu vermeiden.
Das Softwaresystem wird in wiederverwendbare, zusammenhängende und gekapselte Komponenteneinheiten zerlegt.
Jede Komponente verfügt über eine eigene Schnittstelle, die die erforderlichen und bereitgestellten Ports angibt. Jede Komponente verbirgt ihre detaillierte Implementierung.
Eine Komponente sollte erweitert werden, ohne dass interne Code- oder Designänderungen an den vorhandenen Teilen der Komponente vorgenommen werden müssen.
Abhängig von Abstraktionskomponenten hängen sie nicht von anderen konkreten Komponenten ab, was die Schwierigkeit der Verbrauchbarkeit erhöht.
Konnektoren verbinden Komponenten und spezifizieren und regeln die Interaktion zwischen Komponenten. Der Interaktionstyp wird durch die Schnittstellen der Komponenten angegeben.
Die Komponenteninteraktion kann in Form von Methodenaufrufen, asynchronen Aufrufen, Broadcasting, nachrichtengesteuerten Interaktionen, Datenstromkommunikation und anderen protokollspezifischen Interaktionen erfolgen.
Für eine Serverklasse sollten spezielle Schnittstellen erstellt werden, um Hauptkategorien von Clients zu bedienen. In der Schnittstelle sollten nur die Vorgänge angegeben werden, die für eine bestimmte Kategorie von Clients relevant sind.
Eine Komponente kann auf andere Komponenten ausgedehnt werden und bietet dennoch eigene Erweiterungspunkte. Es ist das Konzept einer Plug-in-basierten Architektur. Dadurch kann ein Plugin eine andere Plugin-API anbieten.

Entwurfsrichtlinien auf Komponentenebene
Erstellt eine Namenskonvention für Komponenten, die als Teil des Architekturmodells angegeben werden, und verfeinert oder arbeitet sie dann als Teil des Modells auf Komponentenebene aus.
Ruft Namen von Architekturkomponenten aus der Problemdomäne ab und stellt sicher, dass sie für alle Beteiligten, die das Architekturmodell anzeigen, von Bedeutung sind.
Extrahiert die Geschäftsprozessentitäten, die unabhängig voneinander existieren können, ohne dass eine Abhängigkeit von anderen Entitäten besteht.
Erkennt und entdeckt diese unabhängigen Entitäten als neue Komponenten.
Verwendet Namen von Infrastrukturkomponenten, die ihre implementierungsspezifische Bedeutung widerspiegeln.
Modelliert alle Abhängigkeiten von links nach rechts und die Vererbung von oben (Basisklasse) nach unten (abgeleitete Klassen).
Modellieren Sie alle Komponentenabhängigkeiten als Schnittstellen, anstatt sie als direkte Abhängigkeit von Komponente zu Komponente darzustellen.
Entwurf auf Komponentenebene durchführen
Erkennt alle Entwurfsklassen, die der im Analysemodell und im Architekturmodell definierten Problemdomäne entsprechen.
Erkennt alle Entwurfsklassen, die der Infrastrukturdomäne entsprechen.
Beschreibt alle Entwurfsklassen, die nicht als wiederverwendbare Komponenten erfasst wurden, und gibt Nachrichtendetails an.
Identifiziert geeignete Schnittstellen für jede Komponente und erarbeitet Attribute und definiert Datentypen und Datenstrukturen, die für deren Implementierung erforderlich sind.
Beschreibt den Verarbeitungsablauf innerhalb jeder Operation im Detail anhand von Pseudocode- oder UML-Aktivitätsdiagrammen.
Beschreibt persistente Datenquellen (Datenbanken und Dateien) und identifiziert die Klassen, die für deren Verwaltung erforderlich sind.
Entwickeln und erarbeiten Sie Verhaltensrepräsentationen für eine Klasse oder Komponente. Dies kann erreicht werden, indem die für das Analysemodell erstellten UML-Zustandsdiagramme erstellt und alle Anwendungsfälle untersucht werden, die für die Entwurfsklasse relevant sind.
Entwickelt Bereitstellungsdiagramme, um zusätzliche Implementierungsdetails bereitzustellen.
Demonstriert die Position von Schlüsselpaketen oder Komponentenklassen in einem System mithilfe von Klasseninstanzen und unter Angabe einer bestimmten Hardware- und Betriebssystemumgebung.
Die endgültige Entscheidung kann unter Verwendung festgelegter Gestaltungsprinzipien und Richtlinien getroffen werden. Erfahrene Designer prüfen alle (oder die meisten) alternativen Designlösungen, bevor sie sich für das endgültige Designmodell entscheiden.
Vorteile
Ease of deployment - Wenn neue kompatible Versionen verfügbar werden, ist es einfacher, vorhandene Versionen zu ersetzen, ohne dass dies Auswirkungen auf die anderen Komponenten oder das gesamte System hat.
Reduced cost - Durch die Verwendung von Komponenten von Drittanbietern können Sie die Kosten für Entwicklung und Wartung verteilen.
Ease of development - Komponenten implementieren bekannte Schnittstellen, um definierte Funktionen bereitzustellen, die eine Entwicklung ermöglichen, ohne andere Teile des Systems zu beeinträchtigen.
Reusable - Durch die Verwendung wiederverwendbarer Komponenten können die Entwicklungs- und Wartungskosten auf mehrere Anwendungen oder Systeme verteilt werden.
Modification of technical complexity - Eine Komponente ändert die Komplexität durch die Verwendung eines Komponentencontainers und seiner Dienste.
Reliability - Die Gesamtsystemzuverlässigkeit steigt, da die Zuverlässigkeit jeder einzelnen Komponente die Zuverlässigkeit des gesamten Systems durch Wiederverwendung erhöht.
System maintenance and evolution - Einfache Änderung und Aktualisierung der Implementierung, ohne den Rest des Systems zu beeinträchtigen.
Independent- Unabhängigkeit und flexible Konnektivität von Komponenten. Unabhängige Entwicklung von Komponenten durch verschiedene Gruppen parallel. Produktivität für die Softwareentwicklung und zukünftige Softwareentwicklung.
Die Benutzeroberfläche ist der erste Eindruck eines Softwaresystems aus Sicht des Benutzers. Daher muss jedes Softwaresystem die Anforderungen des Benutzers erfüllen. Die Benutzeroberfläche führt hauptsächlich zwei Funktionen aus:
Akzeptieren der Benutzereingaben
Anzeige der Ausgabe
Die Benutzeroberfläche spielt in jedem Softwaresystem eine entscheidende Rolle. Es ist möglicherweise der einzige sichtbare Aspekt eines Softwaresystems als -
Benutzer sehen zunächst die Architektur der externen Benutzeroberfläche des Softwaresystems, ohne die interne Architektur zu berücksichtigen.
Eine gute Benutzeroberfläche muss den Benutzer dazu bringen, das Softwaresystem fehlerfrei zu verwenden. Es soll dem Benutzer helfen, das Softwaresystem leicht zu verstehen, ohne irreführende Informationen zu erhalten. Eine schlechte Benutzeroberfläche kann zu einem Marktversagen gegenüber der Konkurrenz von Softwaresystemen führen.
Die Benutzeroberfläche hat ihre Syntax und Semantik. Die Syntax umfasst Komponententypen wie Text, Symbol, Schaltfläche usw., und die Benutzerfreundlichkeit fasst die Semantik der Benutzeroberfläche zusammen. Die Qualität der Benutzeroberfläche zeichnet sich durch ihr Erscheinungsbild (Syntax) und ihre Benutzerfreundlichkeit (Semantik) aus.
Grundsätzlich gibt es zwei Hauptarten von Benutzeroberflächen: a) Text b) Grafisch.
Software in verschiedenen Domänen erfordert möglicherweise unterschiedliche Stile ihrer Benutzeroberfläche, z. B. benötigt der Taschenrechner nur einen kleinen Bereich zum Anzeigen numerischer Zahlen, aber einen großen Bereich für Befehle. Eine Webseite benötigt Formulare, Links, Registerkarten usw.
Grafische Benutzeroberfläche
Eine grafische Benutzeroberfläche ist die heute am häufigsten verwendete Art der Benutzeroberfläche. Es ist sehr benutzerfreundlich, da es Bilder, Grafiken und Symbole verwendet - daher wird es als "grafisch" bezeichnet.
Es ist auch bekannt als WIMP interface weil es nutzt -
Windows - Ein rechteckiger Bereich auf dem Bildschirm, in dem die häufig verwendeten Anwendungen ausgeführt werden.
Icons - Ein Bild oder Symbol, das zur Darstellung einer Softwareanwendung oder eines Hardwaregeräts verwendet wird.
Menus - Eine Liste von Optionen, aus denen der Benutzer auswählen kann, was er benötigt.
Pointers- Ein Symbol wie ein Pfeil, der sich auf dem Bildschirm bewegt, wenn der Benutzer die Maus bewegt. Es hilft dem Benutzer, Objekte auszuwählen.
Design der Benutzeroberfläche
Es beginnt mit einer Aufgabenanalyse, die die Hauptaufgaben und die Problemdomäne des Benutzers versteht. Es sollte in Bezug auf die Terminologie des Benutzers und den Beginn der Arbeit des Benutzers und nicht in Bezug auf die des Programmierers entworfen werden.
Um eine Analyse der Benutzeroberfläche durchzuführen, muss der Praktiker vier Elemente studieren und verstehen -
Das users Wer wird mit dem System über die Schnittstelle interagieren
Das tasks dass Endbenutzer ausführen müssen, um ihre Arbeit zu erledigen
Das content das wird als Teil der Schnittstelle dargestellt
Das work environment in denen diese Aufgaben durchgeführt werden
Das richtige oder gute UI-Design basiert auf den Fähigkeiten und Einschränkungen des Benutzers, nicht auf den Maschinen. Bei der Gestaltung der Benutzeroberfläche ist auch die Kenntnis der Art der Arbeit und Umgebung des Benutzers von entscheidender Bedeutung.
Die auszuführende Aufgabe kann dann aufgeteilt werden, die dem Benutzer oder der Maschine zugewiesen werden, basierend auf dem Wissen über die Fähigkeiten und Einschränkungen der einzelnen. Das Design einer Benutzeroberfläche ist häufig in vier verschiedene Ebenen unterteilt:
The conceptual level - Es beschreibt die grundlegenden Entitäten unter Berücksichtigung der Sicht des Benutzers auf das System und der auf sie möglichen Aktionen.
The semantic level - Es beschreibt die vom System ausgeführten Funktionen, dh die Beschreibung der Funktionsanforderungen des Systems, geht jedoch nicht darauf ein, wie der Benutzer die Funktionen aufruft.
The syntactic level - Es beschreibt die Sequenzen von Ein- und Ausgängen, die zum Aufrufen der beschriebenen Funktionen erforderlich sind.
The lexical level - Es bestimmt, wie die Ein- und Ausgänge tatsächlich aus primitiven Hardwareoperationen gebildet werden.
Das Design der Benutzeroberfläche ist ein iterativer Prozess, bei dem die gesamte Iteration die in den vorhergehenden Schritten entwickelten Informationen erklärt und verfeinert. Allgemeine Schritte für das Design der Benutzeroberfläche
Definiert Benutzeroberflächenobjekte und -aktionen (Operationen).
Definiert Ereignisse (Benutzeraktionen), durch die sich der Status der Benutzeroberfläche ändert.
Gibt an, wie der Benutzer den Status des Systems anhand der über die Schnittstelle bereitgestellten Informationen interpretiert.
Beschreiben Sie jeden Schnittstellenstatus so, wie er für den Endbenutzer tatsächlich aussieht.
Erstellt von einem Benutzer oder Softwareentwickler, der das Profil der Endbenutzer des Systems basierend auf Alter, Geschlecht, körperlichen Fähigkeiten, Bildung, Motivation, Zielen und Persönlichkeit erstellt.
Berücksichtigt syntaktisches und semantisches Wissen des Benutzers und klassifiziert Benutzer als Anfänger, sachkundige intermittierende und sachkundige häufige Benutzer.
Erstellt von einem Softwareentwickler, der Daten-, Architektur-, Schnittstellen- und Verfahrensdarstellungen der Software enthält.
Abgeleitet aus dem Analysemodell der Anforderungen und gesteuert durch die Informationen in der Anforderungsspezifikation, die bei der Definition des Benutzers des Systems helfen.
Erstellt von den Software-Implementierern, die am Erscheinungsbild der Benutzeroberfläche arbeiten, kombiniert mit allen unterstützenden Informationen (Bücher, Videos, Hilfedateien), die die Systemsyntax und -semantik beschreiben.
Dient als Übersetzung des Entwurfsmodells und versucht, mit dem mentalen Modell des Benutzers übereinzustimmen, sodass Benutzer sich dann mit der Software wohl fühlen und sie effektiv nutzen können.
Erstellt vom Benutzer bei der Interaktion mit der Anwendung. Es enthält das Bild des Systems, das Benutzer in ihren Köpfen tragen.
Die oft als Systemwahrnehmung des Benutzers bezeichnete Richtigkeit der Beschreibung hängt vom Profil des Benutzers und der allgemeinen Vertrautheit mit der Software in der Anwendungsdomäne ab.
- Identifizieren Sie zu Beginn Ihre Architekturziele.
- Identifizieren Sie den Verbraucher unserer Architektur.
- Identifizieren Sie die Einschränkungen.
Überprüfen Sie die Architektur häufig bei wichtigen Projektmeilensteinen und als Reaktion auf andere wichtige architektonische Änderungen.
Das Hauptziel einer Architekturüberprüfung besteht darin, die Machbarkeit von Basis- und Kandidatenarchitekturen zu bestimmen, die die Architektur korrekt verifizieren.
Verknüpft die funktionalen Anforderungen und die Qualitätsmerkmale mit der vorgeschlagenen technischen Lösung. Es hilft auch, Probleme zu identifizieren und Verbesserungsmöglichkeiten zu erkennen
Entwicklungsprozess der Benutzeroberfläche
Es folgt einem Spiralprozess wie im folgenden Diagramm gezeigt -

Interface analysis
Es konzentriert sich auf Benutzer, Aufgaben, Inhalte und Arbeitsumgebungen, die mit dem System interagieren. Definiert die menschlichen und computerorientierten Aufgaben, die zur Erreichung der Systemfunktion erforderlich sind.
Interface design
Es definiert eine Reihe von Schnittstellenobjekten, Aktionen und deren Bildschirmdarstellungen, mit denen ein Benutzer alle definierten Aufgaben auf eine Weise ausführen kann, die jedes für das System definierte Usability-Ziel erfüllt.
Interface construction
Es beginnt mit einem Prototyp, mit dem Nutzungsszenarien bewertet werden können, und setzt sich mit Entwicklungstools fort, um die Konstruktion abzuschließen.
Interface validation
Es konzentriert sich auf die Fähigkeit der Benutzeroberfläche, jede Benutzeraufgabe korrekt zu implementieren, alle Aufgabenvarianten zu berücksichtigen, alle allgemeinen Benutzeranforderungen zu erfüllen und inwieweit die Benutzeroberfläche einfach zu verwenden und leicht zu erlernen ist.
User Interface Models
Wenn eine Benutzeroberfläche analysiert und entworfen wird, werden die folgenden vier Modelle verwendet:
User profile model
Design model
Implementation model
User's mental model
Entwurfsüberlegungen zur Benutzeroberfläche
Benutzerzentriert
Eine Benutzeroberfläche muss ein benutzerzentriertes Produkt sein, an dem Benutzer während des gesamten Entwicklungslebenszyklus eines Produkts beteiligt sind. Der Prototyp einer Benutzeroberfläche sollte den Benutzern zur Verfügung stehen, und das Feedback der Benutzer sollte in das Endprodukt integriert werden.
Einfach und intuitiv
Die Benutzeroberfläche bietet Einfachheit und Intuitivität, sodass sie ohne Anweisungen schnell und effektiv verwendet werden kann. Die Benutzeroberfläche ist besser als die Text-Benutzeroberfläche, da die Benutzeroberfläche aus Menüs, Fenstern und Schaltflächen besteht und einfach mit der Maus bedient wird.
Übernehmen Sie die Kontrolle über Benutzer
Zwingen Sie Benutzer nicht, vordefinierte Sequenzen zu vervollständigen. Geben Sie ihnen Optionen - zum Abbrechen oder Speichern und zum Zurückkehren an die Stelle, an der sie aufgehört haben. Verwenden Sie Begriffe in der gesamten Benutzeroberfläche, die Benutzer verstehen können, anstatt System- oder Entwicklerbegriffe.
Geben Sie den Benutzern einen Hinweis darauf, dass eine Aktion ausgeführt wurde, indem Sie ihnen entweder die Ergebnisse der Aktion anzeigen oder bestätigen, dass die Aktion erfolgreich ausgeführt wurde.
Transparenz
Die Benutzeroberfläche muss transparent sein, damit Benutzer das Gefühl haben, direkt über den Computer zu gelangen und die Objekte, mit denen sie arbeiten, direkt zu bearbeiten. Die Benutzeroberfläche kann transparent gemacht werden, indem Benutzer Arbeitsobjekte anstelle von Systemobjekten erhalten. Benutzer sollten beispielsweise verstehen, dass ihr Systemkennwort mindestens 6 Zeichen umfassen muss und nicht, wie viele Speicherbytes ein Kennwort enthalten muss.
Verwenden Sie die progressive Offenlegung
Bieten Sie immer einfachen Zugriff auf allgemeine Funktionen und häufig verwendete Aktionen. Blenden Sie weniger gebräuchliche Funktionen und Aktionen aus und ermöglichen Sie Benutzern die Navigation. Versuchen Sie nicht, alle Informationen in einem Hauptfenster zusammenzufassen. Verwenden Sie das sekundäre Fenster für Informationen, die keine Schlüsselinformationen sind.
Konsistenz
Die Benutzeroberfläche behält die Konsistenz innerhalb und zwischen den Produkten bei, hält die Interaktionsergebnisse gleich, die Befehle und Menüs der Benutzeroberfläche sollten dasselbe Format haben, die Satzzeichen der Befehle sollten ähnlich sein und die Parameter sollten auf die gleiche Weise an alle Befehle übergeben werden. Die Benutzeroberfläche sollte keine Verhaltensweisen aufweisen, die die Benutzer überraschen können, und sollte die Mechanismen enthalten, mit denen Benutzer sich von ihren Fehlern erholen können.
Integration
Das Softwaresystem sollte sich nahtlos in andere Anwendungen wie MS Notepad und MS-Office integrieren lassen. Es kann Zwischenablagebefehle direkt verwenden, um den Datenaustausch durchzuführen.
Komponentenorientiert
Das UI-Design muss modular aufgebaut sein und eine komponentenorientierte Architektur enthalten, damit das Design der UI dieselben Anforderungen stellt wie das Design des Hauptteils des Softwaresystems. Die Module können einfach geändert und ausgetauscht werden, ohne dass andere Teile des Systems beeinträchtigt werden.
Anpassbar
Die Architektur des gesamten Softwaresystems umfasst Plug-In-Module, mit denen viele verschiedene Personen die Software unabhängig voneinander erweitern können. Es ermöglicht einzelnen Benutzern, aus verschiedenen verfügbaren Formularen auszuwählen, um den persönlichen Vorlieben und Bedürfnissen zu entsprechen.
Reduzieren Sie die Speicherlast der Benutzer
Erzwingen Sie nicht, dass Benutzer sich merken und wiederholen müssen, was der Computer für sie tun soll. Beispielsweise sollten beim Ausfüllen von Online-Formularen Kundennamen, Adressen und Telefonnummern vom System gespeichert werden, sobald ein Benutzer sie eingegeben oder ein Kundendatensatz geöffnet wurde.
Benutzeroberflächen unterstützen das Abrufen des Langzeitgedächtnisses, indem sie Benutzern Elemente bereitstellen, die sie erkennen können, anstatt Informationen abrufen zu müssen.
Trennung
Die Benutzeroberfläche muss durch ihre Implementierung von der Logik des Systems getrennt werden, um die Wiederverwendbarkeit und Wartbarkeit zu verbessern.
Iterativer und inkrementeller Ansatz
Es ist ein iterativer und inkrementeller Ansatz, der aus fünf Hauptschritten besteht und dabei hilft, Kandidatenlösungen zu generieren. Diese Kandidatenlösung kann weiter verfeinert werden, indem diese Schritte wiederholt werden und schließlich ein Architekturdesign erstellt wird, das am besten zu unserer Anwendung passt. Am Ende des Prozesses können wir unsere Architektur überprüfen und allen interessierten Parteien mitteilen.
Dies ist nur ein möglicher Ansatz. Es gibt viele andere formellere Ansätze, mit denen Sie Ihre Architektur definieren, überprüfen und kommunizieren können.
Architekturziel identifizieren
Identifizieren Sie das Architekturziel, das den Architektur- und Entwurfsprozess bildet. Fehlerfreie und definierte Ziele betonen die Architektur, lösen die richtigen Probleme im Entwurf und helfen zu bestimmen, wann die aktuelle Phase abgeschlossen ist und bereit, zur nächsten Phase überzugehen.
Dieser Schritt umfasst die folgenden Aktivitäten:
Beispiele für Architekturaktivitäten sind das Erstellen eines Prototyps, um Feedback zur Benutzeroberfläche für die Auftragsverarbeitung für eine Webanwendung zu erhalten, das Erstellen einer Anwendung zur Auftragsverfolgung für Kunden sowie das Entwerfen der Authentifizierungs- und Autorisierungsarchitektur für eine Anwendung, um eine Sicherheitsüberprüfung durchzuführen.
Schlüsselszenarien
In diesem Schritt liegt der Schwerpunkt auf dem Design, das am wichtigsten ist. Ein Szenario ist eine umfassende und umfassende Beschreibung der Interaktion eines Benutzers mit dem System.
Schlüsselszenarien sind diejenigen, die als die wichtigsten Szenarien für den Erfolg Ihrer Anwendung gelten. Es hilft, Entscheidungen über die Architektur zu treffen. Ziel ist es, ein Gleichgewicht zwischen Benutzer-, Geschäfts- und Systemzielen zu erreichen. Beispielsweise ist die Benutzerauthentifizierung ein Schlüsselszenario, da sie einen Schnittpunkt eines Qualitätsattributs (Sicherheit) mit wichtigen Funktionen darstellt (wie sich ein Benutzer bei Ihrem System anmeldet).
Anwendungsübersicht
Erstellen Sie einen Überblick über die Anwendung, wodurch die Architektur berührbarer wird und sie mit realen Einschränkungen und Entscheidungen verbunden wird. Es besteht aus folgenden Aktivitäten:
Anwendungsart identifizieren
Identifizieren Sie den Anwendungstyp, ob es sich um eine mobile Anwendung, einen Rich Client, eine Rich Internet-Anwendung, einen Dienst, eine Webanwendung oder eine Kombination dieser Typen handelt.
Identifizieren Sie Bereitstellungsbeschränkungen
Wählen Sie eine geeignete Bereitstellungstopologie und lösen Sie Konflikte zwischen der Anwendung und der Zielinfrastruktur.
Identifizieren Sie wichtige Architekturdesignstile
Identifizieren Sie wichtige Architekturdesignstile wie Client / Server, Layered, Message-Bus, domänengesteuertes Design usw., um die Partitionierung zu verbessern und die Wiederverwendung des Designs zu fördern, indem Sie Lösungen für häufig wiederkehrende Probleme bereitstellen. Anwendungen verwenden häufig eine Kombination von Stilen.
Identifizieren Sie die relevanten Technologien
Identifizieren Sie die relevanten Technologien unter Berücksichtigung des von uns entwickelten Anwendungstyps, unserer bevorzugten Optionen für die Topologie der Anwendungsbereitstellung und der Architekturstile. Die Auswahl der Technologien richtet sich auch nach Organisationsrichtlinien, Infrastrukturbeschränkungen, Ressourcenkenntnissen usw.
Schlüsselprobleme oder Schlüssel-Hotspots
Beim Entwerfen einer Anwendung sind Hotspots die Bereiche, in denen am häufigsten Fehler gemacht werden. Identifizieren Sie wichtige Probleme anhand von Qualitätsmerkmalen und Querschnittsthemen. Mögliche Probleme sind das Auftreten neuer Technologien und kritische Geschäftsanforderungen.
Qualitätsattribute sind die allgemeinen Merkmale Ihrer Architektur, die sich auf das Laufzeitverhalten, das Systemdesign und die Benutzererfahrung auswirken. Querschnittsthemen sind die Merkmale unseres Designs, die für alle Ebenen, Komponenten und Ebenen gelten können.
Dies sind auch die Bereiche, in denen am häufigsten schwerwiegende Konstruktionsfehler gemacht werden. Beispiele für Querschnittsthemen sind Authentifizierung und Autorisierung, Kommunikation, Konfigurationsmanagement, Ausnahmemanagement und -validierung usw.
Kandidatenlösungen
Erstellen Sie nach dem Definieren der wichtigsten Hotspots die anfängliche Basisarchitektur oder das erste Design auf hoher Ebene und geben Sie dann die Details ein, um die Kandidatenarchitektur zu generieren.
Die Kandidatenarchitektur umfasst den Anwendungstyp, die Bereitstellungsarchitektur, den Architekturstil, die Auswahl der Technologie, die Qualitätsattribute und die Querschnittsthemen. Wenn die Kandidatenarchitektur eine Verbesserung darstellt, kann sie zur Basis werden, auf der neue Kandidatenarchitekturen erstellt und getestet werden können.
Validieren Sie das Lösungsdesign der Kandidaten anhand der bereits definierten Schlüsselszenarien und -anforderungen, bevor Sie den Zyklus iterativ verfolgen und das Design verbessern.
Wir können architektonische Spitzen verwenden, um die spezifischen Bereiche des Entwurfs zu entdecken oder neue Konzepte zu validieren. Architekturspitzen sind ein Entwurfsprototyp, der die Machbarkeit eines bestimmten Entwurfspfads bestimmt, das Risiko verringert und schnell die Realisierbarkeit verschiedener Ansätze bestimmt. Testen Sie Architekturspitzen anhand von Schlüsselszenarien und Hotspots.
Architekturüberprüfung
Die Überprüfung der Architektur ist die wichtigste Aufgabe, um die Kosten für Fehler zu senken und Architekturprobleme so früh wie möglich zu finden und zu beheben. Dies ist eine etablierte und kostengünstige Methode zur Reduzierung der Projektkosten und der Wahrscheinlichkeit eines Projektversagens.
Szenariobasierte Auswertungen sind eine dominante Methode zur Überprüfung eines Architekturdesigns, die sich auf die Szenarien konzentriert, die aus geschäftlicher Sicht am wichtigsten sind und die den größten Einfluss auf die Architektur haben. Es folgen gängige Überprüfungsmethoden -
Analysemethode für die Softwarearchitektur (SAAM)
Es wurde ursprünglich zur Bewertung der Modifizierbarkeit entwickelt, später jedoch zur Überprüfung der Architektur hinsichtlich Qualitätsmerkmalen erweitert.
Architektur-Kompromiss-Analysemethode (ATAM)
Es handelt sich um eine polierte und verbesserte Version von SAAM, die Architekturentscheidungen in Bezug auf die Anforderungen an Qualitätsattribute und deren Erfüllung bestimmter Qualitätsziele überprüft.
Active Design Review (ADR)
Es eignet sich am besten für unvollständige oder in Bearbeitung befindliche Architekturen, die sich mehr auf eine Reihe von Problemen oder einzelne Abschnitte der Architektur gleichzeitig konzentrieren, als eine allgemeine Überprüfung durchzuführen.
Aktive Überprüfungen von Intermediate Designs (ARID)
Es kombiniert den ADR-Aspekt der Überprüfung der in Bearbeitung befindlichen Architektur mit einem Fokus auf eine Reihe von Themen und den ATAM- und SAAM-Ansatz der szenariobasierten Überprüfung, der sich auf Qualitätsattribute konzentriert.
Kosten-Nutzen-Analyse-Methode (CBAM)
Der Schwerpunkt liegt auf der Analyse der Kosten, des Nutzens und der zeitlichen Auswirkungen von Architekturentscheidungen.
Modifizierbarkeitsanalyse auf Architekturebene (ALMA)
Es schätzt die Modifizierbarkeit der Architektur für Geschäftsinformationssysteme (BIS).
Bewertungsmethode für Familienarchitektur (FAAM)
Es schätzt die Architekturen der Informationssystemfamilie auf Interoperabilität und Erweiterbarkeit.
Kommunikation des Architekturdesigns
Nach Abschluss des Architekturentwurfs müssen wir den Entwurf den anderen Stakeholdern mitteilen, zu denen das Entwicklungsteam, Systemadministratoren, Betreiber, Geschäftsinhaber und andere interessierte Parteien gehören.
Es gibt mehrere bekannte Methoden zur Beschreibung der Architektur für andere: -
4 + 1 Modell
Dieser Ansatz verwendet fünf Ansichten der gesamten Architektur. Darunter vier Ansichten (dielogical view, das process view, das physical view, und die development view) beschreiben die Architektur aus verschiedenen Ansätzen. Eine fünfte Ansicht zeigt die Szenarien und Anwendungsfälle für die Software. Es ermöglicht den Stakeholdern, die Merkmale der Architektur zu sehen, die sie speziell interessieren.
Architekturbeschreibungssprache (ADL)
Dieser Ansatz wird verwendet, um die Softwarearchitektur vor der Systemimplementierung zu beschreiben. Es behandelt die folgenden Probleme - Verhalten, Protokoll und Konnektor.
Der Hauptvorteil von ADL besteht darin, dass wir die Architektur auf Vollständigkeit, Konsistenz, Mehrdeutigkeit und Leistung analysieren können, bevor wir offiziell mit der Verwendung des Designs beginnen.
Agile Modellierung
Dieser Ansatz folgt dem Konzept, dass „Inhalt wichtiger ist als Repräsentation“. Es stellt sicher, dass die erstellten Modelle einfach und leicht verständlich, ausreichend genau, detailliert und konsistent sind.
Agile Modelldokumente zielen auf bestimmte Kunden ab und erfüllen die Arbeitsanstrengungen dieses Kunden. Die Einfachheit des Dokuments stellt sicher, dass die Interessengruppen aktiv an der Modellierung des Artefakts beteiligt sind.
IEEE 1471
IEEE 1471 ist die Kurzbezeichnung für einen Standard, der formal als ANSI / IEEE 1471-2000 bekannt ist: „Empfohlene Vorgehensweise für die Architekturbeschreibung softwareintensiver Systeme“. IEEE 1471 erweitert insbesondere den Inhalt einer Architekturbeschreibung und gibt Kontext, Ansichten und Gesichtspunkten eine spezifische Bedeutung.
Unified Modeling Language (UML)
Dieser Ansatz repräsentiert drei Ansichten eines Systemmodells. Dasfunctional requirements view (funktionale Anforderungen des Systems aus Sicht des Benutzers, einschließlich Anwendungsfälle); the static structural view(Objekte, Attribute, Beziehungen und Operationen einschließlich Klassendiagrammen); und diedynamic behavior view (Zusammenarbeit zwischen Objekten und Änderungen des internen Status von Objekten, einschließlich Sequenz-, Aktivitäts- und Statusdiagrammen).