Weka - Klassifikatoren
Viele Anwendungen für maschinelles Lernen beziehen sich auf die Klassifizierung. Beispielsweise möchten Sie einen Tumor möglicherweise als bösartig oder gutartig klassifizieren. Abhängig von den Wetterbedingungen möchten Sie vielleicht entscheiden, ob Sie ein Spiel im Freien spielen möchten. Im Allgemeinen hängt diese Entscheidung von mehreren Merkmalen / Wetterbedingungen ab. Daher bevorzugen Sie möglicherweise die Verwendung eines Baumklassifikators, um zu entscheiden, ob Sie spielen möchten oder nicht.
In diesem Kapitel erfahren Sie, wie Sie einen solchen Baumklassifikator anhand von Wetterdaten erstellen, um die Spielbedingungen zu bestimmen.
Testdaten einstellen
Wir werden die vorverarbeitete Wetterdatendatei aus der vorherigen Lektion verwenden. Öffnen Sie die gespeicherte Datei mit demOpen file ... Option unter der Preprocess Klicken Sie auf die Registerkarte Classify Registerkarte, und Sie würden den folgenden Bildschirm sehen -
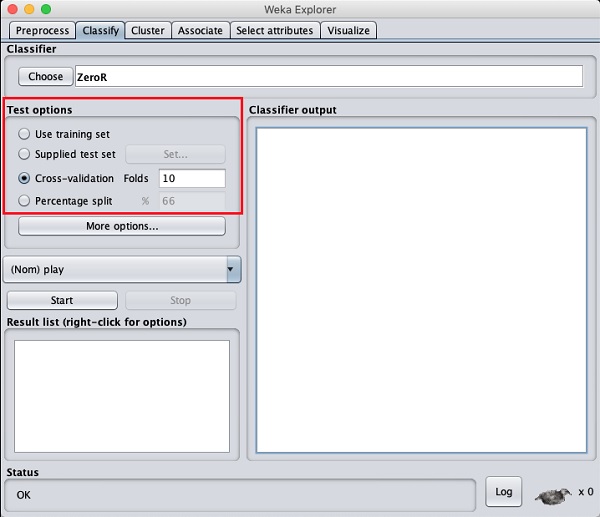
Bevor Sie sich mit den verfügbaren Klassifikatoren vertraut machen, lassen Sie uns die Testoptionen untersuchen. Sie werden vier Testoptionen bemerken, wie unten aufgeführt -
- Trainingsset
- Mitgeliefertes Testset
- Cross-validation
- Prozentuale Aufteilung
Sofern Sie nicht über ein eigenes Trainingsset oder ein vom Kunden bereitgestelltes Testset verfügen, würden Sie Kreuzvalidierungs- oder prozentuale Aufteilungsoptionen verwenden. Unter Kreuzvalidierung können Sie die Anzahl der Falten festlegen, in denen die gesamten Daten aufgeteilt und während jeder Iteration des Trainings verwendet werden. Bei der prozentualen Aufteilung teilen Sie die Daten zwischen Training und Test mit dem festgelegten prozentualen Anteil auf.
Behalten Sie jetzt die Standardeinstellung bei play Option für die Ausgabeklasse -
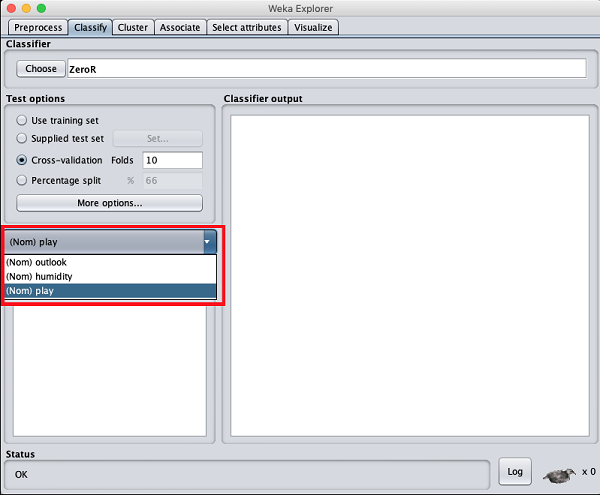
Als nächstes wählen Sie den Klassifikator aus.
Klassifikator auswählen
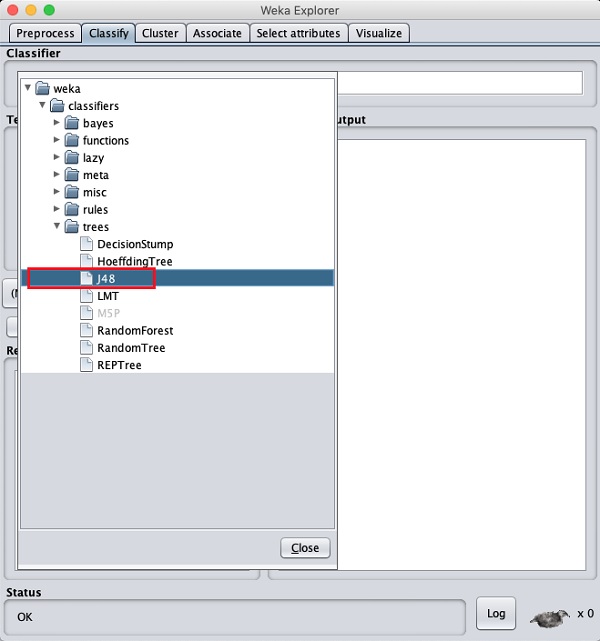
Klicken Sie auf die Schaltfläche Auswählen und wählen Sie den folgenden Klassifikator aus:
weka→classifiers>trees>J48
Dies wird im folgenden Screenshot gezeigt -
Klick auf das StartSchaltfläche, um den Klassifizierungsprozess zu starten. Nach einer Weile werden die Klassifizierungsergebnisse wie hier gezeigt auf Ihrem Bildschirm angezeigt.
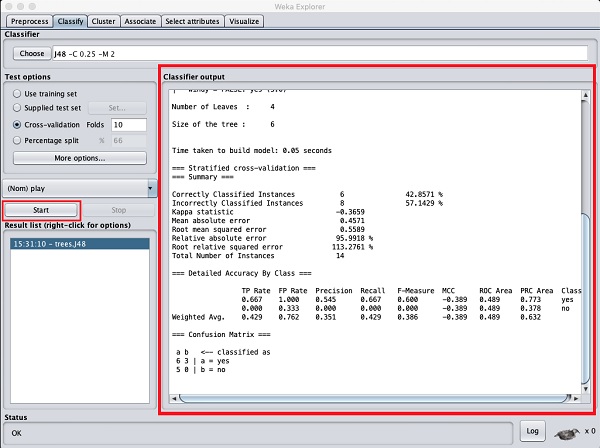
Lassen Sie uns die Ausgabe auf der rechten Seite des Bildschirms untersuchen.
Es heißt, die Größe des Baumes sei 6. Sie werden in Kürze die visuelle Darstellung des Baumes sehen. In der Zusammenfassung heißt es, dass die korrekt klassifizierten Instanzen als 2 und die falsch klassifizierten Instanzen als 3 angegeben sind. Außerdem heißt es, dass der relative absolute Fehler 110% beträgt. Es zeigt auch die Verwirrungsmatrix. Die Analyse dieser Ergebnisse würde den Rahmen dieses Tutorials sprengen. Anhand dieser Ergebnisse können Sie jedoch leicht erkennen, dass die Klassifizierung nicht akzeptabel ist und Sie mehr Daten für die Analyse benötigen, um Ihre Funktionsauswahl zu verfeinern, das Modell neu zu erstellen usw., bis Sie mit der Genauigkeit des Modells zufrieden sind. Genau darum geht es bei WEKA. So können Sie Ihre Ideen schnell testen.
Ergebnisse visualisieren
Um die visuelle Darstellung der Ergebnisse anzuzeigen, klicken Sie mit der rechten Maustaste auf das Ergebnis in der Result listBox. Auf dem Bildschirm werden mehrere Optionen angezeigt, wie hier gezeigt -
Wählen Visualize tree um eine visuelle Darstellung des Traversal Tree zu erhalten, wie im folgenden Screenshot gezeigt -
Auswählen Visualize classifier errors würde die Ergebnisse der Klassifizierung wie hier gezeigt darstellen -
EIN cross repräsentiert eine korrekt klassifizierte Instanz während squaresrepräsentiert falsch klassifizierte Instanzen. In der unteren linken Ecke des Grundstücks sehen Sie across das zeigt an, ob outlook ist dann sonnig playdas Spiel. Dies ist also eine korrekt klassifizierte Instanz. Um Instanzen zu lokalisieren, können Sie etwas Jitter einführen, indem Sie diejitter Schiebeleiste.
Die aktuelle Handlung ist outlook gegen play. Diese werden durch die beiden Dropdown-Listenfelder am oberen Bildschirmrand angezeigt.
Versuchen Sie nun in jedem dieser Felder eine andere Auswahl und stellen Sie fest, wie sich die X- und Y-Achsen ändern. Das gleiche kann erreicht werden, indem die horizontalen Streifen auf der rechten Seite des Diagramms verwendet werden. Jeder Streifen repräsentiert ein Attribut. Ein Linksklick auf den Streifen legt das ausgewählte Attribut auf der X-Achse fest, während ein Rechtsklick es auf die Y-Achse setzt.
Es gibt mehrere andere Diagramme für Ihre eingehendere Analyse. Verwenden Sie sie mit Bedacht, um Ihr Modell zu optimieren. Eine solche Handlung vonCost/Benefit analysis wird unten als Kurzreferenz gezeigt.
Das Erläutern der Analyse in diesen Diagrammen würde den Rahmen dieses Lernprogramms sprengen. Der Leser wird ermutigt, sein Wissen über die Analyse von Algorithmen für maschinelles Lernen aufzufrischen.
Im nächsten Kapitel lernen wir den nächsten Satz von Algorithmen für maschinelles Lernen kennen, nämlich das Clustering.