Weka - Kurzanleitung
Die Grundlage jeder Anwendung für maschinelles Lernen sind Daten - nicht nur kleine Daten, sondern große Datenmengen, die als bezeichnet werden Big Data in der aktuellen Terminologie.
Um die Maschine für die Analyse von Big Data zu trainieren, müssen Sie verschiedene Überlegungen zu den Daten anstellen -
- Die Daten müssen sauber sein.
- Es sollte keine Nullwerte enthalten.
Außerdem sind nicht alle Spalten in der Datentabelle für die Art der Analyse nützlich, die Sie erreichen möchten. Die irrelevanten Datenspalten oder 'Features', wie sie in der Terminologie des maschinellen Lernens genannt werden, müssen entfernt werden, bevor die Daten in einen Algorithmus für maschinelles Lernen eingespeist werden.
Kurz gesagt, Ihre Big Data müssen viel vorverarbeitet werden, bevor sie für maschinelles Lernen verwendet werden können. Sobald die Daten fertig sind, wenden Sie verschiedene Algorithmen für maschinelles Lernen an, z. B. Klassifizierung, Regression, Clustering usw., um das Problem an Ihrem Ende zu lösen.
Die Art der Algorithmen, die Sie anwenden, basiert weitgehend auf Ihrem Domänenwissen. Selbst innerhalb desselben Typs, beispielsweise der Klassifizierung, stehen mehrere Algorithmen zur Verfügung. Möglicherweise möchten Sie die verschiedenen Algorithmen unter derselben Klasse testen, um ein effizientes Modell für maschinelles Lernen zu erstellen. Dabei bevorzugen Sie die Visualisierung der verarbeiteten Daten und benötigen daher auch Visualisierungstools.
In den nächsten Kapiteln erfahren Sie mehr über Weka, eine Software, die all das mühelos erledigt und es Ihnen ermöglicht, bequem mit Big Data zu arbeiten.
WEKA - eine Open-Source-Software bietet Tools für die Datenvorverarbeitung, die Implementierung mehrerer Algorithmen für maschinelles Lernen und Visualisierungstools, mit denen Sie Techniken für maschinelles Lernen entwickeln und auf reale Data Mining-Probleme anwenden können. Was WEKA anbietet, ist in der folgenden Abbildung zusammengefasst:
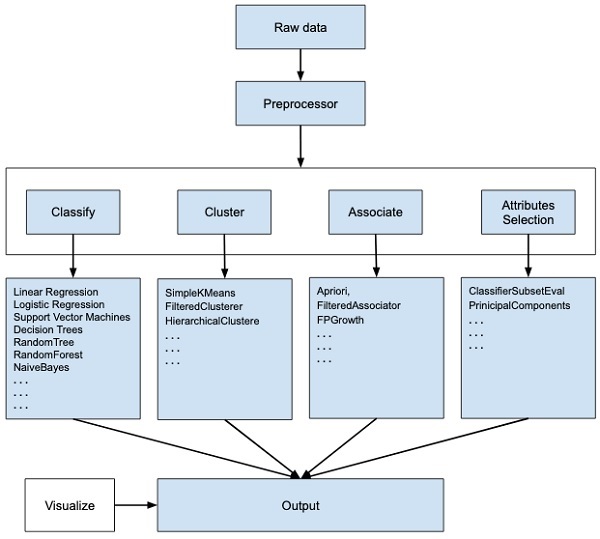
Wenn Sie den Beginn des Bildflusses beobachten, werden Sie verstehen, dass es viele Phasen im Umgang mit Big Data gibt, um es für maschinelles Lernen geeignet zu machen -
Zunächst beginnen Sie mit den aus dem Feld gesammelten Rohdaten. Diese Daten können mehrere Nullwerte und irrelevante Felder enthalten. Sie verwenden die in WEKA bereitgestellten Datenvorverarbeitungstools, um die Daten zu bereinigen.
Anschließend würden Sie die vorverarbeiteten Daten in Ihrem lokalen Speicher speichern, um ML-Algorithmen anzuwenden.
Abhängig von der Art des ML-Modells, das Sie entwickeln möchten, wählen Sie als Nächstes eine der folgenden Optionen aus: Classify, Cluster, oder Associate. DasAttributes Selection Ermöglicht die automatische Auswahl von Features, um einen reduzierten Datensatz zu erstellen.
Beachten Sie, dass WEKA unter jeder Kategorie die Implementierung mehrerer Algorithmen bereitstellt. Sie würden einen Algorithmus Ihrer Wahl auswählen, die gewünschten Parameter einstellen und ihn im Datensatz ausführen.
Dann würde WEKA Ihnen die statistische Ausgabe der Modellverarbeitung geben. Es bietet Ihnen ein Visualisierungstool zur Überprüfung der Daten.
Die verschiedenen Modelle können auf denselben Datensatz angewendet werden. Sie können dann die Ergebnisse verschiedener Modelle vergleichen und das Beste auswählen, das Ihrem Zweck entspricht.
Der Einsatz von WEKA führt somit zu einer schnelleren Entwicklung von Modellen für maschinelles Lernen insgesamt.
Nachdem wir gesehen haben, was WEKA ist und was es tut, lernen wir im nächsten Kapitel, wie Sie WEKA auf Ihrem lokalen Computer installieren.
Um WEKA auf Ihrem Computer zu installieren, besuchen Sie die offizielle Website von WEKA und laden Sie die Installationsdatei herunter. WEKA unterstützt die Installation unter Windows, Mac OS X und Linux. Sie müssen nur die Anweisungen auf dieser Seite befolgen, um WEKA für Ihr Betriebssystem zu installieren.
Die Schritte zur Installation auf einem Mac lauten wie folgt:
- Laden Sie die Mac-Installationsdatei herunter.
- Doppelklicken Sie auf das heruntergeladene weka-3-8-3-corretto-jvm.dmg file.
Nach erfolgreicher Installation wird der folgende Bildschirm angezeigt.
- Klick auf das weak-3-8-3-corretto-jvm Symbol zum Starten von Weka.
- Optional können Sie es über die Befehlszeile starten -
java -jar weka.jarDie WEKA GUI Chooser-Anwendung wird gestartet und Sie sehen den folgenden Bildschirm:
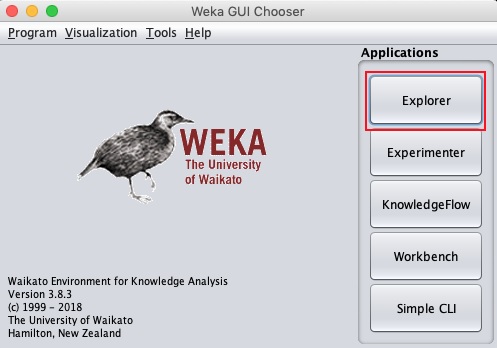
Mit der GUI Chooser-Anwendung können Sie fünf verschiedene Arten von Anwendungen ausführen, wie hier aufgeführt:
- Explorer
- Experimenter
- KnowledgeFlow
- Workbench
- Einfache CLI
Wir werden verwenden Explorer in diesem Tutorial.
Lassen Sie uns in diesem Kapitel verschiedene Funktionen untersuchen, die der Explorer für die Arbeit mit Big Data bereitstellt.
Wenn Sie auf klicken Explorer Schaltfläche in der Applications Auswahl, öffnet es den folgenden Bildschirm -
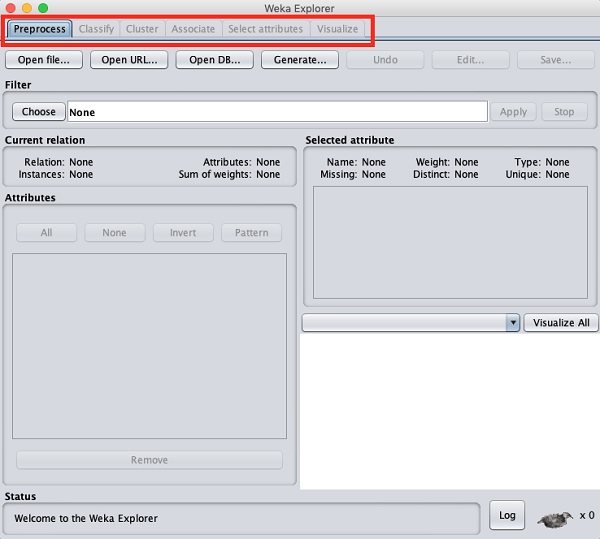
Oben sehen Sie mehrere Registerkarten, wie hier aufgelistet -
- Preprocess
- Classify
- Cluster
- Associate
- Wählen Sie Attribute
- Visualize
Unter diesen Registerkarten befinden sich mehrere vorimplementierte Algorithmen für maschinelles Lernen. Lassen Sie uns jetzt jeden von ihnen im Detail untersuchen.
Registerkarte "Vorverarbeitung"
Wenn Sie den Explorer öffnen, wird zunächst nur die PreprocessRegisterkarte ist aktiviert. Der erste Schritt beim maschinellen Lernen besteht darin, die Daten vorzuverarbeiten. So in derPreprocess Mit dieser Option wählen Sie die Datendatei aus, verarbeiten sie und machen sie für die Anwendung der verschiedenen Algorithmen für maschinelles Lernen geeignet.
Registerkarte "Klassifizieren"
Das ClassifyAuf der Registerkarte finden Sie verschiedene Algorithmen für maschinelles Lernen zur Klassifizierung Ihrer Daten. Um einige aufzulisten, können Sie Algorithmen wie lineare Regression, logistische Regression, Support Vector Machines, Entscheidungsbäume, RandomTree, RandomForest, NaiveBayes usw. anwenden. Die Liste ist sehr vollständig und enthält sowohl überwachte als auch unbeaufsichtigte Algorithmen für maschinelles Lernen.
Registerkarte "Cluster"
Unter dem Cluster Auf der Registerkarte werden verschiedene Clustering-Algorithmen bereitgestellt, z. B. SimpleKMeans, FilteredClusterer, HierarchicalClusterer usw.
Registerkarte zuordnen
Unter dem Associate Auf der Registerkarte finden Sie Apriori, FilteredAssociator und FPGrowth.
Wählen Sie die Registerkarte Attribute
Select Attributes Ermöglicht die Auswahl von Funktionen basierend auf verschiedenen Algorithmen wie ClassifierSubsetEval, PrinicipalComponents usw.
Registerkarte "Visualisieren"
Schließlich die Visualize Mit dieser Option können Sie Ihre verarbeiteten Daten zur Analyse visualisieren.
Wie Sie bemerkt haben, bietet WEKA mehrere gebrauchsfertige Algorithmen zum Testen und Erstellen Ihrer Anwendungen für maschinelles Lernen. Um WEKA effektiv nutzen zu können, müssen Sie über fundierte Kenntnisse dieser Algorithmen verfügen, wie sie funktionieren, welche unter welchen Umständen Sie auswählen müssen, worauf Sie bei der verarbeiteten Ausgabe achten müssen usw. Kurz gesagt, Sie müssen eine solide Grundlage für maschinelles Lernen haben, um WEKA effektiv beim Erstellen Ihrer Apps einsetzen zu können.
In den nächsten Kapiteln werden Sie jede Registerkarte im Explorer eingehend untersuchen.
In diesem Kapitel beginnen wir mit der ersten Registerkarte, auf der Sie die Daten vorverarbeiten. Dies gilt für alle Algorithmen, die Sie zum Erstellen des Modells auf Ihre Daten anwenden würden, und ist ein gemeinsamer Schritt für alle nachfolgenden Operationen in WEKA.
Damit ein Algorithmus für maschinelles Lernen eine akzeptable Genauigkeit bietet, ist es wichtig, dass Sie zuerst Ihre Daten bereinigen. Dies liegt daran, dass die aus dem Feld gesammelten Rohdaten Nullwerte, irrelevante Spalten usw. enthalten können.
In diesem Kapitel erfahren Sie, wie Sie die Rohdaten vorverarbeiten und ein sauberes, aussagekräftiges Dataset für die weitere Verwendung erstellen.
Zunächst lernen Sie, die Datendatei in den WEKA-Explorer zu laden. Die Daten können aus folgenden Quellen geladen werden:
- Lokales Dateisystem
- Web
- Database
In diesem Kapitel werden alle drei Optionen zum Laden von Daten im Detail beschrieben.
Laden von Daten aus dem lokalen Dateisystem
Direkt unter den Registerkarten für maschinelles Lernen, die Sie in der vorherigen Lektion studiert haben, finden Sie die folgenden drei Schaltflächen:
- Datei öffnen …
- Öffne URL …
- DB öffnen…
Klick auf das Open file... Taste. Ein Verzeichnisnavigatorfenster wird geöffnet, wie im folgenden Bildschirm gezeigt -
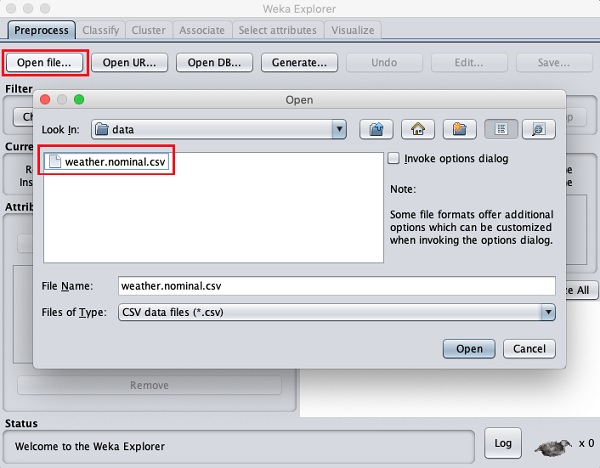
Navigieren Sie nun zu dem Ordner, in dem Ihre Datendateien gespeichert sind. Bei der WEKA-Installation stehen Ihnen viele Beispieldatenbanken zum Experimentieren zur Verfügung. Diese sind in der verfügbardata Ordner der WEKA-Installation.
Wählen Sie zu Lernzwecken eine beliebige Datendatei aus diesem Ordner aus. Der Inhalt der Datei wird in die WEKA-Umgebung geladen. Wir werden sehr bald lernen, wie diese geladenen Daten überprüft und verarbeitet werden. Schauen wir uns vorher an, wie die Datendatei aus dem Web geladen wird.
Laden von Daten aus dem Web
Sobald Sie auf die klicken Open URL … Schaltfläche, können Sie ein Fenster wie folgt sehen -
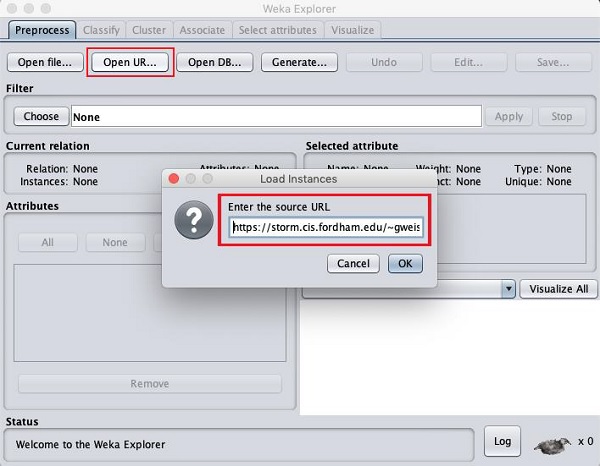
Wir öffnen die Datei über eine öffentliche URL. Geben Sie die folgende URL in das Popup-Feld ein:
https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
Sie können eine andere URL angeben, unter der Ihre Daten gespeichert sind. DasExplorer lädt die Daten vom Remote-Standort in seine Umgebung.
Laden von Daten aus der DB
Sobald Sie auf die klicken Open DB ... Schaltfläche, sehen Sie ein Fenster wie folgt:
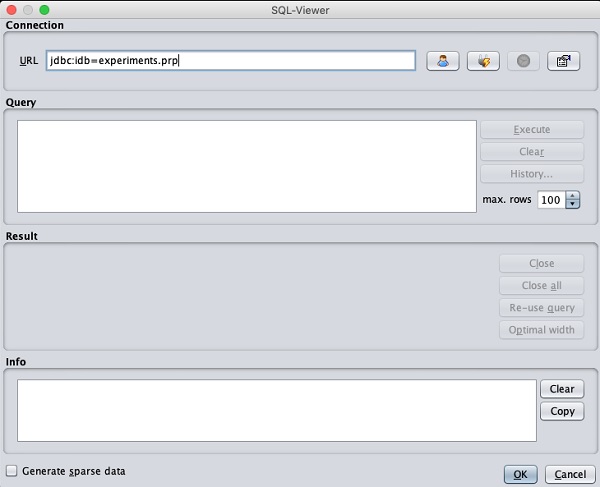
Stellen Sie die Verbindungszeichenfolge zu Ihrer Datenbank ein, richten Sie die Abfrage für die Datenauswahl ein, verarbeiten Sie die Abfrage und laden Sie die ausgewählten Datensätze in WEKA.
WEKA unterstützt eine Vielzahl von Dateiformaten für die Daten. Hier ist die vollständige Liste -
- arff
- arff.gz
- bsi
- csv
- dat
- data
- json
- json.gz
- libsvm
- m
- names
- xrff
- xrff.gz
Die unterstützten Dateitypen werden im Dropdown-Listenfeld am unteren Bildschirmrand aufgelistet. Dies wird im folgenden Screenshot gezeigt.
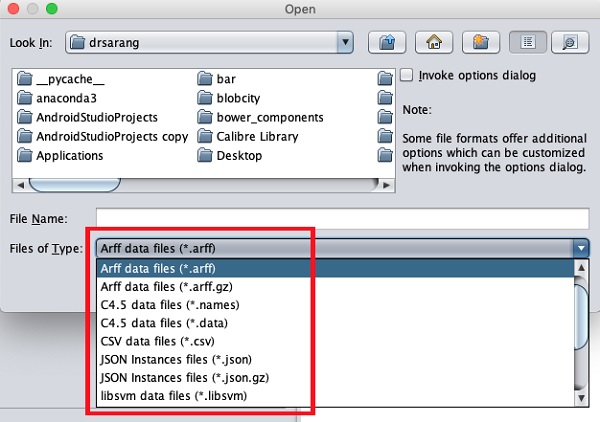
Wie Sie sehen würden, unterstützt es verschiedene Formate, einschließlich CSV und JSON. Der Standarddateityp ist Arff.
Arff-Format
Ein Arff Datei enthält zwei Abschnitte - Header und Daten.
- Der Header beschreibt die Attributtypen.
- Der Datenabschnitt enthält eine durch Kommas getrennte Liste von Daten.
Als Beispiel für das Arff-Format dient das Weather Die aus den WEKA-Beispieldatenbanken geladene Datendatei wird unten angezeigt -

Aus dem Screenshot können Sie die folgenden Punkte ableiten:
Das @ relation-Tag definiert den Namen der Datenbank.
Das @ attribute-Tag definiert die Attribute.
Das @ data-Tag startet die Liste der Datenzeilen, die jeweils die durch Kommas getrennten Felder enthalten.
Die Attribute können Nennwerte annehmen, wie im Fall des hier gezeigten Ausblicks -
@attribute outlook (sunny, overcast, rainy)Die Attribute können wie in diesem Fall reale Werte annehmen -
@attribute temperature realSie können auch eine Ziel- oder Klassenvariable namens play festlegen, wie hier gezeigt -
@attribute play (yes, no)Das Ziel nimmt zwei Nennwerte Ja oder Nein an.
Andere Formate
Der Explorer kann die Daten in jedem der zuvor genannten Formate laden. Da arff das bevorzugte Format in WEKA ist, können Sie die Daten aus einem beliebigen Format laden und zur späteren Verwendung im arff-Format speichern. Speichern Sie die Daten nach der Vorverarbeitung zur weiteren Analyse im Arff-Format.
Nachdem Sie gelernt haben, wie Daten in WEKA geladen werden, erfahren Sie im nächsten Kapitel, wie Sie die Daten vorverarbeiten.
Die vom Feld gesammelten Daten enthalten viele unerwünschte Dinge, die zu falschen Analysen führen. Beispielsweise können die Daten Nullfelder enthalten, sie können Spalten enthalten, die für die aktuelle Analyse irrelevant sind, und so weiter. Daher müssen die Daten vorverarbeitet werden, um die Anforderungen der Art der Analyse zu erfüllen, die Sie suchen. Dies erfolgt im Vorverarbeitungsmodul.
Um die verfügbaren Funktionen in der Vorverarbeitung zu demonstrieren, verwenden wir die Weather Datenbank, die in der Installation bereitgestellt wird.
Verwendung der Open file ... Option unter der Preprocess Tag wählen Sie die weather-nominal.arff Datei.
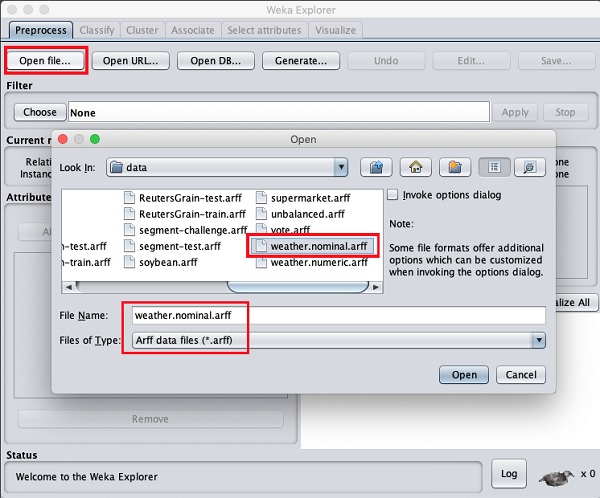
Wenn Sie die Datei öffnen, sieht Ihr Bildschirm wie hier gezeigt aus -
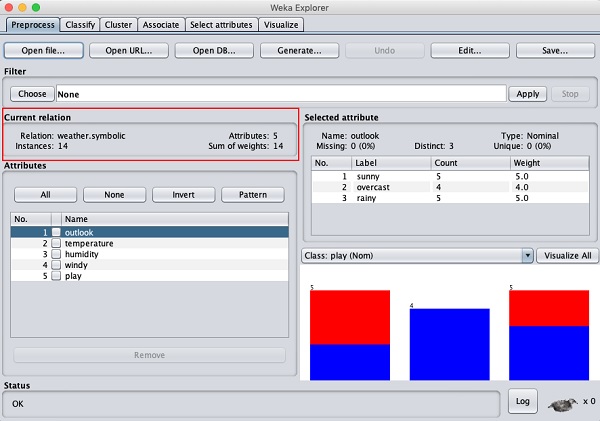
Dieser Bildschirm enthält einige Informationen zu den geladenen Daten, die in diesem Kapitel näher erläutert werden.
Daten verstehen
Schauen wir uns zunächst die hervorgehobenen an Current relationUnterfenster. Es zeigt den Namen der aktuell geladenen Datenbank. Sie können zwei Punkte aus diesem Unterfenster ableiten -
Es gibt 14 Instanzen - die Anzahl der Zeilen in der Tabelle.
Die Tabelle enthält 5 Attribute - die Felder, die in den nächsten Abschnitten erläutert werden.
Beachten Sie auf der linken Seite die Attributes Unterfenster, in dem die verschiedenen Felder in der Datenbank angezeigt werden.
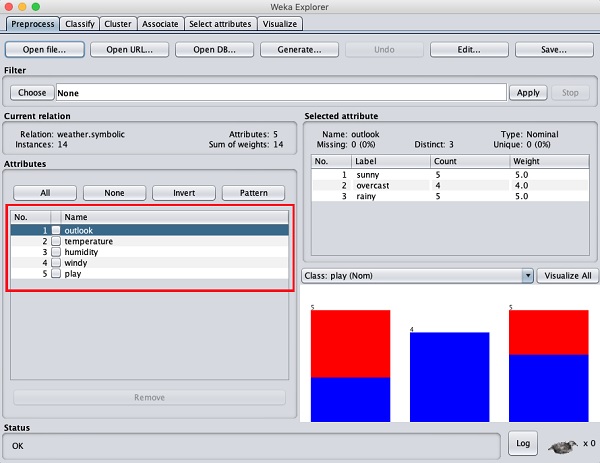
Das weatherDie Datenbank enthält fünf Felder - Ausblick, Temperatur, Luftfeuchtigkeit, Wind und Spiel. Wenn Sie ein Attribut aus dieser Liste auswählen, indem Sie darauf klicken, werden auf der rechten Seite weitere Details zum Attribut selbst angezeigt.
Lassen Sie uns zuerst das Temperaturattribut auswählen. Wenn Sie darauf klicken, wird der folgende Bildschirm angezeigt:
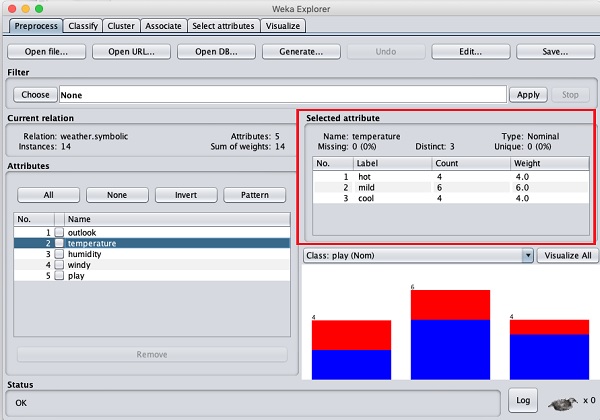
In dem Selected Attribute Unterfenster können Sie Folgendes beobachten:
Der Name und der Typ des Attributs werden angezeigt.
Der Typ für die temperature Attribut ist Nominal.
Die Anzahl der Missing Werte ist Null.
Es gibt drei verschiedene Werte ohne eindeutigen Wert.
Die Tabelle unter diesen Informationen zeigt die Nennwerte für dieses Feld als heiß, mild und kalt.
Es zeigt auch die Anzahl und das Gewicht in Prozent für jeden Nennwert.
Am unteren Rand des Fensters sehen Sie die visuelle Darstellung des class Werte.
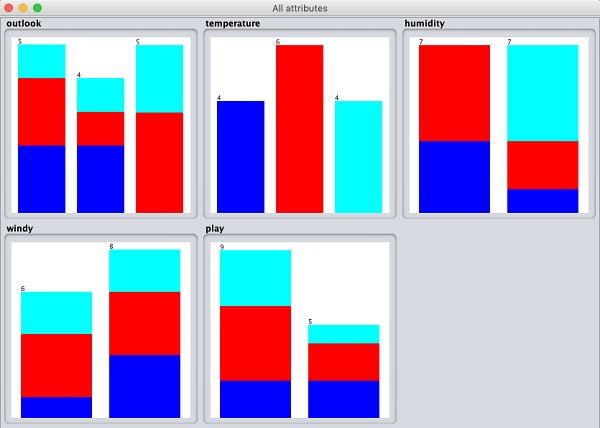
Wenn Sie auf klicken Visualize All Schaltfläche, können Sie alle Funktionen in einem einzigen Fenster sehen, wie hier gezeigt -
Attribute entfernen
Die Daten, die Sie für die Modellbildung verwenden möchten, enthalten häufig viele irrelevante Felder. Beispielsweise kann die Kundendatenbank seine Handynummer enthalten, die für die Analyse seiner Bonität relevant ist.
Um Attribute zu entfernen, wählen Sie sie aus und klicken Sie auf Remove Schaltfläche unten.
Die ausgewählten Attribute werden aus der Datenbank entfernt. Nachdem Sie die Daten vollständig vorverarbeitet haben, können Sie sie für die Modellbildung speichern.
Als Nächstes lernen Sie, die Daten durch Anwenden von Filtern auf diese Daten vorzuverarbeiten.
Anwenden von Filtern
Einige der maschinellen Lerntechniken wie das Assoziationsregel-Mining erfordern kategoriale Daten. Um die Verwendung von Filtern zu veranschaulichen, werden wir verwendenweather-numeric.arff Datenbank, die zwei enthält numeric Attribute - temperature und humidity.
Wir werden diese in konvertieren nominaldurch Anwenden eines Filters auf unsere Rohdaten. Klick auf dasChoose Schaltfläche in der Filter Unterfenster und wählen Sie den folgenden Filter -
weka→filters→supervised→attribute→Discretize

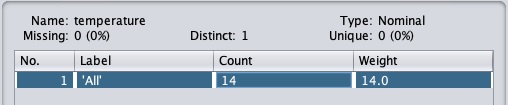
Klick auf das Apply Knopf und überprüfen Sie die temperature und / oder humidityAttribut. Sie werden feststellen, dass sich diese von numerischen zu nominalen Typen geändert haben.
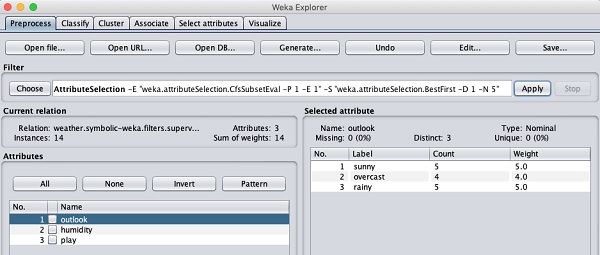
Schauen wir uns jetzt einen anderen Filter an. Angenommen, Sie möchten die besten Attribute für die Entscheidung auswählenplay. Wählen Sie den folgenden Filter aus und wenden Sie ihn an:
weka→filters→supervised→attribute→AttributeSelection
Sie werden feststellen, dass die Temperatur- und Feuchtigkeitsattribute aus der Datenbank entfernt werden.
Wenn Sie mit der Vorverarbeitung Ihrer Daten zufrieden sind, speichern Sie die Daten, indem Sie auf klicken Save... Taste. Sie verwenden diese gespeicherte Datei für die Modellbildung.
Im nächsten Kapitel werden wir die Modellbildung mit mehreren vordefinierten ML-Algorithmen untersuchen.
Viele Anwendungen für maschinelles Lernen beziehen sich auf die Klassifizierung. Beispielsweise möchten Sie einen Tumor möglicherweise als bösartig oder gutartig klassifizieren. Abhängig von den Wetterbedingungen möchten Sie vielleicht entscheiden, ob Sie ein Spiel im Freien spielen möchten. Im Allgemeinen hängt diese Entscheidung von mehreren Merkmalen / Wetterbedingungen ab. Daher bevorzugen Sie möglicherweise die Verwendung eines Baumklassifikators, um zu entscheiden, ob Sie spielen möchten oder nicht.
In diesem Kapitel erfahren Sie, wie Sie einen solchen Baumklassifikator anhand von Wetterdaten erstellen, um die Spielbedingungen zu bestimmen.
Testdaten einstellen
Wir werden die vorverarbeitete Wetterdatendatei aus der vorherigen Lektion verwenden. Öffnen Sie die gespeicherte Datei mit demOpen file ... Option unter der Preprocess Klicken Sie auf die Registerkarte Classify Registerkarte, und Sie würden den folgenden Bildschirm sehen -
Bevor Sie sich mit den verfügbaren Klassifikatoren vertraut machen, lassen Sie uns die Testoptionen untersuchen. Sie werden vier Testoptionen bemerken, wie unten aufgeführt -
- Trainingsset
- Mitgeliefertes Testset
- Cross-validation
- Prozentuale Aufteilung
Sofern Sie nicht über ein eigenes Trainingsset oder ein vom Kunden bereitgestelltes Testset verfügen, würden Sie Kreuzvalidierungs- oder prozentuale Aufteilungsoptionen verwenden. Unter Kreuzvalidierung können Sie die Anzahl der Falten festlegen, in denen die gesamten Daten aufgeteilt und während jeder Iteration des Trainings verwendet werden. Bei der prozentualen Aufteilung teilen Sie die Daten zwischen Training und Test mit dem festgelegten prozentualen Anteil auf.
Behalten Sie jetzt die Standardeinstellung bei play Option für die Ausgabeklasse -
Als nächstes wählen Sie den Klassifikator aus.
Klassifikator auswählen
Klicken Sie auf die Schaltfläche Auswählen und wählen Sie den folgenden Klassifikator aus:
weka→classifiers>trees>J48
Dies wird im folgenden Screenshot gezeigt -
Klick auf das StartSchaltfläche, um den Klassifizierungsprozess zu starten. Nach einer Weile werden die Klassifizierungsergebnisse wie hier gezeigt auf Ihrem Bildschirm angezeigt.
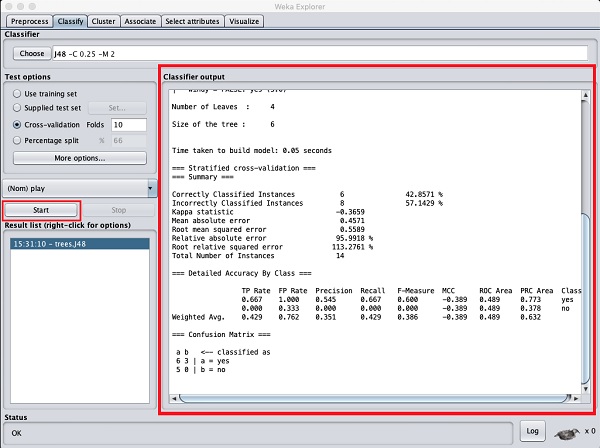
Lassen Sie uns die Ausgabe auf der rechten Seite des Bildschirms untersuchen.
Es heißt, die Größe des Baumes sei 6. Sie werden in Kürze die visuelle Darstellung des Baumes sehen. In der Zusammenfassung heißt es, dass die korrekt klassifizierten Instanzen als 2 und die falsch klassifizierten Instanzen als 3 angegeben sind. Außerdem heißt es, dass der relative absolute Fehler 110% beträgt. Es zeigt auch die Verwirrungsmatrix. Die Analyse dieser Ergebnisse würde den Rahmen dieses Tutorials sprengen. Anhand dieser Ergebnisse können Sie jedoch leicht erkennen, dass die Klassifizierung nicht akzeptabel ist und Sie mehr Daten für die Analyse benötigen, um Ihre Funktionsauswahl zu verfeinern, das Modell neu zu erstellen usw., bis Sie mit der Genauigkeit des Modells zufrieden sind. Genau darum geht es bei WEKA. So können Sie Ihre Ideen schnell testen.
Ergebnisse visualisieren
Um die visuelle Darstellung der Ergebnisse anzuzeigen, klicken Sie mit der rechten Maustaste auf das Ergebnis in der Result listBox. Auf dem Bildschirm werden mehrere Optionen angezeigt, wie hier gezeigt -
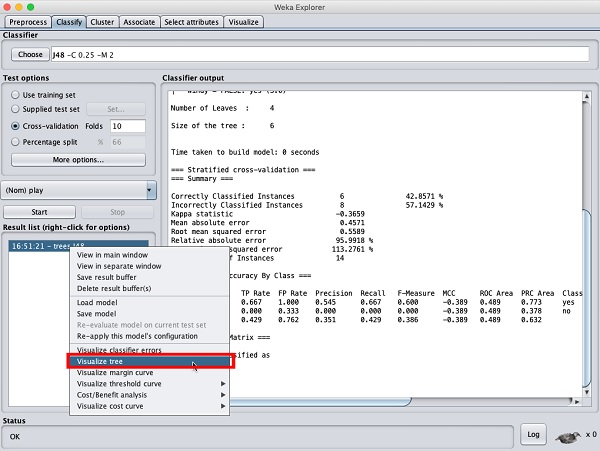
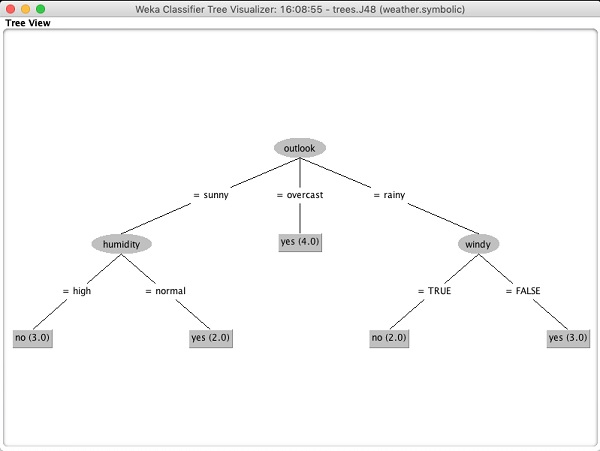
Wählen Visualize tree um eine visuelle Darstellung des Traversal Tree zu erhalten, wie im folgenden Screenshot gezeigt -
Auswählen Visualize classifier errors würde die Ergebnisse der Klassifizierung wie hier gezeigt darstellen -
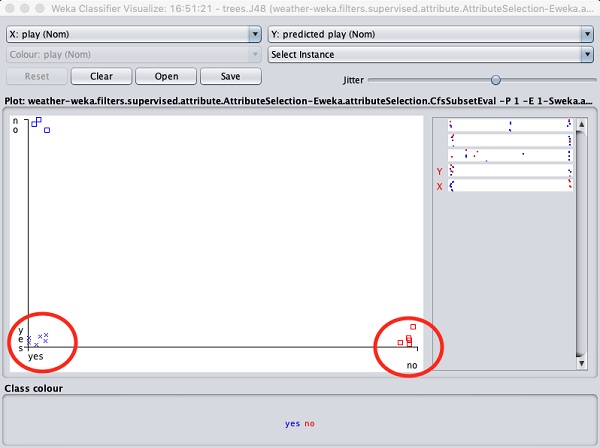
EIN cross repräsentiert eine korrekt klassifizierte Instanz während squaresrepräsentiert falsch klassifizierte Instanzen. In der unteren linken Ecke des Grundstücks sehen Sie across das zeigt an, ob outlook ist dann sonnig playdas Spiel. Dies ist also eine korrekt klassifizierte Instanz. Um Instanzen zu lokalisieren, können Sie etwas Jitter einführen, indem Sie diejitter Schiebeleiste.
Die aktuelle Handlung ist outlook gegen play. Diese werden durch die beiden Dropdown-Listenfelder am oberen Bildschirmrand angezeigt.
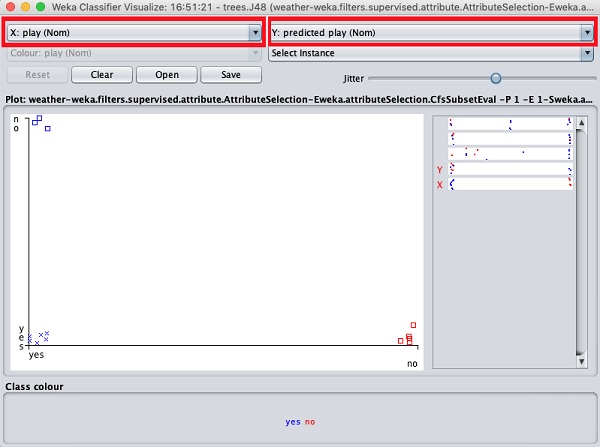
Versuchen Sie nun in jedem dieser Felder eine andere Auswahl und stellen Sie fest, wie sich die X- und Y-Achsen ändern. Das gleiche kann erreicht werden, indem die horizontalen Streifen auf der rechten Seite des Diagramms verwendet werden. Jeder Streifen repräsentiert ein Attribut. Ein Linksklick auf den Streifen legt das ausgewählte Attribut auf der X-Achse fest, während ein Rechtsklick es auf die Y-Achse setzt.
Es gibt mehrere andere Diagramme für Ihre eingehendere Analyse. Verwenden Sie sie mit Bedacht, um Ihr Modell zu optimieren. Eine solche Handlung vonCost/Benefit analysis wird unten als Kurzreferenz gezeigt.
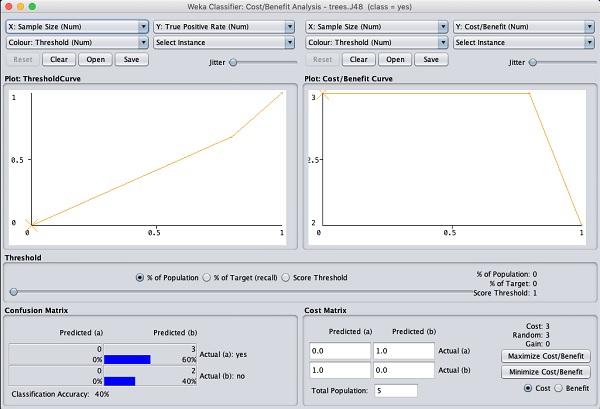
Das Erläutern der Analyse in diesen Diagrammen würde den Rahmen dieses Lernprogramms sprengen. Der Leser wird ermutigt, sein Wissen über die Analyse von Algorithmen für maschinelles Lernen aufzufrischen.
Im nächsten Kapitel lernen wir den nächsten Satz von Algorithmen für maschinelles Lernen kennen, nämlich das Clustering.
Ein Clustering-Algorithmus findet Gruppen ähnlicher Instanzen im gesamten Datensatz. WEKA unterstützt verschiedene Clustering-Algorithmen wie EM, FilteredClusterer, HierarchicalClusterer, SimpleKMeans usw. Sie sollten diese Algorithmen vollständig verstehen, um die WEKA-Funktionen vollständig nutzen zu können.
Wie bei der Klassifizierung können Sie mit WEKA die erkannten Cluster grafisch darstellen. Um das Clustering zu demonstrieren, verwenden wir die bereitgestellte Iris-Datenbank. Der Datensatz enthält drei Klassen mit jeweils 50 Instanzen. Jede Klasse bezieht sich auf eine Art Irispflanze.
Lade Daten
Wählen Sie im WEKA Explorer die PreprocessTab. Klick auf dasOpen file ... und wählen Sie die iris.arffDatei im Dateiauswahldialog. Wenn Sie die Daten laden, sieht der Bildschirm wie folgt aus:
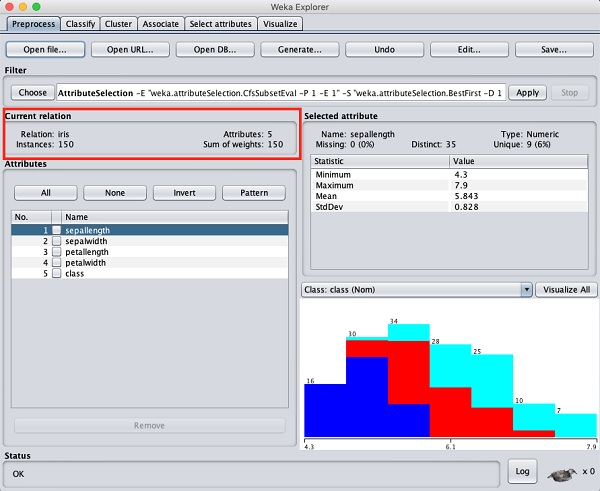
Sie können beobachten, dass es 150 Instanzen und 5 Attribute gibt. Die Namen der Attribute werden als aufgeführtsepallength, sepalwidth, petallength, petalwidth und class. Die ersten vier Attribute sind vom numerischen Typ, während die Klasse ein nominaler Typ mit 3 verschiedenen Werten ist. Untersuchen Sie jedes Attribut, um die Funktionen der Datenbank zu verstehen. Wir werden diese Daten nicht vorverarbeiten und sofort mit der Modellbildung fortfahren.
Clustering
Klick auf das ClusterTAB, um die Clustering-Algorithmen auf unsere geladenen Daten anzuwenden. Klick auf dasChooseTaste. Sie sehen den folgenden Bildschirm -

Wählen Sie nun EMals Clustering-Algorithmus. In demCluster mode Unterfenster, wählen Sie die Classes to clusters evaluation Option wie im Screenshot unten gezeigt -

Klick auf das StartSchaltfläche zum Verarbeiten der Daten. Nach einer Weile werden die Ergebnisse auf dem Bildschirm angezeigt.
Lassen Sie uns als nächstes die Ergebnisse untersuchen.
Ausgabe untersuchen
Die Ausgabe der Datenverarbeitung wird im folgenden Bildschirm angezeigt -
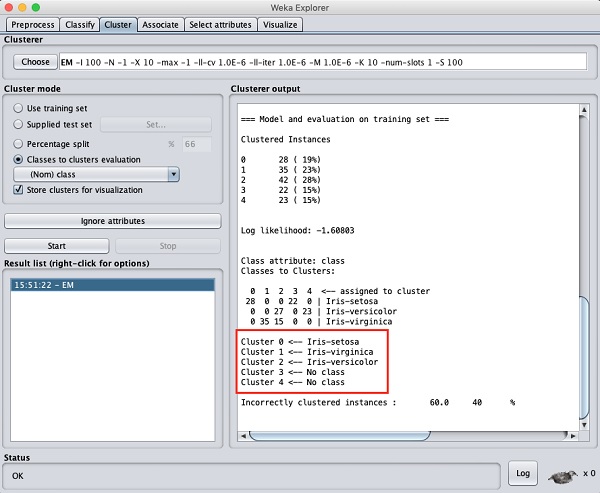
Auf dem Ausgabebildschirm können Sie Folgendes beobachten:
In der Datenbank wurden 5 Clusterinstanzen erkannt.
Das Cluster 0 stellt setosa dar, Cluster 1 repräsentiert virginica, Cluster 2 stellt versicolor dar, während den letzten beiden Clustern keine Klasse zugeordnet ist.
Wenn Sie im Ausgabefenster nach oben scrollen, werden auch einige Statistiken angezeigt, die den Mittelwert und die Standardabweichung für jedes der Attribute in den verschiedenen erkannten Clustern angeben. Dies wird im folgenden Screenshot gezeigt -
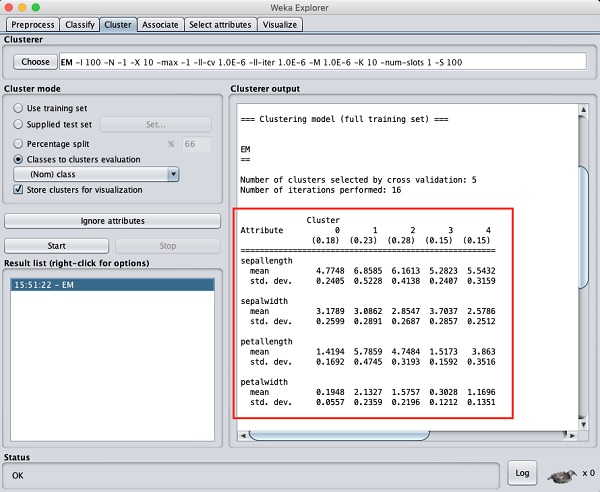
Als nächstes betrachten wir die visuelle Darstellung der Cluster.
Cluster visualisieren
Um die Cluster anzuzeigen, klicken Sie mit der rechten Maustaste auf EM Ergebnis in der Result list. Sie sehen die folgenden Optionen -
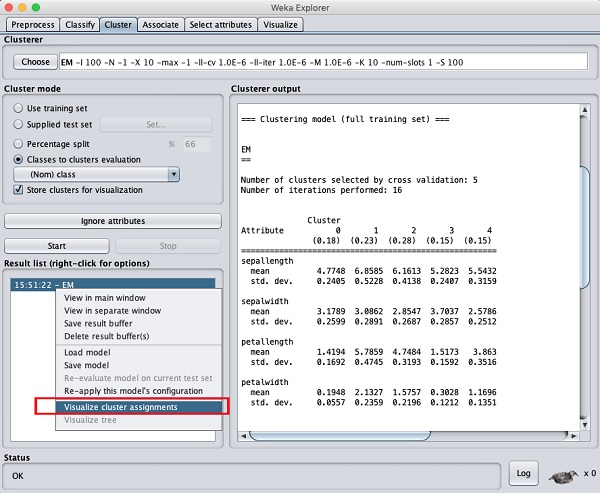
Wählen Visualize cluster assignments. Sie sehen die folgende Ausgabe -
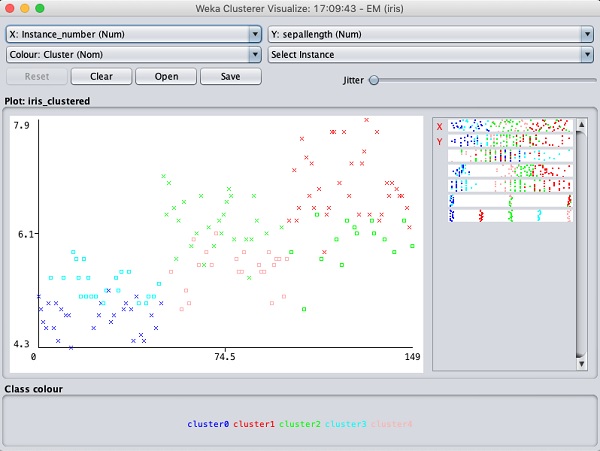
Wie bei der Klassifizierung werden Sie die Unterscheidung zwischen korrekt und falsch identifizierten Instanzen feststellen. Sie können herumspielen, indem Sie die X- und Y-Achse ändern, um die Ergebnisse zu analysieren. Sie können Jittering wie im Fall der Klassifizierung verwenden, um die Konzentration korrekt identifizierter Instanzen zu ermitteln. Die Operationen im Visualisierungsdiagramm ähneln denen, die Sie im Fall der Klassifizierung untersucht haben.
Hierarchischen Clusterer anwenden
Um die Leistungsfähigkeit von WEKA zu demonstrieren, betrachten wir nun eine Anwendung eines anderen Clustering-Algorithmus. Wählen Sie im WEKA-Explorer die ausHierarchicalClusterer als Ihr ML-Algorithmus wie im folgenden Screenshot gezeigt -
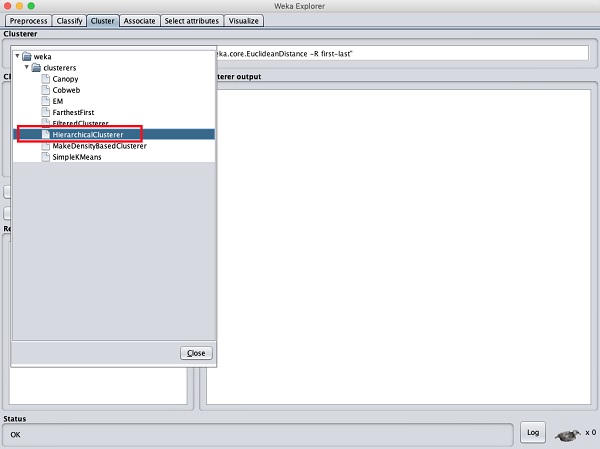
Wählen Sie das Cluster mode Auswahl zu Classes to cluster evaluationund klicken Sie auf StartTaste. Sie sehen die folgende Ausgabe -
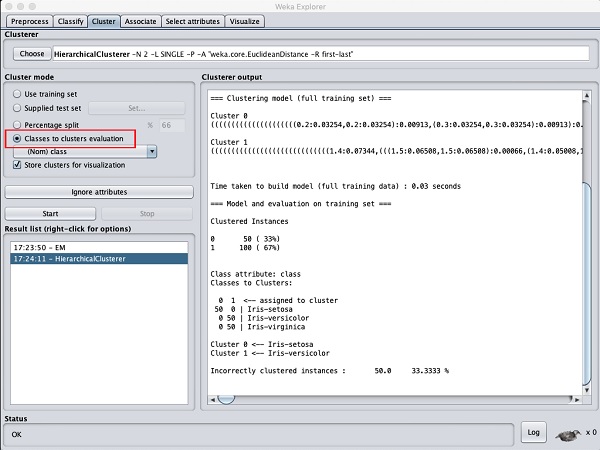
Beachten Sie, dass in der Result listEs sind zwei Ergebnisse aufgeführt: Das erste ist das EM-Ergebnis und das zweite ist das aktuelle hierarchische Ergebnis. Ebenso können Sie mehrere ML-Algorithmen auf denselben Datensatz anwenden und deren Ergebnisse schnell vergleichen.
Wenn Sie den von diesem Algorithmus erzeugten Baum untersuchen, sehen Sie die folgende Ausgabe:
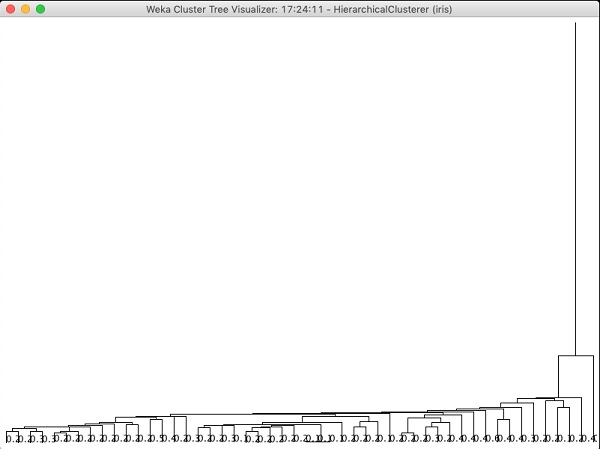
Im nächsten Kapitel werden Sie die Associate Art der ML-Algorithmen.
Es wurde beobachtet, dass Menschen, die Bier kaufen, gleichzeitig auch Windeln kaufen. Das heißt, es gibt eine Vereinigung beim gemeinsamen Kauf von Bier und Windeln. Obwohl dies nicht sehr überzeugend zu sein scheint, wurde diese Assoziationsregel aus riesigen Datenbanken von Supermärkten gewonnen. Ebenso kann eine Assoziation zwischen Erdnussbutter und Brot gefunden werden.
Das Finden solcher Assoziationen ist für Supermärkte von entscheidender Bedeutung, da sie neben Bier Windeln lagern, damit die Kunden beide Artikel leicht finden können, was zu einem erhöhten Verkauf für den Supermarkt führt.
Das AprioriDer Algorithmus ist ein solcher Algorithmus in ML, der die wahrscheinlichen Assoziationen herausfindet und Assoziationsregeln erstellt. WEKA bietet die Implementierung des Apriori-Algorithmus. Sie können die Mindestunterstützung und ein akzeptables Konfidenzniveau definieren, während Sie diese Regeln berechnen. Sie werden die anwendenApriori Algorithmus zum supermarket Daten in der WEKA-Installation.
Lade Daten
Öffnen Sie im WEKA-Explorer die Preprocess Klicken Sie auf die Registerkarte Open file ... und wählen Sie supermarket.arffDatenbank aus dem Installationsordner. Nachdem die Daten geladen wurden, sehen Sie den folgenden Bildschirm:
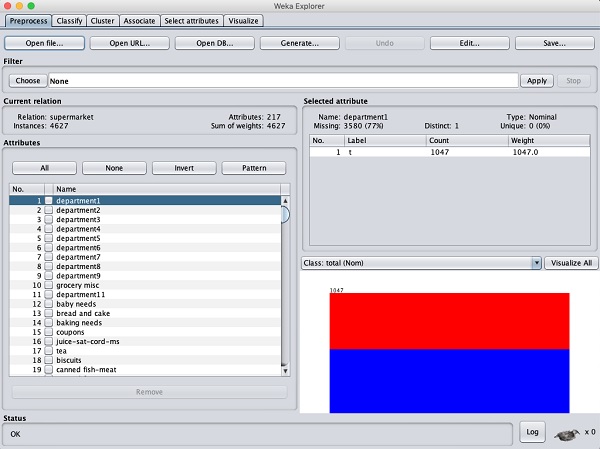
Die Datenbank enthält 4627 Instanzen und 217 Attribute. Sie können leicht verstehen, wie schwierig es wäre, die Assoziation zwischen einer so großen Anzahl von Attributen zu erkennen. Glücklicherweise wird diese Aufgabe mit Hilfe des Apriori-Algorithmus automatisiert.
Mitarbeiter
Klick auf das Associate TAB und klicken Sie auf ChooseTaste. Wähle ausApriori Assoziation wie im Screenshot gezeigt -
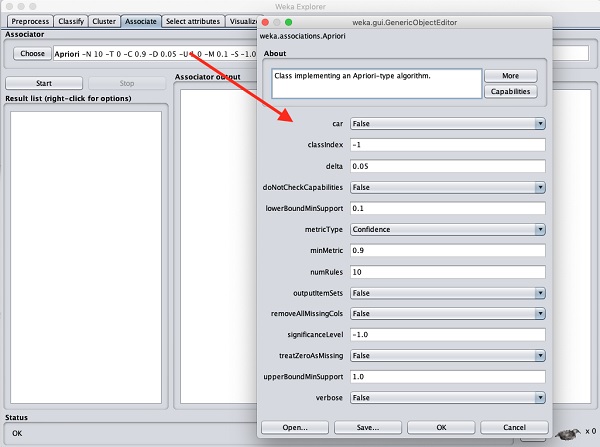
Um die Parameter für den Apriori-Algorithmus festzulegen, klicken Sie auf seinen Namen. Ein Fenster wie unten gezeigt wird geöffnet, in dem Sie die Parameter festlegen können.
Nachdem Sie die Parameter eingestellt haben, klicken Sie auf StartTaste. Nach einer Weile sehen Sie die Ergebnisse wie im folgenden Screenshot gezeigt -
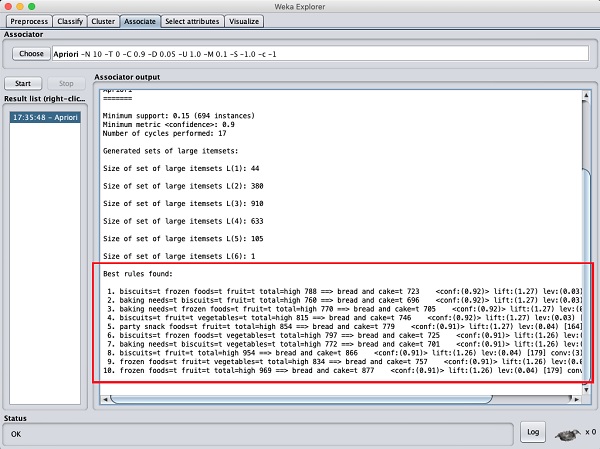
Unten finden Sie die besten Assoziationsregeln. Dies wird dem Supermarkt helfen, seine Produkte in geeigneten Regalen zu lagern.
Wenn eine Datenbank eine große Anzahl von Attributen enthält, gibt es mehrere Attribute, die in der aktuell gesuchten Analyse nicht von Bedeutung sind. Das Entfernen unerwünschter Attribute aus dem Datensatz wird daher zu einer wichtigen Aufgabe bei der Entwicklung eines guten Modells für maschinelles Lernen.
Sie können den gesamten Datensatz visuell untersuchen und über die irrelevanten Attribute entscheiden. Dies könnte eine große Aufgabe für Datenbanken sein, die eine große Anzahl von Attributen enthalten, wie beispielsweise den Supermarktfall, den Sie in einer früheren Lektion gesehen haben. Glücklicherweise bietet WEKA ein automatisiertes Tool zur Funktionsauswahl.
In diesem Kapitel wird diese Funktion in einer Datenbank demonstriert, die eine große Anzahl von Attributen enthält.
Lade Daten
In dem Preprocess Wählen Sie das Tag des WEKA-Explorers aus labor.arffDatei zum Laden in das System. Wenn Sie die Daten laden, wird der folgende Bildschirm angezeigt:
Beachten Sie, dass es 17 Attribute gibt. Unsere Aufgabe ist es, einen reduzierten Datensatz zu erstellen, indem einige der Attribute entfernt werden, die für unsere Analyse nicht relevant sind.
Eigenschaften Extraktion
Klick auf das Select attributesTAB.Sie sehen den folgenden Bildschirm -
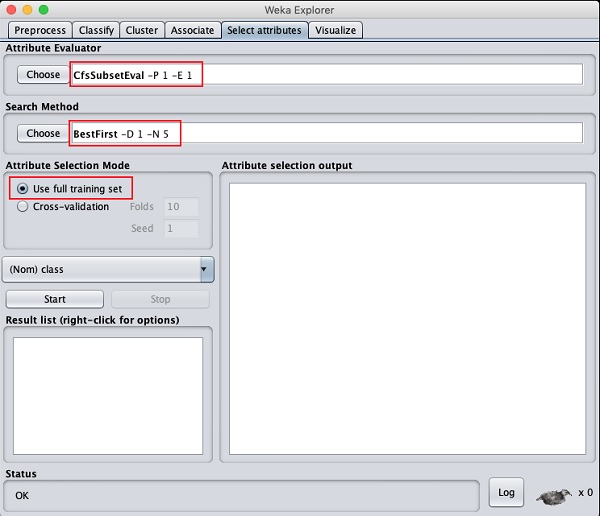
Unter dem Attribute Evaluator und Search Methodfinden Sie mehrere Möglichkeiten. Wir werden hier nur die Standardeinstellungen verwenden. In demAttribute Selection ModeVerwenden Sie die Option für den vollständigen Trainingssatz.
Klicken Sie auf die Schaltfläche Start, um den Datensatz zu verarbeiten. Sie sehen die folgende Ausgabe -

Am unteren Rand des Ergebnisfensters erhalten Sie die Liste von SelectedAttribute. Um die visuelle Darstellung zu erhalten, klicken Sie mit der rechten Maustaste auf das Ergebnis in derResult Liste.
Die Ausgabe wird im folgenden Screenshot gezeigt -
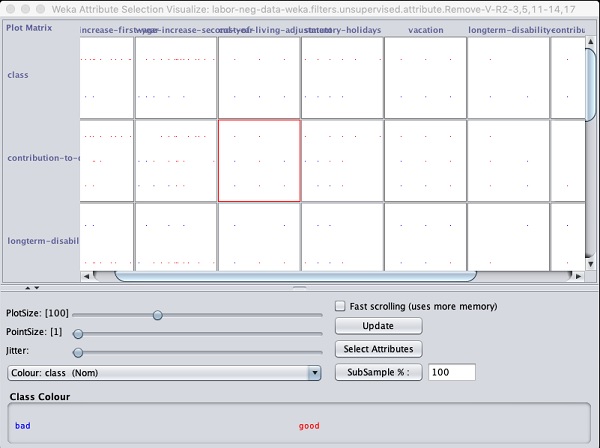
Wenn Sie auf eines der Quadrate klicken, erhalten Sie das Datenplot für Ihre weitere Analyse. Ein typisches Datenplot ist unten dargestellt -
Dies ähnelt denen, die wir in den früheren Kapiteln gesehen haben. Spielen Sie mit den verschiedenen Optionen, um die Ergebnisse zu analysieren.
Was kommt als nächstes?
Sie haben bisher die Leistungsfähigkeit von WEKA bei der schnellen Entwicklung von Modellen für maschinelles Lernen gesehen. Was wir verwendet haben, ist ein grafisches Werkzeug namensExplorerfür die Entwicklung dieser Modelle. WEKA bietet auch eine Befehlszeilenschnittstelle, die Ihnen mehr Leistung bietet als im Explorer bereitgestellt.
Klicken Sie auf die Simple CLI Taste in der G.UI Chooser Anwendung startet diese Befehlszeilenschnittstelle, die in der Abbildung unten gezeigt wird -
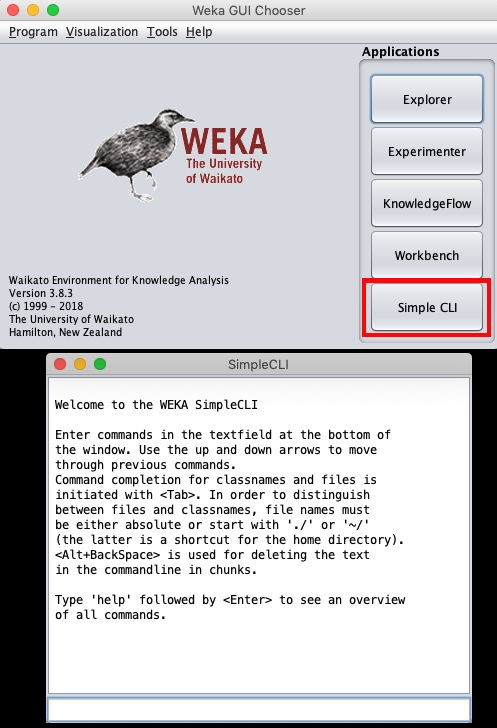
Geben Sie Ihre Befehle in das Eingabefeld unten ein. Sie können alles, was Sie bisher getan haben, im Explorer tun und vieles mehr. Weitere Informationen finden Sie in der WEKA- Dokumentation (https://www.cs.waikato.ac.nz/ml/weka/documentation.html).
Schließlich wurde WEKA in Java entwickelt und bietet eine Schnittstelle zu seiner API. Wenn Sie ein Java-Entwickler sind und WEKA ML-Implementierungen in Ihre eigenen Java-Projekte aufnehmen möchten, können Sie dies ganz einfach tun.
Fazit
WEKA ist ein leistungsstarkes Tool zur Entwicklung von Modellen für maschinelles Lernen. Es bietet die Implementierung mehrerer am häufigsten verwendeter ML-Algorithmen. Bevor diese Algorithmen auf Ihr Dataset angewendet werden, können Sie die Daten auch vorverarbeiten. Die unterstützten Algorithmusarten werden unter den Attributen Klassifizieren, Cluster, Zuordnen und Auswählen klassifiziert. Das Ergebnis in verschiedenen Phasen der Verarbeitung kann mit einer schönen und leistungsstarken visuellen Darstellung visualisiert werden. Dies erleichtert es einem Data Scientist, die verschiedenen Techniken des maschinellen Lernens schnell auf seinen Datensatz anzuwenden, die Ergebnisse zu vergleichen und das beste Modell für die endgültige Verwendung zu erstellen.