Weka - Funktionsauswahl
Wenn eine Datenbank eine große Anzahl von Attributen enthält, gibt es mehrere Attribute, die in der aktuell gesuchten Analyse nicht von Bedeutung sind. Das Entfernen unerwünschter Attribute aus dem Datensatz wird daher zu einer wichtigen Aufgabe bei der Entwicklung eines guten Modells für maschinelles Lernen.
Sie können den gesamten Datensatz visuell untersuchen und über die irrelevanten Attribute entscheiden. Dies könnte eine große Aufgabe für Datenbanken sein, die eine große Anzahl von Attributen enthalten, wie beispielsweise den Supermarktfall, den Sie in einer früheren Lektion gesehen haben. Glücklicherweise bietet WEKA ein automatisiertes Tool zur Funktionsauswahl.
In diesem Kapitel wird diese Funktion in einer Datenbank demonstriert, die eine große Anzahl von Attributen enthält.
Lade Daten
In dem Preprocess Wählen Sie das Tag des WEKA-Explorers aus labor.arffDatei zum Laden in das System. Wenn Sie die Daten laden, wird der folgende Bildschirm angezeigt:
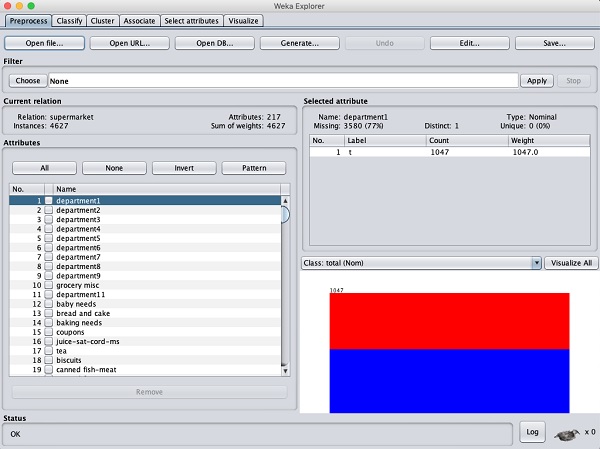
Beachten Sie, dass es 17 Attribute gibt. Unsere Aufgabe ist es, einen reduzierten Datensatz zu erstellen, indem einige der Attribute entfernt werden, die für unsere Analyse nicht relevant sind.
Eigenschaften Extraktion
Klick auf das Select attributesTAB.Sie sehen den folgenden Bildschirm -
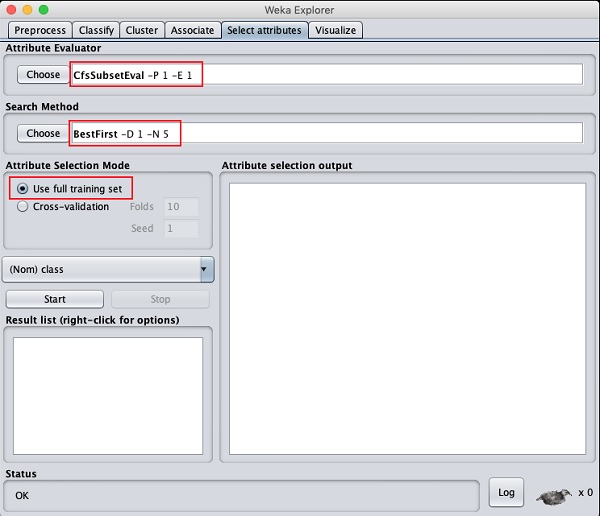
Unter dem Attribute Evaluator und Search Methodfinden Sie mehrere Möglichkeiten. Wir werden hier nur die Standardeinstellungen verwenden. In demAttribute Selection ModeVerwenden Sie die Option für den vollständigen Trainingssatz.
Klicken Sie auf die Schaltfläche Start, um den Datensatz zu verarbeiten. Sie sehen die folgende Ausgabe -

Am unteren Rand des Ergebnisfensters erhalten Sie die Liste von SelectedAttribute. Um die visuelle Darstellung zu erhalten, klicken Sie mit der rechten Maustaste auf das Ergebnis in derResult Liste.
Die Ausgabe wird im folgenden Screenshot gezeigt -
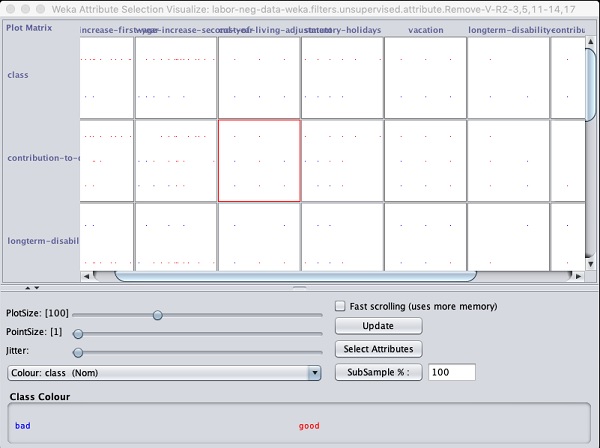
Wenn Sie auf eines der Quadrate klicken, erhalten Sie das Datenplot für Ihre weitere Analyse. Ein typisches Datenplot ist unten dargestellt -
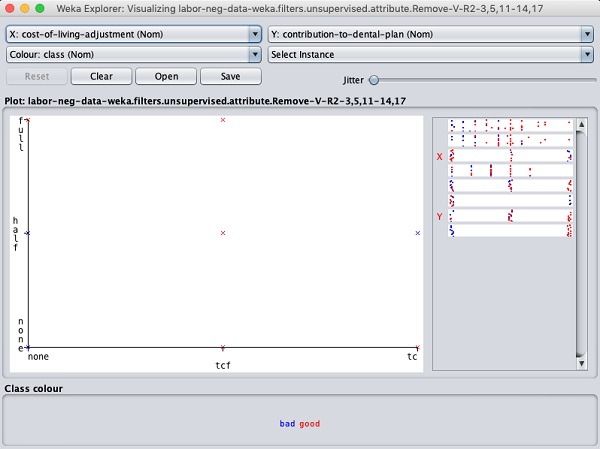
Dies ähnelt denen, die wir in den früheren Kapiteln gesehen haben. Spielen Sie mit den verschiedenen Optionen, um die Ergebnisse zu analysieren.
Was kommt als nächstes?
Sie haben bisher die Leistungsfähigkeit von WEKA bei der schnellen Entwicklung von Modellen für maschinelles Lernen gesehen. Was wir verwendet haben, ist ein grafisches Werkzeug namensExplorerfür die Entwicklung dieser Modelle. WEKA bietet auch eine Befehlszeilenschnittstelle, die Ihnen mehr Leistung bietet als im Explorer bereitgestellt.
Klicken Sie auf die Simple CLI Taste in der G.UI Chooser Anwendung startet diese Befehlszeilenschnittstelle, die in der Abbildung unten gezeigt wird -
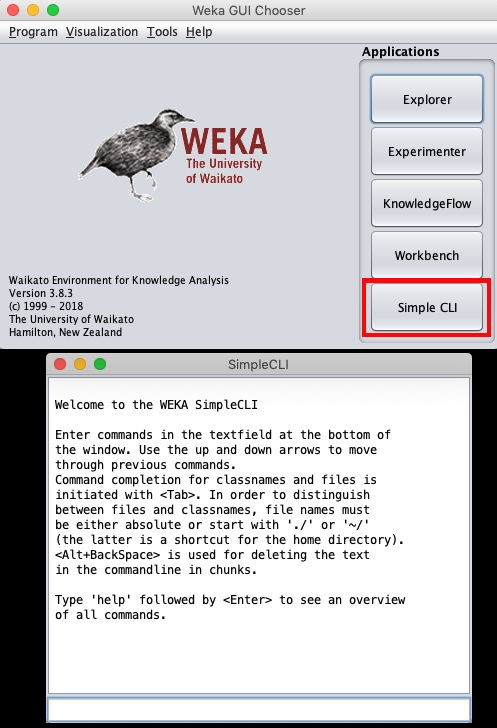
Geben Sie Ihre Befehle in das Eingabefeld unten ein. Sie können alles, was Sie bisher getan haben, im Explorer tun und vieles mehr. Weitere Informationen finden Sie in der WEKA- Dokumentation (https://www.cs.waikato.ac.nz/ml/weka/documentation.html).
Schließlich wurde WEKA in Java entwickelt und bietet eine Schnittstelle zu seiner API. Wenn Sie ein Java-Entwickler sind und WEKA ML-Implementierungen in Ihre eigenen Java-Projekte aufnehmen möchten, können Sie dies ganz einfach tun.
Fazit
WEKA ist ein leistungsstarkes Tool zur Entwicklung von Modellen für maschinelles Lernen. Es bietet die Implementierung mehrerer am häufigsten verwendeter ML-Algorithmen. Bevor diese Algorithmen auf Ihr Dataset angewendet werden, können Sie die Daten auch vorverarbeiten. Die unterstützten Algorithmusarten werden unter den Attributen Klassifizieren, Cluster, Zuordnen und Auswählen klassifiziert. Das Ergebnis in verschiedenen Phasen der Verarbeitung kann mit einer schönen und leistungsstarken visuellen Darstellung visualisiert werden. Dies erleichtert es einem Data Scientist, die verschiedenen Techniken des maschinellen Lernens schnell auf seinen Datensatz anzuwenden, die Ergebnisse zu vergleichen und das beste Modell für die endgültige Verwendung zu erstellen.