Biopython - Módulo BioSQL
BioSQLes un esquema de base de datos genérico diseñado principalmente para almacenar secuencias y sus datos relacionados para todos los motores RDBMS. Está diseñado de tal manera que contiene los datos de todas las bases de datos bioinformáticas populares como GenBank, Swissport, etc. También se puede utilizar para almacenar datos internos.
BioSQL actualmente proporciona un esquema específico para las siguientes bases de datos:
- MySQL (biosqldb-mysql.sql)
- PostgreSQL (biosqldb-pg.sql)
- Oracle (biosqldb-ora / *. Sql)
- SQLite (biosqldb-sqlite.sql)
También proporciona un soporte mínimo para bases de datos Derby y HSQLDB basadas en Java.
BioPython proporciona capacidades ORM muy simples, fáciles y avanzadas para trabajar con bases de datos basadas en BioSQL. BioPython provides a module, BioSQL para hacer la siguiente funcionalidad -
- Crear / eliminar una base de datos BioSQL
- Conéctese a una base de datos de BioSQL
- Analice una base de datos de secuencias como GenBank, Swisport, BLAST result, Entrez result, etc., y cárguela directamente en la base de datos BioSQL
- Obtenga los datos de la secuencia de la base de datos de BioSQL
- Obtenga datos de taxonomía de NCBI BLAST y guárdelos en la base de datos BioSQL
- Ejecute cualquier consulta SQL contra la base de datos BioSQL
Descripción general del esquema de la base de datos de BioSQL
Antes de profundizar en BioSQL, comprendamos los conceptos básicos del esquema de BioSQL. El esquema de BioSQL proporciona más de 25 tablas para contener datos de secuencia, función de secuencia, categoría de secuencia / ontología e información de taxonomía. Algunas de las tablas importantes son las siguientes:
- biodatabase
- bioentry
- biosequence
- seqfeature
- taxon
- taxon_name
- antology
- term
- dxref
Creación de una base de datos BioSQL
En esta sección, creemos una base de datos BioSQL de muestra, biosql, utilizando el esquema proporcionado por el equipo de BioSQL. Trabajaremos con la base de datos SQLite, ya que es muy fácil comenzar y no tiene una configuración compleja.
Aquí, crearemos una base de datos BioSQL basada en SQLite siguiendo los pasos a continuación.
Step 1 - Descargue el motor de base de datos SQLite e instálelo.
Step 2 - Descargue el proyecto BioSQL desde la URL de GitHub. https://github.com/biosql/biosql
Step 3 - Abra una consola y cree un directorio usando mkdir y entre en él.
cd /path/to/your/biopython/sample
mkdir sqlite-biosql
cd sqlite-biosqlStep 4 - Ejecute el siguiente comando para crear una nueva base de datos SQLite.
> sqlite3.exe mybiosql.db
SQLite version 3.25.2 2018-09-25 19:08:10
Enter ".help" for usage hints.
sqlite>Step 5 - Copie el archivo biosqldb-sqlite.sql del proyecto BioSQL (/ sql / biosqldb-sqlite.sql`) y guárdelo en el directorio actual.
Step 6 - Ejecute el siguiente comando para crear todas las tablas.
sqlite> .read biosqldb-sqlite.sqlAhora, todas las tablas se crean en nuestra nueva base de datos.
Step 7 - Ejecute el siguiente comando para ver todas las tablas nuevas en nuestra base de datos.
sqlite> .headers on
sqlite> .mode column
sqlite> .separator ROW "\n"
sqlite> SELECT name FROM sqlite_master WHERE type = 'table';
biodatabase
taxon
taxon_name
ontology
term
term_synonym
term_dbxref
term_relationship
term_relationship_term
term_path
bioentry
bioentry_relationship
bioentry_path
biosequence
dbxref
dbxref_qualifier_value
bioentry_dbxref
reference
bioentry_reference
comment
bioentry_qualifier_value
seqfeature
seqfeature_relationship
seqfeature_path
seqfeature_qualifier_value
seqfeature_dbxref
location
location_qualifier_value
sqlite>Los primeros tres comandos son comandos de configuración para configurar SQLite para mostrar el resultado de forma formateada.
Step 8 - Copie el archivo GenBank de muestra, ls_orchid.gbk proporcionado por el equipo de BioPython https://raw.githubusercontent.com/biopython/biopython/master/Doc/examples/ls_orchid.gbk en el directorio actual y guárdelo como orchid.gbk.
Step 9 - Cree un script de Python, load_orchid.py usando el código siguiente y ejecútelo.
from Bio import SeqIO
from BioSQL import BioSeqDatabase
import os
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
db = server.new_database("orchid")
count = db.load(SeqIO.parse("orchid.gbk", "gb"), True) server.commit()
server.close()El código anterior analiza el registro en el archivo y lo convierte en objetos de Python y lo inserta en la base de datos de BioSQL. Analizaremos el código en una sección posterior.
Finalmente, creamos una nueva base de datos BioSQL y cargamos algunos datos de muestra en ella. Discutiremos las tablas importantes en el próximo capítulo.
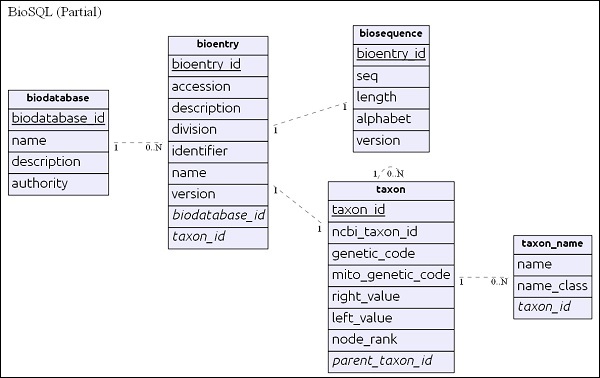
Diagrama ER simple
biodatabase La tabla está en la parte superior de la jerarquía y su propósito principal es organizar un conjunto de datos de secuencia en un solo grupo / base de datos virtual. Every entry in the biodatabase refers to a separate database and it does not mingle with another database. Todas las tablas relacionadas en la base de datos BioSQL tienen referencias a la entrada de la base de datos biológica.
bioentryLa tabla contiene todos los detalles sobre una secuencia, excepto los datos de la secuencia. secuencia de datos de un particularbioentry será almacenado en biosequence mesa.
taxon y taxon_name son detalles de taxonomía y cada entrada hace referencia a esta tabla para especificar su información de taxón.
Después de comprender el esquema, veamos algunas consultas en la siguiente sección.
Consultas de BioSQL
Profundicemos en algunas consultas SQL para comprender mejor cómo se organizan los datos y cómo se relacionan las tablas entre sí. Antes de continuar, abramos la base de datos usando el siguiente comando y establezcamos algunos comandos de formato:
> sqlite3 orchid.db
SQLite version 3.25.2 2018-09-25 19:08:10
Enter ".help" for usage hints.
sqlite> .header on
sqlite> .mode columns.header and .mode are formatting options to better visualize the data. También puede utilizar cualquier editor de SQLite para ejecutar la consulta.
Enumere la base de datos de secuencia virtual disponible en el sistema como se indica a continuación:
select
*
from
biodatabase;
*** Result ***
sqlite> .width 15 15 15 15
sqlite> select * from biodatabase;
biodatabase_id name authority description
--------------- --------------- --------------- ---------------
1 orchid
sqlite>Aquí, solo tenemos una base de datos, orchid.
Enumere las entradas (las 3 principales) disponibles en la base de datos orchid con el código dado a continuación
select
be.*,
bd.name
from
bioentry be
inner join
biodatabase bd
on bd.biodatabase_id = be.biodatabase_id
where
bd.name = 'orchid' Limit 1,
3;
*** Result ***
sqlite> .width 15 15 10 10 10 10 10 50 10 10
sqlite> select be.*, bd.name from bioentry be inner join biodatabase bd on
bd.biodatabase_id = be.biodatabase_id where bd.name = 'orchid' Limit 1,3;
bioentry_id biodatabase_id taxon_id name accession identifier division description version name
--------------- --------------- ---------- ---------- ---------- ---------- ----------
---------- ---------- ----------- ---------- --------- ---------- ----------
2 1 19 Z78532 Z78532 2765657 PLN
C.californicum 5.8S rRNA gene and ITS1 and ITS2 DN 1
orchid
3 1 20 Z78531 Z78531 2765656 PLN
C.fasciculatum 5.8S rRNA gene and ITS1 and ITS2 DN 1
orchid
4 1 21 Z78530 Z78530 2765655 PLN
C.margaritaceum 5.8S rRNA gene and ITS1 and ITS2 D 1
orchid
sqlite>Enumere los detalles de la secuencia asociados con una entrada (accesión - Z78530, nombre - gen del ARNr de C. fasciculatum 5.8S y ADN de ITS1 e ITS2) con el código dado -
select
substr(cast(bs.seq as varchar), 0, 10) || '...' as seq,
bs.length,
be.accession,
be.description,
bd.name
from
biosequence bs
inner join
bioentry be
on be.bioentry_id = bs.bioentry_id
inner join
biodatabase bd
on bd.biodatabase_id = be.biodatabase_id
where
bd.name = 'orchid'
and be.accession = 'Z78532';
*** Result ***
sqlite> .width 15 5 10 50 10
sqlite> select substr(cast(bs.seq as varchar), 0, 10) || '...' as seq,
bs.length, be.accession, be.description, bd.name from biosequence bs inner
join bioentry be on be.bioentry_id = bs.bioentry_id inner join biodatabase bd
on bd.biodatabase_id = be.biodatabase_id where bd.name = 'orchid' and
be.accession = 'Z78532';
seq length accession description name
------------ ---------- ---------- ------------ ------------ ---------- ---------- -----------------
CGTAACAAG... 753 Z78532 C.californicum 5.8S rRNA gene and ITS1 and ITS2 DNA orchid
sqlite>Obtenga la secuencia completa asociada con una entrada (accesión - Z78530, nombre - gen de ARNr de C. fasciculatum 5.8S y ADN de ITS1 e ITS2) usando el siguiente código -
select
bs.seq
from
biosequence bs
inner join
bioentry be
on be.bioentry_id = bs.bioentry_id
inner join
biodatabase bd
on bd.biodatabase_id = be.biodatabase_id
where
bd.name = 'orchid'
and be.accession = 'Z78532';
*** Result ***
sqlite> .width 1000
sqlite> select bs.seq from biosequence bs inner join bioentry be on
be.bioentry_id = bs.bioentry_id inner join biodatabase bd on bd.biodatabase_id =
be.biodatabase_id where bd.name = 'orchid' and be.accession = 'Z78532';
seq
----------------------------------------------------------------------------------------
----------------------------
CGTAACAAGGTTTCCGTAGGTGAACCTGCGGAAGGATCATTGTTGAGACAACAGAATATATGATCGAGTGAATCT
GGAGGACCTGTGGTAACTCAGCTCGTCGTGGCACTGCTTTTGTCGTGACCCTGCTTTGTTGTTGGGCCTCC
TCAAGAGCTTTCATGGCAGGTTTGAACTTTAGTACGGTGCAGTTTGCGCCAAGTCATATAAAGCATCACTGATGAATGACATTATTGT
CAGAAAAAATCAGAGGGGCAGTATGCTACTGAGCATGCCAGTGAATTTTTATGACTCTCGCAACGGATATCTTGGCTC
TAACATCGATGAAGAACGCAG
sqlite>Listar taxón asociado con la base de datos biológica, orquídea
select distinct
tn.name
from
biodatabase d
inner join
bioentry e
on e.biodatabase_id = d.biodatabase_id
inner join
taxon t
on t.taxon_id = e.taxon_id
inner join
taxon_name tn
on tn.taxon_id = t.taxon_id
where
d.name = 'orchid' limit 10;
*** Result ***
sqlite> select distinct tn.name from biodatabase d inner join bioentry e on
e.biodatabase_id = d.biodatabase_id inner join taxon t on t.taxon_id =
e.taxon_id inner join taxon_name tn on tn.taxon_id = t.taxon_id where d.name =
'orchid' limit 10;
name
------------------------------
Cypripedium irapeanum
Cypripedium californicum
Cypripedium fasciculatum
Cypripedium margaritaceum
Cypripedium lichiangense
Cypripedium yatabeanum
Cypripedium guttatum
Cypripedium acaule
pink lady's slipper
Cypripedium formosanum
sqlite>Cargar datos en la base de datos BioSQL
Aprendamos cómo cargar datos de secuencia en la base de datos de BioSQL en este capítulo. Ya tenemos el código para cargar datos en la base de datos en la sección anterior y el código es el siguiente:
from Bio import SeqIO
from BioSQL import BioSeqDatabase
import os
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
DBSCHEMA = "biosqldb-sqlite.sql"
SQL_FILE = os.path.join(os.getcwd(), DBSCHEMA)
server.load_database_sql(SQL_FILE)
server.commit()
db = server.new_database("orchid")
count = db.load(SeqIO.parse("orchid.gbk", "gb"), True) server.commit()
server.close()Veremos en profundidad cada línea del código y su propósito:
Line 1 - Carga el módulo SeqIO.
Line 2- Carga el módulo BioSeqDatabase. Este módulo proporciona toda la funcionalidad para interactuar con la base de datos BioSQL.
Line 3 - Módulo de carga del sistema operativo.
Line 5- open_database abre la base de datos especificada (db) con el controlador configurado (controlador) y devuelve un identificador a la base de datos BioSQL (servidor). Biopython admite bases de datos sqlite, mysql, postgresql y oracle.
Line 6-10- El método load_database_sql carga el sql desde el archivo externo y lo ejecuta. El método de confirmación confirma la transacción. Podemos omitir este paso porque ya creamos la base de datos con el esquema.
Line 12 - Los métodos new_database crean una nueva base de datos virtual, orchid y devuelve un identificador db para ejecutar el comando contra la base de datos de orchid.
Line 13- El método de carga carga las entradas de secuencia (SeqRecord iterable) en la base de datos de orquídeas. SqlIO.parse analiza la base de datos de GenBank y devuelve todas las secuencias en ella como SeqRecord iterable. El segundo parámetro (Verdadero) del método de carga le indica que obtenga los detalles de la taxonomía de los datos de secuencia del sitio web de NCBI blast, si aún no está disponible en el sistema.
Line 14 - confirmar confirma la transacción.
Line 15 - cerrar cierra la conexión de la base de datos y destruye el identificador del servidor.
Obtener los datos de la secuencia
Busquemos una secuencia con identificador, 2765658 de la base de datos de orquídeas como se muestra a continuación:
from BioSQL import BioSeqDatabase
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
db = server["orchid"]
seq_record = db.lookup(gi = 2765658)
print(seq_record.id, seq_record.description[:50] + "...")
print("Sequence length %i," % len(seq_record.seq))Aquí, el servidor ["orchid"] devuelve el identificador para recuperar datos de la base de datos virtualorchid. lookup El método proporciona una opción para seleccionar secuencias en función de los criterios y hemos seleccionado la secuencia con el identificador, 2765658. lookupdevuelve la información de secuencia como SeqRecordobject. Dado que ya sabemos cómo trabajar con SeqRecord`, es fácil obtener datos de él.
Eliminar una base de datos
Eliminar una base de datos es tan simple como llamar al método remove_database con el nombre de base de datos adecuado y luego confirmarlo como se especifica a continuación:
from BioSQL import BioSeqDatabase
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
server.remove_database("orchids")
server.commit()