Gráficos por computadora - Guía rápida
Los gráficos por computadora son un arte de hacer dibujos en las pantallas de las computadoras con la ayuda de la programación. Implica cálculos, creación y manipulación de datos. En otras palabras, podemos decir que la infografía es una herramienta de renderizado para la generación y manipulación de imágenes.
Tubo de rayos catódicos
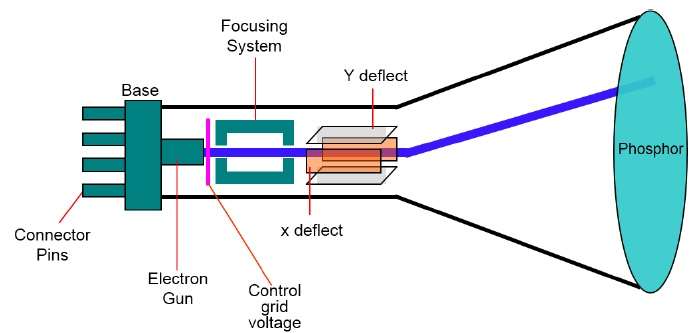
El dispositivo de salida principal en un sistema gráfico es el monitor de video. El elemento principal de un monitor de video es elCathode Ray Tube (CRT), que se muestra en la siguiente ilustración.
El funcionamiento de CRT es muy simple:
El cañón de electrones emite un haz de electrones (rayos catódicos).
El haz de electrones pasa a través de sistemas de enfoque y deflexión que lo dirigen hacia posiciones específicas en la pantalla recubierta de fósforo.
Cuando el rayo golpea la pantalla, el fósforo emite una pequeña mancha de luz en cada posición contactada por el rayo de electrones.
Vuelve a dibujar la imagen dirigiendo el haz de electrones hacia atrás rápidamente sobre los mismos puntos de la pantalla.
Hay dos formas (exploración aleatoria y exploración ráster) mediante las que podemos mostrar un objeto en la pantalla.
Escaneo de trama
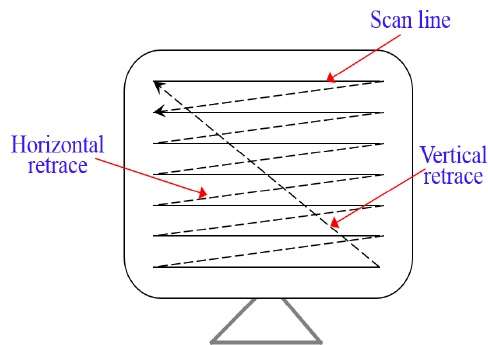
En un sistema de barrido de trama, el haz de electrones se desplaza por la pantalla, una fila a la vez, de arriba a abajo. A medida que el haz de electrones se mueve a través de cada fila, la intensidad del haz se enciende y apaga para crear un patrón de puntos iluminados.
La definición de la imagen se almacena en un área de memoria llamada Refresh Buffer o Frame Buffer. Esta área de memoria contiene el conjunto de valores de intensidad para todos los puntos de la pantalla. Los valores de intensidad almacenados se recuperan del búfer de actualización y se "pintan" en la pantalla una fila (línea de exploración) a la vez, como se muestra en la siguiente ilustración.
Cada punto de la pantalla se denomina pixel (picture element) o pel. Al final de cada línea de escaneo, el haz de electrones vuelve al lado izquierdo de la pantalla para comenzar a mostrar la siguiente línea de escaneo.
Escaneo aleatorio (escaneo vectorial)
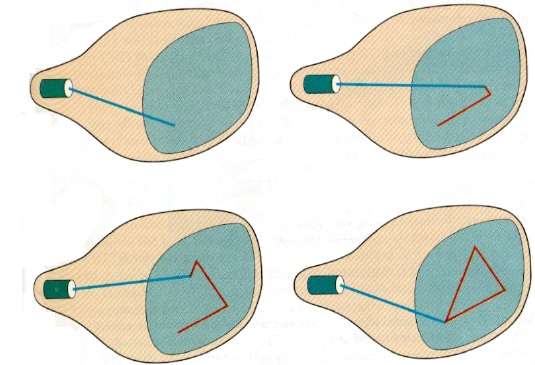
En esta técnica, el haz de electrones se dirige solo a la parte de la pantalla donde se va a dibujar la imagen en lugar de escanear de izquierda a derecha y de arriba a abajo como en el escaneo de trama. También es llamadovector display, stroke-writing display, o calligraphic display.
La definición de imagen se almacena como un conjunto de comandos de dibujo de líneas en un área de memoria denominada refresh display file. Para mostrar una imagen específica, el sistema recorre el conjunto de comandos en el archivo de pantalla, dibujando cada línea de componente a su vez. Una vez procesados todos los comandos de dibujo de líneas, el sistema vuelve al comando de la primera línea de la lista.
Las pantallas de escaneo aleatorio están diseñadas para dibujar todas las líneas componentes de una imagen de 30 a 60 veces por segundo.
Aplicación de gráficos por computadora
Computer Graphics tiene numerosas aplicaciones, algunas de las cuales se enumeran a continuación:
Computer graphics user interfaces (GUIs) - Un paradigma gráfico, orientado al mouse, que permite al usuario interactuar con una computadora.
Business presentation graphics - "Una imagen vale más que mil palabras".
Cartography - Dibujar mapas.
Weather Maps - Mapeo en tiempo real, representaciones simbólicas.
Satellite Imaging - Imágenes geodésicas.
Photo Enhancement - Nitidez de fotografías borrosas.
Medical imaging - RMN, TAC, etc. - Exploración interna no invasiva.
Engineering drawings - mecánicos, eléctricos, civiles, etc. - Sustitución de los planos del pasado.
Typography - El uso de imágenes de personajes en la publicación, reemplazando el tipo duro del pasado.
Architecture - Planos de construcción, bocetos exteriores - reemplazando los planos y dibujos a mano del pasado.
Art - Las computadoras proporcionan un nuevo medio para los artistas.
Training - Simuladores de vuelo, instrucción asistida por ordenador, etc.
Entertainment - Películas y juegos.
Simulation and modeling - Reemplazo del modelado físico y representaciones.
Una línea conecta dos puntos. Es un elemento básico en gráficos. Para dibujar una línea, necesita dos puntos entre los cuales puede dibujar una línea. En los siguientes tres algoritmos, nos referimos a un punto de la línea como$X_{0}, Y_{0}$ y el segundo punto de la línea como $X_{1}, Y_{1}$.
Algoritmo DDA
El algoritmo del analizador diferencial digital (DDA) es un algoritmo de generación de línea simple que se explica paso a paso aquí.
Step 1 - Obtenga la entrada de dos puntos finales $(X_{0}, Y_{0})$ y $(X_{1}, Y_{1})$.
Step 2 - Calcule la diferencia entre dos puntos finales.
dx = X1 - X0
dy = Y1 - Y0Step 3- Según la diferencia calculada en el paso 2, debe identificar el número de pasos para colocar píxeles. Si dx> dy, entonces necesita más pasos en la coordenada x; de lo contrario, en la coordenada y.
if (absolute(dx) > absolute(dy))
Steps = absolute(dx);
else
Steps = absolute(dy);Step 4 - Calcular el incremento en la coordenada xy la coordenada y.
Xincrement = dx / (float) steps;
Yincrement = dy / (float) steps;Step 5 - Coloque el píxel incrementando con éxito las coordenadas xey en consecuencia y complete el dibujo de la línea.
for(int v=0; v < Steps; v++)
{
x = x + Xincrement;
y = y + Yincrement;
putpixel(Round(x), Round(y));
}Generación de líneas de Bresenham
El algoritmo de Bresenham es otro algoritmo de conversión de exploración incremental. La gran ventaja de este algoritmo es que utiliza solo cálculos enteros. Moviéndose a través del eje x en intervalos unitarios y en cada paso elija entre dos coordenadas y diferentes.
Por ejemplo, como se muestra en la siguiente ilustración, desde la posición (2, 3) debe elegir entre (3, 3) y (3, 4). Le gustaría el punto que está más cerca de la línea original.
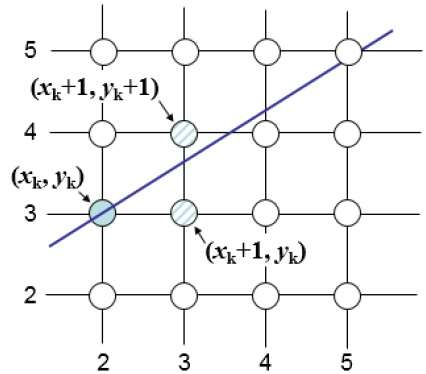
En posición de muestra $X_{k}+1,$ las separaciones verticales de la línea matemática se etiquetan como $d_{upper}$ y $d_{lower}$.
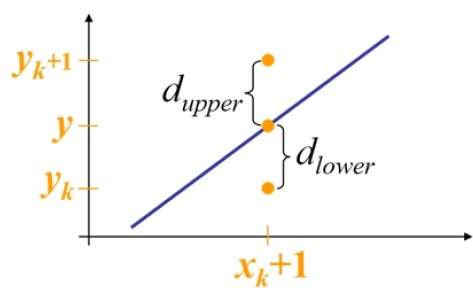
De la ilustración anterior, la coordenada y en la línea matemática en $x_{k}+1$ es -
Y = m ($X_{k}$+1) + b
Entonces, $d_{upper}$ y $d_{lower}$ se dan de la siguiente manera:
$$d_{lower} = y-y_{k}$$
$$= m(X_{k} + 1) + b - Y_{k}$$
y
$$d_{upper} = (y_{k} + 1) - y$$
$= Y_{k} + 1 - m (X_{k} + 1) - b$
Puede usarlos para tomar una decisión simple sobre qué píxel está más cerca de la línea matemática. Esta simple decisión se basa en la diferencia entre las dos posiciones de los píxeles.
$$d_{lower} - d_{upper} = 2m(x_{k} + 1) - 2y_{k} + 2b - 1$$
Sustituyamos m con dy / dx donde dx y dy son las diferencias entre los puntos finales.
$$dx (d_{lower} - d_{upper}) =dx(2\frac{\mathrm{d} y}{\mathrm{d} x}(x_{k} + 1) - 2y_{k} + 2b - 1)$$
$$ = 2dy.x_{k} - 2dx.y_{k} + 2dy + 2dx(2b-1)$$
$$ = 2dy.x_{k} - 2dx.y_{k} + C$$
Entonces, un parámetro de decisión $P_{k}$porque el k- ésimo paso a lo largo de una línea está dado por -
$$p_{k} = dx(d_{lower} - d_{upper})$$
$$ = 2dy.x_{k} - 2dx.y_{k} + C$$
El signo del parámetro de decisión $P_{k}$ es el mismo que el de $d_{lower} - d_{upper}$.
Si $p_{k}$ es negativo, elija el píxel inferior; de lo contrario, elija el píxel superior.
Recuerde, los cambios de coordenadas ocurren a lo largo del eje x en pasos unitarios, por lo que puede hacer todo con cálculos enteros. En el paso k + 1, el parámetro de decisión se da como -
$$p_{k +1} = 2dy.x_{k + 1} - 2dx.y_{k + 1} + C$$
Restando $p_{k}$ de esto obtenemos -
$$p_{k + 1} - p_{k} = 2dy(x_{k + 1} - x_{k}) - 2dx(y_{k + 1} - y_{k})$$
Pero, $x_{k+1}$ es lo mismo que $x_{k+1}$. Entonces ...
$$p_{k+1} = p_{k} + 2dy - 2dx(y_{k+1} - y_{k})$$
Dónde, $Y_{k+1} – Y_{k}$ es 0 o 1 dependiendo del signo de $P_{k}$.
El primer parámetro de decisión $p_{0}$ se evalúa en $(x_{0}, y_{0})$ se da como -
$$p_{0} = 2dy - dx$$
Ahora, teniendo en cuenta todos los puntos y cálculos anteriores, aquí está el algoritmo de Bresenham para pendiente m <1 -
Step 1 - Ingrese los dos puntos finales de la línea, almacenando el punto final izquierdo en $(x_{0}, y_{0})$.
Step 2 - Trazar el punto $(x_{0}, y_{0})$.
Step 3 - Calcule las constantes dx, dy, 2dy y (2dy - 2dx) y obtenga el primer valor para el parámetro de decisión como -
$$p_{0} = 2dy - dx$$
Step 4 - En cada $X_{k}$ a lo largo de la línea, comenzando en k = 0, realice la siguiente prueba:
Si $p_{k}$ <0, el siguiente punto a graficar es $(x_{k}+1, y_{k})$ y
$$p_{k+1} = p_{k} + 2dy$$ De otra manera,
$$(x_{k}, y_{k}+1)$$
$$p_{k+1} = p_{k} + 2dy - 2dx$$
Step 5 - Repita el paso 4 (dx - 1) veces.
Para m> 1, averigüe si necesita incrementar x mientras incrementa y cada vez.
Después de resolver, la ecuación para el parámetro de decisión $P_{k}$ será muy similar, solo se intercambian las xey de la ecuación.
Algoritmo de punto medio
El algoritmo de punto medio se debe a Bresenham, que fue modificado por Pitteway y Van Aken. Suponga que ya ha colocado el punto P en la coordenada (x, y) y que la pendiente de la recta es 0 ≤ k ≤ 1 como se muestra en la siguiente ilustración.
Ahora debe decidir si colocar el siguiente punto en E o N. Esto se puede elegir identificando el punto de intersección Q más cercano al punto N o E. Si el punto de intersección Q está más cercano al punto N, entonces N se considera como el siguiente punto; de lo contrario E.
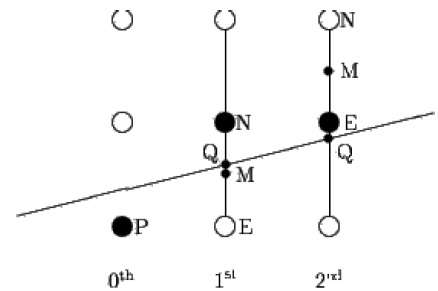
Para determinar eso, primero calcule el punto medio M (x + 1, y + ½). Si el punto de intersección Q de la línea con la línea vertical que conecta E y N está por debajo de M, entonces tome E como el siguiente punto; de lo contrario, tome N como el siguiente punto.
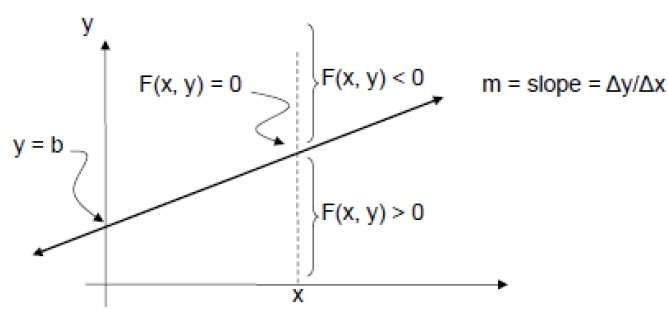
Para verificar esto, debemos considerar la ecuación implícita:
F (x, y) = mx + b - y
Para m positivo en cualquier X dado,
- Si y está en la línea, entonces F (x, y) = 0
- Si y está por encima de la línea, entonces F (x, y) <0
- Si y está por debajo de la línea, entonces F (x, y)> 0
Dibujar un círculo en la pantalla es un poco complejo que dibujar una línea. Hay dos algoritmos populares para generar un círculo:Bresenham’s Algorithm y Midpoint Circle Algorithm. Estos algoritmos se basan en la idea de determinar los puntos posteriores necesarios para dibujar el círculo. Analicemos los algoritmos en detalle:
La ecuación del círculo es $X^{2} + Y^{2} = r^{2},$ donde r es el radio.
Algoritmo de Bresenham
No podemos mostrar un arco continuo en la pantalla ráster. En cambio, tenemos que elegir la posición de píxel más cercana para completar el arco.
En la siguiente ilustración, puede ver que hemos colocado el píxel en la ubicación (X, Y) y ahora debemos decidir dónde colocar el siguiente píxel: en N (X + 1, Y) o en S (X + 1, Y-1).
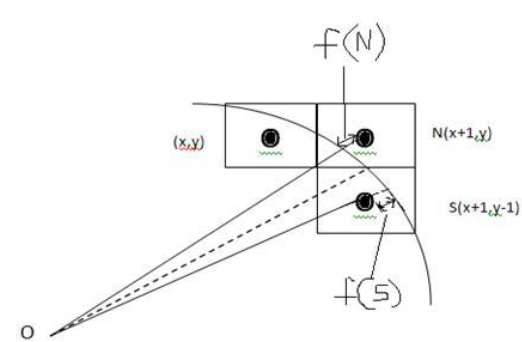
Esto puede decidirse mediante el parámetro de decisión d.
- Si d <= 0, entonces N (X + 1, Y) debe elegirse como siguiente píxel.
- Si d> 0, entonces S (X + 1, Y-1) debe elegirse como el siguiente píxel.
Algoritmo
Step 1- Obtenga las coordenadas del centro del círculo y el radio, y guárdelas en x, y y R respectivamente. Establezca P = 0 y Q = R.
Step 2 - Establecer el parámetro de decisión D = 3 - 2R.
Step 3 - Repita hasta el paso 8 mientras P ≤ Q.
Step 4 - Llamar a Draw Circle (X, Y, P, Q).
Step 5 - Incrementar el valor de P.
Step 6 - Si D <0 entonces D = D + 4P + 6.
Step 7 - Else Set R = R - 1, D = D + 4 (PQ) + 10.
Step 8 - Llamar a Draw Circle (X, Y, P, Q).
Draw Circle Method(X, Y, P, Q).
Call Putpixel (X + P, Y + Q).
Call Putpixel (X - P, Y + Q).
Call Putpixel (X + P, Y - Q).
Call Putpixel (X - P, Y - Q).
Call Putpixel (X + Q, Y + P).
Call Putpixel (X - Q, Y + P).
Call Putpixel (X + Q, Y - P).
Call Putpixel (X - Q, Y - P).Algoritmo de punto medio
Step 1 - Radio de entrada r y centro del círculo $(x_{c,} y_{c})$ y obtenga el primer punto en la circunferencia del círculo centrado en el origen como
(x0, y0) = (0, r)Step 2 - Calcular el valor inicial del parámetro de decisión como
$P_{0}$ = 5/4 - r (Consulte la siguiente descripción para simplificar esta ecuación).
f(x, y) = x2 + y2 - r2 = 0
f(xi - 1/2 + e, yi + 1)
= (xi - 1/2 + e)2 + (yi + 1)2 - r2
= (xi- 1/2)2 + (yi + 1)2 - r2 + 2(xi - 1/2)e + e2
= f(xi - 1/2, yi + 1) + 2(xi - 1/2)e + e2 = 0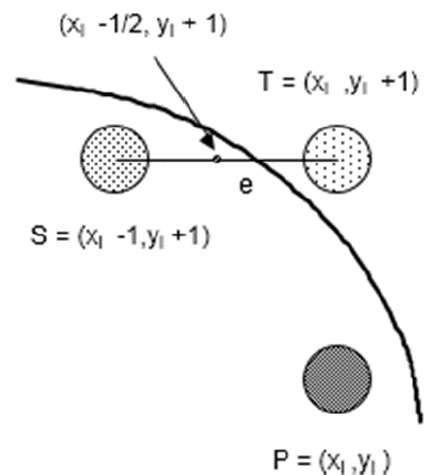
Let di = f(xi - 1/2, yi + 1) = -2(xi - 1/2)e - e2
Thus,
If e < 0 then di > 0 so choose point S = (xi - 1, yi + 1).
di+1 = f(xi - 1 - 1/2, yi + 1 + 1) = ((xi - 1/2) - 1)2 + ((yi + 1) + 1)2 - r2
= di - 2(xi - 1) + 2(yi + 1) + 1
= di + 2(yi + 1 - xi + 1) + 1
If e >= 0 then di <= 0 so choose point T = (xi, yi + 1)
di+1 = f(xi - 1/2, yi + 1 + 1)
= di + 2yi+1 + 1
The initial value of di is
d0 = f(r - 1/2, 0 + 1) = (r - 1/2)2 + 12 - r2
= 5/4 - r {1-r can be used if r is an integer}
When point S = (xi - 1, yi + 1) is chosen then
di+1 = di + -2xi+1 + 2yi+1 + 1
When point T = (xi, yi + 1) is chosen then
di+1 = di + 2yi+1 + 1Step 3 - En cada $X_{K}$ posición comenzando en K = 0, realice la siguiente prueba -
If PK < 0 then next point on circle (0,0) is (XK+1,YK) and
PK+1 = PK + 2XK+1 + 1
Else
PK+1 = PK + 2XK+1 + 1 – 2YK+1
Where, 2XK+1 = 2XK+2 and 2YK+1 = 2YK-2.Step 4 - Determinar los puntos de simetría en otros siete octantes.
Step 5 - Mueva cada posición de cálculo de píxeles (X, Y) a la ruta circular centrada en $(X_{C,} Y_{C})$ y trazar los valores de las coordenadas.
X = X + XC, Y = Y + YCStep 6 - Repita del paso 3 al 5 hasta que X> = Y.
Polígono es una lista ordenada de vértices como se muestra en la siguiente figura. Para rellenar polígonos con colores particulares, debe determinar los píxeles que caen en el borde del polígono y los que caen dentro del polígono. En este capítulo, veremos cómo podemos rellenar polígonos utilizando diferentes técnicas.

Algoritmo de línea de exploración
Este algoritmo funciona mediante la intersección de la línea de exploración con los bordes del polígono y llena el polígono entre pares de intersecciones. Los siguientes pasos describen cómo funciona este algoritmo.
Step 1 - Descubra Ymin e Ymax del polígono dado.
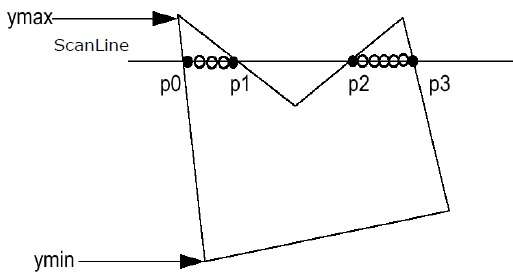
Step 2- ScanLine se cruza con cada borde del polígono desde Ymin hasta Ymax. Nombra cada punto de intersección del polígono. Según la figura que se muestra arriba, se denominan p0, p1, p2, p3.
Step 3 - Ordene el punto de intersección en el orden creciente de la coordenada X, es decir, (p0, p1), (p1, p2) y (p2, p3).
Step 4 - Rellena todos esos pares de coordenadas que están dentro de polígonos e ignora los pares alternos.
Algoritmo de relleno por inundación
A veces nos encontramos con un objeto donde queremos llenar el área y su límite con diferentes colores. Podemos pintar tales objetos con un color interior específico en lugar de buscar un color de límite particular como en el algoritmo de relleno de límites.
En lugar de depender del límite del objeto, se basa en el color de relleno. En otras palabras, reemplaza el color interior del objeto con el color de relleno. Cuando no existen más píxeles del color interior original, se completa el algoritmo.
Una vez más, este algoritmo se basa en el método de cuatro conexiones o ocho conexiones para rellenar los píxeles. Pero en lugar de buscar el color del límite, busca todos los píxeles adyacentes que forman parte del interior.
Algoritmo de relleno de límites
El algoritmo de relleno de límites funciona como su nombre. Este algoritmo elige un punto dentro de un objeto y comienza a llenarse hasta que llega al límite del objeto. El color del límite y el color que rellenamos deben ser diferentes para que este algoritmo funcione.
En este algoritmo, asumimos que el color del límite es el mismo para todo el objeto. El algoritmo de relleno de límites se puede implementar mediante 4 píxeles conectados u 8 píxeles conectados.
Polígono 4 conectados
En esta técnica se utilizan 4 píxeles conectados como se muestra en la figura. Estamos poniendo los píxeles arriba, abajo, a la derecha y al lado izquierdo de los píxeles actuales y este proceso continuará hasta que encontremos un límite con un color diferente.
Algoritmo
Step 1 - Inicialice el valor del punto de semilla (seedx, seedy), fcolor y dcol.
Step 2 - Definir los valores de los límites del polígono.
Step 3 - Verifique si el punto de semilla actual es del color predeterminado, luego repita los pasos 4 y 5 hasta alcanzar los píxeles del límite.
If getpixel(x, y) = dcol then repeat step 4 and 5Step 4 - Cambie el color predeterminado con el color de relleno en el punto inicial.
setPixel(seedx, seedy, fcol)Step 5 - Seguir de forma recursiva el procedimiento con cuatro puntos de vecindad.
FloodFill (seedx – 1, seedy, fcol, dcol)
FloodFill (seedx + 1, seedy, fcol, dcol)
FloodFill (seedx, seedy - 1, fcol, dcol)
FloodFill (seedx – 1, seedy + 1, fcol, dcol)Step 6 - Salir
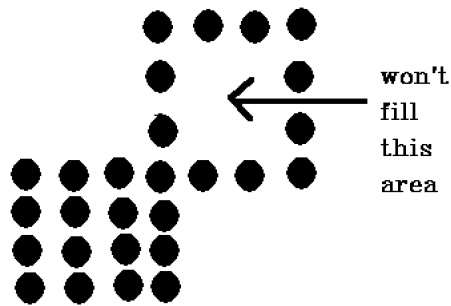
Hay un problema con esta técnica. Considere el caso que se muestra a continuación, donde intentamos llenar toda la región. Aquí, la imagen se llena solo parcialmente. En tales casos, no se puede utilizar la técnica de 4 píxeles conectados.
Polígono 8 conectados
En esta técnica se utilizan 8 píxeles conectados como se muestra en la figura. Estamos poniendo píxeles arriba, abajo, derecho e izquierdo de los píxeles actuales como lo estábamos haciendo en la técnica de 4 conectados.
Además de esto, también colocamos píxeles en diagonales para cubrir el área completa del píxel actual. Este proceso continuará hasta que encontremos un límite con diferente color.

Algoritmo
Step 1 - Inicialice el valor del punto de semilla (seedx, seedy), fcolor y dcol.
Step 2 - Definir los valores de los límites del polígono.
Step 3 - Verifique si el punto de semilla actual es del color predeterminado y luego repita los pasos 4 y 5 hasta alcanzar los píxeles de límite
If getpixel(x,y) = dcol then repeat step 4 and 5Step 4 - Cambie el color predeterminado con el color de relleno en el punto inicial.
setPixel(seedx, seedy, fcol)Step 5 - Seguir de forma recursiva el procedimiento con cuatro puntos vecinos
FloodFill (seedx – 1, seedy, fcol, dcol)
FloodFill (seedx + 1, seedy, fcol, dcol)
FloodFill (seedx, seedy - 1, fcol, dcol)
FloodFill (seedx, seedy + 1, fcol, dcol)
FloodFill (seedx – 1, seedy + 1, fcol, dcol)
FloodFill (seedx + 1, seedy + 1, fcol, dcol)
FloodFill (seedx + 1, seedy - 1, fcol, dcol)
FloodFill (seedx – 1, seedy - 1, fcol, dcol)Step 6 - Salir
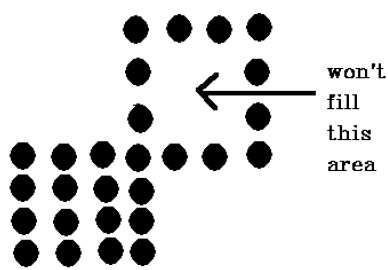
La técnica de 4 píxeles conectados no logró llenar el área marcada en la siguiente figura, lo que no sucederá con la técnica de 8 conectados.
Prueba interior-exterior
Este método también se conoce como counting number method. Al llenar un objeto, a menudo necesitamos identificar si un punto en particular está dentro o fuera del objeto. Hay dos métodos mediante los cuales podemos identificar si un punto en particular está dentro o fuera de un objeto.
- Regla de pares impares
- Regla de número de bobinado distinto de cero
Regla de pares impares
En esta técnica, contamos el borde que cruza a lo largo de la línea desde cualquier punto (x, y) hasta el infinito. Si el número de interacciones es impar, entonces el punto (x, y) es un punto interior. Si el número de interacciones es par, el punto (x, y) es un punto exterior. Aquí está el ejemplo para darle una idea clara:
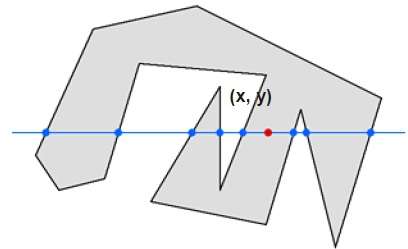
En la figura anterior, podemos ver que desde el punto (x, y), el número de puntos de interacción en el lado izquierdo es 5 y en el lado derecho es 3. Entonces el número total de puntos de interacción es 8, que es impar. . Por tanto, el punto se considera dentro del objeto.
Regla de número de bobinado distinto de cero
Este método también se usa con los polígonos simples para probar si el punto dado es interior o no. Se puede entender simplemente con la ayuda de un alfiler y una goma elástica. Fije el alfiler en uno de los bordes del polígono y ate la banda elástica y luego estire la banda elástica a lo largo de los bordes del polígono.
Cuando todos los bordes del polígono estén cubiertos por la banda elástica, revise el pasador que se ha fijado en el punto a probar. Si encontramos al menos un viento en el punto considérelo dentro del polígono, de lo contrario podemos decir que el punto no está dentro del polígono.
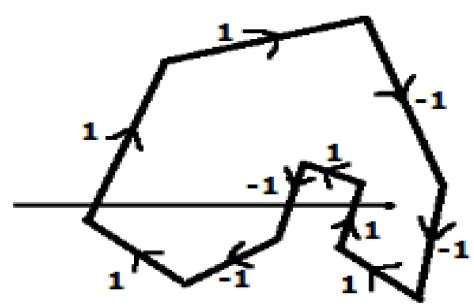
En otro método alternativo, dé direcciones a todos los bordes del polígono. Dibuje una línea de exploración desde el punto que se va a probar hacia el extremo izquierdo de la dirección X.
Dé el valor 1 a todos los bordes que van hacia arriba y todos los demás -1 como valores de dirección.
Compruebe los valores de la dirección del borde por los que pasa la línea de exploración y resúmalos.
Si la suma total de este valor de dirección es distinta de cero, entonces este punto a probar es un interior point, de lo contrario es un exterior point.
En la figura anterior, sumamos los valores de dirección desde los cuales pasa la línea de escaneo, entonces el total es 1 - 1 + 1 = 1; que no es cero. Entonces se dice que el punto es un punto interior.
El uso principal del recorte en gráficos por computadora es eliminar objetos, líneas o segmentos de línea que están fuera del panel de visualización. La transformación de visualización es insensible a la posición de los puntos en relación con el volumen de visualización, especialmente aquellos puntos detrás del espectador, y es necesario eliminar estos puntos antes de generar la vista.
Recorte de puntos
Recortar un punto de una ventana determinada es muy fácil. Considere la siguiente figura, donde el rectángulo indica la ventana. El recorte de puntos nos dice si el punto dado (X, Y) está dentro de la ventana dada o no; y decide si usaremos las coordenadas mínima y máxima de la ventana.
La coordenada X del punto dado está dentro de la ventana, si X se encuentra entre Wx1 ≤ X ≤ Wx2. De la misma manera, la coordenada Y del punto dado está dentro de la ventana, si Y se encuentra entre Wy1 ≤ Y ≤ Wy2.

Recorte de línea
El concepto de recorte de línea es el mismo que el de recorte de puntos. En el recorte de línea, cortaremos la parte de la línea que está fuera de la ventana y mantendremos solo la parte que está dentro de la ventana.
Recortes de líneas de Cohen-Sutherland
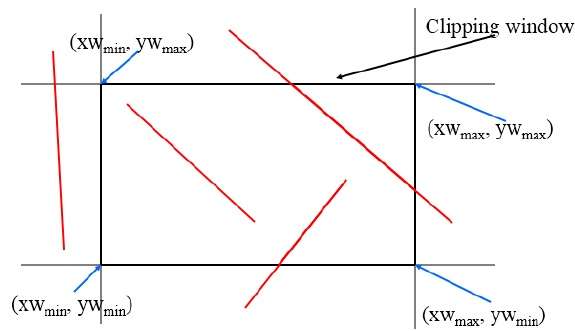
Este algoritmo utiliza la ventana de recorte como se muestra en la siguiente figura. La coordenada mínima para la región de recorte es$(XW_{min,} YW_{min})$ y la coordenada máxima para la región de recorte es $(XW_{max,} YW_{max})$.
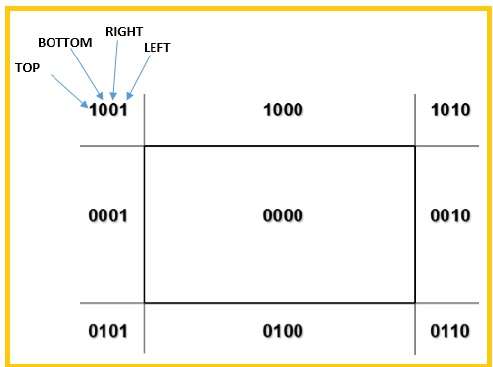
Usaremos 4 bits para dividir toda la región. Estos 4 bits representan la parte superior, inferior, derecha e izquierda de la región, como se muestra en la siguiente figura. Aquí elTOP y LEFT bit se establece en 1 porque es el TOP-LEFT esquina.
Hay 3 posibilidades para la línea:
La línea puede estar completamente dentro de la ventana (esta línea debe aceptarse).
La línea puede estar completamente fuera de la ventana (esta línea se eliminará por completo de la región).
La línea puede estar parcialmente dentro de la ventana (encontraremos el punto de intersección y dibujaremos solo la parte de la línea que está dentro de la región).
Algoritmo
Step 1 - Asignar un código de región para cada punto final.
Step 2 - Si ambos extremos tienen un código de región 0000 luego acepta esta línea.
Step 3 - De lo contrario, realiza lo lógico ANDoperación para ambos códigos de región.
Step 3.1 - Si el resultado no es 0000, luego rechace la línea.
Step 3.2 - De lo contrario, necesita recorte.
Step 3.2.1 - Elija un punto final de la línea que esté fuera de la ventana.
Step 3.2.2 - Busque el punto de intersección en el límite de la ventana (basado en el código de región).
Step 3.2.3 - Reemplace el punto final con el punto de intersección y actualice el código de región.
Step 3.2.4 - Repita el paso 2 hasta que encontremos una línea recortada aceptada trivialmente o rechazada trivialmente.
Step 4 - Repita el paso 1 para otras líneas.
Algoritmo de recorte de línea Cyrus-Beck
Este algoritmo es más eficiente que el algoritmo de Cohen-Sutherland. Emplea representación de líneas paramétricas y productos de puntos simples.
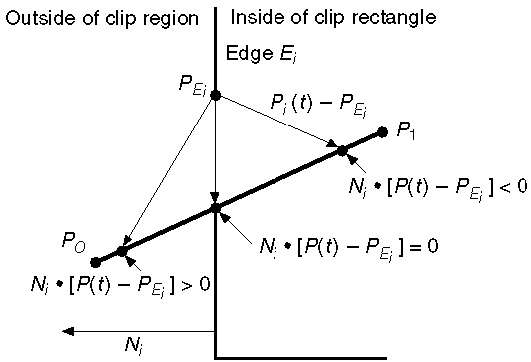
La ecuación paramétrica de la recta es -
P0P1:P(t) = P0 + t(P1-P0)Sea N i el borde normal exterior E i . Ahora elija cualquier punto arbitrario P Ei en el borde E i, luego el producto escalar N i ∙ [P (t) - P Ei ] determina si el punto P (t) está "dentro del borde del clip" o "fuera" del borde del clip o "En" el borde del clip.
El punto P (t) está dentro si N i . [P (t) - P Ei ] <0
El punto P (t) está fuera si N i . [P (t) - P Ei ]> 0
El punto P (t) está en el borde si N i . [P (t) - P Ei ] = 0 (Punto de intersección)
N i . [P (t) - P Ei ] = 0
N i . [P 0 + t (P 1 -P 0 ) - P Ei ] = 0 (Reemplazando P (t) con P 0 + t (P 1 -P 0 ))
N i . [P 0 - P Ei ] + N i .t [P 1 -P 0 ] = 0
N i . [P 0 - P Ei ] + N i ∙ tD = 0 (sustituyendo D por [P 1 -P 0 ])
N yo . [P 0 - P Ei ] = - N yo ∙ tD
La ecuación para t se convierte en,
$$t = \tfrac{N_{i}.[P_{o} - P_{Ei}]}{{- N_{i}.D}}$$
Es válido para las siguientes condiciones:
- N i ≠ 0 (el error no puede ocurrir)
- D ≠ 0 (P 1 ≠ P 0 )
- N i ∙ D ≠ 0 (P 0 P 1 no paralelo a E i )
Recorte de polígonos (algoritmo de Sutherland Hodgman)
También se puede recortar un polígono especificando la ventana de recorte. El algoritmo de recorte de polígonos de Sutherland Hodgeman se utiliza para el recorte de polígonos. En este algoritmo, todos los vértices del polígono se recortan contra cada borde de la ventana de recorte.
Primero, el polígono se recorta contra el borde izquierdo de la ventana del polígono para obtener nuevos vértices del polígono. Estos nuevos vértices se utilizan para recortar el polígono contra el borde derecho, el borde superior, el borde inferior de la ventana de recorte como se muestra en la siguiente figura.
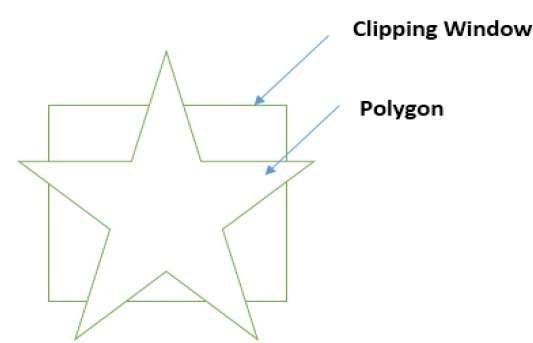
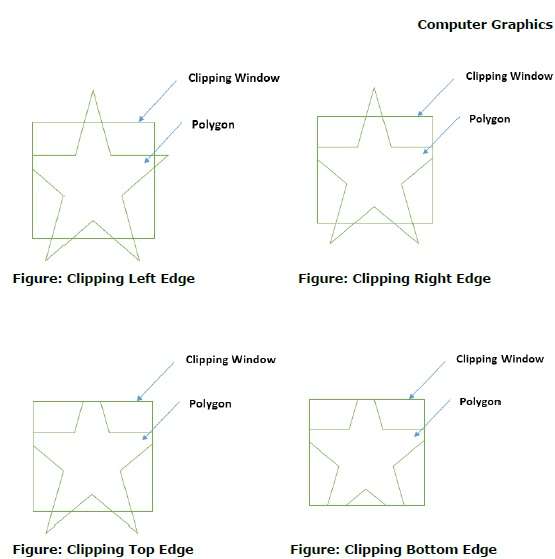
Al procesar un borde de un polígono con ventana de recorte, se encuentra un punto de intersección si el borde no está completamente dentro de la ventana de recorte y se recorta un borde parcial desde el punto de intersección al borde exterior. Las siguientes figuras muestran recortes de borde izquierdo, derecho, superior e inferior:
Recorte de texto
Se utilizan varias técnicas para proporcionar recorte de texto en un gráfico de computadora. Depende de los métodos utilizados para generar caracteres y los requisitos de una aplicación en particular. Hay tres métodos para el recorte de texto que se enumeran a continuación:
- Recorte de cadena todo o nada
- Recorte de todos o ninguno caracteres
- Recorte de texto
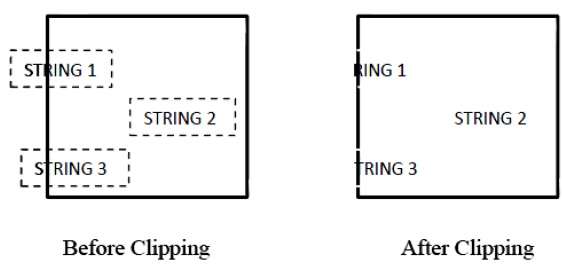
La siguiente figura muestra todo o nada de recorte de cadenas:
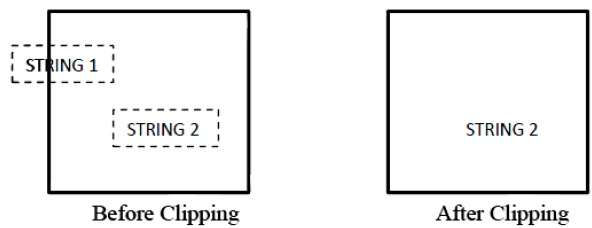
En el método de recorte de cadena todo o nada, mantenemos la cadena completa o rechazamos la cadena completa en función de la ventana de recorte. Como se muestra en la figura anterior, STRING2 está completamente dentro de la ventana de recorte, por lo que lo mantenemos y STRING1 está solo parcialmente dentro de la ventana, lo rechazamos.
La siguiente figura muestra el recorte de todos o ninguno de los caracteres:
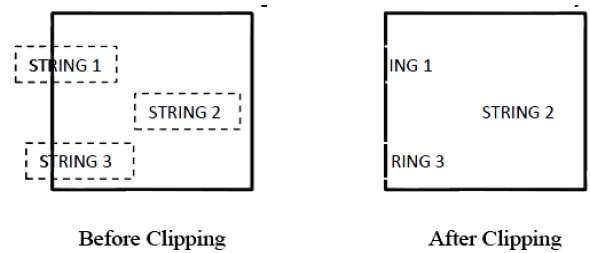
Este método de recorte se basa en caracteres en lugar de una cadena completa. En este método, si la cadena está completamente dentro de la ventana de recorte, la mantenemos. Si está parcialmente fuera de la ventana, entonces:
Rechaza solo la parte de la cuerda que está fuera
Si el carácter está en el límite de la ventana de recorte, descartamos ese carácter completo y nos quedamos con el resto de la cadena.
La siguiente figura muestra el recorte de texto:
Este método de recorte se basa en caracteres en lugar de en toda la cadena. En este método, si la cadena está completamente dentro de la ventana de recorte, la mantenemos. Si está parcialmente fuera de la ventana, entonces
Rechaza solo la porción de cuerda que está afuera.
Si el personaje está en el límite de la ventana de recorte, descartamos solo la parte del carácter que está fuera de la ventana de recorte.
Gráficos de mapa de bits
Un mapa de bits es una colección de píxeles que describe una imagen. Es un tipo de gráficos de computadora que la computadora usa para almacenar y mostrar imágenes. En este tipo de gráficos, las imágenes se almacenan bit a bit y, por lo tanto, se denominan gráficos de mapa de bits. Para una mejor comprensión, consideremos el siguiente ejemplo en el que dibujamos una cara sonriente utilizando gráficos de mapa de bits.

Ahora veremos cómo esta carita sonriente se almacena poco a poco en los gráficos por computadora.
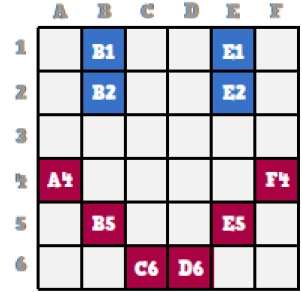
Al observar de cerca la carita sonriente original, podemos ver que hay dos líneas azules que se representan como B1, B2 y E1, E2 en la figura anterior.
De la misma manera, el emoticón se representa usando la combinación de bits de A4, B5, C6, D6, E5 y F4 respectivamente.
Las principales desventajas de los gráficos de mapa de bits son:
No podemos cambiar el tamaño de la imagen de mapa de bits. Si intenta cambiar el tamaño, los píxeles se vuelven borrosos.
Los mapas de bits de colores pueden ser muy grandes.
La transformación significa cambiar algunos gráficos en otra cosa mediante la aplicación de reglas. Podemos tener varios tipos de transformaciones como traslación, escalado hacia arriba o hacia abajo, rotación, corte, etc. Cuando una transformación tiene lugar en un plano 2D, se llama transformación 2D.
Las transformaciones juegan un papel importante en los gráficos por computadora para reposicionar los gráficos en la pantalla y cambiar su tamaño u orientación.
Coordenadas homogéneas
Para realizar una secuencia de transformación como la traducción seguida de rotación y escalado, necesitamos seguir un proceso secuencial:
- Traducir las coordenadas,
- Gire las coordenadas trasladadas y luego
- Escale las coordenadas rotadas para completar la transformación compuesta.
Para acortar este proceso, tenemos que usar una matriz de transformación de 3 × 3 en lugar de una matriz de transformación de 2 × 2. Para convertir una matriz de 2 × 2 en una matriz de 3 × 3, tenemos que agregar una coordenada ficticia adicional W.
De esta manera, podemos representar el punto con 3 números en lugar de 2 números, lo que se llama Homogenous Coordinatesistema. En este sistema, podemos representar todas las ecuaciones de transformación en la multiplicación de matrices. Cualquier punto cartesiano P (X, Y) se puede convertir en coordenadas homogéneas mediante P '(X h , Y h , h).
Traducción
Una traducción mueve un objeto a una posición diferente en la pantalla. Puede trasladar un punto en 2D agregando la coordenada de traslación (t x , t y ) a la coordenada original (X, Y) para obtener la nueva coordenada (X ', Y').
De la figura anterior, puede escribir eso:
X’ = X + tx
Y’ = Y + ty
El par (t x , t y ) se denomina vector de traslación o vector de desplazamiento. Las ecuaciones anteriores también se pueden representar utilizando los vectores de columna.
$P = \frac{[X]}{[Y]}$ p '= $\frac{[X']}{[Y']}$T = $\frac{[t_{x}]}{[t_{y}]}$
Podemos escribirlo como -
P’ = P + T
Rotación
En rotación, rotamos el objeto en un ángulo particular θ (theta) desde su origen. En la siguiente figura, podemos ver que el punto P (X, Y) está ubicado en el ángulo φ de la coordenada X horizontal con una distancia r del origen.
Supongamos que desea rotarlo en el ángulo θ. Después de rotarlo a una nueva ubicación, obtendrá un nuevo punto P '(X', Y ').

Usando trigonométrica estándar, la coordenada original del punto P (X, Y) se puede representar como -
$X = r \, cos \, \phi ...... (1)$
$Y = r \, sin \, \phi ...... (2)$
De la misma manera podemos representar el punto P '(X', Y ') como -
${x}'= r \: cos \: \left ( \phi \: + \: \theta \right ) = r\: cos \: \phi \: cos \: \theta \: − \: r \: sin \: \phi \: sin \: \theta ....... (3)$
${y}'= r \: sin \: \left ( \phi \: + \: \theta \right ) = r\: cos \: \phi \: sin \: \theta \: + \: r \: sin \: \phi \: cos \: \theta ....... (4)$
Sustituyendo la ecuación (1) y (2) en (3) y (4) respectivamente, obtendremos
${x}'= x \: cos \: \theta − \: y \: sin \: \theta $
${y}'= x \: sin \: \theta + \: y \: cos \: \theta $
Representando la ecuación anterior en forma de matriz,
$$[X' Y'] = [X Y] \begin{bmatrix} cos\theta & sin\theta \\ −sin\theta & cos\theta \end{bmatrix}OR $$
P '= P ∙ R
Donde R es la matriz de rotación
$$R = \begin{bmatrix} cos\theta & sin\theta \\ −sin\theta & cos\theta \end{bmatrix}$$
El ángulo de rotación puede ser positivo y negativo.
Para un ángulo de rotación positivo, podemos usar la matriz de rotación anterior. Sin embargo, para la rotación de ángulo negativo, la matriz cambiará como se muestra a continuación:
$$R = \begin{bmatrix} cos(−\theta) & sin(−\theta) \\ -sin(−\theta) & cos(−\theta) \end{bmatrix}$$
$$=\begin{bmatrix} cos\theta & −sin\theta \\ sin\theta & cos\theta \end{bmatrix} \left (\because cos(−\theta ) = cos \theta \; and\; sin(−\theta ) = −sin \theta \right )$$
Escalada
Para cambiar el tamaño de un objeto, se utiliza la transformación de escala. En el proceso de escalado, expande o comprime las dimensiones del objeto. La escala se puede lograr multiplicando las coordenadas originales del objeto con el factor de escala para obtener el resultado deseado.
Supongamos que las coordenadas originales son (X, Y), los factores de escala son (S X , S Y ) y las coordenadas producidas son (X ', Y'). Esto se puede representar matemáticamente como se muestra a continuación:
X' = X . SX and Y' = Y . SY
El factor de escala S X , S Y escala el objeto en la dirección X e Y respectivamente. Las ecuaciones anteriores también se pueden representar en forma de matriz como se muestra a continuación:
$$\binom{X'}{Y'} = \binom{X}{Y} \begin{bmatrix} S_{x} & 0\\ 0 & S_{y} \end{bmatrix}$$
O
P’ = P . S
Donde S es la matriz de escala. El proceso de escalado se muestra en la siguiente figura.
Si proporcionamos valores menores que 1 al factor de escala S, entonces podemos reducir el tamaño del objeto. Si proporcionamos valores mayores que 1, entonces podemos aumentar el tamaño del objeto.
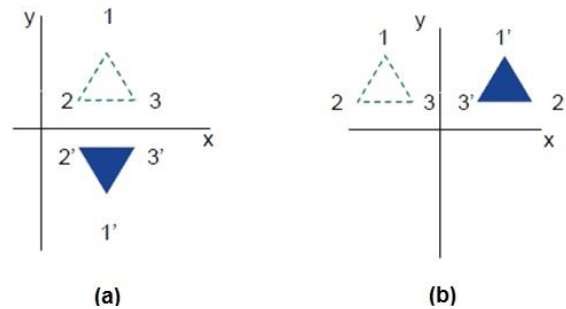
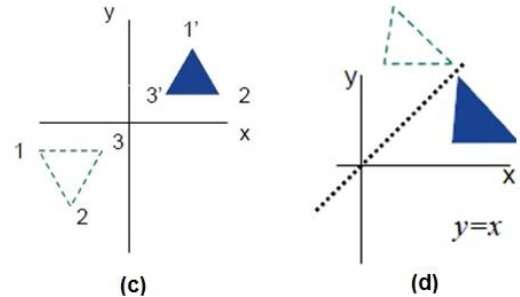
Reflexión
El reflejo es la imagen especular del objeto original. En otras palabras, podemos decir que es una operación de rotación con 180 °. En la transformación de reflexión, el tamaño del objeto no cambia.
Las siguientes figuras muestran reflexiones con respecto a los ejes X e Y, y sobre el origen respectivamente.
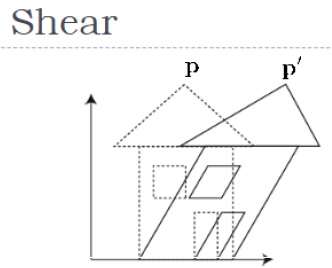
Cortar
Una transformación que inclina la forma de un objeto se llama transformación de corte. Hay dos transformaciones de corteX-Shear y Y-Shear. Uno cambia los valores de las coordenadas X y el otro cambia los valores de las coordenadas Y. Sin embargo; en ambos casos, sólo una coordenada cambia sus coordenadas y la otra conserva sus valores. El cizallamiento también se denominaSkewing.
X-Shear
El X-Shear conserva la coordenada Y y se realizan cambios en las coordenadas X, lo que hace que las líneas verticales se incline hacia la derecha o hacia la izquierda como se muestra en la siguiente figura.
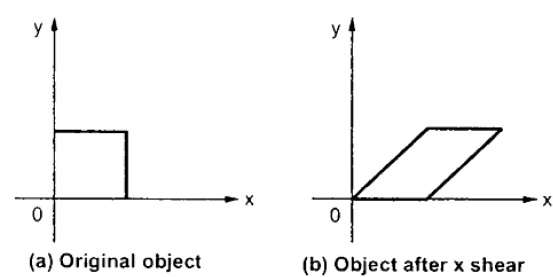
La matriz de transformación para X-Shear se puede representar como:
$$X_{sh} = \begin{bmatrix} 1& shx& 0\\ 0& 1& 0\\ 0& 0& 1 \end{bmatrix}$$
Y '= Y + Sh y . X
X '= X
Y-Shear
El Y-Shear conserva las coordenadas X y cambia las coordenadas Y, lo que hace que las líneas horizontales se transformen en líneas que se inclinan hacia arriba o hacia abajo como se muestra en la siguiente figura.
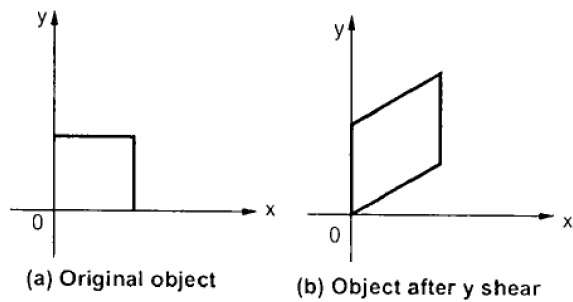
El corte en Y se puede representar en una matriz de la siguiente manera:
$$Y_{sh} \begin{bmatrix} 1& 0& 0\\ shy& 1& 0\\ 0& 0& 1 \end{bmatrix}$$
X '= X + Sh x . Y
Y '= Y
Transformación compuesta
Si una transformación del plano T1 va seguida de una transformación de segundo plano T2, entonces el resultado en sí mismo puede estar representado por una sola transformación T que es la composición de T1 y T2 tomadas en ese orden. Esto se escribe como T = T1 ∙ T2.
La transformación compuesta se puede lograr mediante la concatenación de matrices de transformación para obtener una matriz de transformación combinada.
Una matriz combinada -
[T][X] = [X] [T1] [T2] [T3] [T4] …. [Tn]
Donde [Ti] es cualquier combinación de
- Translation
- Scaling
- Shearing
- Rotation
- Reflection
El cambio en el orden de transformación daría lugar a resultados diferentes, ya que en general la multiplicación de matrices no es acumulativa, es decir [A]. [B] ≠ [B]. [A] y el orden de multiplicación. El propósito básico de componer transformaciones es ganar eficiencia aplicando una sola transformación compuesta a un punto, en lugar de aplicar una serie de transformaciones, una tras otra.
Por ejemplo, para rotar un objeto sobre un punto arbitrario (X p , Y p ), tenemos que realizar tres pasos:
- Traslade el punto (X p , Y p ) al origen.
- Gíralo sobre el origen.
- Finalmente, traslade el centro de rotación a donde pertenecía.
En el sistema 2D, usamos solo dos coordenadas X e Y, pero en 3D, se agrega una coordenada Z adicional. Las técnicas de gráficos 3D y su aplicación son fundamentales para las industrias del entretenimiento, los juegos y el diseño asistido por computadora. Es un área continua de investigación en visualización científica.
Además, los componentes de gráficos 3D son ahora parte de casi todas las computadoras personales y, aunque tradicionalmente estaban destinados a software de uso intensivo de gráficos, como juegos, otras aplicaciones los utilizan cada vez más.
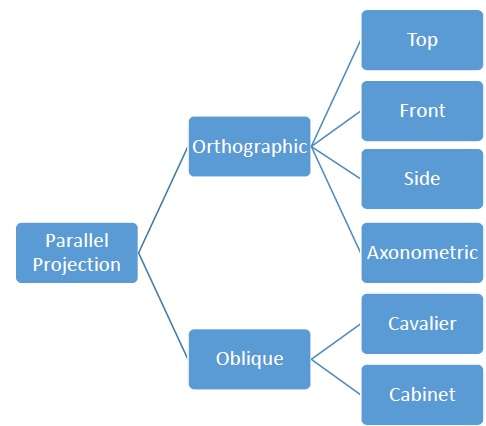
Proyección paralela
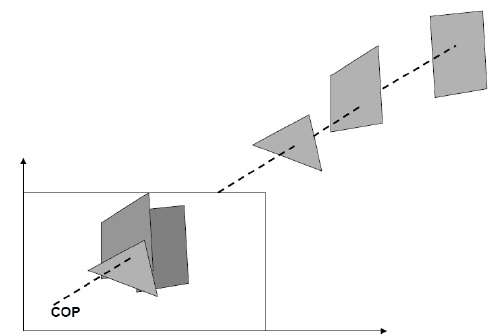
La proyección paralela descarta la coordenada zy las líneas paralelas de cada vértice del objeto se extienden hasta que intersecan el plano de vista. En la proyección paralela, especificamos una dirección de proyección en lugar del centro de proyección.
En proyección paralela, la distancia desde el centro de proyección al plano del proyecto es infinita. En este tipo de proyección, conectamos los vértices proyectados por segmentos de línea que corresponden a conexiones en el objeto original.
Las proyecciones paralelas son menos realistas, pero son buenas para medidas exactas. En este tipo de proyecciones, las líneas paralelas permanecen paralelas y los ángulos no se conservan. En la siguiente jerarquía se muestran varios tipos de proyecciones paralelas.
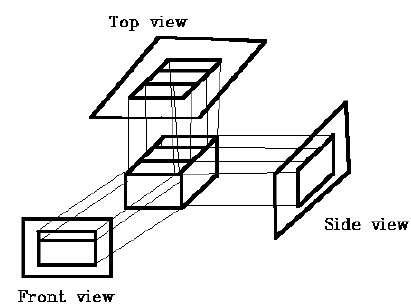
Proyección ortográfica
En la proyección ortográfica, la dirección de proyección es normal a la proyección del plano. Hay tres tipos de proyecciones ortográficas:
- Proyección frontal
- Proyección superior
- Proyección lateral
Proyección oblicua
En proyección oblicua, la dirección de proyección no es normal a la proyección del plano. En proyección oblicua, podemos ver el objeto mejor que en proyección ortográfica.
Hay dos tipos de proyecciones oblicuas: Cavalier y Cabinet. La proyección de Cavalier forma un ángulo de 45 ° con el plano de proyección. La proyección de una línea perpendicular al plano de la vista tiene la misma longitud que la línea misma en la proyección de Cavalier. En una proyección arrogante, los factores de escorzo para las tres direcciones principales son iguales.
La proyección del gabinete forma un ángulo de 63,4 ° con el plano de proyección. En la proyección de gabinete, las líneas perpendiculares a la superficie de visualización se proyectan a la mitad de su longitud real. Ambas proyecciones se muestran en la siguiente figura:

Proyecciones isométricas
Las proyecciones ortográficas que muestran más de un lado de un objeto se denominan axonometric orthographic projections. La proyección axonométrica más común es unaisometric projectiondonde el plano de proyección interseca cada eje de coordenadas en el sistema de coordenadas del modelo a la misma distancia. En esta proyección se conserva el paralelismo de líneas pero no se conservan los ángulos. La siguiente figura muestra una proyección isométrica:

Proyección en perspectiva
En la proyección en perspectiva, la distancia desde el centro de proyección al plano del proyecto es finita y el tamaño del objeto varía inversamente con la distancia, lo que parece más realista.
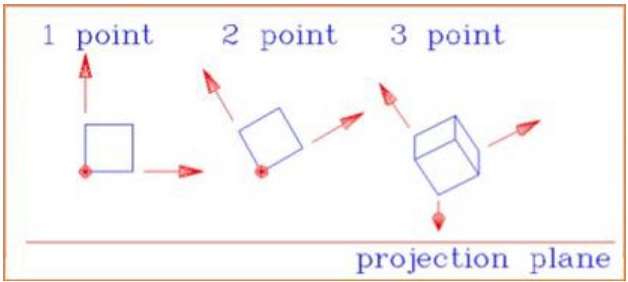
La distancia y los ángulos no se conservan y las líneas paralelas no permanecen paralelas. En cambio, todos convergen en un solo punto llamadocenter of projection o projection reference point. Hay 3 tipos de proyecciones en perspectiva que se muestran en el siguiente cuadro.
One point La proyección en perspectiva es fácil de dibujar.
Two point la proyección en perspectiva da una mejor impresión de profundidad.
Three point La proyección en perspectiva es más difícil de dibujar.
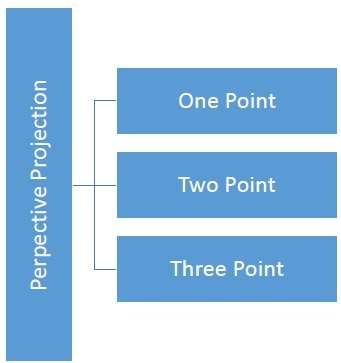
La siguiente figura muestra los tres tipos de proyección en perspectiva:
Traducción
En la traducción 3D, transferimos la coordenada Z junto con las coordenadas X e Y. El proceso de traducción en 3D es similar a la traducción en 2D. Una traducción mueve un objeto a una posición diferente en la pantalla.
La siguiente figura muestra el efecto de la traducción:
Un punto se puede traducir en 3D agregando coordenadas de traducción $(t_{x,} t_{y,} t_{z})$ a la coordenada original (X, Y, Z) para obtener la nueva coordenada (X ', Y', Z ').
$T = \begin{bmatrix} 1& 0& 0& 0\\ 0& 1& 0& 0\\ 0& 0& 1& 0\\ t_{x}& t_{y}& t_{z}& 1\\ \end{bmatrix}$
P '= P ∙ T
$[X′ \:\: Y′ \:\: Z′ \:\: 1] \: = \: [X \:\: Y \:\: Z \:\: 1] \: \begin{bmatrix} 1& 0& 0& 0\\ 0& 1& 0& 0\\ 0& 0& 1& 0\\ t_{x}& t_{y}& t_{z}& 1\\ \end{bmatrix}$
$= [X + t_{x} \:\:\: Y + t_{y} \:\:\: Z + t_{z} \:\:\: 1]$
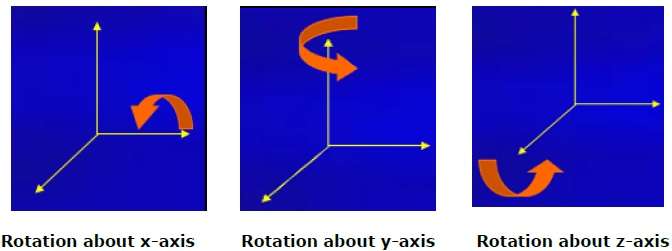
Rotación
La rotación 3D no es lo mismo que la rotación 2D. En la rotación 3D, tenemos que especificar el ángulo de rotación junto con el eje de rotación. Podemos realizar una rotación 3D sobre los ejes X, Y y Z. Están representados en forma de matriz como se muestra a continuación:
$$R_{x}(\theta) = \begin{bmatrix} 1& 0& 0& 0\\ 0& cos\theta & −sin\theta& 0\\ 0& sin\theta & cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix} R_{y}(\theta) = \begin{bmatrix} cos\theta& 0& sin\theta& 0\\ 0& 1& 0& 0\\ −sin\theta& 0& cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix} R_{z}(\theta) =\begin{bmatrix} cos\theta & −sin\theta & 0& 0\\ sin\theta & cos\theta & 0& 0\\ 0& 0& 1& 0\\ 0& 0& 0& 1 \end{bmatrix}$$
La siguiente figura explica la rotación sobre varios ejes:
Escalada
Puede cambiar el tamaño de un objeto mediante la transformación de escala. En el proceso de escalado, expande o comprime las dimensiones del objeto. La escala se puede lograr multiplicando las coordenadas originales del objeto con el factor de escala para obtener el resultado deseado. La siguiente figura muestra el efecto de la escala 3D:
En la operación de escalado 3D, se utilizan tres coordenadas. Supongamos que las coordenadas originales son (X, Y, Z), los factores de escala son$(S_{X,} S_{Y,} S_{z})$respectivamente, y las coordenadas producidas son (X ', Y', Z '). Esto se puede representar matemáticamente como se muestra a continuación:
$S = \begin{bmatrix} S_{x}& 0& 0& 0\\ 0& S_{y}& 0& 0\\ 0& 0& S_{z}& 0\\ 0& 0& 0& 1 \end{bmatrix}$
P '= P ∙ S
$[{X}' \:\:\: {Y}' \:\:\: {Z}' \:\:\: 1] = [X \:\:\:Y \:\:\: Z \:\:\: 1] \:\: \begin{bmatrix} S_{x}& 0& 0& 0\\ 0& S_{y}& 0& 0\\ 0& 0& S_{z}& 0\\ 0& 0& 0& 1 \end{bmatrix}$
$ = [X.S_{x} \:\:\: Y.S_{y} \:\:\: Z.S_{z} \:\:\: 1]$
Cortar
Una transformación que inclina la forma de un objeto se llama shear transformation. Al igual que en el corte 2D, podemos cortar un objeto a lo largo del eje X, eje Y o eje Z en 3D.
Como se muestra en la figura anterior, hay una coordenada P. Puede cortarla para obtener una nueva coordenada P ', que se puede representar en forma de matriz 3D como se muestra a continuación:
$Sh = \begin{bmatrix} 1 & sh_{x}^{y} & sh_{x}^{z} & 0 \\ sh_{y}^{x} & 1 & sh_{y}^{z} & 0 \\ sh_{z}^{x} & sh_{z}^{y} & 1 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}$
P '= P ∙ Sh
$X’ = X + Sh_{x}^{y} Y + Sh_{x}^{z} Z$
$Y' = Sh_{y}^{x}X + Y +sh_{y}^{z}Z$
$Z' = Sh_{z}^{x}X + Sh_{z}^{y}Y + Z$
Matrices de transformación
La matriz de transformación es una herramienta básica para la transformación. Una matriz con nxm dimensiones se multiplica por las coordenadas de los objetos. Por lo general, se utilizan matrices de 3 x 3 o 4 x 4 para la transformación. Por ejemplo, considere la siguiente matriz para varias operaciones.
| $T = \begin{bmatrix} 1& 0& 0& 0\\ 0& 1& 0& 0\\ 0& 0& 1& 0\\ t_{x}& t_{y}& t_{z}& 1\\ \end{bmatrix}$ | $S = \begin{bmatrix} S_{x}& 0& 0& 0\\ 0& S_{y}& 0& 0\\ 0& 0& S_{z}& 0\\ 0& 0& 0& 1 \end{bmatrix}$ | $Sh = \begin{bmatrix} 1& sh_{x}^{y}& sh_{x}^{z}& 0\\ sh_{y}^{x}& 1 & sh_{y}^{z}& 0\\ sh_{z}^{x}& sh_{z}^{y}& 1& 0\\ 0& 0& 0& 1 \end{bmatrix}$ |
| Translation Matrix | Scaling Matrix | Shear Matrix |
| $R_{x}(\theta) = \begin{bmatrix} 1& 0& 0& 0\\ 0& cos\theta & -sin\theta& 0\\ 0& sin\theta & cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix}$ | $R_{y}(\theta) = \begin{bmatrix} cos\theta& 0& sin\theta& 0\\ 0& 1& 0& 0\\ -sin\theta& 0& cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix}$ | $R_{z}(\theta) = \begin{bmatrix} cos\theta & -sin\theta & 0& 0\\ sin\theta & cos\theta & 0& 0\\ 0& 0& 1& 0\\ 0& 0& 0& 1 \end{bmatrix}$ |
| Rotation Matrix | ||
En los gráficos por computadora, a menudo necesitamos dibujar diferentes tipos de objetos en la pantalla. Los objetos no son planos todo el tiempo y necesitamos dibujar curvas muchas veces para dibujar un objeto.
Tipos de curvas
Una curva es un conjunto de puntos infinitamente grande. Cada punto tiene dos vecinos, excepto los extremos. Las curvas se pueden clasificar en tres categorías:explicit, implicit, y parametric curves.
Curvas implícitas
Las representaciones de curvas implícitas definen el conjunto de puntos en una curva mediante el empleo de un procedimiento que puede probar para ver si un punto está dentro de la curva. Por lo general, una curva implícita se define mediante una función implícita de la forma:
f (x, y) = 0
Puede representar curvas de varios valores (varios valores de y para un valor de x). Un ejemplo común es el círculo, cuya representación implícita es
x2 + y2 - R2 = 0
Curvas explícitas
Una función matemática y = f (x) se puede trazar como una curva. Tal función es la representación explícita de la curva. La representación explícita no es general, ya que no puede representar líneas verticales y también tiene un valor único. Para cada valor de x, la función normalmente calcula un único valor de y.
Curvas paramétricas
Las curvas que tienen forma paramétrica se denominan curvas paramétricas. Las representaciones de curvas explícitas e implícitas se pueden usar solo cuando se conoce la función. En la práctica se utilizan las curvas paramétricas. Una curva paramétrica bidimensional tiene la siguiente forma:
P (t) = f (t), g (t) o P (t) = x (t), y (t)
Las funciones fyg se convierten en las coordenadas (x, y) de cualquier punto de la curva, y los puntos se obtienen cuando el parámetro t se varía en un cierto intervalo [a, b], normalmente [0, 1].
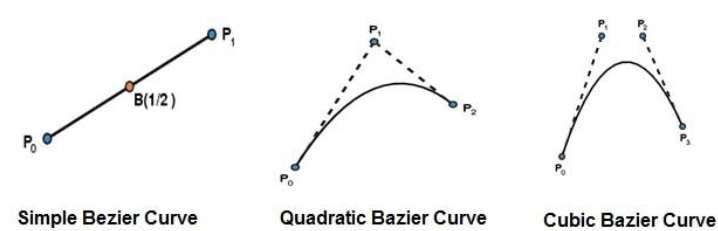
Curvas de Bezier
La curva de Bezier es descubierta por el ingeniero francés Pierre Bézier. Estas curvas se pueden generar bajo el control de otros puntos. Las tangentes aproximadas mediante el uso de puntos de control se utilizan para generar la curva. La curva de Bezier se puede representar matemáticamente como:
$$\sum_{k=0}^{n} P_{i}{B_{i}^{n}}(t)$$
Dónde $p_{i}$ es el conjunto de puntos y ${B_{i}^{n}}(t)$ representa los polinomios de Bernstein que están dados por -
$${B_{i}^{n}}(t) = \binom{n}{i} (1 - t)^{n-i}t^{i}$$
Dónde n es el grado del polinomio, i es el índice, y t es la variable.
La curva de Bézier más simple es la línea recta desde el punto $P_{0}$ a $P_{1}$. Una curva de Bézier cuadrática está determinada por tres puntos de control. Una curva de Bézier cúbica está determinada por cuatro puntos de control.
Propiedades de las curvas de Bezier
Las curvas de Bézier tienen las siguientes propiedades:
Generalmente siguen la forma del polígono de control, que consiste en los segmentos que unen los puntos de control.
Siempre pasan por el primer y último punto de control.
Están contenidos en el casco convexo de los puntos de control que los definen.
El grado del polinomio que define el segmento de la curva es uno menos que el número de puntos que definen el polígono. Por lo tanto, para 4 puntos de control, el grado del polinomio es 3, es decir, polinomio cúbico.
Una curva de Bezier generalmente sigue la forma del polígono que la define.
La dirección del vector tangente en los puntos finales es la misma que la del vector determinado por el primer y último segmento.
La propiedad de casco convexo para una curva de Bezier asegura que el polinomio siga suavemente los puntos de control.
Ninguna línea recta interseca una curva de Bézier más veces de las que intersecta su polígono de control.
Son invariantes bajo una transformación afín.
Las curvas de Bézier exhiben un control global significa que mover un punto de control altera la forma de toda la curva.
Una curva de Bezier dada se puede subdividir en un punto t = t0 en dos segmentos de Bezier que se unen en el punto correspondiente al valor del parámetro t = t0.
Curvas B-Spline
La curva de Bezier producida por la función de base de Bernstein tiene una flexibilidad limitada.
Primero, el número de vértices de polígono especificado fija el orden del polinomio resultante que define la curva.
La segunda característica limitante es que el valor de la función de combinación es distinto de cero para todos los valores de los parámetros en toda la curva.
La base B-spline contiene la base de Bernstein como caso especial. La base de B-spline no es global.
Una curva B-spline se define como una combinación lineal de puntos de control Pi y función básica B-spline $N_{i,}$ k (t) dado por
$C(t) = \sum_{i=0}^{n}P_{i}N_{i,k}(t),$ $n\geq k-1,$ $t\: \epsilon \: [ tk-1,tn+1 ]$
Dónde,
{$p_{i}$: i = 0, 1, 2… .n} son los puntos de control
k es el orden de los segmentos polinomiales de la curva B-spline. El orden k significa que la curva está formada por segmentos polinomiales por partes de grado k - 1,
la $N_{i,k}(t)$son las "funciones de combinación B-spline normalizadas". Se describen por el orden ky por una secuencia no decreciente de números reales normalmente llamada "secuencia de nudos".
$${t_{i}:i = 0, ... n + K}$$
Las funciones N i , k se describen a continuación:
$$N_{i,1}(t) = \left\{\begin{matrix} 1,& if \:u \: \epsilon \: [t_{i,}t_{i+1}) \\ 0,& Otherwise \end{matrix}\right.$$
y si k> 1,
$$N_{i,k}(t) = \frac{t-t_{i}}{t_{i+k-1}} N_{i,k-1}(t) + \frac{t_{i+k}-t}{t_{i+k} - t_{i+1}} N_{i+1,k-1}(t)$$
y
$$t \: \epsilon \: [t_{k-1},t_{n+1})$$
Propiedades de la curva B-spline
Las curvas B-spline tienen las siguientes propiedades:
La suma de las funciones básicas de B-spline para cualquier valor de parámetro es 1.
Cada función básica es positiva o cero para todos los valores de los parámetros.
Cada función base tiene precisamente un valor máximo, excepto k = 1.
El orden máximo de la curva es igual al número de vértices del polígono de definición.
El grado del polinomio B-spline es independiente del número de vértices del polígono de definición.
B-spline permite el control local sobre la superficie de la curva porque cada vértice afecta la forma de una curva solo en un rango de valores de parámetros donde su función base asociada es distinta de cero.
La curva exhibe la propiedad de disminución de la variación.
La curva generalmente sigue la forma de definir el polígono.
Cualquier transformación afín se puede aplicar a la curva aplicándola a los vértices del polígono de definición.
La línea curva dentro del casco convexo de su polígono definitorio.
Superficies poligonales
Los objetos se representan como una colección de superficies. La representación de objetos 3D se divide en dos categorías.
Boundary Representations (B-reps) - Describe un objeto 3D como un conjunto de superficies que separa el interior del objeto del entorno.
Space–partitioning representations - Se utiliza para describir propiedades interiores, al dividir la región espacial que contiene un objeto en un conjunto de sólidos contiguos pequeños, no superpuestos (generalmente cubos).
La representación de límites más utilizada para un objeto de gráficos 3D es un conjunto de polígonos de superficie que encierran el interior del objeto. Muchos sistemas gráficos utilizan este método. El conjunto de polígonos se almacena para la descripción del objeto. Esto simplifica y acelera la representación de la superficie y la visualización del objeto, ya que todas las superficies se pueden describir con ecuaciones lineales.
Las superficies poligonales son comunes en aplicaciones de diseño y modelado de sólidos, ya que su wireframe displayse puede hacer rápidamente para dar una indicación general de la estructura de la superficie. Luego, se producen escenas realistas interpolando patrones de sombreado en la superficie del polígono para iluminar.
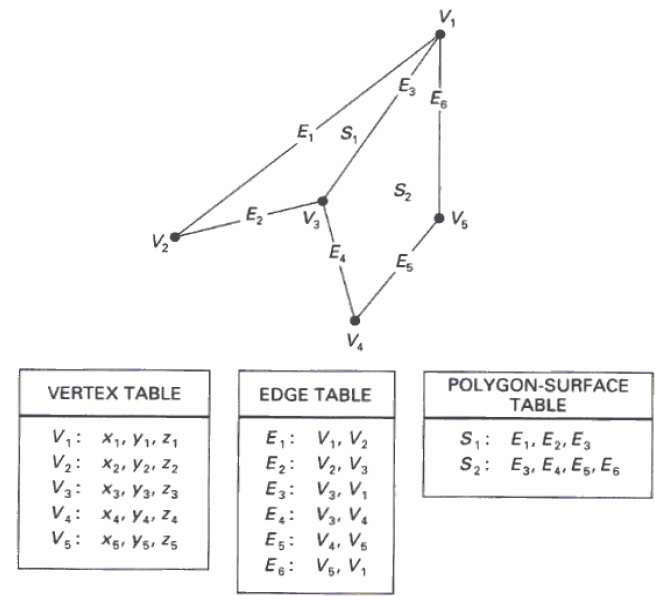
Tablas de polígono
En este método, la superficie se especifica mediante el conjunto de coordenadas de vértice y atributos asociados. Como se muestra en la siguiente figura, hay cinco vértices, desde v 1 hasta v 5 .
Cada vértice almacena información de las coordenadas x, y y z que se representa en la tabla como v 1 : x 1 , y 1 , z 1 .
La tabla Edge se utiliza para almacenar la información del borde del polígono. En la siguiente figura, el borde E 1 se encuentra entre el vértice v 1 y v 2, que se representa en la tabla como E 1 : v 1 , v 2 .
La tabla de superficies de polígono almacena el número de superficies presentes en el polígono. En la siguiente figura, la superficie S 1 está cubierta por los bordes E 1 , E 2 y E 3 que se pueden representar en la tabla de superficies poligonales como S 1 : E 1 , E 2 y E 3 .
Ecuaciones planas
La ecuación para la superficie plana se puede expresar como:
Ax + Por + Cz + D = 0
Donde (x, y, z) es cualquier punto del plano y los coeficientes A, B, C y D son constantes que describen las propiedades espaciales del plano. Podemos obtener los valores de A, B, C y D resolviendo un conjunto de ecuaciones de tres planos usando los valores de coordenadas para tres puntos no colineales en el plano. Supongamos que tres vértices del plano son (x 1 , y 1 , z 1 ), (x 2 , y 2 , z 2 ) y (x 3 , y 3 , z 3 ).
Resolvamos las siguientes ecuaciones simultáneas para las relaciones A / D, B / D y C / D. Obtienes los valores de A, B, C y D.
(A / D) x 1 + (B / D) y 1 + (C / D) z 1 = -1
(A / D) x 2 + (B / D) y 2 + (C / D) z 2 = -1
(A / D) x 3 + (B / D) y 3 + (C / D) z 3 = -1
Para obtener las ecuaciones anteriores en forma determinante, aplique la regla de Cramer a las ecuaciones anteriores.
$A = \begin{bmatrix} 1& y_{1}& z_{1}\\ 1& y_{2}& z_{2}\\ 1& y_{3}& z_{3} \end{bmatrix} B = \begin{bmatrix} x_{1}& 1& z_{1}\\ x_{2}& 1& z_{2}\\ x_{3}& 1& z_{3} \end{bmatrix} C = \begin{bmatrix} x_{1}& y_{1}& 1\\ x_{2}& y_{2}& 1\\ x_{3}& y_{3}& 1 \end{bmatrix} D = - \begin{bmatrix} x_{1}& y_{1}& z_{1}\\ x_{2}& y_{2}& z_{2}\\ x_{3}& y_{3}& z_{3} \end{bmatrix}$
Para cualquier punto (x, y, z) con los parámetros A, B, C y D, podemos decir que:
Ax + By + Cz + D ≠ 0 significa que el punto no está en el plano.
Ax + By + Cz + D <0 significa que el punto está dentro de la superficie.
Ax + By + Cz + D> 0 significa que el punto está fuera de la superficie.
Mallas poligonales
Las superficies 3D y los sólidos se pueden aproximar mediante un conjunto de elementos poligonales y lineales. Tales superficies se llamanpolygonal meshes. En la malla poligonal, cada borde es compartido por dos polígonos como máximo. El conjunto de polígonos o caras, juntos forman la "piel" del objeto.
Este método se puede utilizar para representar una amplia clase de sólidos / superficies en gráficos. Una malla poligonal se puede renderizar utilizando algoritmos de eliminación de superficies ocultas. La malla poligonal se puede representar de tres formas:
- Representación explícita
- Punteros a una lista de vértices
- Punteros a una lista de bordes
Ventajas
- Se puede utilizar para modelar casi cualquier objeto.
- Son fáciles de representar como una colección de vértices.
- Son fáciles de transformar.
- Son fáciles de dibujar en la pantalla de la computadora.
Desventajas
- Las superficies curvas solo se pueden describir de forma aproximada.
- Es difícil simular algún tipo de objetos como cabello o líquido.
Cuando vemos una imagen que contiene objetos y superficies no transparentes, no podemos ver esos objetos de la vista que están detrás de los objetos más cercanos al ojo. Debemos eliminar estas superficies ocultas para obtener una imagen de pantalla realista. La identificación y eliminación de estas superficies se denominaHidden-surface problem.
Hay dos enfoques para eliminar los problemas de superficies ocultas: Object-Space method y Image-space method. El método de espacio de objetos se implementa en un sistema de coordenadas físico y el método de espacio de imagen se implementa en un sistema de coordenadas de pantalla.
Cuando queremos mostrar un objeto 3D en una pantalla 2D, necesitamos identificar aquellas partes de una pantalla que son visibles desde una posición de visualización elegida.
Método de búfer de profundidad (búfer Z)
Este método es desarrollado por Cutmull. Es un enfoque de espacio de imagen. La idea básica es probar la profundidad Z de cada superficie para determinar la superficie más cercana (visible).
En este método, cada superficie se procesa por separado, una posición de píxel a la vez en la superficie. Se comparan los valores de profundidad de un píxel y la superficie más cercana (z más pequeña) determina el color que se mostrará en el búfer de fotogramas.
Se aplica de manera muy eficiente en superficies de polígono. Las superficies se pueden procesar en cualquier orden. Para anular los polígonos más cercanos de los lejanos, dos búferes denominadosframe buffer y depth buffer, son usados.
Depth buffer se utiliza para almacenar valores de profundidad para la posición (x, y), a medida que se procesan las superficies (0 ≤ profundidad ≤ 1).
los frame buffer se utiliza para almacenar el valor de intensidad del valor de color en cada posición (x, y).
Las coordenadas z normalmente se normalizan al rango [0, 1]. El valor 0 para la coordenada z indica el panel de recorte posterior y el valor 1 para las coordenadas z indica el panel de recorte frontal.
Algoritmo
Step-1 - Establecer los valores del búfer -
Depthbuffer (x, y) = 0
Framebuffer (x, y) = color de fondo
Step-2 - Procesar cada polígono (uno a la vez)
Para cada posición de píxel proyectada (x, y) de un polígono, calcule la profundidad z.
Si Z> búfer de profundidad (x, y)
Calcular el color de la superficie,
establecer el búfer de profundidad (x, y) = z,
framebuffer (x, y) = surfacecolor (x, y)
Ventajas
- Es fácil de implementar.
- Reduce el problema de velocidad si se implementa en hardware.
- Procesa un objeto a la vez.
Desventajas
- Requiere mucha memoria.
- Es un proceso que requiere mucho tiempo.
Método de línea de escaneo
Es un método de espacio de imagen para identificar la superficie visible. Este método tiene información de profundidad para una sola línea de exploración. Para requerir una línea de exploración de valores de profundidad, debemos agrupar y procesar todos los polígonos que cruzan una línea de exploración dada al mismo tiempo antes de procesar la siguiente línea de exploración. Dos tablas importantes,edge table y polygon table, se mantienen para esto.
The Edge Table - Contiene puntos finales de coordenadas de cada línea en la escena, la pendiente inversa de cada línea y punteros en la tabla de polígono para conectar los bordes a las superficies.
The Polygon Table - Contiene los coeficientes del plano, las propiedades del material de la superficie, otros datos de la superficie y pueden ser indicadores de la tabla de bordes.

Para facilitar la búsqueda de superficies que cruzan una línea de exploración determinada, se forma una lista activa de bordes. La lista activa almacena solo aquellos bordes que cruzan la línea de exploración en orden creciente de x. También se establece una bandera para cada superficie para indicar si una posición a lo largo de una línea de exploración está dentro o fuera de la superficie.
Las posiciones de los píxeles en cada línea de exploración se procesan de izquierda a derecha. En la intersección izquierda con una superficie, la bandera de superficie se enciende y en la derecha, la bandera se apaga. Solo necesita realizar cálculos de profundidad cuando varias superficies tienen sus indicadores encendidos en una determinada posición de línea de exploración.
Método de subdivisión de área
El método de subdivisión de áreas aprovecha la ubicación de las áreas de visualización que representan parte de una sola superficie. Divida el área de visualización total en rectángulos cada vez más pequeños hasta que cada área pequeña sea la proyección de parte de una única superficie visible o ninguna superficie.
Continúe este proceso hasta que las subdivisiones se analicen fácilmente como pertenecientes a una sola superficie o hasta que se reduzcan al tamaño de un solo píxel. Una forma sencilla de hacerlo es dividir sucesivamente el área en cuatro partes iguales en cada paso. Hay cuatro relaciones posibles que puede tener una superficie con un límite de área específico.
Surrounding surface - Uno que encierra completamente el área.
Overlapping surface - Uno que esté en parte dentro y en parte fuera del área.
Inside surface - Uno que esté completamente dentro del área.
Outside surface - Uno que esté completamente fuera del área.
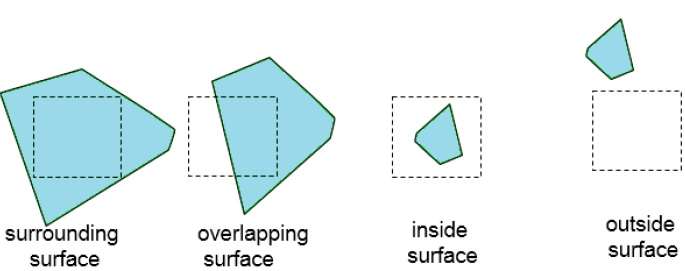
Las pruebas para determinar la visibilidad de la superficie dentro de un área se pueden establecer en términos de estas cuatro clasificaciones. No se necesitan más subdivisiones de un área específica si se cumple una de las siguientes condiciones:
- Todas las superficies son superficies exteriores con respecto al área.
- Solo hay una superficie interior, superpuesta o circundante en el área.
- Una superficie circundante oscurece todas las demás superficies dentro de los límites del área.
Detección de cara trasera
Un método de espacio de objetos rápido y simple para identificar las caras posteriores de un poliedro se basa en las pruebas "de adentro hacia afuera". Un punto (x, y, z) está "dentro" de una superficie poligonal con parámetros planos A, B, C y D si Cuando un punto interior está a lo largo de la línea de visión hacia la superficie, el polígono debe ser una cara posterior ( estamos dentro de esa cara y no podemos ver el frente desde nuestra posición de visualización).
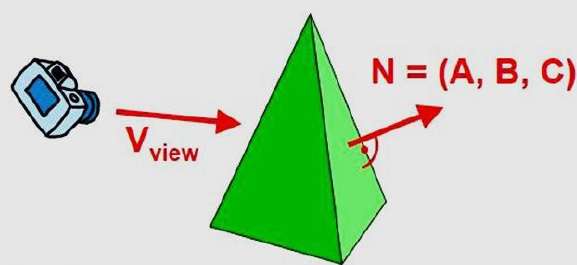
Podemos simplificar esta prueba considerando el vector normal N a una superficie poligonal, que tiene componentes cartesianos (A, B, C).
En general, si V es un vector en la dirección de visualización desde la posición del ojo (o "cámara"), entonces este polígono es una cara posterior si
V.N > 0
Además, si las descripciones de los objetos se convierten en coordenadas de proyección y la dirección de visualización es paralela al eje z de visualización, entonces:
V = (0, 0, V z ) y V.N = V Z C
De modo que solo debemos considerar el signo de C como la componente del vector normal N.
En un sistema de visualización para diestros con dirección de visualización a lo largo del negativo $Z_{V}$eje, el polígono es una cara posterior si C <0. Además, no podemos ver ninguna cara cuya normal tenga el componente z C = 0, ya que su dirección de visión es hacia ese polígono. Por lo tanto, en general, podemos etiquetar cualquier polígono como una cara posterior si su vector normal tiene un valor de componente az:
C <= 0
Se pueden utilizar métodos similares en paquetes que emplean un sistema de visualización para zurdos. En estos paquetes, los parámetros de plano A, B, C y D se pueden calcular a partir de las coordenadas de los vértices del polígono especificadas en el sentido de las agujas del reloj (a diferencia de la dirección en sentido contrario a las agujas del reloj utilizada en un sistema para diestros).
Además, las caras posteriores tienen vectores normales que apuntan en sentido contrario a la posición de visualización y se identifican con C> = 0 cuando la dirección de visualización es a lo largo de la posición positiva. $Z_{v}$eje. Al examinar el parámetro C para los diferentes planos que definen un objeto, podemos identificar inmediatamente todas las caras posteriores.
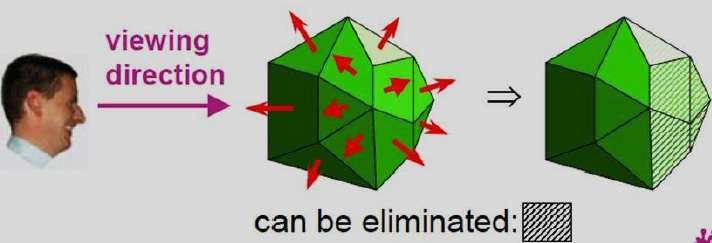
Método de tampón A
El método de búfer A es una extensión del método de búfer de profundidad. El método A-buffer es un método de detección de visibilidad desarrollado en Lucas Film Studios para el sistema de renderizado Renders Everything You Ever Saw (REYES).
El búfer A amplía el método del búfer de profundidad para permitir transparencias. La estructura de datos clave en el búfer A es el búfer de acumulación.
Cada posición en el búfer A tiene dos campos:
Depth field - Almacena un número real positivo o negativo
Intensity field - Almacena información sobre la intensidad de la superficie o un valor de puntero

Si profundidad> = 0, el número almacenado en esa posición es la profundidad de una sola superficie que se superpone al área de píxeles correspondiente. El campo de intensidad luego almacena los componentes RGB del color de la superficie en ese punto y el porcentaje de cobertura de píxeles.
Si la profundidad <0, indica contribuciones de múltiples superficies a la intensidad del píxel. El campo de intensidad luego almacena un puntero a una lista vinculada de datos de superficie. El búfer de superficie en el búfer A incluye:
- Componentes de intensidad RGB
- Parámetro de opacidad
- Depth
- Porcentaje de cobertura de área
- Identificador de superficie
El algoritmo procede como el algoritmo de búfer de profundidad. Los valores de profundidad y opacidad se utilizan para determinar el color final de un píxel.
Método de clasificación por profundidad
El método de clasificación de profundidad utiliza operaciones de espacio de imagen y espacio de objeto. El método de clasificación en profundidad realiza dos funciones básicas:
Primero, las superficies se clasifican en orden decreciente de profundidad.
En segundo lugar, las superficies se escanean y se convierten en orden, comenzando por la superficie de mayor profundidad.
La conversión de escaneo de las superficies poligonales se realiza en el espacio de la imagen. Este método para resolver el problema de la superficie oculta a menudo se denominapainter's algorithm. La siguiente figura muestra el efecto de la clasificación en profundidad:
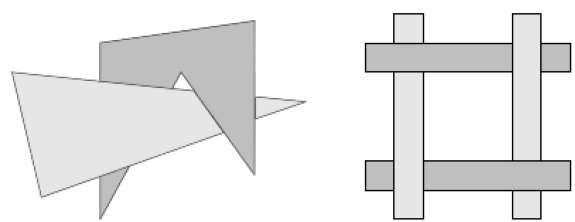
El algoritmo comienza ordenando por profundidad. Por ejemplo, la estimación de la "profundidad" inicial de un polígono puede tomarse como el valor z más cercano de cualquier vértice del polígono.
Tomemos el polígono P al final de la lista. Considere todos los polígonos Q cuyas extensiones z se superponen a P. Antes de dibujar P, realizamos las siguientes pruebas. Si alguna de las siguientes pruebas es positiva, podemos suponer que P se puede dibujar antes que Q.
- ¿No se superponen las extensiones x?
- ¿No se superponen las extensiones y?
- ¿Está P completamente en el lado opuesto del plano de Q desde el punto de vista?
- ¿Está Q completamente en el mismo lado del plano de P que el punto de vista?
- ¿No se superponen las proyecciones de los polígonos?
Si todas las pruebas fallan, entonces dividimos P o Q usando el plano del otro. Los nuevos polígonos de corte se insertan en el orden de profundidad y el proceso continúa. Teóricamente, esta partición podría generar O (n 2 ) polígonos individuales, pero en la práctica, el número de polígonos es mucho menor.
Árboles de partición de espacio binario (BSP)
La partición del espacio binario se utiliza para calcular la visibilidad. Para construir los árboles BSP, se debe comenzar con polígonos y etiquetar todos los bordes. Trabajando solo con un borde a la vez, extienda cada borde de modo que divida el plano en dos. Coloque el primer borde del árbol como raíz. Agregue aristas posteriores en función de si están adentro o afuera. Los bordes que abarcan la extensión de un borde que ya está en el árbol se dividen en dos y ambos se agregan al árbol.

De la figura anterior, primero tome A como raíz.
Haga una lista de todos los nodos en la figura (a).
Pon todos los nodos que están delante de root A al lado izquierdo del nodo A y poner todos esos nodos que están detrás de la raíz A hacia el lado derecho como se muestra en la figura (b).
Procese primero todos los nodos frontales y luego los nodos posteriores.
Como se muestra en la figura (c), primero procesaremos el nodo B. Como no hay nada frente al nodoB, hemos puesto NIL. Sin embargo, tenemos nodoC en la parte posterior del nodo B, entonces nodo C irá al lado derecho del nodo B.
Repite el mismo proceso para el nodo. D.
Un matemático franco-estadounidense, el Dr. Benoit Mandelbrot, descubrió los fractales. La palabra fractal se deriva de una palabra latina fractus que significa roto.
¿Qué son los fractales?
Los fractales son imágenes muy complejas generadas por una computadora a partir de una sola fórmula. Se crean mediante iteraciones. Esto significa que una fórmula se repite con valores ligeramente diferentes una y otra vez, teniendo en cuenta los resultados de la iteración anterior.
Los fractales se utilizan en muchas áreas, como:
Astronomy - Para analizar galaxias, anillos de Saturno, etc.
Biology/Chemistry - Para representar cultivos de bacterias, reacciones químicas, anatomía humana, moléculas, plantas,
Others - Para representar nubes, costas y fronteras, compresión de datos, difusión, economía, arte fractal, música fractal, paisajes, efectos especiales, etc.

Generación de fractales
Los fractales se pueden generar repitiendo la misma forma una y otra vez, como se muestra en la siguiente figura. En la figura (a) se muestra un triángulo equilátero. En la figura (b), podemos ver que el triángulo se repite para crear una forma de estrella. En la figura (c), podemos ver que la forma de estrella en la figura (b) se repite una y otra vez para crear una nueva forma.
Podemos hacer un número ilimitado de iteraciones para crear la forma deseada. En términos de programación, la recursividad se usa para crear tales formas.

Fractales Geométricos
Los fractales geométricos tratan con formas que se encuentran en la naturaleza y que tienen dimensiones fractales o no enteras. Para construir geométricamente un fractal auto-similar determinista (no aleatorio), comenzamos con una forma geométrica dada, llamadainitiator. Las subpartes del iniciador se reemplazan luego con un patrón, llamadogenerator.

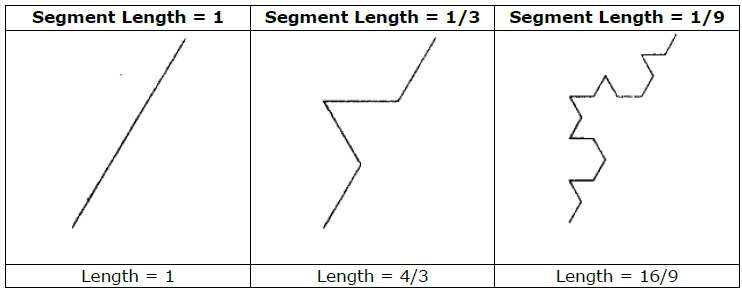
Como ejemplo, si usamos el iniciador y el generador que se muestran en la figura anterior, podemos construir un buen patrón repitiéndolo. Cada segmento de línea recta en el iniciador se reemplaza con cuatro segmentos de línea de igual longitud en cada paso. El factor de escala es 1/3, por lo que la dimensión fractal es D = ln 4 / ln 3 ≈ 1.2619.
Además, la longitud de cada segmento de línea en el iniciador aumenta en un factor de 4/3 en cada paso, de modo que la longitud de la curva fractal tiende al infinito a medida que se agregan más detalles a la curva como se muestra en la siguiente figura:
La animación significa dar vida a cualquier objeto en gráficos por computadora. Tiene el poder de inyectar energía y emociones en los objetos aparentemente inanimados. La animación asistida por computadora y la animación generada por computadora son dos categorías de animación por computadora. Puede presentarse mediante película o video.
La idea básica detrás de la animación es reproducir las imágenes grabadas a una velocidad lo suficientemente rápida como para engañar al ojo humano para que las interprete como un movimiento continuo. La animación puede hacer que una serie de imágenes muertas cobren vida. La animación se puede utilizar en muchas áreas como entretenimiento, diseño asistido por computadora, visualización científica, capacitación, educación, comercio electrónico y arte por computadora.
Técnicas de animación
Los animadores han inventado y utilizado una variedad de técnicas de animación diferentes. Básicamente, hay seis técnicas de animación que discutiremos una por una en esta sección.
Animación tradicional (cuadro por cuadro)
Tradicionalmente, la mayor parte de la animación se hacía a mano. Todos los fotogramas de una animación tenían que dibujarse a mano. Dado que cada segundo de animación requiere 24 fotogramas (película), la cantidad de esfuerzos necesarios para crear incluso las películas más cortas puede ser enorme.
Fotogramas clave
En esta técnica, se establece un guión gráfico y luego los artistas dibujan los cuadros principales de la animación. Los marcos principales son aquellos en los que se producen cambios importantes. Son los puntos clave de la animación. El fotograma clave requiere que el animador especifique posiciones críticas o clave para los objetos. Luego, la computadora completa automáticamente los fotogramas faltantes interpolando suavemente entre esas posiciones.
Procesal
En una animación de procedimiento, los objetos se animan mediante un procedimiento, un conjunto de reglas, no mediante fotogramas clave. El animador especifica reglas y condiciones iniciales y ejecuta la simulación. Las reglas a menudo se basan en reglas físicas del mundo real expresadas por ecuaciones matemáticas.
Conductual
En la animación conductual, un personaje autónomo determina sus propias acciones, al menos hasta cierto punto. Esto le da al personaje cierta habilidad para improvisar y libera al animador de la necesidad de especificar cada detalle del movimiento de cada personaje.
Basado en rendimiento (captura de movimiento)
Otra técnica es la captura de movimiento, en la que sensores magnéticos o basados en la visión registran las acciones de un objeto humano o animal en tres dimensiones. Luego, una computadora usa estos datos para animar el objeto.
Esta tecnología ha permitido a varios atletas famosos suministrar las acciones de los personajes en los videojuegos deportivos. La captura de movimiento es bastante popular entre los animadores principalmente porque algunas de las acciones humanas comunes se pueden capturar con relativa facilidad. Sin embargo, puede haber serias discrepancias entre las formas o dimensiones del sujeto y el carácter gráfico y esto puede conducir a problemas de ejecución exacta.
Basado físicamente (dinámica)
A diferencia del encuadre clave y la imagen en movimiento, la simulación utiliza las leyes de la física para generar movimiento de imágenes y otros objetos. Las simulaciones se pueden utilizar fácilmente para producir secuencias ligeramente diferentes manteniendo el realismo físico. En segundo lugar, las simulaciones en tiempo real permiten un mayor grado de interactividad donde la persona real puede maniobrar las acciones del personaje simulado.
Por el contrario, las aplicaciones basadas en el encuadre clave y el movimiento de selección y modificación de movimientos forman una biblioteca de movimientos precalculada. Un inconveniente que adolece de la simulación es la experiencia y el tiempo necesarios para crear los sistemas de control adecuados.
Encuadre clave
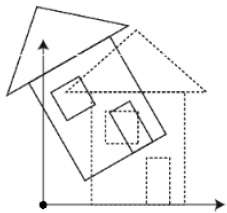
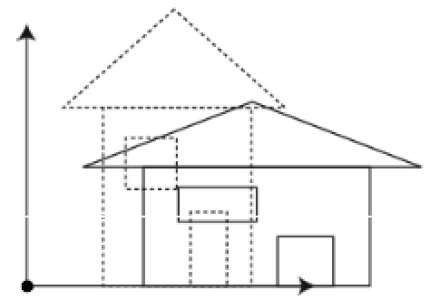
Un fotograma clave es un fotograma donde definimos cambios en la animación. Cada fotograma es un fotograma clave cuando creamos una animación fotograma a fotograma. Cuando alguien crea una animación 3D en una computadora, generalmente no especifica la posición exacta de un objeto dado en cada fotograma. Crean fotogramas clave.
Los fotogramas clave son fotogramas importantes durante los cuales un objeto cambia de tamaño, dirección, forma u otras propiedades. Luego, la computadora calcula todos los fotogramas intermedios y ahorra una cantidad extrema de tiempo para el animador. Las siguientes ilustraciones representan los marcos dibujados por el usuario y los marcos generados por computadora.


Morphing
The transformation of object shapes from one form to another form is called morphing. It is one of the most complicated transformations.

A morph looks as if two images melt into each other with a very fluid motion. In technical terms, two images are distorted and a fade occurs between them.