DAA - Guía rápida
Un algoritmo es un conjunto de pasos de operaciones para resolver un problema realizando tareas de cálculo, procesamiento de datos y razonamiento automatizado. Un algoritmo es un método eficiente que se puede expresar en una cantidad finita de tiempo y espacio.
Un algoritmo es la mejor manera de representar la solución de un problema en particular de una manera muy simple y eficiente. Si tenemos un algoritmo para un problema específico, entonces podemos implementarlo en cualquier lenguaje de programación, lo que significa que elalgorithm is independent from any programming languages.
Diseño de algoritmos
Los aspectos importantes del diseño de algoritmos incluyen la creación de un algoritmo eficiente para resolver un problema de manera eficiente utilizando el mínimo de tiempo y espacio.
Para resolver un problema, se pueden seguir diferentes enfoques. Algunos de ellos pueden ser eficientes con respecto al consumo de tiempo, mientras que otros enfoques pueden ser eficientes en memoria. Sin embargo, hay que tener en cuenta que tanto el consumo de tiempo como el uso de memoria no se pueden optimizar simultáneamente. Si necesitamos que un algoritmo se ejecute en menos tiempo, tenemos que invertir en más memoria y si necesitamos que un algoritmo se ejecute con menos memoria, necesitamos tener más tiempo.
Pasos para el desarrollo del problema
Los siguientes pasos están involucrados en la resolución de problemas computacionales.
- Definición del problema
- Desarrollo de un modelo
- Especificación de un algoritmo
- Diseñar un algoritmo
- Comprobación de la corrección de un algoritmo
- Análisis de un algoritmo
- Implementación de un algoritmo
- Prueba del programa
- Documentation
Características de los algoritmos
Las principales características de los algoritmos son las siguientes:
Los algoritmos deben tener un nombre único
Los algoritmos deben tener un conjunto definido explícitamente de entradas y salidas
Los algoritmos están bien ordenados con operaciones inequívocas
Los algoritmos se detienen en un período de tiempo finito. Los algoritmos no deben ejecutarse hasta el infinito, es decir, un algoritmo debe terminar en algún punto
Pseudocódigo
El pseudocódigo proporciona una descripción de alto nivel de un algoritmo sin la ambigüedad asociada con el texto plano, pero también sin la necesidad de conocer la sintaxis de un lenguaje de programación en particular.
El tiempo de ejecución se puede estimar de una manera más general utilizando pseudocódigo para representar el algoritmo como un conjunto de operaciones fundamentales que luego se pueden contar.
Diferencia entre algoritmo y pseudocódigo
Un algoritmo es una definición formal con algunas características específicas que describe un proceso, que podría ser ejecutado por una computadora completa de Turing para realizar una tarea específica. Generalmente, la palabra "algoritmo" se puede utilizar para describir cualquier tarea de alto nivel en informática.
Por otro lado, el pseudocódigo es una descripción informal y (a menudo rudimentaria) legible por humanos de un algoritmo que deja muchos detalles granulares del mismo. Escribir un pseudocódigo no tiene restricciones de estilos y su único objetivo es describir los pasos de alto nivel del algoritmo de una manera muy realista en lenguaje natural.
Por ejemplo, a continuación se muestra un algoritmo para la ordenación por inserción.
Algorithm: Insertion-Sort
Input: A list L of integers of length n
Output: A sorted list L1 containing those integers present in L
Step 1: Keep a sorted list L1 which starts off empty
Step 2: Perform Step 3 for each element in the original list L
Step 3: Insert it into the correct position in the sorted list L1.
Step 4: Return the sorted list
Step 5: StopAquí hay un pseudocódigo que describe cómo el proceso abstracto de alto nivel mencionado anteriormente en el algoritmo Insertion-Sort podría describirse de una manera más realista.
for i <- 1 to length(A)
x <- A[i]
j <- i
while j > 0 and A[j-1] > x
A[j] <- A[j-1]
j <- j - 1
A[j] <- xEn este tutorial, los algoritmos se presentarán en forma de pseudocódigo, que es similar en muchos aspectos a C, C ++, Java, Python y otros lenguajes de programación.
En el análisis teórico de algoritmos, es común estimar su complejidad en el sentido asintótico, es decir, estimar la función de complejidad para una entrada arbitrariamente grande. El termino"analysis of algorithms" fue acuñado por Donald Knuth.
El análisis de algoritmos es una parte importante de la teoría de la complejidad computacional, que proporciona una estimación teórica de los recursos necesarios de un algoritmo para resolver un problema computacional específico. La mayoría de los algoritmos están diseñados para trabajar con entradas de longitud arbitraria. El análisis de algoritmos es la determinación de la cantidad de recursos de tiempo y espacio necesarios para ejecutarlo.
Por lo general, la eficiencia o el tiempo de ejecución de un algoritmo se establece como una función que relaciona la longitud de entrada con el número de pasos, conocida como time complexity, o volumen de memoria, conocido como space complexity.
La necesidad de análisis
En este capítulo, discutiremos la necesidad de análisis de algoritmos y cómo elegir un algoritmo mejor para un problema particular, ya que un problema computacional puede resolverse mediante diferentes algoritmos.
Al considerar un algoritmo para un problema específico, podemos comenzar a desarrollar el reconocimiento de patrones de modo que tipos similares de problemas se puedan resolver con la ayuda de este algoritmo.
Los algoritmos suelen ser bastante diferentes entre sí, aunque el objetivo de estos algoritmos es el mismo. Por ejemplo, sabemos que un conjunto de números se puede ordenar utilizando diferentes algoritmos. El número de comparaciones realizadas por un algoritmo puede variar con otros para la misma entrada. Por tanto, la complejidad temporal de esos algoritmos puede diferir. Al mismo tiempo, necesitamos calcular el espacio de memoria requerido por cada algoritmo.
El análisis de algoritmo es el proceso de analizar la capacidad de resolución de problemas del algoritmo en términos de tiempo y tamaño requerido (el tamaño de la memoria para el almacenamiento durante la implementación). Sin embargo, la principal preocupación del análisis de algoritmos es el tiempo o el rendimiento necesarios. Generalmente, realizamos los siguientes tipos de análisis:
Worst-case - El número máximo de pasos realizados en cualquier instancia de tamaño a.
Best-case - El número mínimo de pasos realizados en cualquier instancia de tamaño a.
Average case - Un número medio de pasos realizados en cualquier instancia de tamaño. a.
Amortized - Una secuencia de operaciones aplicadas a la entrada de tamaño a promediado en el tiempo.
Para resolver un problema, debemos considerar el tiempo y la complejidad del espacio, ya que el programa puede ejecutarse en un sistema donde la memoria es limitada pero hay suficiente espacio disponible o puede ser viceversa. En este contexto, si comparamosbubble sort y merge sort. La clasificación de burbujas no requiere memoria adicional, pero la clasificación por combinación requiere espacio adicional. Aunque la complejidad temporal de la clasificación de burbujas es mayor en comparación con la clasificación por fusión, es posible que necesitemos aplicar la clasificación de burbujas si el programa necesita ejecutarse en un entorno donde la memoria es muy limitada.
Para medir el consumo de recursos de un algoritmo, se utilizan diferentes estrategias como se analiza en este capítulo.
Análisis asintótico
El comportamiento asintótico de una función f(n) se refiere al crecimiento de f(n) como n se hace grande.
Normalmente ignoramos pequeños valores de n, ya que generalmente estamos interesados en estimar qué tan lento será el programa en entradas grandes.
Una buena regla general es que cuanto más lenta sea la tasa de crecimiento asintótico, mejor será el algoritmo. Aunque no siempre es cierto.
Por ejemplo, un algoritmo lineal $f(n) = d * n + k$ es siempre asintóticamente mejor que una cuadrática, $f(n) = c.n^2 + q$.
Resolver ecuaciones de recurrencia
Una recurrencia es una ecuación o desigualdad que describe una función en términos de su valor en entradas más pequeñas. Las recurrencias se utilizan generalmente en el paradigma de divide y vencerás.
Dejenos considerar T(n) ser el tiempo de ejecución de un problema de tamaño n.
Si el tamaño del problema es lo suficientemente pequeño, diga n < c dónde c es una constante, la solución sencilla toma un tiempo constante, que se escribe como θ(1). Si la división del problema produce varios subproblemas con el tamaño$\frac{n}{b}$.
Para resolver el problema, el tiempo requerido es a.T(n/b). Si consideramos que el tiempo necesario para la división esD(n) y el tiempo necesario para combinar los resultados de los subproblemas es C(n), la relación de recurrencia se puede representar como -
$$T(n)=\begin{cases}\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\theta(1) & if\:n\leqslant c\\a T(\frac{n}{b})+D(n)+C(n) & otherwise\end{cases}$$
Una relación de recurrencia se puede resolver utilizando los siguientes métodos:
Substitution Method - En este método, adivinamos un límite y, mediante inducción matemática, probamos que nuestra suposición era correcta.
Recursion Tree Method - En este método, se forma un árbol de recurrencia donde cada nodo representa el costo.
Master’s Theorem - Esta es otra técnica importante para encontrar la complejidad de una relación de recurrencia.
Análisis amortizado
El análisis amortizado se usa generalmente para ciertos algoritmos donde se realiza una secuencia de operaciones similares.
El análisis amortizado proporciona un límite al costo real de toda la secuencia, en lugar de limitar el costo de la secuencia de operaciones por separado.
El análisis amortizado difiere del análisis de casos promedio; la probabilidad no está involucrada en el análisis amortizado. El análisis amortizado garantiza el rendimiento medio de cada operación en el peor de los casos.
No es solo una herramienta de análisis, es una forma de pensar el diseño, ya que diseño y análisis están íntimamente relacionados.
Método agregado
El método agregado ofrece una visión global de un problema. En este método, sin las operaciones toman el peor de los casos T(n)en total. Entonces el costo amortizado de cada operación esT(n)/n. Aunque diferentes operaciones pueden llevar un tiempo diferente, en este método se descuidan los costos variables.
Método contable
En este método, se asignan diferentes cargos a diferentes operaciones de acuerdo con su costo real. Si el costo amortizado de una operación excede su costo real, la diferencia se asigna al objeto como crédito. Este crédito ayuda a pagar operaciones posteriores cuyo costo amortizado sea menor que el costo real.
Si el costo real y el costo amortizado de ith operación son $c_{i}$ y $\hat{c_{l}}$, luego
$$\displaystyle\sum\limits_{i=1}^n \hat{c_{l}}\geqslant\displaystyle\sum\limits_{i=1}^n c_{i}$$
Método potencial
Este método representa el trabajo prepago como energía potencial, en lugar de considerar el trabajo prepago como crédito. Esta energía se puede liberar para pagar operaciones futuras.
Si realizamos n operaciones que comienzan con una estructura de datos inicial D0. Dejenos considerar,ci como el costo real y Di como estructura de datos de ithoperación. La función potencial Ф se asigna a un número real Ф (Di), el potencial asociado de Di. El costo amortizado$\hat{c_{l}}$ puede ser definido por
$$\hat{c_{l}}=c_{i}+\Phi (D_{i})-\Phi (D_{i-1})$$
Por lo tanto, el costo total amortizado es
$$\displaystyle\sum\limits_{i=1}^n \hat{c_{l}}=\displaystyle\sum\limits_{i=1}^n (c_{i}+\Phi (D_{i})-\Phi (D_{i-1}))=\displaystyle\sum\limits_{i=1}^n c_{i}+\Phi (D_{n})-\Phi (D_{0})$$
Tabla dinámica
Si el espacio asignado para la mesa no es suficiente, debemos copiar la tabla en una tabla de mayor tamaño. De manera similar, si se borra una gran cantidad de miembros de la tabla, es una buena idea reasignar la tabla con un tamaño más pequeño.
Usando el análisis amortizado, podemos mostrar que el costo amortizado de inserción y eliminación es constante y el espacio no utilizado en una tabla dinámica nunca excede una fracción constante del espacio total.
En el siguiente capítulo de este tutorial, analizaremos brevemente las notaciones asintóticas.
Al diseñar un algoritmo, el análisis de la complejidad de un algoritmo es un aspecto esencial. Principalmente, la complejidad algorítmica se preocupa por su rendimiento, qué tan rápido o lento funciona.
La complejidad de un algoritmo describe la eficiencia del algoritmo en términos de la cantidad de memoria necesaria para procesar los datos y el tiempo de procesamiento.
La complejidad de un algoritmo se analiza en dos perspectivas: Time y Space.
Complejidad del tiempo
Es una función que describe la cantidad de tiempo necesaria para ejecutar un algoritmo en términos del tamaño de la entrada. "Tiempo" puede significar el número de accesos a memoria realizados, el número de comparaciones entre enteros, el número de veces que se ejecuta algún bucle interno o alguna otra unidad natural relacionada con la cantidad de tiempo real que tomará el algoritmo.
Complejidad espacial
Es una función que describe la cantidad de memoria que toma un algoritmo en términos del tamaño de la entrada al algoritmo. A menudo hablamos de memoria "extra" necesaria, sin contar la memoria necesaria para almacenar la entrada en sí. Nuevamente, usamos unidades naturales (pero de longitud fija) para medir esto.
La complejidad del espacio a veces se ignora porque el espacio utilizado es mínimo y / o obvio, sin embargo, a veces se convierte en un problema tan importante como el tiempo.
Notaciones asintóticas
El tiempo de ejecución de un algoritmo depende del conjunto de instrucciones, la velocidad del procesador, la velocidad de E / S del disco, etc. Por lo tanto, estimamos la eficiencia de un algoritmo de forma asintótica.
La función de tiempo de un algoritmo está representada por T(n), dónde n es el tamaño de entrada.
Se utilizan diferentes tipos de notaciones asintóticas para representar la complejidad de un algoritmo. Las siguientes notaciones asintóticas se utilizan para calcular la complejidad del tiempo de ejecución de un algoritmo.
O - Oh grande
Ω - Gran omega
θ - Gran theta
o - pequeño oh
ω - Pequeño omega
O: límite superior asintótico
'O' (Big Oh) es la notación más utilizada. Una funciónf(n) puede ser representado es el orden de g(n) es decir O(g(n)), si existe un valor de entero positivo n como n0 y una constante positiva c tal que -
$f(n)\leqslant c.g(n)$ para $n > n_{0}$ en todo caso
Por lo tanto, función g(n) es un límite superior para la función f(n), como g(n) crece más rápido que f(n).
Ejemplo
Consideremos una función dada, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
Considerando $g(n) = n^3$,
$f(n)\leqslant 5.g(n)$ para todos los valores de $n > 2$
Por tanto, la complejidad de f(n) se puede representar como $O(g(n))$, es decir $O(n^3)$
Ω: límite inferior asintótico
Nosotros decimos eso $f(n) = \Omega (g(n))$ cuando existe constante c ese $f(n)\geqslant c.g(n)$ para todo valor suficientemente grande de n. aquínes un número entero positivo. Significa funcióng es un límite inferior para la función f; después de un cierto valor den, f nunca irá abajo g.
Ejemplo
Consideremos una función dada, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$.
Considerando $g(n) = n^3$, $f(n)\geqslant 4.g(n)$ para todos los valores de $n > 0$.
Por tanto, la complejidad de f(n) se puede representar como $\Omega (g(n))$, es decir $\Omega (n^3)$
θ: Asymptotic Tight Bound
Nosotros decimos eso $f(n) = \theta(g(n))$ cuando existen constantes c1 y c2 ese $c_{1}.g(n) \leqslant f(n) \leqslant c_{2}.g(n)$ para todo valor suficientemente grande de n. aquín es un número entero positivo.
Esto significa función g es un límite estrecho para la función f.
Ejemplo
Consideremos una función dada, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
Considerando $g(n) = n^3$, $4.g(n) \leqslant f(n) \leqslant 5.g(n)$ para todos los grandes valores de n.
Por tanto, la complejidad de f(n) se puede representar como $\theta (g(n))$, es decir $\theta (n^3)$.
O - notación
El límite superior asintótico proporcionado por O-notationpuede o no ser asintóticamente apretado. El límite$2.n^2 = O(n^2)$ es asintóticamente apretado, pero el límite $2.n = O(n^2)$ no es.
Usamos o-notation para denotar un límite superior que no es asintóticamente apretado.
Definimos formalmente o(g(n)) (pequeño-oh de g de n) como el conjunto f(n) = o(g(n)) para cualquier constante positiva $c > 0$ y existe un valor $n_{0} > 0$, tal que $0 \leqslant f(n) \leqslant c.g(n)$.
Intuitivamente, en el o-notation, la función f(n) se vuelve insignificante en relación con g(n) como nse acerca al infinito; es decir,
$$\lim_{n \rightarrow \infty}\left(\frac{f(n)}{g(n)}\right) = 0$$
Ejemplo
Consideremos la misma función, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
Considerando $g(n) = n^{4}$,
$$\lim_{n \rightarrow \infty}\left(\frac{4.n^3 + 10.n^2 + 5.n + 1}{n^4}\right) = 0$$
Por tanto, la complejidad de f(n) se puede representar como $o(g(n))$, es decir $o(n^4)$.
ω - Notación
Usamos ω-notationpara denotar un límite inferior que no es asintóticamente apretado. Formalmente, sin embargo, definimosω(g(n)) (pequeño omega de g de n) como el conjunto f(n) = ω(g(n)) para cualquier constante positiva C > 0 y existe un valor $n_{0} > 0$, tal que $ 0 \ leqslant cg (n) <f (n) $.
Por ejemplo, $\frac{n^2}{2} = \omega (n)$, pero $\frac{n^2}{2} \neq \omega (n^2)$. La relación$f(n) = \omega (g(n))$ implica que existe el siguiente límite
$$\lim_{n \rightarrow \infty}\left(\frac{f(n)}{g(n)}\right) = \infty$$
Es decir, f(n) se vuelve arbitrariamente grande en relación con g(n) como n se acerca al infinito.
Ejemplo
Consideremos la misma función, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
Considerando $g(n) = n^2$,
$$\lim_{n \rightarrow \infty}\left(\frac{4.n^3 + 10.n^2 + 5.n + 1}{n^2}\right) = \infty$$
Por tanto, la complejidad de f(n) se puede representar como $o(g(n))$, es decir $\omega (n^2)$.
Análisis apriori y apostólico
Análisis a priori significa que el análisis se realiza antes de ejecutarlo en un sistema específico. Este análisis es una etapa en la que se define una función mediante algún modelo teórico. Por lo tanto, determinamos la complejidad de tiempo y espacio de un algoritmo simplemente mirando el algoritmo en lugar de ejecutarlo en un sistema en particular con una memoria, procesador y compilador diferente.
El análisis apostólico de un algoritmo significa que realizamos el análisis de un algoritmo solo después de ejecutarlo en un sistema. Depende directamente del sistema y cambia de un sistema a otro.
En una industria, no podemos realizar análisis Apostiari ya que el software generalmente está hecho para un usuario anónimo, que lo ejecuta en un sistema diferente de los presentes en la industria.
A priori, es la razón por la que usamos notaciones asintóticas para determinar la complejidad del tiempo y el espacio a medida que cambian de una computadora a otra; sin embargo, asintóticamente son iguales.
En este capítulo, discutiremos la complejidad de los problemas computacionales con respecto a la cantidad de espacio que requiere un algoritmo.
La complejidad espacial comparte muchas de las características de la complejidad temporal y sirve como una forma más de clasificar los problemas de acuerdo con sus dificultades computacionales.
¿Qué es la complejidad espacial?
La complejidad del espacio es una función que describe la cantidad de memoria (espacio) que toma un algoritmo en términos de la cantidad de entrada al algoritmo.
A menudo hablamos de extra memorynecesario, sin contar la memoria necesaria para almacenar la entrada en sí. Nuevamente, usamos unidades naturales (pero de longitud fija) para medir esto.
Podemos usar bytes, pero es más fácil usar, digamos, el número de enteros usados, el número de estructuras de tamaño fijo, etc.
Al final, la función que se nos ocurra será independiente del número real de bytes necesarios para representar la unidad.
La complejidad del espacio a veces se ignora porque el espacio utilizado es mínimo y / o obvio, sin embargo, a veces se convierte en un tema tan importante como la complejidad del tiempo.
Definición
Dejar M ser determinista Turing machine (TM)que se detiene en todas las entradas. La complejidad espacial deM es la función $f \colon N \rightarrow N$, dónde f(n) es el número máximo de celdas de cinta y M escanea cualquier entrada de longitud M. Si la complejidad espacial deM es f(n), podemos decir eso M corre en el espacio f(n).
Estimamos la complejidad espacial de la máquina de Turing utilizando notación asintótica.
Dejar $f \colon N \rightarrow R^+$ser una función. Las clases de complejidad espacial se pueden definir de la siguiente manera:
SPACE = {L | L is a language decided by an O(f(n)) space deterministic TM}
SPACE = {L | L is a language decided by an O(f(n)) space non-deterministic TM}
PSPACE es la clase de lenguajes que se pueden decidir en un espacio polinomial en una máquina de Turing determinista.
En otras palabras, PSPACE = Uk SPACE (nk)
Teorema de Savitch
Uno de los primeros teoremas relacionados con la complejidad espacial es el teorema de Savitch. Según este teorema, una máquina determinista puede simular máquinas no deterministas utilizando una pequeña cantidad de espacio.
Para la complejidad del tiempo, tal simulación parece requerir un aumento exponencial en el tiempo. Para la complejidad espacial, este teorema muestra que cualquier máquina de Turing no determinista que utilicef(n) el espacio se puede convertir en una TM determinista que utiliza f2(n) espacio.
Por tanto, el teorema de Savitch establece que, para cualquier función, $f \colon N \rightarrow R^+$, dónde $f(n) \geqslant n$
NSPACE(f(n)) ⊆ SPACE(f(n))
Relación entre clases de complejidad
El siguiente diagrama muestra la relación entre diferentes clases de complejidad.

Hasta ahora, no hemos discutido las clases P y NP en este tutorial. Estos se discutirán más adelante.
Muchos algoritmos son de naturaleza recursiva para resolver un problema dado que trata de manera recursiva con subproblemas.
En divide and conquer approach, un problema se divide en problemas más pequeños, luego los problemas más pequeños se resuelven de forma independiente y, finalmente, las soluciones de problemas más pequeños se combinan en una solución para el problema grande.
Generalmente, los algoritmos de divide y vencerás tienen tres partes:
Divide the problem en una serie de subproblemas que son instancias más pequeñas del mismo problema.
Conquer the sub-problemsresolviéndolos de forma recursiva. Si son lo suficientemente pequeños, resuelva los subproblemas como casos base.
Combine the solutions a los subproblemas en la solución del problema original.
Pros y contras del enfoque de dividir y conquistar
El enfoque de dividir y conquistar apoya el paralelismo ya que los subproblemas son independientes. Por lo tanto, un algoritmo diseñado con esta técnica puede ejecutarse en el sistema multiprocesador o en diferentes máquinas simultáneamente.
En este enfoque, la mayoría de los algoritmos se diseñan mediante recursividad, por lo que la gestión de la memoria es muy alta. Para la función recursiva, se usa la pila, donde se debe almacenar el estado de la función.
Aplicación del enfoque de divide y vencerás
A continuación se presentan algunos problemas que se resuelven utilizando el enfoque de dividir y conquistar.
- Encontrar el máximo y el mínimo de una secuencia de números
- Multiplicación de matrices de Strassen
- Combinar ordenación
- Búsqueda binaria
Consideremos un problema simple que se puede resolver mediante la técnica de dividir y conquistar.
Planteamiento del problema
El problema Max-Min en el análisis de algoritmos es encontrar el valor máximo y mínimo en una matriz.
Solución
Para encontrar los números máximo y mínimo en una matriz dada numbers[] de tamaño n, se puede utilizar el siguiente algoritmo. Primero estamos representando elnaive method y luego te presentaremos divide and conquer approach.
Método ingenuo
El método ingenuo es un método básico para resolver cualquier problema. En este método, el número máximo y mínimo se puede encontrar por separado. Para encontrar los números máximos y mínimos, se puede utilizar el siguiente algoritmo sencillo.
Algorithm: Max-Min-Element (numbers[])
max := numbers[1]
min := numbers[1]
for i = 2 to n do
if numbers[i] > max then
max := numbers[i]
if numbers[i] < min then
min := numbers[i]
return (max, min)Análisis
El número de comparación en el método Naive es 2n - 2.
El número de comparaciones se puede reducir utilizando el enfoque de divide y vencerás. A continuación se muestra la técnica.
Enfoque de dividir y conquistar
En este enfoque, la matriz se divide en dos mitades. Luego, utilizando el enfoque recursivo, se encuentran los números máximos y mínimos en cada mitad. Posteriormente, devuelve el máximo de dos máximos de cada mitad y el mínimo de dos mínimos de cada mitad.
En este problema dado, el número de elementos en una matriz es $y - x + 1$, dónde y es mayor o igual a x.
$\mathbf{\mathit{Max - Min(x, y)}}$ devolverá los valores máximo y mínimo de una matriz $\mathbf{\mathit{numbers[x...y]}}$.
Algorithm: Max - Min(x, y)
if y – x ≤ 1 then
return (max(numbers[x], numbers[y]), min((numbers[x], numbers[y]))
else
(max1, min1):= maxmin(x, ⌊((x + y)/2)⌋)
(max2, min2):= maxmin(⌊((x + y)/2) + 1)⌋,y)
return (max(max1, max2), min(min1, min2))Análisis
Dejar T(n) ser el número de comparaciones realizadas por $\mathbf{\mathit{Max - Min(x, y)}}$, donde el número de elementos $n = y - x + 1$.
Si T(n) representa los números, entonces la relación de recurrencia se puede representar como
$$T(n) = \begin{cases}T\left(\lfloor\frac{n}{2}\rfloor\right)+T\left(\lceil\frac{n}{2}\rceil\right)+2 & for\: n>2\\1 & for\:n = 2 \\0 & for\:n = 1\end{cases}$$
Asumamos que n está en forma de poder de 2. Por lo tanto,n = 2k dónde k es la altura del árbol de recursividad.
Entonces,
$$T(n) = 2.T (\frac{n}{2}) + 2 = 2.\left(\begin{array}{c}2.T(\frac{n}{4}) + 2\end{array}\right) + 2 ..... = \frac{3n}{2} - 2$$
En comparación con el método Naive, en el enfoque de divide y vencerás, el número de comparaciones es menor. Sin embargo, usando la notación asintótica, ambos enfoques están representados porO(n).
En este capítulo, discutiremos la ordenación por fusión y analizaremos su complejidad.
Planteamiento del problema
El problema de ordenar una lista de números se presta inmediatamente a una estrategia de dividir y vencer: dividir la lista en dos mitades, ordenar recursivamente cada mitad y luego fusionar las dos sublistas ordenadas.
Solución
En este algoritmo, los números se almacenan en una matriz. numbers[]. Aquí,p y q representa el índice inicial y final de una submatriz.
Algorithm: Merge-Sort (numbers[], p, r)
if p < r then
q = ⌊(p + r) / 2⌋
Merge-Sort (numbers[], p, q)
Merge-Sort (numbers[], q + 1, r)
Merge (numbers[], p, q, r)Function: Merge (numbers[], p, q, r)
n1 = q – p + 1
n2 = r – q
declare leftnums[1…n1 + 1] and rightnums[1…n2 + 1] temporary arrays
for i = 1 to n1
leftnums[i] = numbers[p + i - 1]
for j = 1 to n2
rightnums[j] = numbers[q+ j]
leftnums[n1 + 1] = ∞
rightnums[n2 + 1] = ∞
i = 1
j = 1
for k = p to r
if leftnums[i] ≤ rightnums[j]
numbers[k] = leftnums[i]
i = i + 1
else
numbers[k] = rightnums[j]
j = j + 1Análisis
Consideremos, el tiempo de ejecución de Merge-Sort como T(n). Por lo tanto,
$T(n)=\begin{cases}c & if\:n\leqslant 1\\2\:x\:T(\frac{n}{2})+d\:x\:n & otherwise\end{cases}$donde c y d son constantes
Por lo tanto, usando esta relación de recurrencia,
$$T(n) = 2^i T(\frac{n}{2^i}) + i.d.n$$
Como, $i = log\:n,\: T(n) = 2^{log\:n} T(\frac{n}{2^{log\:n}}) + log\:n.d.n$
$=\:c.n + d.n.log\:n$
Por lo tanto, $T(n) = O(n\:log\:n)$
Ejemplo
En el siguiente ejemplo, mostramos el algoritmo Merge-Sort paso a paso. Primero, cada matriz de iteración se divide en dos submatrices, hasta que la submatriz contiene solo un elemento. Cuando estas submatrices no se pueden dividir más, se realizan las operaciones de combinación.
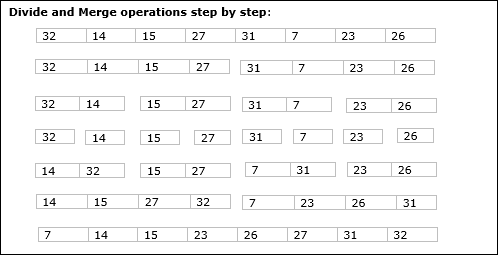
En este capítulo, discutiremos otro algoritmo basado en el método de divide y vencerás.
Planteamiento del problema
La búsqueda binaria se puede realizar en una matriz ordenada. En este enfoque, el índice de un elementoxse determina si el elemento pertenece a la lista de elementos. Si la matriz no está ordenada, se utiliza la búsqueda lineal para determinar la posición.
Solución
En este algoritmo, queremos encontrar si el elemento x pertenece a un conjunto de números almacenados en una matriz numbers[]. Dóndel y r representan el índice izquierdo y derecho de una submatriz en la que se debe realizar la operación de búsqueda.
Algorithm: Binary-Search(numbers[], x, l, r)
if l = r then
return l
else
m := ⌊(l + r) / 2⌋
if x ≤ numbers[m] then
return Binary-Search(numbers[], x, l, m)
else
return Binary-Search(numbers[], x, m+1, r)Análisis
La búsqueda lineal se ejecuta en O(n)hora. Mientras que la búsqueda binaria produce el resultado enO(log n) hora
Dejar T(n) ser el número de comparaciones en el peor de los casos en una matriz de n elementos.
Por lo tanto,
$$T(n)=\begin{cases}0 & if\:n= 1\\T(\frac{n}{2})+1 & otherwise\end{cases}$$
Usando esta relación de recurrencia $T(n) = log\:n$.
Por lo tanto, la búsqueda binaria utiliza $O(log\:n)$ hora.
Ejemplo
En este ejemplo, buscaremos el elemento 63.

En este capítulo, primero discutiremos el método general de multiplicación de matrices y luego discutiremos el algoritmo de multiplicación de matrices de Strassen.
Planteamiento del problema
Consideremos dos matrices X y Y. Queremos calcular la matriz resultanteZ multiplicando X y Y.
Método ingenuo
Primero, discutiremos el método ingenuo y su complejidad. Aquí estamos calculandoZ = X × Y. Usando el método Naïve, dos matrices (X y Y) se puede multiplicar si el orden de estas matrices es p × q y q × r. A continuación se muestra el algoritmo.
Algorithm: Matrix-Multiplication (X, Y, Z)
for i = 1 to p do
for j = 1 to r do
Z[i,j] := 0
for k = 1 to q do
Z[i,j] := Z[i,j] + X[i,k] × Y[k,j]Complejidad
Aquí, asumimos que las operaciones enteras toman O(1)hora. Hay tresforbucles en este algoritmo y uno está anidado en otro. Por lo tanto, el algoritmo tomaO(n3) tiempo para ejecutar.
Algoritmo de multiplicación de matrices de Strassen
En este contexto, utilizando el algoritmo de multiplicación de matrices de Strassen, el consumo de tiempo se puede mejorar un poco.
La multiplicación de matrices de Strassen solo se puede realizar en square matrices dónde n es un power of 2. El orden de ambas matrices esn × n.
Dividir X, Y y Z en cuatro (n / 2) × (n / 2) matrices como se representa a continuación -
$Z = \begin{bmatrix}I & J \\K & L \end{bmatrix}$ $X = \begin{bmatrix}A & B \\C & D \end{bmatrix}$ y $Y = \begin{bmatrix}E & F \\G & H \end{bmatrix}$
Usando el algoritmo de Strassen, calcule lo siguiente:
$$M_{1} \: \colon= (A+C) \times (E+F)$$
$$M_{2} \: \colon= (B+D) \times (G+H)$$
$$M_{3} \: \colon= (A-D) \times (E+H)$$
$$M_{4} \: \colon= A \times (F-H)$$
$$M_{5} \: \colon= (C+D) \times (E)$$
$$M_{6} \: \colon= (A+B) \times (H)$$
$$M_{7} \: \colon= D \times (G-E)$$
Luego,
$$I \: \colon= M_{2} + M_{3} - M_{6} - M_{7}$$
$$J \: \colon= M_{4} + M_{6}$$
$$K \: \colon= M_{5} + M_{7}$$
$$L \: \colon= M_{1} - M_{3} - M_{4} - M_{5}$$
Análisis
$T(n)=\begin{cases}c & if\:n= 1\\7\:x\:T(\frac{n}{2})+d\:x\:n^2 & otherwise\end{cases}$donde c y d son constantes
Usando esta relación de recurrencia, obtenemos $T(n) = O(n^{log7})$
Por tanto, la complejidad del algoritmo de multiplicación de matrices de Strassen es $O(n^{log7})$.
Entre todos los enfoques algorítmicos, el enfoque más simple y directo es el método Greedy. En este enfoque, la decisión se toma sobre la base de la información disponible actual sin preocuparse por el efecto de la decisión actual en el futuro.
Los algoritmos codiciosos construyen una solución parte por parte, eligiendo la siguiente parte de tal manera que brinde un beneficio inmediato. Este enfoque nunca reconsidera las opciones tomadas anteriormente. Este enfoque se utiliza principalmente para resolver problemas de optimización. El método codicioso es fácil de implementar y bastante eficiente en la mayoría de los casos. Por lo tanto, podemos decir que el algoritmo Greedy es un paradigma algorítmico basado en la heurística que sigue la elección óptima local en cada paso con la esperanza de encontrar una solución óptima global.
En muchos problemas, no produce una solución óptima, aunque ofrece una solución aproximada (casi óptima) en un tiempo razonable.
Componentes del algoritmo codicioso
Los algoritmos codiciosos tienen los siguientes cinco componentes:
A candidate set - Se crea una solución a partir de este conjunto.
A selection function - Se utiliza para elegir el mejor candidato para agregar a la solución.
A feasibility function - Se utiliza para determinar si se puede utilizar un candidato para contribuir a la solución.
An objective function - Se utiliza para asignar un valor a una solución o una solución parcial.
A solution function - Se utiliza para indicar si se ha alcanzado una solución completa.
Areas de aplicación
El enfoque codicioso se utiliza para resolver muchos problemas, como
Encontrar el camino más corto entre dos vértices usando el algoritmo de Dijkstra.
Encontrar el árbol de expansión mínimo en un gráfico usando el algoritmo de Prim / Kruskal, etc.
Donde el enfoque codicioso falla
En muchos problemas, el algoritmo Greedy no logra encontrar una solución óptima; además, puede producir la peor solución. Problemas como el viajante de comercio y la mochila no se pueden resolver con este enfoque.
El algoritmo Greedy podría entenderse muy bien con un problema bien conocido denominado problema de la mochila. Aunque el mismo problema podría resolverse empleando otros enfoques algorítmicos, el enfoque codicioso resuelve el problema de la mochila fraccionada razonablemente en un buen momento. Discutamos el problema de la mochila en detalle.
Problema de la mochila
Dado un conjunto de elementos, cada uno con un peso y un valor, determine un subconjunto de elementos para incluir en una colección de modo que el peso total sea menor o igual a un límite dado y el valor total sea lo más grande posible.
El problema de la mochila está en el problema de la optimización combinatoria. Aparece como un subproblema en muchos modelos matemáticos más complejos de problemas del mundo real. Un enfoque general para problemas difíciles es identificar la restricción más restrictiva, ignorar las otras, resolver un problema de mochila y ajustar de alguna manera la solución para satisfacer las restricciones ignoradas.
Aplicaciones
En muchos casos de asignación de recursos junto con alguna restricción, el problema puede derivarse de una manera similar al problema de la mochila. A continuación se muestra un conjunto de ejemplos.
- Encontrar la forma menos derrochadora de cortar materias primas
- optimización de cartera
- Problemas de stock de corte
Escenario de problemas
Un ladrón está robando una tienda y puede llevar un peso máximo de Wen su mochila. Hay n artículos disponibles en la tienda y el peso deith el artículo es wi y su beneficio es pi. ¿Qué objetos debe llevarse el ladrón?
En este contexto, los artículos deben seleccionarse de tal manera que el ladrón lleve aquellos artículos por los que obtendrá el máximo beneficio. Por tanto, el objetivo del ladrón es maximizar la ganancia.
Según la naturaleza de los elementos, los problemas de mochila se clasifican como
- Mochila fraccionada
- Knapsack
Mochila fraccionada
En este caso, los artículos se pueden dividir en pedazos más pequeños, por lo que el ladrón puede seleccionar fracciones de artículos.
Según el planteamiento del problema,
Existen n artículos en la tienda
Peso de ith articulo $w_{i} > 0$
Beneficio para ith articulo $p_{i} > 0$ y
La capacidad de la mochila es W
En esta versión del problema de la mochila, los artículos se pueden romper en pedazos más pequeños. Entonces, el ladrón puede tomar solo una fracciónxi de ith articulo.
$$0 \leqslant x_{i} \leqslant 1$$
los ith artículo aporta el peso $x_{i}.w_{i}$ al peso total en la mochila y al beneficio $x_{i}.p_{i}$ al beneficio total.
Por tanto, el objetivo de este algoritmo es
$$maximize\:\displaystyle\sum\limits_{n=1}^n (x_{i}.p_{}i)$$
sujeto a restricciones,
$$\displaystyle\sum\limits_{n=1}^n (x_{i}.w_{}i) \leqslant W$$
Está claro que una solución óptima debe llenar la mochila exactamente, de lo contrario podríamos agregar una fracción de uno de los elementos restantes y aumentar la ganancia general.
Por tanto, se puede obtener una solución óptima
$$\displaystyle\sum\limits_{n=1}^n (x_{i}.w_{}i) = W$$
En este contexto, primero debemos ordenar esos elementos de acuerdo con el valor de $\frac{p_{i}}{w_{i}}$, así que eso $\frac{p_{i}+1}{w_{i}+1}$ ≤ $\frac{p_{i}}{w_{i}}$. Aquí,x es una matriz para almacenar la fracción de elementos.
Algorithm: Greedy-Fractional-Knapsack (w[1..n], p[1..n], W)
for i = 1 to n
do x[i] = 0
weight = 0
for i = 1 to n
if weight + w[i] ≤ W then
x[i] = 1
weight = weight + w[i]
else
x[i] = (W - weight) / w[i]
weight = W
break
return xAnálisis
Si los elementos proporcionados ya están ordenados en orden decreciente de $\mathbf{\frac{p_{i}}{w_{i}}}$, luego el whileloop tarda un tiempo en O(n); Por lo tanto, el tiempo total que incluye la clasificación está enO(n logn).
Ejemplo
Consideremos que la capacidad de la mochila W = 60 y la lista de elementos proporcionados se muestran en la siguiente tabla:
| Articulo | UN | segundo | C | re |
|---|---|---|---|---|
| Lucro | 280 | 100 | 120 | 120 |
| Peso | 40 | 10 | 20 | 24 |
| Proporción $(\frac{p_{i}}{w_{i}})$ | 7 | 10 | 6 | 5 |
Como los elementos proporcionados no se ordenan según $\mathbf{\frac{p_{i}}{w_{i}}}$. Después de ordenar, los elementos se muestran en la siguiente tabla.
| Articulo | segundo | UN | C | re |
|---|---|---|---|---|
| Lucro | 100 | 280 | 120 | 120 |
| Peso | 10 | 40 | 20 | 24 |
| Proporción $(\frac{p_{i}}{w_{i}})$ | 10 | 7 | 6 | 5 |
Solución
Después de ordenar todos los elementos según $\frac{p_{i}}{w_{i}}$. Primero todo deB se elige como peso de Bes menor que la capacidad de la mochila. Proximo articuloA se elige, ya que la capacidad disponible de la mochila es mayor que el peso de A. Ahora,Cse elige como el siguiente elemento. Sin embargo, no se puede elegir el artículo completo ya que la capacidad restante de la mochila es menor que el peso deC.
Por tanto, fracción de C (es decir, (60 - 50) / 20) se elige.
Ahora, la capacidad de la mochila es igual a los elementos seleccionados. Por tanto, no se pueden seleccionar más elementos.
El peso total de los elementos seleccionados es 10 + 40 + 20 * (10/20) = 60
Y la ganancia total es 100 + 280 + 120 * (10/20) = 380 + 60 = 440
Ésta es la solución óptima. No podemos obtener más ganancias seleccionando una combinación diferente de artículos.
Planteamiento del problema
En el problema de secuenciación de trabajos, el objetivo es encontrar una secuencia de trabajos, que se complete dentro de sus plazos y dé el máximo beneficio.
Solución
Consideremos, un conjunto de ndeterminados trabajos que están asociados con fechas límite y se obtienen ganancias, si un trabajo se completa antes de su fecha límite. Estos trabajos deben ordenarse de tal manera que se obtenga el máximo beneficio.
Puede suceder que todos los trabajos dados no se completen dentro de sus plazos.
Supongamos, fecha límite de ith trabajo Ji es di y la ganancia recibida de este trabajo es pi. Por tanto, la solución óptima de este algoritmo es una solución factible con el máximo beneficio.
Así, $D(i) > 0$ para $1 \leqslant i \leqslant n$.
Inicialmente, estos trabajos se ordenan según el beneficio, es decir $p_{1} \geqslant p_{2} \geqslant p_{3} \geqslant \:... \: \geqslant p_{n}$.
Algorithm: Job-Sequencing-With-Deadline (D, J, n, k)
D(0) := J(0) := 0
k := 1
J(1) := 1 // means first job is selected
for i = 2 … n do
r := k
while D(J(r)) > D(i) and D(J(r)) ≠ r do
r := r – 1
if D(J(r)) ≤ D(i) and D(i) > r then
for l = k … r + 1 by -1 do
J(l + 1) := J(l)
J(r + 1) := i
k := k + 1Análisis
En este algoritmo, estamos usando dos bucles, uno dentro del otro. Por tanto, la complejidad de este algoritmo es$O(n^2)$.
Ejemplo
Consideremos un conjunto de trabajos dados como se muestra en la siguiente tabla. Tenemos que encontrar una secuencia de trabajos, que se completarán dentro de sus plazos y darán el máximo beneficio. Cada trabajo está asociado con una fecha límite y una ganancia.
| Trabajo | J1 | J2 | J3 | J4 | J5 |
|---|---|---|---|---|---|
| Fecha límite | 2 | 1 | 3 | 2 | 1 |
| Lucro | 60 | 100 | 20 | 40 | 20 |
Solución
Para resolver este problema, los trabajos dados se ordenan de acuerdo con su beneficio en orden descendente. Por lo tanto, después de la clasificación, los trabajos se ordenan como se muestra en la siguiente tabla.
| Trabajo | J2 | J1 | J4 | J3 | J5 |
|---|---|---|---|---|---|
| Fecha límite | 1 | 2 | 2 | 3 | 1 |
| Lucro | 100 | 60 | 40 | 20 | 20 |
De este conjunto de trabajos, primero seleccionamos J2, ya que se puede completar dentro de su plazo y aporta el máximo beneficio.
Próximo, J1 se selecciona porque da más beneficios en comparación con J4.
En el próximo reloj J4 no se puede seleccionar porque su fecha límite ha terminado, por lo tanto J3 se selecciona ya que se ejecuta dentro de su fecha límite.
El trabajo J5 se descarta porque no se puede ejecutar dentro de su fecha límite.
Por tanto, la solución es la secuencia de trabajos (J2, J1, J3), que se ejecutan dentro de su plazo y dan el máximo beneficio.
El beneficio total de esta secuencia es 100 + 60 + 20 = 180.
Combine un conjunto de archivos ordenados de diferente longitud en un solo archivo ordenado. Necesitamos encontrar una solución óptima, donde el archivo resultante se generará en un tiempo mínimo.
Si se proporciona el número de archivos ordenados, hay muchas formas de combinarlos en un solo archivo ordenado. Esta combinación se puede realizar por parejas. Por lo tanto, este tipo de fusión se denomina2-way merge patterns.
Dado que los diferentes emparejamientos requieren diferentes cantidades de tiempo, en esta estrategia queremos determinar una forma óptima de fusionar muchos archivos. En cada paso, se fusionan dos secuencias más cortas.
Para fusionar un p-record file y un q-record file requiere posiblemente p + q movimientos de registro, siendo la elección obvia fusionar los dos archivos más pequeños en cada paso.
Los patrones de fusión bidireccionales se pueden representar mediante árboles de fusión binarios. Consideremos un conjunto den archivos ordenados {f1, f2, f3, …, fn}. Inicialmente, cada elemento de esto se considera como un árbol binario de un solo nodo. Para encontrar esta solución óptima, se utiliza el siguiente algoritmo.
Algorithm: TREE (n)
for i := 1 to n – 1 do
declare new node
node.leftchild := least (list)
node.rightchild := least (list)
node.weight) := ((node.leftchild).weight) + ((node.rightchild).weight)
insert (list, node);
return least (list);Al final de este algoritmo, el peso del nodo raíz representa el costo óptimo.
Ejemplo
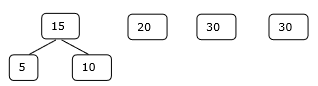
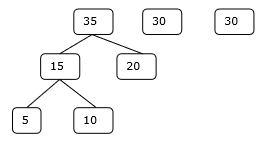
Consideremos los archivos dados, f 1 , f 2 , f 3 , f 4 y f 5 con 20, 30, 10, 5 y 30 números de elementos respectivamente.
Si las operaciones de combinación se realizan de acuerdo con la secuencia proporcionada, entonces
M1 = merge f1 and f2 => 20 + 30 = 50
M2 = merge M1 and f3 => 50 + 10 = 60
M3 = merge M2 and f4 => 60 + 5 = 65
M4 = merge M3 and f5 => 65 + 30 = 95
Por tanto, el número total de operaciones es
50 + 60 + 65 + 95 = 270
Ahora, surge la pregunta: ¿hay alguna solución mejor?
Clasificando los números según su tamaño en orden ascendente, obtenemos la siguiente secuencia:
f4, f3, f1, f2, f5
Por lo tanto, las operaciones de combinación se pueden realizar en esta secuencia
M1 = merge f4 and f3 => 5 + 10 = 15
M2 = merge M1 and f1 => 15 + 20 = 35
M3 = merge M2 and f2 => 35 + 30 = 65
M4 = merge M3 and f5 => 65 + 30 = 95
Por tanto, el número total de operaciones es
15 + 35 + 65 + 95 = 210
Evidentemente, este es mejor que el anterior.
En este contexto, ahora vamos a resolver el problema utilizando este algoritmo.
Conjunto inicial

Paso 1
Paso 2
Paso 3
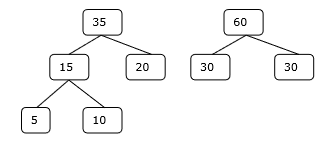
Etapa 4
Por lo tanto, la solución requiere 15 + 35 + 60 + 95 = 205 número de comparaciones.
La programación dinámica también se utiliza en problemas de optimización. Al igual que el método de divide y vencerás, la programación dinámica resuelve problemas combinando las soluciones de subproblemas. Además, el algoritmo de programación dinámica resuelve cada subproblema solo una vez y luego guarda su respuesta en una tabla, evitando así el trabajo de volver a calcular la respuesta cada vez.
Dos propiedades principales de un problema sugieren que el problema dado se puede resolver mediante la programación dinámica. Estas propiedades sonoverlapping sub-problems and optimal substructure.
Subproblemas superpuestos
Al igual que en el enfoque de dividir y conquistar, la programación dinámica también combina soluciones a subproblemas. Se utiliza principalmente cuando se necesita repetidamente la solución de un subproblema. Las soluciones calculadas se almacenan en una tabla, por lo que no es necesario volver a calcularlas. Por lo tanto, esta técnica es necesaria cuando existe un subproblema superpuesto.
Por ejemplo, la búsqueda binaria no tiene subproblemas superpuestos. Mientras que el programa recursivo de números de Fibonacci tiene muchos subproblemas superpuestos.
Subestructura óptima
Un problema dado tiene la propiedad de subestructura óptima, si la solución óptima del problema dado se puede obtener utilizando soluciones óptimas de sus subproblemas.
Por ejemplo, el problema de la ruta más corta tiene la siguiente propiedad de subestructura óptima:
Si un nodo x se encuentra en la ruta más corta desde un nodo de origen u al nodo de destino v, luego el camino más corto desde u a v es la combinación del camino más corto desde u a x, y el camino más corto desde x a v.
Los algoritmos estándar de todos los pares de ruta más corta como Floyd-Warshall y Bellman-Ford son ejemplos típicos de programación dinámica.
Pasos del enfoque de programación dinámica
El algoritmo de programación dinámica está diseñado utilizando los siguientes cuatro pasos:
- Caracterizar la estructura de una solución óptima.
- Defina de forma recursiva el valor de una solución óptima.
- Calcule el valor de una solución óptima, normalmente de forma ascendente.
- Construya una solución óptima a partir de la información calculada.
Aplicaciones del enfoque de programación dinámica
- Multiplicación en cadena de matrices
- Subsecuencia común más larga
- Problema del vendedor ambulante
En este tutorial, hemos discutido anteriormente el problema de la mochila fraccionada usando el enfoque Greedy. Hemos demostrado que el enfoque codicioso ofrece una solución óptima para la mochila fraccionada. Sin embargo, este capítulo cubrirá el problema de la mochila 0-1 y su análisis.
En 0-1 Mochila, los artículos no se pueden romper, lo que significa que el ladrón debe tomar el artículo como un todo o dejarlo. Esta es la razón detrás de llamarlo 0-1 Mochila.
Por tanto, en el caso de 0-1 Mochila, el valor de xi pueden ser cualquiera de los dos 0 o 1, donde otras restricciones siguen siendo las mismas.
0-1 Mochila no se puede resolver con un enfoque codicioso. El enfoque codicioso no garantiza una solución óptima. En muchos casos, el enfoque Codicioso puede brindar una solución óptima.
Los siguientes ejemplos establecerán nuestra declaración.
Ejemplo 1
Consideremos que la capacidad de la mochila es W = 25 y los elementos son los que se muestran en la siguiente tabla.
| Articulo | UN | segundo | C | re |
|---|---|---|---|---|
| Lucro | 24 | 18 | 18 | 10 |
| Peso | 24 | 10 | 10 | 7 |
Sin considerar la ganancia por unidad de peso (pi/wi), si aplicamos el enfoque Greedy para resolver este problema, el primer elemento Aserán seleccionados, ya que contribuirá max i ganancias madre entre todos los elementos.
Después de seleccionar el artículo A, no se seleccionarán más elementos. Por tanto, para este conjunto dado de elementos, la ganancia total es24. Considerando que, la solución óptima se puede lograr seleccionando elementos,B y C, donde la ganancia total es 18 + 18 = 36.
Ejemplo 2
En lugar de seleccionar los elementos en función del beneficio general, en este ejemplo los elementos se seleccionan en función de la relación p i / w i . Consideremos que la capacidad de la mochila es W = 60 y los ítems son los que se muestran en la siguiente tabla.
| Articulo | UN | segundo | C |
|---|---|---|---|
| Precio | 100 | 280 | 120 |
| Peso | 10 | 40 | 20 |
| Proporción | 10 | 7 | 6 |
Usando el enfoque codicioso, primer elemento Aestá seleccionado. Luego, el siguiente elementoBesta elegido. Por tanto, la ganancia total es100 + 280 = 380. Sin embargo, la solución óptima de esta instancia se puede lograr seleccionando elementos,B y C, donde el beneficio total es 280 + 120 = 400.
Por lo tanto, se puede concluir que el enfoque codicioso puede no dar una solución óptima.
Para resolver 0-1 Mochila, se requiere un enfoque de Programación Dinámica.
Planteamiento del problema
Un ladrón está robando una tienda y puede transportar un máximo i peso del malWen su mochila. Existenn artículos y peso de ith el artículo es wi y el beneficio de seleccionar este artículo es pi. ¿Qué objetos debe llevarse el ladrón?
Enfoque de programación dinámica
Dejar i ser el elemento con el número más alto en una solución óptima S para Wdolares LuegoS' = S - {i} es una solución óptima para W - wi dólares y el valor de la solución S es Vi más el valor del subproblema.
Podemos expresar este hecho en la siguiente fórmula: definir c[i, w] ser la solución para los artículos 1,2, … , iy la max i peso mamáw.
El algoritmo toma las siguientes entradas
El max i peso mamáW
La cantidad de elementos n
Las dos secuencias v = <v1, v2, …, vn> y w = <w1, w2, …, wn>
Dynamic-0-1-knapsack (v, w, n, W)
for w = 0 to W do
c[0, w] = 0
for i = 1 to n do
c[i, 0] = 0
for w = 1 to W do
if wi ≤ w then
if vi + c[i-1, w-wi] then
c[i, w] = vi + c[i-1, w-wi]
else c[i, w] = c[i-1, w]
else
c[i, w] = c[i-1, w]El conjunto de elementos a llevar se puede deducir de la tabla, comenzando en c[n, w] y rastrear hacia atrás de dónde provienen los valores óptimos.
Si c [i, w] = c [i-1, w] , entonces el elementoi no es parte de la solución, y seguimos rastreando con c[i-1, w]. De lo contrario, artículoi es parte de la solución, y seguimos rastreando con c[i-1, w-W].
Análisis
Este algoritmo toma θ ( n , w ) veces, ya que la tabla c tiene ( n + 1). ( W + 1) entradas, donde cada entrada requiere θ (1) tiempo para calcular.
El problema de subsecuencia común más largo es encontrar la secuencia más larga que existe en ambas cadenas dadas.
Subsiguiente
Consideremos una secuencia S = <s 1 , s 2 , s 3 , s 4 ,…, s n >.
Una secuencia Z = <z 1 , z 2 , z 3 , z 4 ,…, z m > sobre S se denomina subsecuencia de S, si y sólo si puede derivarse de la eliminación de S de algunos elementos.
Subsecuencia común
Suponer, X y Yson dos secuencias sobre un conjunto finito de elementos. Podemos decir esoZ es una subsecuencia común de X y Y, Si Z es una subsecuencia de ambos X y Y.
Subsecuencia común más larga
Si se proporciona un conjunto de secuencias, el problema de subsecuencia común más largo es encontrar una subsecuencia común de todas las secuencias que sea de longitud máxima.
El problema de subsecuencia común más extenso es un problema informático clásico, la base de los programas de comparación de datos, como la utilidad diff, y tiene aplicaciones en bioinformática. También es ampliamente utilizado por los sistemas de control de revisiones, como SVN y Git, para conciliar múltiples cambios realizados en una colección de archivos controlados por revisiones.
Método ingenuo
Dejar X ser una secuencia de longitud m y Y una secuencia de longitud n. Verifique cada subsecuencia deX si es una subsecuencia de Yy devuelve la subsecuencia común más larga encontrada.
Existen 2m subsecuencias de X. Probar secuencias, sea o no una subsecuencia deY toma O(n)hora. Por lo tanto, el algoritmo ingenuo tomaríaO(n2m) hora.
Programación dinámica
Sean X = <x 1 , x 2 , x 3 ,…, x m > e Y = <y 1 , y 2 , y 3 ,…, y n > las secuencias. Para calcular la longitud de un elemento se utiliza el siguiente algoritmo.
En este procedimiento, la tabla C[m, n] se calcula en orden de fila mayor y otra tabla B[m,n] se calcula para construir la solución óptima.
Algorithm: LCS-Length-Table-Formulation (X, Y)
m := length(X)
n := length(Y)
for i = 1 to m do
C[i, 0] := 0
for j = 1 to n do
C[0, j] := 0
for i = 1 to m do
for j = 1 to n do
if xi = yj
C[i, j] := C[i - 1, j - 1] + 1
B[i, j] := ‘D’
else
if C[i -1, j] ≥ C[i, j -1]
C[i, j] := C[i - 1, j] + 1
B[i, j] := ‘U’
else
C[i, j] := C[i, j - 1]
B[i, j] := ‘L’
return C and BAlgorithm: Print-LCS (B, X, i, j)
if i = 0 and j = 0
return
if B[i, j] = ‘D’
Print-LCS(B, X, i-1, j-1)
Print(xi)
else if B[i, j] = ‘U’
Print-LCS(B, X, i-1, j)
else
Print-LCS(B, X, i, j-1)Este algoritmo imprimirá la subsecuencia común más larga de X y Y.
Análisis
Para poblar la mesa, el exterior for bucle itera m tiempos y el interior for bucle itera nveces. Por tanto, la complejidad del algoritmo es O (m, n) , dondem y n son la longitud de dos cuerdas.
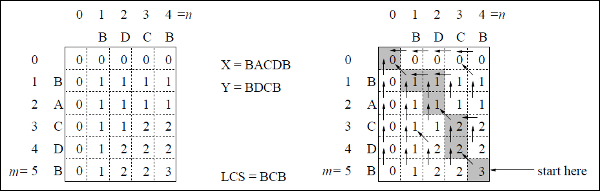
Ejemplo
En este ejemplo, tenemos dos cadenas X = BACDB y Y = BDCB para encontrar la subsecuencia común más larga.
Siguiendo el algoritmo LCS-Length-Table-Formulation (como se indicó anteriormente), hemos calculado la tabla C (que se muestra en el lado izquierdo) y la tabla B (que se muestra en el lado derecho).
En la tabla B, en lugar de 'D', 'L' y 'U', estamos usando la flecha diagonal, la flecha hacia la izquierda y la flecha hacia arriba, respectivamente. Después de generar la tabla B, el LCS se determina mediante la función LCS-Print. El resultado es BCB.
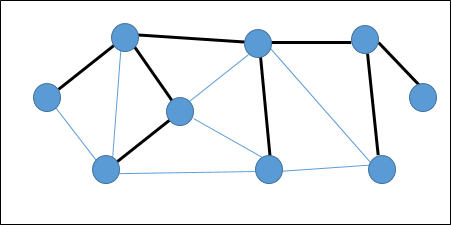
UN spanning tree es un subconjunto de un gráfico no dirigido que tiene todos los vértices conectados por un número mínimo de aristas.
Si todos los vértices están conectados en un gráfico, entonces existe al menos un árbol de expansión. En un gráfico, puede haber más de un árbol de expansión.
Propiedades
- Un árbol de expansión no tiene ningún ciclo.
- Se puede llegar a cualquier vértice desde cualquier otro vértice.
Ejemplo
En el siguiente gráfico, los bordes resaltados forman un árbol de expansión.
Árbol de expansión mínimo
UN Minimum Spanning Tree (MST)es un subconjunto de aristas de un grafo no dirigido ponderado conectado que conecta todos los vértices con el peso de arista total mínimo posible. Para derivar un MST, se puede utilizar el algoritmo de Prim o el algoritmo de Kruskal. Por lo tanto, discutiremos el algoritmo de Prim en este capítulo.
Como hemos comentado, un gráfico puede tener más de un árbol de expansión. Si hayn número de vértices, el árbol de expansión debería tener n - 1número de aristas. En este contexto, si cada borde del gráfico está asociado con un peso y existe más de un árbol de expansión, necesitamos encontrar el árbol de expansión mínimo del gráfico.
Además, si existen bordes ponderados duplicados, el gráfico puede tener múltiples árboles de expansión mínimos.
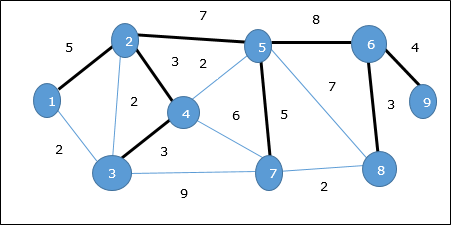
En el gráfico anterior, mostramos un árbol de expansión, aunque no es el árbol de expansión mínimo. El costo de este árbol de expansión es (5 + 7 + 3 + 3 + 5 + 8 + 3 + 4) = 38.
Usaremos el algoritmo de Prim para encontrar el árbol de expansión mínimo.
Algoritmo de Prim
El algoritmo de Prim es un enfoque codicioso para encontrar el árbol de expansión mínimo. En este algoritmo, para formar un MST podemos partir de un vértice arbitrario.
Algorithm: MST-Prim’s (G, w, r)
for each u є G.V
u.key = ∞
u.∏ = NIL
r.key = 0
Q = G.V
while Q ≠ Ф
u = Extract-Min (Q)
for each v є G.adj[u]
if each v є Q and w(u, v) < v.key
v.∏ = u
v.key = w(u, v)La función Extract-Min devuelve el vértice con un coste de borde mínimo. Esta función funciona en min-heap.
Ejemplo
Usando el algoritmo de Prim, podemos comenzar desde cualquier vértice, comencemos desde el vértice 1.
Vértice 3 está conectado al vértice 1 con un costo de borde mínimo, por lo tanto, borde (1, 2) se agrega al árbol de expansión.
Siguiente, borde (2, 3) se considera que este es el mínimo entre los bordes {(1, 2), (2, 3), (3, 4), (3, 7)}.
En el siguiente paso, obtenemos ventaja (3, 4) y (2, 4)con costo mínimo. Borde(3, 4) se selecciona al azar.
De manera similar, los bordes (4, 5), (5, 7), (7, 8), (6, 8) y (6, 9)están seleccionados. Como se visitan todos los vértices, ahora el algoritmo se detiene.
El costo del árbol de expansión es (2 + 2 + 3 + 2 + 5 + 2 + 3 + 4) = 23. No hay más árbol de expansión en este gráfico con un costo menor que 23.
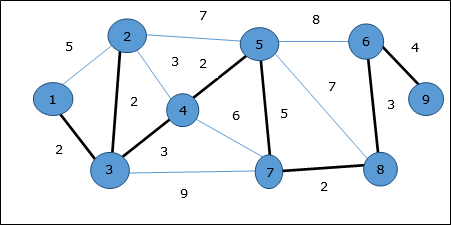
Algoritmo de Dijkstra
El algoritmo de Dijkstra resuelve el problema de rutas más cortas de fuente única en un gráfico ponderado dirigido G = (V, E) , donde todos los bordes son no negativos (es decir, w (u, v) ≥ 0 para cada borde (u, v ) Є E ).
En el siguiente algoritmo, usaremos una función Extract-Min(), que extrae el nodo con la clave más pequeña.
Algorithm: Dijkstra’s-Algorithm (G, w, s)
for each vertex v Є G.V
v.d := ∞
v.∏ := NIL
s.d := 0
S := Ф
Q := G.V
while Q ≠ Ф
u := Extract-Min (Q)
S := S U {u}
for each vertex v Є G.adj[u]
if v.d > u.d + w(u, v)
v.d := u.d + w(u, v)
v.∏ := uAnálisis
La complejidad de este algoritmo depende completamente de la implementación de la función Extract-Min. Si la función de extracción mínima se implementa mediante búsqueda lineal, la complejidad de este algoritmo esO(V2 + E).
En este algoritmo, si usamos min-heap en el que Extract-Min() La función funciona para devolver el nodo desde Q con la clave más pequeña, la complejidad de este algoritmo se puede reducir aún más.
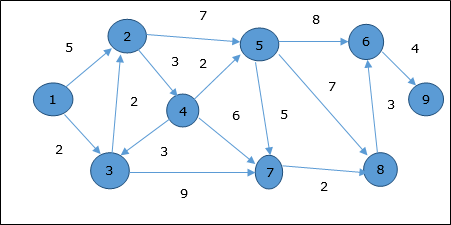
Ejemplo
Consideremos el vértice 1 y 9como vértice de inicio y de destino respectivamente. Inicialmente, todos los vértices excepto el vértice inicial están marcados con ∞ y el vértice inicial está marcado con0.
| Vértice | Inicial | Paso 1 V 1 | Paso 2 V 3 | Paso 3 V 2 | Paso 4 V 4 | Paso 5 V 5 | Paso 6 V 7 | Paso 7 V 8 | Paso 8 V 6 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | ∞ | 5 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 3 | ∞ | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 4 | ∞ | ∞ | ∞ | 7 | 7 | 7 | 7 | 7 | 7 |
| 5 | ∞ | ∞ | ∞ | 11 | 9 | 9 | 9 | 9 | 9 |
| 6 | ∞ | ∞ | ∞ | ∞ | ∞ | 17 | 17 | dieciséis | dieciséis |
| 7 | ∞ | ∞ | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| 8 | ∞ | ∞ | ∞ | ∞ | ∞ | dieciséis | 13 | 13 | 13 |
| 9 | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | 20 |
Por tanto, la distancia mínima del vértice 9 desde el vértice 1 es 20. Y el camino es
1 → 3 → 7 → 8 → 6 → 9
Esta ruta se determina en función de la información del predecesor.
Algoritmo Bellman Ford
Este algoritmo resuelve el problema de la ruta más corta de una sola fuente de un gráfico dirigido G = (V, E)en el que los pesos de los bordes pueden ser negativos. Además, este algoritmo se puede aplicar para encontrar el camino más corto, si no existe ningún ciclo ponderado negativo.
Algorithm: Bellman-Ford-Algorithm (G, w, s)
for each vertex v Є G.V
v.d := ∞
v.∏ := NIL
s.d := 0
for i = 1 to |G.V| - 1
for each edge (u, v) Є G.E
if v.d > u.d + w(u, v)
v.d := u.d +w(u, v)
v.∏ := u
for each edge (u, v) Є G.E
if v.d > u.d + w(u, v)
return FALSE
return TRUEAnálisis
El primero for El bucle se utiliza para la inicialización, que se ejecuta en O(V)veces. El siguientefor se ejecuta el bucle |V - 1| pasa sobre los bordes, lo que llevaO(E) veces.
Por tanto, el algoritmo de Bellman-Ford se ejecuta en O(V, E) hora.
Ejemplo
El siguiente ejemplo muestra cómo funciona el algoritmo Bellman-Ford paso a paso. Este gráfico tiene un borde negativo pero no tiene ningún ciclo negativo, por lo que el problema se puede resolver utilizando esta técnica.
En el momento de la inicialización, todos los vértices excepto la fuente están marcados con ∞ y la fuente está marcada con 0.
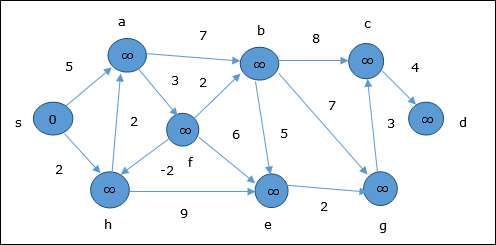
En el primer paso, todos los vértices que son accesibles desde la fuente se actualizan por costo mínimo. Por tanto, vérticesa y h se actualizan.
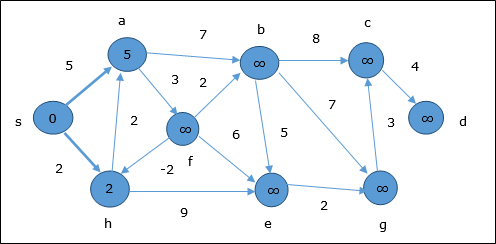
En el siguiente paso, vértices a, b, f y e se actualizan.
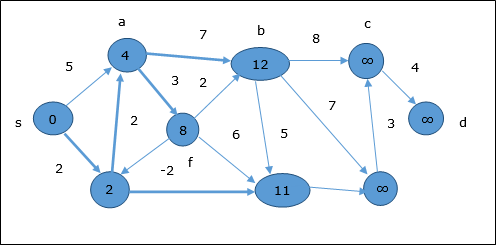
Siguiendo la misma lógica, en este paso los vértices b, f, c y g se actualizan.
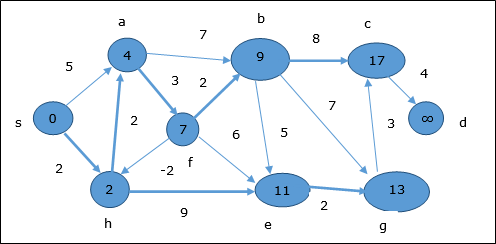
Aquí vértices c y d se actualizan.
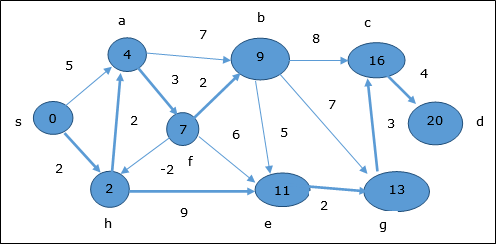
Por lo tanto, la distancia mínima entre vértices s y vértice d es 20.
Según la información del predecesor, la ruta es s → h → e → g → c → d
Un gráfico de varias etapas G = (V, E) es un gráfico dirigido donde los vértices se dividen en k (dónde k > 1) número de subconjuntos disjuntos S = {s1,s2,…,sk}tal que el borde (u, v) está en E, entonces u Є s i y v Є s 1 + 1 para algunos subconjuntos en la partición y |s1| = |sk| = 1.
El vértice s Є s1 se llama el source y el vértice t Є sk se llama sink.
Ggeneralmente se asume que es un gráfico ponderado. En este gráfico, el costo de una arista (i, j) está representado por c (i, j) . Por lo tanto, el costo de la ruta desde la fuentes hundir t es la suma de los costos de cada borde en este camino.
El problema del gráfico de varias etapas es encontrar la ruta con un costo mínimo desde la fuente s hundir t.
Ejemplo
Considere el siguiente ejemplo para comprender el concepto de gráfico de varias etapas.
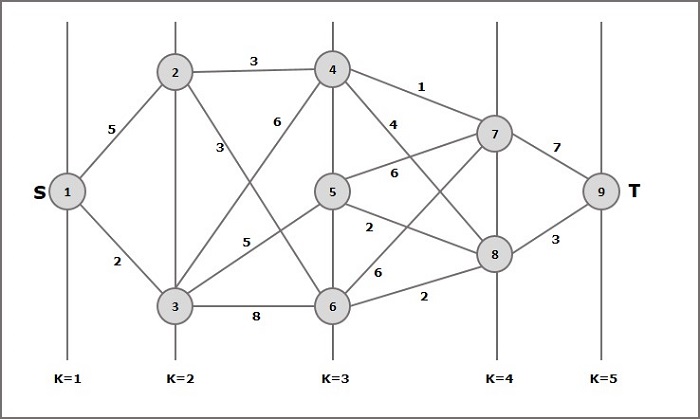
Según la fórmula, tenemos que calcular el costo (i, j) usando los siguientes pasos
Paso 1: Costo (K-2, j)
En este paso, se seleccionan tres nodos (nodo 4, 5. 6) como j. Por lo tanto, tenemos tres opciones para elegir el costo mínimo en este paso.
Costo (3, 4) = mínimo {c (4, 7) + Costo (7, 9), c (4, 8) + Costo (8, 9)} = 7
Costo (3, 5) = mínimo {c (5, 7) + Costo (7, 9), c (5, 8) + Costo (8, 9)} = 5
Costo (3, 6) = mínimo {c (6, 7) + Costo (7, 9), c (6, 8) + Costo (8, 9)} = 5
Paso 2: Costo (K-3, j)
Se seleccionan dos nodos como j porque en la etapa k - 3 = 2 hay dos nodos, 2 y 3. Entonces, el valor i = 2 y j = 2 y 3.
Coste (2, 2) = min {c (2, 4) + Coste (4, 8) + Coste (8, 9), c (2, 6) +
Costo (6, 8) + Costo (8, 9)} = 8
Costo (2, 3) = {c (3, 4) + Costo (4, 8) + Costo (8, 9), c (3, 5) + Costo (5, 8) + Costo (8, 9), c (3, 6) + Costo (6, 8) + Costo (8, 9)} = 10
Paso 3: Costo (K-4, j)
Costo (1, 1) = {c (1, 2) + Costo (2, 6) + Costo (6, 8) + Costo (8, 9), c (1, 3) + Costo (3, 5) + Costo (5, 8) + Costo (8, 9))} = 12
c (1, 3) + Costo (3, 6) + Costo (6, 8 + Costo (8, 9))} = 13
Por lo tanto, la ruta que tiene el costo mínimo es 1→ 3→ 5→ 8→ 9.
Planteamiento del problema
Un viajero necesita visitar todas las ciudades de una lista, donde se conocen las distancias entre todas las ciudades y cada ciudad debe visitarse una sola vez. ¿Cuál es la ruta más corta posible que visita cada ciudad exactamente una vez y regresa a la ciudad de origen?
Solución
El problema del vendedor ambulante es el problema computacional más notorio. Podemos utilizar un enfoque de fuerza bruta para evaluar cada recorrido posible y seleccionar el mejor. porn número de vértices en un gráfico, hay (n - 1)! número de posibilidades.
En lugar de utilizar la fuerza bruta mediante un enfoque de programación dinámica, la solución se puede obtener en menos tiempo, aunque no existe un algoritmo de tiempo polinomial.
Consideremos un gráfico G = (V, E), dónde V es un conjunto de ciudades y Ees un conjunto de bordes ponderados. Un bordee(u, v) representa esos vértices u y vestan conectados. Distancia entre vérticesu y v es d(u, v), que no debe ser negativo.
Supongamos que hemos comenzado en la ciudad 1 y después de visitar algunas ciudades ahora estamos en la ciudad j. Por lo tanto, este es un recorrido parcial. Ciertamente necesitamos saberj, ya que esto determinará qué ciudades son las más convenientes para visitar a continuación. También necesitamos conocer todas las ciudades visitadas hasta ahora, para no repetir ninguna de ellas. Por tanto, este es un subproblema apropiado.
Para un subconjunto de ciudades S Є {1, 2, 3, ... , n} eso incluye 1y j Є S, dejar C(S, j) ser la longitud de la ruta más corta que visita cada nodo en S exactamente una vez, comenzando en 1 y termina en j.
Cuando |S| > 1, definimosC(S, 1) = ∝ ya que la ruta no puede comenzar y terminar en 1.
Ahora, expresemos C(S, j)en términos de subproblemas más pequeños. Tenemos que empezar en1 y terminar en j. Debemos seleccionar la siguiente ciudad de tal manera que
$$C(S, j) = min \:C(S - \lbrace j \rbrace, i) + d(i, j)\:where\: i\in S \: and\: i \neq jc(S, j) = minC(s- \lbrace j \rbrace, i)+ d(i,j) \:where\: i\in S \: and\: i \neq j $$
Algorithm: Traveling-Salesman-Problem
C ({1}, 1) = 0
for s = 2 to n do
for all subsets S Є {1, 2, 3, … , n} of size s and containing 1
C (S, 1) = ∞
for all j Є S and j ≠ 1
C (S, j) = min {C (S – {j}, i) + d(i, j) for i Є S and i ≠ j}
Return minj C ({1, 2, 3, …, n}, j) + d(j, i)Análisis
Hay como máximo $2^n.n$subproblemas y cada uno requiere un tiempo lineal para resolverlo. Por lo tanto, el tiempo total de ejecución es$O(2^n.n^2)$.
Ejemplo
En el siguiente ejemplo, ilustraremos los pasos para resolver el problema del viajante.

A partir del gráfico anterior, se prepara la siguiente tabla.
| 1 | 2 | 3 | 4 | |
| 1 | 0 | 10 | 15 | 20 |
| 2 | 5 | 0 | 9 | 10 |
| 3 | 6 | 13 | 0 | 12 |
| 4 | 8 | 8 | 9 | 0 |
S = Φ
$$\small Cost (2,\Phi,1) = d (2,1) = 5\small Cost(2,\Phi,1)=d(2,1)=5$$
$$\small Cost (3,\Phi,1) = d (3,1) = 6\small Cost(3,\Phi,1)=d(3,1)=6$$
$$\small Cost (4,\Phi,1) = d (4,1) = 8\small Cost(4,\Phi,1)=d(4,1)=8$$
S = 1
$$\small Cost (i,s) = min \lbrace Cost (j,s – (j)) + d [i,j]\rbrace\small Cost (i,s)=min \lbrace Cost (j,s)-(j))+ d [i,j]\rbrace$$
$$\small Cost (2,\lbrace 3 \rbrace,1) = d [2,3] + Cost (3,\Phi,1) = 9 + 6 = 15cost(2,\lbrace3 \rbrace,1)=d[2,3]+cost(3,\Phi ,1)=9+6=15$$
$$\small Cost (2,\lbrace 4 \rbrace,1) = d [2,4] + Cost (4,\Phi,1) = 10 + 8 = 18cost(2,\lbrace4 \rbrace,1)=d[2,4]+cost(4,\Phi,1)=10+8=18$$
$$\small Cost (3,\lbrace 2 \rbrace,1) = d [3,2] + Cost (2,\Phi,1) = 13 + 5 = 18cost(3,\lbrace2 \rbrace,1)=d[3,2]+cost(2,\Phi,1)=13+5=18$$
$$\small Cost (3,\lbrace 4 \rbrace,1) = d [3,4] + Cost (4,\Phi,1) = 12 + 8 = 20cost(3,\lbrace4 \rbrace,1)=d[3,4]+cost(4,\Phi,1)=12+8=20$$
$$\small Cost (4,\lbrace 3 \rbrace,1) = d [4,3] + Cost (3,\Phi,1) = 9 + 6 = 15cost(4,\lbrace3 \rbrace,1)=d[4,3]+cost(3,\Phi,1)=9+6=15$$
$$\small Cost (4,\lbrace 2 \rbrace,1) = d [4,2] + Cost (2,\Phi,1) = 8 + 5 = 13cost(4,\lbrace2 \rbrace,1)=d[4,2]+cost(2,\Phi,1)=8+5=13$$
S = 2
$$\small Cost(2, \lbrace 3, 4 \rbrace, 1)=\begin{cases}d[2, 3] + Cost(3, \lbrace 4 \rbrace, 1) = 9 + 20 = 29\\d[2, 4] + Cost(4, \lbrace 3 \rbrace, 1) = 10 + 15 = 25=25\small Cost (2,\lbrace 3,4 \rbrace,1)\\\lbrace d[2,3]+ \small cost(3,\lbrace4\rbrace,1)=9+20=29d[2,4]+ \small Cost (4,\lbrace 3 \rbrace ,1)=10+15=25\end{cases}= 25$$
$$\small Cost(3, \lbrace 2, 4 \rbrace, 1)=\begin{cases}d[3, 2] + Cost(2, \lbrace 4 \rbrace, 1) = 13 + 18 = 31\\d[3, 4] + Cost(4, \lbrace 2 \rbrace, 1) = 12 + 13 = 25=25\small Cost (3,\lbrace 2,4 \rbrace,1)\\\lbrace d[3,2]+ \small cost(2,\lbrace4\rbrace,1)=13+18=31d[3,4]+ \small Cost (4,\lbrace 2 \rbrace ,1)=12+13=25\end{cases}= 25$$
$$\small Cost(4, \lbrace 2, 3 \rbrace, 1)=\begin{cases}d[4, 2] + Cost(2, \lbrace 3 \rbrace, 1) = 8 + 15 = 23\\d[4, 3] + Cost(3, \lbrace 2 \rbrace, 1) = 9 + 18 = 27=23\small Cost (4,\lbrace 2,3 \rbrace,1)\\\lbrace d[4,2]+ \small cost(2,\lbrace3\rbrace,1)=8+15=23d[4,3]+ \small Cost (3,\lbrace 2 \rbrace ,1)=9+18=27\end{cases}= 23$$
S = 3
$$\small Cost(1, \lbrace 2, 3, 4 \rbrace, 1)=\begin{cases}d[1, 2] + Cost(2, \lbrace 3, 4 \rbrace, 1) = 10 + 25 = 35\\d[1, 3] + Cost(3, \lbrace 2, 4 \rbrace, 1) = 15 + 25 = 40\\d[1, 4] + Cost(4, \lbrace 2, 3 \rbrace, 1) = 20 + 23 = 43=35 cost(1,\lbrace 2,3,4 \rbrace),1)\\d[1,2]+cost(2,\lbrace 3,4 \rbrace,1)=10+25=35\\d[1,3]+cost(3,\lbrace 2,4 \rbrace,1)=15+25=40\\d[1,4]+cost(4,\lbrace 2,3 \rbrace ,1)=20+23=43=35\end{cases}$$
La ruta de costo mínimo es 35.
Comience desde el costo {1, {2, 3, 4}, 1}, obtenemos el valor mínimo para d [1, 2]. Cuandos = 3, seleccione la ruta de 1 a 2 (el costo es 10) y luego retroceda. Cuandos = 2, obtenemos el valor mínimo para d [4, 2]. Seleccione la ruta de 2 a 4 (el costo es 10) y luego retroceda.
Cuando s = 1, obtenemos el valor mínimo para d [4, 3]. Seleccionando la ruta 4 a 3 (el costo es 9), luego iremos a luego iremos as = Φpaso. Obtenemos el valor mínimo parad [3, 1] (el costo es 6).

Un árbol de búsqueda binaria (BST) es un árbol donde los valores clave se almacenan en los nodos internos. Los nodos externos son nodos nulos. Las claves están ordenadas lexicográficamente, es decir, para cada nodo interno todas las claves del subárbol izquierdo son menores que las claves del nodo, y todas las claves del subárbol derecho son mayores.
Cuando conocemos la frecuencia de búsqueda de cada una de las claves, es bastante fácil calcular el costo esperado de acceder a cada nodo del árbol. Un árbol de búsqueda binario óptimo es un BST, que tiene un costo mínimo esperado para ubicar cada nodo
El tiempo de búsqueda de un elemento en una BST es O(n), mientras que en una búsqueda BST equilibrada el tiempo es O(log n). Una vez más, el tiempo de búsqueda se puede mejorar en el árbol de búsqueda binaria de costo óptimo, colocando los datos más utilizados en la raíz y más cerca del elemento raíz, mientras que los datos utilizados con menos frecuencia cerca de las hojas y en las hojas.
Aquí, se presenta el algoritmo de árbol de búsqueda binario óptimo. Primero, construimos un BST a partir de un conjunto den número de claves distintas < k1, k2, k3, ... kn >. Aquí asumimos, la probabilidad de acceder a una claveKi es pi. Algunas llaves ficticias (d0, d1, d2, ... dn) se añaden ya que se pueden realizar algunas búsquedas para los valores que no están presentes en el conjunto de claves K. Suponemos, para cada clave ficticiadi probabilidad de acceso es qi.
Optimal-Binary-Search-Tree(p, q, n)
e[1…n + 1, 0…n],
w[1…n + 1, 0…n],
root[1…n + 1, 0…n]
for i = 1 to n + 1 do
e[i, i - 1] := qi - 1
w[i, i - 1] := qi - 1
for l = 1 to n do
for i = 1 to n – l + 1 do
j = i + l – 1 e[i, j] := ∞
w[i, i] := w[i, i -1] + pj + qj
for r = i to j do
t := e[i, r - 1] + e[r + 1, j] + w[i, j]
if t < e[i, j]
e[i, j] := t
root[i, j] := r
return e and rootAnálisis
El algoritmo requiere O (n3) tiempo, desde tres anidados forse utilizan bucles. Cada uno de estos bucles adquiere como máximon valores.
Ejemplo
Considerando el siguiente árbol, el costo es 2.80, aunque este no es un resultado óptimo.
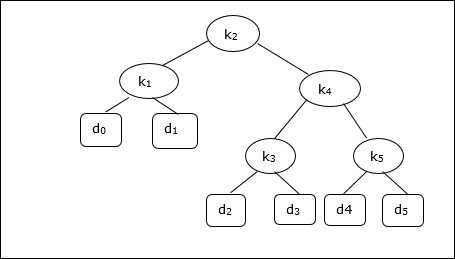
| Nodo | Profundidad | Probabilidad | Contribución |
|---|---|---|---|
| k 1 | 1 | 0,15 | 0,30 |
| k 2 | 0 | 0,10 | 0,10 |
| k 3 | 2 | 0,05 | 0,15 |
| k 4 | 1 | 0,10 | 0,20 |
| k 5 | 2 | 0,20 | 0,60 |
| d 0 | 2 | 0,05 | 0,15 |
| d 1 | 2 | 0,10 | 0,30 |
| d 2 | 3 | 0,05 | 0,20 |
| d 3 | 3 | 0,05 | 0,20 |
| d 4 | 3 | 0,05 | 0,20 |
| d 5 | 3 | 0,10 | 0.40 |
| Total | 2,80 |
Para obtener una solución óptima, utilizando el algoritmo discutido en este capítulo, se generan las siguientes tablas.
En las siguientes tablas, el índice de columna es i y el índice de fila es j.
| mi | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 5 | 2,75 | 2,00 | 1,30 | 0,90 | 0,50 | 0,10 |
| 4 | 1,75 | 1,20 | 0,60 | 0,30 | 0,05 | |
| 3 | 1,25 | 0,70 | 0,25 | 0,05 | ||
| 2 | 0,90 | 0.40 | 0,05 | |||
| 1 | 0,45 | 0,10 | ||||
| 0 | 0,05 |
| w | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 5 | 1,00 | 0,80 | 0,60 | 0,50 | 0,35 | 0,10 |
| 4 | 0,70 | 0,50 | 0,30 | 0,20 | 0,05 | |
| 3 | 0,55 | 0,35 | 0,15 | 0,05 | ||
| 2 | 0,45 | 0,25 | 0,05 | |||
| 1 | 0,30 | 0,10 | ||||
| 0 | 0,05 |
| raíz | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 5 | 2 | 4 | 5 | 5 | 5 |
| 4 | 2 | 2 | 4 | 4 | |
| 3 | 2 | 2 | 3 | ||
| 2 | 1 | 2 | |||
| 1 | 1 |
A partir de estas tablas, se puede formar el árbol óptimo.
Hay varios tipos de montones, sin embargo, en este capítulo, discutiremos el montón binario. UNbinary heapes una estructura de datos, que se parece a un árbol binario completo. La estructura de datos del montón obedece a las propiedades de ordenación que se describen a continuación. Generalmente, un montón está representado por una matriz. En este capítulo, estamos representando un montón porH.
Como los elementos de un montón se almacenan en una matriz, considerando el índice inicial como 1, la posición del nodo padre de ith El elemento se puede encontrar en ⌊ i/2 ⌋. Hijo izquierdo y hijo derecho deith el nodo está en la posición 2i y 2i + 1.
Un montón binario se puede clasificar además como un max-heap o un min-heap basado en la propiedad de pedido.
Max-Heap
En este montón, el valor de clave de un nodo es mayor o igual que el valor de clave del hijo más alto.
Por lo tanto, H[Parent(i)] ≥ H[i]
Min-Heap
En mean-heap, el valor de clave de un nodo es menor o igual que el valor de clave del hijo más bajo.
Por lo tanto, H[Parent(i)] ≤ H[i]
En este contexto, las operaciones básicas se muestran a continuación con respecto a Max-Heap. La inserción y eliminación de elementos en y desde montones necesita una reorganización de elementos. Por lo tanto,Heapify la función necesita ser llamada.
Representación de matriz
Un árbol binario completo puede ser representado por una matriz, almacenando sus elementos usando el orden de nivel transversal.
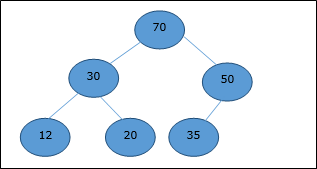
Consideremos un montón (como se muestra a continuación) que estará representado por una matriz H.
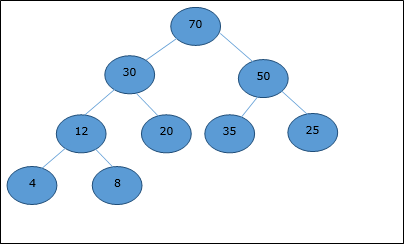
Considerando el índice inicial como 0, utilizando el orden de nivel transversal, los elementos se mantienen en una matriz de la siguiente manera.
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ... |
| elements | 70 | 30 | 50 | 12 | 20 | 35 | 25 | 4 | 8 | ... |
En este contexto, las operaciones en el montón se representan con respecto a Max-Heap.
Para encontrar el índice del padre de un elemento en el índice i, el siguiente algoritmo Parent (numbers[], i) se utiliza.
Algorithm: Parent (numbers[], i)
if i == 1
return NULL
else
[i / 2]El índice del hijo izquierdo de un elemento en el índice i se puede encontrar usando el siguiente algoritmo, Left-Child (numbers[], i).
Algorithm: Left-Child (numbers[], i)
If 2 * i ≤ heapsize
return [2 * i]
else
return NULLEl índice del hijo derecho de un elemento en el índice i se puede encontrar usando el siguiente algoritmo, Right-Child(numbers[], i).
Algorithm: Right-Child (numbers[], i)
if 2 * i < heapsize
return [2 * i + 1]
else
return NULLPara insertar un elemento en un montón, el nuevo elemento se agrega inicialmente al final del montón como último elemento de la matriz.
Después de insertar este elemento, la propiedad del montón se puede violar, por lo tanto, la propiedad del montón se repara comparando el elemento agregado con su padre y moviendo el elemento agregado hacia arriba un nivel, intercambiando posiciones con el padre. Este proceso se llamapercolation up.
La comparación se repite hasta que el padre es mayor o igual que el elemento de filtración.
Algorithm: Max-Heap-Insert (numbers[], key)
heapsize = heapsize + 1
numbers[heapsize] = -∞
i = heapsize
numbers[i] = key
while i > 1 and numbers[Parent(numbers[], i)] < numbers[i]
exchange(numbers[i], numbers[Parent(numbers[], i)])
i = Parent (numbers[], i)Análisis
Inicialmente, se agrega un elemento al final de la matriz. Si viola la propiedad del montón, el elemento se intercambia con su padre. La altura del árbol eslog n. Máximolog n número de operaciones necesarias.
Por tanto, la complejidad de esta función es O(log n).
Ejemplo
Consideremos un montón máximo, como se muestra a continuación, donde es necesario agregar un nuevo elemento 5.
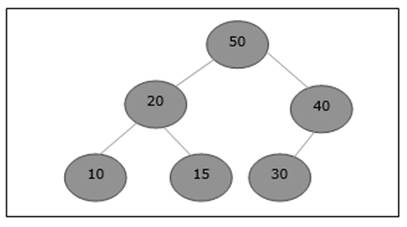
Inicialmente, se agregarán 55 al final de esta matriz.
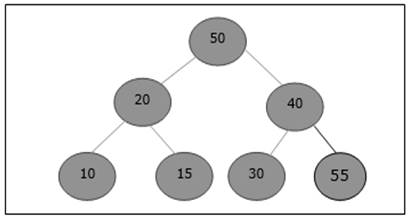
Después de la inserción, viola la propiedad del montón. Por lo tanto, el elemento debe intercambiarse con su padre. Después del intercambio, el montón tiene el siguiente aspecto.
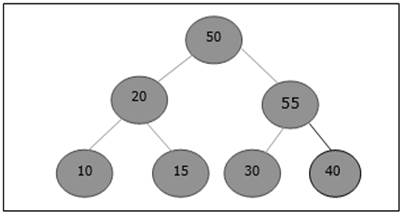
Nuevamente, el elemento viola la propiedad de heap. Por lo tanto, se intercambia con su padre.
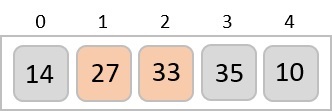
Ahora tenemos que parar.
El método Heapify reordena los elementos de una matriz donde el subárbol izquierdo y derecho de ith elemento obedece a la propiedad del montón.
Algorithm: Max-Heapify(numbers[], i)
leftchild := numbers[2i]
rightchild := numbers [2i + 1]
if leftchild ≤ numbers[].size and numbers[leftchild] > numbers[i]
largest := leftchild
else
largest := i
if rightchild ≤ numbers[].size and numbers[rightchild] > numbers[largest]
largest := rightchild
if largest ≠ i
swap numbers[i] with numbers[largest]
Max-Heapify(numbers, largest)Cuando la matriz proporcionada no obedece a la propiedad del montón, el montón se construye según el siguiente algoritmo Build-Max-Heap (numbers[]).
Algorithm: Build-Max-Heap(numbers[])
numbers[].size := numbers[].length
fori = ⌊ numbers[].length/2 ⌋ to 1 by -1
Max-Heapify (numbers[], i)El método de extracción se utiliza para extraer el elemento raíz de un montón. A continuación se muestra el algoritmo.
Algorithm: Heap-Extract-Max (numbers[])
max = numbers[1]
numbers[1] = numbers[heapsize]
heapsize = heapsize – 1
Max-Heapify (numbers[], 1)
return maxEjemplo
Consideremos el mismo ejemplo discutido anteriormente. Ahora queremos extraer un elemento. Este método devolverá el elemento raíz del montón.
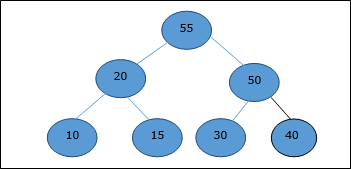
Después de eliminar el elemento raíz, el último elemento se moverá a la posición raíz.
Ahora, se llamará a la función Heapify. Después de Heapify, se genera el siguiente montón.
Bubble Sort es un algoritmo de clasificación elemental, que funciona intercambiando repetidamente elementos adyacentes, si es necesario. Cuando no se requieren intercambios, el archivo se ordena.
Ésta es la técnica más sencilla entre todos los algoritmos de clasificación.
Algorithm: Sequential-Bubble-Sort (A)
fori← 1 to length [A] do
for j ← length [A] down-to i +1 do
if A[A] < A[j - 1] then
Exchange A[j] ↔ A[j-1]Implementación
voidbubbleSort(int numbers[], intarray_size) {
inti, j, temp;
for (i = (array_size - 1); i >= 0; i--)
for (j = 1; j <= i; j++)
if (numbers[j - 1] > numbers[j]) {
temp = numbers[j-1];
numbers[j - 1] = numbers[j];
numbers[j] = temp;
}
}Análisis
Aquí, el número de comparaciones es
1 + 2 + 3 +...+ (n - 1) = n(n - 1)/2 = O(n2)
Claramente, el gráfico muestra el n2 naturaleza del tipo de burbuja.
En este algoritmo, el número de comparación es independiente del conjunto de datos, es decir, si los elementos de entrada proporcionados están ordenados o en orden inverso o aleatorio.
Requisito de memoria
A partir del algoritmo indicado anteriormente, está claro que la clasificación de burbujas no requiere memoria adicional.
Ejemplo
Unsorted list: |
|
1 st iteración:
5 > 2 swap |
|
|||||||
5 > 1 swap |
|
|||||||
5 > 4 swap |
|
|||||||
5 > 3 swap |
|
|||||||
5 < 7 no swap |
|
|||||||
7 > 6 swap |
|
2 nd iteración:
2 > 1 swap |
|
|||||||
2 < 4 no swap |
|
|||||||
4 > 3 swap |
|
|||||||
4 < 5 no swap |
|
|||||||
5 < 6 no swap |
|
No hay cambios en la 3ª , 4ª , 5ª y 6ª iteración.
Finalmente,
the sorted list is |
|
La clasificación por inserción es un método muy sencillo para clasificar números en orden ascendente o descendente. Este método sigue el método incremental. Se puede comparar con la técnica de cómo se clasifican las cartas en el momento de jugar un juego.
Los números, que deben ordenarse, se conocen como keys. Aquí está el algoritmo del método de ordenación por inserción.
Algorithm: Insertion-Sort(A)
for j = 2 to A.length
key = A[j]
i = j – 1
while i > 0 and A[i] > key
A[i + 1] = A[i]
i = i -1
A[i + 1] = keyAnálisis
El tiempo de ejecución de este algoritmo depende en gran medida de la entrada dada.
Si los números dados están ordenados, este algoritmo se ejecuta en O(n)hora. Si los números dados están en orden inverso, el algoritmo se ejecuta enO(n2) hora.
Ejemplo
Unsorted list: |
|
1st iteration:
Clave = a [2] = 13
a [1] = 2 <13
Swap, no swap |
|
2nd iteration:
Clave = a [3] = 5
a [2] = 13> 5
Intercambiar 5 y 13 |
|
A continuación, a [1] = 2 <13
Swap, no swap |
|
3rd iteration:
Clave = a [4] = 18
a [3] = 13 <18,
a [2] = 5 <18,
a [1] = 2 <18
Swap, no swap |
|
4th iteration:
Clave = a [5] = 14
a [4] = 18> 14
Intercambiar 18 y 14 |
|
A continuación, a [3] = 13 <14,
a [2] = 5 <14,
a [1] = 2 <14
Entonces, sin intercambio |
|
Finalmente,
the sorted list is |
|
Este tipo de clasificación se llama Selection Sortya que funciona ordenando elementos repetidamente. Funciona de la siguiente manera: primero encuentre el más pequeño en la matriz e intercambie con el elemento en la primera posición, luego busque el segundo elemento más pequeño e intercambie con el elemento en la segunda posición, y continúe de esta manera hasta que toda la matriz esté ordenados.
Algorithm: Selection-Sort (A)
fori ← 1 to n-1 do
min j ← i;
min x ← A[i]
for j ←i + 1 to n do
if A[j] < min x then
min j ← j
min x ← A[j]
A[min j] ← A [i]
A[i] ← min xEl ordenamiento por selección es una de las técnicas de ordenación más simples y funciona muy bien para archivos pequeños. Tiene una aplicación bastante importante, ya que cada elemento se mueve como máximo una vez.
La clasificación de secciones es un método de elección para clasificar archivos con objetos muy grandes (registros) y claves pequeñas. El peor de los casos ocurre si la matriz ya está ordenada en orden descendente y queremos ordenarlas en orden ascendente.
No obstante, el tiempo requerido por el algoritmo de clasificación de selección no es muy sensible al orden original de la matriz que se va a clasificar: la prueba si A[j] < min x se ejecuta exactamente el mismo número de veces en todos los casos.
La ordenación por selección pasa la mayor parte del tiempo tratando de encontrar el elemento mínimo en la parte no ordenada de la matriz. Muestra claramente la similitud entre el ordenamiento por selección y el ordenamiento por burbujas.
La clasificación de burbujas selecciona el máximo de elementos restantes en cada etapa, pero desperdicia algo de esfuerzo en impartir algo de orden a una parte no clasificada de la matriz.
El ordenamiento por selección es cuadrático tanto en el peor de los casos como en el promedio, y no requiere memoria adicional.
Para cada i desde 1 a n - 1, hay un intercambio y n - i comparaciones, por lo que hay un total de n - 1 intercambios y
(n − 1) + (n − 2) + ...+ 2 + 1 = n(n − 1)/2 comparaciones.
Estas observaciones son válidas, independientemente de los datos de entrada.
En el peor de los casos, esto podría ser cuadrático, pero en el caso promedio, esta cantidad es O(n log n). Implica que elrunning time of Selection sort is quite insensitive to the input.
Implementación
Void Selection-Sort(int numbers[], int array_size) {
int i, j;
int min, temp;
for (i = 0; I < array_size-1; i++) {
min = i;
for (j = i+1; j < array_size; j++)
if (numbers[j] < numbers[min])
min = j;
temp = numbers[i];
numbers[i] = numbers[min];
numbers[min] = temp;
}
}Ejemplo
Unsorted list: |
|
1 st iteración:
Más pequeño = 5
2 <5, más pequeño = 2
1 <2, más pequeño = 1
4> 1, más pequeño = 1
3> 1, más pequeño = 1
Intercambiar 5 y 1 |
|
2 nd iteración:
Más pequeño = 2
2 <5, más pequeño = 2
2 <4, más pequeño = 2
2 <3, más pequeño = 2
Sin intercambio |
|
3 ª iteración:
Más pequeño = 5
4 <5, más pequeño = 4
3 <4, más pequeño = 3
Intercambiar 5 y 3 |
|
4 º iteración:
Más pequeño = 4
4 <5, más pequeño = 4
Sin intercambio |
|
Finalmente,
the sorted list is |
|
Se utiliza según el principio de divide y vencerás. La clasificación rápida es un algoritmo de elección en muchas situaciones, ya que no es difícil de implementar. Es un buen tipo de propósito general y consume relativamente menos recursos durante la ejecución.
Ventajas
Está en su lugar ya que utiliza solo una pequeña pila auxiliar.
Solo requiere n (log n) hora de ordenar n artículos.
Tiene un lazo interior extremadamente corto.
Este algoritmo ha sido sometido a un análisis matemático completo, se puede hacer una declaración muy precisa sobre problemas de rendimiento.
Desventajas
Es recursivo. Especialmente, si la recursividad no está disponible, la implementación es extremadamente complicada.
Requiere tiempo cuadrático (es decir, n2) en el peor de los casos.
Es frágil, es decir, un simple error en la implementación puede pasar desapercibido y hacer que funcione mal.
La clasificación rápida funciona particionando una matriz determinada A[p ... r] en dos submatrices no vacías A[p ... q] y A[q+1 ... r] tal que cada tecla en A[p ... q] es menor o igual que cada clave en A[q+1 ... r].
Luego, las dos submatrices se ordenan mediante llamadas recursivas a Quick sort. La posición exacta de la partición depende de la matriz y el índice dadosq se calcula como parte del procedimiento de partición.
Algorithm: Quick-Sort (A, p, r)
if p < r then
q Partition (A, p, r)
Quick-Sort (A, p, q)
Quick-Sort (A, q + r, r)Tenga en cuenta que para ordenar la matriz completa, la llamada inicial debe ser Quick-Sort (A, 1, length[A])
Como primer paso, Quick Sort elige uno de los elementos de la matriz para ordenarlo como pivote. Luego, la matriz se divide a ambos lados del pivote. Los elementos que son menores o iguales que pivotar se moverán hacia la izquierda, mientras que los elementos que son mayores o iguales que pivotar se moverán hacia la derecha.
Particionar la matriz
El procedimiento de particionamiento reorganiza las submatrices en su lugar.
Function: Partition (A, p, r)
x ← A[p]
i ← p-1
j ← r+1
while TRUE do
Repeat j ← j - 1
until A[j] ≤ x
Repeat i← i+1
until A[i] ≥ x
if i < j then
exchange A[i] ↔ A[j]
else
return jAnálisis
La complejidad del peor caso del algoritmo de clasificación rápida es O(n2). Sin embargo, al usar esta técnica, en casos promedio generalmente obtenemos la salida enO(n log n) hora.
Radix sortes un método pequeño que muchas personas usan intuitivamente al ordenar alfabéticamente una gran lista de nombres. Específicamente, la lista de nombres se ordena primero según la primera letra de cada nombre, es decir, los nombres se organizan en 26 clases.
Intuitivamente, uno podría querer ordenar los números por su dígito más significativo. Sin embargo, la ordenación por Radix funciona de forma contraria a la intuición al ordenar primero los dígitos menos significativos. En la primera pasada, todos los números se ordenan por el dígito menos significativo y se combinan en una matriz. Luego, en la segunda pasada, los números completos se ordenan nuevamente en el segundo dígito menos significativo y se combinan en una matriz y así sucesivamente.
Algorithm: Radix-Sort (list, n)
shift = 1
for loop = 1 to keysize do
for entry = 1 to n do
bucketnumber = (list[entry].key / shift) mod 10
append (bucket[bucketnumber], list[entry])
list = combinebuckets()
shift = shift * 10Análisis
Cada tecla se mira una vez para cada dígito (o letra si las teclas son alfabéticas) de la clave más larga. Por tanto, si la clave más larga tienem dígitos y hay n llaves, orden de radix tiene orden O(m.n).
Sin embargo, si miramos estos dos valores, el tamaño de las claves será relativamente pequeño en comparación con el número de claves. Por ejemplo, si tenemos claves de seis dígitos, podríamos tener un millón de registros diferentes.
Aquí vemos que el tamaño de las claves no es significativo, y este algoritmo es de complejidad lineal O(n).
Ejemplo
El siguiente ejemplo muestra cómo la ordenación de Radix opera en siete números de 3 dígitos.
| Entrada | 1 er pase | 2 nd Pass | 3 er pase |
|---|---|---|---|
| 329 | 720 | 720 | 329 |
| 457 | 355 | 329 | 355 |
| 657 | 436 | 436 | 436 |
| 839 | 457 | 839 | 457 |
| 436 | 657 | 355 | 657 |
| 720 | 329 | 457 | 720 |
| 355 | 839 | 657 | 839 |
En el ejemplo anterior, la primera columna es la entrada. Las columnas restantes muestran la lista después de ordenaciones sucesivas en posiciones de dígitos cada vez más significativos. El código para la ordenación de Radix asume que cada elemento en una matrizA de n elementos tiene d dígitos, donde dígito 1 es el dígito de menor orden y d es el dígito de orden más alto.
Para entender la clase P y NP, primero debemos conocer el modelo computacional. Por tanto, en este capítulo analizaremos dos modelos computacionales importantes.
Computación determinista y la clase P
Máquina de Turing determinista
Uno de estos modelos es la máquina Turing determinista de una sola cinta. Esta máquina consta de un control de estado finito, un cabezal de lectura-escritura y una cinta de dos vías con secuencia infinita.
A continuación se muestra el diagrama esquemático de una máquina de Turing determinista de una cinta.
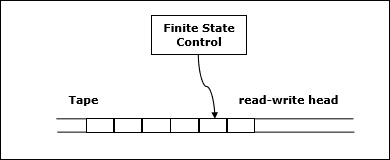
Un programa para una máquina de Turing determinista especifica la siguiente información:
- Un conjunto finito de símbolos de cinta (símbolos de entrada y un símbolo en blanco)
- Un conjunto finito de estados
- Una función de transición
En el análisis algorítmico, si un problema se puede resolver en tiempo polinomial mediante una máquina de Turing determinista de una cinta, el problema pertenece a la clase P.
Computación no determinista y la clase NP
Máquina de Turing no determinista
Para resolver el problema computacional, otro modelo es la Máquina de Turing no determinista (NDTM). La estructura de NDTM es similar a DTM, sin embargo, aquí tenemos un módulo adicional conocido como módulo de adivinación, que está asociado con un cabezal de solo escritura.
A continuación se muestra el diagrama esquemático.
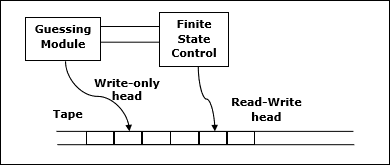
Si el problema se puede resolver en tiempo polinomial mediante una máquina de Turing no determinista, el problema pertenece a la clase NP.
En un gráfico no dirigido, un cliquees un subgráfico completo del gráfico dado. El subgráfico completo significa que todos los vértices de este subgráfico están conectados a todos los demás vértices de este subgráfico.
El problema Max-Clique es el problema computacional de encontrar la camarilla máxima del gráfico. Max clique se utiliza en muchos problemas del mundo real.
Consideremos una aplicación de redes sociales, donde los vértices representan el perfil de las personas y los bordes representan el conocimiento mutuo en un gráfico. En este gráfico, una camarilla representa un subconjunto de personas que se conocen entre sí.
Para encontrar una camarilla máxima, se pueden inspeccionar sistemáticamente todos los subconjuntos, pero este tipo de búsqueda de fuerza bruta consume demasiado tiempo para las redes que comprenden más de unas pocas docenas de vértices.
Algorithm: Max-Clique (G, n, k)
S := Φ
for i = 1 to k do
t := choice (1…n)
if t Є S then
return failure
S := S ∪ t
for all pairs (i, j) such that i Є S and j Є S and i ≠ j do
if (i, j) is not a edge of the graph then
return failure
return successAnálisis
El problema de Max-Clique es un algoritmo no determinista. En este algoritmo, primero intentamos determinar un conjunto dek vértices distintos y luego tratamos de probar si estos vértices forman un gráfico completo.
No existe un algoritmo determinista de tiempo polinomial para resolver este problema. Este problema es NP-Complete.
Ejemplo
Eche un vistazo al siguiente gráfico. Aquí, el sub-gráfico que contiene los vértices 2, 3, 4 y 6 forma un gráfico completo. Por tanto, este subgrafo es unclique. Como este es el subgráfico máximo completo del gráfico proporcionado, es un4-Clique.

Una cobertura de vértice de un gráfico no dirigido G = (V, E) es un subconjunto de vértices V' ⊆ V tal que si borde (u, v) es un borde de G, entonces tambien u en V o v en V' o ambos.
Encuentre una cobertura de vértice de tamaño máximo en un gráfico no dirigido dado. Esta cobertura de vértice óptima es la versión de optimización de un problema NP-completo. Sin embargo, no es demasiado difícil encontrar una cobertura de vértices cercana a la óptima.
APPROX-VERTEX_COVER (G: Graph) c ← { } E' ← E[G]
while E' is not empty do
Let (u, v) be an arbitrary edge of E' c ← c U {u, v}
Remove from E' every edge incident on either u or v
return cEjemplo
El conjunto de aristas del gráfico dado es:
{(1,6),(1,2),(1,4),(2,3),(2,4),(6,7),(4,7),(7,8),(3,8),(3,5),(8,5)}
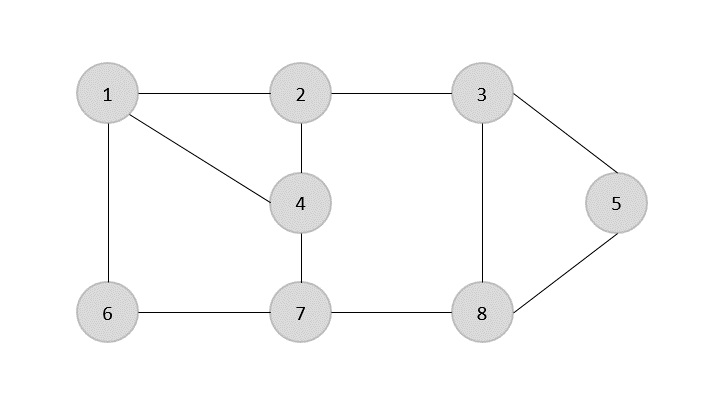
Ahora, comenzamos seleccionando un borde arbitrario (1,6). Eliminamos todos los bordes, que son incidentes al vértice 1 o 6 y agregamos borde (1,6) para cubrir.
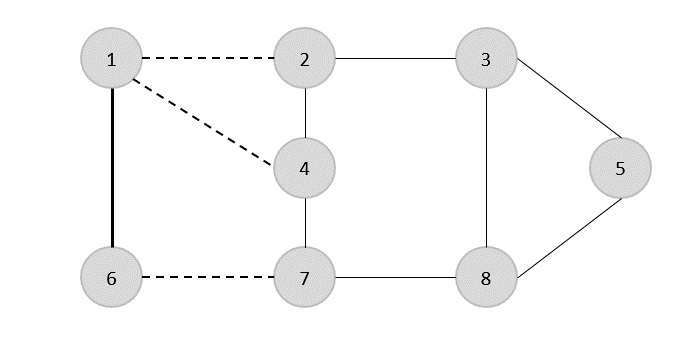
En el siguiente paso, hemos elegido otro borde (2,3) al azar
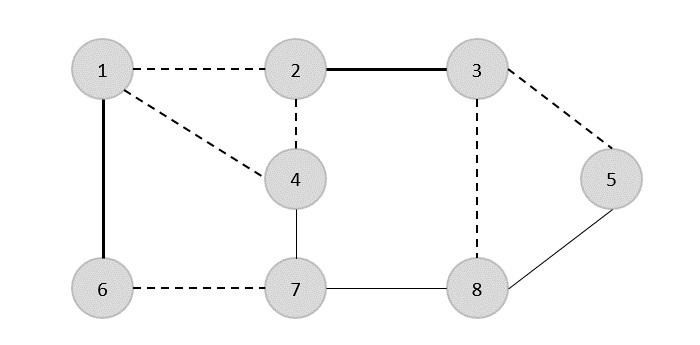
Ahora seleccionamos otro borde (4,7).
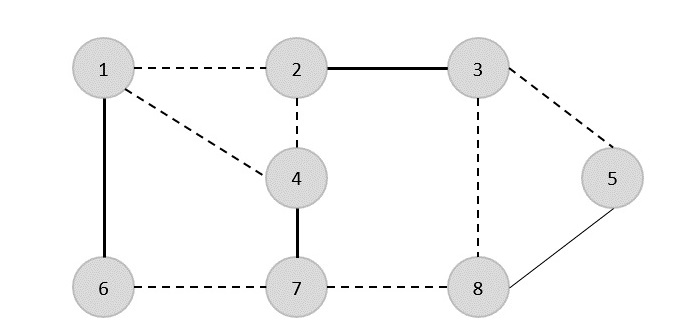
Seleccionamos otro borde (8,5).
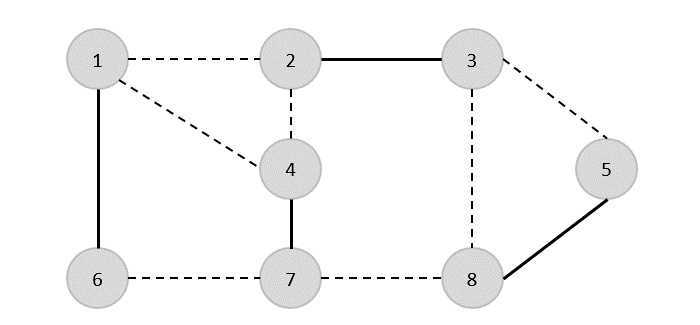
Por lo tanto, la cobertura de vértices de este gráfico es {1,2,4,5}.
Análisis
Es fácil ver que el tiempo de ejecución de este algoritmo es O(V + E), usando la lista de adyacencia para representar E'.
En Ciencias de la Computación se resuelven muchos problemas donde el objetivo es maximizar o minimizar algunos valores, mientras que en otros problemas tratamos de buscar si hay solución o no. Por lo tanto, los problemas se pueden clasificar de la siguiente manera:
Problema de optimizacion
Los problemas de optimización son aquellos cuyo objetivo es maximizar o minimizar algunos valores. Por ejemplo,
Encontrar el número mínimo de colores necesarios para colorear un gráfico determinado.
Encontrar el camino más corto entre dos vértices en un gráfico.
Problema de decisión
Hay muchos problemas para los cuales la respuesta es un Sí o un No. Estos tipos de problemas se conocen como decision problems. Por ejemplo,
Si un gráfico determinado se puede colorear con solo 4 colores.
Encontrar el ciclo hamiltoniano en un gráfico no es un problema de decisión, mientras que verificar un gráfico es hamiltoniano o no es un problema de decisión.
¿Qué es idioma?
Cada problema de decisión puede tener solo dos respuestas, sí o no. Por tanto, un problema de decisión puede pertenecer a un lenguaje si da una respuesta "sí" para una entrada específica. Un idioma es la totalidad de entradas para las que la respuesta es sí. La mayoría de los algoritmos discutidos en los capítulos anteriores sonpolynomial time algorithms.
Para tamaño de entrada n, si la complejidad temporal del peor de los casos de un algoritmo es O(nk), dónde k es una constante, el algoritmo es un algoritmo de tiempo polinomial.
Los algoritmos como la multiplicación de la cadena de matrices, la ruta más corta de una sola fuente, la ruta más corta de todos los pares, el árbol de expansión mínimo, etc. se ejecutan en tiempo polinomial. Sin embargo, hay muchos problemas, como el vendedor ambulante, el color óptimo del gráfico, los ciclos hamiltonianos, encontrar la ruta más larga en un gráfico y satisfacer una fórmula booleana, para la que no se conocen algoritmos de tiempo polinomial. Estos problemas pertenecen a una clase interesante de problemas, denominadaNP-Complete problemas, cuyo estado se desconoce.
En este contexto, podemos categorizar los problemas de la siguiente manera:
Clase P
La clase P está formada por aquellos problemas que se pueden resolver en tiempo polinomial, es decir, estos problemas se pueden resolver en el tiempo O(nk) en el peor de los casos, donde k es constante.
Estos problemas se llaman tractable, mientras que otros se llaman intractable or superpolynomial.
Formalmente, un algoritmo es un algoritmo de tiempo polinomial, si existe un polinomio p(n) tal que el algoritmo pueda resolver cualquier instancia de tamaño n en un tiempo O(p(n)).
Problema que requiere Ω(n50) tiempo para resolver son esencialmente intratables para grandes n. El algoritmo de tiempo polinomial más conocido se ejecuta en el tiempoO(nk) por un valor bastante bajo de k.
Las ventajas de considerar la clase de algoritmos de tiempo polinomial es que todos los deterministic single processor model of computation se pueden simular entre sí con como máximo un polinomio lento-d
Clase NP
La clase NP está formada por aquellos problemas que son verificables en tiempo polinomial. NP es la clase de problemas de decisión para los que es fácil verificar la exactitud de una respuesta afirmada, con la ayuda de un poco de información adicional. Por lo tanto, no estamos pidiendo una forma de encontrar una solución, sino solo para verificar que una supuesta solución realmente sea correcta.
Todos los problemas de esta clase se pueden resolver en tiempo exponencial mediante una búsqueda exhaustiva.
P versus NP
Cada problema de decisión que se puede resolver mediante un algoritmo de tiempo polinomial determinista también se puede resolver mediante un algoritmo no determinista de tiempo polinomial.
Todos los problemas en P se pueden resolver con algoritmos de tiempo polinomial, mientras que todos los problemas en NP - P son intratables.
No se sabe si P = NP. Sin embargo, en NP se conocen muchos problemas con la propiedad de que si pertenecen a P, entonces se puede demostrar que P = NP.
Si P ≠ NP, hay problemas en NP que no están ni en P ni en NP-Complete.
El problema pertenece a la clase Psi es fácil encontrar una solución al problema. El problema pertenece aNP, si es fácil comprobar una solución que puede haber sido muy tediosa de encontrar.
Stephen Cook presentó cuatro teoremas en su artículo "La complejidad de los procedimientos de demostración de teoremas". Estos teoremas se enuncian a continuación. Entendemos que se están utilizando muchos términos desconocidos en este capítulo, pero no tenemos ningún margen para discutir todo en detalle.
Los siguientes son los cuatro teoremas de Stephen Cook:
Teorema-1
Si un conjunto S de cadenas es aceptado por alguna máquina de Turing no determinista dentro del tiempo polinomial, luego S es P-reducible a {tautologías DNF}.
Teorema 2
Los siguientes conjuntos son P-reducibles entre sí en pares (y, por lo tanto, cada uno tiene el mismo grado de dificultad polinomial): {tautologías}, {tautologías DNF}, D3, {pares de sub-gráficos}.
Teorema 3
Para cualquier TQ(k) de tipo Q, $\mathbf{\frac{T_{Q}(k)}{\frac{\sqrt{k}}{(log\:k)^2}}}$ es ilimitado
Hay un TQ(k) de tipo Q tal que $T_{Q}(k)\leqslant 2^{k(log\:k)^2}$
Teorema 4
Si el conjunto S de cadenas es aceptado por una máquina no determinista dentro del tiempo T(n) = 2n, y si TQ(k) es una función de tipo honesta (es decir, contable en tiempo real) Q, entonces hay una constante K, entonces S puede ser reconocido por una máquina determinista en el tiempo TQ(K8n).
Primero, enfatizó la importancia de la reductibilidad del tiempo polinomial. Significa que si tenemos una reducción de tiempo polinomial de un problema a otro, esto asegura que cualquier algoritmo de tiempo polinomial del segundo problema se pueda convertir en un algoritmo de tiempo polinomial correspondiente para el primer problema.
En segundo lugar, centró la atención en la clase NP de problemas de decisión que pueden resolverse en tiempo polinomial mediante una computadora no determinista. La mayoría de los problemas intratables pertenecen a esta clase, NP.
En tercer lugar, demostró que un problema particular de NP tiene la propiedad de que todos los demás problemas de NP pueden reducirse polinomialmente a él. Si el problema de satisfacibilidad se puede resolver con un algoritmo de tiempo polinomial, entonces todos los problemas en NP también se pueden resolver en tiempo polinomial. Si algún problema en NP es intratable, entonces el problema de satisfacibilidad debe ser intratable. Por tanto, el problema de satisfacibilidad es el problema más difícil en NP.
En cuarto lugar, Cook sugirió que otros problemas en NP podrían compartir con el problema de satisfacibilidad esta propiedad de ser el miembro más difícil de NP.
Un problema está en la clase NPC si está en NP y es tan hardcomo cualquier problema en NP. Un problema esNP-hard si todos los problemas en NP son polinomiales reducibles en el tiempo, aunque no lo sea en NP mismo.
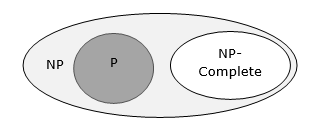
Si existe un algoritmo de tiempo polinomial para cualquiera de estos problemas, todos los problemas en NP podrían resolverse en tiempo polinómico. Estos problemas se llamanNP-complete. El fenómeno de NP-completitud es importante tanto por razones teóricas como prácticas.
Definición de NP-Completitud
Un idioma B es NP-complete si cumple dos condiciones
B está en NP
Cada A en NP es el tiempo polinomial reducible a B.
Si un idioma satisface la segunda propiedad, pero no necesariamente la primera, el idioma B que se conoce como NP-Hard. Informalmente, un problema de búsquedaB es NP-Hard si existe alguna NP-Complete problema A que Turing reduce a B.
El problema en NP-Hard no se puede resolver en tiempo polinomial, hasta P = NP. Si se demuestra que un problema es NPC, no hay necesidad de perder el tiempo tratando de encontrar un algoritmo eficiente. En cambio, podemos centrarnos en el algoritmo de aproximación de diseño.
Problemas NP-Complete
A continuación se presentan algunos problemas NP-Complete, para los cuales no se conoce ningún algoritmo de tiempo polinomial.
- Determinar si una gráfica tiene un ciclo hamiltoniano
- Determinar si una fórmula booleana es satisfactoria, etc.
Problemas NP-Hard
Los siguientes problemas son NP-Hard
- El problema de la satisfacibilidad del circuito
- Establecer cubierta
- Cubierta de vértice
- Problema del vendedor ambulante
En este contexto, ahora discutiremos TSP es NP-Complete
TSP es NP-Complete
El problema del viajante consiste en un vendedor y un conjunto de ciudades. El vendedor tiene que visitar cada una de las ciudades partiendo de una determinada y regresando a la misma ciudad. El desafío del problema es que el viajante quiere minimizar la duración total del viaje.
Prueba
Probar TSP is NP-Complete, primero tenemos que demostrar que TSP belongs to NP. En TSP, buscamos un recorrido y comprobamos que el recorrido contiene cada vértice una vez. Luego se calcula el costo total de los bordes del recorrido. Finalmente, comprobamos si el costo es mínimo. Esto se puede completar en tiempo polinomial. AsíTSP belongs to NP.
En segundo lugar, tenemos que demostrar que TSP is NP-hard. Para probar esto, una forma es demostrar queHamiltonian cycle ≤p TSP (ya que sabemos que el problema del ciclo hamiltoniano es NPcompleto).
Asumir G = (V, E) para ser una instancia del ciclo hamiltoniano.
Por tanto, se construye una instancia de TSP. Creamos el gráfico completoG' = (V, E'), dónde
$$E^{'}=\lbrace(i, j)\colon i, j \in V \:\:and\:i\neq j$$
Por lo tanto, la función de costo se define de la siguiente manera:
$$t(i,j)=\begin{cases}0 & if\: (i, j)\: \in E\\1 & otherwise\end{cases}$$
Ahora, suponga que un ciclo hamiltoniano h existe en G. Está claro que el costo de cada borde enh es 0 en G' como cada borde pertenece a E. Por lo tanto,h tiene un costo de 0 en G'. Por tanto, si graficaG tiene un ciclo hamiltoniano, luego grafica G' tiene un recorrido por 0 costo.
Por el contrario, asumimos que G' tiene un recorrido h' de costo como máximo 0. El costo de los bordes enE' son 0 y 1por definición. Por lo tanto, cada borde debe tener un costo de0 como el costo de h' es 0. Por tanto, concluimos queh' contiene solo bordes en E.
Así hemos probado que G tiene un ciclo hamiltoniano, si y solo si G' tiene un recorrido de costo como máximo 0. TSP es NP-completo.
Los algoritmos discutidos en los capítulos anteriores se ejecutan sistemáticamente. Para lograr el objetivo, es necesario almacenar uno o más caminos explorados previamente hacia la solución para encontrar la solución óptima.
Para muchos problemas, el camino hacia la meta es irrelevante. Por ejemplo, en el problema N-Queens, no necesitamos preocuparnos por la configuración final de las reinas ni por el orden en que se agregan.
Montañismo
Hill Climbing es una técnica para resolver ciertos problemas de optimización. En esta técnica, comenzamos con una solución subóptima y la solución se mejora repetidamente hasta que se maximiza alguna condición.
La idea de comenzar con una solución subóptima se compara con comenzar desde la base de la colina, mejorar la solución se compara con caminar cuesta arriba y, finalmente, maximizar alguna condición se compara con llegar a la cima de la colina.
Por lo tanto, la técnica de escalada puede considerarse como las siguientes fases:
- Construir una solución subóptima que obedezca a las limitaciones del problema
- Mejorando la solución paso a paso
- Mejorar la solución hasta que no sea posible ninguna mejora
La técnica Hill Climbing se utiliza principalmente para resolver problemas computacionalmente difíciles. Solo mira el estado actual y el estado futuro inmediato. Por lo tanto, esta técnica es eficiente en la memoria, ya que no mantiene un árbol de búsqueda.
Algorithm: Hill Climbing
Evaluate the initial state.
Loop until a solution is found or there are no new operators left to be applied:
- Select and apply a new operator
- Evaluate the new state:
goal -→ quit
better than current state -→ new current stateMejora iterativa
En el método de mejora iterativa, la solución óptima se logra al avanzar hacia una solución óptima en cada iteración. Sin embargo, esta técnica puede encontrar máximos locales. En esta situación, no hay un estado cercano para una mejor solución.
Este problema puede evitarse con diferentes métodos. Uno de estos métodos es el recocido simulado.
Reinicio aleatorio
Este es otro método para resolver el problema de los óptimos locales. Esta técnica realiza una serie de búsquedas. Cada vez, comienza desde un estado inicial generado aleatoriamente. Por tanto, se puede obtener una solución óptima o casi óptima comparando las soluciones de las búsquedas realizadas.
Problemas de la técnica de escalada
Máximos locales
Si la heurística no es convexa, Hill Climbing puede converger a máximos locales, en lugar de máximos globales.
Crestas y callejones
Si la función de destino crea una cresta estrecha, entonces el escalador solo puede ascender la cresta o descender el callejón en zig-zag. En este escenario, el escalador necesita dar pasos muy pequeños que requieren más tiempo para alcanzar la meta.
Meseta
Se encuentra una meseta cuando el espacio de búsqueda es plano o lo suficientemente plano como para que el valor devuelto por la función de destino sea indistinguible del valor devuelto para las regiones cercanas, debido a la precisión utilizada por la máquina para representar su valor.
Complejidad de la técnica de escalada
Esta técnica no adolece de problemas relacionados con el espacio, ya que solo analiza el estado actual. Las rutas previamente exploradas no se almacenan.
Para la mayoría de los problemas de la técnica Hill Climbing con reinicio aleatorio, se puede lograr una solución óptima en tiempo polinomial. Sin embargo, para los problemas NP-Complete, el tiempo de cálculo puede ser exponencial según el número de máximos locales.
Aplicaciones de la técnica de escalada
La técnica Hill Climbing se puede utilizar para resolver muchos problemas, donde el estado actual permite una función de evaluación precisa, como el flujo de la red, el problema del vendedor ambulante, el problema de las 8 reinas, el diseño del circuito integrado, etc.
Hill Climbing también se utiliza en métodos de aprendizaje inductivo. Esta técnica se utiliza en robótica para la coordinación entre varios robots en un equipo. Hay muchos otros problemas en los que se utiliza esta técnica.
Ejemplo
Esta técnica se puede aplicar para resolver el problema del viajante. Primero se determina una solución inicial que visita todas las ciudades exactamente una vez. Por tanto, esta solución inicial no es óptima en la mayoría de los casos. Incluso esta solución puede resultar muy pobre. El algoritmo Hill Climbing comienza con una solución inicial de este tipo y la mejora de forma iterativa. Eventualmente, es probable que se obtenga una ruta mucho más corta.