DBMS distribuido: entornos de base de datos
En esta parte del tutorial, estudiaremos los diferentes aspectos que ayudan a diseñar entornos de bases de datos distribuidas. Este capítulo comienza con los tipos de bases de datos distribuidas. Las bases de datos distribuidas se pueden clasificar en bases de datos homogéneas y heterogéneas que tienen más divisiones. La siguiente sección de este capítulo analiza las arquitecturas distribuidas, a saber, cliente-servidor, peer-to-peer y multi-DBMS. Finalmente, se introducen las diferentes alternativas de diseño como replicación y fragmentación.
Tipos de bases de datos distribuidas
Las bases de datos distribuidas se pueden clasificar ampliamente en entornos de bases de datos distribuidos homogéneos y heterogéneos, cada uno con más subdivisiones, como se muestra en la siguiente ilustración.

Bases de datos distribuidas homogéneas
En una base de datos distribuida homogénea, todos los sitios utilizan DBMS y sistemas operativos idénticos. Sus propiedades son:
Los sitios utilizan software muy similar.
Los sitios utilizan DBMS o DBMS idénticos del mismo proveedor.
Cada sitio conoce todos los demás sitios y coopera con otros sitios para procesar las solicitudes de los usuarios.
Se accede a la base de datos a través de una única interfaz como si fuera una única base de datos.
Tipos de bases de datos distribuidas homogéneas
Hay dos tipos de bases de datos distribuidas homogéneas:
Autonomous- Cada base de datos es independiente y funciona por sí sola. Están integrados por una aplicación de control y utilizan el paso de mensajes para compartir actualizaciones de datos.
Non-autonomous - Los datos se distribuyen entre los nodos homogéneos y un DBMS central o maestro coordina las actualizaciones de datos en los sitios.
Bases de datos distribuidas heterogéneas
En una base de datos distribuida heterogénea, diferentes sitios tienen diferentes sistemas operativos, productos DBMS y modelos de datos. Sus propiedades son:
Los diferentes sitios utilizan esquemas y software diferentes.
El sistema puede estar compuesto por una variedad de DBMS como relacionales, de red, jerárquicos u orientados a objetos.
El procesamiento de consultas es complejo debido a esquemas diferentes.
El procesamiento de transacciones es complejo debido a la diferencia de software.
Es posible que un sitio no tenga conocimiento de otros sitios, por lo que existe una cooperación limitada para procesar las solicitudes de los usuarios.
Tipos de bases de datos distribuidas heterogéneas
Federated - Los sistemas de bases de datos heterogéneos son de naturaleza independiente y están integrados entre sí de modo que funcionan como un sistema de base de datos único.
Un-federated - Los sistemas de bases de datos emplean un módulo de coordinación central a través del cual se accede a las bases de datos.
Arquitecturas DBMS distribuidas
Las arquitecturas DDBMS generalmente se desarrollan en función de tres parámetros:
Distribution - Establece la distribución física de los datos en los diferentes sitios.
Autonomy - Indica la distribución del control del sistema de la base de datos y el grado en que cada DBMS constituyente puede operar de forma independiente.
Heterogeneity - Se refiere a la uniformidad o disimilitud de los modelos de datos, componentes del sistema y bases de datos.
Modelos arquitectonicos
Algunos de los modelos arquitectónicos comunes son:
- Cliente - Arquitectura de servidor para DDBMS
- Arquitectura de igual a igual para DDBMS
- Arquitectura multi - DBMS
Cliente - Arquitectura de servidor para DDBMS
Esta es una arquitectura de dos niveles donde la funcionalidad se divide en servidores y clientes. Las funciones del servidor abarcan principalmente la gestión de datos, el procesamiento de consultas, la optimización y la gestión de transacciones. Las funciones del cliente incluyen principalmente la interfaz de usuario. Sin embargo, tienen algunas funciones como la verificación de coherencia y la gestión de transacciones.
Las dos arquitecturas cliente-servidor diferentes son:
- Cliente múltiple de servidor único
- Multiple Server Multiple Client (mostrado en el siguiente diagrama)

Arquitectura de igual a igual para DDBMS
En estos sistemas, cada par actúa como cliente y servidor para impartir servicios de base de datos. Los pares comparten su recurso con otros pares y coordinan sus actividades.
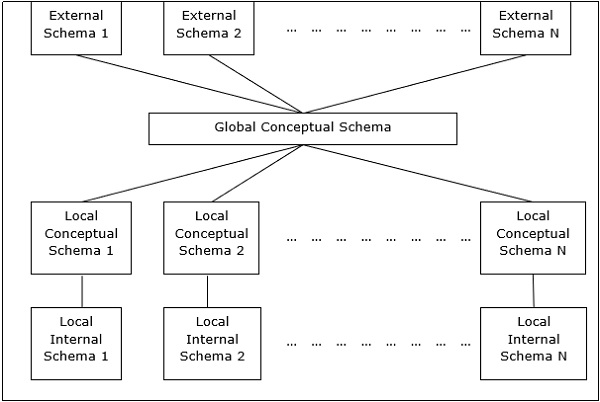
Esta arquitectura generalmente tiene cuatro niveles de esquemas:
Global Conceptual Schema - Representa la vista lógica global de los datos.
Local Conceptual Schema - Representa la organización de datos lógicos en cada sitio.
Local Internal Schema - Representa la organización de datos físicos en cada sitio.
External Schema - Representa la vista del usuario de los datos.
Arquitecturas multi - DBMS
Este es un sistema de base de datos integrado formado por una colección de dos o más sistemas de base de datos autónomos.
Multi-DBMS se puede expresar a través de seis niveles de esquemas:
Multi-database View Level - Representa múltiples vistas de usuario que comprenden subconjuntos de la base de datos distribuida integrada.
Multi-database Conceptual Level - Representa una base de datos múltiple integrada que comprende definiciones de estructura de base de datos múltiple lógica global.
Multi-database Internal Level - Representa la distribución de datos a través de diferentes sitios y de múltiples bases de datos al mapeo de datos locales.
Local database View Level - Representa la vista pública de datos locales.
Local database Conceptual Level - Representa la organización de datos local en cada sitio.
Local database Internal Level - Representa la organización de datos físicos en cada sitio.
Hay dos alternativas de diseño para múltiples DBMS:
- Modelo con nivel conceptual multi-base de datos.
- Modelo sin nivel conceptual de bases de datos múltiples.


Alternativas de diseño
Las alternativas de diseño de distribución para las tablas en un DDBMS son las siguientes:
- No replicado y no fragmentado
- Totalmente replicado
- Parcialmente replicado
- Fragmented
- Mixed
No replicado y no fragmentado
En esta alternativa de diseño, se colocan diferentes mesas en diferentes sitios. Los datos se colocan de manera que estén muy cerca del sitio donde se utilizan más. Es más adecuado para sistemas de bases de datos donde el porcentaje de consultas necesarias para unir información en tablas colocadas en diferentes sitios es bajo. Si se adopta una estrategia de distribución adecuada, esta alternativa de diseño ayuda a reducir el costo de comunicación durante el procesamiento de datos.
Totalmente replicado
En esta alternativa de diseño, en cada sitio, se almacena una copia de todas las tablas de la base de datos. Dado que cada sitio tiene su propia copia de toda la base de datos, las consultas son muy rápidas y requieren un costo de comunicación insignificante. Por el contrario, la redundancia masiva de datos requiere un costo enorme durante las operaciones de actualización. Por lo tanto, esto es adecuado para sistemas donde se requiere manejar una gran cantidad de consultas mientras que la cantidad de actualizaciones de la base de datos es baja.
Parcialmente replicado
Las copias de tablas o porciones de tablas se almacenan en diferentes sitios. La distribución de las tablas se realiza de acuerdo con la frecuencia de acceso. Esto toma en consideración el hecho de que la frecuencia de acceso a las tablas varía considerablemente de un sitio a otro. El número de copias de las tablas (o porciones) depende de la frecuencia con la que se ejecutan las consultas de acceso y del sitio que genera las consultas de acceso.
Fragmentado
En este diseño, una tabla se divide en dos o más piezas denominadas fragmentos o particiones, y cada fragmento se puede almacenar en diferentes sitios. Esto tiene en cuenta el hecho de que rara vez ocurre que todos los datos almacenados en una tabla sean necesarios en un sitio determinado. Además, la fragmentación aumenta el paralelismo y proporciona una mejor recuperación ante desastres. Aquí, solo hay una copia de cada fragmento en el sistema, es decir, no hay datos redundantes.
Las tres técnicas de fragmentación son:
- Fragmentación vertical
- Fragmentación horizontal
- Fragmentación híbrida
Distribución Mixta
Esta es una combinación de fragmentación y replicaciones parciales. Aquí, las tablas se fragmentan inicialmente en cualquier forma (horizontal o vertical), y luego estos fragmentos se replican parcialmente en los diferentes sitios de acuerdo con la frecuencia de acceso a los fragmentos.