DBMS distribuido: recuperación de la base de datos
Para recuperarse de una falla en la base de datos, los sistemas de administración de bases de datos recurren a una serie de técnicas de administración de recuperación. En este capítulo, estudiaremos los diferentes enfoques para la recuperación de bases de datos.
Las estrategias típicas para la recuperación de bases de datos son:
En caso de fallas leves que resulten en inconsistencias en la base de datos, la estrategia de recuperación incluye deshacer o deshacer la transacción. Sin embargo, a veces, la operación de rehacer también se puede adoptar para recuperar un estado consistente de la transacción.
En caso de fallas graves que provoquen daños importantes en la base de datos, las estrategias de recuperación abarcan la restauración de una copia anterior de la base de datos a partir de una copia de seguridad de archivo. Se obtiene un estado más actual de la base de datos al rehacer operaciones de transacciones comprometidas desde el registro de transacciones.
Recuperación de una falla de energía
Un corte de energía provoca la pérdida de información en la memoria no persistente. Cuando se restablece la energía, el sistema operativo y el sistema de administración de la base de datos se reinician. El administrador de recuperación inicia la recuperación de los registros de transacciones.
En el caso del modo de actualización inmediata, el administrador de recuperación realiza las siguientes acciones:
Las transacciones que están en la lista activa y en la lista fallida se deshacen y se escriben en la lista de abortos.
Las transacciones que están en la lista antes de la confirmación se rehacen.
No se realiza ninguna acción para las transacciones en listas de compromiso o aborto.
En caso de modo de actualización diferida, el administrador de recuperación toma las siguientes acciones:
Las transacciones que están en la lista activa y la lista fallida se escriben en la lista de abortos. No se requieren operaciones de deshacer ya que los cambios aún no se han escrito en el disco.
Las transacciones que están en la lista antes de la confirmación se rehacen.
No se realiza ninguna acción para las transacciones en listas de compromiso o aborto.
Recuperación de una falla de disco
Una falla en el disco o un bloqueo duro causa una pérdida total de la base de datos. Para recuperarse de este duro accidente, se prepara un nuevo disco, luego se restaura el sistema operativo y finalmente se recupera la base de datos utilizando la copia de seguridad de la base de datos y el registro de transacciones. El método de recuperación es el mismo para los modos de actualización inmediata y diferida.
El administrador de recuperación realiza las siguientes acciones:
Las transacciones en la lista de confirmación y antes de la confirmación se rehacen y se escriben en la lista de confirmación en el registro de transacciones.
Las transacciones en la lista activa y la lista fallida se deshacen y se escriben en la lista de abortos en el registro de transacciones.
Punto de control
Checkpointes un momento en el que se escribe un registro en la base de datos desde los búferes. Como consecuencia, en caso de una falla del sistema, el administrador de recuperación no tiene que rehacer las transacciones que se han comprometido antes del punto de control. Los puntos de control periódicos acortan el proceso de recuperación.
Los dos tipos de técnicas de puntos de control son:
- Puntos de control consistentes
- Puntos de control difusos
Puntos de control consistentes
Los puntos de control coherentes crean una imagen coherente de la base de datos en el punto de control. Durante la recuperación, solo se deshacen o rehacen aquellas transacciones que están en el lado derecho del último punto de control. Las transacciones al lado izquierdo del último punto de control consistente ya están comprometidas y no necesitan procesarse nuevamente. Las acciones tomadas para los puntos de control son:
- Las transacciones activas se suspenden temporalmente.
- Todos los cambios en los búferes de la memoria principal se escriben en el disco.
- Se escribe un registro de "punto de control" en el registro de transacciones.
- El registro de transacciones se escribe en el disco.
- Se reanudan las transacciones suspendidas.
Si en el paso 4, el registro de transacciones también se archiva, este punto de control ayuda en la recuperación de fallas de disco y fallas de energía; de lo contrario, ayuda a la recuperación solo de fallas de energía.
Puntos de control difusos
En el punto de control difuso, en el momento del punto de control, todas las transacciones activas se escriben en el registro. En caso de falla de energía, el administrador de recuperación procesa solo aquellas transacciones que estaban activas durante el punto de control y posteriormente. Las transacciones que se han confirmado antes del punto de control se escriben en el disco y, por lo tanto, no es necesario rehacerlas.
Ejemplo de puntos de control
Consideremos que en el sistema el tiempo de los puntos de control es tcheck y el momento del bloqueo del sistema es tfail. Sea cuatro transacciones T a , T b , T c y T d tales que -
T a confirma antes del punto de control.
T b comienza antes del punto de control y se confirma antes del bloqueo del sistema.
T c comienza después del punto de control y se confirma antes de la caída del sistema.
T d comienza después del punto de control y estaba activo en el momento del bloqueo del sistema.
La situación se muestra en el siguiente diagrama:
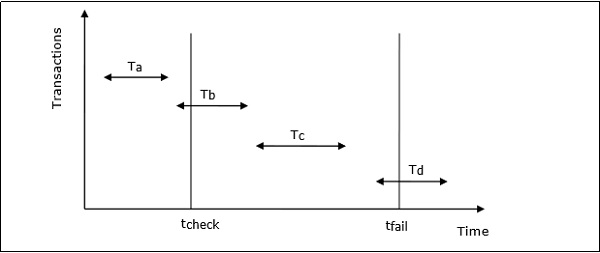
Las acciones que realiza el administrador de recuperación son:
- No se hace nada con T a .
- La operación de rehacer se realiza para T b y T c .
- La operación de deshacer la transacción se realiza para T d .
Recuperación de transacciones mediante UNDO / REDO
La recuperación de transacciones se realiza para eliminar los efectos adversos de transacciones defectuosas en lugar de recuperarse de una falla. Las transacciones defectuosas incluyen todas las transacciones que han cambiado la base de datos a un estado no deseado y las transacciones que han utilizado valores escritos por las transacciones defectuosas.
La recuperación de transacciones en estos casos es un proceso de dos pasos:
DESHAGA todas las transacciones defectuosas y las transacciones que puedan verse afectadas por las transacciones defectuosas.
REHACER todas las transacciones que no son defectuosas pero que se han deshecho debido a las transacciones defectuosas.
Los pasos para la operación UNDO son:
Si la transacción defectuosa se ha insertado, el administrador de recuperación elimina los elementos de datos insertados.
Si la transacción defectuosa se ha eliminado, el administrador de recuperación inserta los elementos de datos eliminados del registro.
Si la transacción defectuosa se ha actualizado, el administrador de recuperación elimina el valor escribiendo el valor anterior a la actualización del registro.
Los pasos para la operación REDO son:
Si la transacción se ha realizado INSERT, el administrador de recuperación genera una inserción desde el registro.
Si la transacción ha realizado ELIMINACIÓN, el administrador de recuperación genera una eliminación del registro.
Si la transacción se ha actualizado, el administrador de recuperación genera una actualización desde el registro.