Optimización de consultas en sistemas distribuidos
Este capítulo analiza la optimización de consultas en el sistema de bases de datos distribuidas.
Arquitectura de procesamiento de consultas distribuidas
En un sistema de base de datos distribuido, procesar una consulta comprende la optimización tanto a nivel global como local. La consulta ingresa al sistema de base de datos en el cliente o sitio de control. Aquí se valida al usuario, se verifica, se traduce y se optimiza la consulta a nivel global.
La arquitectura se puede representar como:
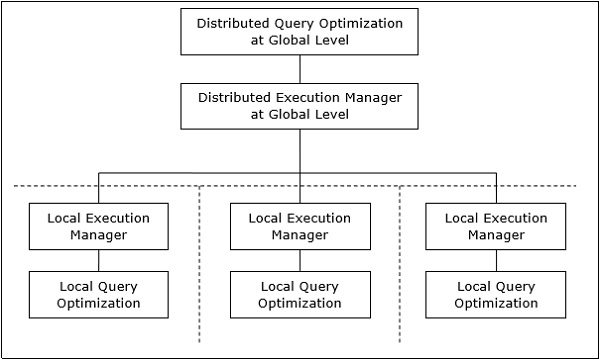
Asignación de consultas globales a consultas locales
El proceso de mapear consultas globales con consultas locales se puede realizar de la siguiente manera:
Las tablas necesarias en una consulta global tienen fragmentos distribuidos en varios sitios. Las bases de datos locales tienen información solo sobre datos locales. El sitio de control utiliza el diccionario de datos globales para recopilar información sobre la distribución y reconstruye la vista global a partir de los fragmentos.
Si no hay replicación, el optimizador global ejecuta consultas locales en los sitios donde se almacenan los fragmentos. Si hay replicación, el optimizador global selecciona el sitio según el costo de comunicación, la carga de trabajo y la velocidad del servidor.
El optimizador global genera un plan de ejecución distribuido para que se produzca la menor cantidad de transferencia de datos entre los sitios. El plan establece la ubicación de los fragmentos, el orden en el que se deben ejecutar los pasos de la consulta y los procesos involucrados en la transferencia de resultados intermedios.
Las consultas locales están optimizadas por los servidores de bases de datos locales. Finalmente, los resultados de la consulta local se fusionan mediante la operación de unión en el caso de fragmentos horizontales y la operación de unión para fragmentos verticales.
Por ejemplo, consideremos que el siguiente esquema de proyecto está fragmentado horizontalmente según la ciudad, siendo las ciudades Nueva Delhi, Kolkata e Hyderabad.
PROYECTO
| PId | Ciudad | Departamento | Estado |
Suponga que hay una consulta para recuperar detalles de todos los proyectos cuyo estado es "En curso".
La consulta global será & inus;
$$ \ sigma_ {status} = {\ small "en curso"} ^ {(PROYECTO)} $$
La consulta en el servidor de Nueva Delhi será:
$$ \ sigma_ {status} = {\ small "en curso"} ^ {({NewD} _- {PROJECT})} $$
La consulta en el servidor de Kolkata será:
$$ \ sigma_ {status} = {\ small "en curso"} ^ {({Kol} _- {PROYECTO})} $$
La consulta en el servidor de Hyderabad será:
$$ \ sigma_ {status} = {\ small "en curso"} ^ {({Hyd} _- {PROJECT})} $$
Para obtener el resultado general, necesitamos unir los resultados de las tres consultas de la siguiente manera:
$ \ sigma_ {estado} = {\ small "en curso"} ^ {({NewD} _- {PROYECTO})} \ cup \ sigma_ {estado} = {\ small "en curso"} ^ {({kol} _- {PROYECTO})} \ cup \ sigma_ {status} = {\ small "en curso"} ^ {({Hyd} _- {PROJECT})} $
Optimización de consultas distribuidas
La optimización de consultas distribuidas requiere la evaluación de una gran cantidad de árboles de consultas, cada uno de los cuales produce los resultados requeridos de una consulta. Esto se debe principalmente a la presencia de una gran cantidad de datos replicados y fragmentados. Por tanto, el objetivo es encontrar una solución óptima en lugar de la mejor solución.
Los principales problemas para la optimización de consultas distribuidas son:
- Aprovechamiento óptimo de recursos en el sistema distribuido.
- Consulta de comercio.
- Reducción del espacio de solución de la consulta.
Utilización óptima de recursos en el sistema distribuido
Un sistema distribuido tiene varios servidores de bases de datos en los distintos sitios para realizar las operaciones correspondientes a una consulta. Los siguientes son los enfoques para la utilización óptima de los recursos:
Operation Shipping- En el envío de operaciones, la operación se ejecuta en el sitio donde se almacenan los datos y no en el sitio del cliente. Luego, los resultados se transfieren al sitio del cliente. Esto es apropiado para operaciones donde los operandos están disponibles en el mismo sitio. Ejemplo: operaciones de selección y proyecto.
Data Shipping- En el envío de datos, los fragmentos de datos se transfieren al servidor de la base de datos, donde se ejecutan las operaciones. Esto se usa en operaciones donde los operandos se distribuyen en diferentes sitios. Esto también es apropiado en sistemas donde los costos de comunicación son bajos y los procesadores locales son mucho más lentos que el servidor cliente.
Hybrid Shipping- Esta es una combinación de envío de datos y operaciones. Aquí, los fragmentos de datos se transfieren a los procesadores de alta velocidad, donde se ejecuta la operación. Luego, los resultados se envían al sitio del cliente.

Comercio de consultas
En el algoritmo de negociación de consultas para sistemas de bases de datos distribuidas, el sitio de control / cliente para una consulta distribuida se denomina comprador y los sitios donde se ejecutan las consultas locales se denominan vendedores. El comprador formula una serie de alternativas para elegir vendedores y reconstruir los resultados globales. El objetivo del comprador es conseguir el coste óptimo.
El algoritmo comienza cuando el comprador asigna subconsultas a los sitios del vendedor. El plan óptimo se crea a partir de planes de consulta optimizados locales propuestos por los vendedores combinados con el costo de comunicación para reconstruir el resultado final. Una vez formulado el plan óptimo global, se ejecuta la consulta.
Reducción del espacio de solución de la consulta
La solución óptima generalmente implica la reducción del espacio de la solución para reducir el costo de la consulta y la transferencia de datos. Esto se puede lograr mediante un conjunto de reglas heurísticas, al igual que la heurística en los sistemas centralizados.
A continuación se presentan algunas de las reglas:
Realice operaciones de selección y proyección lo antes posible. Esto reduce el flujo de datos a través de la red de comunicación.
Simplifique las operaciones en fragmentos horizontales eliminando las condiciones de selección que no son relevantes para un sitio en particular.
En el caso de operaciones de unión y unión que comprendan fragmentos ubicados en varios sitios, transfiera datos fragmentados al sitio donde está presente la mayoría de los datos y realice la operación allí.
Utilice la operación de semifusión para calificar las tuplas que se van a unir. Esto reduce la cantidad de transferencia de datos, lo que a su vez reduce el costo de comunicación.
Combine las hojas y los subárboles comunes en un árbol de consulta distribuido.