Apache Tajo - Guide rapide
Système d'entrepôt de données distribué
L'entrepôt de données est une base de données relationnelle conçue pour les requêtes et l'analyse plutôt que pour le traitement des transactions. Il s'agit d'une collection de données orientée sujet, intégrée, variant dans le temps et non volatile. Ces données aident les analystes à prendre des décisions éclairées dans une organisation, mais les volumes de données relationnelles augmentent de jour en jour.
Pour surmonter les défis, le système d'entrepôt de données distribué partage les données entre plusieurs référentiels de données à des fins de traitement analytique en ligne (OLAP). Chaque entrepôt de données peut appartenir à une ou plusieurs organisations. Il effectue l'équilibrage de charge et l'évolutivité. Les métadonnées sont répliquées et distribuées de manière centralisée.
Apache Tajo est un système d'entrepôt de données distribué qui utilise le système de fichiers distribués Hadoop (HDFS) comme couche de stockage et dispose de son propre moteur d'exécution de requêtes au lieu du framework MapReduce.
Présentation de SQL sur Hadoop
Hadoop est un framework open-source qui permet de stocker et de traiter du big data dans un environnement distribué. C'est extrêmement rapide et puissant. Cependant, Hadoop a des capacités d'interrogation limitées, de sorte que ses performances peuvent être encore améliorées à l'aide de SQL sur Hadoop. Cela permet aux utilisateurs d'interagir avec Hadoop via des commandes SQL simples.
Certains des exemples d'applications SQL sur Hadoop sont Hive, Impala, Drill, Presto, Spark, HAWQ et Apache Tajo.
Qu'est-ce qu'Apache Tajo
Apache Tajo est un framework de traitement de données relationnel et distribué. Il est conçu pour une analyse de requêtes ad hoc à faible latence et évolutive.
Tajo prend en charge SQL standard et divers formats de données. La plupart des requêtes Tajo peuvent être exécutées sans aucune modification.
Tajo a fault-tolerance via un mécanisme de redémarrage pour les tâches ayant échoué et un moteur de réécriture de requêtes extensible.
Tajo effectue le nécessaire ETL (Extract Transform and Load process)opérations pour résumer de grands ensembles de données stockés sur HDFS. C'est un choix alternatif à Hive / Pig.
La dernière version de Tajo offre une meilleure connectivité aux programmes Java et aux bases de données tierces telles qu'Oracle et PostGreSQL.
Caractéristiques d'Apache Tajo
Apache Tajo présente les fonctionnalités suivantes -
- Évolutivité supérieure et performances optimisées
- Faible latence
- Fonctions définies par l'utilisateur
- Cadre de traitement du stockage en ligne / colonne.
- Compatibilité avec HiveQL et Hive MetaStore
- Flux de données simple et maintenance facile.
Avantages d'Apache Tajo
Apache Tajo offre les avantages suivants -
- Facile à utiliser
- Architecture simplifiée
- Optimisation des requêtes basée sur les coûts
- Plan d'exécution de requête vectorisé
- Livraison rapide
- Mécanisme d'E / S simple et prend en charge différents types de stockage.
- Tolérance aux pannes
Cas d'utilisation d'Apache Tajo
Voici quelques exemples d'utilisation d'Apache Tajo:
Entreposage et analyse de données
La société coréenne SK Telecom a utilisé Tajo contre 1,7 téraoctet de données et a constaté qu'elle pouvait répondre à des requêtes plus rapidement que Hive ou Impala.
Découverte de données
Le service de streaming musical coréen Melon utilise Tajo pour le traitement analytique. Tajo exécute les travaux ETL (processus d'extraction-transformation-chargement) 1,5 à 10 fois plus rapidement que Hive.
Analyse du journal
Bluehole Studio, une société coréenne a développé TERA - un jeu en ligne multijoueur fantastique. La société utilise Tajo pour l'analyse des journaux de jeu et la recherche des principales causes des interruptions de qualité de service.
Stockage et formats de données
Apache Tajo prend en charge les formats de données suivants -
- JSON
- Fichier texte (CSV)
- Parquet
- Fichier de séquence
- AVRO
- Tampon de protocole
- Orc Apache
Tajo prend en charge les formats de stockage suivants -
- HDFS
- JDBC
- Amazon S3
- Apache HBase
- Elasticsearch
L'illustration suivante représente l'architecture d'Apache Tajo.

Le tableau suivant décrit chacun des composants en détail.
| S.No. | Composant et description |
|---|---|
| 1 | Client Client soumet les instructions SQL au Tajo Master pour obtenir le résultat. |
| 2 | Master Master est le démon principal. Il est responsable de la planification des requêtes et est le coordinateur des travailleurs. |
| 3 | Catalog server Gère les descriptions de table et d'index. Il est intégré au démon Master. Le serveur de catalogue utilise Apache Derby comme couche de stockage et se connecte via le client JDBC. |
| 4 | Worker Le nœud maître affecte la tâche aux nœuds de travail. TajoWorker traite les données. À mesure que le nombre de TajoWorkers augmente, la capacité de traitement augmente également de manière linéaire. |
| 5 | Query Master Le maître Tajo affecte la requête au maître des requêtes. Le Query Master est responsable du contrôle d'un plan d'exécution distribué. Il lance le TaskRunner et planifie les tâches vers TaskRunner. Le rôle principal du Query Master est de surveiller les tâches en cours et de les signaler au nœud Master. |
| 6 | Node Managers Gère la ressource du nœud worker. Il décide de l'attribution des requêtes au nœud. |
| sept | TaskRunner Agit comme un moteur d'exécution de requêtes local. Il est utilisé pour exécuter et surveiller le processus de requête. Le TaskRunner traite une tâche à la fois. Il a les trois attributs principaux suivants -
|
| 8 | Query Executor Il est utilisé pour exécuter une requête. |
| 9 | Storage service Connecte le stockage de données sous-jacent à Tajo. |
Flux de travail
Tajo utilise Hadoop Distributed File System (HDFS) comme couche de stockage et dispose de son propre moteur d'exécution de requêtes au lieu du framework MapReduce. Un cluster Tajo se compose d'un nœud maître et de plusieurs nœuds de calcul sur les nœuds du cluster.
Le maître est principalement responsable de la planification des requêtes et le coordinateur des travailleurs. Le maître divise une requête en petites tâches et les affecte aux travailleurs. Chaque worker dispose d'un moteur de requête local qui exécute un graphe acyclique dirigé d'opérateurs physiques.
De plus, Tajo peut contrôler un flux de données distribué plus flexible que celui de MapReduce et prend en charge les techniques d'indexation.
L'interface Web de Tajo a les capacités suivantes -
- Option pour savoir comment les requêtes soumises sont planifiées
- Option pour savoir comment les requêtes sont réparties entre les nœuds
- Option pour vérifier l'état du cluster et des nœuds
Pour installer Apache Tajo, vous devez disposer des logiciels suivants sur votre système -
- Hadoop version 2.3 ou supérieure
- Java version 1.7 ou supérieure
- Linux ou Mac OS
Continuons maintenant avec les étapes suivantes pour installer Tajo.
Vérification de l'installation de Java
Espérons que vous avez déjà installé la version 8 de Java sur votre machine. Maintenant, il vous suffit de procéder en le vérifiant.
Pour vérifier, utilisez la commande suivante -
$ java -versionSi Java est correctement installé sur votre machine, vous pouvez voir la version actuelle du Java installé. Si Java n'est pas installé, suivez ces étapes pour installer Java 8 sur votre machine.
Télécharger le JDK
Téléchargez la dernière version de JDK en visitant le lien suivant, puis téléchargez la dernière version.
https://www.oracle.com
La dernière version est JDK 8u 92 et le fichier est “jdk-8u92-linux-x64.tar.gz”. Veuillez télécharger le fichier sur votre machine. Ensuite, extrayez les fichiers et déplacez-les vers un répertoire spécifique. Maintenant, définissez les alternatives Java. Enfin, Java est installé sur votre machine.
Vérification de l'installation de Hadoop
Vous avez déjà installé Hadoopsur votre système. Maintenant, vérifiez-le en utilisant la commande suivante -
$ hadoop versionSi tout va bien avec votre configuration, vous pouvez voir la version de Hadoop. Si Hadoop n'est pas installé, téléchargez et installez Hadoop en visitant le lien suivant -https://www.apache.org
Installation d'Apache Tajo
Apache Tajo propose deux modes d'exécution: le mode local et le mode entièrement distribué. Après avoir vérifié l'installation de Java et Hadoop, procédez comme suit pour installer le cluster Tajo sur votre machine. Une instance Tajo en mode local nécessite des configurations très simples.
Téléchargez la dernière version de Tajo en visitant le lien suivant - https://www.apache.org/dyn/closer.cgi/tajo
Vous pouvez maintenant télécharger le fichier “tajo-0.11.3.tar.gz” de votre machine.
Extraire le fichier Tar
Extrayez le fichier tar en utilisant la commande suivante -
$ cd opt/ $ tar tajo-0.11.3.tar.gz
$ cd tajo-0.11.3Définir la variable d'environnement
Ajoutez les modifications suivantes à “conf/tajo-env.sh” fichier
$ cd tajo-0.11.3
$ vi conf/tajo-env.sh
# Hadoop home. Required
export HADOOP_HOME = /Users/path/to/Hadoop/hadoop-2.6.2
# The java implementation to use. Required.
export JAVA_HOME = /path/to/jdk1.8.0_92.jdk/Ici, vous devez spécifier le chemin Hadoop et Java vers “tajo-env.sh”fichier. Une fois les modifications effectuées, enregistrez le fichier et quittez le terminal.
Démarrez Tajo Server
Pour lancer le serveur Tajo, exécutez la commande suivante -
$ bin/start-tajo.shVous recevrez une réponse similaire à la suivante -
Starting single TajoMaster
starting master, logging to /Users/path/to/Tajo/tajo-0.11.3/bin/../
localhost: starting worker, logging to /Users/path/toe/Tajo/tajo-0.11.3/bin/../logs/
Tajo master web UI: http://local:26080
Tajo Client Service: local:26002Maintenant, tapez la commande «jps» pour voir les démons en cours d'exécution.
$ jps
1010 TajoWorker
1140 Jps
933 TajoMasterLancer Tajo Shell (Tsql)
Pour lancer le client shell Tajo, utilisez la commande suivante -
$ bin/tsqlVous recevrez la sortie suivante -
welcome to
_____ ___ _____ ___
/_ _/ _ |/_ _/ /
/ // /_| |_/ // / /
/_//_/ /_/___/ \__/ 0.11.3
Try \? for help.Quittez Tajo Shell
Exécutez la commande suivante pour quitter Tsql -
default> \q
bye!Ici, la valeur par défaut fait référence au catalogue en Tajo.
UI Web
Tapez l'URL suivante pour lancer l'interface utilisateur Web Tajo - http://localhost:26080/
Vous verrez maintenant l'écran suivant qui est similaire à l'option ExecuteQuery.

Arrêtez Tajo
Pour arrêter le serveur Tajo, utilisez la commande suivante -
$ bin/stop-tajo.shVous obtiendrez la réponse suivante -
localhost: stopping worker
stopping masterLa configuration de Tajo est basée sur le système de configuration de Hadoop. Ce chapitre explique en détail les paramètres de configuration de Tajo.
Paramètres de base
Tajo utilise les deux fichiers de configuration suivants -
- catalog-site.xml - configuration pour le serveur de catalogue.
- tajo-site.xml - configuration pour d'autres modules Tajo.
Configuration du mode distribué
La configuration du mode distribué s'exécute sur Hadoop Distributed File System (HDFS). Suivons les étapes pour configurer la configuration du mode distribué Tajo.
tajo-site.xml
Ce fichier est disponible @ /path/to/tajo/confrépertoire et agit comme configuration pour d'autres modules Tajo. Pour accéder à Tajo en mode distribué, appliquez les modifications suivantes à“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://hostname:port/tajo</value>
</property>
<property>
<name>tajo.master.umbilical-rpc.address</name>
<value>hostname:26001</value>
</property>
<property>
<name>tajo.master.client-rpc.address</name>
<value>hostname:26002</value>
</property>
<property>
<name>tajo.catalog.client-rpc.address</name>
<value>hostname:26005</value>
</property>Configuration du nœud maître
Tajo utilise HDFS comme type de stockage principal. La configuration est la suivante et doit être ajoutée à“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://namenode_hostname:port/path</value>
</property>Configuration du catalogue
Si vous souhaitez personnaliser le service de catalogue, copiez $path/to/Tajo/conf/catalogsite.xml.template à $path/to/Tajo/conf/catalog-site.xml et ajoutez l'une des configurations suivantes si nécessaire.
Par exemple, si vous utilisez “Hive catalog store” pour accéder à Tajo, la configuration doit être comme suit -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HCatalogStore</value>
</property>Si vous avez besoin de stocker MySQL catalogue, puis appliquez les modifications suivantes -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.MySQLStore</value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.id</name>
<value><mysql user name></value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.password</name>
<value><mysql user password></value>
</property>
<property>
<name>tajo.catalog.jdbc.uri</name>
<value>jdbc:mysql://<mysql host name>:<mysql port>/<database name for tajo>
?createDatabaseIfNotExist = true</value>
</property>De même, vous pouvez enregistrer les autres catalogues pris en charge par Tajo dans le fichier de configuration.
Configuration des travailleurs
Par défaut, le TajoWorker stocke les données temporaires sur le système de fichiers local. Il est défini dans le fichier «tajo-site.xml» comme suit -
<property>
<name>tajo.worker.tmpdir.locations</name>
<value>/disk1/tmpdir,/disk2/tmpdir,/disk3/tmpdir</value>
</property>Pour augmenter la capacité d'exécution des tâches de chaque ressource de travail, choisissez la configuration suivante -
<property>
<name>tajo.worker.resource.cpu-cores</name>
<value>12</value>
</property>
<property>
<name>tajo.task.resource.min.memory-mb</name>
<value>2000</value>
</property>
<property>
<name>tajo.worker.resource.disks</name>
<value>4</value>
</property>Pour faire fonctionner le worker Tajo dans un mode dédié, choisissez la configuration suivante -
<property>
<name>tajo.worker.resource.dedicated</name>
<value>true</value>
</property>Dans ce chapitre, nous allons comprendre en détail les commandes de Tajo Shell.
Pour exécuter les commandes du shell Tajo, vous devez démarrer le serveur Tajo et le shell Tajo en utilisant les commandes suivantes -
Démarrer le serveur
$ bin/start-tajo.shDémarrer Shell
$ bin/tsqlLes commandes ci-dessus sont maintenant prêtes à être exécutées.
Commandes méta
Parlons maintenant de la Meta Commands. Les commandes méta Tsql commencent par une barre oblique inverse(‘\’).
Commande d'aide
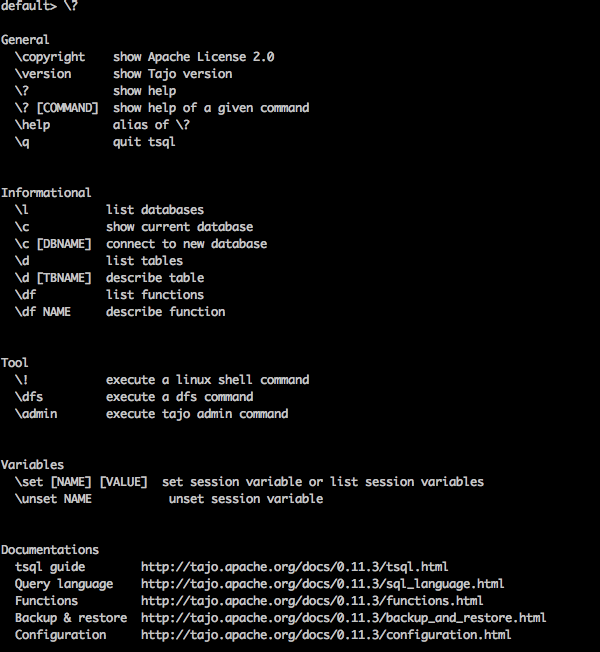
“\?” La commande est utilisée pour afficher l'option d'aide.
Query
default> \?Result
Ce qui précède \?La commande liste toutes les options d'utilisation de base de Tajo. Vous recevrez la sortie suivante -
Base de données de listes
Pour lister toutes les bases de données de Tajo, utilisez la commande suivante -
Query
default> \lResult
Vous recevrez la sortie suivante -
information_schema
defaultÀ l'heure actuelle, nous n'avons créé aucune base de données, il montre donc deux bases de données Tajo intégrées.
Base de données actuelle
\c L'option est utilisée pour afficher le nom actuel de la base de données.
Query
default> \cResult
Vous êtes maintenant connecté à la base de données "par défaut" en tant qu'utilisateur "nom d'utilisateur".
Liste des fonctions intégrées
Pour lister toutes les fonctions intégrées, tapez la requête comme suit -
Query
default> \dfResult
Vous recevrez la sortie suivante -

Décrire la fonction
\df function name - Cette requête renvoie la description complète de la fonction donnée.
Query
default> \df sqrtResult
Vous recevrez la sortie suivante -

Quitter le terminal
Pour quitter le terminal, tapez la requête suivante -
Query
default> \qResult
Vous recevrez la sortie suivante -
bye!Commandes d'administration
Tajo Shell fournit \admin option pour lister toutes les fonctionnalités d'administration.
Query
default> \adminResult
Vous recevrez la sortie suivante -

Informations sur le cluster
Pour afficher les informations de cluster dans Tajo, utilisez la requête suivante
Query
default> \admin -clusterResult
Vous recevrez la sortie suivante -

Afficher maître
La requête suivante affiche les informations de base actuelles.
Query
default> \admin -showmastersResult
localhostDe même, vous pouvez essayer d'autres commandes d'administration.
Variables de session
Le client Tajo se connecte au maître via un identifiant de session unique. La session est active jusqu'à ce que le client soit déconnecté ou expire.
La commande suivante est utilisée pour lister toutes les variables de session.
Query
default> \setResult
'SESSION_LAST_ACCESS_TIME' = '1470206387146'
'CURRENT_DATABASE' = 'default'
‘USERNAME’ = 'user'
'SESSION_ID' = 'c60c9b20-dfba-404a-822f-182bc95d6c7c'
'TIMEZONE' = 'Asia/Kolkata'
'FETCH_ROWNUM' = '200'
‘COMPRESSED_RESULT_TRANSFER' = 'false'le \set key val définira la variable de session nommée key avec la valeur val. Par exemple,
Query
default> \set ‘current_database’='default'Result
usage: \set [[NAME] VALUE]Ici, vous pouvez attribuer la clé et la valeur dans le \setcommander. Si vous devez annuler les modifications, utilisez le\unset commander.
Pour exécuter une requête dans un shell Tajo, ouvrez votre terminal et accédez au répertoire installé de Tajo, puis tapez la commande suivante -
$ bin/tsqlVous verrez maintenant la réponse comme indiqué dans le programme suivant -
default>Vous pouvez maintenant exécuter vos requêtes. Sinon, vous pouvez exécuter vos requêtes via l'application de console Web à l'URL suivante -http://localhost:26080/
Types de données primitifs
Apache Tajo prend en charge la liste suivante de types de données primitifs -
| S.No. | Type de données et description |
|---|---|
| 1 | integer Utilisé pour stocker une valeur entière avec un stockage de 4 octets. |
| 2 | tinyint La valeur entière minuscule est de 1 octet |
| 3 | smallint Utilisé pour stocker une valeur entière de petite taille de 2 octets. |
| 4 | bigint La valeur entière de grande plage a un stockage de 8 octets. |
| 5 | boolean Renvoie vrai / faux. |
| 6 | real Utilisé pour stocker la valeur réelle. La taille est de 4 octets. |
| sept | float Valeur de précision à virgule flottante qui a 4 ou 8 octets d'espace de stockage. |
| 8 | double Valeur de précision à double point stockée sur 8 octets. |
| 9 | char[(n)] Valeur de caractère. |
| dix | varchar[(n)] Données non Unicode de longueur variable. |
| 11 | number Valeurs décimales. |
| 12 | binary Valeurs binaires. |
| 13 | date Date du calendrier (année, mois, jour). Example - DATE '2016-08-22' |
| 14 | time Heure du jour (heure, minute, seconde, milliseconde) sans fuseau horaire. Les valeurs de ce type sont analysées et rendues dans le fuseau horaire de la session. |
| 15 | timezone Heure du jour (heure, minute, seconde, milliseconde) avec un fuseau horaire. Les valeurs de ce type sont rendues en utilisant le fuseau horaire de la valeur. Example - HEURE '01: 02: 03.456 Asie / kolkata ' |
| 16 | timestamp Instant dans le temps qui inclut la date et l'heure du jour sans fuseau horaire. Example - TIMESTAMP '2016-08-22 03: 04: 05.321' |
| 17 | text Texte Unicode de longueur variable. |
Les opérateurs suivants sont utilisés dans Tajo pour effectuer les opérations souhaitées.
| S.No. | Opérateur et description |
|---|---|
| 1 | Opérateurs arithmétiques Presto prend en charge les opérateurs arithmétiques tels que +, -, *, /,%. |
| 2 | Opérateurs relationnels <,>, <=,> =, =, <> |
| 3 | Opérateurs logiques ET, OU, PAS |
| 4 | Opérateurs de chaîne Le '||' L'opérateur effectue la concaténation de chaînes. |
| 5 | Opérateurs de gamme L'opérateur de plage est utilisé pour tester la valeur dans une plage spécifique. Tajo prend en charge les opérateurs BETWEEN, IS NULL, IS NOT NULL. |
À partir de maintenant, vous étiez conscient de l'exécution de requêtes de base simples sur Tajo. Dans les prochains chapitres suivants, nous discuterons des fonctions SQL suivantes -
- Fonctions mathématiques
- Fonctions de chaîne
- Fonctions DateTime
- Fonctions JSON
Les fonctions mathématiques fonctionnent sur des formules mathématiques. Le tableau suivant décrit la liste des fonctions en détail.
| S.No. | Description de la fonction |
|---|---|
| 1 | abs (x) Renvoie la valeur absolue de x. |
| 2 | cbrt (x) Renvoie la racine cubique de x. |
| 3 | ceil (x) Renvoie la valeur x arrondie à l'entier supérieur le plus proche. |
| 4 | plancher (x) Renvoie x arrondi à l'entier inférieur le plus proche. |
| 5 | pi() Renvoie la valeur pi. Le résultat sera renvoyé sous forme de valeur double. |
| 6 | radians (x) convertit l'angle x en degrés radians. |
| sept | degrés (x) Renvoie la valeur du degré pour x. |
| 8 | pow (x, p) Renvoie la puissance de la valeur «p» à la valeur x. |
| 9 | div (x, y) Renvoie le résultat de la division pour les deux valeurs entières x, y données. |
| dix | exp (x) Renvoie le nombre d'Euler e élevé à la puissance d'un nombre. |
| 11 | sqrt (x) Renvoie la racine carrée de x. |
| 12 | signe (x) Renvoie la fonction signum de x, c'est-à-dire -
|
| 13 | mod (n, m) Renvoie le module (reste) de n divisé par m. |
| 14 | rond (x) Renvoie la valeur arrondie de x. |
| 15 | cos (x) Renvoie la valeur cosinus (x). |
| 16 | asin (x) Renvoie la valeur sinusoïdale inverse (x). |
| 17 | acos (x) Renvoie la valeur du cosinus inverse (x). |
| 18 | atan (x) Renvoie la valeur de la tangente inverse (x). |
| 19 | atan2 (y, x) Renvoie la valeur de la tangente inverse (y / x). |
Fonctions de type de données
Le tableau suivant répertorie les fonctions de type de données disponibles dans Apache Tajo.
| S.No. | Description de la fonction |
|---|---|
| 1 | to_bin (x) Renvoie la représentation binaire d'un entier. |
| 2 | to_char (int, texte) Convertit un entier en chaîne. |
| 3 | to_hex (x) Convertit la valeur x en hexadécimal. |
Le tableau suivant répertorie les fonctions de chaîne dans Tajo.
| S.No. | Description de la fonction |
|---|---|
| 1 | concat (chaîne1, ..., chaîneN) Concaténez les chaînes données. |
| 2 | longueur (chaîne) Renvoie la longueur de la chaîne donnée. |
| 3 | inférieur (chaîne) Renvoie le format minuscule de la chaîne. |
| 4 | supérieur (chaîne) Renvoie le format majuscule de la chaîne donnée. |
| 5 | ascii (chaîne de texte) Renvoie le code ASCII du premier caractère du texte. |
| 6 | bit_length (texte de chaîne) Renvoie le nombre de bits dans une chaîne. |
| sept | char_length (chaîne de texte) Renvoie le nombre de caractères dans une chaîne. |
| 8 | octet_length (texte de chaîne) Renvoie le nombre d'octets dans une chaîne. |
| 9 | digest (texte d'entrée, texte de méthode) Calcule le Digesthachage de chaîne. Ici, la deuxième méthode arg fait référence à la méthode de hachage. |
| dix | initcap (chaîne de texte) Convertit la première lettre de chaque mot en majuscules. |
| 11 | md5 (chaîne de texte) Calcule le MD5 hachage de chaîne. |
| 12 | left (chaîne de texte, taille int) Renvoie les n premiers caractères de la chaîne. |
| 13 | right (chaîne de texte, taille int) Renvoie les n derniers caractères de la chaîne. |
| 14 | localiser (texte source, texte cible, start_index) Renvoie l'emplacement de la sous-chaîne spécifiée. |
| 15 | strposb (texte source, texte cible) Renvoie l'emplacement binaire de la sous-chaîne spécifiée. |
| 16 | substr (texte source, index de début, longueur) Renvoie la sous-chaîne pour la longueur spécifiée. |
| 17 | trim (chaîne de texte [, caractères texte]) Supprime les caractères (un espace par défaut) du début / de la fin / des deux extrémités de la chaîne. |
| 18 | split_part (texte de chaîne, texte de délimitation, champ int) Divise une chaîne sur le délimiteur et renvoie le champ donné (à partir de un). |
| 19 | regexp_replace (texte de chaîne, texte de modèle, texte de remplacement) Remplace les sous-chaînes correspondant à un modèle d'expression régulière donné. |
| 20 | reverse (chaîne) Opération inverse effectuée pour la chaîne. |
Apache Tajo prend en charge les fonctions DateTime suivantes.
| S.No. | Description de la fonction |
|---|---|
| 1 | add_days (date, date ou horodatage, jour entier Renvoie la date ajoutée par la valeur du jour donnée. |
| 2 | add_months (date, date ou horodatage, mois entier) Renvoie la date ajoutée par la valeur du mois donné. |
| 3 | date actuelle() Renvoie la date du jour. |
| 4 | heure actuelle() Renvoie l'heure d'aujourd'hui. |
| 5 | extrait (siècle à partir de la date / horodatage) Extrait le siècle du paramètre donné. |
| 6 | extrait (jour de date / horodatage) Extrait le jour du paramètre donné. |
| sept | extrait (décade à partir de la date / horodatage) Extrait la décennie du paramètre donné. |
| 8 | extrait (day dow date / horodatage) Extrait le jour de la semaine du paramètre donné. |
| 9 | extrait (à partir de la date / horodatage) Extrait le jour de l'année du paramètre donné. |
| dix | sélectionner un extrait (heure de l'horodatage) Extrait l'heure du paramètre donné. |
| 11 | sélectionner un extrait (isodow de l'horodatage) Extrait le jour de la semaine du paramètre donné. Ceci est identique à Dow sauf le dimanche. Cela correspond à la numérotation du jour de la semaine ISO 8601. |
| 12 | sélectionner l'extrait (isoyear de la date) Extrait l'année ISO à partir de la date spécifiée. L'année ISO peut être différente de l'année grégorienne. |
| 13 | extraire (microsecondes à partir du temps) Extrait les microsecondes du paramètre donné. Le champ des secondes, y compris les parties fractionnaires, multiplié par 1 000 000; |
| 14 | extrait (millénaire à partir de l'horodatage) Extrait le millénaire du paramètre donné. Un millénaire correspond à 1000 ans. Ainsi, le troisième millénaire a commencé le 1er janvier 2001. |
| 15 | extrait (millisecondes à partir du temps) Extrait les millisecondes du paramètre donné. |
| 16 | extrait (minute de l'horodatage) Extrait minute du paramètre donné. |
| 17 | extrait (quart de l'horodatage) Extrait le trimestre de l'année (1 - 4) du paramètre donné. |
| 18 | date_part (texte du champ, date source ou horodatage ou heure) Extrait le champ de date du texte. |
| 19 | maintenant() Renvoie l'horodatage actuel. |
| 20 | to_char (horodatage, format du texte) Convertit l'horodatage en texte. |
| 21 | to_date (texte src, texte de format) Convertit le texte en date. |
| 22 | to_timestamp (texte src, texte de format) Convertit le texte en horodatage. |
Les fonctions JSON sont répertoriées dans le tableau suivant -
| S.No. | Description de la fonction |
|---|---|
| 1 | json_extract_path_text (js sur texte, json_path texte) Extrait la chaîne JSON d'une chaîne JSON en fonction du chemin json spécifié. |
| 2 | json_array_get (texte json_array, index int4) Renvoie l'élément à l'index spécifié dans le tableau JSON. |
| 3 | json_array_contains (texte du tableau json_, valeur quelconque) Déterminez si la valeur donnée existe dans le tableau JSON. |
| 4 | json_array_length (texte json_ar ray) Renvoie la longueur du tableau json. |
Cette section explique les commandes Tajo DDL. Tajo a une base de données intégrée nomméedefault.
Créer une déclaration de base de données
Create Databaseest une instruction utilisée pour créer une base de données dans Tajo. La syntaxe de cette instruction est la suivante -
CREATE DATABASE [IF NOT EXISTS] <database_name>Requete
default> default> create database if not exists test;Résultat
La requête ci-dessus générera le résultat suivant.
OKLa base de données est l'espace de noms dans Tajo. Une base de données peut contenir plusieurs tables avec un nom unique.
Afficher la base de données actuelle
Pour vérifier le nom actuel de la base de données, exécutez la commande suivante -
Requete
default> \cRésultat
La requête ci-dessus générera le résultat suivant.
You are now connected to database "default" as user “user1".
default>Se connecter à la base de données
À partir de maintenant, vous avez créé une base de données nommée «test». La syntaxe suivante est utilisée pour connecter la base de données «test».
\c <database name>Requete
default> \c testRésultat
La requête ci-dessus générera le résultat suivant.
You are now connected to database "test" as user “user1”.
test>Vous pouvez maintenant voir les changements d'invite de la base de données par défaut à la base de données de test.
Déposer la base de données
Pour supprimer une base de données, utilisez la syntaxe suivante -
DROP DATABASE <database-name>Requete
test> \c default
You are now connected to database "default" as user “user1".
default> drop database test;Résultat
La requête ci-dessus générera le résultat suivant.
OKUne table est une vue logique d'une source de données. Il se compose d'un schéma logique, de partitions, d'une URL et de diverses propriétés. Une table Tajo peut être un répertoire dans HDFS, un seul fichier, une table HBase ou une table SGBDR.
Tajo prend en charge les deux types de tables suivants -
- table externe
- table interne
Table externe
External table needs the location property when the table is created. For example, if your data is already there as Text/JSON files or HBase table, you can register it as Tajo external table.
The following query is an example of external table creation.
create external table sample(col1 int,col2 text,col3 int) location ‘hdfs://path/to/table';Here,
External keyword − This is used to create an external table. This helps to create a table in the specified location.
Sample refers to the table name.
Location − It is a directory for HDFS,Amazon S3, HBase or local file system. To assign a location property for directories, use the below URI examples −
HDFS − hdfs://localhost:port/path/to/table
Amazon S3 − s3://bucket-name/table
local file system − file:///path/to/table
Openstack Swift − swift://bucket-name/table
Table Properties
An external table has the following properties −
TimeZone − Users can specify a time zone for reading or writing a table.
Compression format − Used to make data size compact. For example, the text/json file uses compression.codec property.
Internal Table
A Internal table is also called an Managed Table. It is created in a pre-defined physical location called the Tablespace.
Syntax
create table table1(col1 int,col2 text);By default, Tajo uses “tajo.warehouse.directory” located in “conf/tajo-site.xml” . To assign new location for the table, you can use Tablespace configuration.
Tablespace
Tablespace is used to define locations in the storage system. It is supported for only internal tables. You can access the tablespaces by their names. Each tablespace can use a different storage type. If you don’t specify tablespaces then, Tajo uses the default tablespace in the root directory.
Tablespace Configuration
You have “conf/tajo-site.xml.template” in Tajo. Copy the file and rename it to “storagesite.json”. This file will act as a configuration for Tablespaces. Tajo data formats uses the following configuration −
HDFS Configuration
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}HBase Configuration
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hbase:zk://quorum1:port,quorum2:port/"
}
}
}Text File Configuration
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
“uri”: “hdfs://localhost:9000/path/to/Tajo”
}
}
}Tablespace Creation
Tajo’s internal table records can be accessed from another table only. You can configure it with tablespace.
Syntax
CREATE TABLE [IF NOT EXISTS] <table_name> [(column_list)] [TABLESPACE tablespace_name]
[using <storage_type> [with (<key> = <value>, ...)]] [AS <select_statement>]Here,
IF NOT EXISTS − This avoids an error if the same table has not been created already.
TABLESPACE − This clause is used to assign the tablespace name.
Storage type − Tajo data supports formats like text,JSON,HBase,Parquet,Sequencefile and ORC.
AS select statement − Select records from another table.
Configure Tablespace
Start your Hadoop services and open the file “conf/storage-site.json”, then add the following changes −
$ vi conf/storage-site.json {
"spaces": {
“space1”: {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}Here, Tajo will refer to the data from HDFS location and space1 is the tablespace name. If you do not start Hadoop services, you can’t register tablespace.
Query
default> create table table1(num1 int,num2 text,num3 float) tablespace space1;The above query creates a table named “table1” and “space1” refers to the tablespace name.
Data formats
Tajo supports data formats. Let’s go through each of the formats one by one in detail.
Text
A character-separated values’ plain text file represents a tabular data set consisting of rows and columns. Each row is a plain text line.
Creating Table
default> create external table customer(id int,name text,address text,age int)
using text with('text.delimiter'=',') location ‘file:/Users/workspace/Tajo/customers.csv’;Here, “customers.csv” file refers to a comma separated value file located in the Tajo installation directory.
To create internal table using text format, use the following query −
default> create table customer(id int,name text,address text,age int) using text;In the above query, you have not assigned any tablespace so it will take Tajo’s default tablespace.
Properties
A text file format has the following properties −
text.delimiter − This is a delimiter character. Default is ‘|’.
compression.codec − This is a compression format. By default, it is disabled. you can change the settings using specified algorithm.
timezone − The table used for reading or writing.
text.error-tolerance.max-num − The maximum number of tolerance levels.
text.skip.headerlines − The number of header lines per skipped.
text.serde − This is serialization property.
JSON
Apache Tajo supports JSON format for querying data. Tajo treats a JSON object as SQL record. One object equals one row in a Tajo table. Let’s consider “array.json” as follows −
$ hdfs dfs -cat /json/array.json {
"num1" : 10,
"num2" : "simple json array",
"num3" : 50.5
}After you create this file, switch to the Tajo shell and type the following query to create a table using the JSON format.
Query
default> create external table sample (num1 int,num2 text,num3 float)
using json location ‘json/array.json’;Always remember that the file data must match with the table schema. Otherwise, you can omit the column names and use * which doesn’t require columns list.
To create an internal table, use the following query −
default> create table sample (num1 int,num2 text,num3 float) using json;Parquet
Parquet is a columnar storage format. Tajo uses Parquet format for easy, fast and efficient access.
Table creation
The following query is an example for table creation −
CREATE TABLE parquet (num1 int,num2 text,num3 float) USING PARQUET;Parquet file format has the following properties −
parquet.block.size − size of a row group being buffered in memory.
parquet.page.size − The page size is for compression.
parquet.compression − The compression algorithm used to compress pages.
parquet.enable.dictionary − The boolean value is to enable/disable dictionary encoding.
RCFile
RCFile is the Record Columnar File. It consists of binary key/value pairs.
Table creation
The following query is an example for table creation −
CREATE TABLE Record(num1 int,num2 text,num3 float) USING RCFILE;RCFile has the following properties −
rcfile.serde − custom deserializer class.
compression.codec − compression algorithm.
rcfile.null − NULL character.
SequenceFile
SequenceFile is a basic file format in Hadoop which consists of key/value pairs.
Table creation
The following query is an example for table creation −
CREATE TABLE seq(num1 int,num2 text,num3 float) USING sequencefile;This sequence file has Hive compatibility. This can be written in Hive as,
CREATE TABLE table1 (id int, name string, score float, type string)
STORED AS sequencefile;ORC
ORC (Optimized Row Columnar) is a columnar storage format from Hive.
Table creation
The following query is an example for table creation −
CREATE TABLE optimized(num1 int,num2 text,num3 float) USING ORC;The ORC format has the following properties −
orc.max.merge.distance − ORC file is read, it merges when the distance is lower.
orc.stripe.size − This is the size of each stripe.
orc.buffer.size − The default is 256KB.
orc.rowindex.stride − This is the ORC index stride in number of rows.
In the previous chapter, you have understood how to create tables in Tajo. This chapter explains about the SQL statement in Tajo.
Create Table Statement
Before moving to create a table, create a text file “students.csv” in Tajo installation directory path as follows −
students.csv
| Id | Name | Address | Age | Marks |
|---|---|---|---|---|
| 1 | Adam | 23 New Street | 21 | 90 |
| 2 | Amit | 12 Old Street | 13 | 95 |
| 3 | Bob | 10 Cross Street | 12 | 80 |
| 4 | David | 15 Express Avenue | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | Ganga | 25 North Street | 12 | 55 |
| 7 | Jack | 2 Park Street | 12 | 60 |
| 8 | Leena | 24 South Street | 12 | 70 |
| 9 | Mary | 5 West Street | 12 | 75 |
| 10 | Peter | 16 Park Avenue | 12 | 95 |
After the file has been created, move to the terminal and start the Tajo server and shell one by one.
Create Database
Create a new database using the following command −
Query
default> create database sampledb;
OKConnect to the database “sampledb” which is now created.
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.Then, create a table in “sampledb” as follows −
Query
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;Result
The above query will generate the following result.
OKHere, the external table is created. Now, you just have to enter the file location. If you have to assign the table from hdfs then use hdfs instead of file.
Next, the “students.csv” file contains comma separated values. The text.delimiter field is assigned with ‘,’.
You have now created “mytable” successfully in “sampledb”.
Show Table
To show tables in Tajo, use the following query.
Query
sampledb> \d
mytable
sampledb> \d mytableResult
The above query will generate the following result.
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4List table
To fetch all the records in the table, type the following query −
Query
sampledb> select * from mytable;Result
The above query will generate the following result.

Insert Table Statement
Tajo uses the following syntax to insert records in table.
Syntax
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;Tajo’s insert statement is similar to the INSERT INTO SELECT statement of SQL.
Query
Let’s create a table to overwrite table data of an existing table.
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \dResult
The above query will generate the following result.
mytable
testInsert Records
To insert records in the “test” table, type the following query.
Query
sampledb> insert overwrite into test select * from mytable;Result
The above query will generate the following result.
Progress: 100%, response time: 0.518 secHere, “mytable" records overwrite the “test” table. If you don’t want to create the “test” table, then straight away assign the physical path location as mentioned in an alternative option for insert query.
Fetch records
Use the following query to list out all the records in the “test” table −
Query
sampledb> select * from test;Result
The above query will generate the following result.

This statement is used to add, remove or modify columns of an existing table.
To rename the table use the following syntax −
Alter table table1 RENAME TO table2;Query
sampledb> alter table test rename to students;Result
The above query will generate the following result.
OKTo check the changed table name, use the following query.
sampledb> \d
mytable
studentsNow the table “test” is changed to “students” table.
Add Column
To insert new column in the “students” table, type the following syntax −
Alter table <table_name> ADD COLUMN <column_name> <data_type>Query
sampledb> alter table students add column grade text;Result
The above query will generate the following result.
OKSet Property
This property is used to change the table’s property.
Query
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OKHere, compression type and codec properties are assigned.
To change the text delimiter property, use the following −
Query
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OKResult
The above query will generate the following result.
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXTThe above result shows that the table’s properties are changed using the “SET” property.
Select Statement
The SELECT statement is used to select data from a database.
The syntax for the Select statement is as follows −
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]Clause Où
La clause Where est utilisée pour filtrer les enregistrements de la table.
Requete
sampledb> select * from mytable where id > 5;Résultat
La requête ci-dessus générera le résultat suivant.
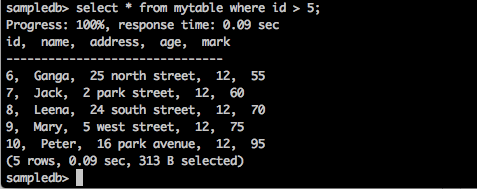
La requête renvoie les enregistrements des étudiants dont l'ID est supérieur à 5.
Requete
sampledb> select * from mytable where name = ‘Peter’;Résultat
La requête ci-dessus générera le résultat suivant.
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12Le résultat filtre uniquement les enregistrements de Peter.
Clause distincte
Une colonne de table peut contenir des valeurs en double. Le mot clé DISTINCT peut être utilisé pour renvoyer uniquement des valeurs distinctes (différentes).
Syntaxe
SELECT DISTINCT column1,column2 FROM table_name;Requete
sampledb> select distinct age from mytable;Résultat
La requête ci-dessus générera le résultat suivant.
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12La requête renvoie l'âge distinct des élèves de mytable.
Clause de groupe
La clause GROUP BY est utilisée en collaboration avec l'instruction SELECT pour organiser des données identiques en groupes.
Syntaxe
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;Requete
select age,sum(mark) as sumofmarks from mytable group by age;Résultat
La requête ci-dessus générera le résultat suivant.
age, sumofmarks
-------------------------------
13, 145
12, 610Ici, la colonne «mytable» a deux types d'âge - 12 et 13. La requête regroupe maintenant les enregistrements par âge et produit la somme des notes pour les âges correspondants des élèves.
Avoir une clause
La clause HAVING vous permet de spécifier des conditions qui filtrent les résultats de groupe qui apparaissent dans les résultats finaux. La clause WHERE place des conditions sur les colonnes sélectionnées, tandis que la clause HAVING place des conditions sur les groupes créés par la clause GROUP BY.
Syntaxe
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]Requete
sampledb> select age from mytable group by age having sum(mark) > 200;Résultat
La requête ci-dessus générera le résultat suivant.
age
-------------------------------
12La requête regroupe les enregistrements par âge et renvoie l'âge lorsque la somme du résultat de la condition (marque)> 200.
Trier par clause
La clause ORDER BY est utilisée pour trier les données par ordre croissant ou décroissant, en fonction d'une ou plusieurs colonnes. La base de données Tajo trie les résultats des requêtes par ordre croissant par défaut.
Syntaxe
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];Requete
sampledb> select * from mytable where mark > 60 order by name desc;Résultat
La requête ci-dessus générera le résultat suivant.

La requête renvoie les noms des élèves par ordre décroissant dont les notes sont supérieures à 60.
Créer une déclaration d'index
L'instruction CREATE INDEX est utilisée pour créer des index dans les tables. L'index est utilisé pour une récupération rapide des données. La version actuelle prend en charge l'index uniquement pour les formats TEXT simples stockés sur HDFS.
Syntaxe
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }Requete
create index student_index on mytable(id);Résultat
La requête ci-dessus générera le résultat suivant.
id
———————————————Pour afficher l'index attribué à la colonne, tapez la requête suivante.
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )Ici, la méthode TWO_LEVEL_BIN_TREE est utilisée par défaut dans Tajo.
Instruction Drop Table
L'instruction Drop Table est utilisée pour supprimer une table de la base de données.
Syntaxe
drop table table name;Requete
sampledb> drop table mytable;Pour vérifier si la table a été supprimée de la table, tapez la requête suivante.
sampledb> \d mytable;Résultat
La requête ci-dessus générera le résultat suivant.
ERROR: relation 'mytable' does not existVous pouvez également vérifier la requête en utilisant la commande «\ d» pour lister les tables Tajo disponibles.
Ce chapitre explique en détail les fonctions d'agrégation et de fenêtre.
Fonctions d'agrégation
Les fonctions d'agrégation produisent un résultat unique à partir d'un ensemble de valeurs d'entrée. Le tableau suivant décrit la liste des fonctions d'agrégation en détail.
| S.No. | Description de la fonction |
|---|---|
| 1 | AVG (exp) Fait la moyenne d'une colonne de tous les enregistrements d'une source de données. |
| 2 | CORR (expression1, expression2) Renvoie le coefficient de corrélation entre un ensemble de paires de nombres. |
| 3 | COMPTER() Renvoie le nombre de lignes. |
| 4 | MAX (expression) Renvoie la plus grande valeur de la colonne sélectionnée. |
| 5 | MIN (expression) Renvoie la plus petite valeur de la colonne sélectionnée. |
| 6 | SUM (expression) Renvoie la somme de la colonne donnée. |
| sept | LAST_VALUE (expression) Renvoie la dernière valeur de la colonne donnée. |
Fonction de fenêtre
Les fonctions Window s'exécutent sur un ensemble de lignes et renvoient une valeur unique pour chaque ligne de la requête. Le terme fenêtre a le sens d'ensemble de lignes pour la fonction.
La fonction Window dans une requête définit la fenêtre à l'aide de la clause OVER ().
le OVER() clause a les capacités suivantes -
- Définit les partitions de fenêtre pour former des groupes de lignes. (Clause PARTITION BY)
- Ordonne les lignes dans une partition. (Clause ORDER BY)
Le tableau suivant décrit les fonctions de la fenêtre en détail.
| Fonction | Type de retour | La description |
|---|---|---|
| rang() | int | Renvoie le rang de la ligne actuelle avec des espaces. |
| row_num () | int | Renvoie la ligne actuelle dans sa partition, à partir de 1. |
| lead (value [, offset integer [, default any]]) | Identique au type d'entrée | Renvoie la valeur évaluée à la ligne qui est décalée des lignes après la ligne actuelle dans la partition. S'il n'y a pas de telle ligne, la valeur par défaut sera renvoyée. |
| lag (value [, offset integer [, default any]]) | Identique au type d'entrée | Renvoie la valeur évaluée à la ligne qui est décalée des lignes avant la ligne actuelle dans la partition. |
| first_value (valeur) | Identique au type d'entrée | Renvoie la première valeur des lignes d'entrée. |
| last_value (valeur) | Identique au type d'entrée | Renvoie la dernière valeur des lignes d'entrée. |
Ce chapitre explique les requêtes importantes suivantes.
- Predicates
- Explain
- Join
Continuons et exécutons les requêtes.
Prédicats
Predicate est une expression qui est utilisée pour évaluer les valeurs vrai / faux et INCONNU. Les prédicats sont utilisés dans la condition de recherche des clauses WHERE et HAVING et d'autres constructions où une valeur booléenne est requise.
Prédicat IN
Détermine si la valeur de l'expression à tester correspond à n'importe quelle valeur de la sous-requête ou de la liste. La sous-requête est une instruction SELECT ordinaire qui a un jeu de résultats d'une colonne et d'une ou plusieurs lignes. Cette colonne ou toutes les expressions de la liste doivent avoir le même type de données que l'expression à tester.
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
La requête ci-dessus générera le résultat suivant.
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenueLa requête renvoie les enregistrements de mytable pour les étudiants id 2,3 et 4.
Query
select id,name,address from mytable where id not in(2,3,4);Result
La requête ci-dessus générera le résultat suivant.
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenueLa requête ci-dessus renvoie les enregistrements de mytable où les étudiants ne sont pas en 2,3 et 4.
Comme prédicat
Le prédicat LIKE compare la chaîne spécifiée dans la première expression pour calculer la valeur de chaîne, qui est référencée comme valeur à tester, avec le modèle défini dans la deuxième expression pour calculer la valeur de chaîne.
Le modèle peut contenir n'importe quelle combinaison de caractères génériques tels que -
Symbole de soulignement (_), qui peut être utilisé à la place de n'importe quel caractère unique dans la valeur à tester.
Signe de pourcentage (%), qui remplace toute chaîne de zéro caractère ou plus dans la valeur à tester.
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
La requête ci-dessus générera le résultat suivant.
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95La requête renvoie les enregistrements de ma table des étudiants dont les noms commencent par «A».
Query
select * from mytable where name like ‘_a%';Result
La requête ci-dessus générera le résultat suivant.
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75La requête renvoie les enregistrements de mytable des élèves dont les noms commencent par «a» comme deuxième caractère.
Utilisation de la valeur NULL dans les conditions de recherche
Voyons maintenant comment utiliser la valeur NULL dans les conditions de recherche.
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
La requête ci-dessus générera le résultat suivant.
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)Ici, le résultat est vrai donc il renvoie tous les noms de la table.
Query
Vérifions maintenant la requête avec la condition NULL.
default> select name from mytable where name is null;Result
La requête ci-dessus générera le résultat suivant.
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)Explique
Explainest utilisé pour obtenir un plan d'exécution de requête. Il montre une exécution de plan logique et globale d'une instruction.
Requête de plan logique
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
La requête ci-dessus générera le résultat suivant.

Le résultat de la requête montre un format de plan logique pour la table donnée. Le plan logique renvoie les trois résultats suivants -
- Liste des cibles
- Out schéma
- Dans le schéma
Requête de plan global
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
La requête ci-dessus générera le résultat suivant.

Ici, le plan global affiche l'ID du bloc d'exécution, l'ordre d'exécution et ses informations.
Rejoint
Les jointures SQL sont utilisées pour combiner des lignes de deux ou plusieurs tables. Voici les différents types de jointures SQL -
- Jointure interne
- {GAUCHE | DROITE | FULL} JOINTURE EXTÉRIEURE
- Jointure croisée
- Auto-rejoindre
- Jointure naturelle
Considérez les deux tableaux suivants pour effectuer des opérations de jointure.
Tableau 1 - Clients
| Id | Nom | Adresse | Âge |
|---|---|---|---|
| 1 | Client 1 | 23 vieille rue | 21 |
| 2 | Client 2 | 12 New Street | 23 |
| 3 | Client 3 | 10 avenue Express | 22 |
| 4 | Client 4 | 15 avenue Express | 22 |
| 5 | Client 5 | 20 rue Garden | 33 |
| 6 | Client 6 | 21 rue Nord | 25 |
Tableau2 - commande_client
| Id | Numéro de commande | ID Emp |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
Continuons maintenant et exécutons les opérations de jointure SQL sur les deux tables ci-dessus.
Jointure interne
La jointure interne sélectionne toutes les lignes des deux tables en cas de correspondance entre les colonnes des deux tables.
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
La requête ci-dessus générera le résultat suivant.
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105La requête correspond à cinq lignes des deux tables. Par conséquent, il renvoie l'âge des lignes correspondantes à partir de la première table.
Jointure externe gauche
Une jointure externe gauche conserve toutes les lignes de la table «gauche», qu'il existe ou non une ligne correspondant à la table «droite».
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
La requête ci-dessus générera le résultat suivant.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,Ici, la jointure externe gauche renvoie les lignes de colonne de nom de la table customers (gauche) et les lignes correspondant à la colonne empid de la table customer_order (droite).
Jointure externe droite
Une jointure externe droite conserve toutes les lignes de la table «droite», qu'il existe ou non une ligne qui correspond à la table «gauche».
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
La requête ci-dessus générera le résultat suivant.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105Ici, la jointure externe droite renvoie les lignes empid de la table customer_order (à droite) et la colonne de nom correspond aux lignes de la table clients.
Jointure externe complète
La jointure externe complète conserve toutes les lignes des tables de gauche et de droite.
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
La requête ci-dessus générera le résultat suivant.

La requête renvoie toutes les lignes correspondantes et non correspondantes des tables clients et commande_client.
Jointure croisée
Cela renvoie le produit cartésien des ensembles d'enregistrements des deux tables jointes ou plus.
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
La requête ci-dessus générera le résultat suivant.
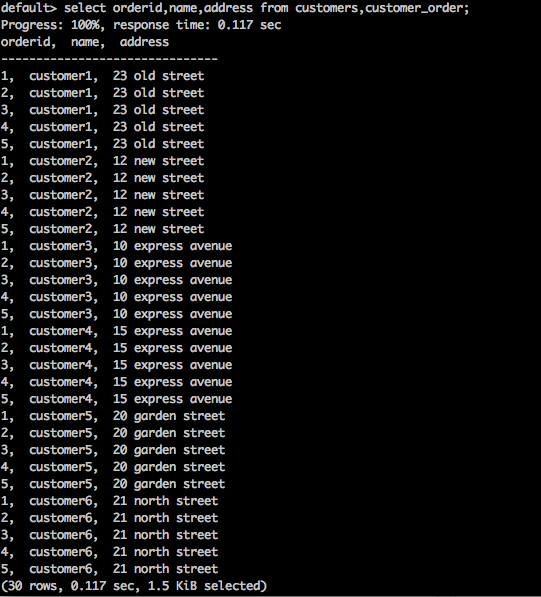
La requête ci-dessus renvoie le produit cartésien de la table.
Jointure naturelle
Une jointure naturelle n'utilise aucun opérateur de comparaison. Il ne concatène pas comme le fait un produit cartésien. Nous ne pouvons effectuer une jointure naturelle que s'il existe au moins un attribut commun entre les deux relations.
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
La requête ci-dessus générera le résultat suivant.

Ici, il existe un identifiant de colonne commun entre deux tables. En utilisant cette colonne commune, leNatural Join joint les deux tables.
Auto-rejoindre
Le SQL SELF JOIN est utilisé pour joindre une table à elle-même comme si la table était deux tables, renommant temporairement au moins une table dans l'instruction SQL.
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
La requête ci-dessus générera le résultat suivant.
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6La requête joint une table client à elle-même.
Tajo prend en charge divers formats de stockage. Pour enregistrer la configuration du plug-in de stockage, vous devez ajouter les modifications au fichier de configuration «storage-site.json».
storage-site.json
La structure est définie comme suit -
{
"storages": {
“storage plugin name“: {
"handler": "${class name}”, "default-format": “plugin name"
}
}
}Chaque instance de stockage est identifiée par URI.
Gestionnaire de stockage PostgreSQL
Tajo prend en charge le gestionnaire de stockage PostgreSQL. Il permet aux requêtes des utilisateurs d'accéder aux objets de base de données dans PostgreSQL. Il s'agit du gestionnaire de stockage par défaut de Tajo, vous pouvez donc le configurer facilement.
configuration
{
"spaces": {
"postgre": {
"uri": "jdbc:postgresql://hostname:port/database1"
"configs": {
"mapped_database": “sampledb”
"connection_properties": {
"user":“tajo", "password": "pwd"
}
}
}
}
}Ici, “database1” se réfère à la postgreSQL base de données mappée à la base de données “sampledb” à Tajo.
Apache Tajo prend en charge l'intégration HBase. Cela nous permet d'accéder aux tables HBase dans Tajo. HBase est une base de données distribuée orientée colonnes construite sur le système de fichiers Hadoop. Il fait partie de l'écosystème Hadoop qui fournit un accès aléatoire en lecture / écriture en temps réel aux données du système de fichiers Hadoop. Les étapes suivantes sont nécessaires pour configurer l'intégration HBase.
Définir la variable d'environnement
Ajoutez les modifications suivantes au fichier «conf / tajo-env.sh».
$ vi conf/tajo-env.sh
# HBase home directory. It is opitional but is required mandatorily to use HBase.
# export HBASE_HOME = path/to/HBaseAprès avoir inclus le chemin HBase, Tajo définira le fichier de bibliothèque HBase sur le chemin de classe.
Créer une table externe
Créez une table externe en utilisant la syntaxe suivante -
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] <table_name> [(<column_name> <data_type>, ... )]
USING hbase WITH ('table' = '<hbase_table_name>'
, 'columns' = ':key,<column_family_name>:<qualifier_name>, ...'
, 'hbase.zookeeper.quorum' = '<zookeeper_address>'
, 'hbase.zookeeper.property.clientPort' = '<zookeeper_client_port>')
[LOCATION 'hbase:zk://<hostname>:<port>/'] ;Pour accéder aux tables HBase, vous devez configurer l'emplacement du tablespace.
Ici,
Table- Définissez le nom de la table d'origine hbase. Si vous souhaitez créer une table externe, la table doit exister sur HBase.
Columns- La clé fait référence à la clé de ligne HBase. Le nombre d'entrées de colonnes doit être égal au nombre de colonnes de la table Tajo.
hbase.zookeeper.quorum - Définissez l'adresse du quorum du gardien de zoo.
hbase.zookeeper.property.clientPort - Définissez le port du client zookeeper.
Query
CREATE EXTERNAL TABLE students (rowkey text,id int,name text)
USING hbase WITH ('table' = 'students', 'columns' = ':key,info:id,content:name')
LOCATION 'hbase:zk://<hostname>:<port>/';Ici, le champ Chemin de l'emplacement définit l'ID de port du client zookeeper. Si vous ne définissez pas le port, Tajo fera référence à la propriété du fichier hbase-site.xml.
Créer une table dans HBase
Vous pouvez démarrer le shell interactif HBase à l'aide de la commande «hbase shell» comme indiqué dans la requête suivante.
Query
/bin/hbase shellResult
La requête ci-dessus générera le résultat suivant.
hbase(main):001:0>Étapes pour interroger HBase
Pour interroger HBase, vous devez suivre les étapes suivantes -
Step 1 - Dirigez les commandes suivantes vers le shell HBase pour créer un tableau «didacticiel».
Query
hbase(main):001:0> create ‘students’,{NAME => ’info’},{NAME => ’content’}
put 'students', ‘row-01', 'content:name', 'Adam'
put 'students', ‘row-01', 'info:id', '001'
put 'students', ‘row-02', 'content:name', 'Amit'
put 'students', ‘row-02', 'info:id', '002'
put 'students', ‘row-03', 'content:name', 'Bob'
put 'students', ‘row-03', 'info:id', ‘003'Step 2 - Maintenant, exécutez la commande suivante dans le shell hbase pour charger les données dans une table.
main):001:0> cat ../hbase/hbase-students.txt | bin/hbase shellStep 3 - Maintenant, retournez au shell Tajo et exécutez la commande suivante pour afficher les métadonnées de la table -
default> \d students;
table name: default.students
table path:
store type: HBASE
number of rows: unknown
volume: 0 B
Options:
'columns' = ':key,info:id,content:name'
'table' = 'students'
schema:
rowkey TEXT
id INT4
name TEXTStep 4 - Pour récupérer les résultats de la table, utilisez la requête suivante -
Query
default> select * from studentsResult
La requête ci-dessus récupérera le résultat suivant -
rowkey, id, name
-------------------------------
row-01, 001, Adam
row-02, 002, Amit
row-03 003, BobTajo prend en charge HiveCatalogStore pour s'intégrer à Apache Hive. Cette intégration permet à Tajo d'accéder aux tables dans Apache Hive.
Définir la variable d'environnement
Ajoutez les modifications suivantes au fichier «conf / tajo-env.sh».
$ vi conf/tajo-env.sh
export HIVE_HOME = /path/to/hiveAprès avoir inclus le chemin Hive, Tajo définira le fichier de bibliothèque Hive sur le chemin de classe.
Configuration du catalogue
Ajoutez les modifications suivantes au fichier «conf / catalog-site.xml».
$ vi conf/catalog-site.xml
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HiveCatalogStore</value>
</property>Une fois HiveCatalogStore configuré, vous pouvez accéder à la table de Hive dans Tajo.
Swift est un magasin d'objets / d'objets blob distribué et cohérent. Swift propose un logiciel de stockage dans le cloud afin que vous puissiez stocker et récupérer de nombreuses données avec une simple API. Tajo prend en charge l'intégration Swift.
Voici les conditions préalables à l'intégration Swift -
- Swift
- Hadoop
Core-site.xml
Ajoutez les modifications suivantes au fichier hadoop «core-site.xml» -
<property>
<name>fs.swift.impl</name>
<value>org.apache.hadoop.fs.swift.snative.SwiftNativeFileSystem</value>
<description>File system implementation for Swift</description>
</property>
<property>
<name>fs.swift.blocksize</name>
<value>131072</value>
<description>Split size in KB</description>
</property>Cela sera utilisé pour Hadoop pour accéder aux objets Swift. Après avoir effectué toutes les modifications, déplacez-vous vers le répertoire Tajo pour définir la variable d'environnement Swift.
conf / tajo-env.h
Ouvrez le fichier de configuration Tajo et ajoutez définir la variable d'environnement comme suit -
$ vi conf/tajo-env.h export TAJO_CLASSPATH = $HADOOP_HOME/share/hadoop/tools/lib/hadoop-openstack-x.x.x.jarDésormais, Tajo pourra interroger les données en utilisant Swift.
Créer une table
Créons une table externe pour accéder aux objets Swift dans Tajo comme suit -
default> create external table swift(num1 int, num2 text, num3 float)
using text with ('text.delimiter' = '|') location 'swift://bucket-name/table1';Une fois la table créée, vous pouvez exécuter les requêtes SQL.
Apache Tajo fournit une interface JDBC pour se connecter et exécuter des requêtes. Nous pouvons utiliser la même interface JDBC pour connecter Tajo à partir de notre application Java. Voyons maintenant comment connecter Tajo et exécuter les commandes dans notre exemple d'application Java à l'aide de l'interface JDBC dans cette section.
Télécharger le pilote JDBC
Téléchargez le pilote JDBC en visitant le lien suivant - http://apache.org/dyn/closer.cgi/tajo/tajo-0.11.3/tajo-jdbc-0.11.3.jar.
Maintenant, le fichier «tajo-jdbc-0.11.3.jar» a été téléchargé sur votre machine.
Définir le chemin de classe
Pour utiliser le pilote JDBC dans votre programme, définissez le chemin de classe comme suit -
CLASSPATH = path/to/tajo-jdbc-0.11.3.jar:$CLASSPATHConnectez-vous à Tajo
Apache Tajo fournit un pilote JDBC sous forme de fichier jar unique et il est disponible @ /path/to/tajo/share/jdbc-dist/tajo-jdbc-0.11.3.jar.
La chaîne de connexion pour connecter l'Apache Tajo est du format suivant -
jdbc:tajo://host/
jdbc:tajo://host/database
jdbc:tajo://host:port/
jdbc:tajo://host:port/databaseIci,
host - Le nom d'hôte du TajoMaster.
port- Le numéro de port que le serveur écoute. Le numéro de port par défaut est 26002.
database- Le nom de la base de données. Le nom de la base de données par défaut est default.
Application Java
Voyons maintenant l'application Java.
Codage
import java.sql.*;
import org.apache.tajo.jdbc.TajoDriver;
public class TajoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("org.apache.tajo.jdbc.TajoDriver");
connection = DriverManager.getConnection(“jdbc:tajo://localhost/default");
statement = connection.createStatement();
String sql;
sql = "select * from mytable”;
// fetch records from mytable.
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}L'application peut être compilée et exécutée à l'aide des commandes suivantes.
Compilation
javac -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample.javaExécution
java -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSampleRésultat
Les commandes ci-dessus généreront le résultat suivant -
ID: 1;
Name: Adam
ID: 2;
Name: Amit
ID: 3;
Name: Bob
ID: 4;
Name: David
ID: 5;
Name: Esha
ID: 6;
Name: Ganga
ID: 7;
Name: Jack
ID: 8;
Name: Leena
ID: 9;
Name: Mary
ID: 10;
Name: PeterApache Tajo prend en charge les fonctions personnalisées / définies par l'utilisateur (UDF). Les fonctions personnalisées peuvent être créées en python.
Les fonctions personnalisées ne sont que des fonctions python simples avec décorateur “@output_type(<tajo sql datatype>)” comme suit -
@ouput_type(“integer”)
def sum_py(a, b):
return a + b;Les scripts python avec UDF peuvent être enregistrés en ajoutant la configuration ci-dessous dans “tajosite.xml”.
<property>
<name>tajo.function.python.code-dir</name>
<value>file:///path/to/script1.py,file:///path/to/script2.py</value>
</property>Une fois les scripts enregistrés, redémarrez le cluster et les UDF seront disponibles directement dans la requête SQL comme suit -
select sum_py(10, 10) as pyfn;Apache Tajo prend également en charge les fonctions d'agrégation définies par l'utilisateur, mais ne prend pas en charge les fonctions de fenêtre définies par l'utilisateur.