Apache Tajo - Instructions SQL
Dans le chapitre précédent, vous avez compris comment créer des tableaux dans Tajo. Ce chapitre explique l'instruction SQL dans Tajo.
Créer une instruction de table
Avant de passer à la création d'une table, créez un fichier texte «étudiants.csv» dans le chemin du répertoire d'installation de Tajo comme suit -
students.csv
| Id | Nom | Adresse | Âge | Des marques |
|---|---|---|---|---|
| 1 | Adam | 23 New Street | 21 | 90 |
| 2 | Amit | 12 Vieille Rue | 13 | 95 |
| 3 | Bob | 10 rue transversale | 12 | 80 |
| 4 | David | 15 avenue Express | 12 | 85 |
| 5 | Esha | 20 rue Garden | 13 | 50 |
| 6 | Ganga | 25 rue Nord | 12 | 55 |
| 7 | Jack | 2 rue Park | 12 | 60 |
| 8 | Leena | 24 rue Sud | 12 | 70 |
| 9 | Marie | 5 rue Ouest | 12 | 75 |
| 10 | Peter | 16 Park Avenue | 12 | 95 |
Une fois le fichier créé, accédez au terminal et démarrez le serveur et le shell Tajo un par un.
Créer une base de données
Créez une nouvelle base de données à l'aide de la commande suivante -
Requete
default> create database sampledb;
OKConnectez-vous à la base de données «sampledb» qui est maintenant créée.
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.Ensuite, créez une table dans «sampledb» comme suit -
Requete
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;Résultat
La requête ci-dessus générera le résultat suivant.
OKIci, la table externe est créée. Il ne vous reste plus qu'à entrer l'emplacement du fichier. Si vous devez affecter la table à partir de hdfs, utilisez hdfs au lieu de file.
Ensuite, le “students.csv”Le fichier contient des valeurs séparées par des virgules. letext.delimiter le champ est attribué avec ','.
Vous avez maintenant créé «mytable» avec succès dans «sampledb».
Afficher la table
Pour afficher les tables dans Tajo, utilisez la requête suivante.
Requete
sampledb> \d
mytable
sampledb> \d mytableRésultat
La requête ci-dessus générera le résultat suivant.
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4Tableau de liste
Pour récupérer tous les enregistrements de la table, tapez la requête suivante -
Requete
sampledb> select * from mytable;Résultat
La requête ci-dessus générera le résultat suivant.

Insérer une instruction de tableau
Tajo utilise la syntaxe suivante pour insérer des enregistrements dans la table.
Syntaxe
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;L'instruction d'insertion de Tajo est similaire à la INSERT INTO SELECT instruction de SQL.
Requete
Créons une table pour écraser les données de table d'une table existante.
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \dRésultat
La requête ci-dessus générera le résultat suivant.
mytable
testInsérer des enregistrements
Pour insérer des enregistrements dans la table «test», tapez la requête suivante.
Requete
sampledb> insert overwrite into test select * from mytable;Résultat
La requête ci-dessus générera le résultat suivant.
Progress: 100%, response time: 0.518 secIci, les enregistrements «mytable» écrasent la table «test». Si vous ne voulez pas créer la table «test», attribuez immédiatement l'emplacement du chemin physique comme indiqué dans une option alternative pour insérer une requête.
Récupérer des enregistrements
Utilisez la requête suivante pour lister tous les enregistrements de la table «test» -
Requete
sampledb> select * from test;Résultat
La requête ci-dessus générera le résultat suivant.

Cette instruction est utilisée pour ajouter, supprimer ou modifier des colonnes d'une table existante.
Pour renommer la table, utilisez la syntaxe suivante -
Alter table table1 RENAME TO table2;Requete
sampledb> alter table test rename to students;Résultat
La requête ci-dessus générera le résultat suivant.
OKPour vérifier le nom de table modifié, utilisez la requête suivante.
sampledb> \d
mytable
studentsMaintenant, la table «test» est remplacée par la table «étudiants».
Ajouter une colonne
Pour insérer une nouvelle colonne dans le tableau «étudiants», saisissez la syntaxe suivante -
Alter table <table_name> ADD COLUMN <column_name> <data_type>Requete
sampledb> alter table students add column grade text;Résultat
La requête ci-dessus générera le résultat suivant.
OKDéfinir la propriété
Cette propriété est utilisée pour modifier la propriété de la table.
Requete
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OKIci, le type de compression et les propriétés du codec sont attribués.
Pour modifier la propriété du délimiteur de texte, utilisez ce qui suit -
Requete
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OKRésultat
La requête ci-dessus générera le résultat suivant.
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXTLe résultat ci-dessus montre que les propriétés de la table sont modifiées à l'aide de la propriété «SET».
Sélectionner une déclaration
L'instruction SELECT est utilisée pour sélectionner des données dans une base de données.
La syntaxe de l'instruction Select est la suivante -
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]Clause Où
La clause Where est utilisée pour filtrer les enregistrements de la table.
Requete
sampledb> select * from mytable where id > 5;Résultat
La requête ci-dessus générera le résultat suivant.
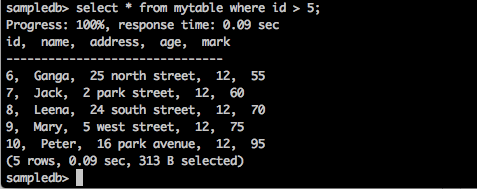
La requête renvoie les enregistrements des étudiants dont l'ID est supérieur à 5.
Requete
sampledb> select * from mytable where name = ‘Peter’;Résultat
La requête ci-dessus générera le résultat suivant.
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12Le résultat filtre uniquement les enregistrements de Peter.
Clause distincte
Une colonne de table peut contenir des valeurs en double. Le mot clé DISTINCT peut être utilisé pour renvoyer uniquement des valeurs distinctes (différentes).
Syntaxe
SELECT DISTINCT column1,column2 FROM table_name;Requete
sampledb> select distinct age from mytable;Résultat
La requête ci-dessus générera le résultat suivant.
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12La requête renvoie l'âge distinct des élèves de mytable.
Clause de groupe
La clause GROUP BY est utilisée en collaboration avec l'instruction SELECT pour organiser des données identiques en groupes.
Syntaxe
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;Requete
select age,sum(mark) as sumofmarks from mytable group by age;Résultat
La requête ci-dessus générera le résultat suivant.
age, sumofmarks
-------------------------------
13, 145
12, 610Ici, la colonne «mytable» a deux types d'âge - 12 et 13. La requête regroupe désormais les enregistrements par âge et produit la somme des notes pour les âges correspondants des élèves.
Avoir une clause
La clause HAVING vous permet de spécifier des conditions qui filtrent les résultats de groupe qui apparaissent dans les résultats finaux. La clause WHERE place des conditions sur les colonnes sélectionnées, tandis que la clause HAVING place des conditions sur les groupes créés par la clause GROUP BY.
Syntaxe
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]Requete
sampledb> select age from mytable group by age having sum(mark) > 200;Résultat
La requête ci-dessus générera le résultat suivant.
age
-------------------------------
12La requête regroupe les enregistrements par âge et renvoie l'âge lorsque la somme du résultat de la condition (marque)> 200.
Trier par clause
La clause ORDER BY est utilisée pour trier les données par ordre croissant ou décroissant, en fonction d'une ou plusieurs colonnes. La base de données Tajo trie les résultats de la requête par ordre croissant par défaut.
Syntaxe
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];Requete
sampledb> select * from mytable where mark > 60 order by name desc;Résultat
La requête ci-dessus générera le résultat suivant.

La requête renvoie les noms des élèves par ordre décroissant dont les notes sont supérieures à 60.
Créer une déclaration d'index
L'instruction CREATE INDEX est utilisée pour créer des index dans les tables. L'index est utilisé pour une récupération rapide des données. La version actuelle prend en charge l'index uniquement pour les formats TEXT simples stockés sur HDFS.
Syntaxe
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }Requete
create index student_index on mytable(id);Résultat
La requête ci-dessus générera le résultat suivant.
id
———————————————Pour afficher l'index attribué à la colonne, tapez la requête suivante.
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )Ici, la méthode TWO_LEVEL_BIN_TREE est utilisée par défaut dans Tajo.
Instruction Drop Table
L'instruction Drop Table est utilisée pour supprimer une table de la base de données.
Syntaxe
drop table table name;Requete
sampledb> drop table mytable;Pour vérifier si la table a été supprimée de la table, tapez la requête suivante.
sampledb> \d mytable;Résultat
La requête ci-dessus générera le résultat suivant.
ERROR: relation 'mytable' does not existVous pouvez également vérifier la requête en utilisant la commande «\ d» pour lister les tables Tajo disponibles.