Apache Tajo - Requêtes SQL
Ce chapitre explique les requêtes importantes suivantes.
- Predicates
- Explain
- Join
Continuons et exécutons les requêtes.
Prédicats
Predicate est une expression qui est utilisée pour évaluer les valeurs vrai / faux et INCONNU. Les prédicats sont utilisés dans la condition de recherche des clauses WHERE et HAVING et d'autres constructions où une valeur booléenne est requise.
Prédicat IN
Détermine si la valeur de l'expression à tester correspond à n'importe quelle valeur de la sous-requête ou de la liste. La sous-requête est une instruction SELECT ordinaire qui a un jeu de résultats d'une colonne et d'une ou plusieurs lignes. Cette colonne ou toutes les expressions de la liste doivent avoir le même type de données que l'expression à tester.
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
La requête ci-dessus générera le résultat suivant.
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenueLa requête renvoie les enregistrements de mytable pour les étudiants id 2,3 et 4.
Query
select id,name,address from mytable where id not in(2,3,4);Result
La requête ci-dessus générera le résultat suivant.
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenueLa requête ci-dessus renvoie les enregistrements de mytable où les étudiants ne sont pas en 2,3 et 4.
Comme prédicat
Le prédicat LIKE compare la chaîne spécifiée dans la première expression pour calculer la valeur de chaîne, qui est référencée comme valeur à tester, avec le modèle défini dans la deuxième expression pour calculer la valeur de chaîne.
Le modèle peut contenir n'importe quelle combinaison de caractères génériques tels que -
Symbole de soulignement (_), qui peut être utilisé à la place de n'importe quel caractère unique dans la valeur à tester.
Signe de pourcentage (%), qui remplace toute chaîne de zéro caractère ou plus dans la valeur à tester.
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
La requête ci-dessus générera le résultat suivant.
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95La requête renvoie les enregistrements de ma table des étudiants dont les noms commencent par «A».
Query
select * from mytable where name like ‘_a%';Result
La requête ci-dessus générera le résultat suivant.
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75La requête renvoie les enregistrements de mytable des élèves dont les noms commencent par «a» comme deuxième caractère.
Utilisation de la valeur NULL dans les conditions de recherche
Voyons maintenant comment utiliser la valeur NULL dans les conditions de recherche.
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
La requête ci-dessus générera le résultat suivant.
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)Ici, le résultat est vrai donc il renvoie tous les noms de la table.
Query
Vérifions maintenant la requête avec la condition NULL.
default> select name from mytable where name is null;Result
La requête ci-dessus générera le résultat suivant.
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)Explique
Explainest utilisé pour obtenir un plan d'exécution de requête. Il montre une exécution de plan logique et globale d'une instruction.
Requête de plan logique
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
La requête ci-dessus générera le résultat suivant.

Le résultat de la requête montre un format de plan logique pour la table donnée. Le plan logique renvoie les trois résultats suivants -
- Liste des cibles
- Out schéma
- Dans le schéma
Requête de plan global
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
La requête ci-dessus générera le résultat suivant.

Ici, le plan global affiche l'ID du bloc d'exécution, l'ordre d'exécution et ses informations.
Rejoint
Les jointures SQL sont utilisées pour combiner des lignes de deux ou plusieurs tables. Voici les différents types de jointures SQL -
- Jointure interne
- {GAUCHE | DROITE | FULL} JOINTURE EXTÉRIEURE
- Jointure croisée
- Auto-rejoindre
- Jointure naturelle
Considérez les deux tableaux suivants pour effectuer des opérations de jointure.
Tableau 1 - Clients
| Id | Nom | Adresse | Âge |
|---|---|---|---|
| 1 | Client 1 | 23 vieille rue | 21 |
| 2 | Client 2 | 12 New Street | 23 |
| 3 | Client 3 | 10 avenue Express | 22 |
| 4 | Client 4 | 15 avenue Express | 22 |
| 5 | Client 5 | 20 rue Garden | 33 |
| 6 | Client 6 | 21 rue Nord | 25 |
Tableau2 - commande_client
| Id | Numéro de commande | ID Emp |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
Continuons maintenant et exécutons les opérations de jointure SQL sur les deux tables ci-dessus.
Jointure interne
La jointure interne sélectionne toutes les lignes des deux tables lorsqu'il existe une correspondance entre les colonnes des deux tables.
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
La requête ci-dessus générera le résultat suivant.
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105La requête correspond à cinq lignes des deux tables. Par conséquent, il renvoie l'âge des lignes correspondantes de la première table.
Jointure externe gauche
Une jointure externe gauche conserve toutes les lignes de la table «gauche», qu'il existe ou non une ligne correspondant à la table «droite».
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
La requête ci-dessus générera le résultat suivant.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,Ici, la jointure externe gauche renvoie les lignes de la colonne de nom de la table customers (à gauche) et les lignes correspondant à la colonne empid de la table customer_order (à droite).
Jointure externe droite
Une jointure externe droite conserve toutes les lignes de la table «droite», qu'il existe ou non une ligne qui correspond à la table «gauche».
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
La requête ci-dessus générera le résultat suivant.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105Ici, la jointure externe droite renvoie les lignes empid de la table customer_order (à droite) et la colonne de nom correspond aux lignes de la table clients.
Jointure externe complète
La jointure externe complète conserve toutes les lignes des tables de gauche et de droite.
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
La requête ci-dessus générera le résultat suivant.

La requête renvoie toutes les lignes correspondantes et non correspondantes des tables clients et commande_client.
Jointure croisée
Cela renvoie le produit cartésien des ensembles d'enregistrements des deux ou plusieurs tables jointes.
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
La requête ci-dessus générera le résultat suivant.
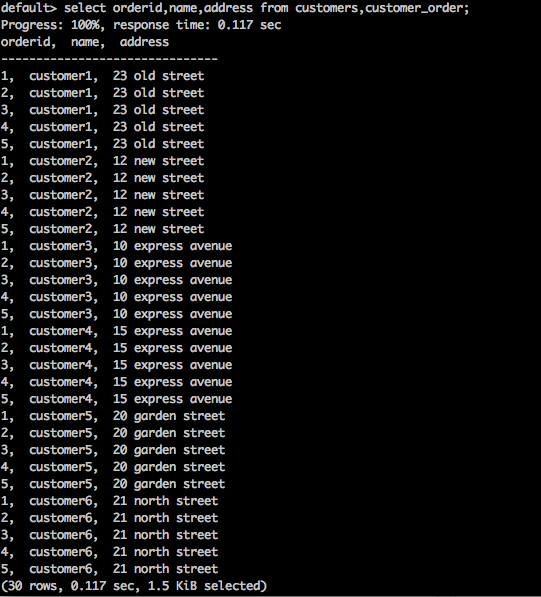
La requête ci-dessus renvoie le produit cartésien de la table.
Jointure naturelle
Une jointure naturelle n'utilise aucun opérateur de comparaison. Il ne concatène pas comme le fait un produit cartésien. Nous ne pouvons effectuer une jointure naturelle que s'il existe au moins un attribut commun entre les deux relations.
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
La requête ci-dessus générera le résultat suivant.

Ici, il existe un identifiant de colonne commun entre deux tables. En utilisant cette colonne commune, leNatural Join joint les deux tables.
Auto-rejoindre
Le SQL SELF JOIN est utilisé pour joindre une table à elle-même comme si la table était deux tables, renommant temporairement au moins une table dans l'instruction SQL.
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
La requête ci-dessus générera le résultat suivant.
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6La requête joint une table client à elle-même.