Entreposage de données - Architecture
Dans ce chapitre, nous aborderons le cadre d'analyse commerciale pour la conception et l'architecture d'un entrepôt de données.
Cadre d'analyse commerciale
L'analyste commercial obtient les informations des entrepôts de données pour mesurer les performances et effectuer des ajustements critiques afin de convaincre les autres acteurs du marché. Avoir un entrepôt de données offre les avantages suivants -
Étant donné qu'un entrepôt de données peut collecter des informations rapidement et efficacement, il peut améliorer la productivité de l'entreprise.
Un entrepôt de données nous fournit une vue cohérente des clients et des articles, par conséquent, il nous aide à gérer la relation client.
Un entrepôt de données permet également de réduire les coûts en suivant les tendances, les modèles sur une longue période de manière cohérente et fiable.
Pour concevoir un entrepôt de données efficace et efficient, nous devons comprendre et analyser les besoins de l'entreprise et construire un business analysis framework. Chaque personne a des points de vue différents sur la conception d'un entrepôt de données. Ces vues sont les suivantes -
The top-down view - Cette vue permet de sélectionner les informations pertinentes nécessaires pour un entrepôt de données.
The data source view - Cette vue présente les informations capturées, stockées et gérées par le système opérationnel.
The data warehouse view- Cette vue inclut les tables de faits et les tables de dimension. Il représente les informations stockées dans l'entrepôt de données.
The business query view - C'est la vue des données du point de vue de l'utilisateur final.
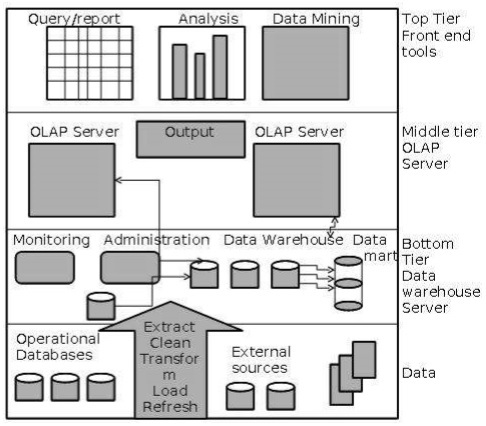
Architecture d'entrepôt de données à trois niveaux
En général, un entrepôt de données adopte une architecture à trois niveaux. Voici les trois niveaux de l'architecture de l'entrepôt de données.
Bottom Tier- Le niveau inférieur de l'architecture est le serveur de base de données de l'entrepôt de données. C'est le système de base de données relationnelle. Nous utilisons les outils et utilitaires back-end pour alimenter les données dans le niveau inférieur. Ces outils et utilitaires principaux exécutent les fonctions d'extraction, de nettoyage, de chargement et d'actualisation.
Middle Tier - Au niveau intermédiaire, nous avons le serveur OLAP qui peut être implémenté de l'une des manières suivantes.
Par Relational OLAP (ROLAP), qui est un système de gestion de base de données relationnelle étendu. Le ROLAP mappe les opérations sur des données multidimensionnelles aux opérations relationnelles standard.
Par modèle OLAP multidimensionnel (MOLAP), qui implémente directement les données et opérations multidimensionnelles.
Top-Tier- Ce niveau est la couche client frontale. Cette couche contient les outils de requête et les outils de reporting, les outils d'analyse et les outils d'exploration de données.
Le diagramme suivant illustre l'architecture à trois niveaux de l'entrepôt de données -
Modèles d'entrepôt de données
Du point de vue de l'architecture de l'entrepôt de données, nous avons les modèles d'entrepôt de données suivants:
- Entrepôt virtuel
- Magasin de données
- Entrepôt d'entreprise
Entrepôt virtuel
La vue sur un entrepôt de données opérationnel est appelée entrepôt virtuel. Il est facile de créer un entrepôt virtuel. La création d'un entrepôt virtuel nécessite une capacité excédentaire sur les serveurs de base de données opérationnels.
Data Mart
Le magasin de données contient un sous-ensemble de données à l'échelle de l'organisation. Ce sous-ensemble de données est précieux pour des groupes spécifiques d'une organisation.
En d'autres termes, nous pouvons affirmer que les data marts contiennent des données spécifiques à un groupe particulier. Par exemple, le magasin de données marketing peut contenir des données relatives aux articles, aux clients et aux ventes. Les data marts se limitent aux sujets.
Points à retenir sur les data marts -
Des serveurs Windows ou Unix / Linux sont utilisés pour implémenter des data marts. Ils sont implémentés sur des serveurs à bas prix.
Les cycles de mise en œuvre du magasin de données sont mesurés sur de courtes périodes, c'est-à-dire en semaines plutôt qu'en mois ou en années.
Le cycle de vie d'un data mart peut être complexe à long terme, si sa planification et sa conception ne sont pas à l'échelle de l'organisation.
Les data marts sont de petite taille.
Les data marts sont personnalisés par département.
La source d'un data mart est l'entrepôt de données structuré par département.
Les data mart sont flexibles.
Entrepôt d'entreprise
Un entrepôt d'entreprise rassemble toutes les informations et les sujets couvrant toute une organisation
Il nous fournit une intégration des données à l'échelle de l'entreprise.
Les données sont intégrées à partir des systèmes opérationnels et des fournisseurs d'informations externes.
Ces informations peuvent varier de quelques gigaoctets à des centaines de gigaoctets, téraoctets ou au-delà.
Gestionnaire de charge
Ce composant effectue les opérations nécessaires pour extraire et charger le processus.
La taille et la complexité du gestionnaire de charge varient entre les solutions spécifiques d'un entrepôt de données à l'autre.
Architecture du gestionnaire de charge
Le gestionnaire de charge remplit les fonctions suivantes -
Extrayez les données du système source.
Rapide Chargez les données extraites dans le magasin de données temporaire.
Effectuez des transformations simples en structure similaire à celle de l'entrepôt de données.
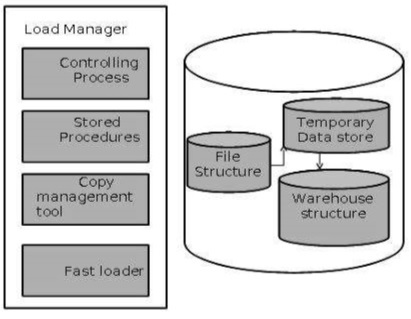
Extraire les données de la source
Les données sont extraites des bases de données opérationnelles ou des fournisseurs d'informations externes. Les passerelles sont les programmes d'application utilisés pour extraire les données. Il est pris en charge par le SGBD sous-jacent et permet au programme client de générer du SQL à exécuter sur un serveur. Open Database Connection (ODBC), Java Database Connection (JDBC), sont des exemples de passerelle.
Charge rapide
Afin de minimiser la fenêtre de chargement total, les données doivent être chargées dans l'entrepôt le plus rapidement possible.
Les transformations affectent la vitesse de traitement des données.
Il est plus efficace de charger les données dans la base de données relationnelle avant d'appliquer les transformations et les vérifications.
La technologie de passerelle s'avère ne pas convenir, car elle a tendance à ne pas être performante lorsque de gros volumes de données sont impliqués.
Transformations simples
Lors du chargement, il peut être nécessaire d'effectuer des transformations simples. Une fois cela terminé, nous sommes en mesure de faire les vérifications complexes. Supposons que nous chargeons la transaction de vente EPOS, nous devons effectuer les vérifications suivantes:
- Supprimez toutes les colonnes qui ne sont pas requises dans l'entrepôt.
- Convertissez toutes les valeurs en types de données requis.
Directeur d'entrepôt
Un responsable d'entrepôt est responsable du processus de gestion de l'entrepôt. Il se compose de logiciels système tiers, de programmes C et de scripts shell.
La taille et la complexité des responsables d'entrepôt varient selon les solutions spécifiques.
Architecture du gestionnaire d'entrepôt
Un responsable d'entrepôt comprend les éléments suivants:
- Le processus de contrôle
- Procédures stockées ou C avec SQL
- Outil de sauvegarde / restauration
- Scripts SQL
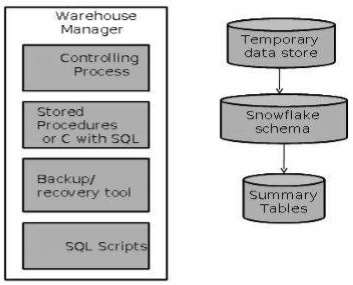
Opérations effectuées par le responsable de l'entrepôt
Un responsable d'entrepôt analyse les données pour effectuer des contrôles de cohérence et d'intégrité référentielle.
Crée des index, des vues d'entreprise, des vues de partition par rapport aux données de base.
Génère de nouvelles agrégations et met à jour les agrégations existantes. Génère des normalisations.
Transforme et fusionne les données source dans l'entrepôt de données publié.
Sauvegardez les données dans l'entrepôt de données.
Archive les données qui ont atteint la fin de leur vie capturée.
Note - Un gestionnaire d'entrepôt analyse également les profils de requête pour déterminer l'index et les agrégations appropriées.
Gestionnaire de requêtes
Le gestionnaire de requêtes est chargé de diriger les requêtes vers les tables appropriées.
En dirigeant les requêtes vers les tables appropriées, la vitesse de requête et de génération de réponse peut être augmentée.
Le gestionnaire de requêtes est chargé de planifier l'exécution des requêtes posées par l'utilisateur.
Architecture du gestionnaire de requêtes
La capture d'écran suivante montre l'architecture d'un gestionnaire de requêtes. Il comprend les éléments suivants:
- Redirection des requêtes via l'outil C ou le SGBDR
- Procédures stockées
- Outil de gestion des requêtes
- Planification des requêtes via l'outil C ou le SGBDR
- Planification des requêtes via un logiciel tiers
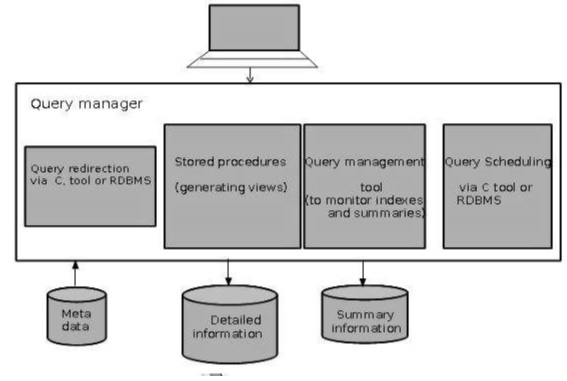
Des informations détaillées
Les informations détaillées ne sont pas conservées en ligne, mais agrégées au niveau de détail suivant, puis archivées sur bande. La partie des informations détaillées de l'entrepôt de données conserve les informations détaillées dans le schéma Starflake. Des informations détaillées sont chargées dans l'entrepôt de données pour compléter les données agrégées.
Le diagramme suivant montre une image illustrant l'emplacement de stockage des informations détaillées et la manière dont elles sont utilisées.
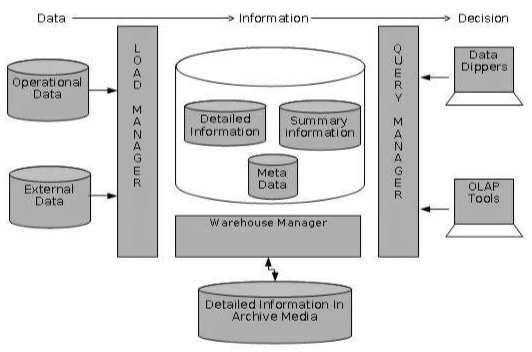
Note - Si des informations détaillées sont conservées hors ligne pour minimiser le stockage sur disque, nous devons nous assurer que les données ont été extraites, nettoyées et transformées en schéma en étoile avant d'être archivées.
Informations résumées
Les informations récapitulatives font partie de l'entrepôt de données qui stocke des agrégations prédéfinies. Ces agrégations sont générées par le responsable de l'entrepôt. Les informations récapitulatives doivent être traitées comme transitoires. Il change en cours de route afin de répondre aux changements de profils de requête.
Les points à noter concernant les informations récapitulatives sont les suivants -
Les informations récapitulatives accélèrent les performances des requêtes courantes.
Cela augmente le coût opérationnel.
Il doit être mis à jour chaque fois que de nouvelles données sont chargées dans l'entrepôt de données.
Il n'a peut-être pas été sauvegardé, car il peut être généré à partir des informations détaillées.