Entreposage de données - Guide rapide
Le terme «entrepôt de données» a été inventé pour la première fois par Bill Inmon en 1990. Selon Inmon, un entrepôt de données est une collection de données orientée sujet, intégrée, variant dans le temps et non volatile. Ces données aident les analystes à prendre des décisions éclairées dans une organisation.
Une base de données opérationnelle subit de fréquents changements au quotidien en raison des transactions effectuées. Supposons qu'un dirigeant d'entreprise souhaite analyser les commentaires précédents sur des données telles qu'un produit, un fournisseur ou des données sur les consommateurs, le dirigeant n'aura alors aucune donnée disponible à analyser car les données précédentes ont été mises à jour en raison de transactions.
Un entrepôt de données nous fournit des données généralisées et consolidées en vue multidimensionnelle. Outre une vue généralisée et consolidée des données, un entrepôt de données nous fournit également des outils de traitement analytique en ligne (OLAP). Ces outils nous aident dans l'analyse interactive et efficace des données dans un espace multidimensionnel. Cette analyse aboutit à la généralisation des données et à l'exploration de données.
Les fonctions d'exploration de données telles que l'association, le regroupement, la classification et la prédiction peuvent être intégrées aux opérations OLAP pour améliorer l'exploration interactive des connaissances à plusieurs niveaux d'abstraction. C'est pourquoi l'entrepôt de données est devenu une plateforme importante pour l'analyse des données et le traitement analytique en ligne.
Comprendre un entrepôt de données
Un entrepôt de données est une base de données, qui est séparée de la base de données opérationnelle de l'organisation.
Il n'y a pas de mise à jour fréquente effectuée dans un entrepôt de données.
Il possède des données historiques consolidées, qui aident l'organisation à analyser son activité.
Un entrepôt de données aide les dirigeants à organiser, comprendre et utiliser leurs données pour prendre des décisions stratégiques.
Les systèmes d'entrepôt de données aident à l'intégration de la diversité des systèmes d'application.
Un système d'entrepôt de données facilite l'analyse des données historiques consolidées.
Pourquoi un entrepôt de données est séparé des bases de données opérationnelles
Un entrepôt de données est séparé des bases de données opérationnelles pour les raisons suivantes -
Une base de données opérationnelle est construite pour des tâches et des charges de travail bien connues telles que la recherche d'enregistrements particuliers, l'indexation, etc. Dans les contrats, les requêtes d'entrepôt de données sont souvent complexes et présentent une forme générale de données.
Les bases de données opérationnelles prennent en charge le traitement simultané de plusieurs transactions. Des mécanismes de contrôle d'accès et de récupération sont nécessaires pour les bases de données opérationnelles afin de garantir la robustesse et la cohérence de la base de données.
Une requête de base de données opérationnelle permet de lire et de modifier des opérations, alors qu'une requête OLAP n'a besoin que read only accès aux données stockées.
Une base de données opérationnelle conserve les données actuelles. D'autre part, un entrepôt de données conserve des données historiques.
Fonctionnalités de l'entrepôt de données
Les principales caractéristiques d'un entrepôt de données sont décrites ci-dessous -
Subject Oriented- Un entrepôt de données est orienté sujet car il fournit des informations sur un sujet plutôt que sur les opérations en cours de l'organisation. Ces sujets peuvent être les produits, les clients, les fournisseurs, les ventes, les revenus, etc. Un entrepôt de données ne se concentre pas sur les opérations en cours, mais plutôt sur la modélisation et l'analyse des données pour la prise de décision.
Integrated - Un entrepôt de données est construit en intégrant des données provenant de sources hétérogènes telles que des bases de données relationnelles, des fichiers plats, etc. Cette intégration améliore l'efficacité de l'analyse des données.
Time Variant- Les données collectées dans un entrepôt de données sont identifiées avec une période de temps particulière. Les données d'un entrepôt de données fournissent des informations du point de vue historique.
Non-volatile- Non volatile signifie que les données précédentes ne sont pas effacées lorsque de nouvelles données y sont ajoutées. Un entrepôt de données est séparé de la base de données opérationnelle et, par conséquent, les changements fréquents dans la base de données opérationnelle ne sont pas reflétés dans l'entrepôt de données.
Note - Un entrepôt de données ne nécessite pas le traitement des transactions, la récupération et les contrôles de concurrence, car il est physiquement stocké et séparé de la base de données opérationnelle.
Applications d'entrepôt de données
Comme indiqué précédemment, un entrepôt de données aide les dirigeants d'entreprise à organiser, analyser et utiliser leurs données pour la prise de décision. Un entrepôt de données fait partie intégrante d'un système de rétroaction plan-exécution-évaluation en «boucle fermée» pour la gestion de l'entreprise. Les entrepôts de données sont largement utilisés dans les domaines suivants -
- Services financiers
- Services bancaires
- Biens de consommation
- Secteurs du commerce de détail
- Fabrication contrôlée
Types d'entrepôt de données
Le traitement de l'information, le traitement analytique et l'exploration de données sont les trois types d'applications d'entrepôt de données qui sont abordés ci-dessous -
Information Processing- Un entrepôt de données permet de traiter les données qui y sont stockées. Les données peuvent être traitées au moyen d'interrogations, d'analyses statistiques de base, de rapports à l'aide de tableaux croisés, de tableaux, de graphiques ou de graphiques.
Analytical Processing- Un entrepôt de données prend en charge le traitement analytique des informations qui y sont stockées. Les données peuvent être analysées au moyen d'opérations OLAP de base, y compris le découpage en dés, l'exploration vers le bas, l'exploration vers le haut et le pivotement.
Data Mining- L'exploration de données soutient la découverte des connaissances en trouvant des modèles et des associations cachés, en construisant des modèles analytiques, en effectuant une classification et une prédiction. Ces résultats d'exploration peuvent être présentés à l'aide des outils de visualisation.
| Sr.No. | Entrepôt de données (OLAP) | Base de données opérationnelle (OLTP) |
|---|---|---|
| 1 | Il s'agit d'un traitement historique de l'information. | Cela implique un traitement au jour le jour. |
| 2 | Les systèmes OLAP sont utilisés par les travailleurs du savoir tels que les cadres, les gestionnaires et les analystes. | Les systèmes OLTP sont utilisés par les commis, les administrateurs de base de données ou les professionnels des bases de données. |
| 3 | Il est utilisé pour analyser l'entreprise. | Il est utilisé pour gérer l'entreprise. |
| 4 | Il se concentre sur l'information. | Il se concentre sur les données au format. |
| 5 | Il est basé sur Star Schema, Snowflake Schema et Fact Constellation Schema. | Il est basé sur le modèle de relation d'entité. |
| 6 | Il se concentre sur l'information. | Il est orienté application. |
| sept | Il contient des données historiques. | Il contient des données actuelles. |
| 8 | Il fournit des données résumées et consolidées. | Il fournit des données primitives et très détaillées. |
| 9 | Il fournit une vue résumée et multidimensionnelle des données. | Il fournit une vue relationnelle détaillée et plate des données. |
| dix | Le nombre d'utilisateurs est en centaines. | Le nombre d'utilisateurs est en milliers. |
| 11 | Le nombre d'enregistrements consultés est en millions. | Le nombre d'enregistrements accédés est en dizaines. |
| 12 | La taille de la base de données est comprise entre 100 Go et 100 To. | La taille de la base de données est comprise entre 100 Mo et 100 Go. |
| 13 | Ceux-ci sont très flexibles. | Il offre des performances élevées. |
Qu'est-ce que l'entreposage de données?
L'entreposage de données est le processus de construction et d'utilisation d'un entrepôt de données. Un entrepôt de données est construit en intégrant des données provenant de plusieurs sources hétérogènes qui prennent en charge les rapports analytiques, les requêtes structurées et / ou ad hoc et la prise de décision. L'entreposage de données implique le nettoyage des données, l'intégration des données et la consolidation des données.
Utilisation des informations de l'entrepôt de données
Il existe des technologies d'aide à la décision qui aident à utiliser les données disponibles dans un entrepôt de données. Ces technologies aident les cadres à utiliser l'entrepôt rapidement et efficacement. Ils peuvent collecter des données, les analyser et prendre des décisions en fonction des informations présentes dans l'entrepôt. Les informations rassemblées dans un entrepôt peuvent être utilisées dans l'un des domaines suivants -
Tuning Production Strategies - Les stratégies produits peuvent être bien ajustées en repositionnant les produits et en gérant les portefeuilles de produits en comparant les ventes trimestrielles ou annuelles.
Customer Analysis - L'analyse client se fait en analysant les préférences d'achat du client, le temps d'achat, les cycles budgétaires, etc.
Operations Analysis- L'entreposage de données aide également à gérer la relation client et à apporter des corrections environnementales. Les informations nous permettent également d'analyser les opérations commerciales.
Intégration de bases de données hétérogènes
Pour intégrer des bases de données hétérogènes, nous avons deux approches -
- Approche basée sur les requêtes
- Approche axée sur les mises à jour
Approche basée sur les requêtes
C'est l'approche traditionnelle pour intégrer des bases de données hétérogènes. Cette approche a été utilisée pour créer des wrappers et des intégrateurs sur plusieurs bases de données hétérogènes. Ces intégrateurs sont également appelés médiateurs.
Processus d'approche basée sur les requêtes
Lorsqu'une requête est émise côté client, un dictionnaire de métadonnées traduit la requête sous une forme appropriée pour les sites hétérogènes individuels impliqués.
Désormais, ces requêtes sont mappées et envoyées au processeur de requêtes local.
Les résultats de sites hétérogènes sont intégrés dans un ensemble de réponses global.
Désavantages
L'approche basée sur les requêtes nécessite des processus complexes d'intégration et de filtrage.
Cette approche est très inefficace.
Cela coûte très cher pour les requêtes fréquentes.
Cette approche est également très coûteuse pour les requêtes qui nécessitent des agrégations.
Approche axée sur les mises à jour
C'est une alternative à l'approche traditionnelle. Les systèmes d'entrepôt de données d'aujourd'hui suivent une approche axée sur les mises à jour plutôt que l'approche traditionnelle évoquée précédemment. Dans une approche axée sur les mises à jour, les informations provenant de plusieurs sources hétérogènes sont intégrées à l'avance et sont stockées dans un entrepôt. Ces informations sont disponibles pour l'interrogation et l'analyse directes.
Avantages
Cette approche présente les avantages suivants -
Cette approche offre des performances élevées.
Les données sont copiées, traitées, intégrées, annotées, résumées et restructurées dans le magasin de données sémantiques à l'avance.
Le traitement des requêtes ne nécessite pas d'interface pour traiter les données à des sources locales.
Fonctions des outils et utilitaires de l'entrepôt de données
Voici les fonctions des outils et utilitaires de l'entrepôt de données -
Data Extraction - Implique la collecte de données à partir de plusieurs sources hétérogènes.
Data Cleaning - Implique la recherche et la correction des erreurs dans les données.
Data Transformation - Implique la conversion des données du format hérité au format d'entrepôt.
Data Loading - Implique le tri, la synthèse, la consolidation, la vérification de l'intégrité et la création d'indices et de partitions.
Refreshing - Implique la mise à jour des sources de données vers l'entrepôt.
Note - Le nettoyage et la transformation des données sont des étapes importantes pour améliorer la qualité des données et les résultats de l'exploration de données.
Dans ce chapitre, nous discuterons de certains des termes les plus couramment utilisés dans l'entreposage de données.
Métadonnées
Les métadonnées sont simplement définies comme des données sur les données. Les données utilisées pour représenter d'autres données sont appelées métadonnées. Par exemple, l'index d'un livre sert de métadonnées pour le contenu du livre. En d'autres termes, nous pouvons dire que les métadonnées sont les données résumées qui nous mènent aux données détaillées.
En termes d'entrepôt de données, nous pouvons définir les métadonnées comme suit -
Les métadonnées sont une feuille de route vers l'entrepôt de données.
Les métadonnées de l'entrepôt de données définissent les objets de l'entrepôt.
Les métadonnées agissent comme un répertoire. Ce répertoire aide le système d'aide à la décision à localiser le contenu d'un entrepôt de données.
Référentiel de métadonnées
Le référentiel de métadonnées fait partie intégrante d'un système d'entrepôt de données. Il contient les métadonnées suivantes -
Business metadata - Il contient les informations sur la propriété des données, la définition de l'entreprise et les politiques changeantes.
Operational metadata- Il comprend la mise à jour des données et le lignage des données. La devise des données fait référence aux données actives, archivées ou purgées. Le lignage des données signifie l'historique des données migrées et la transformation appliquée dessus.
Data for mapping from operational environment to data warehouse - Les métadonnées comprennent les bases de données sources et leur contenu, l'extraction des données, la partition des données, le nettoyage, les règles de transformation, les règles d'actualisation et de purge des données.
The algorithms for summarization - Il comprend des algorithmes de dimension, des données sur la granularité, l'agrégation, la synthèse, etc.
Cube de données
Un cube de données nous aide à représenter les données dans plusieurs dimensions. Il est défini par des dimensions et des faits. Les dimensions sont les entités par rapport auxquelles une entreprise conserve les enregistrements.
Illustration du cube de données
Supposons qu'une entreprise souhaite garder une trace des registres des ventes à l'aide d'un entrepôt de données sur les ventes en ce qui concerne l'heure, l'article, la succursale et l'emplacement. Ces dimensions permettent de suivre les ventes mensuelles et dans quelle succursale les articles ont été vendus. Une table est associée à chaque dimension. Cette table est appelée table de dimension. Par exemple, la table de dimension "article" peut avoir des attributs tels que nom_élément, type_élément et marque_élément.
Le tableau suivant représente la vue 2D des données de vente d'une entreprise en ce qui concerne les dimensions de temps, d'article et d'emplacement.
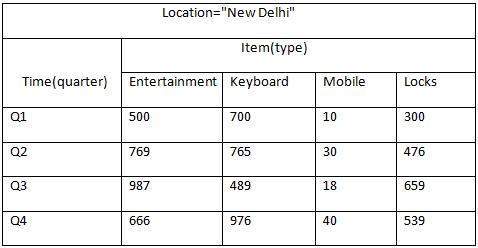
Mais ici, dans ce tableau 2D, nous avons des enregistrements en ce qui concerne le temps et l'élément uniquement. Les ventes pour New Delhi sont présentées en fonction du temps et des dimensions des articles en fonction du type d'articles vendus. Si nous voulons afficher les données de vente avec une autre dimension, par exemple, la dimension de localisation, la vue 3D serait utile. La vue 3D des données de vente en ce qui concerne le temps, l'article et le lieu est indiquée dans le tableau ci-dessous -
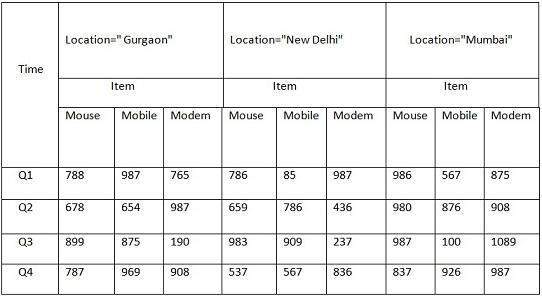
Le tableau 3-D ci-dessus peut être représenté sous forme de cube de données 3-D, comme illustré dans la figure suivante -
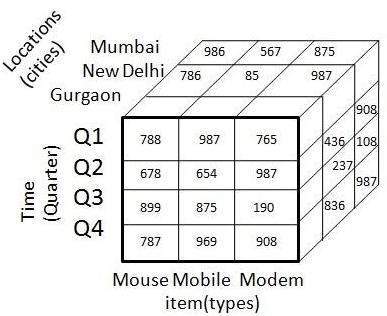
Data Mart
Les data marts contiennent un sous-ensemble de données à l'échelle de l'organisation qui sont précieuses pour des groupes spécifiques de personnes dans une organisation. En d'autres termes, un magasin de données contient uniquement les données spécifiques à un groupe particulier. Par exemple, le magasin de données marketing peut contenir uniquement des données relatives aux articles, aux clients et aux ventes. Les data marts se limitent aux sujets.
Points à retenir sur les Data Marts
Des serveurs Windows ou Unix / Linux sont utilisés pour implémenter des data marts. Ils sont mis en œuvre sur des serveurs à bas prix.
Le cycle de mise en œuvre d'un data mart est mesuré en courtes périodes, c'est-à-dire en semaines plutôt qu'en mois ou en années.
Le cycle de vie des data marts peut être complexe à long terme, si leur planification et leur conception ne sont pas à l'échelle de l'organisation.
Les data marts sont de petite taille.
Les data marts sont personnalisés par département.
La source d'un data mart est l'entrepôt de données structuré par département.
Les data marts sont flexibles.
La figure suivante montre une représentation graphique des data marts.
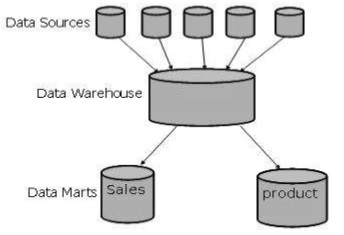
Entrepôt virtuel
La vue sur un entrepôt de données opérationnel est appelée entrepôt virtuel. Il est facile de créer un entrepôt virtuel. La création d'un entrepôt virtuel nécessite une capacité excédentaire sur les serveurs de base de données opérationnels.
Un entrepôt de données n'est jamais statique; il évolue à mesure que l'entreprise se développe. Au fur et à mesure que l'entreprise évolue, ses exigences ne cessent de changer et par conséquent, un entrepôt de données doit être conçu pour s'adapter à ces changements. Par conséquent, un système d'entrepôt de données doit être flexible.
Idéalement, il devrait y avoir un processus de livraison pour fournir un entrepôt de données. Cependant, les projets d'entrepôt de données souffrent normalement de divers problèmes qui rendent difficile l'exécution des tâches et des livrables de la manière stricte et ordonnée exigée par la méthode en cascade. La plupart du temps, les exigences ne sont pas complètement comprises. Les architectures, les conceptions et les composants de construction ne peuvent être achevés qu'après avoir rassemblé et étudié toutes les exigences.
méthode de livraison
La méthode de livraison est une variante de l'approche de développement d'applications conjointes adoptée pour la livraison d'un entrepôt de données. Nous avons organisé le processus de livraison de l'entrepôt de données pour minimiser les risques. L'approche dont nous allons discuter ici ne réduit pas les délais de livraison globaux, mais garantit que les avantages commerciaux sont fournis progressivement tout au long du processus de développement.
Note - Le processus de livraison est divisé en phases pour réduire le risque de projet et de livraison.
Le diagramme suivant explique les étapes du processus de livraison -
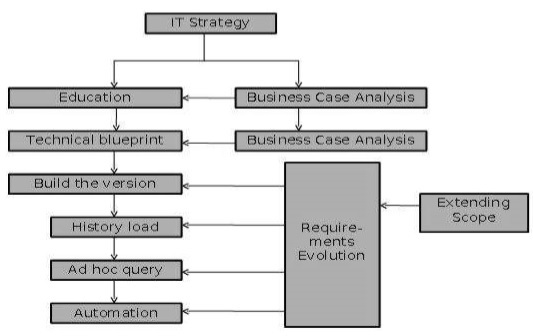
Stratégie informatique
Les entrepôts de données sont des investissements stratégiques qui nécessitent un processus métier pour générer des avantages. Une stratégie informatique est nécessaire pour obtenir et conserver le financement du projet.
Business case
L'objectif de l'analyse de rentabilisation est d'estimer les avantages commerciaux qui devraient découler de l'utilisation d'un entrepôt de données. Ces avantages peuvent ne pas être quantifiables, mais les avantages prévus doivent être clairement énoncés. Si un entrepôt de données ne dispose pas d'une analyse de rentabilisation claire, l'entreprise a tendance à souffrir de problèmes de crédibilité à un certain stade du processus de livraison. Par conséquent, dans les projets d'entrepôt de données, nous devons comprendre l'analyse de rentabilisation de l'investissement.
Éducation et prototypage
Les organisations expérimentent le concept d'analyse des données et se renseignent sur la valeur d'un entrepôt de données avant de se décider pour une solution. Ceci est résolu par le prototypage. Cela aide à comprendre la faisabilité et les avantages d'un entrepôt de données. L'activité de prototypage à petite échelle peut promouvoir le processus éducatif tant que -
Le prototype répond à un objectif technique défini.
Le prototype peut être jeté après la démonstration du concept de faisabilité.
L'activité concerne un petit sous-ensemble du contenu éventuel des données de l'entrepôt de données.
L'échelle de temps des activités n'est pas critique.
Les points suivants doivent être gardés à l'esprit pour produire une version anticipée et offrir des avantages commerciaux.
Identifiez l'architecture qui est capable d'évoluer.
Concentrez-vous sur les exigences de l'entreprise et les phases du plan technique.
Limitez la portée de la première phase de construction au minimum qui offre des avantages commerciaux.
Comprendre les exigences à court et moyen terme de l'entrepôt de données.
Besoins de l'entreprise
Pour fournir des livrables de qualité, nous devons nous assurer que les exigences globales sont comprises. Si nous comprenons les exigences commerciales à court et à moyen terme, nous pouvons concevoir une solution pour répondre aux exigences à court terme. La solution à court terme peut ensuite être transformée en une solution complète.
Les aspects suivants sont déterminés à cette étape -
La règle métier à appliquer aux données.
Le modèle logique des informations dans l'entrepôt de données.
Les profils de requête pour l'exigence immédiate.
Les systèmes sources qui fournissent ces données.
Plan technique
Cette phase doit fournir une architecture globale satisfaisant les exigences à long terme. Cette phase fournit également les composants qui doivent être mis en œuvre à court terme pour en tirer un avantage commercial. Le plan directeur doit identifier les éléments suivants.
- L'architecture globale du système.
- La politique de conservation des données.
- La stratégie de sauvegarde et de restauration.
- L'architecture du serveur et du data mart.
- Le plan de capacité pour le matériel et l'infrastructure.
- Les composants de la conception de bases de données.
Construire la version
Dans cette étape, le premier livrable de production est produit. Ce livrable de production est le plus petit composant d'un entrepôt de données. Ce plus petit composant ajoute un avantage commercial.
Charge historique
Il s'agit de la phase où le reste de l'historique requis est chargé dans l'entrepôt de données. Dans cette phase, nous n'ajoutons pas de nouvelles entités, mais des tables physiques supplémentaires seraient probablement créées pour stocker des volumes de données accrus.
Prenons un exemple. Supposons que la phase de version de construction ait fourni un entrepôt de données d'analyse des ventes au détail avec 2 mois d'historique. Ces informations permettront à l'utilisateur d'analyser uniquement les tendances récentes et de résoudre les problèmes à court terme. Dans ce cas, l'utilisateur ne peut pas identifier les tendances annuelles et saisonnières. Pour l'aider à le faire, l'historique des ventes des 2 dernières années pourrait être chargé à partir des archives. Maintenant, les données de 40 Go sont étendues à 400 Go.
Note - Les procédures de sauvegarde et de restauration peuvent devenir complexes, il est donc recommandé d'effectuer cette activité dans une phase distincte.
Requête ad hoc
Dans cette phase, nous configurons un outil de requête ad hoc qui est utilisé pour faire fonctionner un entrepôt de données. Ces outils peuvent générer la requête de base de données.
Note - Il est recommandé de ne pas utiliser ces outils d'accès lorsque la base de données est en cours de modification substantielle.
Automatisation
Dans cette phase, les processus de gestion opérationnelle sont entièrement automatisés. Ceux-ci comprendraient -
Transformer les données sous une forme adaptée à l'analyse.
Surveillance des profils de requête et détermination des agrégations appropriées pour maintenir les performances du système.
Extraction et chargement de données à partir de différents systèmes sources.
Génération d'agrégations à partir de définitions prédéfinies dans l'entrepôt de données.
Sauvegarde, restauration et archivage des données.
Extension de la portée
Dans cette phase, l'entrepôt de données est étendu pour répondre à un nouvel ensemble d'exigences métier. La portée peut être étendue de deux manières -
En chargeant des données supplémentaires dans l'entrepôt de données.
En introduisant de nouveaux data marts utilisant les informations existantes.
Note - Cette phase doit être réalisée séparément, car elle implique des efforts et une complexité considérables.
Évolution des exigences
Du point de vue du processus de livraison, les exigences sont toujours variables. Ils ne sont pas statiques. Le processus de livraison doit prendre en charge cela et permettre à ces changements d'être reflétés dans le système.
Ce problème est résolu en concevant l'entrepôt de données autour de l'utilisation des données dans les processus métier, par opposition aux exigences de données des requêtes existantes.
L'architecture est conçue pour changer et évoluer pour correspondre aux besoins de l'entreprise, le processus fonctionne comme un processus de développement de pseudo-application, où les nouvelles exigences sont continuellement introduites dans les activités de développement et les livrables partiels sont produits. Ces livrables partiels sont renvoyés aux utilisateurs, puis retravaillés, garantissant que le système global est continuellement mis à jour pour répondre aux besoins de l'entreprise.
Nous avons un nombre fixe d'opérations à appliquer sur les bases de données opérationnelles et nous avons des techniques bien définies telles que use normalized data, keep table small, etc. Ces techniques conviennent pour fournir une solution. Mais dans le cas des systèmes d'aide à la décision, nous ne savons pas quelle requête et quelle opération doivent être exécutées à l'avenir. Par conséquent, les techniques appliquées sur les bases de données opérationnelles ne conviennent pas aux entrepôts de données.
Dans ce chapitre, nous discuterons de la manière de créer des solutions d'entreposage de données sur les principales technologies de système ouvert comme Unix et les bases de données relationnelles.
Flux de processus dans l'entrepôt de données
Il existe quatre processus principaux qui contribuent à un entrepôt de données -
- Extraire et charger les données.
- Nettoyage et transformation des données.
- Sauvegardez et archivez les données.
- Gérer les requêtes et les diriger vers les sources de données appropriées.
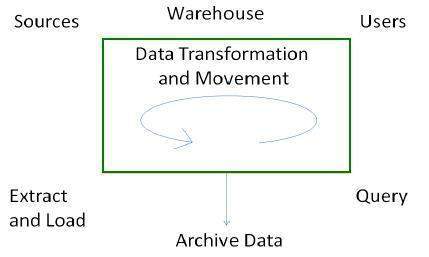
Processus d'extraction et de chargement
L'extraction de données prend les données des systèmes sources. Le chargement des données prend les données extraites et les charge dans l'entrepôt de données.
Note - Avant de charger les données dans l'entrepôt de données, les informations extraites des sources externes doivent être reconstruites.
Contrôle du processus
Le contrôle du processus implique de déterminer quand démarrer l'extraction des données et le contrôle de cohérence des données. Le processus de contrôle garantit que les outils, les modules logiques et les programmes sont exécutés dans le bon ordre et au bon moment.
Quand lancer l'extraction
Les données doivent être dans un état cohérent lorsqu'elles sont extraites, c'est-à-dire que l'entrepôt de données doit représenter une version unique et cohérente des informations pour l'utilisateur.
Par exemple, dans un entrepôt de données de profilage client dans le secteur des télécommunications, il est illogique de fusionner la liste des clients à 20 heures le mercredi d'une base de données clients avec les événements d'abonnement client jusqu'à 20 heures le mardi. Cela signifierait que nous recherchons les clients pour lesquels il n'y a pas d'abonnement associé.
Chargement des données
Après avoir extrait les données, elles sont chargées dans un magasin de données temporaire où elles sont nettoyées et rendues cohérentes.
Note - Les contrôles de cohérence ne sont exécutés que lorsque toutes les sources de données ont été chargées dans le magasin de données temporaire.
Processus de nettoyage et de transformation
Une fois les données extraites et chargées dans le magasin de données temporaire, il est temps d'effectuer le nettoyage et la transformation. Voici la liste des étapes impliquées dans le nettoyage et la transformation -
- Nettoyer et transformer les données chargées en une structure
- Partitionner les données
- Aggregation
Nettoyer et transformer les données chargées en une structure
Le nettoyage et la transformation des données chargées permettent d'accélérer les requêtes. Cela peut être fait en rendant les données cohérentes -
- en lui-même.
- avec d'autres données dans la même source de données.
- avec les données d'autres systèmes sources.
- avec les données existantes présentes dans l'entrepôt.
La transformation implique la conversion des données source en une structure. La structuration des données augmente les performances des requêtes et diminue le coût opérationnel. Les données contenues dans un entrepôt de données doivent être transformées pour prendre en charge les exigences de performance et contrôler les coûts opérationnels permanents.
Partitionner les données
Il optimisera les performances du matériel et simplifiera la gestion de l'entrepôt de données. Ici, nous partitionnons chaque table de faits en plusieurs partitions distinctes.
Agrégation
L'agrégation est nécessaire pour accélérer les requêtes courantes. L'agrégation repose sur le fait que la plupart des requêtes courantes analyseront un sous-ensemble ou une agrégation des données détaillées.
Sauvegarder et archiver les données
Afin de récupérer les données en cas de perte de données, de panne logicielle ou de panne matérielle, il est nécessaire de conserver des sauvegardes régulières. L'archivage consiste à supprimer les anciennes données du système dans un format qui leur permet d'être rapidement restaurées chaque fois que nécessaire.
Par exemple, dans un entrepôt de données d'analyse des ventes au détail, il peut être nécessaire de conserver les données pendant 3 ans, les données des 6 derniers mois étant conservées en ligne. Dans un tel scénario, il est souvent nécessaire de pouvoir faire des comparaisons mensuelles pour cette année et l'année dernière. Dans ce cas, nous avons besoin que certaines données soient restaurées à partir de l'archive.
Processus de gestion des requêtes
Ce processus remplit les fonctions suivantes -
gère les requêtes.
aide à accélérer le temps d'exécution des requêtes.
dirige les requêtes vers leurs sources de données les plus efficaces.
garantit que toutes les sources du système sont utilisées de la manière la plus efficace.
surveille les profils de requête réels.
Les informations générées dans ce processus sont utilisées par le processus de gestion de l'entrepôt pour déterminer les agrégations à générer. Ce processus ne fonctionne généralement pas pendant le chargement régulier d'informations dans l'entrepôt de données.
Dans ce chapitre, nous aborderons le cadre d'analyse commerciale pour la conception et l'architecture d'un entrepôt de données.
Cadre d'analyse commerciale
L'analyste commercial obtient les informations des entrepôts de données pour mesurer les performances et effectuer des ajustements critiques afin de convaincre d'autres acteurs du marché. Avoir un entrepôt de données offre les avantages suivants -
Étant donné qu'un entrepôt de données peut collecter des informations rapidement et efficacement, il peut améliorer la productivité de l'entreprise.
Un entrepôt de données nous fournit une vue cohérente des clients et des articles, par conséquent, il nous aide à gérer la relation client.
Un entrepôt de données permet également de réduire les coûts en suivant les tendances, les modèles sur une longue période de manière cohérente et fiable.
Pour concevoir un entrepôt de données efficace et efficient, nous devons comprendre et analyser les besoins de l'entreprise et construire un business analysis framework. Chaque personne a des points de vue différents sur la conception d'un entrepôt de données. Ces vues sont les suivantes -
The top-down view - Cette vue permet de sélectionner les informations pertinentes nécessaires pour un entrepôt de données.
The data source view - Cette vue présente les informations capturées, stockées et gérées par le système opérationnel.
The data warehouse view- Cette vue inclut les tables de faits et les tables de dimension. Il représente les informations stockées dans l'entrepôt de données.
The business query view - C'est la vue des données du point de vue de l'utilisateur final.
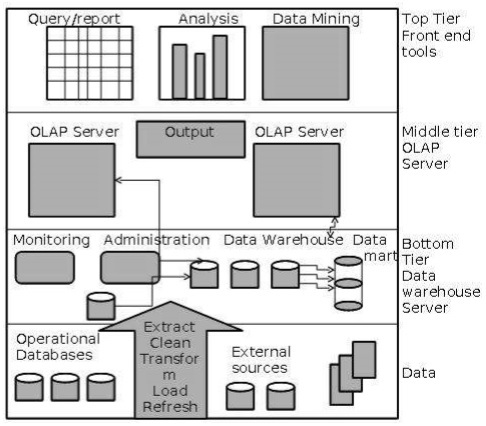
Architecture d'entrepôt de données à trois niveaux
En général, un entrepôt de données adopte une architecture à trois niveaux. Voici les trois niveaux de l'architecture de l'entrepôt de données.
Bottom Tier- Le niveau inférieur de l'architecture est le serveur de base de données de l'entrepôt de données. C'est le système de base de données relationnelle. Nous utilisons les outils et utilitaires back-end pour alimenter les données dans le niveau inférieur. Ces outils et utilitaires principaux exécutent les fonctions d'extraction, de nettoyage, de chargement et d'actualisation.
Middle Tier - Au niveau intermédiaire, nous avons le serveur OLAP qui peut être implémenté de l'une des manières suivantes.
Par Relational OLAP (ROLAP), qui est un système de gestion de base de données relationnelle étendu. Le ROLAP mappe les opérations sur des données multidimensionnelles aux opérations relationnelles standard.
Par modèle OLAP multidimensionnel (MOLAP), qui implémente directement les données et opérations multidimensionnelles.
Top-Tier- Ce niveau est la couche client frontale. Cette couche contient les outils de requête et les outils de reporting, les outils d'analyse et les outils d'exploration de données.
Le diagramme suivant illustre l'architecture à trois niveaux de l'entrepôt de données -
Modèles d'entrepôt de données
Du point de vue de l'architecture de l'entrepôt de données, nous avons les modèles d'entrepôt de données suivants -
- Entrepôt virtuel
- Magasin de données
- Entrepôt d'entreprise
Entrepôt virtuel
La vue sur un entrepôt de données opérationnel est appelée entrepôt virtuel. Il est facile de créer un entrepôt virtuel. La création d'un entrepôt virtuel nécessite une capacité excédentaire sur les serveurs de base de données opérationnels.
Data Mart
Le magasin de données contient un sous-ensemble de données à l'échelle de l'organisation. Ce sous-ensemble de données est précieux pour des groupes spécifiques d'une organisation.
En d'autres termes, nous pouvons affirmer que les data marts contiennent des données spécifiques à un groupe particulier. Par exemple, le magasin de données marketing peut contenir des données relatives aux articles, aux clients et aux ventes. Les data marts se limitent aux sujets.
Points à retenir sur les data marts -
Des serveurs Windows ou Unix / Linux sont utilisés pour implémenter des data marts. Ils sont mis en œuvre sur des serveurs à bas prix.
Les cycles du magasin de données de mise en œuvre sont mesurés sur de courtes périodes, c'est-à-dire en semaines plutôt qu'en mois ou en années.
Le cycle de vie d'un data mart peut être complexe à long terme, si sa planification et sa conception ne sont pas à l'échelle de l'organisation.
Les data marts sont de petite taille.
Les data marts sont personnalisés par département.
La source d'un data mart est l'entrepôt de données structuré par département.
Les data mart sont flexibles.
Entrepôt d'entreprise
Un entrepôt d'entreprise rassemble toutes les informations et les sujets couvrant toute une organisation
Il nous fournit une intégration de données à l'échelle de l'entreprise.
Les données sont intégrées à partir des systèmes opérationnels et des fournisseurs d'informations externes.
Ces informations peuvent varier de quelques gigaoctets à des centaines de gigaoctets, téraoctets ou au-delà.
Gestionnaire de charge
Ce composant effectue les opérations nécessaires pour extraire et charger le processus.
La taille et la complexité du gestionnaire de charge varient entre les solutions spécifiques d'un entrepôt de données à l'autre.
Architecture du gestionnaire de charge
Le gestionnaire de charge remplit les fonctions suivantes -
Extrayez les données du système source.
Rapide Chargez les données extraites dans le magasin de données temporaire.
Effectuez des transformations simples en structure similaire à celle de l'entrepôt de données.
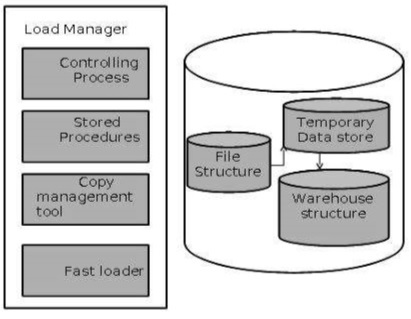
Extraire les données de la source
Les données sont extraites des bases de données opérationnelles ou des fournisseurs d'informations externes. Les passerelles sont les programmes d'application utilisés pour extraire les données. Il est pris en charge par le SGBD sous-jacent et permet au programme client de générer du SQL à exécuter sur un serveur. Open Database Connection (ODBC), Java Database Connection (JDBC), sont des exemples de passerelle.
Charge rapide
Afin de minimiser la fenêtre de chargement total, les données doivent être chargées dans l'entrepôt le plus rapidement possible.
Les transformations affectent la vitesse de traitement des données.
Il est plus efficace de charger les données dans la base de données relationnelle avant d'appliquer les transformations et les vérifications.
La technologie de passerelle s'avère ne pas convenir, car elle a tendance à ne pas être performante lorsque de gros volumes de données sont impliqués.
Transformations simples
Lors du chargement, il peut être nécessaire d'effectuer des transformations simples. Une fois cela terminé, nous sommes en mesure de faire les vérifications complexes. Supposons que nous chargeons la transaction de vente EPOS, nous devons effectuer les vérifications suivantes:
- Supprimez toutes les colonnes qui ne sont pas nécessaires dans l'entrepôt.
- Convertissez toutes les valeurs en types de données requis.
Directeur d'entrepôt
Un responsable d'entrepôt est responsable du processus de gestion de l'entrepôt. Il se compose de logiciels système tiers, de programmes C et de scripts shell.
La taille et la complexité des responsables d'entrepôt varient selon les solutions spécifiques.
Architecture du gestionnaire d'entrepôt
Un responsable d'entrepôt comprend les éléments suivants:
- Le processus de contrôle
- Procédures stockées ou C avec SQL
- Outil de sauvegarde / restauration
- Scripts SQL
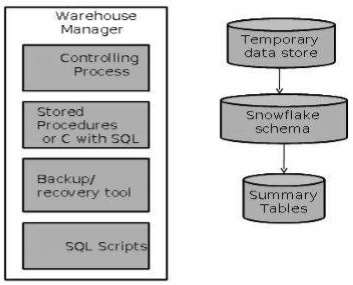
Opérations effectuées par le responsable de l'entrepôt
Un responsable d'entrepôt analyse les données pour effectuer des contrôles de cohérence et d'intégrité référentielle.
Crée des index, des vues d'entreprise, des vues de partition par rapport aux données de base.
Génère de nouvelles agrégations et met à jour les agrégations existantes. Génère des normalisations.
Transforme et fusionne les données source dans l'entrepôt de données publié.
Sauvegardez les données dans l'entrepôt de données.
Archive les données qui ont atteint la fin de leur vie capturée.
Note - Un gestionnaire d'entrepôt analyse également les profils de requête pour déterminer l'index et les agrégations appropriées.
Gestionnaire de requêtes
Le gestionnaire de requêtes est chargé de diriger les requêtes vers les tables appropriées.
En dirigeant les requêtes vers les tables appropriées, la vitesse de requête et de génération de réponse peut être augmentée.
Le gestionnaire de requêtes est responsable de la planification de l'exécution des requêtes posées par l'utilisateur.
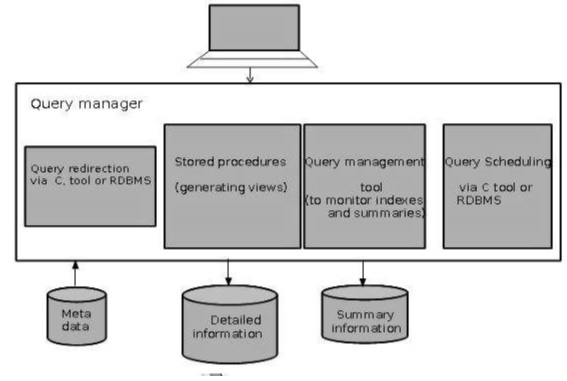
Architecture du gestionnaire de requêtes
La capture d'écran suivante montre l'architecture d'un gestionnaire de requêtes. Il comprend les éléments suivants:
- Redirection des requêtes via l'outil C ou le SGBDR
- Procédures stockées
- Outil de gestion des requêtes
- Planification des requêtes via l'outil C ou le SGBDR
- Planification des requêtes via un logiciel tiers
Des informations détaillées
Les informations détaillées ne sont pas conservées en ligne, mais agrégées au niveau de détail suivant, puis archivées sur bande. La partie des informations détaillées de l'entrepôt de données conserve les informations détaillées dans le schéma Starflake. Des informations détaillées sont chargées dans l'entrepôt de données pour compléter les données agrégées.
Le diagramme suivant montre une image illustrant l'emplacement de stockage des informations détaillées et la manière dont elles sont utilisées.
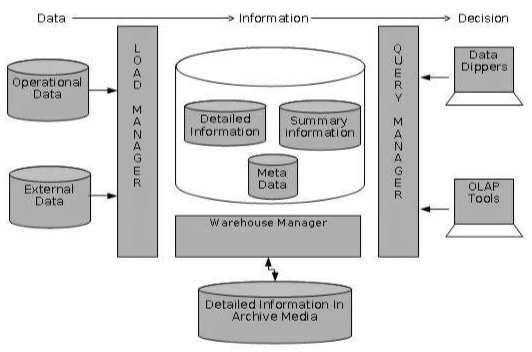
Note - Si des informations détaillées sont conservées hors ligne pour minimiser le stockage sur disque, nous devons nous assurer que les données ont été extraites, nettoyées et transformées en schéma en étoile avant leur archivage.
Informations résumées
Les informations récapitulatives font partie de l'entrepôt de données qui stocke des agrégations prédéfinies. Ces agrégations sont générées par le responsable de l'entrepôt. Les informations récapitulatives doivent être traitées comme transitoires. Il change en cours de route afin de répondre aux changements de profils de requête.
Les points à noter concernant les informations récapitulatives sont les suivants -
Les informations récapitulatives accélèrent les performances des requêtes courantes.
Cela augmente le coût opérationnel.
Il doit être mis à jour chaque fois que de nouvelles données sont chargées dans l'entrepôt de données.
Il peut ne pas avoir été sauvegardé, car il peut être généré à partir des informations détaillées.
Le serveur de traitement analytique en ligne (OLAP) est basé sur le modèle de données multidimensionnel. Il permet aux gestionnaires et aux analystes d'avoir un aperçu des informations grâce à un accès rapide, cohérent et interactif aux informations. Ce chapitre couvre les types d'OLAP, les opérations sur OLAP, la différence entre OLAP et les bases de données statistiques et OLTP.
Types de serveurs OLAP
Nous avons quatre types de serveurs OLAP -
- OLAP relationnel (ROLAP)
- OLAP multidimensionnel (MOLAP)
- OLAP hybride (HOLAP)
- Serveurs SQL spécialisés
OLAP relationnel
Les serveurs ROLAP sont placés entre le serveur principal relationnel et les outils frontaux client. Pour stocker et gérer les données de l'entrepôt, ROLAP utilise un SGBD relationnel ou relationnel étendu.
ROLAP comprend les éléments suivants -
- Implémentation de la logique de navigation d'agrégation.
- Optimisation pour chaque back-end SGBD.
- Outils et services supplémentaires.
OLAP multidimensionnel
MOLAP utilise des moteurs de stockage multidimensionnels basés sur des baies pour des vues multidimensionnelles des données. Avec les magasins de données multidimensionnels, l'utilisation du stockage peut être faible si l'ensemble de données est clairsemé. Par conséquent, de nombreux serveurs MOLAP utilisent deux niveaux de représentation de stockage de données pour gérer des ensembles de données denses et rares.
OLAP hybride
L'OLAP hybride est une combinaison de ROLAP et de MOLAP. Il offre une plus grande évolutivité de ROLAP et un calcul plus rapide de MOLAP. Les serveurs HOLAP permettent de stocker les gros volumes de données d'informations détaillées. Les agrégations sont stockées séparément dans le magasin MOLAP.
Serveurs SQL spécialisés
Les serveurs SQL spécialisés fournissent un langage de requête avancé et une prise en charge du traitement des requêtes pour les requêtes SQL sur des schémas en étoile et en flocon dans un environnement en lecture seule.
Opérations OLAP
Les serveurs OLAP étant basés sur une vue multidimensionnelle des données, nous discuterons des opérations OLAP dans les données multidimensionnelles.
Voici la liste des opérations OLAP -
- Roll-up
- Drill-down
- Émincer
- Pivot (rotation)
Roll-up
Le roll-up effectue une agrégation sur un cube de données de l'une des manières suivantes:
- En gravissant une hiérarchie de concepts pour une dimension
- Par réduction de dimension
Le diagramme suivant illustre le fonctionnement du roll-up.
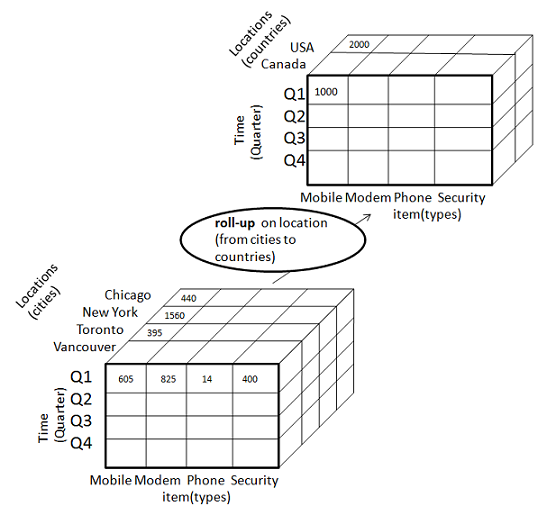
La remontée est effectuée en gravissant une hiérarchie de concept pour l'emplacement de dimension.
Au départ, la hiérarchie des concepts était "rue <ville <province <pays".
Lors du cumul, les données sont agrégées en augmentant la hiérarchie des emplacements du niveau de la ville au niveau du pays.
Les données sont regroupées en villes plutôt qu'en pays.
Lors de la remontée, une ou plusieurs dimensions du cube de données sont supprimées.
Exploration
Le drill-down est l'opération inverse du roll-up. Il est effectué de l'une des manières suivantes -
- En supprimant une hiérarchie de concepts pour une dimension
- En introduisant une nouvelle dimension.
Le diagramme suivant illustre le fonctionnement de l'exploration descendante -

L'exploration descendante est effectuée en abaissant une hiérarchie de concept pour le temps de dimension.
Au départ, la hiérarchie des concepts était "jour <mois <trimestre <année".
Lors de l'exploration vers le bas, la dimension temporelle est descendue du niveau du trimestre au niveau du mois.
Lorsque l'exploration est effectuée, une ou plusieurs dimensions du cube de données sont ajoutées.
Il parcourt les données des données moins détaillées aux données très détaillées.
Tranche
L'opération de tranche sélectionne une dimension particulière à partir d'un cube donné et fournit un nouveau sous-cube. Considérez le diagramme suivant qui montre le fonctionnement de la tranche.
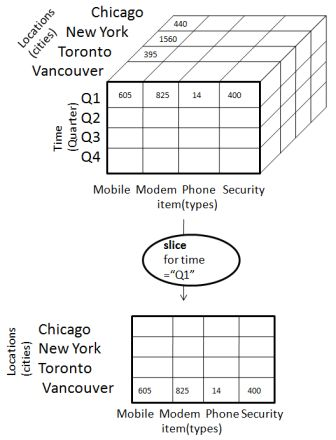
Ici Slice est effectué pour la dimension "temps" en utilisant le critère temps = "Q1".
Il formera un nouveau sous-cube en sélectionnant une ou plusieurs dimensions.
Dé
Dice sélectionne deux dimensions ou plus à partir d'un cube donné et fournit un nouveau sous-cube. Considérez le diagramme suivant qui montre le fonctionnement des dés.

L'opération de dés sur le cube basée sur les critères de sélection suivants implique trois dimensions.
- (location = "Toronto" ou "Vancouver")
- (heure = "Q1" ou "Q2")
- (item = "Mobile" ou "Modem")
Pivot
L'opération de pivot est également connue sous le nom de rotation. Il fait pivoter les axes de données en vue afin de fournir une présentation alternative des données. Considérez le diagramme suivant qui montre l'opération de pivot.

OLAP contre OLTP
| Sr.No. | Entrepôt de données (OLAP) | Base de données opérationnelle (OLTP) |
|---|---|---|
| 1 | Implique un traitement historique des informations. | Implique le traitement au jour le jour. |
| 2 | Les systèmes OLAP sont utilisés par les travailleurs du savoir tels que les cadres, les gestionnaires et les analystes. | Les systèmes OLTP sont utilisés par les commis, les administrateurs de base de données ou les professionnels des bases de données. |
| 3 | Utile pour analyser l'entreprise. | Utile dans la gestion de l'entreprise. |
| 4 | Il se concentre sur l'information. | Il se concentre sur les données au format. |
| 5 | Basé sur Star Schema, Snowflake, Schema et Fact Constellation Schema. | Basé sur le modèle de relation d'entité. |
| 6 | Contient des données historiques. | Contient les données actuelles. |
| sept | Fournit des données résumées et consolidées. | Fournit des données primitives et très détaillées. |
| 8 | Fournit une vue résumée et multidimensionnelle des données. | Fournit une vue relationnelle détaillée et plate des données. |
| 9 | Le nombre d'utilisateurs est en centaines. | Le nombre d'utilisateurs est en milliers. |
| dix | Le nombre d'enregistrements consultés est en millions. | Le nombre d'enregistrements consultés est en dizaines. |
| 11 | La taille de la base de données est comprise entre 100 Go et 1 To | La taille de la base de données est comprise entre 100 Mo et 1 Go. |
| 12 | Très flexible. | Fournit des performances élevées. |
Les serveurs OLAP relationnels sont placés entre le serveur principal relationnel et les outils frontaux clients. Pour stocker et gérer les données de l'entrepôt, l'OLAP relationnel utilise un SGBD relationnel ou relationnel étendu.
ROLAP comprend les éléments suivants -
- Implémentation de la logique de navigation d'agrégation
- Optimisation pour chaque back-end SGBD
- Outils et services supplémentaires
Points à retenir
Les serveurs ROLAP sont hautement évolutifs.
Les outils ROLAP analysent de grands volumes de données sur plusieurs dimensions.
Les outils ROLAP stockent et analysent des données hautement volatiles et modifiables.
Architecture OLAP relationnelle
ROLAP comprend les composants suivants -
- Serveur de base de données
- Serveur ROLAP
- Outil frontal.

Avantages
- Les serveurs ROLAP peuvent être facilement utilisés avec le SGBDR existant.
- Les données peuvent être stockées efficacement, car aucun fait nul ne peut être stocké.
- Les outils ROLAP n'utilisent pas de cubes de données pré-calculés.
- Le serveur DSS de la micro-stratégie adopte l'approche ROLAP.
Désavantages
Mauvaises performances des requêtes.
Certaines limitations de l'évolutivité en fonction de l'architecture technologique utilisée.
OLAP multidimensionnel (MOLAP) utilise des moteurs de stockage multidimensionnels basés sur des baies pour des vues multidimensionnelles des données. Avec des magasins de données multidimensionnels, l'utilisation du stockage peut être faible si l'ensemble de données est clairsemé. Par conséquent, de nombreux serveurs MOLAP utilisent deux niveaux de représentation de stockage de données pour gérer des ensembles de données denses et rares.
Points à retenir -
Les outils MOLAP traitent les informations avec un temps de réponse constant, quel que soit le niveau de synthèse ou de calcul sélectionné.
Les outils MOLAP doivent éviter de nombreuses complexités liées à la création d'une base de données relationnelle pour stocker les données à analyser.
Les outils MOLAP ont besoin des performances les plus rapides possibles.
Le serveur MOLAP adopte deux niveaux de représentation de stockage pour gérer les ensembles de données denses et rares.
Les sous-cubes plus denses sont identifiés et stockés en tant que structure de tableau.
Les sous-cubes clairsemés utilisent la technologie de compression.
Architecture MOLAP
MOLAP comprend les composants suivants -
- Serveur de base de données.
- Serveur MOLAP.
- Outil frontal.

Avantages
- MOLAP permet l'indexation la plus rapide des données résumées précalculées.
- Aide les utilisateurs connectés à un réseau qui ont besoin d'analyser des données plus volumineuses et moins définies.
- Plus facile à utiliser, MOLAP convient donc aux utilisateurs inexpérimentés.
Désavantages
- MOLAP ne peut pas contenir de données détaillées.
- L'utilisation du stockage peut être faible si l'ensemble de données est rare.
MOLAP vs ROLAP
| Sr.No. | MOLAP | ROLAP |
|---|---|---|
| 1 | La recherche d'informations est rapide. | La recherche d'informations est relativement lente. |
| 2 | Utilise un tableau fragmenté pour stocker des ensembles de données. | Utilise une table relationnelle. |
| 3 | MOLAP est le mieux adapté aux utilisateurs inexpérimentés, car il est très facile à utiliser. | ROLAP est le mieux adapté aux utilisateurs expérimentés. |
| 4 | Gère une base de données distincte pour les cubes de données. | Il ne peut pas nécessiter d'espace autre que celui disponible dans l'entrepôt de données. |
| 5 | La fonction SGBD est faible. | La fonction SGBD est solide. |
Le schéma est une description logique de l'ensemble de la base de données. Il comprend le nom et la description des enregistrements de tous les types d'enregistrement, y compris tous les éléments de données et agrégats associés. Tout comme une base de données, un entrepôt de données nécessite également de maintenir un schéma. Une base de données utilise un modèle relationnel, tandis qu'un entrepôt de données utilise le schéma Star, Snowflake et Fact Constellation. Dans ce chapitre, nous aborderons les schémas utilisés dans un entrepôt de données.
Schéma en étoile
Chaque dimension dans un schéma en étoile est représentée avec une seule table à une dimension.
Cette table de dimension contient l'ensemble des attributs.
Le diagramme suivant montre les données de vente d'une entreprise par rapport aux quatre dimensions, à savoir le temps, l'article, la succursale et l'emplacement.
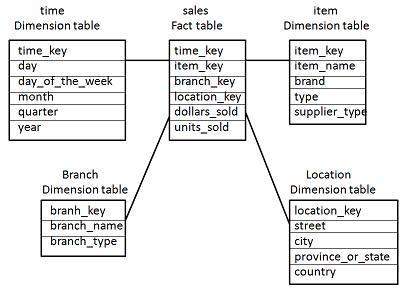
Il y a une table de faits au centre. Il contient les clés de chacune des quatre dimensions.
La table de faits contient également les attributs, à savoir les dollars vendus et les unités vendues.
Note- Chaque dimension n'a qu'une seule table de dimension et chaque table contient un ensemble d'attributs. Par exemple, la table de dimension d'emplacement contient l'ensemble d'attributs {location_key, street, city, province_or_state, country}. Cette contrainte peut entraîner une redondance des données. Par exemple, «Vancouver» et «Victoria», les deux villes se trouvent dans la province canadienne de la Colombie-Britannique. Les entrées pour ces villes peuvent entraîner une redondance des données le long des attributs province_or_state et country.
Schéma de flocon de neige
Certaines tables de dimension du schéma Snowflake sont normalisées.
La normalisation divise les données en tables supplémentaires.
Contrairement au schéma en étoile, la table des dimensions dans un schéma en flocon de neige est normalisée. Par exemple, la table de dimension article dans le schéma en étoile est normalisée et divisée en deux tables de dimension, à savoir la table article et fournisseur.

Désormais, la table de dimension d'article contient les attributs item_key, item_name, type, brand et supplier-key.
La clé fournisseur est liée à la table de dimension fournisseur. La table de dimension fournisseur contient les attributs clé_fournisseur et type_fournisseur.
Note - En raison de la normalisation dans le schéma Snowflake, la redondance est réduite et par conséquent, il devient facile à maintenir et à économiser l'espace de stockage.
Schéma de constellation des faits
Une constellation de faits a plusieurs tables de faits. Il est également connu sous le nom de schéma de galaxie.
Le diagramme suivant montre deux tableaux de faits, à savoir les ventes et les expéditions.
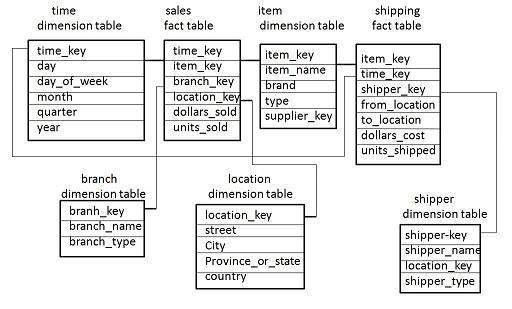
La table de faits sur les ventes est la même que celle du schéma en étoile.
La table de faits d'expédition a les cinq dimensions, à savoir item_key, time_key, shipper_key, from_location, to_location.
Le tableau des données d'expédition contient également deux mesures, à savoir les dollars vendus et les unités vendues.
Il est également possible de partager des tables de dimension entre des tables de faits. Par exemple, les tables de dimension de temps, d'article et d'emplacement sont partagées entre la table de faits sur les ventes et l'expédition.
Définition du schéma
Le schéma multidimensionnel est défini à l'aide du langage de requête d'exploration de données (DMQL). Les deux primitives, définition de cube et définition de dimension, peuvent être utilisées pour définir les entrepôts de données et les magasins de données.
Syntaxe de la définition du cube
define cube < cube_name > [ < dimension-list > }: < measure_list >Syntaxe pour la définition de dimension
define dimension < dimension_name > as ( < attribute_or_dimension_list > )Définition du schéma en étoile
Le schéma en étoile que nous avons discuté peut être défini à l'aide du langage de requête d'exploration de données (DMQL) comme suit -
define cube sales star [time, item, branch, location]:
dollars sold = sum(sales in dollars), units sold = count(*)
define dimension time as (time key, day, day of week, month, quarter, year)
define dimension item as (item key, item name, brand, type, supplier type)
define dimension branch as (branch key, branch name, branch type)
define dimension location as (location key, street, city, province or state, country)Définition du schéma de flocon de neige
Le schéma Snowflake peut être défini en utilisant DMQL comme suit -
define cube sales snowflake [time, item, branch, location]:
dollars sold = sum(sales in dollars), units sold = count(*)
define dimension time as (time key, day, day of week, month, quarter, year)
define dimension item as (item key, item name, brand, type, supplier (supplier key, supplier type))
define dimension branch as (branch key, branch name, branch type)
define dimension location as (location key, street, city (city key, city, province or state, country))Définition du schéma de constellation des faits
Le schéma de constellation de faits peut être défini à l'aide de DMQL comme suit -
define cube sales [time, item, branch, location]:
dollars sold = sum(sales in dollars), units sold = count(*)
define dimension time as (time key, day, day of week, month, quarter, year)
define dimension item as (item key, item name, brand, type, supplier type)
define dimension branch as (branch key, branch name, branch type)
define dimension location as (location key, street, city, province or state,country)
define cube shipping [time, item, shipper, from location, to location]:
dollars cost = sum(cost in dollars), units shipped = count(*)
define dimension time as time in cube sales
define dimension item as item in cube sales
define dimension shipper as (shipper key, shipper name, location as location in cube sales, shipper type)
define dimension from location as location in cube sales
define dimension to location as location in cube salesLe partitionnement est fait pour améliorer les performances et faciliter la gestion des données. Le partitionnement aide également à équilibrer les diverses exigences du système. Il optimise les performances matérielles et simplifie la gestion de l'entrepôt de données en partitionnant chaque table de faits en plusieurs partitions distinctes. Dans ce chapitre, nous aborderons différentes stratégies de partitionnement.
Pourquoi est-il nécessaire de partitionner?
Le partitionnement est important pour les raisons suivantes -
- Pour une gestion facile,
- Pour aider à la sauvegarde / restauration,
- Pour améliorer les performances.
Pour une gestion facile
La table de faits dans un entrepôt de données peut atteindre des centaines de gigaoctets. Cette énorme table de faits est très difficile à gérer comme une seule entité. Par conséquent, il a besoin d'un partitionnement.
Pour assister la sauvegarde / la restauration
Si nous ne partitionnons pas la table de faits, nous devons charger la table de faits complète avec toutes les données. Le partitionnement nous permet de charger uniquement autant de données que nécessaire sur une base régulière. Il réduit le temps de chargement et améliore également les performances du système.
Note- Pour réduire la taille de la sauvegarde, toutes les partitions autres que la partition actuelle peuvent être marquées en lecture seule. On peut alors mettre ces partitions dans un état où elles ne peuvent pas être modifiées. Ensuite, ils peuvent être sauvegardés. Cela signifie que seule la partition actuelle doit être sauvegardée.
Pour améliorer les performances
En partitionnant la table de faits en ensembles de données, les procédures de requête peuvent être améliorées. Les performances des requêtes sont améliorées car désormais la requête analyse uniquement les partitions pertinentes. Il n'est pas nécessaire de scanner toutes les données.
Partitionnement horizontal
Il existe différentes manières de partitionner une table de faits. Dans le partitionnement horizontal, nous devons garder à l'esprit les exigences de gestion de l'entrepôt de données.
Partitionnement par temps en segments égaux
Dans cette stratégie de partitionnement, la table de faits est partitionnée sur la base de la période. Ici, chaque période représente une période de rétention importante au sein de l'entreprise. Par exemple, si l'utilisateur demandemonth to date datail convient alors de partitionner les données en segments mensuels. Nous pouvons réutiliser les tables partitionnées en supprimant les données qu'elles contiennent.
Partition par temps en segments de différentes tailles
Ce type de partition est effectué là où les données anciennes sont rarement consultées. Il est implémenté comme un ensemble de petites partitions pour les données relativement actuelles, une plus grande partition pour les données inactives.
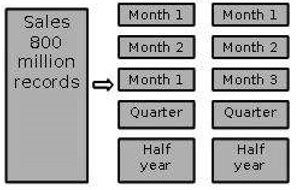
Points à noter
Les informations détaillées restent disponibles en ligne.
Le nombre de tables physiques est maintenu relativement petit, ce qui réduit les coûts d'exploitation.
Cette technique est appropriée lorsqu'un mélange de données plongeant dans l'histoire récente et l'exploration de données à travers l'histoire entière est nécessaire.
Cette technique n'est pas utile lorsque le profil de partitionnement change régulièrement, car le repartitionnement augmentera le coût de fonctionnement de l'entrepôt de données.
Partition sur une dimension différente
La table de faits peut également être partitionnée sur la base de dimensions autres que le temps telles que le groupe de produits, la région, le fournisseur ou toute autre dimension. Prenons un exemple.
Supposons qu'une fonction de marché ait été structurée en départements régionaux distincts comme sur un state by statebase. Si chaque région souhaite interroger les informations capturées dans sa région, il serait plus efficace de partitionner la table de faits en partitions régionales. Cela entraînera une accélération des requêtes car il ne nécessite pas d'analyser les informations qui ne sont pas pertinentes.
Points à noter
La requête n'a pas à analyser les données non pertinentes, ce qui accélère le processus de requête.
Cette technique n'est pas appropriée là où les dimensions sont peu susceptibles de changer à l'avenir. Donc, il vaut la peine de déterminer que la dimension ne change pas à l'avenir.
Si la dimension change, la table de faits entière devra être repartitionnée.
Note - Nous vous recommandons d'effectuer la partition uniquement sur la base de la dimension temporelle, sauf si vous êtes certain que le regroupement de dimensions suggéré ne changera pas pendant la durée de vie de l'entrepôt de données.
Partition par taille de table
Lorsqu'il n'y a pas de base claire pour partitionner la table de faits sur n'importe quelle dimension, alors nous devrions partition the fact table on the basis of their size.Nous pouvons définir la taille prédéterminée comme un point critique. Lorsque la table dépasse la taille prédéterminée, une nouvelle partition de table est créée.
Points à noter
Ce partitionnement est complexe à gérer.
Il nécessite des métadonnées pour identifier les données stockées dans chaque partition.
Partitionnement des dimensions
Si une dimension contient un grand nombre d'entrées, il est alors nécessaire de partitionner les dimensions. Ici, nous devons vérifier la taille d'une dimension.
Considérez une conception de grande taille qui change avec le temps. Si nous devons stocker toutes les variations afin d'appliquer des comparaisons, cette dimension peut être très grande. Cela affecterait certainement le temps de réponse.
Partitions à la ronde
Dans la technique du round robin, lorsqu'une nouvelle partition est nécessaire, l'ancienne est archivée. Il utilise des métadonnées pour permettre à l'outil d'accès utilisateur de faire référence à la partition de table correcte.
Cette technique facilite l'automatisation des fonctions de gestion des tables au sein de l'entrepôt de données.
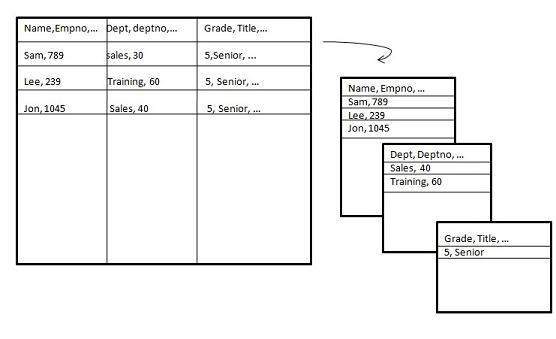
Partition verticale
Partitionnement vertical, divise les données verticalement. Les images suivantes montrent comment le partitionnement vertical est effectué.
Le partitionnement vertical peut être effectué des deux manières suivantes -
- Normalization
- Division de ligne
Normalisation
La normalisation est la méthode relationnelle standard d'organisation de la base de données. Dans cette méthode, les lignes sont regroupées en une seule ligne, ce qui réduit l'espace. Jetez un œil aux tableaux suivants qui montrent comment la normalisation est effectuée.
Tableau avant normalisation
| Product_id | Qté | Valeur | date_vente | Store_id | Nom du magasin | Emplacement | Région |
|---|---|---|---|---|---|---|---|
| 30 | 5 | 3,67 | 3-août-13 | 16 | ensoleillé | Bangalore | S |
| 35 | 4 | 5,33 | 3-sept.-13 | 16 | ensoleillé | Bangalore | S |
| 40 | 5 | 2,50 | 3-sept.-13 | 64 | san | Bombay | W |
| 45 | sept | 5,66 | 3-sept.-13 | 16 | ensoleillé | Bangalore | S |
Tableau après normalisation
| Store_id | Nom du magasin | Emplacement | Région |
|---|---|---|---|
| 16 | ensoleillé | Bangalore | W |
| 64 | san | Bombay | S |
| Product_id | Quantité | Valeur | date_vente | Store_id |
|---|---|---|---|---|
| 30 | 5 | 3,67 | 3-août-13 | 16 |
| 35 | 4 | 5,33 | 3-sept.-13 | 16 |
| 40 | 5 | 2,50 | 3-sept.-13 | 64 |
| 45 | sept | 5,66 | 3-sept.-13 | 16 |
Division de ligne
Le fractionnement de lignes a tendance à laisser une carte univoque entre les partitions. Le motif de la division des rangées est d'accélérer l'accès à une grande table en réduisant sa taille.
Note - Lors de l'utilisation du partitionnement vertical, assurez-vous qu'il n'est pas nécessaire d'effectuer une opération de jointure majeure entre deux partitions.
Identifier la clé de la partition
Il est très important de choisir la bonne clé de partition. Le choix d'une mauvaise clé de partition conduira à réorganiser la table de faits. Prenons un exemple. Supposons que nous voulions partitionner la table suivante.
Account_Txn_Table
transaction_id
account_id
transaction_type
value
transaction_date
region
branch_nameNous pouvons choisir de partitionner sur n'importe quelle clé. Les deux clés possibles pourraient être
- region
- transaction_date
Supposons que l'entreprise soit organisée en 30 régions géographiques et que chaque région ait un nombre différent de succursales. Cela nous donnera 30 partitions, ce qui est raisonnable. Ce partitionnement est suffisant car notre capture des exigences a montré qu'une grande majorité des requêtes sont limitées à la propre région d'activité de l'utilisateur.
Si nous partitionnons par transaction_date au lieu de région, la dernière transaction de chaque région sera dans une partition. Désormais, l'utilisateur qui souhaite consulter des données dans sa propre région doit interroger plusieurs partitions.
Il vaut donc la peine de déterminer la bonne clé de partitionnement.
Qu'est-ce que les métadonnées?
Les métadonnées sont simplement définies comme des données sur les données. Les données utilisées pour représenter d'autres données sont appelées métadonnées. Par exemple, l'index d'un livre sert de métadonnées pour le contenu du livre. En d'autres termes, nous pouvons dire que les métadonnées sont les données résumées qui nous conduisent à des données détaillées. En termes d'entrepôt de données, nous pouvons définir les métadonnées comme suit.
Les métadonnées sont la feuille de route vers un entrepôt de données.
Les métadonnées dans un entrepôt de données définissent les objets de l'entrepôt.
Les métadonnées agissent comme un répertoire. Ce répertoire aide le système d'aide à la décision à localiser le contenu d'un entrepôt de données.
Note- Dans un entrepôt de données, nous créons des métadonnées pour les noms de données et les définitions d'un entrepôt de données donné. Parallèlement à ces métadonnées, des métadonnées supplémentaires sont également créées pour horodater les données extraites, la source des données extraites.
Catégories de métadonnées
Les métadonnées peuvent être globalement classées en trois catégories -
Business Metadata - Il contient les informations sur la propriété des données, la définition de l'entreprise et les politiques changeantes.
Technical Metadata- Il comprend les noms de système de base de données, les noms et tailles de table et de colonne, les types de données et les valeurs autorisées. Les métadonnées techniques comprennent également des informations structurelles telles que les attributs et indices de clés primaires et étrangères.
Operational Metadata- Il comprend la mise à jour des données et le lignage des données. La devise des données signifie si les données sont actives, archivées ou purgées. Le lignage des données signifie l'historique des données migrées et la transformation appliquée dessus.

Rôle des métadonnées
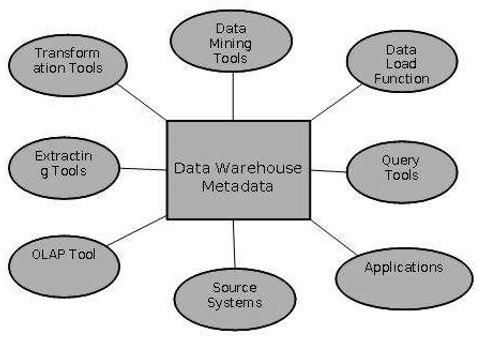
Les métadonnées ont un rôle très important dans un entrepôt de données. Le rôle des métadonnées dans un entrepôt est différent de celui des données de l'entrepôt, mais il joue un rôle important. Les différents rôles des métadonnées sont expliqués ci-dessous.
Les métadonnées agissent comme un répertoire.
Ce répertoire aide le système d'aide à la décision à localiser le contenu de l'entrepôt de données.
Les métadonnées aident au système d'aide à la décision pour la cartographie des données lorsque les données sont transformées de l'environnement opérationnel à l'environnement d'entrepôt de données.
Les métadonnées aident à récapituler entre les données détaillées actuelles et les données hautement résumées.
Les métadonnées aident également à la synthèse entre des données légèrement détaillées et des données hautement résumées.
Les métadonnées sont utilisées pour les outils de requête.
Les métadonnées sont utilisées dans les outils d'extraction et de nettoyage.
Les métadonnées sont utilisées dans les outils de reporting.
Les métadonnées sont utilisées dans les outils de transformation.
Les métadonnées jouent un rôle important dans le chargement des fonctions.
Le diagramme suivant montre les rôles des métadonnées.
Référentiel de métadonnées
Le référentiel de métadonnées fait partie intégrante d'un système d'entrepôt de données. Il a les métadonnées suivantes -
Definition of data warehouse- Il comprend la description de la structure de l'entrepôt de données. La description est définie par le schéma, la vue, les hiérarchies, les définitions de données dérivées et les emplacements et le contenu du magasin de données.
Business metadata - Il contient les informations sur la propriété des données, la définition de l'entreprise et les politiques changeantes.
Operational Metadata- Il comprend la mise à jour des données et le lignage des données. La devise des données signifie si les données sont actives, archivées ou purgées. Le lignage des données signifie l'historique des données migrées et la transformation appliquée dessus.
Data for mapping from operational environment to data warehouse - Il comprend les bases de données sources et leur contenu, l'extraction des données, le nettoyage des partitions de données, les règles de transformation, les règles d'actualisation et de purge des données.
Algorithms for summarization - Il comprend des algorithmes de dimension, des données sur la granularité, l'agrégation, la synthèse, etc.
Défis de la gestion des métadonnées
L'importance des métadonnées ne peut pas être surestimée. Les métadonnées contribuent à la précision des rapports, valident la transformation des données et garantissent l'exactitude des calculs. Les métadonnées appliquent également la définition des termes commerciaux aux utilisateurs finaux de l'entreprise. Avec toutes ces utilisations des métadonnées, elle a aussi ses défis. Certains des défis sont abordés ci-dessous.
Les métadonnées dans une grande organisation sont dispersées dans toute l'organisation. Ces métadonnées sont réparties dans des feuilles de calcul, des bases de données et des applications.
Les métadonnées peuvent être présentes dans des fichiers texte ou des fichiers multimédias. Pour utiliser ces données pour des solutions de gestion de l'information, elles doivent être correctement définies.
Il n'y a pas de normes acceptées à l'échelle de l'industrie. Les fournisseurs de solutions de gestion de données ont une concentration étroite.
Il n'existe pas de méthodes simples et acceptées pour transmettre des métadonnées.
Pourquoi avons-nous besoin d'un Data Mart?
Vous trouverez ci-dessous les raisons de créer un data mart -
Partitionner des données pour imposer access control strategies.
Pour accélérer les requêtes en réduisant le volume de données à analyser.
Pour segmenter les données dans différentes plates-formes matérielles.
Pour structurer les données sous une forme adaptée à un outil d'accès utilisateur.
Note- Ne pas effectuer de data mart pour toute autre raison car le coût de fonctionnement du data marting pourrait être très élevé. Avant le data marting, assurez-vous que la stratégie de data marting est adaptée à votre solution particulière.
Marting de données rentable
Suivez les étapes ci-dessous pour rendre le data marting rentable -
- Identifier les divisions fonctionnelles
- Identifier les exigences de l'outil d'accès utilisateur
- Identifier les problèmes de contrôle d'accès
Identifier les divisions fonctionnelles
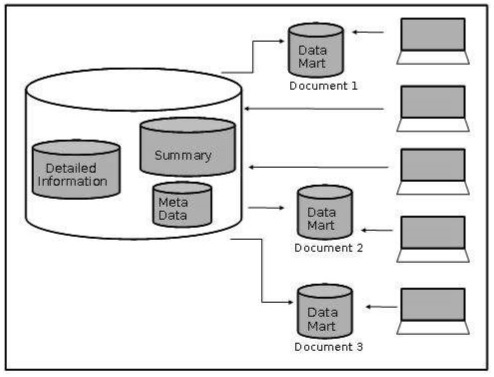
Dans cette étape, nous déterminons si l'organisation présente des divisions fonctionnelles naturelles. Nous recherchons des divisions ministérielles et nous déterminons si la manière dont les ministères utilisent l'information a tendance à être isolée du reste de l'organisation. Prenons un exemple.
Considérons une organisation de vente au détail, où chaque commerçant est responsable de maximiser les ventes d'un groupe de produits. Pour cela, voici les informations précieuses -
- transaction de vente au quotidien
- prévisions de ventes sur une base hebdomadaire
- position de stock sur une base quotidienne
- mouvements de stock au quotidien
Comme le commerçant n'est pas intéressé par les produits avec lesquels il ne traite pas, le data marting est un sous-ensemble des données traitant du groupe de produits qui l'intéresse. Le diagramme suivant montre la marting de données pour différents utilisateurs.
Vous trouverez ci-dessous les problèmes à prendre en compte lors de la détermination de la répartition fonctionnelle -
La structure du département peut changer.
Les produits peuvent passer d'un département à l'autre.
Le commerçant peut interroger la tendance des ventes d'autres produits pour analyser ce qui se passe avec les ventes.
Note - Nous devons déterminer les avantages commerciaux et la faisabilité technique de l'utilisation d'un data mart.
Identifier les exigences de l'outil d'accès utilisateur
Nous avons besoin de data marts pour soutenir user access toolsqui nécessitent des structures de données internes. Les données de ces structures échappent au contrôle de l'entrepôt de données, mais doivent être remplies et mises à jour régulièrement.
Certains outils se remplissent directement à partir du système source, mais certains ne le peuvent pas. Par conséquent, des exigences supplémentaires en dehors du champ d'application de l'outil doivent être identifiées pour l'avenir.
Note - Afin d'assurer la cohérence des données dans tous les outils d'accès, les données ne doivent pas être directement alimentées à partir de l'entrepôt de données, mais chaque outil doit avoir son propre magasin de données.
Identifier les problèmes de contrôle d'accès
Il devrait y avoir des règles de confidentialité pour garantir que les données ne sont accessibles qu'aux utilisateurs autorisés. Par exemple, un entrepôt de données pour une banque de détail garantit que tous les comptes appartiennent à la même entité juridique. Les lois sur la confidentialité peuvent vous obliger à empêcher totalement l'accès à des informations qui n'appartiennent pas à la banque en question.
Les data marts nous permettent de construire un mur complet en séparant physiquement les segments de données au sein de l'entrepôt de données. Pour éviter d'éventuels problèmes de confidentialité, les données détaillées peuvent être supprimées de l'entrepôt de données. Nous pouvons créer un data mart pour chaque entité juridique et le charger via un data warehouse, avec des données de compte détaillées.
Conception de Data Marts
Les data marts doivent être conçus comme une version plus petite du schéma starflake dans l'entrepôt de données et doivent correspondre à la conception de la base de données de l'entrepôt de données. Cela aide à garder le contrôle sur les instances de base de données.
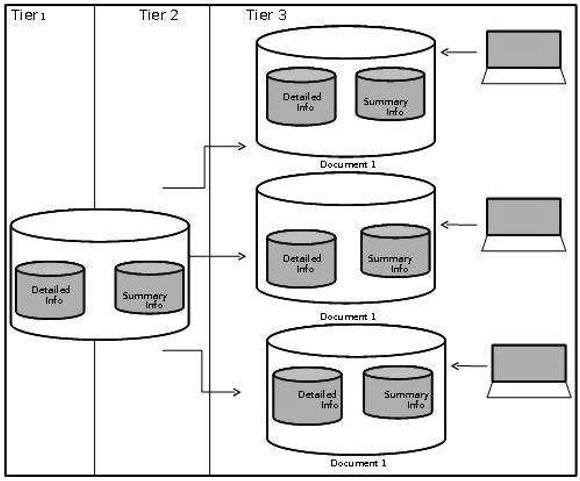
Les résumés sont des données entreposées de la même manière qu'elles auraient été conçues dans l'entrepôt de données. Les tableaux récapitulatifs aident à utiliser toutes les données de dimension dans le schéma starflake.
Coût du data marting
Les mesures de coût pour le data marting sont les suivantes:
- Coût matériel et logiciel
- L'accès au réseau
- Contraintes de fenêtre de temps
Coût matériel et logiciel
Bien que les data marts soient créés sur le même matériel, ils nécessitent du matériel et des logiciels supplémentaires. Pour gérer les requêtes des utilisateurs, il nécessite une puissance de traitement et un stockage sur disque supplémentaires. Si des données détaillées et le magasin de données existent dans l'entrepôt de données, nous serions confrontés à des coûts supplémentaires pour stocker et gérer les données répliquées.
Note - Le data marting est plus coûteux que les agrégations, il doit donc être utilisé comme une stratégie supplémentaire et non comme une stratégie alternative.
L'accès au réseau
Un magasin de données peut être situé à un emplacement différent de celui de l'entrepôt de données, nous devons donc nous assurer que le LAN ou le WAN a la capacité de gérer les volumes de données transférés dans le data mart load process.
Contraintes de fenêtre de temps
La mesure dans laquelle un processus de chargement de magasin de données rongera la fenêtre de temps disponible dépend de la complexité des transformations et des volumes de données expédiés. La détermination du nombre de magasins de données possibles dépend de -
- Capacité du réseau.
- Fenêtre de temps disponible
- Volume de données transférées
- Mécanismes utilisés pour insérer des données dans un magasin de données
La gestion du système est obligatoire pour la mise en œuvre réussie d'un entrepôt de données. Les gestionnaires de système les plus importants sont -
- Gestionnaire de configuration système
- Gestionnaire de planification du système
- Gestionnaire d'événements système
- Gestionnaire de base de données système
- Gestionnaire de récupération de sauvegarde système
Gestionnaire de configuration système
Le gestionnaire de la configuration du système est responsable de la gestion de l'installation et de la configuration de l'entrepôt de données.
La structure du gestionnaire de configuration varie d'un système d'exploitation à l'autre.
Dans la structure de configuration Unix, le gestionnaire varie d'un fournisseur à l'autre.
Les gestionnaires de configuration ont une interface utilisateur unique.
L'interface du gestionnaire de configuration nous permet de contrôler tous les aspects du système.
Note - L'outil de configuration le plus important est le gestionnaire d'E / S.
Gestionnaire de planification système
System Scheduling Manager est responsable de la mise en œuvre réussie de l'entrepôt de données. Son but est de planifier des requêtes ad hoc. Chaque système d'exploitation a son propre planificateur avec une forme de mécanisme de contrôle par lots. La liste des fonctionnalités qu'un gestionnaire de planification système doit avoir est la suivante:
- Travailler au-delà des limites des clusters ou des MPP
- Traiter les décalages horaires internationaux
- Gérer l'échec du travail
- Gérer plusieurs requêtes
- Soutenir les priorités de travail
- Redémarrez ou remettez en file d'attente les travaux ayant échoué
- Notifier l'utilisateur ou un processus lorsque le travail est terminé
- Maintenir les calendriers de travail lors des pannes du système
- Remettre les travaux en file d'attente dans d'autres files d'attente
- Prise en charge de l'arrêt et du démarrage des files d'attente
- Journaliser les tâches en file d'attente
- Traiter le traitement entre les files d'attente
Note - La liste ci-dessus peut être utilisée comme paramètres d'évaluation pour l'évaluation d'un bon ordonnanceur.
Voici quelques tâches importantes qu'un planificateur doit être en mesure de gérer:
- Planification des requêtes quotidiennes et ad hoc
- Exécution des exigences de rapport régulier
- Charge de données
- Traitement de l'information
- Création d'index
- Backup
- Création d'agrégation
- Transformation des données
Note - Si l'entrepôt de données s'exécute sur une architecture en cluster ou MPP, le gestionnaire de planification du système doit être capable de fonctionner sur toute l'architecture.
Gestionnaire d'événements système
Le gestionnaire d'événements est une sorte de logiciel. Le gestionnaire d'événements gère les événements définis sur le système d'entrepôt de données. Nous ne pouvons pas gérer l'entrepôt de données manuellement car la structure de l'entrepôt de données est très complexe. Par conséquent, nous avons besoin d'un outil qui gère automatiquement tous les événements sans aucune intervention de l'utilisateur.
Note- Le gestionnaire d'événements surveille les occurrences d'événements et les traite. Le gestionnaire d'événements suit également la myriade de choses qui peuvent mal tourner sur ce système d'entrepôt de données complexe.
Événements
Les événements sont les actions générées par l'utilisateur ou le système lui-même. On peut noter que l'événement est une occurrence mesurable et observable d'une action définie.
Vous trouverez ci-dessous une liste d'événements courants qui doivent être suivis.
- Erreur matérielle
- Manque d'espace sur certains disques clés
- Un processus en train de mourir
- Un processus renvoyant une erreur
- Utilisation du processeur dépassant un seuil de 805
- Conflit interne sur les points de sérialisation de la base de données
- Les taux de réussite du cache tampon dépassent ou échouent en dessous du seuil
- Une table atteignant au maximum sa taille
- Échange de mémoire excessif
- Une table ne s'étendant pas faute de place
- Disque présentant des goulots d'étranglement d'E / S
- Utilisation de la zone temporaire ou de tri atteignant un certain seuil
- Toute autre utilisation de la mémoire partagée de la base de données
La chose la plus importante à propos des événements est qu'ils doivent être capables de s'exécuter seuls. Les packages d'événements définissent les procédures pour les événements prédéfinis. Le code associé à chaque événement est appelé gestionnaire d'événements. Ce code est exécuté chaque fois qu'un événement se produit.
Gestionnaire de système et de base de données
Le système et le gestionnaire de base de données peuvent être deux logiciels distincts, mais ils font le même travail. L'objectif de ces outils est d'automatiser certains processus et de simplifier l'exécution d'autres. Les critères de choix d'un système et du gestionnaire de base de données sont les suivants -
- augmenter le quota de l'utilisateur.
- attribuer et désattribuer des rôles aux utilisateurs
- attribuer et désattribuer les profils aux utilisateurs
- effectuer la gestion de l'espace de la base de données
- surveiller et rendre compte de l'utilisation de l'espace
- ranger l'espace fragmenté et inutilisé
- ajouter et agrandir l'espace
- ajouter et supprimer des utilisateurs
- gérer le mot de passe utilisateur
- gérer des tableaux récapitulatifs ou temporaires
- attribuer ou désattribuer un espace temporaire à et depuis l'utilisateur
- récupérer l'espace des tables temporaires anciennes ou obsolètes
- gérer les journaux d'erreurs et de suivi
- pour parcourir les fichiers journaux et de trace
- rediriger les informations d'erreur ou de trace
- activer et désactiver la journalisation des erreurs et des traces
- effectuer la gestion de l'espace système
- surveiller et rendre compte de l'utilisation de l'espace
- nettoyer les répertoires de fichiers anciens et inutilisés
- ajouter ou agrandir de l'espace.
Gestionnaire de récupération de sauvegarde système
L'outil de sauvegarde et de restauration permet au personnel d'exploitation et de gestion de sauvegarder facilement les données. Notez que le gestionnaire de sauvegarde du système doit être intégré au logiciel de gestion de planification utilisé. Les fonctionnalités importantes requises pour la gestion des sauvegardes sont les suivantes:
- Scheduling
- Suivi des données de sauvegarde
- Connaissance de la base de données
Les sauvegardes sont effectuées uniquement pour se protéger contre la perte de données. Voici les points importants à retenir -
Le logiciel de sauvegarde conservera une certaine forme de base de données indiquant où et quand les données ont été sauvegardées.
Le gestionnaire de récupération de sauvegarde doit avoir une bonne interface avec cette base de données.
Le logiciel de récupération de sauvegarde doit être compatible avec la base de données.
Connaissant la base de données, le logiciel peut alors être adressé en termes de base de données et n'effectuera pas de sauvegardes qui ne seraient pas viables.
Les gestionnaires de processus sont chargés de maintenir le flux de données à la fois vers et hors de l'entrepôt de données. Il existe trois types différents de gestionnaires de processus -
- Gestionnaire de charge
- Directeur d'entrepôt
- Gestionnaire de requêtes
Gestionnaire de charge de l'entrepôt de données
Le gestionnaire de charge effectue les opérations nécessaires pour extraire et charger les données dans la base de données. La taille et la complexité d'un gestionnaire de charge varient entre les solutions spécifiques d'un entrepôt de données à l'autre.
Architecture du gestionnaire de charge
Le gestionnaire de charge exécute les fonctions suivantes -
Extraire les données du système source.
Chargez rapidement les données extraites dans le magasin de données temporaire.
Effectuez des transformations simples en structure similaire à celle de l'entrepôt de données.
Extraire les données de la source
Les données sont extraites des bases de données opérationnelles ou des fournisseurs d'informations externes. Les passerelles sont les programmes d'application utilisés pour extraire les données. Il est pris en charge par le SGBD sous-jacent et permet au programme client de générer du SQL à exécuter sur un serveur. Open Database Connection (ODBC) et Java Database Connection (JDBC) sont des exemples de passerelle.
Charge rapide
Afin de minimiser la fenêtre de chargement total, les données doivent être chargées dans l'entrepôt le plus rapidement possible.
Les transformations affectent la vitesse de traitement des données.
Il est plus efficace de charger les données dans une base de données relationnelle avant d'appliquer les transformations et les vérifications.
La technologie de passerelle n'est pas adaptée, car elle est inefficace lorsque de gros volumes de données sont impliqués.
Transformations simples
Lors du chargement, il peut être nécessaire d'effectuer des transformations simples. Après avoir effectué des transformations simples, nous pouvons effectuer des vérifications complexes. Supposons que nous chargeons la transaction de vente EPOS, nous devons effectuer les vérifications suivantes -
- Supprimez toutes les colonnes qui ne sont pas nécessaires dans l'entrepôt.
- Convertissez toutes les valeurs en types de données requis.
Directeur d'entrepôt
Le responsable de l'entrepôt est responsable du processus de gestion de l'entrepôt. Il se compose d'un logiciel système tiers, de programmes C et de scripts shell. La taille et la complexité d'un responsable d'entrepôt varient selon les solutions spécifiques.
Architecture du gestionnaire d'entrepôt
Un responsable d'entrepôt comprend les éléments suivants:
- Le processus de contrôle
- Procédures stockées ou C avec SQL
- Outil de sauvegarde / restauration
- Scripts SQL
Fonctions du gestionnaire d'entrepôt
Un responsable d'entrepôt remplit les fonctions suivantes -
Analyse les données pour effectuer des contrôles de cohérence et d'intégrité référentielle.
Crée des index, des vues d'entreprise, des vues de partition par rapport aux données de base.
Génère de nouvelles agrégations et met à jour les agrégations existantes.
Génère des normalisations.
Transforme et fusionne les données source du magasin temporaire dans l'entrepôt de données publié.
Sauvegarde les données dans l'entrepôt de données.
Archive les données qui ont atteint la fin de leur vie capturée.
Note - Un gestionnaire d'entrepôt analyse les profils de requête pour déterminer si l'index et les agrégations sont appropriés.
Gestionnaire de requêtes
Le gestionnaire de requêtes est chargé de diriger les requêtes vers les tables appropriées. En dirigeant les requêtes vers les tables appropriées, il accélère le processus de requête et de réponse. De plus, le gestionnaire de requêtes est responsable de la planification de l'exécution des requêtes envoyées par l'utilisateur.
Architecture du gestionnaire de requêtes
Un gestionnaire de requêtes comprend les composants suivants -
- Redirection des requêtes via l'outil C ou le SGBDR
- Procédures stockées
- Outil de gestion des requêtes
- Planification des requêtes via l'outil C ou le SGBDR
- Planification des requêtes via un logiciel tiers
Fonctions du gestionnaire de requêtes
Il présente les données à l'utilisateur sous une forme qu'il comprend.
Il planifie l'exécution des requêtes envoyées par l'utilisateur final.
Il stocke les profils de requête pour permettre au responsable de l'entrepôt de déterminer quels index et agrégations sont appropriés.
L'objectif d'un entrepôt de données est de rendre de grandes quantités de données facilement accessibles aux utilisateurs, permettant ainsi aux utilisateurs d'extraire des informations sur l'entreprise dans son ensemble. Mais nous savons qu'il pourrait y avoir des restrictions de sécurité appliquées sur les données qui peuvent être un obstacle à l'accès aux informations. Si l'analyste a une vision restreinte des données, il est alors impossible de saisir une image complète des tendances au sein de l'entreprise.
Les données de chaque analyste peuvent être résumées et transmises à la direction où les différents résumés peuvent être agrégés. Comme les agrégations de résumés ne peuvent pas être les mêmes que celles de l'agrégation dans son ensemble, il est possible de passer à côté de certaines tendances de l'information dans les données à moins que quelqu'un analyse les données dans leur ensemble.
Exigences de sécurité
L'ajout de fonctionnalités de sécurité affecte les performances de l'entrepôt de données, il est donc important de déterminer les exigences de sécurité le plus tôt possible. Il est difficile d'ajouter des fonctionnalités de sécurité après la mise en service de l'entrepôt de données.
Pendant la phase de conception de l'entrepôt de données, nous devons garder à l'esprit quelles sources de données peuvent être ajoutées ultérieurement et quel serait l'impact de l'ajout de ces sources de données. Nous devrions considérer les possibilités suivantes pendant la phase de conception.
Si les nouvelles sources de données nécessiteront la mise en œuvre de nouvelles restrictions de sécurité et / ou d'audit?
Si les nouveaux utilisateurs ajoutés ont un accès restreint aux données qui sont déjà généralement disponibles?
Cette situation survient lorsque les futurs utilisateurs et les sources de données ne sont pas bien connus. Dans une telle situation, nous devons utiliser les connaissances commerciales et l'objectif de l'entrepôt de données pour connaître les exigences probables.
Les activités suivantes sont affectées par les mesures de sécurité -
- Accès utilisateur
- Charge de données
- Mouvement de données
- Génération de requêtes
Accès utilisateur
Nous devons d'abord classer les données, puis classer les utilisateurs sur la base des données auxquelles ils peuvent accéder. En d'autres termes, les utilisateurs sont classés en fonction des données auxquelles ils peuvent accéder.
Data Classification
Les deux approches suivantes peuvent être utilisées pour classer les données -
Les données peuvent être classées en fonction de leur sensibilité. Les données hautement sensibles sont classées comme très restreintes et les données moins sensibles sont classées comme moins restrictives.
Les données peuvent également être classées en fonction de la fonction du poste. Cette restriction permet uniquement à des utilisateurs spécifiques d'afficher des données particulières. Ici, nous limitons les utilisateurs à afficher uniquement la partie des données qui les intéresse et dont ils sont responsables.
Il y a quelques problèmes dans la deuxième approche. Pour comprendre, prenons un exemple. Supposons que vous construisiez l'entrepôt de données pour une banque. Considérez que les données stockées dans l'entrepôt de données sont les données de transaction pour tous les comptes. La question ici est de savoir qui est autorisé à voir les données de transaction. La solution consiste à classer les données selon la fonction.
User classification
Les approches suivantes peuvent être utilisées pour classer les utilisateurs -
Les utilisateurs peuvent être classés selon la hiérarchie des utilisateurs dans une organisation, c'est-à-dire que les utilisateurs peuvent être classés par services, sections, groupes, etc.
Les utilisateurs peuvent également être classés en fonction de leur rôle, les personnes étant regroupées dans les services en fonction de leur rôle.
Classification on basis of Department
Prenons un exemple d'entrepôt de données où les utilisateurs sont issus du département des ventes et du marketing. Nous pouvons avoir la sécurité par une vue d'entreprise de haut en bas, avec un accès centré sur les différents services. Mais il pourrait y avoir des restrictions sur les utilisateurs à différents niveaux. Cette structure est illustrée dans le diagramme suivant.
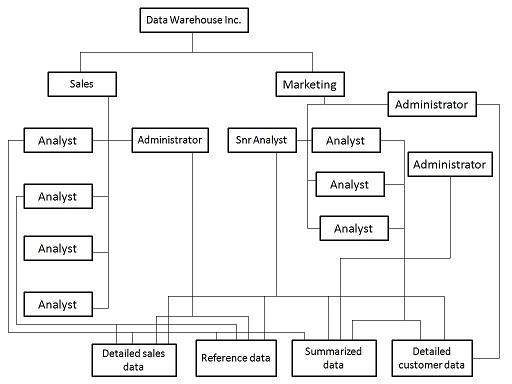
Mais si chaque service accède à des données différentes, nous devons concevoir l'accès de sécurité pour chaque service séparément. Cela peut être réalisé par les centres de données ministériels. Étant donné que ces magasins de données sont séparés de l'entrepôt de données, nous pouvons appliquer des restrictions de sécurité distinctes sur chaque magasin de données. Cette approche est illustrée dans la figure suivante.
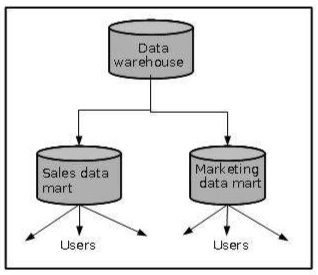
Classification Based on Role
Si les données sont généralement disponibles pour tous les départements, il est alors utile de suivre la hiérarchie d'accès aux rôles. En d'autres termes, si les données sont généralement consultées par tous les services, appliquez des restrictions de sécurité selon le rôle de l'utilisateur. La hiérarchie d'accès aux rôles est illustrée dans la figure suivante.
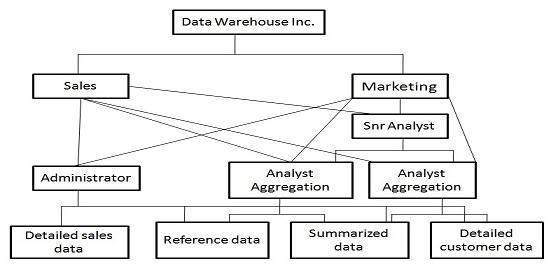
Exigences d'audit
L'audit est un sous-ensemble de la sécurité, une activité coûteuse. L'audit peut entraîner de lourdes charges sur le système. Pour terminer un audit à temps, nous avons besoin de plus de matériel et, par conséquent, il est recommandé que, dans la mesure du possible, l'audit soit désactivé. Les exigences d'audit peuvent être classées comme suit -
- Connections
- Disconnections
- Accès aux données
- Changement de données
Note- Pour chacune des catégories susmentionnées, il est nécessaire de vérifier le succès, l'échec ou les deux. Du point de vue des raisons de sécurité, l'audit des pannes est très important. L'audit des échecs est important car ils peuvent mettre en évidence un accès non autorisé ou frauduleux.
Exigences du réseau
La sécurité du réseau est aussi importante que les autres titres. Nous ne pouvons ignorer l'exigence de sécurité du réseau. Nous devons considérer les questions suivantes -
Est-il nécessaire de crypter les données avant de les transférer vers l'entrepôt de données?
Existe-t-il des restrictions sur les itinéraires réseau que les données peuvent emprunter?
Ces restrictions doivent être examinées attentivement. Voici les points à retenir -
Le processus de cryptage et de décryptage augmentera les frais généraux. Cela exigerait plus de puissance de traitement et de temps de traitement.
Le coût du cryptage peut être élevé si le système est déjà un système chargé car le cryptage est supporté par le système source.
Mouvement de données
Il existe des implications de sécurité potentielles lors du déplacement des données. Supposons que nous devions transférer des données restreintes sous forme de fichier plat à charger. Lorsque les données sont chargées dans l'entrepôt de données, les questions suivantes se posent:
- Où le fichier plat est-il stocké?
- Qui a accès à cet espace disque?
Si nous parlons de la sauvegarde de ces fichiers plats, les questions suivantes se posent -
- Sauvegardez-vous des versions chiffrées ou déchiffrées?
- Ces sauvegardes doivent-elles être effectuées sur des bandes spéciales qui sont stockées séparément?
- Qui a accès à ces bandes?
Certaines autres formes de mouvement de données telles que les ensembles de résultats de requête doivent également être prises en compte. Les questions soulevées lors de la création de la table temporaire sont les suivantes -
- Où se tiendra cette table temporaire?
- Comment rendre ce tableau visible?
Nous devons éviter de bafouer accidentellement les restrictions de sécurité. Si un utilisateur ayant accès aux données restreintes peut générer des tables temporaires accessibles, les données peuvent être visibles par des utilisateurs non autorisés. Nous pouvons surmonter ce problème en ayant une zone temporaire distincte pour les utilisateurs ayant accès à des données restreintes.
Documentation
Les exigences d'audit et de sécurité doivent être correctement documentées. Cela sera traité comme une partie de la justification. Ce document peut contenir toutes les informations recueillies auprès de -
- Classification des données
- Classification des utilisateurs
- Exigences du réseau
- Exigences de mouvement et de stockage des données
- Toutes les actions vérifiables
Impact de la sécurité sur la conception
La sécurité affecte le code de l'application et les délais de développement. La sécurité affecte le domaine suivant -
- Développement d'applications
- Conception de base de données
- Testing
Développement d'applications
La sécurité affecte le développement global de l'application et elle affecte également la conception des composants importants de l'entrepôt de données tels que le gestionnaire de charge, le gestionnaire d'entrepôt et le gestionnaire de requêtes. Le gestionnaire de charge peut exiger un code de vérification pour filtrer les enregistrements et les placer à différents endroits. Des règles de transformation supplémentaires peuvent également être nécessaires pour masquer certaines données. Des métadonnées supplémentaires peuvent également être requises pour gérer les objets supplémentaires.
Pour créer et gérer des vues supplémentaires, le responsable de l'entrepôt peut avoir besoin de codes supplémentaires pour appliquer la sécurité. Des vérifications supplémentaires peuvent devoir être codées dans l'entrepôt de données pour éviter qu'il ne soit dupé en déplaçant des données vers un emplacement où elles ne devraient pas être disponibles. Le gestionnaire de requêtes requiert les modifications pour gérer les restrictions d'accès. Le gestionnaire de requêtes devra connaître toutes les vues et agrégations supplémentaires.
Conception de base de données
La mise en page de la base de données est également affectée car lorsque des mesures de sécurité sont mises en œuvre, il y a une augmentation du nombre de vues et de tables. L'ajout de la sécurité augmente la taille de la base de données et augmente donc la complexité de la conception et de la gestion de la base de données. Cela ajoutera également de la complexité à la gestion des sauvegardes et au plan de récupération.
Essai
Le test de l'entrepôt de données est un processus complexe et long. L'ajout de sécurité à l'entrepôt de données affecte également la complexité du temps de test. Cela affecte les tests des deux manières suivantes -
Cela augmentera le temps requis pour l'intégration et les tests du système.
Il y a des fonctionnalités supplémentaires à tester qui augmenteront la taille de la suite de tests.
Un entrepôt de données est un système complexe et il contient un énorme volume de données. Par conséquent, il est important de sauvegarder toutes les données afin qu'elles deviennent disponibles pour une récupération à l'avenir selon les besoins. Dans ce chapitre, nous aborderons les problèmes liés à la conception de la stratégie de sauvegarde.
Terminologies de sauvegarde
Avant de continuer, vous devez connaître certaines des terminologies de sauvegarde décrites ci-dessous.
Complete backup- Il sauvegarde la base de données entière en même temps. Cette sauvegarde comprend tous les fichiers de base de données, les fichiers de contrôle et les fichiers journaux.
Partial backup- Comme son nom l'indique, il ne crée pas une sauvegarde complète de la base de données. La sauvegarde partielle est très utile dans les grandes bases de données car elle permet une stratégie dans laquelle diverses parties de la base de données sont sauvegardées quotidiennement de manière circulaire, de sorte que toute la base de données est sauvegardée efficacement une fois par semaine.
Cold backup- Une sauvegarde à froid est effectuée lorsque la base de données est complètement arrêtée. Dans un environnement multi-instance, toutes les instances doivent être arrêtées.
Hot backup- La sauvegarde à chaud est effectuée lorsque le moteur de base de données est opérationnel. Les exigences de la sauvegarde à chaud varient du SGBDR au SGBDR.
Online backup - C'est assez similaire à la sauvegarde à chaud.
Sauvegarde matérielle
Il est important de décider quel matériel utiliser pour la sauvegarde. La vitesse de traitement de la sauvegarde et de la restauration dépend du matériel utilisé, de la manière dont le matériel est connecté, de la bande passante du réseau, du logiciel de sauvegarde et de la vitesse du système d'E / S du serveur. Ici, nous allons discuter de certains des choix de matériel disponibles et de leurs avantages et inconvénients. Ces choix sont les suivants -
- Technologie de bande
- Sauvegardes sur disque
Technologie de bande
Le choix de la bande peut être catégorisé comme suit -
- Support de bande
- Lecteurs de bande autonomes
- Empileurs de bandes
- Silos à ruban
Tape Media
Il existe plusieurs variétés de supports de bande. Certaines normes de support de bande sont répertoriées dans le tableau ci-dessous -
| Médias de bande | Capacité | Taux d'E / S |
|---|---|---|
| DLT | 40 Go | 3 Mo / s |
| 3490e | 1,6 Go | 3 Mo / s |
| 8 mm | 14 Go | 1 Mo / s |
Les autres facteurs à prendre en compte sont les suivants:
- Fiabilité du support de bande
- Coût du support de bande par unité
- Scalability
- Coût des mises à niveau du système de bandes
- Coût du support de bande par unité
- Durée de conservation du support de bande
Standalone Tape Drives
Les lecteurs de bande peuvent être connectés des manières suivantes:
- Directement au serveur
- En tant que périphériques disponibles sur le réseau
- À distance vers une autre machine
Des problèmes peuvent survenir lors de la connexion des lecteurs de bande à un entrepôt de données.
Considérez que le serveur est une machine MPP à 48 nœuds. Nous ne connaissons pas le nœud pour connecter le lecteur de bande et nous ne savons pas comment les répartir sur les nœuds du serveur pour obtenir les performances optimales avec le moins de perturbations du serveur et la moindre latence d'E / S interne.
La connexion du lecteur de bande en tant que périphérique disponible sur le réseau nécessite que le réseau soit à la hauteur des énormes taux de transfert de données. Assurez-vous qu'une bande passante suffisante est disponible pendant le temps que vous en avez besoin.
La connexion à distance des lecteurs de bande nécessite également une bande passante élevée.
Empileurs de bandes
La méthode de chargement de plusieurs bandes dans un seul lecteur de bande est connue sous le nom d'empileurs de bandes. L'empileur démonte la bande actuelle quand il en a fini et charge la bande suivante. Par conséquent, une seule bande est disponible à la fois pour y accéder. Le prix et les capacités peuvent varier, mais la capacité commune est qu'ils peuvent effectuer des sauvegardes sans surveillance.
Silos à bande
Les silos à bandes offrent de grandes capacités de stockage. Les silos à bandes peuvent stocker et gérer des milliers de bandes. Ils peuvent intégrer plusieurs lecteurs de bande. Ils ont le logiciel et le matériel nécessaires pour étiqueter et stocker les bandes qu'ils stockent. Il est très courant que le silo soit connecté à distance via un réseau ou une liaison dédiée. Nous devons nous assurer que la bande passante de la connexion est à la hauteur du travail.
Sauvegardes sur disque
Les méthodes de sauvegarde de disque sont -
- Sauvegardes disque à disque
- Miroir cassant
Ces méthodes sont utilisées dans le système OLTP. Ces méthodes minimisent les temps d'arrêt de la base de données et maximisent la disponibilité.
Disk-to-Disk Backups
Ici, la sauvegarde est effectuée sur le disque plutôt que sur la bande. Les sauvegardes de disque à disque sont effectuées pour les raisons suivantes -
- Vitesse des sauvegardes initiales
- Vitesse de restauration
La sauvegarde des données du disque vers le disque est beaucoup plus rapide que sur la bande. Cependant c'est l'étape intermédiaire de sauvegarde. Plus tard, les données sont sauvegardées sur la bande. L'autre avantage des sauvegardes disque à disque est qu'elle vous donne une copie en ligne de la dernière sauvegarde.
Mirror Breaking
L'idée est d'avoir des disques en miroir pour la résilience pendant la journée de travail. Lorsqu'une sauvegarde est requise, l'un des ensembles de miroirs peut être brisé. Cette technique est une variante des sauvegardes de disque à disque.
Note - La base de données peut devoir être arrêtée pour garantir la cohérence de la sauvegarde.
Jukeboxes optiques
Les juke-box optiques permettent de stocker les données près de la ligne. Cette technique permet de gérer un grand nombre de disques optiques de la même manière qu'un empileur de bandes ou un silo à bandes. L'inconvénient de cette technique est qu'elle a une vitesse d'écriture plus lente que les disques. Mais le support optique offre une longue durée de vie et une fiabilité qui en font un bon choix de support d'archivage.
Sauvegardes de logiciels
Il existe des outils logiciels disponibles qui aident dans le processus de sauvegarde. Ces outils logiciels sont fournis sous forme de package. Ces outils ne prennent pas seulement la sauvegarde, ils peuvent gérer et contrôler efficacement les stratégies de sauvegarde. Il existe de nombreux logiciels disponibles sur le marché. Certains d'entre eux sont répertoriés dans le tableau suivant -
| Nom du paquet | Vendeur |
|---|---|
| Networker | Legato |
| ADSM | IBM |
| Époque | Systèmes d'époque |
| Omniback II | HP |
| Alexandrie | Sequent |
Critères de choix des packages logiciels
Les critères de choix du meilleur progiciel sont énumérés ci-dessous -
- Dans quelle mesure le produit est-il évolutif à mesure que des lecteurs de bande sont ajoutés?
- Le package a-t-il l'option client-serveur ou doit-il s'exécuter sur le serveur de base de données lui-même?
- Fonctionnera-t-il dans les environnements de cluster et MPP?
- Quel degré de parallélisme est requis?
- Quelles plates-formes sont prises en charge par le package?
- Le package prend-il en charge un accès facile aux informations sur le contenu de la bande?
- La base de données des packages est-elle consciente?
- Quel lecteur de bande et quel support de bande sont pris en charge par le package?
Un entrepôt de données ne cesse d'évoluer et il est imprévisible quelle requête l'utilisateur va publier à l'avenir. Par conséquent, il devient plus difficile de régler un système d'entrepôt de données. Dans ce chapitre, nous verrons comment régler les différents aspects d'un entrepôt de données tels que les performances, la charge de données, les requêtes, etc.
Difficultés de réglage de l'entrepôt de données
Le réglage d'un entrepôt de données est une procédure difficile pour les raisons suivantes -
L'entrepôt de données est dynamique; il ne reste jamais constant.
Il est très difficile de prédire quelle requête l'utilisateur va publier à l'avenir.
Les exigences commerciales changent avec le temps.
Les utilisateurs et leurs profils changent constamment.
L'utilisateur peut passer d'un groupe à un autre.
La charge de données sur l'entrepôt change également avec le temps.
Note - Il est très important d'avoir une connaissance complète de l'entrepôt de données.
Évaluation de la performance
Voici une liste de mesures objectives de la performance -
- Temps de réponse moyen aux requêtes
- Taux de numérisation
- Temps utilisé par requête de jour
- Utilisation de la mémoire par processus
- Taux de débit d'E / S
Voici les points à retenir.
Il est nécessaire de spécifier les mesures dans l'accord de niveau de service (SLA).
Il ne sert à rien d'essayer de régler les temps de réponse, s'ils sont déjà meilleurs que ceux requis.
Il est essentiel d'avoir des attentes réalistes lors de l'évaluation des performances.
Il est également essentiel que les utilisateurs aient des attentes réalistes.
Pour masquer la complexité du système à l'utilisateur, des agrégations et des vues doivent être utilisées.
Il est également possible que l'utilisateur puisse écrire une requête que vous n'aviez pas réglée.
Réglage de la charge des données
La charge des données est un élément essentiel du traitement de nuit. Rien d'autre ne peut s'exécuter tant que le chargement des données n'est pas terminé. C'est le point d'entrée dans le système.
Note- S'il y a un retard dans le transfert des données, ou dans l'arrivée des données, tout le système est gravement affecté. Par conséquent, il est très important de régler d'abord le chargement des données.
Il existe différentes approches de réglage de la charge de données qui sont décrites ci-dessous -
L'approche très courante consiste à insérer des données à l'aide du SQL Layer. Dans cette approche, des vérifications et des contraintes normales doivent être effectuées. Lorsque les données sont insérées dans la table, le code s'exécute pour rechercher suffisamment d'espace pour insérer les données. Si l'espace disponible n'est pas suffisant, il faudra peut-être allouer plus d'espace à ces tables. Ces vérifications prennent du temps et sont coûteuses pour le processeur.
La seconde approche consiste à contourner tous ces contrôles et contraintes et à placer les données directement dans les blocs préformatés. Ces blocs sont ensuite écrits dans la base de données. C'est plus rapide que la première approche, mais cela ne peut fonctionner qu'avec des blocs entiers de données. Cela peut entraîner un gaspillage d'espace.
La troisième approche est que lors du chargement des données dans la table qui contient déjà la table, nous pouvons maintenir des index.
La quatrième approche dit que pour charger les données dans des tables qui contiennent déjà des données, drop the indexes & recreate themlorsque le chargement des données est terminé. Le choix entre la troisième et la quatrième approche dépend de la quantité de données déjà chargées et du nombre d'index à reconstruire.
Vérifications d'intégrité
La vérification de l'intégrité affecte fortement les performances de la charge. Voici les points à retenir -
Les contrôles d'intégrité doivent être limités car ils nécessitent une puissance de traitement élevée.
Des contrôles d'intégrité doivent être appliqués sur le système source pour éviter une dégradation des performances de la charge de données.
Requêtes de réglage
Nous avons deux types de requêtes dans l'entrepôt de données -
- Requêtes fixes
- Requêtes ad hoc
Requêtes fixes
Les requêtes fixes sont bien définies. Voici les exemples de requêtes fixes -
- rapports réguliers
- Requêtes prédéfinies
- Agrégations courantes
Le réglage des requêtes fixes dans un entrepôt de données est le même que dans un système de base de données relationnelle. La seule différence est que la quantité de données à interroger peut être différente. Il est bon de stocker le plan d'exécution le plus réussi lors du test des requêtes fixes. Le stockage de ces plans d'exécution nous permettra de repérer le changement de taille des données et le biais des données, car cela entraînera une modification du plan d'exécution.
Note - Nous ne pouvons pas faire plus sur la table de faits, mais tout en traitant les tables de dimension ou les agrégations, la collection habituelle d'ajustement SQL, de mécanisme de stockage et de méthodes d'accès peut être utilisée pour régler ces requêtes.
Requêtes ad hoc
Pour comprendre les requêtes ad hoc, il est important de connaître les utilisateurs ad hoc de l'entrepôt de données. Pour chaque utilisateur ou groupe d'utilisateurs, vous devez connaître les éléments suivants:
- Le nombre d'utilisateurs dans le groupe
- S'ils utilisent des requêtes ad hoc à intervalles réguliers
- S'ils utilisent fréquemment des requêtes ad hoc
- S'ils utilisent occasionnellement des requêtes ad hoc à des intervalles inconnus.
- La taille maximale de la requête qu'ils ont tendance à exécuter
- La taille moyenne de la requête qu'ils ont tendance à exécuter
- Si elles nécessitent un accès détaillé aux données de base
- Le temps de connexion écoulé par jour
- L'heure de pointe de l'utilisation quotidienne
- Le nombre de requêtes exécutées par heure de pointe
Points to Note
Il est important de suivre les profils de l'utilisateur et d'identifier les requêtes qui sont régulièrement exécutées.
Il est également important que le réglage effectué n'affecte pas les performances.
Identifiez les requêtes similaires et ad hoc qui sont fréquemment exécutées.
Si ces requêtes sont identifiées, la base de données changera et de nouveaux index pourront être ajoutés pour ces requêtes.
Si ces requêtes sont identifiées, de nouvelles agrégations peuvent être créées spécifiquement pour les requêtes qui entraîneraient leur exécution efficace.
Les tests sont très importants pour les systèmes d'entrepôt de données afin de les faire fonctionner correctement et efficacement. Il existe trois niveaux de test de base effectués sur un entrepôt de données -
- Test unitaire
- Test d'intégration
- Test du système
Test unitaire
Dans les tests unitaires, chaque composant est testé séparément.
Chaque module, c'est-à-dire procédure, programme, script SQL, shell Unix est testé.
Ce test est réalisé par le développeur.
Test d'intégration
Lors des tests d'intégration, les différents modules de l'application sont rassemblés puis testés par rapport au nombre d'entrées.
Il est effectué pour tester si les différents composants fonctionnent bien après l'intégration.
Test du système
Lors des tests système, l'ensemble de l'application d'entrepôt de données est testée ensemble.
Le but des tests du système est de vérifier si l'ensemble du système fonctionne correctement ensemble ou non.
Les tests du système sont effectués par l'équipe de test.
Étant donné que la taille de l'ensemble de l'entrepôt de données est très grande, il est généralement possible d'effectuer des tests système minimaux avant que le plan de test puisse être mis en œuvre.
Calendrier des tests
Tout d'abord, le programme de test est créé lors du développement du plan de test. Dans ce calendrier, nous prévoyons le temps estimé nécessaire pour tester l'ensemble du système d'entrepôt de données.
Il existe différentes méthodologies disponibles pour créer un calendrier de test, mais aucune d'entre elles n'est parfaite car l'entrepôt de données est très complexe et volumineux. Le système d'entrepôt de données évolue également dans la nature. On peut rencontrer les problèmes suivants lors de la création d'un calendrier de test -
Un problème simple peut avoir une grande taille de requête qui peut prendre un jour ou plus à compléter, c'est-à-dire que la requête ne se termine pas dans une échelle de temps souhaitée.
Il peut y avoir des pannes matérielles telles que la perte d'un disque ou des erreurs humaines telles que la suppression accidentelle d'une table ou l'écrasement d'une table volumineuse.
Note - En raison des difficultés mentionnées ci-dessus, il est recommandé de toujours doubler le temps que vous accorderiez normalement pour les tests.
Test de la récupération de sauvegarde
Tester la stratégie de récupération de sauvegarde est extrêmement important. Voici la liste des scénarios pour lesquels ce test est nécessaire -
- Panne de média
- Perte ou endommagement de l'espace table ou du fichier de données
- Perte ou endommagement du fichier de journalisation
- Perte ou détérioration du fichier de contrôle
- Échec de l'instance
- Perte ou endommagement du fichier d'archive
- Perte ou endommagement de la table
- Échec lors d'une panne de données
Test de l'environnement opérationnel
Il y a un certain nombre d'aspects qui doivent être testés. Ces aspects sont énumérés ci-dessous.
Security- Un document de sécurité distinct est requis pour les tests de sécurité. Ce document contient une liste des opérations non autorisées et des tests de conception pour chacune.
Scheduler- Un logiciel de planification est nécessaire pour contrôler les opérations quotidiennes d'un entrepôt de données. Il doit être testé lors des tests du système. Le logiciel de planification nécessite une interface avec l'entrepôt de données, qui aura besoin du planificateur pour contrôler le traitement de nuit et la gestion des agrégations.
Disk Configuration.- La configuration du disque doit également être testée pour identifier les goulots d'étranglement d'E / S. Le test doit être effectué plusieurs fois avec des paramètres différents.
Management Tools.- Il est nécessaire de tester tous les outils de gestion lors des tests du système. Voici la liste des outils à tester.
- Responsable de l'événement
- Gestionnaire système
- Gestionnaire de base de données
- Panneau de configuration
- Gestionnaire de récupération de sauvegarde
Tester la base de données
La base de données est testée des trois manières suivantes -
Testing the database manager and monitoring tools - Pour tester le gestionnaire de base de données et les outils de surveillance, ils doivent être utilisés dans la création, l'exécution et la gestion de la base de données de test.
Testing database features - Voici la liste des fonctionnalités que nous devons tester -
Interroger en parallèle
Créer un index en parallèle
Chargement de données en parallèle
Testing database performance- L'exécution des requêtes joue un rôle très important dans les mesures de performance de l'entrepôt de données. Il existe des ensembles de requêtes fixes qui doivent être exécutées régulièrement et doivent être testées. Pour tester les requêtes ad hoc, il faut parcourir le document des exigences de l'utilisateur et comprendre complètement l'entreprise. Prenez le temps de tester les requêtes les plus délicates que l'entreprise est susceptible de poser par rapport à différentes stratégies d'indexation et d'agrégation.
Test de l'application
Tous les gestionnaires doivent être correctement intégrés et travailler afin de garantir que la charge, l'indexation, l'agrégation et les requêtes de bout en bout fonctionnent conformément aux attentes.
Chaque fonction de chaque manager doit fonctionner correctement
Il est également nécessaire de tester l'application sur une période de temps.
Les tâches de fin de semaine et de fin de mois doivent également être testées.
Logistique du test
Le but du test du système est de tester tous les domaines suivants -
- Logiciel de planification
- Procédures opérationnelles au jour le jour
- Stratégie de récupération de sauvegarde
- Outils de gestion et de planification
- Traitement de nuit
- Performances des requêtes
Note- Le point le plus important est de tester l'évolutivité. Ne pas le faire nous laissera une conception de système qui ne fonctionnera pas lorsque le système se développera.
Voici les aspects futurs de l'entreposage de données.
Comme nous avons vu que la taille de la base de données ouverte a augmenté d'environ le double de son ampleur au cours des dernières années, elle montre la valeur significative qu'elle contient.
Au fur et à mesure que la taille des bases de données augmente, les estimations de ce qui constitue une très grande base de données continuent de croître.
Le matériel et les logiciels disponibles aujourd'hui ne permettent pas de conserver une grande quantité de données en ligne. Par exemple, un enregistrement d'appel Telco nécessite 10 To de données à conserver en ligne, ce qui ne représente que la taille d'un enregistrement d'un mois. S'il faut conserver des registres des ventes, des clients marketing, des employés, etc., la taille sera alors supérieure à 100 To.
L'enregistrement contient des informations textuelles et des données multimédias. Les données multimédias ne peuvent pas être facilement manipulées comme des données textuelles. La recherche des données multimédias n'est pas une tâche facile, alors que les informations textuelles peuvent être récupérées par le logiciel relationnel disponible aujourd'hui.
Outre la planification de la taille, il est complexe de créer et d'exécuter des systèmes d'entrepôt de données dont la taille ne cesse de croître. À mesure que le nombre d'utilisateurs augmente, la taille de l'entrepôt de données augmente également. Ces utilisateurs devront également accéder au système.
Avec la croissance d'Internet, les utilisateurs ont besoin d'accéder aux données en ligne.
Par conséquent, la forme future de l'entrepôt de données sera très différente de ce qui est créé aujourd'hui.