आर्टिफिशियल न्यूरल नेटवर्क - त्वरित गाइड
तंत्रिका नेटवर्क समानांतर कंप्यूटिंग डिवाइस हैं, जो मूल रूप से मस्तिष्क का कंप्यूटर मॉडल बनाने का प्रयास है। मुख्य उद्देश्य पारंपरिक प्रणालियों की तुलना में तेजी से विभिन्न कम्प्यूटेशनल कार्यों को करने के लिए एक प्रणाली विकसित करना है। इन कार्यों में पैटर्न मान्यता और वर्गीकरण, सन्निकटन, अनुकूलन और डेटा क्लस्टरिंग शामिल हैं।
कृत्रिम तंत्रिका नेटवर्क क्या है?
आर्टिफिशियल न्यूरल नेटवर्क (ANN) एक कुशल कंप्यूटिंग सिस्टम है जिसका केंद्रीय विषय जैविक तंत्रिका नेटवर्क के सादृश्य से उधार लिया गया है। ANN को "कृत्रिम तंत्रिका प्रणाली," या "समानांतर वितरित प्रसंस्करण प्रणाली," या "कनेक्शन सिस्टम" के रूप में भी नामित किया जाता है। एएनएन उन इकाइयों का एक बड़ा संग्रह प्राप्त करता है जो इकाइयों के बीच संचार की अनुमति देने के लिए कुछ पैटर्न में परस्पर जुड़े होते हैं। इन इकाइयों, जिन्हें नोड्स या न्यूरॉन्स भी कहा जाता है, सरल प्रोसेसर हैं जो समानांतर में काम करते हैं।
हर न्यूरॉन एक कनेक्शन लिंक के माध्यम से अन्य न्यूरॉन के साथ जुड़ा हुआ है। प्रत्येक कनेक्शन लिंक एक वजन से जुड़ा होता है जिसमें इनपुट सिग्नल के बारे में जानकारी होती है। किसी विशेष समस्या को हल करने के लिए न्यूरॉन्स के लिए यह सबसे उपयोगी जानकारी है क्योंकि वजन आमतौर पर संचार को उत्तेजित या बाधित करता है। प्रत्येक न्यूरॉन में एक आंतरिक स्थिति होती है, जिसे सक्रियण संकेत कहा जाता है। आउटपुट सिग्नल, जो इनपुट सिग्नल और सक्रियण नियम के संयोजन के बाद उत्पन्न होते हैं, अन्य इकाइयों को भेजे जा सकते हैं।
एएनएन का संक्षिप्त इतिहास
ANN के इतिहास को निम्नलिखित तीन युगों में विभाजित किया जा सकता है -
1940 से 1960 के दशक के दौरान एएनएन
इस युग के कुछ प्रमुख घटनाक्रम इस प्रकार हैं -
1943 - यह माना गया है कि तंत्रिका नेटवर्क की अवधारणा फिजियोलॉजिस्ट, वॉरेन मैकुलोच, और गणितज्ञ, वाल्टर पिट्स के काम से शुरू हुई थी, जब 1943 में उन्होंने मस्तिष्क में न्यूरॉन्स कैसे काम कर सकते हैं, इसका वर्णन करने के लिए विद्युत सर्किट का उपयोग करते हुए एक साधारण तंत्रिका नेटवर्क बनाया। ।
1949- डोनाल्ड हेब्ब की पुस्तक, द ऑर्गनाइजेशन ऑफ बिहेवियर , ने इस तथ्य को सामने रखा कि एक न्यूरॉन के दूसरे द्वारा बार-बार सक्रिय होने से उसकी ताकत हर बार इस्तेमाल होने के बाद बढ़ती है।
1956 - टेलर द्वारा एक सहयोगी मेमोरी नेटवर्क पेश किया गया था।
1958 - पेसेक्रोन नाम के मैककुलोच और पिट्स न्यूरॉन मॉडल के लिए एक सीखने की विधि का आविष्कार रोसेनब्लैट ने किया था।
1960 - बर्नार्ड विडो और मार्कियन हॉफ ने "ADALINE" और "MADALINE" नामक मॉडल विकसित किए।
एएनएन 1960 से 1980 के दशक के दौरान
इस युग के कुछ प्रमुख घटनाक्रम इस प्रकार हैं -
1961 - रोसेनब्लट ने एक असफल प्रयास किया, लेकिन बहुपरत नेटवर्क के लिए "बैकप्रोपैजेशन" योजना का प्रस्ताव रखा।
1964 - टेलर ने आउटपुट इकाइयों के बीच अवरोधों के साथ एक विजेता-ऑल-सर्किट का निर्माण किया।
1969 - मल्टीलेयर परसेप्ट्रॉन (MLP) का आविष्कार मिन्स्की और पैपर्ट ने किया था।
1971 - कोहेनन ने एसोसिएटिव यादें विकसित कीं।
1976 - स्टीफन ग्रॉसबर्ग और गेल कारपेंटर ने एडाप्टिव रेजोनेंस सिद्धांत विकसित किया।
1980 से वर्तमान तक ए.एन.एन.
इस युग के कुछ प्रमुख घटनाक्रम इस प्रकार हैं -
1982 - प्रमुख विकास हॉपफील्ड का ऊर्जा दृष्टिकोण था।
1985 - बोल्ट्जमैन मशीन को एक्ले, हिंटन और सेजनोवस्की द्वारा विकसित किया गया था।
1986 - रुमेलेर्ट, हिंटन और विलियम्स ने सामान्यीकृत डेल्टा नियम पेश किया।
1988 - कोस्को ने बाइनरी एसोसिएटरी मेमोरी (बीएएम) विकसित की और एएनएन में फजी लॉजिक की अवधारणा भी दी।
ऐतिहासिक समीक्षा से पता चलता है कि इस क्षेत्र में महत्वपूर्ण प्रगति हुई है। तंत्रिका नेटवर्क आधारित चिप्स उभर रहे हैं और जटिल समस्याओं के अनुप्रयोग विकसित किए जा रहे हैं। निश्चित रूप से, आज तंत्रिका नेटवर्क प्रौद्योगिकी के लिए संक्रमण की अवधि है।
जैविक न्यूरॉन
एक तंत्रिका कोशिका (न्यूरॉन) एक विशेष जैविक कोशिका है जो सूचना को संसाधित करती है। एक अनुमान के अनुसार, बहुत से न्यूरॉन्स हैं, लगभग 10 11 कई इंटरकनेक्शन के साथ, लगभग 10 15 ।
योजनाबद्ध आरेख
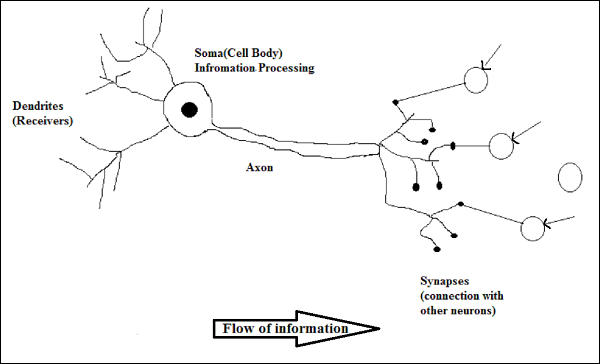
एक जैविक न्यूरॉन का कार्य करना
जैसा कि ऊपर चित्र में दिखाया गया है, एक विशिष्ट न्यूरॉन में निम्नलिखित चार भाग होते हैं जिनकी मदद से हम इसके कार्य की व्याख्या कर सकते हैं -
Dendrites- वे पेड़ जैसी शाखाएं हैं, जो अन्य न्यूरॉन्स से सूचना प्राप्त करने के लिए जिम्मेदार हैं, जो इससे जुड़ा हुआ है। दूसरे अर्थ में, हम कह सकते हैं कि वे न्यूरॉन के कानों की तरह हैं।
Soma - यह न्यूरॉन का कोशिका अंग है और सूचना के प्रसंस्करण के लिए जिम्मेदार है, वे डेंड्राइट्स से प्राप्त हुए हैं।
Axon - यह एक केबल की तरह है, जिसके माध्यम से न्यूरॉन्स सूचना भेजते हैं।
Synapses - यह अक्षतंतु और अन्य न्यूरॉन डेन्ड्राइट के बीच संबंध है।
एएनएन बनाम बीएनएन
आर्टिफिशियल न्यूरल नेटवर्क (एएनएन) और बायोलॉजिकल न्यूरल नेटवर्क (बीएनएन) के बीच अंतरों पर एक नज़र डालने से पहले, आइए इन दोनों के बीच की शब्दावली पर आधारित समानताओं पर एक नज़र डालें।
| जैविक तंत्रिका नेटवर्क (BNN) | कृत्रिम तंत्रिका नेटवर्क (ANN) |
|---|---|
| सोम | नोड |
| डेन्ड्राइट | इनपुट |
| अन्तर्ग्रथन | वजन या परस्पर संबंध |
| एक्सोन | उत्पादन |
निम्नलिखित तालिका एएनएन और बीएनएन के बीच तुलना के कुछ मानदंडों के आधार पर बताती है।
| मानदंड | BNN | ऐन |
|---|---|---|
| Processing | एएनएन की तुलना में बड़े पैमाने पर समानांतर, धीमा लेकिन बेहतर | बीएनएन की तुलना में बड़े पैमाने पर समानांतर, तेज लेकिन हीन |
| Size | 10 11 न्यूरॉन्स और 10 15 इंटरकनेक्ट | 10 2 से 10 4 नोड्स (मुख्य रूप से एप्लिकेशन और नेटवर्क डिजाइनर के प्रकार पर निर्भर करता है) |
| Learning | वे अस्पष्टता को सहन कर सकते हैं | अस्पष्टता को सहन करने के लिए बहुत सटीक, संरचित और स्वरूपित डेटा की आवश्यकता होती है |
| Fault tolerance | आंशिक क्षति के साथ प्रदर्शन कम हो जाता है | यह मजबूत प्रदर्शन करने में सक्षम है, इसलिए इसमें दोष सहिष्णु होने की क्षमता है |
| Storage capacity | अन्तर्ग्रथन में जानकारी संग्रहीत करता है | निरंतर स्मृति स्थानों में जानकारी संग्रहीत करता है |
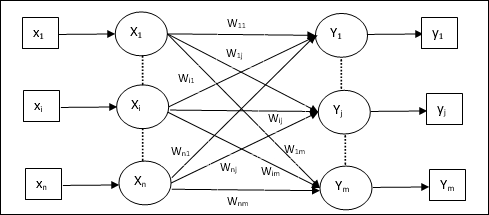
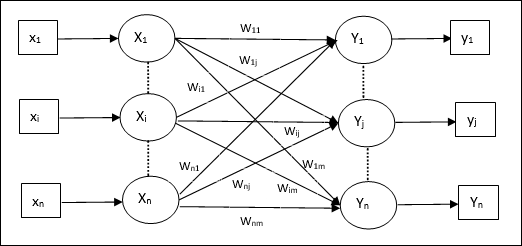
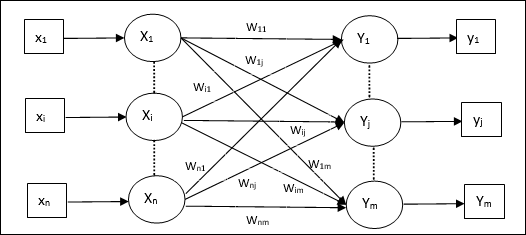
आर्टिफिशियल न्यूरल नेटवर्क का मॉडल
निम्नलिखित आरेख इसके प्रसंस्करण के बाद ANN के सामान्य मॉडल का प्रतिनिधित्व करता है।
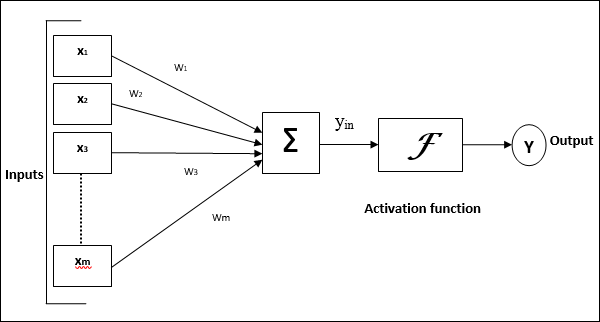
कृत्रिम तंत्रिका नेटवर्क के उपरोक्त सामान्य मॉडल के लिए, शुद्ध इनपुट की गणना निम्नानुसार की जा सकती है -
$$ y_ {में} \: = \: x_ {1} .w_ {1} \: + \: x_ {2} .w_ {2} \: + \: x_ {3} .w_ {3} \: \ dotso \: x_ {m} .w_ {m} $$
अर्थात, नेट इनपुट $ y_ {in} \: = \: \ sum_i ^ m \: x_ {i} .w_ {i} $।
शुद्ध इनपुट पर सक्रियण फ़ंक्शन को लागू करके आउटपुट की गणना की जा सकती है।
$ $ Y \: = \: F (y_ {in}) $ $
आउटपुट = फ़ंक्शन (शुद्ध इनपुट की गणना)
ANN का प्रसंस्करण निम्नलिखित तीन बिल्डिंग ब्लॉक्स पर निर्भर करता है -
- नेटवर्क टोपोलॉजी
- वजन या सीखने का समायोजन
- सक्रियण कार्य
इस अध्याय में, हम एएनएन के इन तीन भवन ब्लॉकों के बारे में विस्तार से चर्चा करेंगे
नेटवर्क टोपोलॉजी
एक नेटवर्क टोपोलॉजी एक नेटवर्क की व्यवस्था है जिसके नोड्स और कनेक्टिंग लाइनें हैं। टोपोलॉजी के अनुसार, ANN को निम्न प्रकारों में वर्गीकृत किया जा सकता है -
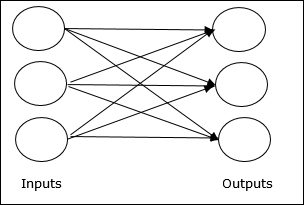
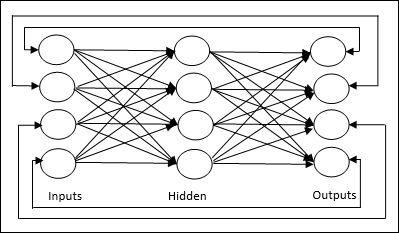
फीडफोवर्ड नेटवर्क
यह एक गैर-आवर्तक नेटवर्क है जिसमें परतों में प्रसंस्करण इकाइयां / नोड्स होते हैं और एक परत में सभी नोड्स पिछली परतों के नोड्स के साथ जुड़े होते हैं। कनेक्शन उन पर अलग वजन है। कोई प्रतिक्रिया नहीं है लूप का मतलब है कि सिग्नल केवल एक दिशा में प्रवाहित हो सकता है, इनपुट से आउटपुट तक। इसे निम्नलिखित दो प्रकारों में विभाजित किया जा सकता है -
Single layer feedforward network- अवधारणा केवल एक भारित परत वाले फीडफर्न ANN की है। दूसरे शब्दों में, हम कह सकते हैं कि इनपुट परत पूरी तरह से आउटपुट लेयर से जुड़ी है।
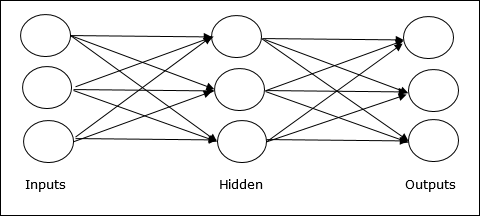
Multilayer feedforward network- अवधारणा एक से अधिक भारित परत वाले फीडफॉर्न ANN की है। चूंकि इस नेटवर्क में इनपुट और आउटपुट लेयर के बीच एक या एक से अधिक लेयर हैं, इसलिए इसे हिडन लेयर्स कहा जाता है।
प्रतिक्रिया नेटवर्क
जैसा कि नाम से पता चलता है, एक फीडबैक नेटवर्क में फीडबैक पथ होते हैं, जिसका अर्थ है कि सिग्नल लूप का उपयोग करके दोनों दिशाओं में प्रवाह कर सकते हैं। यह इसे एक गैर-रेखीय गतिशील प्रणाली बनाता है, जो संतुलन की स्थिति तक पहुंचने तक लगातार बदलता रहता है। इसे निम्न प्रकारों में विभाजित किया जा सकता है -
Recurrent networks- वे बंद छोरों के साथ प्रतिक्रिया नेटवर्क हैं। निम्नलिखित दो प्रकार के आवर्तक नेटवर्क हैं।
Fully recurrent network - यह सबसे सरल तंत्रिका नेटवर्क आर्किटेक्चर है क्योंकि सभी नोड्स अन्य सभी नोड्स से जुड़े हैं और प्रत्येक नोड इनपुट और आउटपुट दोनों के रूप में काम करता है।
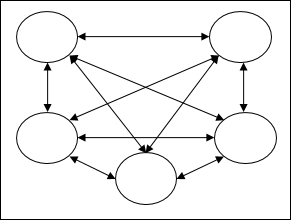
Jordan network - यह एक बंद लूप नेटवर्क है, जिसमें आउटपुट इनपुट पर फिर से फीडबैक के रूप में जाएगा जैसा कि निम्नलिखित चित्र में दिखाया गया है।
वजन या सीखने का समायोजन
सीखना, कृत्रिम तंत्रिका नेटवर्क में, एक निर्दिष्ट नेटवर्क के न्यूरॉन्स के बीच कनेक्शन के वजन को संशोधित करने की विधि है। ANN में सीखना को तीन श्रेणियों में वर्गीकृत किया जा सकता है, अर्थात् पर्यवेक्षित शिक्षण, अनुपयोगी शिक्षण और सुदृढीकरण शिक्षण।
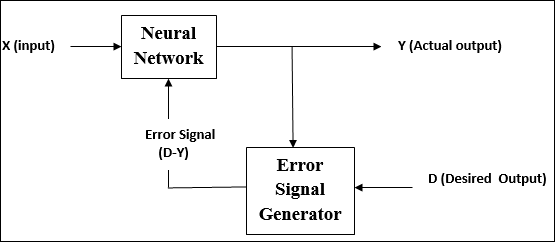
पर्यवेक्षित अध्ययन
जैसा कि नाम से पता चलता है, इस प्रकार की सीख एक शिक्षक की देखरेख में की जाती है। यह सीखने की प्रक्रिया निर्भर है।
पर्यवेक्षित शिक्षण के तहत एएनएन के प्रशिक्षण के दौरान, इनपुट वेक्टर नेटवर्क को प्रस्तुत किया जाता है, जो आउटपुट वेक्टर देगा। इस आउटपुट वेक्टर की तुलना वांछित आउटपुट वेक्टर से की जाती है। एक त्रुटि संकेत उत्पन्न होता है, अगर वास्तविक आउटपुट और वांछित आउटपुट वेक्टर के बीच अंतर होता है। इस त्रुटि संकेत के आधार पर, वजन को तब तक समायोजित किया जाता है जब तक कि वास्तविक आउटपुट को वांछित आउटपुट के साथ मिलान नहीं किया जाता है।
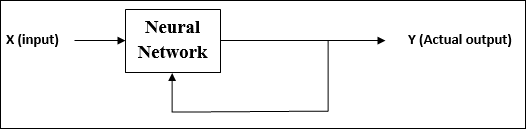
अनसुचित शिक्षा
जैसा कि नाम से पता चलता है, इस प्रकार की सीख शिक्षक की देखरेख के बिना की जाती है। यह सीखने की प्रक्रिया स्वतंत्र है।
अनुपयोगी अधिगम के तहत एएनएन के प्रशिक्षण के दौरान, इसी प्रकार के इनपुट वैक्टर क्लस्टर बनाने के लिए संयुक्त होते हैं। जब एक नया इनपुट पैटर्न लागू किया जाता है, तो तंत्रिका नेटवर्क एक आउटपुट प्रतिक्रिया देता है जो उस वर्ग को इंगित करता है जिसमें इनपुट पैटर्न होता है।
पर्यावरण से कोई प्रतिक्रिया नहीं है कि वांछित आउटपुट क्या होना चाहिए और अगर यह सही है या गलत है। इसलिए, इस प्रकार के सीखने में, नेटवर्क को स्वयं इनपुट डेटा से पैटर्न और सुविधाओं की खोज करनी चाहिए, और आउटपुट पर इनपुट डेटा के लिए संबंध बनाना चाहिए।
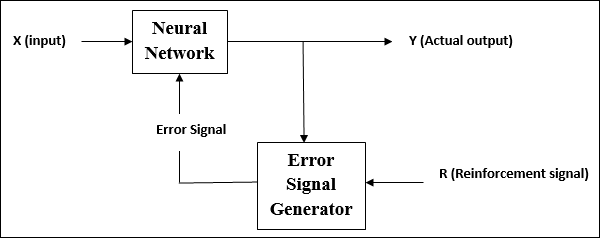
सुदृढीकरण सीखना
जैसा कि नाम से पता चलता है, इस प्रकार के सीखने का उपयोग कुछ आलोचनात्मक सूचनाओं पर नेटवर्क को सुदृढ़ करने या मजबूत करने के लिए किया जाता है। यह सीखने की प्रक्रिया पर्यवेक्षित शिक्षण के समान है, हालांकि हमारे पास बहुत कम जानकारी हो सकती है।
सुदृढीकरण सीखने के तहत नेटवर्क के प्रशिक्षण के दौरान, नेटवर्क को पर्यावरण से कुछ प्रतिक्रिया मिलती है। यह कुछ हद तक पर्यवेक्षित सीखने के समान है। हालांकि, यहां प्राप्त फीडबैक मूल्यांकनात्मक नहीं शिक्षाप्रद है, जिसका अर्थ है कि पर्यवेक्षित शिक्षण में कोई शिक्षक नहीं है। प्रतिक्रिया प्राप्त करने के बाद, नेटवर्क भविष्य में बेहतर आलोचकों की जानकारी प्राप्त करने के लिए भार का समायोजन करता है।
सक्रियण कार्य
इसे एक सटीक आउटपुट प्राप्त करने के लिए इनपुट पर लागू अतिरिक्त बल या प्रयास के रूप में परिभाषित किया जा सकता है। एएनएन में, हम सटीक आउटपुट प्राप्त करने के लिए इनपुट पर सक्रियण फ़ंक्शन भी लागू कर सकते हैं। अनुवर्ती कुछ सक्रियण कार्य हैं -
रैखिक सक्रियण समारोह
इसे पहचान समारोह भी कहा जाता है क्योंकि यह कोई इनपुट संपादन नहीं करता है। इसे इस प्रकार परिभाषित किया जा सकता है -
$$ एफ (एक्स) \: = \: एक्स $$
सिगमॉइड एक्टिवेशन फंक्शन
यह दो प्रकार का होता है -
Binary sigmoidal function- यह सक्रियण फ़ंक्शन 0 और 1 के बीच इनपुट संपादन करता है। यह प्रकृति में सकारात्मक है। यह हमेशा घिरा होता है, जिसका अर्थ है कि इसका उत्पादन 0 से कम नहीं हो सकता है और 1. से अधिक है। यह भी प्रकृति में सख्ती से बढ़ रहा है, जिसका अर्थ है कि जितना अधिक इनपुट आउटपुट होगा। इसे इस रूप में परिभाषित किया जा सकता है
$$ एफ (एक्स) \: = \: sigm (एक्स) \: = \: \ frac {1} {1 \: + \: exp (-x)} $$
Bipolar sigmoidal function- यह सक्रियण फ़ंक्शन -1 और 1. के बीच इनपुट संपादन करता है। यह प्रकृति में सकारात्मक या नकारात्मक हो सकता है। यह हमेशा घिरा होता है, जिसका अर्थ है कि इसका उत्पादन -1 से कम नहीं हो सकता है और 1. से अधिक है। यह सिग्माइड फ़ंक्शन की तरह प्रकृति में भी सख्ती से बढ़ रहा है। इसे इस रूप में परिभाषित किया जा सकता है
$$ एफ (एक्स) \: = \: sigm (एक्स) \: = \: \ frac {2} {1 \: + \: exp (-x)} \: - \: 1 \: = \: \ frac {1 \: - \: exp (x)} {1 \: + \: exp (x)} $$
जैसा कि पहले कहा गया था, एएनएन पूरी तरह से जैविक तंत्रिका तंत्र यानी मानव मस्तिष्क के काम करने के तरीके से प्रेरित है। मानव मस्तिष्क की सबसे प्रभावशाली विशेषता सीखना है, इसलिए उसी विशेषता को एएनएन द्वारा अधिग्रहित किया जाता है।
ANN में क्या सीखना है?
मूल रूप से, सीखने का अर्थ है कि पर्यावरण में परिवर्तन होने पर अपने आप में परिवर्तन करना और उसे अनुकूलित करना। एएनएन एक जटिल प्रणाली है या अधिक सटीक रूप से हम कह सकते हैं कि यह एक जटिल अनुकूली प्रणाली है, जो इसके माध्यम से गुजरने वाली जानकारी के आधार पर इसकी आंतरिक संरचना को बदल सकती है।
यह महत्वपूर्ण क्यों है?
एक जटिल अनुकूली प्रणाली होने के नाते, ANN में सीखने का अर्थ है कि एक प्रसंस्करण इकाई पर्यावरण में परिवर्तन के कारण अपने इनपुट / आउटपुट व्यवहार को बदलने में सक्षम है। एएनएन में सीखने का महत्व निश्चित सक्रियण फ़ंक्शन के साथ-साथ इनपुट / आउटपुट वेक्टर के कारण बढ़ता है, जब किसी विशेष नेटवर्क का निर्माण किया जाता है। अब इनपुट / आउटपुट व्यवहार को बदलने के लिए, हमें वज़न समायोजित करने की आवश्यकता है।
वर्गीकरण
इसे समान वर्गों के नमूनों के बीच सामान्य विशेषताओं को खोजकर विभिन्न वर्गों में नमूनों के डेटा को भेद करने के लिए सीखने की प्रक्रिया के रूप में परिभाषित किया जा सकता है। उदाहरण के लिए, ANN का प्रशिक्षण करने के लिए, हमारे पास अद्वितीय विशेषताओं के साथ कुछ प्रशिक्षण नमूने हैं, और इसके परीक्षण करने के लिए हमारे पास कुछ अद्वितीय विशेषताओं के साथ कुछ परीक्षण नमूने हैं। वर्गीकरण पर्यवेक्षित शिक्षण का एक उदाहरण है।
तंत्रिका नेटवर्क लर्निंग नियम
हम जानते हैं कि, ANN सीखने के दौरान, इनपुट / आउटपुट व्यवहार को बदलने के लिए, हमें वज़न समायोजित करने की आवश्यकता है। इसलिए, एक ऐसी विधि की आवश्यकता है जिसकी सहायता से वज़न को संशोधित किया जा सके। इन विधियों को लर्निंग नियम कहा जाता है, जो केवल एल्गोरिदम या समीकरण हैं। तंत्रिका नेटवर्क के लिए कुछ सीखने के नियम निम्नलिखित हैं -
हेब्बियन लर्निंग रूल
यह नियम, सबसे पुराना और सरलतम में से एक, डोनाल्ड हेब द्वारा 1949 में अपनी पुस्तक द ऑर्गेनाइजेशन ऑफ बिहेवियर में पेश किया गया था । यह एक तरह का फीड-फ़ॉरवर्ड, अनसर्वलाइज़्ड लर्निंग है।
Basic Concept - यह नियम हेब्ब द्वारा दिए गए एक प्रस्ताव पर आधारित है, जिसने लिखा -
“जब सेल A का अक्षतंतु सेल B को उत्तेजित करने के लिए पर्याप्त होता है और बार-बार या लगातार इसे फायर करने में भाग लेता है, तो एक या दोनों कोशिकाओं में कुछ वृद्धि प्रक्रिया या चयापचय परिवर्तन होता है जैसे कि A की दक्षता, जैसे कि सेल में से एक B को फायर करना। , बढ़ गया है।"
उपर्युक्त आसन से, हम यह निष्कर्ष निकाल सकते हैं कि दो न्यूरॉन्स के बीच संबंध मजबूत हो सकते हैं यदि न्यूरॉन्स एक ही समय में आग लगाते हैं और अलग-अलग समय पर फायर करते हैं तो कमजोर हो सकते हैं।
Mathematical Formulation - हेब्बियन लर्निंग नियम के अनुसार, हर बार कदम पर कनेक्शन का वजन बढ़ाने का सूत्र निम्नलिखित है।
$$ \ Delta w_ {ji} (t) \: = \: \ Alpha x_ {i} (t) .y_ {j} (t) $$।
इधर, $ \ Delta w_ {ji} (t) $ re = वेतन वृद्धि जिससे समय कदम पर कनेक्शन का वजन बढ़ता है t
$ \ अल्फा $ = सकारात्मक और निरंतर सीखने की दर
$ x_ {i} (t) $ = समय कदम पर पूर्व-सिनैप्टिक न्यूरॉन से इनपुट मूल्य t
$ y_ {i} (t) $ = एक ही समय कदम पर प्री-सिनैप्टिक न्यूरॉन का उत्पादन t
परसेप्ट्रॉन लर्निंग रूल
यह नियम एक परत है जो रेखीय सक्रियण फ़ंक्शन के साथ सिंगल लेयर फीडफॉर्वर्ड नेटवर्क के पर्यवेक्षित शिक्षण एल्गोरिथ्म को सही करने में त्रुटि है, जो रोसेनब्लट द्वारा प्रस्तुत किया गया है।
Basic Concept- प्रकृति की देखरेख में, त्रुटि की गणना करने के लिए, वांछित / लक्ष्य आउटपुट और वास्तविक आउटपुट के बीच तुलना होगी। यदि कोई अंतर पाया जाता है, तो कनेक्शन के वजन में बदलाव किया जाना चाहिए।
Mathematical Formulation - इसके गणितीय सूत्रीकरण की व्याख्या करने के लिए, मान लीजिए कि हमारे पास परिमित इनपुट वैक्टरों की संख्या 'n' है, x (n), इसके वांछित / लक्ष्य आउटपुट वेक्टर t (n) के साथ, जहाँ n = 1 से N.
अब आउटपुट 'y' की गणना की जा सकती है, जैसा कि पहले नेट इनपुट के आधार पर बताया गया है, और सक्रियण फ़ंक्शन को उस नेट इनपुट पर लागू किया जा रहा है जो निम्नानुसार व्यक्त किया जा सकता है -
$ $ y \: = \: f (y_ {in}) \: = \ _ \ _ {मामलों} 1, और y_ {में} \ _: \ _: \ theta \\ 0, और y_ {in} \: शुरू करें: \ leqslant \: \ थीटा \ अंत {मामलों} $$
कहाँ पे θ दहलीज है।
वजन का अद्यतन निम्नलिखित दो मामलों में किया जा सकता है -
Case I - जब t ≠ y, फिर
$$ डब्ल्यू (नया) \: = \: डब्ल्यू (पुराने) \: + \; tx $$
Case II - जब t = y, फिर
वजन में कोई बदलाव नहीं
डेल्टा लर्निंग नियम (विधवा-हॉफ नियम)
यह बर्नार्ड विडो और मार्सियन हॉफ द्वारा पेश किया जाता है, जिसे सभी प्रशिक्षण पैटर्न पर त्रुटि को कम करने के लिए लिस्ट मीन स्क्वायर (एलएमएस) विधि भी कहा जाता है। यह निरंतर सक्रियण फ़ंक्शन के साथ पर्यवेक्षित शिक्षण एल्गोरिथ्म की तरह है।
Basic Concept- इस नियम का आधार ढाल-वंशीय दृष्टिकोण है, जो हमेशा के लिए जारी रहता है। डेल्टा नियम सिंटैप्टिक वेट को अपडेट करता है ताकि आउटपुट इनपुट और टारगेट वैल्यू को शुद्ध इनपुट कम से कम किया जा सके।
Mathematical Formulation - अन्तर्ग्रथनी भार को अद्यतन करने के लिए, डेल्टा नियम द्वारा दिया गया है
$$ \ Delta w_ {i} \: = \: \ Alpha \: x_ {i} .e_ {j} $ $
यहाँ $ \ डेल्टा w_ {मैं} $ = मैं के लिए वजन परिवर्तन वें pattern;
$ \ अल्फा $ = सकारात्मक और निरंतर सीखने की दर;
$ x_ {i} $ = प्री-सिनैप्टिक न्यूरॉन से इनपुट मान;
$ e_ {j} $ = $ (t \: - \: y_ {in}) $, वांछित / लक्ष्य आउटपुट और वास्तविक आउटपुट के बीच का अंतर y $ y_ {in} $
उपरोक्त डेल्टा नियम केवल एकल आउटपुट इकाई के लिए है।
वजन का अद्यतन निम्नलिखित दो मामलों में किया जा सकता है -
Case-I - जब t ≠ y, फिर
$ $ w (नया) \: = \: w (पुराना) \: + \: \ Delta w $ $
Case-II - जब t = y, फिर
वजन में कोई बदलाव नहीं
प्रतियोगी शिक्षा नियम (विजेता-सभी)
यह अनिश्चित प्रशिक्षण से संबंधित है जिसमें आउटपुट नोड्स इनपुट पैटर्न का प्रतिनिधित्व करने के लिए एक दूसरे के साथ प्रतिस्पर्धा करने की कोशिश करते हैं। इस शिक्षण नियम को समझने के लिए, हमें प्रतिस्पर्धी नेटवर्क को समझना चाहिए, जो इस प्रकार है -
Basic Concept of Competitive Network- यह नेटवर्क आउटपुट के बीच फीडबैक कनेक्शन के साथ सिंगल लेयर फीडफॉर्वर्ड नेटवर्क की तरह है। आउटपुट के बीच कनेक्शन निरोधात्मक प्रकार है, बिंदीदार रेखाओं द्वारा दिखाया गया है, जिसका अर्थ है कि प्रतियोगी कभी भी खुद का समर्थन नहीं करते हैं।
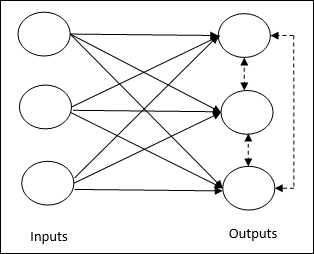
Basic Concept of Competitive Learning Rule- जैसा कि पहले कहा गया था, आउटपुट नोड्स के बीच एक प्रतियोगिता होगी। इसलिए, मुख्य अवधारणा यह है कि प्रशिक्षण के दौरान, किसी दिए गए इनपुट पैटर्न के लिए उच्चतम सक्रियण वाली आउटपुट इकाई को विजेता घोषित किया जाएगा। इस नियम को विनर-टेक-ऑल भी कहा जाता है क्योंकि केवल जीतने वाले न्यूरॉन को अपडेट किया जाता है और बाकी के न्यूरॉन्स को अपरिवर्तित छोड़ दिया जाता है।
Mathematical formulation - इस शिक्षण नियम के गणितीय सूत्रीकरण के तीन महत्वपूर्ण कारक निम्नलिखित हैं -
Condition to be a winner - मान लीजिए अगर एक न्यूरॉन $ y_ {k} $ ants towants विजेता बनना चाहता है तो निम्न कार्य होंगे -
$$ y_ {k} \: = \: \ start {case} 1 & if \: v_ {k} \ _:: \ _: v_ {j} \: for:: \ \ _ j, \: j \: \। neq \: k \\ 0 और अन्यथा \ मामलों {$} $
इसका अर्थ है कि यदि कोई न्यूरॉन, $ y_ {k} $ say कहता है, जीतना चाहता है, तो उसका प्रेरित स्थानीय क्षेत्र (योग इकाई का उत्पादन), $ v_ {k} $ कहें, अन्य सभी न्यूरॉन्स में सबसे बड़ा होना चाहिए नेटवर्क में।
Condition of sum total of weight - प्रतिस्पर्धात्मक शिक्षण नियम पर एक और अड़चन यह है कि एक विशेष आउटपुट न्यूरॉन के कुल वजन का योग 1 होने वाला है। उदाहरण के लिए, यदि हम न्यूरॉन पर विचार करते हैं k तब -
$$ \ displaystyle \ योग \ limits_ {j} {w_ के.जे.} \: = \: 1 \: \: \: \: \: \: \: \: \: के लिए \: सभी \: कश्मीर $$
Change of weight for winner- यदि कोई न्यूरॉन इनपुट पैटर्न पर प्रतिक्रिया नहीं देता है, तो उस न्यूरॉन में कोई सीख नहीं होती है। हालाँकि, यदि कोई विशेष न्यूरॉन जीतता है, तो संबंधित वज़न को निम्नानुसार समायोजित किया जाता है
$$ \ Delta w_ {kj} \: = \: \ start {case} शुरू - \ Alpha (x_ {j} \: - \: w_ {kj}), और if \: न्यूरॉन \: k \: जीतता है \\ 0, और if \: न्यूरॉन \: k \: घाटा \ अंत {मामलों} $ $
यहाँ $ \ अल्फा $ सीखने की दर है।
यह स्पष्ट रूप से दर्शाता है कि हम जीतने वाले न्यूरॉन को उसके वजन को समायोजित करने के पक्ष में हैं और यदि न्यूरॉन की हानि हो रही है, तो हमें इसके वजन को फिर से समायोजित करने की आवश्यकता नहीं है।
आउटस्टार लर्निंग नियम
ग्रॉसबर्ग द्वारा शुरू किया गया यह नियम, पर्यवेक्षित सीखने से संबंधित है क्योंकि वांछित आउटपुट ज्ञात हैं। इसे ग्रॉसबर्ग लर्निंग भी कहा जाता है।
Basic Concept- यह नियम एक परत में व्यवस्थित न्यूरॉन्स के ऊपर लागू किया जाता है। यह विशेष रूप से एक वांछित उत्पादन करने के लिए डिज़ाइन किया गया हैd की परत p न्यूरॉन्स।
Mathematical Formulation - इस नियम में भार समायोजन की गणना निम्नानुसार की जाती है
$$ \ Delta w_ {j} \: = \: \ Alpha \ :( d \: - \: w_ {j}) $$
यहाँ d वांछित न्यूरॉन आउटपुट है और $ \ अल्फा $ सीखने की दर है।
जैसा कि नाम सुझाव देता है, supervised learningएक शिक्षक की देखरेख में होता है। यह सीखने की प्रक्रिया निर्भर है। पर्यवेक्षित शिक्षण के तहत एएनएन के प्रशिक्षण के दौरान, इनपुट वेक्टर नेटवर्क को प्रस्तुत किया जाता है, जो एक आउटपुट वेक्टर का उत्पादन करेगा। इस आउटपुट वेक्टर की तुलना वांछित / लक्ष्य आउटपुट वेक्टर से की जाती है। यदि वास्तविक आउटपुट और वांछित / लक्ष्य आउटपुट वेक्टर के बीच अंतर है, तो एक त्रुटि संकेत उत्पन्न होता है। इस त्रुटि संकेत के आधार पर, वजन तब तक समायोजित किया जाएगा जब तक कि वास्तविक आउटपुट वांछित आउटपुट के साथ मेल नहीं खाता।
perceptron
फ्रेंक रोसेनब्लट द्वारा मैककुलोच और पिट्स मॉडल का उपयोग करके विकसित किया गया है, परसेप्ट्रॉन कृत्रिम तंत्रिका नेटवर्क की बुनियादी परिचालन इकाई है। यह पर्यवेक्षित शिक्षण नियम को नियोजित करता है और डेटा को दो वर्गों में वर्गीकृत करने में सक्षम है।
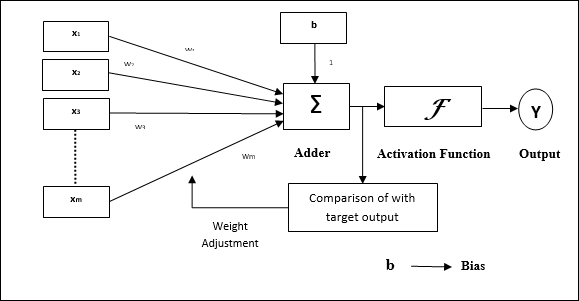
परसेप्ट्रॉन की परिचालन विशेषताएं: इसमें एक एकल न्यूरॉन होता है, जिसमें समायोज्य वजन के साथ-साथ इनपुट की एक मनमानी संख्या होती है, लेकिन थ्रेशोल्ड के आधार पर न्यूरॉन का उत्पादन 1 या 0 होता है। इसमें एक पूर्वाग्रह भी होता है जिसका वजन हमेशा 1 होता है। निम्नलिखित आकृति परसेप्ट्रान का एक योजनाबद्ध प्रतिनिधित्व देती है।
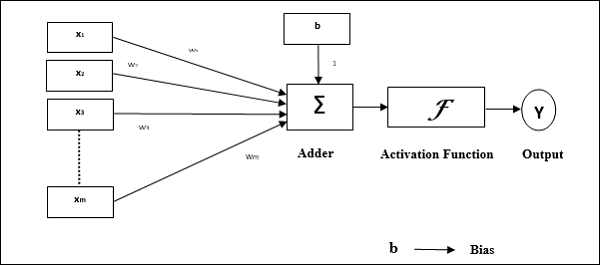
इस प्रकार परसेप्ट्रोन में निम्नलिखित तीन मूल तत्व होते हैं -
Links - इसमें कनेक्शन लिंक का एक सेट होगा, जिसमें एक पूर्वाग्रह सहित वजन होता है जिसमें हमेशा वजन 1 होता है।
Adder - यह इनपुट को उनके संबंधित भार से गुणा करने के बाद जोड़ता है।
Activation function- यह न्यूरॉन के उत्पादन को सीमित करता है। सबसे बुनियादी सक्रियण फ़ंक्शन एक हैविसाइड चरण फ़ंक्शन है जिसमें दो संभावित आउटपुट हैं। यह फ़ंक्शन 1 रिटर्न देता है, यदि इनपुट सकारात्मक है, और किसी भी नकारात्मक इनपुट के लिए 0 है।
प्रशिक्षण एल्गोरिथ्म
Perceptron नेटवर्क को एकल आउटपुट इकाई के साथ-साथ कई आउटपुट इकाइयों के लिए प्रशिक्षित किया जा सकता है।
एकल आउटपुट यूनिट के लिए प्रशिक्षण एल्गोरिथम
Step 1 - प्रशिक्षण शुरू करने के लिए निम्नलिखित बातों का प्रारंभ करें -
- Weights
- Bias
- लर्निंग दर $ \ अल्फा $
आसान गणना और सादगी के लिए, वज़न और पूर्वाग्रह को 0 के बराबर और सीखने की दर को 1 के बराबर सेट करना होगा।
Step 2 - स्टेप 3-8 को जारी रखें जब रोक की स्थिति सही न हो।
Step 3 - हर प्रशिक्षण वेक्टर के लिए चरण 4-6 जारी रखें x।
Step 4 - प्रत्येक इनपुट यूनिट को निम्नानुसार सक्रिय करें -
$$ x_ {मैं} \: = \: s_ {मैं} \ :( मैं \: = \: 1 \: करने के लिए \: एन) $$
Step 5 - अब निम्नलिखित संबंध के साथ शुद्ध इनपुट प्राप्त करें -
$ $ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i}। \: w_ {i} $।
यहाँ ‘b’ पूर्वाग्रह और है ‘n’ इनपुट न्यूरॉन्स की कुल संख्या है।
Step 6 - अंतिम आउटपुट प्राप्त करने के लिए निम्नलिखित सक्रियण फ़ंक्शन लागू करें।
$ $ f (y_ {in}) \: = \: \ start {case} 1 और if \: y_ {in} \ _: \ _ \ _ theta \\ 0 और if \: - \ theta \: \ leqslive \ _ : y_ {in} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {in} \: <\: - \ theta \ end {मामले} $ $
Step 7 - वजन और पूर्वाग्रह को निम्नानुसार समायोजित करें -
Case 1 - अगर y ≠ t फिर,
$$ w_ {मैं} (नया) \: = \: w_ {मैं} (पुराने) \: + \: \ अल्फा \: tx_ {मैं} $$
$ $ b (नया) \: = \: बी (पुराना) \: + \: \ अल्फा टी $ $
Case 2 - अगर y = t फिर,
$$ w_ {मैं} (नया) \: = \: w_ {मैं} (पुराने) $$
$$ ख (नया) \: = \: ख (पुराने) $$
यहाँ ‘y’ वास्तविक उत्पादन है और ‘t’ वांछित / लक्ष्य आउटपुट है।
Step 8 - रोकने की स्थिति के लिए परीक्षण, जो तब होता है जब वजन में कोई बदलाव नहीं होता है।
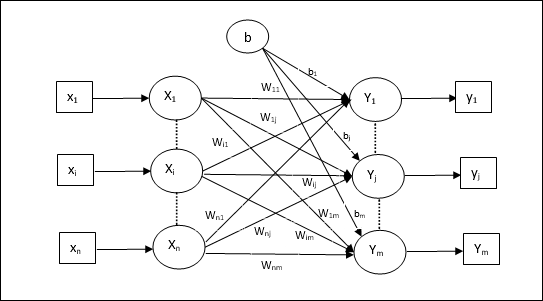
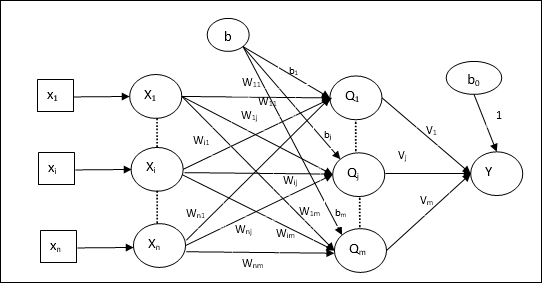
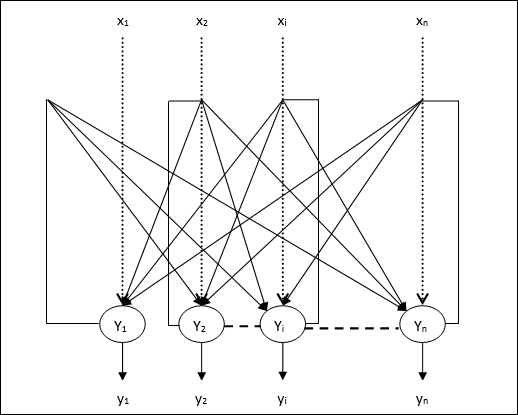
एकाधिक आउटपुट इकाइयों के लिए प्रशिक्षण एल्गोरिथ्म
निम्नलिखित आरेख कई आउटपुट कक्षाओं के लिए अवधारणात्मक की वास्तुकला है।
Step 1 - प्रशिक्षण शुरू करने के लिए निम्नलिखित बातों का प्रारंभ करें -
- Weights
- Bias
- लर्निंग दर $ \ अल्फा $
आसान गणना और सादगी के लिए, वज़न और पूर्वाग्रह को 0 के बराबर और सीखने की दर को 1 के बराबर सेट करना होगा।
Step 2 - स्टेप 3-8 को जारी रखें जब रोक की स्थिति सही न हो।
Step 3 - हर प्रशिक्षण वेक्टर के लिए चरण 4-6 जारी रखें x।
Step 4 - प्रत्येक इनपुट यूनिट को निम्नानुसार सक्रिय करें -
$$ x_ {मैं} \: = \: s_ {मैं} \ :( मैं \: = \: 1 \: करने के लिए \: एन) $$
Step 5 - निम्नलिखित संबंध के साथ शुद्ध इनपुट प्राप्त करें -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {ij} $$
यहाँ ‘b’ पूर्वाग्रह और है ‘n’ इनपुट न्यूरॉन्स की कुल संख्या है।
Step 6 - प्रत्येक आउटपुट यूनिट के लिए अंतिम आउटपुट प्राप्त करने के लिए निम्नलिखित सक्रियण फ़ंक्शन लागू करें j = 1 to m -
$$ f (y_ {in}) \: = \: \ start {मामलों} 1 & if \: y_ {घायल} \ _: \ _ \ _ थीटा \\ 0 और अगर \: - \ थीटा \: \ leqslive \ " : y_ {घायल} \: \ leqslant \: \ theta \\ - 1 और if \: y_ {घायल} \: <\: - \ theta \ end {मामले} $ $
Step 7 - के लिए वजन और पूर्वाग्रह समायोजित करें x = 1 to n तथा j = 1 to m निम्नानुसार है -
Case 1 - अगर yj ≠ tj फिर,
$$ w_ {ij} (नया) \: = \: w_ {ij} (पुराने) \: + \: \ अल्फा \: T_ {j} x_ {मैं} $$
$ $ b_ {j} (नया) \: = \: b_ {j} (पुराना) \: + \: \ अल्फा t_ {j} $ $
Case 2 - अगर yj = tj फिर,
$$ w_ {ij} (नया) \: = \: w_ {ij} (पुराने) $$
$$ b_ {j} (नया) \: = \: b_ {j} (पुराने) $$
यहाँ ‘y’ वास्तविक उत्पादन है और ‘t’ वांछित / लक्ष्य आउटपुट है।
Step 8 - रोकने की स्थिति के लिए परीक्षण, जो तब होगा जब वजन में कोई बदलाव नहीं होगा।
अनुकूली रैखिक न्यूरॉन (एडलिन)
Adaline जो Adaptive Linear Neuron के लिए खड़ा है, एक एकल रैखिक इकाई वाला एक नेटवर्क है। यह 1960 में विडो और हॉफ द्वारा विकसित किया गया था। एडालीन के बारे में कुछ महत्वपूर्ण बिंदु इस प्रकार हैं -
यह द्विध्रुवी सक्रियण फ़ंक्शन का उपयोग करता है।
यह प्रशिक्षण के लिए वास्तविक उत्पादन और वांछित / लक्ष्य आउटपुट के बीच मीन-चुकता त्रुटि (MSE) को कम करने के लिए डेल्टा नियम का उपयोग करता है।
वजन और पूर्वाग्रह समायोज्य हैं।
आर्किटेक्चर
Adaline की मूल संरचना अवधारणात्मक के समान है, जिसकी सहायता से एक अतिरिक्त फीडबैक लूप मिलता है जिसकी मदद से वांछित / लक्ष्य आउटपुट के साथ वास्तविक आउटपुट की तुलना की जाती है। प्रशिक्षण एल्गोरिथ्म के आधार पर तुलना के बाद, वज़न और पूर्वाग्रह को अपडेट किया जाएगा।
प्रशिक्षण एल्गोरिथ्म
Step 1 - प्रशिक्षण शुरू करने के लिए निम्नलिखित बातों का प्रारंभ करें -
- Weights
- Bias
- लर्निंग दर $ \ अल्फा $
आसान गणना और सादगी के लिए, वज़न और पूर्वाग्रह को 0 के बराबर और सीखने की दर को 1 के बराबर सेट करना होगा।
Step 2 - स्टेप 3-8 को जारी रखें जब रोक की स्थिति सही न हो।
Step 3 - हर द्विध्रुवी प्रशिक्षण जोड़ी के लिए चरण 4-6 जारी रखें s:t।
Step 4 - प्रत्येक इनपुट यूनिट को निम्नानुसार सक्रिय करें -
$$ x_ {मैं} \: = \: s_ {मैं} \ :( मैं \: = \: 1 \: करने के लिए \: एन) $$
Step 5 - निम्नलिखित संबंध के साथ शुद्ध इनपुट प्राप्त करें -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {i} $ $
यहाँ ‘b’ पूर्वाग्रह और है ‘n’ इनपुट न्यूरॉन्स की कुल संख्या है।
Step 6 - अंतिम आउटपुट प्राप्त करने के लिए निम्नलिखित सक्रियण फ़ंक्शन लागू करें -
$$ f (y_ {in}) \: = \: \ start {case} 1 & if \: y_ {in} \: \ geqslant \: 0 \\ - 1 और if \: y_ {in} \ <> \: 0 \ end {मामले} $ $
Step 7 - वजन और पूर्वाग्रह को निम्नानुसार समायोजित करें -
Case 1 - अगर y ≠ t फिर,
$ $ w_ {i} (नया) \: = \: w_ {i} (पुराना) \: + \: \ अल्फा (t \: - \: y_ {in}) x_ {i} $ $
$ $ b (नया) \: = \: बी (पुराना) \: + \: \ अल्फा (टी \: - \: y_ {in}) $ $
Case 2 - अगर y = t फिर,
$$ w_ {मैं} (नया) \: = \: w_ {मैं} (पुराने) $$
$$ ख (नया) \: = \: ख (पुराने) $$
यहाँ ‘y’ वास्तविक उत्पादन है और ‘t’ वांछित / लक्ष्य आउटपुट है।
$ (t \: - \; y_ {in}) $ गणना की गई त्रुटि है।
Step 8 - रोकने की स्थिति के लिए परीक्षण, जो तब होगा जब वजन में कोई बदलाव नहीं होता है या प्रशिक्षण के दौरान सबसे अधिक वजन में परिवर्तन निर्दिष्ट सहिष्णुता से छोटा होता है।
मल्टीपल अडैप्टिव लीनियर न्यूरॉन (मैडलीन)
मैडालीन जो कि कई एडेप्टिव लीनियर न्यूरॉन के लिए खड़ा है, एक नेटवर्क है जिसमें समानांतर में कई एडलीन होते हैं। इसकी एकल आउटपुट इकाई होगी। मैडलीन के बारे में कुछ महत्वपूर्ण बिंदु इस प्रकार हैं -
यह एक बहुपरत अवधारणात्मक की तरह है, जहां एडलिन इनपुट और मैडलिन परत के बीच एक छिपी इकाई के रूप में कार्य करेगा।
इनपुट और एडलीन परतों के बीच वजन और पूर्वाग्रह, जैसा कि हम एडलिन वास्तुकला में देखते हैं, समायोज्य हैं।
Adaline और Madaline परतों का वजन और पूर्वाग्रह 1 है।
डेल्टा नियम की सहायता से प्रशिक्षण प्राप्त किया जा सकता है।
आर्किटेक्चर
मैडलिन की वास्तुकला में शामिल हैं “n” इनपुट परत के न्यूरॉन्स, “m”Adaline लेयर के न्यूरॉन्स, और Madaline लेयर के 1 न्यूरॉन। Adaline लेयर को हिडन लेयर माना जा सकता है क्योंकि यह इनपुट लेयर और आउटपुट लेयर यानी Madaline लेयर के बीच होती है।
प्रशिक्षण एल्गोरिथ्म
अब तक हम जानते हैं कि इनपुट और एडलीन परत के बीच केवल वज़न और पूर्वाग्रह को समायोजित किया जाना है, और एडालीन और मैडलाइन परत के बीच के वज़न और पूर्वाग्रह तय हैं।
Step 1 - प्रशिक्षण शुरू करने के लिए निम्नलिखित बातों का प्रारंभ करें -
- Weights
- Bias
- लर्निंग दर $ \ अल्फा $
आसान गणना और सादगी के लिए, वज़न और पूर्वाग्रह को 0 के बराबर और सीखने की दर को 1 के बराबर सेट करना होगा।
Step 2 - स्टेप 3-8 को जारी रखें जब रोक की स्थिति सही न हो।
Step 3 - हर द्विध्रुवी प्रशिक्षण जोड़ी के लिए चरण 4-6 जारी रखें s:t।
Step 4 - प्रत्येक इनपुट यूनिट को निम्नानुसार सक्रिय करें -
$$ x_ {मैं} \: = \: s_ {मैं} \ :( मैं \: = \: 1 \: करने के लिए \: एन) $$
Step 5 - प्रत्येक छिपी हुई परत पर शुद्ध इनपुट प्राप्त करें, अर्थात निम्नलिखित संबंध के साथ एडलिन परत -
$$ Q_ {घायल} \ _: = \ _ b_ {j} \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {ij} \: \: \: j \ _ = \: 1 \: करने के लिए \: मीटर $$
यहाँ ‘b’ पूर्वाग्रह और है ‘n’ इनपुट न्यूरॉन्स की कुल संख्या है।
Step 6 - Adaline और Madaline लेयर में अंतिम आउटपुट प्राप्त करने के लिए निम्नलिखित सक्रियण फ़ंक्शन लागू करें -
$ $ f (x) \: = \: \ शुरू {केस} 1 & if \: x \: \ geqslant \: 0 \\ - 1 और if \: x \: <\: 0 \ end {केस} $। $
छिपी हुई (एडालिन) इकाई में आउटपुट
$$ Q_ {j} \: = \: च (Q_ {इंज}) $$
नेटवर्क का अंतिम आउटपुट
$$ y \: = \: च ({} में y_) $$
i.e. $ \: \: y_ {घायल} \ _: = \: b_ {0} \: + \: \ sum_ {j = 1} ^ m \: Q_ {j} \: v_ {j} $
Step 7 - त्रुटि की गणना करें और निम्नानुसार वज़न समायोजित करें -
Case 1 - अगर y ≠ t तथा t = 1 फिर,
$ $ w_ {ij} (नया) \: = \: w_ {ij} (पुराना) \: + \: \ अल्फा (1 \: - \: Q_ {घायल}) x_ {i} $ $
$ $ b_ {j} (नया) \: = \: b_ {j} (पुराना) \: + \: \ अल्फा (1 \: - \: Q_ {घायल}) $ $
इस मामले में, वज़न को अपडेट किया जाएगा Qj जहां शुद्ध इनपुट 0 के करीब है क्योंकि t = 1।
Case 2 - अगर y ≠ t तथा t = -1 फिर,
$ $ w_ {ik} (नया) \: = \: w_ {ik} (पुराना) \: + \: \ अल्फा (-1 \: - \: Q_ {स्याही}) x_ {i} $ $
$ $ b_ {k} (नया) \: = \: b_ {k} (पुराना) \: + \: \ अल्फा (-1 \: - \: Q_ {स्याही}) $ $
इस मामले में, वज़न को अपडेट किया जाएगा Qk जहां शुद्ध इनपुट सकारात्मक है क्योंकि t = -1।
यहाँ ‘y’ वास्तविक उत्पादन है और ‘t’ वांछित / लक्ष्य आउटपुट है।
Case 3 - अगर y = t फिर
वज़न में कोई बदलाव नहीं होगा।
Step 8 - रोकने की स्थिति के लिए परीक्षण, जो तब होगा जब वजन में कोई बदलाव नहीं होता है या प्रशिक्षण के दौरान सबसे अधिक वजन में परिवर्तन निर्दिष्ट सहिष्णुता से छोटा होता है।
वापस प्रसार तंत्रिका नेटवर्क
Back Propagation Neural (BPN) एक बहुपरत तंत्रिका नेटवर्क है जिसमें इनपुट परत होती है, कम से कम एक छिपी हुई परत और आउटपुट परत। जैसा कि इसके नाम से पता चलता है, इस नेटवर्क में बैक प्रोपेगेटिंग होगा। त्रुटि जो आउटपुट लेयर पर आंकी जाती है, लक्ष्य आउटपुट और वास्तविक आउटपुट की तुलना करके, इनपुट लेयर की ओर वापस प्रचारित होगी।
आर्किटेक्चर
जैसा कि चित्र में दिखाया गया है, BPN की वास्तुकला में तीन परस्पर परतें हैं, जिन पर भार होता है। छिपी हुई परत के साथ-साथ आउटपुट परत में भी पूर्वाग्रह होता है, जिसका वजन उन पर हमेशा 1 होता है। जैसा कि आरेख से स्पष्ट है, BPN का कार्य दो चरणों में होता है। एक चरण इनपुट लेयर से आउटपुट लेयर तक सिग्नल भेजता है, और दूसरा चरण आउटपुट लेयर से इनपुट लेयर तक त्रुटि को फैलाता है।

प्रशिक्षण एल्गोरिथ्म
प्रशिक्षण के लिए, बीपीएन बाइनरी सिग्मॉइड सक्रियण फ़ंक्शन का उपयोग करेगा। बीपीएन के प्रशिक्षण में निम्नलिखित तीन चरण होंगे।
Phase 1 - फीड फॉरवर्ड फेज
Phase 2 - त्रुटि का वापस प्रसार
Phase 3 - वजन का अद्यतन
इन सभी चरणों का समापन एल्गोरिथ्म में किया जाएगा
Step 1 - प्रशिक्षण शुरू करने के लिए निम्नलिखित बातों का प्रारंभ करें -
- Weights
- लर्निंग दर $ \ अल्फा $
आसान गणना और सरलता के लिए, कुछ छोटे यादृच्छिक मान लें।
Step 2 - स्टेप 3-11 तब जारी रखें जब रोक की स्थिति सही न हो।
Step 3 - हर प्रशिक्षण जोड़ी के लिए चरण 4-10 जारी रखें।
चरण 1
Step 4 - प्रत्येक इनपुट यूनिट को इनपुट सिग्नल मिलता है xi और इसे सभी के लिए छिपी इकाई को भेजता है i = 1 to n
Step 5 - निम्नलिखित संबंध का उपयोग कर छिपी हुई इकाई में शुद्ध इनपुट की गणना करें -
$ $ Q_ {घायल} \: = \: b_ {0j} \: + \: \ sum_ {i = 1} ^ n x_ {i} v_ {ij} \: \: \: \: j \: = \ _ : 1 \: करने के लिए \: p $$
यहाँ b0j छिपा इकाई पर पूर्वाग्रह है, vij पर वजन है j छिपी हुई परत की इकाई i इनपुट परत की इकाई।
अब निम्नलिखित सक्रियण फ़ंक्शन को लागू करके शुद्ध आउटपुट की गणना करें
$$ Q_ {j} \: = \: च (Q_ {इंज}) $$
छिपी परत इकाइयों के इन आउटपुट संकेतों को आउटपुट परत इकाइयों में भेजें।
Step 6 - निम्नलिखित संबंध का उपयोग कर आउटपुट परत इकाई में शुद्ध इनपुट की गणना करें -
$ $ y_ {स्याही} \: = \: b_ {0k} \: + \: \ sum_ {j = 1} ^ p \: Q_ {j} \: w_ {jk} \: \: k \: = \ _ : 1 \: करने के लिए \: मीटर $$
यहाँ b0k उत्पादन इकाई पर पूर्वाग्रह, wjk पर वजन है k से आने वाली आउटपुट लेयर की इकाई j छिपी हुई परत की इकाई।
निम्नलिखित सक्रियण फ़ंक्शन को लागू करके शुद्ध आउटपुट की गणना करें
$$ y_ {कश्मीर} \: = \: च (y_ {स्याही}) $$
2 चरण
Step 7 - प्रत्येक आउटपुट इकाई पर प्राप्त लक्ष्य पैटर्न के साथ पत्राचार में, त्रुटि सुधारक शब्द की गणना निम्नानुसार करें -
$$ \ delta_ {कश्मीर} \: = \ :( T_ {कश्मीर} \: - \: y_ {कश्मीर}) च ^ { '} (y_ {स्याही}) $$
इस आधार पर, वजन और पूर्वाग्रह को निम्नानुसार अद्यतन करें -
$$ \ Delta v_ {jk} \: = \: \ Alpha \ delta_ {k} \: Q_ {i}} $ $
$$ \ Delta b_ {0k} \: = \: \ alp \ delta_ {k} $ $
फिर, छिपी हुई परत पर $ \ delta_ {k} $ वापस भेजें।
Step 8 - अब प्रत्येक छिपी इकाई आउटपुट इकाइयों से अपने डेल्टा इनपुट का योग होगी।
$$ \ delta_ {घायल} \ _: = \: \ displaystyle \ sum \ limit_ {k = 1} ^ m \ delta_ {k} \: w_ {jk} $$
त्रुटि शब्द की गणना निम्नानुसार की जा सकती है -
$$ \ delta_ {j} \: = \: \ delta_ {इंज} च ^ { '} (Q_ {इंज}) $$
इस आधार पर, वजन और पूर्वाग्रह को निम्नानुसार अद्यतन करें -
$$ \ Delta w_ {ij} \: = \: \ alp \ delta_ {j} x_ {i} $ $
$$ \ Delta b_ {0j} \: = \: \ alp \ delta_ {j} $ $
चरण 3
Step 9 - प्रत्येक आउटपुट यूनिट (ykk = 1 to m) वजन और पूर्वाग्रह को निम्नानुसार अद्यतन करता है -
$ $ v_ {jk} (नया) \: = \: v_ {jk} (पुराना) \: + \: \ Delta v_ {jk} $$
$$ b_ {0k} (नया) \: = \: b_ {0k} (पुराना) \: + \: \ Delta b_ {0k} $ $
Step 10 - प्रत्येक आउटपुट यूनिट (zjj = 1 to p) वजन और पूर्वाग्रह को निम्नानुसार अद्यतन करता है -
$ $ w_ {ij} (नया) \: = \: w_ {ij} (पुराना) \: + \: \ Delta w_ {ij} $ $
$ $ b_ {0j} (नया) \: = \: b_ {0j} (पुराना) \: + \: \ Delta b_ {0j} $ $
Step 11 - रोकने की स्थिति के लिए जाँच करें, जो या तो पहुंच की संख्या तक पहुंच सकता है या लक्ष्य आउटपुट वास्तविक आउटपुट से मेल खाता है।
सामान्यीकृत डेल्टा लर्निंग नियम
डेल्टा नियम केवल आउटपुट लेयर के लिए काम करता है। दूसरी ओर, सामान्यीकृत डेल्टा नियम, जिसे भी कहा जाता हैback-propagation नियम, छिपी हुई परत के वांछित मूल्यों को बनाने का एक तरीका है।
गणितीय सूत्रीकरण
सक्रियण समारोह के लिए $ y_ {k} \: = \: f (y_ {इंक}) $ शुद्ध परत पर शुद्ध इनपुट के साथ-साथ आउटपुट परत पर भी व्युत्पन्न किया जा सकता है
$$ y_ {स्याही} \: = \: \ displaystyle \ योग \ limits_i \: z_ {मैं} {w_ जेके} $$
और $ \: \: y_ {घायल} \ _: = \: \ sum_i x_ {i} v_ {ij} $
अब जो त्रुटि होनी है वह कम से कम है
$$ ई \: = \: \ frac {1} {2} \ displaystyle \ योग \ limits_ {कश्मीर} \: [T_ {कश्मीर} \: - \: y_ {k}] ^ 2 $$
श्रृंखला नियम का उपयोग करके, हमारे पास है
$$ \ frac {\ आंशिक E} {\ आंशिक w_ {jk}} \: = \: \ frac {\ आंशिक} {\ आंशिक w_ {jk}} (\ frac {1} {2} \ displaystyle / sum \} limits_ {कश्मीर} \: [T_ {कश्मीर} \: - \: y_ {k}] ^ 2) $$
$ $ = \: \ frac {\ आंशिक} {\ आंशिक w_ {jk}} \ lgroup \ frac {1} {2} [t_ {k} \ _: - \: t (y_ {स्याही})] 2 \ _ rgroup $$
$$ = \: - [t_ {k} \: - \: y_ {k}] \ frac {\ आंशिक} {\ आंशिक w_ {jk}} f (y_ {स्याही}) $ $
$ $ = \: - [t_ {k} \: - \: y_ {k}] f (y_ {स्याही}) \ frac {\ आंशिक} {\ आंशिक w_ {jk}} (y_ {स्याही}) $ $
$$ = \: - [T_ {कश्मीर} \: - \: y_ {कश्मीर}] च ^ { '} (y_ {स्याही}) z_ {j} $$
अब हम कहते हैं कि $ \ delta_ {k} \: = \: - [t_ {k} \ _: - \: y_ {k}] f ^ {'} (y_ {इंक}) $
छिपी हुई इकाई के कनेक्शन पर वजन zj द्वारा दिया जा सकता है -
$$ \ frac {\ आंशिक E} {\ आंशिक v_ {ij}} \: = \: - \ displaystyle \ sum \ limit_ {k} \ delta_ {k} \ frac {\ आंशिक} {\ आंशिक v {{ij} } \ :( y_ {स्याही}) $$
$ Y_ {इंक} $ का मूल्य डालते हुए हम निम्नलिखित प्राप्त करेंगे
$$ \ delta_ {j} \: = \: - \ displaystyle \ योग \ limits_ {कश्मीर} \ delta_ {k} {w_ जेके} च ^ { '} (z_ {इंज}) $$
वेट अपडेट इस प्रकार किया जा सकता है -
आउटपुट यूनिट के लिए -
$$ \ Delta w_ {jk} \: = \: - \ Alpha \ frac {\ आंशिक ई} {{आंशिक w_ {jk}} $$
$$ = \: \ अल्फा \: \ delta_ {कश्मीर} \: z_ {j} $$
छिपी हुई इकाई के लिए -
$$ \ Delta v_ {ij} \: = \: - \ Alpha \ frac {\ आंशिक E} {\ आंशिक v_ {ij}} $ $
$$ = \: \ अल्फा \: \ delta_ {j} \: x_ {मैं} $$
जैसा कि नाम से पता चलता है, इस प्रकार की सीख शिक्षक की देखरेख के बिना की जाती है। यह सीखने की प्रक्रिया स्वतंत्र है। अनुपयोगी अधिगम के तहत एएनएन के प्रशिक्षण के दौरान, इसी प्रकार के इनपुट वैक्टर क्लस्टर बनाने के लिए संयुक्त होते हैं। जब एक नया इनपुट पैटर्न लागू किया जाता है, तो तंत्रिका नेटवर्क एक आउटपुट प्रतिक्रिया देता है जो उस वर्ग को इंगित करता है जिसमें इनपुट पैटर्न होता है। इसमें, पर्यावरण से कोई प्रतिक्रिया नहीं होगी कि वांछित आउटपुट क्या होना चाहिए और क्या यह सही है या गलत है। इसलिए, इस प्रकार के सीखने में नेटवर्क को स्वयं इनपुट पैटर्न, सुविधाओं से इनपुट डेटा और आउटपुट पर इनपुट डेटा के संबंध की खोज करनी चाहिए।
विजेता-सभी नेटवर्क
इस प्रकार के नेटवर्क प्रतिस्पर्धी शिक्षण नियम पर आधारित होते हैं और इस रणनीति का उपयोग करेंगे जहां यह विजेता के रूप में सबसे बड़े कुल इनपुट के साथ न्यूरॉन का चयन करता है। आउटपुट न्यूरॉन्स के बीच के कनेक्शन उनके बीच की प्रतिस्पर्धा को दर्शाते हैं और उनमें से एक 'ऑन' होगा जिसका अर्थ है कि यह विजेता होगा और अन्य 'ऑफ' होंगे।
इस सामान्य अवधारणा पर आधारित कुछ नेटवर्क हैं जिनका उपयोग बिना पढ़े हुए शिक्षण के आधार पर किया जाता है।
हैमिंग नेटवर्क
अधिकांश तंत्रिका नेटवर्क में अप्रशिक्षित सीखने का उपयोग करते हुए, दूरी की गणना करना और तुलना करना आवश्यक है। इस तरह का नेटवर्क हैमिंग नेटवर्क है, जहां हर दिए गए इनपुट वैक्टर के लिए, इसे विभिन्न समूहों में जोड़ा जाएगा। हामिंग नेटवर्क की कुछ महत्वपूर्ण विशेषताएं निम्नलिखित हैं -
Lippmann ने 1987 में Hamming नेटवर्क पर काम करना शुरू किया।
यह एक सिंगल लेयर नेटवर्क है।
इनपुट द्विआधारी {0, 1} के बाइनरी {0, 1} हो सकते हैं।
नेट के वजन की गणना अनुकरणीय वैक्टर द्वारा की जाती है।
यह एक निश्चित वजन नेटवर्क है जिसका मतलब है कि प्रशिक्षण के दौरान भी वज़न समान रहेगा।
मैक्स नेट
यह भी एक निश्चित वजन का नेटवर्क है, जो सबसे अधिक इनपुट वाले नोड को चुनने के लिए एक सबनेट के रूप में कार्य करता है। सभी नोड पूरी तरह से परस्पर जुड़े हुए हैं और इन सभी भारित अंतर्संबंधों में सममित भार मौजूद हैं।
आर्किटेक्चर
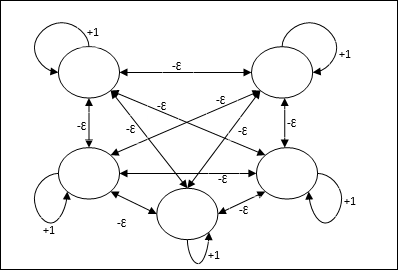
यह तंत्र का उपयोग करता है जो एक पुनरावृत्त प्रक्रिया है और प्रत्येक नोड को कनेक्शन के माध्यम से अन्य सभी नोड्स से निरोधात्मक इनपुट प्राप्त होता है। एकल नोड जिसका मान अधिकतम है सक्रिय या विजेता होगा और अन्य सभी नोड्स की सक्रियता निष्क्रिय होगी। मैक्स नेट $ $ f (x) \: = \: \ start {case} x & if \: x> 0 \\ 0 और if \: x \ leq 0 \ end {केस} $$ के साथ पहचान सक्रियण फ़ंक्शन का उपयोग करता है
इस नेट का कार्य +1 और आपसी निषेध परिमाण के आत्म-उत्तेजना वजन द्वारा पूरा किया जाता है, जो कि [0 <[<$ \ frac {1} {m} $] की तरह निर्धारित होता है जहां “m” नोड्स की कुल संख्या है।
एएनएन में प्रतियोगी लर्निंग
यह अनिश्चित प्रशिक्षण से संबंधित है जिसमें आउटपुट नोड्स इनपुट पैटर्न का प्रतिनिधित्व करने के लिए एक दूसरे के साथ प्रतिस्पर्धा करने की कोशिश करते हैं। इस शिक्षण नियम को समझने के लिए हमें प्रतिस्पर्धी नेट को समझना होगा, जो इस प्रकार है -
प्रतिस्पर्धी नेटवर्क की बुनियादी अवधारणा
यह नेटवर्क आउटपुट के बीच फीडबैक कनेक्शन वाले सिंगल लेयर फीड-फॉरवर्ड नेटवर्क की तरह है। आउटपुट के बीच कनेक्शन निरोधात्मक प्रकार है, जो बिंदीदार रेखाओं द्वारा दिखाया गया है, जिसका अर्थ है कि प्रतियोगी कभी भी खुद का समर्थन नहीं करते हैं।
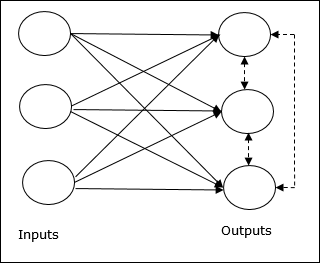
प्रतिस्पर्धात्मक सीखने के नियम का मूल संकल्पना
जैसा कि पहले कहा गया था, आउटपुट नोड्स के बीच प्रतिस्पर्धा होगी, इसलिए मुख्य अवधारणा है - प्रशिक्षण के दौरान, आउटपुट यूनिट जिसमें किसी दिए गए इनपुट पैटर्न के लिए सबसे अधिक सक्रियता है, को विजेता घोषित किया जाएगा। इस नियम को विनर-टेक-ऑल भी कहा जाता है क्योंकि केवल जीतने वाले न्यूरॉन को अपडेट किया जाता है और बाकी के न्यूरॉन्स को अपरिवर्तित छोड़ दिया जाता है।
गणितीय सूत्रीकरण
इस शिक्षण नियम के गणितीय सूत्रीकरण के तीन महत्वपूर्ण कारक निम्नलिखित हैं -
विजेता बनने की शर्त
मान लीजिए अगर एक न्यूरॉन yk विजेता बनना चाहता है, तो निम्नलिखित शर्त होगी
$ $ y_ {k} \: = \: \ start {case} 1 & if \: v_ {k}> v_ {j} \: for:: \ _ all: \: j, \: j \: \ neq \ _ : k \\ 0 & अन्यथा \ end {मामले} $ $
इसका मतलब है कि यदि कोई न्यूरॉन, कहता है, yk जीतना चाहते हैं, फिर इसके प्रेरित स्थानीय क्षेत्र (योग इकाई का उत्पादन), कहते हैं vk, नेटवर्क में अन्य सभी न्यूरॉन्स के बीच सबसे बड़ा होना चाहिए।
कुल योग की स्थिति
प्रतिस्पर्धी शिक्षण नियम पर एक और बाधा एक विशेष उत्पादन के लिए वजन का कुल योग है न्यूरॉन होने जा रहा है 1. उदाहरण के लिए, अगर हम न्यूरॉन पर विचार करते हैं k फिर
$$ \ displaystyle \ sum \ limit_ {k} w_ {kj} \: = \: 1 \: \: \: \: \: for \: all \: \: k $ $
विजेता के लिए वजन में परिवर्तन
यदि एक न्यूरॉन इनपुट पैटर्न का जवाब नहीं देता है, तो उस न्यूरॉन में कोई सीख नहीं होती है। हालांकि, यदि कोई विशेष न्यूरॉन जीतता है, तो संबंधित वज़न को निम्नानुसार समायोजित किया जाता है -
$$ \ Delta w_ {kj} \: = \: \ start {case} शुरू - \ Alpha (x_ {j} \: - \: w_ {kj}), और if \: न्यूरॉन \: k \: जीतता है \\ 0 & if \: न्यूरॉन \: k \: हानियों का अंत {केस} $ $
यहाँ $ \ अल्फा $ सीखने की दर है।
यह स्पष्ट रूप से दर्शाता है कि हम जीतने वाले न्यूरॉन को उसके वजन को समायोजित करके उसका पक्ष ले रहे हैं और यदि एक न्यूरॉन खो गया है, तो हमें उसके वजन को फिर से समायोजित करने के लिए परेशान होने की आवश्यकता नहीं है।
K- मतलब क्लस्टरिंग एल्गोरिथम
K- साधन सबसे लोकप्रिय क्लस्टरिंग एल्गोरिथ्म में से एक है जिसमें हम विभाजन प्रक्रिया की अवधारणा का उपयोग करते हैं। हम एक प्रारंभिक विभाजन से शुरू करते हैं और बार-बार पैटर्न को एक क्लस्टर से दूसरे तक ले जाते हैं, जब तक कि हमें एक संतोषजनक परिणाम नहीं मिलता है।
कलन विधि
Step 1 - चयन करें kप्रारंभिक केंद्रक के रूप में इंगित करता है। प्रारंभk प्रोटोटाइप (w1,…,wk), उदाहरण के लिए, हम उन्हें बेतरतीब ढंग से चुने गए इनपुट वैक्टर के साथ पहचान सकते हैं -
$ $ W_ {j} \: = \: i_ {p}, \: \: \: जहां \: j \: \ in \ lbrace1, ...., k \ rbrace \: और \: p \: \। in \ lbrace1, ...., n \ rbrace $ $
प्रत्येक क्लस्टर Cj प्रोटोटाइप के साथ जुड़ा हुआ है wj।
Step 2 - चरण 3-5 को दोहराएं जब तक कि ई अब घटता नहीं है, या क्लस्टर सदस्यता अब नहीं बदलती है।
Step 3 - प्रत्येक इनपुट वेक्टर के लिए ip कहाँ पे p ∈ {1,…,n}, डाल ip क्लस्टर में Cj* निकटतम प्रोटोटाइप के साथ wj* निम्नलिखित संबंध होने
$$ | i_ {p} \: - \: w_ {j *} | \: \ leq \ |: i_ {p} \: - \: w_ {j} |, \: j \: \ in \ lbrace1 | ...., कश्मीर \ rbrace $$
Step 4 - प्रत्येक क्लस्टर के लिए Cj, कहाँ पे j ∈ { 1,…,k}, प्रोटोटाइप को अपडेट करें wj वर्तमान में सभी नमूनों का केन्द्रक होना Cj , ताकि
$ $ w_ {j} \: = \: \ sum_ {i_ {p} \ _ C_ {j}} में \ _ frac {i_ {p}} {| C_ {j} |} $ $ |
Step 5 - कुल परिमाणीकरण त्रुटि की गणना निम्नानुसार करें -
$ $ E \: = \: \ sum_ {j = 1} ^ k \ sum_ {i_ {p} \ _ in_ {j}} | i_ {p} \: - \: w_ {j} | ^ 2 $ $
Neocognitron
यह एक बहुपरत फीडफ़ॉर्वर्ड नेटवर्क है, जिसे 1980 के दशक में फुकुशिमा द्वारा विकसित किया गया था। यह मॉडल सुपरवाइज्ड लर्निंग पर आधारित है और इसका इस्तेमाल विजुअल पैटर्न रिकग्निशन के लिए किया जाता है, मुख्य रूप से हाथ से लिखे गए किरदारों के लिए। यह मूल रूप से कॉग्निट्रॉन नेटवर्क का विस्तार है, जिसे 1975 में फुकुशिमा द्वारा भी विकसित किया गया था।
आर्किटेक्चर
यह एक पदानुक्रमित नेटवर्क है, जिसमें कई परतें होती हैं और उन परतों में स्थानीय रूप से कनेक्टिविटी का एक पैटर्न होता है।
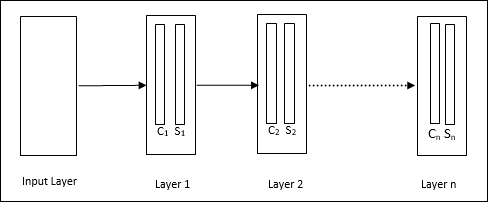
जैसा कि हमने ऊपर दिए गए आरेख में देखा है, नियोकोगिट्रॉन को विभिन्न जुड़े परतों में विभाजित किया गया है और प्रत्येक परत में दो कोशिकाएं हैं। इन कोशिकाओं की व्याख्या निम्नानुसार है -
S-Cell - इसे एक साधारण सेल कहा जाता है, जिसे किसी विशेष पैटर्न या पैटर्न के समूह का जवाब देने के लिए प्रशिक्षित किया जाता है।
C-Cell- इसे एक जटिल सेल कहा जाता है, जो एस-सेल से आउटपुट को जोड़ती है और साथ ही साथ प्रत्येक सरणी में इकाइयों की संख्या को कम करती है। एक अन्य अर्थ में, सी-सेल एस-सेल के परिणाम को विस्थापित करता है।
प्रशिक्षण एल्गोरिथ्म
नियोकोग्निट्रॉन का प्रशिक्षण परत दर परत आगे बढ़ता पाया जाता है। पहली परत के लिए इनपुट परत से वजन प्रशिक्षित और जमे हुए हैं। फिर, पहली परत से दूसरी परत तक के वजन को प्रशिक्षित किया जाता है, और इसी तरह। S- सेल और Ccell के बीच आंतरिक गणना पिछली परतों से आने वाले भार पर निर्भर करती है। इसलिए, हम कह सकते हैं कि प्रशिक्षण एल्गोरिथ्म एस-सेल और सी-सेल पर गणना पर निर्भर करता है।
एस-सेल में गणना
एस-सेल में पिछली परत से प्राप्त एक्सिसिटरी सिग्नल होता है और उसी परत के भीतर प्राप्त निरोधात्मक सिग्नल होते हैं।
$ $ \ थीटा = \: \ sqrt {\ sum \ sum t_ {i} c_ {i} ^ 2} $ $
यहाँ, ti निश्चित वजन है और ci C- सेल से आउटपुट है।
एस-सेल के स्केल किए गए इनपुट की गणना निम्नानुसार की जा सकती है -
$$ x \: = \: \ frac {1 \: + \: ई} {1 \: + \: vw_ {0}} \: - \: 1 $$
यहाँ, $ e \: = \: \ sum_i c_ {i} w_ {i} $
wi सी-सेल से एस-सेल तक समायोजित वजन है।
w0 इनपुट और एस-सेल के बीच समायोज्य वजन है।
v C- सेल से उत्तेजक इनपुट है।
आउटपुट सिग्नल की सक्रियता है,
$ $ s \: = \: \ start {case} x, और if \: x \ geq 0 \\ 0, और if \: x <0 \ end {केस} $ $
सी-सेल में गणना
C- लेयर का शुद्ध इनपुट है
$ $ C \: = \: \ displaystyle \ sum \ limit_i s_ {i} x_ {i} $ +
यहाँ, si एस-सेल और से उत्पादन है xi एस-सेल से सी-सेल तक निश्चित वजन है।
अंतिम आउटपुट निम्नानुसार है -
$$ C_ {out} \: = \: \ start {case} \ frac {C} {a + C}, और if \: C> 0 \\ 0, और अन्यथा \ end {केस} $$
यहाँ ‘a’ वह पैरामीटर है जो नेटवर्क के प्रदर्शन पर निर्भर करता है।
सदिश परिमाणीकरण (LVQ) सीखना, सदिश परिमाणीकरण (VQ) और कोहेनन सेल्फ-आर्गेनाइजिंग मैप्स (KSOM) से अलग है, मूल रूप से एक प्रतिस्पर्धी नेटवर्क है जो पर्यवेक्षित शिक्षण का उपयोग करता है। हम इसे उन पैटर्नों को वर्गीकृत करने की प्रक्रिया के रूप में परिभाषित कर सकते हैं जहां प्रत्येक आउटपुट यूनिट एक क्लास का प्रतिनिधित्व करती है। जैसा कि यह पर्यवेक्षित शिक्षण का उपयोग करता है, नेटवर्क को आउटपुट वर्ग के प्रारंभिक वितरण के साथ ज्ञात वर्गीकरण के साथ प्रशिक्षण पैटर्न का एक सेट दिया जाएगा। प्रशिक्षण प्रक्रिया को पूरा करने के बाद, LVQ एक इनपुट वेक्टर को आउटपुट यूनिट के समान वर्ग में असाइन करके वर्गीकृत करेगा।
आर्किटेक्चर
निम्नलिखित आंकड़ा LVQ की वास्तुकला को दर्शाता है जो KSOM की वास्तुकला के समान है। जैसा कि हम देख सकते हैं, वहाँ हैं“n” इनपुट इकाइयों की संख्या और “m”उत्पादन इकाइयों की संख्या। उन पर भार होने के साथ परतें पूरी तरह से परस्पर जुड़ी हुई हैं।

पैरामीटर्स का इस्तेमाल किया
एलवीक्यू प्रशिक्षण प्रक्रिया के साथ-साथ फ्लोचार्ट में उपयोग किए जाने वाले पैरामीटर निम्नलिखित हैं
x= प्रशिक्षण वेक्टर (x 1 , ..., x i , ..., x n )
T = सदिश प्रशिक्षण के लिए कक्षा x
wj = के लिए वजन वेक्टर jth उत्पादन इकाई
Cj = के साथ जुड़े वर्ग jth उत्पादन इकाई
प्रशिक्षण एल्गोरिथ्म
Step 1 - प्रारंभिक संदर्भ वैक्टर, जो निम्नानुसार किया जा सकता है -
Step 1(a) - प्रशिक्षण वैक्टर के दिए गए सेट से, पहले ले लो "m"(क्लस्टर्स की संख्या) प्रशिक्षण वैक्टर और उन्हें वजन वैक्टर के रूप में उपयोग करते हैं। शेष वैक्टर का उपयोग प्रशिक्षण के लिए किया जा सकता है।
Step 1(b) - प्रारंभिक वजन और वर्गीकरण को यादृच्छिक रूप से असाइन करें।
Step 1(c) - K- साधन क्लस्टरिंग विधि लागू करें।
Step 2 - प्रारंभिक संदर्भ वेक्टर $ \ अल्फा $
Step 3 - 4-9 कदम के साथ जारी रखें, अगर इस एल्गोरिथ्म को रोकने के लिए शर्त पूरी नहीं हुई है।
Step 4 - प्रत्येक प्रशिक्षण इनपुट वेक्टर के लिए चरण 5-6 का पालन करें x।
Step 5 - यूक्लिडियन दूरी के वर्ग की गणना करें j = 1 to m तथा i = 1 to n
$$ D (j) \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n \ displaystyle \ sum \ limit_ {j = 1} ^ m (x_ {i} \ _: \ _ \ _ ij) }) ^ 2 $$
Step 6 - विजेता इकाई को प्राप्त करें J कहाँ पे D(j) न्यूनतम है।
Step 7 - निम्नलिखित संबंध द्वारा विजेता इकाई के नए वजन की गणना करें -
अगर T = Cj तब $ w_ {j} (नया) \: = \: w_ {j} (पुराना) \: + \: \ अल्फा [x \: - \: w_ {j} (पुराना)] $
अगर T ≠ Cj तब $ w_ {j} (नया) \: = \: w_ {j} (पुराना) \: - \: \ अल्फा [x \: - \: w_ {j} (पुराना)] $
Step 8 - सीखने की दर $ \ अल्फा $ कम करें।
Step 9- रोकने की स्थिति के लिए परीक्षण। यह इस प्रकार हो सकता है -
- अधिक से अधिक संख्या में युगान्तर पहुँचे।
- सीखने की दर एक नगण्य मूल्य तक कम हो गई।
फ़्लोचार्ट
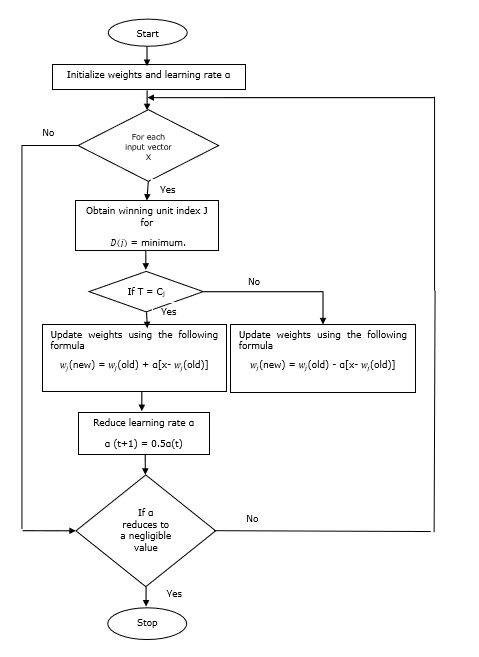
वेरिएंट
तीन अन्य वेरिएंट जैसे कि LVQ2, LVQ2.1 और LVQ3 को कोहेन द्वारा विकसित किया गया है। इन तीनों वेरिएंट में जटिलता, इस अवधारणा के कारण कि विजेता के साथ-साथ उपविजेता इकाई भी सीखेगी, LVQ से अधिक है।
LVQ2
जैसा कि चर्चा की गई है, ऊपर एलवीक्यू के अन्य वेरिएंट की अवधारणा, एलवीक्यू 2 की स्थिति खिड़की से बनती है। यह विंडो निम्नलिखित मापदंडों पर आधारित होगी -
x - वर्तमान इनपुट वेक्टर
yc - संदर्भ वेक्टर निकटतम है x
yr - अन्य संदर्भ वेक्टर, जो अगले निकटतम है x
dc - से दूरी x सेवा yc
dr - से दूरी x सेवा yr
इनपुट वेक्टर x खिड़की में गिर जाता है, अगर
$$ \ frac {d_ {c}} {d_ {r}} \:> \: 1 \: - \: \ थीटा \: \: और \: \: \ frac {d_ {r}} {{c d_ }} \:> \: 1 \: + \: \ थीटा $$
यहाँ, $ theta $ प्रशिक्षण नमूनों की संख्या है।
अद्यतन निम्न सूत्र के साथ किया जा सकता है -
$ Y_ {c} (टी \: + \: 1) \: = \: y_ {c} (टी) \: + \: \ अल्फा (टी) [x (टी) \: - \: y_ {c} (टी)] $ (belongs to different class)
$ Y_ {r} (टी \: + \: 1) \: = \: y_ {r} (टी) \: + \: \ अल्फा (टी) [x (टी) \: - \: y_ {r} (टी)] $ (belongs to same class)
यहाँ $ \ अल्फा $ सीखने की दर है।
LVQ2.1
LVQ2.1 में, हम दो निकटतम वैक्टरों को क्रमशः लेंगे yc1 तथा yc2 और खिड़की की स्थिति इस प्रकार है -
$$ मिनट \ शुरू {bmatrix} \ frac {{d_ c1}} {{d_ c2}} \ frac {{d_ c2}} {{d_ c1}} \ अंत {bmatrix} \:> \ :( 1 \ : - \: \ थीटा) $$
$$ मैक्स \ begin {bmatrix} \ frac {{d_ c1}} {{d_ c2}} \ frac {{d_ c2}} {{d_ c1}} \ अंत {bmatrix} \: <\ :( 1 \ : + \: \ थीटा) $$
अद्यतन निम्न सूत्र के साथ किया जा सकता है -
$ Y_ {c1} (टी \: + \: 1) \: = \: y_ {c1} (टी) \: + \: \ अल्फा (टी) [x (टी) \: - \: y_ {c1} (टी)] $ (belongs to different class)
$ Y_ {c2} (टी \: + \: 1) \: = \: y_ {c2} (टी) \: + \: \ अल्फा (टी) [x (टी) \: - \: y_ {c2} (टी)] $ (belongs to same class)
यहाँ, $ \ Alpha $ सीखने की दर है।
LVQ3
LVQ3 में, हम दो निकटतम वैक्टरों को लेंगे yc1 तथा yc2 और खिड़की की स्थिति इस प्रकार है -
$$ मिनट \ शुरू {bmatrix} \ frac {{d_ c1}} {{d_ c2}} \ frac {{d_ c2}} {{d_ c1}} \ अंत {bmatrix} \:> \ :( 1 \ : - \: \ थीटा) (1 \: + \: \ थीटा) $$
यहाँ $ $ थीटा लगभग $ 0.2 है
अद्यतन निम्न सूत्र के साथ किया जा सकता है -
$ Y_ {c1} (टी \: + \: 1) \: = \: y_ {c1} (टी) \: + \: \ बीटा (टी) [x (टी) \: - \: y_ {c1} (टी)] $ (belongs to different class)
$ Y_ {c2} (टी \: + \: 1) \: = \: y_ {c2} (टी) \: + \: \ बीटा (टी) [x (टी) \: - \: y_ {c2} (टी)] $ (belongs to same class)
यहाँ $ \ beta $ सीखने की दर $ \ अल्फा $ और के कई है $\beta\:=\:m \alpha(t)$ हर एक के लिए 0.1 < m < 0.5
इस नेटवर्क को 1987 में स्टीफन ग्रॉसबर्ग और गेल कारपेंटर द्वारा विकसित किया गया था। यह प्रतिस्पर्धा पर आधारित है और बिना पढ़े हुए मॉडल का उपयोग करता है। अनुकूली अनुनाद सिद्धांत (ART) नेटवर्क, जैसा कि नाम से पता चलता है, हमेशा पुराने पैटर्न (अनुनाद) को खोए बिना नए सीखने (अनुकूली) के लिए खुला है। मूल रूप से, एआरटी नेटवर्क एक वेक्टर क्लासिफायरियर है, जो एक इनपुट वेक्टर को स्वीकार करता है और इसे उन श्रेणियों में से एक में वर्गीकृत करता है, जिनके आधार पर यह संग्रहीत पैटर्न से सबसे अधिक मिलता-जुलता है।
संचालन प्रधानाचार्य ने किया
एआरटी वर्गीकरण के मुख्य संचालन को निम्नलिखित चरणों में विभाजित किया जा सकता है -
Recognition phase- इनपुट वेक्टर की तुलना आउटपुट लेयर में प्रत्येक नोड पर प्रस्तुत वर्गीकरण से की जाती है। न्यूरॉन का आउटपुट "1" हो जाता है अगर यह वर्गीकरण के साथ सबसे अच्छा मेल खाता है, अन्यथा यह "0" बन जाता है।
Comparison phase- इस चरण में, इनपुट लेयर वेक्टर की तुलना लेयर वेक्टर से की जाती है। रीसेट के लिए शर्त यह है कि समानता की डिग्री सतर्कता पैरामीटर से कम होगी।
Search phase- इस चरण में, नेटवर्क रीसेट के साथ-साथ उपरोक्त चरणों में किए गए मैच की खोज करेगा। इसलिए, यदि कोई रीसेट नहीं होगा और मैच काफी अच्छा है, तो वर्गीकरण समाप्त हो गया है। अन्यथा, प्रक्रिया दोहराई जाएगी और सही मिलान खोजने के लिए अन्य संग्रहीत पैटर्न को भेजा जाना चाहिए।
art1
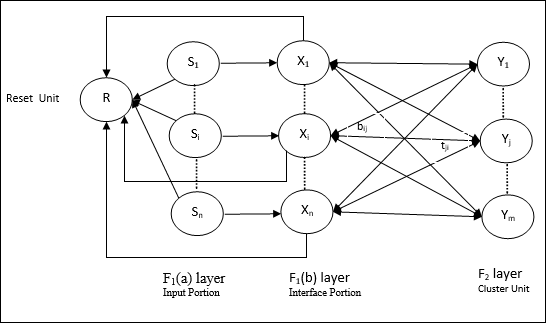
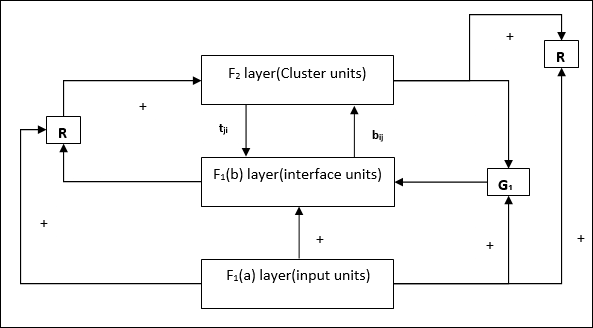
यह एक प्रकार का ART है, जो बाइनरी वैक्टर क्लस्टर करने के लिए डिज़ाइन किया गया है। हम इसके बारे में वास्तुकला के साथ समझ सकते हैं।
ART1 का आर्किटेक्चर
इसमें निम्नलिखित दो इकाइयाँ शामिल हैं -
Computational Unit - यह निम्नलिखित से बना है -
Input unit (F1 layer) - इसके आगे दो भाग हैं -
F1(a) layer (Input portion)- ART1 में, केवल इनपुट वैक्टर होने के बजाय इस हिस्से में कोई प्रसंस्करण नहीं होगा। यह F 1 (b) लेयर (इंटरफ़ेस भाग) से जुड़ा है ।
F1(b) layer (Interface portion)- यह भाग इनपुट भाग से संकेत को F 2 परत के साथ जोड़ता है । F 1 (b) लेयर F 2 लेयर से बॉटम अप वेट के जरिए जुड़ा हैbijऔर F 2 लेयर, F 1 (b) लेयर से ऊपर के वज़न से जुड़ी होती हैtji।
Cluster Unit (F2 layer)- यह एक प्रतिस्पर्धी परत है। इनपुट पैटर्न सीखने के लिए सबसे बड़ी शुद्ध इनपुट वाली इकाई का चयन किया जाता है। अन्य सभी क्लस्टर इकाई की सक्रियता 0 पर सेट है।
Reset Mechanism- इस तंत्र का काम टॉप-डाउन वजन और इनपुट वेक्टर के बीच समानता पर आधारित है। अब, यदि इस समानता की डिग्री सतर्कता पैरामीटर से कम है, तो क्लस्टर को पैटर्न सीखने की अनुमति नहीं है और एक बाकी होगा।
Supplement Unit - वास्तव में रीसेट तंत्र के साथ मुद्दा यह है कि परत F2कुछ शर्तों के तहत बाधित होना चाहिए और कुछ सीखने के दौरान भी उपलब्ध होना चाहिए। इसीलिए दो पूरक इकाइयाँ,G1 तथा G2 रीसेट इकाई के साथ जोड़ा जाता है, R। वे कहते हैंgain control units। ये इकाइयाँ नेटवर्क में मौजूद अन्य इकाइयों को सिग्नल प्राप्त करती हैं और भेजती हैं।‘+’ जबकि एक उत्तेजक संकेत इंगित करता है ‘−’ एक निरोधात्मक संकेत इंगित करता है।
पैरामीटर्स का इस्तेमाल किया
निम्नलिखित मापदंडों का उपयोग किया जाता है -
n - इनपुट वेक्टर में घटकों की संख्या
m - अधिकतम संख्या में क्लस्टर बनाए जा सकते हैं
bij- F 1 (b) से F 2 लेयर तक का वजन, यानी बॉटम-अप वेट
tji- F 2 से F 1 (b) लेयर यानी टॉप-डाउन वेट से वजन
ρ - सतर्कता पैरामीटर
||x|| - वेक्टर x का सामान्य
कलन विधि
Step 1 - सीखने की दर, सतर्कता पैरामीटर, और भार इस प्रकार है -
$$ \ अल्फा \:> \: 1 \: \: और \: \: 0 \: <\ रो \: \ Leq \: 1 $$
$$ 0 \: <\: b_ {ij} (0) \: <\: \ frac {\ अल्फा} {\ अल्फा \: - \: 1 \: + \: n} \: \: और \: \: T_ {ij} (0) \: = \: 1 $$
Step 2 - स्टेप 3-9 को जारी रखें, जब रोक की स्थिति सही न हो।
Step 3 - हर प्रशिक्षण इनपुट के लिए चरण 4-6 जारी रखें।
Step 4- निम्नानुसार सभी एफ 1 (ए) और एफ 1 इकाइयों की सक्रियण सेट करें
F2 = 0 and F1(a) = input vectors
Step 5- एफ 1 (ए) से एफ 1 (बी) परत तक इनपुट सिग्नल को भेजा जाना चाहिए
$$ s_ {मैं} \: = \: x_ {मैं} $$
Step 6- हर बाधित एफ 2 नोड के लिए
$ y_ {j} \: = \: \ sum_i b_ {ij} x_ {i} $ हालत: yj ≠ -1
Step 7 - रीसेट सत्य होने पर 8-10 चरण करें।
Step 8 - खोजें J के लिये yJ ≥ yj सभी नोड्स के लिए j
Step 9- फिर से एफ 1 (बी) पर सक्रियण की गणना निम्नानुसार करें
$$ x_ {मैं} \: = \: sitJi $$
Step 10 - अब, वेक्टर के आदर्श की गणना के बाद x और वेक्टर s, हम रीसेट हालत की जाँच करने की जरूरत है इस प्रकार है -
अगर ||x||/ ||s|| <सतर्कता पैरामीटर ρ, Odetheninhibit node J और चरण 7 पर जाएं
और यदि ||x||/ ||s|| Parameter सतर्कता पैरामीटर ρ, फिर आगे बढ़ें।
Step 11 - नोड के लिए वजन अद्यतन J निम्नानुसार किया जा सकता है -
$ $ b_ {ij} (नया) \: = \: \ frac {\ अल्फा x_ {i}} {\ अल्फा \: - \: 1 \: + \: || x ||} $ $
$$ T_ {ij} (नया) \: = \: x_ {मैं} $$
Step 12 - एल्गोरिथ्म के लिए रोक की स्थिति की जाँच की जानी चाहिए और यह निम्नानुसार हो सकती है -
- वजन में कोई बदलाव न करें।
- इकाइयों के लिए रीसेट नहीं किया जाता है।
- अधिक से अधिक संख्या में युगान्तर पहुँचे।
मान लीजिए कि हमारे पास मनमाने आयामों के कुछ पैटर्न हैं, हालांकि, हमें एक आयाम या दो आयामों में उनकी आवश्यकता है। तब वाइड मैपिंग स्पेस को एक विशिष्ट फीचर स्पेस में बदलने के लिए फीचर मैपिंग की प्रक्रिया बहुत उपयोगी होगी। अब, सवाल उठता है कि हमें स्व-सुव्यवस्थित सुविधा मानचित्र की आवश्यकता क्यों है? कारण, मनमाने आयामों को 1-डी या 2-डी में परिवर्तित करने की क्षमता के साथ-साथ इसमें पड़ोसी टोपोलॉजी को संरक्षित करने की क्षमता भी होनी चाहिए।
कोहेनन एसओएम में पड़ोसी टोपोलॉजी
विभिन्न टोपोलॉजी हो सकती हैं, हालांकि निम्नलिखित दो टोपोलॉजी का उपयोग सबसे अधिक किया जाता है -
आयताकार ग्रिड टोपोलॉजी
इस टोपोलॉजी में दूरी -2 ग्रिड में 24 नोड्स, दूरी -1 ग्रिड में 16 नोड्स, और दूरी -1 ग्रिड में 8 नोड्स हैं, जिसका अर्थ है कि प्रत्येक आयताकार ग्रिड के बीच का अंतर 8 नोड्स है। विजेता इकाई # द्वारा इंगित की गई है।
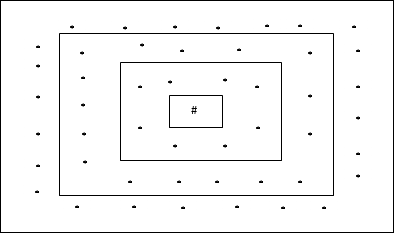
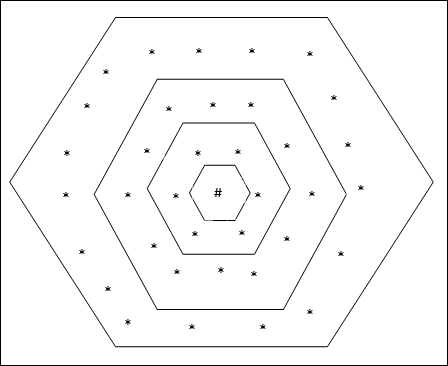
हेक्सागोनल ग्रिड टोपोलॉजी
इस टोपोलॉजी में दूरी -2 ग्रिड में 18 नोड्स, दूरी -1 ग्रिड में 12 नोड्स, और दूरी -1 ग्रिड में 6 नोड्स हैं, जिसका अर्थ है कि प्रत्येक आयताकार ग्रिड के बीच का अंतर 6 नोड्स है। विजेता इकाई # द्वारा इंगित की गई है।
आर्किटेक्चर
केएसओएम की वास्तुकला प्रतिस्पर्धी नेटवर्क के समान है। पहले से चर्चा की गई पड़ोस की योजनाओं की सहायता से, प्रशिक्षण नेटवर्क के विस्तारित क्षेत्र में हो सकता है।
प्रशिक्षण के लिए एल्गोरिदम
Step 1 - वजन, सीखने की दर का आरम्भ α और पड़ोस सामयिक योजना।
Step 2 - स्टेप 3-9 को जारी रखें, जब रोक की स्थिति सही न हो।
Step 3 - हर इनपुट वेक्टर के लिए चरण 4-6 जारी रखें x।
Step 4 - यूक्लिडियन दूरी के वर्ग की गणना करें j = 1 to m
$$ D (j) \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n \ displaystyle \ sum \ limit_ {j = 1} ^ m (x_ {i} \ _: \ _ \ _ ij) }) ^ 2 $$
Step 5 - विजेता इकाई को प्राप्त करें J कहाँ पे D(j) न्यूनतम है।
Step 6 - निम्नलिखित संबंध द्वारा विजेता इकाई के नए वजन की गणना करें -
$$ w_ {ij} (नया) \: = \: w_ {ij} (पुराने) \: + \: \ अल्फा [x_ {मैं} \: - \: w_ {ij} (पुराने)] $$
Step 7 - सीखने की दर का अद्यतन करें α निम्नलिखित संबंध द्वारा -
$ $ \ अल्फा (t \: + \: 1) \: = \: 0.5 \ अल्फा टी $ $
Step 8 - टोपोलॉजिकल स्कीम के दायरे को कम करें।
Step 9 - नेटवर्क के लिए रोक स्थिति के लिए जाँच करें।
इस प्रकार के तंत्रिका नेटवर्क पैटर्न एसोसिएशन के आधार पर काम करते हैं, जिसका अर्थ है कि वे विभिन्न पैटर्न को स्टोर कर सकते हैं और आउटपुट देने के समय वे दिए गए इनपुट पैटर्न के साथ मिलान करके संग्रहीत पैटर्न में से एक का उत्पादन कर सकते हैं। इस प्रकार की यादों को भी कहा जाता हैContent-Addressable Memory(सीएएम)। साहचर्य मेमोरी डेटा फ़ाइलों के रूप में संग्रहीत पैटर्न के साथ एक समानांतर खोज करती है।
निम्नलिखित दो प्रकार की साहचर्य यादें हैं जिन्हें हम देख सकते हैं -
- ऑटो एसोसिएटिव मेमोरी
- हेटेरो एसोसिएटिव मेमोरी
ऑटो एसोसिएटिव मेमोरी
यह एकल परत तंत्रिका नेटवर्क है जिसमें इनपुट प्रशिक्षण वेक्टर और आउटपुट लक्ष्य वैक्टर समान हैं। वजन निर्धारित किया जाता है ताकि नेटवर्क पैटर्न का एक सेट स्टोर करे।
आर्किटेक्चर
जैसा कि निम्नलिखित आंकड़े में दिखाया गया है, ऑटो एसोसिएटिव मेमोरी नेटवर्क की वास्तुकला है ‘n’ इनपुट प्रशिक्षण वैक्टर और इसी तरह की संख्या ‘n’ आउटपुट लक्ष्य वैक्टर की संख्या।
प्रशिक्षण एल्गोरिथ्म
प्रशिक्षण के लिए, यह नेटवर्क हेब या डेल्टा लर्निंग नियम का उपयोग कर रहा है।
Step 1 - के रूप में शून्य करने के लिए सभी वजन शुरू wij = 0 (i = 1 to n, j = 1 to n)
Step 2 - प्रत्येक इनपुट वेक्टर के लिए चरण 3-4 करें।
Step 3 - प्रत्येक इनपुट यूनिट को निम्नानुसार सक्रिय करें -
$$ x_ {मैं} \: = \: s_ {मैं} \ :( मैं \: = \: 1 \: करने के लिए \: एन) $$
Step 4 - प्रत्येक आउटपुट यूनिट को निम्नानुसार सक्रिय करें -
$$ y_ {j} \: = \: s_ {j} \ :( जे \: = \: 1 \: करने के लिए \: एन) $$
Step 5 - निम्नानुसार वज़न समायोजित करें -
$$ w_ {ij} (नया) \: = \: w_ {ij} (पुराने) \: + \: x_ {मैं} {y_ j} $$
परीक्षण एल्गोरिथ्म
Step 1 - हेब्ब के शासन के लिए प्रशिक्षण के दौरान प्राप्त वजन निर्धारित करें।
Step 2 - प्रत्येक इनपुट वेक्टर के लिए चरण 3-5 करें।
Step 3 - इनपुट वेक्टर के बराबर इनपुट इकाइयों की सक्रियता सेट करें।
Step 4 - प्रत्येक आउटपुट यूनिट के लिए नेट इनपुट की गणना करें j = 1 to n
$ $ y_ {घायल} \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n x_ {i} w_ {ij} $ $
Step 5 - आउटपुट की गणना करने के लिए निम्नलिखित सक्रियण फ़ंक्शन लागू करें
$ $ y_ {j} \: = \: f (y_ {घायल}) \: = \: \ शुरू {मामलों} +1 और अगर \: y_ {घायल} \ _>: \ _: 0 \\ - 1 और अगर \: y_ {इंज} \: \ leqslant \: 0 \ अंत {मामलों} $$
हेटेरो एसोसिएटिव मेमोरी
ऑटो एसोसिएटिव मेमोरी नेटवर्क के समान, यह भी एक सिंगल लेयर न्यूरल नेटवर्क है। हालांकि, इस नेटवर्क में इनपुट प्रशिक्षण वेक्टर और आउटपुट लक्ष्य वैक्टर समान नहीं हैं। वजन निर्धारित किया जाता है ताकि नेटवर्क पैटर्न का एक सेट स्टोर करे। हेटेरो एसोसिएटिव नेटवर्क प्रकृति में स्थिर है, इसलिए, गैर-रैखिक और विलंब संचालन नहीं होगा।
आर्किटेक्चर
जैसा कि निम्नलिखित आकृति में दिखाया गया है, हेटेरो एसोसिएटिव मेमोरी नेटवर्क की वास्तुकला है ‘n’ इनपुट प्रशिक्षण वैक्टर की संख्या और ‘m’ आउटपुट लक्ष्य वैक्टर की संख्या।
प्रशिक्षण एल्गोरिथ्म
प्रशिक्षण के लिए, यह नेटवर्क हेब या डेल्टा लर्निंग नियम का उपयोग कर रहा है।
Step 1 - के रूप में शून्य करने के लिए सभी वजन शुरू wij = 0 (i = 1 to n, j = 1 to m)
Step 2 - प्रत्येक इनपुट वेक्टर के लिए चरण 3-4 करें।
Step 3 - प्रत्येक इनपुट यूनिट को निम्नानुसार सक्रिय करें -
$$ x_ {मैं} \: = \: s_ {मैं} \ :( मैं \: = \: 1 \: करने के लिए \: एन) $$
Step 4 - प्रत्येक आउटपुट यूनिट को निम्नानुसार सक्रिय करें -
$$ y_ {j} \: = \: s_ {j} \ :( जे \: = \: 1 \: करने के लिए \: मी) $$
Step 5 - निम्नानुसार वज़न समायोजित करें -
$$ w_ {ij} (नया) \: = \: w_ {ij} (पुराने) \: + \: x_ {मैं} {y_ j} $$
परीक्षण एल्गोरिथ्म
Step 1 - हेब्ब के शासन के लिए प्रशिक्षण के दौरान प्राप्त वजन निर्धारित करें।
Step 2 - प्रत्येक इनपुट वेक्टर के लिए चरण 3-5 करें।
Step 3 - इनपुट वेक्टर के बराबर इनपुट इकाइयों की सक्रियता सेट करें।
Step 4 - प्रत्येक आउटपुट यूनिट के लिए नेट इनपुट की गणना करें j = 1 to m;
$ $ y_ {घायल} \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n x_ {i} w_ {ij} $ $
Step 5 - आउटपुट की गणना करने के लिए निम्नलिखित सक्रियण फ़ंक्शन लागू करें
$ $ y_ {j} \: = \: f (y_ {घायल}) \: = \ _ \ _ {मामलों} +1 और if \: y_ {घायल} \ _:> \ _ 0 \\ 0 और if \ : y_ {घायल} \ _: = \: 0 \\ - 1 और if \: y_ {घायल} \ _: <\: 0 \ end {मामले} $ $
होपफील्ड न्यूरल नेटवर्क का आविष्कार डॉ। जॉन जे। हॉपफील्ड ने 1982 में किया था। इसमें एक एकल परत होती है जिसमें एक या एक से अधिक पूरी तरह से जुड़ा हुआ न्यूरॉन होता है। हॉपफील्ड नेटवर्क आमतौर पर ऑटो-एसोसिएशन और अनुकूलन कार्यों के लिए उपयोग किया जाता है।
असतत हॉपफील्ड नेटवर्क
एक हॉपफील्ड नेटवर्क जो एक असतत लाइन फैशन या दूसरे शब्दों में संचालित होता है, यह कहा जा सकता है कि इनपुट और आउटपुट पैटर्न असतत वेक्टर हैं, जो प्रकृति में द्विआधारी (0,1) या द्विध्रुवीय (+1, -1) हो सकते हैं। नेटवर्क में बिना सेल्फ कनेक्शन वाले सममित वज़न हैं,wij = wji तथा wii = 0।
आर्किटेक्चर
असतत Hopfield नेटवर्क के बारे में ध्यान में रखने के लिए कुछ महत्वपूर्ण बिंदु निम्नलिखित हैं -
इस मॉडल में एक inverting और एक गैर-inverting आउटपुट के साथ न्यूरॉन्स होते हैं।
प्रत्येक न्यूरॉन का आउटपुट अन्य न्यूरॉन्स का इनपुट होना चाहिए, लेकिन स्वयं का इनपुट नहीं होना चाहिए।
वजन / कनेक्शन शक्ति द्वारा दर्शाया गया है wij।
कनेक्शन उत्तेजक होने के साथ-साथ निरोधात्मक भी हो सकते हैं। यह उत्तेजक होगा, अगर न्यूरॉन का आउटपुट इनपुट के समान है, अन्यथा निरोधात्मक।
वजन सममित होना चाहिए, अर्थात wij = wji
से आउटपुट Y1 जा रहा हूँ Y2, Yi तथा Yn वज़न है w12, w1i तथा w1nक्रमशः। इसी तरह, अन्य चापों का वजन उन पर होता है।
प्रशिक्षण एल्गोरिथ्म
असतत हॉपफील्ड नेटवर्क के प्रशिक्षण के दौरान, वज़न अपडेट किया जाएगा। जैसा कि हम जानते हैं कि हमारे पास बाइनरी इनपुट वैक्टर और द्विध्रुवी इनपुट वैक्टर हो सकते हैं। इसलिए, दोनों मामलों में, निम्न संबंध के साथ वजन अपडेट किया जा सकता है
Case 1 - बाइनरी इनपुट पैटर्न
बाइनरी पैटर्न के एक सेट के लिए s(p), p = 1 to P
यहाँ, s(p) = s1(p), s2(p),..., si(p),..., sn(p)
वेट मैट्रिक्स द्वारा दिया जाता है
$$ w_ {ij} \: = \: \ sum_ {पी = 1} ^ पी [2s_ {मैं} (पी) - \: 1] [2s_ {j} (पी) - \: 1] \: \: \: \: \: \ के लिए: मैं \: \ neq \: j $$
Case 2 - द्विध्रुवी इनपुट पैटर्न
बाइनरी पैटर्न के एक सेट के लिए s(p), p = 1 to P
यहाँ, s(p) = s1(p), s2(p),..., si(p),..., sn(p)
वेट मैट्रिक्स द्वारा दिया जाता है
$$ w_ {ij} \: = \: \ sum_ {पी = 1} ^ पी [s_ {मैं} (पी)] [s_ {j} (पी)] \: \: \: \: \: के लिए \ : मैं \: \ neq \: j $$
परीक्षण एल्गोरिथ्म
Step 1 - वज़न को आरम्भ करना, जो हेब्बियन सिद्धांत का उपयोग करके प्रशिक्षण एल्गोरिथ्म से प्राप्त किया जाता है।
Step 2 - चरण 3-9 करें, यदि नेटवर्क की सक्रियता समेकित नहीं है।
Step 3 - प्रत्येक इनपुट वेक्टर के लिए X, चरण 4-8 का प्रदर्शन करें।
Step 4 - बाहरी इनपुट वेक्टर के बराबर नेटवर्क की प्रारंभिक सक्रियण बनाएं X निम्नानुसार है -
$$ y_ {मैं} \: = \: x_ {मैं} \: \: \: के लिए \: मैं \: = \: 1 \: करने के लिए \: n $$
Step 5 - प्रत्येक इकाई के लिए Yi, कदम 6-9।
Step 6 - नेटवर्क के शुद्ध इनपुट की गणना इस प्रकार है -
$$ y_ {आरं} \: = \: x_ {मैं} \: + \: \ displaystyle \ योग \ limits_ {j} {y_ j} {w_ जी} $$
Step 7 - आउटपुट की गणना करने के लिए नेट इनपुट पर निम्नानुसार सक्रियण लागू करें -
$ $ y_ {i} \: = \ _ {मामलों} 1 & if \: y_ {ini} \ _: \ _ \ _ theta_ {i} \\ y_ {i} और if \: y_ {ini} \ _ = \ _ \ _ थीटा {{}} \\ ० & if \ _: y_ {ini} \ _: <\: \ theta_ {i} \ end {मामले} $ $
यहाँ $ \ theta_ {i} $ सीमा है।
Step 8 - इस आउटपुट को प्रसारित करें yi अन्य सभी इकाइयों के लिए।
Step 9 - संयोजन के लिए नेटवर्क का परीक्षण करें।
एनर्जी फंक्शन का मूल्यांकन
एक ऊर्जा फ़ंक्शन को एक फ़ंक्शन के रूप में परिभाषित किया जाता है जो सिस्टम की स्थिति के बंधुआ और गैर-बढ़ते फ़ंक्शन है।
ऊर्जा समारोह Ef, also कहा जाता है Lyapunov function असतत हॉपफील्ड नेटवर्क की स्थिरता को निर्धारित करता है, और निम्नानुसार विशेषता है -
$ $ E_ {f} \: = \: - \ frac {1} {2} \ displaystyle \ sum \ limit_ {i = 1} ^ n \ displaystyle \ sum \ limit_ {j = 1} ^ n y_ / i} y_ {j} w_ {ij} \: - \: \ displaystyle \ sum \ limit_ {i = 1} ^ n x_ {i} y_ {i} \: + \: \ displaystyle \ sum \ limit_ i = 1} ^ n \ theta_ {i} y_ {i} $ $
Condition - एक स्थिर नेटवर्क में, जब भी नोड की स्थिति बदलती है, तो उपरोक्त ऊर्जा फ़ंक्शन कम हो जाएगा।
मान लीजिए जब नोड i ने $ y_i ^ से राज्य बदल दिया है {{(k)} $ से $ y_i ^ {(k \: + \: 1)} $ enthen ऊर्जा परिवर्तन $ \ Delta E_ {f} $ निम्नलिखित संबंध द्वारा दिया गया है
$$ \ Delta E_ {f} \: = \: E_ {f} (y_i ^ {(k + 1)}) \: - \: E_ {f} (y_i ^ {(k))) $$
$ $ = \: - \ बाएँ (\ शुरू {सरणी} {c} \ displaystyle \ sum \ limit_ {j = 1} ^ n w_ {ij} y_i ^ {(k)} \ _: \ _: x_ {}} \: - \: \ theta_ {मैं} \ अंत {सरणी} \ right) (y_i ^ {(k + 1)} \: - \: y_i ^ {(के)}) $$
$$ = \: - \ :( net_ {i}) \ Delta y_ {i} $ $
यहाँ $ \ Delta y_ {i} \: = \: y_i ^ {(k \: + \: 1)} \: - \: y_i ^ {(k)} $
ऊर्जा में परिवर्तन इस तथ्य पर निर्भर करता है कि एक समय में केवल एक इकाई अपनी सक्रियता को अपडेट कर सकती है।
सतत हॉपफील्ड नेटवर्क
डिस्क्रीट हॉपफील्ड नेटवर्क के साथ तुलना में, निरंतर नेटवर्क में एक निरंतर चर के रूप में समय होता है। इसका उपयोग ऑटो एसोसिएशन और अनुकूलन समस्याओं जैसे यात्रा विक्रेता समस्या में भी किया जाता है।
Model - मॉडल या आर्किटेक्चर का निर्माण इलेक्ट्रिकल कंपोनेंट्स जैसे एम्पलीफायरों को जोड़कर किया जा सकता है जो एक सिग्माइड एक्टिवेशन फंक्शन पर आउटपुट वोल्टेज के लिए इनपुट वोल्टेज को मैप कर सकते हैं।
एनर्जी फंक्शन का मूल्यांकन
$ $ E_f = \ frac {1} {2} \ displaystyle \ sum \ limit_ {i = 1} ^ n \ sum _ {\ substack {j = 1 \\ j \ ne i}} ^ n y_i yj w_ {ij} -> का प्रदर्शन \ _ \ _ \ _ \ _ \ _ फर्क {1} {\ lambda} \ displaystyle \ sum \ limit_ {i = १} ^ n \ _ \ _ \ _ घटाना {j = 1 \\ j \ ne i}} ^ n w_ {ij} g_ {ri} \ int_ {0} ^ {y_i} a ^ {- 1} (y) डाई $ $
यहाँ λ लाभ पैरामीटर है और gri इनपुट चालन।
ये स्टोकेस्टिक सीखने की प्रक्रियाएं हैं जो आवर्तक संरचना हैं और एएनएन में उपयोग की जाने वाली शुरुआती अनुकूलन तकनीकों का आधार हैं। बोल्ट्जमैन मशीन का आविष्कार 1985 में ज्योफ्री हिंटन और टेरी सेजनोव्स्की ने किया था। बोल्ट्जमैन मशीन पर हिंटन के शब्दों में अधिक स्पष्टता देखी जा सकती है।
“इस नेटवर्क की एक आश्चर्यजनक विशेषता यह है कि यह केवल स्थानीय रूप से उपलब्ध जानकारी का उपयोग करता है। वजन में बदलाव केवल दो इकाइयों के व्यवहार पर निर्भर करता है जो इसे जोड़ता है, भले ही परिवर्तन एक वैश्विक माप का अनुकूलन करता है ”- एकली, हिंटन 1985।
बोल्ट्जमैन मशीन के बारे में कुछ महत्वपूर्ण बिंदु -
वे आवर्तक संरचना का उपयोग करते हैं।
इनमें स्टोकेस्टिक न्यूरॉन्स होते हैं, जिनमें दो संभावित राज्यों में से एक या तो 1 या 0 होता है।
इसमें से कुछ न्यूरॉन्स अनुकूली (मुक्त अवस्था) हैं और कुछ क्लैम्पड (जमे हुए राज्य) हैं।
अगर हम असतत होपफील्ड नेटवर्क पर नकली एनेलिंग लागू करते हैं, तो यह बोल्ट्जमैन मशीन बन जाएगी।
बोल्ट्जमैन मशीन का उद्देश्य
बोल्ट्जमैन मशीन का मुख्य उद्देश्य किसी समस्या के समाधान का अनुकूलन करना है। उस विशेष समस्या से संबंधित भार और मात्रा को अनुकूलित करना बोल्ट्जमैन मशीन का काम है।
आर्किटेक्चर
निम्नलिखित आरेख बोल्ट्जमैन मशीन की वास्तुकला को दर्शाता है। आरेख से यह स्पष्ट है, कि यह इकाइयों का द्वि-आयामी सरणी है। यहाँ, इकाइयों के बीच परस्पर संबंध पर भार हैं–p कहाँ पे p > 0। स्व-कनेक्शनों का वजन द्वारा दिया जाता हैb कहाँ पे b > 0।
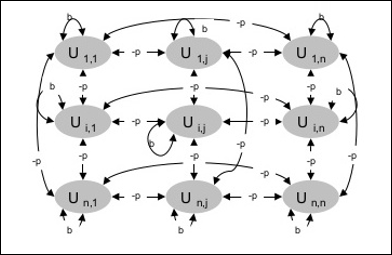
प्रशिक्षण एल्गोरिथ्म
जैसा कि हम जानते हैं कि बोल्ट्जमन मशीनों ने वज़न तय कर लिया है, इसलिए प्रशिक्षण एल्गोरिथ्म नहीं होगा क्योंकि हमें नेटवर्क में वज़न को अपडेट करने की आवश्यकता नहीं है। हालाँकि, नेटवर्क का परीक्षण करने के लिए हमें वज़न सेट करने के साथ-साथ सर्वसम्मति फ़ंक्शन (CF) का पता लगाना होगा।
बोल्ट्जमैन मशीन में इकाइयों का एक सेट है Ui तथा Uj और उन पर द्वि-दिशात्मक कनेक्शन हैं।
हम तय वजन पर विचार कर रहे हैं wij।
wij ≠ 0 अगर Ui तथा Uj जुड़े हुए हैं।
वेटेड इंटरकनेक्शन में एक समरूपता भी मौजूद है, अर्थात wij = wji।
wii यह भी मौजूद है, अर्थात् इकाइयों के बीच आत्म-संबंध होगा।
किसी भी इकाई के लिए Ui, इसकी अवस्था ui या तो 1 या 0 होगा।
बोल्ट्जमैन मशीन का मुख्य उद्देश्य आम सहमति समारोह (सीएफ) को अधिकतम करना है जो निम्नलिखित संबंध द्वारा दिया जा सकता है
$ $ CF \: = \: \ displaystyle \ sum \ limit_ {i} \ displaystyle \ sum \ limit_ {j \ leqslant i} w_ {ij} u_ {i} u_ {j} $ $
अब, जब राज्य 1 से 0 से या 0 से 1 में बदलता है, तो सर्वसम्मति में परिवर्तन निम्नलिखित संबंध द्वारा दिया जा सकता है -
$$ \ Delta CF \: = \ :( 1 \: - \: 2u_ {i}) (w_ {ij} \: + \: \ displaystyle \ sum \ limit_ {j \ neq i} u_ {i / w_ {} ij}) $$
यहाँ ui की वर्तमान स्थिति है Ui।
गुणांक में भिन्नता (1 - 2ui) निम्नलिखित संबंध द्वारा दिया गया है -
$ $ (1 \: - \: 2u_ {i}) \: = \: \ शुरू {मामलों} +1, और U_ {i} \: is \: वर्तमान में \ _- 1, & U_ {i } \: \ वर्तमान में: है \ पर \ अंत {मामलों} $$
आम तौर पर, इकाई Uiअपनी स्थिति को नहीं बदलता है, लेकिन यदि ऐसा होता है, तो जानकारी इकाई के स्थानीय निवासी होगी। उस परिवर्तन के साथ, नेटवर्क की सर्वसम्मति में भी वृद्धि होगी।
इकाई की स्थिति में परिवर्तन को स्वीकार करने के लिए नेटवर्क की संभावना निम्नलिखित संबंध द्वारा दी गई है -
$ $ AF (i, T) \: = \: \ frac {1} {1 \ _: + \: exp [- \ frac {\ Delta CF (i)} {T}]} $ $
यहाँ, Tनियंत्रक पैरामीटर है। अधिकतम मूल्य तक पहुंचते ही यह घट जाएगा।
परीक्षण एल्गोरिथ्म
Step 1 - प्रशिक्षण शुरू करने के लिए निम्नलिखित बातों का प्रारंभ करें -
- समस्या की बाधा का प्रतिनिधित्व करने वाले भार
- नियंत्रण पैरामीटर T
Step 2 - स्टेप 3-8 को जारी रखें, जब रोक की स्थिति सही न हो।
Step 3 - चरण 4-7।
Step 4 - मान लें कि राज्य में से एक ने वजन बदल दिया है और पूर्णांक चुनें I, J के बीच यादृच्छिक मूल्यों के रूप में 1 तथा n।
Step 5 - सर्वसम्मति में परिवर्तन की गणना इस प्रकार है -
$$ \ Delta CF \: = \ :( 1 \: - \: 2u_ {i}) (w_ {ij} \: + \: \ displaystyle \ sum \ limit_ {j \ neq i} u_ {i / w_ {} ij}) $$
Step 6 - संभावना की गणना करें कि यह नेटवर्क राज्य में परिवर्तन को स्वीकार करेगा
$ $ AF (i, T) \: = \: \ frac {1} {1 \ _: + \: exp [- \ frac {\ Delta CF (i)} {T}]} $ $
Step 7 - इस परिवर्तन को इस प्रकार स्वीकार या अस्वीकार करें -
Case I - अगर R < AFपरिवर्तन स्वीकार करें।
Case II - अगर R ≥ AF, परिवर्तन को अस्वीकार करें।
यहाँ, R 0 और 1 के बीच यादृच्छिक संख्या है।
Step 8 निम्नानुसार नियंत्रण पैरामीटर (तापमान) कम करें -
T(new) = 0.95T(old)
Step 9 - रोकने की शर्तों के लिए परीक्षण जो निम्नानुसार हो सकते हैं -
- तापमान एक निर्दिष्ट मूल्य तक पहुँचता है
- पुनरावृत्तियों की एक निर्दिष्ट संख्या के लिए राज्य में कोई परिवर्तन नहीं है
ब्रेन-स्टेट-इन-द-बॉक्स (BSB) तंत्रिका नेटवर्क एक nonlinear ऑटो-सहयोगी तंत्रिका नेटवर्क है और इसे दो या अधिक परतों के साथ हेटेरो-एसोसिएशन तक बढ़ाया जा सकता है। यह भी होपफील्ड नेटवर्क के समान है। यह 1977 में जेए एंडरसन, जेडब्ल्यू सिल्वरस्टीन, एसए रिट्ज और आरएस जोन्स द्वारा प्रस्तावित किया गया था।
BSB नेटवर्क के बारे में याद रखने के लिए कुछ महत्वपूर्ण बिंदु -
यह एक पूरी तरह से जुड़ा हुआ नेटवर्क है जो कि आयामीता पर निर्भर करता है n इनपुट स्थान का।
सभी न्यूरॉन्स एक साथ अपडेट किए जाते हैं।
न्यूरॉन्स -1 से +1 के बीच मान लेते हैं।
गणितीय योगों
बीएसबी नेटवर्क में प्रयुक्त नोड फ़ंक्शन एक रैंप फ़ंक्शन है, जिसे निम्नानुसार परिभाषित किया जा सकता है -
$$ च (शुद्ध) \: = \: न्यूनतम (1, \: अधिकतम (-1, \: शुद्ध)) $$
यह रैंप फ़ंक्शन बाध्य और निरंतर है।
जैसा कि हम जानते हैं कि प्रत्येक नोड अपने राज्य को बदल देगा, यह निम्नलिखित गणितीय संबंधों की मदद से किया जा सकता है -
$ $ x_ {t} (t \: + \: 1) \: = \: f \ left (\ start {array} {c} \ displaystyle \ sum \ limit_ {j = 1} ^ n w_ {i, j) } x_ {j} (टी) \ अंत {सरणी} \ right) $$
यहाँ, xi(t) की अवस्था है ith समय पर नोड t।
से वजन होता है ith को नोड jth नोड को निम्नलिखित संबंध से मापा जा सकता है -
$$ w_ {ij} \: = \: \ frac {1} {P} \ displaystyle \ sum \ limit_ {p = 1} ^ P (v_ {p, i} \ _: v_ {p, j}} $ $
यहाँ, P प्रशिक्षण पैटर्न की संख्या है, जो द्विध्रुवी हैं।
अनुकूलन डिजाइन, स्थिति, संसाधन और सिस्टम जैसी किसी चीज़ को यथासंभव प्रभावी बनाने की एक क्रिया है। लागत फ़ंक्शन और ऊर्जा फ़ंक्शन के बीच समानता का उपयोग करके, हम अनुकूलन समस्याओं को हल करने के लिए अत्यधिक परस्पर न्यूरॉन्स का उपयोग कर सकते हैं। इस तरह का तंत्रिका नेटवर्क होपफील्ड नेटवर्क है, जिसमें एक ही परत होती है जिसमें एक या एक से अधिक पूरी तरह से जुड़े हुए न्यूरॉन होते हैं। यह अनुकूलन के लिए इस्तेमाल किया जा सकता है।
अनुकूलन के लिए हॉपफील्ड नेटवर्क का उपयोग करते समय याद रखने वाले बिंदु -
ऊर्जा फ़ंक्शन नेटवर्क का न्यूनतम होना चाहिए।
यह संग्रहीत प्रतिमानों में से किसी एक को चुनने के बजाय संतोषजनक समाधान प्राप्त करेगा।
हॉपफील्ड नेटवर्क द्वारा पाए जाने वाले समाधान की गुणवत्ता नेटवर्क की प्रारंभिक स्थिति पर काफी निर्भर करती है।
ट्रैवलिंग सेल्समैन की समस्या
सेल्समैन द्वारा यात्रा किए गए सबसे छोटे मार्ग का पता लगाना कम्प्यूटेशनल समस्याओं में से एक है, जिसे हॉपफील्ड न्यूरल नेटवर्क का उपयोग करके अनुकूलित किया जा सकता है।
टीएसपी की बुनियादी अवधारणा
ट्रैवलिंग सेल्समैन प्रॉब्लम (TSP) एक क्लासिकल ऑप्टिमाइज़ेशन प्रॉब्लम है जिसमें सेल्समैन को यात्रा करनी पड़ती है nशहर, जो एक दूसरे के साथ जुड़े हुए हैं, लागत को बनाए रखने के साथ-साथ न्यूनतम दूरी तय करते हैं। उदाहरण के लिए, सेल्समैन को 4 शहरों A, B, C, D के सेट की यात्रा करनी होती है और लक्ष्य सबसे छोटा गोलाकार दौरा, ABC-D ढूंढना होता है, ताकि लागत को कम किया जा सके, जिसमें से यात्रा की लागत भी शामिल है पहला शहर ए के आखिरी शहर डी।
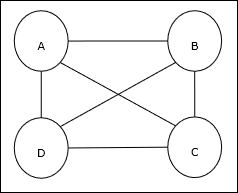
मैट्रिक्स का प्रतिनिधित्व
वास्तव में एन-शहर टीएसपी के प्रत्येक दौरे को व्यक्त किया जा सकता है n × n मैट्रिक्स जिसका ith पंक्ति वर्णन करती है ithशहर का स्थान। यह मैट्रिक्स,M4 शहरों ए, बी, सी, डी के लिए निम्नानुसार व्यक्त किया जा सकता है -
$$ M = \ start {bmatrix} A: & 1 & 0 & 0 & 0 \\ B: & 0 & 1 & 0 & 0 & \\ C: & & 0 & 1 & 0 & 1 & 0 \\ D: & 0 & 0 & 0 & 1 \ end {bmatrix} $$
हॉपफील्ड नेटवर्क द्वारा समाधान
हॉपफील्ड नेटवर्क द्वारा इस टीएसपी के समाधान पर विचार करते समय, नेटवर्क में प्रत्येक नोड मैट्रिक्स में एक तत्व से मेल खाता है।
ऊर्जा समारोह गणना
अनुकूलित समाधान होने के लिए, ऊर्जा फ़ंक्शन न्यूनतम होना चाहिए। निम्नलिखित बाधाओं के आधार पर, हम निम्न प्रकार से ऊर्जा कार्य की गणना कर सकते हैं -
बाधा-मैं
पहला अवरोध, जिसके आधार पर हम ऊर्जा क्रियाओं की गणना करेंगे, यह है कि मैट्रिक्स की प्रत्येक पंक्ति में एक तत्व 1 के बराबर होना चाहिए M और प्रत्येक पंक्ति में अन्य तत्वों के बराबर होना चाहिए 0क्योंकि प्रत्येक शहर TSP दौरे में केवल एक ही स्थिति में हो सकता है। यह बाधा गणितीय रूप से निम्नानुसार लिखी जा सकती है -
$$ \ displaystyle \ sum \ limit_ {j = 1} ^ n M_ {x, j} \: = \: 1 \: for \: x \: \ in \: \ lbrace1, ..., n \ rbrace $ $
अब ऊर्जा को कम करने के लिए, उपरोक्त बाधा के आधार पर, इसमें एक शब्द अनुपात होगा -
$$ \ displaystyle \ sum \ limit_ {x = 1} ^ n \ left (\ start {array} {c} 1 \: - \: \ displaystyle \ sum \ limit_ {j = 1} ^ n M_ {x, j) } \ अंत {सरणी} \ right) ^ 2 $$
बाधा द्वितीय
जैसा कि हम जानते हैं, टीएसपी में एक शहर मैट्रिक्स के प्रत्येक कॉलम में दौरे में किसी भी स्थिति में हो सकता है M, एक तत्व 1 के बराबर होना चाहिए और अन्य तत्व 0. के बराबर होना चाहिए। यह बाधा गणितीय रूप से निम्नानुसार लिखी जा सकती है -
$$ \ displaystyle \ sum \ limit_ {x = 1} ^ n M_ {x, j} \ _: = \: 1 \: for \: j \: \ in \: \ lbrace1, ..., n \ rbrace $ $
अब ऊर्जा को कम करने के लिए, उपरोक्त बाधा के आधार पर, इसमें एक शब्द अनुपात होगा -
$$ \ displaystyle \ sum \ limit_ {j = 1} ^ n \ left (\ start {array} {c} 1 \: - \: \ displaystyle \ sum \ limit_ {x = 1} ^ n M_ {x, j) } \ अंत {सरणी} \ right) ^ 2 $$
लागत समारोह गणना
मान लीजिए कि एक चौकोर मैट्रिक्सn × n) द्वारा चिह्नित C के लिए TSP की लागत मैट्रिक्स को दर्शाता है n शहर जहां n > 0। लागत फ़ंक्शन की गणना करते समय कुछ पैरामीटर निम्नलिखित हैं -
Cx, y - लागत मैट्रिक्स का तत्व शहर से यात्रा की लागत को दर्शाता है x सेवा y।
ए और बी के तत्वों की निकटता निम्नलिखित संबंध द्वारा दिखाई जा सकती है -
$ $ M_ {x, i} \: = \: 1 \: \: और \: \: M_ {y, i \ pm 1} \: = \: 1 $ $
जैसा कि हम जानते हैं, मैट्रिक्स में प्रत्येक नोड का आउटपुट मान 0 या 1 हो सकता है, इसलिए शहरों ए के प्रत्येक जोड़े के लिए, बी हम निम्नलिखित फ़ंक्शन को ऊर्जा फ़ंक्शन में जोड़ सकते हैं -
$$ \ displaystyle \ sum \ limit_ {i = 1} ^ n C_ {x, y} M_ {x, i} (M_ {y, i + 1} \ _: + \ _: M_ {y, i-1}) $$
उपरोक्त लागत फ़ंक्शन और बाधा मूल्य के आधार पर, अंतिम ऊर्जा फ़ंक्शन E इस प्रकार दिया जा सकता है -
$ $ E \: = \: \ frac {1} {2} \ displaystyle \ sum \ limit_ {i = 1} ^ n \ displaystyle \ sum \ limit_ {x} \ displaystyle \ sum \ limit_ {y neq x} C_ {एक्स, वाई} M_ {x, मैं} (M_ {y, i + 1} \: + \: M_ {y i-1}) \: + $$
$$ \: \ start {bmatrix} \ Gamma_ {1} \ displaystyle \ sum \ limit_ {x} \ left (\ start {array} {c} 1 \ _: - \: \ displaystyle \ sum \ limit_ i_ M_) {x, i} \ end {array} \ right) ^ 2 \: + \: \ gamma_ {2} \ displaystyle \ sum \ limit_ {i} \ बाएँ (\ शुरू {सरणी} {c} 1 \ _: \ _ : \ displaystyle \ sum \ limit_ {x} M_ {x, i} \ end {array} \ right) ^ 2 \ end {bmatrix} $$
यहाँ, γ1 तथा γ2 दो वजन वाले स्थिरांक हैं।
Iterated Gradient Descent Technique
ग्रेडिएंट डिसेंट, जिसे स्टीपेस्ट डिसेंट के रूप में भी जाना जाता है, एक फ़ंक्शन का स्थानीय न्यूनतम खोजने के लिए एक पुनरावृत्ति अनुकूलन एल्गोरिथ्म है। फ़ंक्शन को कम करते समय, हम कम से कम लागत या त्रुटि के साथ चिंतित हैं (याद रखें ट्रैवलिंग सेल्समैन समस्या)। गहन शिक्षा में इसका बड़े पैमाने पर उपयोग किया जाता है, जो विभिन्न प्रकार की स्थितियों में उपयोगी है। यहां याद रखने वाली बात यह है कि हम स्थानीय अनुकूलन से संबंधित हैं न कि वैश्विक अनुकूलन से।
मुख्य कार्य आइडिया
हम निम्न चरणों की मदद से ढाल वंश के मुख्य कार्य विचार को समझ सकते हैं -
सबसे पहले, समाधान के प्रारंभिक अनुमान के साथ शुरू करें।
फिर, उस बिंदु पर फ़ंक्शन का ग्रेडिएंट लें।
बाद में, ढाल की नकारात्मक दिशा में समाधान को आगे बढ़ाते हुए प्रक्रिया को दोहराएं।
उपरोक्त चरणों का पालन करके, एल्गोरिथ्म अंततः अभिसरण करेगा जहां ढाल शून्य है।
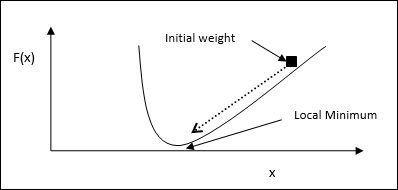
गणितीय अवधारणा
मान लीजिए कि हमारे पास एक फ़ंक्शन है f(x)और हम इस फ़ंक्शन का न्यूनतम पता लगाने का प्रयास कर रहे हैं। निम्नलिखित में से न्यूनतम खोजने के लिए चरण हैंf(x)।
सबसे पहले, कुछ प्रारंभिक मूल्य $ x_ {0} \: for: \ x $ दें
अब ग्रेडिएंट $ \ nabla f $ ,of फ़ंक्शन लें, इस अंतर्ज्ञान के साथ कि ढाल उस पर वक्र का ढलान देगा x और इसकी दिशा फ़ंक्शन को बढ़ाने, इसे कम करने के लिए सबसे अच्छी दिशा का पता लगाने के लिए इंगित करेगी।
अब x को इस प्रकार बदलें -
$ $ x_ {n \: + \: 1} \: = \: x_ {n} \: - \: \ theta \ nabla f (x_ {n}) $$
यहाँ, θ > 0 प्रशिक्षण दर (स्टेप साइज) है जो एल्गोरिदम को छोटे जंप लेने के लिए मजबूर करती है।
चरण आकार का अनुमान लगाना
दरअसल एक गलत स्टेप साइज θअभिसरण तक नहीं पहुंच सकता है, इसलिए उसी का सावधानीपूर्वक चयन बहुत महत्वपूर्ण है। चरण आकार का चयन करते समय निम्नलिखित बिंदुओं को याद रखना होगा
बहुत बड़े चरण आकार का चयन न करें, अन्यथा इसका नकारात्मक प्रभाव पड़ेगा, अर्थात यह अभिसरण के बजाय विचलन करेगा।
बहुत छोटे स्टेप साइज़ का चुनाव न करें, अन्यथा कंवर्ट होने में बहुत समय लगता है।
चरण आकार चुनने के संबंध में कुछ विकल्प -
एक विकल्प एक निश्चित चरण आकार चुनना है।
एक अन्य विकल्प हर पुनरावृत्ति के लिए एक अलग चरण आकार चुनना है।
तैयार किए हुयी धातु पे पानी चढाने की कला
सिलेक्टेड एनीलिंग (एसए) की मूल अवधारणा ठोस पदार्थों में एनेलिंग से प्रेरित है। एनीलिंग की प्रक्रिया में, यदि हम किसी धातु को उसके गलनांक से ऊपर गर्म करते हैं और उसे ठंडा करते हैं तो संरचनात्मक गुण शीतलन की दर पर निर्भर करेगा। हम यह भी कह सकते हैं कि SA annealing की धातुकर्म प्रक्रिया का अनुकरण करता है।
ANN में उपयोग करें
एसए एक स्टोकेस्टिक कम्प्यूटेशनल पद्धति है, जो किसी दिए गए फ़ंक्शन के वैश्विक अनुकूलन को अनुमानित करने के लिए एनीलिंग सादृश्य द्वारा प्रेरित है। हम फ़ीड-फॉरवर्ड न्यूरल नेटवर्क को प्रशिक्षित करने के लिए SA का उपयोग कर सकते हैं।
कलन विधि
Step 1 - एक यादृच्छिक समाधान उत्पन्न करें।
Step 2 - कुछ लागत फ़ंक्शन का उपयोग करके इसकी लागत की गणना करें।
Step 3 - एक यादृच्छिक पड़ोसी समाधान उत्पन्न करें।
Step 4 - समान लागत फ़ंक्शन द्वारा नए समाधान लागत की गणना करें।
Step 5 - पुराने समाधान के साथ एक नए समाधान की लागत की तुलना इस प्रकार है -
अगर CostNew Solution < CostOld Solution फिर नए समाधान पर जाएं।
Step 6 - रोकने की स्थिति के लिए परीक्षण, जो अधिकतम संख्या में पुनरावृत्तियों तक पहुंच सकता है या स्वीकार्य समाधान प्राप्त कर सकता है।
प्रकृति हमेशा सभी मानव जाति के लिए प्रेरणा का एक बड़ा स्रोत रही है। जेनेटिक एल्गोरिदम (जीए) प्राकृतिक चयन और आनुवंशिकी की अवधारणाओं के आधार पर खोज-आधारित एल्गोरिदम हैं। GAs संगणना की एक बहुत बड़ी शाखा का सबसेट हैंEvolutionary Computation।
GA को जॉन हॉलैंड और उनके छात्रों और सहयोगियों द्वारा मिशिगन विश्वविद्यालय में विकसित किया गया था, विशेष रूप से डेविड ई। गोल्डबर्ग और तब से उच्च अनुकूलन सफलता के साथ विभिन्न अनुकूलन समस्याओं पर कोशिश की गई है।
जीएएस में, हमारे पास एक पूल या दी गई समस्या के संभावित समाधानों की आबादी है। इसके बाद ये समाधान पुनर्संयोजन और उत्परिवर्तन (जैसे प्राकृतिक आनुवांशिकी) से गुजरते हैं, नए बच्चे पैदा करते हैं, और इस प्रक्रिया को विभिन्न पीढ़ियों से दोहराया जाता है। प्रत्येक व्यक्ति (या उम्मीदवार समाधान) को एक फिटनेस मूल्य (इसके उद्देश्य फ़ंक्शन मूल्य के आधार पर) सौंपा गया है और फिटर व्यक्तियों को अधिक "फिटर" व्यक्तियों को संभोग करने और उपज देने का एक उच्च मौका दिया जाता है। यह "सर्वाइवल ऑफ द फिटेस्ट" की डार्विनियन थ्योरी के अनुरूप है।
इस तरह, हम पीढ़ियों तक "विकसित" बेहतर व्यक्तियों या समाधानों को बनाए रखते हैं, जब तक कि हम एक रोक मापदंड तक नहीं पहुंचते हैं।
जेनेटिक एल्गोरिदम प्रकृति में पर्याप्त रूप से यादृच्छिक हैं, हालांकि वे यादृच्छिक स्थानीय खोज की तुलना में बहुत बेहतर प्रदर्शन करते हैं (जिसमें हम अभी तक विभिन्न यादृच्छिक समाधानों का प्रयास करते हैं, अब तक का सबसे अच्छा ट्रैक रखते हुए), क्योंकि वे ऐतिहासिक जानकारी का भी शोषण करते हैं।
जीए के लाभ
जीएएस के विभिन्न फायदे हैं जिन्होंने उन्हें बेहद लोकप्रिय बना दिया है। इनमें शामिल हैं -
किसी भी व्युत्पन्न जानकारी की आवश्यकता नहीं है (जो कई वास्तविक दुनिया की समस्याओं के लिए उपलब्ध नहीं हो सकती है)।
पारंपरिक तरीकों की तुलना में तेज और अधिक कुशल है।
बहुत अच्छी समानांतर क्षमताएं हैं।
दोनों सतत और असतत कार्यों के साथ-साथ बहुउद्देश्यीय समस्याओं का अनुकूलन करता है।
"अच्छे" समाधानों की सूची प्रदान करता है, न कि केवल एक समाधान।
हमेशा समस्या का जवाब मिलता है, जो समय के साथ बेहतर हो जाता है।
उपयोगी जब खोज स्थान बहुत बड़ा है और इसमें बड़ी संख्या में पैरामीटर शामिल हैं।
जीए की सीमाएं
किसी भी तकनीक की तरह, GA भी कुछ सीमाओं से ग्रस्त है। इनमें शामिल हैं -
जीए सभी समस्याओं के लिए अनुकूल नहीं हैं, विशेष रूप से ऐसी समस्याएं जो सरल हैं और जिनके लिए व्युत्पन्न जानकारी उपलब्ध है।
फिटनेस मूल्य की गणना बार-बार की जाती है, जो कुछ समस्याओं के लिए कम्प्यूटेशनल रूप से महंगा हो सकता है।
स्टोकेस्टिक होने के नाते, इष्टतमता या समाधान की गुणवत्ता पर कोई गारंटी नहीं है।
यदि ठीक से लागू नहीं किया गया है, तो जीए इष्टतम समाधान में परिवर्तित नहीं हो सकता है।
जीए - प्रेरणा
जेनेटिक एल्गोरिदम में "अच्छा-पर्याप्त" समाधान "फास्ट-पर्याप्त" देने की क्षमता है। यह अनुकूलन समस्याओं को हल करने में उपयोग के लिए गैस को आकर्षक बनाता है। जीए की आवश्यकता के कारण निम्नानुसार हैं -
कठिन समस्याओं का समाधान
कंप्यूटर विज्ञान में, समस्याओं का एक बड़ा समूह है, जो हैं NP-Hard। इसका अनिवार्य रूप से मतलब यह है कि, उस समस्या को हल करने के लिए, यहां तक कि सबसे शक्तिशाली कंप्यूटिंग सिस्टम बहुत लंबा समय (यहां तक कि!) लेते हैं। ऐसे परिदृश्य में, GA प्रदान करने के लिए एक कुशल उपकरण साबित होता हैusable near-optimal solutions कम समय में।
ग्रेडिएंट आधारित विधियों की विफलता
पारंपरिक कैलकुलस आधारित विधियाँ एक यादृच्छिक बिंदु पर शुरू करके और ढाल की दिशा में चलते हुए तब तक काम करती हैं, जब तक हम पहाड़ी की चोटी पर नहीं पहुँच जाते। यह तकनीक कुशल है और रैखिक प्रतिगमन में लागत समारोह जैसे एकल-शिखर उद्देश्य कार्यों के लिए बहुत अच्छी तरह से काम करती है। हालांकि, अधिकांश वास्तविक दुनिया की स्थितियों में, हमें एक बहुत ही जटिल समस्या है जिसे परिदृश्य कहा जाता है, कई चोटियों और कई घाटियों से बना है, जो इस तरह के तरीकों को विफल करने का कारण बनता है, क्योंकि वे स्थानीय ऑप्टिमा पर फंसने की अंतर्निहित प्रवृत्ति से पीड़ित हैं। निम्नलिखित आकृति में।
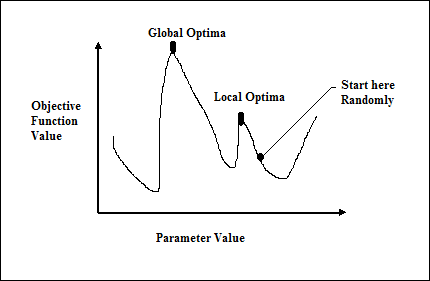
एक अच्छा समाधान तेजी से हो रही है
ट्रैवलिंग सेल्समैन प्रॉब्लम (TSP) जैसी कुछ कठिन समस्याओं में, वास्तविक दुनिया में पथ खोजने और वीएलएसआई डिज़ाइन जैसे अनुप्रयोग हैं। अब कल्पना करें कि आप अपने जीपीएस नेविगेशन सिस्टम का उपयोग कर रहे हैं, और स्रोत से गंतव्य तक "इष्टतम" पथ की गणना करने में कुछ मिनट (या कुछ घंटे) लगते हैं। इस तरह के वास्तविक दुनिया के अनुप्रयोगों में देरी स्वीकार्य नहीं है और इसलिए एक "अच्छा-पर्याप्त" समाधान है, जिसे "तेज" वितरित किया जाता है जो आवश्यक है।
अनुकूलन समस्याओं के लिए GA का उपयोग कैसे करें?
हम पहले से ही जानते हैं कि अनुकूलन डिजाइन, स्थिति, संसाधन, और सिस्टम जैसे कुछ को यथासंभव प्रभावी बनाने की एक क्रिया है। अनुकूलन प्रक्रिया को निम्न आरेख में दिखाया गया है।

अनुकूलन प्रक्रिया के लिए GA तंत्र के चरण
समस्याओं के अनुकूलन के लिए उपयोग किए जाने पर जीए तंत्र के चरणों का पालन किया जाता है।
प्रारंभिक जनसंख्या को अनियमित रूप से उत्पन्न करें।
सबसे अच्छा फिटनेस मूल्यों के साथ प्रारंभिक समाधान का चयन करें।
म्यूटेशन और क्रॉसओवर ऑपरेटरों का उपयोग करके चयनित समाधानों को पुन: व्यवस्थित करें।
संतानों को आबादी में सम्मिलित करें।
अब अगर स्टॉप की शर्त पूरी हो जाती है, तो उनके सबसे अच्छे फिटनेस मूल्य के साथ समाधान वापस करें। एल्स, चरण 2 पर जाएं।
उन क्षेत्रों का अध्ययन करने से पहले जहां एएनएन का बड़े पैमाने पर उपयोग किया गया है, हमें यह समझने की आवश्यकता है कि एएनएन आवेदन का पसंदीदा विकल्प क्यों होगा।
कृत्रिम तंत्रिका नेटवर्क क्यों?
हमें उपरोक्त प्रश्न के उत्तर को मानव के उदाहरण के साथ समझने की आवश्यकता है। एक बच्चे के रूप में, हम अपने बड़ों की मदद से चीजें सीखते थे, जिसमें हमारे माता-पिता या शिक्षक शामिल होते हैं। फिर बाद में स्व-शिक्षा या अभ्यास के द्वारा हम जीवन भर सीखते रहते हैं। वैज्ञानिक और शोधकर्ता भी इंसान की तरह ही मशीन को बुद्धिमान बना रहे हैं, और एएनएन निम्नलिखित कारणों से उसी में बहुत महत्वपूर्ण भूमिका निभाता है -
तंत्रिका नेटवर्क की मदद से, हम ऐसी समस्याओं का समाधान पा सकते हैं जिनके लिए एल्गोरिथम विधि महंगी है या मौजूद नहीं है।
तंत्रिका नेटवर्क उदाहरण के द्वारा सीख सकते हैं, इसलिए हमें इसे बहुत हद तक प्रोग्राम करने की आवश्यकता नहीं है।
तंत्रिका नेटवर्क की सटीकता और पारंपरिक गति की तुलना में काफी तेज गति है।
अनुप्रयोग के क्षेत्र
अनुगमन कुछ ऐसे क्षेत्र हैं, जहाँ ANN का उपयोग किया जा रहा है। यह बताता है कि एएनएन के विकास और अनुप्रयोगों में एक अंतःविषय दृष्टिकोण है।
वाक् पहचान
भाषण मानव-मानव बातचीत में एक प्रमुख भूमिका निभाता है। इसलिए, लोगों के लिए कंप्यूटर के साथ भाषण इंटरफेस की उम्मीद करना स्वाभाविक है। वर्तमान युग में, मशीनों के साथ संचार के लिए, मनुष्यों को अभी भी परिष्कृत भाषाओं की आवश्यकता है जो सीखना और उपयोग करना मुश्किल है। इस संचार बाधा को कम करने के लिए, एक सरल समाधान हो सकता है, एक बोली जाने वाली भाषा में संचार जो कि मशीन को समझने के लिए संभव है।
इस क्षेत्र में महान प्रगति हुई है, हालांकि, अभी भी इस तरह की प्रणालियों को सीमित शब्दावली या व्याकरण की समस्या का सामना करना पड़ रहा है और साथ ही विभिन्न स्थितियों में अलग-अलग वक्ताओं के लिए प्रणाली को फिर से जारी करने का मुद्दा है। ANN इस क्षेत्र में एक प्रमुख भूमिका निभा रहा है। भाषण मान्यता के लिए निम्नलिखित ANN का उपयोग किया गया है -
बहुपरत नेटवर्क
आवर्ती कनेक्शन के साथ बहुपरत नेटवर्क
कोहेनन आत्म-आयोजन सुविधा मानचित्र
इसके लिए सबसे उपयोगी नेटवर्क कोहेनन सेल्फ-ऑर्गेनाइजिंग फीचर मैप है, जिसमें इसका इनपुट भाषण तरंग के छोटे खंडों के रूप में है। यह आउटपुट ऐरे के रूप में एक ही तरह के फोनीम्स को मैप करेगा, जिसे फीचर निष्कर्षण तकनीक कहा जाता है। फीचर्स निकालने के बाद, बैक-एंड प्रोसेसिंग के रूप में कुछ ध्वनिक मॉडल की मदद से, यह उच्चारण को पहचान लेगा।
चरित्र पहचान
यह एक दिलचस्प समस्या है जो पैटर्न मान्यता के सामान्य क्षेत्र के अंतर्गत आती है। कई तंत्रिका नेटवर्क हस्तलिखित वर्णों की स्वचालित मान्यता के लिए विकसित किए गए हैं, या तो पत्र या अंक। निम्नलिखित कुछ ANN हैं जिनका उपयोग चरित्र पहचान के लिए किया गया है -
- बहुपरत तंत्रिका नेटवर्क जैसे कि बैकप्रोपैजेशन तंत्रिका नेटवर्क।
- Neocognitron
हालांकि बैक-प्रसार तंत्रिका नेटवर्क में कई छिपी हुई परतें हैं, एक परत से अगली तक कनेक्शन का पैटर्न स्थानीयकृत है। इसी तरह, नियोकोगनिट्रॉन में भी कई छिपी हुई परतें होती हैं और इस तरह के अनुप्रयोगों के लिए इसका प्रशिक्षण परत-दर-परत किया जाता है।
हस्ताक्षर सत्यापन आवेदन
हस्ताक्षर किसी व्यक्ति को कानूनी लेनदेन को अधिकृत करने और प्रमाणित करने के सबसे उपयोगी तरीकों में से एक हैं। हस्ताक्षर सत्यापन तकनीक एक गैर-दृष्टि आधारित तकनीक है।
इस एप्लिकेशन के लिए, पहला तरीका यह है कि फीचर को निकालना है या सिग्नेचर को दर्शाते हुए जियोमेट्रिक फीचर सेट करना है। इन सुविधा सेटों के साथ, हमें एक कुशल तंत्रिका नेटवर्क एल्गोरिथ्म का उपयोग करके तंत्रिका नेटवर्क को प्रशिक्षित करना होगा। यह प्रशिक्षित तंत्रिका नेटवर्क सत्यापन चरण के तहत हस्ताक्षर को वास्तविक या जाली के रूप में वर्गीकृत करेगा।
मानव चेहरा पहचान
यह दिए गए चेहरे की पहचान करने के लिए बॉयोमीट्रिक तरीकों में से एक है। यह "गैर-चेहरे" छवियों के लक्षण वर्णन के कारण एक विशिष्ट कार्य है। हालांकि, अगर एक तंत्रिका नेटवर्क को अच्छी तरह से प्रशिक्षित किया जाता है, तो इसे दो वर्गों में विभाजित किया जा सकता है अर्थात् चेहरे वाले चित्र और छवियां जिनके चेहरे नहीं होते हैं।
सबसे पहले, सभी इनपुट छवियों को प्रीप्रोसेस किया जाना चाहिए। फिर, उस छवि की गतिशीलता को कम किया जाना चाहिए। और, अंत में इसे तंत्रिका नेटवर्क प्रशिक्षण एल्गोरिथ्म का उपयोग करके वर्गीकृत किया जाना चाहिए। अनुलोम-विलोम छवि के साथ प्रशिक्षण उद्देश्यों के लिए निम्नलिखित तंत्रिका नेटवर्क का उपयोग किया जाता है -
पूरी तरह से जुड़ा हुआ बहुपरत फीड-फॉरवर्ड न्यूरल नेटवर्क जिसे बैक-प्रोपगोरेशन एल्गोरिदम की मदद से प्रशिक्षित किया गया है।
आयामीता में कमी के लिए, प्रधान घटक विश्लेषण (पीसीए) का उपयोग किया जाता है।