पायथन में लॉजिस्टिक रिग्रेशन - डेटा प्राप्त करना
पायथन में लॉजिस्टिक प्रतिगमन करने के लिए डेटा प्राप्त करने में शामिल चरणों पर इस अध्याय में विस्तार से चर्चा की गई है।
डाटसेट डाउनलोड करना
यदि आपने पहले बताए गए यूसीआई डेटासेट को पहले से डाउनलोड नहीं किया है, तो इसे अभी यहां से डाउनलोड करें । डेटा फ़ोल्डर पर क्लिक करें। आप निम्न स्क्रीन देखेंगे -

दिए गए लिंक पर क्लिक करके bank.zip फ़ाइल डाउनलोड करें। ज़िप फ़ाइल में निम्न फ़ाइलें हैं -

हम अपने मॉडल विकास के लिए bank.csv फ़ाइल का उपयोग करेंगे। बैंक- names.txt फ़ाइल में उस डेटाबेस का विवरण होता है जिसकी आपको बाद में जरूरत पड़ने वाली है। बैंक- full.csv में एक बहुत बड़ा डेटासेट है जिसे आप अधिक उन्नत विकास के लिए उपयोग कर सकते हैं।
यहां हमने डाउनलोड करने योग्य स्रोत ज़िप में bank.csv फ़ाइल को शामिल किया है। इस फ़ाइल में अल्पविराम-सीमांकित फ़ील्ड हैं। हमने फ़ाइल में कुछ संशोधन भी किए हैं। यह अनुशंसा की जाती है कि आप अपने सीखने के लिए प्रोजेक्ट स्रोत ज़िप में शामिल फ़ाइल का उपयोग करें।
डेटा लोड हो रहा है
सीएसवी फ़ाइल से डेटा लोड करने के लिए जिसे आपने अभी कॉपी किया था, निम्न कथन टाइप करें और कोड चलाएँ।
In [2]: df = pd.read_csv('bank.csv', header=0)आप निम्न कोड स्टेटमेंट चलाकर लोड किए गए डेटा की जांच करने में भी सक्षम होंगे -
IN [3]: df.head()कमांड चलाने के बाद, आप निम्न आउटपुट देखेंगे -
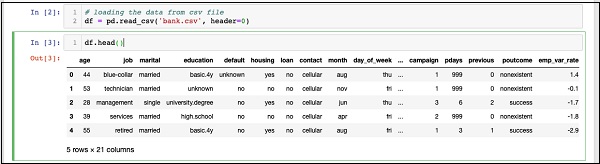
मूल रूप से, इसने लोड किए गए डेटा की पहली पांच पंक्तियों को मुद्रित किया है। मौजूद 21 कॉलम की जांच करें। हम अपने मॉडल विकास के लिए इनमें से केवल कुछ कॉलम का उपयोग करेंगे।
अगला, हमें डेटा को साफ करने की आवश्यकता है। डेटा में कुछ पंक्तियाँ हो सकती हैंNaN। ऐसी पंक्तियों को समाप्त करने के लिए, निम्नलिखित कमांड का उपयोग करें -
IN [4]: df = df.dropna()सौभाग्य से, bank.csv में NaN के साथ कोई पंक्तियाँ नहीं हैं, इसलिए यह कदम वास्तव में हमारे मामले में आवश्यक नहीं है। हालांकि, सामान्य तौर पर एक विशाल डेटाबेस में ऐसी पंक्तियों की खोज करना मुश्किल है। इसलिए डेटा को साफ करने के लिए उपरोक्त कथन को चलाना हमेशा सुरक्षित होता है।
Note - आप निम्नलिखित विवरण का उपयोग करके आसानी से किसी भी समय डेटा आकार की जांच कर सकते हैं -
IN [5]: print (df.shape)
(41188, 21)आउटपुट में पंक्तियों और स्तंभों की संख्या मुद्रित की जाएगी जैसा कि ऊपर दूसरी पंक्ति में दिखाया गया है।
अगली बात यह है कि मॉडल के लिए प्रत्येक कॉलम की उपयुक्तता की जांच करना है जिसे हम बनाने की कोशिश कर रहे हैं।