पाइथन में लॉजिस्टिक रिग्रेशन - क्विक गाइड
लॉजिस्टिक रिग्रेशन वस्तुओं के वर्गीकरण का एक सांख्यिकीय तरीका है। यह अध्याय कुछ उदाहरणों की मदद से लॉजिस्टिक प्रतिगमन का परिचय देगा।
वर्गीकरण
लॉजिस्टिक रिग्रेशन को समझने के लिए, आपको पता होना चाहिए कि वर्गीकरण का क्या मतलब है। आइए इसे बेहतर समझने के लिए निम्नलिखित उदाहरणों पर विचार करें -
- एक डॉक्टर ट्यूमर को घातक या सौम्य के रूप में वर्गीकृत करता है।
- एक बैंक लेनदेन धोखाधड़ी या वास्तविक हो सकता है।
कई वर्षों से, मनुष्य ऐसे कार्य करते रहे हैं - भले ही वे त्रुटिपूर्ण हों। सवाल यह है कि क्या हम अपने लिए बेहतर सटीकता के साथ इन कार्यों को करने के लिए मशीनों को प्रशिक्षित कर सकते हैं?
वर्गीकरण करने वाली मशीन का एक ऐसा उदाहरण ईमेल है Clientआपकी मशीन पर जो हर आने वाले मेल को "स्पैम" या "स्पैम नहीं" के रूप में वर्गीकृत करता है और यह इसे काफी बड़ी सटीकता के साथ करता है। ईमेल क्लाइंट में लॉजिस्टिक रिग्रेशन की सांख्यिकीय तकनीक को सफलतापूर्वक लागू किया गया है। इस मामले में, हमने वर्गीकरण समस्या को हल करने के लिए हमारी मशीन को प्रशिक्षित किया है।
लॉजिस्टिक रिग्रेशन इस तरह के बाइनरी वर्गीकरण समस्या को हल करने के लिए इस्तेमाल की जाने वाली मशीन लर्निंग का सिर्फ एक हिस्सा है। कई अन्य मशीन सीखने की तकनीकें हैं जो पहले से ही विकसित हैं और अन्य प्रकार की समस्याओं को हल करने के लिए अभ्यास में हैं।
यदि आपने नोट किया है, तो उपरोक्त सभी उदाहरणों में, पूर्वानुमान के परिणाम में केवल दो मूल्य हैं - हां या नहीं। हम इन्हें कक्षाओं के रूप में कहते हैं - इसलिए जैसा कि हम कहते हैं कि हमारा क्लासिफायर ऑब्जेक्ट को दो वर्गों में वर्गीकृत करता है। तकनीकी शब्दों में, हम कह सकते हैं कि परिणाम या लक्ष्य चर प्रकृति में द्विभाजित है।
अन्य वर्गीकरण समस्याएं हैं जिनमें आउटपुट को दो से अधिक वर्गों में वर्गीकृत किया जा सकता है। उदाहरण के लिए, फलों से भरी टोकरी को देखते हुए, आपको विभिन्न प्रकार के फलों को अलग करने के लिए कहा जाता है। अब, टोकरी में संतरे, सेब, आम आदि हो सकते हैं। इसलिए जब आप फलों को अलग करते हैं, तो आप उन्हें दो से अधिक वर्गों में अलग करते हैं। यह एक बहुभिन्नरूपी वर्गीकरण समस्या है।
इस बात पर विचार करें कि एक बैंक आपके पास एक मशीन लर्निंग एप्लिकेशन विकसित करने के लिए पहुंचता है जो संभावित ग्राहकों की पहचान करने में उनकी मदद करेगा जो उनके साथ एक टर्म डिपॉजिट (कुछ बैंकों द्वारा फिक्स्ड डिपॉजिट भी कहा जाता है) खोलेंगे। संभावित ग्राहकों के बारे में जानकारी एकत्र करने के लिए बैंक नियमित रूप से टेलीफ़ोनिक कॉल या वेब फॉर्म के माध्यम से एक सर्वेक्षण करता है। सर्वेक्षण प्रकृति में सामान्य है और एक बहुत बड़े दर्शकों पर आयोजित किया जाता है, जिनमें से कई को इस बैंक के साथ काम करने में रुचि नहीं हो सकती है। शेष में से, केवल कुछ ही सावधि जमा खोलने में दिलचस्पी ले सकते हैं। दूसरों को बैंक द्वारा दी जाने वाली अन्य सुविधाओं में रुचि हो सकती है। इसलिए टीडी खोलने वाले ग्राहकों की पहचान के लिए सर्वेक्षण आवश्यक रूप से नहीं किया गया है। आपका कार्य उन सभी ग्राहकों की पहचान करना है, जो बैंक आपके साथ साझा करने जा रहे विनम्र सर्वेक्षण डेटा से टीडी खोलने की उच्च संभावना रखते हैं।
सौभाग्य से, मशीन लर्निंग मॉडल विकसित करने के इच्छुक लोगों के लिए इस तरह का एक डेटा सार्वजनिक रूप से उपलब्ध है। यह डेटा कुछ छात्रों द्वारा यूसी इरविन में बाहरी फंडिंग के साथ तैयार किया गया था। डेटाबेस के एक भाग के रूप में उपलब्ध हैUCI Machine Learning Repositoryऔर दुनिया भर में छात्रों, शिक्षकों और शोधकर्ताओं द्वारा व्यापक रूप से उपयोग किया जाता है। यहां से डाटा डाउनलोड किया जा सकता है ।
अगले अध्यायों में, अब हम उसी डेटा का उपयोग करके एप्लिकेशन डेवलपमेंट करते हैं।
इस अध्याय में, हम पायथन में लॉजिस्टिक प्रतिगमन करने के लिए एक परियोजना स्थापित करने में शामिल प्रक्रिया को विस्तार से समझेंगे।
जुपिटर स्थापित करना
हम मशीन सीखने के लिए सबसे व्यापक रूप से इस्तेमाल किए जाने वाले प्लेटफार्मों में से एक - जुपिटर का उपयोग करेंगे। यदि आपके पास अपनी मशीन पर जुपाइटर स्थापित नहीं है, तो इसे यहां से डाउनलोड करें । स्थापना के लिए, आप मंच को स्थापित करने के लिए उनकी साइट पर दिए गए निर्देशों का पालन कर सकते हैं। जैसा कि साइट का सुझाव है, आप उपयोग करना पसंद कर सकते हैंAnaconda Distributionजो साइंटिफिक कंप्यूटिंग और डेटा साइंस के लिए पायथन और कई आमतौर पर इस्तेमाल किए जाने वाले पाइथन पैकेज के साथ आता है। यह इन पैकेजों को व्यक्तिगत रूप से स्थापित करने की आवश्यकता को कम करेगा।
जुपिटर की सफल स्थापना के बाद, एक नई परियोजना शुरू करें, इस स्तर पर आपकी स्क्रीन आपके कोड को स्वीकार करने के लिए निम्नलिखित तैयार होगी।
अब, से प्रोजेक्ट का नाम बदलें Untitled1 to “Logistic Regression” शीर्षक नाम पर क्लिक करके और उसे संपादित करके।
सबसे पहले, हम कई पायथन पैकेजों का आयात करेंगे, जिनकी हमें अपने कोड में आवश्यकता होगी।
पायथन पैकेज आयात करना
इस उद्देश्य के लिए, कोड संपादक में निम्न कोड टाइप या कट-पेस्ट करें -
In [1]: # import statements
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_splitतुम्हारी Notebook इस स्तर पर निम्नलिखित की तरह दिखना चाहिए -
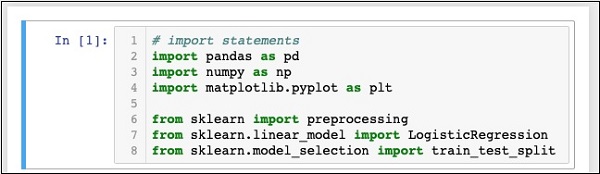
पर क्लिक करके कोड चलाएँ Runबटन। यदि कोई त्रुटि उत्पन्न नहीं होती है, तो आपने सफलतापूर्वक जुपिटर स्थापित किया है और अब बाकी के विकास के लिए तैयार हैं।
पहले तीन आयात विवरण हमारी परियोजना में पांडा, सुस्ता और matplotlib.pyplot संकुल आयात करते हैं। अगले तीन कथन स्केलेर से निर्दिष्ट मॉड्यूल आयात करते हैं।
हमारा अगला कार्य हमारी परियोजना के लिए आवश्यक डेटा डाउनलोड करना है। हम इसे अगले अध्याय में जानेंगे।
पायथन में लॉजिस्टिक प्रतिगमन करने के लिए डेटा प्राप्त करने में शामिल चरणों पर इस अध्याय में विस्तार से चर्चा की गई है।
डाटसेट डाउनलोड करना
यदि आपने पहले बताए गए यूसीआई डेटासेट को पहले से डाउनलोड नहीं किया है, तो इसे अभी यहां से डाउनलोड करें । डेटा फ़ोल्डर पर क्लिक करें। आप निम्न स्क्रीन देखेंगे -

दिए गए लिंक पर क्लिक करके bank.zip फ़ाइल डाउनलोड करें। ज़िप फ़ाइल में निम्न फ़ाइलें हैं -

हम अपने मॉडल विकास के लिए bank.csv फ़ाइल का उपयोग करेंगे। बैंक- names.txt फ़ाइल में उस डेटाबेस का विवरण होता है जिसकी आपको बाद में जरूरत पड़ने वाली है। बैंक- full.csv में एक बहुत बड़ा डेटासेट है जिसे आप अधिक उन्नत विकास के लिए उपयोग कर सकते हैं।
यहां हमने डाउनलोड करने योग्य स्रोत ज़िप में bank.csv फ़ाइल को शामिल किया है। इस फ़ाइल में अल्पविराम-सीमांकित फ़ील्ड हैं। हमने फ़ाइल में कुछ संशोधन भी किए हैं। यह अनुशंसा की जाती है कि आप अपने सीखने के लिए प्रोजेक्ट स्रोत ज़िप में शामिल फ़ाइल का उपयोग करें।
डेटा लोड हो रहा है
सीएसवी फ़ाइल से डेटा लोड करने के लिए जिसे आपने अभी कॉपी किया था, निम्न कथन टाइप करें और कोड चलाएँ।
In [2]: df = pd.read_csv('bank.csv', header=0)आप निम्न कोड स्टेटमेंट चलाकर लोड किए गए डेटा की जांच करने में भी सक्षम होंगे -
IN [3]: df.head()कमांड चलाने के बाद, आप निम्न आउटपुट देखेंगे -
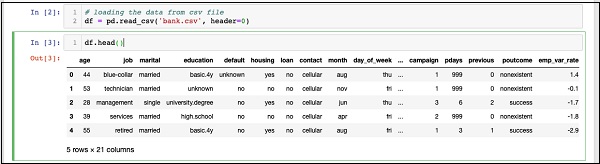
मूल रूप से, इसने लोड किए गए डेटा की पहली पांच पंक्तियों को मुद्रित किया है। मौजूद 21 कॉलम की जांच करें। हम अपने मॉडल विकास के लिए इनमें से केवल कुछ कॉलम का उपयोग करेंगे।
अगला, हमें डेटा को साफ करने की आवश्यकता है। डेटा में कुछ पंक्तियाँ हो सकती हैंNaN। ऐसी पंक्तियों को समाप्त करने के लिए, निम्नलिखित कमांड का उपयोग करें -
IN [4]: df = df.dropna()सौभाग्य से, bank.csv में NaN के साथ कोई पंक्तियाँ नहीं हैं, इसलिए यह कदम वास्तव में हमारे मामले में आवश्यक नहीं है। हालांकि, सामान्य तौर पर एक विशाल डेटाबेस में ऐसी पंक्तियों की खोज करना मुश्किल है। इसलिए डेटा को साफ करने के लिए उपरोक्त कथन को चलाना हमेशा सुरक्षित होता है।
Note - आप निम्नलिखित विवरण का उपयोग करके आसानी से किसी भी समय डेटा आकार की जांच कर सकते हैं -
IN [5]: print (df.shape)
(41188, 21)आउटपुट में पंक्तियों और स्तंभों की संख्या मुद्रित की जाएगी जैसा कि ऊपर दूसरी पंक्ति में दिखाया गया है।
अगली बात यह है कि मॉडल के लिए प्रत्येक कॉलम की उपयुक्तता की जांच करना है जिसे हम बनाने की कोशिश कर रहे हैं।
जब भी कोई संगठन एक सर्वेक्षण आयोजित करता है, तो वे ग्राहक से यथासंभव अधिक से अधिक जानकारी एकत्र करने की कोशिश करते हैं, इस विचार के साथ कि यह जानकारी एक समय में एक या दूसरे तरीके से संगठन के लिए उपयोगी होगी। वर्तमान समस्या को हल करने के लिए, हमें उस जानकारी को चुनना होगा जो सीधे हमारी समस्या के लिए प्रासंगिक है।
सभी फ़ील्ड प्रदर्शित करना
अब, देखते हैं कि हमारे लिए उपयोगी डेटा फ़ील्ड का चयन कैसे करें। कोड संपादक में निम्न कथन चलाएँ।
In [6]: print(list(df.columns))आप निम्न आउटपुट देखेंगे -
['age', 'job', 'marital', 'education', 'default', 'housing', 'loan',
'contact', 'month', 'day_of_week', 'duration', 'campaign', 'pdays',
'previous', 'poutcome', 'emp_var_rate', 'cons_price_idx', 'cons_conf_idx',
'euribor3m', 'nr_employed', 'y']आउटपुट डेटाबेस के सभी कॉलम के नाम दिखाता है। अंतिम कॉलम "y" एक बूलियन मूल्य है जो यह दर्शाता है कि इस ग्राहक का बैंक में सावधि जमा है या नहीं। इस क्षेत्र के मूल्य या तो "y" या "n" हैं। आप प्रत्येक कॉलम के विवरण और उद्देश्य को बैंकों के नाम-पाठ फ़ाइल में पढ़ सकते हैं जिसे डेटा के भाग के रूप में डाउनलोड किया गया था।
अवांछित फील्ड को खत्म करना
स्तंभ नामों की जांच करने पर, आपको पता चल जाएगा कि कुछ क्षेत्रों में समस्या का कोई महत्व नहीं है। उदाहरण के लिए, फ़ील्ड जैसेmonth, day_of_week, अभियान, आदि हमारे किसी काम के नहीं हैं। हम अपने डेटाबेस से इन क्षेत्रों को समाप्त कर देंगे। एक कॉलम को छोड़ने के लिए, हम नीचे दिखाए गए अनुसार ड्रॉप कमांड का उपयोग करते हैं -
In [8]: #drop columns which are not needed.
df.drop(df.columns[[0, 3, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19]],
axis = 1, inplace = True)कमांड कहता है कि ड्रॉप कॉलम नंबर 0, 3, 7, 8 और इसी तरह से। यह सुनिश्चित करने के लिए कि सूचकांक ठीक से चयनित है, निम्नलिखित कथन का उपयोग करें -
In [7]: df.columns[9]
Out[7]: 'day_of_week'यह दिए गए इंडेक्स के कॉलम नाम को प्रिंट करता है।
जिन कॉलमों की आवश्यकता नहीं है, उन्हें छोड़ने के बाद, हेड स्टेटमेंट के साथ डेटा की जांच करें। स्क्रीन आउटपुट यहाँ दिखाया गया है -
In [9]: df.head()
Out[9]:
job marital default housing loan poutcome y
0 blue-collar married unknown yes no nonexistent 0
1 technician married no no no nonexistent 0
2 management single no yes no success 1
3 services married no no no nonexistent 0
4 retired married no yes no success 1अब, हमारे पास केवल वे फ़ील्ड हैं जो हमें लगता है कि हमारे डेटा विश्लेषण और भविष्यवाणी के लिए महत्वपूर्ण हैं। की अहमियतData Scientistइस कदम पर तस्वीर में आता है। डेटा वैज्ञानिक को मॉडल निर्माण के लिए उपयुक्त कॉलम का चयन करना होगा।
उदाहरण के लिए, का प्रकार jobहालांकि पहली नज़र में डेटाबेस में शामिल करने के लिए हर किसी को मना नहीं किया जा सकता है, यह एक बहुत ही उपयोगी क्षेत्र होगा। सभी प्रकार के ग्राहक टीडी नहीं खोलेंगे। कम आय वाले लोग टीडीएस नहीं खोल सकते हैं, जबकि उच्च आय वाले लोग आमतौर पर अपने अतिरिक्त धन को टीडीएस में पार्क करेंगे। तो इस परिदृश्य में नौकरी का प्रकार काफी प्रासंगिक हो जाता है। इसी तरह, उन कॉलमों का ध्यानपूर्वक चयन करें जो आपको लगता है कि आपके विश्लेषण के लिए प्रासंगिक होगा।
अगले अध्याय में, हम मॉडल के निर्माण के लिए अपना डेटा तैयार करेंगे।
क्लासिफायर बनाने के लिए, हमें डेटा को एक ऐसे फॉर्मेट में तैयार करना चाहिए जो क्लासिफायरियर बिल्डिंग मॉड्यूल द्वारा पूछा जाता है। हम डेटा को तैयार करके करते हैंOne Hot Encoding।
डेटा एन्कोडिंग
हम जल्द ही चर्चा करेंगे कि डेटा को एन्कोडिंग से हमारा क्या मतलब है। सबसे पहले, हम कोड चलाते हैं। कोड विंडो में निम्न कमांड चलाएँ।
In [10]: # creating one hot encoding of the categorical columns.
data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])जैसा कि टिप्पणी कहती है, उपरोक्त कथन डेटा के एक गर्म एन्कोडिंग का निर्माण करेगा। आइए देखें कि इसने क्या बनाया है? बनाए गए डेटा की जांच करें“data” डेटाबेस में हेड रिकॉर्ड को प्रिंट करके।
In [11]: data.head()आप निम्न आउटपुट देखेंगे -
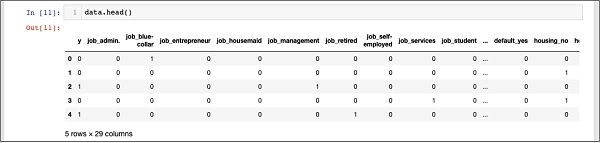
उपरोक्त आंकड़ों को समझने के लिए, हम कॉलम नामों को सूचीबद्ध करके चलाएंगे data.columns नीचे दिखाए अनुसार कमांड -
In [12]: data.columns
Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'job_unknown', 'marital_divorced', 'marital_married', 'marital_single',
'marital_unknown', 'default_no', 'default_unknown', 'default_yes',
'housing_no', 'housing_unknown', 'housing_yes', 'loan_no',
'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent',
'poutcome_success'], dtype='object')अब, हम बताएंगे कि कैसे एक गर्म एन्कोडिंग द्वारा किया जाता है get_dummiesआदेश। नव-निर्मित डेटाबेस में पहला कॉलम "y" फ़ील्ड है जो इंगित करता है कि इस ग्राहक ने TD में सदस्यता ली है या नहीं। अब, हम उन कॉलमों को देखते हैं जो एन्कोडेड हैं। पहला एन्कोडेड कॉलम है“job”। डेटाबेस में, आप पाएंगे कि "नौकरी" कॉलम में "व्यवस्थापक", "ब्लू-कॉलर", "उद्यमी" जैसे कई संभावित मूल्य हैं, और इसी तरह। प्रत्येक संभावित मान के लिए, हमारे पास डेटाबेस में एक नया कॉलम बना है, जिसमें स्तंभ नाम उपसर्ग के रूप में जोड़ा गया है।
इस प्रकार, हमारे पास "job_admin", "job_blue-कॉलर", और इसी तरह के कॉलम हैं। हमारे मूल डेटाबेस में प्रत्येक एन्कोडेड फ़ील्ड के लिए, आपको बनाए गए डेटाबेस में सभी संभावित मानों के साथ स्तंभों की एक सूची मिलेगी, जो मूल डेटाबेस में स्तंभ लेता है। डेटा को नए डेटाबेस में कैसे मैप किया जाता है, यह समझने के लिए कॉलम की सूची की सावधानीपूर्वक जाँच करें।
डेटा मैपिंग को समझना
उत्पन्न डेटा को समझने के लिए, हम डेटा कमांड का उपयोग करके संपूर्ण डेटा का प्रिंट आउट करते हैं। कमांड चलाने के बाद आंशिक आउटपुट नीचे दिखाया गया है।
In [13]: data
उपरोक्त स्क्रीन पहले बारह पंक्तियों को दिखाती है। यदि आप और नीचे स्क्रॉल करते हैं, तो आप देखेंगे कि मैपिंग सभी पंक्तियों के लिए की गई है।
डेटाबेस के नीचे एक आंशिक स्क्रीन आउटपुट आपके त्वरित संदर्भ के लिए यहां दिखाया गया है।
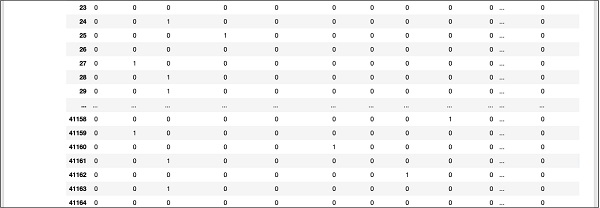
मैप किए गए डेटा को समझने के लिए, हम पहली पंक्ति की जांच करते हैं।

यह कहता है कि इस ग्राहक ने "y" फ़ील्ड में मूल्य के अनुसार टीडी की सदस्यता नहीं ली है। यह भी इंगित करता है कि यह ग्राहक "ब्लू-कॉलर" ग्राहक है। क्षैतिज रूप से नीचे स्क्रॉल करने पर, यह आपको बताएगा कि उसके पास "आवास" है और उसने "ऋण" नहीं लिया है।
इस एक हॉट एन्कोडिंग के बाद, हमें अपने मॉडल का निर्माण शुरू करने से पहले कुछ और डेटा प्रोसेसिंग की आवश्यकता होगी।
"अज्ञात" को छोड़ना
यदि हम मैप किए गए डेटाबेस में कॉलम की जांच करते हैं, तो आपको "अज्ञात" के साथ समाप्त होने वाले कुछ कॉलम की उपस्थिति मिलेगी। उदाहरण के लिए, स्क्रीनशॉट में दिखाए गए कमांड के साथ सूचकांक 12 पर कॉलम की जांच करें -
In [14]: data.columns[12]
Out[14]: 'job_unknown'यह इंगित करता है कि निर्दिष्ट ग्राहक के लिए नौकरी अज्ञात है। जाहिर है, हमारे विश्लेषण और मॉडल निर्माण में ऐसे स्तंभों को शामिल करने का कोई मतलब नहीं है। इस प्रकार, "अज्ञात" मान वाले सभी स्तंभों को छोड़ दिया जाना चाहिए। यह निम्नलिखित कमांड के साथ किया जाता है -
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)सुनिश्चित करें कि आप सही कॉलम संख्या निर्दिष्ट करते हैं। एक संदेह के मामले में, आप कॉलम के नाम को किसी भी समय इसके सूचकांक को निर्दिष्ट करके कभी भी जांच कर सकते हैं जैसा कि पहले बताया गया है।
अवांछित कॉलम को छोड़ने के बाद, आप कॉलम की अंतिम सूची की जांच कर सकते हैं जैसा कि नीचे दिए गए आउटपुट में दिखाया गया है -
In [16]: data.columns
Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'marital_divorced', 'marital_married', 'marital_single', 'default_no',
'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes',
'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'],
dtype='object')इस बिंदु पर, हमारा डेटा मॉडल निर्माण के लिए तैयार है।
हमारे पास लगभग इकतालीस हजार और विषम रिकॉर्ड हैं। यदि हम मॉडल निर्माण के लिए संपूर्ण डेटा का उपयोग करते हैं, तो हमें परीक्षण के लिए किसी भी डेटा के साथ नहीं छोड़ा जाएगा। इसलिए आमतौर पर, हम पूरे डेटा को दो भागों में विभाजित करते हैं, कहते हैं 70/30 प्रतिशत। हम मॉडल निर्माण के लिए 70% डेटा का उपयोग करते हैं और बाकी हमारे बनाए मॉडल की भविष्यवाणी में सटीकता का परीक्षण करने के लिए करते हैं। आप अपनी आवश्यकता के अनुसार एक अलग विभाजन अनुपात का उपयोग कर सकते हैं।
ऐरे बनाना
डेटा को विभाजित करने से पहले, हम डेटा को दो सरणियों X और Y में अलग करते हैं। X सरणी में वे सभी विशेषताएं (डेटा कॉलम) हैं, जिनका हम विश्लेषण करना चाहते हैं और Y सरणी बूलियन मानों का एकल आयामी सरणी है जो आउटपुट है भविष्यवाणी। इसे समझने के लिए, हम कुछ कोड चलाते हैं।
सबसे पहले, एक्स सरणी बनाने के लिए निम्नलिखित पायथन कथन को निष्पादित करें -
In [17]: X = data.iloc[:,1:]की सामग्री की जांच करने के लिए X उपयोग headकुछ प्रारंभिक रिकॉर्ड मुद्रित करने के लिए। निम्न स्क्रीन एक्स सरणी की सामग्री को दिखाती है।
In [18]: X.head ()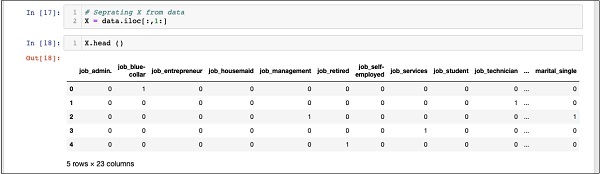
सरणी में कई पंक्तियाँ और 23 स्तंभ हैं।
अगला, हम आउटपुट एरे को बनाएंगेyमान।
आउटपुट सरणी बनाना
अनुमानित मूल्य स्तंभ के लिए एक सरणी बनाने के लिए, निम्नलिखित पायथन कथन का उपयोग करें -
In [19]: Y = data.iloc[:,0]कॉल करके इसकी सामग्री की जाँच करें head। नीचे दिया गया स्क्रीन आउटपुट परिणाम दिखाता है -
In [20]: Y.head()
Out[20]: 0 0
1 0
2 1
3 0
4 1
Name: y, dtype: int64अब, निम्नलिखित कमांड का उपयोग करके डेटा को विभाजित करें -
In [21]: X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)यह नामक चार सरणियों का निर्माण करेगा X_train, Y_train, X_test, and Y_test। पहले की तरह, आप हेड कमांड का उपयोग करके इन सरणियों की सामग्री की जांच कर सकते हैं। हम अपने मॉडल के प्रशिक्षण के लिए X_train और Y_train सरणियों का उपयोग करेंगे और परीक्षण और सत्यापन के लिए X_test और Y_test सरणियों का उपयोग करेंगे।
अब, हम अपना क्लासिफायर बनाने के लिए तैयार हैं। हम अगले अध्याय में इस पर गौर करेंगे।
यह आवश्यक नहीं है कि आपको स्क्रैच से क्लासिफायर का निर्माण करना होगा। बिल्डिंग क्लासीफायर जटिल है और इसके लिए कई क्षेत्रों जैसे सांख्यिकी, संभाव्यता सिद्धांत, अनुकूलन तकनीक और इतने पर ज्ञान की आवश्यकता होती है। बाजार में कई प्री-बिल्ट लाइब्रेरी उपलब्ध हैं, जिनका इन क्लासिफायरियर का पूरी तरह से परीक्षण और बहुत कुशल कार्यान्वयन है। हम इस तरह के एक पूर्व निर्मित मॉडल का उपयोग करेंगेsklearn।
Sklearn क्लासिफायरियर
स्केलेर टूलकिट से लॉजिस्टिक रिग्रेशन क्लासिफायर बनाना तुच्छ है और एकल कार्यक्रम स्टेटमेंट में दिखाया गया है -
In [22]: classifier = LogisticRegression(solver='lbfgs',random_state=0)एक बार क्लासिफायरियर बनने के बाद, आप अपने ट्रेनिंग डेटा को क्लासिफायर में फीड कर देंगे, ताकि वह अपने आंतरिक मापदंडों को ट्यून कर सके और आपके भविष्य के डेटा पर भविष्यवाणियों के लिए तैयार हो सके। क्लासिफायर को ट्यून करने के लिए, हम निम्नलिखित स्टेटमेंट चलाते हैं -
In [23]: classifier.fit(X_train, Y_train)क्लासिफायर अब परीक्षण के लिए तैयार है। निम्नलिखित कोड उपरोक्त दो कथनों के निष्पादन का आउटपुट है -
Out[23]: LogisticRegression(C = 1.0, class_weight = None, dual = False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2', random_state=0,
solver='lbfgs', tol=0.0001, verbose=0, warm_start=False))अब, हम बनाए गए क्लासिफ़ायर का परीक्षण करने के लिए तैयार हैं। हम अगले अध्याय में इससे निपटेंगे।
हम उपरोक्त बनाए गए क्लासिफायर का परीक्षण करने से पहले इसे उत्पादन उपयोग में डालते हैं। यदि परीक्षण से पता चलता है कि मॉडल वांछित सटीकता को पूरा नहीं करता है, तो हमें उपरोक्त प्रक्रिया में वापस जाना होगा, सुविधाओं के एक और सेट (डेटा फ़ील्ड) का चयन करें, फिर से मॉडल का निर्माण करें और इसका परीक्षण करें। यह तब तक चलने वाला कदम होगा जब तक कि क्लासिफायर वांछित सटीकता की आपकी आवश्यकता को पूरा नहीं करता। तो आइए हम अपने वर्गीकरण का परीक्षण करें।
टेस्ट डेटा की भविष्यवाणी करना
क्लासिफायर का परीक्षण करने के लिए, हम पहले चरण में उत्पन्न परीक्षण डेटा का उपयोग करते हैं। हम कहते हैंpredict निर्मित वस्तु पर विधि और पास X निम्न कमांड में दिखाए गए परीक्षण डेटा की सरणी -
In [24]: predicted_y = classifier.predict(X_test)यह एक्स ट्रे में प्रत्येक पंक्ति के लिए भविष्यवाणी देने वाले संपूर्ण प्रशिक्षण डेटा सेट के लिए एक एकल आयामी सरणी उत्पन्न करता है। आप निम्न कमांड का उपयोग करके इस सरणी की जांच कर सकते हैं -
In [25]: predicted_yनिम्नलिखित दो आदेशों के निष्पादन पर निम्नलिखित आउटपुट है -
Out[25]: array([0, 0, 0, ..., 0, 0, 0])आउटपुट इंगित करता है कि पहले और अंतिम तीन ग्राहक इसके लिए संभावित उम्मीदवार नहीं हैं Term Deposit। आप संभावित ग्राहकों को छाँटने के लिए संपूर्ण सरणी की जाँच कर सकते हैं। ऐसा करने के लिए, निम्नलिखित पायथन कोड स्निपेट का उपयोग करें -
In [26]: for x in range(len(predicted_y)):
if (predicted_y[x] == 1):
print(x, end="\t")उपरोक्त कोड चलाने का आउटपुट नीचे दिखाया गया है -

आउटपुट उन सभी पंक्तियों के अनुक्रमित को दिखाता है जो टीडी की सदस्यता के लिए संभावित उम्मीदवार हैं। अब आप इस आउटपुट को बैंक की मार्केटिंग टीम को दे सकते हैं जो चयनित पंक्ति में प्रत्येक ग्राहक के लिए संपर्क विवरण लेगी और अपनी नौकरी के साथ आगे बढ़ेगी।
इससे पहले कि हम इस मॉडल को उत्पादन में डाल दें, हमें भविष्यवाणी की सटीकता को सत्यापित करने की आवश्यकता है।
सटीकता का सत्यापन
मॉडल की सटीकता का परीक्षण करने के लिए, क्लासिफायर पर स्कोर विधि का उपयोग करें जैसा कि नीचे दिखाया गया है -
In [27]: print('Accuracy: {:.2f}'.format(classifier.score(X_test, Y_test)))इस कमांड को चलाने का स्क्रीन आउटपुट नीचे दिखाया गया है -
Accuracy: 0.90यह दर्शाता है कि हमारे मॉडल की सटीकता 90% है जिसे अधिकांश अनुप्रयोगों में बहुत अच्छा माना जाता है। इस प्रकार, आगे ट्यूनिंग की आवश्यकता नहीं है। अब, हमारा ग्राहक अगला अभियान चलाने के लिए तैयार है, संभावित ग्राहकों की सूची प्राप्त करें और सफलता की संभावित उच्च दर के साथ टीडी खोलने के लिए उनका पीछा करें।
जैसा कि आपने ऊपर के उदाहरण से देखा है, मशीन लर्निंग के लिए लॉजिस्टिक रिग्रेशन लागू करना कोई मुश्किल काम नहीं है। हालाँकि, यह अपनी सीमाओं के साथ आता है। लॉजिस्टिक प्रतिगमन बड़ी संख्या में श्रेणीबद्ध विशेषताओं को संभालने में सक्षम नहीं होगा। अब तक हमने जिस उदाहरण पर चर्चा की है, उसमें हमने बहुत हद तक सुविधाओं की संख्या कम कर दी है।
हालांकि, अगर ये विशेषताएं हमारी भविष्यवाणी में महत्वपूर्ण थीं, तो हम उन्हें शामिल करने के लिए मजबूर होंगे, लेकिन तब लॉजिस्टिक प्रतिगमन हमें एक अच्छी सटीकता देने में विफल होगा। लॉजिस्टिक रिग्रेशन भी ओवरफिटिंग की चपेट में है। इसे एक गैर-रैखिक समस्या पर लागू नहीं किया जा सकता है। यह स्वतंत्र चर के साथ खराब प्रदर्शन करेगा जो कि लक्ष्य से संबंधित नहीं हैं और एक दूसरे से संबंधित हैं। इस प्रकार, आपको उस समस्या के लिए लॉजिस्टिक प्रतिगमन की उपयुक्तता का सावधानीपूर्वक मूल्यांकन करना होगा जिसे आप हल करने का प्रयास कर रहे हैं।
मशीन लर्निंग के कई क्षेत्र हैं जहाँ अन्य तकनीकों को निर्दिष्ट किया जाता है। कुछ का नाम रखने के लिए, हमारे पास k- निकटतम पड़ोसी (kNN), रेखीय प्रतिगमन, सपोर्ट वेक्टर मशीनें (SVM), निर्णय पेड़, Naive Bayes जैसे एल्गोरिदम हैं। किसी विशेष मॉडल को अंतिम रूप देने से पहले, आपको इन विभिन्न तकनीकों की प्रयोज्यता का मूल्यांकन करना होगा जिस समस्या को हम हल करने का प्रयास कर रहे हैं।
लॉजिस्टिक रिग्रेशन बाइनरी वर्गीकरण की एक सांख्यिकीय तकनीक है। इस ट्यूटोरियल में, आपने सीखा कि लॉजिस्टिक रिग्रेशन का उपयोग करने के लिए मशीन को कैसे प्रशिक्षित किया जाए। मशीन लर्निंग मॉडल बनाना, सबसे महत्वपूर्ण आवश्यकता डेटा की उपलब्धता है। पर्याप्त और प्रासंगिक डेटा के बिना, आप बस सीखने की मशीन नहीं बना सकते।
आपके पास डेटा होने के बाद, आपका अगला प्रमुख कार्य डेटा को साफ़ करना, अवांछित पंक्तियों, फ़ील्ड्स को समाप्त करना और आपके मॉडल विकास के लिए उपयुक्त फ़ील्ड का चयन करना है। ऐसा करने के बाद, आपको डेटा को उसके प्रशिक्षण के लिए क्लासिफायर द्वारा आवश्यक प्रारूप में मैप करना होगा। इस प्रकार, किसी भी मशीन लर्निंग एप्लिकेशन में डेटा तैयार करना एक प्रमुख कार्य है। एक बार जब आप डेटा के साथ तैयार हो जाते हैं, तो आप एक विशेष प्रकार के क्लासिफायरियर का चयन कर सकते हैं।
इस ट्यूटोरियल में आपने सीखा कि किस तरह से लॉजिस्टिक रिग्रेशन क्लासिफायर का उपयोग किया जाता है sklearnपुस्तकालय। क्लासिफायर को प्रशिक्षित करने के लिए, हम मॉडल के प्रशिक्षण के लिए लगभग 70% डेटा का उपयोग करते हैं। हम परीक्षण के लिए शेष डेटा का उपयोग करते हैं। हम मॉडल की सटीकता का परीक्षण करते हैं। यदि यह स्वीकार्य सीमा के भीतर नहीं है, तो हम सुविधाओं के नए सेट का चयन करने के लिए वापस जाते हैं।
एक बार फिर, डेटा तैयार करने की पूरी प्रक्रिया का पालन करें, मॉडल को प्रशिक्षित करें, और इसका परीक्षण करें, जब तक कि आप इसकी सटीकता से संतुष्ट न हों। किसी भी मशीन लर्निंग प्रोजेक्ट को लेने से पहले, आपको कई प्रकार की तकनीकों के बारे में जानना और सीखना होगा, जिन्हें अब तक विकसित किया गया है और जिन्हें उद्योग में सफलतापूर्वक लागू किया गया है।