Algoritma Klasifikasi - Pohon Keputusan
Pengantar Pohon Keputusan
Secara umum, analisis pohon keputusan adalah alat pemodelan prediktif yang dapat diterapkan di banyak area. Pohon keputusan dapat dibangun dengan pendekatan algoritmik yang dapat membagi kumpulan data dengan cara yang berbeda berdasarkan kondisi yang berbeda. Decision tress adalah algoritma paling kuat yang termasuk dalam kategori algoritma yang diawasi.
Mereka dapat digunakan untuk tugas klasifikasi dan regresi. Dua entitas utama dari pohon adalah node keputusan, di mana datanya terpecah dan keluar, di mana kami mendapat hasil. Contoh pohon biner untuk memprediksi apakah seseorang bugar atau tidak bugar memberikan berbagai informasi seperti usia, kebiasaan makan dan kebiasaan olahraga, diberikan di bawah ini -
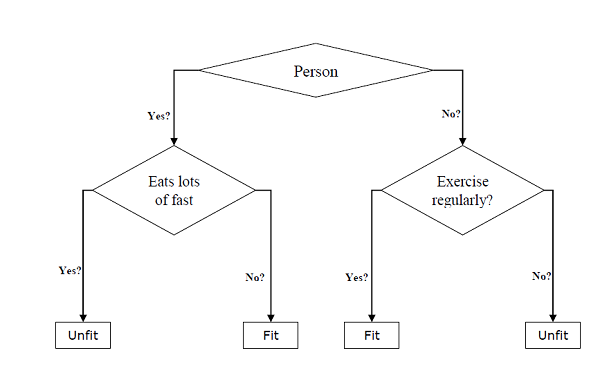
Pada pohon keputusan di atas, pertanyaannya adalah simpul keputusan dan hasil akhir adalah daun. Kami memiliki dua jenis pohon keputusan berikut -
Classification decision trees- Dalam pohon keputusan semacam ini, variabel keputusan bersifat kategorikal. Pohon keputusan di atas adalah contoh pohon keputusan klasifikasi.
Regression decision trees - Dalam pohon keputusan semacam ini, variabel keputusan bersifat kontinu.
Menerapkan Algoritma Pohon Keputusan
Indeks Gini
Ini adalah nama fungsi biaya yang digunakan untuk mengevaluasi pemisahan biner dalam kumpulan data dan bekerja dengan variabel target kategorial "Sukses" atau "Kegagalan".
Semakin tinggi nilai indeks Gini maka semakin tinggi homogenitasnya. Nilai indeks Gini yang sempurna adalah 0 dan yang terburuk adalah 0,5 (untuk masalah 2 kelas). Indeks Gini untuk perpecahan dapat dihitung dengan bantuan langkah-langkah berikut -
Pertama, hitung indeks Gini untuk sub-node dengan menggunakan rumus p ^ 2 + q ^ 2, yang merupakan jumlah kuadrat probabilitas untuk sukses dan gagal.
Selanjutnya, hitung indeks Gini untuk pemisahan menggunakan skor Gini terbobot dari setiap node dari pemisahan tersebut.
Algoritma Classification and Regression Tree (CART) menggunakan metode Gini untuk menghasilkan binary split.
Split Creation
Pemisahan pada dasarnya termasuk atribut dalam dataset dan nilai. Kita dapat membuat pemisahan dalam dataset dengan bantuan tiga bagian berikut -
Part1: Calculating Gini Score - Kami baru saja membahas bagian ini di bagian sebelumnya.
Part2: Splitting a dataset- Ini dapat didefinisikan sebagai memisahkan kumpulan data menjadi dua daftar baris yang memiliki indeks atribut dan nilai terpisah dari atribut itu. Setelah mendapatkan dua kelompok - kanan dan kiri, dari dataset tersebut, kita dapat menghitung nilai split dengan menggunakan skor Gini yang dihitung pada bagian pertama. Nilai pemisahan akan menentukan di grup mana atribut akan berada.
Part3: Evaluating all splits- Bagian selanjutnya setelah menemukan skor Gini dan dataset pemisahan adalah evaluasi semua perpecahan. Untuk tujuan ini, pertama, kita harus memeriksa setiap nilai yang terkait dengan setiap atribut sebagai kandidat pemisahan. Kemudian kita perlu menemukan pemisahan terbaik dengan mengevaluasi biaya pemisahan tersebut. Pembagian terbaik akan digunakan sebagai node di pohon keputusan.
Membangun Pohon
Seperti kita ketahui bahwa sebuah pohon memiliki simpul akar dan simpul terminal. Setelah membuat simpul akar, kita dapat membangun pohon dengan mengikuti dua bagian -
Part1: Pembuatan node terminal
Saat membuat node terminal dari pohon keputusan, satu poin penting adalah memutuskan kapan harus berhenti menumbuhkan pohon atau membuat node terminal lebih lanjut. Hal tersebut dapat dilakukan dengan menggunakan dua kriteria yaitu kedalaman pohon maksimum dan catatan simpul minimum sebagai berikut -
Maximum Tree Depth- Seperti namanya, ini adalah jumlah maksimum node di pohon setelah node root. Kita harus berhenti menambahkan node terminal setelah pohon mencapai kedalaman maksimum, yaitu setelah pohon mendapatkan jumlah node terminal maksimum.
Minimum Node Records- Ini dapat didefinisikan sebagai jumlah minimum pola pelatihan yang menjadi tanggung jawab node tertentu. Kita harus berhenti menambahkan node terminal setelah pohon mencapai catatan node minimum ini atau di bawah minimum ini.
Node terminal digunakan untuk membuat prediksi akhir.
Part2: Pemisahan Rekursif
Seperti yang kita pahami tentang kapan membuat simpul terminal, sekarang kita bisa mulai membangun pohon kita. Pemisahan rekursif adalah metode untuk membangun pohon. Dalam metode ini, setelah sebuah node dibuat, kita dapat membuat node anak (node ditambahkan ke node yang sudah ada) secara rekursif pada setiap grup data, dihasilkan dengan memisahkan dataset, dengan memanggil fungsi yang sama berulang kali.
Ramalan
Setelah membangun pohon keputusan, kita perlu membuat prediksi tentangnya. Pada dasarnya, prediksi melibatkan navigasi pohon keputusan dengan baris data yang disediakan secara khusus.
Kita bisa membuat prediksi dengan bantuan fungsi rekursif, seperti yang dilakukan di atas. Rutin prediksi yang sama dipanggil lagi dengan node kiri atau kanan anak.
Asumsi
Berikut ini adalah beberapa asumsi yang kami buat saat membuat pohon keputusan -
Saat menyiapkan pohon keputusan, set pelatihan adalah sebagai simpul akar.
Pengklasifikasi pohon keputusan lebih menyukai nilai fitur menjadi kategorikal. Jika Anda ingin menggunakan nilai kontinu maka nilai tersebut harus dilakukan secara diskrit sebelum pembuatan model.
Berdasarkan nilai atribut, record didistribusikan secara rekursif.
Pendekatan statistik akan digunakan untuk menempatkan atribut pada posisi node manapun yaitu sebagai node root atau node internal.
Implementasi dengan Python
Contoh
Dalam contoh berikut, kami akan mengimplementasikan pengklasifikasi Pohon Keputusan pada Pima Indian Diabetes -
Pertama, mulailah dengan mengimpor paket python yang diperlukan -
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_splitSelanjutnya, unduh dataset iris dari tautan webnya sebagai berikut -
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
pima = pd.read_csv(r"C:\pima-indians-diabetes.csv", header=None, names=col_names)
pima.head()pregnant glucose bp skin insulin bmi pedigree age label
0 6 148 72 35 0 33.6 0.627 50 1
1 1 85 66 29 0 26.6 0.351 31 0
2 8 183 64 0 0 23.3 0.672 32 1
3 1 89 66 23 94 28.1 0.167 21 0
4 0 137 40 35 168 43.1 2.288 33 1Sekarang, pisahkan dataset menjadi fitur dan variabel target sebagai berikut -
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # Features
y = pima.label # Target variableSelanjutnya kita akan membagi data menjadi train and test split. Kode berikut akan membagi dataset menjadi 70% data pelatihan dan 30% data pengujian -
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)Selanjutnya, latih model dengan bantuan kelas DecisionTreeClassifier dari sklearn sebagai berikut -
clf = DecisionTreeClassifier()
clf = clf.fit(X_train,y_train)Akhirnya kita perlu membuat prediksi. Itu dapat dilakukan dengan bantuan skrip berikut -
y_pred = clf.predict(X_test)Selanjutnya, kita bisa mendapatkan skor akurasi, matriks kebingungan dan laporan klasifikasi sebagai berikut -
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)Keluaran
Confusion Matrix:
[[116 30]
[ 46 39]]
Classification Report:
precision recall f1-score support
0 0.72 0.79 0.75 146
1 0.57 0.46 0.51 85
micro avg 0.67 0.67 0.67 231
macro avg 0.64 0.63 0.63 231
weighted avg 0.66 0.67 0.66 231
Accuracy: 0.670995670995671Memvisualisasikan Pohon Keputusan
Pohon keputusan di atas dapat divisualisasikan dengan bantuan kode berikut -
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('Pima_diabetes_Tree.png')
Image(graph.create_png())