Algoritme Pengelompokan - Pengelompokan Hierarki
Pengantar Hierarchical Clustering
Pengelompokan hierarkis adalah algoritme pembelajaran tanpa pengawasan lainnya yang digunakan untuk mengelompokkan titik data tak berlabel yang memiliki karakteristik serupa. Algoritme pengelompokan hierarki terbagi dalam dua kategori berikut -
Agglomerative hierarchical algorithms- Dalam algoritme hierarki aglomeratif, setiap titik data diperlakukan sebagai satu cluster dan kemudian secara berturut-turut menggabungkan atau menggabungkan (pendekatan bottom-up) pasangan cluster. Hierarki cluster direpresentasikan sebagai dendrogram atau struktur pohon.
Divisive hierarchical algorithms - Di sisi lain, dalam algoritma hierarki pemecah belah, semua titik data diperlakukan sebagai satu cluster besar dan proses clustering melibatkan pembagian (pendekatan Top-down) satu cluster besar menjadi berbagai cluster kecil.
Langkah-langkah untuk Melakukan Agglomerative Hierarchical Clustering
Kami akan menjelaskan pengelompokan hierarki yang paling banyak digunakan dan penting yaitu aglomeratif. Langkah-langkah untuk melakukan hal yang sama adalah sebagai berikut -
Step 1- Perlakukan setiap titik data sebagai cluster tunggal. Oleh karena itu, kita akan memiliki, katakanlah kluster K di awal. Jumlah titik data juga akan menjadi K di awal.
Step 2- Sekarang, pada langkah ini kita perlu membentuk cluster besar dengan menggabungkan dua titik data lemari. Ini akan menghasilkan total cluster K-1.
Step 3- Sekarang, untuk membentuk lebih banyak cluster, kita perlu menggabungkan dua cluster lemari. Ini akan menghasilkan total cluster K-2.
Step 4 - Sekarang, untuk membentuk satu cluster besar ulangi tiga langkah di atas sampai K menjadi 0 yaitu tidak ada lagi titik data yang tersisa untuk digabungkan.
Step 5 - Akhirnya, setelah membuat satu cluster besar, dendrogram akan digunakan untuk membagi menjadi beberapa cluster tergantung pada masalahnya.
Peran Dendrogram dalam Agglomerative Hierarchical Clustering
Seperti yang telah kita bahas pada langkah terakhir, peran dendrogram dimulai setelah cluster besar terbentuk. Dendrogram akan digunakan untuk membagi cluster menjadi beberapa cluster titik data terkait tergantung pada masalah kita. Ini dapat dipahami dengan bantuan contoh berikut -
Contoh 1
Untuk memahami, mari kita mulai dengan mengimpor perpustakaan yang diperlukan sebagai berikut -
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as npSelanjutnya, kita akan memplot titik data yang telah kita ambil untuk contoh ini -
X = np.array([[7,8],[12,20],[17,19],[26,15],[32,37],[87,75],[73,85], [62,80],[73,60],[87,96],])
labels = range(1, 11)
plt.figure(figsize=(10, 7))
plt.subplots_adjust(bottom=0.1)
plt.scatter(X[:,0],X[:,1], label='True Position')
for label, x, y in zip(labels, X[:, 0], X[:, 1]):
plt.annotate(label,xy=(x, y), xytext=(-3, 3),textcoords='offset points', ha='right', va='bottom')
plt.show()
Dari diagram di atas, sangat mudah untuk melihat bahwa kita memiliki dua cluster di titik data tetapi di data dunia nyata, bisa ada ribuan cluster. Selanjutnya, kita akan merencanakan dendrogram titik data kita dengan menggunakan perpustakaan Scipy -
from scipy.cluster.hierarchy import dendrogram, linkage
from matplotlib import pyplot as plt
linked = linkage(X, 'single')
labelList = range(1, 11)
plt.figure(figsize=(10, 7))
dendrogram(linked, orientation='top',labels=labelList, distance_sort='descending',show_leaf_counts=True)
plt.show()
Sekarang, setelah cluster besar terbentuk, jarak vertikal terpanjang dipilih. Garis vertikal kemudian ditarik melaluinya seperti yang ditunjukkan pada diagram berikut. Saat garis horizontal melintasi garis biru di dua titik, jumlah cluster akan menjadi dua.

Selanjutnya, kita perlu mengimpor kelas untuk pengelompokan dan memanggil metode fit_predict untuk memprediksi kluster. Kami mengimpor kelas AgglomerativeClustering dari perpustakaan sklearn.cluster -
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
cluster.fit_predict(X)Selanjutnya, plot cluster dengan bantuan kode berikut -
plt.scatter(X[:,0],X[:,1], c=cluster.labels_, cmap='rainbow')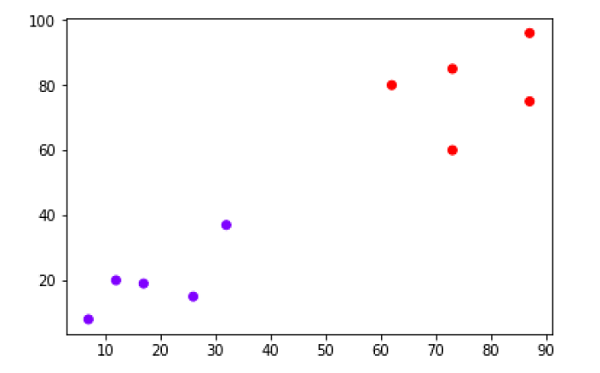
Diagram di atas menunjukkan dua cluster dari titik data kami.
Contoh2
Karena kita memahami konsep dendrogram dari contoh sederhana yang dibahas di atas, mari kita beralih ke contoh lain di mana kita membuat cluster titik data di Pima Indian Diabetes Dataset dengan menggunakan pengelompokan hierarkis -
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
import numpy as np
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
data.shape
(768, 9)
data.head()| slno. | preg | Plas | Pres | kulit | uji | massa | pedi | usia | kelas |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0,627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0,672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0,167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
patient_data = data.iloc[:, 3:5].values
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
plt.title("Patient Dendograms")
dend = shc.dendrogram(shc.linkage(data, method='ward'))
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward')
cluster.fit_predict(patient_data)
plt.figure(figsize=(10, 7))
plt.scatter(patient_data[:,0], patient_data[:,1], c=cluster.labels_, cmap='rainbow')