Penggalian & Ekstraksi Informasi
Apa itu Chunking?
Chunking, salah satu proses penting dalam pemrosesan bahasa alami, digunakan untuk mengidentifikasi part of speech (POS) dan frasa pendek. Dengan kata lain, dengan chunking kita bisa mendapatkan struktur kalimatnya. Itu juga disebutpartial parsing.
Pola dan celah potongan
Chunk patternsadalah pola tag part-of-speech (POS) yang menentukan jenis kata apa yang membentuk sebagian. Kita dapat mendefinisikan pola potongan dengan bantuan ekspresi reguler yang dimodifikasi.
Selain itu, kami juga dapat menentukan pola untuk jenis kata apa yang tidak boleh dalam potongan dan kata-kata yang tidak dipotong ini dikenal sebagai chinks.
Contoh implementasi
Pada contoh di bawah ini, beserta hasil parsing kalimat tersebut “the book has many chapters”, ada tata bahasa untuk frasa kata benda yang menggabungkan pola chunk dan chink -
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()Keluaran
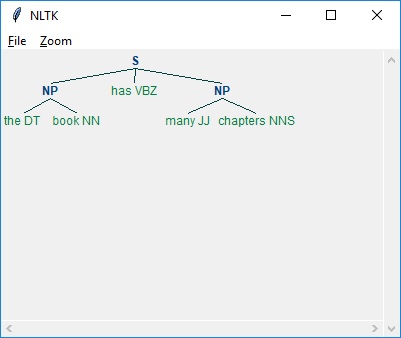
Seperti yang terlihat di atas, pola untuk menentukan potongan adalah dengan menggunakan kurung kurawal sebagai berikut -
{<DT><NN>}Dan untuk menentukan celah, kita dapat membalik kawat gigi seperti berikut -
}<VB>{.Sekarang, untuk tipe frase tertentu, aturan-aturan ini dapat digabungkan ke dalam tata bahasa.
Ekstraksi Informasi
Kami telah melalui taggers serta parser yang dapat digunakan untuk membangun mesin ekstraksi informasi. Mari kita lihat pipa ekstraksi informasi dasar -
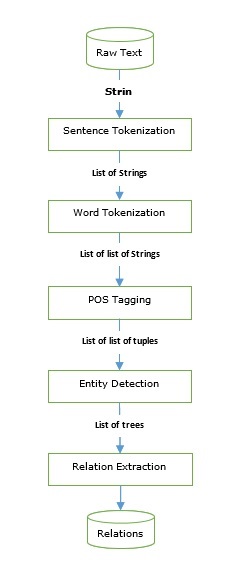
Ekstraksi informasi memiliki banyak aplikasi termasuk -
- Intelijen bisnis
- Lanjutkan panen
- Analisis media
- Deteksi sentimen
- Pencarian paten
- Pemindaian email
Pengakuan entitas bernama (NER)
Pengenalan entitas-bernama (NER) sebenarnya adalah cara untuk mengekstrak beberapa entitas yang paling umum seperti nama, organisasi, lokasi, dll. Mari kita lihat contoh yang mengambil semua langkah praproses seperti tokenisasi kalimat, penandaan POS, pemotongan, NER, dan mengikuti pipa yang disediakan pada gambar di atas.
Contoh
Import nltk
file = open (
# provide here the absolute path for the file of text for which we want NER
)
data_text = file.read()
sentences = nltk.sent_tokenize(data_text)
tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences]
for sent in tagged_sentences:
print nltk.ne_chunk(sent)Beberapa dari Named-entity recognition (NER) yang dimodifikasi juga dapat digunakan untuk mengekstrak entitas seperti nama produk, entitas bio-medis, nama merek, dan banyak lagi.
Ekstraksi hubungan
Ekstraksi relasi, operasi ekstraksi informasi lain yang umum digunakan, adalah proses mengekstraksi hubungan yang berbeda antara berbagai entitas. Mungkin ada hubungan yang berbeda seperti pewarisan, sinonim, analogi, dll., Yang definisinya tergantung pada kebutuhan informasi. Misalkan jika kita ingin mencari tulisan sebuah buku maka pengarangnya adalah hubungan antara nama penulis dan nama buku.
Contoh
Dalam contoh berikut, kami menggunakan pipeline IE yang sama, seperti yang ditunjukkan pada diagram di atas, yang kami gunakan hingga Named-entity relation (NER) dan memperluasnya dengan pola relasi berdasarkan tag NER.
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))Keluaran
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia']
[ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo']
[ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington']
[ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington']
[ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles']
[ORG: 'Open Text'] ', based in' [LOC: 'Waterloo']
[ORG: 'WGBH'] 'in' [LOC: 'Boston']
[ORG: 'Bastille Opera'] 'in' [LOC: 'Paris']
[ORG: 'Omnicom'] 'in' [LOC: 'New York']
[ORG: 'DDB Needham'] 'in' [LOC: 'New York']
[ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York']
[ORG: 'BBDO South'] 'in' [LOC: 'Atlanta']
[ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']Dalam kode di atas, kami telah menggunakan korpus inbuilt bernama ieer. Dalam korpus ini, kalimat diberi tag sampai relasi entitas-bernama (NER). Di sini kita hanya perlu menentukan pola relasi yang kita inginkan dan jenis NER yang ingin kita definisikan relasinya. Dalam contoh kami, kami mendefinisikan hubungan antara organisasi dan lokasi. Kami mengekstrak semua kombinasi pola ini.