Perangkat Bahasa Alami - Unigram Tagger
Apa itu Unigram Tagger?
Sesuai dengan namanya, unigram tagger adalah sebuah tagger yang hanya menggunakan satu kata sebagai konteksnya untuk menentukan tag POS (Part-of-Speech). Sederhananya, Unigram Tagger adalah sebuah tagger berbasis konteks yang konteksnya adalah satu kata, yaitu Unigram.
Bagaimana cara kerjanya?
NLTK menyediakan modul bernama UnigramTaggeruntuk tujuan ini. Tetapi sebelum mendalami cara kerjanya, mari kita pahami hierarki dengan bantuan diagram berikut -
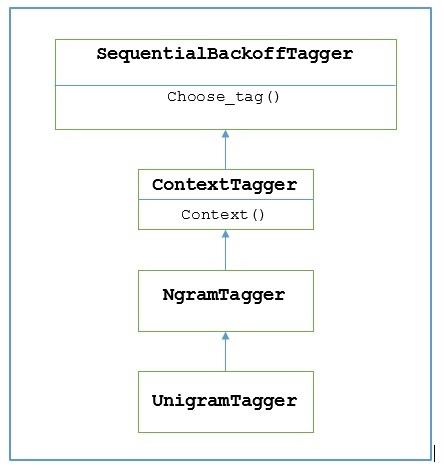
Dari diagram di atas, dapat dipahami bahwa UnigramTagger diwarisi dari NgramTagger yang merupakan subclass dari ContextTagger, yang diwarisi dari SequentialBackoffTagger.
Pekerjaan UnigramTagger dijelaskan dengan bantuan langkah-langkah berikut -
Seperti yang telah kita lihat, UnigramTagger mewarisi dari ContextTagger, itu mengimplementasikan a context()metode. Inicontext() metode mengambil tiga argumen yang sama seperti choose_tag() metode.
Hasil dari context()Metode akan menjadi token kata yang selanjutnya digunakan untuk membuat model. Setelah model dibuat, kata token juga digunakan untuk mencari tag terbaik.
Lewat sini, UnigramTagger akan membangun model konteks dari daftar kalimat yang diberi tag.
Melatih Unigram Tagger
NLTK UnigramTaggerdapat dilatih dengan memberikan daftar kalimat yang diberi tag pada saat inisialisasi. Pada contoh di bawah ini, kita akan menggunakan kalimat yang diberi tag dari treebank corpus. Kami akan menggunakan 2.500 kalimat pertama dari korpus itu.
Contoh
Pertama impor modul UniframTagger dari nltk -
from nltk.tag import UnigramTaggerSelanjutnya, impor korpus yang ingin Anda gunakan. Di sini kami menggunakan treebank corpus -
from nltk.corpus import treebankSekarang, ambillah kalimat untuk tujuan pelatihan. Kami mengambil 2.500 kalimat pertama untuk tujuan pelatihan dan akan menandainya -
train_sentences = treebank.tagged_sents()[:2500]Selanjutnya, terapkan UnigramTagger pada kalimat yang digunakan untuk tujuan pelatihan -
Uni_tagger = UnigramTagger(train_sentences)Ambil beberapa kalimat, baik sama dengan atau kurang diambil untuk tujuan pelatihan, yaitu 2500, untuk tujuan pengujian. Di sini kami mengambil 1500 pertama untuk tujuan pengujian -
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sents)Keluaran
0.8942306156033808Di sini, kami mendapatkan sekitar 89 persen akurasi untuk tagger yang menggunakan pencarian kata tunggal untuk menentukan tag POS.
Contoh implementasi lengkap
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Keluaran
0.8942306156033808Mengesampingkan model konteks
Dari diagram di atas menunjukkan hierarki untuk UnigramTagger, kami mengetahui semua pemberi tag yang diwarisi dari ContextTagger, alih-alih melatih sendiri, dapat mengambil model yang telah dibuat sebelumnya. Model yang dibuat sebelumnya ini hanyalah kamus Python yang memetakan kunci konteks ke sebuah tag. Dan untukUnigramTagger, kunci konteks adalah kata individual sedangkan untuk lainnya NgramTagger subclass, itu akan menjadi tupel.
Kita bisa mengganti model konteks ini dengan meneruskan model sederhana lainnya ke UnigramTaggerkelas alih-alih melewati set pelatihan. Biarkan kami memahaminya dengan bantuan contoh mudah di bawah ini -
Contoh
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])Keluaran
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]Karena model kami berisi 'Vinken' sebagai satu-satunya kunci konteks, Anda dapat mengamati dari output di atas bahwa hanya kata ini yang mendapat tag dan setiap kata lain memiliki None sebagai tag.
Menetapkan ambang frekuensi minimum
Untuk memutuskan tag mana yang paling mungkin untuk konteks tertentu, file ContextTaggerkelas menggunakan frekuensi kemunculan. Ini akan melakukannya secara default bahkan jika kata konteks dan tag muncul hanya sekali, tetapi kita dapat mengatur ambang frekuensi minimum dengan meneruskancutoff nilai ke UnigramTaggerkelas. Dalam contoh di bawah ini, kami meneruskan nilai cutoff dalam resep sebelumnya di mana kami melatih UnigramTagger -
Contoh
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences, cutoff = 4)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Keluaran
0.7357651629613641