Perangkat Bahasa Alami - Panduan Cepat
Apa itu Natural Language Processing (NLP)?
Metode komunikasi yang dengannya manusia dapat berbicara, membaca, dan menulis, adalah bahasa. Dengan kata lain, kita manusia dapat berpikir, membuat rencana, membuat keputusan dalam bahasa alami kita. Di sini pertanyaan besarnya adalah, di era kecerdasan buatan, pembelajaran mesin, dan pembelajaran mendalam, dapatkah manusia berkomunikasi dalam bahasa alami dengan komputer / mesin? Mengembangkan aplikasi NLP merupakan tantangan besar bagi kami karena komputer memerlukan data terstruktur, tetapi di sisi lain, ucapan manusia tidak terstruktur dan seringkali bersifat ambigu.
Bahasa alami adalah subbidang ilmu komputer, lebih khusus lagi AI, yang memungkinkan komputer / mesin untuk memahami, memproses, dan memanipulasi bahasa manusia. Dengan kata sederhana, NLP adalah cara mesin untuk menganalisis, memahami, dan memperoleh makna dari bahasa alami manusia seperti Hindi, Inggris, Prancis, Belanda, dll.
Bagaimana cara kerjanya?
Sebelum mendalami cara kerja NLP, kita harus memahami bagaimana manusia menggunakan bahasa. Setiap hari, kita manusia menggunakan ratusan atau ribuan kata dan manusia lain menafsirkannya dan menjawabnya sesuai. Ini komunikasi sederhana untuk manusia, bukan? Tapi kita tahu kata-kata berjalan jauh lebih dalam dari itu dan kita selalu mendapatkan konteks dari apa yang kita katakan dan bagaimana kita mengatakannya. Itu sebabnya kami dapat mengatakan daripada berfokus pada modulasi suara, NLP memang mengacu pada pola kontekstual.
Mari kita pahami dengan sebuah contoh -
Man is to woman as king is to what?
We can interpret it easily and answer as follows:
Man relates to king, so woman can relate to queen.
Hence the answer is Queen.Bagaimana manusia tahu arti kata apa? Jawaban atas pertanyaan ini adalah kita belajar melalui pengalaman kita. Tapi, bagaimana mesin / komputer mempelajari hal yang sama?
Biarkan kami memahaminya dengan mengikuti langkah-langkah mudah berikut -
Pertama, kita perlu memberi makan mesin dengan data yang cukup sehingga mesin dapat belajar dari pengalaman.
Kemudian mesin akan membuat vektor kata, dengan menggunakan algoritma pembelajaran mendalam, dari data yang kita masukkan sebelumnya serta dari data sekitarnya.
Kemudian dengan melakukan operasi aljabar sederhana pada vektor kata ini, mesin akan dapat memberikan jawaban sebagai manusia.
Komponen NLP
Diagram berikut mewakili komponen pemrosesan bahasa alami (NLP) -
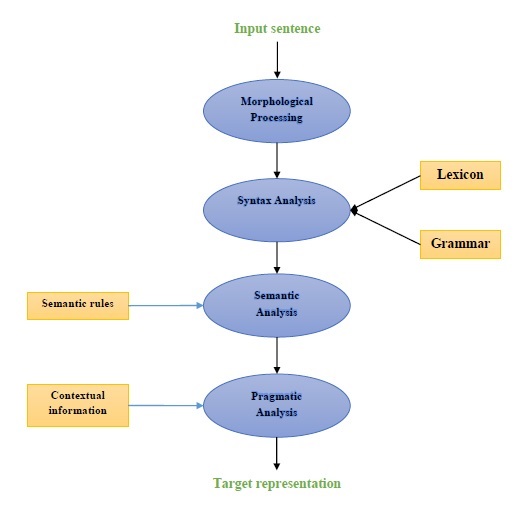
Pengolahan Morfologi
Pemrosesan morfologi adalah komponen pertama dari NLP. Ini termasuk memecah potongan masukan bahasa menjadi set token yang sesuai dengan paragraf, kalimat, dan kata. Misalnya, kata suka“everyday” dapat dipecah menjadi dua token sub-kata sebagai “every-day”.
Analisis sintaks
Analisis Sintaks, komponen kedua, adalah salah satu komponen terpenting NLP. Tujuan dari komponen ini adalah sebagai berikut -
Untuk memeriksa apakah kalimat terbentuk dengan baik atau tidak.
Untuk memecahnya menjadi struktur yang menunjukkan hubungan sintaksis antara kata-kata yang berbeda.
Misalnya kalimat seperti “The school goes to the student” akan ditolak oleh penganalisis sintaks.
Analisis semantik
Analisis Semantik adalah komponen ketiga dari NLP yang digunakan untuk memeriksa kebermaknaan teks. Ini termasuk menggambar makna yang tepat, atau kita bisa mengatakan arti kamus dari teks. Misalnya, kalimat seperti "Ini es krim panas". akan dibuang oleh penganalisis semantik.
Analisis pragmatis
Analisis pragmatis adalah komponen keempat dari NLP. Termasuk menyesuaikan objek atau peristiwa aktual yang ada di setiap konteks dengan referensi objek yang diperoleh dari komponen sebelumnya yaitu analisis semantik. Misalnya kalimat seperti“Put the fruits in the basket on the table” dapat memiliki dua interpretasi semantik sehingga penganalisis pragmatis akan memilih di antara dua kemungkinan ini.
Contoh Aplikasi NLP
NLP, teknologi baru, mendapatkan berbagai bentuk AI yang biasa kita lihat saat ini. Untuk aplikasi kognitif yang semakin meningkat hari ini dan besok, penggunaan NLP dalam menciptakan antarmuka yang mulus dan interaktif antara manusia dan mesin akan terus menjadi prioritas utama. Berikut adalah beberapa aplikasi NLP yang sangat berguna.
Mesin penerjemah
Terjemahan mesin (MT) adalah salah satu aplikasi terpenting dari pemrosesan bahasa alami. MT pada dasarnya adalah proses menerjemahkan satu bahasa sumber atau teks ke bahasa lain. Sistem terjemahan mesin dapat dalam dua bahasa atau multibahasa.
Memerangi Spam
Karena peningkatan besar dalam email yang tidak diinginkan, filter spam menjadi penting karena ini adalah garis pertahanan pertama melawan masalah ini. Dengan mempertimbangkan masalah positif palsu dan negatif palsu sebagai masalah utama, fungsionalitas NLP dapat digunakan untuk mengembangkan sistem penyaringan spam.
Pemodelan N-gram, Word Stemming dan klasifikasi Bayesian adalah beberapa model NLP yang ada yang dapat digunakan untuk penyaringan spam.
Pengambilan informasi & pencarian Web
Sebagian besar mesin pencari seperti Google, Yahoo, Bing, WolframAlpha, dll., Mendasarkan teknologi terjemahan mesin (MT) mereka pada model pembelajaran mendalam NLP. Model pembelajaran mendalam semacam itu memungkinkan algoritme untuk membaca teks di halaman web, menafsirkan maknanya, dan menerjemahkannya ke bahasa lain.
Peringkasan Teks Otomatis
Peringkasan teks otomatis adalah teknik yang membuat ringkasan pendek dan akurat dari dokumen teks yang lebih panjang. Karenanya, ini membantu kami mendapatkan informasi yang relevan dalam waktu yang lebih singkat. Di era digital ini, kita sangat membutuhkan peringkasan teks otomatis karena kita mendapatkan banjir informasi melalui internet yang tidak akan berhenti. NLP dan fungsinya memainkan peran penting dalam mengembangkan peringkasan teks otomatis.
Koreksi Tata Bahasa
Koreksi ejaan & koreksi tata bahasa adalah fitur yang sangat berguna dari perangkat lunak pengolah kata seperti Microsoft Word. Pemrosesan bahasa alami (NLP) banyak digunakan untuk tujuan ini.
Menjawab pertanyaan
Menjawab pertanyaan, aplikasi utama lain dari pemrosesan bahasa alami (NLP), berfokus pada membangun sistem yang secara otomatis menjawab pertanyaan yang dikirim oleh pengguna dalam bahasa alami mereka.
Analisis sentimen
Analisis sentimen adalah salah satu aplikasi penting lainnya dari pemrosesan bahasa alami (NLP). Sesuai dengan namanya, Analisis sentimen digunakan untuk -
Identifikasi sentimen di antara beberapa pos dan
Identifikasi sentimen di mana emosi tidak diekspresikan secara eksplisit.
Perusahaan E-commerce online seperti Amazon, ebay, dll., Menggunakan analisis sentimen untuk mengidentifikasi opini dan sentimen pelanggan mereka secara online. Ini akan membantu mereka memahami apa yang dipikirkan pelanggan tentang produk dan layanan mereka.
Mesin ucapan
Mesin ucapan seperti Siri, Google Voice, Alexa dibangun di atas NLP sehingga kita dapat berkomunikasi dengannya dalam bahasa alami kita.
Menerapkan NLP
Untuk membangun aplikasi yang disebutkan di atas, kita perlu memiliki keahlian khusus dengan pemahaman yang baik tentang bahasa dan alat untuk memproses bahasa secara efisien. Untuk mencapai ini, kami memiliki berbagai alat sumber terbuka yang tersedia. Beberapa di antaranya bersumber terbuka sementara yang lain dikembangkan oleh organisasi untuk membangun aplikasi NLP mereka sendiri. Berikut adalah daftar dari beberapa alat NLP -
Kit Alat Bahasa Alami (NLTK)
Mallet
GATE
Buka NLP
UIMA
Genism
Perangkat Stanford
Sebagian besar alat ini ditulis di Java.
Kit Alat Bahasa Alami (NLTK)
Di antara alat NLP yang disebutkan di atas, skor NLTK sangat tinggi dalam hal kemudahan penggunaan dan penjelasan konsep. Kurva belajar Python sangat cepat dan NLTK ditulis dengan Python sehingga NLTK juga memiliki perangkat pembelajaran yang sangat bagus. NLTK telah memasukkan sebagian besar tugas seperti tokenisasi, stemming, Lemmatization, Punctuation, Character Count, dan Word count. Ini sangat elegan dan mudah digunakan.
Untuk menginstal NLTK, kita harus menginstal Python di komputer kita. Anda dapat pergi ke link www.python.org/downloads dan pilih versi terbaru untuk OS Anda yaitu Windows, Mac dan Linux / Unix. Untuk tutorial dasar tentang Python, Anda dapat merujuk ke tautan www.tutorialspoint.com/python3/index.htm .
Sekarang, setelah Anda menginstal Python di sistem komputer Anda, beri tahu kami bagaimana kami dapat menginstal NLTK.
Menginstal NLTK
Kami dapat menginstal NLTK di berbagai OS sebagai berikut -
Di Windows
Untuk menginstal NLTK di OS Windows, ikuti langkah-langkah di bawah ini -
Pertama, buka command prompt Windows dan arahkan ke lokasi file pip map.
Selanjutnya, masukkan perintah berikut untuk menginstal NLTK -
pip3 install nltkSekarang, buka PythonShell dari Start Menu Windows dan ketik perintah berikut untuk memverifikasi instalasi NLTK -
Import nltkJika Anda tidak mendapatkan kesalahan, Anda telah berhasil menginstal NLTK di OS Windows Anda yang memiliki Python3.
Di Mac / Linux
Untuk menginstal NLTK di Mac / Linux OS, tulis perintah berikut -
sudo pip install -U nltkJika Anda tidak menginstal pip di komputer Anda, ikuti instruksi yang diberikan di bawah ini untuk menginstal pertama pip -
Pertama, perbarui indeks paket dengan mengikuti menggunakan perintah berikut -
sudo apt updateSekarang, ketik perintah berikut untuk menginstal pip untuk python 3 -
sudo apt install python3-pipMelalui Anaconda
Untuk menginstal NLTK melalui Anaconda, ikuti langkah-langkah di bawah ini -
Pertama, untuk menginstal Anaconda, buka link www.anaconda.com/distribution/#download-section lalu pilih versi Python yang perlu diinstal.
Setelah Anda memiliki Anaconda di sistem komputer Anda, buka prompt perintahnya dan tulis perintah berikut -
conda install -c anaconda nltk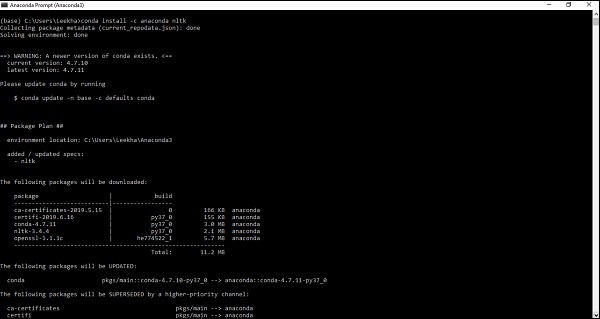
Anda perlu meninjau hasilnya dan memasukkan 'ya'. NLTK akan diunduh dan diinstal dalam paket Anaconda Anda.
Mengunduh Set Data dan Paket NLTK
Sekarang kami telah menginstal NLTK di komputer kami tetapi untuk menggunakannya kami perlu mengunduh kumpulan data (korpus) yang tersedia di dalamnya. Beberapa set data penting yang tersedia adalahstpwords, guntenberg, framenet_v15 dan seterusnya.
Dengan bantuan perintah berikut, kami dapat mengunduh semua kumpulan data NLTK -
import nltk
nltk.download()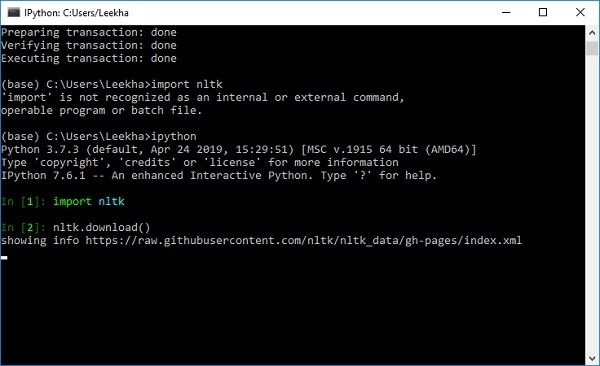
Anda akan mendapatkan jendela unduhan NLTK berikut.
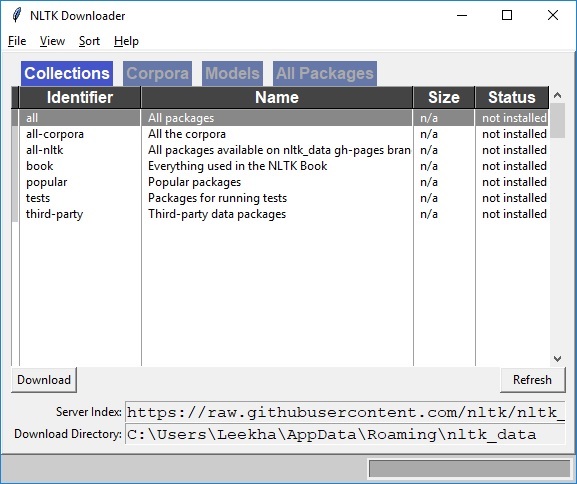
Sekarang, klik tombol unduh untuk mengunduh kumpulan data.
Bagaimana cara menjalankan skrip NLTK?
Berikut adalah contoh penerapan algoritma Porter Stemmer dengan menggunakan PorterStemmerkelas nltk. dengan contoh ini Anda akan dapat memahami cara menjalankan skrip NLTK.
Pertama, kita perlu mengimpor toolkit bahasa alami (nltk).
import nltkSekarang, impor file PorterStemmer kelas untuk mengimplementasikan algoritma Porter Stemmer.
from nltk.stem import PorterStemmerSelanjutnya, buat instance kelas Porter Stemmer sebagai berikut -
word_stemmer = PorterStemmer()Sekarang, masukkan kata yang ingin Anda batang. -
word_stemmer.stem('writing')Keluaran
'write'word_stemmer.stem('eating')Keluaran
'eat'Apa itu Tokenisasi?
Ini dapat didefinisikan sebagai proses memecah sepotong teks menjadi bagian-bagian yang lebih kecil, seperti kalimat dan kata. Bagian yang lebih kecil ini disebut token. Misalnya, kata adalah token dalam kalimat, dan kalimat adalah token dalam paragraf.
Seperti yang kita ketahui bahwa NLP digunakan untuk membangun aplikasi seperti analisis sentimen, sistem QA, terjemahan bahasa, chatbot pintar, sistem suara, dll., Oleh karena itu, untuk membangunnya, penting untuk memahami pola dalam teks. Token yang disebutkan di atas sangat berguna dalam menemukan dan memahami pola-pola ini. Tokenisasi dapat dianggap sebagai langkah dasar untuk resep lain seperti stemming dan lemmatisasi.
Paket NLTK
nltk.tokenize adalah paket yang disediakan oleh modul NLTK untuk mencapai proses tokenisasi.
Tokenisasi kalimat menjadi kata-kata
Memisahkan kalimat menjadi kata-kata atau membuat daftar kata dari string merupakan bagian penting dari setiap aktivitas pemrosesan teks. Mari kita pahami dengan bantuan berbagai fungsi / modul yang disediakan olehnltk.tokenize paket.
modul word_tokenize
word_tokenizemodul digunakan untuk tokenisasi kata dasar. Contoh berikut akan menggunakan modul ini untuk membagi kalimat menjadi kata-kata.
Contoh
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('Tutorialspoint.com provides high quality technical tutorials for free.')Keluaran
['Tutorialspoint.com', 'provides', 'high', 'quality', 'technical', 'tutorials', 'for', 'free', '.']Kelas TreebankWordTokenizer
word_tokenize modul, yang digunakan di atas pada dasarnya adalah fungsi pembungkus yang memanggil fungsi tokenize () sebagai turunan dari TreebankWordTokenizerkelas. Ini akan memberikan output yang sama seperti yang kita dapatkan saat menggunakan modul word_tokenize () untuk membagi kalimat menjadi kata. Mari kita lihat contoh yang sama yang diterapkan di atas -
Contoh
Pertama, kita perlu mengimpor toolkit bahasa alami (nltk).
import nltkSekarang, impor file TreebankWordTokenizer kelas untuk menerapkan algoritma tokenizer kata -
from nltk.tokenize import TreebankWordTokenizerSelanjutnya, buat instance kelas TreebankWordTokenizer sebagai berikut -
Tokenizer_wrd = TreebankWordTokenizer()Sekarang, masukkan kalimat yang ingin Anda ubah menjadi token -
Tokenizer_wrd.tokenize(
'Tutorialspoint.com provides high quality technical tutorials for free.'
)Keluaran
[
'Tutorialspoint.com', 'provides', 'high', 'quality',
'technical', 'tutorials', 'for', 'free', '.'
]Contoh implementasi lengkap
Mari kita lihat contoh implementasi lengkapnya di bawah ini
import nltk
from nltk.tokenize import TreebankWordTokenizer
tokenizer_wrd = TreebankWordTokenizer()
tokenizer_wrd.tokenize('Tutorialspoint.com provides high quality technical
tutorials for free.')Keluaran
[
'Tutorialspoint.com', 'provides', 'high', 'quality',
'technical', 'tutorials','for', 'free', '.'
]Ketentuan paling signifikan dari tokenizer adalah memisahkan kontraksi. Misalnya, jika kita menggunakan modul word_tokenize () untuk tujuan ini, itu akan memberikan output sebagai berikut -
Contoh
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('won’t')Keluaran
['wo', "n't"]]Konvensi semacam itu oleh TreebankWordTokenizertidak bisa diterima. Itu sebabnya kami memiliki dua alternatif kata tokenizers yaituPunktWordTokenizer dan WordPunctTokenizer.
Kelas WordPunktTokenizer
Tokenizer kata alternatif yang membagi semua tanda baca menjadi token terpisah. Mari kita pahami dengan contoh sederhana berikut -
Contoh
from nltk.tokenize import WordPunctTokenizer
tokenizer = WordPunctTokenizer()
tokenizer.tokenize(" I can't allow you to go home early")Keluaran
['I', 'can', "'", 't', 'allow', 'you', 'to', 'go', 'home', 'early']Tokenisasi teks menjadi kalimat
Pada bagian ini kita akan membagi teks / paragraf menjadi kalimat. NLTK menyediakansent_tokenize modul untuk tujuan ini.
Mengapa ini dibutuhkan?
Sebuah pertanyaan jelas yang muncul di benak kita adalah ketika kita memiliki kata tokenizer lalu mengapa kita membutuhkan tokenizer kalimat atau mengapa kita perlu mentokenisasi teks menjadi kalimat. Misalkan kita perlu menghitung kata rata-rata dalam kalimat, bagaimana kita bisa melakukan ini? Untuk menyelesaikan tugas ini, kita membutuhkan tokenisasi kalimat dan tokenisasi kata.
Mari kita pahami perbedaan antara kalimat dan kata tokenizer dengan bantuan contoh sederhana berikut -
Contoh
import nltk
from nltk.tokenize import sent_tokenize
text = "Let us understand the difference between sentence & word tokenizer.
It is going to be a simple example."
sent_tokenize(text)Keluaran
[
"Let us understand the difference between sentence & word tokenizer.",
'It is going to be a simple example.'
]Tokenisasi kalimat menggunakan ekspresi reguler
Jika Anda merasa bahwa keluaran dari kata tokenizer tidak dapat diterima dan ingin kontrol penuh atas cara membuat token teks, kami memiliki ekspresi reguler yang dapat digunakan saat melakukan tokenisasi kalimat. NLTK menyediakanRegexpTokenizer kelas untuk mencapai ini.
Mari kita pahami konsepnya dengan bantuan dua contoh di bawah ini.
Dalam contoh pertama kami akan menggunakan ekspresi reguler untuk mencocokkan token alfanumerik ditambah tanda kutip tunggal sehingga kami tidak membagi kontraksi seperti “won’t”.
Contoh 1
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer("[\w']+")
tokenizer.tokenize("won't is a contraction.")
tokenizer.tokenize("can't is a contraction.")Keluaran
["won't", 'is', 'a', 'contraction']
["can't", 'is', 'a', 'contraction']Dalam contoh pertama, kami akan menggunakan ekspresi reguler untuk membuat token di spasi.
Contoh 2
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = True)
tokenizer.tokenize("won't is a contraction.")Keluaran
["won't", 'is', 'a', 'contraction']Dari output di atas, kita dapat melihat bahwa tanda baca tetap ada di token. Parameter gaps = True berarti pola akan mengidentifikasi celah untuk dijadikan token. Sebaliknya, jika kita akan menggunakan parameter gaps = False maka pola tersebut akan digunakan untuk mengidentifikasi token yang dapat dilihat pada contoh berikut -
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = False)
tokenizer.tokenize("won't is a contraction.")Keluaran
[ ]Ini akan memberi kita keluaran kosong.
Mengapa melatih tokenizer kalimat sendiri?
Ini adalah pertanyaan yang sangat penting bahwa jika kita memiliki tokenizer kalimat default NLTK lalu mengapa kita perlu melatih tokenizer kalimat? Jawaban atas pertanyaan ini terletak pada kualitas tokenizer kalimat default NLTK. Tokenizer default NLTK pada dasarnya adalah tokenizer tujuan umum. Meskipun berfungsi dengan sangat baik tetapi ini mungkin bukan pilihan yang baik untuk teks tidak standar, mungkin teks kita, atau untuk teks yang memiliki format unik. Untuk membuat token teks semacam itu dan mendapatkan hasil terbaik, kita harus melatih tokenizer kalimat kita sendiri.
Contoh Implementasi
Untuk contoh ini, kami akan menggunakan korpus webtext. File teks yang akan kita gunakan dari korpus ini memiliki format teks seperti dialog yang ditunjukkan di bawah ini -
Guy: How old are you?
Hipster girl: You know, I never answer that question. Because to me, it's about
how mature you are, you know? I mean, a fourteen year old could be more mature
than a twenty-five year old, right? I'm sorry, I just never answer that question.
Guy: But, uh, you're older than eighteen, right?
Hipster girl: Oh, yeah.Kami telah menyimpan file teks ini dengan nama training_tokenizer. NLTK menyediakan kelas bernamaPunktSentenceTokenizerdengan bantuan yang bisa kita latih pada teks mentah untuk menghasilkan tokenizer kalimat khusus. Kita bisa mendapatkan teks mentah baik dengan membaca dalam file atau dari korpus NLTK menggunakanraw() metode.
Mari kita lihat contoh di bawah ini untuk mendapatkan lebih banyak wawasan tentangnya -
Pertama, impor PunktSentenceTokenizer kelas dari nltk.tokenize paket -
from nltk.tokenize import PunktSentenceTokenizerSekarang, impor webtext korpus dari nltk.corpus paket
from nltk.corpus import webtextSelanjutnya, dengan menggunakan raw() metode, dapatkan teks mentah dari training_tokenizer.txt mengajukan sebagai berikut -
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')Sekarang, buat instance PunktSentenceTokenizer dan cetak kalimat tokenisasi dari file teks sebagai berikut -
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])Keluaran
White guy: So, do you have any plans for this evening?
print(sents_1[1])
Output:
Asian girl: Yeah, being angry!
print(sents_1[670])
Output:
Guy: A hundred bucks?
print(sents_1[675])
Output:
Girl: But you already have a Big Mac...Contoh implementasi lengkap
from nltk.tokenize import PunktSentenceTokenizer
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])Keluaran
White guy: So, do you have any plans for this evening?Untuk memahami perbedaan antara tokenizer kalimat default NLTK dan tokenizer kalimat terlatih kita sendiri, mari kita membuat token file yang sama dengan tokenizer kalimat default yaitu sent_tokenize ().
from nltk.tokenize import sent_tokenize
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sents_2 = sent_tokenize(text)
print(sents_2[0])
Output:
White guy: So, do you have any plans for this evening?
print(sents_2[675])
Output:
Hobo: Y'know what I'd do if I was rich?Dengan bantuan perbedaan dalam output, kita dapat memahami konsep mengapa berguna untuk melatih tokenizer kalimat kita sendiri.
Apa itu stopwords?
Beberapa kata umum yang ada dalam teks tetapi tidak berkontribusi dalam arti kalimat. Kata-kata seperti itu sama sekali tidak penting untuk tujuan pencarian informasi atau pemrosesan bahasa alami. Kata sandi yang paling umum adalah 'the' dan 'a'.
Korpus stopwords NLTK
Sebenarnya, Natural Language Tool kit hadir dengan korpus stopword yang berisi daftar kata untuk banyak bahasa. Mari kita pahami penggunaannya dengan bantuan contoh berikut -
Pertama, impor kopus stopwords dari paket nltk.corpus -
from nltk.corpus import stopwordsSekarang, kami akan menggunakan stopwords dari Bahasa Inggris
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]Keluaran
['I', 'writer']Contoh implementasi lengkap
from nltk.corpus import stopwords
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]Keluaran
['I', 'writer']Menemukan daftar lengkap bahasa yang didukung
Dengan bantuan skrip Python berikut, kami juga dapat menemukan daftar lengkap bahasa yang didukung oleh NLTK stopwords corpus -
from nltk.corpus import stopwords
stopwords.fileids()Keluaran
[
'arabic', 'azerbaijani', 'danish', 'dutch', 'english', 'finnish', 'french',
'german', 'greek', 'hungarian', 'indonesian', 'italian', 'kazakh', 'nepali',
'norwegian', 'portuguese', 'romanian', 'russian', 'slovene', 'spanish',
'swedish', 'tajik', 'turkish'
]Apa itu Wordnet?
Wordnet adalah database leksikal bahasa Inggris yang besar, yang dibuat oleh Princeton. Ini adalah bagian dari korpus NLTK. Kata benda, kata kerja, kata sifat dan kata keterangan semuanya dikelompokkan ke dalam set synset, yaitu sinonim kognitif. Di sini setiap set synset mengungkapkan arti yang berbeda. Berikut adalah beberapa kasus penggunaan Wordnet -
- Ini dapat digunakan untuk mencari definisi sebuah kata
- Kita dapat menemukan sinonim dan antonim dari sebuah kata
- Hubungan dan persamaan kata dapat dieksplorasi menggunakan Wordnet
- Disambiguasi pengertian kata untuk kata-kata yang memiliki banyak kegunaan dan definisi
Bagaimana cara mengimpor Wordnet?
Wordnet dapat diimpor dengan bantuan perintah berikut -
from nltk.corpus import wordnetUntuk perintah yang lebih ringkas, gunakan yang berikut ini -
from nltk.corpus import wordnet as wnContoh sinkronisasi
Sinonim adalah pengelompokan kata-kata sinonim yang mengungkapkan konsep yang sama. Saat Anda menggunakan Wordnet untuk mencari kata, Anda akan mendapatkan daftar instance Synset.
wordnet.synsets (kata)
Untuk mendapatkan daftar Synsets, kita dapat mencari kata apapun di Wordnet dengan menggunakan wordnet.synsets(word). Misalnya, dalam resep Python berikutnya, kita akan mencari Synset untuk 'anjing' bersama dengan beberapa properti dan metode Synset -
Contoh
Pertama, impor wordnet sebagai berikut -
from nltk.corpus import wordnet as wnSekarang, berikan kata yang ingin Anda cari Synset-nya -
syn = wn.synsets('dog')[0]Di sini, kami menggunakan metode name () untuk mendapatkan nama unik untuk synset yang dapat digunakan untuk mendapatkan Synset secara langsung -
syn.name()
Output:
'dog.n.01'Selanjutnya, kita menggunakan metode definition () yang akan memberi kita definisi dari kata -
syn.definition()
Output:
'a member of the genus Canis (probably descended from the common wolf) that has
been domesticated by man since prehistoric times; occurs in many breeds'Metode lain adalah contoh () yang akan memberi kita contoh yang terkait dengan kata -
syn.examples()
Output:
['the dog barked all night']Contoh implementasi lengkap
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.name()
syn.definition()
syn.examples()Mendapatkan Hypernyms
Synsets diatur dalam struktur seperti pohon pewarisan Hypernyms mewakili istilah yang lebih abstrak sementara Hyponymsmewakili istilah yang lebih spesifik. Salah satu hal penting adalah bahwa pohon ini dapat ditelusuri hingga ke hypernym root. Mari kita pahami konsepnya dengan bantuan contoh berikut -
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()Keluaran
[Synset('canine.n.02'), Synset('domestic_animal.n.01')]Di sini, kita bisa melihat bahwa canine dan domestic_animal adalah hypernyms dari 'dog'.
Sekarang, kita dapat menemukan hiponim dari 'dog' sebagai berikut -
syn.hypernyms()[0].hyponyms()Keluaran
[
Synset('bitch.n.04'),
Synset('dog.n.01'),
Synset('fox.n.01'),
Synset('hyena.n.01'),
Synset('jackal.n.01'),
Synset('wild_dog.n.01'),
Synset('wolf.n.01')
]Dari output di atas, kita dapat melihat bahwa 'dog' hanyalah salah satu dari banyak hiponim 'domestic_animals'.
Untuk menemukan root dari semua ini, kita dapat menggunakan perintah berikut -
syn.root_hypernyms()Keluaran
[Synset('entity.n.01')]Dari keluaran di atas, kita dapat melihat bahwa ia hanya memiliki satu root.
Contoh implementasi lengkap
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()
syn.hypernyms()[0].hyponyms()
syn.root_hypernyms()Keluaran
[Synset('entity.n.01')]Lemma di Wordnet
Dalam ilmu linguistik, bentuk kanonik atau bentuk morfologi suatu kata disebut lemma. Untuk menemukan sinonim dan antonim dari sebuah kata, kita juga dapat mencari lemma di WordNet. Mari kita lihat caranya.
Menemukan Sinonim
Dengan menggunakan metode lemma (), kita dapat menemukan jumlah sinonim dari sebuah Synset. Mari kita terapkan metode ini pada synset 'dog' -
Contoh
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
lemmas = syn.lemmas()
len(lemmas)Keluaran
3Output di atas menunjukkan 'anjing' memiliki tiga lemma.
Mendapatkan nama lemma pertama sebagai berikut -
lemmas[0].name()
Output:
'dog'Mendapatkan nama lemma kedua sebagai berikut -
lemmas[1].name()
Output:
'domestic_dog'Mendapatkan nama lemma ketiga sebagai berikut -
lemmas[2].name()
Output:
'Canis_familiaris'Sebenarnya, Synset mewakili sekelompok lemma yang semuanya memiliki arti yang sama sementara lemma mewakili bentuk kata yang berbeda.
Menemukan Antonim
Di WordNet, beberapa lemma juga memiliki antonim. Misalnya, kata 'baik' memiliki total 27 sinet, di antaranya, 5 memiliki lemma dengan antonim. Mari kita cari antonimnya (ketika kata 'good' digunakan sebagai kata benda dan ketika kata 'good' digunakan sebagai kata sifat).
Contoh 1
from nltk.corpus import wordnet as wn
syn1 = wn.synset('good.n.02')
antonym1 = syn1.lemmas()[0].antonyms()[0]
antonym1.name()Keluaran
'evil'antonym1.synset().definition()Keluaran
'the quality of being morally wrong in principle or practice'Contoh di atas menunjukkan bahwa kata 'baik', bila digunakan sebagai kata benda, memiliki antonim pertama 'jahat'.
Contoh 2
from nltk.corpus import wordnet as wn
syn2 = wn.synset('good.a.01')
antonym2 = syn2.lemmas()[0].antonyms()[0]
antonym2.name()Keluaran
'bad'antonym2.synset().definition()Keluaran
'having undesirable or negative qualities’Contoh di atas menunjukkan bahwa kata 'baik', jika digunakan sebagai kata sifat, memiliki antonim pertama 'buruk'.
Apa itu Stemming?
Stemming adalah teknik yang digunakan untuk mengekstrak bentuk dasar kata dengan menghilangkan imbuhan darinya. Ini seperti menebang dahan pohon ke batangnya. Misalnya, akar kataeating, eats, eaten adalah eat.
Mesin pencari menggunakan stemming untuk mengindeks kata-kata. Itulah mengapa daripada menyimpan semua bentuk kata, mesin pencari hanya dapat menyimpan batangnya. Dengan cara ini, stemming mengurangi ukuran indeks dan meningkatkan akurasi pengambilan.
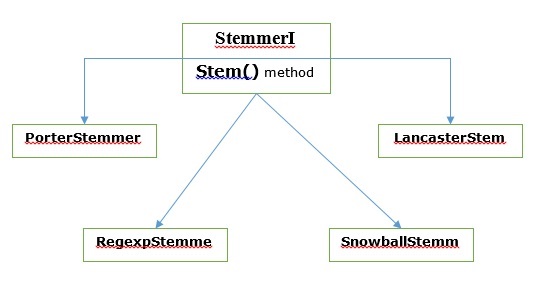
Berbagai algoritma Stemming
Di NLTK, stemmerI, yang memiliki stem()metode, antarmuka memiliki semua stemmer yang akan kita bahas selanjutnya. Mari kita pahami dengan diagram berikut
Algoritme stemming porter
Ini adalah salah satu algoritma stemming yang paling umum yang pada dasarnya dirancang untuk menghapus dan mengganti sufiks kata-kata bahasa Inggris yang terkenal.
Kelas PorterStemmer
NLTK memiliki PorterStemmerkelas dengan bantuan yang kita dapat dengan mudah menerapkan algoritma Porter Stemmer untuk kata yang ingin kita stem. Kelas ini mengetahui beberapa bentuk kata biasa dan sufiks dengan bantuan yang dapat mengubah kata masukan menjadi akar akhir. Akar yang dihasilkan seringkali merupakan kata yang lebih pendek yang memiliki arti akar yang sama. Mari kita lihat contohnya -
Pertama, kita perlu mengimpor toolkit bahasa alami (nltk).
import nltkSekarang, impor file PorterStemmer kelas untuk mengimplementasikan algoritma Porter Stemmer.
from nltk.stem import PorterStemmerSelanjutnya, buat instance kelas Porter Stemmer sebagai berikut -
word_stemmer = PorterStemmer()Sekarang, masukkan kata yang ingin Anda batang.
word_stemmer.stem('writing')Keluaran
'write'word_stemmer.stem('eating')Keluaran
'eat'Contoh implementasi lengkap
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('writing')Keluaran
'write'Algoritma stemming Lancaster
Ini dikembangkan di Lancaster University dan merupakan algoritma stemming yang sangat umum.
Kelas LancasterStemmer
NLTK memiliki LancasterStemmerkelas dengan bantuan yang kita dapat dengan mudah menerapkan algoritma Lancaster Stemmer untuk kata yang ingin kita stem. Mari kita lihat contohnya -
Pertama, kita perlu mengimpor toolkit bahasa alami (nltk).
import nltkSekarang, impor file LancasterStemmer kelas untuk mengimplementasikan algoritma Lancaster Stemmer
from nltk.stem import LancasterStemmerSelanjutnya, buat instance LancasterStemmer kelas sebagai berikut -
Lanc_stemmer = LancasterStemmer()Sekarang, masukkan kata yang ingin Anda batang.
Lanc_stemmer.stem('eats')Keluaran
'eat'Contoh implementasi lengkap
import nltk
from nltk.stem import LancatserStemmer
Lanc_stemmer = LancasterStemmer()
Lanc_stemmer.stem('eats')Keluaran
'eat'Algoritme stemming Ekspresi Reguler
Dengan bantuan algoritma stemming ini, kita dapat membuat stemmer kita sendiri.
Kelas RegexpStemmer
NLTK memiliki RegexpStemmerkelas dengan bantuan yang kita dapat dengan mudah menerapkan algoritma Regular Expression Stemmer. Ini pada dasarnya mengambil satu ekspresi reguler dan menghapus awalan atau sufiks yang cocok dengan ekspresi tersebut. Mari kita lihat contohnya -
Pertama, kita perlu mengimpor toolkit bahasa alami (nltk).
import nltkSekarang, impor file RegexpStemmer kelas untuk mengimplementasikan algoritma Regular Expression Stemmer.
from nltk.stem import RegexpStemmerSelanjutnya, buat instance RegexpStemmer kelas dan berikan sufiks atau awalan yang ingin Anda hapus dari kata sebagai berikut -
Reg_stemmer = RegexpStemmer(‘ing’)Sekarang, masukkan kata yang ingin Anda batang.
Reg_stemmer.stem('eating')Keluaran
'eat'Reg_stemmer.stem('ingeat')Keluaran
'eat'
Reg_stemmer.stem('eats')Keluaran
'eat'Contoh implementasi lengkap
import nltk
from nltk.stem import RegexpStemmer
Reg_stemmer = RegexpStemmer()
Reg_stemmer.stem('ingeat')Keluaran
'eat'Algoritma stemming bola salju
Ini adalah algoritma stemming yang sangat berguna.
Kelas SnowballStemmer
NLTK memiliki SnowballStemmerkelas dengan bantuan yang kita dapat dengan mudah menerapkan algoritma Snowball Stemmer. Ini mendukung 15 bahasa non-Inggris. Untuk menggunakan kelas pengukusan ini, kita perlu membuat sebuah instance dengan nama bahasa yang kita gunakan dan kemudian memanggil metode stem (). Mari kita lihat contohnya -
Pertama, kita perlu mengimpor toolkit bahasa alami (nltk).
import nltkSekarang, impor file SnowballStemmer kelas untuk mengimplementasikan algoritma Snowball Stemmer
from nltk.stem import SnowballStemmerMari kita lihat bahasa yang didukungnya -
SnowballStemmer.languagesKeluaran
(
'arabic',
'danish',
'dutch',
'english',
'finnish',
'french',
'german',
'hungarian',
'italian',
'norwegian',
'porter',
'portuguese',
'romanian',
'russian',
'spanish',
'swedish'
)Selanjutnya, buat instance kelas SnowballStemmer dengan bahasa yang ingin Anda gunakan. Di sini, kami membuat stemmer untuk bahasa 'Prancis'.
French_stemmer = SnowballStemmer(‘french’)Sekarang, panggil metode stem () dan masukkan kata yang ingin Anda stem.
French_stemmer.stem (‘Bonjoura’)Keluaran
'bonjour'Contoh implementasi lengkap
import nltk
from nltk.stem import SnowballStemmer
French_stemmer = SnowballStemmer(‘french’)
French_stemmer.stem (‘Bonjoura’)Keluaran
'bonjour'Apa itu lemmatisasi?
Teknik lemmatisasi seperti stemming. Output yang akan kita dapatkan setelah lemmatization disebut 'lemma', yang merupakan kata dasar daripada akar kata, keluaran dari stemming. Setelah lemmatisasi, kita akan mendapatkan kata yang valid yang artinya sama.
NLTK menyediakan WordNetLemmatizer kelas yang merupakan pembungkus tipis di sekitar wordnetkorpus. Kelas ini menggunakanmorphy() berfungsi ke WordNet CorpusReaderkelas untuk menemukan lemma. Mari kita pahami dengan sebuah contoh -
Contoh
Pertama, kita perlu mengimpor toolkit bahasa alami (nltk).
import nltkSekarang, impor file WordNetLemmatizer kelas untuk menerapkan teknik lemmatization.
from nltk.stem import WordNetLemmatizerSelanjutnya, buat instance WordNetLemmatizer kelas.
lemmatizer = WordNetLemmatizer()Sekarang, panggil metode lemmatize () dan masukkan kata yang ingin Anda temukan lemma.
lemmatizer.lemmatize('eating')Keluaran
'eating'lemmatizer.lemmatize('books')Keluaran
'book'Contoh implementasi lengkap
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('books')Keluaran
'book'Perbedaan antara Stemming & Lemmatization
Mari kita pahami perbedaan antara Stemming dan Lemmatization dengan bantuan contoh berikut -
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('believes')Keluaran
believimport nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize(' believes ')Keluaran
believOutput dari kedua program menunjukkan perbedaan utama antara stemming dan lemmatization. PorterStemmerkelas memotong 'es' dari kata. Di samping itu,WordNetLemmatizerkelas menemukan kata yang valid. Secara sederhana, teknik stemming hanya melihat pada bentuk kata sedangkan teknik lemmatisasi melihat pada arti kata tersebut. Artinya setelah menerapkan lemmatisasi, kita akan selalu mendapatkan kata yang valid.
Stemming dan lemmatization dapat dianggap sebagai semacam kompresi linguistik. Dalam pengertian yang sama, penggantian kata dapat dianggap sebagai normalisasi teks atau koreksi kesalahan.
Tetapi mengapa kami membutuhkan penggantian kata? Misalkan jika kita berbicara tentang tokenisasi, maka itu mengalami masalah dengan kontraksi (seperti tidak bisa, tidak mau, dll.). Jadi, untuk menangani masalah seperti itu kita membutuhkan penggantian kata. Misalnya, kita dapat mengganti kontraksi dengan bentuknya yang diperluas.
Penggantian kata menggunakan ekspresi reguler
Pertama, kami akan mengganti kata-kata yang cocok dengan ekspresi reguler. Tetapi untuk ini kita harus memiliki pemahaman dasar tentang ekspresi reguler serta modul ulang python. Pada contoh di bawah ini, kita akan mengganti kontraksi dengan bentuk yang diperluas (misalnya “tidak bisa” akan diganti dengan “tidak bisa”), semua itu dengan menggunakan ekspresi reguler.
Contoh
Pertama, impor kembali paket yang diperlukan untuk bekerja dengan ekspresi reguler.
import re
from nltk.corpus import wordnetSelanjutnya, tentukan pola penggantian pilihan Anda sebagai berikut -
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]Sekarang, buat kelas yang dapat digunakan untuk mengganti kata -
class REReplacer(object):
def __init__(self, pattern = R_patterns):
self.pattern = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.pattern:
s = re.sub(pattern, repl, s)
return sSimpan program python ini (katakanlah repRE.py) dan jalankan dari command prompt python. Setelah menjalankannya, impor kelas REReplacer ketika Anda ingin mengganti kata. Mari kita lihat caranya.
from repRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")
Output:
'I will not do it'
rep_word.replace("I can’t do it")
Output:
'I cannot do it'Contoh implementasi lengkap
import re
from nltk.corpus import wordnet
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]
class REReplacer(object):
def __init__(self, patterns=R_patterns):
self.patterns = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.patterns:
s = re.sub(pattern, repl, s)
return sSekarang setelah Anda menyimpan program di atas dan menjalankannya, Anda dapat mengimpor kelas dan menggunakannya sebagai berikut -
from replacerRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")Keluaran
'I will not do it'Penggantian sebelum pemrosesan teks
Salah satu praktik umum saat bekerja dengan pemrosesan bahasa alami (NLP) adalah membersihkan teks sebelum pemrosesan teks. Dalam perhatian ini kita juga bisa menggunakan fileREReplacer kelas yang dibuat di atas pada contoh sebelumnya, sebagai langkah awal sebelum pemrosesan teks yaitu tokenisasi.
Contoh
from nltk.tokenize import word_tokenize
from replacerRE import REReplacer
rep_word = REReplacer()
word_tokenize("I won't be able to do this now")
Output:
['I', 'wo', "n't", 'be', 'able', 'to', 'do', 'this', 'now']
word_tokenize(rep_word.replace("I won't be able to do this now"))
Output:
['I', 'will', 'not', 'be', 'able', 'to', 'do', 'this', 'now']Dalam resep Python di atas, kita dapat dengan mudah memahami perbedaan antara keluaran kata tokenizer tanpa dan dengan menggunakan ganti ekspresi reguler.
Penghapusan karakter berulang
Apakah kita ketat gramatikal dalam bahasa sehari-hari kita? Tidak, bukan kami. Misalnya, terkadang kita menulis 'Hiiiiiiiiiiii Mohan' untuk menekankan kata 'Hi'. Tetapi sistem komputer tidak mengetahui bahwa 'Hiiiiiiiiiiii' adalah variasi dari kata “Hi”. Pada contoh di bawah ini, kami akan membuat kelas bernamarep_word_removal yang dapat digunakan untuk menghapus kata-kata yang berulang.
Contoh
Pertama, impor kembali paket yang diperlukan untuk bekerja dengan ekspresi reguler
import re
from nltk.corpus import wordnetSekarang, buat kelas yang dapat digunakan untuk menghapus kata-kata yang berulang -
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
repl_word = self.repeat_regexp.sub(self.repl, word)
if repl_word != word:
return self.replace(repl_word)
else:
return repl_wordSimpan program python ini (katakan removalrepeat.py) dan jalankan dari prompt perintah python. Setelah menjalankannya, imporRep_word_removalkelas ketika Anda ingin menghapus kata-kata yang berulang. Mari kita lihat bagaimana caranya?
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")
Output:
'Hi'
rep_word.replace("Hellooooooooooooooo")
Output:
'Hello'Contoh implementasi lengkap
import re
from nltk.corpus import wordnet
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
replace_word = self.repeat_regexp.sub(self.repl, word)
if replace_word != word:
return self.replace(replace_word)
else:
return replace_wordSekarang setelah Anda menyimpan program di atas dan menjalankannya, Anda dapat mengimpor kelas dan menggunakannya sebagai berikut -
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")Keluaran
'Hi'Mengganti kata dengan sinonim umum
Saat bekerja dengan NLP, terutama dalam kasus analisis frekuensi dan pengindeksan teks, selalu bermanfaat untuk mengompresi kosakata tanpa kehilangan artinya karena menghemat banyak memori. Untuk mencapai ini, kita harus mendefinisikan pemetaan kata ke sinonimnya. Pada contoh di bawah ini, kami akan membuat kelas bernamaword_syn_replacer yang dapat digunakan untuk mengganti kata-kata dengan sinonim umumnya.
Contoh
Pertama, impor paket yang diperlukan re untuk bekerja dengan ekspresi reguler.
import re
from nltk.corpus import wordnetSelanjutnya, buat kelas yang menggunakan pemetaan penggantian kata -
class word_syn_replacer(object):
def __init__(self, word_map):
self.word_map = word_map
def replace(self, word):
return self.word_map.get(word, word)Simpan program python ini (katakanlah replacesyn.py) dan jalankan dari command prompt python. Setelah menjalankannya, imporword_syn_replacerkelas ketika Anda ingin mengganti kata-kata dengan sinonim umum. Mari kita lihat caranya.
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)Keluaran
'birthday'Contoh implementasi lengkap
import re
from nltk.corpus import wordnet
class word_syn_replacer(object):
def __init__(self, word_map):
self.word_map = word_map
def replace(self, word):
return self.word_map.get(word, word)Sekarang setelah Anda menyimpan program di atas dan menjalankannya, Anda dapat mengimpor kelas dan menggunakannya sebagai berikut -
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)Keluaran
'birthday'Kerugian dari metode di atas adalah kita harus melakukan hardcode sinonim dalam kamus Python. Kami memiliki dua alternatif yang lebih baik dalam bentuk file CSV dan YAML. Kami dapat menyimpan kosakata sinonim kami di salah satu file yang disebutkan di atas dan dapat membuatnyaword_mapkamus dari mereka. Mari kita pahami konsepnya dengan bantuan contoh.
Menggunakan file CSV
Untuk menggunakan file CSV untuk tujuan ini, file harus memiliki dua kolom, kolom pertama berisi kata dan kolom kedua berisi sinonim yang dimaksudkan untuk menggantikannya. Biarkan kami menyimpan file ini sebagaisyn.csv. Pada contoh di bawah ini, kami akan membuat kelas bernama CSVword_syn_replacer yang akan meluas word_syn_replacer di replacesyn.py file dan akan digunakan untuk membuat file word_map kamus dari syn.csv mengajukan.
Contoh
Pertama, impor paket yang diperlukan.
import csvSelanjutnya, buat kelas yang menggunakan pemetaan penggantian kata -
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)Setelah menjalankannya, impor CSVword_syn_replacerkelas ketika Anda ingin mengganti kata-kata dengan sinonim umum. Mari kita lihat bagaimana caranya?
from replacesyn import CSVword_syn_replacer
rep_syn = CSVword_syn_replacer (‘syn.csv’)
rep_syn.replace(‘bday’)Keluaran
'birthday'Contoh implementasi lengkap
import csv
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)Sekarang setelah Anda menyimpan program di atas dan menjalankannya, Anda dapat mengimpor kelas dan menggunakannya sebagai berikut -
from replacesyn import CSVword_syn_replacer
rep_syn = CSVword_syn_replacer (‘syn.csv’)
rep_syn.replace(‘bday’)Keluaran
'birthday'Menggunakan file YAML
Karena kami telah menggunakan file CSV, kami juga dapat menggunakan file YAML untuk tujuan ini (kami harus menginstal PyYAML). Biarkan kami menyimpan file sebagaisyn.yaml. Pada contoh di bawah ini, kami akan membuat kelas bernama YAMLword_syn_replacer yang akan meluas word_syn_replacer di replacesyn.py file dan akan digunakan untuk membuat file word_map kamus dari syn.yaml mengajukan.
Contoh
Pertama, impor paket yang diperlukan.
import yamlSelanjutnya, buat kelas yang menggunakan pemetaan penggantian kata -
class YAMLword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = yaml.load(open(fname))
super(YamlWordReplacer, self).__init__(word_map)Setelah menjalankannya, impor YAMLword_syn_replacerkelas ketika Anda ingin mengganti kata-kata dengan sinonim umum. Mari kita lihat bagaimana caranya?
from replacesyn import YAMLword_syn_replacer
rep_syn = YAMLword_syn_replacer (‘syn.yaml’)
rep_syn.replace(‘bday’)Keluaran
'birthday'Contoh implementasi lengkap
import yaml
class YAMLword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = yaml.load(open(fname))
super(YamlWordReplacer, self).__init__(word_map)Sekarang setelah Anda menyimpan program di atas dan menjalankannya, Anda dapat mengimpor kelas dan menggunakannya sebagai berikut -
from replacesyn import YAMLword_syn_replacer
rep_syn = YAMLword_syn_replacer (‘syn.yaml’)
rep_syn.replace(‘bday’)Keluaran
'birthday'Penggantian antonim
Seperti kita ketahui bahwa antonim adalah kata yang memiliki arti berlawanan dengan kata lain, dan kebalikan dari pengganti sinonim disebut dengan pengganti antonim. Pada bagian ini, kita akan berurusan dengan penggantian antonim, yaitu mengganti kata-kata dengan antonim yang tidak ambigu dengan menggunakan WordNet. Pada contoh di bawah ini, kami akan membuat kelas bernamaword_antonym_replacer yang memiliki dua metode, satu untuk mengganti kata dan lainnya untuk menghilangkan negasi.
Contoh
Pertama, impor paket yang diperlukan.
from nltk.corpus import wordnetSelanjutnya, buat kelas bernama word_antonym_replacer -
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsSimpan program python ini (katakan replaceantonym.py) dan jalankan dari prompt perintah python. Setelah menjalankannya, imporword_antonym_replacerkelas ketika Anda ingin mengganti kata dengan antonim yang tidak ambigu. Mari kita lihat caranya.
from replacerantonym import word_antonym_replacer
rep_antonym = word_antonym_replacer ()
rep_antonym.replace(‘uglify’)Keluaran
['beautify'']
sentence = ["Let us", 'not', 'uglify', 'our', 'country']
rep_antonym.replace _negations(sentence)Keluaran
["Let us", 'beautify', 'our', 'country']Contoh implementasi lengkap
nltk.corpus import wordnet
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsSekarang setelah Anda menyimpan program di atas dan menjalankannya, Anda dapat mengimpor kelas dan menggunakannya sebagai berikut -
from replacerantonym import word_antonym_replacer
rep_antonym = word_antonym_replacer ()
rep_antonym.replace(‘uglify’)
sentence = ["Let us", 'not', 'uglify', 'our', 'country']
rep_antonym.replace _negations(sentence)Keluaran
["Let us", 'beautify', 'our', 'country']Apa itu corpus?
Korpus adalah kumpulan besar, dalam format terstruktur, teks yang dapat dibaca mesin yang telah diproduksi dalam pengaturan komunikatif alami. Kata Corpora adalah bentuk jamak dari Corpus. Corpus dapat diturunkan dengan berbagai cara sebagai berikut -
- Dari teks yang aslinya elektronik
- Dari transkrip bahasa lisan
- Dari pengenalan karakter optik dan sebagainya
Corpus Representativeness, Corpus Balance, Sampling, Corpus Size merupakan elemen yang memegang peranan penting dalam mendesain corpus. Beberapa corpus paling populer untuk tugas NLP adalah TreeBank, PropBank, VarbNet dan WordNet.
Bagaimana cara membangun korpus khusus?
Saat mengunduh NLTK, kami juga menginstal paket data NLTK. Jadi, kami sudah menginstal paket data NLTK di komputer kami. Jika kita berbicara tentang Windows, kita akan menganggap bahwa paket data ini diinstal diC:\natural_language_toolkit_data dan jika kita berbicara tentang Linux, Unix dan Mac OS X, kita akan berasumsi bahwa paket data ini diinstal di /usr/share/natural_language_toolkit_data.
Dalam resep Python berikut, kita akan membuat corpora khusus yang harus berada dalam salah satu jalur yang ditentukan oleh NLTK. Karena dapat ditemukan oleh NLTK. Untuk menghindari konflik dengan paket data NLTK resmi, mari kita buat direktori natural_language_toolkit_data kustom di direktori home kita.
import os, os.path
path = os.path.expanduser('~/natural_language_toolkit_data')
if not os.path.exists(path):
os.mkdir(path)
os.path.exists(path)Keluaran
TrueSekarang, Mari kita periksa apakah kita memiliki direktori natural_language_toolkit_data di direktori home kita atau tidak -
import nltk.data
path in nltk.data.pathKeluaran
TrueKarena kita sudah mendapatkan output True, berarti kita punya nltk_data direktori di direktori home kami.
Sekarang kita akan membuat file daftar kata, bernama wordfile.txt dan taruh di folder bernama corpus in nltk_data direktori (~/nltk_data/corpus/wordfile.txt) dan akan memuatnya dengan menggunakan nltk.data.load -
import nltk.data
nltk.data.load(‘corpus/wordfile.txt’, format = ‘raw’)Keluaran
b’tutorialspoint\n’Pembaca korpus
NLTK menyediakan berbagai kelas CorpusReader. Kami akan membahasnya dalam resep python berikut
Membuat korpus daftar kata
NLTK memiliki WordListCorpusReaderkelas yang menyediakan akses ke file yang berisi daftar kata. Untuk resep Python berikut, kita perlu membuat file daftar kata yang bisa berupa CSV atau file teks biasa. Misalnya, kami telah membuat file bernama 'list' yang berisi data berikut -
tutorialspoint
Online
Free
TutorialsSekarang Mari kita contoh a WordListCorpusReader kelas yang menghasilkan daftar kata dari file yang kami buat ‘list’.
from nltk.corpus.reader import WordListCorpusReader
reader_corpus = WordListCorpusReader('.', ['list'])
reader_corpus.words()Keluaran
['tutorialspoint', 'Online', 'Free', 'Tutorials']Membuat korpus kata dengan tag POS
NLTK memiliki TaggedCorpusReaderkelas dengan bantuan yang kita dapat membuat korpus kata dengan tag POS. Sebenarnya, penandaan POS adalah proses mengidentifikasi tag part-of-speech untuk sebuah kata.
Salah satu format paling sederhana untuk korpus yang diberi tag adalah dalam bentuk 'kata / tag'seperti kutipan berikut dari korpus coklat -
The/at-tl expense/nn and/cc time/nn involved/vbn are/ber
astronomical/jj ./.Dalam kutipan di atas, setiap kata memiliki tag yang menunjukkan POS-nya. Sebagai contoh,vb mengacu pada kata kerja.
Sekarang Mari kita contoh a TaggedCorpusReaderkelas memproduksi kata-kata dengan tag POS dari file ‘list.pos’, yang memiliki kutipan di atas.
from nltk.corpus.reader import TaggedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.pos')
reader_corpus.tagged_words()Keluaran
[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ...]Membuat korpus frase yang terpotong-potong
NLTK memiliki ChnkedCorpusReaderkelas dengan bantuan yang kita dapat membuat corpus frase Chunked. Sebenarnya, potongan adalah frasa pendek dalam sebuah kalimat.
Misalnya, kami memiliki kutipan berikut dari tag treebank korpus -
[Earlier/JJR staff-reduction/NN moves/NNS] have/VBP trimmed/VBN about/
IN [300/CD jobs/NNS] ,/, [the/DT spokesman/NN] said/VBD ./.Dalam kutipan di atas, setiap potongan adalah frase kata benda tetapi kata-kata yang tidak ada dalam tanda kurung adalah bagian dari pohon kalimat dan bukan bagian dari subpohon frase kata benda.
Sekarang Mari kita contoh a ChunkedCorpusReader kelas memproduksi frase potongan dari file ‘list.chunk’, yang memiliki kutipan di atas.
from nltk.corpus.reader import ChunkedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.chunk')
reader_corpus.chunked_words()Keluaran
[
Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS')]),
('have', 'VBP'), ...
]Membuat korpus teks yang dikategorikan
NLTK memiliki CategorizedPlaintextCorpusReaderkelas dengan bantuan yang kita dapat membuat korpus teks yang dikategorikan. Ini sangat berguna jika kita memiliki korpus teks yang besar dan ingin mengkategorikannya menjadi beberapa bagian terpisah.
Misalnya, korpus coklat memiliki beberapa kategori berbeda. Mari kita cari tahu mereka dengan bantuan kode Python berikut -
from nltk.corpus import brown^M
brown.categories()Keluaran
[
'adventure', 'belles_lettres', 'editorial', 'fiction', 'government',
'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion',
'reviews', 'romance', 'science_fiction'
]Salah satu cara termudah untuk mengkategorikan korpus adalah dengan memiliki satu file untuk setiap kategori. Misalnya, mari kita lihat dua kutipan darimovie_reviews korpus -
movie_pos.txt
Garis merah tipis cacat tetapi memprovokasi.
movie_neg.txt
Anggaran besar dan produksi yang mengilap tidak bisa menutupi kurangnya spontanitas yang merembes ke acara TV mereka.
Jadi, dari dua file di atas, kami memiliki dua kategori yaitu pos dan neg.
Sekarang mari kita contohkan CategorizedPlaintextCorpusReader kelas.
from nltk.corpus.reader import CategorizedPlaintextCorpusReader
reader_corpus = CategorizedPlaintextCorpusReader('.', r'movie_.*\.txt',
cat_pattern = r'movie_(\w+)\.txt')
reader_corpus.categories()
reader_corpus.fileids(categories = [‘neg’])
reader_corpus.fileids(categories = [‘pos’])Keluaran
['neg', 'pos']
['movie_neg.txt']
['movie_pos.txt']Apa itu penandaan POS?
Pemberian tag, sejenis klasifikasi, adalah penetapan otomatis dari deskripsi token. Kami menyebutnya 'tag' deskriptor, yang mewakili salah satu bagian ucapan (kata benda, kata kerja, kata keterangan, kata sifat, kata ganti, kata sambung dan subkategorinya), informasi semantik, dan sebagainya.
Di sisi lain, jika kita berbicara tentang penandaan Part-of-Speech (POS), itu dapat didefinisikan sebagai proses mengubah kalimat dalam bentuk daftar kata, menjadi daftar tupel. Disini tupelnya berbentuk (word, tag). Kita juga dapat menyebut penandaan POS sebagai proses penugasan salah satu bagian kata ke kata tertentu.
Tabel berikut mewakili notifikasi POS yang paling sering digunakan dalam Penn Treebank corpus -
| Sr Tidak | Menandai | Deskripsi |
|---|---|---|
| 1 | NNP | Kata benda yang tepat, tunggal |
| 2 | NNPS | Kata benda yang tepat, jamak |
| 3 | PDT | Penentu pra |
| 4 | POS | Akhir yang posesif |
| 5 | PRP | Kata ganti orang |
| 6 | PRP $ | Kata ganti posesif |
| 7 | RB | Kata keterangan |
| 8 | RBR | Kata keterangan, komparatif |
| 9 | RBS | Kata keterangan, superlatif |
| 10 | RP | Partikel |
| 11 | SYM | Simbol (matematika atau ilmiah) |
| 12 | UNTUK | untuk |
| 13 | UH | Kata seru |
| 14 | VB | Kata kerja, bentuk dasar |
| 15 | VBD | Kata kerja, bentuk lampau |
| 16 | VBG | Kata kerja, gerund / present participle |
| 17 | VBN | Kata kerja, masa lalu |
| 18 | WP | A-kata ganti |
| 19 | WP $ | Kata ganti wh posesif |
| 20 | WRB | Adverb |
| 21 | # | Tanda pound |
| 22 | $ | Tanda dollar |
| 23 | . | Tanda baca akhir kalimat |
| 24 | , | Koma |
| 25 | : | Usus besar, titik koma |
| 26 | ( | Karakter tanda kurung kiri |
| 27 | ) | Karakter kurung siku |
| 28 | " | Kutipan ganda lurus |
| 29 | ' | Kutipan tunggal terbuka kiri |
| 30 | " | Kutipan ganda terbuka kiri |
| 31 | ' | Kutipan tunggal dekat kanan |
| 32 | " | Kutip ganda buka kanan |
Contoh
Mari kita pahami dengan eksperimen Python -
import nltk
from nltk import word_tokenize
sentence = "I am going to school"
print (nltk.pos_tag(word_tokenize(sentence)))Keluaran
[('I', 'PRP'), ('am', 'VBP'), ('going', 'VBG'), ('to', 'TO'), ('school', 'NN')]Mengapa penandaan POS?
Penandaan POS adalah bagian penting dari NLP karena berfungsi sebagai prasyarat untuk analisis NLP lebih lanjut sebagai berikut -
- Chunking
- Penguraian Sintaks
- Ekstraksi informasi
- Mesin penerjemah
- Analisis Sentimen
- Analisis tata bahasa & disambiguasi arti kata
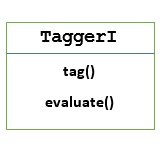
TaggerI - Kelas dasar
Semua pemberi tag berada dalam paket nltk.tag NLTK. Kelas dasar dari pemberi tag ini adalahTaggerI, berarti semua pemberi tag diwarisi dari kelas ini.
Methods - Kelas TaggerI memiliki dua metode berikut yang harus diimplementasikan oleh semua subkelasnya -
tag() method - Sesuai dengan namanya, metode ini mengambil daftar kata sebagai masukan dan mengembalikan daftar kata yang diberi tag sebagai keluaran.
evaluate() method - Dengan bantuan metode ini, kami dapat mengevaluasi keakuratan tagger.
Dasar dari Pemberian Tag POS
Baseline atau langkah dasar penandaan POS adalah Default Tagging, yang dapat dilakukan dengan menggunakan kelas DefaultTagger dari NLTK. Penandaan default hanya menetapkan tag POS yang sama untuk setiap token. Pemberian tag default juga memberikan dasar untuk mengukur peningkatan akurasi.
Kelas DefaultTagger
Penandaan default dilakukan dengan menggunakan DefaultTagging class, yang mengambil argumen tunggal, yaitu tag yang ingin kita terapkan.
Bagaimana cara kerjanya?
Seperti yang diceritakan sebelumnya, semua tagger diwarisi dari TaggerIkelas. ItuDefaultTagger diwarisi dari SequentialBackoffTagger yang merupakan subclass dari TaggerI class. Mari kita pahami dengan diagram berikut -
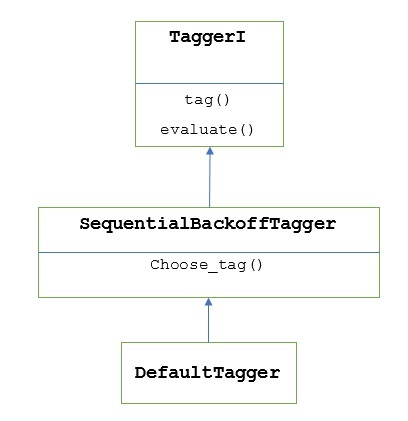
Sebagai bagian dari SeuentialBackoffTagger, itu DefaultTagger harus mengimplementasikan metode pick_tag () yang mengambil tiga argumen berikut.
- Daftar Token
- Indeks token saat ini
- Daftar token sebelumnya, yaitu sejarah
Contoh
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag(['Tutorials','Point'])Keluaran
[('Tutorials', 'NN'), ('Point', 'NN')]Dalam contoh ini, kami memilih tag kata benda karena ini adalah jenis kata yang paling umum. Bahkan,DefaultTagger juga paling berguna saat kita memilih tag POS yang paling umum.
Evaluasi akurasi
Itu DefaultTaggerjuga merupakan dasar untuk mengevaluasi keakuratan pemberi tag. Itulah alasan kita bisa menggunakannya bersamaevaluate()metode untuk mengukur akurasi. Ituevaluate() Metode mengambil daftar token yang diberi tag sebagai standar emas untuk mengevaluasi pemberi tag.
Berikut adalah contoh di mana kami menggunakan tagger default kami, bernama exptagger, dibuat di atas, untuk mengevaluasi keakuratan subset dari treebank corpus tagged kalimat -
Contoh
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
from nltk.corpus import treebank
testsentences = treebank.tagged_sents() [1000:]
exptagger.evaluate (testsentences)Keluaran
0.13198749536374715Output di atas menunjukkan itu dengan memilih NN untuk setiap tag, kami dapat mencapai sekitar 13% pengujian akurasi pada 1000 entri file treebank korpus.
Memberi tag pada daftar kalimat
Daripada menandai satu kalimat, NLTK's TaggerI kelas juga memberi kita a tag_sents()metode dengan bantuan yang kita dapat menandai daftar kalimat. Berikut adalah contoh di mana kami menandai dua kalimat sederhana
Contoh
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag_sents([['Hi', ','], ['How', 'are', 'you', '?']])Keluaran
[
[
('Hi', 'NN'),
(',', 'NN')
],
[
('How', 'NN'),
('are', 'NN'),
('you', 'NN'),
('?', 'NN')
]
]Dalam contoh di atas, kami menggunakan tagger default yang kami buat sebelumnya bernama exptagger.
Menghapus penandaan kalimat
Kami juga dapat menghapus tag pada kalimat. NLTK menyediakan metode nltk.tag.untag () untuk tujuan ini. Ini akan mengambil kalimat yang diberi tag sebagai masukan dan menyediakan daftar kata tanpa tanda. Mari kita lihat contohnya -
Contoh
import nltk
from nltk.tag import untag
untag([('Tutorials', 'NN'), ('Point', 'NN')])Keluaran
['Tutorials', 'Point']Apa itu Unigram Tagger?
Sesuai dengan namanya, unigram tagger adalah sebuah tagger yang hanya menggunakan satu kata sebagai konteksnya untuk menentukan tag POS (Part-of-Speech). Sederhananya, Unigram Tagger adalah sebuah tagger berbasis konteks yang konteksnya berupa satu kata, yaitu Unigram.
Bagaimana cara kerjanya?
NLTK menyediakan modul bernama UnigramTaggeruntuk tujuan ini. Tetapi sebelum mendalami cara kerjanya, mari kita pahami hierarki dengan bantuan diagram berikut -
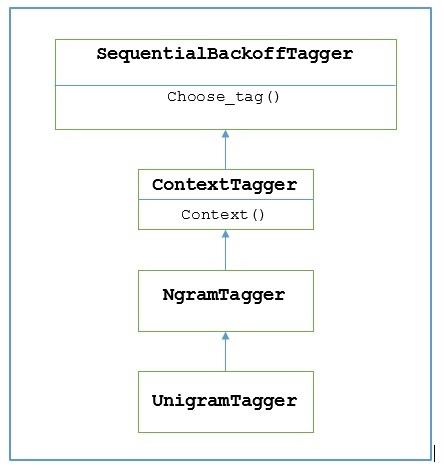
Dari diagram di atas, dapat dipahami bahwa UnigramTagger diwarisi dari NgramTagger yang merupakan subclass dari ContextTagger, yang diwarisi dari SequentialBackoffTagger.
Pekerjaan UnigramTagger dijelaskan dengan bantuan langkah-langkah berikut -
Seperti yang telah kita lihat, UnigramTagger mewarisi dari ContextTagger, itu mengimplementasikan a context()metode. Inicontext() metode mengambil tiga argumen yang sama seperti choose_tag() metode.
Hasil dari context()metode akan menjadi kata token yang selanjutnya digunakan untuk membuat model. Setelah model dibuat, kata token juga digunakan untuk mencari tag terbaik.
Lewat sini, UnigramTagger akan membangun model konteks dari daftar kalimat yang diberi tag.
Melatih Unigram Tagger
NLTK UnigramTaggerdapat dilatih dengan memberikan daftar kalimat yang diberi tag pada saat inisialisasi. Pada contoh di bawah ini, kita akan menggunakan kalimat yang diberi tag dari treebank corpus. Kami akan menggunakan 2.500 kalimat pertama dari korpus itu.
Contoh
Pertama impor modul UniframTagger dari nltk -
from nltk.tag import UnigramTaggerSelanjutnya, impor korpus yang ingin Anda gunakan. Di sini kami menggunakan treebank corpus -
from nltk.corpus import treebankSekarang, ambillah kalimat untuk tujuan pelatihan. Kami mengambil 2.500 kalimat pertama untuk tujuan pelatihan dan akan menandainya -
train_sentences = treebank.tagged_sents()[:2500]Selanjutnya, terapkan UnigramTagger pada kalimat yang digunakan untuk tujuan pelatihan -
Uni_tagger = UnigramTagger(train_sentences)Ambil beberapa kalimat, baik sama dengan atau kurang diambil untuk tujuan pelatihan, yaitu 2500, untuk tujuan pengujian. Di sini kami mengambil 1500 pertama untuk tujuan pengujian -
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sents)Keluaran
0.8942306156033808Di sini, kami mendapatkan sekitar 89 persen akurasi untuk tagger yang menggunakan pencarian kata tunggal untuk menentukan tag POS.
Contoh implementasi lengkap
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Keluaran
0.8942306156033808Mengesampingkan model konteks
Dari diagram di atas menunjukkan hierarki untuk UnigramTagger, kami mengetahui semua pemberi tag yang diwarisi dari ContextTagger, alih-alih melatih sendiri, dapat mengambil model yang dibuat sebelumnya. Model yang dibuat sebelumnya ini hanyalah kamus Python yang memetakan kunci konteks ke sebuah tag. Dan untukUnigramTagger, kunci konteks adalah kata individual sedangkan untuk lainnya NgramTagger subclass, itu akan menjadi tupel.
Kita bisa mengganti model konteks ini dengan meneruskan model sederhana lainnya ke UnigramTaggerkelas alih-alih melewati set pelatihan. Biarkan kami memahaminya dengan bantuan contoh mudah di bawah ini -
Contoh
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])Keluaran
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]Karena model kami berisi 'Vinken' sebagai satu-satunya kunci konteks, Anda dapat mengamati dari output di atas bahwa hanya kata ini yang mendapat tag dan setiap kata lain memiliki None sebagai tag.
Menetapkan ambang batas frekuensi minimum
Untuk memutuskan tag mana yang paling mungkin untuk konteks tertentu, file ContextTaggerkelas menggunakan frekuensi kemunculan. Ini akan melakukannya secara default bahkan jika kata konteks dan tag muncul hanya sekali, tetapi kita dapat mengatur ambang frekuensi minimum dengan meneruskancutoff nilai ke UnigramTaggerkelas. Pada contoh di bawah ini, kita meneruskan nilai cutoff dalam resep sebelumnya di mana kita melatih UnigramTagger -
Contoh
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences, cutoff = 4)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Keluaran
0.7357651629613641Menggabungkan Pemberi Tag
Menggabungkan penanda atau rantai penanda satu sama lain adalah salah satu fitur penting dari NLTK. Konsep utama di balik penggabungan tagger adalah, jika satu pemberi tag tidak tahu cara memberi tag pada sebuah kata, kata itu akan diteruskan ke tagger yang dirantai. Untuk mencapai tujuan ini,SequentialBackoffTagger memberi kami Backoff tagging fitur.
Pemberian Tag Backoff
Seperti yang diceritakan sebelumnya, penandaan mundur adalah salah satu fitur penting dari SequentialBackoffTagger, yang memungkinkan kita untuk menggabungkan pemberi tag dengan cara yang jika satu pemberi tag tidak tahu cara memberi tag pada sebuah kata, kata tersebut akan diteruskan ke pemberi tag berikutnya dan seterusnya sampai tidak ada penanda mundur yang tersisa untuk diperiksa.
Bagaimana cara kerjanya?
Sebenarnya, setiap subclass dari SequentialBackoffTaggerdapat mengambil argumen kata kunci 'backoff'. Nilai argumen kata kunci ini adalah contoh lain dari aSequentialBackoffTagger. Sekarang kapanpun iniSequentialBackoffTaggerkelas diinisialisasi, daftar internal penanda backoff (dengan dirinya sendiri sebagai elemen pertama) akan dibuat. Selain itu, jika pemberi tag backoff diberikan, daftar internal pemberi tag backoff ini akan ditambahkan.
Pada contoh di bawah ini, kami mengambil DefaulTagger sebagai tagger backoff dalam resep Python di atas yang telah kita latih UnigramTagger.
Contoh
Dalam contoh ini, kami menggunakan DefaulTaggersebagai pemberi tag backoff. KapanpunUnigramTagger tidak dapat menandai kata, tagger backoff, yaitu DefaulTagger, dalam kasus kami, akan menandainya dengan 'NN'.
from nltk.tag import UnigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Uni_tagger = UnigramTagger(train_sentences, backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Keluaran
0.9061975746536931Dari keluaran di atas, Anda dapat mengamati bahwa dengan menambahkan tagger backoff keakuratannya meningkat sekitar 2%.
Menyimpan tagger dengan acar
Seperti yang telah kita lihat bahwa melatih tagger sangat rumit dan juga membutuhkan waktu. Untuk menghemat waktu, kita dapat membuatkan tagger terlatih untuk digunakan nanti. Pada contoh di bawah ini, kita akan melakukan ini ke tagger yang sudah dilatih bernama‘Uni_tagger’.
Contoh
import pickle
f = open('Uni_tagger.pickle','wb')
pickle.dump(Uni_tagger, f)
f.close()
f = open('Uni_tagger.pickle','rb')
Uni_tagger = pickle.load(f)Kelas NgramTagger
Dari diagram hierarki yang dibahas di unit sebelumnya, UnigramTagger diwarisi dari NgarmTagger kelas tetapi kami memiliki dua subkelas lagi NgarmTagger kelas -
Subkelas BigramTagger
Sebenarnya sebuah ngram adalah kelanjutan dari n item, oleh karena itu, seperti namanya, BigramTaggersubclass melihat dua item. Item pertama adalah kata yang diberi tag sebelumnya dan item kedua adalah kata yang diberi tag saat ini.
Subclass TrigramTagger
Pada catatan yang sama tentang BigramTagger, TrigramTagger subclass melihat pada tiga item yaitu dua kata yang diberi tag sebelumnya dan satu kata yang diberi tag saat ini.
Praktis jika kita melamar BigramTagger dan TrigramTaggersubkelas secara individual seperti yang kami lakukan dengan subkelas UnigramTagger, keduanya berkinerja sangat buruk. Mari kita lihat pada contoh di bawah ini:
Menggunakan BigramTagger Subclass
from nltk.tag import BigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Bi_tagger = BigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Bi_tagger.evaluate(test_sentences)Keluaran
0.44669191071913594Menggunakan Subclass TrigramTagger
from nltk.tag import TrigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Tri_tagger = TrigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Tri_tagger.evaluate(test_sentences)Keluaran
0.41949863394526193Anda dapat membandingkan kinerja UnigramTagger, yang kami gunakan sebelumnya (memberikan akurasi sekitar 89%) dengan BigramTagger (memberikan akurasi sekitar 44%) dan TrigramTagger (memberikan akurasi sekitar 41%). Alasannya adalah Bigram dan Trigram taggers tidak dapat mempelajari konteks dari kata pertama dalam sebuah kalimat. Di sisi lain, kelas UnigramTagger tidak peduli dengan konteks sebelumnya dan menebak tag yang paling umum untuk setiap kata, sehingga dapat memiliki akurasi dasar yang tinggi.
Menggabungkan pemberi tag ngram
Dari contoh di atas, terlihat jelas bahwa Bigram dan Trigram taggers dapat berkontribusi jika kita menggabungkannya dengan backoff tagging. Pada contoh di bawah ini, kami menggabungkan penanda Unigram, Bigram dan Trigram dengan penandaan backoff. Konsepnya sama dengan resep sebelumnya saat menggabungkan UnigramTagger dengan tagger backoff. Satu-satunya perbedaan adalah bahwa kita menggunakan fungsi bernama backoff_tagger () dari tagger_util.py, yang diberikan di bawah ini, untuk operasi backoff.
def backoff_tagger(train_sentences, tagger_classes, backoff=None):
for cls in tagger_classes:
backoff = cls(train_sentences, backoff=backoff)
return backoffContoh
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Keluaran
0.9234530029238365Dari keluaran di atas, kita dapat melihatnya meningkatkan akurasi sekitar 3%.
Pasang Pemberi Tag
Salah satu kelas penting dari subkelas ContextTagger adalah AffixTagger. Di kelas AffixTagger, konteksnya adalah awalan atau akhiran sebuah kata. Itulah alasan kelas AffixTagger dapat mempelajari tag berdasarkan substring dengan panjang tetap di awal atau akhir kata.
Bagaimana cara kerjanya?
Cara kerjanya tergantung pada argumen bernama affix_length yang menentukan panjang prefiks atau sufiks. Nilai defaultnya adalah 3. Tapi bagaimana membedakan apakah kelas AffixTagger mempelajari prefiks atau sufiks kata?
affix_length=positive - Jika affix_lenght bernilai positif maka kelas AffixTagger akan mempelajari prefiks kata.
affix_length=negative - Jika nilai affix_lenght negatif maka kelas AffixTagger akan mempelajari suffix kata.
Untuk membuatnya lebih jelas, pada contoh di bawah ini, kita akan menggunakan class AffixTagger pada kalimat treebank yang diberi tag.
Contoh
Dalam contoh ini, AffixTagger akan mempelajari prefiks kata karena kita tidak menentukan nilai apa pun untuk argumen affix_length. Argumen akan mengambil nilai default 3 -
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Keluaran
0.2800492099250667Mari kita lihat pada contoh di bawah ini apa yang akan menjadi akurasi ketika kita memberikan nilai 4 ke argumen panjang_kategori -
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences, affix_length=4 )
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Keluaran
0.18154947354966527Contoh
Dalam contoh ini, AffixTagger akan mempelajari sufiks kata karena kita akan menentukan nilai negatif untuk argumen panjang_kesan.
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Suffix_tagger = AffixTagger(train_sentences, affix_length = -3)
test_sentences = treebank.tagged_sents()[1500:]
Suffix_tagger.evaluate(test_sentences)Keluaran
0.2800492099250667Brill Tagger
Brill Tagger adalah tagger berbasis transformasi. NLTK menyediakanBrillTagger kelas yang merupakan tagger pertama yang bukan subkelas dari SequentialBackoffTagger. Berlawanan dengan itu, serangkaian aturan untuk memperbaiki hasil tagger awal digunakan olehBrillTagger.
Bagaimana cara kerjanya?
Untuk melatih a BrillTagger kelas menggunakan BrillTaggerTrainer kami mendefinisikan fungsi berikut -
def train_brill_tagger(initial_tagger, train_sentences, **kwargs) -
templates = [
brill.Template(brill.Pos([-1])),
brill.Template(brill.Pos([1])),
brill.Template(brill.Pos([-2])),
brill.Template(brill.Pos([2])),
brill.Template(brill.Pos([-2, -1])),
brill.Template(brill.Pos([1, 2])),
brill.Template(brill.Pos([-3, -2, -1])),
brill.Template(brill.Pos([1, 2, 3])),
brill.Template(brill.Pos([-1]), brill.Pos([1])),
brill.Template(brill.Word([-1])),
brill.Template(brill.Word([1])),
brill.Template(brill.Word([-2])),
brill.Template(brill.Word([2])),
brill.Template(brill.Word([-2, -1])),
brill.Template(brill.Word([1, 2])),
brill.Template(brill.Word([-3, -2, -1])),
brill.Template(brill.Word([1, 2, 3])),
brill.Template(brill.Word([-1]), brill.Word([1])),
]
trainer = brill_trainer.BrillTaggerTrainer(initial_tagger, templates, deterministic=True)
return trainer.train(train_sentences, **kwargs)Seperti yang bisa kita lihat, fungsi ini membutuhkan initial_tagger dan train_sentences. Dibutuhkaninitial_tagger argumen dan daftar template, yang mengimplementasikan BrillTemplateantarmuka. ItuBrillTemplate antarmuka ditemukan di nltk.tbl.templatemodul. Salah satu implementasi tersebut adalahbrill.Template kelas.
Peran utama tagger berbasis transformasi adalah untuk menghasilkan aturan transformasi yang mengoreksi keluaran tagger awal agar lebih sejalan dengan kalimat pelatihan. Mari kita lihat alur kerja di bawah ini -
Contoh
Untuk contoh ini, kami akan menggunakan combine_tagger yang kami buat saat menyisir pemberi tag (di resep sebelumnya) dari rantai backoff NgramTagger kelas, sebagai initial_tagger. Pertama, mari kita evaluasi hasilnya menggunakanCombine.tagger dan kemudian gunakan itu sebagai initial_tagger untuk melatih brill tagger.
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(
train_sentences, [UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger
)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Keluaran
0.9234530029238365Sekarang, mari kita lihat hasil evaluasi kapan Combine_tagger digunakan sebagai initial_tagger untuk melatih brill tagger -
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Keluaran
0.9246832510505041Kita bisa melihat itu BrillTagger kelas memiliki sedikit peningkatan akurasi atas Combine_tagger.
Contoh implementasi lengkap
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Keluaran
0.9234530029238365
0.9246832510505041TnT Tagger
TnT Tagger, singkatan dari Trigrams'nTags, adalah tagger statistik yang didasarkan pada model Markov orde dua.
Bagaimana cara kerjanya?
Kami dapat memahami cara kerja tagger TnT dengan bantuan langkah-langkah berikut -
Pertama berdasarkan data pelatihan, TnT tegger memelihara beberapa internal FreqDist dan ConditionalFreqDist contoh.
Setelah itu unigram, bigram dan trigram akan dihitung oleh distribusi frekuensi ini.
Sekarang, selama penandaan, dengan menggunakan frekuensi, itu akan menghitung kemungkinan tag yang mungkin untuk setiap kata.
Itulah mengapa alih-alih membangun rantai backoff NgramTagger, ia menggunakan semua model ngram bersama-sama untuk memilih tag terbaik untuk setiap kata. Mari kita evaluasi akurasi dengan tagger TnT pada contoh berikut -
from nltk.tag import tnt
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
tnt_tagger = tnt.TnT()
tnt_tagger.train(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
tnt_tagger.evaluate(test_sentences)Keluaran
0.9165508316157791Kami memiliki akurasi yang sedikit kurang dari yang kami dapatkan dengan Brill Tagger.
Harap dicatat bahwa kami perlu menelepon train() sebelum evaluate() jika tidak kita akan mendapatkan akurasi 0%.
Parsing dan relevansinya di NLP
Kata 'Parsing' yang asalnya dari kata Latin ‘pars’ (yang berarti ‘part’), digunakan untuk menggambar makna yang tepat atau makna kamus dari teks. Ini juga disebut analisis sintaksis atau analisis sintaksis. Membandingkan aturan tata bahasa formal, analisis sintaksis memeriksa kebermaknaan teks. Kalimat seperti "Beri aku es krim panas", misalnya, akan ditolak oleh pengurai atau penganalisis sintaksis.
Dalam pengertian ini, kita dapat mendefinisikan parsing atau analisis sintaksis atau analisis sintaks sebagai berikut -
Ini dapat didefinisikan sebagai proses menganalisis string simbol dalam bahasa alami yang sesuai dengan aturan tata bahasa formal.
Kami dapat memahami relevansi parsing di NLP dengan bantuan poin-poin berikut -
Parser digunakan untuk melaporkan kesalahan sintaks apa pun.
Ini membantu untuk memulihkan dari kesalahan yang biasa terjadi sehingga pemrosesan sisa program dapat dilanjutkan.
Pohon Parse dibuat dengan bantuan parser.
Parser digunakan untuk membuat tabel simbol, yang berperan penting dalam NLP.
Parser juga digunakan untuk menghasilkan representasi perantara (IR).
Parsing Jauh Vs Dangkal
| Parsing Dalam | Parsing Dangkal |
|---|---|
| Pada deep parsing, strategi pencarian akan memberikan struktur sintaksis yang lengkap pada sebuah kalimat. | Ini adalah tugas untuk mengurai bagian terbatas informasi sintaksis dari tugas yang diberikan. |
| Sangat cocok untuk aplikasi NLP yang kompleks. | Ini dapat digunakan untuk aplikasi NLP yang tidak terlalu rumit. |
| Sistem dialog dan ringkasan adalah contoh aplikasi NLP yang menggunakan parsing mendalam. | Ekstraksi informasi dan penambangan teks adalah contoh aplikasi NLP di mana parsing dalam digunakan. |
| Ini juga disebut parsing penuh. | Ini juga disebut chunking. |
Berbagai jenis parser
Seperti dibahas, parser pada dasarnya adalah interpretasi tata bahasa prosedural. Ia menemukan pohon yang optimal untuk kalimat yang diberikan setelah mencari melalui ruang berbagai pohon. Mari kita lihat beberapa parser yang tersedia di bawah ini -
Pengurai keturunan rekursif
Penguraian turunan rekursif adalah salah satu bentuk penguraian yang paling mudah. Berikut adalah beberapa poin penting tentang parser keturunan rekursif -
Ini mengikuti proses top down.
Ini mencoba untuk memverifikasi bahwa sintaks dari aliran input sudah benar atau tidak.
Itu membaca kalimat input dari kiri ke kanan.
Satu operasi yang diperlukan untuk parser keturunan rekursif adalah membaca karakter dari aliran input dan mencocokkannya dengan terminal dari tata bahasa.
Pengurai shift-kurangi
Berikut adalah beberapa poin penting tentang pengurai shift-kurangi -
Ini mengikuti proses bottom-up sederhana.
Ia mencoba menemukan urutan kata dan frasa yang sesuai dengan sisi kanan produksi tata bahasa dan menggantikannya dengan sisi kiri produksi.
Upaya di atas untuk menemukan urutan kata berlanjut hingga seluruh kalimat dikurangi.
Dengan kata lain, parser shift-reduce dimulai dengan simbol input dan mencoba membangun pohon parser hingga simbol awal.
Pengurai bagan
Berikut adalah beberapa poin penting tentang pengurai bagan -
Ini terutama berguna atau cocok untuk tata bahasa yang ambigu, termasuk tata bahasa alam.
Ini menerapkan pemrograman dinamis untuk masalah parsing.
Karena pemrograman dinamis, sebagian hasil yang dihipotesiskan disimpan dalam struktur yang disebut 'bagan'.
'Grafik' juga bisa digunakan kembali.
Parser ekspresi reguler
Penguraian reguler adalah salah satu teknik penguraian yang paling banyak digunakan. Berikut adalah beberapa poin penting tentang parser Regexp -
Sesuai dengan namanya, ini menggunakan ekspresi reguler yang didefinisikan dalam bentuk tata bahasa di atas string yang diberi tag POS.
Ini pada dasarnya menggunakan ekspresi reguler ini untuk mengurai kalimat input dan menghasilkan pohon parse dari ini.
Contoh
Berikut adalah contoh kerja Regexp Parser -
import nltk
sentence = [
("a", "DT"),
("clever", "JJ"),
("fox","NN"),
("was","VBP"),
("jumping","VBP"),
("over","IN"),
("the","DT"),
("wall","NN")
]
grammar = "NP:{<DT>?<JJ>*<NN>}"
Reg_parser = nltk.RegexpParser(grammar)
Reg_parser.parse(sentence)
Output = Reg_parser.parse(sentence)
Output.draw()Keluaran
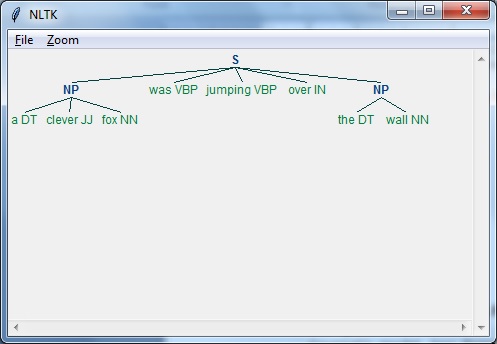
Penguraian Ketergantungan
Dependency Parsing (DP), mekanisme parsing modern, yang konsep utamanya adalah bahwa setiap unit linguistik yaitu kata-kata berhubungan satu sama lain melalui tautan langsung. Tautan langsung ini sebenarnya‘dependencies’dalam linguistik. Misalnya, diagram berikut menunjukkan tata bahasa ketergantungan untuk kalimat tersebut“John can hit the ball”.

Paket NLTK
Kami telah mengikuti dua cara untuk melakukan parsing dependensi dengan NLTK -
Pengurai ketergantungan proyektif dan probabilistik
Ini adalah cara pertama kita dapat melakukan penguraian dependensi dengan NLTK. Tetapi pengurai ini memiliki batasan pelatihan dengan kumpulan data pelatihan terbatas.
Stanford parser
Ini adalah cara lain kita dapat melakukan penguraian ketergantungan dengan NLTK. Stanford parser adalah pengurai dependensi yang canggih. NLTK memiliki pembungkus di sekitarnya. Untuk menggunakannya kita perlu mengunduh dua hal berikut -
The Stanford CoreNLP parser .
Model bahasa untuk bahasa yang diinginkan. Misalnya model bahasa Inggris.
Contoh
Setelah Anda mengunduh model, kami dapat menggunakannya melalui NLTK sebagai berikut -
from nltk.parse.stanford import StanfordDependencyParser
path_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser.jar'
path_models_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser-3.4.1-models.jar'
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
result = dep_parser.raw_parse('I shot an elephant in my sleep')
depndency = result.next()
list(dependency.triples())Keluaran
[
((u'shot', u'VBD'), u'nsubj', (u'I', u'PRP')),
((u'shot', u'VBD'), u'dobj', (u'elephant', u'NN')),
((u'elephant', u'NN'), u'det', (u'an', u'DT')),
((u'shot', u'VBD'), u'prep', (u'in', u'IN')),
((u'in', u'IN'), u'pobj', (u'sleep', u'NN')),
((u'sleep', u'NN'), u'poss', (u'my', u'PRP$'))
]Apa itu Chunking?
Chunking, salah satu proses penting dalam pemrosesan bahasa alami, digunakan untuk mengidentifikasi part of speech (POS) dan frasa pendek. Dengan kata lain, dengan chunking kita bisa mendapatkan struktur kalimatnya. Itu juga disebutpartial parsing.
Pola dan celah potongan
Chunk patternsadalah pola tag part-of-speech (POS) yang menentukan jenis kata apa yang membentuk sebagian. Kita dapat mendefinisikan pola potongan dengan bantuan ekspresi reguler yang dimodifikasi.
Selain itu, kami juga dapat menentukan pola untuk jenis kata apa yang tidak boleh dalam potongan dan kata-kata yang tidak dipotong ini dikenal sebagai chinks.
Contoh implementasi
Pada contoh di bawah ini, beserta hasil parsing kalimat tersebut “the book has many chapters”, ada tata bahasa untuk frasa kata benda yang menggabungkan pola chunk dan chink -
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()Keluaran
Seperti yang terlihat di atas, pola untuk menentukan potongan adalah dengan menggunakan kurung kurawal sebagai berikut -
{<DT><NN>}Dan untuk menentukan celah, kita dapat membalik kawat gigi seperti berikut -
}<VB>{.Sekarang, untuk tipe frase tertentu, aturan-aturan ini dapat digabungkan ke dalam tata bahasa.
Ekstraksi Informasi
Kami telah membahas taggers serta parser yang dapat digunakan untuk membangun mesin ekstraksi informasi. Mari kita lihat pipa ekstraksi informasi dasar -
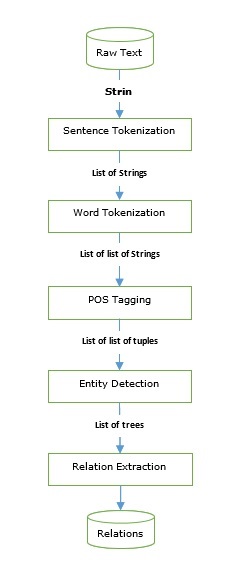
Ekstraksi informasi memiliki banyak aplikasi termasuk -
- Intelijen bisnis
- Lanjutkan panen
- Analisis media
- Deteksi sentimen
- Pencarian paten
- Pemindaian email
Pengakuan entitas bernama (NER)
Pengenalan entitas-bernama (NER) sebenarnya adalah cara untuk mengekstrak beberapa entitas yang paling umum seperti nama, organisasi, lokasi, dll. Mari kita lihat contoh yang mengambil semua langkah praproses seperti tokenisasi kalimat, penandaan POS, pemotongan, NER, dan mengikuti pipa yang disediakan pada gambar di atas.
Contoh
Import nltk
file = open (
# provide here the absolute path for the file of text for which we want NER
)
data_text = file.read()
sentences = nltk.sent_tokenize(data_text)
tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences]
for sent in tagged_sentences:
print nltk.ne_chunk(sent)Beberapa dari Named-entity recognition (NER) yang dimodifikasi juga dapat digunakan untuk mengekstrak entitas seperti nama produk, entitas bio-medis, nama merek, dan banyak lagi.
Ekstraksi hubungan
Ekstraksi relasi, operasi ekstraksi informasi lain yang umum digunakan, adalah proses mengekstraksi hubungan yang berbeda antara berbagai entitas. Mungkin ada hubungan yang berbeda seperti pewarisan, sinonim, analogi, dll., Yang definisinya tergantung pada kebutuhan informasi. Misalkan jika kita ingin mencari penulisan sebuah buku maka pengarangnya adalah hubungan antara nama pengarang dan nama buku.
Contoh
Dalam contoh berikut, kami menggunakan pipeline IE yang sama, seperti yang ditunjukkan pada diagram di atas, yang kami gunakan hingga Named-entity relation (NER) dan memperluasnya dengan pola relasi berdasarkan tag NER.
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))Keluaran
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia']
[ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo']
[ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington']
[ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington']
[ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles']
[ORG: 'Open Text'] ', based in' [LOC: 'Waterloo']
[ORG: 'WGBH'] 'in' [LOC: 'Boston']
[ORG: 'Bastille Opera'] 'in' [LOC: 'Paris']
[ORG: 'Omnicom'] 'in' [LOC: 'New York']
[ORG: 'DDB Needham'] 'in' [LOC: 'New York']
[ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York']
[ORG: 'BBDO South'] 'in' [LOC: 'Atlanta']
[ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']Dalam kode di atas, kami telah menggunakan korpus inbuilt bernama ieer. Dalam korpus ini, kalimat diberi tag sampai relasi entitas-bernama (NER). Di sini kita hanya perlu menentukan pola relasi yang kita inginkan dan jenis NER yang ingin kita definisikan relasinya. Dalam contoh kami, kami mendefinisikan hubungan antara organisasi dan lokasi. Kami mengekstrak semua kombinasi pola ini.
Mengapa mengubah potongan?
Sampai saat ini kita telah mendapatkan potongan atau frase dari kalimat tapi apa yang harus kita lakukan dengannya. Salah satu tugas penting adalah mengubahnya. Tapi kenapa? Untuk melakukan hal berikut -
- koreksi tata bahasa dan
- mengatur ulang frase
Memfilter kata-kata yang tidak penting / tidak berguna
Misalkan jika Anda ingin menilai arti sebuah frase maka ada banyak kata yang umum digunakan seperti, 'the', 'a', tidak signifikan atau tidak berguna. Misalnya, lihat frasa berikut -
'Filmnya bagus'.
Di sini kata yang paling penting adalah 'film' dan 'bagus'. Kata lain, 'the' dan 'was' keduanya tidak berguna atau tidak signifikan. Itu karena tanpa mereka juga kita bisa mendapatkan arti kalimat yang sama. 'Film bagus'.
Dalam resep python berikut, kita akan belajar bagaimana menghapus kata-kata yang tidak berguna / tidak penting dan menyimpan kata-kata penting dengan bantuan tag POS.
Contoh
Pertama, dengan melihat-lihat treebankcorpus untuk stopwords kita perlu memutuskan tag bagian-of-speech mana yang signifikan dan mana yang tidak. Mari kita lihat tabel kata-kata dan tag yang tidak penting berikut -
| Kata | Menandai |
|---|---|
| Sebuah | DT |
| Semua | PDT |
| Sebuah | DT |
| Dan | CC |
| Atau | CC |
| Bahwa | WDT |
| Itu | DT |
Dari tabel di atas, kita dapat melihat selain CC, semua tag lainnya diakhiri dengan DT yang berarti kita dapat menyaring kata-kata yang tidak penting dengan melihat sufiks tag.
Untuk contoh ini, kita akan menggunakan fungsi bernama filter()yang mengambil satu potongan dan mengembalikan potongan baru tanpa kata-kata yang tidak ditandai. Fungsi ini menyaring semua tag yang diakhiri dengan DT atau CC.
Contoh
import nltk
def filter(chunk, tag_suffixes=['DT', 'CC']):
significant = []
for word, tag in chunk:
ok = True
for suffix in tag_suffixes:
if tag.endswith(suffix):
ok = False
break
if ok:
significant.append((word, tag))
return (significant)Sekarang, mari kita gunakan filter fungsi ini () dalam resep Python kita untuk menghapus kata-kata yang tidak penting -
from chunk_parse import filter
filter([('the', 'DT'),('good', 'JJ'),('movie', 'NN')])Keluaran
[('good', 'JJ'), ('movie', 'NN')]Koreksi Kata Kerja
Seringkali, dalam bahasa dunia nyata kita melihat bentuk kata kerja yang salah. Misalnya, 'Anda baik-baik saja?' tidak benar. Bentuk kata kerja salah dalam kalimat ini. Kalimatnya harus 'apakah kamu baik-baik saja?' NLTK memberi kita cara untuk memperbaiki kesalahan tersebut dengan membuat pemetaan koreksi kata kerja. Pemetaan koreksi ini digunakan tergantung pada apakah ada kata benda jamak atau tunggal dalam potongan.
Contoh
Untuk mengimplementasikan resep Python, pertama-tama kita perlu mendefinisikan pemetaan koreksi kata kerja. Mari kita buat dua pemetaan sebagai berikut -
Plural to Singular mappings
plural= {
('is', 'VBZ'): ('are', 'VBP'),
('was', 'VBD'): ('were', 'VBD')
}Singular to Plural mappings
singular = {
('are', 'VBP'): ('is', 'VBZ'),
('were', 'VBD'): ('was', 'VBD')
}Seperti yang terlihat di atas, setiap pemetaan memiliki kata kerja yang diberi tag yang memetakan ke kata kerja lain yang diberi tag. Pemetaan awal dalam contoh kami mencakup dasar-dasar pemetaanis to are, was to were, dan sebaliknya.
Selanjutnya, kami akan menentukan fungsi bernama verbs(), di mana Anda dapat melewati celah dengan bentuk kata kerja yang salah dan akan mendapatkan bagian yang dikoreksi kembali. Untuk menyelesaikannya,verb() fungsi menggunakan fungsi pembantu bernama index_chunk() yang akan mencari potongan untuk posisi kata pertama yang diberi tag.
Mari kita lihat fungsi-fungsi ini -
def index_chunk(chunk, pred, start = 0, step = 1):
l = len(chunk)
end = l if step > 0 else -1
for i in range(start, end, step):
if pred(chunk[i]):
return i
return None
def tag_startswith(prefix):
def f(wt):
return wt[1].startswith(prefix)
return f
def verbs(chunk):
vbidx = index_chunk(chunk, tag_startswith('VB'))
if vbidx is None:
return chunk
verb, vbtag = chunk[vbidx]
nnpred = tag_startswith('NN')
nnidx = index_chunk(chunk, nnpred, start = vbidx+1)
if nnidx is None:
nnidx = index_chunk(chunk, nnpred, start = vbidx-1, step = -1)
if nnidx is None:
return chunk
noun, nntag = chunk[nnidx]
if nntag.endswith('S'):
chunk[vbidx] = plural.get((verb, vbtag), (verb, vbtag))
else:
chunk[vbidx] = singular.get((verb, vbtag), (verb, vbtag))
return chunkSimpan fungsi ini dalam file Python di direktori lokal Anda tempat Python atau Anaconda diinstal dan jalankan. Saya telah menyimpannya sebagaiverbcorrect.py.
Sekarang, mari kita telepon verbs() berfungsi pada POS dengan tag is you fine potongan -
from verbcorrect import verbs
verbs([('is', 'VBZ'), ('you', 'PRP$'), ('fine', 'VBG')])Keluaran
[('are', 'VBP'), ('you', 'PRP$'), ('fine','VBG')]Menghilangkan kalimat pasif dari frase
Tugas berguna lainnya adalah menghilangkan kalimat pasif dari frasa. Ini dapat dilakukan dengan bantuan menukar kata-kata di sekitar kata kerja. Sebagai contoh,‘the tutorial was great’ dapat diubah menjadi ‘the great tutorial’.
Contoh
Untuk mencapai ini kita mendefinisikan fungsi bernama eliminate_passive()yang akan menukar sisi kanan potongan dengan sisi kiri dengan menggunakan kata kerja sebagai titik pivot. Untuk menemukan kata kerja yang akan berputar, itu juga akan menggunakanindex_chunk() fungsi yang didefinisikan di atas.
def eliminate_passive(chunk):
def vbpred(wt):
word, tag = wt
return tag != 'VBG' and tag.startswith('VB') and len(tag) > 2
vbidx = index_chunk(chunk, vbpred)
if vbidx is None:
return chunk
return chunk[vbidx+1:] + chunk[:vbidx]Sekarang, mari kita telepon eliminate_passive() berfungsi pada POS dengan tag the tutorial was great potongan -
from passiveverb import eliminate_passive
eliminate_passive(
[
('the', 'DT'), ('tutorial', 'NN'), ('was', 'VBD'), ('great', 'JJ')
]
)Keluaran
[('great', 'JJ'), ('the', 'DT'), ('tutorial', 'NN')]Menukar kata benda kardinal
Seperti yang kita ketahui, kata utama seperti 5, ditandai sebagai CD dalam sebuah potongan. Kata-kata utama ini sering muncul sebelum atau sesudah kata benda, tetapi untuk tujuan normalisasi, sebaiknya selalu diletakkan sebelum kata benda. Misalnya tanggalJanuary 5 dapat ditulis sebagai 5 January. Mari kita pahami dengan contoh berikut.
Contoh
Untuk mencapai ini kita mendefinisikan fungsi bernama swapping_cardinals()yang akan menukar kardinal apa pun yang muncul segera setelah kata benda dengan kata benda. Dengan ini, kardinal akan muncul tepat sebelum kata benda. Untuk melakukan perbandingan kesetaraan dengan tag yang diberikan, itu menggunakan fungsi pembantu yang kami namai sebagaitag_eql().
def tag_eql(tag):
def f(wt):
return wt[1] == tag
return fSekarang kita bisa mendefinisikan swapping_cardinals () -
def swapping_cardinals (chunk):
cdidx = index_chunk(chunk, tag_eql('CD'))
if not cdidx or not chunk[cdidx-1][1].startswith('NN'):
return chunk
noun, nntag = chunk[cdidx-1]
chunk[cdidx-1] = chunk[cdidx]
chunk[cdidx] = noun, nntag
return chunkSekarang, mari kita telepon swapping_cardinals() berfungsi pada kencan “January 5” -
from Cardinals import swapping_cardinals()
swapping_cardinals([('Janaury', 'NNP'), ('5', 'CD')])Keluaran
[('10', 'CD'), ('January', 'NNP')]
10 JanuaryBerikut adalah dua alasan untuk mengubah pohon -
- Untuk memodifikasi pohon parse dalam dan
- Untuk meratakan pohon parse yang dalam
Mengubah Pohon atau Subtree menjadi Kalimat
Resep pertama yang akan kita bahas di sini adalah mengubah Pohon atau subpohon kembali menjadi kalimat atau rangkaian potongan. Ini sangat sederhana, mari kita lihat pada contoh berikut -
Contoh
from nltk.corpus import treebank_chunk
tree = treebank_chunk.chunked_sents()[2]
' '.join([w for w, t in tree.leaves()])Keluaran
'Rudolph Agnew , 55 years old and former chairman of Consolidated Gold Fields
PLC , was named a nonexecutive director of this British industrial
conglomerate .'Perataan pohon dalam
Pohon yang dalam dari frase bersarang tidak dapat digunakan untuk melatih bongkahan sehingga kita harus meratakannya sebelum menggunakan. Dalam contoh berikut, kita akan menggunakan kalimat parsing ke-3, yang merupakan pohon dalam frase bersarang, daritreebank korpus.
Contoh
Untuk mencapai ini, kami mendefinisikan fungsi bernama deeptree_flat()yang akan mengambil satu Pohon dan akan mengembalikan Pohon baru yang hanya menyimpan pohon dengan tingkat terendah. Untuk melakukan sebagian besar pekerjaan, ini menggunakan fungsi helper yang kami namai sebagaichildtree_flat().
from nltk.tree import Tree
def childtree_flat(trees):
children = []
for t in trees:
if t.height() < 3:
children.extend(t.pos())
elif t.height() == 3:
children.append(Tree(t.label(), t.pos()))
else:
children.extend(flatten_childtrees([c for c in t]))
return children
def deeptree_flat(tree):
return Tree(tree.label(), flatten_childtrees([c for c in tree]))Sekarang, mari kita telepon deeptree_flat() fungsi pada kalimat parsing ke-3, yang merupakan pohon dalam dari frasa bersarang, dari treebankkorpus. Kami menyimpan fungsi ini dalam file bernama deeptree.py.
from deeptree import deeptree_flat
from nltk.corpus import treebank
deeptree_flat(treebank.parsed_sents()[2])Keluaran
Tree('S', [Tree('NP', [('Rudolph', 'NNP'), ('Agnew', 'NNP')]),
(',', ','), Tree('NP', [('55', 'CD'),
('years', 'NNS')]), ('old', 'JJ'), ('and', 'CC'),
Tree('NP', [('former', 'JJ'),
('chairman', 'NN')]), ('of', 'IN'), Tree('NP', [('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC',
'NNP')]), (',', ','), ('was', 'VBD'),
('named', 'VBN'), Tree('NP-SBJ', [('*-1', '-NONE-')]),
Tree('NP', [('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN')]),
('of', 'IN'), Tree('NP',
[('this', 'DT'), ('British', 'JJ'),
('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])Membangun pohon dangkal
Di bagian sebelumnya, kita meratakan pohon dalam frase bersarang dengan hanya mempertahankan subpohon tingkat terendah. Pada bagian ini, kita akan mempertahankan hanya subpohon tingkat tertinggi yaitu untuk membangun pohon dangkal. Dalam contoh berikut kita akan menggunakan kalimat parsing ke-3, yang merupakan pohon dalam frase bersarang, daritreebank korpus.
Contoh
Untuk mencapai ini, kami mendefinisikan fungsi bernama tree_shallow() yang akan menghilangkan semua subpohon bersarang dengan hanya mempertahankan label subpohon teratas.
from nltk.tree import Tree
def tree_shallow(tree):
children = []
for t in tree:
if t.height() < 3:
children.extend(t.pos())
else:
children.append(Tree(t.label(), t.pos()))
return Tree(tree.label(), children)Sekarang, mari kita telepon tree_shallow()fungsi pada 3 rd diurai kalimat, yang merupakan pohon yang dalam frase bersarang, daritreebankkorpus. Kami menyimpan fungsi ini dalam file bernama shallowtree.py.
from shallowtree import shallow_tree
from nltk.corpus import treebank
tree_shallow(treebank.parsed_sents()[2])Keluaran
Tree('S', [Tree('NP-SBJ-1', [('Rudolph', 'NNP'), ('Agnew', 'NNP'), (',', ','),
('55', 'CD'), ('years', 'NNS'), ('old', 'JJ'), ('and', 'CC'),
('former', 'JJ'), ('chairman', 'NN'), ('of', 'IN'), ('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC', 'NNP'), (',', ',')]),
Tree('VP', [('was', 'VBD'), ('named', 'VBN'), ('*-1', '-NONE-'), ('a', 'DT'),
('nonexecutive', 'JJ'), ('director', 'NN'), ('of', 'IN'), ('this', 'DT'),
('British', 'JJ'), ('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])Kita bisa melihat perbedaannya dengan bantuan ketinggian pohon -
from nltk.corpus import treebank
tree_shallow(treebank.parsed_sents()[2]).height()Keluaran
3from nltk.corpus import treebank
treebank.parsed_sents()[2].height()Keluaran
9Konversi label pohon
Di pohon parse ada berbagai macam Treejenis label yang tidak ada di pohon potongan. Tetapi saat menggunakan pohon parse untuk melatih pemecah, kami ingin mengurangi variasi ini dengan mengubah beberapa label Pohon menjadi jenis label yang lebih umum. Sebagai contoh, kami memiliki dua subpohon NP alternatif yaitu NP-SBL dan NP-TMP. Kita bisa mengubah keduanya menjadi NP. Mari kita lihat bagaimana melakukannya dalam contoh berikut.
Contoh
Untuk mencapai ini kita mendefinisikan fungsi bernama tree_convert() yang membutuhkan dua argumen berikut -
- Pohon untuk diubah
- Pemetaan konversi label
Fungsi ini akan mengembalikan Pohon baru dengan semua label yang cocok diganti berdasarkan nilai dalam pemetaan.
from nltk.tree import Tree
def tree_convert(tree, mapping):
children = []
for t in tree:
if isinstance(t, Tree):
children.append(convert_tree_labels(t, mapping))
else:
children.append(t)
label = mapping.get(tree.label(), tree.label())
return Tree(label, children)Sekarang, mari kita telepon tree_convert() fungsi pada kalimat parsing ke-3, yang merupakan pohon dalam dari frasa bersarang, dari treebankkorpus. Kami menyimpan fungsi-fungsi ini dalam sebuah file bernamaconverttree.py.
from converttree import tree_convert
from nltk.corpus import treebank
mapping = {'NP-SBJ': 'NP', 'NP-TMP': 'NP'}
convert_tree_labels(treebank.parsed_sents()[2], mapping)Keluaran
Tree('S', [Tree('NP-SBJ-1', [Tree('NP', [Tree('NNP', ['Rudolph']),
Tree('NNP', ['Agnew'])]), Tree(',', [',']),
Tree('UCP', [Tree('ADJP', [Tree('NP', [Tree('CD', ['55']),
Tree('NNS', ['years'])]),
Tree('JJ', ['old'])]), Tree('CC', ['and']),
Tree('NP', [Tree('NP', [Tree('JJ', ['former']),
Tree('NN', ['chairman'])]), Tree('PP', [Tree('IN', ['of']),
Tree('NP', [Tree('NNP', ['Consolidated']),
Tree('NNP', ['Gold']), Tree('NNP', ['Fields']),
Tree('NNP', ['PLC'])])])])]), Tree(',', [','])]),
Tree('VP', [Tree('VBD', ['was']),Tree('VP', [Tree('VBN', ['named']),
Tree('S', [Tree('NP', [Tree('-NONE-', ['*-1'])]),
Tree('NP-PRD', [Tree('NP', [Tree('DT', ['a']),
Tree('JJ', ['nonexecutive']), Tree('NN', ['director'])]),
Tree('PP', [Tree('IN', ['of']), Tree('NP',
[Tree('DT', ['this']), Tree('JJ', ['British']), Tree('JJ', ['industrial']),
Tree('NN', ['conglomerate'])])])])])])]), Tree('.', ['.'])])Apa itu klasifikasi teks?
Klasifikasi teks, sesuai dengan namanya, adalah cara untuk mengkategorikan potongan teks atau dokumen. Tetapi di sini muncul pertanyaan mengapa kita perlu menggunakan pengklasifikasi teks? Setelah memeriksa penggunaan kata dalam dokumen atau bagian teks, pengklasifikasi akan dapat memutuskan label kelas apa yang harus diberikan padanya.
Pengklasifikasi Biner
Sesuai namanya, pengklasifikasi biner akan memutuskan di antara dua label. Misalnya positif atau negatif. Dalam hal ini, bagian teks atau dokumen dapat berupa satu label atau lainnya, tetapi tidak keduanya.
Pengklasifikasi Multi-label
Berlawanan dengan pengklasifikasi biner, pengklasifikasi multi-label dapat menetapkan satu atau beberapa label ke bagian teks atau dokumen.
Kumpulan Fitur Berlabel Vs Tidak Berlabel
Pemetaan nilai kunci dari nama fitur ke nilai fitur disebut kumpulan fitur. Kumpulan fitur berlabel atau data pelatihan sangat penting untuk pelatihan klasifikasi agar nantinya bisa mengklasifikasikan set fitur tak berlabel.
| Set Fitur Berlabel | Set Fitur Tidak Berlabel |
|---|---|
| Ini adalah tupel yang terlihat seperti (feat, label). | Itu adalah prestasi tersendiri. |
| Ini adalah instance dengan label kelas yang dikenal. | Tanpa label terkait, kita dapat menyebutnya sebagai instance. |
| Digunakan untuk melatih algoritme klasifikasi. | Setelah dilatih, algoritme klasifikasi dapat mengklasifikasikan kumpulan fitur yang tidak berlabel. |
Ekstraksi Fitur Teks
Ekstraksi fitur teks, seperti namanya, adalah proses mengubah daftar kata menjadi kumpulan fitur yang dapat digunakan oleh pengklasifikasi. Kita harus mengubah teks kita menjadi‘dict’ gaya fitur diatur karena Natural Language Tool Kit (NLTK) mengharapkan ‘dict’ set fitur gaya.
Model Bag of Words (BoW)
BoW, salah satu model paling sederhana di NLP, digunakan untuk mengekstrak fitur dari potongan teks atau dokumen sehingga dapat digunakan dalam pemodelan seperti dalam algoritma ML. Ini pada dasarnya membangun set fitur kehadiran kata dari semua kata dalam sebuah instance. Konsep di balik metode ini adalah metode ini tidak peduli berapa kali suatu kata muncul atau urutan kata, metode ini hanya peduli apakah kata tersebut ada dalam daftar kata atau tidak.
Contoh
Untuk contoh ini, kita akan mendefinisikan sebuah fungsi bernama bow () -
def bow(words):
return dict([(word, True) for word in words])Sekarang, mari kita telepon bow()berfungsi pada kata-kata. Kami menyimpan fungsi ini dalam file bernama bagwords.py.
from bagwords import bow
bow(['we', 'are', 'using', 'tutorialspoint'])Keluaran
{'we': True, 'are': True, 'using': True, 'tutorialspoint': True}Pengklasifikasi pelatihan
Di bagian sebelumnya, kami mempelajari cara mengekstrak fitur dari teks. Jadi sekarang kita bisa melatih pengklasifikasi. Pengklasifikasi pertama dan termudah adalahNaiveBayesClassifier kelas.
Penggolong Naïve Bayes
Untuk memprediksi probabilitas suatu set fitur tertentu milik label tertentu, digunakan teorema Bayes. Rumus teorema Bayes adalah sebagai berikut.
$$P(A|B)=\frac{P(B|A)P(A)}{P(B)}$$Sini,
P(A|B) - Ini juga disebut probabilitas posterior yaitu probabilitas peristiwa pertama yaitu A terjadi mengingat peristiwa kedua yaitu B terjadi.
P(B|A) - Ini adalah probabilitas peristiwa kedua yaitu B terjadi setelah peristiwa pertama yaitu A terjadi.
P(A), P(B) - Disebut juga probabilitas prior yaitu probabilitas kejadian pertama yaitu A atau event kedua yaitu B terjadi.
Untuk melatih pengklasifikasi Naïve Bayes, kami akan menggunakan movie_reviewskorpus dari NLTK. Korpus ini memiliki dua kategori teks, yaitu:pos dan neg. Kategori ini membuat pengklasifikasi dilatihkan padanya sebagai pengklasifikasi biner. Setiap file dalam korpus terdiri dari dua, satu review film positif dan review film negatif. Dalam contoh kami, kami akan menggunakan setiap file sebagai contoh tunggal untuk melatih dan menguji pengklasifikasi.
Contoh
Untuk pengklasifikasi pelatihan, kita memerlukan daftar set fitur berlabel, yang akan berbentuk [(featureset, label)]. Di sinifeatureset variabel adalah a dict dan label adalah label kelas yang dikenal untuk featureset. Kami akan membuat fungsi bernamalabel_corpus() yang akan mengambil korpus bernama movie_reviewsdan juga fungsi bernama feature_detector, yang secara default adalah bag of words. Ini akan membangun dan mengembalikan pemetaan dari bentuk, {label: [featureset]}. Setelah itu kita akan menggunakan pemetaan ini untuk membuat daftar contoh pelatihan berlabel dan contoh pengujian.
import collections
def label_corpus(corp, feature_detector=bow):
label_feats = collections.defaultdict(list)
for label in corp.categories():
for fileid in corp.fileids(categories=[label]):
feats = feature_detector(corp.words(fileids=[fileid]))
label_feats[label].append(feats)
return label_featsDengan bantuan fungsi di atas kita akan mendapatkan pemetaan {label:fetaureset}. Sekarang kita akan mendefinisikan satu fungsi lagi bernamasplit yang akan mengambil kembali pemetaan dari label_corpus() berfungsi dan membagi setiap daftar set fitur menjadi pelatihan berlabel serta contoh pengujian.
def split(lfeats, split=0.75):
train_feats = []
test_feats = []
for label, feats in lfeats.items():
cutoff = int(len(feats) * split)
train_feats.extend([(feat, label) for feat in feats[:cutoff]])
test_feats.extend([(feat, label) for feat in feats[cutoff:]])
return train_feats, test_featsSekarang, mari kita gunakan fungsi-fungsi ini pada korpus kita, yaitu movieroulette -
from nltk.corpus import movie_reviews
from featx import label_feats_from_corpus, split_label_feats
movie_reviews.categories()Keluaran
['neg', 'pos']Contoh
lfeats = label_feats_from_corpus(movie_reviews)
lfeats.keys()Keluaran
dict_keys(['neg', 'pos'])Contoh
train_feats, test_feats = split_label_feats(lfeats, split = 0.75)
len(train_feats)Keluaran
1500Contoh
len(test_feats)Keluaran
500Kami telah melihatnya di movie_reviewskorpus, ada 1000 file pos dan 1000 file neg. Kami juga mendapatkan 1500 contoh pelatihan berlabel dan 500 contoh pengujian berlabel.
Sekarang mari kita berlatih NaïveBayesClassifier menggunakan nya train() metode kelas -
from nltk.classify import NaiveBayesClassifier
NBC = NaiveBayesClassifier.train(train_feats)
NBC.labels()Keluaran
['neg', 'pos']Pengklasifikasi Pohon Keputusan
Pengklasifikasi penting lainnya adalah pengklasifikasi pohon keputusan. Di sini untuk melatihnyaDecisionTreeClassifierkelas akan membuat struktur pohon. Dalam struktur pohon ini setiap node berhubungan dengan nama fitur dan cabang sesuai dengan nilai fitur. Dan di bawah cabang kita akan sampai ke daun pohon yaitu label klasifikasi.
Untuk melatih pengklasifikasi pohon keputusan, kita akan menggunakan fitur pelatihan dan pengujian yang sama, yaitu train_feats dan test_feats, variabel yang kita buat movie_reviews korpus.
Contoh
Untuk melatih pengklasifikasi ini, kami akan memanggil DecisionTreeClassifier.train() metode kelas sebagai berikut -
from nltk.classify import DecisionTreeClassifier
decisiont_classifier = DecisionTreeClassifier.train(
train_feats, binary = True, entropy_cutoff = 0.8,
depth_cutoff = 5, support_cutoff = 30
)
accuracy(decisiont_classifier, test_feats)Keluaran
0.725Pengklasifikasi Entropi Maksimum
Pengklasifikasi penting lainnya adalah MaxentClassifier yang juga dikenal sebagai a conditional exponential classifier atau logistic regression classifier. Di sini untuk melatihnya,MaxentClassifier kelas akan mengonversi set fitur berlabel ke vektor menggunakan pengkodean.
Untuk melatih pengklasifikasi pohon keputusan, kita akan menggunakan fitur pelatihan dan pengujian yang sama, yaitu train_featsdan test_feats, variabel yang kita buat movie_reviews korpus.
Contoh
Untuk melatih pengklasifikasi ini, kami akan memanggil MaxentClassifier.train() metode kelas sebagai berikut -
from nltk.classify import MaxentClassifier
maxent_classifier = MaxentClassifier
.train(train_feats,algorithm = 'gis', trace = 0, max_iter = 10, min_lldelta = 0.5)
accuracy(maxent_classifier, test_feats)Keluaran
0.786Scikit-learn Classifier
Salah satu library machine learning (ML) terbaik adalah Scikit-learn. Ini sebenarnya berisi semua jenis algoritma ML untuk berbagai tujuan, tetapi semuanya memiliki pola desain yang sama seperti berikut -
- Menyesuaikan model dengan data
- Dan gunakan model itu untuk membuat prediksi
Daripada mengakses model scikit-learn secara langsung, di sini kita akan menggunakan NLTK SklearnClassifierkelas. Kelas ini adalah kelas pembungkus di sekitar model scikit-learn agar sesuai dengan antarmuka Pengklasifikasi NLTK.
Kami akan mengikuti langkah-langkah berikut untuk melatih a SklearnClassifier kelas -
Step 1 - Pertama kita akan membuat fitur pelatihan seperti yang kita lakukan di resep sebelumnya.
Step 2 - Sekarang, pilih dan impor algoritma Scikit-learn.
Step 3 - Selanjutnya, kita perlu membangun a SklearnClassifier kelas dengan algoritma yang dipilih.
Step 4 - Terakhir, kami akan berlatih SklearnClassifier kelas dengan fitur pelatihan kami.
Mari kita terapkan langkah-langkah ini dalam resep Python di bawah ini -
from nltk.classify.scikitlearn import SklearnClassifier
from sklearn.naive_bayes import MultinomialNB
sklearn_classifier = SklearnClassifier(MultinomialNB())
sklearn_classifier.train(train_feats)
<SklearnClassifier(MultinomialNB(alpha = 1.0,class_prior = None,fit_prior = True))>
accuracy(sk_classifier, test_feats)Keluaran
0.885Mengukur presisi dan perolehan
Saat melatih berbagai pengklasifikasi, kami juga telah mengukur akurasinya. Namun selain akurasi, ada sejumlah metrik lain yang digunakan untuk mengevaluasi pengklasifikasi. Dua dari metrik ini adalahprecision dan recall.
Contoh
Dalam contoh ini, kita akan menghitung presisi dan perolehan dari kelas NaiveBayesClassifier yang kita latih sebelumnya. Untuk mencapai ini kita akan membuat fungsi bernama metrics_PR () yang akan mengambil dua argumen, satu adalah pengklasifikasi terlatih dan lainnya adalah fitur pengujian berlabel. Kedua argumen tersebut sama seperti yang kami berikan saat menghitung keakuratan pengklasifikasi -
import collections
from nltk import metrics
def metrics_PR(classifier, testfeats):
refsets = collections.defaultdict(set)
testsets = collections.defaultdict(set)
for i, (feats, label) in enumerate(testfeats):
refsets[label].add(i)
observed = classifier.classify(feats)
testsets[observed].add(i)
precisions = {}
recalls = {}
for label in classifier.labels():
precisions[label] = metrics.precision(refsets[label],testsets[label])
recalls[label] = metrics.recall(refsets[label], testsets[label])
return precisions, recallsMari kita panggil fungsi ini untuk menemukan presisi dan penarikan -
from metrics_classification import metrics_PR
nb_precisions, nb_recalls = metrics_PR(nb_classifier,test_feats)
nb_precisions['pos']Keluaran
0.6713532466435213Contoh
nb_precisions['neg']Keluaran
0.9676271186440678Contoh
nb_recalls['pos']Keluaran
0.96Contoh
nb_recalls['neg']Keluaran
0.478Kombinasi pengklasifikasi dan pemungutan suara
Menggabungkan pengklasifikasi adalah salah satu cara terbaik untuk meningkatkan kinerja klasifikasi. Dan pemungutan suara adalah salah satu cara terbaik untuk menggabungkan beberapa pengklasifikasi. Untuk pemungutan suara kita perlu memiliki jumlah pengklasifikasi ganjil. Dalam resep Python berikut kita akan menggabungkan tiga pengklasifikasi yaitu kelas NaiveBayesClassifier, kelas DecisionTreeClassifier, dan kelas MaxentClassifier.
Untuk mencapai ini kita akan mendefinisikan fungsi bernama voting_classifiers () sebagai berikut.
import itertools
from nltk.classify import ClassifierI
from nltk.probability import FreqDist
class Voting_classifiers(ClassifierI):
def __init__(self, *classifiers):
self._classifiers = classifiers
self._labels = sorted(set(itertools.chain(*[c.labels() for c in classifiers])))
def labels(self):
return self._labels
def classify(self, feats):
counts = FreqDist()
for classifier in self._classifiers:
counts[classifier.classify(feats)] += 1
return counts.max()Mari kita panggil fungsi ini untuk menggabungkan tiga pengklasifikasi dan menemukan akurasi -
from vote_classification import Voting_classifiers
combined_classifier = Voting_classifiers(NBC, decisiont_classifier, maxent_classifier)
combined_classifier.labels()Keluaran
['neg', 'pos']Contoh
accuracy(combined_classifier, test_feats)Keluaran
0.948Dari keluaran di atas, kita dapat melihat bahwa pengklasifikasi gabungan mendapatkan akurasi tertinggi daripada pengklasifikasi individu.