Jaringan Neural Dalam
Jaringan neural dalam (DNN) adalah ANN dengan beberapa lapisan tersembunyi antara lapisan masukan dan keluaran. Mirip dengan ANN dangkal, DNN dapat membuat model hubungan non-linier yang kompleks.
Tujuan utama dari jaringan neural adalah untuk menerima serangkaian masukan, melakukan penghitungan yang semakin kompleks, dan memberikan keluaran untuk memecahkan masalah dunia nyata seperti klasifikasi. Kami membatasi diri untuk meneruskan jaringan saraf.
Kami memiliki masukan, keluaran, dan aliran data sekuensial di jaringan dalam.
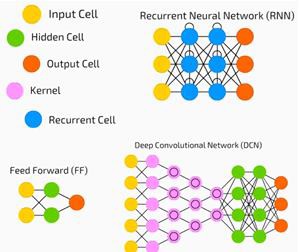
Jaringan saraf banyak digunakan dalam pembelajaran yang diawasi dan masalah pembelajaran penguatan. Jaringan ini didasarkan pada sekumpulan lapisan yang terhubung satu sama lain.
Dalam pembelajaran mendalam, jumlah lapisan tersembunyi, kebanyakan non-linier, bisa sangat besar; katakanlah sekitar 1000 lapisan.
Model DL menghasilkan hasil yang jauh lebih baik daripada jaringan ML normal.
Kami kebanyakan menggunakan metode penurunan gradien untuk mengoptimalkan jaringan dan meminimalkan fungsi kerugian.
Kita bisa menggunakan Imagenet, tempat penyimpanan jutaan gambar digital untuk mengklasifikasikan kumpulan data ke dalam kategori seperti kucing dan anjing. Jaringan DL semakin banyak digunakan untuk gambar dinamis selain dari gambar statis dan untuk deret waktu dan analisis teks.
Melatih kumpulan data merupakan bagian penting dari model Pembelajaran Mendalam. Selain itu, Backpropagation adalah algoritme utama dalam melatih model DL.
DL menangani pelatihan jaringan neural besar dengan transformasi input output yang kompleks.
Salah satu contoh DL adalah pemetaan foto ke nama orang dalam foto seperti yang mereka lakukan di jejaring sosial dan mendeskripsikan gambar dengan frasa adalah aplikasi DL terbaru lainnya.
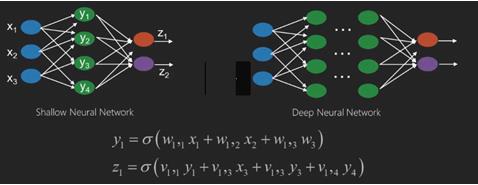
Jaringan neural adalah fungsi yang memiliki input seperti x1, x2, x3… yang diubah menjadi output seperti z1, z2, z3, dan seterusnya dalam dua (jaringan dangkal) atau beberapa operasi perantara yang juga disebut lapisan (jaringan dalam).
Bobot dan bias berubah dari lapisan ke lapisan. 'w' dan 'v' adalah bobot atau sinapsis dari lapisan jaringan saraf.
Kasus penggunaan terbaik dari pembelajaran mendalam adalah masalah pembelajaran yang diawasi. Di sini, kami memiliki sejumlah besar input data dengan serangkaian output yang diinginkan.
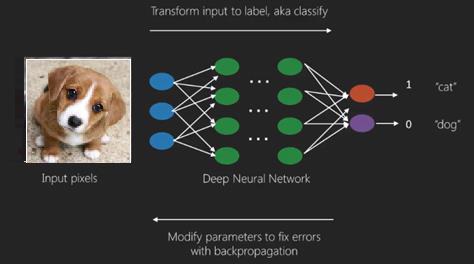
Di sini kami menerapkan algoritma propagasi balik untuk mendapatkan prediksi keluaran yang benar.
Kumpulan data paling dasar dari deep learning adalah MNIST, kumpulan data dari angka tulisan tangan.
Kita dapat melatih Jaringan Neural Konvolusional dengan Keras untuk mengklasifikasikan gambar digit tulisan tangan dari kumpulan data ini.
Pengaktifan atau aktivasi pengklasifikasi jaringan saraf menghasilkan skor. Misalnya, untuk mengklasifikasikan pasien sebagai sakit dan sehat, kami mempertimbangkan parameter seperti tinggi badan, berat badan dan suhu tubuh, tekanan darah, dll.
Skor tinggi berarti pasien sakit dan skor rendah berarti sehat.
Setiap node dalam output dan lapisan tersembunyi memiliki pengklasifikasi sendiri. Lapisan masukan mengambil masukan dan meneruskan skornya ke lapisan tersembunyi berikutnya untuk aktivasi lebih lanjut dan ini berlangsung hingga keluaran tercapai.
Kemajuan dari input ke output dari kiri ke kanan dalam arah maju disebut forward propagation.
Credit assignment path (CAP) pada neural network merupakan rangkaian transformasi yang dimulai dari input hingga output. CAPs menguraikan kemungkinan hubungan sebab akibat antara input dan output.
Kedalaman CAP untuk jaringan saraf maju umpan tertentu atau kedalaman CAP adalah jumlah lapisan tersembunyi ditambah satu sebagai lapisan keluaran disertakan. Untuk jaringan neural berulang, di mana sinyal dapat merambat melalui lapisan beberapa kali, kedalaman CAP berpotensi tidak terbatas.
Jaring Dalam dan Jaring Dangkal
Tidak ada ambang batas kedalaman yang jelas yang memisahkan pembelajaran dangkal dari pembelajaran dalam; tetapi sebagian besar disepakati bahwa untuk pembelajaran mendalam yang memiliki beberapa lapisan non-linier, CAP harus lebih besar dari dua.
Simpul dasar dalam jaringan saraf adalah persepsi yang meniru neuron dalam jaringan saraf biologis. Kemudian kami memiliki Persepsi atau MLP berlapis-lapis. Setiap set input dimodifikasi oleh satu set bobot dan bias; setiap sisi memiliki bobot yang unik dan setiap node memiliki bias yang unik.
Prediksinya accuracy jaringan saraf tergantung padanya weights and biases.
Proses meningkatkan akurasi jaringan saraf disebut training. Output dari jaring penyangga maju dibandingkan dengan nilai yang diketahui benar.
Itu cost function or the loss function adalah perbedaan antara keluaran yang dihasilkan dan keluaran aktual.
Inti dari pelatihan adalah membuat biaya pelatihan sekecil mungkin di jutaan contoh pelatihan. Untuk melakukan ini, jaringan menyesuaikan bobot dan bias hingga prediksi cocok dengan keluaran yang benar.
Setelah dilatih dengan baik, jaringan saraf berpotensi membuat prediksi yang akurat setiap saat.
Ketika polanya menjadi kompleks dan Anda ingin komputer Anda mengenalinya, Anda harus menggunakan jaringan neural. Dalam skenario pola yang kompleks seperti itu, jaringan saraf mengungguli semua algoritme pesaing lainnya.
Sekarang ada GPU yang bisa melatih mereka lebih cepat dari sebelumnya. Jaringan neural dalam sudah merevolusi bidang AI
Komputer telah terbukti pandai melakukan kalkulasi berulang dan mengikuti instruksi terperinci tetapi tidak begitu baik dalam mengenali pola yang rumit.
Jika ada masalah pengenalan pola sederhana, mesin vektor dukungan (svm) atau pengklasifikasi regresi logistik dapat melakukan pekerjaan dengan baik, tetapi karena kompleksitas pola meningkat, tidak ada cara lain selain menggunakan jaringan saraf yang dalam.
Oleh karena itu, untuk pola kompleks seperti wajah manusia, jaringan saraf dangkal gagal dan tidak memiliki alternatif selain menggunakan jaringan saraf dalam dengan lebih banyak lapisan. Jaring dalam mampu melakukan tugasnya dengan memecah pola kompleks menjadi pola yang lebih sederhana. Misalnya wajah manusia; adeep net akan menggunakan tepian untuk mendeteksi bagian seperti bibir, hidung, mata, telinga, dan sebagainya, lalu menggabungkannya kembali untuk membentuk wajah manusia.
Keakuratan prediksi yang benar menjadi begitu akurat sehingga baru-baru ini di Google Pattern Recognition Challenge, jaring yang dalam mengalahkan manusia.
Ide tentang jaringan perceptron berlapis ini telah ada selama beberapa waktu; di area ini, jaring yang dalam meniru otak manusia. Tetapi satu kelemahan dari ini adalah mereka membutuhkan waktu lama untuk berlatih, kendala perangkat keras
Namun GPU performa tinggi baru-baru ini telah mampu melatih jaring yang begitu dalam kurang dari seminggu; sementara fast cpus bisa memakan waktu berminggu-minggu atau mungkin berbulan-bulan untuk melakukan hal yang sama.
Memilih Deep Net
Bagaimana cara memilih jaring yang dalam? Kita harus memutuskan apakah kita sedang membangun pengklasifikasi atau jika kita mencoba menemukan pola dalam data dan jika kita akan menggunakan pembelajaran tanpa pengawasan. Untuk mengekstrak pola dari sekumpulan data yang tidak berlabel, kami menggunakan mesin Boltzman Terbatas atau encoder Otomatis.
Pertimbangkan poin-poin berikut saat memilih jaring dalam -
Untuk pemrosesan teks, analisis sentimen, penguraian, dan pengenalan entitas nama, kami menggunakan jaringan tensor neural jaringan atau rekursif berulang atau RNTN;
Untuk setiap model bahasa yang beroperasi pada level karakter, kami menggunakan jaringan berulang.
Untuk pengenalan gambar, kami menggunakan DBN jaringan keyakinan dalam atau jaringan konvolusional.
Untuk pengenalan objek, kami menggunakan RNTN atau jaringan konvolusional.
Untuk pengenalan suara, kami menggunakan jaringan berulang.
Secara umum, jaringan kepercayaan dalam dan perceptron multilayer dengan unit linier yang diperbaiki atau RELU keduanya merupakan pilihan yang baik untuk klasifikasi.
Untuk analisis deret waktu, selalu disarankan untuk menggunakan jaringan berulang.
Jaringan saraf telah ada selama lebih dari 50 tahun; tapi baru sekarang mereka menjadi terkenal. Alasannya adalah karena mereka sulit untuk dilatih; ketika kita mencoba melatihnya dengan metode yang disebut propagasi mundur, kita mengalami masalah yang disebut gradien lenyap atau meledak. Bila itu terjadi, pelatihan membutuhkan waktu lebih lama dan keakuratan mengambil tempat di belakang. Saat melatih kumpulan data, kami terus menghitung fungsi biaya, yang merupakan perbedaan antara keluaran yang diprediksi dan keluaran aktual dari sekumpulan data pelatihan berlabel. Fungsi biaya kemudian diminimalkan dengan menyesuaikan nilai bobot dan bias hingga nilai terendah diperoleh. Proses pelatihan menggunakan gradien, yaitu tingkat di mana biaya akan berubah sehubungan dengan perubahan bobot atau nilai bias.
Jaringan Boltzman atau Autoencoder Terbatas - RBN
Pada tahun 2006, sebuah terobosan telah dicapai dalam mengatasi masalah gradien yang hilang. Geoff Hinton merancang strategi baru yang mengarah pada pengembanganRestricted Boltzman Machine - RBM, jaring dua lapis yang dangkal.
Lapisan pertama adalah visible lapisan dan lapisan kedua adalah hiddenlapisan. Setiap node di lapisan yang terlihat terhubung ke setiap node di lapisan tersembunyi. Jaringan dikenal sebagai jaringan terbatas karena tidak ada dua lapisan dalam lapisan yang sama yang diizinkan untuk berbagi koneksi.
Autoencoder adalah jaringan yang menyandikan data masukan sebagai vektor. Mereka membuat representasi data mentah yang tersembunyi, atau terkompresi. Vektor berguna dalam reduksi dimensi; vektor memampatkan data mentah menjadi sejumlah kecil dimensi penting. Autoencoder dipasangkan dengan decoder, yang memungkinkan rekonstruksi data input berdasarkan representasi tersembunyinya.
RBM adalah padanan matematika dari penerjemah dua arah. Sebuah forward pass mengambil input dan menerjemahkannya menjadi satu set angka yang mengkodekan input. Sementara itu, backward pass mengambil rangkaian angka ini dan menerjemahkannya kembali menjadi input yang direkonstruksi. Jaring yang terlatih dapat menopang punggung dengan tingkat akurasi yang tinggi.
Di kedua langkah tersebut, bobot dan bias memiliki peran penting; mereka membantu RBM dalam memecahkan kode keterkaitan antara input dan dalam memutuskan input mana yang penting dalam mendeteksi pola. Melalui forward dan backward pass, RBM dilatih untuk membangun kembali masukan dengan bobot dan bias yang berbeda hingga masukan dan konstruksi sedekat mungkin. Aspek yang menarik dari RBM adalah bahwa data tidak perlu diberi label. Ini ternyata sangat penting untuk kumpulan data dunia nyata seperti foto, video, suara, dan data sensor, yang semuanya cenderung tidak berlabel. Alih-alih memberi label data secara manual oleh manusia, RBM secara otomatis menyortir data; dengan menyesuaikan bobot dan bias dengan benar, RBM dapat mengekstrak fitur penting dan merekonstruksi input. RBM adalah bagian dari jaringan neural ekstraktor fitur, yang dirancang untuk mengenali pola yang melekat dalam data. Ini juga disebut pembuat enkode otomatis karena harus menyandikan strukturnya sendiri.

Deep Belief Networks - DBN
Jaringan keyakinan mendalam (DBN) dibentuk dengan menggabungkan RBM dan memperkenalkan metode pelatihan yang cerdas. Kami memiliki model baru yang akhirnya memecahkan masalah gradien lenyap. Geoff Hinton menemukan RBM dan Deep Belief Nets sebagai alternatif untuk propagasi mundur.
DBN memiliki struktur yang mirip dengan MLP (Multi-layer perceptron), tetapi sangat berbeda dalam hal pelatihan. Ini adalah pelatihan yang memungkinkan DBN untuk mengungguli rekan-rekan mereka yang dangkal
DBN dapat divisualisasikan sebagai tumpukan RBM di mana lapisan tersembunyi dari salah satu RBM adalah lapisan RBM yang terlihat di atasnya. RBM pertama dilatih untuk merekonstruksi masukannya seakurat mungkin.
Lapisan tersembunyi dari RBM pertama diambil sebagai lapisan yang terlihat dari RBM kedua dan RBM kedua dilatih menggunakan keluaran dari RBM pertama. Proses ini diulang sampai setiap lapisan dalam jaringan dilatih.
Dalam DBN, setiap RBM mempelajari seluruh input. DBN bekerja secara global dengan menyelaraskan seluruh input secara berurutan karena modelnya perlahan meningkat seperti lensa kamera yang secara perlahan memfokuskan gambar. Tumpukan RBM mengungguli satu RBM karena MLP perceptron multi-layer mengungguli satu perceptron.
Pada tahap ini, RBM telah mendeteksi pola yang melekat dalam data tetapi tanpa nama atau label. Untuk menyelesaikan pelatihan DBN, kami harus memperkenalkan label pada pola dan menyempurnakan jaringan dengan pembelajaran yang diawasi.
Kami membutuhkan sekumpulan kecil sampel berlabel sehingga fitur dan pola dapat dikaitkan dengan sebuah nama. Kumpulan data berlabel kecil ini digunakan untuk pelatihan. Kumpulan data berlabel ini bisa sangat kecil jika dibandingkan dengan kumpulan data asli.
Bobot dan bias diubah sedikit, menghasilkan perubahan kecil dalam persepsi pola jaringan dan seringkali sedikit peningkatan dalam akurasi total.
Pelatihan juga dapat diselesaikan dalam waktu yang wajar dengan menggunakan GPU yang memberikan hasil yang sangat akurat dibandingkan dengan jaring dangkal dan kami juga melihat solusi untuk menghilangkan masalah gradien.
Generative Adversarial Networks - GANs
Jaringan permusuhan generatif adalah jaringan saraf dalam yang terdiri dari dua jaring, diadu satu dengan yang lain, sehingga disebut sebagai "permusuhan".
GAN diperkenalkan dalam sebuah makalah yang diterbitkan oleh para peneliti di University of Montreal pada tahun 2014. Pakar AI Facebook Yann LeCun, mengacu pada GAN, menyebut pelatihan adversarial sebagai "ide paling menarik dalam 10 tahun terakhir di ML".
Potensi GAN sangat besar, karena pemindaian jaringan belajar untuk meniru distribusi data apa pun. GAN dapat diajarkan untuk menciptakan dunia paralel yang sangat mirip dengan milik kita di domain apa pun: gambar, musik, ucapan, prosa. Mereka adalah seniman robot, dan hasil mereka cukup mengesankan.
Dalam GAN, satu jaringan neural, yang dikenal sebagai generator, menghasilkan instance data baru, sementara yang lain, diskriminator, mengevaluasi keasliannya.
Misalkan kita mencoba untuk menghasilkan angka tulisan tangan seperti yang ditemukan di dataset MNIST, yang diambil dari dunia nyata. Pekerjaan diskriminator, ketika diperlihatkan contoh dari dataset MNIST yang sebenarnya, adalah mengenali mereka sebagai asli.
Sekarang pertimbangkan langkah-langkah GAN berikut -
Jaringan generator mengambil input dalam bentuk bilangan acak dan mengembalikan gambar.
Gambar yang dihasilkan ini diberikan sebagai masukan ke jaringan diskriminator bersama dengan aliran gambar yang diambil dari dataset yang sebenarnya.
Diskriminator mengambil gambar asli dan palsu serta probabilitas pengembalian, angka antara 0 dan 1, dengan 1 mewakili prediksi keaslian dan 0 mewakili palsu.
Jadi, Anda memiliki umpan balik ganda -
Diskriminator berada dalam lingkaran umpan balik dengan kebenaran dasar gambar, yang kita ketahui.
Generator berada dalam loop umpan balik dengan diskriminator.
Jaringan Neural Berulang - RNN
RNNJaringan syaraf tiruan di mana data dapat mengalir ke segala arah. Jaringan ini digunakan untuk aplikasi seperti pemodelan bahasa atau Natural Language Processing (NLP).
Konsep dasar yang mendasari RNN adalah memanfaatkan informasi berurutan. Dalam jaringan saraf normal diasumsikan bahwa semua input dan output tidak bergantung satu sama lain. Jika kita ingin memprediksi kata berikutnya dalam sebuah kalimat, kita harus tahu kata mana yang muncul sebelumnya.
RNN disebut berulang karena mereka mengulangi tugas yang sama untuk setiap elemen dari suatu urutan, dengan keluaran yang didasarkan pada perhitungan sebelumnya. Dengan demikian RNN dapat dikatakan memiliki "memori" yang menangkap informasi tentang apa yang telah dihitung sebelumnya. Secara teori, RNN dapat menggunakan informasi dalam urutan yang sangat panjang, tetapi pada kenyataannya, RNN hanya dapat melihat beberapa langkah ke belakang.
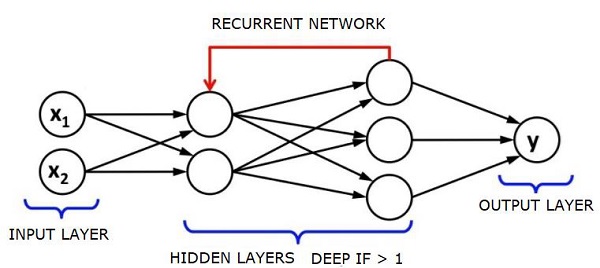
Jaringan memori jangka pendek (LSTM) adalah RNN yang paling umum digunakan.
Bersama dengan Jaringan Neural konvolusional, RNN telah digunakan sebagai bagian dari model untuk menghasilkan deskripsi untuk gambar yang tidak berlabel. Sungguh menakjubkan seberapa baik ini tampaknya bekerja.
Convolutional Deep Neural Networks - CNN
Jika kita menambah jumlah lapisan dalam jaringan saraf untuk membuatnya lebih dalam, itu meningkatkan kompleksitas jaringan dan memungkinkan kita untuk memodelkan fungsi yang lebih rumit. Namun, jumlah bobot dan bias akan meningkat secara eksponensial. Faktanya, mempelajari masalah yang sulit seperti itu bisa menjadi tidak mungkin untuk jaringan saraf normal. Ini mengarah pada solusi, jaringan saraf konvolusional.
CNN banyak digunakan dalam computer vision; telah diterapkan juga dalam pemodelan akustik untuk pengenalan suara otomatis.
Ide di balik jaringan saraf konvolusional adalah ide tentang "filter bergerak" yang melewati gambar. Filter bergerak ini, atau konvolusi, berlaku untuk lingkungan node tertentu yang misalnya mungkin piksel, di mana filter yang diterapkan adalah 0,5 x nilai node -
Peneliti terkemuka Yann LeCun memelopori jaringan saraf konvolusional. Facebook sebagai software pengenal wajah menggunakan jaring tersebut. CNN telah menjadi solusi tepat untuk proyek-proyek visi mesin. Ada banyak lapisan pada jaringan konvolusional. Dalam tantangan Imagenet, sebuah mesin mampu mengalahkan manusia pada pengenalan objek pada tahun 2015.
Singkatnya, Convolutional Neural Networks (CNNs) adalah jaringan saraf multi-layer. Lapisan terkadang hingga 17 atau lebih dan menganggap data input berupa gambar.
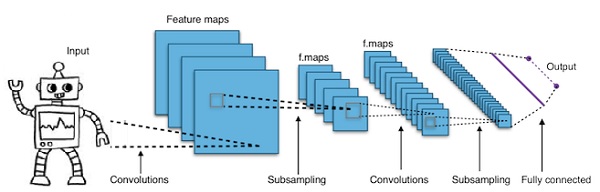
CNN secara drastis mengurangi jumlah parameter yang perlu disetel. Jadi, CNN secara efisien menangani dimensi tinggi dari gambar mentah.