PyTorch - Panduan Cepat
PyTorch didefinisikan sebagai pustaka pembelajaran mesin sumber terbuka untuk Python. Ini digunakan untuk aplikasi seperti pemrosesan bahasa alami. Ini awalnya dikembangkan oleh kelompok penelitian kecerdasan buatan Facebook, dan perangkat lunak Pyro Uber untuk pemrograman probabilistik yang dibangun di atasnya.
Awalnya, PyTorch dikembangkan oleh Hugh Perkins sebagai pembungkus Python untuk LusJIT berdasarkan kerangka kerja Torch. Ada dua varian PyTorch.
PyTorch mendesain ulang dan mengimplementasikan Torch dengan Python sambil berbagi pustaka C inti yang sama untuk kode backend. Pengembang PyTorch menyetel kode back-end ini untuk menjalankan Python secara efisien. Mereka juga mempertahankan akselerasi hardware berbasis GPU serta fitur ekstensibilitas yang membuat Torch berbasis Lua.
fitur
Fitur utama PyTorch disebutkan di bawah ini -
Easy Interface- PyTorch menawarkan API yang mudah digunakan; karena itu dianggap sangat sederhana untuk dioperasikan dan dijalankan dengan Python. Eksekusi kode dalam kerangka ini cukup mudah.
Python usage- Library ini dianggap Pythonic yang terintegrasi dengan mulus dengan tumpukan data science Python. Dengan demikian, ini dapat memanfaatkan semua layanan dan fungsi yang ditawarkan oleh lingkungan Python.
Computational graphs- PyTorch menyediakan platform luar biasa yang menawarkan grafik komputasi dinamis. Jadi, pengguna dapat mengubahnya selama waktu proses. Ini sangat berguna saat developer tidak mengetahui berapa banyak memori yang diperlukan untuk membuat model jaringan neural.
PyTorch dikenal memiliki tiga tingkat abstraksi seperti yang diberikan di bawah ini -
Tensor - Larik n-dimensi imperatif yang berjalan pada GPU.
Variabel - Node dalam grafik komputasi. Ini menyimpan data dan gradien.
Modul - Lapisan jaringan saraf yang akan menyimpan status atau bobot yang dapat dipelajari.
Keuntungan dari PyTorch
Berikut ini adalah keunggulan PyTorch -
Sangat mudah untuk men-debug dan memahami kodenya.
Ini mencakup banyak lapisan sebagai Torch.
Ini mencakup banyak fungsi kerugian.
Ini dapat dianggap sebagai ekstensi NumPy ke GPU.
Ini memungkinkan membangun jaringan yang strukturnya bergantung pada komputasi itu sendiri.
TensorFlow vs. PyTorch
Kami akan melihat perbedaan utama antara TensorFlow dan PyTorch di bawah ini -
| PyTorch | TensorFlow |
|---|---|
PyTorch terkait erat dengan kerangka kerja Torch berbasis lua yang secara aktif digunakan di Facebook. |
TensorFlow dikembangkan oleh Google Brain dan secara aktif digunakan di Google. |
PyTorch relatif baru dibandingkan dengan teknologi kompetitif lainnya. |
TensorFlow bukanlah hal baru dan dianggap sebagai fitur yang bisa digunakan oleh banyak peneliti dan profesional industri. |
PyTorch mencakup semuanya dengan cara yang imperatif dan dinamis. |
TensorFlow menyertakan grafik statis dan dinamis sebagai kombinasi. |
Grafik komputasi di PyTorch ditentukan selama runtime. |
TensorFlow tidak menyertakan opsi waktu proses apa pun. |
PyTorch menyertakan fitur penerapan untuk kerangka kerja seluler dan tersemat. |
TensorFlow berfungsi lebih baik untuk framework tersemat. |
PyTorch adalah framework pembelajaran mendalam yang populer. Dalam tutorial ini, kami menganggap "Windows 10" sebagai sistem operasi kami. Langkah-langkah untuk pengaturan lingkungan yang sukses adalah sebagai berikut -
Langkah 1
Tautan berikut menyertakan daftar paket yang menyertakan paket yang sesuai untuk PyTorch.
https://drive.google.com/drive/folders/0B-X0-FlSGfCYdTNldW02UGl4MXMYang perlu Anda lakukan hanyalah mengunduh paket masing-masing dan menginstalnya seperti yang ditunjukkan pada tangkapan layar berikut -


Langkah 2
Ini melibatkan verifikasi instalasi kerangka kerja PyTorch menggunakan Kerangka Anaconda.
Perintah berikut digunakan untuk memverifikasi hal yang sama -
conda list
"Conda list" menunjukkan daftar framework yang diinstal.

Bagian yang disorot menunjukkan bahwa PyTorch telah berhasil diinstal di sistem kami.
Matematika sangat penting dalam algoritme pembelajaran mesin apa pun dan mencakup berbagai konsep inti matematika untuk mendapatkan algoritme yang tepat yang dirancang dengan cara tertentu.
Pentingnya topik matematika untuk pembelajaran mesin dan ilmu data disebutkan di bawah -

Sekarang, mari kita fokus pada konsep matematika utama dari pembelajaran mesin yang penting dari sudut pandang Pemrosesan Bahasa Alami -
Vektor
Vektor dianggap sebagai larik bilangan yang kontinu atau diskrit dan ruang yang terdiri dari vektor disebut ruang vektor. Dimensi ruang vektor dapat berupa finite atau infinite tetapi telah diamati bahwa masalah machine learning dan data science berhubungan dengan vektor dengan panjang tetap.
Representasi vektor ditampilkan seperti yang disebutkan di bawah ini -
temp = torch.FloatTensor([23,24,24.5,26,27.2,23.0])
temp.size()
Output - torch.Size([6])Dalam pembelajaran mesin, kami menangani data multidimensi. Jadi vektor menjadi sangat penting dan dianggap sebagai fitur masukan untuk pernyataan masalah prediksi apa pun.
Scalars
Skalar disebut memiliki dimensi nol yang hanya berisi satu nilai. Untuk PyTorch, ini tidak menyertakan tensor khusus dengan dimensi nol; maka deklarasi akan dibuat sebagai berikut -
x = torch.rand(10)
x.size()
Output - torch.Size([10])Matriks
Sebagian besar data terstruktur biasanya direpresentasikan dalam bentuk tabel atau matriks tertentu. Kami akan menggunakan kumpulan data yang disebut Harga Rumah Boston, yang sudah tersedia di pustaka pembelajaran mesin scikit-learn Python.
boston_tensor = torch.from_numpy(boston.data)
boston_tensor.size()
Output: torch.Size([506, 13])
boston_tensor[:2]
Output:
Columns 0 to 7
0.0063 18.0000 2.3100 0.0000 0.5380 6.5750 65.2000 4.0900
0.0273 0.0000 7.0700 0.0000 0.4690 6.4210 78.9000 4.9671
Columns 8 to 12
1.0000 296.0000 15.3000 396.9000 4.9800
2.0000 242.0000 17.8000 396.9000 9.1400Prinsip utama jaringan saraf tiruan mencakup kumpulan elemen dasar, yaitu neuron buatan atau perceptron. Ini mencakup beberapa input dasar seperti x1, x2… .. xn yang menghasilkan output biner jika jumlahnya lebih besar dari potensi aktivasi.
Representasi skematis dari sampel neuron disebutkan di bawah ini -

Output yang dihasilkan dapat dianggap sebagai jumlah tertimbang dengan potensi aktivasi atau bias.
$$ Output = \ sum_jw_jx_j + Bias $$
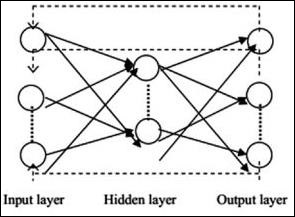
Arsitektur jaringan saraf tipikal dijelaskan di bawah ini -

Lapisan antara masukan dan keluaran disebut sebagai lapisan tersembunyi, dan kepadatan serta jenis koneksi antar lapisan adalah konfigurasinya. Misalnya, konfigurasi yang sepenuhnya terhubung memiliki semua neuron dari lapisan L yang terhubung ke L + 1. Untuk pelokalan yang lebih jelas, kita hanya dapat menghubungkan lingkungan lokal, katakanlah sembilan neuron, ke lapisan berikutnya. Gambar 1-9 mengilustrasikan dua lapisan tersembunyi dengan koneksi yang padat.
Berbagai jenis jaringan saraf adalah sebagai berikut -
Jaringan Neural Feedforward
Jaringan saraf maju mundur mencakup unit dasar keluarga jaringan saraf. Pergerakan data dalam jenis jaringan saraf ini adalah dari lapisan masukan ke lapisan keluaran, melalui lapisan tersembunyi yang ada. Output dari satu lapisan berfungsi sebagai lapisan masukan dengan batasan pada semua jenis loop dalam arsitektur jaringan.

Jaringan Neural Berulang
Jaringan Neural Berulang adalah saat pola data berubah secara konsekuen selama periode tertentu. Di RNN, lapisan yang sama diterapkan untuk menerima parameter masukan dan menampilkan parameter keluaran dalam jaringan saraf tertentu.
Jaringan saraf dapat dibangun menggunakan paket torch.nn.

Ini adalah jaringan umpan-maju sederhana. Ia mengambil masukan, memberinya makan melalui beberapa lapisan satu demi satu, dan akhirnya memberikan keluaran.
Dengan bantuan PyTorch, kita dapat menggunakan langkah-langkah berikut untuk prosedur pelatihan umum untuk jaringan saraf -
- Tentukan jaringan saraf yang memiliki beberapa parameter (atau bobot) yang dapat dipelajari.
- Iterasi di atas kumpulan data masukan.
- Proses input melalui jaringan.
- Hitung kerugian (seberapa jauh keluaran dari yang benar).
- Sebarkan gradien kembali ke parameter jaringan.
- Perbarui bobot jaringan, biasanya menggunakan pembaruan sederhana seperti yang diberikan di bawah ini
rule: weight = weight -learning_rate * gradientArtificial Intelligence sedang menjadi tren saat ini. Pembelajaran mesin dan pembelajaran mendalam merupakan kecerdasan buatan. Diagram Venn yang disebutkan di bawah menjelaskan hubungan pembelajaran mesin dan pembelajaran mendalam.

Pembelajaran mesin
Pembelajaran mesin adalah seni sains yang memungkinkan komputer bertindak sesuai dengan algoritma yang dirancang dan diprogram. Banyak peneliti berpikir bahwa pembelajaran mesin adalah cara terbaik untuk membuat kemajuan menuju AI tingkat manusia. Ini mencakup berbagai jenis pola seperti -
- Pola Pembelajaran Terbimbing
- Pola Pembelajaran Tanpa Pengawasan
Pembelajaran Mendalam
Pembelajaran mendalam adalah subbidang pembelajaran mesin di mana algoritme terkait terinspirasi oleh struktur dan fungsi otak yang disebut Jaringan Syaraf Tiruan.
Pembelajaran mendalam menjadi sangat penting melalui pembelajaran yang diawasi atau pembelajaran dari data dan algoritma berlabel. Setiap algoritma dalam pembelajaran mendalam melewati proses yang sama. Ini mencakup hierarki transformasi nonlinier masukan dan penggunaan untuk membuat model statistik sebagai keluaran.
Proses pembelajaran mesin ditentukan menggunakan langkah-langkah berikut -
- Mengidentifikasi kumpulan data yang relevan dan mempersiapkannya untuk analisis.
- Memilih jenis algoritma yang akan digunakan.
- Membangun model analitik berdasarkan algoritma yang digunakan.
- Melatih model pada kumpulan data pengujian, merevisinya sesuai kebutuhan.
- Menjalankan model untuk menghasilkan skor tes.
Pada bab ini, kita akan membahas perbedaan utama antara konsep Machine dan Deep learning.
Jumlah Data
Pembelajaran mesin bekerja dengan jumlah data yang berbeda dan terutama digunakan untuk sejumlah kecil data. Pembelajaran mendalam di sisi lain bekerja secara efisien jika jumlah data meningkat dengan cepat. Diagram berikut menggambarkan cara kerja machine learning dan deep learning sehubungan dengan jumlah data -

Ketergantungan Hardware
Algoritme pembelajaran mendalam dirancang untuk sangat bergantung pada mesin kelas atas yang bertentangan dengan algoritme pembelajaran mesin tradisional. Algoritme pembelajaran mendalam melakukan operasi perkalian matriks dalam jumlah besar yang membutuhkan dukungan perangkat keras yang sangat besar.
Rekayasa Fitur
Rekayasa fitur adalah proses menempatkan pengetahuan domain ke dalam fitur tertentu untuk mengurangi kompleksitas data dan membuat pola yang terlihat oleh algoritme pembelajaran.
Misalnya, pola pembelajaran mesin tradisional berfokus pada piksel dan atribut lain yang diperlukan untuk proses rekayasa fitur. Algoritme pembelajaran mendalam berfokus pada fitur tingkat tinggi dari data. Ini mengurangi tugas mengembangkan ekstraktor fitur baru untuk setiap masalah baru.
PyTorch menyertakan fitur khusus untuk membuat dan mengimplementasikan jaringan saraf. Dalam bab ini, kita akan membuat jaringan saraf sederhana dengan satu lapisan tersembunyi yang mengembangkan satu unit keluaran.
Kami akan menggunakan langkah-langkah berikut untuk mengimplementasikan jaringan saraf pertama menggunakan PyTorch -
Langkah 1
Pertama, kita perlu mengimpor pustaka PyTorch menggunakan perintah di bawah ini -
import torch
import torch.nn as nnLangkah 2
Tentukan semua lapisan dan ukuran kumpulan untuk mulai menjalankan jaringan saraf seperti yang ditunjukkan di bawah ini -
# Defining input size, hidden layer size, output size and batch size respectively
n_in, n_h, n_out, batch_size = 10, 5, 1, 10LANGKAH 3
Karena jaringan saraf menyertakan kombinasi data masukan untuk mendapatkan data keluaran masing-masing, kami akan mengikuti prosedur yang sama seperti yang diberikan di bawah ini -
# Create dummy input and target tensors (data)
x = torch.randn(batch_size, n_in)
y = torch.tensor([[1.0], [0.0], [0.0],
[1.0], [1.0], [1.0], [0.0], [0.0], [1.0], [1.0]])LANGKAH 4
Buat model sekuensial dengan bantuan fungsi built-in. Menggunakan baris kode di bawah ini, buat model sekuensial -
# Create a model
model = nn.Sequential(nn.Linear(n_in, n_h),
nn.ReLU(),
nn.Linear(n_h, n_out),
nn.Sigmoid())LANGKAH 5
Bangun fungsi kerugian dengan bantuan pengoptimal Gradient Descent seperti yang ditunjukkan di bawah ini -
Construct the loss function
criterion = torch.nn.MSELoss()
# Construct the optimizer (Stochastic Gradient Descent in this case)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)LANGKAH 6
Menerapkan model penurunan gradien dengan loop iterasi dengan baris kode yang diberikan -
# Gradient Descent
for epoch in range(50):
# Forward pass: Compute predicted y by passing x to the model
y_pred = model(x)
# Compute and print loss
loss = criterion(y_pred, y)
print('epoch: ', epoch,' loss: ', loss.item())
# Zero gradients, perform a backward pass, and update the weights.
optimizer.zero_grad()
# perform a backward pass (backpropagation)
loss.backward()
# Update the parameters
optimizer.step()LANGKAH 7
Output yang dihasilkan adalah sebagai berikut -
epoch: 0 loss: 0.2545787990093231
epoch: 1 loss: 0.2545052170753479
epoch: 2 loss: 0.254431813955307
epoch: 3 loss: 0.25435858964920044
epoch: 4 loss: 0.2542854845523834
epoch: 5 loss: 0.25421255826950073
epoch: 6 loss: 0.25413978099823
epoch: 7 loss: 0.25406715273857117
epoch: 8 loss: 0.2539947032928467
epoch: 9 loss: 0.25392240285873413
epoch: 10 loss: 0.25385022163391113
epoch: 11 loss: 0.25377824902534485
epoch: 12 loss: 0.2537063956260681
epoch: 13 loss: 0.2536346912384033
epoch: 14 loss: 0.25356316566467285
epoch: 15 loss: 0.25349172949790955
epoch: 16 loss: 0.25342053174972534
epoch: 17 loss: 0.2533493936061859
epoch: 18 loss: 0.2532784342765808
epoch: 19 loss: 0.25320762395858765
epoch: 20 loss: 0.2531369626522064
epoch: 21 loss: 0.25306645035743713
epoch: 22 loss: 0.252996027469635
epoch: 23 loss: 0.2529257833957672
epoch: 24 loss: 0.25285571813583374
epoch: 25 loss: 0.25278574228286743
epoch: 26 loss: 0.25271597504615784
epoch: 27 loss: 0.25264623761177063
epoch: 28 loss: 0.25257670879364014
epoch: 29 loss: 0.2525072991847992
epoch: 30 loss: 0.2524380087852478
epoch: 31 loss: 0.2523689270019531
epoch: 32 loss: 0.25229987502098083
epoch: 33 loss: 0.25223103165626526
epoch: 34 loss: 0.25216227769851685
epoch: 35 loss: 0.252093642950058
epoch: 36 loss: 0.25202515721321106
epoch: 37 loss: 0.2519568204879761
epoch: 38 loss: 0.251888632774353
epoch: 39 loss: 0.25182053446769714
epoch: 40 loss: 0.2517525553703308
epoch: 41 loss: 0.2516847252845764
epoch: 42 loss: 0.2516169846057892
epoch: 43 loss: 0.2515493929386139
epoch: 44 loss: 0.25148195028305054
epoch: 45 loss: 0.25141456723213196
epoch: 46 loss: 0.2513473629951477
epoch: 47 loss: 0.2512802183628082
epoch: 48 loss: 0.2512132525444031
epoch: 49 loss: 0.2511464059352875Melatih algoritme pembelajaran mendalam melibatkan langkah-langkah berikut -
- Membangun pipeline data
- Membangun arsitektur jaringan
- Mengevaluasi arsitektur menggunakan fungsi kerugian
- Mengoptimalkan bobot arsitektur jaringan menggunakan algoritme pengoptimalan
Melatih algoritme pembelajaran mendalam tertentu adalah persyaratan yang tepat untuk mengubah jaringan neural menjadi blok fungsional seperti yang ditunjukkan di bawah ini -

Sehubungan dengan diagram di atas, algoritme pembelajaran mendalam apa pun melibatkan mendapatkan data masukan, membangun arsitektur masing-masing yang mencakup sekumpulan lapisan yang tertanam di dalamnya.
Jika Anda mengamati diagram di atas, keakuratannya dievaluasi menggunakan fungsi kerugian sehubungan dengan pengoptimalan bobot jaringan saraf.
Dalam bab ini, kita akan membahas beberapa istilah yang paling umum digunakan di PyTorch.
PyTorch NumPy
Tensor PyTorch identik dengan array NumPy. Tensor adalah larik berdimensi-n dan sehubungan dengan PyTorch, ia menyediakan banyak fungsi untuk beroperasi pada tensor ini.
Tensor PyTorch biasanya menggunakan GPU untuk mempercepat komputasi numeriknya. Tensor yang dibuat di PyTorch ini dapat digunakan untuk menyesuaikan jaringan dua lapisan ke data acak. Pengguna dapat secara manual mengimplementasikan forward dan backward melewati jaringan.
Variabel dan Autograd
Saat menggunakan autograd, penerusan jaringan Anda akan menentukan a computational graph - node dalam grafik akan menjadi Tensor, dan edge akan menjadi fungsi yang menghasilkan Tensor keluaran dari Tensor input.
Tensor PyTorch dapat dibuat sebagai objek variabel di mana variabel mewakili node dalam grafik komputasi.
Grafik Dinamis
Grafik statis bagus karena pengguna dapat mengoptimalkan grafik di depan. Jika pemrogram menggunakan kembali grafik yang sama berulang kali, maka pengoptimalan di muka yang berpotensi mahal ini dapat dipertahankan karena grafik yang sama dijalankan ulang berulang kali.
Perbedaan utama di antara keduanya adalah grafik komputasi Tensor Flow bersifat statis dan PyTorch menggunakan grafik komputasi dinamis.
Paket Optim
Paket optim di PyTorch mengabstraksi gagasan tentang algoritme pengoptimalan yang diimplementasikan dalam banyak cara dan memberikan ilustrasi algoritme pengoptimalan yang umum digunakan. Ini bisa disebut dalam pernyataan impor.
Multiprocessing
Multiprocessing mendukung operasi yang sama, sehingga semua tensor bekerja pada banyak prosesor. Antrian akan memindahkan datanya ke memori bersama dan hanya akan mengirim pegangan ke proses lain.
PyTorch menyertakan paket yang disebut torchvision yang digunakan untuk memuat dan menyiapkan kumpulan data. Ini mencakup dua fungsi dasar yaitu Dataset dan DataLoader yang membantu dalam transformasi dan pemuatan dataset.
Himpunan data
Set data digunakan untuk membaca dan mengubah titik data dari set data yang diberikan. Sintaks dasar yang akan diterapkan disebutkan di bawah -
trainset = torchvision.datasets.CIFAR10(root = './data', train = True,
download = True, transform = transform)DataLoader digunakan untuk mengocok dan mengumpulkan data. Ini dapat digunakan untuk memuat data secara paralel dengan pekerja multiprosesing.
trainloader = torch.utils.data.DataLoader(trainset, batch_size = 4,
shuffle = True, num_workers = 2)Contoh: Memuat File CSV
Kami menggunakan paket Python Panda untuk memuat file csv. File asli memiliki format berikut: (nama gambar, 68 tengara - setiap tengara memiliki sumbu, koordinat y).
landmarks_frame = pd.read_csv('faces/face_landmarks.csv')
n = 65
img_name = landmarks_frame.iloc[n, 0]
landmarks = landmarks_frame.iloc[n, 1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2)Pada bab ini, kita akan berfokus pada contoh dasar penerapan regresi linier menggunakan TensorFlow. Regresi logistik atau regresi linier adalah pendekatan pembelajaran mesin yang diawasi untuk klasifikasi kategori pesanan berlainan. Tujuan kita dalam bab ini adalah untuk membangun model yang dapat digunakan pengguna untuk memprediksi hubungan antara variabel prediktor dan satu atau lebih variabel independen.
Hubungan antara kedua variabel ini dianggap linier yaitu jika y sebagai variabel terikat dan x dianggap sebagai variabel bebas, maka hubungan regresi linier kedua variabel akan terlihat seperti persamaan yang disebutkan di bawah ini -
Y = Ax+bSelanjutnya, kita akan merancang algoritme untuk regresi linier yang memungkinkan kita memahami dua konsep penting yang diberikan di bawah ini -
- Fungsi Biaya
- Algoritma Penurunan Gradien
Representasi skematis dari regresi linier disebutkan di bawah ini
Menafsirkan hasilnya
$$ Y = ax + b $$
Nilai dari a adalah lereng.
Nilai dari b adalah y − intercept.
r adalah correlation coefficient.
r2 adalah correlation coefficient.
Tampilan grafik dari persamaan regresi linier disebutkan di bawah ini -

Langkah-langkah berikut digunakan untuk mengimplementasikan regresi linier menggunakan PyTorch -
Langkah 1
Impor paket yang diperlukan untuk membuat regresi linier di PyTorch menggunakan kode di bawah ini -
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import seaborn as sns
import pandas as pd
%matplotlib inline
sns.set_style(style = 'whitegrid')
plt.rcParams["patch.force_edgecolor"] = TrueLangkah 2
Buat satu set pelatihan dengan set data yang tersedia seperti yang ditunjukkan di bawah ini -
m = 2 # slope
c = 3 # interceptm = 2 # slope
c = 3 # intercept
x = np.random.rand(256)
noise = np.random.randn(256) / 4
y = x * m + c + noise
df = pd.DataFrame()
df['x'] = x
df['y'] = y
sns.lmplot(x ='x', y ='y', data = df)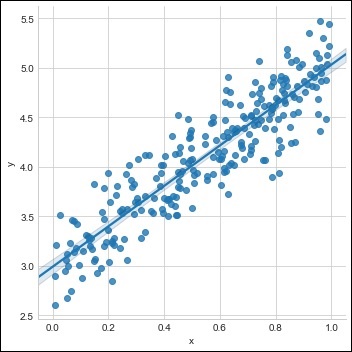
LANGKAH 3
Menerapkan regresi linier dengan pustaka PyTorch seperti yang disebutkan di bawah ini -
import torch
import torch.nn as nn
from torch.autograd import Variable
x_train = x.reshape(-1, 1).astype('float32')
y_train = y.reshape(-1, 1).astype('float32')
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
input_dim = x_train.shape[1]
output_dim = y_train.shape[1]
input_dim, output_dim(1, 1)
model = LinearRegressionModel(input_dim, output_dim)
criterion = nn.MSELoss()
[w, b] = model.parameters()
def get_param_values():
return w.data[0][0], b.data[0]
def plot_current_fit(title = ""):
plt.figure(figsize = (12,4))
plt.title(title)
plt.scatter(x, y, s = 8)
w1 = w.data[0][0]
b1 = b.data[0]
x1 = np.array([0., 1.])
y1 = x1 * w1 + b1
plt.plot(x1, y1, 'r', label = 'Current Fit ({:.3f}, {:.3f})'.format(w1, b1))
plt.xlabel('x (input)')
plt.ylabel('y (target)')
plt.legend()
plt.show()
plot_current_fit('Before training')Plot yang dihasilkan adalah sebagai berikut -

Pembelajaran mendalam adalah divisi pembelajaran mesin dan dianggap sebagai langkah penting yang diambil oleh para peneliti dalam beberapa dekade terakhir. Contoh implementasi pembelajaran mendalam mencakup aplikasi seperti pengenalan gambar dan pengenalan suara.
Dua jenis jaringan neural dalam yang penting diberikan di bawah ini -
- Jaringan Neural Konvolusional
- Jaringan Neural Berulang.
Pada bab ini, kita akan fokus pada tipe pertama yaitu Convolutional Neural Networks (CNN).
Jaringan Neural Konvolusional
Jaringan Neural Konvolusional dirancang untuk memproses data melalui beberapa lapisan array. Jenis jaringan saraf ini digunakan dalam aplikasi seperti pengenalan gambar atau pengenalan wajah.
Perbedaan utama antara CNN dan jaringan saraf biasa lainnya adalah bahwa CNN mengambil masukan sebagai larik dua dimensi dan beroperasi secara langsung pada gambar daripada berfokus pada ekstraksi fitur yang menjadi fokus jaringan saraf lain.
Pendekatan dominan CNN mencakup solusi untuk masalah pengenalan. Perusahaan top seperti Google dan Facebook telah berinvestasi dalam proyek penelitian dan pengembangan proyek pengakuan untuk menyelesaikan aktivitas dengan kecepatan yang lebih tinggi.
Setiap jaringan saraf konvolusional mencakup tiga ide dasar -
- Bidang masing-masing lokal
- Convolution
- Pooling
Mari kita pahami masing-masing terminologi ini secara rinci.
Bidang Respektif Lokal
CNN memanfaatkan korelasi spasial yang ada dalam data masukan. Masing-masing di lapisan jaringan saraf bersamaan menghubungkan beberapa neuron masukan. Wilayah khusus ini disebut Bidang Penerimaan Lokal. Ini hanya berfokus pada neuron tersembunyi. Neuron tersembunyi akan memproses data masukan di dalam bidang tersebut tanpa menyadari perubahan di luar batas tertentu.
Representasi diagram untuk menghasilkan bidang masing-masing lokal disebutkan di bawah ini -

Lilitan
Pada gambar di atas, kami mengamati bahwa setiap koneksi mempelajari bobot neuron tersembunyi dengan koneksi terkait dengan pergerakan dari satu lapisan ke lapisan lainnya. Di sini, neuron individu melakukan pergeseran dari waktu ke waktu. Proses ini disebut "konvolusi".
Pemetaan koneksi dari lapisan masukan ke peta fitur tersembunyi didefinisikan sebagai "bobot bersama" dan bias yang disertakan disebut "bias bersama".
Pooling
Jaringan neural konvolusional menggunakan lapisan penggabungan yang ditempatkan segera setelah deklarasi CNN. Ini mengambil masukan dari pengguna sebagai peta fitur yang keluar dari jaringan konvolusional dan menyiapkan peta fitur yang dipadatkan. Pooling layer membantu dalam membuat lapisan dengan neuron dari lapisan sebelumnya.
Implementasi PyTorch
Langkah-langkah berikut digunakan untuk membuat Jaringan Neural Konvolusional menggunakan PyTorch.
Langkah 1
Impor paket yang diperlukan untuk membuat jaringan neural sederhana.
from torch.autograd import Variable
import torch.nn.functional as FLangkah 2
Buat kelas dengan representasi batch jaringan neural konvolusional. Bentuk batch kita untuk input x adalah dengan dimensi (3, 32, 32).
class SimpleCNN(torch.nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
#Input channels = 3, output channels = 18
self.conv1 = torch.nn.Conv2d(3, 18, kernel_size = 3, stride = 1, padding = 1)
self.pool = torch.nn.MaxPool2d(kernel_size = 2, stride = 2, padding = 0)
#4608 input features, 64 output features (see sizing flow below)
self.fc1 = torch.nn.Linear(18 * 16 * 16, 64)
#64 input features, 10 output features for our 10 defined classes
self.fc2 = torch.nn.Linear(64, 10)LANGKAH 3
Hitung aktivasi perubahan ukuran konvolusi pertama dari (3, 32, 32) menjadi (18, 32, 32).
Ukuran dimensi berubah dari (18, 32, 32) menjadi (18, 16, 16). Bentuk kembali dimensi data dari lapisan masukan jaringan saraf karena ukurannya berubah dari (18, 16, 16) menjadi (1, 4608).
Ingatlah bahwa -1 menyimpulkan dimensi ini dari dimensi lain yang diberikan.
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(x)
x = x.view(-1, 18 * 16 *16)
x = F.relu(self.fc1(x))
#Computes the second fully connected layer (activation applied later)
#Size changes from (1, 64) to (1, 10)
x = self.fc2(x)
return(x)Jaringan saraf rekuren adalah salah satu jenis algoritma berorientasi pembelajaran dalam yang mengikuti pendekatan sekuensial. Dalam jaringan neural, kami selalu menganggap bahwa setiap input dan output tidak bergantung pada semua lapisan lainnya. Jenis jaringan saraf ini disebut berulang karena mereka melakukan perhitungan matematika secara berurutan menyelesaikan satu tugas demi tugas.
Diagram di bawah menentukan pendekatan lengkap dan cara kerja jaringan saraf berulang -

Pada gambar di atas, c1, c2, c3 dan x1 dianggap sebagai input yang mencakup beberapa nilai input tersembunyi yaitu h1, h2 dan h3 yang memberikan output masing-masing o1. Kami sekarang akan fokus pada penerapan PyTorch untuk membuat gelombang sinus dengan bantuan jaringan saraf berulang.
Selama pelatihan, kita akan mengikuti pendekatan pelatihan untuk model kita dengan satu titik data pada satu waktu. Urutan masukan x terdiri dari 20 titik data, dan urutan target dianggap sama dengan urutan masukan.
Langkah 1
Impor paket yang diperlukan untuk mengimplementasikan jaringan neural berulang menggunakan kode di bawah ini -
import torch
from torch.autograd import Variable
import numpy as np
import pylab as pl
import torch.nn.init as initLangkah 2
Kita akan mengatur parameter hyper model dengan ukuran input layer menjadi 7. Akan ada 6 neuron konteks dan 1 neuron input untuk membuat urutan target.
dtype = torch.FloatTensor
input_size, hidden_size, output_size = 7, 6, 1
epochs = 300
seq_length = 20
lr = 0.1
data_time_steps = np.linspace(2, 10, seq_length + 1)
data = np.sin(data_time_steps)
data.resize((seq_length + 1, 1))
x = Variable(torch.Tensor(data[:-1]).type(dtype), requires_grad=False)
y = Variable(torch.Tensor(data[1:]).type(dtype), requires_grad=False)Kami akan menghasilkan data pelatihan, di mana x adalah urutan data masukan dan y diperlukan urutan target.
LANGKAH 3
Bobot diinisialisasi di jaringan saraf berulang menggunakan distribusi normal dengan rata-rata nol. W1 akan mewakili penerimaan variabel input dan w2 akan mewakili output yang dihasilkan seperti yang ditunjukkan di bawah ini -
w1 = torch.FloatTensor(input_size,
hidden_size).type(dtype)
init.normal(w1, 0.0, 0.4)
w1 = Variable(w1, requires_grad = True)
w2 = torch.FloatTensor(hidden_size, output_size).type(dtype)
init.normal(w2, 0.0, 0.3)
w2 = Variable(w2, requires_grad = True)LANGKAH 4
Sekarang, penting untuk membuat fungsi feed forward yang secara unik mendefinisikan jaringan saraf.
def forward(input, context_state, w1, w2):
xh = torch.cat((input, context_state), 1)
context_state = torch.tanh(xh.mm(w1))
out = context_state.mm(w2)
return (out, context_state)LANGKAH 5
Langkah selanjutnya adalah memulai prosedur pelatihan implementasi gelombang sinus jaringan saraf rekuren. Loop luar melakukan iterasi pada setiap loop dan loop dalam melakukan iterasi melalui elemen urutan. Di sini, kami juga akan menghitung Mean Square Error (MSE) yang membantu dalam prediksi variabel kontinu.
for i in range(epochs):
total_loss = 0
context_state = Variable(torch.zeros((1, hidden_size)).type(dtype), requires_grad = True)
for j in range(x.size(0)):
input = x[j:(j+1)]
target = y[j:(j+1)]
(pred, context_state) = forward(input, context_state, w1, w2)
loss = (pred - target).pow(2).sum()/2
total_loss += loss
loss.backward()
w1.data -= lr * w1.grad.data
w2.data -= lr * w2.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
context_state = Variable(context_state.data)
if i % 10 == 0:
print("Epoch: {} loss {}".format(i, total_loss.data[0]))
context_state = Variable(torch.zeros((1, hidden_size)).type(dtype), requires_grad = False)
predictions = []
for i in range(x.size(0)):
input = x[i:i+1]
(pred, context_state) = forward(input, context_state, w1, w2)
context_state = context_state
predictions.append(pred.data.numpy().ravel()[0])LANGKAH 6
Sekarang, saatnya memplot gelombang sinus sesuai kebutuhan.
pl.scatter(data_time_steps[:-1], x.data.numpy(), s = 90, label = "Actual")
pl.scatter(data_time_steps[1:], predictions, label = "Predicted")
pl.legend()
pl.show()Keluaran
Output dari proses di atas adalah sebagai berikut -

Dalam bab ini, kami akan lebih fokus torchvision.datasetsdan berbagai jenisnya. PyTorch menyertakan pemuat set data berikut -
- MNIST
- COCO (Teks dan Deteksi)
Set data mencakup mayoritas dari dua jenis fungsi yang diberikan di bawah ini -
Transform- fungsi yang mengambil gambar dan mengembalikan versi modifikasi dari barang standar. Ini dapat disusun bersama dengan transformasi.
Target_transform- fungsi yang mengambil target dan mengubahnya. Misalnya, mengambil string teks dan mengembalikan tensor indeks dunia.
MNIST
Berikut ini adalah contoh kode untuk dataset MNIST -
dset.MNIST(root, train = TRUE, transform = NONE,
target_transform = None, download = FALSE)Parameternya adalah sebagai berikut -
root - direktori root dari dataset tempat data yang diproses ada.
train - True = Set latihan, False = Set tes
download - True = mendownload dataset dari internet dan meletakkannya di root.
KELAPA
Ini membutuhkan COCO API untuk diinstal. Contoh berikut digunakan untuk mendemonstrasikan implementasi COCO dari dataset menggunakan PyTorch -
import torchvision.dataset as dset
import torchvision.transforms as transforms
cap = dset.CocoCaptions(root = ‘ dir where images are’,
annFile = ’json annotation file’,
transform = transforms.ToTensor())
print(‘Number of samples: ‘, len(cap))
print(target)Output yang dicapai adalah sebagai berikut -
Number of samples: 82783
Image Size: (3L, 427L, 640L)Convents adalah tentang membangun model CNN dari awal. Arsitektur jaringan akan berisi kombinasi dari langkah-langkah berikut -
- Conv2d
- MaxPool2d
- Satuan Linear yang Diperbaiki
- View
- Lapisan Linear
Melatih Model
Melatih model adalah proses yang sama seperti masalah klasifikasi gambar. Cuplikan kode berikut menyelesaikan prosedur model pelatihan pada set data yang disediakan -
def fit(epoch,model,data_loader,phase
= 'training',volatile = False):
if phase == 'training':
model.train()
if phase == 'training':
model.train()
if phase == 'validation':
model.eval()
volatile=True
running_loss = 0.0
running_correct = 0
for batch_idx , (data,target) in enumerate(data_loader):
if is_cuda:
data,target = data.cuda(),target.cuda()
data , target = Variable(data,volatile),Variable(target)
if phase == 'training':
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output,target)
running_loss + =
F.nll_loss(output,target,size_average =
False).data[0]
preds = output.data.max(dim = 1,keepdim = True)[1]
running_correct + =
preds.eq(target.data.view_as(preds)).cpu().sum()
if phase == 'training':
loss.backward()
optimizer.step()
loss = running_loss/len(data_loader.dataset)
accuracy = 100. * running_correct/len(data_loader.dataset)
print(f'{phase} loss is {loss:{5}.{2}} and {phase} accuracy is {running_correct}/{len(data_loader.dataset)}{accuracy:{return loss,accuracy}})Metode tersebut mencakup logika yang berbeda untuk pelatihan dan validasi. Ada dua alasan utama untuk menggunakan mode yang berbeda -
Dalam mode kereta, pelolosan menghapus persentase nilai, yang seharusnya tidak terjadi dalam fase validasi atau pengujian.
Untuk mode pelatihan, kami menghitung gradien dan mengubah nilai parameter model, tetapi propagasi mundur tidak diperlukan selama fase pengujian atau validasi.
Dalam bab ini, kita akan fokus pada pembuatan biara dari awal. Ini menyimpulkan dalam menciptakan biara masing-masing atau jaringan saraf sampel dengan obor.
Langkah 1
Buat kelas yang diperlukan dengan parameter masing-masing. Parameter tersebut termasuk bobot dengan nilai acak.
class Neural_Network(nn.Module):
def __init__(self, ):
super(Neural_Network, self).__init__()
self.inputSize = 2
self.outputSize = 1
self.hiddenSize = 3
# weights
self.W1 = torch.randn(self.inputSize,
self.hiddenSize) # 3 X 2 tensor
self.W2 = torch.randn(self.hiddenSize, self.outputSize) # 3 X 1 tensorLangkah 2
Buat pola feed forward fungsi dengan fungsi sigmoid.
def forward(self, X):
self.z = torch.matmul(X, self.W1) # 3 X 3 ".dot"
does not broadcast in PyTorch
self.z2 = self.sigmoid(self.z) # activation function
self.z3 = torch.matmul(self.z2, self.W2)
o = self.sigmoid(self.z3) # final activation
function
return o
def sigmoid(self, s):
return 1 / (1 + torch.exp(-s))
def sigmoidPrime(self, s):
# derivative of sigmoid
return s * (1 - s)
def backward(self, X, y, o):
self.o_error = y - o # error in output
self.o_delta = self.o_error * self.sigmoidPrime(o) # derivative of sig to error
self.z2_error = torch.matmul(self.o_delta, torch.t(self.W2))
self.z2_delta = self.z2_error * self.sigmoidPrime(self.z2)
self.W1 + = torch.matmul(torch.t(X), self.z2_delta)
self.W2 + = torch.matmul(torch.t(self.z2), self.o_delta)LANGKAH 3
Buat model pelatihan dan prediksi seperti yang disebutkan di bawah -
def train(self, X, y):
# forward + backward pass for training
o = self.forward(X)
self.backward(X, y, o)
def saveWeights(self, model):
# Implement PyTorch internal storage functions
torch.save(model, "NN")
# you can reload model with all the weights and so forth with:
# torch.load("NN")
def predict(self):
print ("Predicted data based on trained weights: ")
print ("Input (scaled): \n" + str(xPredicted))
print ("Output: \n" + str(self.forward(xPredicted)))Jaringan neural konvolusional mencakup fitur utama, extraction. Langkah-langkah berikut digunakan untuk mengimplementasikan ekstraksi fitur jaringan saraf konvolusional.
Langkah 1
Impor model masing-masing untuk membuat model ekstraksi fitur dengan "PyTorch".
import torch
import torch.nn as nn
from torchvision import modelsLangkah 2
Buat kelas ekstraktor fitur yang dapat dipanggil jika diperlukan.
class Feature_extractor(nn.module):
def forward(self, input):
self.feature = input.clone()
return input
new_net = nn.Sequential().cuda() # the new network
target_layers = [conv_1, conv_2, conv_4] # layers you want to extract`
i = 1
for layer in list(cnn):
if isinstance(layer,nn.Conv2d):
name = "conv_"+str(i)
art_net.add_module(name,layer)
if name in target_layers:
new_net.add_module("extractor_"+str(i),Feature_extractor())
i+=1
if isinstance(layer,nn.ReLU):
name = "relu_"+str(i)
new_net.add_module(name,layer)
if isinstance(layer,nn.MaxPool2d):
name = "pool_"+str(i)
new_net.add_module(name,layer)
new_net.forward(your_image)
print (new_net.extractor_3.feature)Pada bab ini, kita akan berfokus pada model visualisasi data dengan bantuan biara. Langkah-langkah berikut diperlukan untuk mendapatkan gambaran visualisasi yang sempurna dengan jaringan saraf tiruan konvensional.
Langkah 1
Impor modul yang diperlukan yang penting untuk visualisasi jaringan saraf konvensional.
import os
import numpy as np
import pandas as pd
from scipy.misc import imread
from sklearn.metrics import accuracy_score
import keras
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Flatten, Activation, Input
from keras.layers import Conv2D, MaxPooling2D
import torchLangkah 2
Untuk menghentikan potensi keacakan dengan data pelatihan dan pengujian, panggil kumpulan data masing-masing seperti yang diberikan dalam kode di bawah ini -
seed = 128
rng = np.random.RandomState(seed)
data_dir = "../../datasets/MNIST"
train = pd.read_csv('../../datasets/MNIST/train.csv')
test = pd.read_csv('../../datasets/MNIST/Test_fCbTej3.csv')
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, 'train', img_name)
img = imread(filepath, flatten=True)LANGKAH 3
Plot gambar yang diperlukan untuk mendapatkan data pelatihan dan pengujian yang didefinisikan dengan sempurna menggunakan kode di bawah ini -
pylab.imshow(img, cmap ='gray')
pylab.axis('off')
pylab.show()Outputnya ditampilkan seperti di bawah ini -

Dalam bab ini, kami mengusulkan pendekatan alternatif yang mengandalkan jaringan neural konvolusional 2D tunggal di kedua urutan. Setiap lapisan jaringan kami mengkodekan ulang token sumber berdasarkan urutan keluaran yang dihasilkan sejauh ini. Karenanya, properti seperti perhatian tersebar di seluruh jaringan.
Di sini, kami akan fokus creating the sequential network with specific pooling from the values included in dataset. Proses ini juga paling baik diterapkan dalam "Modul Pengenalan Gambar".

Langkah-langkah berikut digunakan untuk membuat model pemrosesan urutan dengan konvent menggunakan PyTorch -
Langkah 1
Impor modul yang diperlukan untuk kinerja pemrosesan urutan menggunakan konvent.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
import numpy as npLangkah 2
Lakukan operasi yang diperlukan untuk membuat pola dalam urutan masing-masing menggunakan kode di bawah ini -
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000,28,28,1)
x_test = x_test.reshape(10000,28,28,1)
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)LANGKAH 3
Kompilasi model dan sesuaikan pola dalam model jaringan saraf konvensional yang disebutkan seperti yang ditunjukkan di bawah ini -
model.compile(loss =
keras.losses.categorical_crossentropy,
optimizer = keras.optimizers.Adadelta(), metrics =
['accuracy'])
model.fit(x_train, y_train,
batch_size = batch_size, epochs = epochs,
verbose = 1, validation_data = (x_test, y_test))
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])Output yang dihasilkan adalah sebagai berikut -

Dalam bab ini, kita akan memahami model embedding kata yang terkenal - word2vec. Model Word2vec digunakan untuk menghasilkan embedding kata dengan bantuan kelompok model terkait. Model Word2vec diimplementasikan dengan kode-C murni dan gradien dihitung secara manual.
Implementasi model word2vec di PyTorch dijelaskan dalam langkah-langkah di bawah ini -
Langkah 1
Menerapkan pustaka dalam penyematan kata seperti yang disebutkan di bawah ini -
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as FLangkah 2
Menerapkan Model Lewati Gram dari kata embedding dengan kelas yang disebut word2vec. Itu termasukemb_size, emb_dimension, u_embedding, v_embedding jenis atribut.
class SkipGramModel(nn.Module):
def __init__(self, emb_size, emb_dimension):
super(SkipGramModel, self).__init__()
self.emb_size = emb_size
self.emb_dimension = emb_dimension
self.u_embeddings = nn.Embedding(emb_size, emb_dimension, sparse=True)
self.v_embeddings = nn.Embedding(emb_size, emb_dimension, sparse = True)
self.init_emb()
def init_emb(self):
initrange = 0.5 / self.emb_dimension
self.u_embeddings.weight.data.uniform_(-initrange, initrange)
self.v_embeddings.weight.data.uniform_(-0, 0)
def forward(self, pos_u, pos_v, neg_v):
emb_u = self.u_embeddings(pos_u)
emb_v = self.v_embeddings(pos_v)
score = torch.mul(emb_u, emb_v).squeeze()
score = torch.sum(score, dim = 1)
score = F.logsigmoid(score)
neg_emb_v = self.v_embeddings(neg_v)
neg_score = torch.bmm(neg_emb_v, emb_u.unsqueeze(2)).squeeze()
neg_score = F.logsigmoid(-1 * neg_score)
return -1 * (torch.sum(score)+torch.sum(neg_score))
def save_embedding(self, id2word, file_name, use_cuda):
if use_cuda:
embedding = self.u_embeddings.weight.cpu().data.numpy()
else:
embedding = self.u_embeddings.weight.data.numpy()
fout = open(file_name, 'w')
fout.write('%d %d\n' % (len(id2word), self.emb_dimension))
for wid, w in id2word.items():
e = embedding[wid]
e = ' '.join(map(lambda x: str(x), e))
fout.write('%s %s\n' % (w, e))
def test():
model = SkipGramModel(100, 100)
id2word = dict()
for i in range(100):
id2word[i] = str(i)
model.save_embedding(id2word)LANGKAH 3
Menerapkan metode utama untuk menampilkan model embedding kata dengan cara yang benar.
if __name__ == '__main__':
test()Jaringan neural dalam memiliki fitur eksklusif untuk memungkinkan terobosan dalam pembelajaran mesin yang memahami proses bahasa alami. Teramati bahwa sebagian besar model ini memperlakukan bahasa sebagai urutan kata atau karakter datar, dan menggunakan sejenis model yang disebut sebagai jaringan saraf berulang atau RNN.
Banyak peneliti sampai pada kesimpulan bahwa bahasa paling baik dipahami sehubungan dengan hierarki frasa. Jenis ini termasuk dalam jaringan saraf rekursif yang mempertimbangkan struktur tertentu.
PyTorch memiliki fitur khusus yang membantu membuat model pemrosesan bahasa alami yang kompleks ini jauh lebih mudah. Ini adalah kerangka kerja berfitur lengkap untuk semua jenis pembelajaran mendalam dengan dukungan kuat untuk visi komputer.
Fitur Jaringan Neural Rekursif
Jaringan neural rekursif dibuat sedemikian rupa sehingga mencakup penerapan kumpulan bobot yang sama dengan struktur mirip grafik yang berbeda.
Node dilintasi dalam urutan topologi.
Jenis jaringan ini dilatih oleh mode kebalikan dari diferensiasi otomatis.
Pemrosesan bahasa alami mencakup kasus khusus jaringan saraf rekursif.
Jaringan tensor saraf rekursif ini mencakup berbagai simpul fungsional komposisi di pohon.
Contoh jaringan saraf rekursif ditunjukkan di bawah ini -
