SciPy - CSGraph
CSGraph adalah singkatan dari Compressed Sparse Graph, yang berfokus pada algoritma grafik Cepat berdasarkan representasi matriks renggang.
Representasi Grafik
Untuk memulainya, mari kita pahami apa itu grafik renggang dan bagaimana hal itu membantu dalam representasi grafik.
Apa sebenarnya grafik renggang itu?
Grafik hanyalah kumpulan node, yang memiliki tautan di antara mereka. Grafik dapat mewakili hampir semua hal - koneksi jaringan sosial, di mana setiap node adalah orang dan terhubung ke kenalan; gambar, di mana setiap node adalah piksel dan terhubung ke piksel tetangga; titik dalam distribusi dimensi tinggi, di mana setiap node terhubung ke tetangga terdekatnya; dan hampir semua hal lain yang dapat Anda bayangkan.
Salah satu cara yang sangat efisien untuk merepresentasikan data grafik adalah dalam matriks renggang: sebut saja G. Matriks G berukuran N x N, dan G [i, j] memberikan nilai hubungan antara node 'i' dan node 'j'. Grafik renggang sebagian besar berisi nol - artinya, sebagian besar node hanya memiliki sedikit koneksi. Properti ini ternyata benar dalam banyak kasus yang menarik.
Pembuatan submodul grafik renggang dimotivasi oleh beberapa algoritme yang digunakan dalam scikit-learn yang mencakup berikut ini -
Isomap - Algoritma pembelajaran berjenis, yang membutuhkan pencarian jalur terpendek dalam grafik.
Hierarchical clustering - Algoritme pengelompokan berdasarkan pohon rentang minimum.
Spectral Decomposition - Algoritma proyeksi berdasarkan grafik laplacians jarang.
Sebagai contoh konkret, bayangkan kita ingin merepresentasikan graf tak berarah berikut -
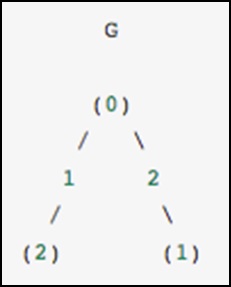
Grafik ini memiliki tiga node, di mana node 0 dan 1 dihubungkan oleh tepi berbobot 2, dan node 0 dan 2 dihubungkan oleh tepi bobot 1. Kita dapat membuat representasi padat, bertopeng, dan jarang seperti yang ditunjukkan pada contoh berikut , perlu diingat bahwa grafik yang tidak berarah direpresentasikan oleh matriks simetris.
G_dense = np.array([ [0, 2, 1],
[2, 0, 0],
[1, 0, 0] ])
G_masked = np.ma.masked_values(G_dense, 0)
from scipy.sparse import csr_matrix
G_sparse = csr_matrix(G_dense)
print G_sparse.dataProgram di atas akan menghasilkan keluaran sebagai berikut.
array([2, 1, 2, 1])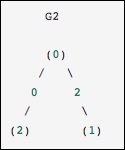
Ini identik dengan grafik sebelumnya, kecuali node 0 dan 2 dihubungkan oleh tepi tanpa bobot. Dalam hal ini, representasi padat di atas mengarah pada ambiguitas - bagaimana non-edge dapat direpresentasikan, jika nol adalah nilai yang berarti. Dalam hal ini, representasi bertopeng atau jarang harus digunakan untuk menghilangkan ambiguitas.
Mari kita perhatikan contoh berikut.
from scipy.sparse.csgraph import csgraph_from_dense
G2_data = np.array
([
[np.inf, 2, 0 ],
[2, np.inf, np.inf],
[0, np.inf, np.inf]
])
G2_sparse = csgraph_from_dense(G2_data, null_value=np.inf)
print G2_sparse.dataProgram di atas akan menghasilkan keluaran sebagai berikut.
array([ 2., 0., 2., 0.])Tangga kata menggunakan grafik renggang
Tangga kata adalah permainan yang diciptakan oleh Lewis Carroll, di mana kata-kata dihubungkan dengan mengubah satu huruf di setiap langkah. Misalnya -
APE → APT → AIT → BIT → BIG → BAG → MAG → MAN
Di sini, kami telah beralih dari "APE" ke "MAN" dalam tujuh langkah, mengubah satu huruf setiap kali. Pertanyaannya adalah - Bisakah kita menemukan jalur yang lebih pendek di antara kata-kata ini menggunakan aturan yang sama? Masalah ini secara alami dinyatakan sebagai masalah graf renggang. Node akan sesuai dengan kata-kata individu, dan kami akan membuat hubungan antara kata-kata yang paling berbeda - satu huruf.
Memperoleh Daftar Kata
Pertama, tentunya kita harus mendapatkan daftar kata yang valid. Saya menjalankan Mac, dan Mac memiliki kamus kata di lokasi yang diberikan di blok kode berikut. Jika Anda menggunakan arsitektur yang berbeda, Anda mungkin harus mencari sedikit untuk menemukan kamus sistem Anda.
wordlist = open('/usr/share/dict/words').read().split()
print len(wordlist)Program di atas akan menghasilkan keluaran sebagai berikut.
235886Kami sekarang ingin melihat kata-kata dengan panjang 3, jadi mari kita pilih hanya kata-kata dengan panjang yang benar. Kami juga akan menghilangkan kata-kata, yang dimulai dengan huruf besar (kata benda yang tepat) atau berisi karakter non-alfa-numerik seperti apostrof dan tanda hubung. Terakhir, kami akan memastikan semuanya menggunakan huruf kecil untuk perbandingan nanti.
word_list = [word for word in word_list if len(word) == 3]
word_list = [word for word in word_list if word[0].islower()]
word_list = [word for word in word_list if word.isalpha()]
word_list = map(str.lower, word_list)
print len(word_list)Program di atas akan menghasilkan keluaran sebagai berikut.
1135Sekarang, kami memiliki daftar 1135 kata tiga huruf yang valid (jumlah persisnya dapat berubah tergantung pada daftar tertentu yang digunakan). Masing-masing kata ini akan menjadi simpul dalam grafik kami, dan kami akan membuat tepi yang menghubungkan simpul yang terkait dengan setiap pasangan kata, yang berbeda hanya dengan satu huruf.
import numpy as np
word_list = np.asarray(word_list)
word_list.dtype
word_list.sort()
word_bytes = np.ndarray((word_list.size, word_list.itemsize),
dtype = 'int8',
buffer = word_list.data)
print word_bytes.shapeProgram di atas akan menghasilkan keluaran sebagai berikut.
(1135, 3)Kami akan menggunakan jarak Hamming antara setiap titik untuk menentukan, pasangan kata mana yang terhubung. Jarak Hamming mengukur pecahan entri antara dua vektor, yang berbeda: dua kata apa pun dengan jarak hamming sama dengan 1 / N1 / N, di mana NN adalah jumlah huruf, yang dihubungkan dalam kata ladder.
from scipy.spatial.distance import pdist, squareform
from scipy.sparse import csr_matrix
hamming_dist = pdist(word_bytes, metric = 'hamming')
graph = csr_matrix(squareform(hamming_dist < 1.5 / word_list.itemsize))Saat membandingkan jarak, kami tidak menggunakan persamaan karena ini bisa jadi tidak stabil untuk nilai titik mengambang. Ketidaksamaan memberikan hasil yang diinginkan selama tidak ada dua entri dari daftar kata yang identik. Sekarang, setelah grafik kita siap, kita akan menggunakan pencarian jalur terpendek untuk menemukan jalur di antara dua kata dalam grafik.
i1 = word_list.searchsorted('ape')
i2 = word_list.searchsorted('man')
print word_list[i1],word_list[i2]Program di atas akan menghasilkan keluaran sebagai berikut.
ape, manKita perlu memeriksa apakah ini cocok, karena jika kata-kata tersebut tidak ada dalam daftar akan ada kesalahan pada keluarannya. Sekarang, yang kita butuhkan hanyalah menemukan jalur terpendek di antara dua indeks ini dalam grafik. Kami akan menggunakandijkstra’s algoritma, karena memungkinkan kita menemukan jalur hanya untuk satu node.
from scipy.sparse.csgraph import dijkstra
distances, predecessors = dijkstra(graph, indices = i1, return_predecessors = True)
print distances[i2]Program di atas akan menghasilkan keluaran sebagai berikut.
5.0Jadi, kita melihat bahwa jalur terpendek antara 'kera' dan 'manusia' hanya terdiri dari lima langkah. Kita dapat menggunakan pendahulu yang dikembalikan oleh algoritme untuk merekonstruksi jalur ini.
path = []
i = i2
while i != i1:
path.append(word_list[i])
i = predecessors[i]
path.append(word_list[i1])
print path[::-1]i2]Program di atas akan menghasilkan keluaran sebagai berikut.
['ape', 'ope', 'opt', 'oat', 'mat', 'man']