SciPy - Panduan Cepat
SciPy, diucapkan sebagai Sigh Pi, adalah python ilmiah open source, didistribusikan di bawah perpustakaan berlisensi BSD untuk melakukan Perhitungan Matematika, Ilmiah dan Teknik.
Pustaka SciPy bergantung pada NumPy, yang menyediakan manipulasi larik N-dimensi yang mudah dan cepat. Library SciPy dibangun untuk bekerja dengan array NumPy dan menyediakan banyak praktik numerik yang ramah pengguna dan efisien seperti rutinitas untuk integrasi dan pengoptimalan numerik. Bersama-sama, mereka berjalan di semua sistem operasi populer, cepat dipasang dan gratis. NumPy dan SciPy mudah digunakan, tetapi cukup kuat untuk diandalkan oleh beberapa ilmuwan dan insinyur terkemuka dunia.
Sub-paket SciPy
SciPy diatur ke dalam sub-paket yang mencakup domain komputasi ilmiah yang berbeda. Ini diringkas dalam tabel berikut -
| scipy.cluster | Kuantisasi vektor / Kmeans |
| scipy.constants | Konstanta fisik dan matematika |
| scipy.fftpack | Transformasi Fourier |
| scipy.integrate | Rutinitas integrasi |
| scipy.interpolate | Interpolasi |
| scipy.io | Masukan dan keluaran data |
| scipy.linalg | Rutinitas aljabar linier |
| scipy.ndimage | paket gambar n-dimensi |
| scipy.odr | Regresi jarak ortogonal |
| scipy.optimize | Optimasi |
| scipy.signal | Pemrosesan sinyal |
| scipy.sparse | Matriks renggang |
| scipy.spatial | Algoritma dan struktur data spasial |
| scipy.special | Fungsi matematika khusus apa pun |
| scipy.stats | Statistik |
Struktur data
Struktur data dasar yang digunakan oleh SciPy adalah array multidimensi yang disediakan oleh modul NumPy. NumPy menyediakan beberapa fungsi untuk Aljabar Linear, Transformasi Fourier, dan Pembuatan Angka Acak, tetapi tidak dengan fungsi umum yang setara di SciPy.
Distribusi Python standar tidak dibundel dengan modul SciPy apa pun. Alternatif ringan adalah menginstal SciPy menggunakan penginstal paket Python yang populer,
pip install pandasJika kita menginstal Anaconda Python package, Panda akan dipasang secara default. Berikut adalah paket dan tautan untuk menginstalnya di sistem operasi yang berbeda.
Windows
Anaconda (dari https://www.continuum.io) adalah distribusi Python gratis untuk tumpukan SciPy. Ini juga tersedia untuk Linux dan Mac.
Canopy (https://www.enthought.com/products/canopy/) tersedia gratis, serta untuk distribusi komersial dengan tumpukan SciPy lengkap untuk Windows, Linux, dan Mac.
Python (x,y)- Ini adalah distribusi Python gratis dengan SciPy stack dan Spyder IDE untuk OS Windows. (Dapat diunduh darihttps://python-xy.github.io/)
Linux
Manajer paket dari masing-masing distribusi Linux digunakan untuk menginstal satu atau lebih paket dalam tumpukan SciPy.
Ubuntu
Kita dapat menggunakan jalur berikut untuk menginstal Python di Ubuntu.
sudo apt-get install python-numpy python-scipy
python-matplotlibipythonipython-notebook python-pandas python-sympy python-noseFedora
Kita dapat menggunakan jalur berikut untuk menginstal Python di Fedora.
sudo yum install numpyscipy python-matplotlibipython python-pandas
sympy python-nose atlas-develSecara default, semua fungsi NumPy telah tersedia melalui namespace SciPy. Tidak perlu mengimpor fungsi NumPy secara eksplisit, saat SciPy diimpor. Objek utama NumPy adalah array multidimensi yang homogen. Ini adalah tabel elemen (biasanya angka), semua jenis yang sama, diindeks oleh tupel bilangan bulat positif. Dalam NumPy, dimensi disebut sebagai sumbu. Jumlahaxes disebut sebagai rank.
Sekarang, mari kita merevisi fungsi dasar Vektor dan Matriks di NumPy. Karena SciPy dibangun di atas array NumPy, pemahaman tentang dasar-dasar NumPy diperlukan. Karena sebagian besar bagian aljabar linier hanya berurusan dengan matriks.
Vektor NumPy
Vektor dapat dibuat dengan berbagai cara. Beberapa di antaranya dijelaskan di bawah ini.
Mengonversi objek mirip array Python ke NumPy
Mari kita perhatikan contoh berikut.
import numpy as np
list = [1,2,3,4]
arr = np.array(list)
print arrOutput dari program di atas adalah sebagai berikut.
[1 2 3 4]Pembuatan NumPy Array Intrinsik
NumPy memiliki fungsi bawaan untuk membuat array dari awal. Beberapa dari fungsi ini dijelaskan di bawah.
Menggunakan nol ()
Fungsi nol (bentuk) akan membuat array yang diisi dengan nilai 0 dengan bentuk yang ditentukan. Tipe defaultnya adalah float64. Mari kita perhatikan contoh berikut.
import numpy as np
print np.zeros((2, 3))Output dari program di atas adalah sebagai berikut.
array([[ 0., 0., 0.],
[ 0., 0., 0.]])Menggunakan ones ()
Fungsi ones (bentuk) akan membuat array yang diisi dengan 1 nilai. Ini identik dengan nol dalam semua hal lainnya. Mari kita perhatikan contoh berikut.
import numpy as np
print np.ones((2, 3))Output dari program di atas adalah sebagai berikut.
array([[ 1., 1., 1.],
[ 1., 1., 1.]])Menggunakan arange ()
Fungsi arange () akan membuat array dengan nilai yang bertambah secara teratur. Mari kita perhatikan contoh berikut.
import numpy as np
print np.arange(7)Program di atas akan menghasilkan keluaran sebagai berikut.
array([0, 1, 2, 3, 4, 5, 6])Mendefinisikan tipe data dari nilai
Mari kita perhatikan contoh berikut.
import numpy as np
arr = np.arange(2, 10, dtype = np.float)
print arr
print "Array Data Type :",arr.dtypeProgram di atas akan menghasilkan keluaran sebagai berikut.
[ 2. 3. 4. 5. 6. 7. 8. 9.]
Array Data Type : float64Menggunakan linspace ()
Fungsi linspace () akan membuat array dengan sejumlah elemen tertentu, yang akan diberi jarak yang sama antara nilai awal dan akhir yang ditentukan. Mari kita perhatikan contoh berikut.
import numpy as np
print np.linspace(1., 4., 6)Program di atas akan menghasilkan keluaran sebagai berikut.
array([ 1. , 1.6, 2.2, 2.8, 3.4, 4. ])Matriks
Matriks adalah larik 2-D khusus yang mempertahankan sifat 2-Dnya melalui operasi. Ia memiliki operator khusus tertentu, seperti * (perkalian matriks) dan ** (daya matriks). Mari kita perhatikan contoh berikut.
import numpy as np
print np.matrix('1 2; 3 4')Program di atas akan menghasilkan keluaran sebagai berikut.
matrix([[1, 2],
[3, 4]])Konjugasi Transpos Matriks
Fitur ini mengembalikan transpos konjugasi (kompleks) dari self. Mari kita perhatikan contoh berikut.
import numpy as np
mat = np.matrix('1 2; 3 4')
print mat.HProgram di atas akan menghasilkan keluaran sebagai berikut.
matrix([[1, 3],
[2, 4]])Transposisi Matriks
Fitur ini mengembalikan pengalihan diri. Mari kita perhatikan contoh berikut.
import numpy as np
mat = np.matrix('1 2; 3 4')
mat.TProgram di atas akan menghasilkan keluaran sebagai berikut.
matrix([[1, 3],
[2, 4]])Saat kami mengubah urutan matriks, kami membuat matriks baru yang barisnya merupakan kolom dari aslinya. Transposisi konjugasi, di sisi lain, menukar baris dan indeks kolom untuk setiap elemen matriks. Invers dari suatu matriks adalah matriks yang jika dikalikan dengan matriks aslinya akan menghasilkan matriks identitas.
K-means clusteringadalah metode untuk menemukan cluster dan pusat cluster dalam sekumpulan data yang tidak berlabel. Secara intuitif, kita mungkin menganggap cluster sebagai - terdiri dari sekelompok titik data, yang jarak antar titiknya kecil dibandingkan dengan jarak ke titik di luar cluster. Diberikan set awal pusat K, algoritma K-means mengulangi dua langkah berikut -
Untuk setiap pusat, subset titik pelatihan (clusternya) yang lebih dekat dengannya diidentifikasi daripada pusat lainnya.
Rata-rata setiap fitur untuk titik data di setiap cluster dihitung, dan vektor rata-rata ini menjadi pusat baru untuk cluster tersebut.
Kedua langkah ini diulang sampai pusat tidak lagi bergerak atau tugas tidak lagi berubah. Lalu, poin baruxdapat ditugaskan ke cluster prototipe terdekat. Library SciPy menyediakan implementasi yang baik dari algoritme K-Means melalui paket cluster. Mari kita pahami bagaimana cara menggunakannya.
Implementasi K-Means di SciPy
Kami akan memahami bagaimana menerapkan K-Means di SciPy.
Impor K-Means
Kami akan melihat implementasi dan penggunaan setiap fungsi yang diimpor.
from SciPy.cluster.vq import kmeans,vq,whitenPembuatan data
Kami harus mensimulasikan beberapa data untuk mengeksplorasi clustering.
from numpy import vstack,array
from numpy.random import rand
# data generation with three features
data = vstack((rand(100,3) + array([.5,.5,.5]),rand(100,3)))Sekarang, kami harus memeriksa data. Program di atas akan menghasilkan keluaran sebagai berikut.
array([[ 1.48598868e+00, 8.17445796e-01, 1.00834051e+00],
[ 8.45299768e-01, 1.35450732e+00, 8.66323621e-01],
[ 1.27725864e+00, 1.00622682e+00, 8.43735610e-01],
…………….Normalisasi grup pengamatan pada setiap fitur dasar. Sebelum menjalankan K-Means, ada baiknya untuk mengubah skala setiap dimensi fitur set pengamatan dengan pemutihan. Setiap fitur dibagi dengan deviasi standarnya di semua pengamatan untuk memberikan varian satuan.
Memutihkan data
Kami harus menggunakan kode berikut untuk memutihkan data.
# whitening of data
data = whiten(data)Hitung K-Means dengan Tiga Cluster
Mari kita sekarang menghitung K-Means dengan tiga cluster menggunakan kode berikut.
# computing K-Means with K = 3 (2 clusters)
centroids,_ = kmeans(data,3)Kode di atas menjalankan K-Means pada satu set vektor observasi yang membentuk kluster K. Algoritma K-Means menyesuaikan sentroid sampai kemajuan yang memadai tidak dapat dibuat, yaitu perubahan dalam distorsi, karena iterasi terakhir kurang dari beberapa ambang batas. Di sini, kita dapat mengamati centroid cluster dengan mencetak variabel centroid menggunakan kode yang diberikan di bawah ini.
print(centroids)Kode di atas akan menghasilkan keluaran sebagai berikut.
print(centroids)[ [ 2.26034702 1.43924335 1.3697022 ]
[ 2.63788572 2.81446462 2.85163854]
[ 0.73507256 1.30801855 1.44477558] ]Tetapkan setiap nilai ke cluster dengan menggunakan kode yang diberikan di bawah ini.
# assign each sample to a cluster
clx,_ = vq(data,centroids)Itu vq fungsi membandingkan setiap vektor pengamatan di 'M' dengan 'N' obsarray dengan centroids dan menetapkan observasi ke cluster terdekat. Ini mengembalikan cluster dari setiap observasi dan distorsi. Kami juga dapat memeriksa distorsi. Mari kita periksa cluster masing-masing observasi menggunakan kode berikut.
# check clusters of observation
print clxKode di atas akan menghasilkan keluaran sebagai berikut.
array([1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 2, 0, 2, 0, 1, 1, 1,
0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0,
0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 0, 2, 2, 2, 2, 2, 0, 0,
2, 2, 2, 1, 0, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 0, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2], dtype=int32)Nilai berbeda 0, 1, 2 dari larik di atas menunjukkan cluster.
Paket konstanta SciPy menyediakan berbagai konstanta, yang digunakan dalam bidang ilmiah umum.
Paket Konstanta SciPy
Itu scipy.constants packagemenyediakan berbagai konstanta. Kami harus mengimpor konstanta yang diperlukan dan menggunakannya sesuai kebutuhan. Mari kita lihat bagaimana variabel konstan ini diimpor dan digunakan.
Untuk memulai, mari kita bandingkan nilai 'pi' dengan mempertimbangkan contoh berikut.
#Import pi constant from both the packages
from scipy.constants import pi
from math import pi
print("sciPy - pi = %.16f"%scipy.constants.pi)
print("math - pi = %.16f"%math.pi)Program di atas akan menghasilkan keluaran sebagai berikut.
sciPy - pi = 3.1415926535897931
math - pi = 3.1415926535897931Daftar Konstanta Tersedia
Tabel berikut menjelaskan secara singkat berbagai konstanta.
Konstanta Matematika
| No Sr | Konstan | Deskripsi |
|---|---|---|
| 1 | pi | pi |
| 2 | keemasan | Rasio Emas |
Konstanta Fisik
Tabel berikut mencantumkan konstanta fisik yang paling umum digunakan.
| No Sr | Konstan & Deskripsi |
|---|---|
| 1 | c Kecepatan cahaya dalam ruang hampa |
| 2 | speed_of_light Kecepatan cahaya dalam ruang hampa |
| 3 | h Konstanta Planck |
| 4 | Planck Konstanta Planck h |
| 5 | G Konstanta gravitasi Newton |
| 6 | e Muatan dasar |
| 7 | R Konstanta gas molar |
| 8 | Avogadro Konstanta Avogadro |
| 9 | k Konstanta Boltzmann |
| 10 | electron_mass(OR) m_e Massa elektronik |
| 11 | proton_mass (OR) m_p Massa proton |
| 12 | neutron_mass(OR)m_n Massa neutron |
Unit
Tabel berikut memiliki daftar unit SI.
| No Sr | Satuan | Nilai |
|---|---|---|
| 1 | mili | 0,001 |
| 2 | mikro | 1e-06 |
| 3 | kilo | 1000 |
Satuan ini berkisar dari yotta, zetta, exa, peta, tera …… kilo, hector,… nano, pico,… to zepto.
Konstanta Penting Lainnya
Tabel berikut mencantumkan konstanta penting lainnya yang digunakan dalam SciPy.
| No Sr | Satuan | Nilai |
|---|---|---|
| 1 | gram | 0,001 kg |
| 2 | massa atom | Konstanta massa atom |
| 3 | gelar | Gelar dalam radian |
| 4 | menit | Satu menit dalam hitungan detik |
| 5 | hari | Suatu hari dalam hitungan detik |
| 6 | inci | Satu inci dalam meter |
| 7 | mikron | Satu mikron dalam meter |
| 8 | light_year | Satu tahun cahaya dalam meter |
| 9 | ATM | Suasana standar di pascal |
| 10 | acre | Satu hektar dalam meter persegi |
| 11 | liter | Satu liter dalam meter kubik |
| 12 | galon | Satu galon dalam meter kubik |
| 13 | kmh | Kilometer per jam dalam meter per detik |
| 14 | degree_Fahrenheit | Satu Fahrenheit dalam kelvin |
| 15 | eV | Satu volt elektron dalam joule |
| 16 | hp | Satu tenaga kuda dalam watt |
| 17 | dyn | Satu dyne di newton |
| 18 | lambda2nu.dll | Ubah panjang gelombang menjadi frekuensi optik |
Mengingat semua ini agak sulit. Cara mudah untuk mendapatkan kunci mana untuk fungsi mana denganscipy.constants.find()metode. Mari kita perhatikan contoh berikut.
import scipy.constants
res = scipy.constants.physical_constants["alpha particle mass"]
print resProgram di atas akan menghasilkan keluaran sebagai berikut.
[
'alpha particle mass',
'alpha particle mass energy equivalent',
'alpha particle mass energy equivalent in MeV',
'alpha particle mass in u',
'electron to alpha particle mass ratio'
]Metode ini mengembalikan daftar kunci, jika tidak, tidak ada jika kata kunci tidak cocok.
Fourier Transformationdihitung pada sinyal domain waktu untuk memeriksa perilakunya dalam domain frekuensi. Transformasi Fourier menemukan aplikasinya dalam disiplin ilmu seperti pemrosesan sinyal dan noise, pemrosesan gambar, pemrosesan sinyal audio, dll. SciPy menawarkan modul fftpack, yang memungkinkan pengguna menghitung transformasi Fourier dengan cepat.
Berikut adalah contoh fungsi sinus yang akan digunakan untuk menghitung transformasi Fourier menggunakan modul fftpack.
Transformasi Fourier Cepat
Mari kita pahami apa itu transformasi Fourier cepat secara detail.
Transformasi Fourier Diskrit Satu Dimensi
FFT y [k] dengan panjang N dari urutan panjang-N x [n] dihitung dengan fft () dan transformasi invers dihitung menggunakan ifft (). Mari kita perhatikan contoh berikut
#Importing the fft and inverse fft functions from fftpackage
from scipy.fftpack import fft
#create an array with random n numbers
x = np.array([1.0, 2.0, 1.0, -1.0, 1.5])
#Applying the fft function
y = fft(x)
print yProgram di atas akan menghasilkan keluaran sebagai berikut.
[ 4.50000000+0.j 2.08155948-1.65109876j -1.83155948+1.60822041j
-1.83155948-1.60822041j 2.08155948+1.65109876j ]Mari kita lihat contoh lainnya
#FFT is already in the workspace, using the same workspace to for inverse transform
yinv = ifft(y)
print yinvProgram di atas akan menghasilkan keluaran sebagai berikut.
[ 1.0+0.j 2.0+0.j 1.0+0.j -1.0+0.j 1.5+0.j ]Itu scipy.fftpackmodul memungkinkan komputasi transformasi Fourier cepat. Sebagai ilustrasi, sinyal input (berisik) mungkin terlihat sebagai berikut -
import numpy as np
time_step = 0.02
period = 5.
time_vec = np.arange(0, 20, time_step)
sig = np.sin(2 * np.pi / period * time_vec) + 0.5 *np.random.randn(time_vec.size)
print sig.sizeKami membuat sinyal dengan langkah waktu 0,02 detik. Pernyataan terakhir mencetak ukuran sinyal sig. Outputnya adalah sebagai berikut -
1000Kami tidak tahu frekuensi sinyalnya; kita hanya mengetahui langkah waktu sampling dari sinyal sig. Sinyal seharusnya berasal dari fungsi nyata, sehingga transformasi Fourier akan menjadi simetris. Ituscipy.fftpack.fftfreq() fungsi akan menghasilkan frekuensi sampling dan scipy.fftpack.fft() akan menghitung transformasi Fourier cepat.
Mari kita pahami ini dengan bantuan sebuah contoh.
from scipy import fftpack
sample_freq = fftpack.fftfreq(sig.size, d = time_step)
sig_fft = fftpack.fft(sig)
print sig_fftProgram di atas akan menghasilkan keluaran sebagai berikut.
array([
25.45122234 +0.00000000e+00j, 6.29800973 +2.20269471e+00j,
11.52137858 -2.00515732e+01j, 1.08111300 +1.35488579e+01j,
…….])Transformasi Cosine Diskrit
SEBUAH Discrete Cosine Transform (DCT)mengekspresikan urutan titik data yang terbatas dalam hal sejumlah fungsi kosinus yang berosilasi pada frekuensi yang berbeda. SciPy menyediakan DCT dengan fungsi tersebutdct dan IDCT yang sesuai dengan fungsinya idct. Mari kita perhatikan contoh berikut.
from scipy.fftpack import dct
print dct(np.array([4., 3., 5., 10., 5., 3.]))Program di atas akan menghasilkan keluaran sebagai berikut.
array([ 60., -3.48476592, -13.85640646, 11.3137085, 6., -6.31319305])Transformasi kosinus diskrit terbalik merekonstruksi urutan dari koefisien transformasi kosinus diskrit (DCT). Fungsi idct adalah kebalikan dari fungsi dct. Mari kita pahami ini dengan contoh berikut.
from scipy.fftpack import dct
print idct(np.array([4., 3., 5., 10., 5., 3.]))Program di atas akan menghasilkan keluaran sebagai berikut.
array([ 39.15085889, -20.14213562, -6.45392043, 7.13341236,
8.14213562, -3.83035081])Ketika suatu fungsi tidak dapat diintegrasikan secara analitis, atau sangat sulit untuk diintegrasikan secara analitis, orang biasanya beralih ke metode integrasi numerik. SciPy memiliki sejumlah rutinitas untuk melakukan integrasi numerik. Kebanyakan dari mereka ditemukan di tempat yang samascipy.integratePerpustakaan. Tabel berikut mencantumkan beberapa fungsi yang umum digunakan.
| No Sr | Deskripsi fungsi |
|---|---|
| 1 | quad Integrasi tunggal |
| 2 | dblquad Integrasi ganda |
| 3 | tplquad Integrasi rangkap tiga |
| 4 | nquad integrasi ganda n -fold |
| 5 | fixed_quad Kuadratur Gaussian, orde n |
| 6 | quadrature Kuadrat Gaussian terhadap toleransi |
| 7 | romberg Integrasi Romberg |
| 8 | trapz Aturan trapesium |
| 9 | cumtrapz Aturan trapesium untuk menghitung integral secara kumulatif |
| 10 | simps Aturan Simpson |
| 11 | romb Integrasi Romberg |
| 12 | polyint Integrasi polinomial analitik (NumPy) |
| 13 | poly1d Fungsi pembantu untuk polyint (NumPy) |
Integral Tunggal
Fungsi Quad adalah pekerja keras dari fungsi integrasi SciPy. Integrasi numerik terkadang disebutquadrature, maka nama. Biasanya merupakan pilihan default untuk menjalankan integral tunggal dari suatu fungsi f (x) selama rentang tetap tertentu dari a hingga b.
$$\int_{a}^{b} f(x)dx$$
Bentuk umum dari quad adalah scipy.integrate.quad(f, a, b), Di mana 'f' adalah nama fungsi yang akan diintegrasikan. Sedangkan 'a' dan 'b' masing-masing adalah batas bawah dan atas. Mari kita lihat contoh fungsi Gaussian, terintegrasi pada rentang 0 dan 1.
Pertama-tama kita perlu mendefinisikan fungsi → $f(x) = e^{-x^2}$ , ini bisa dilakukan dengan menggunakan ekspresi lambda dan kemudian memanggil metode quad pada fungsi itu.
import scipy.integrate
from numpy import exp
f= lambda x:exp(-x**2)
i = scipy.integrate.quad(f, 0, 1)
print iProgram di atas akan menghasilkan keluaran sebagai berikut.
(0.7468241328124271, 8.291413475940725e-15)Fungsi kuad mengembalikan dua nilai, di mana angka pertama adalah nilai integral dan nilai kedua adalah perkiraan kesalahan absolut dalam nilai integral.
Note- Karena quad membutuhkan fungsi sebagai argumen pertama, kita tidak bisa langsung mengirimkan exp sebagai argumen. Fungsi Quad menerima ketidakterbatasan positif dan negatif sebagai batas. Fungsi Quad dapat mengintegrasikan fungsi NumPy standar yang telah ditentukan sebelumnya dari variabel tunggal, seperti exp, sin dan cos.
Beberapa Integral
Mekanika untuk integrasi ganda dan rangkap tiga telah dibungkus ke dalam fungsi dblquad, tplquad dan nquad. Fungsi-fungsi ini mengintegrasikan empat atau enam argumen, masing-masing. Batas semua integral dalam perlu didefinisikan sebagai fungsi.
Integral Ganda
Bentuk umum dblquadadalah scipy.integrate.dblquad (func, a, b, gfun, hfun). Di mana, func adalah nama fungsi yang akan diintegrasikan, 'a' dan 'b' masing-masing adalah batas bawah dan atas dari variabel x, sedangkan gfun dan hfun adalah nama dari fungsi yang menentukan batas bawah dan atas dari variabel y.
Sebagai contoh, mari kita lakukan metode integral ganda.
$$\int_{0}^{1/2} dy \int_{0}^{\sqrt{1-4y^2}} 16xy \:dx$$
Kami mendefinisikan fungsi f, g, dan h, menggunakan ekspresi lambda. Perhatikan bahwa bahkan jika g dan h adalah konstanta, seperti dalam banyak kasus, keduanya harus didefinisikan sebagai fungsi, seperti yang telah kita lakukan di sini untuk batas bawah.
import scipy.integrate
from numpy import exp
from math import sqrt
f = lambda x, y : 16*x*y
g = lambda x : 0
h = lambda y : sqrt(1-4*y**2)
i = scipy.integrate.dblquad(f, 0, 0.5, g, h)
print iProgram di atas akan menghasilkan keluaran sebagai berikut.
(0.5, 1.7092350012594845e-14)Selain rutinitas yang dijelaskan di atas, scipy.integrate memiliki sejumlah rutinitas integrasi lainnya, termasuk nquad, yang melakukan integrasi ganda n-fold, serta rutinitas lain yang menerapkan berbagai algoritme integrasi. Namun, quad dan dblquad akan memenuhi sebagian besar kebutuhan kita akan integrasi numerik.
Dalam bab ini, kita akan membahas bagaimana interpolasi membantu dalam SciPy.
Apa itu Interpolasi?
Interpolasi adalah proses menemukan nilai antara dua titik pada garis atau kurva. Untuk membantu kita mengingat apa artinya, kita harus memikirkan bagian pertama dari kata, 'inter,' sebagai arti 'enter,' yang mengingatkan kita untuk melihat 'ke dalam' data yang semula kita miliki. Alat ini, interpolasi, tidak hanya berguna dalam statistik, tetapi juga berguna dalam sains, bisnis, atau ketika ada kebutuhan untuk memprediksi nilai yang termasuk dalam dua titik data yang ada.
Mari kita buat beberapa data dan lihat bagaimana interpolasi ini dapat dilakukan menggunakan scipy.interpolate paket.
import numpy as np
from scipy import interpolate
import matplotlib.pyplot as plt
x = np.linspace(0, 4, 12)
y = np.cos(x**2/3+4)
print x,yProgram di atas akan menghasilkan keluaran sebagai berikut.
(
array([0., 0.36363636, 0.72727273, 1.09090909, 1.45454545, 1.81818182,
2.18181818, 2.54545455, 2.90909091, 3.27272727, 3.63636364, 4.]),
array([-0.65364362, -0.61966189, -0.51077021, -0.31047698, -0.00715476,
0.37976236, 0.76715099, 0.99239518, 0.85886263, 0.27994201,
-0.52586509, -0.99582185])
)Sekarang, kami memiliki dua array. Dengan asumsi kedua larik tersebut sebagai dua dimensi dari titik-titik dalam ruang, mari kita plot menggunakan program berikut dan melihat tampilannya.
plt.plot(x, y,’o’)
plt.show()Program di atas akan menghasilkan keluaran sebagai berikut.
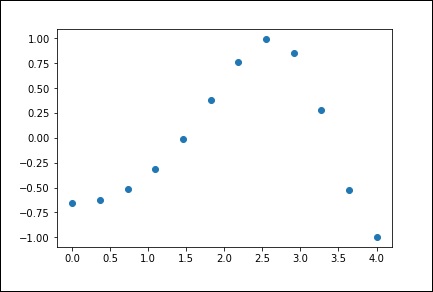
Interpolasi 1-D
Kelas interp1d di scipy.interpolate adalah metode yang mudah untuk membuat fungsi berdasarkan titik data tetap, yang dapat dievaluasi di mana saja dalam domain yang ditentukan oleh data yang diberikan menggunakan interpolasi linier.
Dengan menggunakan data di atas, mari kita buat fungsi interpolasi dan gambar grafik interpolasi baru.
f1 = interp1d(x, y,kind = 'linear')
f2 = interp1d(x, y, kind = 'cubic')Menggunakan fungsi interp1d, kami membuat dua fungsi f1 dan f2. Fungsi-fungsi ini, untuk masukan yang diberikan x mengembalikan y. Jenis variabel ketiga mewakili jenis teknik interpolasi. 'Linear', 'Nearest', 'Zero', 'Slinear', 'Quadratic', 'Cubic' adalah beberapa teknik interpolasi.
Sekarang, mari kita buat input baru yang lebih panjang untuk melihat perbedaan interpolasi yang jelas. Kami akan menggunakan fungsi yang sama dari data lama pada data baru.
xnew = np.linspace(0, 4,30)
plt.plot(x, y, 'o', xnew, f(xnew), '-', xnew, f2(xnew), '--')
plt.legend(['data', 'linear', 'cubic','nearest'], loc = 'best')
plt.show()Program di atas akan menghasilkan keluaran sebagai berikut.
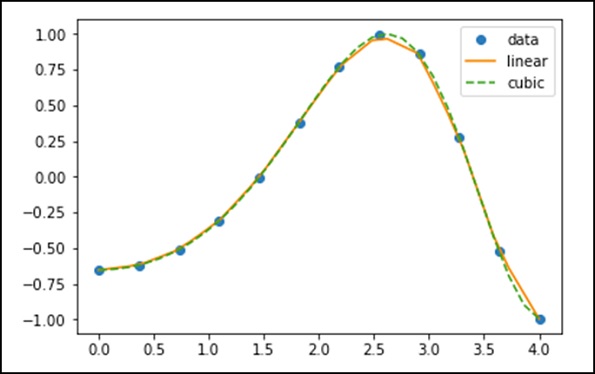
Splines
Untuk menggambar kurva halus melalui titik-titik data, perancang pernah menggunakan potongan tipis fleksibel dari kayu, karet keras, logam atau plastik yang disebut splines mekanis. Untuk menggunakan spline mekanis, pin ditempatkan pada titik-titik yang dipilih dengan cermat di sepanjang kurva dalam desain, dan kemudian spline dibengkokkan, sehingga menyentuh setiap pin ini.
Jelas, dengan konstruksi ini, spline menginterpolasi kurva pada pin ini. Ini dapat digunakan untuk mereproduksi kurva di gambar lain. Titik-titik di mana pin berada disebut simpul. Kita dapat mengubah bentuk kurva yang ditentukan oleh spline dengan menyesuaikan lokasi simpul.
Spline Univariat
Spline smoothing satu dimensi cocok dengan kumpulan titik data tertentu. Kelas UnivariateSpline di scipy.interpolate adalah metode yang mudah untuk membuat sebuah fungsi, berdasarkan kelas poin data tetap - scipy.interpolate.UnivariateSpline (x, y, w = None, bbox = [None, None], k = 3, s = Tidak ada, ext = 0, check_finite = False).
Parameters - Berikut adalah parameter dari Univariate Spline.
Ini cocok dengan spline y = spl (x) derajat k ke data x, y yang tersedia.
'w' - Menentukan bobot untuk pemasangan spline. Harus positif. Jika tidak ada (default), semua bobot sama.
's' - Menentukan jumlah simpul dengan menentukan kondisi penghalusan.
'k' - Derajat spline penghalusan. Harus <= 5. Default-nya adalah k = 3, spline kubik.
Ext - Mengontrol mode ekstrapolasi untuk elemen yang tidak dalam interval yang ditentukan oleh urutan simpul.
jika ext = 0 atau 'extrapolate', mengembalikan nilai yang diekstrapolasi.
jika ext = 1 atau 'nol', mengembalikan 0
jika ext = 2 atau 'raise', memunculkan ValueError
jika ext = 3 dari 'const', mengembalikan nilai batas.
check_finite - Apakah akan memeriksa bahwa array input hanya berisi angka terbatas.
Mari kita perhatikan contoh berikut.
import matplotlib.pyplot as plt
from scipy.interpolate import UnivariateSpline
x = np.linspace(-3, 3, 50)
y = np.exp(-x**2) + 0.1 * np.random.randn(50)
plt.plot(x, y, 'ro', ms = 5)
plt.show()Gunakan nilai default untuk parameter penghalusan.
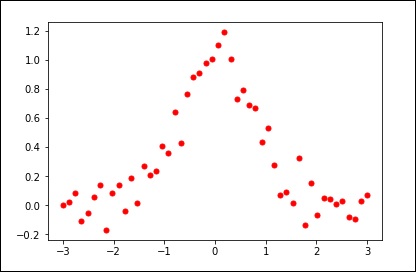
spl = UnivariateSpline(x, y)
xs = np.linspace(-3, 3, 1000)
plt.plot(xs, spl(xs), 'g', lw = 3)
plt.show()Ubah jumlah smoothing secara manual.
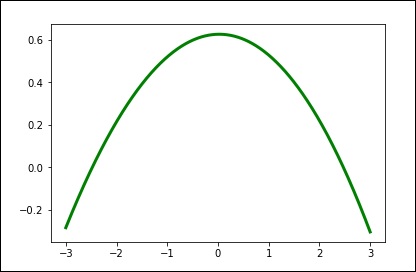
spl.set_smoothing_factor(0.5)
plt.plot(xs, spl(xs), 'b', lw = 3)
plt.show()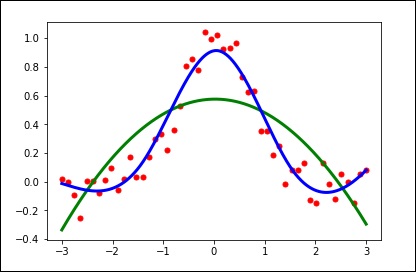
Paket Scipy.io (Input dan Output) menyediakan berbagai fungsi untuk dikerjakan dengan berbagai format file. Beberapa dari format ini adalah -
- Matlab
- IDL
- Pasar Matriks
- Wave
- Arff
- Netcdf, dll.
Mari kita bahas secara rinci tentang format file yang paling umum digunakan -
MATLAB
Berikut adalah fungsi yang digunakan untuk memuat dan menyimpan file .mat.
| No Sr | Deskripsi fungsi |
|---|---|
| 1 | loadmat Memuat file MATLAB |
| 2 | savemat Menyimpan file MATLAB |
| 3 | whosmat Daftar variabel di dalam file MATLAB |
Mari kita perhatikan contoh berikut.
import scipy.io as sio
import numpy as np
#Save a mat file
vect = np.arange(10)
sio.savemat('array.mat', {'vect':vect})
#Now Load the File
mat_file_content = sio.loadmat(‘array.mat’)
Print mat_file_contentProgram di atas akan menghasilkan keluaran sebagai berikut.
{
'vect': array([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]), '__version__': '1.0',
'__header__': 'MATLAB 5.0 MAT-file Platform: posix, Created on: Sat Sep 30
09:49:32 2017', '__globals__': []
}Kita dapat melihat larik beserta informasi Meta. Jika kita ingin memeriksa isi file MATLAB tanpa membaca data ke dalam memori, gunakanwhosmat command seperti gambar dibawah.
import scipy.io as sio
mat_file_content = sio.whosmat(‘array.mat’)
print mat_file_contentProgram di atas akan menghasilkan keluaran sebagai berikut.
[('vect', (1, 10), 'int64')]SciPy dibuat menggunakan yang dioptimalkan ATLAS LAPACK dan BLASperpustakaan. Ia memiliki kemampuan aljabar linier yang sangat cepat. Semua rutinitas aljabar linier ini mengharapkan objek yang dapat diubah menjadi array dua dimensi. Output dari rutinitas ini juga berupa larik dua dimensi.
SciPy.linalg vs NumPy.linalg
Sebuah scipy.linalg berisi semua fungsi yang ada di numpy.linalg. Selain itu, scipy.linalg juga memiliki beberapa fungsi lanjutan lain yang tidak ada di numpy.linalg. Keuntungan lain menggunakan scipy.linalg daripada numpy.linalg adalah selalu dikompilasi dengan dukungan BLAS / LAPACK, sedangkan untuk NumPy ini opsional. Oleh karena itu, versi SciPy mungkin lebih cepat tergantung pada bagaimana NumPy diinstal.
Persamaan linear
Itu scipy.linalg.solve fitur memecahkan persamaan linier a * x + b * y = Z, untuk nilai x, y yang tidak diketahui.
Sebagai contoh, asumsikan bahwa diinginkan untuk menyelesaikan persamaan simultan berikut.
x + 3y + 5z = 10
2x + 5y + z = 8
2x + 3y + 8z = 3
Untuk menyelesaikan persamaan di atas untuk nilai x, y, z, kita dapat mencari vektor solusi menggunakan invers matriks seperti gambar di bawah ini.
$$\begin{bmatrix} x\\ y\\ z \end{bmatrix} = \begin{bmatrix} 1 & 3 & 5\\ 2 & 5 & 1\\ 2 & 3 & 8 \end{bmatrix}^{-1} \begin{bmatrix} 10\\ 8\\ 3 \end{bmatrix} = \frac{1}{25} \begin{bmatrix} -232\\ 129\\ 19 \end{bmatrix} = \begin{bmatrix} -9.28\\ 5.16\\ 0.76 \end{bmatrix}.$$
Namun, lebih baik menggunakan linalg.solve perintah, yang bisa lebih cepat dan lebih stabil secara numerik.
Fungsi menyelesaikan mengambil dua input 'a' dan 'b' di mana 'a' mewakili koefisien dan 'b' mewakili nilai sisi kanan masing-masing dan mengembalikan array solusi.
Mari kita perhatikan contoh berikut.
#importing the scipy and numpy packages
from scipy import linalg
import numpy as np
#Declaring the numpy arrays
a = np.array([[3, 2, 0], [1, -1, 0], [0, 5, 1]])
b = np.array([2, 4, -1])
#Passing the values to the solve function
x = linalg.solve(a, b)
#printing the result array
print xProgram di atas akan menghasilkan keluaran sebagai berikut.
array([ 2., -2., 9.])Menemukan Penentu
Determinan dari matriks persegi A sering dilambangkan sebagai | A | dan merupakan besaran yang sering digunakan dalam aljabar linier. Di SciPy, ini dihitung menggunakan filedet()fungsi. Dibutuhkan matriks sebagai input dan mengembalikan nilai skalar.
Mari kita perhatikan contoh berikut.
#importing the scipy and numpy packages
from scipy import linalg
import numpy as np
#Declaring the numpy array
A = np.array([[1,2],[3,4]])
#Passing the values to the det function
x = linalg.det(A)
#printing the result
print xProgram di atas akan menghasilkan keluaran sebagai berikut.
-2.0Nilai Eigen dan Vektor Eigen
Masalah eigenvalue-eigenvector adalah salah satu operasi aljabar linier yang paling umum digunakan. Kita dapat menemukan nilai Eigen (λ) dan vektor Eigen yang sesuai (v) dari matriks persegi (A) dengan mempertimbangkan hubungan berikut:
Av = λv
scipy.linalg.eigmenghitung nilai eigen dari masalah nilai eigen biasa atau umum. Fungsi ini mengembalikan nilai Eigen dan vektor Eigen.
Mari kita perhatikan contoh berikut.
#importing the scipy and numpy packages
from scipy import linalg
import numpy as np
#Declaring the numpy array
A = np.array([[1,2],[3,4]])
#Passing the values to the eig function
l, v = linalg.eig(A)
#printing the result for eigen values
print l
#printing the result for eigen vectors
print vProgram di atas akan menghasilkan keluaran sebagai berikut.
array([-0.37228132+0.j, 5.37228132+0.j]) #--Eigen Values
array([[-0.82456484, -0.41597356], #--Eigen Vectors
[ 0.56576746, -0.90937671]])Dekomposisi Nilai Singular
Dekomposisi Nilai Singular (SVD) dapat dianggap sebagai perpanjangan dari masalah nilai eigen ke matriks yang tidak persegi.
Itu scipy.linalg.svd memfaktorkan matriks 'a' menjadi dua matriks kesatuan 'U' dan 'Vh' dan array 1-D 's' dengan nilai singular (nyata, non-negatif) sehingga a == U * S * Vh, di mana 'S 'adalah matriks angka nol yang sesuai dengan diagonal utama' s '.
Mari kita perhatikan contoh berikut.
#importing the scipy and numpy packages
from scipy import linalg
import numpy as np
#Declaring the numpy array
a = np.random.randn(3, 2) + 1.j*np.random.randn(3, 2)
#Passing the values to the eig function
U, s, Vh = linalg.svd(a)
# printing the result
print U, Vh, sProgram di atas akan menghasilkan keluaran sebagai berikut.
(
array([
[ 0.54828424-0.23329795j, -0.38465728+0.01566714j,
-0.18764355+0.67936712j],
[-0.27123194-0.5327436j , -0.57080163-0.00266155j,
-0.39868941-0.39729416j],
[ 0.34443818+0.4110186j , -0.47972716+0.54390586j,
0.25028608-0.35186815j]
]),
array([ 3.25745379, 1.16150607]),
array([
[-0.35312444+0.j , 0.32400401+0.87768134j],
[-0.93557636+0.j , -0.12229224-0.33127251j]
])
)Submodul gambar SciPy didedikasikan untuk pemrosesan gambar. Di sini, ndimage berarti gambar berdimensi-n.
Beberapa tugas yang paling umum dalam pemrosesan gambar adalah sebagai berikut & miuns;
- Input / Output, menampilkan gambar
- Manipulasi dasar - Memotong, membalik, memutar, dll.
- Pemfilteran gambar - Menghilangkan noise, penajaman, dll.
- Segmentasi gambar - Memberi label piksel sesuai dengan objek yang berbeda
- Classification
- Ekstraksi fitur
- Registration
Mari kita bahas bagaimana beberapa di antaranya dapat dicapai dengan menggunakan SciPy.
Membuka dan Menulis ke File Gambar
Itu misc packagedi SciPy dilengkapi dengan beberapa gambar. Kami menggunakan gambar-gambar itu untuk mempelajari manipulasi gambar. Mari kita perhatikan contoh berikut.
from scipy import misc
f = misc.face()
misc.imsave('face.png', f) # uses the Image module (PIL)
import matplotlib.pyplot as plt
plt.imshow(f)
plt.show()Program di atas akan menghasilkan keluaran sebagai berikut.

Gambar apa pun dalam format mentahnya adalah kombinasi warna yang diwakili oleh angka dalam format matriks. Mesin memahami dan memanipulasi gambar hanya berdasarkan angka-angka itu. RGB adalah cara representasi yang populer.
Mari kita lihat informasi statistik dari gambar di atas.
from scipy import misc
face = misc.face(gray = False)
print face.mean(), face.max(), face.min()Program di atas akan menghasilkan keluaran sebagai berikut.
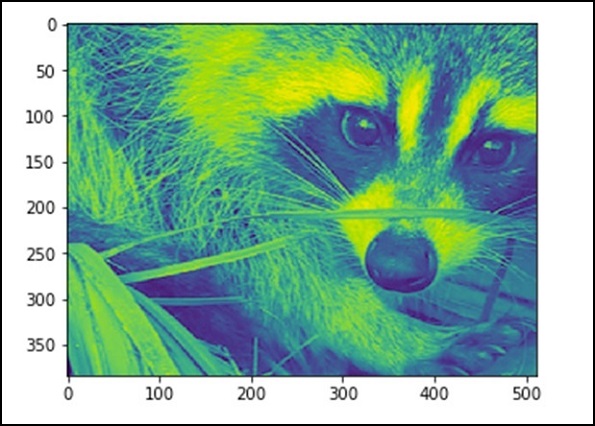
110.16274388631184, 255, 0Sekarang, kita tahu bahwa gambar terbuat dari angka, jadi setiap perubahan nilai angka akan mengubah gambar aslinya. Mari kita lakukan beberapa transformasi geometris pada gambar. Operasi geometris dasar adalah pemotongan
from scipy import misc
face = misc.face(gray = True)
lx, ly = face.shape
# Cropping
crop_face = face[lx / 4: - lx / 4, ly / 4: - ly / 4]
import matplotlib.pyplot as plt
plt.imshow(crop_face)
plt.show()Program di atas akan menghasilkan keluaran sebagai berikut.
Kami juga dapat melakukan beberapa operasi dasar seperti membalikkan gambar seperti yang dijelaskan di bawah ini.
# up <-> down flip
from scipy import misc
face = misc.face()
flip_ud_face = np.flipud(face)
import matplotlib.pyplot as plt
plt.imshow(flip_ud_face)
plt.show()Program di atas akan menghasilkan keluaran sebagai berikut.

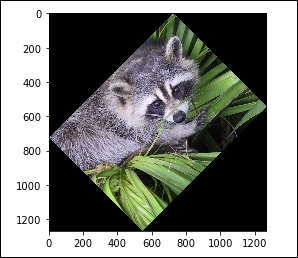
Selain itu, kami memiliki file rotate() function, yang memutar gambar dengan sudut tertentu.
# rotation
from scipy import misc,ndimage
face = misc.face()
rotate_face = ndimage.rotate(face, 45)
import matplotlib.pyplot as plt
plt.imshow(rotate_face)
plt.show()Program di atas akan menghasilkan keluaran sebagai berikut.
Filter
Mari kita bahas bagaimana filter membantu dalam pemrosesan gambar.
Apa yang dimaksud dengan pemfilteran dalam pemrosesan gambar?
Pemfilteran adalah teknik untuk mengubah atau meningkatkan gambar. Misalnya, Anda dapat memfilter gambar untuk menekankan fitur tertentu atau menghapus fitur lainnya. Operasi pemrosesan gambar yang diimplementasikan dengan pemfilteran termasuk Smoothing, Sharpening, dan Edge Enhancement.
Pemfilteran adalah operasi lingkungan, di mana nilai piksel tertentu dalam gambar keluaran ditentukan dengan menerapkan beberapa algoritma ke nilai piksel di lingkungan piksel masukan yang sesuai. Sekarang mari kita melakukan beberapa operasi menggunakan SciPy ndimage.
Buram
Pemburaman banyak digunakan untuk mengurangi noise pada gambar. Kita dapat melakukan operasi filter dan melihat perubahan pada gambar. Mari kita perhatikan contoh berikut.
from scipy import misc
face = misc.face()
blurred_face = ndimage.gaussian_filter(face, sigma=3)
import matplotlib.pyplot as plt
plt.imshow(blurred_face)
plt.show()Program di atas akan menghasilkan keluaran sebagai berikut.

Nilai sigma menunjukkan tingkat keburaman pada skala lima. Perubahan kualitas gambar dapat dilihat dengan melakukan tuning pada nilai sigma. Untuk detail lebih lanjut tentang pemburaman, klik → DIP (Pemrosesan Gambar Digital) Tutorial.
Deteksi Tepi
Mari kita bahas bagaimana deteksi tepi membantu dalam pemrosesan gambar.
Apa itu Deteksi Tepi?
Deteksi tepi adalah teknik pemrosesan gambar untuk menemukan batas-batas objek di dalam gambar. Ia bekerja dengan mendeteksi diskontinuitas dalam kecerahan. Deteksi tepi digunakan untuk segmentasi gambar dan ekstraksi data di area seperti Pemrosesan Gambar, Computer Vision, dan Machine Vision.
Algoritme deteksi tepi yang paling umum digunakan termasuk
- Sobel
- Canny
- Prewitt
- Roberts
- Metode Fuzzy Logic
Mari kita perhatikan contoh berikut.
import scipy.ndimage as nd
import numpy as np
im = np.zeros((256, 256))
im[64:-64, 64:-64] = 1
im[90:-90,90:-90] = 2
im = ndimage.gaussian_filter(im, 8)
import matplotlib.pyplot as plt
plt.imshow(im)
plt.show()Program di atas akan menghasilkan keluaran sebagai berikut.

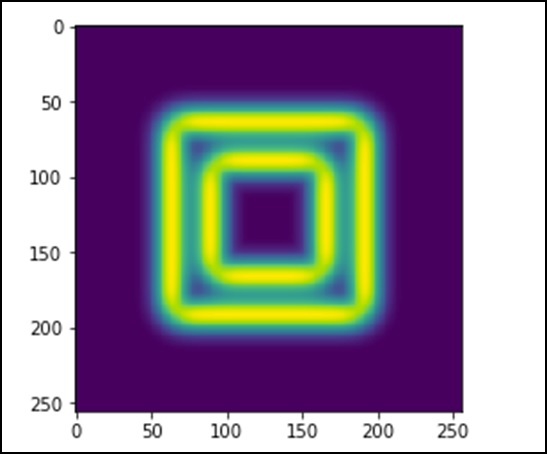
Gambar terlihat seperti blok warna persegi. Sekarang, kita akan mendeteksi tepi balok berwarna itu. Di sini, ndimage menyediakan fungsi yang disebutSobeluntuk melakukan operasi ini. Padahal, NumPy menyediakan fileHypot berfungsi untuk menggabungkan dua matriks yang dihasilkan menjadi satu.
Mari kita perhatikan contoh berikut.
import scipy.ndimage as nd
import matplotlib.pyplot as plt
im = np.zeros((256, 256))
im[64:-64, 64:-64] = 1
im[90:-90,90:-90] = 2
im = ndimage.gaussian_filter(im, 8)
sx = ndimage.sobel(im, axis = 0, mode = 'constant')
sy = ndimage.sobel(im, axis = 1, mode = 'constant')
sob = np.hypot(sx, sy)
plt.imshow(sob)
plt.show()Program di atas akan menghasilkan keluaran sebagai berikut.
Itu scipy.optimize packagemenyediakan beberapa algoritme pengoptimalan yang umum digunakan. Modul ini berisi aspek-aspek berikut -
Minimisasi fungsi skalar multivariat yang tidak dibatasi dan dibatasi (minimalkan ()) menggunakan berbagai algoritme (misalnya BFGS, simplex Nelder-Mead, Newton Conjugate Gradient, COBYLA atau SLSQP)
Rutinitas pengoptimalan global (brute-force) (misalnya, anneal (), basinhopping ())
Algoritme minimisasi kuadrat-terkecil (leastsq ()) dan penyesuaian kurva (curve_fit ())
Minimizer fungsi univariat skalar (minimalkan_skalar ()) dan pencari root (newton ())
Pemecah sistem persamaan multivariat (root ()) menggunakan berbagai algoritma (misalnya hibrid Powell, Levenberg-Marquardt atau metode skala besar seperti Newton-Krylov)
Minimisasi fungsi skalar multivariasi yang tidak dibatasi & dibatasi
Itu minimize() function menyediakan antarmuka umum untuk algoritma minimisasi tidak dibatasi dan dibatasi untuk fungsi skalar multivariasi di scipy.optimize. Untuk mendemonstrasikan fungsi minimisasi, pertimbangkan masalah meminimalkan fungsi Rosenbrock dari variabel NN -
$$f(x) = \sum_{i = 1}^{N-1} \:100(x_i - x_{i-1}^{2})$$
Nilai minimum fungsi ini adalah 0, yang dicapai jika xi = 1.
Algoritma Simplex Nelder – Mead
Dalam contoh berikut, Rutinminimalkan () digunakan dengan Nelder-Mead simplex algorithm (method = 'Nelder-Mead')(dipilih melalui parameter metode). Mari kita perhatikan contoh berikut.
import numpy as np
from scipy.optimize import minimize
def rosen(x):
x0 = np.array([1.3, 0.7, 0.8, 1.9, 1.2])
res = minimize(rosen, x0, method='nelder-mead')
print(res.x)Program di atas akan menghasilkan keluaran sebagai berikut.
[7.93700741e+54 -5.41692163e+53 6.28769150e+53 1.38050484e+55 -4.14751333e+54]Algoritme simpleks mungkin merupakan cara paling sederhana untuk meminimalkan fungsi yang berperilaku cukup baik. Ini hanya membutuhkan evaluasi fungsi dan merupakan pilihan yang baik untuk masalah minimisasi sederhana. Namun, karena tidak menggunakan evaluasi gradien apa pun, mungkin perlu waktu lebih lama untuk menemukan nilai minimum.
Algoritme pengoptimalan lain yang hanya membutuhkan pemanggilan fungsi untuk menemukan nilai minimum adalah Powell‘s method, yang tersedia dengan menyetel method = 'powell' dalam fungsi minimalkan ().
Kotak Terkecil
Selesaikan masalah kuadrat-terkecil nonlinier dengan batas pada variabel. Mengingat residual f (x) (fungsi riil berdimensi-m dari n variabel riil) dan fungsi kerugian rho (s) (fungsi skalar), least_squares menemukan minimum lokal dari fungsi biaya F (x). Mari kita perhatikan contoh berikut.
Dalam contoh ini, kami menemukan fungsi Rosenbrock minimum tanpa batasan pada variabel independen.
#Rosenbrock Function
def fun_rosenbrock(x):
return np.array([10 * (x[1] - x[0]**2), (1 - x[0])])
from scipy.optimize import least_squares
input = np.array([2, 2])
res = least_squares(fun_rosenbrock, input)
print resPerhatikan bahwa, kami hanya menyediakan vektor dari residu. Algoritme membangun fungsi biaya sebagai jumlah kuadrat dari residual, yang memberikan fungsi Rosenbrock. Minimum persisnya adalah pada x = [1.0,1.0].
Program di atas akan menghasilkan keluaran sebagai berikut.
active_mask: array([ 0., 0.])
cost: 9.8669242910846867e-30
fun: array([ 4.44089210e-15, 1.11022302e-16])
grad: array([ -8.89288649e-14, 4.44089210e-14])
jac: array([[-20.00000015,10.],[ -1.,0.]])
message: '`gtol` termination condition is satisfied.'
nfev: 3
njev: 3
optimality: 8.8928864934219529e-14
status: 1
success: True
x: array([ 1., 1.])Penemuan root
Mari kita pahami bagaimana pencarian root membantu dalam SciPy.
Fungsi skalar
Jika seseorang memiliki persamaan variabel tunggal, ada empat algoritma pencarian akar yang berbeda, yang dapat dicoba. Masing-masing algoritme ini membutuhkan titik akhir dari interval di mana akar diharapkan (karena fungsi mengubah tanda). Secara umum,brentq adalah pilihan terbaik, tetapi metode lain mungkin berguna dalam keadaan tertentu atau untuk tujuan akademis.
Pemecahan titik tetap
Masalah yang berkaitan erat dengan mencari nol suatu fungsi adalah masalah menemukan titik tetap dari suatu fungsi. Titik tetap suatu fungsi adalah titik di mana evaluasi fungsi mengembalikan titik: g (x) = x. Jelas titik tetap dariggadalah akar dari f (x) = g (x) −x. Sama halnya, root dariffadalah titik_ketentuan dari g (x) = f (x) + x. Fixed_point rutin menyediakan metode iteratif sederhana menggunakanAitkens sequence acceleration untuk memperkirakan titik tetap gg, jika titik awal diberikan.
Kumpulan persamaan
Menemukan akar dari himpunan persamaan non-linier dapat dilakukan dengan menggunakan root() function. Beberapa metode tersedia, di antaranyahybr (default) dan lm, masing-masing menggunakan hybrid method of Powell dan Levenberg-Marquardt method dari MINPACK.
Contoh berikut mempertimbangkan persamaan transendental variabel tunggal.
x2 + 2cos(x) = 0
Akar yang dapat ditemukan sebagai berikut -
import numpy as np
from scipy.optimize import root
def func(x):
return x*2 + 2 * np.cos(x)
sol = root(func, 0.3)
print solProgram di atas akan menghasilkan keluaran sebagai berikut.
fjac: array([[-1.]])
fun: array([ 2.22044605e-16])
message: 'The solution converged.'
nfev: 10
qtf: array([ -2.77644574e-12])
r: array([-3.34722409])
status: 1
success: True
x: array([-0.73908513])Semua fungsi statistik terletak di sub-paket scipy.stats dan daftar yang cukup lengkap dari fungsi-fungsi ini dapat diperoleh dengan menggunakan info(stats)fungsi. Daftar variabel acak yang tersedia juga dapat diperoleh daridocstringuntuk sub-paket statistik. Modul ini berisi sejumlah besar distribusi probabilitas serta pustaka fungsi statistik yang terus berkembang.
Setiap distribusi univariat memiliki subkelasnya sendiri seperti yang dijelaskan dalam tabel berikut -
| No Sr | Kelas & Deskripsi |
|---|---|
| 1 | rv_continuous Kelas variabel acak kontinu generik yang dimaksudkan untuk subclass |
| 2 | rv_discrete Kelas variabel acak diskrit generik yang dimaksudkan untuk subclassing |
| 3 | rv_histogram Menghasilkan distribusi yang diberikan oleh histogram |
Variabel Acak Kontinu Normal
Distribusi probabilitas di mana variabel acak X dapat mengambil nilai apa pun adalah variabel acak kontinu. Kata kunci lokasi (loc) menentukan mean. Kata kunci skala (skala) menentukan deviasi standar.
Sebagai contoh dari rv_continuous kelas, norm objek mewarisi darinya kumpulan metode umum dan melengkapinya dengan detail khusus untuk distribusi khusus ini.
Untuk menghitung CDF di sejumlah titik, kita dapat mengirimkan daftar atau array NumPy. Mari kita perhatikan contoh berikut.
from scipy.stats import norm
import numpy as np
print norm.cdf(np.array([1,-1., 0, 1, 3, 4, -2, 6]))Program di atas akan menghasilkan keluaran sebagai berikut.
array([ 0.84134475, 0.15865525, 0.5 , 0.84134475, 0.9986501 ,
0.99996833, 0.02275013, 1. ])Untuk mencari median suatu distribusi, kita dapat menggunakan Percent Point Function (PPF), yang merupakan kebalikan dari CDF. Mari kita pahami dengan menggunakan contoh berikut.
from scipy.stats import norm
print norm.ppf(0.5)Program di atas akan menghasilkan keluaran sebagai berikut.
0.0Untuk menghasilkan urutan variasi acak, kita harus menggunakan argumen kata kunci size, yang ditunjukkan pada contoh berikut.
from scipy.stats import norm
print norm.rvs(size = 5)Program di atas akan menghasilkan keluaran sebagai berikut.
array([ 0.20929928, -1.91049255, 0.41264672, -0.7135557 , -0.03833048])Output di atas tidak dapat diproduksi ulang. Untuk menghasilkan nomor acak yang sama, gunakan fungsi benih.
Distribusi Seragam
Distribusi seragam dapat dihasilkan menggunakan fungsi seragam. Mari kita perhatikan contoh berikut.
from scipy.stats import uniform
print uniform.cdf([0, 1, 2, 3, 4, 5], loc = 1, scale = 4)Program di atas akan menghasilkan keluaran sebagai berikut.
array([ 0. , 0. , 0.25, 0.5 , 0.75, 1. ])Bangun Distribusi Diskrit
Mari kita buat sampel acak dan bandingkan frekuensi yang diamati dengan probabilitasnya.
Distribusi Binomial
Sebagai contoh dari rv_discrete class, itu binom objectmewarisi darinya kumpulan metode umum dan melengkapinya dengan detail khusus untuk distribusi khusus ini. Mari kita perhatikan contoh berikut.
from scipy.stats import uniform
print uniform.cdf([0, 1, 2, 3, 4, 5], loc = 1, scale = 4)Program di atas akan menghasilkan keluaran sebagai berikut.
array([ 0. , 0. , 0.25, 0.5 , 0.75, 1. ])Statistik deskriptif
Statistik dasar seperti Min, Max, Mean dan Variance menggunakan array NumPy sebagai input dan mengembalikan hasil masing-masing. Beberapa fungsi statistik dasar tersedia discipy.stats package dijelaskan dalam tabel berikut.
| No Sr | Deskripsi fungsi |
|---|---|
| 1 | describe() Menghitung beberapa statistik deskriptif dari larik yang dilewati |
| 2 | gmean() Menghitung rata-rata geometris sepanjang sumbu yang ditentukan |
| 3 | hmean() Menghitung rata-rata harmonik di sepanjang sumbu yang ditentukan |
| 4 | kurtosis() Menghitung kurtosis |
| 5 | mode() Mengembalikan nilai modal |
| 6 | skew() Menguji kemiringan data |
| 7 | f_oneway() Melakukan ANOVA 1 arah |
| 8 | iqr() Menghitung rentang interkuartil dari data sepanjang sumbu yang ditentukan |
| 9 | zscore() Menghitung skor z dari setiap nilai dalam sampel, relatif terhadap rata-rata sampel dan deviasi standar |
| 10 | sem() Menghitung kesalahan standar dari mean (atau kesalahan standar pengukuran) dari nilai-nilai dalam larik input |
Beberapa dari fungsi ini memiliki versi serupa di scipy.stats.mstats, yang berfungsi untuk array bertopeng. Mari kita pahami ini dengan contoh yang diberikan di bawah ini.
from scipy import stats
import numpy as np
x = np.array([1,2,3,4,5,6,7,8,9])
print x.max(),x.min(),x.mean(),x.var()Program di atas akan menghasilkan keluaran sebagai berikut.
(9, 1, 5.0, 6.666666666666667)Uji-t
Mari kita pahami bagaimana T-test berguna di SciPy.
ttest_1samp
Menghitung uji-T untuk mean dari SATU kelompok skor. Ini adalah tes dua sisi untuk hipotesis nol bahwa nilai yang diharapkan (mean) dari sampel pengamatan independen 'a' sama dengan mean populasi yang diberikan,popmean. Mari kita perhatikan contoh berikut.
from scipy import stats
rvs = stats.norm.rvs(loc = 5, scale = 10, size = (50,2))
print stats.ttest_1samp(rvs,5.0)Program di atas akan menghasilkan keluaran sebagai berikut.
Ttest_1sampResult(statistic = array([-1.40184894, 2.70158009]),
pvalue = array([ 0.16726344, 0.00945234]))Membandingkan dua sampel
Dalam contoh berikut, ada dua sampel, yang dapat berasal dari distribusi yang sama atau berbeda, dan kami ingin menguji apakah sampel ini memiliki properti statistik yang sama.
ttest_ind- Menghitung T-test rata-rata dari dua sampel skor independen. Ini adalah pengujian dua sisi untuk hipotesis nol bahwa dua sampel independen memiliki nilai rata-rata (yang diharapkan) yang identik. Tes ini mengasumsikan bahwa populasi memiliki varian identik secara default.
Kami dapat menggunakan tes ini, jika kami mengamati dua sampel independen dari populasi yang sama atau berbeda. Mari kita perhatikan contoh berikut.
from scipy import stats
rvs1 = stats.norm.rvs(loc = 5,scale = 10,size = 500)
rvs2 = stats.norm.rvs(loc = 5,scale = 10,size = 500)
print stats.ttest_ind(rvs1,rvs2)Program di atas akan menghasilkan keluaran sebagai berikut.
Ttest_indResult(statistic = -0.67406312233650278, pvalue = 0.50042727502272966)Anda dapat menguji hal yang sama dengan array baru dengan panjang yang sama, tetapi dengan mean yang bervariasi. Gunakan nilai yang berbeda diloc dan uji yang sama.
CSGraph adalah singkatan dari Compressed Sparse Graph, yang berfokus pada algoritma grafik Cepat berdasarkan representasi matriks renggang.
Representasi Grafik
Untuk memulainya, mari kita pahami apa itu grafik renggang dan bagaimana grafik itu membantu dalam representasi grafik.
Apa sebenarnya grafik renggang itu?
Grafik hanyalah kumpulan node, yang memiliki hubungan di antara mereka. Grafik dapat mewakili hampir semua hal - koneksi jaringan sosial, di mana setiap node adalah orang dan terhubung ke kenalan; gambar, di mana setiap node adalah piksel dan terhubung ke piksel tetangga; titik dalam distribusi berdimensi tinggi, di mana setiap node terhubung ke tetangga terdekatnya; dan hampir semua hal lain yang dapat Anda bayangkan.
Salah satu cara yang sangat efisien untuk merepresentasikan data grafik adalah dalam matriks renggang: sebut saja G. Matriks G berukuran N x N, dan G [i, j] memberikan nilai hubungan antara node 'i' dan node 'j'. Grafik renggang sebagian besar berisi nol - artinya, sebagian besar node hanya memiliki sedikit koneksi. Properti ini ternyata benar dalam banyak kasus yang menarik.
Pembuatan submodul grafik renggang dimotivasi oleh beberapa algoritme yang digunakan dalam scikit-learn yang mencakup berikut ini -
Isomap - Algoritma pembelajaran berjenis, yang membutuhkan pencarian jalur terpendek dalam grafik.
Hierarchical clustering - Algoritme pengelompokan berdasarkan pohon rentang minimum.
Spectral Decomposition - Algoritma proyeksi berdasarkan laplacians grafik jarang.
Sebagai contoh konkret, bayangkan kita ingin merepresentasikan graf tak berarah berikut -
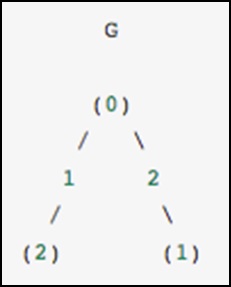
Grafik ini memiliki tiga node, di mana node 0 dan 1 dihubungkan oleh edge of weight 2, dan node 0 dan 2 dihubungkan oleh edge of weight 1. Kita dapat membuat representasi padat, bertopeng, dan jarang seperti yang ditunjukkan pada contoh berikut , perlu diingat bahwa grafik yang tidak berarah direpresentasikan oleh matriks simetris.
G_dense = np.array([ [0, 2, 1],
[2, 0, 0],
[1, 0, 0] ])
G_masked = np.ma.masked_values(G_dense, 0)
from scipy.sparse import csr_matrix
G_sparse = csr_matrix(G_dense)
print G_sparse.dataProgram di atas akan menghasilkan keluaran sebagai berikut.
array([2, 1, 2, 1])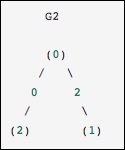
Ini identik dengan grafik sebelumnya, kecuali node 0 dan 2 dihubungkan oleh tepi tanpa bobot. Dalam hal ini, representasi padat di atas mengarah pada ambiguitas - bagaimana non-edge dapat direpresentasikan, jika nol adalah nilai yang berarti. Dalam hal ini, representasi bertopeng atau jarang harus digunakan untuk menghilangkan ambiguitas.
Mari kita perhatikan contoh berikut.
from scipy.sparse.csgraph import csgraph_from_dense
G2_data = np.array
([
[np.inf, 2, 0 ],
[2, np.inf, np.inf],
[0, np.inf, np.inf]
])
G2_sparse = csgraph_from_dense(G2_data, null_value=np.inf)
print G2_sparse.dataProgram di atas akan menghasilkan keluaran sebagai berikut.
array([ 2., 0., 2., 0.])Tangga kata menggunakan grafik renggang
Tangga kata adalah permainan yang diciptakan oleh Lewis Carroll, di mana kata-kata dihubungkan dengan mengubah satu huruf di setiap langkah. Misalnya -
APE → APT → AIT → BIT → BIG → BAG → MAG → MAN
Di sini, kami telah beralih dari "APE" ke "MAN" dalam tujuh langkah, mengubah satu huruf setiap kali. Pertanyaannya adalah - Bisakah kita menemukan jalur yang lebih pendek di antara kata-kata ini menggunakan aturan yang sama? Masalah ini secara alami diekspresikan sebagai masalah grafik renggang. Node akan sesuai dengan kata-kata individu, dan kami akan membuat hubungan antara kata-kata yang paling berbeda - satu huruf.
Memperoleh Daftar Kata
Pertama, tentunya kita harus mendapatkan daftar kata yang valid. Saya menjalankan Mac, dan Mac memiliki kamus kata di lokasi yang diberikan di blok kode berikut. Jika Anda menggunakan arsitektur yang berbeda, Anda mungkin harus mencari sedikit untuk menemukan kamus sistem Anda.
wordlist = open('/usr/share/dict/words').read().split()
print len(wordlist)Program di atas akan menghasilkan keluaran sebagai berikut.
235886Kami sekarang ingin melihat kata-kata dengan panjang 3, jadi mari kita pilih hanya kata-kata dengan panjang yang benar. Kami juga akan menghilangkan kata-kata, yang dimulai dengan huruf besar (kata benda yang tepat) atau berisi karakter non-alfa-numerik seperti apostrof dan tanda hubung. Terakhir, kami akan memastikan semuanya menggunakan huruf kecil untuk perbandingan nanti.
word_list = [word for word in word_list if len(word) == 3]
word_list = [word for word in word_list if word[0].islower()]
word_list = [word for word in word_list if word.isalpha()]
word_list = map(str.lower, word_list)
print len(word_list)Program di atas akan menghasilkan keluaran sebagai berikut.
1135Sekarang, kami memiliki daftar 1135 kata tiga huruf yang valid (jumlah persisnya dapat berubah tergantung pada daftar tertentu yang digunakan). Masing-masing kata ini akan menjadi simpul dalam grafik kami, dan kami akan membuat tepi yang menghubungkan simpul yang terkait dengan setiap pasangan kata, yang berbeda hanya dengan satu huruf.
import numpy as np
word_list = np.asarray(word_list)
word_list.dtype
word_list.sort()
word_bytes = np.ndarray((word_list.size, word_list.itemsize),
dtype = 'int8',
buffer = word_list.data)
print word_bytes.shapeProgram di atas akan menghasilkan keluaran sebagai berikut.
(1135, 3)Kami akan menggunakan jarak Hamming antara setiap titik untuk menentukan, pasangan kata mana yang terhubung. Jarak Hamming mengukur pecahan entri antara dua vektor, yang berbeda: dua kata apa pun dengan jarak hamming sama dengan 1 / N1 / N, di mana NN adalah jumlah huruf, yang terhubung dalam kata ladder.
from scipy.spatial.distance import pdist, squareform
from scipy.sparse import csr_matrix
hamming_dist = pdist(word_bytes, metric = 'hamming')
graph = csr_matrix(squareform(hamming_dist < 1.5 / word_list.itemsize))Saat membandingkan jarak, kami tidak menggunakan persamaan karena ini bisa jadi tidak stabil untuk nilai titik mengambang. Ketidaksamaan memberikan hasil yang diinginkan selama tidak ada dua entri dari daftar kata yang identik. Sekarang, setelah grafik kita siap, kita akan menggunakan pencarian jalur terpendek untuk menemukan jalur antara dua kata dalam grafik.
i1 = word_list.searchsorted('ape')
i2 = word_list.searchsorted('man')
print word_list[i1],word_list[i2]Program di atas akan menghasilkan keluaran sebagai berikut.
ape, manKita perlu memeriksa apakah ini cocok, karena jika kata-kata tersebut tidak ada dalam daftar akan ada kesalahan pada keluarannya. Sekarang, yang kita butuhkan hanyalah menemukan jalur terpendek di antara dua indeks ini dalam grafik. Kami akan menggunakandijkstra’s algoritma, karena memungkinkan kita menemukan jalur hanya untuk satu node.
from scipy.sparse.csgraph import dijkstra
distances, predecessors = dijkstra(graph, indices = i1, return_predecessors = True)
print distances[i2]Program di atas akan menghasilkan keluaran sebagai berikut.
5.0Jadi, kita melihat bahwa jalur terpendek antara 'kera' dan 'manusia' hanya terdiri dari lima langkah. Kita bisa menggunakan pendahulu yang dikembalikan oleh algoritme untuk merekonstruksi jalur ini.
path = []
i = i2
while i != i1:
path.append(word_list[i])
i = predecessors[i]
path.append(word_list[i1])
print path[::-1]i2]Program di atas akan menghasilkan keluaran sebagai berikut.
['ape', 'ope', 'opt', 'oat', 'mat', 'man']Itu scipy.spatial package dapat menghitung Triangulasi, Diagram Voronoi, dan Convex Hulls dari sekumpulan titik, dengan memanfaatkan Qhull library. Apalagi mengandungKDTree implementations untuk kueri titik tetangga terdekat dan utilitas untuk penghitungan jarak dalam berbagai metrik.
Triangulasi Delaunay
Mari kita pahami apa itu Delaunay Triangulations dan bagaimana penggunaannya di SciPy.
Apa itu Triangulasi Delaunay?
Dalam matematika dan geometri komputasi, triangulasi Delaunay untuk himpunan tertentu P titik diskrit dalam bidang adalah triangulasi DT(P) sedemikian rupa sehingga tidak ada gunanya P berada di dalam lingkaran sirkit segitiga apa pun di DT (P).
Kita dapat menghitungnya melalui SciPy. Mari kita perhatikan contoh berikut.
from scipy.spatial import Delaunay
points = np.array([[0, 4], [2, 1.1], [1, 3], [1, 2]])
tri = Delaunay(points)
import matplotlib.pyplot as plt
plt.triplot(points[:,0], points[:,1], tri.simplices.copy())
plt.plot(points[:,0], points[:,1], 'o')
plt.show()Program di atas akan menghasilkan keluaran sebagai berikut.

Coplanar Points
Mari kita pahami apa itu Coplanar Points dan bagaimana penggunaannya di SciPy.
Apa itu Poin Coplanar?
Titik koplanar adalah tiga titik atau lebih yang terletak pada bidang yang sama. Ingatlah bahwa bidang adalah permukaan datar, yang memanjang tanpa ujung ke segala arah. Biasanya ini ditampilkan dalam buku teks matematika sebagai gambar empat sisi.
Mari kita lihat bagaimana kita dapat menemukannya menggunakan SciPy. Mari kita perhatikan contoh berikut.
from scipy.spatial import Delaunay
points = np.array([[0, 0], [0, 1], [1, 0], [1, 1], [1, 1]])
tri = Delaunay(points)
print tri.coplanarProgram di atas akan menghasilkan keluaran sebagai berikut.
array([[4, 0, 3]], dtype = int32)Ini berarti titik 4 berada di dekat segitiga 0 dan titik 3, tetapi tidak termasuk dalam triangulasi.
Lambung cembung
Mari kita pahami apa itu convex hull dan bagaimana penggunaannya di SciPy.
Apa itu Convex Hulls?
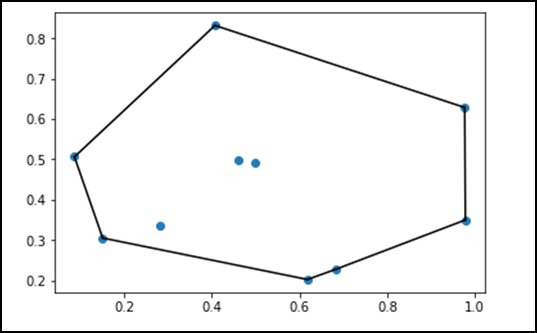
Dalam matematika, file convex hull atau convex envelope dari satu set titik X di bidang Euclidean atau di ruang Euclidean (atau, lebih umum, di ruang affine di atas real) adalah yang terkecil convex set yang berisi X.
Mari kita perhatikan contoh berikut untuk memahaminya secara detail.
from scipy.spatial import ConvexHull
points = np.random.rand(10, 2) # 30 random points in 2-D
hull = ConvexHull(points)
import matplotlib.pyplot as plt
plt.plot(points[:,0], points[:,1], 'o')
for simplex in hull.simplices:
plt.plot(points[simplex,0], points[simplex,1], 'k-')
plt.show()Program di atas akan menghasilkan keluaran sebagai berikut.
ODR adalah singkatan dari Orthogonal Distance Regression, yang digunakan dalam studi regresi. Regresi linier dasar sering digunakan untuk mengestimasi hubungan antara kedua variabely dan x dengan menggambar garis yang paling sesuai pada grafik.
Metode matematika yang digunakan untuk ini dikenal sebagai Least Squares, dan bertujuan untuk meminimalkan jumlah kesalahan kuadrat untuk setiap poin. Pertanyaan kuncinya di sini adalah bagaimana Anda menghitung kesalahan (juga dikenal sebagai residual) untuk setiap poin?
Dalam regresi linier standar, tujuannya adalah untuk memprediksi nilai Y dari nilai X - jadi hal yang perlu dilakukan adalah menghitung kesalahan pada nilai Y (ditunjukkan sebagai garis abu-abu pada gambar berikut). Namun, terkadang lebih bijaksana untuk memperhitungkan kesalahan pada X dan Y (seperti yang ditunjukkan oleh garis merah putus-putus pada gambar berikut).
Misalnya - Ketika Anda tahu pengukuran X Anda tidak pasti, atau ketika Anda tidak ingin fokus pada kesalahan satu variabel di atas yang lain.
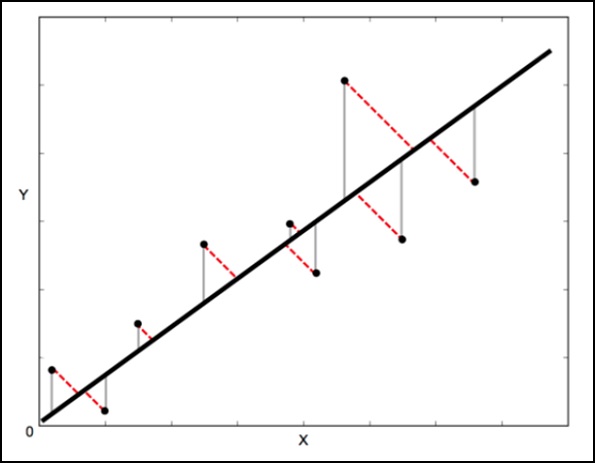
Orthogonal Distance Regression (ODR) adalah metode yang dapat melakukan ini (ortogonal dalam konteks ini berarti tegak lurus - sehingga menghitung kesalahan tegak lurus terhadap garis, bukan hanya 'vertikal').
scipy.odr Implementasi untuk Regresi Univariat
Contoh berikut menunjukkan implementasi scipy.odr untuk regresi univariat.
import numpy as np
import matplotlib.pyplot as plt
from scipy.odr import *
import random
# Initiate some data, giving some randomness using random.random().
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([i**2 + random.random() for i in x])
# Define a function (quadratic in our case) to fit the data with.
def linear_func(p, x):
m, c = p
return m*x + c
# Create a model for fitting.
linear_model = Model(linear_func)
# Create a RealData object using our initiated data from above.
data = RealData(x, y)
# Set up ODR with the model and data.
odr = ODR(data, linear_model, beta0=[0., 1.])
# Run the regression.
out = odr.run()
# Use the in-built pprint method to give us results.
out.pprint()Program di atas akan menghasilkan keluaran sebagai berikut.
Beta: [ 5.51846098 -4.25744878]
Beta Std Error: [ 0.7786442 2.33126407]
Beta Covariance: [
[ 1.93150969 -4.82877433]
[ -4.82877433 17.31417201
]]
Residual Variance: 0.313892697582
Inverse Condition #: 0.146618499389
Reason(s) for Halting:
Sum of squares convergenceFungsi yang tersedia dalam paket khusus adalah fungsi universal, yang mengikuti penyiaran dan pengulangan array otomatis.
Mari kita lihat beberapa fungsi khusus yang paling sering digunakan -
- Fungsi Akar Kubik
- Fungsi eksponensial
- Fungsi Eksponensial Eror Relatif
- Fungsi Eksponensial Log Sum
- Fungsi Lambert
- Fungsi Permutasi dan Kombinasi
- Fungsi Gamma
Mari kita sekarang memahami masing-masing fungsi ini secara singkat.
Fungsi Akar Kubik
Sintaks dari fungsi akar kubik ini adalah - scipy.special.cbrt (x). Ini akan mengambil akar pangkat tiga dari segi elemenx.
Mari kita perhatikan contoh berikut.
from scipy.special import cbrt
res = cbrt([10, 9, 0.1254, 234])
print resProgram di atas akan menghasilkan keluaran sebagai berikut.
[ 2.15443469 2.08008382 0.50053277 6.16224015]Fungsi eksponensial
Sintaks dari fungsi eksponensial adalah - scipy.special.exp10 (x). Ini akan menghitung 10 ** x elemen secara bijaksana.
Mari kita perhatikan contoh berikut.
from scipy.special import exp10
res = exp10([2, 9])
print resProgram di atas akan menghasilkan keluaran sebagai berikut.
[1.00000000e+02 1.00000000e+09]Fungsi Eksponensial Eror Relatif
Sintaks untuk fungsi ini adalah - scipy.special.exprel (x). Ini menghasilkan kesalahan relatif eksponensial, (exp (x) - 1) / x.
Kapan xmendekati nol, exp (x) mendekati 1, sehingga kalkulasi numerik dari exp (x) - 1 dapat menyebabkan kehilangan presisi yang sangat besar. Kemudian exprel (x) diimplementasikan untuk menghindari hilangnya presisi, yang terjadi saatx mendekati nol.
Mari kita perhatikan contoh berikut.
from scipy.special import exprel
res = exprel([-0.25, -0.1, 0, 0.1, 0.25])
print resProgram di atas akan menghasilkan keluaran sebagai berikut.
[0.88479687 0.95162582 1. 1.05170918 1.13610167]Fungsi Eksponensial Log Sum
Sintaks untuk fungsi ini adalah - scipy.special.logsumexp (x). Ini membantu untuk menghitung log dari jumlah eksponensial elemen input.
Mari kita perhatikan contoh berikut.
from scipy.special import logsumexp
import numpy as np
a = np.arange(10)
res = logsumexp(a)
print resProgram di atas akan menghasilkan keluaran sebagai berikut.
9.45862974443Fungsi Lambert
Sintaks untuk fungsi ini adalah - scipy.special.lambertw (x). Ini juga disebut sebagai fungsi Lambert W. Fungsi Lambert W W (z) didefinisikan sebagai fungsi kebalikan dari w * exp (w). Dengan kata lain, nilai W (z) sedemikian rupa sehingga z = W (z) * exp (W (z)) untuk bilangan kompleks z.
Fungsi Lambert W adalah fungsi multinilai dengan banyak cabang tak terhingga. Setiap cabang memberikan solusi terpisah dari persamaan z = w exp (w). Di sini, cabang diindeks oleh bilangan bulat k.
Mari kita perhatikan contoh berikut. Di sini, fungsi Lambert W adalah kebalikan dari w exp (w).
from scipy.special import lambertw
w = lambertw(1)
print w
print w * np.exp(w)Program di atas akan menghasilkan keluaran sebagai berikut.
(0.56714329041+0j)
(1+0j)Permutasi & Kombinasi
Mari kita bahas permutasi dan kombinasi secara terpisah untuk memahaminya dengan jelas.
Combinations- Sintaks untuk fungsi kombinasi adalah - scipy.special.comb (N, k). Mari kita perhatikan contoh berikut -
from scipy.special import comb
res = comb(10, 3, exact = False,repetition=True)
print resProgram di atas akan menghasilkan keluaran sebagai berikut.
220.0Note- Argumen array diterima hanya untuk kasus exact = False. Jika k> N, N <0, atau k <0, maka 0 dikembalikan.
Permutations- Sintaks untuk fungsi kombinasi adalah - scipy.special.perm (N, k). Permutasi dari N hal yang diambil k pada satu waktu, yaitu k-permutasi dari N. Ini juga dikenal sebagai “permutasi parsial”.
Mari kita perhatikan contoh berikut.
from scipy.special import perm
res = perm(10, 3, exact = True)
print resProgram di atas akan menghasilkan keluaran sebagai berikut.
720Fungsi Gamma
Fungsi gamma sering disebut sebagai faktorial umum karena z * gamma (z) = gamma (z + 1) dan gamma (n + 1) = n !, untuk bilangan asli 'n'.
Sintaks untuk fungsi kombinasi adalah - scipy.special.gamma (x). Permutasi dari N hal yang diambil k pada satu waktu, yaitu k-permutasi dari N. Ini juga dikenal sebagai “permutasi parsial”.
Sintaks untuk fungsi kombinasi adalah - scipy.special.gamma (x). Permutasi dari N hal yang diambil k pada satu waktu, yaitu k-permutasi dari N. Ini juga dikenal sebagai “permutasi parsial”.
from scipy.special import gamma
res = gamma([0, 0.5, 1, 5])
print resProgram di atas akan menghasilkan keluaran sebagai berikut.
[inf 1.77245385 1. 24.]