ApacheSolr-Hadoop上
SolrはHadoopと一緒に使用できます。Hadoopは大量のデータを処理するため、Solrはそのような大規模なソースから必要な情報を見つけるのに役立ちます。このセクションでは、システムにHadoopをインストールする方法を理解しましょう。
Hadoopのダウンロード
以下に、Hadoopをシステムにダウンロードするための手順を示します。
Step 1−Hadoopのホームページに移動します。リンクを使用できます-www.hadoop.apache.org/。リンクをクリックしてくださいReleases、次のスクリーンショットで強調表示されているように。
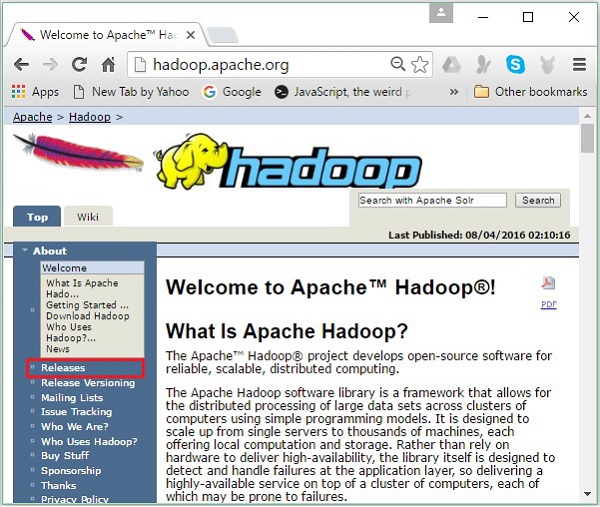
にリダイレクトされます Apache Hadoop Releases 次のように、Hadoopのさまざまなバージョンのソースファイルとバイナリファイルのミラーへのリンクを含むページ-
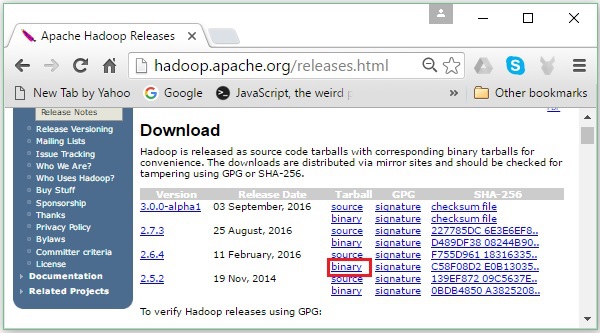
Step 2 − Hadoopの最新バージョン(チュートリアルでは2.6.4)を選択し、 binary link。Hadoopバイナリのミラーが利用可能なページに移動します。これらのミラーの1つをクリックして、Hadoopをダウンロードします。
コマンドプロンプトからHadoopをダウンロードする
Linuxターミナルを開き、スーパーユーザーとしてログインします。
$ su
password:次のコードブロックに示すように、Hadoopをインストールする必要があるディレクトリに移動し、前にコピーしたリンクを使用してそこにファイルを保存します。
# cd /usr/local
# wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop-
2.6.4/hadoop-2.6.4.tar.gzHadoopをダウンロードした後、次のコマンドを使用して解凍します。
# tar zxvf hadoop-2.6.4.tar.gz
# mkdir hadoop
# mv hadoop-2.6.4/* to hadoop/
# exitHadoopのインストール
以下の手順に従ってインストールしてください Hadoop 疑似分散モードで。
ステップ1:Hadoopを設定する
次のコマンドをに追加することで、Hadoop環境変数を設定できます。 ~/.bashrc ファイル。
export HADOOP_HOME = /usr/local/hadoop export
HADOOP_MAPRED_HOME = $HADOOP_HOME export
HADOOP_COMMON_HOME = $HADOOP_HOME export
HADOOP_HDFS_HOME = $HADOOP_HOME export
YARN_HOME = $HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native
export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL = $HADOOP_HOME次に、現在実行中のシステムにすべての変更を適用します。
$ source ~/.bashrcステップ2:Hadoop構成
すべてのHadoop構成ファイルは、「$ HADOOP_HOME / etc / hadoop」の場所にあります。Hadoopインフラストラクチャに応じて、これらの構成ファイルを変更する必要があります。
$ cd $HADOOP_HOME/etc/hadoopJavaでHadoopプログラムを開発するには、Java環境変数をリセットする必要があります。 hadoop-env.sh 置き換えることによってファイル JAVA_HOME システム内のJavaの場所による値。
export JAVA_HOME = /usr/local/jdk1.7.0_71以下は、Hadoopを構成するために編集する必要のあるファイルのリストです。
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
ザ・ core-site.xml ファイルには、Hadoopインスタンスに使用されるポート番号、ファイルシステムに割り当てられたメモリ、データを格納するためのメモリ制限、読み取り/書き込みバッファのサイズなどの情報が含まれています。
core-site.xmlを開き、<configuration>、</ configuration>タグ内に次のプロパティを追加します。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
ザ・ hdfs-site.xml ファイルには、レプリケーションデータの値などの情報が含まれています。 namenode パス、および datanodeローカルファイルシステムのパス。これは、Hadoopインフラストラクチャを保存する場所を意味します。
以下のデータを想定します。
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeこのファイルを開き、<configuration>、</ configuration>タグ内に次のプロパティを追加します。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note −上記のファイルでは、すべてのプロパティ値がユーザー定義であり、Hadoopインフラストラクチャに応じて変更を加えることができます。
yarn-site.xml
このファイルは、Hadoopにyarnを構成するために使用されます。ヤーンサイト.xmlファイルを開き、このファイルの<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
このファイルは、使用しているMapReduceフレームワークを指定するために使用されます。デフォルトでは、Hadoopにはyarn-site.xmlのテンプレートが含まれています。まず、ファイルをコピーする必要がありますmapred-site,xml.template に mapred-site.xml 次のコマンドを使用してファイルします。
$ cp mapred-site.xml.template mapred-site.xml開いた mapred-site.xml ファイルを作成し、<configuration>、</ configuration>タグ内に次のプロパティを追加します。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Hadoopのインストールの確認
次の手順は、Hadoopのインストールを確認するために使用されます。
ステップ1:ノードのセットアップに名前を付ける
次のようにコマンド「hdfsnamenode–format」を使用してnamenodeを設定します。
$ cd ~
$ hdfs namenode -format期待される結果は以下のとおりです。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/ステップ2:Hadoopdfsを確認する
次のコマンドを使用して、Hadoopdfsを開始します。このコマンドを実行すると、Hadoopファイルシステムが起動します。
$ start-dfs.sh期待される出力は次のとおりです-
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]ステップ3:ヤーンスクリプトの確認
次のコマンドを使用して、Yarnスクリプトを開始します。このコマンドを実行すると、Yarnデーモンが起動します。
$ start-yarn.sh期待される出力は次のとおりです-
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
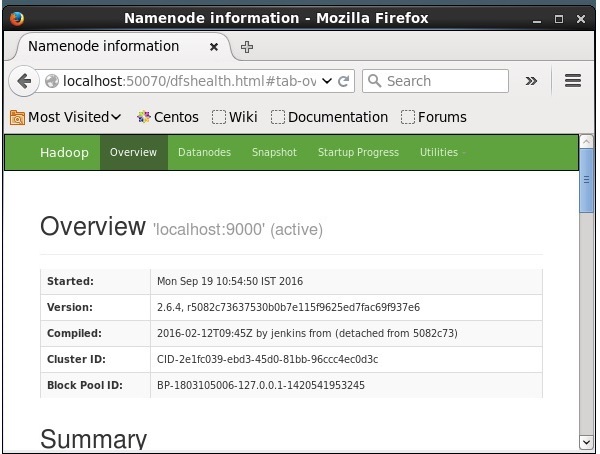
2.6.4/logs/yarn-hadoop-nodemanager-localhost.outステップ4:ブラウザーでHadoopにアクセスする
Hadoopにアクセスするためのデフォルトのポート番号は50070です。ブラウザーでHadoopサービスを取得するには、次のURLを使用します。
http://localhost:50070/
HadoopへのSolrのインストール
以下の手順に従って、Solrをダウンロードしてインストールします。
ステップ1
次のリンクをクリックして、ApacheSolrのホームページを開きます- https://lucene.apache.org/solr/
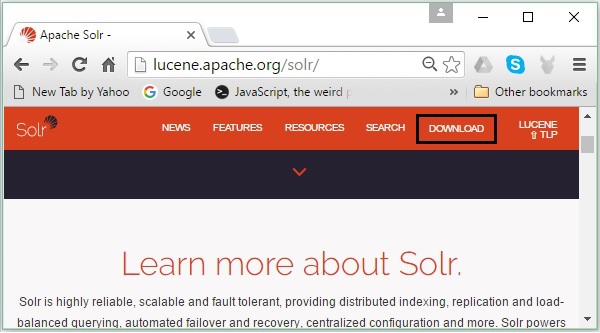
ステップ2
クリック download button(上のスクリーンショットで強調表示されています)。クリックすると、ApacheSolrのさまざまなミラーがあるページにリダイレクトされます。ミラーを選択してクリックすると、次のスクリーンショットに示すように、ApacheSolrのソースファイルとバイナリファイルをダウンロードできるページにリダイレクトされます。
ステップ3
クリックすると、という名前のフォルダ Solr-6.2.0.tqzシステムのダウンロードフォルダにダウンロードされます。ダウンロードしたフォルダの内容を抽出します。
ステップ4
以下に示すように、HadoopホームディレクトリにSolrという名前のフォルダーを作成し、抽出したフォルダーの内容をそのフォルダーに移動します。
$ mkdir Solr
$ cd Downloads
$ mv Solr-6.2.0 /home/Hadoop/検証
を閲覧する bin Solrホームディレクトリのフォルダを使用して、インストールを確認します。 version 次のコードブロックに示すように、オプション。
$ cd bin/
$ ./Solr version
6.2.0家と道を設定する
を開きます .bashrc 次のコマンドを使用してファイル-
[Hadoop@localhost ~]$ source ~/.bashrc次に、ApacheSolrのホームディレクトリとパスディレクトリを次のように設定します。
export SOLR_HOME = /home/Hadoop/Solr
export PATH = $PATH:/$SOLR_HOME/bin/ターミナルを開き、次のコマンドを実行します-
[Hadoop@localhost Solr]$ source ~/.bashrcこれで、任意のディレクトリからSolrのコマンドを実行できます。