ApacheSolr-クイックガイド
Solr 構築に使用されるオープンソースの検索プラットフォームです search applications。それは上に建てられましたLucene(全文検索エンジン)。Solrは、エンタープライズ対応で、高速で、拡張性に優れています。Solrを使用して構築されたアプリケーションは洗練されており、高性能を提供します。
そうだった Yonik SeelyCNETネットワークの会社のWebサイトに検索機能を追加するために2004年にSolrを作成した人。2006年1月、Apache SoftwareFoundationの下でオープンソースプロジェクトになりました。最新バージョンのSolr6.0は、並列SQLクエリの実行をサポートする2016年にリリースされました。
SolrはHadoopと一緒に使用できます。Hadoopは大量のデータを処理するため、Solrはそのような大規模なソースから必要な情報を見つけるのに役立ちます。Solrは検索だけでなく、保管目的にも使用できます。他のNoSQLデータベースと同様に、non-relational data storage そして processing technology。
つまり、Solrは、大量のテキスト中心のデータを検索するように最適化された、スケーラブルですぐにデプロイできる検索/ストレージエンジンです。
ApacheSolrの機能
Solrは、LuceneのJavaAPIをラップアラウンドしたものです。したがって、Solrを使用すると、Luceneのすべての機能を活用できます。Solrの最も顕著な機能のいくつかを見てみましょう-
Restful APIs− Solrと通信するために、Javaプログラミングスキルを持っている必要はありません。代わりに、RESTfulサービスを使用して通信できます。XML、JSON、.CSVなどのファイル形式でSolrにドキュメントを入力し、同じファイル形式で結果を取得します。
Full text search − Solrは、トークン、フレーズ、スペルチェック、ワイルドカード、オートコンプリートなど、全文検索に必要なすべての機能を提供します。
Enterprise ready −組織のニーズに応じて、Solrは、スタンドアロン、分散、クラウドなど、あらゆる種類のシステム(大小)にデプロイできます。
Flexible and Extensible − Javaクラスを拡張し、それに応じて構成することで、Solrのコンポーネントを簡単にカスタマイズできます。
NoSQL database − Solrは、クラスターに沿って検索タスクを分散できるビッグデータスケールのNOSQLデータベースとしても使用できます。
Admin Interface − Solrは、使いやすく、ユーザーフレンドリーで、機能を備えたユーザーインターフェースを提供します。これを使用して、ログの管理、ドキュメントの追加、削除、更新、検索など、考えられるすべてのタスクを実行できます。
Highly Scalable − HadoopでSolrを使用しているときに、レプリカを追加することで容量を拡張できます。
Text-Centric and Sorted by Relevance − Solrは主にテキストドキュメントの検索に使用され、結果はユーザーのクエリとの関連性に従って順番に配信されます。
Luceneとは異なり、ApacheSolrでの作業中にJavaプログラミングスキルを持っている必要はありません。Luceneが提供していない、オートコンプリートを備えた検索ボックスを構築するための、すぐにデプロイできるすばらしいサービスを提供します。Solrを使用すると、大規模(ビッグデータ)アプリケーション向けにインデックスをスケーリング、配布、および管理できます。
検索アプリケーションのLucene
Luceneは、シンプルでありながら強力なJavaベースの検索ライブラリです。これは、検索機能を追加するために任意のアプリケーションで使用できます。Luceneは、事実上あらゆる種類のテキストのインデックス作成と検索に使用されるスケーラブルで高性能なライブラリです。Luceneライブラリは、次のような検索アプリケーションに必要なコア操作を提供します。Indexing そして Searching。
膨大な量のデータを含むWebポータルがある場合、膨大なデータプールから関連情報を抽出するためにポータルに検索エンジンが必要になる可能性があります。Luceneは、あらゆる検索アプリケーションの中心として機能し、インデックス作成と検索に関連する重要な操作を提供します。
検索エンジンは、Webページ、ニュースグループ、プログラム、画像などのインターネットリソースの巨大なデータベースを指します。これは、ワールドワイドウェブ上の情報を見つけるのに役立ちます。
ユーザーは、キーワードまたはフレーズの形式で検索エンジンにクエリを渡すことにより、情報を検索できます。次に、検索エンジンはデータベースを検索し、関連するリンクをユーザーに返します。
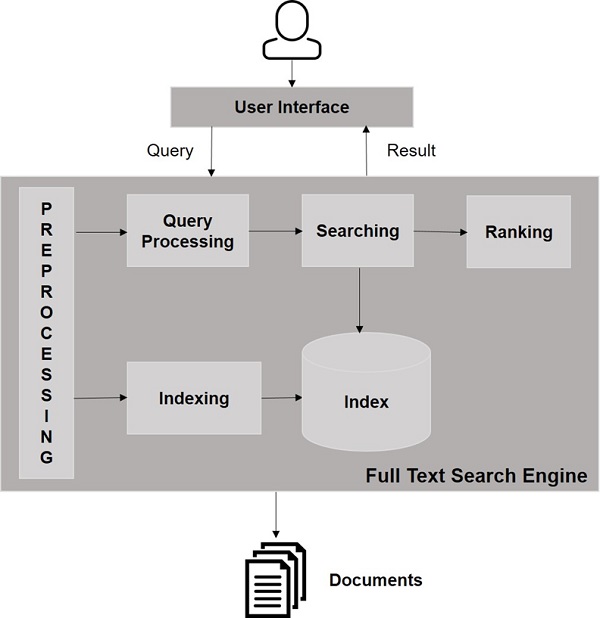
検索エンジンのコンポーネント
一般的に、検索エンジンには以下の3つの基本的なコンポーネントがあります。
Web Crawler −Webクローラーは別名 spiders または bots。これは、Webをトラバースして情報を収集するソフトウェアコンポーネントです。
Database−Web上のすべての情報はデータベースに保存されます。それらには膨大な量のWebリソースが含まれています。
Search Interfaces−このコンポーネントは、ユーザーとデータベース間のインターフェースです。これは、ユーザーがデータベースを検索するのに役立ちます。
検索エンジンはどのように機能しますか?
以下の操作の一部またはすべてを実行するには、検索アプリケーションが必要です。
| ステップ | 題名 | 説明 |
|---|---|---|
1 |
生のコンテンツを取得する |
検索アプリケーションの最初のステップは、検索が実行されるターゲットコンテンツを収集することです。 |
2 |
ドキュメントを作成する |
次のステップは、検索アプリケーションが簡単に理解して解釈できる生のコンテンツからドキュメントを作成することです。 |
3 |
ドキュメントを分析する |
インデックス作成を開始する前に、ドキュメントを分析する必要があります。 |
4 |
ドキュメントのインデックス作成 |
ドキュメントが作成および分析されたら、次のステップは、ドキュメントのコンテンツ全体ではなく、特定のキーに基づいてこのドキュメントを取得できるように、ドキュメントにインデックスを付けることです。 索引付けは、本の最後にある索引に似ており、一般的な単語がページ番号とともに表示されるため、本全体を検索する代わりに、これらの単語をすばやく追跡できます。 |
5 |
検索用のユーザーインターフェイス |
インデックスのデータベースの準備ができたら、アプリケーションは検索操作を実行できます。ユーザーが検索を行えるようにするには、アプリケーションは、ユーザーがテキストを入力して検索プロセスを開始できるユーザーインターフェイスを提供する必要があります。 |
6 |
ビルドクエリ |
ユーザーがテキストの検索を要求すると、アプリケーションはそのテキストを使用してクエリオブジェクトを準備する必要があります。これを使用して、インデックスデータベースに問い合わせ、関連する詳細を取得できます。 |
7 |
検索クエリ |
クエリオブジェクトを使用して、インデックスデータベースがチェックされ、関連する詳細とコンテンツドキュメントが取得されます。 |
8 |
結果をレンダリングする |
必要な結果を受け取ったら、アプリケーションはユーザーインターフェイスを使用して結果をユーザーに表示する方法を決定する必要があります。 |
次の図を見てください。これは、検索エンジンがどのように機能するかについての全体像を示しています。
これらの基本的な操作とは別に、検索アプリケーションは、管理者がユーザープロファイルに基づいて検索のレベルを制御するのに役立つ管理ユーザーインターフェイスを提供することもできます。検索結果の分析は、検索アプリケーションのもう1つの重要で高度な側面です。
この章では、Windows環境でSolrをセットアップする方法について説明します。WindowsシステムにSolrをインストールするには、以下の手順に従う必要があります-
Apache Solrのホームページにアクセスし、ダウンロードボタンをクリックします。
ミラーの1つを選択して、ApacheSolrのインデックスを取得します。そこからという名前のファイルをダウンロードしますSolr-6.2.0.zip。
からファイルを移動します downloads folder 必要なディレクトリに移動し、解凍します。
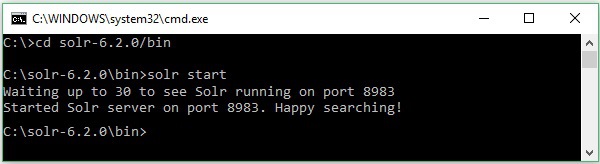
SolrファイルをダウンロードしてCドライブに抽出したとします。このような場合、次のスクリーンショットに示すようにSolrを起動できます。
インストールを確認するには、ブラウザで次のURLを使用します。
http://localhost:8983/
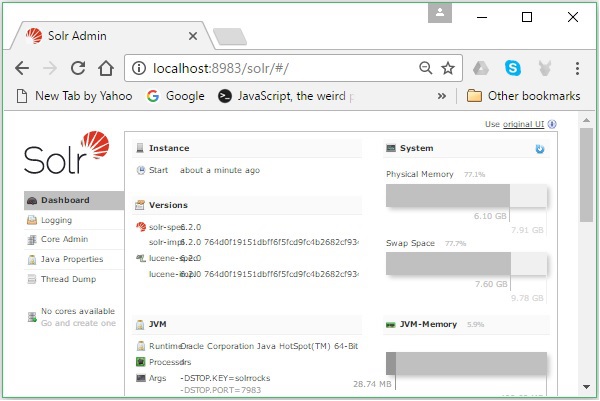
インストールプロセスが成功すると、以下に示すように、ApacheSolrユーザーインターフェイスのダッシュボードが表示されます。
Java環境の設定
Javaライブラリを使用してApacheSolrと通信することもできます。ただし、Java APIを使用してSolrにアクセスする前に、これらのライブラリのクラスパスを設定する必要があります。
クラスパスの設定
をセットする classpath のSolrライブラリへ .bashrcファイル。開いた.bashrc 以下に示すように、いずれかのエディターで。
$ gedit ~/.bashrcSolrライブラリのクラスパスを設定します(lib 以下に示すように、HBaseのフォルダー)。
export CLASSPATH = $CLASSPATH://home/hadoop/Solr/lib/*これは、JavaAPIを使用してHBaseにアクセスする際の「クラスが見つかりません」という例外を防ぐためです。
SolrはHadoopと一緒に使用できます。Hadoopは大量のデータを処理するため、Solrはそのような大規模なソースから必要な情報を見つけるのに役立ちます。このセクションでは、システムにHadoopをインストールする方法を理解しましょう。
Hadoopのダウンロード
以下に、Hadoopをシステムにダウンロードするための手順を示します。
Step 1−Hadoopのホームページに移動します。リンクを使用できます-www.hadoop.apache.org/。リンクをクリックしてくださいReleases、次のスクリーンショットで強調表示されているように。
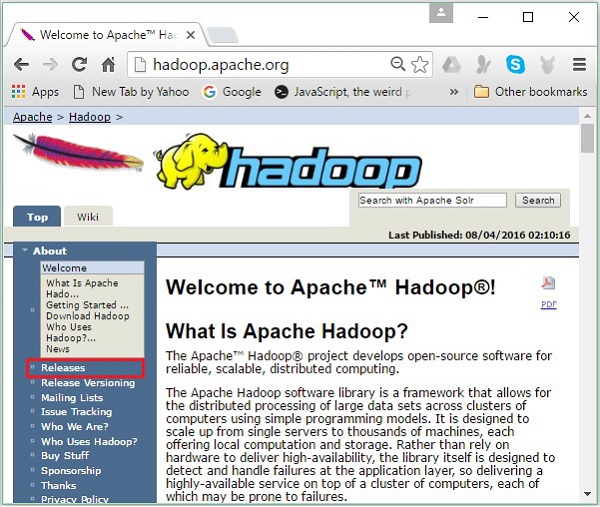
にリダイレクトされます Apache Hadoop Releases 次のように、Hadoopのさまざまなバージョンのソースファイルとバイナリファイルのミラーへのリンクを含むページ-
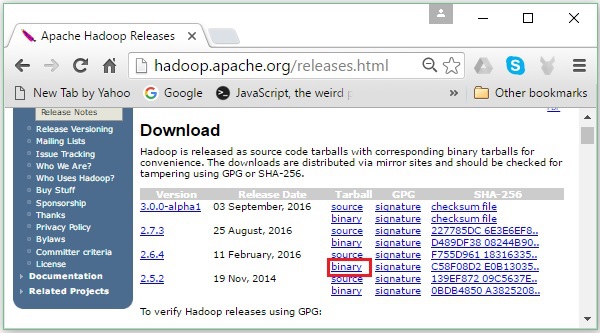
Step 2 − Hadoopの最新バージョン(チュートリアルでは2.6.4)を選択し、 binary link。Hadoopバイナリのミラーが利用可能なページに移動します。これらのミラーの1つをクリックして、Hadoopをダウンロードします。
コマンドプロンプトからHadoopをダウンロードする
Linuxターミナルを開き、スーパーユーザーとしてログインします。
$ su
password:次のコードブロックに示すように、Hadoopをインストールする必要があるディレクトリに移動し、前にコピーしたリンクを使用してそこにファイルを保存します。
# cd /usr/local
# wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop-
2.6.4/hadoop-2.6.4.tar.gzHadoopをダウンロードした後、次のコマンドを使用して解凍します。
# tar zxvf hadoop-2.6.4.tar.gz
# mkdir hadoop
# mv hadoop-2.6.4/* to hadoop/
# exitHadoopのインストール
以下の手順に従ってインストールしてください Hadoop 疑似分散モードで。
ステップ1:Hadoopを設定する
次のコマンドをに追加することで、Hadoop環境変数を設定できます。 ~/.bashrc ファイル。
export HADOOP_HOME = /usr/local/hadoop export
HADOOP_MAPRED_HOME = $HADOOP_HOME export
HADOOP_COMMON_HOME = $HADOOP_HOME export
HADOOP_HDFS_HOME = $HADOOP_HOME export
YARN_HOME = $HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native
export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL = $HADOOP_HOME次に、現在実行中のシステムにすべての変更を適用します。
$ source ~/.bashrcステップ2:Hadoop構成
すべてのHadoop構成ファイルは、「$ HADOOP_HOME / etc / hadoop」の場所にあります。Hadoopインフラストラクチャに応じて、これらの構成ファイルを変更する必要があります。
$ cd $HADOOP_HOME/etc/hadoopJavaでHadoopプログラムを開発するには、Java環境変数をリセットする必要があります。 hadoop-env.sh 置き換えることによってファイル JAVA_HOME システム内のJavaの場所による値。
export JAVA_HOME = /usr/local/jdk1.7.0_71以下は、Hadoopを構成するために編集する必要のあるファイルのリストです。
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
ザ・ core-site.xml ファイルには、Hadoopインスタンスに使用されるポート番号、ファイルシステムに割り当てられたメモリ、データを格納するためのメモリ制限、読み取り/書き込みバッファのサイズなどの情報が含まれています。
core-site.xmlを開き、<configuration>、</ configuration>タグ内に次のプロパティを追加します。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
ザ・ hdfs-site.xml ファイルには、レプリケーションデータの値などの情報が含まれています。 namenode パス、および datanodeローカルファイルシステムのパス。これは、Hadoopインフラストラクチャを保存する場所を意味します。
以下のデータを想定します。
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeこのファイルを開き、<configuration>、</ configuration>タグ内に次のプロパティを追加します。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note −上記のファイルでは、すべてのプロパティ値がユーザー定義であり、Hadoopインフラストラクチャに応じて変更を加えることができます。
yarn-site.xml
このファイルは、Hadoopにyarnを構成するために使用されます。ヤーンサイト.xmlファイルを開き、このファイルの<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
このファイルは、使用しているMapReduceフレームワークを指定するために使用されます。デフォルトでは、Hadoopにはyarn-site.xmlのテンプレートが含まれています。まず、ファイルをコピーする必要がありますmapred-site,xml.template に mapred-site.xml 次のコマンドを使用してファイルします。
$ cp mapred-site.xml.template mapred-site.xml開いた mapred-site.xml ファイルを作成し、<configuration>、</ configuration>タグ内に次のプロパティを追加します。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Hadoopのインストールの確認
次の手順は、Hadoopのインストールを確認するために使用されます。
ステップ1:ノードのセットアップに名前を付ける
次のようにコマンド「hdfsnamenode–format」を使用してnamenodeを設定します。
$ cd ~
$ hdfs namenode -format期待される結果は以下のとおりです。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/ステップ2:Hadoopdfsを確認する
次のコマンドを使用して、Hadoopdfsを開始します。このコマンドを実行すると、Hadoopファイルシステムが起動します。
$ start-dfs.sh期待される出力は次のとおりです-
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]ステップ3:ヤーンスクリプトの確認
次のコマンドを使用して、Yarnスクリプトを開始します。このコマンドを実行すると、Yarnデーモンが起動します。
$ start-yarn.sh期待される出力は次のとおりです-
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.6.4/logs/yarn-hadoop-nodemanager-localhost.outステップ4:ブラウザーでHadoopにアクセスする
Hadoopにアクセスするためのデフォルトのポート番号は50070です。ブラウザーでHadoopサービスを取得するには、次のURLを使用します。
http://localhost:50070/
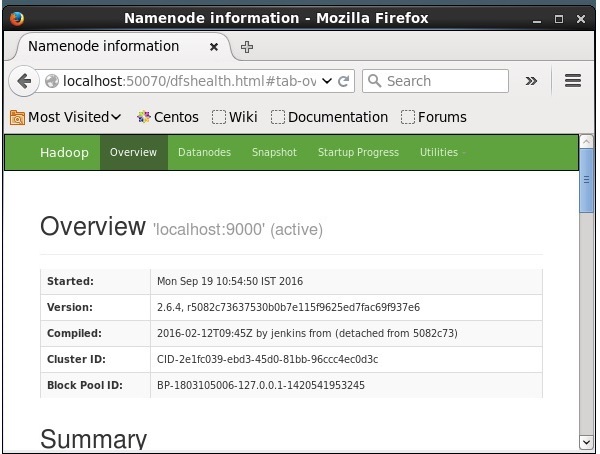
HadoopへのSolrのインストール
以下の手順に従って、Solrをダウンロードしてインストールします。
ステップ1
次のリンクをクリックして、ApacheSolrのホームページを開きます- https://lucene.apache.org/solr/
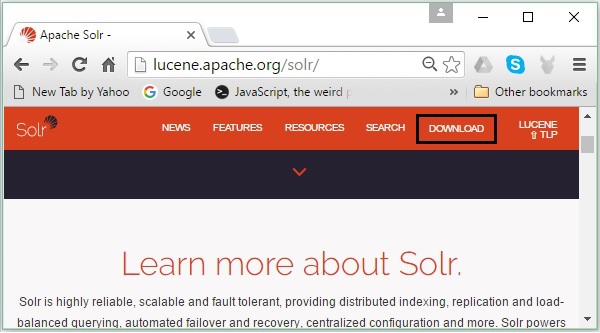
ステップ2
クリック download button(上のスクリーンショットで強調表示されています)。クリックすると、ApacheSolrのさまざまなミラーがあるページにリダイレクトされます。ミラーを選択してクリックすると、次のスクリーンショットに示すように、ApacheSolrのソースファイルとバイナリファイルをダウンロードできるページにリダイレクトされます。
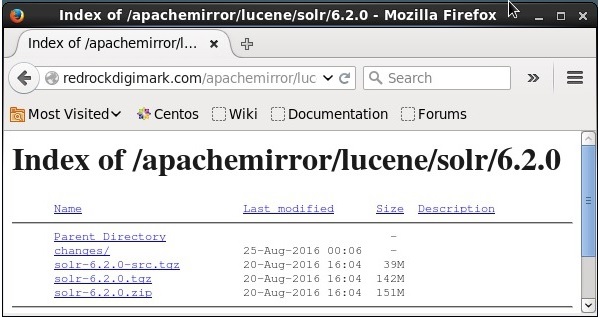
ステップ3
クリックすると、という名前のフォルダ Solr-6.2.0.tqzシステムのダウンロードフォルダにダウンロードされます。ダウンロードしたフォルダの内容を抽出します。
ステップ4
以下に示すように、HadoopホームディレクトリにSolrという名前のフォルダーを作成し、抽出したフォルダーの内容をそのフォルダーに移動します。
$ mkdir Solr
$ cd Downloads
$ mv Solr-6.2.0 /home/Hadoop/検証
を閲覧する bin Solrホームディレクトリのフォルダを使用して、インストールを確認します。 version 次のコードブロックに示すように、オプション。
$ cd bin/
$ ./Solr version
6.2.0家と道を設定する
を開きます .bashrc 次のコマンドを使用してファイル-
[Hadoop@localhost ~]$ source ~/.bashrc次に、ApacheSolrのホームディレクトリとパスディレクトリを次のように設定します。
export SOLR_HOME = /home/Hadoop/Solr
export PATH = $PATH:/$SOLR_HOME/bin/ターミナルを開き、次のコマンドを実行します-
[Hadoop@localhost Solr]$ source ~/.bashrcこれで、任意のディレクトリからSolrのコマンドを実行できます。
この章では、ApacheSolrのアーキテクチャーについて説明します。次の図は、ApacheSolrのアーキテクチャーのブロック図を示しています。
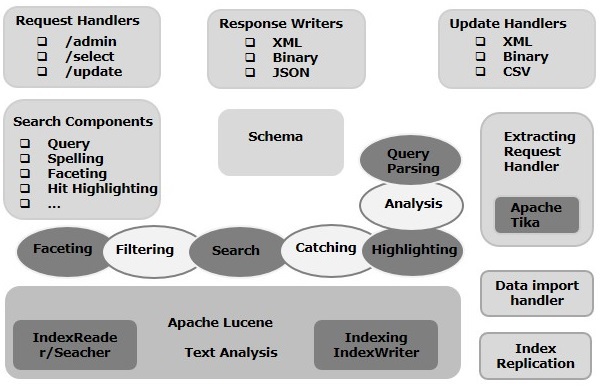
Solrアーキテクチャ─ビルディングブロック
以下は、Apache Solrの主要な構成要素(コンポーネント)です。
Request Handler− Apache Solrに送信するリクエストは、これらのリクエストハンドラーによって処理されます。要求は、クエリ要求またはインデックス更新要求である可能性があります。要件に基づいて、リクエストハンドラを選択する必要があります。Solrにリクエストを渡すために、通常、ハンドラーを特定のURIエンドポイントにマップし、指定されたリクエストがそれによって処理されます。
Search Component−検索コンポーネントは、Apache Solrで提供される検索のタイプ(機能)です。スペルチェック、クエリ、ファセット、ヒットハイライトなどが考えられます。これらの検索コンポーネントは次のように登録されています。search handlers。複数のコンポーネントを検索ハンドラーに登録できます。
Query Parser− Apache Solrクエリパーサーは、Solrに渡すクエリを解析し、構文エラーがないかクエリを検証します。クエリを解析した後、Luceneが理解できる形式に変換します。
Response Writer− Apache Solrの応答ライターは、ユーザークエリ用にフォーマットされた出力を生成するコンポーネントです。Solrは、XML、JSON、CSVなどの応答形式をサポートしています。応答のタイプごとに異なる応答ライターがあります。
Analyzer/tokenizer− Luceneは、トークンの形式でデータを認識します。Apache Solrはコンテンツを分析してトークンに分割し、これらのトークンをLuceneに渡します。Apache Solrのアナライザーは、フィールドのテキストを調べて、トークン・ストリームを生成します。トークナイザーは、アナライザーによって準備されたトークンストリームをトークンに分割します。
Update Request Processor −更新リクエストをApache Solrに送信するときはいつでも、リクエストはプラグインのセット(署名、ロギング、インデックス作成)を介して実行されます。 update request processor。このプロセッサは、フィールドの削除、フィールドの追加などの変更を担当します。
この章では、Solrでの作業中に頻繁に使用されるいくつかの用語の本当の意味を理解しようとします。
一般的な用語
以下は、すべてのタイプのSolrセットアップで使用される一般的な用語のリストです。
Instance −ちょうど tomcat instance または jetty instance、この用語は、JVM内で実行されるアプリケーションサーバーを指します。Solrのホームディレクトリは、これらのSolrインスタンスのそれぞれへの参照を提供します。ここで、1つ以上のコアを各インスタンスで実行するように構成できます。
Core −アプリケーションで複数のインデックスを実行しているときに、それぞれが1つのコアを持つ複数のインスタンスではなく、各インスタンスに複数のコアを持つことができます。
Home − $ SOLR_HOMEという用語は、コアとそのインデックス、構成、および依存関係に関するすべての情報を含むホームディレクトリを指します。
Shard −分散環境では、データは複数のSolrインスタンス間で分割され、データの各チャンクは Shard。インデックス全体のサブセットが含まれています。
SolrCloudの用語
前の章では、ApacheSolrをスタンドアロンモードでインストールする方法について説明しました。Solrがマスタースレーブパターンでインストールされる分散モード(クラウド環境)でSolrをインストールすることもできることに注意してください。分散モードでは、インデックスはマスターサーバー上に作成され、1つ以上のスレーブサーバーに複製されます。
SolrCloudに関連する重要な用語は次のとおりです-
Node − Solrクラウドでは、Solrの各単一インスタンスは node。
Cluster −環境のすべてのノードを組み合わせて、 cluster。
Collection −クラスターには、と呼ばれる論理インデックスがあります。 collection。
Shard −シャードは、インデックスのレプリカが1つ以上あるコレクションの一部です。
Replica − Solr Coreでは、ノードで実行されるシャードのコピーは、 replica。
Leader −これはシャードのレプリカでもあり、SolrCloudのリクエストを残りのレプリカに分散します。
Zookeeper −これは、Solr Cloudが一元化された構成と調整、クラスターの管理、およびリーダーの選出に使用するApacheプロジェクトです。
構成ファイル
ApacheSolrの主な設定ファイルは次のとおりです-
Solr.xml−これは、SolrCloud関連情報を含む$ SOLR_HOMEディレクトリー内のファイルです。コアをロードするために、Solrはこのファイルを参照します。これはコアの識別に役立ちます。
Solrconfig.xml −このファイルには、要求の処理と応答のフォーマットに関連する定義とコア固有の構成、およびインデックス作成、構成、メモリの管理、コミットの作成が含まれています。
Schema.xml −このファイルには、スキーマ全体とフィールドおよびフィールドタイプが含まれています。
Core.properties−このファイルには、コアに固有の構成が含まれています。それはのために参照されますcore discovery、コアの名前とデータディレクトリのパスが含まれているため。これは任意のディレクトリで使用でき、その後は次のように扱われます。core directory。
Solrの開始
Solrをインストールした後、 bin Solrホームディレクトリのフォルダに移動し、次のコマンドを使用してSolrを起動します。
[Hadoop@localhost ~]$ cd
[Hadoop@localhost ~]$ cd Solr/
[Hadoop@localhost Solr]$ cd bin/
[Hadoop@localhost bin]$ ./Solr startこのコマンドは、バックグラウンドでSolrを起動し、次のメッセージを表示してポート8983でリッスンします。
Waiting up to 30 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid = 6035). Happy searching!フォアグラウンドでSolrを開始する
始めたら Solr を使用して startコマンドを実行すると、Solrがバックグラウンドで起動します。代わりに、を使用してフォアグラウンドでSolrを開始できます。–f option。
[Hadoop@localhost bin]$ ./Solr start –f
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/extraction/lib/xmlbeans-2.6.0.jar' to
classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/dist/Solr-cell-6.2.0.jar' to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/carrot2-guava-18.0.jar'
to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/attributes-binder1.3.1.jar'
to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/simple-xml-2.7.1.jar'
to classloader
……………………………………………………………………………………………………………………………………………………………………………………………………………
………………………………………………………………………………………………………………………………………………………………………………………………….
12901 INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample] o.a.s.u.UpdateLog
Took 24.0ms to seed version buckets with highest version 1546058939881226240 12902
INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample]
o.a.s.c.CoreContainer registering core: Solr_sample
12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.u.UpdateLog Took
16.0ms to seed version buckets with highest version 1546058939894857728
12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.c.CoreContainer
registering core: my_core別のポートでSolrを開始する
使用する –p option の start 次のコードブロックに示すように、コマンドを実行すると、別のポートでSolrを起動できます。
[Hadoop@localhost bin]$ ./Solr start -p 8984
Waiting up to 30 seconds to see Solr running on port 8984 [-]
Started Solr server on port 8984 (pid = 10137). Happy searching!Solrの停止
Solrを停止するには、 stop コマンド。
$ ./Solr stopこのコマンドはSolrを停止し、以下に示すようなメッセージを表示します。
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to
allow Jetty process 6035 to stop gracefully.Solrを再起動します
ザ・ restartSolrのコマンドはSolrを5秒間停止し、再開します。次のコマンドを使用してSolrを再起動できます-
./Solr restartこのコマンドはSolrを再起動し、次のメッセージを表示します-
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to
allow Jetty process 6671 to stop gracefully.
Waiting up to 30 seconds to see Solr running on port 8983 [|] [/]
Started Solr server on port 8983 (pid = 6906). Happy searching!Solr─ヘルプコマンド
ザ・ help Solrのコマンドを使用して、Solrプロンプトとそのオプションの使用法を確認できます。
[Hadoop@localhost bin]$ ./Solr -help
Usage: Solr COMMAND OPTIONS
where COMMAND is one of: start, stop, restart, status, healthcheck,
create, create_core, create_collection, delete, version, zk
Standalone server example (start Solr running in the background on port 8984):
./Solr start -p 8984
SolrCloud example (start Solr running in SolrCloud mode using localhost:2181
to connect to Zookeeper, with 1g max heap size and remote Java debug options enabled):
./Solr start -c -m 1g -z localhost:2181 -a "-Xdebug -
Xrunjdwp:transport = dt_socket,server = y,suspend = n,address = 1044"
Pass -help after any COMMAND to see command-specific usage information,
such as: ./Solr start -help or ./Solr stop -helpSolr─statusコマンド
この statusSolrのコマンドを使用して、コンピューター上で実行中のSolrインスタンスを検索および検索できます。バージョン、メモリ使用量など、Solrインスタンスに関する情報を提供できます。
次のようにstatusコマンドを使用して、Solrインスタンスのステータスを確認できます。
[Hadoop@localhost bin]$ ./Solr status上記のコマンドを実行すると、Solrのステータスが次のように表示されます。
Found 1 Solr nodes:
Solr process 6906 running on port 8983 {
"Solr_home":"/home/Hadoop/Solr/server/Solr",
"version":"6.2.0 764d0f19151dbff6f5fcd9fc4b2682cf934590c5 -
mike - 2016-08-20 05:41:37",
"startTime":"2016-09-20T06:00:02.877Z",
"uptime":"0 days, 0 hours, 5 minutes, 14 seconds",
"memory":"30.6 MB (%6.2) of 490.7 MB"
}Solr管理者
Apache Solrを起動した後、のホームページにアクセスできます。 Solr web interface 以下のURLを使用してください。
Localhost:8983/Solr/SolrAdminのインターフェースは次のように表示されます-
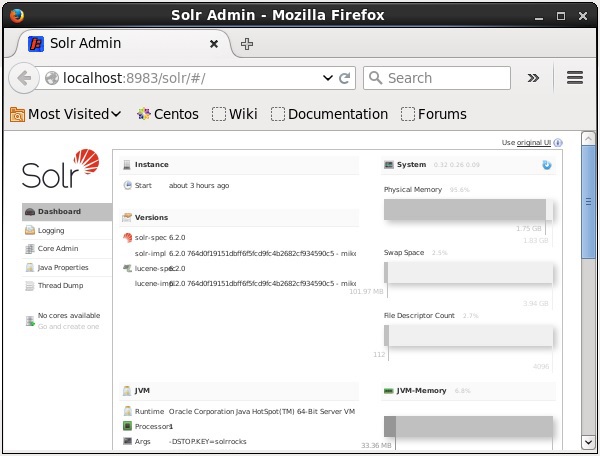
Solr Coreは、Luceneインデックスの実行中のインスタンスであり、それを使用するために必要なすべてのSolr構成ファイルが含まれています。インデックス作成や分析などの操作を実行するには、Solrコアを作成する必要があります。
Solrアプリケーションには、1つまたは複数のコアが含まれる場合があります。必要に応じて、Solrアプリケーションの2つのコアが相互に通信できます。
コアの作成
Solrをインストールして起動すると、Solrのクライアント(Webインターフェース)に接続できます。
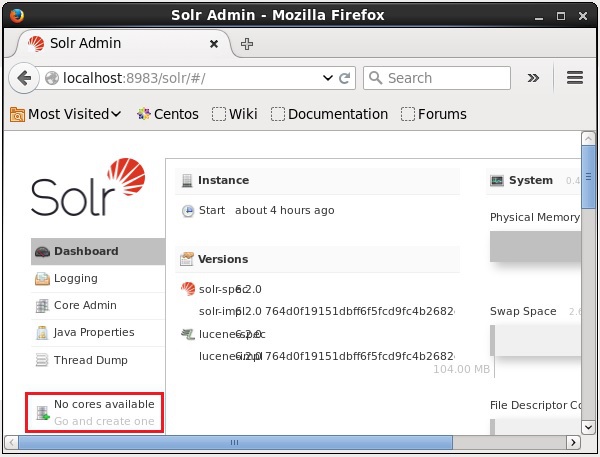
次のスクリーンショットで強調表示されているように、最初はApacheSolrにコアはありません。ここで、Solrでコアを作成する方法を見ていきます。
createコマンドの使用
コアを作成する1つの方法は、 schema-less core を使用して create 以下に示すように、コマンド-
[Hadoop@localhost bin]$ ./Solr create -c Solr_sampleここでは、という名前のコアを作成しようとしています Solr_sampleApacheSolrで。このコマンドは、次のメッセージを表示するコアを作成します。
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/Solr_sample
Creating new core 'Solr_sample' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=Solr_sample&instanceD
ir = Solr_sample {
"responseHeader":{
"status":0,
"QTime":11550
},
"core":"Solr_sample"
}Solrで複数のコアを作成できます。Solr Adminの左側に、core selector 次のスクリーンショットに示すように、ここで新しく作成されたコアを選択できます。
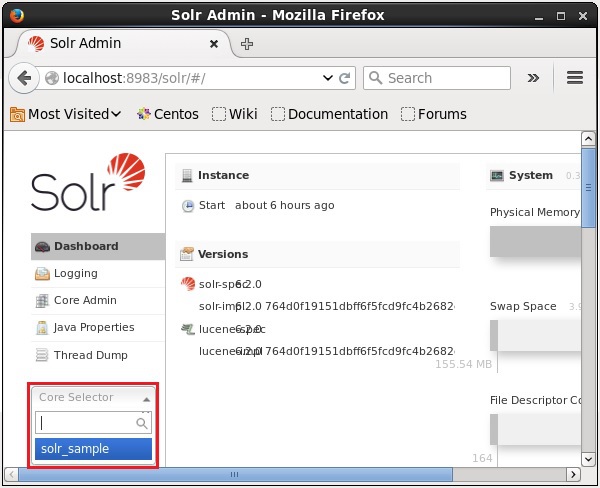
create_coreコマンドの使用
または、を使用してコアを作成することもできます create_coreコマンド。このコマンドには次のオプションがあります-
| –c core_name | 作成したいコアの名前 |
| -p port_name | コアを作成するポート |
| -d conf_dir | ポートの構成ディレクトリ |
使用方法を見てみましょう create_coreコマンド。ここでは、という名前のコアを作成しようとしますmy_core。
[Hadoop@localhost bin]$ ./Solr create_core -c my_core上記のコマンドを実行すると、次のメッセージを表示するコアが作成されます-
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/my_core
Creating new core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=my_core&instanceD
ir = my_core {
"responseHeader":{
"status":0,
"QTime":1346
},
"core":"my_core"
}コアの削除
を使用してコアを削除できます deleteApacheSolrのコマンド。名前の付いたコアがあるとしましょうmy_core 次のスクリーンショットに示すように、Solrで。
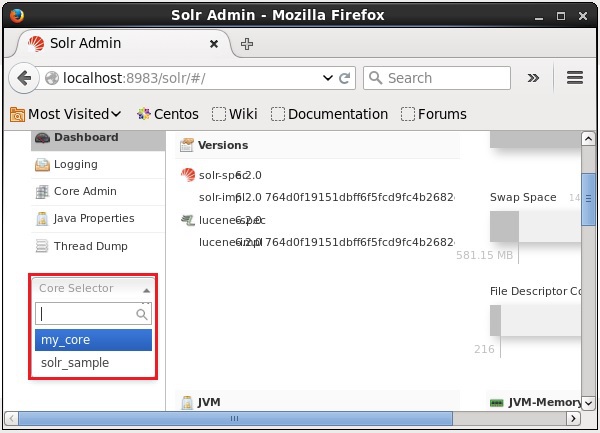
このコアは、を使用して削除できます。 delete 次のように、コアの名前をこのコマンドに渡すことによってコマンドを実行します-
[Hadoop@localhost bin]$ ./Solr delete -c my_core上記のコマンドを実行すると、指定したコアが削除され、次のメッセージが表示されます。
Deleting core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=UNLOAD&core = my_core&deleteIndex
= true&deleteDataDir = true&deleteInstanceDir = true {
"responseHeader" :{
"status":0,
"QTime":170
}
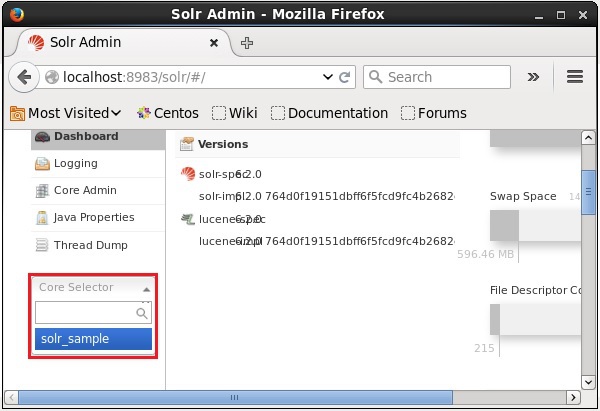
}SolrのWebインターフェースを開いて、コアが削除されているかどうかを確認できます。
一般に、 indexing文書または(他のエンティティ)を体系的に配置したものです。インデックスを作成すると、ユーザーはドキュメント内の情報を見つけることができます。
インデックス作成は、ドキュメントを収集、解析、および保存します。
インデックス作成は、必要なドキュメントを検索しながら検索クエリの速度とパフォーマンスを向上させるために行われます。
ApacheSolrでのインデックス作成
Apache Solrでは、xml、csv、pdfなどのさまざまなドキュメント形式にインデックスを付ける(追加、削除、変更)ことができます。いくつかの方法でSolrインデックスにデータを追加できます。
この章では、インデックス作成について説明します-
- SolrWebインターフェースの使用。
- Java、PythonなどのクライアントAPIのいずれかを使用します。
- を使用して post tool。
この章では、さまざまなインターフェース(コマンドライン、Webインターフェース、およびJavaクライアントAPI)を使用してApacheSolrのインデックスにデータを追加する方法について説明します。
Postコマンドを使用したドキュメントの追加
Solrには post その中のコマンド bin/ディレクトリ。このコマンドを使用すると、Apache SolrでJSON、XML、CSVなどのさまざまな形式のファイルにインデックスを付けることができます。
を閲覧する bin Apache Solrのディレクトリを実行し、 –h option 次のコードブロックに示すように、postコマンドの
[Hadoop@localhost bin]$ cd $SOLR_HOME
[Hadoop@localhost bin]$ ./post -h上記のコマンドを実行すると、のオプションのリストが表示されます post command、以下に示すように。
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'例
次の名前のファイルがあるとします。 sample.csv 次の内容で( bin ディレクトリ)。
| 学生証 | ファーストネーム | ラスト名 | 電話 | 市 |
|---|---|---|---|---|
| 001 | ラジブ | レディ | 9848022337 | ハイデラバード |
| 002 | シッダールス | バタチャリヤ | 9848022338 | コルカタ |
| 003 | ラジェッシュ | カンナ | 9848022339 | デリー |
| 004 | Preethi | アガルワル | 9848022330 | プネ |
| 005 | Trupthi | モハンティ | 9848022336 | ブバネシュワール |
| 006 | アルカナ | ミシュラ | 9848022335 | チェンナイ |
上記のデータセットには、学生ID、名、姓、電話番号、都市などの個人情報が含まれています。データセットのCSVファイルを以下に示します。ここで、最初の行を文書化して、スキーマについて言及する必要があることに注意する必要があります。
id, first_name, last_name, phone_no, location
001, Pruthvi, Reddy, 9848022337, Hyderabad
002, kasyap, Sastry, 9848022338, Vishakapatnam
003, Rajesh, Khanna, 9848022339, Delhi
004, Preethi, Agarwal, 9848022330, Pune
005, Trupthi, Mohanty, 9848022336, Bhubaneshwar
006, Archana, Mishra, 9848022335, Chennaiこのデータには、という名前のコアの下でインデックスを付けることができます sample_Solr を使用して post 次のようにコマンド-
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv上記のコマンドを実行すると、指定されたドキュメントは指定されたコアの下にインデックスが付けられ、次の出力が生成されます。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files
org.apache.Solr.util.SimplePostTool sample.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file sample.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to
http://localhost:8983/Solr/Solr_sample/update...
Time spent: 0:00:00.228次のURLを使用してSolrWebUIのホームページにアクセスします-
http://localhost:8983/
コアを選択します Solr_sample。デフォルトでは、リクエストハンドラは/selectクエリは「:」です。変更を加えずに、ExecuteQuery ページ下部のボタン。
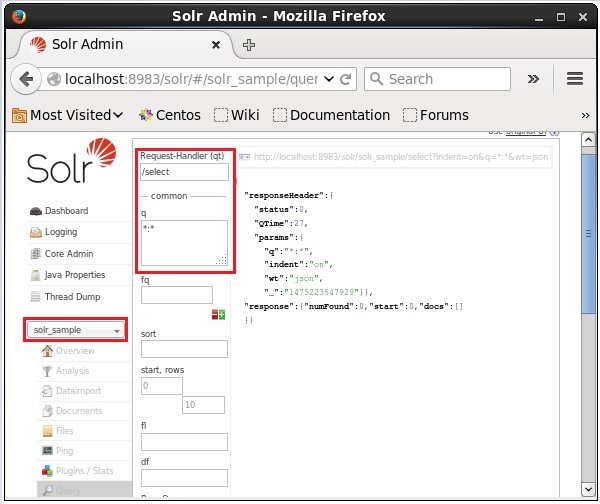
クエリを実行すると、次のスクリーンショットに示すように、JSON形式(デフォルト)のインデックス付きCSVドキュメントの内容を確認できます。
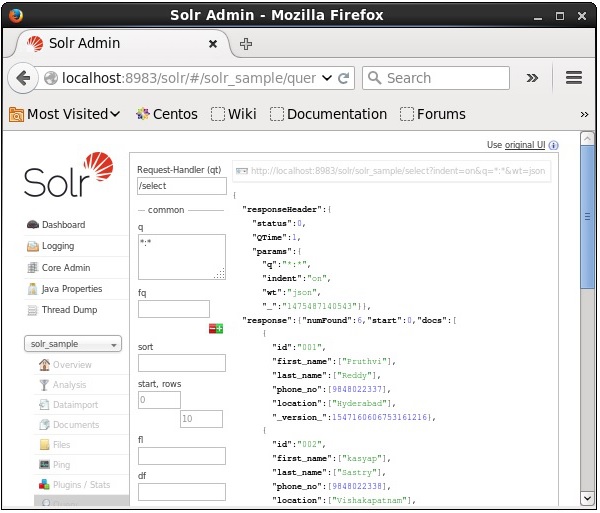
Note −同様に、JSON、XML、CSVなどの他のファイル形式にインデックスを付けることができます。
SolrWebインターフェースを使用したドキュメントの追加
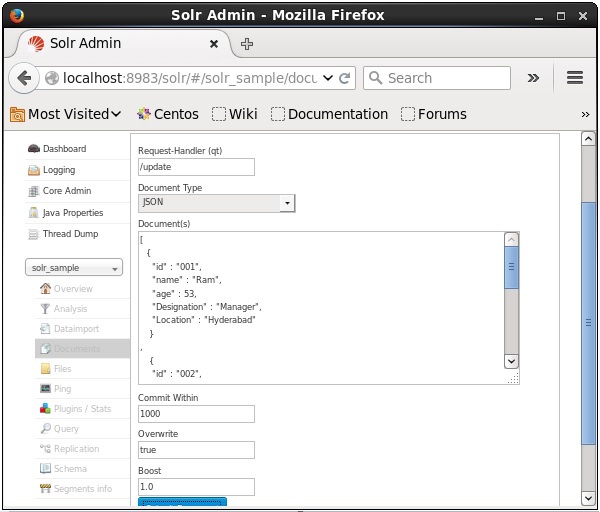
Solrが提供するWebインターフェースを使用して文書に索引を付けることもできます。次のJSONドキュメントにインデックスを付ける方法を見てみましょう。
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]ステップ1
次のURLを使用してSolrWebインターフェースを開きます-
http://localhost:8983/
Step 2
コアを選択します Solr_sample。次のスクリーンショットに示すように、デフォルトでは、フィールドRequest Handler、Common Within、Overwrite、およびBoostの値はそれぞれ/ update、1000、true、および1.0です。
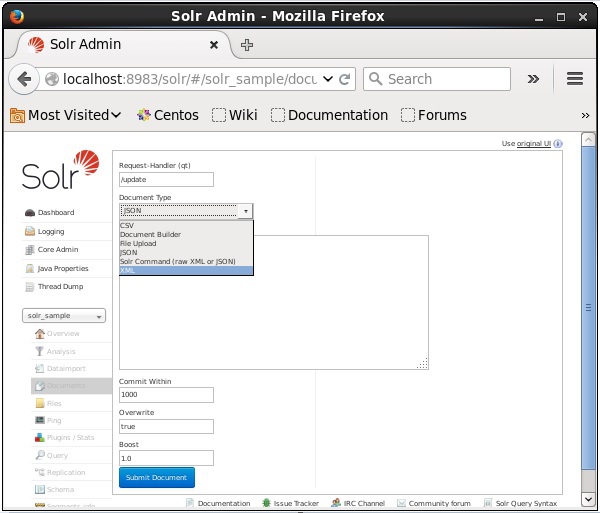
次に、JSON、CSV、XMLなどから必要なドキュメント形式を選択します。インデックスを作成するドキュメントをテキスト領域に入力し、[ Submit Document 次のスクリーンショットに示すように、ボタン。
JavaクライアントAPIを使用したドキュメントの追加
以下は、ApacheSolrインデックスにドキュメントを追加するJavaプログラムです。このコードを名前のファイルに保存しますAddingDocument.java。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}ターミナルで次のコマンドを実行して、上記のコードをコンパイルします-
[Hadoop@localhost bin]$ javac AddingDocument
[Hadoop@localhost bin]$ java AddingDocument上記のコマンドを実行すると、次の出力が得られます。
Documents added前の章では、JSONおよび.CSVファイル形式のデータをSolrに追加する方法について説明しました。この章では、XMLドキュメント形式を使用してApacheSolrインデックスにデータを追加する方法を示します。
サンプルデータ
XMLファイル形式を使用してSolrインデックスに次のデータを追加する必要があるとします。
| 学生証 | ファーストネーム | 苗字 | 電話 | 市 |
|---|---|---|---|---|
| 001 | ラジブ | レディ | 9848022337 | ハイデラバード |
| 002 | シッダールス | バタチャリヤ | 9848022338 | コルカタ |
| 003 | ラジェッシュ | カンナ | 9848022339 | デリー |
| 004 | Preethi | アガルワル | 9848022330 | プネ |
| 005 | Trupthi | モハンティ | 9848022336 | ブバネシュワール |
| 006 | アルカナ | ミシュラ | 9848022335 | チェンナイ |
XMLを使用したドキュメントの追加
上記のデータをSolrインデックスに追加するには、以下に示すようにXMLドキュメントを準備する必要があります。このドキュメントを名前のファイルに保存しますsample.xml。
<add>
<doc>
<field name = "id">001</field>
<field name = "first name">Rajiv</field>
<field name = "last name">Reddy</field>
<field name = "phone">9848022337</field>
<field name = "city">Hyderabad</field>
</doc>
<doc>
<field name = "id">002</field>
<field name = "first name">Siddarth</field>
<field name = "last name">Battacharya</field>
<field name = "phone">9848022338</field>
<field name = "city">Kolkata</field>
</doc>
<doc>
<field name = "id">003</field>
<field name = "first name">Rajesh</field>
<field name = "last name">Khanna</field>
<field name = "phone">9848022339</field>
<field name = "city">Delhi</field>
</doc>
<doc>
<field name = "id">004</field>
<field name = "first name">Preethi</field>
<field name = "last name">Agarwal</field>
<field name = "phone">9848022330</field>
<field name = "city">Pune</field>
</doc>
<doc>
<field name = "id">005</field>
<field name = "first name">Trupthi</field>
<field name = "last name">Mohanthy</field>
<field name = "phone">9848022336</field>
<field name = "city">Bhuwaeshwar</field>
</doc>
<doc>
<field name = "id">006</field>
<field name = "first name">Archana</field>
<field name = "last name">Mishra</field>
<field name = "phone">9848022335</field>
<field name = "city">Chennai</field>
</doc>
</add>ご覧のとおり、インデックスにデータを追加するために書き込まれたXMLファイルには、<add> </ add>、<doc> </ doc>、および<field> </ field>という3つの重要なタグが含まれています。
add−これはドキュメントをインデックスに追加するためのルートタグです。追加される1つ以上のドキュメントが含まれています。
doc−追加するドキュメントは、<doc> </ doc>タグで囲む必要があります。このドキュメントには、フィールド形式のデータが含まれています。
field −フィールドタグは、ドキュメントのフィールドの名前と値を保持します。
ドキュメントを準備した後、前の章で説明した手段のいずれかを使用して、このドキュメントをインデックスに追加できます。
XMLファイルがに存在するとします。 bin Solrのディレクトリであり、名前の付いたコアでインデックスが作成されます。 my_core、次に、を使用してSolrインデックスに追加できます。 post 次のようなツール-
[Hadoop@localhost bin]$ ./post -c my_core sample.xml上記のコマンドを実行すると、次の出力が得られます。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-
core6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool sample.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,
xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file sample.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.201検証
Apache Solr Webインターフェースのホームページにアクセスして、コアを選択します my_core。テキスト領域にクエリ「:」を渡して、すべてのドキュメントを取得してみてくださいqクエリを実行します。実行すると、目的のデータがSolrインデックスに追加されていることがわかります。
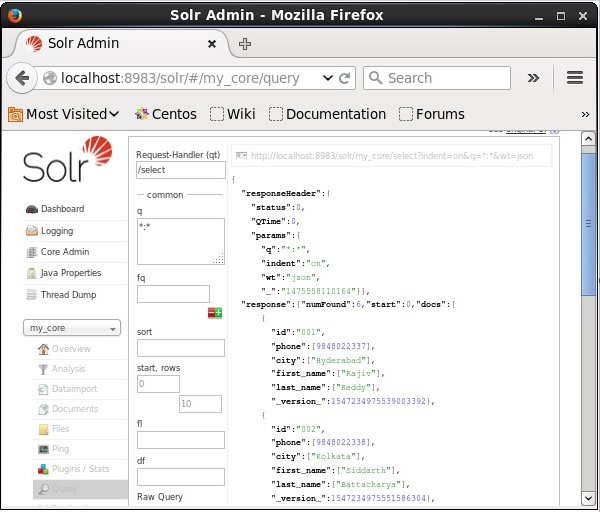
XMLを使用したドキュメントの更新
以下は、既存のドキュメントのフィールドを更新するために使用されるXMLファイルです。これを名前のファイルに保存しますupdate.xml。
<add>
<doc>
<field name = "id">001</field>
<field name = "first name" update = "set">Raj</field>
<field name = "last name" update = "add">Malhotra</field>
<field name = "phone" update = "add">9000000000</field>
<field name = "city" update = "add">Delhi</field>
</doc>
</add>ご覧のとおり、データを更新するために作成されたXMLファイルは、ドキュメントの追加に使用するものとまったく同じです。しかし、唯一の違いは、update フィールドの属性。
この例では、上記のドキュメントを使用して、ドキュメントのフィールドをIDで更新しようとします。 001。
XMLドキュメントがに存在するとします binSolrのディレクトリ。名前の付いたコアに存在するインデックスを更新しているのでmy_core、を使用して更新できます post 次のようなツール-
[Hadoop@localhost bin]$ ./post -c my_core update.xml上記のコマンドを実行すると、次の出力が得られます。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool update.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file update.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.159検証
Apache Solr Webインターフェースのホームページにアクセスし、コアを次のように選択します。 my_core。テキスト領域にクエリ「:」を渡して、すべてのドキュメントを取得してみてくださいqクエリを実行します。実行すると、ドキュメントが更新されていることがわかります。
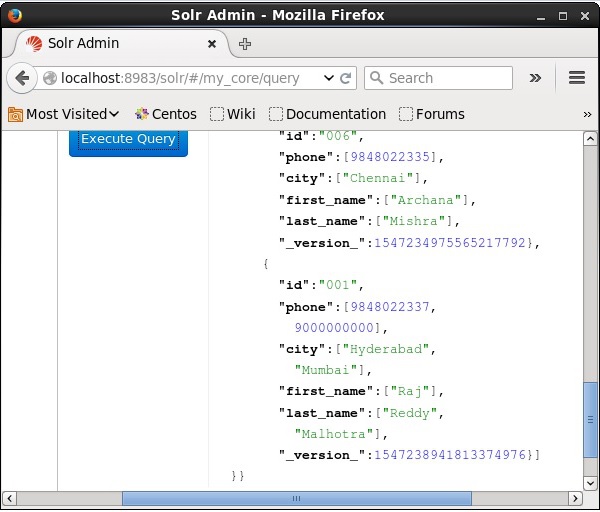
Javaを使用したドキュメントの更新(クライアントAPI)
以下は、ApacheSolrインデックスにドキュメントを追加するJavaプログラムです。このコードを名前のファイルに保存しますUpdatingDocument.java。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.UpdateRequest;
import org.apache.Solr.client.Solrj.response.UpdateResponse;
import org.apache.Solr.common.SolrInputDocument;
public class UpdatingDocument {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.setAction( UpdateRequest.ACTION.COMMIT, false, false);
SolrInputDocument myDocumentInstantlycommited = new SolrInputDocument();
myDocumentInstantlycommited.addField("id", "002");
myDocumentInstantlycommited.addField("name", "Rahman");
myDocumentInstantlycommited.addField("age","27");
myDocumentInstantlycommited.addField("addr","hyderabad");
updateRequest.add( myDocumentInstantlycommited);
UpdateResponse rsp = updateRequest.process(Solr);
System.out.println("Documents Updated");
}
}ターミナルで次のコマンドを実行して、上記のコードをコンパイルします-
[Hadoop@localhost bin]$ javac UpdatingDocument
[Hadoop@localhost bin]$ java UpdatingDocument上記のコマンドを実行すると、次の出力が得られます。
Documents updatedドキュメントの削除
Apache Solrのインデックスからドキュメントを削除するには、削除するドキュメントのIDを<delete> </ delete>タグの間に指定する必要があります。
<delete>
<id>003</id>
<id>005</id>
<id>004</id>
<id>002</id>
</delete>ここで、このXMLコードは、IDを持つドキュメントを削除するために使用されます 003 そして 005。このコードを名前のファイルに保存しますdelete.xml。
名前の付いたコアに属するインデックスからドキュメントを削除する場合 my_core、その後、投稿することができます delete.xml を使用してファイル post 以下に示すように、ツール。
[Hadoop@localhost bin]$ ./post -c my_core delete.xml上記のコマンドを実行すると、次の出力が得られます。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool delete.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log
POSTing file delete.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.179検証
Apache Solr Webインターフェースのホームページにアクセスし、コアを次のように選択します。 my_core。テキスト領域にクエリ「:」を渡して、すべてのドキュメントを取得してみてくださいqクエリを実行します。実行すると、指定したドキュメントが削除されていることがわかります。
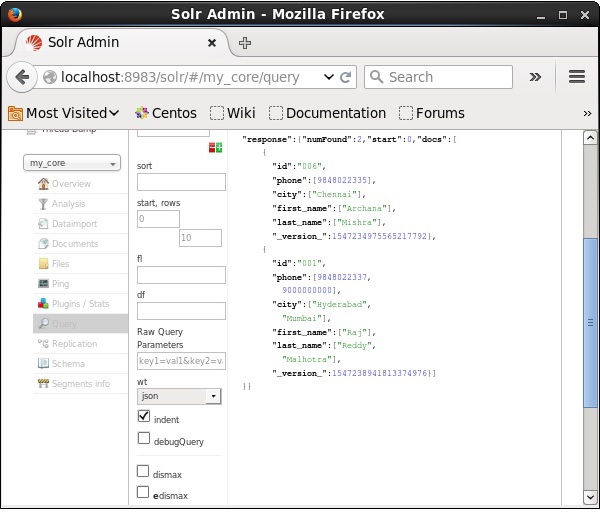
フィールドの削除
ID以外のフィールドに基づいてドキュメントを削除する必要がある場合があります。たとえば、都市がチェンナイであるドキュメントを削除する必要がある場合があります。
このような場合、<query> </ query>タグペア内のフィールドの名前と値を指定する必要があります。
<delete>
<query>city:Chennai</query>
</delete>名前を付けて保存 delete_field.xml 名前の付いたコアで削除操作を実行します my_core を使用して post Solrのツール。
[Hadoop@localhost bin]$ ./post -c my_core delete_field.xml上記のコマンドを実行すると、次の出力が生成されます。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool delete_field.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log
POSTing file delete_field.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.084検証
Apache Solr Webインターフェースのホームページにアクセスし、コアを次のように選択します。 my_core。テキスト領域にクエリ「:」を渡して、すべてのドキュメントを取得してみてくださいqクエリを実行します。実行すると、指定したフィールドと値のペアを含むドキュメントが削除されていることがわかります。
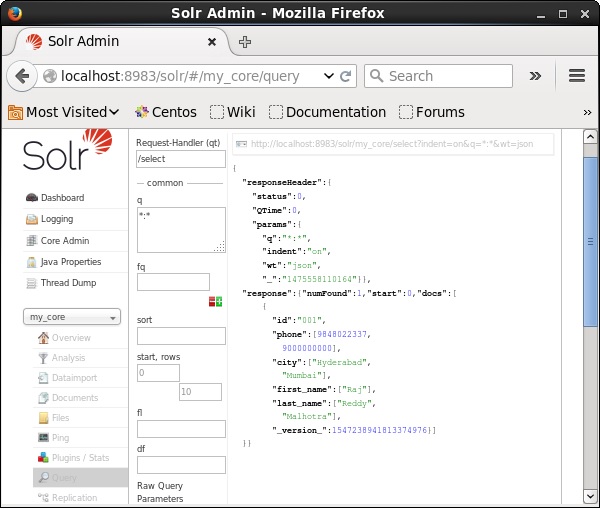
すべてのドキュメントを削除する
特定のフィールドを削除するのと同じように、インデックスからすべてのドキュメントを削除する場合は、次に示すように、タグ<query> </ query>の間に記号「:」を渡す必要があります。
<delete>
<query>*:*</query>
</delete>名前を付けて保存 delete_all.xml 名前の付いたコアで削除操作を実行します my_core を使用して post Solrのツール。
[Hadoop@localhost bin]$ ./post -c my_core delete_all.xml上記のコマンドを実行すると、次の出力が生成されます。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool deleteAll.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file deleteAll.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.138検証
Apache Solr Webインターフェースのホームページにアクセスし、コアを次のように選択します。 my_core。テキスト領域にクエリ「:」を渡して、すべてのドキュメントを取得してみてくださいqクエリを実行します。実行すると、指定したフィールドと値のペアを含むドキュメントが削除されていることがわかります。
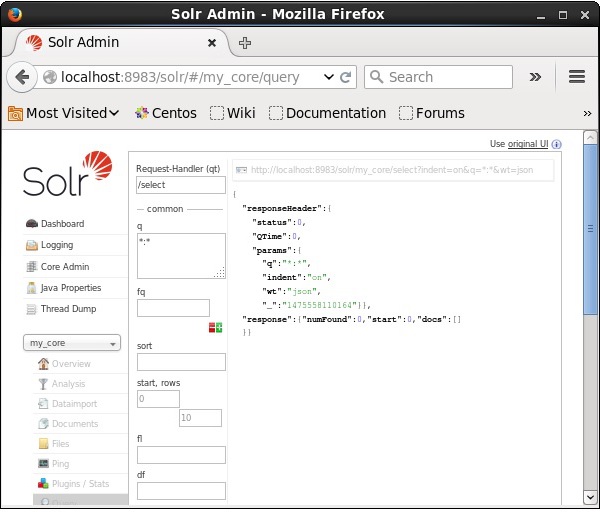
Java(クライアントAPI)を使用してすべてのドキュメントを削除する
以下は、ApacheSolrインデックスにドキュメントを追加するJavaプログラムです。このコードを名前のファイルに保存しますUpdatingDocument.java。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class DeletingAllDocuments {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Deleting the documents from Solr
Solr.deleteByQuery("*");
//Saving the document
Solr.commit();
System.out.println("Documents deleted");
}
}ターミナルで次のコマンドを実行して、上記のコードをコンパイルします-
[Hadoop@localhost bin]$ javac DeletingAllDocuments
[Hadoop@localhost bin]$ java DeletingAllDocuments上記のコマンドを実行すると、次の出力が得られます。
Documents deletedこの章では、JavaクライアントAPIを使用してデータを取得する方法について説明します。名前の付いた.csvドキュメントがあるとします。sample.csv 以下の内容で。
001,9848022337,Hyderabad,Rajiv,Reddy
002,9848022338,Kolkata,Siddarth,Battacharya
003,9848022339,Delhi,Rajesh,Khannaこのデータには、という名前のコアの下でインデックスを付けることができます sample_Solr を使用して post コマンド。
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv以下は、ApacheSolrインデックスにドキュメントを追加するJavaプログラムです。このコードを名前付きのファイルに保存しますRetrievingData.java。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrDocumentList;
public class RetrievingData {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing Solr query
SolrQuery query = new SolrQuery();
query.setQuery("*:*");
//Adding the field to be retrieved
query.addField("*");
//Executing the query
QueryResponse queryResponse = Solr.query(query);
//Storing the results of the query
SolrDocumentList docs = queryResponse.getResults();
System.out.println(docs);
System.out.println(docs.get(0));
System.out.println(docs.get(1));
System.out.println(docs.get(2));
//Saving the operations
Solr.commit();
}
}ターミナルで次のコマンドを実行して、上記のコードをコンパイルします-
[Hadoop@localhost bin]$ javac RetrievingData
[Hadoop@localhost bin]$ java RetrievingData上記のコマンドを実行すると、次の出力が得られます。
{numFound = 3,start = 0,docs = [SolrDocument{id=001, phone = [9848022337],
city = [Hyderabad], first_name = [Rajiv], last_name = [Reddy],
_version_ = 1547262806014820352}, SolrDocument{id = 002, phone = [9848022338],
city = [Kolkata], first_name = [Siddarth], last_name = [Battacharya],
_version_ = 1547262806026354688}, SolrDocument{id = 003, phone = [9848022339],
city = [Delhi], first_name = [Rajesh], last_name = [Khanna],
_version_ = 1547262806029500416}]}
SolrDocument{id = 001, phone = [9848022337], city = [Hyderabad], first_name = [Rajiv],
last_name = [Reddy], _version_ = 1547262806014820352}
SolrDocument{id = 002, phone = [9848022338], city = [Kolkata], first_name = [Siddarth],
last_name = [Battacharya], _version_ = 1547262806026354688}
SolrDocument{id = 003, phone = [9848022339], city = [Delhi], first_name = [Rajesh],
last_name = [Khanna], _version_ = 1547262806029500416}データの保存に加えて、Apache Solrは、必要に応じてデータをクエリバックする機能も提供します。Solrは、そこに格納されているデータを照会するために使用できる特定のパラメーターを提供します。
次の表に、ApacheSolrで使用できるさまざまなクエリパラメーターを示します。
| パラメータ | 説明 |
|---|---|
| q | これはApacheSolrのメインクエリパラメーターであり、ドキュメントはこのパラメーターの用語との類似性によってスコアリングされます。 |
| fq | このパラメーターは、Apache Solrのフィルター・クエリを表し、結果セットをこのフィルターに一致するドキュメントに制限します。 |
| 開始 | startパラメーターは、ページ結果の開始オフセットを表します。このパラメーターのデフォルト値は0です。 |
| 行 | このパラメーターは、ページごとに取得されるドキュメントの数を表します。このパラメーターのデフォルト値は10です。 |
| ソート | このパラメーターは、クエリの結果をソートするための基準となる、コンマで区切られたフィールドのリストを指定します。 |
| fl | このパラメーターは、結果セット内の各ドキュメントに対して返されるフィールドのリストを指定します。 |
| wt | このパラメーターは、結果を表示したい応答ライターのタイプを表します。 |
これらすべてのパラメーターは、ApacheSolrを照会するためのオプションとして表示できます。ApacheSolrのホームページにアクセスしてください。ページの左側で、[クエリ]オプションをクリックします。ここでは、クエリのパラメータのフィールドを確認できます。
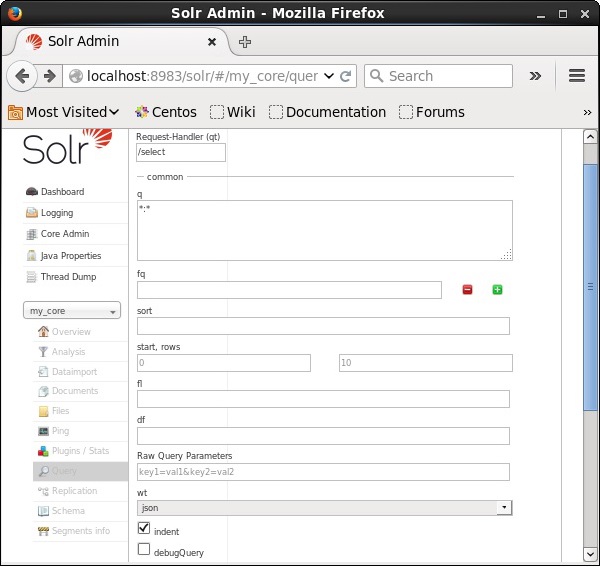
レコードの取得
名前の付いたコアに3つのレコードがあると仮定します my_core。選択したコアから特定のレコードを取得するには、特定のドキュメントのフィールドの名前と値のペアを渡す必要があります。たとえば、フィールドの値を含むレコードを取得する場合id、フィールドの名前と値のペアを-として渡す必要があります Id:001 パラメータの値として q クエリを実行します。
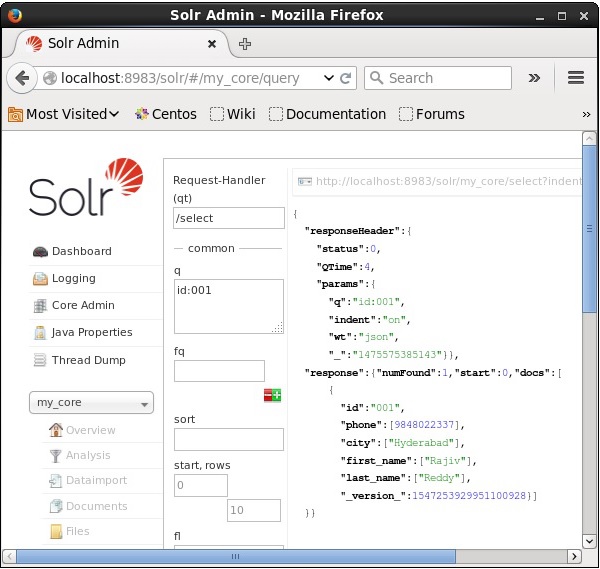
同様に、*:*を値としてパラメーターに渡すことにより、インデックスからすべてのレコードを取得できます。 q、次のスクリーンショットに示すように。
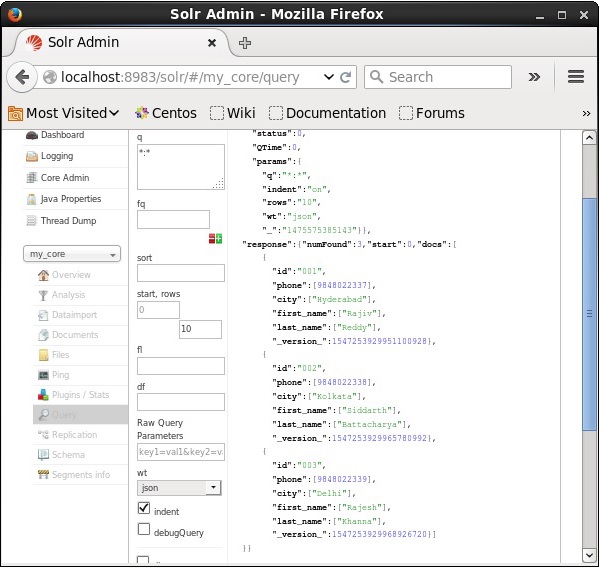
2番目のレコードから取得
パラメータに値として2を渡すことにより、2番目のレコードからレコードを取得できます start、次のスクリーンショットに示すように。
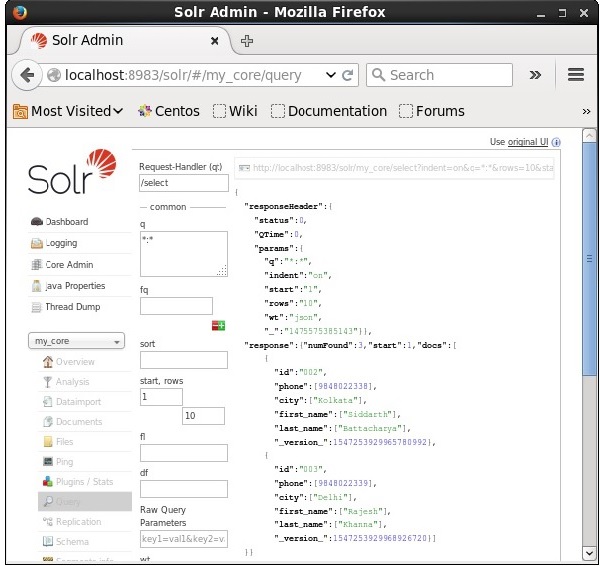
レコード数の制限
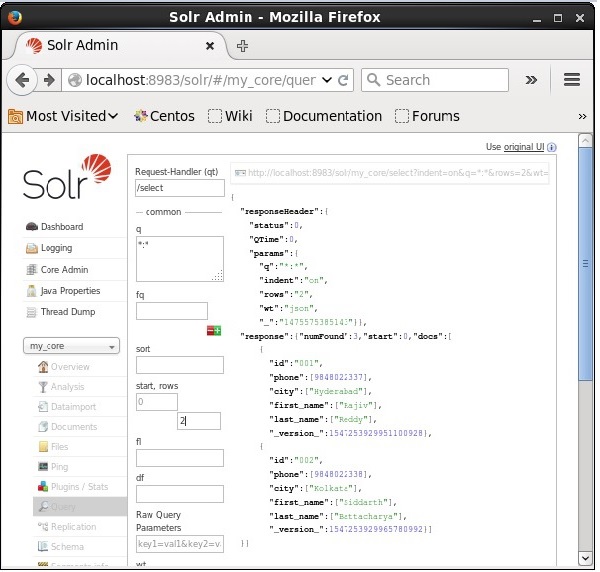
に値を指定することにより、レコード数を制限できます。 rowsパラメータ。たとえば、値2をパラメータに渡すことで、クエリ結果のレコードの総数を2に制限できます。rows、次のスクリーンショットに示すように。
応答ライタータイプ
パラメータの提供された値から1つを選択することにより、必要なドキュメントタイプで応答を取得できます。 wt。
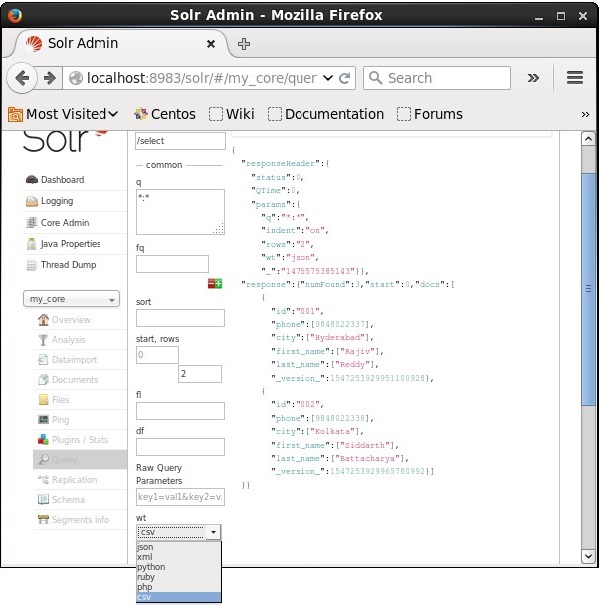
上記の例では、 .csv 応答を取得するためのフォーマット。
フィールドのリスト
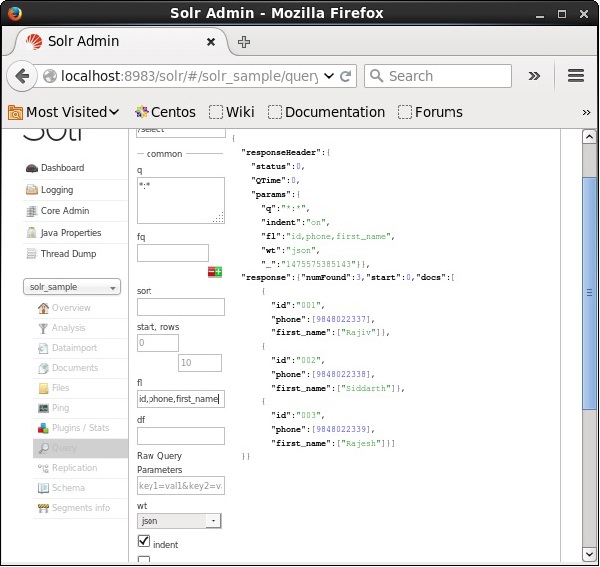
結果のドキュメントに特定のフィールドを含める場合は、必須フィールドのリストを値としてプロパティにコンマで区切って渡す必要があります。 fl。
次の例では、フィールドを取得しようとしています- id, phone, そして first_name。
Apache Solrのファセットとは、検索結果をさまざまなカテゴリに分類することです。この章では、ApacheSolrで使用できるファセットのタイプについて説明します。
Query faceting −指定されたクエリにも一致する現在の検索結果内のドキュメントの数を返します。
Date faceting −特定の日付範囲内にあるドキュメントの数を返します。
ファセットコマンドは通常のSolrクエリ要求に追加され、ファセットカウントは同じクエリ応答で返されます。
ファセットクエリの例
フィールドの使用 faceting、すべての用語のカウントを取得することも、特定のフィールドの上位の用語のみを取得することもできます。
例として、次のことを考えてみましょう。 books.csv さまざまな本に関するデータを含むファイル。
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s
0553573403,book,A Game of Thrones,5.99,true,George R.R. Martin,"A Song of Ice
and Fire",1,fantasy
0553579908,book,A Clash of Kings,10.99,true,George R.R. Martin,"A Song of Ice
and Fire",2,fantasy
055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice
and Fire",3,fantasy
0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi
0812521390,book,The Black Company,4.99,false,Glen Cook,The Chronicles of The
Black Company,1,fantasy
0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi
0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy
0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of
Amber,1,fantasy
0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,1,fantasy
080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,2,fantasyこのファイルをApacheSolrに投稿しましょう。 post ツール。
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv上記のコマンドを実行すると、指定されたすべてのドキュメント .csv ファイルはApacheSolrにアップロードされます。
次に、フィールドでファセットクエリを実行しましょう author コレクション/コアに0行あり my_core。
ApacheSolrのWebUIを開き、ページの左側にあるチェックボックスをオンにします facet、次のスクリーンショットに示すように。
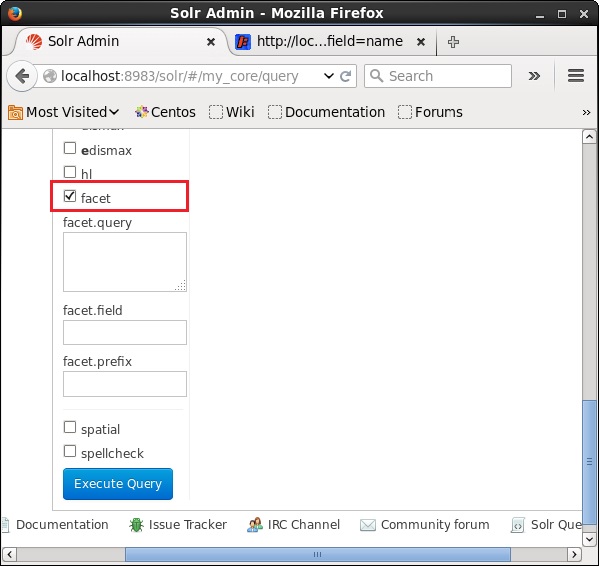
チェックボックスをオンにすると、ファセット検索のパラメータを渡すために、さらに3つのテキストフィールドが表示されます。ここで、クエリのパラメータとして、次の値を渡します。
q = *:*, rows = 0, facet.field = author最後に、をクリックしてクエリを実行します Execute Query ボタン。
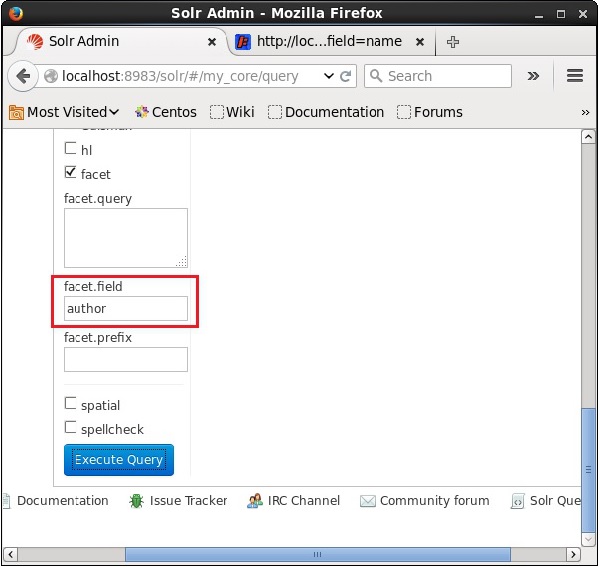
実行すると、次のような結果になります。
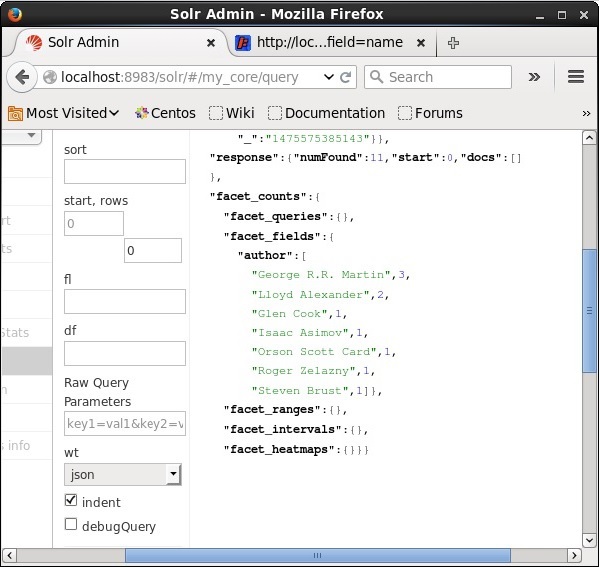
著者に基づいてインデックス内のドキュメントを分類し、各著者が寄稿した本の数を指定します。
JavaクライアントAPIを使用したファセット
以下は、ApacheSolrインデックスにドキュメントを追加するJavaプログラムです。このコードを名前のファイルに保存しますHitHighlighting.java。
import java.io.IOException;
import java.util.List;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.QueryRequest;
import org.apache.Solr.client.Solrj.response.FacetField;
import org.apache.Solr.client.Solrj.response.FacetField.Count;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrInputDocument;
public class HitHighlighting {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//String query = request.query;
SolrQuery query = new SolrQuery();
//Setting the query string
query.setQuery("*:*");
//Setting the no.of rows
query.setRows(0);
//Adding the facet field
query.addFacetField("author");
//Creating the query request
QueryRequest qryReq = new QueryRequest(query);
//Creating the query response
QueryResponse resp = qryReq.process(Solr);
//Retrieving the response fields
System.out.println(resp.getFacetFields());
List<FacetField> facetFields = resp.getFacetFields();
for (int i = 0; i > facetFields.size(); i++) {
FacetField facetField = facetFields.get(i);
List<Count> facetInfo = facetField.getValues();
for (FacetField.Count facetInstance : facetInfo) {
System.out.println(facetInstance.getName() + " : " +
facetInstance.getCount() + " [drilldown qry:" +
facetInstance.getAsFilterQuery());
}
System.out.println("Hello");
}
}
}ターミナルで次のコマンドを実行して、上記のコードをコンパイルします-
[Hadoop@localhost bin]$ javac HitHighlighting
[Hadoop@localhost bin]$ java HitHighlighting上記のコマンドを実行すると、次の出力が得られます。
[author:[George R.R. Martin (3), Lloyd Alexander (2), Glen Cook (1), Isaac
Asimov (1), Orson Scott Card (1), Roger Zelazny (1), Steven Brust (1)]]