ApacheSolr-検索エンジンの基本
検索エンジンは、Webページ、ニュースグループ、プログラム、画像などのインターネットリソースの巨大なデータベースを指します。これは、ワールドワイドウェブ上の情報を見つけるのに役立ちます。
ユーザーは、キーワードまたはフレーズの形式で検索エンジンにクエリを渡すことにより、情報を検索できます。次に、検索エンジンはデータベースを検索し、関連するリンクをユーザーに返します。
検索エンジンのコンポーネント
一般的に、検索エンジンには以下の3つの基本的なコンポーネントがあります。
Web Crawler −Webクローラーは別名 spiders または bots。これは、Webをトラバースして情報を収集するソフトウェアコンポーネントです。
Database−Web上のすべての情報はデータベースに保存されます。それらには膨大な量のWebリソースが含まれています。
Search Interfaces−このコンポーネントは、ユーザーとデータベース間のインターフェースです。これは、ユーザーがデータベースを検索するのに役立ちます。
検索エンジンはどのように機能しますか?
以下の操作の一部またはすべてを実行するには、検索アプリケーションが必要です。
| ステップ | 題名 | 説明 |
|---|---|---|
1 |
生のコンテンツを取得する |
検索アプリケーションの最初のステップは、検索が実行されるターゲットコンテンツを収集することです。 |
2 |
ドキュメントを作成する |
次のステップは、検索アプリケーションが簡単に理解して解釈できる生のコンテンツからドキュメントを作成することです。 |
3 |
ドキュメントを分析する |
インデックス作成を開始する前に、ドキュメントを分析する必要があります。 |
4 |
ドキュメントのインデックス作成 |
ドキュメントが作成および分析されたら、次のステップは、ドキュメントのコンテンツ全体ではなく、特定のキーに基づいてこのドキュメントを取得できるように、ドキュメントにインデックスを付けることです。 索引付けは、本の最後にある索引に似ており、一般的な単語がページ番号とともに表示されるため、本全体を検索する代わりに、これらの単語をすばやく追跡できます。 |
5 |
検索用のユーザーインターフェイス |
インデックスのデータベースの準備ができたら、アプリケーションは検索操作を実行できます。ユーザーが検索を行えるようにするには、アプリケーションは、ユーザーがテキストを入力して検索プロセスを開始できるユーザーインターフェイスを提供する必要があります。 |
6 |
ビルドクエリ |
ユーザーがテキストの検索を要求すると、アプリケーションはそのテキストを使用してクエリオブジェクトを準備する必要があります。これを使用して、インデックスデータベースに問い合わせ、関連する詳細を取得できます。 |
7 |
検索クエリ |
クエリオブジェクトを使用して、インデックスデータベースがチェックされ、関連する詳細とコンテンツドキュメントが取得されます。 |
8 |
結果をレンダリングする |
必要な結果を受け取ったら、アプリケーションはユーザーインターフェイスを使用して結果をユーザーに表示する方法を決定する必要があります。 |
次の図を見てください。これは、検索エンジンがどのように機能するかについての全体像を示しています。
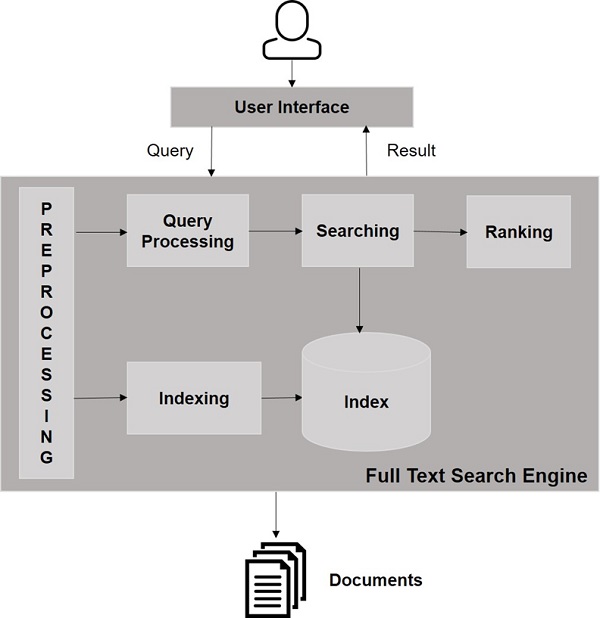
これらの基本的な操作とは別に、検索アプリケーションは、管理者がユーザープロファイルに基づいて検索のレベルを制御するのに役立つ管理ユーザーインターフェイスを提供することもできます。検索結果の分析は、検索アプリケーションのもう1つの重要で高度な側面です。