ApacheStorm-コアコンセプト
Apache Stormは、一方の端からリアルタイムデータの生のストリームを読み取り、それを一連の小さな処理ユニットに渡し、もう一方の端で処理された/有用な情報を出力します。
次の図は、ApacheStormのコアコンセプトを示しています。

ここで、ApacheStormのコンポーネントを詳しく見てみましょう-
| コンポーネント | 説明 |
|---|---|
| タプル | タプルはStormの主要なデータ構造です。順序付けられた要素のリストです。デフォルトでは、タプルはすべてのデータ型をサポートします。通常、これはコンマ区切りの値のセットとしてモデル化され、Stormクラスターに渡されます。 |
| ストリーム | ストリームは、順序付けられていないタプルのシーケンスです。 |
| 注ぎ口 | ストリームのソース。通常、Stormは、Twitter Streaming API、Apache Kafkaキュー、Kestrelキューなどの生データソースからの入力データを受け入れます。それ以外の場合は、データソースからデータを読み取るためのスパウトを書き込むことができます。「ISpout」は、スパウトを実装するためのコアインターフェイスです。特定のインターフェイスには、IRichSpout、BaseRichSpout、KafkaSpoutなどがあります。 |
| ボルト | ボルトは論理処理ユニットです。注ぎ口はデータをボルトとボルトプロセスに渡し、新しい出力ストリームを生成します。Boltsは、フィルタリング、集約、結合、データソースおよびデータベースとの対話の操作を実行できます。ボルトはデータを受信し、1つまたは複数のボルトに放出します。「IBolt」は、ボルトを実装するためのコアインターフェイスです。一般的なインターフェイスには、IRichBolt、IBasicBoltなどがあります。 |
「TwitterAnalysis」のリアルタイムの例を見て、ApacheStormでモデル化する方法を見てみましょう。次の図は、構造を示しています。

「Twitter分析」への入力は、TwitterストリーミングAPIから取得されます。Spoutは、Twitter Streaming APIを使用してユーザーのツイートを読み取り、タプルのストリームとして出力します。注ぎ口からの単一のタプルには、Twitterのユーザー名と1つのツイートがコンマ区切りの値として含まれます。次に、このタプルの蒸気がBoltに転送され、Boltはツイートを個々の単語に分割し、単語数を計算して、構成されたデータソースに情報を保持します。これで、データソースにクエリを実行することで簡単に結果を取得できます。
トポロジー
注ぎ口とボルトは互いに接続されており、トポロジーを形成しています。リアルタイムアプリケーションロジックは、Stormトポロジ内で指定されます。簡単に言うと、トポロジは、頂点が計算でエッジがデータのストリームである有向グラフです。
単純なトポロジーは、注ぎ口から始まります。注ぎ口は、データを1つまたは複数のボルトに放出します。ボルトは、処理ロジックが最小のトポロジ内のノードを表し、ボルトの出力を入力として別のボルトに放出できます。
Stormは、トポロジを強制終了するまで、トポロジを常に実行し続けます。Apache Stormの主な仕事はトポロジを実行することであり、特定の時間に任意の数のトポロジを実行します。
タスク
これで、注ぎ口とボルトの基本的な考え方がわかりました。これらはトポロジの最小の論理ユニットであり、トポロジは単一の注ぎ口とボルトの配列を使用して構築されます。トポロジを正常に実行するには、特定の順序で適切に実行する必要があります。ストームによるすべての注ぎ口とボルトの実行は「タスク」と呼ばれます。簡単に言うと、タスクは注ぎ口またはボルトの実行です。ある時点で、各注ぎ口とボルトは、複数の別々のスレッドで実行されている複数のインスタンスを持つことができます。
労働者
トポロジは、複数のワーカーノードで分散して実行されます。Stormは、すべてのワーカーノードにタスクを均等に分散します。ワーカーノードの役割は、ジョブをリッスンし、新しいジョブが到着するたびにプロセスを開始または停止することです。
ストリームのグループ化
データのストリームは、注ぎ口からボルトへ、または1つのボルトから別のボルトへと流れます。ストリームのグループ化は、トポロジ内でのタプルのルーティング方法を制御し、トポロジ内のタプルのフローを理解するのに役立ちます。以下に説明するように、4つの組み込みグループがあります。
シャッフルグループ化
シャッフルグループ化では、ボルトを実行するすべてのワーカーに同数のタプルがランダムに分散されます。次の図は、構造を示しています。

フィールドのグループ化
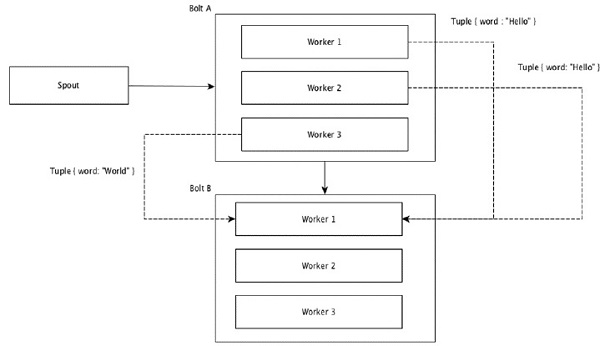
タプル内の同じ値を持つフィールドはグループ化され、残りのタプルは外部に保持されます。次に、同じフィールド値を持つタプルが、ボルトを実行している同じワーカーに転送されます。たとえば、ストリームがフィールド「word」でグループ化されている場合、同じ文字列「Hello」のタプルは同じワーカーに移動します。次の図は、フィールドグループ化がどのように機能するかを示しています。

グローバルグループ化
すべてのストリームをグループ化して、1つのボルトに転送できます。このグループ化により、ソースのすべてのインスタンスによって生成されたタプルが単一のターゲットインスタンスに送信されます(具体的には、IDが最小のワーカーを選択します)。
すべてのグループ化
All Groupingは、各タプルの単一のコピーを受信ボルトのすべてのインスタンスに送信します。この種のグループ化は、ボルトに信号を送信するために使用されます。すべてのグループ化は、結合操作に役立ちます。
