ApacheStorm-クイックガイド
Apache Stormとは何ですか?
Apache Stormは、分散型のリアルタイムビッグデータ処理システムです。Stormは、フォールトトレラントで水平方向にスケーラブルな方法で大量のデータを処理するように設計されています。これは、最高の取り込み率の機能を備えたストリーミングデータフレームワークです。Stormはステートレスですが、ApacheZooKeeperを介して分散環境とクラスター状態を管理します。シンプルで、リアルタイムデータに対してあらゆる種類の操作を並行して実行できます。
Apache Stormは、リアルタイムデータ分析のリーダーであり続けています。Stormはセットアップと操作が簡単で、すべてのメッセージがトポロジを介して少なくとも1回処理されることを保証します。
ApacheStormとHadoop
基本的に、HadoopおよびStormフレームワークはビッグデータの分析に使用されます。それらの両方は互いに補完し合い、いくつかの面で異なります。Apache Stormは永続性を除くすべての操作を実行しますが、Hadoopはすべてに優れていますが、リアルタイム計算には遅れがあります。次の表は、StormとHadoopの属性を比較しています。
| 嵐 | Hadoop |
|---|---|
| リアルタイムストリーム処理 | バッチ処理 |
| ステートレス | ステートフル |
| ZooKeeperベースの調整によるマスター/スレーブアーキテクチャ。マスターノードは次のように呼ばれますnimbus と奴隷は supervisors。 | ZooKeeperベースの調整がある場合とない場合のマスタースレーブアーキテクチャ。マスターノードはjob tracker スレーブノードは task tracker。 |
| ストームストリーミングプロセスは、クラスター上で1秒あたり数万のメッセージにアクセスできます。 | Hadoop分散ファイルシステム(HDFS)は、MapReduceフレームワークを使用して、数分または数時間かかる大量のデータを処理します。 |
| ストームトポロジは、ユーザーによるシャットダウンまたは予期しない回復不能な障害まで実行されます。 | MapReduceジョブは順番に実行され、最終的に完了します。 |
| Both are distributed and fault-tolerant | |
| ニンバス/スーパーバイザーが停止した場合、再起動すると停止した場所から続行されるため、影響はありません。 | JobTrackerが停止すると、実行中のすべてのジョブが失われます。 |
ユースケース-ApacheStormの事例
Apache Stormは、リアルタイムのビッグデータストリーム処理で非常に有名です。このため、ほとんどの企業は、システムの不可欠な部分としてStormを使用しています。いくつかの注目すべき例は次のとおりです-
Twitter− Twitterは、さまざまな「パブリッシャー分析製品」にApacheStormを使用しています。「PublisherAnalyticsProducts」は、Twitterプラットフォームのすべてのツイートとクリックを処理します。Apache Stormは、Twitterインフラストラクチャと緊密に統合されています。
NaviSite− NaviSiteは、イベントログの監視/監査システムにStormを使用しています。システムで生成されたすべてのログはストームを通過します。Stormは、構成された正規表現のセットに対してメッセージをチェックし、一致する場合は、その特定のメッセージがデータベースに保存されます。
Wego− Wegoは、シンガポールにある旅行メタ検索エンジンです。旅行関連のデータは、さまざまなタイミングで世界中の多くのソースから取得されます。Stormは、Wegoがリアルタイムデータを検索し、同時実行の問題を解決し、エンドユーザーに最適なものを見つけるのに役立ちます。
ApacheStormのメリット
ApacheStormが提供する利点のリストは次のとおりです-
Stormはオープンソースで、堅牢で、ユーザーフレンドリーです。大企業だけでなく中小企業でも利用できます。
Stormは、フォールトトレラント、柔軟性、信頼性があり、あらゆるプログラミング言語をサポートします。
リアルタイムのストリーム処理を可能にします。
Stormは、データを処理する非常に強力な能力を備えているため、信じられないほど高速です。
Stormは、リソースを直線的に追加することで、負荷が増加してもパフォーマンスを維持できます。非常にスケーラブルです。
Stormは、問題に応じて、データの更新とエンドツーエンドの配信応答を数秒または数分で実行します。レイテンシーは非常に低いです。
ストームには運用インテリジェンスがあります。
Stormは、クラスター内の接続されたノードのいずれかが停止したり、メッセージが失われた場合でも、保証されたデータ処理を提供します。
Apache Stormは、一方の端からリアルタイムデータの生のストリームを読み取り、それを一連の小さな処理ユニットに渡し、もう一方の端で処理された/有用な情報を出力します。
次の図は、ApacheStormのコアコンセプトを示しています。

ここで、ApacheStormのコンポーネントを詳しく見てみましょう-
| コンポーネント | 説明 |
|---|---|
| タプル | タプルはStormの主要なデータ構造です。順序付けられた要素のリストです。デフォルトでは、タプルはすべてのデータ型をサポートします。通常、これはコンマ区切りの値のセットとしてモデル化され、Stormクラスターに渡されます。 |
| ストリーム | ストリームは、順序付けられていないタプルのシーケンスです。 |
| 注ぎ口 | ストリームのソース。通常、Stormは、Twitter Streaming API、Apache Kafkaキュー、Kestrelキューなどの生データソースからの入力データを受け入れます。それ以外の場合は、データソースからデータを読み取るためのスパウトを書き込むことができます。「ISpout」は、スパウトを実装するためのコアインターフェイスです。特定のインターフェイスには、IRichSpout、BaseRichSpout、KafkaSpoutなどがあります。 |
| ボルト | ボルトは論理処理ユニットです。注ぎ口はデータをボルトとボルトプロセスに渡し、新しい出力ストリームを生成します。Boltsは、フィルタリング、集約、結合、データソースおよびデータベースとの対話の操作を実行できます。ボルトはデータを受信し、1つまたは複数のボルトに放出します。「IBolt」は、ボルトを実装するためのコアインターフェイスです。一般的なインターフェイスには、IRichBolt、IBasicBoltなどがあります。 |
「TwitterAnalysis」のリアルタイムの例を見て、ApacheStormでモデル化する方法を見てみましょう。次の図は、構造を示しています。

「Twitter分析」への入力は、TwitterストリーミングAPIから取得されます。Spoutは、Twitter Streaming APIを使用してユーザーのツイートを読み取り、タプルのストリームとして出力します。注ぎ口からの単一のタプルには、Twitterのユーザー名と1つのツイートがコンマ区切りの値として含まれます。次に、このタプルの蒸気がBoltに転送され、Boltはツイートを個々の単語に分割し、単語数を計算して、構成されたデータソースに情報を保持します。これで、データソースにクエリを実行することで簡単に結果を取得できます。
トポロジー
注ぎ口とボルトは互いに接続されており、トポロジーを形成しています。リアルタイムアプリケーションロジックは、Stormトポロジ内で指定されます。簡単に言うと、トポロジは、頂点が計算でエッジがデータのストリームである有向グラフです。
単純なトポロジーは、注ぎ口から始まります。注ぎ口は、データを1つまたは複数のボルトに放出します。ボルトは、処理ロジックが最小のトポロジ内のノードを表し、ボルトの出力を入力として別のボルトに放出できます。
Stormは、トポロジを強制終了するまで、トポロジを常に実行し続けます。Apache Stormの主な仕事はトポロジを実行することであり、特定の時間に任意の数のトポロジを実行します。
タスク
これで、注ぎ口とボルトの基本的な考え方がわかりました。これらはトポロジの最小の論理ユニットであり、トポロジは単一の注ぎ口とボルトの配列を使用して構築されます。トポロジを正常に実行するには、特定の順序で適切に実行する必要があります。ストームによるすべての注ぎ口とボルトの実行は「タスク」と呼ばれます。簡単に言うと、タスクは注ぎ口またはボルトの実行です。ある時点で、各注ぎ口とボルトは、複数の別々のスレッドで実行されている複数のインスタンスを持つことができます。
労働者
トポロジは、複数のワーカーノードで分散して実行されます。Stormは、すべてのワーカーノードにタスクを均等に分散します。ワーカーノードの役割は、ジョブをリッスンし、新しいジョブが到着するたびにプロセスを開始または停止することです。
ストリームのグループ化
データのストリームは、注ぎ口からボルトへ、または1つのボルトから別のボルトへと流れます。ストリームのグループ化は、トポロジ内でのタプルのルーティング方法を制御し、トポロジ内のタプルのフローを理解するのに役立ちます。以下に説明するように、4つの組み込みグループがあります。
シャッフルグループ化
シャッフルグループ化では、ボルトを実行するすべてのワーカーに同数のタプルがランダムに分散されます。次の図は、構造を示しています。

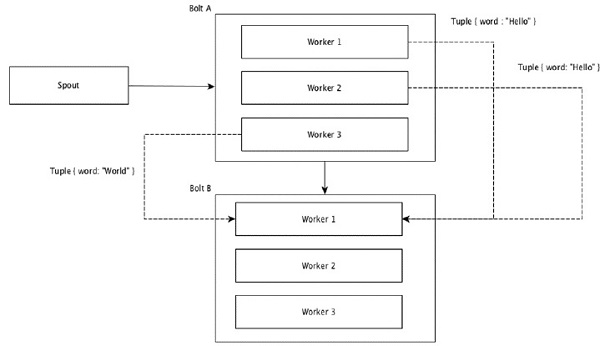
フィールドのグループ化
タプル内の同じ値を持つフィールドはグループ化され、残りのタプルは外部に保持されます。次に、同じフィールド値を持つタプルが、ボルトを実行している同じワーカーに転送されます。たとえば、ストリームがフィールド「word」でグループ化されている場合、同じ文字列「Hello」のタプルは同じワーカーに移動します。次の図は、フィールドグループ化がどのように機能するかを示しています。

グローバルグループ化
すべてのストリームをグループ化して、1つのボルトに転送できます。このグループ化により、ソースのすべてのインスタンスによって生成されたタプルが単一のターゲットインスタンスに送信されます(具体的には、IDが最小のワーカーを選択します)。
すべてのグループ化
All Groupingは、各タプルの単一のコピーを受信ボルトのすべてのインスタンスに送信します。この種のグループ化は、ボルトに信号を送信するために使用されます。すべてのグループ化は、結合操作に役立ちます。

Apache Stormの主なハイライトの1つは、フォールトトレラントで高速であり、「単一障害点」(SPOF)分散アプリケーションがないことです。アプリケーションの容量を増やすために、必要な数のシステムにApacheStormをインストールできます。
ApacheStormクラスターがどのように設計されているかとその内部アーキテクチャーを見てみましょう。次の図は、クラスターの設計を示しています。

Apache Stormには、2種類のノードがあります。 Nimbus (マスターノード)と Supervisor(ワーカーノード)。ニンバスはApacheStormの中心的なコンポーネントです。Nimbusの主な仕事は、Stormトポロジを実行することです。Nimbusはトポロジを分析し、実行するタスクを収集します。次に、タスクを使用可能なスーパーバイザーに配布します。
スーパーバイザーには、1つ以上のワーカープロセスがあります。スーパーバイザーは、タスクをワーカープロセスに委任します。ワーカープロセスは、必要な数のエグゼキューターを生成し、タスクを実行します。Apache Stormは、ニンバスとスーパーバイザー間の通信に内部分散メッセージングシステムを使用します。
| コンポーネント | 説明 |
|---|---|
| ニンバス | Nimbusは、Stormクラスターのマスターノードです。クラスタ内の他のすべてのノードは、worker nodes。マスターノードは、すべてのワーカーノード間でデータを分散し、ワーカーノードにタスクを割り当て、障害を監視する役割を果たします。 |
| スーパーバイザー | ニンバスの指示に従うノードは、スーパーバイザーと呼ばれます。Asupervisor 複数のワーカープロセスがあり、ニンバスによって割り当てられたタスクを完了するためにワーカープロセスを管理します。 |
| 労働者のプロセス | ワーカープロセスは、特定のトポロジに関連するタスクを実行します。ワーカープロセスはそれ自体ではタスクを実行せず、代わりに作成しますexecutors特定のタスクを実行するように依頼します。ワーカープロセスには複数のエグゼキュータがあります。 |
| エグゼキュータ | エグゼキュータは、ワーカープロセスによって生成される単一のスレッドに他なりません。エグゼキュータは1つ以上のタスクを実行しますが、特定の注ぎ口またはボルトに対してのみ実行します。 |
| 仕事 | タスクは実際のデータ処理を実行します。だから、それは注ぎ口かボルトのどちらかです。 |
| ZooKeeperフレームワーク | Apache ZooKeeperは、クラスター(ノードのグループ)が相互に調整し、堅牢な同期技術を使用して共有データを維持するために使用するサービスです。Nimbusはステートレスであるため、作業ノードのステータスを監視するのはZooKeeperに依存します。 ZooKeeperは、スーパーバイザーがニンバスと対話するのに役立ちます。ニンバスとスーパーバイザーの状態を維持する責任があります。 |
嵐は本質的にステートレスです。ステートレスの性質には独自の欠点がありますが、実際には、Stormが可能な限り迅速な方法でリアルタイムデータを処理するのに役立ちます。
ただし、ストームは完全にステートレスではありません。状態をApacheZooKeeperに保存します。状態はApacheZooKeeperで利用できるため、失敗したニンバスを再起動して、元の場所から動作させることができます。通常、次のようなサービス監視ツールmonit Nimbusを監視し、障害が発生した場合は再起動します。
Apache Stormには、と呼ばれる高度なトポロジもあります。 Trident Topology状態のメンテナンスがあり、Pigのような高レベルのAPIも提供します。これらすべての機能については、次の章で説明します。
動作中のStormクラスターには、1つのニンバスと1つ以上のスーパーバイザーが必要です。もう1つの重要なノードはApacheZooKeeperです。これは、ニンバスとスーパーバイザーの間の調整に使用されます。
ここで、ApacheStormのワークフローを詳しく見てみましょう-
最初に、ニンバスは「ストームトポロジ」が送信されるのを待ちます。
トポロジが送信されると、トポロジが処理され、実行されるすべてのタスクとタスクが実行される順序が収集されます。
次に、ニンバスは、使用可能なすべてのスーパーバイザーにタスクを均等に分散します。
特定の時間間隔で、すべてのスーパーバイザーはハートビートをニンバスに送信して、まだ生きていることを通知します。
スーパーバイザが死亡し、ハートビートをニンバスに送信しない場合、ニンバスはタスクを別のスーパーバイザに割り当てます。
ニンバス自体が停止すると、スーパーバイザーは問題なくすでに割り当てられたタスクに取り組みます。
すべてのタスクが完了すると、スーパーバイザーは新しいタスクが着信するのを待ちます。
その間、デッドニンバスはサービス監視ツールによって自動的に再起動されます。
再起動されたニンバスは、停止したところから続行されます。同様に、死んだスーパーバイザーも自動的に再起動できます。ニンバスとスーパーバイザーの両方を自動的に再起動でき、両方とも以前と同じように続行されるため、Stormはすべてのタスクを少なくとも1回処理することが保証されています。
すべてのトポロジが処理されると、ニンバスは新しいトポロジが到着するのを待ち、同様にスーパーバイザは新しいタスクを待ちます。
デフォルトでは、ストームクラスターには2つのモードがあります-
Local mode−このモードは、すべてのトポロジコンポーネントが連携して動作することを確認する最も簡単な方法であるため、開発、テスト、およびデバッグに使用されます。このモードでは、さまざまなStorm構成環境でトポロジがどのように実行されるかを確認できるようにするパラメーターを調整できます。ローカルモードでは、ストームトポロジは単一のJVMのローカルマシンで実行されます。
Production mode−このモードでは、トポロジを、通常は異なるマシンで実行されている多くのプロセスで構成される作業ストームクラスターに送信します。ストームのワークフローで説明したように、動作中のクラスターは、シャットダウンされるまで無期限に実行されます。
Apache Stormはリアルタイムデータを処理し、入力は通常、メッセージキューシステムから送信されます。外部分散メッセージングシステムは、リアルタイム計算に必要な入力を提供します。Spoutは、メッセージングシステムからデータを読み取り、それをタプルに変換して、ApacheStormに入力します。興味深い事実は、ApacheStormがニンバスとスーパーバイザー間の通信に独自の分散メッセージングシステムを内部的に使用していることです。
分散メッセージングシステムとは何ですか?
分散メッセージングは、信頼性の高いメッセージキューの概念に基づいています。メッセージは、クライアントアプリケーションとメッセージングシステム間で非同期にキューに入れられます。分散メッセージングシステムは、信頼性、スケーラビリティ、および永続性の利点を提供します。
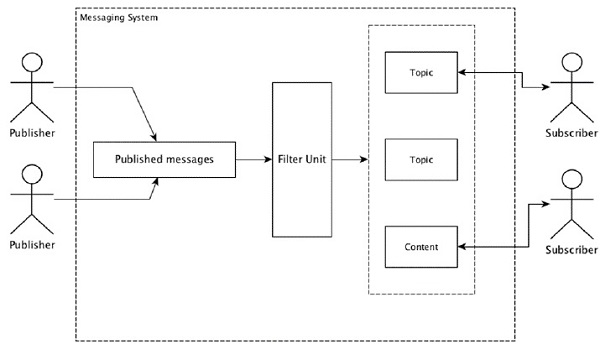
ほとんどのメッセージングパターンは、 publish-subscribe モデル(単に Pub-Sub)メッセージの送信者が呼び出される場所 publishers そしてメッセージを受け取りたい人は呼ばれます subscribers。
メッセージが送信者によって公開されると、サブスクライバーはフィルタリングオプションを使用して選択したメッセージを受信できます。通常、2種類のフィルタリングがあります。1つはtopic-based filtering もう1つは content-based filtering。
pub-subモデルは、メッセージを介してのみ通信できることに注意してください。これは非常に疎結合のアーキテクチャです。送信者でさえ、サブスクライバーが誰であるかを知りません。メッセージパターンの多くは、メッセージブローカーで公開メッセージを交換して多くのサブスクライバーがタイムリーにアクセスできるようにします。実際の例は、スポーツ、映画、音楽などのさまざまなチャンネルを公開しているDish TVです。誰でも自分のチャンネルのセットを購読して、購読しているチャンネルが利用可能になるといつでもそれらを取得できます。
次の表は、一般的な高スループットメッセージングシステムの一部を示しています。
| 分散メッセージングシステム | 説明 |
|---|---|
| Apache Kafka | KafkaはLinkedInCorporationで開発され、後にApacheのサブプロジェクトになりました。Apache Kafkaは、ブローカー対応の永続的な分散パブリッシュ/サブスクライブモデルに基づいています。Kafkaは高速でスケーラブルで、非常に効率的です。 |
| RabbitMQ | RabbitMQは、オープンソースの分散型の堅牢なメッセージングアプリケーションです。使いやすく、すべてのプラットフォームで実行できます。 |
| JMS(Javaメッセージサービス) | JMSは、あるアプリケーションから別のアプリケーションへのメッセージの作成、読み取り、および送信をサポートするオープンソースAPIです。保証されたメッセージ配信を提供し、パブリッシュ/サブスクライブモデルに従います。 |
| ActiveMQ | ActiveMQメッセージングシステムは、JMSのオープンソースAPIです。 |
| ZeroMQ | ZeroMQは、ブローカーレスのピアピアメッセージ処理です。プッシュプル、ルーターディーラーのメッセージパターンを提供します。 |
| チョウゲンボウ | Kestrelは、高速で信頼性が高く、シンプルな分散メッセージキューです。 |
Thriftプロトコル
Thriftは、クロスランゲージサービス開発とリモートプロシージャコール(RPC)のためにFacebookで構築されました。その後、オープンソースのApacheプロジェクトになりました。ApacheThriftはInterface Definition Language 定義されたデータ型の上に新しいデータ型とサービスの実装を簡単に定義できます。
Apache Thriftは、組み込みシステム、モバイルアプリケーション、Webアプリケーション、およびその他の多くのプログラミング言語をサポートする通信フレームワークでもあります。Apache Thriftに関連する重要な機能のいくつかは、そのモジュール性、柔軟性、および高性能です。さらに、分散アプリケーションでストリーミング、メッセージング、およびRPCを実行できます。
Stormは、内部通信とデータ定義にThriftProtocolを幅広く使用しています。ストームトポロジは単純ですThrift Structs。ApacheStormでトポロジを実行するStormNimbusは、Thrift service。
次に、ApacheStormフレームワークをマシンにインストールする方法を見てみましょう。ここには3つのマジョステップがあります-
- Javaをまだインストールしていない場合は、システムにインストールします。
- ZooKeeperフレームワークをインストールします。
- ApacheStormフレームワークをインストールします。
ステップ1-Javaインストールの確認
次のコマンドを使用して、Javaがシステムにすでにインストールされているかどうかを確認します。
$ java -versionJavaがすでに存在する場合は、そのバージョン番号が表示されます。それ以外の場合は、最新バージョンのJDKをダウンロードしてください。
ステップ1.1-JDKをダウンロードする
次のリンクを使用して、JDKの最新バージョンをダウンロードします-www.oracle.com
最新バージョンはJDK8u 60で、ファイルは “jdk-8u60-linux-x64.tar.gz”。マシンにファイルをダウンロードします。
ステップ1.2-ファイルを抽出する
通常、ファイルはにダウンロードされています downloadsフォルダ。次のコマンドを使用して、tarセットアップを抽出します。
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzステップ1.3-optディレクトリに移動します
すべてのユーザーがJavaを使用できるようにするには、抽出したJavaコンテンツを「/ usr / local / java」フォルダーに移動します。
$ su
password: (type password of root user)
$ mkdir /opt/jdk
$ mv jdk-1.8.0_60 /opt/jdk/ステップ1.4-パスを設定する
パス変数とJAVA_HOME変数を設定するには、次のコマンドを〜/ .bashrcファイルに追加します。
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/bin次に、現在実行中のシステムにすべての変更を適用します。
$ source ~/.bashrcステップ1.5-Javaの代替
次のコマンドを使用して、Javaの代替を変更します。
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100ステップ1.6
次に、verificationコマンドを使用してJavaインストールを検証します。 (java -version) 手順1で説明します。
ステップ2-ZooKeeperフレームワークのインストール
ステップ2.1-ZooKeeperをダウンロードする
マシンにZooKeeperフレームワークをインストールするには、次のリンクにアクセスして、ZooKeeperの最新バージョンをダウンロードしてください。 http://zookeeper.apache.org/releases.html
現在、ZooKeeperの最新バージョンは3.4.6(ZooKeeper-3.4.6.tar.gz)です。
ステップ2.2-tarファイルを抽出する
次のコマンドを使用してtarファイルを抽出します-
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz
$ cd zookeeper-3.4.6
$ mkdir dataステップ2.3-構成ファイルを作成する
コマンド「viconf / zoo.cfg」を使用し、次のすべてのパラメーターを開始点として設定して、「conf /zoo.cfg」という名前の構成ファイルを開きます。
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2構成ファイルが正常に保存されたら、ZooKeeperサーバーを起動できます。
ステップ2.4-ZooKeeperサーバーを起動します
次のコマンドを使用して、ZooKeeperサーバーを起動します。
$ bin/zkServer.sh startこのコマンドを実行すると、次のような応答が返されます。
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg
$ Starting zookeeper ... STARTEDステップ2.5-CLIを開始します
次のコマンドを使用してCLIを開始します。
$ bin/zkCli.sh上記のコマンドを実行すると、ZooKeeperサーバーに接続され、次の応答が返されます。
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]ステップ2.6-ZooKeeperサーバーを停止する
サーバーに接続してすべての操作を実行した後、次のコマンドを使用してZooKeeperサーバーを停止できます。
bin/zkServer.sh stopこれで、JavaとZooKeeperがマシンに正常にインストールされました。次に、ApacheStormフレームワークをインストールする手順を見てみましょう。
ステップ3-ApacheStormFrameworkのインストール
ステップ3.1Stormをダウンロードする
Stormフレームワークをマシンにインストールするには、次のリンクにアクセスして、Stormの最新バージョンをダウンロードしてください。 http://storm.apache.org/downloads.html
現在、Stormの最新バージョンは「apache-storm-0.9.5.tar.gz」です。
ステップ3.2-tarファイルを抽出する
次のコマンドを使用してtarファイルを抽出します-
$ cd opt/
$ tar -zxf apache-storm-0.9.5.tar.gz
$ cd apache-storm-0.9.5
$ mkdir dataステップ3.3-構成ファイルを開く
Stormの現在のリリースには、Stormデーモンを構成する「conf /storm.yaml」にファイルが含まれています。そのファイルに次の情報を追加します。
$ vi conf/storm.yaml
storm.zookeeper.servers:
- "localhost"
storm.local.dir: “/path/to/storm/data(any path)”
nimbus.host: "localhost"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703すべての変更を適用した後、保存してターミナルに戻ります。
ステップ3.4-ニンバスを起動します
$ bin/storm nimbusステップ3.5-スーパーバイザーを開始します
$ bin/storm supervisorステップ3.6UIを開始します
$ bin/storm uiStormユーザーインターフェイスアプリケーションを起動した後、URLを入力します http://localhost:8080お気に入りのブラウザで、Stormクラスター情報とその実行トポロジーを確認できます。ページは次のスクリーンショットのようになります。

Apache Stormの主要な技術的詳細を確認しました。次に、いくつかの簡単なシナリオをコーディングします。
シナリオ–モバイル通話ログアナライザー
モバイル通話とその継続時間はApacheStormへの入力として提供され、Stormは同じ発信者と受信者の間の通話と、それらの通話の総数を処理してグループ化します。
注ぎ口の作成
注ぎ口は、データ生成に使用されるコンポーネントです。基本的に、注ぎ口はIRichSpoutインターフェースを実装します。「IRichSpout」インターフェースには、次の重要なメソッドがあります。
open−注ぎ口に実行する環境を提供します。エグゼキュータはこのメソッドを実行して、注ぎ口を初期化します。
nextTuple −コレクターを介して生成されたデータを出力します。
close −このメソッドは、注ぎ口がシャットダウンするときに呼び出されます。
declareOutputFields −タプルの出力スキーマを宣言します。
ack −特定のタプルが処理されたことを確認します
fail −特定のタプルが処理されず、再処理されないことを指定します。
開いた
の署名 open 方法は次のとおりです-
open(Map conf, TopologyContext context, SpoutOutputCollector collector)conf −この注ぎ口にストーム構成を提供します。
context −トポロジ内の注ぎ口の場所、そのタスクID、入力および出力情報に関する完全な情報を提供します。
collector −ボルトで処理されるタプルを放出できるようにします。
nextTuple
の署名 nextTuple 方法は次のとおりです-
nextTuple()nextTuple()は、ack()およびfail()メソッドと同じループから定期的に呼び出されます。他のメソッドが呼び出される可能性があるように、実行する作業がないときにスレッドの制御を解放する必要があります。したがって、nextTupleの最初の行は、処理が終了したかどうかを確認します。その場合、戻る前にプロセッサの負荷を軽減するために、少なくとも1ミリ秒スリープする必要があります。
閉じる
の署名 close 方法は次のとおりです-
close()宣言出力フィールド
の署名 declareOutputFields 方法は次のとおりです-
declareOutputFields(OutputFieldsDeclarer declarer)declarer −出力ストリームID、出力フィールドなどを宣言するために使用されます。
このメソッドは、タプルの出力スキーマを指定するために使用されます。
ack
の署名 ack 方法は次のとおりです-
ack(Object msgId)このメソッドは、特定のタプルが処理されたことを確認します。
不合格
の署名 nextTuple 方法は次のとおりです-
ack(Object msgId)このメソッドは、特定のタプルが完全に処理されていないことを通知します。Stormは特定のタプルを再処理します。
FakeCallLogReaderSpout
このシナリオでは、通話ログの詳細を収集する必要があります。通話記録の情報にはが含まれています。
- 発信者番号
- レシーバー番号
- duration
通話記録のリアルタイム情報がないため、偽の通話記録を生成します。偽の情報は、Randomクラスを使用して作成されます。完全なプログラムコードを以下に示します。
コーディング-FakeCallLogReaderSpout.java
import java.util.*;
//import storm tuple packages
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import Spout interface packages
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
//Create a class FakeLogReaderSpout which implement IRichSpout interface
to access functionalities
public class FakeCallLogReaderSpout implements IRichSpout {
//Create instance for SpoutOutputCollector which passes tuples to bolt.
private SpoutOutputCollector collector;
private boolean completed = false;
//Create instance for TopologyContext which contains topology data.
private TopologyContext context;
//Create instance for Random class.
private Random randomGenerator = new Random();
private Integer idx = 0;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
if(this.idx <= 1000) {
List<String> mobileNumbers = new ArrayList<String>();
mobileNumbers.add("1234123401");
mobileNumbers.add("1234123402");
mobileNumbers.add("1234123403");
mobileNumbers.add("1234123404");
Integer localIdx = 0;
while(localIdx++ < 100 && this.idx++ < 1000) {
String fromMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
String toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
while(fromMobileNumber == toMobileNumber) {
toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
}
Integer duration = randomGenerator.nextInt(60);
this.collector.emit(new Values(fromMobileNumber, toMobileNumber, duration));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("from", "to", "duration"));
}
//Override all the interface methods
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}ボルトの作成
Boltは、タプルを入力として受け取り、タプルを処理し、出力として新しいタプルを生成するコンポーネントです。ボルトは実装しますIRichBoltインターフェース。このプログラムでは、2つのボルトクラスCallLogCreatorBolt そして CallLogCounterBolt 操作を実行するために使用されます。
IRichBoltインターフェースには次のメソッドがあります-
prepare−ボルトに実行環境を提供します。エグゼキュータはこのメソッドを実行して、注ぎ口を初期化します。
execute −入力の単一タプルを処理します。
cleanup −ボルトがシャットダウンするときに呼び出されます。
declareOutputFields −タプルの出力スキーマを宣言します。
準備する
の署名 prepare 方法は次のとおりです-
prepare(Map conf, TopologyContext context, OutputCollector collector)conf −このボルトのストーム構成を提供します。
context −トポロジ内のボルトの位置、そのタスクID、入力および出力情報などに関する完全な情報を提供します。
collector −処理されたタプルを発行できるようにします。
実行する
の署名 execute 方法は次のとおりです-
execute(Tuple tuple)ここに tuple 処理される入力タプルです。
ザ・ executeメソッドは、一度に1つのタプルを処理します。タプルデータには、タプルクラスのgetValueメソッドからアクセスできます。入力タプルをすぐに処理する必要はありません。複数のタプルを処理して、単一の出力タプルとして出力できます。処理されたタプルは、OutputCollectorクラスを使用して発行できます。
掃除
の署名 cleanup 方法は次のとおりです-
cleanup()宣言出力フィールド
の署名 declareOutputFields 方法は次のとおりです-
declareOutputFields(OutputFieldsDeclarer declarer)ここでパラメータ declarer 出力ストリームID、出力フィールドなどを宣言するために使用されます。
このメソッドは、タプルの出力スキーマを指定するために使用されます
ログクリエーターボルトを呼び出す
通話記録作成ボルトは、通話記録タプルを受け取ります。コールログタプルには、発信者番号、受信者番号、および通話時間が含まれます。このボルトは、発信者番号と受信者番号を組み合わせて新しい値を作成するだけです。新しい値の形式は「発信者番号–受信者番号」であり、新しいフィールド「call」という名前が付けられています。完全なコードを以下に示します。
コーディング-CallLogCreatorBolt.java
//import util packages
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
//import Storm IRichBolt package
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
//Create a class CallLogCreatorBolt which implement IRichBolt interface
public class CallLogCreatorBolt implements IRichBolt {
//Create instance for OutputCollector which collects and emits tuples to produce output
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String from = tuple.getString(0);
String to = tuple.getString(1);
Integer duration = tuple.getInteger(2);
collector.emit(new Values(from + " - " + to, duration));
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call", "duration"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}通話記録カウンターボルト
コールログカウンターボルトは、コールとその期間をタプルとして受け取ります。このボルトは、prepareメソッドの辞書(Map)オブジェクトを初期化します。にexecuteメソッドでは、タプルをチェックし、タプル内の新しい「呼び出し」値ごとにディクショナリオブジェクトに新しいエントリを作成し、ディクショナリオブジェクトに値1を設定します。ディクショナリですでに使用可能なエントリの場合、値をインクリメントするだけです。簡単に言うと、このボルトは呼び出しとそのカウントを辞書オブジェクトに保存します。呼び出しとそのカウントを辞書に保存する代わりに、データソースに保存することもできます。完全なプログラムコードは次のとおりです-
コーディング-CallLogCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class CallLogCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String call = tuple.getString(0);
Integer duration = tuple.getInteger(1);
if(!counterMap.containsKey(call)){
counterMap.put(call, 1);
}else{
Integer c = counterMap.get(call) + 1;
counterMap.put(call, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}トポロジの作成
ストームトポロジは基本的にスリフト構造です。TopologyBuilderクラスは、複雑なトポロジを作成するためのシンプルで簡単なメソッドを提供します。TopologyBuilderクラスには、注ぎ口を設定するメソッドがあります(setSpout) とボルトを設定します (setBolt)。最後に、TopologyBuilderにはトポロジを作成するためのcreateTopologyがあります。次のコードスニペットを使用してトポロジを作成します-
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));shuffleGrouping そして fieldsGrouping メソッドは、注ぎ口とボルトのストリームグループを設定するのに役立ちます。
ローカルクラスター
開発目的では、「LocalCluster」オブジェクトを使用してローカルクラスターを作成し、「LocalCluster」クラスの「submitTopology」メソッドを使用してトポロジを送信できます。「submitTopology」の引数の1つは、「Config」クラスのインスタンスです。「Config」クラスは、トポロジを送信する前に構成オプションを設定するために使用されます。この構成オプションは、実行時にクラスター構成とマージされ、prepareメソッドを使用してすべてのタスク(注ぎ口とボルト)に送信されます。トポロジがクラスターに送信されると、クラスターが送信されたトポロジを計算するまで10秒間待機し、「LocalCluster」の「shutdown」メソッドを使用してクラスターをシャットダウンします。完全なプログラムコードは次のとおりです-
コーディング-LogAnalyserStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import storm configuration packages
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
//Create main class LogAnalyserStorm submit topology.
public class LogAnalyserStorm {
public static void main(String[] args) throws Exception{
//Create Config instance for cluster configuration
Config config = new Config();
config.setDebug(true);
//
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LogAnalyserStorm", config, builder.createTopology());
Thread.sleep(10000);
//Stop the topology
cluster.shutdown();
}
}アプリケーションの構築と実行
完全なアプリケーションには4つのJavaコードがあります。彼らは-
- FakeCallLogReaderSpout.java
- CallLogCreaterBolt.java
- CallLogCounterBolt.java
- LogAnalyerStorm.java
アプリケーションは、次のコマンドを使用して構築できます-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaアプリケーションは、次のコマンドを使用して実行できます-
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserStorm出力
アプリケーションが開始されると、クラスターの起動プロセス、注ぎ口とボルトの処理、そして最後にクラスターのシャットダウンプロセスに関する完全な詳細が出力されます。「CallLogCounterBolt」では、呼び出しとそのカウントの詳細を出力しました。この情報は、コンソールに次のように表示されます-
1234123402 - 1234123401 : 78
1234123402 - 1234123404 : 88
1234123402 - 1234123403 : 105
1234123401 - 1234123404 : 74
1234123401 - 1234123403 : 81
1234123401 - 1234123402 : 81
1234123403 - 1234123404 : 86
1234123404 - 1234123401 : 63
1234123404 - 1234123402 : 82
1234123403 - 1234123402 : 83
1234123404 - 1234123403 : 86
1234123403 - 1234123401 : 93非JVM言語
ストームトポロジはThriftインターフェイスによって実装されているため、任意の言語でトポロジを簡単に送信できます。Stormは、Ruby、Python、およびその他の多くの言語をサポートしています。Pythonバインディングを見てみましょう。
Pythonバインディング
Pythonは、汎用のインタープリター型、インタラクティブ、オブジェクト指向、および高水準プログラミング言語です。Stormは、Pythonをサポートしてトポロジを実装します。Pythonは、放出、アンカー、確認、およびロギング操作をサポートしています。
ご存知のように、ボルトはどの言語でも定義できます。別の言語で記述されたボルトはサブプロセスとして実行され、Stormはstdin / stdoutを介してJSONメッセージでそれらのサブプロセスと通信します。まず、PythonバインディングをサポートするサンプルボルトWordCountを取得します。
public static class WordCount implements IRichBolt {
public WordSplit() {
super("python", "splitword.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}ここでクラス WordCount を実装します IRichBoltインターフェイスとPython実装で実行すると、スーパーメソッド引数「splitword.py」が指定されます。次に、「splitword.py」という名前のPython実装を作成します。
import storm
class WordCountBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
WordCountBolt().run()これは、特定の文の単語をカウントするPythonのサンプル実装です。同様に、他のサポート言語とバインドすることもできます。
トライデントはストームの拡張です。ストームと同様に、トライデントもツイッターによって開発されました。Tridentの開発の背後にある主な理由は、ステートフルストリーム処理と低レイテンシの分散クエリとともに、Stormの上に高レベルの抽象化を提供することです。
トライデントは注ぎ口とボルトを使用しますが、これらの低レベルのコンポーネントは実行前にトライデントによって自動生成されます。Tridentには、関数、フィルター、結合、グループ化、および集約があります。
トライデントは、トランザクションと呼ばれる一連のバッチとしてストリームを処理します。一般に、これらの小さなバッチのサイズは、入力ストリームに応じて、数千または数百万のタプルのオーダーになります。このように、Tridentは、タプルごとの処理を実行するStormとは異なります。
バッチ処理の概念は、データベーストランザクションと非常によく似ています。すべてのトランザクションにはトランザクションIDが割り当てられます。すべての処理が完了すると、トランザクションは成功したと見なされます。ただし、トランザクションのタプルの1つを処理できなかった場合、トランザクション全体が再送信されます。バッチごとに、Tridentはトランザクションの開始時にbeginCommitを呼び出し、トランザクションの終了時にコミットします。
トライデントトポロジー
Trident APIは、「TridentTopology」クラスを使用してTridentトポロジを作成するための簡単なオプションを公開しています。基本的に、Tridentトポロジは、スパウトから入力ストリームを受信し、ストリームに対して順序付けられた一連の操作(フィルター、集約、グループ化など)を実行します。ストームタプルはトライデントタプルに置き換えられ、ボルトは操作に置き換えられます。単純なトライデントトポロジは、次のように作成できます。
TridentTopology topology = new TridentTopology();トライデントタプル
トライデントタプルは、名前付きの値のリストです。TridentTupleインターフェースは、Tridentトポロジのデータモデルです。TridentTupleインターフェースは、Tridentトポロジーで処理できるデータの基本単位です。
トライデントスパウト
トライデントスパウトはストームスパウトに似ていますが、トライデントの機能を使用するための追加オプションがあります。実際には、Stormトポロジで使用したIRichSpoutを引き続き使用できますが、本質的に非トランザクションであり、Tridentが提供する利点を使用することはできません。
トライデントの機能を使用するためのすべての機能を備えた基本的な注ぎ口は「ITridentSpout」です。トランザクションセマンティクスと不透明なトランザクションセマンティクスの両方をサポートします。他の注ぎ口は、IBatchSpout、IPartitionedTridentSpout、およびIOpaquePartitionedTridentSpoutです。
これらの一般的な注ぎ口に加えて、トライデントにはトライデント注ぎ口の多くのサンプル実装があります。そのうちの1つはFeederBatchSpoutスパウトです。これを使用すると、バッチ処理や並列処理などを気にすることなく、トライデントタプルの名前付きリストを簡単に送信できます。
FeederBatchSpoutの作成とデータフィードは、以下のように実行できます。
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(
ImmutableList.of("fromMobileNumber", "toMobileNumber", “duration”));
topology.newStream("fixed-batch-spout", testSpout)
testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123402", 20)));トライデントオペレーション
トライデントは、トライデントタプルの入力ストリームを処理するために「トライデント操作」に依存しています。Trident APIには、単純なものから複雑なものまでのストリーム処理を処理するための多数の組み込み操作があります。これらの操作は、単純な検証から、トライデントタプルの複雑なグループ化および集約にまで及びます。最も重要で頻繁に使用される操作を見ていきましょう。
フィルタ
フィルタは、入力検証のタスクを実行するために使用されるオブジェクトです。トライデントフィルターは、トライデントタプルフィールドのサブセットを入力として取得し、特定の条件が満たされているかどうかに応じてtrueまたはfalseを返します。trueが返された場合、タプルは出力ストリームに保持されます。それ以外の場合、タプルはストリームから削除されます。フィルタは基本的にから継承しますBaseFilter クラスと実装 isKeep方法。これがフィルター操作のサンプル実装です-
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(1) % 2 == 0;
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2]
[1, 4]フィルタ関数は、「each」メソッドを使用してトポロジで呼び出すことができます。「fields」クラスを使用して、入力(トライデントタプルのサブセット)を指定できます。サンプルコードは次のとおりです-
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields("a", "b"), new MyFilter())関数
Functionは、単一のトライデントタプルに対して簡単な操作を実行するために使用されるオブジェクトです。トライデントタプルフィールドのサブセットを取り、0個以上の新しいトライデントタプルフィールドを出力します。
Function 基本的にから継承します BaseFunction クラスと実装 execute方法。実装例を以下に示します-
public class MyFunction extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
int a = tuple.getInteger(0);
int b = tuple.getInteger(1);
collector.emit(new Values(a + b));
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2, 3]
[1, 3, 4]
[1, 4, 5]フィルタ操作と同様に、関数操作は、 each方法。サンプルコードは次のとおりです-
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d")));集約
集約は、入力バッチ、パーティション、またはストリームで集約操作を実行するために使用されるオブジェクトです。トライデントには3種類の集計があります。それらは次のとおりです-
aggregate−トライデントタプルの各バッチを個別に集約します。集約プロセス中に、タプルは最初にグローバルグループ化を使用して再パーティション化され、同じバッチのすべてのパーティションが1つのパーティションに結合されます。
partitionAggregate−トライデントタプルのバッチ全体ではなく、各パーティションを集約します。パーティションアグリゲートの出力は、入力タプルを完全に置き換えます。パーティションアグリゲートの出力には、単一のフィールドタプルが含まれます。
persistentaggregate −すべてのバッチのすべてのトライデントタプルを集約し、結果をメモリまたはデータベースに保存します。
TridentTopology topology = new TridentTopology();
// aggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.aggregate(new Count(), new Fields(“count”))
// partitionAggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.partitionAggregate(new Count(), new Fields(“count"))
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));集約操作は、CombinerAggregator、ReducerAggregator、または汎用Aggregatorインターフェースのいずれかを使用して作成できます。上記の例で使用されている「count」アグリゲーターは、組み込みアグリゲーターの1つであり、「CombinerAggregator」を使用して実装されています。実装は次のとおりです。
public class Count implements CombinerAggregator<Long> {
@Override
public Long init(TridentTuple tuple) {
return 1L;
}
@Override
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
@Override
public Long zero() {
return 0L;
}
}グループ化
グループ化操作は組み込みの操作であり、 groupBy方法。groupByメソッドは、指定されたフィールドでpartitionByを実行してストリームを再パーティション化し、各パーティション内で、グループフィールドが等しいタプルをグループ化します。通常、グループ化された集計を取得するには、「persistentAggregate」とともに「groupBy」を使用します。サンプルコードは次のとおりです-
TridentTopology topology = new TridentTopology();
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.groupBy(new Fields(“d”)
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));マージと結合
マージと結合は、それぞれ「マージ」と「結合」の方法を使用して実行できます。マージは、1つ以上のストリームを結合します。結合はマージと似ていますが、結合では両側のトライデントタプルフィールドを使用して2つのストリームをチェックして結合する点が異なります。さらに、参加はバッチレベルでのみ機能します。サンプルコードは次のとおりです-
TridentTopology topology = new TridentTopology();
topology.merge(stream1, stream2, stream3);
topology.join(stream1, new Fields("key"), stream2, new Fields("x"),
new Fields("key", "a", "b", "c"));状態の維持
トライデントは、状態を維持するためのメカニズムを提供します。状態情報はトポロジ自体に保存できますが、それ以外の場合は別のデータベースに保存することもできます。その理由は、処理中にいずれかのタプルが失敗した場合、失敗したタプルが再試行されるという状態を維持するためです。このタプルの状態が以前に更新されたかどうかがわからないため、状態の更新中に問題が発生します。状態を更新する前にタプルに障害が発生した場合、タプルを再試行すると状態が安定します。ただし、状態の更新後にタプルに障害が発生した場合、同じタプルを再試行すると、データベース内のカウントが再び増加し、状態が不安定になります。メッセージが1回だけ処理されるようにするには、次の手順を実行する必要があります。
タプルを小さなバッチで処理します。
各バッチに一意のIDを割り当てます。バッチが再試行されると、同じ一意のIDが割り当てられます。
状態の更新は、バッチ間で順序付けられます。たとえば、2番目のバッチの状態更新は、最初のバッチの状態更新が完了するまでできません。
分散RPC
分散RPCは、Tridentトポロジから結果をクエリおよび取得するために使用されます。Stormには分散RPCサーバーが組み込まれています。分散RPCサーバーは、クライアントからRPC要求を受信し、それをトポロジーに渡します。トポロジは要求を処理し、結果を分散RPCサーバーに送信します。分散RPCサーバーは、分散RPCサーバーによってクライアントにリダイレクトされます。Tridentの分散RPCクエリは、これらのクエリが並行して実行されることを除いて、通常のRPCクエリと同じように実行されます。
トライデントを使用するのはいつですか?
多くのユースケースと同様に、クエリを1回だけ処理する必要がある場合は、Tridentでトポロジを作成することでそれを実現できます。一方、ストームの場合、一度だけ処理するのは難しいでしょう。したがって、Tridentは、1回だけ処理する必要があるユースケースに役立ちます。Tridentは、Stormに複雑さを追加し、状態を管理するため、すべてのユースケース、特に高性能のユースケースに適しているわけではありません。
トライデントの実例
前のセクションで作成した通話ログアナライザーアプリケーションをTridentフレームワークに変換します。トライデントアプリケーションは、その高レベルのAPIのおかげで、プレーンストームと比較して比較的簡単になります。Stormは基本的に、TridentでFunction、Filter、Aggregate、GroupBy、Join、Mergeのいずれかの操作を実行するために必要になります。最後に、を使用してDRPCサーバーを起動しますLocalDRPC クラスを使用して、を使用していくつかのキーワードを検索します execute LocalDRPCクラスのメソッド。
通話情報のフォーマット
FormatCallクラスの目的は、「発信者番号」と「受信者番号」で構成される通話情報をフォーマットすることです。完全なプログラムコードは次のとおりです-
コーディング:FormatCall.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class FormatCall extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String fromMobileNumber = tuple.getString(0);
String toMobileNumber = tuple.getString(1);
collector.emit(new Values(fromMobileNumber + " - " + toMobileNumber));
}
}CSVSplit
CSVSplitクラスの目的は、「comma(、)」に基づいて入力文字列を分割し、文字列内のすべての単語を出力することです。この関数は、分散クエリの入力引数を解析するために使用されます。完全なコードは次のとおりです-
コーディング:CSVSplit.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class CSVSplit extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
for(String word: tuple.getString(0).split(",")) {
if(word.length() > 0) {
collector.emit(new Values(word));
}
}
}
}ログアナライザー
これがメインアプリケーションです。最初に、アプリケーションはTridentTopologyを初期化し、を使用して発信者情報をフィードしますFeederBatchSpout。トライデントトポロジストリームは、newStreamTridentTopologyクラスのメソッド。同様に、トライデントトポロジのDRPCストリームは、newDRCPStreamTridentTopologyクラスのメソッド。LocalDRPCクラスを使用して、単純なDRCPサーバーを作成できます。LocalDRPCいくつかのキーワードを検索するためのexecuteメソッドがあります。完全なコードを以下に示します。
コーディング:LogAnalyserTrident.java
import java.util.*;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.utils.DRPCClient;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import storm.trident.TridentState;
import storm.trident.TridentTopology;
import storm.trident.tuple.TridentTuple;
import storm.trident.operation.builtin.FilterNull;
import storm.trident.operation.builtin.Count;
import storm.trident.operation.builtin.Sum;
import storm.trident.operation.builtin.MapGet;
import storm.trident.operation.builtin.Debug;
import storm.trident.operation.BaseFilter;
import storm.trident.testing.FixedBatchSpout;
import storm.trident.testing.FeederBatchSpout;
import storm.trident.testing.Split;
import storm.trident.testing.MemoryMapState;
import com.google.common.collect.ImmutableList;
public class LogAnalyserTrident {
public static void main(String[] args) throws Exception {
System.out.println("Log Analyser Trident");
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(ImmutableList.of("fromMobileNumber",
"toMobileNumber", "duration"));
TridentState callCounts = topology
.newStream("fixed-batch-spout", testSpout)
.each(new Fields("fromMobileNumber", "toMobileNumber"),
new FormatCall(), new Fields("call"))
.groupBy(new Fields("call"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(),
new Fields("count"));
LocalDRPC drpc = new LocalDRPC();
topology.newDRPCStream("call_count", drpc)
.stateQuery(callCounts, new Fields("args"), new MapGet(), new Fields("count"));
topology.newDRPCStream("multiple_call_count", drpc)
.each(new Fields("args"), new CSVSplit(), new Fields("call"))
.groupBy(new Fields("call"))
.stateQuery(callCounts, new Fields("call"), new MapGet(),
new Fields("count"))
.each(new Fields("call", "count"), new Debug())
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
Config conf = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident", conf, topology.build());
Random randomGenerator = new Random();
int idx = 0;
while(idx < 10) {
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123402", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123403", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123404", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123402",
"1234123403", randomGenerator.nextInt(60))));
idx = idx + 1;
}
System.out.println("DRPC : Query starts");
System.out.println(drpc.execute("call_count","1234123401 - 1234123402"));
System.out.println(drpc.execute("multiple_call_count", "1234123401 -
1234123402,1234123401 - 1234123403"));
System.out.println("DRPC : Query ends");
cluster.shutdown();
drpc.shutdown();
// DRPCClient client = new DRPCClient("drpc.server.location", 3772);
}
}アプリケーションの構築と実行
完全なアプリケーションには3つのJavaコードがあります。それらは次のとおりです-
- FormatCall.java
- CSVSplit.java
- LogAnalyerTrident.java
アプリケーションは、次のコマンドを使用して構築できます-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaアプリケーションは、次のコマンドを使用して実行できます-
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserTrident出力
アプリケーションが開始されると、アプリケーションは、クラスターの起動プロセス、操作処理、DRPCサーバーとクライアントの情報、そして最後にクラスターのシャットダウンプロセスに関する完全な詳細を出力します。この出力は、以下に示すようにコンソールに表示されます。
DRPC : Query starts
[["1234123401 - 1234123402",10]]
DEBUG: [1234123401 - 1234123402, 10]
DEBUG: [1234123401 - 1234123403, 10]
[[20]]
DRPC : Query endsこの章では、ApacheStormのリアルタイムアプリケーションについて説明します。TwitterでStormがどのように使用されているかを見ていきます。
ツイッター
Twitterは、ユーザーのツイートを送受信するためのプラットフォームを提供するオンラインソーシャルネットワーキングサービスです。登録ユーザーはツイートを読んだり投稿したりできますが、未登録ユーザーはツイートを読むことしかできません。ハッシュタグは、関連するキーワードの前に#を追加することにより、キーワードでツイートを分類するために使用されます。次に、トピックごとに最も使用されているハッシュタグを見つけるリアルタイムのシナリオを考えてみましょう。
注ぎ口の作成
注ぎ口の目的は、できるだけ早く人々からツイートを投稿してもらうことです。Twitterは、人々が投稿したツイートをリアルタイムで取得するためのWebサービスベースのツールである「TwitterStreamingAPI」を提供しています。Twitter Streaming APIには、任意のプログラミング言語でアクセスできます。
twitter4j はオープンソースの非公式Javaライブラリであり、Twitter StreamingAPIに簡単にアクセスするためのJavaベースのモジュールを提供します。 twitter4jツイートにアクセスするためのリスナーベースのフレームワークを提供します。Twitter Streaming APIにアクセスするには、Twitter開発者アカウントにサインインする必要があり、次のOAuth認証の詳細を取得する必要があります。
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
ストームはツイッターの注ぎ口を提供します、 TwitterSampleSpout,そのスターターキットで。ツイートの取得に使用します。注ぎ口には、OAuth認証の詳細と少なくともキーワードが必要です。注ぎ口は、キーワードに基づいてリアルタイムのツイートを送信します。完全なプログラムコードを以下に示します。
コーディング:TwitterSampleSpout.java
import java.util.Map;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.FilterQuery;
import twitter4j.StallWarning;
import twitter4j.Status;
import twitter4j.StatusDeletionNotice;
import twitter4j.StatusListener;
import twitter4j.TwitterStream;
import twitter4j.TwitterStreamFactory;
import twitter4j.auth.AccessToken;
import twitter4j.conf.ConfigurationBuilder;
import backtype.storm.Config;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
@SuppressWarnings("serial")
public class TwitterSampleSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
LinkedBlockingQueue<Status> queue = null;
TwitterStream _twitterStream;
String consumerKey;
String consumerSecret;
String accessToken;
String accessTokenSecret;
String[] keyWords;
public TwitterSampleSpout(String consumerKey, String consumerSecret,
String accessToken, String accessTokenSecret, String[] keyWords) {
this.consumerKey = consumerKey;
this.consumerSecret = consumerSecret;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
this.keyWords = keyWords;
}
public TwitterSampleSpout() {
// TODO Auto-generated constructor stub
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
queue = new LinkedBlockingQueue<Status>(1000);
_collector = collector;
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
}
@Override
public void onDeletionNotice(StatusDeletionNotice sdn) {}
@Override
public void onTrackLimitationNotice(int i) {}
@Override
public void onScrubGeo(long l, long l1) {}
@Override
public void onException(Exception ex) {}
@Override
public void onStallWarning(StallWarning arg0) {
// TODO Auto-generated method stub
}
};
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
_twitterStream = new TwitterStreamFactory(cb.build()).getInstance();
_twitterStream.addListener(listener);
if (keyWords.length == 0) {
_twitterStream.sample();
}else {
FilterQuery query = new FilterQuery().track(keyWords);
_twitterStream.filter(query);
}
}
@Override
public void nextTuple() {
Status ret = queue.poll();
if (ret == null) {
Utils.sleep(50);
} else {
_collector.emit(new Values(ret));
}
}
@Override
public void close() {
_twitterStream.shutdown();
}
@Override
public Map<String, Object> getComponentConfiguration() {
Config ret = new Config();
ret.setMaxTaskParallelism(1);
return ret;
}
@Override
public void ack(Object id) {}
@Override
public void fail(Object id) {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tweet"));
}
}ハッシュタグリーダーボルト
注ぎ口から発せられたツイートはに転送されます HashtagReaderBolt、ツイートを処理し、利用可能なすべてのハッシュタグを発行します。HashtagReaderBoltはgetHashTagEntitiestwitter4jが提供するメソッド。getHashTagEntitiesはツイートを読み取り、ハッシュタグのリストを返します。完全なプログラムコードは次のとおりです-
コーディング:HashtagReaderBolt.java
import java.util.HashMap;
import java.util.Map;
import twitter4j.*;
import twitter4j.conf.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagReaderBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
Status tweet = (Status) tuple.getValueByField("tweet");
for(HashtagEntity hashtage : tweet.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
this.collector.emit(new Values(hashtage.getText()));
}
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}ハッシュタグカウンターボルト
放出されたハッシュタグはに転送されます HashtagCounterBolt。このボルトは、すべてのハッシュタグを処理し、JavaMapオブジェクトを使用してすべてのハッシュタグとそのカウントをメモリに保存します。完全なプログラムコードを以下に示します。
コーディング:HashtagCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String key = tuple.getString(0);
if(!counterMap.containsKey(key)){
counterMap.put(key, 1);
}else{
Integer c = counterMap.get(key) + 1;
counterMap.put(key, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println("Result: " + entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}トポロジの送信
トポロジの送信がメインアプリケーションです。Twitterトポロジはで構成されていますTwitterSampleSpout、 HashtagReaderBolt、および HashtagCounterBolt。次のプログラムコードは、トポロジを送信する方法を示しています。
コーディング:TwitterHashtagStorm.java
import java.util.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class TwitterHashtagStorm {
public static void main(String[] args) throws Exception{
String consumerKey = args[0];
String consumerSecret = args[1];
String accessToken = args[2];
String accessTokenSecret = args[3];
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 4, arguments.length);
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("twitter-spout", new TwitterSampleSpout(consumerKey,
consumerSecret, accessToken, accessTokenSecret, keyWords));
builder.setBolt("twitter-hashtag-reader-bolt", new HashtagReaderBolt())
.shuffleGrouping("twitter-spout");
builder.setBolt("twitter-hashtag-counter-bolt", new HashtagCounterBolt())
.fieldsGrouping("twitter-hashtag-reader-bolt", new Fields("hashtag"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("TwitterHashtagStorm", config,
builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}アプリケーションの構築と実行
完全なアプリケーションには4つのJavaコードがあります。それらは次のとおりです-
- TwitterSampleSpout.java
- HashtagReaderBolt.java
- HashtagCounterBolt.java
- TwitterHashtagStorm.java
次のコマンドを使用してアプリケーションをコンパイルできます-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*” *.java次のコマンドを使用してアプリケーションを実行します-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*”:.
TwitterHashtagStorm <customerkey> <customersecret> <accesstoken> <accesstokensecret>
<keyword1> <keyword2> … <keywordN>出力
アプリケーションは、現在利用可能なハッシュタグとその数を出力します。出力は次のようになります-
Result: jazztastic : 1
Result: foodie : 1
Result: Redskins : 1
Result: Recipe : 1
Result: cook : 1
Result: android : 1
Result: food : 2
Result: NoToxicHorseMeat : 1
Result: Purrs4Peace : 1
Result: livemusic : 1
Result: VIPremium : 1
Result: Frome : 1
Result: SundayRoast : 1
Result: Millennials : 1
Result: HealthWithKier : 1
Result: LPs30DaysofGratitude : 1
Result: cooking : 1
Result: gameinsight : 1
Result: Countryfile : 1
Result: androidgames : 1Yahoo! 財務は、インターネットをリードするビジネスニュースおよび財務データのWebサイトです。Yahoo!の一部です。金融ニュース、市場統計、国際市場データ、および誰もがアクセスできる金融リソースに関するその他の情報に関する情報を提供します。
登録済みのYahoo! ユーザーの場合、Yahoo!をカスタマイズできます。その特定の製品を利用するための資金調達。Yahoo! Finance APIは、Yahoo!から財務データをクエリするために使用されます。
このAPIは、リアルタイムから15分遅れたデータを表示し、1分ごとにデータベースを更新して、現在の株式関連情報にアクセスします。ここで、会社のリアルタイムシナリオを取り上げて、株価が100を下回ったときにアラートを発する方法を見てみましょう。
注ぎ口の作成
注ぎ口の目的は、会社の詳細を取得し、価格をボルトに放出することです。次のプログラムコードを使用して、注ぎ口を作成できます。
コーディング:YahooFinanceSpout.java
import java.util.*;
import java.io.*;
import java.math.BigDecimal;
//import yahoofinace packages
import yahoofinance.YahooFinance;
import yahoofinance.Stock;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
public class YahooFinanceSpout implements IRichSpout {
private SpoutOutputCollector collector;
private boolean completed = false;
private TopologyContext context;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector){
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
try {
Stock stock = YahooFinance.get("INTC");
BigDecimal price = stock.getQuote().getPrice();
this.collector.emit(new Values("INTC", price.doubleValue()));
stock = YahooFinance.get("GOOGL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("GOOGL", price.doubleValue()));
stock = YahooFinance.get("AAPL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("AAPL", price.doubleValue()));
} catch(Exception e) {}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("company", "price"));
}
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}ボルトの作成
ここで、boltの目的は、価格が100を下回ったときに、指定された会社の価格を処理することです。JavaMapオブジェクトを使用して、カットオフ価格制限アラートを次のように設定します。 true株価が100を下回ったとき。それ以外の場合はfalse。完全なプログラムコードは次のとおりです-
コーディング:PriceCutOffBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class PriceCutOffBolt implements IRichBolt {
Map<String, Integer> cutOffMap;
Map<String, Boolean> resultMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.cutOffMap = new HashMap <String, Integer>();
this.cutOffMap.put("INTC", 100);
this.cutOffMap.put("AAPL", 100);
this.cutOffMap.put("GOOGL", 100);
this.resultMap = new HashMap<String, Boolean>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String company = tuple.getString(0);
Double price = tuple.getDouble(1);
if(this.cutOffMap.containsKey(company)){
Integer cutOffPrice = this.cutOffMap.get(company);
if(price < cutOffPrice) {
this.resultMap.put(company, true);
} else {
this.resultMap.put(company, false);
}
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Boolean> entry:resultMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("cut_off_price"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}トポロジの送信
これは、YahooFinanceSpout.javaとPriceCutOffBolt.javaが相互に接続され、トポロジを生成するメインアプリケーションです。次のプログラムコードは、トポロジを送信する方法を示しています。
コーディング:YahooFinanceStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class YahooFinanceStorm {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("yahoo-finance-spout", new YahooFinanceSpout());
builder.setBolt("price-cutoff-bolt", new PriceCutOffBolt())
.fieldsGrouping("yahoo-finance-spout", new Fields("company"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("YahooFinanceStorm", config, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}アプリケーションの構築と実行
完全なアプリケーションには3つのJavaコードがあります。それらは次のとおりです-
- YahooFinanceSpout.java
- PriceCutOffBolt.java
- YahooFinanceStorm.java
アプリケーションは、次のコマンドを使用して構築できます-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*” *.javaアプリケーションは、次のコマンドを使用して実行できます-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*”:.
YahooFinanceStorm出力
出力は次のようになります-
GOOGL : false
AAPL : false
INTC : trueApache Stormフレームワークは、今日の最高の産業用アプリケーションの多くをサポートしています。この章では、Stormの最も注目すべきアプリケーションのいくつかの非常に簡単な概要を説明します。
Klout
Kloutは、ソーシャルメディア分析を使用して、オンラインの社会的影響に基づいてユーザーをランク付けするアプリケーションです。 Klout Score、これは1〜100の数値です。Kloutは、Apache Stormに組み込まれているTrident抽象化を使用して、データをストリーミングする複雑なトポロジを作成します。
天気予報チャンネル
Weather Channelは、Stormトポロジを使用して気象データを取り込みます。Twitterと提携して、Twitterやモバイルアプリケーションでの気象情報に基づく広告を可能にしています。OpenSignal は、ワイヤレスカバレッジマッピングを専門とする会社です。 StormTag そして WeatherSignalOpenSignalによって作成された気象ベースのプロジェクトです。StormTagは、キーチェーンに接続するBluetooth気象ステーションです。デバイスによって収集された気象データは、WeatherSignalアプリとOpenSignalサーバーに送信されます。
電気通信産業
電気通信プロバイダーは、1秒間に数百万件の電話を処理します。通話が切れたり、音質が悪い場合にフォレンジックを実行します。通話詳細レコードは毎秒数百万の速度で流入し、Apache Stormはそれらをリアルタイムで処理し、問題のあるパターンを特定します。ストーム分析を使用して、通話品質を継続的に向上させることができます。