Microsoft CognitiveToolkit-クイックガイド
この章では、CNTKとは何か、その機能、バージョン1.0と2.0の違い、およびバージョン2.7の重要なハイライトについて学習します。
Microsoft Cognitive Toolkit(CNTK)とは何ですか?
以前はComputationalNetworkToolkitとして知られていたMicrosoftCognitive Toolkit(CNTK)は、人間の脳のように学習するための深層学習アルゴリズムをトレーニングできる、無料で使いやすいオープンソースの商用グレードのツールキットです。これにより、次のような人気のあるディープラーニングシステムを作成できます。feed-forward neural network time series prediction systems and Convolutional neural network (CNN) image classifiers。
最適なパフォーマンスを得るために、そのフレームワーク関数はC ++で記述されています。C ++を使用してその関数を呼び出すことはできますが、同じために最も一般的に使用されるアプローチは、Pythonプログラムを使用することです。
CNTKの機能
以下は、MicrosoftCNTKの最新バージョンで提供される機能の一部です。
組み込みコンポーネント
CNTKには、Python、C ++、またはBrainScriptからの多次元の密または疎データを処理できる高度に最適化された組み込みコンポーネントがあります。
CNN、FNN、RNN、バッチ正規化、シーケンスからシーケンスへの実装には注意が必要です。
PythonからGPUに新しいユーザー定義のコアコンポーネントを追加する機能を提供します。
また、自動ハイパーパラメータ調整も提供します。
強化学習、生成的敵対的ネットワーク(GAN)、教師あり学習、教師なし学習を実装できます。
大規模なデータセットの場合、CNTKには最適化されたリーダーが組み込まれています。
リソースの効率的な使用
CNTKは、1ビットSGDを介して、複数のGPU /マシンで高精度の並列処理を提供します。
最大のモデルをGPUメモリに収めるために、メモリ共有やその他の組み込みメソッドを提供します。
独自のネットワークを簡単に表現する
CNTKには、Python、C ++、およびBrainScriptからの独自のネットワーク、学習者、リーダー、トレーニングと評価を定義するための完全なAPIがあります。
CNTKを使用すると、Python、C ++、C#、またはBrainScriptでモデルを簡単に評価できます。
高レベルと低レベルの両方のAPIを提供します。
私たちのデータに基づいて、それは自動的に推論を形作ることができます。
シンボリックリカレントニューラルネットワーク(RNN)ループが完全に最適化されています。
モデルのパフォーマンスの測定
CNTKは、構築するニューラルネットワークのパフォーマンスを測定するためのさまざまなコンポーネントを提供します。
モデルと関連するオプティマイザーからログデータを生成します。これを使用してトレーニングプロセスを監視できます。
バージョン1.0とバージョン2.0
次の表は、CNTKバージョン1.0と2.0を比較しています。
| バージョン1.0 | バージョン2.0 |
|---|---|
| 2016年にリリースされました。 | これは1.0バージョンの大幅な書き直しであり、2017年6月にリリースされました。 |
| BrainScriptと呼ばれる独自のスクリプト言語を使用しました。 | そのフレームワーク関数は、C ++、Pythonを使用して呼び出すことができます。モジュールはC#またはJavaで簡単にロードできます。BrainScriptはバージョン2.0でもサポートされています。 |
| WindowsとLinuxの両方のシステムで動作しますが、MacOSでは直接動作しません。 | また、Windows(Win 8.1、Win 10、Server 2012 R2以降)とLinuxシステムの両方で実行されますが、MacOSでは直接実行されません。 |
バージョン2.7の重要なハイライト
Version 2.7は、Microsoft CognitiveToolkitの最後のメインリリースバージョンです。ONNX1.4.1を完全にサポートしています。以下は、この最後にリリースされたバージョンのCNTKのいくつかの重要なハイライトです。
ONNX1.4.1の完全サポート。
WindowsシステムとLinuxシステムの両方でのCUDA10のサポート。
ONNXエクスポートで高度なリカレントニューラルネットワーク(RNN)ループをサポートします。
ONNX形式で2GB以上のモデルをエクスポートできます。
BrainScriptスクリプト言語のトレーニングアクションでFP16をサポートします。
ここでは、WindowsおよびLinuxへのCNTKのインストールについて理解します。さらに、この章では、CNTKパッケージのインストール、Anacondaをインストールする手順、CNTKファイル、ディレクトリ構造、およびCNTKライブラリの構成について説明します。
前提条件
CNTKをインストールするには、コンピューターにPythonをインストールする必要があります。あなたはリンクに行くことができますhttps://www.python.org/downloads/OSの最新バージョン(WindowsおよびLinux / Unix)を選択します。Pythonの基本的なチュートリアルについては、リンクを参照してくださいhttps://www.tutorialspoint.com/python3/index.htm。

CNTKはWindowsとLinuxでサポートされているため、両方について説明します。
Windowsへのインストール
WindowsでCNTKを実行するために、 Anaconda versionPythonの。AnacondaはPythonの再配布であることを私たちは知っています。それはのような追加のパッケージが含まれていますScipy そしてScikit-learn これらは、さまざまな有用な計算を実行するためにCNTKによって使用されます。
それで、最初にあなたのマシンにAnacondaをインストールするステップを見てみましょう-
Step 1−最初に公開Webサイトからセットアップファイルをダウンロードします https://www.anaconda.com/distribution/。
Step 2 −セットアップファイルをダウンロードしたら、インストールを開始し、リンクの指示に従います。 https://docs.anaconda.com/anaconda/install/。
Step 3−インストールされると、Anacondaは他のユーティリティもインストールします。これにより、すべてのAnaconda実行可能ファイルがコンピューターのPATH変数に自動的に含まれます。このプロンプトからPython環境を管理し、パッケージをインストールしてPythonスクリプトを実行できます。
CNTKパッケージのインストール
Anacondaのインストールが完了したら、次のコマンドを使用して、pip実行可能ファイルを介してCNTKパッケージをインストールする最も一般的な方法を使用できます。
pip install cntkマシンにCognitiveToolkitをインストールする方法は他にもさまざまです。Microsoftには、他のインストール方法を詳細に説明する一連の優れたドキュメントがあります。リンクをたどってくださいhttps://docs.microsoft.com/en-us/cognitive-toolkit/Setup-CNTK-on-your-machine。
Linuxへのインストール
LinuxへのCNTKのインストールは、Windowsへのインストールとは少し異なります。ここでは、Linuxの場合はAnacondaを使用してCNTKをインストールしますが、Anacondaのグラフィカルインストーラーの代わりに、Linuxではターミナルベースのインストーラーを使用します。インストーラーはほとんどすべてのLinuxディストリビューションで動作しますが、説明はUbuntuに限定しました。
それで、最初にあなたのマシンにAnacondaをインストールするステップを見てみましょう-
Anacondaをインストールする手順
Step 1− Anacondaをインストールする前に、システムが完全に最新であることを確認してください。確認するには、まず端末内で次の2つのコマンドを実行します-
sudo apt update
sudo apt upgradeStep 2 −コンピュータが更新されたら、公開WebサイトからURLを取得します https://www.anaconda.com/distribution/ 最新のAnacondaインストールファイル用。
Step 3 − URLがコピーされたら、ターミナルウィンドウを開き、次のコマンドを実行します−
wget -0 anaconda-installer.sh url SHAPE \* MERGEFORMAT
y
f
x
| }を交換してください url AnacondaWebサイトからコピーされたURLのプレースホルダー。
Step 4 −次に、次のコマンドを使用して、Anacondaをインストールできます−
sh ./anaconda-installer.sh上記のコマンドはデフォルトでインストールされます Anaconda3 ホームディレクトリ内。
CNTKパッケージのインストール
Anacondaのインストールが完了したら、次のコマンドを使用して、pip実行可能ファイルを介してCNTKパッケージをインストールする最も一般的な方法を使用できます。
pip install cntkCNTKファイルとディレクトリ構造の調査
CNTKがPythonパッケージとしてインストールされると、そのファイルとディレクトリ構造を調べることができます。にありますC:\Users\

CNTKインストールの確認
CNTKがPythonパッケージとしてインストールされたら、CNTKが正しくインストールされていることを確認する必要があります。Anacondaコマンドシェルから、次のように入力してPythonインタープリターを起動しますipython. 次に、インポートします CNTK 次のコマンドを入力します。
import cntk as cインポートしたら、次のコマンドを使用してバージョンを確認します-
print(c.__version__)インタープリターは、インストールされているCNTKバージョンで応答します。応答しない場合は、インストールに問題があります。
CNTKライブラリ組織
技術的にはPythonパッケージであるCNTKは、13の高レベルサブパッケージと8つの小さなサブパッケージに編成されています。次の表は、最も頻繁に使用される10個のパッケージで構成されています。
| シニア番号 | パッケージ名と説明 |
|---|---|
| 1 | cntk.io データを読み取るための関数が含まれています。例:next_minibatch() |
| 2 | cntk.layers ニューラルネットワークを作成するための高レベルの関数が含まれています。例:Dense() |
| 3 | cntk.learners トレーニング用の関数が含まれています。例:sgd() |
| 4 | cntk.losses トレーニングエラーを測定する関数が含まれています。例:squared_error() |
| 5 | cntk.metrics モデルエラーを測定する関数が含まれています。例:classificatoin_error |
| 6 | cntk.ops ニューラルネットワークを作成するための低レベルの関数が含まれています。例:tanh() |
| 7 | cntk.random 乱数を生成する関数が含まれています。例:normal() |
| 8 | cntk.train トレーニング機能が含まれています。例:train_minibatch() |
| 9 | cntk.initializer モデルパラメータ初期化子が含まれています。例:normal()およびuniform() |
| 10 | cntk.variables 低レベルの構成が含まれています。例:Parameter()およびVariable() |
Microsoft Cognitive Toolkitは、CPUのみとGPUのみの2つの異なるビルドバージョンを提供します。
CPUのみのビルドバージョン
CPUのみのビルドバージョンのCNTKは、最適化されたIntel MKLMLを使用します。MKLMLはMKL(Math Kernel Library)のサブセットであり、MKL-DNN用のIntelMKLの終了バージョンとしてIntelMKL-DNNとともにリリースされます。
GPUのみのビルドバージョン
一方、CNTKのGPUのみのビルドバージョンは、次のような高度に最適化されたNVIDIAライブラリを使用します。 CUB そして cuDNN。複数のGPUと複数のマシンにわたる分散トレーニングをサポートします。CNTKでさらに高速な分散トレーニングを行うために、GPUビルドバージョンには次のものも含まれています。
MSRが開発した1ビット量子化SGD。
ブロック運動量SGD並列トレーニングアルゴリズム。
WindowsでCNTKを使用してGPUを有効にする
前のセクションでは、CPUで使用するCNTKの基本バージョンをインストールする方法を説明しました。それでは、GPUで使用するためにCNTKをインストールする方法について説明しましょう。ただし、深く掘り下げる前に、まずサポートされているグラフィックカードが必要です。
現在、CNTKは少なくともCUDA3.0をサポートするNVIDIAグラフィックカードをサポートしています。確認するには、次のURLで確認できます。https://developer.nvidia.com/cuda-gpus GPUがCUDAをサポートしているかどうか。
それでは、WindowsOSでCNTKを使用してGPUを有効にする手順を見てみましょう-
Step 1 −使用しているグラフィックカードに応じて、最初にグラフィックカード用の最新のGeForceまたはQuadroドライバが必要です。
Step 2 −ドライバーをダウンロードしたら、NVIDIAWebサイトからWindows用のCUDAツールキットバージョン9.0をインストールする必要があります。 https://developer.nvidia.com/cuda-90-download-archive?target_os=Windows&target_arch=x86_64。インストール後、インストーラーを実行し、指示に従います。
Step 3 −次に、NVIDIAWebサイトからcuDNNバイナリをインストールする必要があります https://developer.nvidia.com/rdp/form/cudnn-download-survey。CUDA 9.0バージョンでは、cuDNN7.4.1が適切に機能します。基本的に、cuDNNは、CNTKによって使用されるCUDAの上のレイヤーです。
Step 4 − cuDNNバイナリをダウンロードした後、zipファイルをCUDAツールキットインストールのルートフォルダに抽出する必要があります。
Step 5−これは、CNTK内でのGPUの使用を可能にする最後のステップです。WindowsOSのAnacondaプロンプト内で次のコマンドを実行します-
pip install cntk-gpuLinuxでCNTKを使用してGPUを有効にする
LinuxOSでCNTKを使用してGPUを有効にする方法を見てみましょう-
CUDAツールキットのダウンロード
まず、NVIDIA Webサイトhttps://developer.nvidia.com/cuda-90-download-archive?target_os=Linux&target_arch=x86_64&target_distro=Ubuntu&target_version=1604&target_type = runfilelocalからCUDAツールキットをインストールする必要があります。
インストーラーの実行
これで、ディスクにバイナリができたら、ターミナルを開いて次のコマンドと画面の指示を実行してインストーラーを実行します。
sh cuda_9.0.176_384.81_linux-runBashプロファイルスクリプトを変更する
LinuxマシンにCUDAツールキットをインストールした後、BASHプロファイルスクリプトを変更する必要があります。このためには、最初にテキストエディタで$ HOME /.bashrcファイルを開きます。ここで、スクリプトの最後に、次の行を含めます-
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}} export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64\ ${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
InstallingcuDNNライブラリのインストール
最後に、cuDNNバイナリをインストールする必要があります。NVIDIAのWebサイトからダウンロードできますhttps://developer.nvidia.com/rdp/form/cudnn-download-survey。CUDA 9.0バージョンでは、cuDNN7.4.1が適切に機能します。基本的に、cuDNNは、CNTKによって使用されるCUDAの上のレイヤーです。
Linux用のバージョンをダウンロードしたら、それをに抽出します。 /usr/local/cuda-9.0 次のコマンドを使用してフォルダ-
tar xvzf -C /usr/local/cuda-9.0/ cudnn-9.0-linux-x64-v7.4.1.5.tgz必要に応じて、パスをファイル名に変更します。
この章では、CNTKのシーケンスとその分類について詳しく学習します。
テンソル
CNTKが機能するコンセプトは tensor。基本的に、CNTKの入力、出力、およびパラメーターは次のように編成されます。tensors、これは一般化された行列と見なされることがよくあります。すべてのテンソルにはrank −
ランク0のテンソルはスカラーです。
ランク1のテンソルはベクトルです。
ランク2のテンソルは行列です。
ここでは、これらの異なる寸法は axes.
静的軸と動的軸
名前が示すように、静的軸はネットワークの存続期間を通じて同じ長さです。一方、動的軸の長さはインスタンスごとに異なる可能性があります。実際、それらの長さは通常、各ミニバッチが提示される前にはわかりません。
動的軸は、テンソルに含まれる数値の意味のあるグループ化も定義するため、静的軸に似ています。
例
明確にするために、短いビデオクリップのミニバッチがCNTKでどのように表されるかを見てみましょう。ビデオクリップの解像度がすべて640 * 480であると仮定します。また、クリップは通常3つのチャネルでエンコードされるカラーで撮影されます。さらに、ミニバッチには次のものがあることを意味します-
それぞれ長さ640、480、3の3つの静的軸。
2つの動的軸。ビデオの長さとミニバッチ軸。
これは、ミニバッチにそれぞれ240フレームの長さの16本のビデオがある場合、次のように表されることを意味します。 16*240*3*640*480 テンソル。
CNTKでのシーケンスの操作
最初に長短期記憶ネットワークについて学習して、CNTKのシーケンスを理解しましょう。
長短期記憶ネットワーク(LSTM)

長短期記憶(LSTM)ネットワークは、Hochreiter&Schmidhuberによって導入されました。これにより、基本的な繰り返しレイヤーに長い間物事を記憶させるという問題が解決されました。LSTMのアーキテクチャは、上の図に示されています。ご覧のとおり、入力ニューロン、メモリセル、出力ニューロンがあります。勾配消失問題と戦うために、長短期記憶ネットワークは明示的記憶セル(以前の値を格納)と次のゲートを使用します-
Forget gate−名前が示すように、以前の値を忘れるようにメモリセルに指示します。メモリセルは、ゲート、つまり「ゲートを忘れる」が値を忘れるように指示するまで値を格納します。
Input gate −名前が示すように、セルに新しいものを追加します。
Output gate −名前が示すように、出力ゲートは、セルから次の非表示状態にベクトルを渡すタイミングを決定します。
CNTKでシーケンスを操作するのは非常に簡単です。次の例の助けを借りてそれを見てみましょう-
import sys
import os
from cntk import Trainer, Axis
from cntk.io import MinibatchSource, CTFDeserializer, StreamDef, StreamDefs,\
INFINITELY_REPEAT
from cntk.learners import sgd, learning_parameter_schedule_per_sample
from cntk import input_variable, cross_entropy_with_softmax, \
classification_error, sequence
from cntk.logging import ProgressPrinter
from cntk.layers import Sequential, Embedding, Recurrence, LSTM, Dense
def create_reader(path, is_training, input_dim, label_dim):
return MinibatchSource(CTFDeserializer(path, StreamDefs(
features=StreamDef(field='x', shape=input_dim, is_sparse=True),
labels=StreamDef(field='y', shape=label_dim, is_sparse=False)
)), randomize=is_training,
max_sweeps=INFINITELY_REPEAT if is_training else 1)
def LSTM_sequence_classifier_net(input, num_output_classes, embedding_dim,
LSTM_dim, cell_dim):
lstm_classifier = Sequential([Embedding(embedding_dim),
Recurrence(LSTM(LSTM_dim, cell_dim)),
sequence.last,
Dense(num_output_classes)])
return lstm_classifier(input)
def train_sequence_classifier():
input_dim = 2000
cell_dim = 25
hidden_dim = 25
embedding_dim = 50
num_output_classes = 5
features = sequence.input_variable(shape=input_dim, is_sparse=True)
label = input_variable(num_output_classes)
classifier_output = LSTM_sequence_classifier_net(
features, num_output_classes, embedding_dim, hidden_dim, cell_dim)
ce = cross_entropy_with_softmax(classifier_output, label)
pe = classification_error(classifier_output, label)
rel_path = ("../../../Tests/EndToEndTests/Text/" +
"SequenceClassification/Data/Train.ctf")
path = os.path.join(os.path.dirname(os.path.abspath(__file__)), rel_path)
reader = create_reader(path, True, input_dim, num_output_classes)
input_map = {
features: reader.streams.features,
label: reader.streams.labels
}
lr_per_sample = learning_parameter_schedule_per_sample(0.0005)
progress_printer = ProgressPrinter(0)
trainer = Trainer(classifier_output, (ce, pe),
sgd(classifier_output.parameters, lr=lr_per_sample),progress_printer)
minibatch_size = 200
for i in range(255):
mb = reader.next_minibatch(minibatch_size, input_map=input_map)
trainer.train_minibatch(mb)
evaluation_average = float(trainer.previous_minibatch_evaluation_average)
loss_average = float(trainer.previous_minibatch_loss_average)
return evaluation_average, loss_average
if __name__ == '__main__':
error, _ = train_sequence_classifier()
print(" error: %f" % error)average since average since examples
loss last metric last
------------------------------------------------------
1.61 1.61 0.886 0.886 44
1.61 1.6 0.714 0.629 133
1.6 1.59 0.56 0.448 316
1.57 1.55 0.479 0.41 682
1.53 1.5 0.464 0.449 1379
1.46 1.4 0.453 0.441 2813
1.37 1.28 0.45 0.447 5679
1.3 1.23 0.448 0.447 11365
error: 0.333333上記のプログラムの詳細な説明は、特にリカレントニューラルネットワークを構築するときに、次のセクションで説明します。
この章では、CNTKでのロジスティック回帰モデルの構築について説明します。
ロジスティック回帰モデルの基礎
最も単純なML手法の1つであるロジスティック回帰は、特に二項分類の手法です。言い換えると、予測する変数の値が2つのカテゴリ値のいずれかになる可能性がある状況で予測モデルを作成することです。ロジスティック回帰の最も簡単な例の1つは、年齢、声、髪の毛などに基づいて、その人が男性か女性かを予測することです。
例
別の例を使用して、ロジスティック回帰の概念を数学的に理解しましょう。
ローン申請の信用度を予測したいとします。申請者に基づいて、0は拒否を意味し、1は承認を意味しますdebt , income そして credit rating。負債をX1、収入をX2、信用格付けをX3で表します。
ロジスティック回帰では、次の式で表される重み値を決定します。 w、すべての機能と単一のバイアス値について、 b。
今、仮定します、
X1 = 3.0
X2 = -2.0
X3 = 1.0そして、次のように重みとバイアスを決定するとします。
W1 = 0.65, W2 = 1.75, W3 = 2.05 and b = 0.33ここで、クラスを予測するには、次の式を適用する必要があります。
Z = (X1*W1)+(X2*W2)+(X3+W3)+b
i.e. Z = (3.0)*(0.65) + (-2.0)*(1.75) + (1.0)*(2.05) + 0.33
= 0.83次に、計算する必要があります P = 1.0/(1.0 + exp(-Z))。ここで、exp()関数はオイラーの数です。
P = 1.0/(1.0 + exp(-0.83)
= 0.6963P値は、クラスが1である確率として解釈できます。P<0.5の場合、予測はクラス= 0であり、そうでない場合、予測(P> = 0.5)はクラス= 1です。
重みとバイアスの値を決定するには、既知の入力予測値と既知の正しいクラスラベル値を持つトレーニングデータのセットを取得する必要があります。その後、重みとバイアスの値を見つけるために、アルゴリズム、通常は最急降下法を使用できます。
LRモデルの実装例
このLRモデルでは、次のデータセットを使用します-
1.0, 2.0, 0
3.0, 4.0, 0
5.0, 2.0, 0
6.0, 3.0, 0
8.0, 1.0, 0
9.0, 2.0, 0
1.0, 4.0, 1
2.0, 5.0, 1
4.0, 6.0, 1
6.0, 5.0, 1
7.0, 3.0, 1
8.0, 5.0, 1CNTKでこのLRモデルの実装を開始するには、最初に次のパッケージをインポートする必要があります-
import numpy as np
import cntk as Cプログラムは次のようにmain()関数で構成されています-
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")ここで、次のようにトレーニングデータをメモリにロードする必要があります-
data_file = ".\\dataLRmodel.txt"
print("Loading data from " + data_file + "\n")
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[0,1])
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[2], ndmin=2)ここで、トレーニングデータと互換性のあるロジスティック回帰モデルを作成するトレーニングプログラムを作成します-
features_dim = 2
labels_dim = 1
X = C.ops.input_variable(features_dim, np.float32)
y = C.input_variable(labels_dim, np.float32)
W = C.parameter(shape=(features_dim, 1)) # trainable cntk.Parameter
b = C.parameter(shape=(labels_dim))
z = C.times(X, W) + b
p = 1.0 / (1.0 + C.exp(-z))
model = pここで、次のようにLernerとtrainerを作成する必要があります-
ce_error = C.binary_cross_entropy(model, y) # CE a bit more principled for LR
fixed_lr = 0.010
learner = C.sgd(model.parameters, fixed_lr)
trainer = C.Trainer(model, (ce_error), [learner])
max_iterations = 4000LRモデルトレーニング
LRモデルを作成したら、次にトレーニングプロセスを開始します-
np.random.seed(4)
N = len(features_mat)
for i in range(0, max_iterations):
row = np.random.choice(N,1) # pick a random row from training items
trainer.train_minibatch({ X: features_mat[row], y: labels_mat[row] })
if i % 1000 == 0 and i > 0:
mcee = trainer.previous_minibatch_loss_average
print(str(i) + " Cross-entropy error on curr item = %0.4f " % mcee)これで、次のコードを使用して、モデルの重みとバイアスを出力できます。
np.set_printoptions(precision=4, suppress=True)
print("Model weights: ")
print(W.value)
print("Model bias:")
print(b.value)
print("")
if __name__ == "__main__":
main()ロジスティック回帰モデルのトレーニング-完全な例
import numpy as np
import cntk as C
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
print("Loading data from " + data_file + "\n")
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[0,1])
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[2], ndmin=2)
features_dim = 2
labels_dim = 1
X = C.ops.input_variable(features_dim, np.float32)
y = C.input_variable(labels_dim, np.float32)
W = C.parameter(shape=(features_dim, 1)) # trainable cntk.Parameter
b = C.parameter(shape=(labels_dim))
z = C.times(X, W) + b
p = 1.0 / (1.0 + C.exp(-z))
model = p
ce_error = C.binary_cross_entropy(model, y) # CE a bit more principled for LR
fixed_lr = 0.010
learner = C.sgd(model.parameters, fixed_lr)
trainer = C.Trainer(model, (ce_error), [learner])
max_iterations = 4000
np.random.seed(4)
N = len(features_mat)
for i in range(0, max_iterations):
row = np.random.choice(N,1) # pick a random row from training items
trainer.train_minibatch({ X: features_mat[row], y: labels_mat[row] })
if i % 1000 == 0 and i > 0:
mcee = trainer.previous_minibatch_loss_average
print(str(i) + " Cross-entropy error on curr item = %0.4f " % mcee)
np.set_printoptions(precision=4, suppress=True)
print("Model weights: ")
print(W.value)
print("Model bias:")
print(b.value)
if __name__ == "__main__":
main()出力
Using CNTK version = 2.7
1000 cross entropy error on curr item = 0.1941
2000 cross entropy error on curr item = 0.1746
3000 cross entropy error on curr item = 0.0563
Model weights:
[-0.2049]
[0.9666]]
Model bias:
[-2.2846]訓練されたLRモデルを使用した予測
LRモデルがトレーニングされると、次のように予測に使用できます。
まず、評価プログラムはnumpyパッケージをインポートし、上記で実装したトレーニングプログラムと同じ方法で、トレーニングデータを機能マトリックスとクラスラベルマトリックスにロードします。
import numpy as np
def main():
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=(0,1))
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=[2], ndmin=2)次に、トレーニングプログラムによって決定された重みとバイアスの値を設定します。
print("Setting weights and bias values \n")
weights = np.array([0.0925, 1.1722], dtype=np.float32)
bias = np.array([-4.5400], dtype=np.float32)
N = len(features_mat)
features_dim = 2次に、評価プログラムは、次のように各トレーニング項目をウォークスルーすることにより、ロジスティック回帰確率を計算します。
print("item pred_prob pred_label act_label result")
for i in range(0, N): # each item
x = features_mat[i]
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
pred_prob = 1.0 / (1.0 + np.exp(-z))
pred_label = 0 if pred_prob < 0.5 else 1
act_label = labels_mat[i]
pred_str = ‘correct’ if np.absolute(pred_label - act_label) < 1.0e-5 \
else ‘WRONG’
print("%2d %0.4f %0.0f %0.0f %s" % \ (i, pred_prob, pred_label, act_label, pred_str))それでは、予測を行う方法を示しましょう-
x = np.array([9.5, 4.5], dtype=np.float32)
print("\nPredicting class for age, education = ")
print(x)
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
p = 1.0 / (1.0 + np.exp(-z))
print("Predicted p = " + str(p))
if p < 0.5: print("Predicted class = 0")
else: print("Predicted class = 1")完全な予測評価プログラム
import numpy as np
def main():
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=(0,1))
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=[2], ndmin=2)
print("Setting weights and bias values \n")
weights = np.array([0.0925, 1.1722], dtype=np.float32)
bias = np.array([-4.5400], dtype=np.float32)
N = len(features_mat)
features_dim = 2
print("item pred_prob pred_label act_label result")
for i in range(0, N): # each item
x = features_mat[i]
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
pred_prob = 1.0 / (1.0 + np.exp(-z))
pred_label = 0 if pred_prob < 0.5 else 1
act_label = labels_mat[i]
pred_str = ‘correct’ if np.absolute(pred_label - act_label) < 1.0e-5 \
else ‘WRONG’
print("%2d %0.4f %0.0f %0.0f %s" % \ (i, pred_prob, pred_label, act_label, pred_str))
x = np.array([9.5, 4.5], dtype=np.float32)
print("\nPredicting class for age, education = ")
print(x)
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
p = 1.0 / (1.0 + np.exp(-z))
print("Predicted p = " + str(p))
if p < 0.5: print("Predicted class = 0")
else: print("Predicted class = 1")
if __name__ == "__main__":
main()出力
重みとバイアス値の設定。
Item pred_prob pred_label act_label result
0 0.3640 0 0 correct
1 0.7254 1 0 WRONG
2 0.2019 0 0 correct
3 0.3562 0 0 correct
4 0.0493 0 0 correct
5 0.1005 0 0 correct
6 0.7892 1 1 correct
7 0.8564 1 1 correct
8 0.9654 1 1 correct
9 0.7587 1 1 correct
10 0.3040 0 1 WRONG
11 0.7129 1 1 correct
Predicting class for age, education =
[9.5 4.5]
Predicting p = 0.526487952
Predicting class = 1この章では、CNTKに関するニューラルネットワークの概念について説明します。
私たちが知っているように、ニューロンのいくつかの層はニューラルネットワークを作るために使用されます。しかし、CNTKでは、NNのレイヤーをどのようにモデル化できるのかという疑問が生じます。これは、レイヤーモジュールで定義されたレイヤー関数を使用して実行できます。
レイヤー機能
実際、CNTKでは、レイヤーを操作することで、明確な関数型プログラミングの感覚が得られます。レイヤー関数は通常の関数のように見え、事前定義されたパラメーターのセットを使用して数学関数を生成します。レイヤー関数を使用して、最も基本的なレイヤータイプであるDenseを作成する方法を見てみましょう。
例
次の基本的な手順の助けを借りて、最も基本的なレイヤータイプを作成できます-
Step 1 −まず、CNTKのレイヤーパッケージから高密度レイヤー関数をインポートする必要があります。
from cntk.layers import DenseStep 2 −次に、CNTKルートパッケージから、input_variable関数をインポートする必要があります。
from cntk import input_variableStep 3−ここで、input_variable関数を使用して新しい入力変数を作成する必要があります。そのサイズも提供する必要があります。
feature = input_variable(100)Step 4 −最後に、必要な数のニューロンを提供するとともに、高密度関数を使用して新しいレイヤーを作成します。
layer = Dense(40)(feature)これで、構成済みのDense layer関数を呼び出して、Denseレイヤーを入力に接続できます。
完全な実装例
from cntk.layers import Dense
from cntk import input_variable
feature= input_variable(100)
layer = Dense(40)(feature)レイヤーのカスタマイズ
これまで見てきたように、CNTKは、NNを構築するための非常に優れたデフォルトのセットを提供します。に基づくactivation選択した機能やその他の設定では、NNの動作とパフォーマンスが異なります。これは、もう1つの非常に便利なステミングアルゴリズムです。それが理由です。何を構成できるかを理解するのは良いことです。
高密度レイヤーを構成する手順
NNの各レイヤーには独自の構成オプションがあり、高密度レイヤーについて説明するときは、次の重要な設定を定義します。
shape −名前が示すように、レイヤーの出力形状を定義し、そのレイヤー内のニューロンの数をさらに決定します。
activation −そのレイヤーの活性化関数を定義するため、入力データを変換できます。
init−そのレイヤーの初期化機能を定義します。NNのトレーニングを開始すると、レイヤーのパラメーターが初期化されます。
構成できる手順を見てみましょう Dense レイヤー-
Step1 −まず、インポートする必要があります Dense CNTKのレイヤーパッケージのレイヤー関数。
from cntk.layers import DenseStep2 −次に、CNTK opsパッケージから、インポートする必要があります sigmoid operator。活性化関数として構成するために使用されます。
from cntk.ops import sigmoidStep3 −ここで、初期化パッケージから、インポートする必要があります glorot_uniform イニシャライザ。
from cntk.initializer import glorot_uniformStep4 −最後に、最初の引数としてニューロンの数を指定するとともに、Dense関数を使用して新しいレイヤーを作成します。また、sigmoid としての演算子 activation 機能と glorot_uniform として init レイヤーの機能。
layer = Dense(50, activation = sigmoid, init = glorot_uniform)完全な実装例-
from cntk.layers import Dense
from cntk.ops import sigmoid
from cntk.initializer import glorot_uniform
layer = Dense(50, activation = sigmoid, init = glorot_uniform)パラメータの最適化
これまで、NNの構造を作成する方法と、さまざまな設定を構成する方法を見てきました。ここでは、NNのパラメータを最適化する方法を説明します。つまり、2つのコンポーネントの組み合わせの助けを借りてlearners そして trainers、NNのパラメータを最適化できます。
トレーナーコンポーネント
NNのパラメータを最適化するために使用される最初のコンポーネントは trainer成分。基本的に、バックプロパゲーションプロセスを実装します。その動作について話すと、データをNNに渡して、予測を取得します。
その後、NNのパラメーターの新しい値を取得するために、learnerと呼ばれる別のコンポーネントを使用します。新しい値を取得すると、これらの新しい値を適用し、終了基準が満たされるまでプロセスを繰り返します。
学習者コンポーネント
NNのパラメータを最適化するために使用される2番目のコンポーネントは learner コンポーネント。基本的に、勾配降下アルゴリズムの実行を担当します。
CNTKライブラリに含まれる学習者
以下は、CNTKライブラリに含まれている興味深い学習者のリストです-
Stochastic Gradient Descent (SGD) −この学習者は、基本的な確率的勾配降下法を追加なしで表します。
Momentum Stochastic Gradient Descent (MomentumSGD) − SGDを使用すると、この学習者は極大値の問題を克服するために勢いを適用します。
RMSProp −この学習者は、降下率を制御するために、減衰する学習率を使用します。
Adam −この学習者は、時間の経過とともに降下率を下げるために、減衰する運動量を使用します。
Adagrad −この学習者は、頻繁に発生する機能とまれに発生する機能について、さまざまな学習率を使用します。
CNTK-最初のニューラルネットワークの作成
この章では、CNTKでのニューラルネットワークの作成について詳しく説明します。
ネットワーク構造を構築する
CNTKの概念を適用して最初のNNを構築するために、NNを使用して、がく片の幅と長さ、および花びらの幅と長さの物理的特性に基づいてアヤメの花の種を分類します。さまざまな種類のアイリスの花の物理的特性を説明するアイリスデータセットを使用するデータセット-
- がく片の長さ
- がく片の幅
- 花びらの長さ
- 花びらの幅
- クラスすなわちアイリスsetosaまたはアイリスversicolorまたはアイリスvirginica
ここでは、フィードフォワードNNと呼ばれる通常のNNを構築します。NN −の構造を構築するための実装手順を見てみましょう。
Step 1 −まず、レイヤータイプ、活性化関数、NNの入力変数を定義できる関数などの必要なコンポーネントをCNTKライブラリからインポートします。
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, reluStep 2−その後、シーケンシャル関数を使用してモデルを作成します。作成したら、必要なレイヤーをフィードします。ここでは、NNに2つの異なるレイヤーを作成します。1つは4つのニューロンを持ち、もう1つは3つのニューロンを持ちます。
model = Sequential([Dense(4, activation=relu), Dense(3, activation=log_sogtmax)])Step 3−最後に、NNをコンパイルするために、ネットワークを入力変数にバインドします。4つのニューロンを持つ入力層と3つのニューロンを持つ出力層があります。
feature= input_variable(4)
z = model(feature)活性化関数を適用する
選択できる活性化関数はたくさんあり、適切な活性化関数を選択することで、ディープラーニングモデルのパフォーマンスに大きな違いが生まれます。
出力層で
を選択する activation 出力層での関数は、モデルで解決しようとしている問題の種類によって異なります。
回帰問題の場合、 linear activation function 出力層で。
バイナリ分類問題の場合、 sigmoid activation function 出力層で。
マルチクラス分類問題の場合、 softmax activation function 出力層で。
ここでは、3つのクラスのいずれかを予測するためのモデルを構築します。それは私たちが使用する必要があることを意味しますsoftmax activation function 出力層で。
隠された層で
を選択する activation 隠れ層の機能では、パフォーマンスを監視してどの活性化関数が適切に機能するかを確認するための実験が必要です。
分類問題では、サンプルが特定のクラスに属する確率を予測する必要があります。だから私たちは必要ですactivation functionそれは私たちに確率的な値を与えます。この目標を達成するために、sigmoid activation function 私たちを助けることができます。
シグモイド関数に関連する主要な問題の1つは、勾配消失問題です。このような問題を克服するために、ReLU activation function これは、すべての負の値をゼロに変換し、正の値のパススルーフィルターとして機能します。
損失関数の選択
NNモデルの構造ができたら、それを最適化する必要があります。最適化するには、loss function。とは異なりactivation functions、選択できる損失関数が非常に少なくなっています。ただし、損失関数の選択は、モデルで解決しようとしている問題の種類によって異なります。
たとえば、分類問題では、予測されたクラスと実際のクラスの差を測定できる損失関数を使用する必要があります。
損失関数
分類問題については、NNモデルで解きます。 categorical cross entropy損失関数が最適な候補です。CNTKでは、次のように実装されますcross_entropy_with_softmax からインポートすることができます cntk.losses パッケージ、次のように-
label= input_variable(3)
loss = cross_entropy_with_softmax(z, label)指標
NNモデルの構造と適用する損失関数があれば、深層学習モデルを最適化するためのレシピの作成を開始するためのすべての要素が揃っています。しかし、これを深く掘り下げる前に、メトリックについて学ぶ必要があります。
cntk.metricsCNTKには次の名前のパッケージがあります cntk.metrics使用するメトリックをインポートできます。分類モデルを構築しているので、classification_error 0から1までの数値を生成する行列。0から1までの数値は、正しく予測されたサンプルのパーセンテージを示します。
まず、からメトリックをインポートする必要があります cntk.metrics パッケージ-
from cntk.metrics import classification_error
error_rate = classification_error(z, label)上記の関数は、実際にはNNの出力と入力として期待されるラベルを必要とします。
CNTK-ニューラルネットワークのトレーニング
ここでは、CNTKでのニューラルネットワークのトレーニングについて理解します。
CNTKでモデルをトレーニングする
前のセクションでは、深層学習モデルのすべてのコンポーネントを定義しました。今それを訓練する時が来ました。前に説明したように、次の組み合わせを使用して、CNTKでNNモデルをトレーニングできます。learner そして trainer。
学習者の選択とトレーニングの設定
このセクションでは、 learner。CNTKはいくつかを提供しますlearnersから選択します。前のセクションで定義したモデルでは、Stochastic Gradient Descent (SGD) learner。
ニューラルネットワークをトレーニングするために、 learner そして trainer 次の手順の助けを借りて-
Step 1 −まず、インポートする必要があります sgd からの機能 cntk.lerners パッケージ。
from cntk.learners import sgdStep 2 −次に、インポートする必要があります Trainer からの機能 cntk.train.trainerパッケージ。
from cntk.train.trainer import TrainerStep 3 −次に、を作成する必要があります learner。を呼び出すことで作成できますsgd モデルのパラメーターと学習率の値を提供するとともに機能します。
learner = sgd(z.parametrs, 0.01)Step 4 −最後に、初期化する必要があります trainer。ネットワーク、の組み合わせを提供する必要がありますloss そして metric 一緒に learner。
trainer = Trainer(z, (loss, error_rate), [learner])最適化の速度を制御する学習率は、0.1から0.001の間の小さな数値である必要があります。
学習者の選択とトレーニングの設定-完全な例
from cntk.learners import sgd
from cntk.train.trainer import Trainer
learner = sgd(z.parametrs, 0.01)
trainer = Trainer(z, (loss, error_rate), [learner])トレーナーへのデータのフィード
トレーナーを選択して構成したら、データセットをロードします。保存しましたiris としてのデータセット。CSV ファイルと私たちはという名前のデータラングリングパッケージを使用します pandas データセットをロードします。
.CSVファイルからデータセットを読み込む手順
Step 1 −まず、インポートする必要があります pandas パッケージ。
from import pandas as pdStep 2 −次に、という名前の関数を呼び出す必要があります read_csv ディスクから.csvファイルをロードする関数。
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’,
‘petal_length’, ‘petal_width’, index_col=False)データセットを読み込んだら、それを一連の機能とラベルに分割する必要があります。
データセットを機能とラベルに分割する手順
Step 1−まず、データセットからすべての行と最初の4列を選択する必要があります。それはを使用して行うことができますiloc 関数。
x = df_source.iloc[:, :4].valuesStep 2−次に、アイリスデータセットから種の列を選択する必要があります。基になる値にアクセスするためにvaluesプロパティを使用しますnumpy アレイ。
x = df_source[‘species’].values種の列を数値ベクトル表現にエンコードする手順
前に説明したように、モデルは分類に基づいており、数値の入力値が必要です。したがって、ここでは、種の列を数値ベクトル表現にエンコードする必要があります。それを行うための手順を見てみましょう-
Step 1−まず、配列内のすべての要素を反復処理するリスト式を作成する必要があります。次に、各値についてlabel_mappingディクショナリでルックアップを実行します。
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Step 2−次に、この変換された数値をワンホットエンコードされたベクトルに変換します。使用しますone_hot 次のように機能します-
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return resultStep 3 −最後に、この変換されたリストをに変換する必要があります numpy アレイ。
y = np.array([one_hot(label_mapping[v], 3) for v in y])過剰適合を検出する手順
モデルがサンプルを記憶しているが、トレーニングサンプルからルールを推測できない状況は、過剰適合です。次の手順の助けを借りて、モデルの過剰適合を検出できます-
Step 1 −まず、 sklearn パッケージ、インポート train_test_split からの機能 model_selection モジュール。
from sklearn.model_selection import train_test_splitStep 2 −次に、次のように、特徴xとラベルyを使用してtrain_test_split関数を呼び出す必要があります。
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0-2,
stratify=y)全データの20%を確保するために、test_sizeを0.2に指定しました。
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}トレーニングセットと検証セットをモデルにフィードする手順
Step 1 −モデルをトレーニングするために、まず、 train_minibatch方法。次に、NNとそれに関連する損失関数を定義するために使用した入力変数に入力データをマップする辞書を提供します。
trainer.train_minibatch({ features: X_train, label: y_train})Step 2 −次に、 train_minibatch 次のforループを使用して-
for _epoch in range(10):
trainer.train_minbatch ({ feature: X_train, label: y_train})
print(‘Loss: {}, Acc: {}’.format(
trainer.previous_minibatch_loss_average,
trainer.previous_minibatch_evaluation_average))トレーナーへのデータのフィード-完全な例
from import pandas as pd
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, index_col=False)
x = df_source.iloc[:, :4].values
x = df_source[‘species’].values
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return result
y = np.array([one_hot(label_mapping[v], 3) for v in y])
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0-2, stratify=y)
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
trainer.train_minibatch({ features: X_train, label: y_train})
for _epoch in range(10):
trainer.train_minbatch ({ feature: X_train, label: y_train})
print(‘Loss: {}, Acc: {}’.format(
trainer.previous_minibatch_loss_average,
trainer.previous_minibatch_evaluation_average))NNのパフォーマンスの測定
NNモデルを最適化するために、トレーナーにデータを渡すたびに、トレーナー用に構成したメトリックを介してモデルのパフォーマンスを測定します。トレーニング中のNNモデルのパフォーマンスのこのような測定は、トレーニングデータに基づいています。ただし、一方で、モデルのパフォーマンスを完全に分析するには、テストデータも使用する必要があります。
したがって、テストデータを使用してモデルのパフォーマンスを測定するには、 test_minibatch 上の方法 trainer 次のように-
trainer.test_minibatch({ features: X_test, label: y_test})NNで予測する
ディープラーニングモデルをトレーニングしたら、それを使用して予測を行うことが最も重要です。上記の訓練されたNNから予測を行うために、与えられた手順に従うことができます-
Step 1 −まず、次の関数を使用して、テストセットからランダムなアイテムを選択する必要があります−
np.random.choiceStep 2 −次に、を使用してテストセットからサンプルデータを選択する必要があります。 sample_index。
Step 3 −ここで、NNへの数値出力を実際のラベルに変換するために、反転マッピングを作成します。
Step 4 −次に、選択したものを使用します sampleデータ。NNzを関数として呼び出して予測を行います。
Step 5−ここで、予測された出力を取得したら、最も高い値を持つニューロンのインデックスを予測値として取得します。それはを使用して行うことができますnp.argmax からの機能 numpy パッケージ。
Step 6 −最後に、を使用してインデックス値を実際のラベルに変換します inverted_mapping。
NNで予測する-完全な例
sample_index = np.random.choice(X_test.shape[0])
sample = X_test[sample_index]
inverted_mapping = {
1:’Iris-setosa’,
2:’Iris-versicolor’,
3:’Iris-virginica’
}
prediction = z(sample)
predicted_label = inverted_mapping[np.argmax(prediction)]
print(predicted_label)出力
上記の深層学習モデルをトレーニングして実行すると、次の出力が得られます。
Iris-versicolorCNTK-インメモリおよび大規模なデータセット
この章では、CNTKでメモリ内の大規模なデータセットを操作する方法について学習します。
小さなメモリデータセットを使用したトレーニング
CNTKトレーナーへのデータのフィードについて説明する場合、さまざまな方法がありますが、データセットのサイズとデータの形式によって異なります。データセットは、メモリ内の小さなデータセットでも大きなデータセットでもかまいません。
このセクションでは、メモリ内のデータセットを操作します。このために、次の2つのフレームワークを使用します-
- Numpy
- Pandas
Numpy配列の使用
ここでは、CNTKでランダムに生成されたnumpyベースのデータセットを使用します。この例では、バイナリ分類問題のデータをシミュレートします。4つの特徴を持つ一連の観測値があり、深層学習モデルを使用して2つの可能なラベルを予測するとします。
実装例
このために、最初に、ラベルのワンホットベクトル表現を含むラベルのセットを生成する必要があります。これを予測します。それは次のステップの助けを借りて行うことができます-
Step 1 −インポート numpy 次のようにパッケージ-
import numpy as np
num_samples = 20000Step 2 −次に、を使用してラベルマッピングを生成します np.eye 次のように機能します-
label_mapping = np.eye(2)Step 3 −今を使用して np.random.choice 関数、次のように20000のランダムサンプルを収集します-
y = label_mapping[np.random.choice(2,num_samples)].astype(np.float32)Step 4 −最後に、np.random.random関数を使用して、次のようにランダムな浮動小数点値の配列を生成します。
x = np.random.random(size=(num_samples, 4)).astype(np.float32)ランダムな浮動小数点値の配列を生成したら、それらを32ビット浮動小数点数に変換して、CNTKで期待される形式に一致させる必要があります。これを行うには、以下の手順に従ってください-
Step 5 −次のようにcntk.layersモジュールからDenseおよびSequentialレイヤー関数をインポートします−
from cntk.layers import Dense, SequentialStep 6−次に、ネットワーク内のレイヤーの活性化関数をインポートする必要があります。インポートしましょうsigmoid 活性化関数として-
from cntk import input_variable, default_options
from cntk.ops import sigmoidStep 7−次に、ネットワークをトレーニングするために損失関数をインポートする必要があります。インポートしましょうbinary_cross_entropy 損失関数として-
from cntk.losses import binary_cross_entropyStep 8−次に、ネットワークのデフォルトオプションを定義する必要があります。ここでは、sigmoidデフォルト設定としての活性化関数。また、次のようにシーケンシャルレイヤー関数を使用してモデルを作成します。
with default_options(activation=sigmoid):
model = Sequential([Dense(6),Dense(2)])Step 9 −次に、初期化 input_variable ネットワークの入力として機能する4つの入力機能を備えています。
features = input_variable(4)Step 10 −ここで、それを完了するために、機能変数をNNに接続する必要があります。
z = model(features)これで、次の手順を使用してNNが作成されました。メモリ内のデータセットを使用して、NNをトレーニングしましょう。
Step 11 −このNNをトレーニングするには、最初に学習者をからインポートする必要があります cntk.learnersモジュール。輸入しますsgd 次のように学習者-
from cntk.learners import sgdStep 12 −それに加えて、 ProgressPrinter から cntk.logging モジュールも。
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)Step 13 −次に、ラベルの新しい入力変数を次のように定義します−
labels = input_variable(2)Step 14 − NNモデルをトレーニングするには、次に、を使用して損失を定義する必要があります。 binary_cross_entropy関数。また、モデルzとlabels変数を指定します。
loss = binary_cross_entropy(z, labels)Step 15 −次に、を初期化します sgd 次のように学習者-
learner = sgd(z.parameters, lr=0.1)Step 16−最後に、損失関数でtrainメソッドを呼び出します。また、入力データを提供します。sgd 学習者と progress_printer.−
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer])完全な実装例
import numpy as np
num_samples = 20000
label_mapping = np.eye(2)
y = label_mapping[np.random.choice(2,num_samples)].astype(np.float32)
x = np.random.random(size=(num_samples, 4)).astype(np.float32)
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid
from cntk.losses import binary_cross_entropy
with default_options(activation=sigmoid):
model = Sequential([Dense(6),Dense(2)])
features = input_variable(4)
z = model(features)
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)
labels = input_variable(2)
loss = binary_cross_entropy(z, labels)
learner = sgd(z.parameters, lr=0.1)
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer])出力
Build info:
Built time: *** ** **** 21:40:10
Last modified date: *** *** ** 21:08:46 2019
Build type: Release
Build target: CPU-only
With ASGD: yes
Math lib: mkl
Build Branch: HEAD
Build SHA1:ae9c9c7c5f9e6072cc9c94c254f816dbdc1c5be6 (modified)
MPI distribution: Microsoft MPI
MPI version: 7.0.12437.6
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.52 1.52 0 0 32
1.51 1.51 0 0 96
1.48 1.46 0 0 224
1.45 1.42 0 0 480
1.42 1.4 0 0 992
1.41 1.39 0 0 2016
1.4 1.39 0 0 4064
1.39 1.39 0 0 8160
1.39 1.39 0 0 16352パンダデータフレームの使用
Numpy配列には、含めることができるものと、データを格納する最も基本的な方法の1つが非常に制限されています。たとえば、単一のn次元配列には、単一のデータ型のデータを含めることができます。しかし一方で、多くの実際のケースでは、単一のデータセットで複数のデータ型を処理できるライブラリが必要です。
Pandasと呼ばれるPythonライブラリの1つを使用すると、このような種類のデータセットを簡単に操作できます。DataFrame(DF)の概念を紹介し、さまざまな形式でDFとして保存されているディスクからデータセットをロードできるようにします。たとえば、CSV、JSON、Excelなどとして保存されているDFを読み取ることができます。
Python Pandasライブラリについて詳しくは、次のURLをご覧ください。 https://www.tutorialspoint.com/python_pandas/index.htm.
実装例
この例では、4つのプロパティに基づいてアイリスの花の3つの可能な種を分類する例を使用します。この深層学習モデルは、前のセクションでも作成しました。モデルは次のとおりです-
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid, log_softmax
from cntk.losses import binary_cross_entropy
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
z = model(features)上記のモデルには、予測可能なクラスの数に一致する3つのニューロンを持つ1つの隠れ層と出力層が含まれています。
次に、 train メソッドと lossネットワークを訓練する機能。このためには、最初にアイリスデータセットをロードして前処理し、NNの予想されるレイアウトとデータ形式に一致させる必要があります。それは次のステップの助けを借りて行うことができます-
Step 1 −インポート numpy そして Pandas 次のようにパッケージ-
import numpy as np
import pandas as pdStep 2 −次に、 read_csv データセットをメモリにロードする関数-
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’,
‘petal_length’, ‘petal_width’, ‘species’], index_col=False)Step 3 −次に、データセット内のラベルを対応する数値表現でマッピングする辞書を作成する必要があります。
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Step 4 −さて、 iloc 上のインデクサ DataFrame、次のように最初の4列を選択します-
x = df_source.iloc[:, :4].valuesStep 5−次に、データセットのラベルとして種の列を選択する必要があります。それは次のように行うことができます-
y = df_source[‘species’].valuesStep 6 −次に、データセット内のラベルをマッピングする必要があります。これは、を使用して行うことができます。 label_mapping。また、使用one_hot それらをワンホットエンコーディング配列に変換するためのエンコーディング。
y = np.array([one_hot(label_mapping[v], 3) for v in y])Step 7 −次に、CNTKでフィーチャとマップされたラベルを使用するには、両方をフロートに変換する必要があります−
x= x.astype(np.float32)
y= y.astype(np.float32)ご存知のとおり、ラベルは文字列としてデータセットに保存され、CNTKはこれらの文字列を処理できません。そのため、ラベルを表すワンホットエンコードされたベクトルが必要です。このために、次のような関数を定義できます。one_hot 次のように-
def one_hot(index, length):
result = np.zeros(length)
result[index] = index
return resultこれで、numpy配列が正しい形式になりました。次の手順を実行すると、それらを使用してモデルをトレーニングできます。
Step 8−まず、ネットワークをトレーニングするために損失関数をインポートする必要があります。インポートしましょうbinary_cross_entropy_with_softmax 損失関数として-
from cntk.losses import binary_cross_entropy_with_softmaxStep 9 −このNNをトレーニングするには、学習者をからインポートする必要もあります。 cntk.learnersモジュール。輸入しますsgd 次のように学習者-
from cntk.learners import sgdStep 10 −それに加えて、 ProgressPrinter から cntk.logging モジュールも。
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)Step 11 −次に、ラベルの新しい入力変数を次のように定義します−
labels = input_variable(3)Step 12 − NNモデルをトレーニングするには、次に、を使用して損失を定義する必要があります。 binary_cross_entropy_with_softmax関数。モデルzとlabels変数も提供します。
loss = binary_cross_entropy_with_softmax (z, labels)Step 13 −次に、初期化 sgd 次のように学習者-
learner = sgd(z.parameters, 0.1)Step 14−最後に、損失関数でtrainメソッドを呼び出します。また、入力データを提供します。sgd 学習者と progress_printer。
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=
[progress_writer],minibatch_size=16,max_epochs=5)完全な実装例
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid, log_softmax
from cntk.losses import binary_cross_entropy
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
z = model(features)
import numpy as np
import pandas as pd
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
x = df_source.iloc[:, :4].values
y = df_source[‘species’].values
y = np.array([one_hot(label_mapping[v], 3) for v in y])
x= x.astype(np.float32)
y= y.astype(np.float32)
def one_hot(index, length):
result = np.zeros(length)
result[index] = index
return result
from cntk.losses import binary_cross_entropy_with_softmax
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)
labels = input_variable(3)
loss = binary_cross_entropy_with_softmax (z, labels)
learner = sgd(z.parameters, 0.1)
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer],minibatch_size=16,max_epochs=5)出力
Build info:
Built time: *** ** **** 21:40:10
Last modified date: *** *** ** 21:08:46 2019
Build type: Release
Build target: CPU-only
With ASGD: yes
Math lib: mkl
Build Branch: HEAD
Build SHA1:ae9c9c7c5f9e6072cc9c94c254f816dbdc1c5be6 (modified)
MPI distribution: Microsoft MPI
MPI version: 7.0.12437.6
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.1 1.1 0 0 16
0.835 0.704 0 0 32
1.993 1.11 0 0 48
1.14 1.14 0 0 112
[………]大規模なデータセットを使用したトレーニング
前のセクションでは、Numpyとpandasを使用して小さなメモリ内データセットを操作しましたが、すべてのデータセットがそれほど小さいわけではありません。特に、画像、ビデオ、音声サンプルを含むデータセットは大きいです。MinibatchSourceは、このような大規模なデータセットを処理するためにCNTKによって提供される、チャンクでデータをロードできるコンポーネントです。の機能のいくつかMinibatchSource コンポーネントは次のとおりです-
MinibatchSource データソースから読み取ったサンプルを自動的にランダム化することにより、NNの過剰適合を防ぐことができます。
データを拡張するために使用できる変換パイプラインが組み込まれています。
トレーニングプロセスとは別のバックグラウンドスレッドにデータをロードします。
次のセクションでは、メモリ不足のデータを含むミニバッチソースを使用して、大規模なデータセットを操作する方法について説明します。また、それを使用してNNをトレーニングするためのフィードを作成する方法についても説明します。
MinibatchSourceインスタンスの作成
前のセクションでは、アイリスの花の例を使用し、PandasDataFramesを使用して小さなメモリ内データセットを操作しました。ここでは、パンダDFからのデータを使用するコードを次のように置き換えます。MinibatchSource。まず、のインスタンスを作成する必要がありますMinibatchSource 次の手順の助けを借りて-
実装例
Step 1 −まず、 cntk.io モジュールは、次のようにミニバッチソースのコンポーネントをインポートします-
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer,
INFINITY_REPEATStep 2 −さて、 StreamDef クラス、ラベルのストリーム定義を作成します。
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)Step 3 −次に、入力ファイルからファイルされたフィーチャを読み取るために作成し、次の別のインスタンスを作成します。 StreamDef 次のように。
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)Step 4 −今、私たちは提供する必要があります iris.ctf 入力としてファイルを作成し、 deserializer 次のように-
deserializer = CTFDeserializer(‘iris.ctf’, StreamDefs(labels=
label_stream, features=features_stream)Step 5 −最後に、のインスタンスを作成する必要があります minisourceBatch を使用して deserializer 次のように-
Minibatch_source = MinibatchSource(deserializer, randomize=True)MinibatchSourceインスタンスの作成-完全な実装例
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer, INFINITY_REPEAT
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)
deserializer = CTFDeserializer(‘iris.ctf’, StreamDefs(labels=label_stream, features=features_stream)
Minibatch_source = MinibatchSource(deserializer, randomize=True)MCTFファイルの作成
上で見たように、「iris.ctf」ファイルからデータを取得しています。CNTK Text Format(CTF)と呼ばれるファイル形式があります。のデータを取得するには、CTFファイルを作成する必要があります。MinibatchSource上で作成したインスタンス。CTFファイルを作成する方法を見てみましょう。
実装例
Step 1 −まず、次のようにパンダとnumpyパッケージをインポートする必要があります−
import pandas as pd
import numpy as npStep 2−次に、データファイル、つまりiris.csvをメモリにロードする必要があります。次に、それをに保存しますdf_source 変数。
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)Step 3 −さて、 ilocインデクサーを機能として、最初の4列のコンテンツを取得します。また、種の列のデータを次のように使用します-
features = df_source.iloc[: , :4].values
labels = df_source[‘species’].valuesStep 4−次に、ラベル名とその数値表現の間のマッピングを作成する必要があります。それは作成することによって行うことができますlabel_mapping 次のように-
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Step 5 −次に、次のようにラベルをワンホットエンコードされたベクトルのセットに変換します。
labels = [one_hot(label_mapping[v], 3) for v in labels]ここで、前に行ったように、というユーティリティ関数を作成します。 one_hotラベルをエンコードします。それは次のように行うことができます-
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return resultデータをロードして前処理したので、CTFファイル形式でディスクに保存します。次のPythonコードの助けを借りてそれを行うことができます-
With open(‘iris.ctf’, ‘w’) as output_file:
for index in range(0, feature.shape[0]):
feature_values = ‘ ‘.join([str(x) for x in np.nditer(features[index])])
label_values = ‘ ‘.join([str(x) for x in np.nditer(labels[index])])
output_file.write(‘features {} | labels {} \n’.format(feature_values, label_values))MCTFファイルの作成-完全な実装例
import pandas as pd
import numpy as np
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)
features = df_source.iloc[: , :4].values
labels = df_source[‘species’].values
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
labels = [one_hot(label_mapping[v], 3) for v in labels]
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return result
With open(‘iris.ctf’, ‘w’) as output_file:
for index in range(0, feature.shape[0]):
feature_values = ‘ ‘.join([str(x) for x in np.nditer(features[index])])
label_values = ‘ ‘.join([str(x) for x in np.nditer(labels[index])])
output_file.write(‘features {} | labels {} \n’.format(feature_values, label_values))データのフィード
作成したら MinibatchSource,たとえば、トレーニングする必要があります。小さなメモリ内データセットで作業したときに使用したものと同じトレーニングロジックを使用できます。ここでは、MinibatchSource 次のように、損失関数のトレインメソッドの入力としてのインスタンス-
実装例
Step 1 −トレーニングセッションの出力をログに記録するには、最初にProgressPrinterをからインポートします。 cntk.logging 次のようにモジュール-
from cntk.logging import ProgressPrinterStep 2 −次に、トレーニングセッションを設定するには、 trainer そして training_session から cntk.train 次のようにモジュール-
from cntk.train import Trainer,Step 3 −次に、次のような定数のセットを定義する必要があります。 minibatch_size、 samples_per_epoch そして num_epochs 次のように-
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30Step 4 −次に、トレーニング中にCNTKがデータを読み取る方法を知るために、ネットワークの入力変数とミニバッチソースのストリームの間のマッピングを定義する必要があります。
input_map = {
features: minibatch.source.streams.features,
labels: minibatch.source.streams.features
}Step 5 −次に、トレーニングプロセスの出力をログに記録するには、 progress_printer 新しい変数 ProgressPrinter 次のようなインスタンス-
progress_writer = ProgressPrinter(0)Step 6 −最後に、次のように損失に対してtrainメソッドを呼び出す必要があります−
train_history = loss.train(minibatch_source,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer],
epoch_size=samples_per_epoch,
max_epochs=num_epochs)データのフィード-完全な実装例
from cntk.logging import ProgressPrinter
from cntk.train import Trainer, training_session
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
input_map = {
features: minibatch.source.streams.features,
labels: minibatch.source.streams.features
}
progress_writer = ProgressPrinter(0)
train_history = loss.train(minibatch_source,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer],
epoch_size=samples_per_epoch,
max_epochs=num_epochs)出力
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.21 1.21 0 0 32
1.15 0.12 0 0 96
[………]CNTK-パフォーマンスの測定
この章では、CNKTでモデルのパフォーマンスを測定する方法について説明します。
モデルのパフォーマンスを検証するための戦略
MLモデルを構築した後、データサンプルのセットを使用してモデルをトレーニングしていました。このトレーニングにより、MLモデルはいくつかの一般的なルールを学習して導き出します。MLモデルのパフォーマンスは、新しいサンプル、つまりトレーニング時に提供されたものとは異なるサンプルをモデルにフィードするときに重要になります。その場合、モデルの動作は異なります。これらの新しいサンプルを適切に予測することは、より悪い場合があります。
ただし、本番環境ではトレーニング目的でサンプルデータを使用した場合とは異なる入力が得られるため、モデルは新しいサンプルでも適切に機能する必要があります。そのため、トレーニング目的で使用したサンプルとは異なるサンプルのセットを使用して、MLモデルを検証する必要があります。ここでは、NNを検証するためのデータセットを作成するための2つの異なる手法について説明します。
ホールドアウトデータセット
これは、NNを検証するためのデータセットを作成するための最も簡単な方法の1つです。名前が示すように、この方法では、トレーニングからのサンプルの1セット(たとえば20%)を抑制し、それを使用してMLモデルのパフォーマンスをテストします。次の図は、トレーニングサンプルと検証サンプルの比率を示しています-

ホールドアウトデータセットモデルは、MLモデルをトレーニングするのに十分なデータがあることを保証すると同時に、モデルのパフォーマンスを適切に測定するための妥当な数のサンプルを用意します。
トレーニングセットとテストセットに含めるには、メインデータセットからランダムサンプルを選択することをお勧めします。これにより、トレーニングセットとテストセットの間で均等に分散されます。
以下は、以下を使用して独自のホールドアウトデータセットを作成する例です。 train_test_split からの機能 scikit-learn 図書館。
例
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# Here above test_size = 0.2 represents that we provided 20% of the data as test data.
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors=3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)出力
Predictions: ['versicolor', 'virginica']CNTKを使用している間、モデルをトレーニングするたびにデータセットの順序をランダム化する必要があります。
深層学習アルゴリズムは、乱数ジェネレーターの影響を強く受けます。
トレーニング中にサンプルをNNに提供する順序は、そのパフォーマンスに大きく影響します。
ホールドアウトデータセット手法を使用することの主な欠点は、非常に良い結果が得られることもあれば、悪い結果が得られることもあるため、信頼性が低いことです。
K分割交差検定
MLモデルの信頼性を高めるために、K分割交差検定と呼ばれる手法があります。自然界では、K分割交差検定手法は前の手法と同じですが、それを数回(通常は約5〜10回)繰り返します。次の図はその概念を表しています-

K分割交差検定の動作
K分割交差検定の動作は、次の手順を使用して理解できます。
Step 1−ハンドアウトデータセット手法と同様に、K分割交差検証手法では、最初にデータセットをトレーニングセットとテストセットに分割する必要があります。理想的には、比率は80〜20、つまりトレーニングセットの80%とテストセットの20%です。
Step 2 −次に、トレーニングセットを使用してモデルをトレーニングする必要があります。
Step 3−最後に、テストセットを使用してモデルのパフォーマンスを測定します。ホールドアウトデータセット手法とk-cross検証手法の唯一の違いは、上記のプロセスが通常5〜10回繰り返され、最後にすべてのパフォーマンスメトリックの平均が計算されることです。その平均が最終的なパフォーマンス指標になります。
小さなデータセットの例を見てみましょう-
例
from numpy import array
from sklearn.model_selection import KFold
data = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
kfold = KFold(5, True, 1)
for train, test in kfold.split(data):
print('train: %s, test: %s' % (data[train],(data[test]))出力
train: [0.1 0.2 0.4 0.5 0.6 0.7 0.8 0.9], test: [0.3 1. ]
train: [0.1 0.2 0.3 0.4 0.6 0.8 0.9 1. ], test: [0.5 0.7]
train: [0.2 0.3 0.5 0.6 0.7 0.8 0.9 1. ], test: [0.1 0.4]
train: [0.1 0.3 0.4 0.5 0.6 0.7 0.9 1. ], test: [0.2 0.8]
train: [0.1 0.2 0.3 0.4 0.5 0.7 0.8 1. ], test: [0.6 0.9]ご覧のとおり、より現実的なトレーニングとテストシナリオを使用しているため、k分割交差検証手法を使用すると、はるかに安定したパフォーマンス測定が可能になりますが、欠点として、深層学習モデルの検証に多くの時間がかかります。
CNTKはk-cross検証をサポートしていないため、独自のスクリプトを作成する必要があります。
過適合と過剰適合の検出
ハンドアウトデータセットを使用するか、k分割交差検定手法を使用するかにかかわらず、トレーニングに使用されるデータセットと検証に使用されるデータセットでは、メトリックの出力が異なることがわかります。
過剰適合の検出
過剰適合と呼ばれる現象は、MLモデルがトレーニングデータを非常にうまくモデル化するが、テストデータではうまく機能しない、つまりテストデータを予測できなかった状況です。
MLモデルがトレーニングデータから特定のパターンとノイズをある程度学習すると、トレーニングデータから新しいデータ(つまり、見えないデータ)に一般化するモデルの能力に悪影響を及ぼします。ここで、ノイズはデータセット内の無関係な情報またはランダム性です。
以下は、モデルが過剰適合しているかどうかを検出するための2つの方法です。
過剰適合モデルは、トレーニングに使用したのと同じサンプルで良好に機能しますが、新しいサンプル、つまりトレーニングとは異なるサンプルでは非常にパフォーマンスが低下します。
テストセットのメトリックが同じメトリックよりも低い場合、検証中にモデルが過剰適合します。トレーニングセットで使用します。
アンダーフィッティングの検出
私たちのMLで発生する可能性のある別の状況は、不十分です。これは、MLモデルがトレーニングデータを適切にモデル化せず、有用な出力を予測できない状況です。最初のエポックのトレーニングを開始すると、モデルの適合度は低くなりますが、トレーニングが進むにつれて適合度が低くなります。
モデルが適合していないかどうかを検出する方法の1つは、トレーニングセットとテストセットのメトリックを調べることです。テストセットのメトリックがトレーニングセットのメトリックよりも高い場合、モデルは適合しません。
CNTK-ニューラルネットワーク分類
この章では、CNTKを使用してニューラルネットワークを分類する方法を学習します。
前書き
分類は、特定の入力データのカテゴリ出力ラベルまたは応答を予測するプロセスとして定義できます。モデルがトレーニングフェーズで学習した内容に基づく分類された出力は、「黒」、「白」、「スパム」、「スパムなし」などの形式になります。
一方、数学的には、マッピング関数を近似するタスクです。 f 入力変数からXと言い、出力変数からYと言います。
分類問題の典型的な例は、電子メールでのスパム検出です。出力には「スパム」と「スパムなし」の2つのカテゴリしかないことは明らかです。
このような分類を実装するには、最初に、「スパム」および「スパムなし」の電子メールがトレーニングデータとして使用される分類器のトレーニングを行う必要があります。分類器が正常にトレーニングされると、未知の電子メールを検出するために使用できます。
ここでは、次のようなアイリスフラワーデータセットを使用して4-5-3NNを作成します。
4入力ノード(予測値ごとに1つ)。
5-隠された処理ノード。
3-出力ノード(アイリスデータセットには3つの可能な種があるため)。
データセットの読み込み
がく片の幅と長さ、花びらの幅と長さの物理的特性に基づいて、アイリスの花の種を分類するアイリスの花のデータセットを使用します。データセットは、さまざまな種類のアヤメの花の物理的特性を記述しています-
がく片の長さ
がく片の幅
花びらの長さ
花びらの幅
クラスすなわちアイリスsetosaまたはアイリスversicolorまたはアイリスvirginica
我々は持っています iris.CSV前の章でも使用したファイル。それはの助けを借りてロードすることができますPandas図書館。ただし、CNTKで簡単に使用できるように、使用または分類子にロードする前に、トレーニングファイルとテストファイルを準備する必要があります。
トレーニングとテストファイルの準備
アイリスデータセットは、MLプロジェクトで最も人気のあるデータセットの1つです。150のデータ項目があり、生データは次のようになります-
5.1 3.5 1.4 0.2 setosa
4.9 3.0 1.4 0.2 setosa
…
7.0 3.2 4.7 1.4 versicolor
6.4 3.2 4.5 1.5 versicolor
…
6.3 3.3 6.0 2.5 virginica
5.8 2.7 5.1 1.9 virginica前に述べたように、各行の最初の4つの値は、さまざまな品種の物理的特性、つまり、がく片の長さ、がく片の幅、花びらの長さ、アイリスの花の花びらの幅を表します。
ただし、データをCNTKで簡単に使用できる形式に変換する必要があり、その形式は.ctfファイルです(前のセクションでも1つのiris.ctfを作成しました)。次のようになります-
|attribs 5.1 3.5 1.4 0.2|species 1 0 0
|attribs 4.9 3.0 1.4 0.2|species 1 0 0
…
|attribs 7.0 3.2 4.7 1.4|species 0 1 0
|attribs 6.4 3.2 4.5 1.5|species 0 1 0
…
|attribs 6.3 3.3 6.0 2.5|species 0 0 1
|attribs 5.8 2.7 5.1 1.9|species 0 0 1上記のデータでは、| attribsタグは機能値の開始をマークし、| speciesはクラスラベル値をタグ付けします。アイテムIDを追加することもできますが、他の任意のタグ名を使用することもできます。たとえば、次のデータを見てください-
|ID 001 |attribs 5.1 3.5 1.4 0.2|species 1 0 0 |#setosa
|ID 002 |attribs 4.9 3.0 1.4 0.2|species 1 0 0 |#setosa
…
|ID 051 |attribs 7.0 3.2 4.7 1.4|species 0 1 0 |#versicolor
|ID 052 |attribs 6.4 3.2 4.5 1.5|species 0 1 0 |#versicolor
…アイリスデータセットには合計150のデータ項目があり、この例では、80〜20のホールドアウトデータセットルールを使用します。つまり、トレーニング目的で80%(120項目)のデータ項目を使用し、テスト用に残りの20%(30項目)のデータ項目を使用します。目的。
分類モデルの構築
まず、CNTK形式のデータファイルを処理する必要があります。そのために、という名前のヘルパー関数を使用します。 create_reader 次のように-
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='attribs', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='species', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src次に、NNのアーキテクチャ引数を設定し、データファイルの場所も指定する必要があります。それは次のPythonコードの助けを借りて行うことができます-
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 5
output_dim = 3
train_file = ".\\...\\" #provide the name of the training file(120 data items)
test_file = ".\\...\\" #provide the name of the test file(30 data items)さて、次のコード行の助けを借りて、私たちのプログラムは訓練されていないNNを作成します-
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)ここで、トレーニングされていないデュアルモデルを作成したら、Learnerアルゴリズムオブジェクトを設定し、それを使用してTrainerトレーニングオブジェクトを作成する必要があります。SGDラーナーを使用してcross_entropy_with_softmax 損失関数-
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 2000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])学習アルゴリズムを次のようにコーディングします-
max_iter = 2000
batch_size = 10
lr_schedule = C.learning_parameter_schedule_per_sample([(1000, 0.05), (1, 0.01)])
mom_sch = C.momentum_schedule([(100, 0.99), (0, 0.95)], batch_size)
learner = C.fsadagrad(nnet.parameters, lr=lr_schedule, momentum=mom_sch)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])さて、Trainerオブジェクトを使い終わったら、トレーニングデータを読み取るためのリーダー関数を作成する必要があります-
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }NNモデルをトレーニングする時が来ました-
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))トレーニングが終わったら、テストデータ項目を使用してモデルを評価しましょう-
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 30
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)トレーニング済みのNNモデルの精度を評価した後、それを使用して、見えないデータの予測を行います。
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[6.4, 3.2, 4.5, 1.5]], dtype=np.float32)
print("\nPredicting Iris species for input features: ")
print(unknown[0]) pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])完全な分類モデル
Import numpy as np
Import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='attribs', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='species', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 5
output_dim = 3
train_file = ".\\...\\" #provide the name of the training file(120 data items)
test_file = ".\\...\\" #provide the name of the test file(30 data items)
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 2000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
max_iter = 2000
batch_size = 10
lr_schedule = C.learning_parameter_schedule_per_sample([(1000, 0.05), (1, 0.01)])
mom_sch = C.momentum_schedule([(100, 0.99), (0, 0.95)], batch_size)
learner = C.fsadagrad(nnet.parameters, lr=lr_schedule, momentum=mom_sch)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 30
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[7.0, 3.2, 4.7, 1.4]], dtype=np.float32)
print("\nPredicting species for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities: ")
print(pred_prob[0])
if __name__== ”__main__”:
main()出力
Using CNTK version = 2.7
batch 0: mean loss = 1.0986, mean accuracy = 40.00%
batch 500: mean loss = 0.6677, mean accuracy = 80.00%
batch 1000: mean loss = 0.5332, mean accuracy = 70.00%
batch 1500: mean loss = 0.2408, mean accuracy = 100.00%
Evaluating test data
Classification accuracy = 94.58%
Predicting species for input features:
[7.0 3.2 4.7 1.4]
Prediction probabilities:
[0.0847 0.736 0.113]トレーニング済みモデルの保存
このアイリスデータセットには150個のデータ項目しかないため、NN分類器モデルのトレーニングには数秒しかかかりませんが、数百または数千個のデータ項目を持つ大規模なデータセットのトレーニングには数時間または数日かかる場合があります。
モデルを保存して、最初から保持する必要がないようにすることができます。次のPythonコードの助けを借りて、トレーニング済みのNNを保存できます-
nn_classifier = “.\\neuralclassifier.model” #provide the name of the file
model.save(nn_classifier, format=C.ModelFormat.CNTKv2)以下はの議論です save() 上記で使用した関数−
ファイル名はの最初の引数です save()関数。ファイルのパスと一緒に書き込むこともできます。
別のパラメータは format デフォルト値を持つパラメータ C.ModelFormat.CNTKv2。
トレーニング済みモデルの読み込み
トレーニング済みモデルを保存すると、そのモデルを簡単にロードできます。使用する必要があるのはload ()関数。次の例でこれを確認しましょう-
import numpy as np
import cntk as C
model = C.ops.functions.Function.load(“.\\neuralclassifier.model”)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[7.0, 3.2, 4.7, 1.4]], dtype=np.float32)
print("\nPredicting species for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities: ")
print(pred_prob[0])保存されたモデルの利点は、保存されたモデルをロードすると、モデルがトレーニングされたばかりの場合とまったく同じように使用できることです。
CNTK-ニューラルネットワークの二項分類
この章では、CNTKを使用したニューラルネットワークの二項分類とは何かを理解しましょう。
NNを使用した二項分類は、マルチクラス分類に似ています。唯一のことは、3つ以上ではなく2つの出力ノードしかないことです。ここでは、ニューラルネットワークを使用して、1ノードと2ノードの2つの手法を使用して二項分類を実行します。1ノード手法は2ノード手法よりも一般的です。
データセットの読み込み
NNを使用して実装するこれらの手法の両方で、紙幣データセットを使用します。データセットは、UCI Machine LearningRepositoryからダウンロードできます。https://archive.ics.uci.edu/ml/datasets/banknote+authentication.
この例では、クラスforgery = 0の50個の本物のデータアイテムと、クラスforgery = 1の最初の50個の偽のアイテムを使用します。
トレーニングとテストファイルの準備
完全なデータセットには1372個のデータ項目があります。生のデータセットは次のようになります-
3.6216, 8.6661, -2.8076, -0.44699, 0
4.5459, 8.1674, -2.4586, -1.4621, 0
…
-1.3971, 3.3191, -1.3927, -1.9948, 1
0.39012, -0.14279, -0.031994, 0.35084, 1ここで、最初にこの生データを2ノードのCNTK形式に変換する必要があります。これは次のようになります。
|stats 3.62160000 8.66610000 -2.80730000 -0.44699000 |forgery 0 1 |# authentic
|stats 4.54590000 8.16740000 -2.45860000 -1.46210000 |forgery 0 1 |# authentic
. . .
|stats -1.39710000 3.31910000 -1.39270000 -1.99480000 |forgery 1 0 |# fake
|stats 0.39012000 -0.14279000 -0.03199400 0.35084000 |forgery 1 0 |# fake次のPythonプログラムを使用して、生データからCNTK形式のデータを作成できます-
fin = open(".\\...", "r") #provide the location of saved dataset text file.
for line in fin:
line = line.strip()
tokens = line.split(",")
if tokens[4] == "0":
print("|stats %12.8f %12.8f %12.8f %12.8f |forgery 0 1 |# authentic" % \
(float(tokens[0]), float(tokens[1]), float(tokens[2]), float(tokens[3])) )
else:
print("|stats %12.8f %12.8f %12.8f %12.8f |forgery 1 0 |# fake" % \
(float(tokens[0]), float(tokens[1]), float(tokens[2]), float(tokens[3])) )
fin.close()2ノード二項分類モデル
2ノード分類とマルチクラス分類の違いはほとんどありません。ここでは、最初に、CNTK形式のデータファイルを処理する必要があります。そのために、という名前のヘルパー関数を使用します。create_reader 次のように-
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src次に、NNのアーキテクチャ引数を設定し、データファイルの場所も指定する必要があります。それは次のPythonコードの助けを借りて行うことができます-
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 2
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test fileさて、次のコード行の助けを借りて、私たちのプログラムは訓練されていないNNを作成します-
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)ここで、トレーニングされていないデュアルモデルを作成したら、Learnerアルゴリズムオブジェクトを設定し、それを使用してTrainerトレーニングオブジェクトを作成する必要があります。SGDラーナーとcross_entropy_with_softmax損失関数を使用します-
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 500
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])さて、Trainerオブジェクトを使い終わったら、トレーニングデータを読み取るためのリーダー関数を作成する必要があります-
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }さて、NNモデルをトレーニングする時が来ました-
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))トレーニングが完了したら、テストデータ項目を使用してモデルを評価しましょう-
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)トレーニング済みのNNモデルの精度を評価した後、それを使用して、見えないデータの予測を行います。
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])
if pred_prob[0,0] < pred_prob[0,1]:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)完全な2ノード分類モデル
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 2
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test file
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
withC.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 500
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])
if pred_prob[0,0] < pred_prob[0,1]:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)
if __name__== ”__main__”:
main()出力
Using CNTK version = 2.7
batch 0: mean loss = 0.6928, accuracy = 80.00%
batch 50: mean loss = 0.6877, accuracy = 70.00%
batch 100: mean loss = 0.6432, accuracy = 80.00%
batch 150: mean loss = 0.4978, accuracy = 80.00%
batch 200: mean loss = 0.4551, accuracy = 90.00%
batch 250: mean loss = 0.3755, accuracy = 90.00%
batch 300: mean loss = 0.2295, accuracy = 100.00%
batch 350: mean loss = 0.1542, accuracy = 100.00%
batch 400: mean loss = 0.1581, accuracy = 100.00%
batch 450: mean loss = 0.1499, accuracy = 100.00%
Evaluating test data
Classification accuracy = 84.58%
Predicting banknote authenticity for input features:
[0.6 1.9 -3.3 -0.3]
Prediction probabilities are:
[0.7847 0.2536]
Prediction: fake1ノードの二項分類モデル
実装プログラムは、2ノード分類について上記で行ったのとほぼ同じです。主な変更点は、2ノード分類手法を使用する場合です。
CNTKの組み込みclassification_error()関数を使用できますが、1ノード分類の場合、CNTKはclassification_error()関数をサポートしていません。これが、プログラム定義関数を次のように実装する必要がある理由です。
def class_acc(mb, x_var, y_var, model):
num_correct = 0; num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
p = model.eval(x_mat[i]
y = y_mat[i]
if p[0,0] < 0.5 and y[0,0] == 0.0 or p[0,0] >= 0.5 and y[0,0] == 1.0:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)その変更で、完全な1ノード分類の例を見てみましょう-
完全な1ノード分類モデル
import numpy as np
import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def class_acc(mb, x_var, y_var, model):
num_correct = 0; num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
p = model.eval(x_mat[i]
y = y_mat[i]
if p[0,0] < 0.5 and y[0,0] == 0.0 or p[0,0] >= 0.5 and y[0,0] == 1.0:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test file
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = oLayer
tr_loss = C.cross_entropy_with_softmax(model, Y)
max_iter = 1000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(model.parameters, learn_rate)
trainer = C.Trainer(model, (tr_loss), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = {X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 100 == 0:
mcee=trainer.previous_minibatch_loss_average
ca = class_acc(curr_batch, X,Y, model)
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, ca))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map)
acc = class_acc(all_test, X,Y, model)
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval({X:unknown})
print("Prediction probability: ")
print(“%0.4f” % pred_prob[0,0])
if pred_prob[0,0] < 0.5:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)
if __name__== ”__main__”:
main()出力
Using CNTK version = 2.7
batch 0: mean loss = 0.6936, accuracy = 10.00%
batch 100: mean loss = 0.6882, accuracy = 70.00%
batch 200: mean loss = 0.6597, accuracy = 50.00%
batch 300: mean loss = 0.5298, accuracy = 70.00%
batch 400: mean loss = 0.4090, accuracy = 100.00%
batch 500: mean loss = 0.3790, accuracy = 90.00%
batch 600: mean loss = 0.1852, accuracy = 100.00%
batch 700: mean loss = 0.1135, accuracy = 100.00%
batch 800: mean loss = 0.1285, accuracy = 100.00%
batch 900: mean loss = 0.1054, accuracy = 100.00%
Evaluating test data
Classification accuracy = 84.00%
Predicting banknote authenticity for input features:
[0.6 1.9 -3.3 -0.3]
Prediction probability:
0.8846
Prediction: fakeCNTK-ニューラルネットワーク回帰
この章は、CNTKに関するニューラルネットワークの回帰を理解するのに役立ちます。
前書き
ご存知のとおり、1つ以上の予測変数から数値を予測するために、回帰を使用します。たとえば、100の町の1つにある家の中央値を予測する例を見てみましょう。そのために、次のようなデータがあります。
各町の犯罪統計。
各町の家の年齢。
各町から一等地までの距離の尺度。
各町の生徒と教師の比率。
各町の人種人口統計。
各町の住宅価格の中央値。
これらの5つの予測変数に基づいて、住宅価値の中央値を予測したいと思います。そしてこのために、次の線に沿って線形回帰モデルを作成できます。
Y = a0+a1(crime)+a2(house-age)+(a3)(distance)+(a4)(ratio)+(a5)(racial)上記の式で-
Y 予測された中央値です
a0は定数であり、
a1から a5はすべて、上記で説明した5つの予測子に関連付けられた定数です。
ニューラルネットワークを使用する別のアプローチもあります。より正確な予測モデルを作成します。
ここでは、CNTKを使用してニューラルネットワーク回帰モデルを作成します。
データセットの読み込み
CNTKを使用してニューラルネットワーク回帰を実装するために、ボストンエリアハウス値データセットを使用します。データセットは、UCI Machine LearningRepositoryからダウンロードできます。https://archive.ics.uci.edu/ml/machine-learning-databases/housing/。このデータセットには、合計14の変数と506のインスタンスがあります。
ただし、実装プログラムでは、14個の変数のうち6個と100個のインスタンスを使用します。6つのうち、5つは予測子として、1つは予測値として。100のインスタンスから、トレーニングに80を使用し、テスト目的に20を使用します。予測したい値は、町の住宅価格の中央値です。使用する5つの予測子を見てみましょう-
Crime per capita in the town −この予測子には小さい値が関連付けられると予想されます。
Proportion of owner -1940年より前に建てられた占有ユニット-値が大きいほど古い家を意味するため、この予測子には小さい値が関連付けられると予想されます。
Weighed distance of the town to five Boston employment centers.
Area school pupil-to-teacher ratio.
An indirect metric of the proportion of black residents in the town.
トレーニングとテストファイルの準備
以前と同様に、最初に生データをCNTK形式に変換する必要があります。最初の80個のデータ項目をトレーニング目的で使用するため、タブ区切りのCNTK形式は次のようになります。
|predictors 1.612820 96.90 3.76 21.00 248.31 |medval 13.50
|predictors 0.064170 68.20 3.36 19.20 396.90 |medval 18.90
|predictors 0.097440 61.40 3.38 19.20 377.56 |medval 20.00
. . .次の20個のアイテムもCNTK形式に変換され、テスト目的で使用されます。
回帰モデルの構築
まず、CNTK形式のデータファイルを処理する必要があります。そのために、という名前のヘルパー関数を使用します。 create_reader 次のように-
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='predictors', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='medval', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src次に、CNTKミニバッチオブジェクトを受け入れ、カスタム精度メトリックを計算するヘルパー関数を作成する必要があります。
def mb_accuracy(mb, x_var, y_var, model, delta):
num_correct = 0
num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
v = model.eval(x_mat[i])
y = y_mat[i]
if np.abs(v[0,0] – y[0,0]) < delta:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)次に、NNのアーキテクチャ引数を設定し、データファイルの場所も指定する必要があります。それは次のPythonコードの助けを借りて行うことができます-
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 5
hidden_dim = 20
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file(80 data items)
test_file = ".\\...\\" #provide the name of the test file(20 data items)さて、次のコード行の助けを借りて、私たちのプログラムは訓練されていないNNを作成します-
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = C.ops.alias(oLayer)ここで、トレーニングされていないデュアルモデルを作成したら、Learnerアルゴリズムオブジェクトを設定する必要があります。SGDラーナーを使用してsquared_error 損失関数-
tr_loss = C.squared_error(model, Y)
max_iter = 3000
batch_size = 5
base_learn_rate = 0.02
sch=C.learning_parameter_schedule([base_learn_rate, base_learn_rate/2], minibatch_size=batch_size, epoch_size=int((max_iter*batch_size)/2))
learner = C.sgd(model.parameters, sch)
trainer = C.Trainer(model, (tr_loss), [learner])ここで、学習アルゴリズムオブジェクトを終了したら、トレーニングデータを読み取るためのリーダー関数を作成する必要があります-
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }さて、NNモデルをトレーニングする時が来ました-
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=boston_input_map) trainer.train_minibatch(curr_batch)
if i % int(max_iter/10) == 0:
mcee = trainer.previous_minibatch_loss_average
acc = mb_accuracy(curr_batch, X, Y, model, delta=3.00)
print("batch %4d: mean squared error = %8.4f, accuracy = %5.2f%% " \ % (i, mcee, acc))トレーニングが終わったら、テストデータ項目を使用してモデルを評価しましょう-
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=boston_input_map)
acc = mb_accuracy(all_test, X, Y, model, delta=3.00)
print("Prediction accuracy = %0.2f%%" % acc)トレーニング済みのNNモデルの精度を評価した後、それを使用して、見えないデータの予測を行います。
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])完全な回帰モデル
import numpy as np
import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='predictors', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='medval', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def mb_accuracy(mb, x_var, y_var, model, delta):
num_correct = 0
num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
v = model.eval(x_mat[i])
y = y_mat[i]
if np.abs(v[0,0] – y[0,0]) < delta:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 5
hidden_dim = 20
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file(80 data items)
test_file = ".\\...\\" #provide the name of the test file(20 data items)
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = C.ops.alias(oLayer)
tr_loss = C.squared_error(model, Y)
max_iter = 3000
batch_size = 5
base_learn_rate = 0.02
sch = C.learning_parameter_schedule([base_learn_rate, base_learn_rate/2], minibatch_size=batch_size, epoch_size=int((max_iter*batch_size)/2))
learner = C.sgd(model.parameters, sch)
trainer = C.Trainer(model, (tr_loss), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=boston_input_map) trainer.train_minibatch(curr_batch)
if i % int(max_iter/10) == 0:
mcee = trainer.previous_minibatch_loss_average
acc = mb_accuracy(curr_batch, X, Y, model, delta=3.00)
print("batch %4d: mean squared error = %8.4f, accuracy = %5.2f%% " \ % (i, mcee, acc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=boston_input_map)
acc = mb_accuracy(all_test, X, Y, model, delta=3.00)
print("Prediction accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])
if __name__== ”__main__”:
main()出力
Using CNTK version = 2.7
batch 0: mean squared error = 385.6727, accuracy = 0.00%
batch 300: mean squared error = 41.6229, accuracy = 20.00%
batch 600: mean squared error = 28.7667, accuracy = 40.00%
batch 900: mean squared error = 48.6435, accuracy = 40.00%
batch 1200: mean squared error = 77.9562, accuracy = 80.00%
batch 1500: mean squared error = 7.8342, accuracy = 60.00%
batch 1800: mean squared error = 47.7062, accuracy = 60.00%
batch 2100: mean squared error = 40.5068, accuracy = 40.00%
batch 2400: mean squared error = 46.5023, accuracy = 40.00%
batch 2700: mean squared error = 15.6235, accuracy = 60.00%
Evaluating test data
Prediction accuracy = 64.00%
Predicting median home value for feature/predictor values:
[0.09 50. 4.5 17. 350.]
Predicted value is:
$21.02(x1000)トレーニング済みモデルの保存
このボストンホームの価値データセットには、506個のデータ項目しかありません(そのうち100個だけを訴えました)。したがって、NNリグレッサモデルのトレーニングには数秒しかかかりませんが、数百または数千のデータ項目を含む大規模なデータセットでのトレーニングには数時間または数日かかる場合があります。
モデルを保存できるので、最初からモデルを保持する必要がありません。次のPythonコードの助けを借りて、トレーニング済みのNNを保存できます-
nn_regressor = “.\\neuralregressor.model” #provide the name of the file
model.save(nn_regressor, format=C.ModelFormat.CNTKv2)以下は、上記で使用したsave()関数の引数です。
ファイル名はの最初の引数です save()関数。ファイルのパスと一緒に書き込むこともできます。
別のパラメータは format デフォルト値を持つパラメータ C.ModelFormat.CNTKv2。
トレーニング済みモデルの読み込み
トレーニング済みモデルを保存すると、そのモデルを簡単にロードできます。load()関数を使用するだけで済みます。次の例でこれを確認しましょう-
import numpy as np
import cntk as C
model = C.ops.functions.Function.load(“.\\neuralregressor.model”)
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting area median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])保存されたモデルの利点は、保存されたモデルをロードすると、モデルがトレーニングされたばかりの場合とまったく同じように使用できることです。
CNTK-分類モデル
この章は、CNTKで分類モデルのパフォーマンスを測定する方法を理解するのに役立ちます。混同行列から始めましょう。
混同行列
混同行列-予測出力と期待出力の表は、分類問題のパフォーマンスを測定する最も簡単な方法です。出力は2つ以上のタイプのクラスである可能性があります。
それがどのように機能するかを理解するために、クレジットカード取引が正常であったか不正であるかを予測するバイナリ分類モデルの混同行列を作成します。次のように表示されます-
| 実際の詐欺 | 実際の正常 | |
|---|---|---|
| Predicted fraud |
真のポジティブ |
偽陽性 |
| Predicted normal |
偽陰性 |
真のネガティブ |
ご覧のとおり、上記のサンプル混同行列には2つの列が含まれています。1つはクラス詐欺用で、もう1つはクラス通常用です。2つの行があるのと同じように、1つはクラス詐欺用に追加され、もう1つはクラス通常用に追加されます。以下は、混同行列に関連する用語の説明です。
True Positives −データポイントの実際のクラスと予測されたクラスの両方が1の場合。
True Negatives −データポイントの実際のクラスと予測されたクラスの両方が0の場合。
False Positives −データポイントの実際のクラスが0で、データポイントの予測クラスが1の場合。
False Negatives −データポイントの実際のクラスが1で、データポイントの予測クラスが0の場合。
混同行列からさまざまなものの数を計算する方法を見てみましょう-
Accuracy−これは、ML分類モデルによって行われた正しい予測の数です。次の式を使用して計算できます-
Precision-予測したすべてのサンプルのうち、正しく予測されたサンプルの数がわかります。次の式を使用して計算できます-
Recall or Sensitivity−リコールは、ML分類モデルによって返されたポジティブの数です。つまり、データセット内の不正事例のうち、モデルによって実際に検出されたものの数がわかります。次の式を使用して計算できます-
Specificity−思い出すのとは反対に、ML分類モデルによって返されるネガの数を示します。次の式を使用して計算できます-




Fメジャー
混同行列の代わりにFメジャーを使用できます。この背後にある主な理由は、再現率と適合率を同時に最大化できないことです。これらの指標の間には非常に強い関係があり、それは次の例の助けを借りて理解することができます-
DLモデルを使用して、細胞サンプルを癌性または正常として分類するとします。ここで、最大の精度に到達するには、予測の数を1に減らす必要があります。ただし、これにより約100%の精度に到達できますが、再現率は非常に低くなります。
一方、最大のリコールを達成したい場合は、できるだけ多くの予測を行う必要があります。これにより、約100%のリコールに到達できますが、精度は非常に低くなります。
実際には、適合率と再現率のバランスをとる方法を見つける必要があります。Fメジャーメトリックは、適合率と再現率の間の調和平均を表すため、これを行うことができます。

この式はF1メジャーと呼ばれ、適合率と再現率の比率を等しくするために、Bと呼ばれる追加の項が1に設定されます。想起を強調するために、係数Bを2に設定できます。一方、精度を強調するために、係数Bを0.5に設定できます。
CNTKを使用した分類パフォーマンスの測定
前のセクションでは、アイリスフラワーデータセットを使用して分類モデルを作成しました。ここでは、混同行列とFメジャーメトリックを使用してそのパフォーマンスを測定します。
混同行列の作成
すでにモデルを作成しているので、検証プロセスを開始できます。 confusion matrix、同じように。まず、の助けを借りて混同行列を作成しますconfusion_matrix からの機能 scikit-learn。このためには、テストサンプルの実際のラベルと同じテストサンプルの予測ラベルが必要です。
次のPythonコードを使用して混同行列を計算しましょう-
from sklearn.metrics import confusion_matrix
y_true = np.argmax(y_test, axis=1)
y_pred = np.argmax(z(X_test), axis=1)
matrix = confusion_matrix(y_true=y_true, y_pred=y_pred)
print(matrix)出力
[[10 0 0]
[ 0 1 9]
[ 0 0 10]]ヒートマップ関数を使用して、次のように混同行列を視覚化することもできます。
import seaborn as sns
import matplotlib.pyplot as plt
g = sns.heatmap(matrix,
annot=True,
xticklabels=label_encoder.classes_.tolist(),
yticklabels=label_encoder.classes_.tolist(),
cmap='Blues')
g.set_yticklabels(g.get_yticklabels(), rotation=0)
plt.show()
また、モデルを比較するために使用できる単一のパフォーマンス数値が必要です。このために、を使用して分類誤差を計算する必要がありますclassification_error 分類モデルの作成中に行われた、CNTKのメトリックパッケージからの関数。
次に、分類エラーを計算するために、データセットを使用して損失関数でテストメソッドを実行します。その後、CNTKは、この関数の入力として提供したサンプルを取得し、入力特徴X_に基づいて予測を行います。test。
loss.test([X_test, y_test])出力
{'metric': 0.36666666666, 'samples': 30}Fメジャーの実装
F-Measuresを実装するために、CNTKにはfmeasuresと呼ばれる関数も含まれています。セルを交換することでNNをトレーニングしながら、この機能を使用できますcntk.metrics.classification_error、への呼び出しで cntk.losses.fmeasure 基準ファクトリ関数を次のように定義する場合-
import cntk
@cntk.Function
def criterion_factory(output, target):
loss = cntk.losses.cross_entropy_with_softmax(output, target)
metric = cntk.losses.fmeasure(output, target)
return loss, metriccntk.losses.fmeasure関数を使用した後、異なる出力が得られます。 loss.test 次のように与えられたメソッド呼び出し-
loss.test([X_test, y_test])出力
{'metric': 0.83101488749, 'samples': 30}CNTK-回帰モデル
ここでは、回帰モデルに関するパフォーマンスの測定について学習します。
回帰モデルの検証の基本
回帰モデルは分類モデルとは異なることがわかっているので、個人のサンプルの正誤のバイナリ測定値はありません。回帰モデルでは、予測が実際の値にどれだけ近いかを測定する必要があります。予測値が期待される出力に近いほど、モデルのパフォーマンスは向上します。
ここでは、さまざまなエラー率関数を使用して、回帰に使用されるNNのパフォーマンスを測定します。
エラーマージンの計算
前に説明したように、回帰モデルを検証している間、予測が正しいか間違っているかを判断することはできません。予測をできるだけ実際の値に近づけたいと考えています。ただし、ここではわずかな許容誤差が許容されます。
許容誤差の計算式は次のとおりです。

ここに、
Predicted value =帽子でyを示す
Real value = yによって予測
まず、予測値と実際の値の間の距離を計算する必要があります。次に、全体的なエラー率を取得するには、これらの2乗距離を合計し、平均を計算する必要があります。これは、mean squared エラー関数。
ただし、許容誤差を表すパフォーマンスの数値が必要な場合は、絶対誤差を表す式が必要です。の式mean absolute 誤差関数は次のとおりです-

上記の式は、予測値と実際の値の間の絶対距離を取ります。
CNTKを使用した回帰パフォーマンスの測定
ここでは、CNTKと組み合わせて説明したさまざまなメトリックの使用方法を見ていきます。以下の手順を使用して、自動車の1ガロンあたりのマイル数を予測する回帰モデルを使用します。
実装手順-
Step 1 −まず、必要なコンポーネントをからインポートする必要があります cntk 次のようにパッケージ-
from cntk import default_option, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import reluStep 2 −次に、を使用してデフォルトの活性化関数を定義する必要があります。 default_options関数。次に、新しいシーケンシャルレイヤーセットを作成し、それぞれ64個のニューロンを持つ2つの高密度レイヤーを提供します。次に、追加の高密度レイヤー(出力レイヤーとして機能します)をシーケンシャルレイヤーセットに追加し、次のようにアクティブ化せずに1つのニューロンを与えます-
with default_options(activation=relu):
model = Sequential([Dense(64),Dense(64),Dense(1,activation=None)])Step 3−ネットワークが作成されたら、入力フィーチャを作成する必要があります。トレーニングに使用する機能と同じ形状であることを確認する必要があります。
features = input_variable(X.shape[1])Step 4 −次に、別のものを作成する必要があります input_variable サイズ1。NNの期待値を格納するために使用されます。
target = input_variable(1)
z = model(features)ここで、モデルをトレーニングする必要があります。そのために、データセットを分割し、次の実装手順を使用して前処理を実行します。
Step 5−まず、sklearn.preprocessingからStandardScalerをインポートして、-1から+1までの値を取得します。これは、NNでの勾配問題の爆発を防ぐのに役立ちます。
from sklearn.preprocessing import StandardScalarStep 6 −次に、次のようにsklearn.model_selectionからtrain_test_splitをインポートします−
from sklearn.model_selection import train_test_splitStep 7 −ドロップ mpg を使用してデータセットの列 drop方法。最後に、データセットをトレーニングと検証のセットに分割します。train_test_split 次のように機能します-
x = df_cars.drop(columns=[‘mpg’]).values.astype(np.float32)
y=df_cars.iloc[: , 0].values.reshape(-1, 1).astype(np.float32)
scaler = StandardScaler()
X = scaler.fit_transform(x)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Step 8 −ここで、サイズ1の別のinput_variableを作成する必要があります。これはNNの期待値を格納するために使用されます。
target = input_variable(1)
z = model(features)データを分割して前処理したので、NNをトレーニングする必要があります。回帰モデルの作成中に前のセクションで行ったように、損失と損失の組み合わせを定義する必要がありますmetric モデルをトレーニングする関数。
import cntk
def absolute_error(output, target):
return cntk.ops.reduce_mean(cntk.ops.abs(output – target))
@ cntk.Function
def criterion_factory(output, target):
loss = squared_error(output, target)
metric = absolute_error(output, target)
return loss, metricそれでは、トレーニング済みモデルの使用方法を見てみましょう。このモデルでは、損失とメトリックの組み合わせとしてcriteria_factoryを使用します。
from cntk.losses import squared_error
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_printer = ProgressPrinter(0)
loss = criterion_factory (z, target)
learner = sgd(z.parameters, 0.001)
training_summary=loss.train((x_train,y_train),parameter_learners=[learner],callbacks=[progress_printer],minibatch_size=16,max_epochs=10)完全な実装例
from cntk import default_option, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import relu
with default_options(activation=relu):
model = Sequential([Dense(64),Dense(64),Dense(1,activation=None)])
features = input_variable(X.shape[1])
target = input_variable(1)
z = model(features)
from sklearn.preprocessing import StandardScalar
from sklearn.model_selection import train_test_split
x = df_cars.drop(columns=[‘mpg’]).values.astype(np.float32)
y=df_cars.iloc[: , 0].values.reshape(-1, 1).astype(np.float32)
scaler = StandardScaler()
X = scaler.fit_transform(x)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
target = input_variable(1)
z = model(features)
import cntk
def absolute_error(output, target):
return cntk.ops.reduce_mean(cntk.ops.abs(output – target))
@ cntk.Function
def criterion_factory(output, target):
loss = squared_error(output, target)
metric = absolute_error(output, target)
return loss, metric
from cntk.losses import squared_error
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_printer = ProgressPrinter(0)
loss = criterion_factory (z, target)
learner = sgd(z.parameters, 0.001)
training_summary=loss.train((x_train,y_train),parameter_learners=[learner],callbacks=[progress_printer],minibatch_size=16,max_epochs=10)出力
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.001
690 690 24.9 24.9 16
654 636 24.1 23.7 48
[………]回帰モデルを検証するには、モデルがトレーニングデータと同じように新しいデータを処理することを確認する必要があります。このために、を呼び出す必要がありますtest 上の方法 loss そして metric 次のようなテストデータとの組み合わせ-
loss.test([X_test, y_test])出力-
{'metric': 1.89679785619, 'samples': 79}CNTK-メモリ不足のデータセット
この章では、メモリ不足のデータセットのパフォーマンスを測定する方法について説明します。
前のセクションでは、NNのパフォーマンスを検証するためのさまざまな方法について説明しましたが、説明した方法は、メモリに収まるデータセットを処理する方法です。
ここで、メモリ不足のデータセットについてはどうでしょうか。本番シナリオでは、トレーニングに大量のデータが必要になるためです。 NN。このセクションでは、ミニバッチソースと手動ミニバッチループを使用する場合のパフォーマンスを測定する方法について説明します。
ミニバッチソース
メモリ不足のデータセット、つまりミニバッチソースを操作する場合、小さなデータセット、つまりメモリ内のデータセットを操作するときに使用した設定とは、損失とメトリックの設定が少し異なります。まず、NNモデルのトレーナーにデータをフィードする方法を設定する方法を説明します。
以下は実装手順です-
Step 1 −まず、 cntk.ioモジュールは、ミニバッチソースを作成するためのコンポーネントを次のようにインポートします-
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer,
INFINITY_REPEATStep 2 −次に、sayという名前の新しい関数を作成します create_datasource。この関数には、filenameとlimitの2つのパラメーターがあり、デフォルト値はINFINITELY_REPEAT。
def create_datasource(filename, limit =INFINITELY_REPEAT)Step 3 −関数内で、 StreamDefクラスは、3つの機能を持つlabelsフィールドから読み取るラベルのストリーム定義を作成します。また、設定する必要がありますis_sparse に False 次のように-
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)Step 4 −次に、入力ファイルからファイルされたフィーチャを読み取るために作成し、次の別のインスタンスを作成します。 StreamDef 次のように。
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)Step 5 −ここで、を初期化します CTFDeserializerインスタンスクラス。デシリアライズする必要のあるファイル名とストリームを次のように指定します-
deserializer = CTFDeserializer(filename, StreamDefs(labels=
label_stream, features=features_stream)Step 6 −次に、次のようにデシリアライザーを使用してminisourceBatchのインスタンスを作成する必要があります−
Minibatch_source = MinibatchSource(deserializer, randomize=True, max_sweeps=limit)
return minibatch_sourceStep 7−最後に、前のセクションでも作成したトレーニングとテストのソースを提供する必要があります。アイリスフラワーデータセットを使用しています。
training_source = create_datasource(‘Iris_train.ctf’)
test_source = create_datasource(‘Iris_test.ctf’, limit=1)作成したら MinibatchSourceたとえば、トレーニングする必要があります。小さなメモリ内データセットで作業したときに使用したものと同じトレーニングロジックを使用できます。ここでは、MinibatchSource たとえば、損失関数のトレインメソッドの入力として次のようになります。
以下は実装手順です-
Step 1 −トレーニングセッションの出力をログに記録するには、最初に ProgressPrinter から cntk.logging 次のようにモジュール-
from cntk.logging import ProgressPrinterStep 2 −次に、トレーニングセッションを設定するには、 trainer そして training_session から cntk.train 次のようにモジュール-
from cntk.train import Trainer, training_sessionStep 3 −次に、次のような定数のセットを定義する必要があります。 minibatch_size、 samples_per_epoch そして num_epochs 次のように-
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
max_samples = samples_per_epoch * num_epochsStep 4 −次に、CNTKでのトレーニング中にデータを読み取る方法を知るために、ネットワークの入力変数とミニバッチソースのストリームの間のマッピングを定義する必要があります。
input_map = {
features: training_source.streams.features,
labels: training_source.streams.labels
}Step 5 −次に、トレーニングプロセスの出力をログに記録するために、 progress_printer 新しい変数 ProgressPrinterインスタンス。また、を初期化しますtrainer 次のようにモデルを提供します-
progress_writer = ProgressPrinter(0)
trainer: training_source.streams.labelsStep 6 −最後に、トレーニングプロセスを開始するには、 training_session 次のように機能します-
session = training_session(trainer,
mb_source=training_source,
mb_size=minibatch_size,
model_inputs_to_streams=input_map,
max_samples=max_samples,
test_config=test_config)
session.train()モデルをトレーニングしたら、を使用してこの設定に検証を追加できます。 TestConfig オブジェクトを作成し、に割り当てます test_config のキーワード引数 train_session 関数。
以下は実装手順です-
Step 1 −まず、インポートする必要があります TestConfig モジュールからのクラス cntk.train 次のように-
from cntk.train import TestConfigStep 2 −次に、の新しいインスタンスを作成する必要があります TestConfig とともに test_source 入力として-
Test_config = TestConfig(test_source)完全な例
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer, INFINITY_REPEAT
def create_datasource(filename, limit =INFINITELY_REPEAT)
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(labels=label_stream, features=features_stream)
Minibatch_source = MinibatchSource(deserializer, randomize=True, max_sweeps=limit)
return minibatch_source
training_source = create_datasource(‘Iris_train.ctf’)
test_source = create_datasource(‘Iris_test.ctf’, limit=1)
from cntk.logging import ProgressPrinter
from cntk.train import Trainer, training_session
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
max_samples = samples_per_epoch * num_epochs
input_map = {
features: training_source.streams.features,
labels: training_source.streams.labels
}
progress_writer = ProgressPrinter(0)
trainer: training_source.streams.labels
session = training_session(trainer,
mb_source=training_source,
mb_size=minibatch_size,
model_inputs_to_streams=input_map,
max_samples=max_samples,
test_config=test_config)
session.train()
from cntk.train import TestConfig
Test_config = TestConfig(test_source)出力
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.57 1.57 0.214 0.214 16
1.38 1.28 0.264 0.289 48
[………]
Finished Evaluation [1]: Minibatch[1-1]:metric = 69.65*30;手動ミニバッチループ
上記のように、CNTKで通常のAPIを使用してトレーニングするときにメトリックを使用することで、トレーニング中およびトレーニング後のNNモデルのパフォーマンスを簡単に測定できます。しかし、一方で、手動のミニバッチループで作業している間は、物事はそれほど簡単ではありません。
ここでは、前のセクションでも作成したIrisFlowerデータセットからの4つの入力と3つの出力を使用して以下のモデルを使用しています-
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, relu, sigmoid
from cntk.learners import sgd
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
labels = input_variable(3)
z = model(features)次に、モデルの損失は、クロスエントロピー損失関数と、前のセクションで使用したFメジャーメトリックの組み合わせとして定義されます。を使用しますcriterion_factory 以下に示すように、これをCNTK関数オブジェクトとして作成するユーティリティ。
import cntk
from cntk.losses import cross_entropy_with_softmax, fmeasure
@cntk.Function
def criterion_factory(outputs, targets):
loss = cross_entropy_with_softmax(outputs, targets)
metric = fmeasure(outputs, targets, beta=1)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, 0.1)
label_mapping = {
'Iris-setosa': 0,
'Iris-versicolor': 1,
'Iris-virginica': 2
}ここで、損失関数を定義したので、それをトレーナーで使用して、手動トレーニングセッションを設定する方法を見ていきます。
以下は実装手順です-
Step 1 −まず、次のような必要なパッケージをインポートする必要があります。 numpy そして pandas データをロードして前処理します。
import pandas as pd
import numpy as npStep 2 −次に、トレーニング中に情報をログに記録するために、 ProgressPrinter 次のようにクラス-
from cntk.logging import ProgressPrinterStep 3 −次に、次のようにcntk.trainモジュールからトレーナーモジュールをインポートする必要があります−
from cntk.train import TrainerStep 4 −次に、の新しいインスタンスを作成します ProgressPrinter 次のように-
progress_writer = ProgressPrinter(0)Step 5 −ここで、損失、学習者、およびパラメータを使用してトレーナーを初期化する必要があります。 progress_writer 次のように-
trainer = Trainer(z, loss, learner, progress_writer)Step 6−次に、モデルをトレーニングするために、データセットを30回反復するループを作成します。これが外側のトレーニングループになります。
for _ in range(0,30):Step 7−次に、パンダを使用してディスクからデータをロードする必要があります。次に、データセットをロードするためにmini-batches、 をセットする chunksize 16へのキーワード引数。
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)Step 8 −次に、ループの内部トレーニングを作成して、各ループを反復処理します。 mini-batches。
for df_batch in input_data:Step 9 −このループ内で、を使用して最初の4列を読み取ります。 iloc インデクサ、 features トレーニングしてfloat32に変換する-
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)Step 10 −次に、最後の列をトレーニングのラベルとして次のように読み取ります。
label_values = df_batch.iloc[:,-1]Step 11 −次に、ワンホットベクトルを使用して、次のようにラベル文字列を数値表示に変換します。
label_values = label_values.map(lambda x: label_mapping[x])Step 12−その後、ラベルの数値表示を行います。次に、それらをnumpy配列に変換して、次のように操作しやすくします。
label_values = label_values.valuesStep 13 −次に、変換したラベル値と同じ行数を持つ新しいnumpy配列を作成する必要があります。
encoded_labels = np.zeros((label_values.shape[0], 3))Step 14 −ここで、ワンホットエンコードされたラベルを作成するために、数値のラベル値に基づいて列を選択します。
encoded_labels[np.arange(label_values.shape[0]), label_values] = 1.Step 15 −最後に、を呼び出す必要があります train_minibatch トレーナーのメソッドとミニバッチの処理された機能とラベルを提供します。
trainer.train_minibatch({features: feature_values, labels: encoded_labels})完全な例
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, relu, sigmoid
from cntk.learners import sgd
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
labels = input_variable(3)
z = model(features)
import cntk
from cntk.losses import cross_entropy_with_softmax, fmeasure
@cntk.Function
def criterion_factory(outputs, targets):
loss = cross_entropy_with_softmax(outputs, targets)
metric = fmeasure(outputs, targets, beta=1)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, 0.1)
label_mapping = {
'Iris-setosa': 0,
'Iris-versicolor': 1,
'Iris-virginica': 2
}
import pandas as pd
import numpy as np
from cntk.logging import ProgressPrinter
from cntk.train import Trainer
progress_writer = ProgressPrinter(0)
trainer = Trainer(z, loss, learner, progress_writer)
for _ in range(0,30):
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)
for df_batch in input_data:
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)
label_values = df_batch.iloc[:,-1]
label_values = label_values.map(lambda x: label_mapping[x])
label_values = label_values.values
encoded_labels = np.zeros((label_values.shape[0], 3))
encoded_labels[np.arange(label_values.shape[0]),
label_values] = 1.
trainer.train_minibatch({features: feature_values, labels: encoded_labels})出力
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.45 1.45 -0.189 -0.189 16
1.24 1.13 -0.0382 0.0371 48
[………]上記の出力では、トレーニング中の損失の出力とメトリックの両方を取得しました。これは、関数オブジェクトでメトリックと損失を組み合わせ、トレーナー構成で進行状況プリンターを使用したためです。
ここで、モデルのパフォーマンスを評価するには、モデルのトレーニングと同じタスクを実行する必要がありますが、今回は、 Evaluatorモデルをテストするインスタンス。次のPythonコードで示されています-
from cntk import Evaluator
evaluator = Evaluator(loss.outputs[1], [progress_writer])
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)
for df_batch in input_data:
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)
label_values = df_batch.iloc[:,-1]
label_values = label_values.map(lambda x: label_mapping[x])
label_values = label_values.values
encoded_labels = np.zeros((label_values.shape[0], 3))
encoded_labels[np.arange(label_values.shape[0]), label_values] = 1.
evaluator.test_minibatch({ features: feature_values, labels:
encoded_labels})
evaluator.summarize_test_progress()ここで、次のような出力が得られます。
出力
Finished Evaluation [1]: Minibatch[1-11]:metric = 74.62*143;CNTK-モデルの監視
この章では、CNTKでモデルを監視する方法を理解します。
前書き
前のセクションでは、NNモデルでいくつかの検証を行いました。しかし、トレーニング中にモデルを監視することも必要であり、可能ですか?
はい、すでに使用しています ProgressWriterモデルを監視するクラスがあり、それを行う方法は他にもたくさんあります。方法を深く理解する前に、まず、CNTKでの監視がどのように機能し、それを使用してNNモデルの問題を検出する方法を見てみましょう。
CNTKでのコールバック
実際、トレーニングと検証中に、CNTKではAPIのいくつかの場所でコールバックを指定できます。まず、CNTKがコールバックを呼び出すタイミングを詳しく見てみましょう。
CNTKがコールバックを呼び出すのはいつですか?
CNTKは、トレーニングとテストの設定された瞬間にコールバックを呼び出します。
ミニバッチが完了しました。
データセットの完全なスイープは、トレーニング中に完了します。
テストのミニバッチが完了しました。
データセットの完全なスイープは、テスト中に完了します。
コールバックの指定
CNTKを使用している間、APIのいくつかの場所でコールバックを指定できます。例-
損失関数で列車を呼び出すときは?
ここで、損失関数でtrainを呼び出すと、次のように、callbacks引数を介して一連のコールバックを指定できます。
training_summary=loss.train((x_train,y_train),
parameter_learners=[learner],
callbacks=[progress_writer]),
minibatch_size=16, max_epochs=15)ミニバッチソースを使用する場合、または手動ミニバッチループを使用する場合-
この場合、作成中に監視目的でコールバックを指定できます Trainer 次のように-
from cntk.logging import ProgressPrinter
callbacks = [
ProgressPrinter(0)
]
Trainer = Trainer(z, (loss, metric), learner, [callbacks])さまざまな監視ツール
さまざまな監視ツールについて調べてみましょう。
ProgressPrinter
このチュートリアルを読んでいると、 ProgressPrinter最も使用されている監視ツールとして。の特徴のいくつかProgressPrinter 監視ツールは-
ProgressPrinterクラスは、モデルを監視するための基本的なコンソールベースのログを実装します。必要なディスクにログを記録できます。
分散トレーニングシナリオでの作業中に特に役立ちます。
また、コンソールにログインしてPythonプログラムの出力を確認できないシナリオで作業しているときにも非常に役立ちます。
次のコードの助けを借りて、次のインスタンスを作成できます ProgressPrinter−
ProgressPrinter(0, log_to_file=’test.txt’)前のセクションで見たものを出力します-
Test.txt
CNTKCommandTrainInfo: train : 300
CNTKCommandTrainInfo: CNTKNoMoreCommands_Total : 300
CNTKCommandTrainBegin: train
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.45 1.45 -0.189 -0.189 16
1.24 1.13 -0.0382 0.0371 48
[………]TensorBoard
ProgressPrinterを使用することの欠点の1つは、時間の経過に伴う損失とメトリックの進行がどのように難しいかをよく理解できないことです。TensorBoardProgressWriterは、CNTKのProgressPrinterクラスの優れた代替手段です。
使用する前に、次のコマンドを使用して最初にインストールする必要があります-
pip install tensorboardここで、TensorBoardを使用するには、セットアップする必要があります TensorBoardProgressWriter 次のようにトレーニングコードで-
import time
from cntk.logging import TensorBoardProgressWriter
tensorbrd_writer = TensorBoardProgressWriter(log_dir=’logs/{}’.format(time.time()),freq=1,model=z)closeメソッドを呼び出すことをお勧めします TensorBoardProgressWriter のトレーニングを終えた後のインスタンス NNモデル。
視覚化できます TensorBoard 次のコマンドを使用してデータをログに記録する-
Tensorboard –logdir logsCNTK-畳み込みニューラルネットワーク
この章では、CNTKで畳み込みニューラルネットワーク(CNN)を構築する方法を学習しましょう。
前書き
畳み込みニューラルネットワーク(CNN)もニューロンで構成されており、学習可能な重みとバイアスがあります。そのため、このように、通常のニューラルネットワーク(NN)のようになります。
通常のNNの動作を思い出すと、すべてのニューロンは1つ以上の入力を受け取り、加重和を取り、活性化関数を通過して最終出力を生成します。ここで、CNNと通常のNNに非常に多くの類似点がある場合、これら2つのネットワークが互いに異なる理由は何でしょうか。
それらの違いは、入力データとレイヤーのタイプの扱いです。通常のNNでは、入力データの構造は無視され、すべてのデータはネットワークに送られる前に1次元配列に変換されます。
ただし、畳み込みニューラルネットワークアーキテクチャは、画像の2D構造を考慮して処理し、画像に固有のプロパティを抽出できるようにします。さらに、CNNには、CNNの主要な構成要素である1つ以上の畳み込み層とプーリング層があるという利点があります。
これらの層の後には、標準の多層NNの場合と同様に、1つ以上の完全に接続された層が続きます。したがって、CNNは、完全に接続されたネットワークの特殊なケースと考えることができます。
畳み込みニューラルネットワーク(CNN)アーキテクチャ
CNNのアーキテクチャは、基本的に3次元、つまり画像ボリュームの幅、高さ、深さを3次元の出力ボリュームに変換するレイヤーのリストです。ここで注意すべき重要な点の1つは、現在の層のすべてのニューロンが前の層からの出力の小さなパッチに接続されていることです。これは、入力画像にN * Nフィルターをオーバーレイするようなものです。
基本的にエッジやコーナーなどの特徴を抽出する特徴抽出器であるMフィルターを使用します。以下はレイヤーです [INPUT-CONV-RELU-POOL-FC] 畳み込みニューラルネットワーク(CNN)の構築に使用される-
INPUT−名前が示すように、このレイヤーは生のピクセル値を保持します。生のピクセル値は、画像のデータをそのまま意味します。たとえば、INPUT [64×64×3]は、幅64、高さ64、奥行き3の3チャンネルのRGB画像です。
CONV−ほとんどの計算はこの層で行われるため、この層はCNNの構成要素の1つです。例-上記のINPUT [64×64×3]で6つのフィルターを使用すると、ボリューム[64×64×6]になる可能性があります。
RELU−前の層の出力に活性化関数を適用する、正規化線形ユニット層とも呼ばれます。他の方法では、非線形性はRELUによってネットワークに追加されます。
POOL−この層、つまりプーリング層は、CNNのもう1つの構成要素です。このレイヤーの主なタスクはダウンサンプリングです。つまり、入力のすべてのスライスで独立して動作し、空間的にサイズを変更します。
FC−完全接続層、より具体的には出力層と呼ばれます。これは、出力クラススコアの計算に使用され、結果の出力は、サイズ1 * 1 * Lのボリュームです。ここで、Lはクラススコアに対応する数値です。
次の図は、CNNの典型的なアーキテクチャを表しています-

CNN構造の作成
CNNのアーキテクチャと基本を見てきたので、次にCNTKを使用して畳み込みネットワークを構築します。ここでは、最初にCNNの構造をまとめる方法を確認し、次にCNNのパラメーターをトレーニングする方法を確認します。
最後に、さまざまな異なるレイヤー設定でその構造を変更することにより、ニューラルネットワークをどのように改善できるかを見ていきます。MNIST画像データセットを使用します。
それでは、最初にCNN構造を作成しましょう。一般に、画像のパターンを認識するためのCNNを構築する場合、次のことを行います。
畳み込みレイヤーとプーリングレイヤーを組み合わせて使用します。
ネットワークの最後にある1つ以上の隠れ層。
最後に、分類のためにソフトマックス層でネットワークを完成させます。
次の手順の助けを借りて、ネットワーク構造を構築できます-
Step 1−まず、CNNに必要なレイヤーをインポートする必要があります。
from cntk.layers import Convolution2D, Sequential, Dense, MaxPoolingStep 2−次に、CNNの活性化関数をインポートする必要があります。
from cntk.ops import log_softmax, reluStep 3−その後、畳み込み層を後で初期化するために、インポートする必要があります glorot_uniform_initializer 次のように-
from cntk.initializer import glorot_uniformStep 4−次に、入力変数を作成するには、 input_variable関数。そしてインポートdefault_option 関数、NNの構成を少し簡単にします。
from cntk import input_variable, default_optionsStep 5−入力画像を保存するには、新しい画像を作成します input_variable。赤、緑、青の3つのチャンネルが含まれます。サイズは28x28ピクセルになります。
features = input_variable((3,28,28))Step 6−次に、別のものを作成する必要があります input_variable 予測するラベルを保存します。
labels = input_variable(10)Step 7−次に、を作成する必要があります default_optionNNのために。そして、私たちは使用する必要がありますglorot_uniform 初期化関数として。
with default_options(initialization=glorot_uniform, activation=relu):Step 8−次に、NNの構造を設定するために、新しいものを作成する必要があります Sequential レイヤーセット。
Step 9−次に、を追加する必要があります Convolutional2D との層 filter_shape 5のと strides の設定 1、 以内 Sequentialレイヤーセット。また、パディングを有効にして、元のサイズを維持するために画像がパディングされるようにします。
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),Step 10−次に、を追加します。 MaxPooling との層 filter_shape 2の、そして strides 画像を半分に圧縮するには2に設定します。
MaxPooling(filter_shape=(2,2), strides=(2,2)),Step 11−ここで、ステップ9で行ったように、別のを追加する必要があります Convolutional2D との層 filter_shape 5のと strides1に設定すると、16個のフィルターを使用します。また、パディングを有効にして、前のプーリングレイヤーによって生成された画像のサイズを保持するようにします。
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),Step 12−ここで、手順10で行ったように、別の MaxPooling との層 filter_shape 3と strides 3に設定すると、画像が3分の1に縮小されます。
MaxPooling(filter_shape=(3,3), strides=(3,3)),Step 13−最後に、ネットワークが予測できる10個の可能なクラスに対して10個のニューロンを持つ高密度レイヤーを追加します。ネットワークを分類モデルに変えるには、log_siftmax 活性化関数。
Dense(10, activation=log_softmax)
])CNN構造を作成するための完全な例
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling
from cntk.ops import log_softmax, relu
from cntk.initializer import glorot_uniform
from cntk import input_variable, default_options
features = input_variable((3,28,28))
labels = input_variable(10)
with default_options(initialization=glorot_uniform, activation=relu):
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),
MaxPooling(filter_shape=(2,2), strides=(2,2)),
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),
MaxPooling(filter_shape=(3,3), strides=(3,3)),
Dense(10, activation=log_softmax)
])
z = model(features)画像を使用したCNNのトレーニング
ネットワークの構造を作成したので、次はネットワークをトレーニングします。ただし、ネットワークのトレーニングを開始する前に、ミニバッチソースを設定する必要があります。これは、画像を処理するNNのトレーニングには、ほとんどのコンピューターよりも多くのメモリが必要になるためです。
前のセクションですでにミニバッチソースを作成しました。以下は、2つのミニバッチソースを設定するためのPythonコードです-
私たちが持っているように create_datasource 関数を使用すると、モデルをトレーニングするために2つの別々のデータソース(トレーニングとテスト)を作成できます。
train_datasource = create_datasource('mnist_train')
test_datasource = create_datasource('mnist_test', max_sweeps=1, train=False)これで、画像を準備したので、NNのトレーニングを開始できます。前のセクションで行ったように、損失関数でtrainメソッドを使用して、トレーニングを開始できます。以下はこのためのコードです-
from cntk import Function
from cntk.losses import cross_entropy_with_softmax
from cntk.metrics import classification_error
from cntk.learners import sgd
@Function
def criterion_factory(output, targets):
loss = cross_entropy_with_softmax(output, targets)
metric = classification_error(output, targets)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, lr=0.2)前のコードの助けを借りて、NNの損失と学習者を設定しました。次のコードは、NN-をトレーニングおよび検証します。
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
labels: train_datasource.streams.labels
}
loss.train(train_datasource,
max_epochs=10,
minibatch_size=64,
epoch_size=60000,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config])完全な実装例
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling
from cntk.ops import log_softmax, relu
from cntk.initializer import glorot_uniform
from cntk import input_variable, default_options
features = input_variable((3,28,28))
labels = input_variable(10)
with default_options(initialization=glorot_uniform, activation=relu):
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),
MaxPooling(filter_shape=(2,2), strides=(2,2)),
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),
MaxPooling(filter_shape=(3,3), strides=(3,3)),
Dense(10, activation=log_softmax)
])
z = model(features)
import os
from cntk.io import MinibatchSource, StreamDef, StreamDefs, ImageDeserializer, INFINITELY_REPEAT
import cntk.io.transforms as xforms
def create_datasource(folder, train=True, max_sweeps=INFINITELY_REPEAT):
mapping_file = os.path.join(folder, 'mapping.bin')
image_transforms = []
if train:
image_transforms += [
xforms.crop(crop_type='randomside', side_ratio=0.8),
xforms.scale(width=28, height=28, channels=3, interpolations='linear')
]
stream_definitions = StreamDefs(
features=StreamDef(field='image', transforms=image_transforms),
labels=StreamDef(field='label', shape=10)
)
deserializer = ImageDeserializer(mapping_file, stream_definitions)
return MinibatchSource(deserializer, max_sweeps=max_sweeps)
train_datasource = create_datasource('mnist_train')
test_datasource = create_datasource('mnist_test', max_sweeps=1, train=False)
from cntk import Function
from cntk.losses import cross_entropy_with_softmax
from cntk.metrics import classification_error
from cntk.learners import sgd
@Function
def criterion_factory(output, targets):
loss = cross_entropy_with_softmax(output, targets)
metric = classification_error(output, targets)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, lr=0.2)
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
labels: train_datasource.streams.labels
}
loss.train(train_datasource,
max_epochs=10,
minibatch_size=64,
epoch_size=60000,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config])出力
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.2
142 142 0.922 0.922 64
1.35e+06 1.51e+07 0.896 0.883 192
[………]画像変換
これまで見てきたように、画像認識に使用されるNNをトレーニングすることは困難であり、トレーニングにも大量のデータが必要です。もう1つの問題は、トレーニング中に使用される画像に過剰適合する傾向があることです。例を挙げてみましょう。直立した顔の写真がある場合、モデルは別の方向に回転している顔を認識するのに苦労します。
このような問題を克服するために、画像のミニバッチソースを作成するときに、画像拡張を使用でき、CNTKは特定の変換をサポートします。次のようにいくつかの変換を使用できます-
トレーニングに使用する画像を数行のコードでランダムにトリミングできます。
スケールやカラーもご利用いただけます。
次のPythonコードを使用して、以前にミニバッチソースを作成するために使用した関数内にトリミング変換を含めることにより、変換のリストを変更する方法を見てみましょう。
import os
from cntk.io import MinibatchSource, StreamDef, StreamDefs, ImageDeserializer, INFINITELY_REPEAT
import cntk.io.transforms as xforms
def create_datasource(folder, train=True, max_sweeps=INFINITELY_REPEAT):
mapping_file = os.path.join(folder, 'mapping.bin')
image_transforms = []
if train:
image_transforms += [
xforms.crop(crop_type='randomside', side_ratio=0.8),
xforms.scale(width=28, height=28, channels=3, interpolations='linear')
]
stream_definitions = StreamDefs(
features=StreamDef(field='image', transforms=image_transforms),
labels=StreamDef(field='label', shape=10)
)
deserializer = ImageDeserializer(mapping_file, stream_definitions)
return MinibatchSource(deserializer, max_sweeps=max_sweeps)上記のコードの助けを借りて、画像変換のセットを含めるように関数を拡張できます。これにより、トレーニング時に画像をランダムにトリミングして、画像のバリエーションを増やすことができます。
CNTK-リカレントニューラルネットワーク
ここで、CNTKでリカレントニューラルネットワーク(RNN)を構築する方法を理解しましょう。
前書き
ニューラルネットワークで画像を分類する方法を学びました。これはディープラーニングの象徴的な仕事の1つです。しかし、ニューラルネットワークが得意で多くの研究が行われているもう1つの分野は、リカレントニューラルネットワーク(RNN)です。ここでは、RNNとは何か、時系列データを処理する必要があるシナリオでRNNをどのように使用できるかを理解します。
リカレントニューラルネットワークとは何ですか?
リカレントニューラルネットワーク(RNN)は、時間の経過とともに推論できる特殊な種類のNNとして定義できます。RNNは主に、時間の経過とともに変化する値、つまり時系列データを処理する必要があるシナリオで使用されます。それをよりよく理解するために、通常のニューラルネットワークとリカレントニューラルネットワークを少し比較してみましょう-
ご存知のように、通常のニューラルネットワークでは、1つの入力しか提供できません。これにより、予測が1つだけになるように制限されます。例を挙げると、通常のニューラルネットワークを使用してテキストの翻訳ジョブを実行できます。
一方、リカレントニューラルネットワークでは、単一の予測をもたらす一連のサンプルを提供できます。言い換えると、RNNを使用して、入力シーケンスに基づいて出力シーケンスを予測できます。たとえば、翻訳タスクでRNNを使用した実験はかなり成功しています。
リカレントニューラルネットワークの使用
RNNはいくつかの方法で使用できます。それらのいくつかは次のとおりです-
単一の出力を予測する
手順を深く掘り下げる前に、RNNがシーケンスに基づいて単一の出力を予測する方法について、基本的なRNNがどのように見えるかを見てみましょう-

上の図でわかるように、RNNには入力へのループバック接続が含まれており、値のシーケンスをフィードすると、シーケンス内の各要素がタイムステップとして処理されます。
さらに、ループバック接続により、RNNは生成された出力をシーケンス内の次の要素の入力と組み合わせることができます。このようにして、RNNは、予測を行うために使用できるシーケンス全体にわたってメモリを構築します。
RNNで予測を行うために、次の手順を実行できます-
まず、初期の非表示状態を作成するには、入力シーケンスの最初の要素をフィードする必要があります。
その後、更新された非表示状態を生成するには、初期の非表示状態を取得して、入力シーケンスの2番目の要素と組み合わせる必要があります。
最後に、最終的な非表示状態を生成し、RNNの出力を予測するには、入力シーケンスの最後の要素を取得する必要があります。
このように、このループバック接続の助けを借りて、RNNに時間の経過とともに発生するパターンを認識するように教えることができます。
シーケンスの予測
上で説明したRNNの基本モデルは、他のユースケースにも拡張できます。たとえば、これを使用して、単一の入力に基づいて値のシーケンスを予測できます。このシナリオでは、RNNを使用して予測を行うために、次の手順を実行できます。
まず、初期の非表示状態を作成し、出力シーケンスの最初の要素を予測するには、入力サンプルをニューラルネットワークにフィードする必要があります。
その後、更新された非表示状態と出力シーケンスの2番目の要素を生成するには、初期の非表示状態を同じサンプルと組み合わせる必要があります。
最後に、非表示状態をもう一度更新し、出力シーケンスの最後の要素を予測するために、サンプルをもう一度フィードします。
シーケンスの予測
シーケンスに基づいて単一の値を予測する方法と、単一の値に基づいてシーケンスを予測する方法を見てきました。次に、シーケンスのシーケンスを予測する方法を見てみましょう。このシナリオでは、RNNを使用して予測を行うために、次の手順を実行できます。
まず、初期の非表示状態を作成し、出力シーケンスの最初の要素を予測するには、入力シーケンスの最初の要素を取得する必要があります。
その後、非表示状態を更新し、出力シーケンスの2番目の要素を予測するには、最初の非表示状態を取得する必要があります。
最後に、出力シーケンスの最後の要素を予測するには、更新された非表示状態と入力シーケンスの最後の要素を取得する必要があります。
RNNの働き
リカレントニューラルネットワーク(RNN)の動作を理解するには、まずネットワーク内のリカレント層がどのように機能するかを理解する必要があります。したがって、最初に、eが標準の反復層を使用して出力を予測する方法について説明しましょう。
標準のRNNレイヤーを使用した出力の予測
前に説明したように、RNNの基本レイヤーは、ニューラルネットワークの通常のレイヤーとはかなり異なります。前のセクションでは、RNNの基本的なアーキテクチャも図で示しました。初めてのステップインシーケンスの非表示状態を更新するには、次の式を使用できます。

上記の式では、初期の非表示状態と一連の重みの間の内積を計算することにより、新しい非表示状態を計算します。
次のステップでは、現在のタイムステップの非表示状態が、シーケンス内の次のタイムステップの初期非表示状態として使用されます。そのため、2番目のタイムステップの非表示状態を更新するには、次のように1番目のタイムステップで実行された計算を繰り返すことができます。
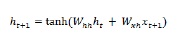
次に、以下のように、シーケンスの3番目の最後のステップで非表示状態を更新するプロセスを繰り返すことができます。

そして、上記のすべてのステップをシーケンスで処理したら、次のように出力を計算できます。

上記の式では、3番目の重みのセットと最後のタイムステップからの非表示状態を使用しました。
高度な回帰ユニット
基本的な反復層の主な問題は勾配消失問題であり、このため、長期的な相関関係の学習はあまり得意ではありません。簡単に言えば、基本的な反復層は長いシーケンスをうまく処理しません。これが、より長いシーケンスでの作業にはるかに適した他のいくつかの反復レイヤータイプが次のとおりである理由です。
長短期記憶(LSTM)

長短期記憶(LSTM)ネットワークは、Hochreiter&Schmidhuberによって導入されました。これにより、基本的な繰り返しレイヤーに長い間物事を記憶させるという問題が解決されました。LSTMのアーキテクチャは、上の図に示されています。ご覧のとおり、入力ニューロン、メモリセル、出力ニューロンがあります。勾配消失問題と戦うために、長短期記憶ネットワークは明示的記憶セル(以前の値を格納)と次のゲートを使用します-
Forget gate−名前が示すように、以前の値を忘れるようにメモリセルに指示します。メモリセルは、ゲート、つまり「ゲートを忘れる」が値を忘れるように指示するまで値を格納します。
Input gate−名前が示すように、セルに新しいものを追加します。
Output gate−名前が示すように、出力ゲートは、セルから次の非表示状態にベクトルを渡すタイミングを決定します。
ゲート付き回帰ユニット(GRU)

Gradient recurrent units(GRU)は、LSTMネットワークのわずかなバリエーションです。ゲートが1つ少なく、LSTMとはわずかに異なる配線になっています。そのアーキテクチャは上の図に示されています。入力ニューロン、ゲートメモリセル、および出力ニューロンがあります。ゲート付き回帰ユニットネットワークには、次の2つのゲートがあります-
Update gate−次の2つを決定します−
最後の状態からどのくらいの量の情報を保持する必要がありますか?
前のレイヤーからどのくらいの量の情報を取り込む必要がありますか?
Reset gate−リセットゲートの機能は、LSTMネットワークの忘却ゲートの機能とよく似ています。唯一の違いは、位置が少し異なることです。
長期短期記憶ネットワークとは対照的に、ゲート付き回帰ユニットネットワークはわずかに高速で実行が簡単です。
RNN構造の作成
開始する前に、データソースからの出力について予測を行う前に、まずRNNを構築する必要があります。RNNの構築は、前のセクションで通常のニューラルネットワークを構築した場合とまったく同じです。以下はそれを構築するためのコードです-
from cntk.losses import squared_error
from cntk.io import CTFDeserializer, MinibatchSource, INFINITELY_REPEAT, StreamDefs, StreamDef
from cntk.learners import adam
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
BATCH_SIZE = 14 * 10
EPOCH_SIZE = 12434
EPOCHS = 10複数のレイヤーをステーキング
CNTKで複数の反復レイヤーをスタックすることもできます。たとえば、次のレイヤーの組み合わせを使用できます-
from cntk import sequence, default_options, input_variable
from cntk.layers import Recurrence, LSTM, Dropout, Dense, Sequential, Fold
features = sequence.input_variable(1)
with default_options(initial_state = 0.1):
model = Sequential([
Fold(LSTM(15)),
Dense(1)
])(features)
target = input_variable(1, dynamic_axes=model.dynamic_axes)上記のコードでわかるように、CNTKでRNNをモデル化する方法は次の2つあります。
まず、リカレントレイヤーの最終出力のみが必要な場合は、 Fold GRU、LSTM、さらにはRNNStepなどのリカレントレイヤーと組み合わせたレイヤー。
次に、別の方法として、 Recurrence ブロック。
時系列データを使用したRNNのトレーニング
モデルを構築したら、CNTKでRNNをトレーニングする方法を見てみましょう-
from cntk import Function
@Function
def criterion_factory(z, t):
loss = squared_error(z, t)
metric = squared_error(z, t)
return loss, metric
loss = criterion_factory(model, target)
learner = adam(model.parameters, lr=0.005, momentum=0.9)データをトレーニングプロセスにロードするには、一連のCTFファイルからシーケンスを逆シリアル化する必要があります。次のコードにはcreate_datasource 関数。トレーニングデータソースとテストデータソースの両方を作成するための便利なユーティリティ関数です。
target_stream = StreamDef(field='target', shape=1, is_sparse=False)
features_stream = StreamDef(field='features', shape=1, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(features=features_stream, target=target_stream))
datasource = MinibatchSource(deserializer, randomize=True, max_sweeps=sweeps)
return datasource
train_datasource = create_datasource('Training data filename.ctf')#we need to provide the location of training file we created from our dataset.
test_datasource = create_datasource('Test filename.ctf', sweeps=1) #we need to provide the location of testing file we created from our dataset.これで、データソース、モデル、および損失関数を設定したので、トレーニングプロセスを開始できます。これは、基本的なニューラルネットワークを使用して前のセクションで行ったのと非常によく似ています。
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
target: train_datasource.streams.target
}
history = loss.train(
train_datasource,
epoch_size=EPOCH_SIZE,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config],
minibatch_size=BATCH_SIZE,
max_epochs=EPOCHS
)次のような出力が得られます-
出力-
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.005
0.4 0.4 0.4 0.4 19
0.4 0.4 0.4 0.4 59
0.452 0.495 0.452 0.495 129
[…]モデルの検証
実際にRNNを使用して予測することは、他のCNKモデルを使用して予測を行うことと非常に似ています。唯一の違いは、単一のサンプルではなくシーケンスを提供する必要があることです。
これで、RNNのトレーニングが最終的に完了したので、次のようにいくつかのサンプルシーケンスを使用してモデルをテストすることでモデルを検証できます。
import pickle
with open('test_samples.pkl', 'rb') as test_file:
test_samples = pickle.load(test_file)
model(test_samples) * NORMALIZE出力-
array([[ 8081.7905],
[16597.693 ],
[13335.17 ],
...,
[11275.804 ],
[15621.697 ],
[16875.555 ]], dtype=float32)