自然言語処理-はじめに
言語は、私たちが話したり、読んだり、書いたりできるコミュニケーションの方法です。たとえば、私たちは自然言語で意思決定や計画などを行うと考えています。正確には、言葉で。しかし、このAIの時代に直面する大きな問題は、コンピューターと同じように通信できるかどうかです。言い換えれば、人間は自然言語でコンピューターと通信できるのでしょうか。コンピューターには構造化データが必要であるため、NLPアプリケーションを開発することは私たちにとって課題ですが、人間の発話は構造化されておらず、本質的にあいまいなことがよくあります。
この意味で、自然言語処理(NLP)は、コンピューターサイエンス、特に人工知能(AI)のサブフィールドであり、コンピューターが人間の言語を理解して処理できるようにすることを目的としています。技術的には、NLPの主なタスクは、大量の自然言語データを分析および処理するためのコンピューターをプログラムすることです。
NLPの歴史
NLPの歴史を4つのフェーズに分けました。フェーズには独特の懸念とスタイルがあります。
第1フェーズ(機械翻訳フェーズ)-1940年代後半から1960年代後半
このフェーズで行われる作業は、主に機械翻訳(MT)に焦点を当てていました。この段階は、熱意と楽観的な時期でした。
ここで、最初のフェーズに含まれていたすべてを見てみましょう。
NLPの研究は、ブース&リケンズの調査と1949年の機械翻訳に関するウィーバーの覚書の後の1950年代初頭に始まりました。
1954年は、ジョージタウン-IBM実験で、ロシア語から英語への自動翻訳に関する限定的な実験が実証された年でした。
同年、MT(機械翻訳)誌の発行を開始しました。
機械翻訳(MT)に関する最初の国際会議は1952年に開催され、2回目は1956年に開催されました。
1961年、言語の機械翻訳と応用言語分析に関するテディントン国際会議で発表された作業は、このフェーズの最高点でした。
第2フェーズ(AI影響フェーズ)– 1960年代後半から1970年代後半
このフェーズでは、行われた作業は主に世界の知識と、意味表現の構築と操作におけるその役割に関連していました。そのため、このフェーズはAIフレーバーフェーズとも呼ばれます。
フェーズには、次のようなものがありました。
1961年の初めに、データまたは知識ベースのアドレス指定と構築の問題に関する作業が開始されました。この作品はAIの影響を受けました。
同年、BASEBALLの質問応答システムも開発されました。このシステムへの入力は制限されており、関連する言語処理は単純なものでした。
はるかに高度なシステムがMinsky(1968)で説明されました。このシステムは、BASEBALLの質問応答システムと比較した場合、言語入力の解釈と応答における知識ベースの推論の必要性が認識され、提供されました。
第3フェーズ(文法的フェーズ)– 1970年代後半から1980年代後半
このフェーズは、文法的フェーズとして説明できます。最終段階での実用的なシステム構築の失敗により、研究者はAIでの知識表現と推論のためのロジックの使用に移行しました。
第3フェーズには次のものが含まれていました-
10年の終わりに向けて、文法論理的アプローチは、SRIのコア言語エンジンや談話表現理論などの強力な汎用文プロセッサを使用するのに役立ちました。これは、より拡張された談話に取り組む手段を提供しました。
このフェーズでは、パーサーなどの実用的なリソースとツール、たとえばAlvey Natural Language Toolsと、データベースクエリなどのより運用および商用のシステムを入手しました。
1980年代の語彙目録に関する研究も、文法学的アプローチの方向を示していました。
第4フェーズ(字句およびコーパスフェーズ)– 1990年代
これは、語彙とコーパスのフェーズとして説明できます。このフェーズには、1980年代後半に登場し、ますます影響力を持つようになった文法への語彙化されたアプローチがありました。この10年間で、言語処理用の機械学習アルゴリズムの導入により、自然言語処理に革命が起こりました。
人間の言語の研究
言語は人間の生活にとって重要な要素であり、私たちの行動の最も基本的な側面でもあります。私たちは主に2つの形でそれを体験することができます-書かれたものと話されたものです。書面では、それは私たちの知識をある世代から次の世代に伝える方法です。話し言葉では、それは人間が日常の行動で互いに調整するための主要な媒体です。言語はさまざまな学問分野で研究されています。各分野には、独自の一連の問題とそれらに対処するための一連の解決策が付属しています。
これを理解するために次の表を検討してください-
| 規律 | 問題 | ツール |
|---|---|---|
言語学者 |
フレーズや文章はどのように単語で形成できますか? 文の考えられる意味を妨げるものは何ですか? |
整形式性と意味についての直感。 構造の数学的モデル。たとえば、モデル理論のセマンティクス、形式言語理論。 |
心理言語学者 |
人間はどのようにして文の構造を識別できますか? 単語の意味はどのように識別できますか? 理解はいつ行われますか? |
主に人間のパフォーマンスを測定するための実験手法。 観測の統計分析。 |
哲学者 |
単語や文はどのように意味を獲得しますか? オブジェクトは単語によってどのように識別されますか? 意味は何ですか? |
直感を使った自然言語の議論。 論理やモデル理論のような数学的モデル。 |
計算言語学者 |
文の構造をどのように特定できますか 知識と推論をどのようにモデル化できますか? 言語を使用して特定のタスクを実行するにはどうすればよいですか? |
アルゴリズム データ構造 表現と推論の正式なモデル。 検索と表現の方法などのAI技術。 |
言語の曖昧さと不確実性
自然言語処理で一般的に使用されるあいまいさは、複数の方法で理解される能力と呼ぶことができます。簡単に言えば、あいまいさは複数の方法で理解される能力であると言えます。自然言語は非常に曖昧です。NLPには次のタイプのあいまいさがあります-
語彙のあいまいさ
1つの単語のあいまいさは、語彙のあいまいさと呼ばれます。たとえば、単語を扱うsilver 名詞、形容詞、または動詞として。
構文のあいまいさ
この種のあいまいさは、文がさまざまな方法で解析されるときに発生します。たとえば、「男は望遠鏡で少女を見た」という文です。男が望遠鏡を持っている少女を見たのか、望遠鏡を通して彼女を見たのかは曖昧です。
セマンティックのあいまいさ
この種のあいまいさは、単語自体の意味が誤って解釈される可能性がある場合に発生します。言い換えると、意味のあいまいさは、文にあいまいな単語または句が含まれている場合に発生します。たとえば、「車が移動中にポールに当たった」という文は、「車が移動中にポールに当たった」と「車がポールに当たったときにポールに当たった」と解釈できるため、意味があいまいになります。
照応のあいまいさ
この種のあいまいさは、談話で照応エンティティを使用するために発生します。たとえば、馬は丘を駆け上がった。とても急でした。すぐに疲れました。ここで、2つの状況での「それ」の照応参照はあいまいさを引き起こします。
語用論的曖昧さ
このような曖昧さは、フレーズの文脈が複数の解釈を与える状況を指します。簡単に言えば、文が具体的でない場合、語用論的な曖昧さが生じると言えます。たとえば、「私もあなたが好きです」という文は、私があなたを好き(あなたが私を好きなように)、私があなたを好き(他の誰かが服用するように)のように複数の解釈を持つことができます。
NLPフェーズ
次の図は、自然言語処理のフェーズまたは論理ステップを示しています。
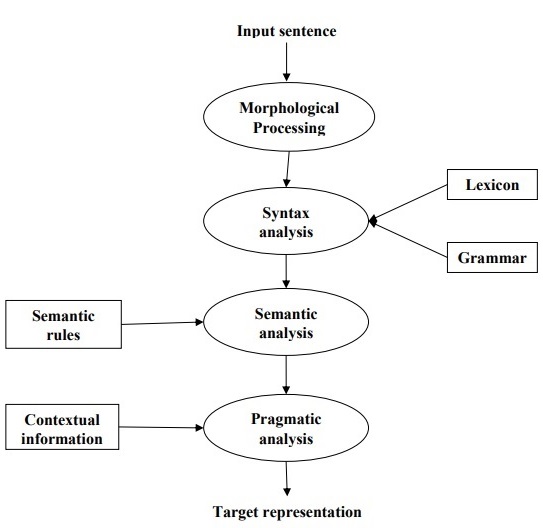
形態学的処理
これはNLPの最初のフェーズです。このフェーズの目的は、言語入力のチャンクを、段落、文、および単語に対応するトークンのセットに分割することです。たとえば、次のような単語“uneasy” 次のように2つのサブワードトークンに分割できます “un-easy”。
構文解析
これはNLPの第2フェーズです。このフェーズの目的は2つあります。文が適切に形成されているかどうかを確認することと、異なる単語間の構文上の関係を示す構造に分割することです。たとえば、次のような文“The school goes to the boy” 構文アナライザーまたはパーサーによって拒否されます。
セマンティック分析
これはNLPの第3フェーズです。このフェーズの目的は、正確な意味を引き出すことです。または、テキストから辞書の意味を言うことができます。テキストの意味がチェックされます。たとえば、セマンティックアナライザーは「Hotice-cream」のような文を拒否します。
語用論的分析
これはNLPの第4フェーズです。語用論的分析は、特定のコンテキストに存在する実際のオブジェクト/イベントを、最後のフェーズ(セマンティック分析)中に取得されたオブジェクト参照に単純に適合させます。たとえば、「バナナを棚のバスケットに入れる」という文には、2つの意味解釈があり、語用論的アナライザーはこれら2つの可能性から選択します。