NLP-単語レベルの分析
この章では、自然言語処理における世界レベルの分析について理解します。
正規表現
正規表現(RE)は、テキスト検索文字列を指定するための言語です。REは、パターンに保持された特殊な構文を使用して、他の文字列または文字列のセットを照合または検索するのに役立ちます。正規表現は、UNIXでもMSWORDでも同じ方法でテキストを検索するために使用されます。多くのRE機能を使用したさまざまな検索エンジンがあります。
正規表現のプロパティ
以下は、RE −の重要な特性の一部です。
アメリカの数学者スティーブンコールクリーンは、正規表現言語を形式化しました。
REは特別な言語の数式であり、文字列の単純なクラス、記号のシーケンスを指定するために使用できます。言い換えれば、REは文字列のセットを特徴付ける代数表記であると言えます。
正規表現には2つのことが必要です。1つは検索したいパターンであり、もう1つは検索する必要のあるテキストのコーパスです。
数学的には、正規表現は次のように定義できます。
ε は正規表現であり、言語に空の文字列があることを示します。
φ 空の言語であることを示す正規表現です。
場合 X そして Y は正規表現であり、
X, Y
X.Y(Concatenation of XY)
X+Y (Union of X and Y)
X*, Y* (Kleen Closure of X and Y)
正規表現でもあります。
文字列が上記のルールから派生している場合、それも正規表現になります。
正規表現の例
次の表に、正規表現の例をいくつか示します。
| 正規表現 | レギュラーセット |
|---|---|
| (0 + 10 *) | {0、1、10、100、1000、10000、…} |
| (0 * 10 *) | {1、01、10、010、0010、…} |
| (0 +ε)(1 +ε) | {ε、0、1、01} |
| (a + b)* | これは、任意の長さのaとbの文字列のセットであり、ヌル文字列も含まれます。つまり、{ε、a、b、aa、ab、bb、ba、aaa……。} |
| (a + b)* abb | これは、文字列abbで終わるaとbの文字列のセットになります。つまり、{abb、aabb、babb、aaabb、ababb、…………..} |
| (11)* | 空の文字列、つまり{ε、11、1111、111111、………。}も含む偶数の1で構成されるように設定されます。 |
| (aa)*(bb)* b | これは、偶数のaとそれに続く奇数のbで構成される文字列のセットになります。つまり、{b、aab、aabbb、aabbbbb、aaaab、aaaabbb、…………..} |
| (aa + ab + ba + bb)* | nullを含む文字列aa、ab、ba、およびbbの任意の組み合わせを連結することによって取得できるのは、偶数の長さのaとbの文字列、つまり{aa、ab、ba、bb、aaab、aaba、…………。 。} |
通常のセットとそのプロパティ
これは、正規表現の値を表し、特定のプロパティで構成されるセットとして定義できます。
通常のセットのプロパティ
2つの通常のセットの和集合を実行すると、結果のセットもregulaになります。
2つの通常のセットの共通部分を実行すると、結果のセットも通常になります。
通常のセットの補集合を行うと、結果のセットも通常になります。
2つの通常のセットの違いを実行すると、結果のセットも通常になります。
通常のセットを逆にすると、結果のセットも通常になります。
通常のセットを閉じると、結果のセットも通常になります。
2つの通常のセットを連結すると、結果のセットも通常になります。
有限状態オートマトン
「自走式」を意味するギリシャ語の「αὐτόματα」に由来するオートマトンという用語は、複数のオートマトンであり、所定の一連の操作を自動的に実行する抽象的な自走式コンピューティングデバイスとして定義できます。
有限数の状態を持つオートマトンは、有限オートマトン(FA)または有限状態オートマトン(FSA)と呼ばれます。
数学的には、オートマトンは5タプル(Q、Σ、δ、q0、F)で表すことができます。
Qは有限の状態のセットです。
Σは、オートマトンのアルファベットと呼ばれる有限の記号のセットです。
δは遷移関数です
q0は、入力が処理される初期状態です(q0∈Q)。
Fは、Qの最終状態/状態のセットです(F⊆Q)。
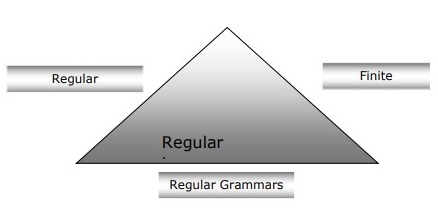
有限オートマトン、正規文法、正規表現の関係
以下の点から、有限オートマトン、正規文法、正規表現の関係について明確に理解できます。
有限状態オートマトンは計算作業の理論的基盤であり、正規表現はそれらを記述する1つの方法です。
正規表現はFSAとして実装でき、FSAは正規表現で記述できると言えます。
一方、正規表現は、正規言語と呼ばれる一種の言語を特徴付ける方法です。したがって、正規言語はFSAと正規表現の両方の助けを借りて記述できると言えます。
正規文法は、右正規または左正規のどちらでもかまいませんが、正規言語を特徴付けるもう1つの方法です。
次の図は、有限オートマトン、正規表現、および正規文法が、正規言語を記述するための同等の方法であることを示しています。
有限状態自動化(FSA)の種類
有限状態の自動化には2つのタイプがあります。タイプが何であるかを見てみましょう。
決定性有限自動化(DFA)
これは、すべての入力シンボルについて、マシンが移動する状態を決定できる有限自動化のタイプとして定義できます。状態の数には限りがあるため、このマシンは決定性有限オートマトン(DFA)と呼ばれます。
数学的には、DFAは5タプル(Q、Σ、δ、q0、F)で表すことができます。ここで、-
Qは有限の状態のセットです。
Σは、オートマトンのアルファベットと呼ばれる有限の記号のセットです。
δは遷移関数です。ここで、δ:Q×Σ→Qです。
q0は、入力が処理される初期状態です(q0∈Q)。
Fは、Qの最終状態/状態のセットです(F⊆Q)。
一方、グラフィカルに、DFAは状態図と呼ばれる図で表すことができます。
状態はによって表されます vertices。
遷移はラベル付きで示されます arcs。
初期状態は、 empty incoming arc。
最終状態はで表されます double circle。
DFAの例
DFAが
Q = {a、b、c}、
Σ= {0、1}、
q 0 = {a}、
F = {c}、
遷移関数δを次のように表に示します。
| 現在の状態 | 入力0の次の状態 | 入力1の次の状態 |
|---|---|---|
| A | A | B |
| B | b | A |
| C | c | C |
このDFAのグラフィック表現は次のようになります-

非決定性有限自動化(NDFA)
これは、すべての入力シンボルについて、マシンが移動する状態を判別できない、つまりマシンが状態の任意の組み合わせに移動できる、有限自動化のタイプとして定義できます。状態の数には限りがあるため、このマシンは非決定性有限自動化(NDFA)と呼ばれます。
数学的には、NDFAは5タプル(Q、Σ、δ、q0、F)で表すことができます。ここで、-
Qは有限の状態のセットです。
Σは、オートマトンのアルファベットと呼ばれる有限の記号のセットです。
δ:Q×Σ→2:状態遷移関数δ-is Qを。
q0:-入力が処理される初期状態です(q0∈Q)。
F:-Qの最終状態/状態のセットです(F⊆Q)。
グラフィカルに(DFAと同じ)、NDFAは状態図と呼ばれる図で表すことができます。
状態はによって表されます vertices。
遷移はラベル付きで示されます arcs。
初期状態は、 empty incoming arc。
最終状態はdoubleで表されます circle。
NDFAの例
NDFAが
Q = {a、b、c}、
Σ= {0、1}、
q 0 = {a}、
F = {c}、
遷移関数δを次のように表に示します。
| 現在の状態 | 入力0の次の状態 | 入力1の次の状態 |
|---|---|---|
| A | a、b | B |
| B | C | 交流 |
| C | b、c | C |
このNDFAのグラフィック表現は次のようになります-

形態学的解析
形態素構文解析という用語は、形態素の構文解析に関連しています。形態素解析は、単語が形態素と呼ばれる意味のある小さな単位に分解されて、ある種の言語構造を生成することを認識する問題として定義できます。たとえば、foxesという単語をfoxと-esの2つに分割できます。foxesという単語は、2つの形態素で構成されていることがわかります。1つはfoxで、もう1つは-esです。
別の意味では、形態学は-の研究であると言うことができます
言葉の形成。
言葉の由来。
単語の文法形式。
単語の形成における接頭辞と接尾辞の使用。
言語の品詞(PoS)がどのように形成されるか。
形態素の種類
最小の意味を持つ単位である形態素は、2つのタイプに分けることができます-
Stems
語順
茎
それは単語の核となる意味のある単位です。それが言葉のルーツとも言えます。たとえば、キツネという言葉では、茎はキツネです。
Affixes−名前が示すように、それらは単語にいくつかの追加の意味と文法機能を追加します。たとえば、キツネという単語では、接辞は-esです。
さらに、接辞は次の4つのタイプに分けることもできます-
Prefixes−名前が示すように、接頭辞は語幹の前にあります。たとえば、unbuckleという単語では、unが接頭辞です。
Suffixes−名前が示すように、接尾辞は語幹の後に続きます。たとえば、catsという単語では、-sが接尾辞です。
Infixes−名前が示すように、中置辞は語幹の内側に挿入されます。たとえば、cupfulという単語は、-sを中置として使用することにより、cupsfulとして複数形にすることができます。
Circumfixes−それらは語幹の前後にあります。英語の接周辞の例は非常に少ないです。非常に一般的な例は「A-ing」で、語幹の前に-Aを使用し、後に-ingを使用できます。
語順
単語の順序は、形態学的構文解析によって決定されます。形態学的パーサーを構築するための要件を見てみましょう-
レキシコン
形態学的パーサーを構築するための最初の要件はレキシコンです。これには、語幹と接辞のリスト、およびそれらに関する基本情報が含まれています。たとえば、語幹が名詞語幹か動詞語幹かなどの情報。
形態戦術
これは基本的に形態素順序のモデルです。別の意味では、どのクラスの形態素が単語内の他のクラスの形態素に従うことができるかを説明するモデル。たとえば、形態素の事実は、英語の複数形の形態素が常に名詞の前ではなく後に続くということです。
正書法の規則
これらのスペル規則は、単語で発生する変更をモデル化するために使用されます。たとえば、yをieに変換するルールは、city + s = citysではなくcitysのようになります。