自然言語処理-クイックガイド
言語は、私たちが話したり、読んだり、書いたりできるコミュニケーションの方法です。たとえば、私たちは自然言語で意思決定や計画などを行うと考えています。正確には、言葉で。しかし、このAIの時代に直面する大きな問題は、コンピューターと同じように通信できるかどうかです。言い換えれば、人間は自然言語でコンピューターと通信できるのでしょうか。コンピューターには構造化データが必要であるため、NLPアプリケーションを開発することは私たちにとって課題ですが、人間の発話は構造化されておらず、本質的にあいまいであることがよくあります。
この意味で、自然言語処理(NLP)は、コンピューターサイエンス、特にコンピューターが人間の言語を理解して処理できるようにすることを懸念する人工知能(AI)のサブフィールドであると言えます。技術的には、NLPの主なタスクは、大量の自然言語データを分析および処理するためのコンピューターをプログラムすることです。
NLPの歴史
NLPの歴史を4つのフェーズに分けました。フェーズには独特の懸念とスタイルがあります。
第1フェーズ(機械翻訳フェーズ)-1940年代後半から1960年代後半
このフェーズで行われる作業は、主に機械翻訳(MT)に焦点を当てていました。この段階は、熱意と楽観的な時期でした。
ここで、最初のフェーズに含まれていたすべてを見てみましょう-
NLPの研究は、ブース&リケンズの調査と1949年の機械翻訳に関するウィーバーの覚書の後の1950年代初頭に始まりました。
1954年は、ジョージタウン-IBM実験で、ロシア語から英語への自動翻訳に関する限定的な実験が実証された年でした。
同年、MT(機械翻訳)誌の発行を開始しました。
機械翻訳(MT)に関する最初の国際会議は1952年に開催され、2回目は1956年に開催されました。
1961年、言語の機械翻訳と応用言語分析に関するテディントン国際会議で発表された作業は、このフェーズの最高点でした。
第2フェーズ(AI影響フェーズ)– 1960年代後半から1970年代後半
このフェーズでは、行われた作業は主に世界の知識と、意味表現の構築と操作におけるその役割に関連していました。そのため、このフェーズはAIフレーバーフェーズとも呼ばれます。
フェーズには、次のようなものがありました。
1961年の初めに、データまたは知識ベースのアドレス指定と構築の問題に関する作業が開始されました。この作品はAIの影響を受けました。
同年、BASEBALLの質問応答システムも開発されました。このシステムへの入力は制限されており、関連する言語処理は単純なものでした。
はるかに高度なシステムがMinsky(1968)で説明されました。このシステムは、BASEBALLの質問応答システムと比較した場合、言語入力の解釈と応答における知識ベースの推論の必要性が認識され、提供されました。
第3フェーズ(文法的フェーズ)– 1970年代後半から1980年代後半
このフェーズは、文法的フェーズとして説明できます。最終段階での実用的なシステム構築の失敗により、研究者はAIでの知識表現と推論のためのロジックの使用に移行しました。
第3フェーズには次のものが含まれていました-
10年の終わりに向けて、文法論理的アプローチは、SRIのコア言語エンジンや談話表現理論などの強力な汎用文プロセッサを使用するのに役立ちました。これは、より拡張された談話に取り組む手段を提供しました。
このフェーズでは、パーサーなどの実用的なリソースとツール、たとえばAlvey Natural Language Toolsと、データベースクエリなどのより運用および商用のシステムを入手しました。
1980年代の語彙目録に関する研究も、文法学的アプローチの方向を示していました。
第4フェーズ(字句およびコーパスフェーズ)– 1990年代
これは、語彙とコーパスのフェーズとして説明できます。このフェーズには、1980年代後半に登場し、ますます影響力を持つようになった文法への語彙化されたアプローチがありました。この10年間で、言語処理用の機械学習アルゴリズムの導入により、自然言語処理に革命が起こりました。
人間の言語の研究
言語は人間の生活にとって重要な要素であり、私たちの行動の最も基本的な側面でもあります。私たちは主に2つの形でそれを体験することができます-書かれたものと話されたものです。書面では、それは私たちの知識をある世代から次の世代に伝える方法です。話し言葉では、それは人間が日常の行動で互いに調整するための主要な媒体です。言語はさまざまな学問分野で研究されています。各分野には、独自の一連の問題とそれらに対処するための一連の解決策が付属しています。
これを理解するために次の表を検討してください-
| 規律 | 問題 | ツール |
|---|---|---|
言語学者 |
フレーズや文章はどのように単語で形成できますか? 文の考えられる意味を妨げるものは何ですか? |
整形式性と意味についての直感。 構造の数学的モデル。たとえば、モデル理論のセマンティクス、形式言語理論。 |
心理言語学者 |
人間はどのようにして文の構造を識別できますか? 単語の意味はどのように識別できますか? 理解はいつ行われますか? |
主に人間のパフォーマンスを測定するための実験手法。 観測の統計分析。 |
哲学者 |
単語や文はどのように意味を獲得しますか? オブジェクトは単語によってどのように識別されますか? 意味は何ですか? |
直感を使った自然言語の議論。 論理やモデル理論のような数学的モデル。 |
計算言語学者 |
文の構造をどのように特定できますか 知識と推論をどのようにモデル化できますか? 言語を使用して特定のタスクを実行するにはどうすればよいですか? |
アルゴリズム データ構造 表現と推論の正式なモデル。 検索と表現の方法などのAI技術。 |
言語の曖昧さと不確実性
自然言語処理で一般的に使用されるあいまいさは、複数の方法で理解される能力と呼ぶことができます。簡単に言えば、あいまいさは複数の方法で理解される能力であると言えます。自然言語は非常に曖昧です。NLPには次のタイプのあいまいさがあります-
語彙のあいまいさ
1つの単語のあいまいさは、語彙のあいまいさと呼ばれます。たとえば、単語を扱うsilver 名詞、形容詞、または動詞として。
構文のあいまいさ
この種のあいまいさは、文がさまざまな方法で解析されるときに発生します。たとえば、「男は望遠鏡で少女を見た」という文です。男が望遠鏡を持っている少女を見たのか、望遠鏡を通して彼女を見たのかは曖昧です。
セマンティックのあいまいさ
この種のあいまいさは、単語自体の意味が誤って解釈される可能性がある場合に発生します。言い換えると、意味のあいまいさは、文にあいまいな単語または句が含まれている場合に発生します。たとえば、「車が移動中にポールに当たった」という文は、「車が移動中にポールに当たった」と「車がポールに当たったときにポールに当たった」と解釈できるため、意味があいまいになります。
照応のあいまいさ
この種のあいまいさは、談話で照応エンティティを使用するために発生します。たとえば、馬は丘を駆け上がった。とても急でした。すぐに疲れました。ここで、2つの状況での「それ」の照応参照はあいまいさを引き起こします。
語用論的曖昧さ
このような曖昧さは、フレーズの文脈が複数の解釈を与える状況を指します。簡単に言えば、文が具体的でない場合、語用論的な曖昧さが生じると言えます。たとえば、「私もあなたが好きです」という文は、私があなたを好き(あなたが私を好きなように)、私があなたを好き(他の誰かが服用するように)のように複数の解釈を持つことができます。
NLPフェーズ
次の図は、自然言語処理のフェーズまたは論理ステップを示しています。
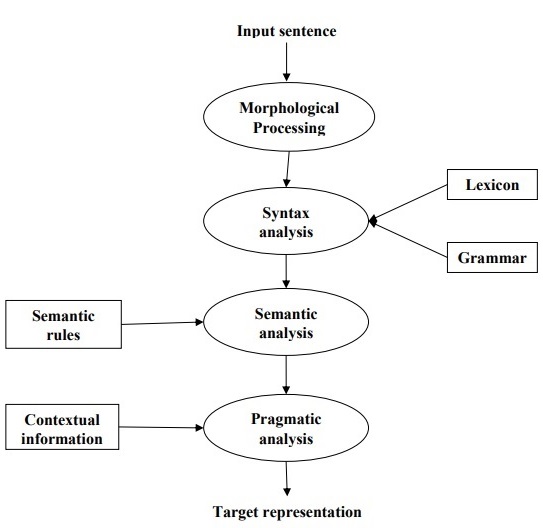
形態学的処理
これはNLPの最初のフェーズです。このフェーズの目的は、言語入力のチャンクを、段落、文、および単語に対応するトークンのセットに分割することです。たとえば、次のような単語“uneasy” 次のように2つのサブワードトークンに分割できます “un-easy”。
構文解析
これはNLPの第2フェーズです。このフェーズの目的は2つあります。文が適切に形成されているかどうかを確認することと、異なる単語間の構文上の関係を示す構造に分割することです。たとえば、次のような文“The school goes to the boy” 構文アナライザーまたはパーサーによって拒否されます。
セマンティック分析
これはNLPの第3フェーズです。このフェーズの目的は、正確な意味を引き出すことです。または、テキストから辞書の意味を言うことができます。テキストの意味がチェックされます。たとえば、セマンティックアナライザは「Hotice-cream」のような文を拒否します。
語用論的分析
これはNLPの第4フェーズです。語用論的分析は、特定のコンテキストに存在する実際のオブジェクト/イベントを、最後のフェーズで取得されたオブジェクト参照に単純に適合させます(セマンティック分析)。たとえば、「バナナを棚のバスケットに入れる」という文には、2つの意味解釈があり、語用論的アナライザーはこれら2つの可能性から選択します。
この章では、自然言語処理の言語リソースについて学習します。
コーパス
コーパスは、自然なコミュニケーション環境で作成された、機械で読み取り可能なテキストの大規模で構造化されたセットです。その複数形はコーパスです。それらは、元々電子的であったテキスト、話し言葉の写し、光学式文字認識など、さまざまな方法で導き出すことができます。
コーパスデザインの要素
言語は無限ですが、コーパスのサイズは有限でなければなりません。コーパスのサイズを有限にするには、適切なコーパスデザインを確保するために、さまざまな種類のテキストをサンプリングして比例的に含める必要があります。
コーパス設計のいくつかの重要な要素について学びましょう-
コーパスの代表性
代表性は、コーパス設計の特徴です。リーチとビーバーという2人の偉大な研究者による次の定義は、コーパスの代表性を理解するのに役立ちます。
According to Leech (1991), 「コーパスは、その内容に基づく調査結果をその言語の種類に一般化できる場合、それが表すことになっている言語の種類を表すと考えられています」。
According to Biber (1993), 「代表性とは、サンプルに母集団の変動の全範囲が含まれる程度を指します」。
このように、コーパスの代表性は次の2つの要因によって決定されると結論付けることができます。
Balance −コーパスに含まれるジャンルの範囲
Sampling −各ジャンルのチャンクの選択方法。
コーパスバランス
コーパスデザインのもう1つの非常に重要な要素は、コーパスのバランスです。これは、コーパスに含まれるジャンルの範囲です。一般的なコーパスの代表性は、コーパスのバランスに依存することはすでに研究しました。バランスの取れたコーパスは、言語の代表であると思われる幅広いテキストカテゴリをカバーします。私たちはバランスのための信頼できる科学的尺度を持っていませんが、最良の推定と直感はこの懸念で機能します。言い換えれば、受け入れられたバランスは、その使用目的によってのみ決定されると言えます。
サンプリング
コーパス設計のもう1つの重要な要素は、サンプリングです。コーパスの代表性とバランスは、サンプリングと非常に密接に関連しています。そのため、コーパス構築ではサンプリングは避けられないと言えます。
による Biber(1993)、「コーパスを構築する際の最初の考慮事項のいくつかは、全体的なデザインに関係します。たとえば、含まれるテキストの種類、テキストの数、特定のテキストの選択、テキスト内からのテキストサンプルの選択、テキストの長さなどです。サンプル。これらのそれぞれには、意識的かどうかにかかわらず、サンプリングの決定が含まれます。」
代表的なサンプルを取得する際には、次のことを考慮する必要があります。
Sampling unit−サンプルが必要なユニットを指します。たとえば、書かれたテキストの場合、サンプリング単位は新聞、雑誌、または本である可能性があります。
Sampling frame −すべてのサンプリングユニットのリストは、サンプリングフレームと呼ばれます。
Population−すべてのサンプリングユニットのアセンブリと呼ばれる場合があります。それは、言語の生成、言語の受容、または製品としての言語の観点から定義されます。
コーパスサイズ
コーパスデザインのもう1つの重要な要素は、そのサイズです。コーパスの大きさはどれくらいですか?この質問に対する具体的な答えはありません。コーパスのサイズは、それが意図されている目的と、次のようないくつかの実際的な考慮事項によって異なります。
ユーザーから予想されるクエリの種類。
ユーザーがデータを調査するために使用する方法論。
データソースの可用性。
技術の進歩に伴い、コーパスのサイズも大きくなります。次の比較表は、コーパスサイズがどのように機能するかを理解するのに役立ちます-
| 年 | コーパスの名前 | サイズ(言葉で) |
|---|---|---|
| 1960〜70年代 | ブラウンとLOB | 100万語 |
| 1980年代 | バーミンガムコーパス | 2,000万語 |
| 1990年代 | 英国国立コーパス | 1億語 |
| 初期の21番目の世紀 | 英語コーパス銀行 | 6億5000万語 |
以降のセクションでは、コーパスの例をいくつか見ていきます。
TreeBankコーパス
これは、構文的または意味的な文の構造に注釈を付ける、言語的に解析されたテキストコーパスとして定義できます。Geoffrey Leechは、「ツリーバンク」という用語を作り出しました。これは、文法分析を表す最も一般的な方法がツリー構造によるものであることを表しています。一般に、ツリーバンクは、品詞タグで既に注釈が付けられているコーパスの上部に作成されます。
TreeBankコーパスの種類
セマンティックツリーバンクとシンタックスツリーバンクは、言語学で最も一般的な2つのタイプのツリーバンクです。これらのタイプについて詳しく学びましょう-
セマンティックツリーバンク
これらのツリーバンクは、文の意味構造の正式な表現を使用します。それらは、意味表現の深さが異なります。ロボットコマンドTreebank、Geoquery、Groningen Meaning Bank、RoboCup Corpusは、セマンティックツリーバンクの例です。
構文ツリーバンク
セマンティックツリーバンクとは反対に、構文ツリーバンクシステムへの入力は、解析されたツリーバンクデータの変換から取得された形式言語の表現です。このようなシステムの出力は、述語論理ベースの意味表現です。これまでに、さまざまな言語のさまざまな構文ツリーバンクが作成されてきました。例えば、Penn Arabic Treebank, Columbia Arabic Treebank アラビア語で作成された構文ツリーバンクです。 Sininca 中国語で作成された構文ツリーバンク。 Lucy, Susane そして BLLIP WSJ 英語で作成された構文コーパス。
TreeBankコーパスのアプリケーション
以下は、TreeBanksのアプリケーションの一部です-
計算言語学において
計算言語学について話す場合、TreeBanksの最適な使用法は、品詞タガー、パーサー、セマンティックアナライザー、機械翻訳システムなどの最先端の自然言語処理システムを設計することです。
コーパス言語学
コーパス言語学の場合、Treebanksの最適な使用法は構文現象を研究することです。
理論言語学と心理言語学において
理論的および心理言語学におけるツリーバンクの最良の使用法は、相互作用の証拠です。
PropBankコーパス
より具体的に「命題バンク」と呼ばれるPropBankは、口頭の命題とその議論で注釈が付けられたコーパスです。コーパスは動詞指向のリソースです。ここでの注釈は、構文レベルとより密接に関連しています。コロラド大学ボルダー校言語学部のマーサ・パーマー他が開発しました。PropBankという用語は、命題とその引数で注釈が付けられたコーパスを指す一般的な名詞として使用できます。
自然言語処理(NLP)では、PropBankプロジェクトが非常に重要な役割を果たしてきました。セマンティックロールのラベル付けに役立ちます。
VerbNet(VN)
VerbNet(VN)は、英語で存在する階層ドメインに依存しない最大の語彙リソースであり、その内容に関する意味情報と構文情報の両方が組み込まれています。VNは、WordNet、Xtag、FrameNetなどの他の語彙リソースへのマッピングを備えた広範囲の動詞レキシコンです。これは、クラスメンバー間の構文的および意味的一貫性を実現するためのサブクラスの改良と追加によって、Levinクラスを拡張する動詞クラスに編成されています。
各VerbNet(VN)クラスには-が含まれます
構文記述または構文フレームのセット
他動詞、自動詞、前置詞句、結果構文、および多数の素因交代などの構文の項構造の可能な表面実現を描写するため。
アニメーション、人間、組織などのセマンティック記述のセット
制約のために、引数によって許可される主題の役割のタイプ、およびさらなる制限が課される場合があります。これは、主題の役割に関連付けられている可能性が高い構成要素の構文上の性質を示すのに役立ちます。
WordNet
Princetonによって作成されたWordNetは、英語の語彙データベースです。これはNLTKコーパスの一部です。WordNetでは、名詞、動詞、形容詞、副詞は、次のような認知同義語のセットにグループ化されます。Synsets。すべてのシンセットは、概念的意味論的および語彙的関係の助けを借りてリンクされています。その構造により、自然言語処理(NLP)に非常に役立ちます。
情報システムでは、WordNetは、語義の曖昧性解消、情報検索、自動テキスト分類、機械翻訳などのさまざまな目的で使用されます。WordNetの最も重要な用途の1つは、単語間の類似性を見つけることです。このタスクのために、PerlのSimilarity、PythonのNLTK、JavaのADWなどのさまざまなパッケージにさまざまなアルゴリズムが実装されています。
この章では、自然言語処理における世界レベルの分析について理解します。
正規表現
正規表現(RE)は、テキスト検索文字列を指定するための言語です。REは、パターンに保持された特殊な構文を使用して、他の文字列または文字列のセットを照合または検索するのに役立ちます。正規表現は、UNIXでもMSWORDでも同じ方法でテキストを検索するために使用されます。多くのRE機能を使用したさまざまな検索エンジンがあります。
正規表現のプロパティ
以下は、RE −の重要な特性の一部です。
アメリカの数学者スティーブンコールクリーンは、正規表現言語を形式化しました。
REは特別な言語の数式であり、文字列の単純なクラス、記号のシーケンスを指定するために使用できます。言い換えれば、REは文字列のセットを特徴付ける代数表記であると言えます。
正規表現には2つのことが必要です。1つは検索したいパターンであり、もう1つは検索する必要のあるテキストのコーパスです。
数学的には、正規表現は次のように定義できます。
ε は正規表現であり、言語に空の文字列があることを示します。
φ 空の言語であることを示す正規表現です。
場合 X そして Y は正規表現であり、
X, Y
X.Y(Concatenation of XY)
X+Y (Union of X and Y)
X*, Y* (Kleen Closure of X and Y)
正規表現でもあります。
文字列が上記のルールから派生している場合、それも正規表現になります。
正規表現の例
次の表に、正規表現の例をいくつか示します。
| 正規表現 | レギュラーセット |
|---|---|
| (0 + 10 *) | {0、1、10、100、1000、10000、…} |
| (0 * 10 *) | {1、01、10、010、0010、…} |
| (0 +ε)(1 +ε) | {ε、0、1、01} |
| (a + b)* | これは、任意の長さのaとbの文字列のセットであり、ヌル文字列も含まれます。つまり、{ε、a、b、aa、ab、bb、ba、aaa……。} |
| (a + b)* abb | これは、文字列abbで終わるaとbの文字列のセットになります。つまり、{abb、aabb、babb、aaabb、ababb、…………..} |
| (11)* | 空の文字列、つまり{ε、11、1111、111111、………。}も含む偶数の1で構成されるように設定されます。 |
| (aa)*(bb)* b | これは、偶数のaとそれに続く奇数のbで構成される文字列のセットになります。つまり、{b、aab、aabbb、aabbbbb、aaaab、aaaabbb、…………..} |
| (aa + ab + ba + bb)* | nullを含む文字列aa、ab、ba、およびbbの任意の組み合わせを連結することによって取得できるのは、偶数の長さのaとbの文字列、つまり{aa、ab、ba、bb、aaab、aaba、…………。 。} |
通常のセットとそのプロパティ
これは、正規表現の値を表し、特定のプロパティで構成されるセットとして定義できます。
通常のセットのプロパティ
2つの通常のセットの和集合を実行すると、結果のセットもregulaになります。
2つの通常のセットの共通部分を実行すると、結果のセットも通常になります。
通常のセットの補集合を行うと、結果のセットも通常になります。
2つの通常のセットの違いを実行すると、結果のセットも通常になります。
通常のセットを逆にすると、結果のセットも通常になります。
通常のセットを閉じると、結果のセットも通常になります。
2つの通常のセットを連結すると、結果のセットも通常になります。
有限状態オートマトン
「自走式」を意味するギリシャ語の「αὐτόματα」に由来するオートマトンという用語は、複数のオートマトンであり、所定の一連の操作を自動的に実行する抽象的な自走式コンピューティングデバイスとして定義できます。
有限数の状態を持つオートマトンは、有限オートマトン(FA)または有限状態オートマトン(FSA)と呼ばれます。
数学的には、オートマトンは5タプル(Q、Σ、δ、q0、F)で表すことができます。
Qは有限の状態のセットです。
Σは、オートマトンのアルファベットと呼ばれる有限の記号のセットです。
δは遷移関数です
q0は、入力が処理される初期状態です(q0∈Q)。
Fは、Qの最終状態/状態のセットです(F⊆Q)。
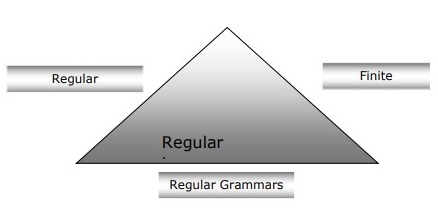
有限オートマトン、正規文法、正規表現の関係
以下の点から、有限オートマトン、正規文法、正規表現の関係について明確に理解できます。
有限状態オートマトンは計算作業の理論的基盤であり、正規表現はそれらを記述する1つの方法です。
正規表現はFSAとして実装でき、FSAは正規表現で記述できると言えます。
一方、正規表現は、正規言語と呼ばれる一種の言語を特徴付ける方法です。したがって、正規言語はFSAと正規表現の両方の助けを借りて記述できると言えます。
正規文法は、右正規または左正規のどちらでもかまいませんが、正規言語を特徴付けるもう1つの方法です。
次の図は、有限オートマトン、正規表現、および正規文法が、正規言語を記述する同等の方法であることを示しています。
有限状態自動化(FSA)の種類
有限状態の自動化には2つのタイプがあります。タイプが何であるかを見てみましょう。
決定性有限自動化(DFA)
これは、すべての入力シンボルについて、マシンが移動する状態を決定できる有限自動化のタイプとして定義できます。状態の数には限りがあるため、このマシンは決定性有限オートマトン(DFA)と呼ばれます。
数学的には、DFAは5タプル(Q、Σ、δ、q0、F)で表すことができます。ここで、-
Qは有限の状態のセットです。
Σは、オートマトンのアルファベットと呼ばれる有限の記号のセットです。
δは遷移関数です。ここで、δ:Q×Σ→Qです。
q0は、入力が処理される初期状態です(q0∈Q)。
Fは、Qの最終状態/状態のセットです(F⊆Q)。
一方、グラフィカルに、DFAは状態図と呼ばれる図で表すことができます。
状態はによって表されます vertices。
遷移はラベル付きで示されます arcs。
初期状態は、 empty incoming arc。
最終状態はで表されます double circle。
DFAの例
DFAが
Q = {a、b、c}、
Σ= {0、1}、
q 0 = {a}、
F = {c}、
遷移関数δを次のように表に示します。
| 現在の状態 | 入力0の次の状態 | 入力1の次の状態 |
|---|---|---|
| A | a | B |
| B | b | A |
| C | c | C |
このDFAのグラフィック表現は次のようになります-

非決定性有限自動化(NDFA)
これは、すべての入力シンボルについて、マシンが移動する状態を判別できない、つまりマシンが状態の任意の組み合わせに移動できる、有限自動化のタイプとして定義できます。状態の数には限りがあるため、このマシンは非決定性有限自動化(NDFA)と呼ばれます。
数学的には、NDFAは5タプル(Q、Σ、δ、q0、F)で表すことができます。ここで、-
Qは有限の状態のセットです。
Σは、オートマトンのアルファベットと呼ばれる有限の記号のセットです。
δ:Q×Σ→2:状態遷移関数δ-is Qを。
q0:-入力が処理される初期状態です(q0∈Q)。
F:-Qの最終状態/状態のセットです(F⊆Q)。
グラフィカルに(DFAと同じ)、NDFAは状態図と呼ばれる図で表すことができます。
状態はによって表されます vertices。
遷移はラベル付きで示されます arcs。
初期状態は、 empty incoming arc。
最終状態はdoubleで表されます circle。
NDFAの例
NDFAが
Q = {a、b、c}、
Σ= {0、1}、
q 0 = {a}、
F = {c}、
遷移関数δを次のように表に示します。
| 現在の状態 | 入力0の次の状態 | 入力1の次の状態 |
|---|---|---|
| A | a、b | B |
| B | C | 交流 |
| C | b、c | C |
このNDFAのグラフィック表現は次のようになります-

形態学的解析
形態素構文解析という用語は、形態素の構文解析に関連しています。形態素解析は、単語が形態素と呼ばれる意味のある小さな単位に分解されて、ある種の言語構造を生成することを認識する問題として定義できます。たとえば、foxesという単語をfoxと-esの2つに分割できます。foxesという単語は、2つの形態素で構成されていることがわかります。1つはfoxで、もう1つは-esです。
別の意味では、形態学は-の研究であると言うことができます
言葉の形成。
言葉の由来。
単語の文法形式。
単語の形成における接頭辞と接尾辞の使用。
言語の品詞(PoS)がどのように形成されるか。
形態素の種類
最小の意味を持つ単位である形態素は、2つのタイプに分けることができます-
Stems
語順
茎
それは単語の核となる意味のある単位です。それが言葉のルーツとも言えます。たとえば、キツネという言葉では、茎はキツネです。
Affixes−名前が示すように、それらは単語にいくつかの追加の意味と文法機能を追加します。たとえば、キツネという単語では、接辞は-esです。
さらに、接辞は次の4つのタイプに分けることもできます-
Prefixes−名前が示すように、接頭辞は語幹の前にあります。たとえば、unbuckleという単語では、unが接頭辞です。
Suffixes−名前が示すように、接尾辞は語幹の後に続きます。たとえば、catsという単語では、-sが接尾辞です。
Infixes−名前が示すように、中置辞は語幹の内側に挿入されます。たとえば、cupfulという単語は、-sを中置として使用することにより、cupsfulとして複数形にすることができます。
Circumfixes−それらは語幹の前後にあります。英語の接周辞の例は非常に少ないです。非常に一般的な例は「A-ing」で、語幹の前に-Aを使用し、後に-ingを使用できます。
語順
単語の順序は、形態学的構文解析によって決定されます。形態学的パーサーを構築するための要件を見てみましょう-
レキシコン
形態学的パーサーを構築するための最初の要件はレキシコンです。これには、語幹と接辞のリスト、およびそれらに関する基本情報が含まれています。たとえば、語幹が名詞語幹か動詞語幹かなどの情報。
形態戦術
これは基本的に形態素順序のモデルです。別の意味では、どのクラスの形態素が単語内の他のクラスの形態素に従うことができるかを説明するモデル。たとえば、形態素の事実は、英語の複数形の形態素が常に名詞の前ではなく後に続くということです。
正書法の規則
これらのスペル規則は、単語で発生する変更をモデル化するために使用されます。たとえば、yをieに変換するルールは、city + s = citysではなくcitysのようになります。
構文解析または構文解析または構文解析は、NLPの第3フェーズです。このフェーズの目的は、正確な意味を引き出すことです。または、テキストから辞書の意味を言うことができます。構文解析は、形式文法の規則と比較して、テキストの意味をチェックします。たとえば、「hot ice-cream」のような文は、セマンティックアナライザーによって拒否されます。
この意味で、構文解析または構文解析は、形式文法の規則に準拠した自然言語の記号の文字列を分析するプロセスとして定義できます。言葉の由来‘parsing’ ラテン語からです ‘pars’ つまり、 ‘part’。
パーサーの概念
これは、解析のタスクを実装するために使用されます。これは、入力データ(テキスト)を取得し、形式文法に従って正しい構文をチェックした後、入力の構造表現を提供するために設計されたソフトウェアコンポーネントとして定義できます。また、一般に解析ツリーまたは抽象構文ツリーまたはその他の階層構造の形式でデータ構造を構築します。

解析の主な役割は次のとおりです。
構文エラーを報告します。
プログラムの残りの処理を続行できるように、一般的に発生するエラーから回復するため。
解析ツリーを作成します。
シンボルテーブルを作成します。
中間表現(IR)を生成します。
構文解析の種類
導出は、構文解析を次の2つのタイプに分けます-
トップダウン構文解析
ボトムアップ構文解析
トップダウン構文解析
この種の解析では、パーサーは開始シンボルから解析ツリーの構築を開始し、次に開始シンボルを入力に変換しようとします。トップダウン構文解析の最も一般的な形式は、再帰的手順を使用して入力を処理します。再帰下降構文解析の主な欠点は、バックトラックです。
ボトムアップ構文解析
この種の構文解析では、パーサーは入力シンボルから開始し、開始シンボルまでパーサーツリーを構築しようとします。
派生の概念
入力文字列を取得するには、一連のプロダクションルールが必要です。派生は、一連の生産ルールです。構文解析中に、非終端記号を決定する必要があります。非終端記号は、非終端記号を置き換える生産ルールを決定するとともに、置き換える必要があります。
派生の種類
このセクションでは、2種類の派生について学習します。これらの派生は、どの非終端記号をプロダクションルールに置き換えるかを決定するために使用できます。
左端の派生
左端の派生では、入力のセンテンス形式がスキャンされ、左から右に置き換えられます。この場合のセンテンスフォームは、左センテンスフォームと呼ばれます。
右端の派生
左端の派生では、入力のセンテンス形式がスキャンされ、右から左に置き換えられます。この場合のセンテンスフォームは、右センテンスフォームと呼ばれます。
解析ツリーの概念
これは、派生物のグラフィック描写として定義できます。派生の開始記号は、解析ツリーのルートとして機能します。すべての解析ツリーで、リーフノードは終端記号であり、内部ノードは非終端記号です。解析ツリーの特性は、順序どおりのトラバーサルが元の入力文字列を生成することです。
文法の概念
文法は、整形式のプログラムの構文構造を説明するために非常に重要で重要です。文学的な意味では、それらは自然言語での会話の構文規則を示します。言語学は、英語、ヒンディー語などの自然言語の開始以来、文法を定義しようと試みてきました。
形式言語の理論は、主にプログラミング言語とデータ構造のコンピュータサイエンスの分野にも適用できます。たとえば、「C」言語では、正確な文法規則により、リストとステートメントから関数を作成する方法が示されます。
文法の数学的モデルはによって与えられました Noam Chomsky 1956年に、これはコンピュータ言語を書くのに効果的です。
数学的には、文法Gは正式には4タプル(N、T、S、P)として記述できます。
N または VN =非終端記号のセット、つまり変数。
T または ∑ =終端記号のセット。
S =S∈Nである開始記号
P非終端記号だけでなく、終端記号の生成規則を示します。これは、α→β、α及びβは、V上の文字列である場合フォーム有するN ∪Σ及び少なくともαの一つのシンボルがVに属するNを
句構造または構成要素の文法
ノーム・チョムスキーによって導入された句構造文法は、構成要素の関係に基づいています。そのため、構成文法とも呼ばれます。依存文法とは逆です。
例
構成文法の例を示す前に、構成文法と構成関係についての基本的なポイントを知る必要があります。
関連するすべてのフレームワークは、構成要素の関係の観点から文の構造を表示します。
構成要素の関係は、ラテン語とギリシャ語の文法の主語と述語の区分から導き出されます。
基本的な節の構造は、次の観点から理解されます。 noun phrase NP そして verb phrase VP。
文章を書くことができます “This tree is illustrating the constituency relation” 次のように-

依存文法
これは、構成要素の文法とは反対であり、従属関係に基づいています。ルシアン・テニエールによって紹介されました。依存文法(DG)は、句動詞ノードがないため、構成文法とは逆です。
例
依存文法の例を示す前に、依存文法と従属関係についての基本的なポイントを知る必要があります。
DGでは、言語単位、つまり単語は、有向リンクによって相互に接続されます。
動詞は節構造の中心になります。
他のすべての構文単位は、有向リンクの観点から動詞に接続されています。これらの構文単位はdependencies。
文章を書くことができます “This tree is illustrating the dependency relation” 次のように;

Constituency文法を使用する解析ツリーは、Constituencyベースの解析ツリーと呼ばれます。依存文法を使用する解析ツリーは、依存関係ベースの解析ツリーと呼ばれます。
文脈自由文法
CFGとも呼ばれる文脈自由文法は、言語を記述するための表記法であり、正規文法のスーパーセットです。次の図で見ることができます-

CFGの定義
CFGは、次の4つの要素を持つ文法規則の有限集合で構成されています-
非終端記号のセット
非終端記号は文字列のセットを表す構文変数であり、文法によって生成される言語の定義にさらに役立ちます。
ターミナルのセット
トークンとも呼ばれ、Σで定義されます。文字列は、端子の基本記号で形成されます。
プロダクションのセット
これはPで表されます。このセットは、終端記号と非終端記号を組み合わせる方法を定義します。すべてのプロダクション(P)は、非終端記号、矢印、および終端記号(終端記号のシーケンス)で構成されます。非終端記号はプロダクションの左側と呼ばれ、終端記号はプロダクションの右側と呼ばれます。
開始記号
生産はスタートシンボルから始まります。記号Sで示されます。非終端記号は常に開始記号として指定されます。
セマンティック分析の目的は、正確な意味を引き出すことです。または、テキストから辞書の意味を言うことができます。セマンティックアナライザーの仕事は、テキストの意味をチェックすることです。
字句解析も単語の意味を扱うことはすでに知っていますが、意味解析は字句解析とどのように異なりますか?字句解析は小さなトークンに基づいていますが、反対側では意味解析は大きなチャンクに焦点を合わせています。そのため、セマンティック分析は次の2つの部分に分けることができます。
個々の単語の意味を学ぶ
これは、個々の単語の意味の研究が行われる意味解析の最初の部分です。この部分は語彙意味論と呼ばれます。
個々の単語の組み合わせを学ぶ
第二部では、個々の単語を組み合わせて、文の意味を提供します。
セマンティック分析の最も重要なタスクは、文の適切な意味を取得することです。たとえば、文を分析します“Ram is great.”この文では、話者はラム卿またはラムという名前の人について話している。そのため、文の正しい意味を理解するために、セマンティックアナライザーの仕事が重要です。
セマンティック分析の要素
以下は、セマンティック分析のいくつかの重要な要素です-
下位概念
これは、一般的な用語とその一般的な用語のインスタンスとの間の関係として定義できます。ここで、一般的な用語は上位概念と呼ばれ、そのインスタンスは下位概念と呼ばれます。たとえば、色という単語は上位概念であり、青、黄色などの色は下位概念です。
同音異義語
それは、同じ綴りまたは同じ形をしているが、異なった無関係な意味を持っている単語として定義されるかもしれません。たとえば、「バット」という単語は同音異義語です。バットはボールを打つための道具になる可能性があるため、またはバットは夜行性の飛ぶ哺乳類でもあるためです。
多義性
多義語はギリシャ語で、「多くの兆候」を意味します。これは、異なるが関連する意味を持つ単語またはフレーズです。言い換えれば、多義性は同じ綴りですが、異なる関連する意味を持っていると言うことができます。たとえば、「銀行」という単語は、次の意味を持つ多義語です。
金融機関。
そのような機関が置かれている建物。
「頼る」の同義語。
多義語と同音異義語の違い
多義語と同音異義語はどちらも同じ構文またはスペルです。それらの主な違いは、多義語では単語の意味が関連しているが、同音異義語では単語の意味が関連していないことです。たとえば、同じ単語「銀行」について話す場合、「金融機関」または「川岸」という意味を書くことができます。その場合、意味は互いに無関係であるため、同音異義語の例になります。
同義語
これは、形式は異なるが同じまたは密接な意味を表す2つの語彙アイテム間の関係です。例は「作者/作家」、「運命/運命」です。
反意語
これは、軸に対して意味コンポーネント間で対称性を持つ2つの語彙アイテム間の関係です。反抗の範囲は次のとおりです-
Application of property or not −例は「生/死」、「確実性/不確実性」です
Application of scalable property −例は「リッチ/プア」、「ホット/コールド」です。
Application of a usage −例は「父/息子」、「月/太陽」です。
意味表現
セマンティック分析は、文の意味の表現を作成します。しかし、意味表現に関連する概念とアプローチに入る前に、意味体系の構成要素を理解する必要があります。
セマンティックシステムのビルディングブロック
単語表現または単語の意味の表現では、次の構成要素が重要な役割を果たします-
Entities−特定の人物、場所などの個人を表します。たとえば、ハリヤーナ。インド、ラムはすべて実体です。
Concepts −人、都市など、個人の一般的なカテゴリを表します。
Relations−エンティティと概念の関係を表します。たとえば、ラムは人です。
Predicates−動詞の構造を表します。たとえば、セマンティックロールと格文法は述語の例です。
これで、意味表現がセマンティックシステムの構成要素をまとめる方法を示していることが理解できます。言い換えれば、状況を説明するためにエンティティ、概念、関係、および述語を組み合わせる方法を示しています。また、セマンティックの世界についての推論も可能にします。
意味表現へのアプローチ
セマンティック分析では、意味の表現に次のアプローチを使用します-
一階述語論理(FOPL)
セマンティックネット
Frames
概念依存性(CD)
ルールベースのアーキテクチャ
格文法
概念グラフ
意味表現の必要性
ここで生じる疑問は、なぜ意味表現が必要なのかということです。以下は同じ理由です-
言語要素の非言語要素へのリンク
一番最初の理由は、意味表現の助けを借りて、言語要素を非言語要素にリンクすることができるということです。
語彙レベルで多様性を表す
意味表現の助けを借りて、明確で標準的な形式を語彙レベルで表現できます。
推論に使用できます
意味表現は、世界で何が真実であるかを検証する理由を説明するため、および意味表現から知識を推測するために使用できます。
語彙意味論
個々の単語の意味を研究する意味分析の最初の部分は、語彙意味論と呼ばれます。単語、サブ単語、接辞(サブユニット)、複合語、フレーズも含まれます。すべての単語、サブ単語などは、まとめて語彙アイテムと呼ばれます。言い換えれば、語彙セマンティクスは、語彙アイテム、文の意味、および文の構文の間の関係であると言えます。
以下は語彙意味論に含まれるステップです-
単語、サブ単語、接辞などの語彙アイテムの分類は、語彙セマンティクスで実行されます。
単語、サブ単語、接辞などの語彙アイテムの分解は、語彙セマンティクスで実行されます。
さまざまな語彙意味構造間の相違点と類似点も分析されます。
単語は、文中の使用状況に基づいて異なる意味を持つことを理解しています。私たちが人間の言語について話す場合、多くの単語はそれらの出現の文脈に応じて複数の方法で解釈される可能性があるため、それらもあいまいです。
自然言語処理(NLP)における語義の曖昧性解消は、特定の文脈で単語を使用することによって単語のどの意味が活性化されるかを決定する能力として定義できます。構文的または意味的な語彙のあいまいさは、NLPシステムが直面する最初の問題の1つです。高レベルの精度を備えた品詞(POS)タガーは、Wordの構文のあいまいさを解決できます。一方、意味のあいまいさを解決する問題は、WSD(語義の曖昧性解消)と呼ばれます。意味のあいまいさを解決することは、構文のあいまいさを解決することよりも困難です。
たとえば、単語に存在する明確な意味の2つの例を考えてみましょう。 “bass” −
低音が聞こえます。
彼は焼きバスを食べるのが好きです。
単語の出現 bass明確な意味を明確に示しています。最初の文では、それは意味しますfrequency そして第二に、それは意味します fish。したがって、WSDによって明確化される場合、上記の文の正しい意味は次のように割り当てることができます。
低音/周波数音が聞こえます。
彼は焼きバス/魚を食べるのが好きです。
WSDの評価
WSDの評価には、次の2つの入力が必要です。
辞書
WSDを評価するための最初の入力は辞書です。これは、曖昧さを解消する感覚を指定するために使用されます。
テストコーパス
WSDに必要なもう1つの入力は、ターゲットまたは正しい感覚を持つ高注釈のテストコーパスです。テストコーパスには2つのタイプがあります&minsu;
Lexical sample −この種のコーパスはシステムで使用され、単語の小さなサンプルを明確にする必要があります。
All-words −この種のコーパスはシステムで使用され、実行中のテキスト内のすべての単語を明確にすることが期待されます。
語義曖昧性解消(WSD)へのアプローチと方法
WSDへのアプローチと方法は、語義の曖昧性解消に使用される知識のソースに従って分類されます。
ここで、WSDの4つの従来の方法を見てみましょう。
辞書ベースまたは知識ベースの方法
名前が示すように、曖昧さを解消するために、これらの方法は主に辞書、宝物、語彙知識ベースに依存しています。彼らは、曖昧さを解消するためにコーパスの証拠を使用しません。Lesk法は、1986年にMichaelLeskによって導入された独創的な辞書ベースの方法です。Leskアルゴリズムの基礎となるLesk定義は次のとおりです。“measure overlap between sense definitions for all words in context”。ただし、2000年に、KilgarriffとRosensweigは、簡略化されたLeskの定義を次のように示しました。“measure overlap between sense definitions of word and current context”、これはさらに、一度に1つの単語の正しい意味を識別することを意味します。ここで、現在のコンテキストは、周囲の文または段落内の単語のセットです。
監視ありメソッド
曖昧さを解消するために、機械学習手法では、意味のある注釈付きコーパスを使用してトレーニングを行います。これらの方法は、文脈がそれ自体で感覚を明確にするのに十分な証拠を提供できることを前提としています。これらの方法では、知識と推論という言葉は不要と見なされます。文脈は、単語の「特徴」のセットとして表されます。周囲の単語に関する情報も含まれています。サポートベクターマシンとメモリベースの学習は、WSDへの最も成功した教師あり学習アプローチです。これらの方法は、手動でセンスタグを付けたコーパスを大量に使用するため、作成に非常に費用がかかります。
半教師あり方法
トレーニングコーパスがないため、ほとんどの語義曖昧性解消アルゴリズムは半教師あり学習方法を使用します。これは、半教師ありメソッドがラベル付きデータとラベルなしデータの両方を使用するためです。これらの方法では、非常に少量の注釈付きテキストと大量のプレーンな注釈なしテキストが必要です。半教師あり方法で使用される手法は、シードデータからのブートストラップです。
教師なしメソッド
これらの方法は、同様の感覚が同様の文脈で発生することを前提としています。そのため、文脈の類似性の尺度を使用して単語の出現をクラスタリングすることにより、テキストから感覚を誘発することができます。このタスクは、単語感覚の誘導または識別と呼ばれます。教師なし手法は、手作業に依存しないため、知識獲得のボトルネックを克服する大きな可能性を秘めています。
語義曖昧性解消(WSD)の応用
語義曖昧性解消(WSD)は、言語テクノロジーのほぼすべてのアプリケーションに適用されます。
WSDの範囲を見てみましょう-
機械翻訳
機械翻訳またはMTは、WSDの最も明白なアプリケーションです。MTでは、異なる意味で異なる翻訳を持つ単語の字句の選択は、WSDによって行われます。MTの感覚は、ターゲット言語の単語として表されます。ほとんどの機械翻訳システムは、明示的なWSDモジュールを使用していません。
情報検索(IR)
情報検索(IR)は、ドキュメントリポジトリからの情報、特にテキスト情報の編成、保存、検索、および評価を処理するソフトウェアプログラムとして定義できます。このシステムは基本的に、ユーザーが必要な情報を見つけるのを支援しますが、質問の回答を明示的に返すことはありません。WSDは、IRシステムに提供されるクエリのあいまいさを解決するために使用されます。MTと同様に、現在のIRシステムはWSDモジュールを明示的に使用せず、ユーザーがクエリに十分なコンテキストを入力して関連するドキュメントのみを取得するという概念に依存しています。
テキストマイニングと情報抽出(IE)
ほとんどのアプリケーションでは、テキストを正確に分析するためにWSDが必要です。たとえば、WSDは、インテリジェントな収集システムが正しい単語のフラグ付けを行うのに役立ちます。たとえば、医療インテリジェントシステムでは、「医療薬物」ではなく「違法薬物」のフラグを立てる必要がある場合があります。
辞書編集
最新の辞書編集はコーパスベースであるため、WSDと辞書編集はループで連携できます。辞書編集を使用すると、WSDは、大まかな経験的感覚のグループ化と、統計的に有意な感覚の文脈的指標を提供します。
語義曖昧性解消(WSD)の難しさ
以下は、語義曖昧性解消(WSD)が直面するいくつかの困難です。
辞書の違い
WSDの主な問題は、異なる感覚が非常に密接に関連している可能性があるため、単語の感覚を決定することです。異なる辞書や類義語辞典でさえ、単語の感覚への異なる分割を提供することができます。
さまざまなアプリケーションのためのさまざまなアルゴリズム
WSDのもう1つの問題は、アプリケーションごとにまったく異なるアルゴリズムが必要になる可能性があることです。たとえば、機械翻訳では、ターゲット単語の選択という形を取ります。情報検索では、センスインベントリは必要ありません。
裁判官間の差異
WSDのもう1つの問題は、WSDシステムは一般に、タスクの結果を人間のタスクと比較してテストすることです。これは、裁判官間の分散の問題と呼ばれます。
言葉の意味の離散性
WSDのもう1つの問題は、単語を個別のサブ意味に簡単に分割できないことです。
AIの最も難しい問題は、コンピューターで自然言語を処理することです。言い換えれば、自然言語処理は、人工知能の最も難しい問題です。NLPの主要な問題について話す場合、NLPの主要な問題の1つは、談話処理です。つまり、発話がどのようにくっついて形成されるかについての理論とモデルを構築します。coherent discourse。実際、この言語は、映画のように孤立した無関係な文ではなく、常に併置され、構造化され、一貫性のある文のグループで構成されています。これらの一貫した文のグループは、談話と呼ばれます。
コヒーレンスの概念
コヒーレンスと談話構造は多くの方法で相互に関連しています。コヒーレンスは、優れたテキストの特性とともに、自然言語生成システムの出力品質を評価するために使用されます。ここで生じる問題は、テキストが首尾一貫しているとはどういう意味ですか?新聞のすべてのページから1つの文を集めたとしたら、それは談話になるのでしょうか。もちろん違います。これらの文は一貫性を示さないためです。首尾一貫した談話は以下の特性を持たなければならない-
発話間のコヒーレンス関係
発話間に意味のあるつながりがあれば、談話は首尾一貫しているでしょう。この特性はコヒーレンス関係と呼ばれます。たとえば、発話間の関係を正当化するために、何らかの説明が必要です。
エンティティ間の関係
談話を首尾一貫させるもう一つの特性は、実体とのある種の関係がなければならないということです。このような種類のコヒーレンスは、エンティティベースのコヒーレンスと呼ばれます。
談話構造
談話に関する重要な問題は、談話がどのような構造を持たなければならないかということです。この質問への答えは、談話に適用したセグメンテーションによって異なります。談話のセグメンテーションは、大規模な談話の構造のタイプを決定することとして定義できます。談話セグメンテーションを実装することは非常に困難ですが、それは非常に重要ですinformation retrieval, text summarization and information extraction 一種のアプリケーション。
談話セグメンテーションのアルゴリズム
このセクションでは、談話セグメンテーションのアルゴリズムについて学習します。アルゴリズムは以下のとおりです-
教師なし談話セグメンテーション
教師なし談話セグメンテーションのクラスは、線形セグメンテーションとして表されることがよくあります。例を使用して、線形セグメンテーションのタスクを理解できます。この例では、テキストを複数段落単位にセグメント化するタスクがあります。単位は元のテキストのパッセージを表します。これらのアルゴリズムは、テキスト単位を結び付けるための特定の言語デバイスの使用として定義される可能性のある凝集性に依存しています。一方、語彙のまとまりは、同義語の使用のように、2つの単位内の2つ以上の単語間の関係によって示されるまとまりです。
教師あり談話セグメンテーション
以前の方法には、手作業でラベル付けされたセグメント境界がありません。一方、教師あり談話セグメンテーションには、境界ラベル付きのトレーニングデータが必要です。入手はとても簡単です。教師あり談話セグメンテーションでは、談話マーカーまたはキューワードが重要な役割を果たします。談話マーカーまたはキューワードは、談話構造を示すように機能する単語またはフレーズです。これらの談話マーカーはドメイン固有です。
テキストの一貫性
語彙の繰り返しは、談話の構造を見つける方法ですが、一貫した談話であるという要件を満たしていません。首尾一貫した談話を達成するために、私たちは具体的に首尾一貫した関係に焦点を合わせなければなりません。私たちが知っているように、一貫性の関係は、談話における発話間の可能な接続を定義します。ヘブは次のような関係を提案しています-
私たちは2つの用語を取っています S0 そして S1 関連する2つの文の意味を表す-
結果
それは、用語によって主張された状態を推測します S0 によって主張された状態を引き起こす可能性があります S1。たとえば、2つのステートメントは、関係の結果を示しています。ラムは火事に巻き込まれました。彼の皮膚は焼けた。
説明
それは、によって主張された状態が S1 によって主張された状態を引き起こす可能性があります S0。たとえば、2つのステートメントは関係を示しています-ラムはシャムの友人と戦った。彼は酔っていた。
平行
のアサーションからp(a1、a2、…)を推測します S0 およびアサーションからのp(b1、b2、…) S1。ここで、aiとbiはすべてのiで類似しています。たとえば、2つのステートメントは並列です-ラムは車を望んでいました。シャムはお金が欲しかった。
精緻化
それは両方の主張から同じ命題Pを推測します- S0 そして S1たとえば、2つのステートメントは、関係の詳細を示しています。ラムはチャンディーガル出身でした。シャムはケララ州出身でした。
機会
これは、状態の変化が次のアサーションから推測できる場合に発生します。 S0、その最終状態はから推測することができます S1およびその逆。たとえば、2つのステートメントは、関係の機会を示しています。ラムは本を手に取りました。彼はそれをシャムに渡した。
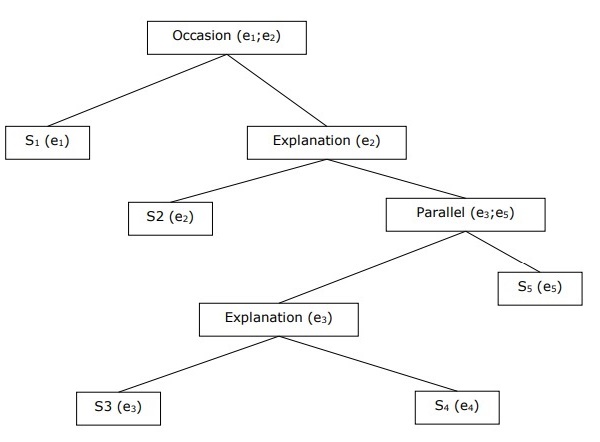
階層的談話構造の構築
談話全体の一貫性は、一貫性関係間の階層構造によっても考慮することができます。たとえば、次のパッセージは階層構造として表すことができます-
S1 −ラムはお金を預けるために銀行に行きました。
S2 −その後、彼は電車に乗ってシャムの洋服店に行きました。
S3 −彼は服を買いたかった。
S4 −彼はパーティー用の新しい服を持っていません。
S5 −彼はまた彼の健康についてシャムと話をしたかった
照応解析
談話からの文の解釈は別の重要なタスクであり、これを達成するために、誰またはどのエンティティが話しているのかを知る必要があります。ここでは、解釈の参照が重要な要素です。Referenceエンティティまたは個人を示すための言語表現として定義される場合があります。例えば、通路に、ラム、ABC銀行のマネージャーは、見た彼の店で友人シャムを。彼は彼に会いに行きました、ラム、彼、彼のような言語表現は参照です。
同じように、 reference resolution どのエンティティがどの言語表現によって参照されるかを決定するタスクとして定義される場合があります。
参照解決で使用される用語
参照解決では、次の用語を使用します-
Referring expression−参照を実行するために使用される自然言語式は、参照式と呼ばれます。たとえば、上記で使用されているパッセージは参照式です。
Referent−参照されるのはエンティティです。たとえば、最後に示した例では、Ramが指示対象です。
Corefer− 2つの式を使用して同じエンティティを参照する場合、それらはコアファーと呼ばれます。例えば、Ram そして he コアファーです。
Antecedent−その用語には、別の用語を使用するためのライセンスがあります。例えば、Ram 参照の先行詞です he。
Anaphora & Anaphoric−これは、以前に文に導入されたエンティティへの参照として定義される場合があります。そして、参照表現は照応と呼ばれます。
Discourse model −談話で参照されたエンティティの表現とそれらが関与している関係を含むモデル。
参照式の種類
ここで、さまざまなタイプの参照式を見てみましょう。以下に5種類の参照式について説明します。
不定代名詞句
そのような種類の参照は、談話の文脈において聞き手にとって新しい実体を表します。たとえば、ラムが彼に食べ物を持ってくるためにある日を回っていたという文の中で、いくつかは無期限の参照です。
明確な名詞句
上記とは反対に、そのような種類の参照は、談話の文脈で聞き手にとって新しいものでも識別可能なものでもないエンティティを表します。たとえば、「The Times of India」を読んでいた文の中で、The Times ofIndiaは明確な参考資料です。
代名詞
それは明確な参照の一形態です。たとえば、ラムはできるだけ大声で笑った。言葉he 代名詞参照式を表します。
指示語
これらは、単純な明確な代名詞とは異なる方法で示し、動作します。たとえば、これとそれは指示代名詞です。
名前
これは、最も単純なタイプの参照式です。人、組織、場所の名前にすることもできます。たとえば、上記の例では、Ramは名前を参照する式です。
照応タスク
2つの参照解決タスクを以下に説明します。
共参照解決
これは、同じエンティティを参照するテキスト内の参照式を見つけるタスクです。簡単に言えば、それはコアファー式を見つけるタスクです。相互参照式のセットは、共参照チェーンと呼ばれます。たとえば、彼、チーフマネージャー、および彼は、例として示されている最初の節の表現を参照しています。
共参照解決の制約
英語では、共参照解決の主な問題は代名詞itです。この背後にある理由は、代名詞には多くの用途があるためです。たとえば、彼と彼女のように参照できます。代名詞は、特定のものを指していないものも指します。たとえば、雨が降っています。本当にいいです。
代名詞照応解決
共参照解決とは異なり、代名詞照応解決は、単一の代名詞の先行詞を見つけるタスクとして定義できます。たとえば、代名詞は彼のものであり、代名詞照応解決のタスクは、Ramが先行詞であるため、Ramという単語を見つけることです。
タグ付けは、トークンへの説明の自動割り当てとして定義できる一種の分類です。ここで、記述子はタグと呼ばれ、品詞、意味情報などの1つを表す場合があります。
ここで、品詞(PoS)のタグ付けについて説明すると、品詞の1つを特定の単語に割り当てるプロセスとして定義できます。これは一般にPOSタグ付けと呼ばれます。簡単に言えば、品詞タグ付けは、文の各単語に適切な品詞でラベルを付けるタスクであると言えます。品詞には、名詞、動詞、副詞、形容詞、代名詞、接続詞、およびそれらのサブカテゴリが含まれることはすでにわかっています。
ほとんどのPOSタグ付けは、ルールベースのPOSタグ付け、確率的POSタグ付け、および変換ベースのタグ付けに分類されます。
ルールベースのPOSタグ付け
タグ付けの最も古い手法の1つは、ルールベースのPOSタグ付けです。ルールベースのタガーは、辞書または辞書を使用して、各単語にタグを付けるための可能なタグを取得します。単語に複数の可能なタグがある場合、ルールベースのタガーは手書きのルールを使用して正しいタグを識別します。曖昧さの解消は、単語の言語的特徴をその前後の単語とともに分析することにより、ルールベースのタグ付けで実行することもできます。たとえば、単語の前の単語が冠詞である場合、単語は名詞でなければなりません。
名前が示すように、ルールベースのPOSタグ付けにおけるそのような種類の情報はすべて、ルールの形式でコード化されます。これらのルールは次のいずれかです。
コンテキストパターンルール
または、有限状態オートマトンにコンパイルされた正規表現として、字句的にあいまいな文表現と交差しました。
また、ルールベースのPOSタグ付けは、その2段階のアーキテクチャによって理解できます。
First stage −最初の段階では、辞書を使用して、各単語に潜在的な品詞のリストを割り当てます。
Second stage −第2段階では、手書きの曖昧性解消ルールの大規模なリストを使用して、リストを単語ごとに1つの品詞に分類します。
ルールベースのPOSタグ付けのプロパティ
ルールベースのPOSタガーには、次のプロパティがあります。
これらのタガーは知識主導のタガーです。
ルールベースのPOSタグ付けのルールは、手動で作成されます。
情報はルールの形式でコード化されます。
ルールの数には、約1000の制限があります。
平滑化と言語モデリングは、ルールベースのタガーで明示的に定義されています。
確率的POSタグ付け
タグ付けのもう1つの手法は、確率的POSタグ付けです。ここで発生する問題は、どのモデルが確率的である可能性があるかということです。頻度または確率(統計)を含むモデルは、確率論的と呼ぶことができます。品詞のタグ付けの問題に対するさまざまなアプローチは、確率的タガーと呼ばれます。
最も単純な確率的タガーは、POSタギングに次のアプローチを適用します-
単語頻度アプローチ
このアプローチでは、確率的タガーは、特定のタグで単語が出現する確率に基づいて単語の曖昧さを解消します。また、トレーニングセット内の単語で最も頻繁に遭遇するタグは、その単語のあいまいなインスタンスに割り当てられたタグであるとも言えます。このアプローチの主な問題は、許容できないタグのシーケンスが生成される可能性があることです。
タグシーケンスの確率
これは確率的タグ付けの別のアプローチであり、タガーはタグの特定のシーケンスが発生する確率を計算します。n-gramアプローチとも呼ばれます。これは、特定の単語に最適なタグが、前のn個のタグで発生する確率によって決定されるためです。
確率的POSTタグ付けのプロパティ
確率的POSタガーは次の特性を持っています-
このPOSタグ付けは、タグが発生する確率に基づいています。
コーパスのトレーニングが必要です
コーパスに存在しない単語の可能性はありません。
さまざまなテストコーパス(トレーニングコーパス以外)を使用します。
トレーニングコーパスの単語に関連付けられた最も頻繁なタグを選択するため、これは最も単純なPOSタグ付けです。
変換ベースのタグ付け
変換ベースのタグ付けは、ブリルタグ付けとも呼ばれます。これは、変換ベースの学習(TBL)のインスタンスであり、指定されたテキストへのPOSの自動タグ付けのためのルールベースのアルゴリズムです。TBLは、読みやすい形式で言語知識を持つことを可能にし、変換規則を使用して1つの状態を別の状態に変換します。
これは、前に説明したタガー(ルールベースと確率論)の両方からインスピレーションを得ています。ルールベースと変換タガーの間に類似性が見られる場合、ルールベースと同様に、どのタグをどの単語に割り当てる必要があるかを指定するルールにも基づいています。一方、確率論的タガーと変換タガーの類似性を見ると、確率論的のように、データからルールが自動的に誘導される機械学習手法です。
変革ベースの学習(TBL)の働き
変換ベースのタガーの動作と概念を理解するには、変換ベースの学習の動作を理解する必要があります。TBLの動作を理解するには、次の手順を検討してください。
Start with the solution − TBLは通常、問題の解決策から始まり、周期的に機能します。
Most beneficial transformation chosen −各サイクルで、TBLは最も有益な変換を選択します。
Apply to the problem −最後のステップで選択した変換が問題に適用されます。
手順2で選択した変換で値が追加されないか、選択する変換がなくなると、アルゴリズムは停止します。このような種類の学習は、分類タスクに最適です。
変換ベースの学習(TBL)の利点
TBLの利点は次のとおりです-
簡単なルールの小さなセットを学び、これらのルールはタグ付けに十分です。
学習したルールは理解しやすいため、TBLでは開発とデバッグが非常に簡単です。
TBLには、機械学習されたルールと人間が生成したルールが混在しているため、タグ付けの複雑さが軽減されます。
変換ベースのタガーは、マルコフモデルのタガーよりもはるかに高速です。
変換ベースの学習(TBL)のデメリット
TBLのデメリットは次のとおりです。
変換ベースの学習(TBL)は、タグの確率を提供しません。
TBLでは、特に大規模なコーパスでは、トレーニング時間が非常に長くなります。
隠れマルコフモデル(HMM)の品詞タグ付け
HMM POSタグ付けを深く掘り下げる前に、隠れマルコフモデル(HMM)の概念を理解する必要があります。
隠れマルコフモデル
HMMモデルは、基礎となる確率過程が隠されている、二重に埋め込まれた確率モデルとして定義できます。この隠れた確率過程は、一連の観測を生成する別の一連の確率過程を通じてのみ観測できます。
例
たとえば、一連の隠されたコイントス実験が行われ、頭と尾からなる観察シーケンスのみが表示されます。プロセスの実際の詳細(使用されたコインの数、選択された順序)は、私たちには隠されています。この頭と尾のシーケンスを観察することにより、シーケンスを説明するためにいくつかのHMMを構築できます。以下は、この問題の隠れマルコフモデルの一形態です。

HMMには2つの状態があり、それぞれの状態が異なるバイアスされたコインの選択に対応していると仮定しました。次の行列は、状態遷移確率を示します-
$$A = \begin{bmatrix}a11 & a12 \\a21 & a22 \end{bmatrix}$$
ここに、
aij =ある状態から別の状態へのiからjへの遷移の確率。
a11 + a12= 1、21 + 22 = 1
P1 =最初のコインの頭の確率、つまり最初のコインのバイアス。
P2 = 2番目のコインの頭の確率、つまり2番目のコインのバイアス。
コインが3枚以上あると仮定してHMMモデルを作成することもできます。
このように、次の要素によってHMMを特徴付けることができます-
N、モデル内の状態の数(上記の例ではN = 2、2つの状態のみ)。
M、上記の例の各状態で表示される可能性のある個別の観測値の数M = 2、つまりHまたはT)。
A、状態遷移確率分布-上記の例の行列A。
P、各状態(この例ではP1とP2)での観測可能なシンボルの確率分布。
私、初期状態の分布。
POSタグ付けのためのHMMの使用
POSタグ付けプロセスは、特定の単語シーケンスを生成した可能性が最も高いタグのシーケンスを見つけるプロセスです。このPOSプロセスは、隠れマルコフモデル(HMM)を使用してモデル化できます。tags は hidden states それは observable output, つまり、 words。
数学的には、POSタグ付けでは、-を最大化するタグシーケンス(C)を見つけることに常に関心があります。
P (C|W)
どこ、
C = C 1、C 2、C 3 ... C T
W = W 1、W 2、W 3、W T
コインの反対側では、実際には、そのような種類のシーケンスを合理的に推定するには、多くの統計データが必要です。ただし、問題を単純化するために、いくつかの仮定とともにいくつかの数学的変換を適用できます。
POSタグ付けを行うためのHMMの使用は、ベイズ干渉の特殊なケースです。したがって、ベイズの定理を使用して問題を言い換えることから始めます。これは、上記の条件付き確率が-に等しいことを示しています。
(PROB (C1,..., CT) * PROB (W1,..., WT | C1,..., CT)) / PROB (W1,..., WT)
上記の値を最大化するシーケンスCを見つけることに関心があるため、これらすべての場合で分母を削除できます。これは私たちの答えには影響しません。さて、私たちの問題は、最大化するシーケンスCを見つけることになります。
PROB (C1,..., CT) * PROB (W1,..., WT | C1,..., CT) (1)
上記の式の問題を減らした後でも、大量のデータが必要になります。この問題を克服するために、上記の式の2つの確率について合理的な独立性の仮定を立てることができます。
最初の仮定
タグの確率は、前の1つ(バイグラムモデル)または前の2つ(トリグラムモデル)または前のn個のタグ(n-グラムモデル)に依存します。これは数学的に次のように説明できます。
PROB (C1,..., CT) = Πi=1..T PROB (Ci|Ci-n+1…Ci-1) (n-gram model)
PROB (C1,..., CT) = Πi=1..T PROB (Ci|Ci-1) (bigram model)
文の始まりは、各タグの初期確率を仮定することで説明できます。
PROB (C1|C0) = PROB initial (C1)
2番目の仮定
上記の式(1)の2番目の確率は、単語が前後のカテゴリの単語とは独立したカテゴリに出現すると仮定することで概算できます。これは、数学的に次のように説明できます。
PROB (W1,..., WT | C1,..., CT) = Πi=1..T PROB (Wi|Ci)
ここで、上記の2つの仮定に基づいて、私たちの目標は、最大化するシーケンスCを見つけることになります。
Πi=1...T PROB(Ci|Ci-1) * PROB(Wi|Ci)
ここで発生する問題は、問題を上記の形式に変換することが本当に役に立ちました。答えは-はい、そうです。タグ付けされた大きなコーパスがある場合、上記の式の2つの確率は次のように計算できます。
PROB (Ci=VERB|Ci-1=NOUN) = (# of instances where Verb follows Noun) / (# of instances where Noun appears) (2)
PROB (Wi|Ci) = (# of instances where Wi appears in Ci) /(# of instances where Ci appears) (3)
この章では、自然言語処理における自然言語の開始について説明します。まず、自然言語文法とは何かを理解しましょう。
自然言語文法
言語学の場合、言語は任意の音声記号のグループです。言語は創造的であり、規則に支配され、生得的であると同時に普遍的であると言えます。一方で、それは人間的にもです。言語の性質は人によって異なります。言語の性質については多くの誤解があります。そのため、あいまいな用語の意味を理解することが非常に重要です。‘grammar’。言語学では、文法という用語は、どの言語が機能するかを利用した規則または原則として定義される場合があります。広い意味で、文法は2つのカテゴリーに分けることができます-
記述文法
言語学と文法学者が話者の文法を定式化する一連の規則は、記述文法と呼ばれます。
パースペクティブ文法
これは非常に異なる文法の意味であり、言語の正確さの基準を維持しようとします。このカテゴリは、言語の実際の動作とはほとんど関係がありません。
言語の構成要素
学習言語は、相互に関連するコンポーネントに分割されます。これらのコンポーネントは、言語調査の従来の区分と任意の区分です。これらのコンポーネントの説明は次のとおりです-
音韻論
言語の最初の要素は音韻論です。それは特定の言語のスピーチ音の研究です。単語の起源はギリシャ語にさかのぼることができます。「電話」は音または声を意味します。音韻論の下位区分である音声学は、人間の言語の発話音を、その生成、知覚、または物理的特性の観点から研究することです。IPA(International Phonetic Alphabet)は、音韻論を研究しながら、人間の音を通常の方法で表現するツールです。IPAでは、書かれたすべての記号は1つだけの音声を表し、その逆も同様です。
音素
これは、ある言語で1つの単語を他の単語と区別する音の単位の1つとして定義できます。言語学では、音素はスラッシュの間に書かれます。たとえば、音素/k/ キット、スキットなどの単語で発生します。
形態学
それは言語の2番目の要素です。それは特定の言語の単語の構造と分類の研究です。単語の起源はギリシャ語にあり、「モーフ」という単語は「フォーム」を意味します。形態論は、言語における単語の形成の原則を考慮します。言い換えれば、音が接頭辞、接尾辞、語根などの意味のある単位にどのように組み合わされるかです。また、単語を品詞にグループ化する方法についても検討します。
語彙素
言語学では、1つの単語がとる一連の形式に対応する形態素解析の抽象的な単位は語彙素と呼ばれます。語彙素が文で使用される方法は、その文法範疇によって決定されます。語彙素は、個々の単語または複数の単語にすることができます。たとえば、単語talkは、個々の単語の語彙素の例であり、talks、talked、talkingなどの多くの文法上の変形がある場合があります。マルチワード語彙素は、複数の正字法の単語で構成できます。たとえば、話す、プルスルーなどは、マルチワード語彙素の例です。
構文
それは言語の3番目の要素です。それは、単語の順序と配置をより大きな単位に研究することです。この言葉はギリシャ語にさかのぼることができます。ここで、suntasseinという言葉は「整理する」という意味です。文の種類とその構造、節、句を研究します。
セマンティクス
それは言語の4番目の要素です。それは意味がどのように伝えられるかについての研究です。意味は、外の世界に関連している場合もあれば、文の文法に関連している場合もあります。この言葉はギリシャ語にさかのぼることができます。セマイネインという言葉は、「意味する」、「表示する」、「信号」を意味します。
語用論
それは言語の5番目の要素です。それは言語の機能と文脈におけるその使用の研究です。単語の起源は、単語「プラグマ」が「行為」、「情事」を意味するギリシャ語にさかのぼることができます。
文法範疇
文法範疇は、言語の文法内の単位または機能のクラスとして定義できます。これらのユニットは言語の構成要素であり、共通の特性セットを共有しています。文法範疇は、文法素性とも呼ばれます。
文法範疇の一覧は以下のとおりです。
数
これは最も単純な文法範疇です。このカテゴリに関連する2つの用語、単数形と複数形があります。単数形は「1つ」の概念ですが、複数形は「複数」の概念です。たとえば、犬/犬、これ/これら。
性別
文法的な性別は、人称代名詞と3人称の変化によって表されます。文法的な性別の例は単数です-彼、彼女、それ。一人称と二人称が形成されます-私、私たち、そしてあなた。三人称複数形は、通性または中性のいずれかです。
人
もう1つの単純な文法範疇は人です。この下で、以下の3つの用語が認識されます-
1st person −話している人は1人称として認識されます。
2nd person −聞き手または話しかけられた人は、2人称として認識されます。
3rd person −私たちが話している人または物は3人称として認識されます。
場合
これは、最も難しい文法範疇の1つです。これは、名詞句(NP)の機能、または名詞句と動詞または文内の他の名詞句との関係を示すものとして定義できます。個人代名詞と疑問代名詞で表現された次の3つのケースがあります-
Nominative case−それは主語の機能です。たとえば、私、私たち、あなた、彼、彼女、それ、彼ら、そして主格の人。
Genitive case−それは所有者の機能です。たとえば、my / mine、our / ours、his、her / hers、its、their / theirs、属格です。
Objective case−それはオブジェクトの機能です。たとえば、私、私たち、あなた、彼、彼女、彼らは客観的です。
程度
この文法範疇は形容詞と副詞に関連しています。次の3つの用語があります-
Positive degree−品質を表現しています。たとえば、大きく、速く、美しくはポジティブな程度です。
Comparative degree−2つの項目のうちの1つで品質の程度または強度が高いことを表します。たとえば、より大きく、より速く、より美しくは比較級です。
Superlative degree−3つ以上の項目の1つで品質の最大の程度または強度を表します。たとえば、最大、最速、最も美しいのは最上級です。
確定性と不確定性
これらの概念はどちらも非常に単純です。私たちが知っている明確さは、話し手または聞き手によって知られている、よく知られている、または識別可能な指示対象を表します。一方、不確定性は、知られていない、またはなじみのない指示対象を表します。この概念は、名詞との記事の共起で理解できます-
definite article-
indefinite article− a / an
時制
この文法範疇は動詞に関連しており、行動の時間の言語的指標として定義することができます。時制は、話す瞬間に対してイベントの時間を示すため、関係を確立します。大まかに次の3種類があります-
Present tense−現時点でのアクションの発生を表します。たとえば、Ramは一生懸命働きます。
Past tense−現時点より前のアクションの発生を表します。たとえば、雨が降った。
Future tense−現時点以降のアクションの発生を表します。たとえば、雨が降ります。
側面
この文法範疇は、イベントのビューとして定義できます。次のタイプがあります-
Perfective aspect−ビューは全体としてとらえられ、アスペクト全体で完全です。たとえば、次のような単純過去形yesterday I met my friend, 英語では、イベントが完全で全体として見られるため、完全な側面を持っています。
Imperfective aspect−この見解は、その側面において継続的かつ不完全であると見なされます。たとえば、現在分詞の時制は次のようになりますI am working on this problem, 英語では、イベントが不完全で進行中であると見なされるため、側面が不完全です。
気分
この文法範疇を定義するのは少し難しいですが、それは彼/彼女が話していることに対する話者の態度の指標として簡単に述べることができます。動詞の文法的な特徴でもあります。これは、文法的な時制や文法的な側面とは異なります。気分の例は、直説法、質問法、命令法、差し止め命令法、接続法、潜在的、希求法、動名詞、分詞です。
契約
コンコードとも呼ばれます。これは、単語が関連する他の単語に依存することから変化したときに発生します。言い換えれば、文法範疇の値を異なる単語や品詞の間で一致させることが含まれます。以下は、他の文法範疇に基づく合意です-
Agreement based on Person−主語と動詞の一致です。たとえば、私たちは常に「私は」と「彼は」を使用しますが、「彼は」と「私は」は使用しません。
Agreement based on Number−この合意は主語と動詞の間です。この場合、一人称単数形、二人称複数形などの特定の動詞形式があります。たとえば、1人称単数形:私は本当に、2人称複数形:私たちは本当にそうです、3人称単数形:男の子が歌います、3人称複数形:男の子が歌います。
Agreement based on Gender−英語では、代名詞と先行詞の間で性別の一致があります。たとえば、彼は目的地に到着しました。船は目的地に到着した。
Agreement based on Case−この種の合意は英語の重要な特徴ではありません。たとえば、誰が最初に来たのですか?彼または彼の妹ですか?
音声言語構文
書かれた英語と話された英語の文法には多くの共通の特徴がありますが、それに伴い、それらは多くの面でも異なります。次の機能は、話し言葉と書き言葉の英語の文法を区別します-
流暢さと修理
この印象的な機能により、話し言葉と書き言葉の英語の文法が互いに異なります。それは個別に流暢さの現象として、そして集合的に修復の現象として知られています。流暢さには、以下の使用が含まれます-
Fillers words−文の間に時々フィラーワードを使用します。それらはフィラーポーズのフィラーと呼ばれます。そのような言葉の例は、ええと、ええとです。
Reparandum and repair−文の間に繰り返される単語のセグメントは、レパランダムと呼ばれます。同じセグメントで、変更された単語は修復と呼ばれます。これを理解するために次の例を検討してください-
Does ABC airlines offer any one-way flights uh one-way fares for 5000 rupees?
上記の文では、片道のフライトはリパラダムであり、片道のフライトは修理です。
再起動
フィラーが一時停止した後、再起動が発生します。たとえば、上記の文では、話者が片道のフライトについて尋ね始めてから停止し、フィラーポーズで自分自身を修正してから、片道の運賃について尋ね始めたときに再開が発生します。
単語の断片
時々、私たちは小さな単語の断片で文章を話します。例えば、wwha-what is the time? ここに言葉 w-wha 単語の断片です。
情報検索(IR)は、ドキュメントリポジトリからの情報、特にテキスト情報の編成、保存、検索、および評価を処理するソフトウェアプログラムとして定義できます。このシステムは、ユーザーが必要な情報を見つけるのを支援しますが、質問の回答を明示的に返すことはありません。必要な情報で構成される可能性のあるドキュメントの存在と場所を通知します。ユーザーの要件を満たすドキュメントは、関連ドキュメントと呼ばれます。完璧なIRシステムは、関連するドキュメントのみを取得します。
次の図の助けを借りて、私たちは情報検索(IR)のプロセスを理解することができます-

上の図から、情報が必要なユーザーは、自然言語でクエリの形式でリクエストを作成する必要があることが明らかです。次に、IRシステムは、必要な情報について、ドキュメントの形式で関連する出力を取得することによって応答します。
情報検索(IR)システムにおける古典的な問題
IR研究の主な目標は、ドキュメントのリポジトリから情報を取得するためのモデルを開発することです。ここでは、という名前の古典的な問題について説明しますad-hoc retrieval problem、IRシステムに関連します。
アドホック検索では、ユーザーは必要な情報を説明する自然言語でクエリを入力する必要があります。次に、IRシステムは、必要な情報に関連する必要なドキュメントを返します。たとえば、インターネットで何かを検索していて、要件に従って関連性のある正確なページがいくつか表示されているが、関連性のないページもいくつかあるとします。これは、アドホック検索の問題が原因です。
アドホック検索の側面
以下は、IR研究で扱われるアドホック検索のいくつかの側面です-
関連性フィードバックの助けを借りて、ユーザーはどのようにしてクエリの元の定式化を改善できますか?
データベースのマージを実装する方法、つまり、異なるテキストデータベースの結果を1つの結果セットにマージする方法は?
部分的に破損したデータを処理する方法は?どのモデルが同じに適していますか?
情報検索(IR)モデル
数学的には、モデルは、現実世界のある現象を理解することを目的とした多くの科学分野で使用されています。情報検索のモデルは、ユーザーが特定のクエリに関連して何を見つけるかを予測して説明します。IRモデルは、基本的に、検索手順の上記の側面を定義するパターンであり、次のもので構成されます。
ドキュメントのモデル。
クエリのモデル。
クエリをドキュメントと比較するマッチング関数。
数学的には、検索モデルは次のもので構成されます。
D −ドキュメントの表現。
R −クエリの表現。
F − D、Qのモデリングフレームワークとそれらの間の関係。
R (q,di)−クエリに関してドキュメントを順序付ける類似性関数。ランキングとも呼ばれます。
情報検索(IR)モデルの種類
情報モデル(IR)モデルは、次の3つのモデルに分類できます。
古典的なIRモデル
これは、IRモデルを実装するのに最も簡単で簡単です。このモデルは、簡単に認識および理解できる数学的知識に基づいています。ブール、ベクトル、確率は3つの古典的なIRモデルです。
非古典的IRモデル
これは、従来のIRモデルとは完全に反対です。このような種類のIRモデルは、類似性、確率、ブール演算以外の原則に基づいています。非古典的IRモデルの例としては、情報論理モデル、状況理論モデル、相互作用モデルがあります。
代替IRモデル
これは、他のいくつかの分野からのいくつかの特定の技術を利用した古典的なIRモデルの拡張です。クラスターモデル、ファジーモデル、潜在意味インデックス(LSI)モデルは、代替IRモデルの例です。
情報検索(IR)システムの設計機能
IRシステムの設計機能について学びましょう-
転置インデックス
ほとんどのIRシステムの主要なデータ構造は、転置インデックスの形式です。転置インデックスは、単語ごとに、それを含むすべてのドキュメントとドキュメント内での出現頻度を一覧表示するデータ構造として定義できます。クエリワードの「ヒット」を簡単に検索できます。
単語の削除を停止します
ストップワードは、検索に役立つ可能性が低いと見なされる高頻度の単語です。それらは意味的な重みが少ない。そのような種類の単語はすべて、ストップリストと呼ばれるリストに含まれています。たとえば、冠詞「a」、「an」、「the」、および「in」、「of」、「for」、「at」などの前置詞は、ストップワードの例です。転置インデックスのサイズは、ストップリストによって大幅に縮小できます。ジップの法則に従って、数十語をカバーするストップリストは転置インデックスのサイズをほぼ半分に減らします。一方、ストップワードを削除すると、検索に役立つ用語が削除される場合があります。たとえば、「ビタミンA」からアルファベット「A」を削除した場合、それは意味がありません。
ステミング
形態素解析の簡略化された形式であるステミングは、単語の末尾を切り落とすことによって単語の基本形式を抽出するヒューリスティックプロセスです。たとえば、「笑う」、「笑う」、「笑う」という単語は、「笑う」という語根に由来します。
以降のセクションでは、いくつかの重要で有用なIRモデルについて説明します。
ブールモデル
これは最も古い情報検索(IR)モデルです。このモデルは、集合論とブール代数に基づいています。ここで、ドキュメントは用語のセットであり、クエリは用語のブール式です。ブールモデルは次のように定義できます-
D−単語のセット、つまり、ドキュメントに存在する索引語。ここで、各用語は存在する(1)または存在しない(0)のいずれかです。
Q −ブール式。ここで、用語はインデックス用語であり、演算子は論理積です-AND、論理和-ORおよび論理差-NOT
F −用語のセットおよびドキュメントのセットに対するブール代数
関連性フィードバックについて話す場合、ブールIRモデルでは、関連性予測は次のように定義できます。
R −ドキュメントは、クエリ式を次のように満たす場合にのみ、クエリ式に関連すると予測されます。
((˅)˄˄〜ℎ)
このモデルは、一連のドキュメントの明確な定義としてのクエリ用語によって説明できます。
たとえば、クエリ用語 “economic” 用語で索引付けされたドキュメントのセットを定義します “economic”。
さて、用語をブールAND演算子と組み合わせた後の結果はどうなるでしょうか?これは、単一の用語のいずれかのドキュメントセット以下のドキュメントセットを定義します。たとえば、用語を含むクエリ“social” そして “economic”両方の用語で索引付けされたドキュメントのドキュメントセットを生成します。つまり、両方のセットが交差するドキュメントセットです。
さて、用語をブールOR演算子と組み合わせた後の結果はどうなるでしょうか?単一の用語のいずれかのドキュメントセット以上のドキュメントセットを定義します。たとえば、用語を含むクエリ“social” または “economic” いずれかの用語で索引付けされたドキュメントのドキュメントセットを生成します “social” または “economic”。つまり、両方のセットを結合したドキュメントセットです。
ブールモードの利点
ブールモデルの利点は次のとおりです。
セットに基づく最も単純なモデル。
理解と実装が簡単です。
完全一致のみを取得します
これにより、ユーザーはシステムを制御できるようになります。
ブールモデルのデメリット
ブールモデルの欠点は次のとおりです。
モデルの類似度関数はブール値です。したがって、部分的な一致はありません。これはユーザーにとって迷惑になる可能性があります。
このモデルでは、ブール演算子の使用法は、重要な単語よりもはるかに大きな影響を及ぼします。
クエリ言語は表現力豊かですが、複雑でもあります。
取得したドキュメントのランキングはありません。
ベクトル空間モデル
ブールモデルの上記の欠点のために、Gerard Saltonと彼の同僚は、Luhnの類似性基準に基づくモデルを提案しました。Luhnによって策定された類似性基準は、「特定の要素とそれらの分布で合意された2つの表現が多いほど、それらが類似した情報を表す可能性が高くなる」と述べています。
ベクトル空間モデルについてさらに理解するには、次の重要な点を考慮してください。
インデックス表現(ドキュメント)とクエリは、高次元のユークリッド空間に埋め込まれたベクトルと見なされます。
ドキュメントベクトルとクエリベクトルの類似性の尺度は、通常、それらの間の角度の余弦です。
コサイン類似度測定式
コサインは正規化された内積であり、次の式を使用して計算できます。
$$Score \lgroup \vec{d} \vec{q} \rgroup= \frac{\sum_{k=1}^m d_{k}\:.q_{k}}{\sqrt{\sum_{k=1}^m\lgroup d_{k}\rgroup^2}\:.\sqrt{\sum_{k=1}^m}m\lgroup q_{k}\rgroup^2 }$$
$$Score \lgroup \vec{d} \vec{q}\rgroup =1\:when\:d =q $$
$$Score \lgroup \vec{d} \vec{q}\rgroup =0\:when\:d\:and\:q\:share\:no\:items$$
クエリとドキュメントによるベクトル空間表現
クエリとドキュメントは、2次元のベクトル空間で表されます。用語はcar そして insurance。ベクトル空間には1つのクエリと3つのドキュメントがあります。

車と保険の条件に応じて上位にランク付けされたドキュメントがドキュメントになります d2 間の角度のため q そして d2最小です。この背後にある理由は、自動車と保険の両方の概念がd 2で顕著であり、したがって重みが高いためです。反対側では、d1 そして d3 また、両方の用語についても言及していますが、いずれの場合も、どちらか一方がドキュメントの中心的な重要な用語ではありません。
用語の重み付け
用語の重み付けとは、ベクトル空間の用語の重みを意味します。用語の重みが大きいほど、コサインに対する用語の影響が大きくなります。モデル内のより重要な用語には、より多くの重みを割り当てる必要があります。ここで発生する問題は、これをどのようにモデル化できるかということです。
これを行う1つの方法は、ドキュメント内の単語を用語の重みとしてカウントすることです。しかし、それは効果的な方法だと思いますか?
より効果的な別の方法は、を使用することです term frequency (tfij), document frequency (dfi) そして collection frequency (cfi)。
期間頻度(tf ij)
それはの発生数として定義されるかもしれません wi に dj。用語の頻度によって取得される情報は、特定のドキュメント内で単語がどれだけ目立つかということです。言い換えると、用語の頻度が高いほど、その単語はそのドキュメントの内容を適切に説明していると言えます。
ドキュメントの頻度(df i)
これは、wiが発生するコレクション内のドキュメントの総数として定義できます。それは有益性の指標です。意味的に焦点が合っていない単語とは異なり、意味的に焦点が合っている単語は、ドキュメント内で数回出現します。
収集頻度(cf i)
これは、の発生の総数として定義できます。 wi コレクション内。
数学的には、 $df_{i}\leq cf_{i}\:and\:\sum_{j}tf_{ij} = cf_{i}$
ドキュメント頻度の重み付けの形式
ここで、ドキュメントの頻度の重み付けのさまざまな形式について学習しましょう。フォームは以下のとおりです-
用語頻度因子
これは、用語頻度因子としても分類されます。つまり、 t ドキュメントに頻繁に表示され、その後、 tそのドキュメントを取得する必要があります。単語を組み合わせることができますterm frequency (tfij) そして document frequency (dfi) 次のように単一の重みに-
$$weight \left ( i,j \right ) =\begin{cases}(1+log(tf_{ij}))log\frac{N}{df_{i}}\:if\:tf_{i,j}\:\geq1\\0 \:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\: if\:tf_{i,j}\:=0\end{cases}$$
ここで、Nはドキュメントの総数です。
逆ドキュメント頻度(idf)
これはドキュメント頻度の重み付けの別の形式であり、idf重み付けまたは逆ドキュメント頻度重み付けと呼ばれることがよくあります。idfの重み付けの重要な点は、コレクション全体での用語の不足がその重要性の尺度であり、重要性が発生頻度に反比例することです。
数学的には、
$$idf_{t} = log\left(1+\frac{N}{n_{t}}\right)$$
$$idf_{t} = log\left(\frac{N-n_{t}}{n_{t}}\right)$$
ここに、
N =コレクション内のドキュメント
n t =用語tを含むドキュメント
ユーザークエリの改善
情報検索システムの主な目標は、ユーザーの要件に従って関連するドキュメントを作成するための正確さでなければなりません。ただし、ここで発生する問題は、ユーザーのクエリ形成スタイルを改善することによって、出力をどのように改善できるかということです。確かに、IRシステムの出力はユーザーのクエリに依存しており、適切にフォーマットされたクエリはより正確な結果を生成します。ユーザーはの助けを借りて自分のクエリを改善することができますrelevance feedback、IRモデルの重要な側面。
関連性のフィードバック
関連性フィードバックは、指定されたクエリから最初に返される出力を受け取ります。この初期出力を使用して、ユーザー情報を収集し、その出力が新しいクエリの実行に関連しているかどうかを知ることができます。フィードバックは次のように分類できます-
明示的なフィードバック
これは、関連性の評価者から得られるフィードバックとして定義できます。これらの評価者は、クエリから取得したドキュメントの関連性も示します。クエリ検索のパフォーマンスを向上させるには、関連性フィードバック情報を元のクエリで補間する必要があります。
システムの評価者または他のユーザーは、以下の関連性システムを使用して、関連性を明示的に示すことができます。
Binary relevance system −この関連性フィードバックシステムは、ドキュメントが特定のクエリに関連性がある(1)または関連性がない(0)ことを示します。
Graded relevance system−採点された関連性フィードバックシステムは、数字、文字、または説明を使用した採点に基づいて、特定のクエリに対するドキュメントの関連性を示します。説明は、「関連性がない」、「やや関連性がある」、「非常に関連性がある」、「関連性がある」などのようになります。
暗黙のフィードバック
ユーザーの行動から推測されるのはフィードバックです。この動作には、ユーザーがドキュメントの表示に費やした時間、表示用に選択されたドキュメントと選択されていないドキュメント、ページの参照とスクロールアクションなどが含まれます。暗黙的なフィードバックの最良の例の1つは次のとおりです。dwell time、これは、ユーザーが検索結果でリンクされているページを表示するのに費やした時間の尺度です。
疑似フィードバック
ブラインドフィードバックとも呼ばれます。自動ローカル分析の方法を提供します。関連性フィードバックの手動部分は、疑似関連性フィードバックの助けを借りて自動化されているため、ユーザーは、長時間の対話なしで検索パフォーマンスを向上させることができます。このフィードバックシステムの主な利点は、明示的な関連性フィードバックシステムのように評価者を必要としないことです。
このフィードバックを実装するには、次の手順を検討してください-
Step 1−最初に、最初のクエリによって返された結果を関連する結果として取得する必要があります。関連する結果の範囲は、上位10〜50の結果に含まれている必要があります。
Step 2 −次に、たとえば用語頻度(tf)-逆ドキュメント頻度(idf)の重みを使用して、ドキュメントから上位20〜30の用語を選択します。
Step 3−これらの用語をクエリに追加し、返されたドキュメントと一致させます。次に、最も関連性の高いドキュメントを返します。
自然言語処理(NLP)は、現在私たちが目にしているさまざまな形のAIを引き出す新しいテクノロジーであり、人間と機械の間のシームレスでインタラクティブなインターフェースを作成するためのその使用は、今日と明日の最優先事項であり続けますますます認知的なアプリケーション。ここでは、NLPの非常に便利なアプリケーションのいくつかについて説明します。
機械翻訳
あるソース言語またはテキストを別の言語に翻訳するプロセスである機械翻訳(MT)は、NLPの最も重要なアプリケーションの1つです。次のフローチャートを使用して、機械翻訳のプロセスを理解できます。
機械翻訳システムの種類
機械翻訳システムにはさまざまな種類があります。さまざまなタイプが何であるかを見てみましょう。
バイリンガルMTシステム
バイリンガルMTシステムは、2つの特定の言語間の翻訳を生成します。
多言語MTシステム
多言語MTシステムは、言語の任意のペア間の翻訳を生成します。それらは、本質的に単方向または双方向のいずれかである可能性があります。
機械翻訳(MT)へのアプローチ
機械翻訳への重要なアプローチについて学びましょう。MTへのアプローチは次のとおりです-
直接MTアプローチ
それはあまり人気がありませんが、MTの最も古いアプローチです。このアプローチを使用するシステムは、SL(ソース言語)をTL(ターゲット言語)に直接翻訳することができます。このようなシステムは、本質的にバイリンガルで単方向です。
インターリングアアプローチ
インターリングアアプローチを使用するシステムは、SLをインターリングア(IL)と呼ばれる中間言語に翻訳してから、ILをTLに翻訳します。インターリングアアプローチは、次のMTピラミッドの助けを借りて理解することができます-

転送アプローチ
このアプローチには3つの段階があります。
最初の段階では、ソース言語(SL)テキストが抽象的なSL指向の表現に変換されます。
第2段階では、SL指向の表現が同等のターゲット言語(TL)指向の表現に変換されます。
第3段階では、最終的なテキストが生成されます。
経験的MTアプローチ
これはMTの新しいアプローチです。基本的には、並列コーパスの形で大量の生データを使用します。生データは、テキストとその翻訳で構成されています。類推ベース、例ベース、メモリベースの機械翻訳技術は、経験的なMTアプローチを使用します。
スパムとの戦い
最近の最も一般的な問題の1つは、不要な電子メールです。これにより、スパムフィルターはこの問題に対する最初の防衛線であるため、さらに重要になります。
スパムフィルタリングシステムは、主要な誤検知および誤検知の問題を考慮して、NLP機能を使用して開発できます。
スパムフィルタリング用の既存のNLPモデル
以下は、スパムフィルタリングのためのいくつかの既存のNLPモデルです-
Nグラムモデリング
N-Gramモデルは、長い文字列のN文字スライスです。このモデルでは、スパムメールの処理と検出に複数の異なる長さのNグラムが同時に使用されます。
単語のステミング
スパムメールの生成元であるスパマーは、通常、スパム内の攻撃語の1つ以上の文字を変更して、コンテンツベースのスパムフィルターに違反できるようにします。そのため、コンテンツベースのフィルターは、電子メール内の単語やフレーズの意味を理解できない場合は役に立たないと言えます。スパムフィルタリングにおけるこのような問題を排除するために、似ている単語と似ている単語を照合できるルールベースの単語ステミング技術が開発されています。
ベイズ分類
これは現在、スパムフィルタリングに広く使用されているテクノロジーになっています。電子メール内の単語の発生率は、統計的手法で、一方的な(スパム)および正当な(ハム)電子メールメッセージのデータベースでの典型的な発生率に対して測定されます。
自動要約
このデジタル時代において、最も価値のあるものはデータ、つまり情報と言えます。しかし、必要な量の情報だけでなく、本当に役立つのでしょうか。情報が過負荷になり、知識や情報へのアクセスがそれを理解する能力をはるかに超えているため、答えは「いいえ」です。インターネットを介した情報の洪水が止まらないため、自動テキスト要約と情報が深刻に必要とされています。
テキスト要約は、長いテキストドキュメントの短く正確な要約を作成する手法として定義できます。自動テキスト要約は、関連情報をより短時間で提供するのに役立ちます。自然言語処理(NLP)は、自動テキスト要約の開発において重要な役割を果たします。
質問応答
自然言語処理(NLP)のもう1つの主なアプリケーションは、質問応答です。検索エンジンは私たちの指先で世界の情報を提供しますが、人間が自然言語で投稿した質問に答えるということになると、まだ不足しています。グーグルのようなビッグテック企業もこの方向に取り組んでいます。
質問応答は、AIとNLPの分野におけるコンピュータサイエンスの分野です。人間が自然言語で投稿した質問に自動的に答えるシステムの構築に焦点を当てています。自然言語を理解するコンピュータシステムは、人間が書いた文章を内部表現に翻訳するプログラムシステムの機能を備えているため、システムは有効な答えを生成することができます。正確な答えは、質問の構文および意味分析を行うことによって生成できます。語彙のギャップ、あいまいさ、多言語主義は、優れた質問応答システムを構築する上でのNLPの課題の一部です。
感情分析
自然言語処理(NLP)のもう1つの重要なアプリケーションは、感情分析です。名前が示すように、感情分析は、いくつかの投稿の中の感情を識別するために使用されます。また、感情が明示的に表現されていない感情を識別するためにも使用されます。企業は、自然言語処理(NLP)のアプリケーションである感情分析を使用して、オンラインで顧客の意見や感情を特定しています。これは、企業が顧客が製品やサービスについてどう思っているかを理解するのに役立ちます。企業は、感情分析の助けを借りて、顧客の投稿から全体的な評判を判断できます。このように、感情分析は、単純な極性を決定するだけでなく、文脈の中で感情を理解し、表明された意見の背後にあるものをよりよく理解するのに役立つと言えます。
この章では、Pythonを使用した言語処理について学習します。
次の機能により、Pythonは他の言語とは異なります-
Python is interpreted −インタプリタは実行時にPythonを処理するため、Pythonプログラムを実行する前にコンパイルする必要はありません。
Interactive −インタプリタと直接対話してPythonプログラムを作成できます。
Object-oriented − Pythonは本質的にオブジェクト指向であり、このプログラミング手法の助けを借りてコードをオブジェクト内にカプセル化するため、この言語でプログラムを簡単に作成できます。
Beginner can easily learn − Pythonは非常に理解しやすく、幅広いアプリケーションの開発をサポートしているため、初心者言語とも呼ばれます。
前提条件
リリースされたPython3の最新バージョンはPython3.7.1で、Windows、Mac OS、およびLinuxOSのほとんどのフレーバーで使用できます。
Windowsの場合は、リンクwww.python.org/downloads/windows/にアクセスしてPythonをダウンロードしてインストールできます。
MAC OSの場合、リンクwww.python.org/downloads/mac-osx/を使用できます。
Linuxの場合、Linuxのフレーバーが異なれば、新しいパッケージのインストールに異なるパッケージマネージャーが使用されます。
たとえば、UbuntuLinuxにPython3をインストールするには、ターミナルから次のコマンドを使用できます。
$sudo apt-get install python3-minimalPythonプログラミングの詳細については、Python 3の基本チュートリアル– Python3をお読みください。
NLTK入門
英語でテキスト分析を行うために、PythonライブラリNLTK(Natural Language Toolkit)を使用します。自然言語ツールキット(NLTK)は、英語などの自然言語のテキストに含まれる品詞を識別してタグ付けするために特別に設計されたPythonライブラリのコレクションです。
NLTKのインストール
NLTKを使い始める前に、インストールする必要があります。次のコマンドの助けを借りて、Python環境にインストールできます-
pip install nltkAnacondaを使用している場合は、次のコマンドを使用してNLTKのCondaパッケージをビルドできます。
conda install -c anaconda nltkNLTKのデータのダウンロード
NLTKをインストールした後、もう1つの重要なタスクは、プリセットされたテキストリポジトリをダウンロードして、簡単に使用できるようにすることです。ただし、その前に、他のPythonモジュールをインポートする方法でNLTKをインポートする必要があります。次のコマンドは、NLTKのインポートに役立ちます-
import nltk次に、次のコマンドを使用してNLTKデータをダウンロードします-
nltk.download()NLTKの利用可能なすべてのパッケージをインストールするのに少し時間がかかります。
その他の必要なパッケージ
のような他のいくつかのPythonパッケージ gensim そして patternまた、NLTKを使用して自然言語処理アプリケーションを構築するだけでなく、テキスト分析にも非常に必要です。パッケージは以下のようにインストールできます-
gensim
gensimは、多くのアプリケーションに使用できる堅牢なセマンティックモデリングライブラリです。次のコマンドでインストールできます−
pip install gensimパターン
それは作るために使用することができます gensimパッケージは正しく機能します。次のコマンドは、パターンのインストールに役立ちます-
pip install patternトークン化
トークン化は、指定されたテキストをトークンと呼ばれる小さな単位に分割するプロセスとして定義できます。単語、数字、句読点はトークンにすることができます。単語のセグメンテーションとも呼ばれます。
例
Input −ベッドと椅子は家具の一種です。

NLTKが提供するトークン化用のさまざまなパッケージがあります。要件に基づいてこれらのパッケージを使用できます。パッケージとそのインストールの詳細は次のとおりです-
sent_tokenizeパッケージ
このパッケージは、入力テキストを文に分割するために使用できます。次のコマンドを使用してインポートできます-
from nltk.tokenize import sent_tokenizeword_tokenizeパッケージ
このパッケージは、入力テキストを単語に分割するために使用できます。次のコマンドを使用してインポートできます-
from nltk.tokenize import word_tokenizeWordPunctTokenizerパッケージ
このパッケージを使用して、入力テキストを単語と句読点に分割できます。次のコマンドを使用してインポートできます-
from nltk.tokenize import WordPuncttokenizerステミング
文法上の理由から、言語には多くのバリエーションが含まれています。言語、英語、その他の言語も異なる形の単語を持っているという意味でのバリエーション。たとえば、次のような単語democracy、 democratic、および democratization。機械学習プロジェクトの場合、上記のように、これらの異なる単語が同じ基本形式を持っていることを機械が理解することが非常に重要です。そのため、テキストを分析しながら単語の基本形を抽出すると非常に便利です。
ステミングは、単語の端を切り刻むことによって単語の基本形を抽出するのに役立つヒューリスティックプロセスです。
NLTKモジュールによって提供されるステミングのさまざまなパッケージは次のとおりです。
PorterStemmerパッケージ
ポーターのアルゴリズムは、単語の基本形を抽出するためにこのステミングパッケージによって使用されます。次のコマンドを使用して、このパッケージをインポートできます-
from nltk.stem.porter import PorterStemmer例えば、 ‘write’ 単語の出力になります ‘writing’ このステマーへの入力として与えられます。
LancasterStemmerパッケージ
ランカスターのアルゴリズムは、単語の基本形を抽出するためにこのステミングパッケージによって使用されます。次のコマンドの助けを借りて、このパッケージをインポートできます-
from nltk.stem.lancaster import LancasterStemmer例えば、 ‘writ’ 単語の出力になります ‘writing’ このステマーへの入力として与えられます。
SnowballStemmerパッケージ
Snowballのアルゴリズムは、単語の基本形を抽出するためにこのステミングパッケージによって使用されます。次のコマンドの助けを借りて、このパッケージをインポートできます-
from nltk.stem.snowball import SnowballStemmer例えば、 ‘write’ 単語の出力になります ‘writing’ このステマーへの入力として与えられます。
Lemmatization
これは、単語の基本形を抽出する別の方法であり、通常、語彙と形態素解析を使用して語尾変化の終わりを取り除くことを目的としています。補題の後、単語の基本形は補題と呼ばれます。
NLTKモジュールは、レンマ化のために次のパッケージを提供します-
WordNetLemmatizerパッケージ
このパッケージは、名詞として使用されているか動詞として使用されているかに応じて、単語の基本形を抽出します。次のコマンドを使用して、このパッケージをインポートできます-
from nltk.stem import WordNetLemmatizerPOSタグのカウント–チャンキング
品詞(POS)と短いフレーズの識別は、チャンクの助けを借りて行うことができます。これは、自然言語処理における重要なプロセスの1つです。トークンを作成するためのトークン化のプロセスについて知っているので、チャンク化は実際にはそれらのトークンのラベル付けを行うことです。言い換えれば、チャンク化プロセスの助けを借りて、文の構造を取得できると言えます。
例
次の例では、NLTK Pythonモジュールを使用して、文中の名詞句チャンクを検索するチャンクのカテゴリである名詞句チャンクを実装します。
名詞句チャンクを実装するには、次の手順を検討してください。
Step 1: Chunk grammar definition
このステップでは、チャンクの文法を定義する必要があります。それは私たちが従う必要のあるルールで構成されます。
Step 2: Chunk parser creation
次に、チャンクパーサーを作成する必要があります。文法を解析して出力します。
Step 3: The Output
このステップでは、ツリー形式で出力を取得します。
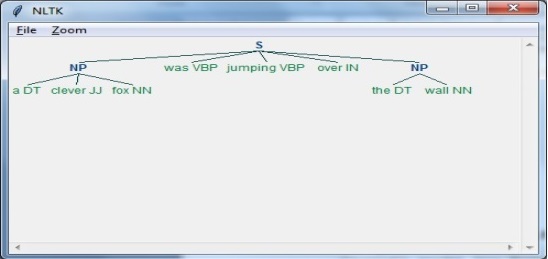
NLPスクリプトの実行
NLTKパッケージをインポートすることから始めます-
import nltk次に、文を定義する必要があります。
ここに、
DTが決定要因です
VBPは動詞です
JJは形容詞です
INは前置詞です
NNは名詞です
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]次に、文法は正規表現の形で与えられるべきです。
grammar = "NP:{<DT>?<JJ>*<NN>}"次に、文法を解析するためのパーサーを定義する必要があります。
parser_chunking = nltk.RegexpParser(grammar)これで、パーサーは次のように文を解析します-
parser_chunking.parse(sentence)次に、出力は次のように変数になります。-
Output = parser_chunking.parse(sentence)次のコードは、出力をツリーの形で描画するのに役立ちます。
output.draw()